Apache Storm - คู่มือฉบับย่อ
Apache Storm คืออะไร?
Apache Storm เป็นระบบประมวลผลข้อมูลขนาดใหญ่แบบเรียลไทม์แบบกระจาย Storm ได้รับการออกแบบมาเพื่อประมวลผลข้อมูลจำนวนมากด้วยวิธีการที่ทนต่อความผิดพลาดและปรับขนาดได้ในแนวนอน เป็นกรอบข้อมูลการสตรีมที่มีอัตราการส่งผ่านข้อมูลสูงสุด แม้ว่า Storm จะไร้สัญชาติ แต่ก็จัดการสภาพแวดล้อมแบบกระจายและสถานะคลัสเตอร์ผ่าน Apache ZooKeeper เป็นเรื่องง่ายและคุณสามารถดำเนินการปรับแต่งทุกรูปแบบกับข้อมูลเรียลไทม์ควบคู่กันได้
Apache Storm ยังคงเป็นผู้นำด้านการวิเคราะห์ข้อมูลแบบเรียลไทม์ Storm นั้นง่ายต่อการติดตั้งใช้งานและรับประกันว่าทุกข้อความจะได้รับการประมวลผลผ่านโทโพโลยีอย่างน้อยหนึ่งครั้ง
Apache Storm กับ Hadoop
โดยทั่วไปเฟรมเวิร์ก Hadoop และ Storm ใช้สำหรับวิเคราะห์ข้อมูลขนาดใหญ่ ทั้งสองเสริมซึ่งกันและกันและแตกต่างกันในบางแง่มุม Apache Storm ดำเนินการทั้งหมดยกเว้นความต่อเนื่องในขณะที่ Hadoop ทำได้ดีในทุกสิ่ง แต่มีความล่าช้าในการคำนวณแบบเรียลไทม์ ตารางต่อไปนี้เปรียบเทียบคุณลักษณะของ Storm และ Hadoop
| พายุ | Hadoop |
|---|---|
| การประมวลผลสตรีมแบบเรียลไทม์ | การประมวลผลแบทช์ |
| ไร้สัญชาติ | สถานะ |
| สถาปัตยกรรม Master / Slave พร้อมการประสานงานตาม ZooKeeper โหนดหลักเรียกว่าเป็นnimbus และทาสคือ supervisors. | สถาปัตยกรรม Master-slave ที่มี / ไม่มีการประสานงานตาม ZooKeeper โหนดหลักคือjob tracker และโหนดทาสคือ task tracker. |
| กระบวนการสตรีม Storm สามารถเข้าถึงข้อความได้หลายหมื่นข้อความต่อวินาทีบนคลัสเตอร์ | Hadoop Distributed File System (HDFS) ใช้กรอบ MapReduce เพื่อประมวลผลข้อมูลจำนวนมหาศาลโดยใช้เวลาไม่กี่นาทีหรือหลายชั่วโมง |
| โทโพโลยีแบบสตอร์มทำงานจนกว่าผู้ใช้จะปิดหรือเกิดความล้มเหลวที่ไม่คาดคิดซึ่งไม่สามารถกู้คืนได้ | งาน MapReduce จะดำเนินการตามลำดับและเสร็จสมบูรณ์ในที่สุด |
| Both are distributed and fault-tolerant | |
| หาก nimbus / หัวหน้างานเสียชีวิตการเริ่มต้นใหม่จะทำให้ดำเนินการต่อจากจุดที่หยุดทำงานจึงไม่มีผลกระทบใด ๆ | หาก JobTracker เสียชีวิตงานที่กำลังดำเนินอยู่ทั้งหมดจะหายไป |
การใช้งานของ Apache Storm
Apache Storm มีชื่อเสียงมากในด้านการประมวลผลสตรีมข้อมูลขนาดใหญ่แบบเรียลไทม์ ด้วยเหตุนี้ บริษัท ส่วนใหญ่จึงใช้ Storm เป็นส่วนหนึ่งของระบบ ตัวอย่างที่น่าสังเกตมีดังนี้ -
Twitter- Twitter ใช้ Apache Storm สำหรับผลิตภัณฑ์ "Publisher Analytics" ที่หลากหลาย “ ผลิตภัณฑ์การวิเคราะห์ผู้เผยแพร่โฆษณา” ประมวลผลทวีตและการคลิกแต่ละรายการในแพลตฟอร์ม Twitter Apache Storm ผสานรวมอย่างลึกซึ้งกับโครงสร้างพื้นฐานของ Twitter
NaviSite- NaviSite ใช้ Storm สำหรับระบบตรวจสอบ / ตรวจสอบบันทึกเหตุการณ์ ทุกบันทึกที่สร้างขึ้นในระบบจะผ่าน Storm Storm จะตรวจสอบข้อความกับชุดนิพจน์ทั่วไปที่กำหนดค่าไว้และหากมีการจับคู่ข้อความนั้นจะถูกบันทึกลงในฐานข้อมูล
Wego- Wego เป็นเครื่องมือค้นหาข้อมูลการเดินทางที่ตั้งอยู่ในสิงคโปร์ ข้อมูลเกี่ยวกับการเดินทางมาจากหลายแหล่งทั่วโลกโดยมีเวลาที่แตกต่างกัน Storm ช่วย Wego ในการค้นหาข้อมูลแบบเรียลไทม์แก้ไขปัญหาการเกิดพร้อมกันและค้นหาคู่ที่ดีที่สุดสำหรับผู้ใช้ปลายทาง
ประโยชน์ของ Apache Storm
นี่คือรายการสิทธิประโยชน์ที่ Apache Storm มอบให้ -
Storm เป็นโอเพ่นซอร์สที่แข็งแกร่งและเป็นมิตรกับผู้ใช้ สามารถใช้ใน บริษัท ขนาดเล็กและ บริษัท ขนาดใหญ่
Storm ทนต่อความผิดพลาดยืดหยุ่นเชื่อถือได้และรองรับภาษาโปรแกรมใด ๆ
อนุญาตให้ประมวลผลสตรีมแบบเรียลไทม์
Storm นั้นเร็วอย่างไม่น่าเชื่อเพราะมีพลังมหาศาลในการประมวลผลข้อมูล
Storm สามารถรักษาประสิทธิภาพได้แม้จะมีภาระเพิ่มขึ้นโดยการเพิ่มทรัพยากรแบบเชิงเส้น สามารถปรับขนาดได้สูง
Storm ทำการรีเฟรชข้อมูลและตอบสนองการส่งมอบแบบ end-to-end ในไม่กี่วินาทีหรือไม่กี่นาทีขึ้นอยู่กับปัญหา มีเวลาแฝงต่ำมาก
สตอร์มมีข่าวกรองในการปฏิบัติการ
Storm ให้การประมวลผลข้อมูลที่รับประกันแม้ว่าโหนดใด ๆ ที่เชื่อมต่อในคลัสเตอร์จะตายหรือข้อความสูญหาย
Apache Storm อ่านกระแสข้อมูลดิบแบบเรียลไทม์จากปลายด้านหนึ่งและส่งผ่านลำดับของหน่วยประมวลผลขนาดเล็กและส่งออกข้อมูลที่ประมวลผล / เป็นประโยชน์ที่ปลายอีกด้านหนึ่ง
แผนภาพต่อไปนี้แสดงถึงแนวคิดหลักของ Apache Storm

ตอนนี้เรามาดูส่วนประกอบของ Apache Storm กันอย่างละเอียดยิ่งขึ้น -
| ส่วนประกอบ | คำอธิบาย |
|---|---|
| ทูเพิล | Tuple เป็นโครงสร้างข้อมูลหลักใน Storm มันคือรายการขององค์ประกอบที่สั่งซื้อ ตามค่าเริ่มต้น Tuple รองรับข้อมูลทุกประเภท โดยทั่วไปจะสร้างแบบจำลองเป็นชุดของค่าที่คั่นด้วยเครื่องหมายจุลภาคและส่งต่อไปยังคลัสเตอร์ Storm |
| กระแส | สตรีมเป็นลำดับสิ่งที่ไม่เรียงลำดับ |
| พวย | แหล่งที่มาของสตรีม โดยทั่วไป Storm ยอมรับข้อมูลอินพุตจากแหล่งข้อมูลดิบเช่น Twitter Streaming API คิว Apache Kafka คิว Kestrel เป็นต้นมิฉะนั้นคุณสามารถเขียน spouts เพื่ออ่านข้อมูลจากแหล่งข้อมูลได้ “ ISpout” เป็นอินเทอร์เฟซหลักสำหรับการใช้งานพวยกาอินเทอร์เฟซเฉพาะบางอย่าง ได้แก่ IRichSpout, BaseRichSpout, KafkaSpout เป็นต้น |
| สลักเกลียว | สลักเกลียวเป็นหน่วยประมวลผลเชิงตรรกะ Spouts ส่งผ่านข้อมูลไปยังกระบวนการสลักเกลียวและสลักเกลียวและสร้างกระแสข้อมูลเอาต์พุตใหม่ สลักเกลียวสามารถดำเนินการกรองการรวมการเข้าร่วมการโต้ตอบกับแหล่งข้อมูลและฐานข้อมูล Bolt รับข้อมูลและส่งไปยังสลักเกลียวหนึ่งตัวหรือมากกว่า “ IBolt” เป็นอินเทอร์เฟซหลักสำหรับการติดตั้งสลักเกลียว อินเทอร์เฟซทั่วไปบางส่วน ได้แก่ IRichBolt, IBasicBolt เป็นต้น |
มาดูตัวอย่าง“ การวิเคราะห์ Twitter” แบบเรียลไทม์และดูว่าสามารถสร้างแบบจำลองใน Apache Storm ได้อย่างไร แผนภาพต่อไปนี้แสดงถึงโครงสร้าง

ข้อมูลสำหรับ“ การวิเคราะห์ Twitter” มาจาก Twitter Streaming API Spout จะอ่านทวีตของผู้ใช้โดยใช้ Twitter Streaming API และส่งออกเป็นสตรีมของ tuples ทูเพิลตัวเดียวจากพวยกาจะมีชื่อผู้ใช้ทวิตเตอร์และทวีตเดียวเป็นค่าที่คั่นด้วยเครื่องหมายจุลภาค จากนั้นไอน้ำของ tuples นี้จะถูกส่งต่อไปยัง Bolt และ Bolt จะแบ่งทวีตออกเป็นแต่ละคำคำนวณจำนวนคำและคงข้อมูลไปยังแหล่งข้อมูลที่กำหนดค่าไว้ ตอนนี้เราสามารถรับผลลัพธ์ได้อย่างง่ายดายโดยการสอบถามแหล่งข้อมูล
โทโพโลยี
Spouts และสลักเกลียวเชื่อมต่อเข้าด้วยกันและสร้างโทโพโลยี ตรรกะแอปพลิเคชันแบบเรียลไทม์ถูกระบุไว้ในโทโพโลยี Storm กล่าวง่ายๆคือโทโพโลยีคือกราฟกำกับโดยจุดยอดคือการคำนวณและขอบเป็นกระแสข้อมูล
โทโพโลยีอย่างง่ายเริ่มต้นด้วยพวยกา พวยกาปล่อยข้อมูลไปยังสลักเกลียวหนึ่งตัวหรือมากกว่า Bolt หมายถึงโหนดในโทโพโลยีที่มีลอจิกการประมวลผลที่เล็กที่สุดและเอาต์พุตของโบลต์สามารถส่งออกไปยังโบลต์อื่นเป็นอินพุตได้
Storm ทำให้โทโพโลยีทำงานอยู่เสมอจนกว่าคุณจะฆ่าโทโพโลยี งานหลักของ Apache Storm คือการเรียกใช้โทโพโลยีและจะเรียกใช้โทโพโลยีจำนวนเท่าใดก็ได้ในเวลาที่กำหนด
งาน
ตอนนี้คุณมีแนวคิดพื้นฐานเกี่ยวกับพวยกาและสลักเกลียว เป็นหน่วยตรรกะที่เล็กที่สุดของโทโพโลยีและโทโพโลยีสร้างขึ้นโดยใช้พวยกาเดียวและอาร์เรย์ของสลักเกลียว ควรดำเนินการอย่างถูกต้องตามลำดับเฉพาะเพื่อให้โทโพโลยีทำงานได้สำเร็จ การดำเนินการของแต่ละพวยกาและโบลต์โดย Storm เรียกว่า "งาน" พูดง่ายๆงานคือการใช้พวยกาหรือโบลต์ ในช่วงเวลาที่กำหนดพวยกาและสลักเกลียวแต่ละตัวสามารถมีหลายอินสแตนซ์ที่ทำงานในเธรดแยกกันหลายชุด
คนงาน
โทโพโลยีทำงานในลักษณะกระจายบนโหนดของผู้ปฏิบัติงานหลายโหนด สตอร์มกระจายงานอย่างเท่าเทียมกันในทุกโหนดของผู้ปฏิบัติงาน บทบาทของโหนดผู้ปฏิบัติงานคือรับฟังงานและเริ่มหรือหยุดกระบวนการเมื่อมีงานใหม่มาถึง
การจัดกลุ่มสตรีม
กระแสข้อมูลไหลจากพวยกาไปยังสลักเกลียวหรือจากสลักเกลียวหนึ่งไปยังสลักเกลียวอื่น การจัดกลุ่มสตรีมจะควบคุมวิธีการกำหนดเส้นทางทูเปิลในโทโพโลยีและช่วยให้เราเข้าใจโฟลว์ของสิ่งทอปเปิลในโทโพโลยี มีการจัดกลุ่มในตัวสี่กลุ่มตามที่อธิบายไว้ด้านล่าง
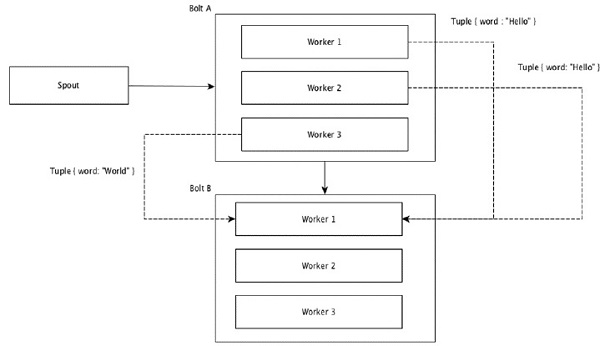
การจัดกลุ่มแบบสุ่ม
ในการจัดกลุ่มแบบสุ่มจำนวนทูเปิลที่เท่ากันจะถูกกระจายแบบสุ่มให้กับคนงานทั้งหมดที่ใช้สลักเกลียว แผนภาพต่อไปนี้แสดงถึงโครงสร้าง

การจัดกลุ่มฟิลด์
ฟิลด์ที่มีค่าเดียวกันในทูเปิลจะถูกจัดกลุ่มเข้าด้วยกันและสิ่งที่เหลือจะถูกเก็บไว้ภายนอก จากนั้นทูเปิลที่มีค่าฟิลด์เดียวกันจะถูกส่งต่อไปยังผู้ปฏิบัติงานคนเดียวกันที่ดำเนินการสลักเกลียว ตัวอย่างเช่นหากสตรีมถูกจัดกลุ่มตามช่อง "word" สิ่งที่มีสตริงเดียวกัน "สวัสดี" จะย้ายไปยังผู้ปฏิบัติงานคนเดียวกัน แผนภาพต่อไปนี้แสดงวิธีการทำงานของ Field Grouping

การจัดกลุ่มทั่วโลก
สตรีมทั้งหมดสามารถจัดกลุ่มและส่งต่อไปยังสายฟ้าเดียว การจัดกลุ่มนี้จะส่งสิ่งที่สร้างขึ้นโดยอินสแตนซ์ทั้งหมดของแหล่งที่มาไปยังอินสแตนซ์เป้าหมายเดียว (โดยเฉพาะเลือกผู้ปฏิบัติงานที่มี ID ต่ำสุด)
การจัดกลุ่มทั้งหมด
การจัดกลุ่มทั้งหมดจะส่งสำเนาทูเพิลแต่ละชุดไปยังอินสแตนซ์ทั้งหมดของสลักเกลียวรับ การจัดกลุ่มแบบนี้ใช้เพื่อส่งสัญญาณไปยังสลักเกลียว การจัดกลุ่มทั้งหมดมีประโยชน์สำหรับการดำเนินการเข้าร่วม

จุดเด่นหลักอย่างหนึ่งของ Apache Storm คือเป็นแอปพลิเคชั่นที่ทนทานต่อความผิดพลาดได้อย่างรวดเร็วโดยไม่มีแอปพลิเคชันแบบกระจาย“ Single Point of Failure” (SPOF) เราสามารถติดตั้ง Apache Storm ในระบบต่างๆได้มากเท่าที่ต้องการเพื่อเพิ่มความจุของแอปพลิเคชัน
มาดูกันว่าคลัสเตอร์ Apache Storm ได้รับการออกแบบและสถาปัตยกรรมภายในอย่างไร แผนภาพต่อไปนี้แสดงถึงการออกแบบคลัสเตอร์

Apache Storm มีโหนดสองประเภท Nimbus (โหนดหลัก) และ Supervisor(โหนดคนงาน) Nimbus เป็นส่วนประกอบหลักของ Apache Storm งานหลักของ Nimbus คือการรันโทโพโลยีของพายุ Nimbus วิเคราะห์โทโพโลยีและรวบรวมงานที่จะดำเนินการ จากนั้นจะกระจายงานไปยังหัวหน้างานที่มีอยู่
หัวหน้างานจะมีกระบวนการทำงานอย่างน้อยหนึ่งกระบวนการ หัวหน้างานจะมอบหมายงานให้กับกระบวนการของผู้ปฏิบัติงาน กระบวนการของผู้ปฏิบัติงานจะสร้างตัวดำเนินการได้มากเท่าที่จำเป็นและเรียกใช้งาน Apache Storm ใช้ระบบการส่งข้อความแบบกระจายภายในสำหรับการสื่อสารระหว่าง nimbus และหัวหน้างาน
| ส่วนประกอบ | คำอธิบาย |
|---|---|
| Nimbus | Nimbus เป็นโหนดหลักของคลัสเตอร์ Storm โหนดอื่น ๆ ทั้งหมดในคลัสเตอร์เรียกว่าเป็นworker nodes. โหนดหลักมีหน้าที่ในการกระจายข้อมูลระหว่างโหนดของผู้ปฏิบัติงานทั้งหมดมอบหมายงานให้กับโหนดของผู้ปฏิบัติงานและการตรวจสอบความล้มเหลว |
| หัวหน้างาน | โหนดที่ทำตามคำแนะนำที่กำหนดโดย nimbus เรียกว่าเป็น Supervisors กsupervisor มีกระบวนการของผู้ปฏิบัติงานหลายขั้นตอนและควบคุมกระบวนการของผู้ปฏิบัติงานเพื่อทำภารกิจที่มอบหมายโดย nimbus |
| กระบวนการของผู้ปฏิบัติงาน | กระบวนการของผู้ปฏิบัติงานจะดำเนินการงานที่เกี่ยวข้องกับโทโพโลยีเฉพาะ กระบวนการของผู้ปฏิบัติงานจะไม่เรียกใช้งานด้วยตัวเอง แต่จะสร้างขึ้นexecutorsและขอให้พวกเขาทำงานเฉพาะ กระบวนการของผู้ปฏิบัติงานจะมีตัวดำเนินการหลายตัว |
| ผู้บริหาร | ตัวดำเนินการคืออะไรนอกจากเธรดเดียวที่เกิดจากกระบวนการของผู้ปฏิบัติงาน ตัวดำเนินการทำงานตั้งแต่หนึ่งงานขึ้นไป แต่สำหรับพวยกาหรือโบลต์เฉพาะเท่านั้น |
| งาน | งานดำเนินการประมวลผลข้อมูลจริง ดังนั้นจึงเป็นทั้งพวยกาหรือโบลต์ |
| กรอบ ZooKeeper | Apache ZooKeeper เป็นบริการที่ใช้โดยคลัสเตอร์ (กลุ่มของโหนด) เพื่อประสานงานระหว่างกันเองและดูแลข้อมูลที่แชร์ด้วยเทคนิคการซิงโครไนซ์ที่มีประสิทธิภาพ Nimbus ไม่มีสถานะดังนั้นจึงขึ้นอยู่กับ ZooKeeper ในการตรวจสอบสถานะโหนดการทำงาน ZooKeeper ช่วยหัวหน้างานในการโต้ตอบกับ nimbus มีหน้าที่รับผิดชอบในการรักษาสถานะของ nimbus และหัวหน้างาน |
พายุไม่มีสัญชาติในธรรมชาติ แม้ว่าธรรมชาติไร้สัญชาติจะมีข้อเสียในตัวเอง แต่ก็ช่วยให้ Storm ประมวลผลข้อมูลแบบเรียลไทม์ด้วยวิธีที่ดีที่สุดและรวดเร็วที่สุด
พายุไม่ได้ไร้สัญชาติโดยสิ้นเชิง มันเก็บสถานะไว้ใน Apache ZooKeeper เนื่องจากสถานะพร้อมใช้งานใน Apache ZooKeeper จึงสามารถรีสตาร์ท nimbus ที่ล้มเหลวและทำให้ทำงานได้จากจุดที่ทิ้งไว้ โดยปกติแล้วเครื่องมือตรวจสอบบริการเช่นmonit จะตรวจสอบ Nimbus และรีสตาร์ทหากมีความล้มเหลว
Apache Storm ยังมีโทโพโลยีขั้นสูงที่เรียกว่า Trident Topologyด้วยการบำรุงรักษาสถานะและยังมี API ระดับสูงเช่น Pig เราจะพูดถึงคุณสมบัติทั้งหมดนี้ในบทต่อ ๆ ไป
คลัสเตอร์ Storm ที่ใช้งานได้ควรมีหนึ่ง nimbus และผู้ควบคุมอย่างน้อยหนึ่งคน อีกโหนดที่สำคัญคือ Apache ZooKeeper ซึ่งจะใช้สำหรับการประสานงานระหว่าง nimbus และผู้บังคับบัญชา
ให้เรามาดูขั้นตอนการทำงานของ Apache Storm อย่างละเอียด -
ในขั้นต้น nimbus จะรอให้ "Storm Topology" ส่งมาให้
เมื่อส่งโทโพโลยีแล้วระบบจะประมวลผลโทโพโลยีและรวบรวมงานทั้งหมดที่ต้องดำเนินการและลำดับที่จะดำเนินการงาน
จากนั้น nimbus จะกระจายงานให้กับหัวหน้างานทั้งหมดที่มีอยู่อย่างเท่าเทียมกัน
ในช่วงเวลาหนึ่งหัวหน้างานทุกคนจะส่งสัญญาณการเต้นของหัวใจไปยัง nimbus เพื่อแจ้งว่าพวกเขายังมีชีวิตอยู่
เมื่อหัวหน้างานเสียชีวิตและไม่ส่งสัญญาณการเต้นของหัวใจไปยัง nimbus ดังนั้น nimbus จะมอบหมายงานให้หัวหน้างานคนอื่น
เมื่อนิมบัสตายผู้บังคับบัญชาจะทำงานที่ได้รับมอบหมายแล้วโดยไม่มีปัญหาใด ๆ
เมื่องานทั้งหมดเสร็จสิ้นหัวหน้างานจะรอให้มีงานใหม่เข้ามา
ในระหว่างนี้นิมบัสที่ตายแล้วจะถูกรีสตาร์ทโดยอัตโนมัติด้วยเครื่องมือตรวจสอบบริการ
นิมบัสที่รีสตาร์ทจะดำเนินการต่อจากจุดที่หยุด ในทำนองเดียวกันหัวหน้างานที่ตายแล้วสามารถเริ่มต้นใหม่ได้โดยอัตโนมัติ เนื่องจากทั้ง nimbus และผู้ควบคุมสามารถเริ่มต้นใหม่ได้โดยอัตโนมัติและทั้งสองจะยังคงดำเนินต่อไปเหมือนเดิม Storm จึงรับประกันว่าจะประมวลผลงานทั้งหมดอย่างน้อยหนึ่งครั้ง
เมื่อโทโพโลยีทั้งหมดได้รับการประมวลผลแล้ว nimbus จะรอให้โทโพโลยีใหม่มาถึงและในทำนองเดียวกันหัวหน้างานก็รองานใหม่
ตามค่าเริ่มต้นมีสองโหมดในคลัสเตอร์ Storm -
Local mode- โหมดนี้ใช้สำหรับการพัฒนาการทดสอบและการดีบักเนื่องจากเป็นวิธีที่ง่ายที่สุดในการดูส่วนประกอบโทโพโลยีทั้งหมดที่ทำงานร่วมกัน ในโหมดนี้เราสามารถปรับพารามิเตอร์ที่ทำให้เราเห็นว่าโทโพโลยีของเราทำงานอย่างไรในสภาพแวดล้อมการกำหนดค่า Storm ต่างๆ ในโหมดโลคัลโทโพโลยีพายุทำงานบนเครื่องโลคัลใน JVM เดียว
Production mode- ในโหมดนี้เราส่งโทโพโลยีของเราไปยังคลัสเตอร์สตอร์มที่ทำงานซึ่งประกอบด้วยหลายกระบวนการโดยปกติจะทำงานบนเครื่องที่แตกต่างกัน ตามที่กล่าวไว้ในขั้นตอนการทำงานของ storm คลัสเตอร์การทำงานจะทำงานไปเรื่อย ๆ จนกว่าจะปิดตัวลง
Apache Storm ประมวลผลข้อมูลแบบเรียลไทม์และอินพุตมักมาจากระบบจัดคิวข้อความ ระบบส่งข้อความแบบกระจายภายนอกจะให้ข้อมูลที่จำเป็นสำหรับการคำนวณแบบเรียลไทม์ Spout จะอ่านข้อมูลจากระบบส่งข้อความและแปลงเป็น tuples และป้อนข้อมูลลงใน Apache Storm ข้อเท็จจริงที่น่าสนใจก็คือ Apache Storm ใช้ระบบส่งข้อความแบบกระจายของตัวเองเป็นการภายในเพื่อการสื่อสารระหว่างเพื่อนกับหัวหน้างาน
ระบบส่งข้อความแบบกระจายคืออะไร?
การส่งข้อความแบบกระจายจะขึ้นอยู่กับแนวคิดของการจัดคิวข้อความที่เชื่อถือได้ ข้อความจะอยู่ในคิวแบบอะซิงโครนัสระหว่างแอปพลิเคชันไคลเอ็นต์และระบบการส่งข้อความ ระบบการส่งข้อความแบบกระจายให้ประโยชน์ของความน่าเชื่อถือความสามารถในการปรับขนาดและความคงอยู่
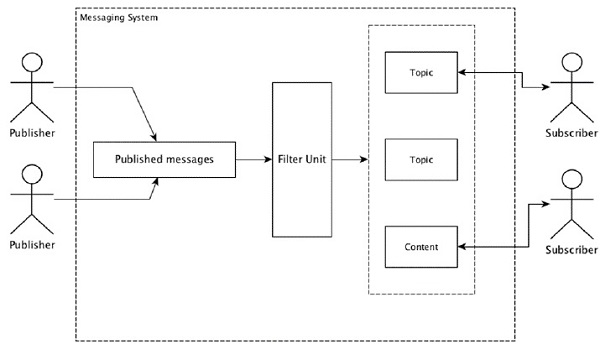
รูปแบบการส่งข้อความส่วนใหญ่เป็นไปตาม publish-subscribe แบบจำลอง (เพียง Pub-Sub) ที่ซึ่งผู้ส่งข้อความถูกเรียก publishers และผู้ที่ต้องการรับข้อความจะถูกเรียก subscribers.
เมื่อผู้ส่งเผยแพร่ข้อความแล้วสมาชิกจะได้รับข้อความที่เลือกด้วยความช่วยเหลือของตัวเลือกการกรอง โดยปกติเรามีการกรองสองประเภทประเภทหนึ่งคือtopic-based filtering และอีกอย่างหนึ่งคือ content-based filtering.
โปรดทราบว่าโมเดลย่อย pub สามารถสื่อสารผ่านข้อความเท่านั้น มันเป็นสถาปัตยกรรมคู่กันอย่างหลวม ๆ แม้แต่ผู้ส่งก็ไม่รู้ว่าใครคือผู้ติดตาม รูปแบบข้อความจำนวนมากเปิดใช้งานกับนายหน้าซื้อขายข้อความเพื่อแลกเปลี่ยนข้อความเผยแพร่เพื่อให้สมาชิกจำนวนมากเข้าถึงได้อย่างทันท่วงที ตัวอย่างในชีวิตจริงคือ Dish TV ซึ่งเผยแพร่ช่องต่างๆเช่นกีฬาภาพยนตร์เพลง ฯลฯ และทุกคนสามารถสมัครรับข้อมูลจากชุดช่องของตนเองและรับเมื่อใดก็ตามที่มีช่องที่สมัครรับข้อมูล
ตารางต่อไปนี้อธิบายถึงระบบการส่งข้อความปริมาณงานสูงยอดนิยม -
| ระบบส่งข้อความแบบกระจาย | คำอธิบาย |
|---|---|
| อาปาเช่คาฟคา | Kafka ได้รับการพัฒนาที่ LinkedIn Corporation และต่อมาได้กลายเป็นโครงการย่อยของ Apache Apache Kafka ขึ้นอยู่กับรูปแบบการสมัครสมาชิกที่เปิดใช้งานแบบถาวรและต่อเนื่องแบบกระจาย Kafka รวดเร็วปรับขนาดได้และมีประสิทธิภาพสูง |
| RabbitMQ | RabbitMQ เป็นแอปพลิเคชั่นส่งข้อความที่มีประสิทธิภาพแบบโอเพนซอร์ส ใช้งานง่ายและทำงานบนทุกแพลตฟอร์ม |
| JMS (Java Message Service) | JMS เป็น API โอเพ่นซอร์สที่รองรับการสร้างอ่านและส่งข้อความจากแอปพลิเคชันหนึ่งไปยังอีกแอปพลิเคชัน มีการรับประกันการส่งข้อความและเป็นไปตามรูปแบบการสมัครสมาชิก |
| ActiveMQ | ระบบส่งข้อความ ActiveMQ เป็น API โอเพ่นซอร์สของ JMS |
| ZeroMQ | ZeroMQ คือการประมวลผลข้อความแบบเพียร์เพียร์ที่ไม่มีนายหน้า มีรูปแบบข้อความ push-pull เราเตอร์ตัวแทนจำหน่าย |
| เคสเตรล | Kestrel เป็นคิวข้อความแบบกระจายที่รวดเร็วเชื่อถือได้และเรียบง่าย |
พิธีสารทริฟท์
Thrift ถูกสร้างขึ้นที่ Facebook สำหรับการพัฒนาบริการข้ามภาษาและการเรียกขั้นตอนระยะไกล (RPC) ต่อมาได้กลายเป็นโครงการ Apache แบบโอเพนซอร์ส Apache Thrift เป็นไฟล์Interface Definition Language และอนุญาตให้กำหนดประเภทข้อมูลและการใช้บริการใหม่ที่ด้านบนของประเภทข้อมูลที่กำหนดได้อย่างง่ายดาย
Apache Thrift ยังเป็นเฟรมเวิร์กการสื่อสารที่รองรับระบบฝังตัวแอปพลิเคชันมือถือเว็บแอปพลิเคชันและภาษาโปรแกรมอื่น ๆ อีกมากมาย คุณสมบัติหลักบางประการที่เกี่ยวข้องกับ Apache Thrift คือความเป็นโมดูลาร์ความยืดหยุ่นและประสิทธิภาพสูง นอกจากนี้ยังสามารถทำการสตรีมการส่งข้อความและ RPC ในแอปพลิเคชันแบบกระจาย
Storm ใช้ Thrift Protocol อย่างกว้างขวางสำหรับการสื่อสารภายในและการกำหนดข้อมูล โทโพโลยีพายุเป็นเพียงThrift Structs. Storm Nimbus ที่เรียกใช้โทโพโลยีใน Apache Storm คือไฟล์Thrift service.
ตอนนี้ให้เราดูวิธีการติดตั้ง Apache Storm framework บนเครื่องของคุณ มีบันไดสามขั้นที่นี่ -
- ติดตั้ง Java บนระบบของคุณหากคุณยังไม่มี
- ติดตั้ง ZooKeeper framework
- ติดตั้ง Apache Storm framework
ขั้นตอนที่ 1 - ตรวจสอบการติดตั้ง Java
ใช้คำสั่งต่อไปนี้เพื่อตรวจสอบว่าคุณได้ติดตั้ง Java บนระบบของคุณแล้วหรือไม่
$ java -versionหากมี Java อยู่แล้วคุณจะเห็นหมายเลขเวอร์ชัน มิฉะนั้นให้ดาวน์โหลด JDK เวอร์ชันล่าสุด
ขั้นตอนที่ 1.1 - ดาวน์โหลด JDK
ดาวน์โหลด JDK เวอร์ชันล่าสุดโดยใช้ลิงค์ต่อไปนี้ - www.oracle.com
เวอร์ชันล่าสุดคือ JDK 8u 60 และไฟล์คือ “jdk-8u60-linux-x64.tar.gz”. ดาวน์โหลดไฟล์บนเครื่องของคุณ
ขั้นตอนที่ 1.2 - แตกไฟล์
โดยทั่วไปไฟล์จะถูกดาวน์โหลดลงในไฟล์ downloadsโฟลเดอร์ แยกการตั้งค่า tar โดยใช้คำสั่งต่อไปนี้
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzขั้นตอนที่ 1.3 - ย้ายไปที่ไดเรกทอรีที่เลือก
ในการทำให้ Java พร้อมใช้งานสำหรับผู้ใช้ทั้งหมดให้ย้ายเนื้อหา java ที่แยกแล้วไปยังโฟลเดอร์“ / usr / local / java”
$ su
password: (type password of root user)
$ mkdir /opt/jdk
$ mv jdk-1.8.0_60 /opt/jdk/ขั้นตอนที่ 1.4 - กำหนดเส้นทาง
ในการกำหนดเส้นทางและตัวแปร JAVA_HOME ให้เพิ่มคำสั่งต่อไปนี้ในไฟล์ ~ / .bashrc
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binตอนนี้ใช้การเปลี่ยนแปลงทั้งหมดในระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 1.5 - ทางเลือก Java
ใช้คำสั่งต่อไปนี้เพื่อเปลี่ยนทางเลือกของ Java
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100ขั้นตอนที่ 1.6
ตอนนี้ตรวจสอบการติดตั้ง Java โดยใช้คำสั่งตรวจสอบ (java -version) อธิบายไว้ในขั้นตอนที่ 1
ขั้นตอนที่ 2 - การติดตั้ง ZooKeeper Framework
ขั้นตอนที่ 2.1 - ดาวน์โหลด ZooKeeper
ในการติดตั้ง ZooKeeper framework บนเครื่องของคุณให้ไปที่ลิงค์ต่อไปนี้และดาวน์โหลด ZooKeeper เวอร์ชันล่าสุด http://zookeeper.apache.org/releases.html
ณ ตอนนี้ ZooKeeper เวอร์ชันล่าสุดคือ 3.4.6 (ZooKeeper-3.4.6.tar.gz)
ขั้นตอนที่ 2.2 - แตกไฟล์ tar
แตกไฟล์ tar โดยใช้คำสั่งต่อไปนี้ -
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz
$ cd zookeeper-3.4.6
$ mkdir dataขั้นตอนที่ 2.3 - สร้างไฟล์กำหนดค่า
เปิดไฟล์คอนฟิกูเรชันชื่อ“ conf / zoo.cfg” โดยใช้คำสั่ง "vi conf / zoo.cfg" และตั้งค่าพารามิเตอร์ต่อไปนี้ทั้งหมดเป็นจุดเริ่มต้น
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2เมื่อบันทึกไฟล์การกำหนดค่าเรียบร้อยแล้วคุณสามารถเริ่มเซิร์ฟเวอร์ ZooKeeper ได้
ขั้นตอนที่ 2.4 - เริ่มเซิร์ฟเวอร์ ZooKeeper
ใช้คำสั่งต่อไปนี้เพื่อเริ่มเซิร์ฟเวอร์ ZooKeeper
$ bin/zkServer.sh startหลังจากดำเนินการคำสั่งนี้คุณจะได้รับคำตอบดังนี้ -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg
$ Starting zookeeper ... STARTEDขั้นตอนที่ 2.5 - เริ่ม CLI
ใช้คำสั่งต่อไปนี้เพื่อเริ่ม CLI
$ bin/zkCli.shหลังจากดำเนินการคำสั่งข้างต้นคุณจะเชื่อมต่อกับเซิร์ฟเวอร์ ZooKeeper และรับคำตอบต่อไปนี้
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]ขั้นตอนที่ 2.6 - หยุดเซิร์ฟเวอร์ ZooKeeper
หลังจากเชื่อมต่อเซิร์ฟเวอร์และดำเนินการทั้งหมดแล้วคุณสามารถหยุดเซิร์ฟเวอร์ ZooKeeper ได้โดยใช้คำสั่งต่อไปนี้
bin/zkServer.sh stopคุณติดตั้ง Java และ ZooKeeper บนเครื่องของคุณสำเร็จแล้ว ให้เราดูขั้นตอนในการติดตั้ง Apache Storm framework
ขั้นตอนที่ 3 - การติดตั้ง Apache Storm Framework
ขั้นตอนที่ 3.1 ดาวน์โหลด Storm
ในการติดตั้ง Storm framework บนเครื่องของคุณให้ไปที่ลิงค์ต่อไปนี้และดาวน์โหลด Storm เวอร์ชันล่าสุด http://storm.apache.org/downloads.html
ณ ตอนนี้ Storm เวอร์ชันล่าสุดคือ“ apache-storm-0.9.5.tar.gz”
ขั้นตอนที่ 3.2 - แตกไฟล์ tar
แตกไฟล์ tar โดยใช้คำสั่งต่อไปนี้ -
$ cd opt/
$ tar -zxf apache-storm-0.9.5.tar.gz
$ cd apache-storm-0.9.5
$ mkdir dataขั้นตอนที่ 3.3 - เปิดไฟล์กำหนดค่า
Storm รุ่นปัจจุบันมีไฟล์ที่“ conf / storm.yaml” ที่กำหนดค่า Storm daemons เพิ่มข้อมูลต่อไปนี้ลงในไฟล์นั้น
$ vi conf/storm.yaml
storm.zookeeper.servers:
- "localhost"
storm.local.dir: “/path/to/storm/data(any path)”
nimbus.host: "localhost"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703หลังจากใช้การเปลี่ยนแปลงทั้งหมดแล้วให้บันทึกและกลับไปที่เทอร์มินัล
ขั้นตอนที่ 3.4 - เริ่ม Nimbus
$ bin/storm nimbusขั้นตอนที่ 3.5 - เริ่มหัวหน้างาน
$ bin/storm supervisorขั้นตอนที่ 3.6 เริ่ม UI
$ bin/storm uiหลังจากเริ่มแอปพลิเคชันส่วนต่อประสานผู้ใช้ Storm ให้พิมพ์ URL http://localhost:8080ในเบราว์เซอร์ที่คุณชื่นชอบและคุณจะเห็นข้อมูลคลัสเตอร์ Storm และโทโพโลยีที่ทำงานอยู่ หน้าควรมีลักษณะคล้ายกับภาพหน้าจอต่อไปนี้

เราได้อ่านรายละเอียดทางเทคนิคหลักของ Apache Storm แล้วและตอนนี้ก็ถึงเวลาเขียนโค้ดสถานการณ์ง่ายๆ
สถานการณ์ - ตัววิเคราะห์บันทึกการโทรมือถือ
การโทรมือถือและระยะเวลาจะได้รับเป็นอินพุตไปยัง Apache Storm และ Storm จะประมวลผลและจัดกลุ่มการโทรระหว่างผู้โทรและผู้รับรายเดียวกันและจำนวนการโทรทั้งหมด
การสร้างรางน้ำ
Spout เป็นส่วนประกอบที่ใช้ในการสร้างข้อมูล โดยทั่วไปพวยกาจะใช้อินเทอร์เฟซ IRichSpout อินเทอร์เฟซ“ IRichSpout” มีวิธีการที่สำคัญดังต่อไปนี้ -
open- จัดเตรียมพวยกาพร้อมสภาพแวดล้อมในการดำเนินการ ตัวดำเนินการจะเรียกใช้วิธีนี้เพื่อเริ่มต้นพวยกา
nextTuple - ปล่อยข้อมูลที่สร้างขึ้นผ่านตัวรวบรวม
close - วิธีนี้เรียกว่าเมื่อพวยกากำลังจะปิดเครื่อง
declareOutputFields - ประกาศสคีมาผลลัพธ์ของทูเปิล
ack - รับทราบว่ามีการประมวลผลทูเปิลเฉพาะ
fail - ระบุว่าทูเปิลเฉพาะไม่ได้ถูกประมวลผลและไม่ต้องประมวลผลซ้ำ
เปิด
ลายเซ็นของ open วิธีการมีดังนี้ -
open(Map conf, TopologyContext context, SpoutOutputCollector collector)conf - จัดเตรียมการกำหนดค่าพายุสำหรับพวยกานี้
context - ให้ข้อมูลที่สมบูรณ์เกี่ยวกับตำแหน่งพวยกาภายในโทโพโลยีรหัสงานข้อมูลอินพุตและเอาต์พุต
collector - ช่วยให้เราสามารถปล่อยทูเปิลที่จะถูกประมวลผลโดยสลักเกลียว
nextTuple
ลายเซ็นของ nextTuple วิธีการมีดังนี้ -
nextTuple()nextTuple () ถูกเรียกเป็นระยะ ๆ จากลูปเดียวกันกับเมธอด ack () และ fail () จะต้องปล่อยการควบคุมเธรดเมื่อไม่มีงานที่ต้องทำเพื่อให้มีโอกาสเรียกใช้วิธีการอื่น ดังนั้นบรรทัดแรกของ nextTuple จะตรวจสอบว่าการประมวลผลเสร็จสิ้นหรือไม่ ในกรณีนี้ควรพักอย่างน้อยหนึ่งมิลลิวินาทีเพื่อลดภาระในโปรเซสเซอร์ก่อนที่จะกลับมา
ปิด
ลายเซ็นของ close วิธีการมีดังนี้ -
close()ประกาศOutputFields
ลายเซ็นของ declareOutputFields วิธีการมีดังนี้ -
declareOutputFields(OutputFieldsDeclarer declarer)declarer - ใช้เพื่อประกาศรหัสสตรีมเอาต์พุตช่องเอาต์พุต ฯลฯ
วิธีนี้ใช้เพื่อระบุสคีมาเอาต์พุตของทูเปิล
ack
ลายเซ็นของ ack วิธีการมีดังนี้ -
ack(Object msgId)วิธีนี้รับทราบว่ามีการประมวลผลทูเปิลเฉพาะ
ล้มเหลว
ลายเซ็นของ nextTuple วิธีการมีดังนี้ -
ack(Object msgId)วิธีนี้แจ้งว่าทูเปิลเฉพาะยังไม่ได้รับการประมวลผลอย่างสมบูรณ์ Storm จะประมวลผลทูเพิลที่เจาะจงอีกครั้ง
FakeCallLogReaderSpout
ในสถานการณ์ของเราเราจำเป็นต้องรวบรวมรายละเอียดบันทึกการโทร ข้อมูลของบันทึกการโทรประกอบด้วย
- หมายเลขผู้โทร
- หมายเลขผู้รับ
- duration
เนื่องจากเราไม่มีข้อมูลบันทึกการโทรแบบเรียลไทม์เราจะสร้างบันทึกการโทรปลอม ข้อมูลปลอมจะถูกสร้างขึ้นโดยใช้คลาสสุ่ม รหัสโปรแกรมที่สมบูรณ์จะได้รับด้านล่าง
การเข้ารหัส - FakeCallLogReaderSpout.java
import java.util.*;
//import storm tuple packages
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import Spout interface packages
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
//Create a class FakeLogReaderSpout which implement IRichSpout interface
to access functionalities
public class FakeCallLogReaderSpout implements IRichSpout {
//Create instance for SpoutOutputCollector which passes tuples to bolt.
private SpoutOutputCollector collector;
private boolean completed = false;
//Create instance for TopologyContext which contains topology data.
private TopologyContext context;
//Create instance for Random class.
private Random randomGenerator = new Random();
private Integer idx = 0;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
if(this.idx <= 1000) {
List<String> mobileNumbers = new ArrayList<String>();
mobileNumbers.add("1234123401");
mobileNumbers.add("1234123402");
mobileNumbers.add("1234123403");
mobileNumbers.add("1234123404");
Integer localIdx = 0;
while(localIdx++ < 100 && this.idx++ < 1000) {
String fromMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
String toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
while(fromMobileNumber == toMobileNumber) {
toMobileNumber = mobileNumbers.get(randomGenerator.nextInt(4));
}
Integer duration = randomGenerator.nextInt(60);
this.collector.emit(new Values(fromMobileNumber, toMobileNumber, duration));
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("from", "to", "duration"));
}
//Override all the interface methods
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}การสร้างกลอน
Bolt เป็นส่วนประกอบที่ใช้ tuples เป็นอินพุตประมวลผลทูเพิลและสร้างสิ่งทอปเปิลใหม่เป็นเอาต์พุต สลักเกลียวจะดำเนินการIRichBoltอินเตอร์เฟซ. ในโปรแกรมนี้คลาสโบลต์สองคลาสCallLogCreatorBolt และ CallLogCounterBolt ใช้ในการดำเนินการ
อินเทอร์เฟซ IRichBolt มีวิธีการดังต่อไปนี้ -
prepare- จัดเตรียมโบลต์พร้อมสภาพแวดล้อมในการดำเนินการ ตัวดำเนินการจะเรียกใช้วิธีนี้เพื่อเริ่มต้นพวยกา
execute - ประมวลผลอินพุตทูเพิลเดียว
cleanup - เรียกเมื่อโบลต์กำลังจะปิด
declareOutputFields - ประกาศสคีมาผลลัพธ์ของทูเปิล
เตรียม
ลายเซ็นของ prepare วิธีการมีดังนี้ -
prepare(Map conf, TopologyContext context, OutputCollector collector)conf - จัดเตรียมการกำหนดค่า Storm สำหรับสายฟ้านี้
context - ให้ข้อมูลที่สมบูรณ์เกี่ยวกับตำแหน่งโบลต์ภายในโทโพโลยีรหัสงานข้อมูลอินพุตและเอาต์พุต ฯลฯ
collector - ช่วยให้เราสามารถปล่อยทูเปิลที่ประมวลผลได้
ดำเนินการ
ลายเซ็นของ execute วิธีการมีดังนี้ -
execute(Tuple tuple)ที่นี่ tuple คือทูเพิลอินพุตที่จะประมวลผล
executeวิธีการประมวลผลทูเพิลเดียวในแต่ละครั้ง ข้อมูลทูเพิลสามารถเข้าถึงได้ด้วยเมธอด getValue ของคลาส Tuple ไม่จำเป็นต้องประมวลผลทูเพิลอินพุตทันที สามารถประมวลผลทูเปิลหลายตัวและส่งออกเป็นทูเพิลเอาต์พุตเดียว ทูเปิลที่ประมวลผลแล้วสามารถปล่อยออกมาได้โดยใช้คลาส OutputCollector
ทำความสะอาด
ลายเซ็นของ cleanup วิธีการมีดังนี้ -
cleanup()ประกาศOutputFields
ลายเซ็นของ declareOutputFields วิธีการมีดังนี้ -
declareOutputFields(OutputFieldsDeclarer declarer)นี่คือพารามิเตอร์ declarer ใช้เพื่อประกาศรหัสสตรีมเอาต์พุตฟิลด์เอาต์พุต ฯลฯ
วิธีนี้ใช้เพื่อระบุสคีมาเอาต์พุตของทูเปิล
บันทึกการโทรผู้สร้าง Bolt
ผู้สร้างบันทึกการโทรได้รับทูเปิลบันทึกการโทร ทูเปิลบันทึกการโทรมีหมายเลขผู้โทรหมายเลขผู้รับและระยะเวลาการโทร สายฟ้านี้สร้างค่าใหม่โดยการรวมหมายเลขผู้โทรและหมายเลขผู้รับ รูปแบบของค่าใหม่คือ "หมายเลขผู้โทร - หมายเลขผู้รับ" และตั้งชื่อเป็นช่องใหม่ว่า "โทร" รหัสที่สมบูรณ์จะได้รับด้านล่าง
การเข้ารหัส - CallLogCreatorBolt.java
//import util packages
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
//import Storm IRichBolt package
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
//Create a class CallLogCreatorBolt which implement IRichBolt interface
public class CallLogCreatorBolt implements IRichBolt {
//Create instance for OutputCollector which collects and emits tuples to produce output
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String from = tuple.getString(0);
String to = tuple.getString(1);
Integer duration = tuple.getInteger(2);
collector.emit(new Values(from + " - " + to, duration));
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call", "duration"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}บันทึกการโทร Counter Bolt
สลักตัวนับบันทึกการโทรรับสายและระยะเวลาเป็นทูเพิล สลักเกลียวนี้เริ่มต้นวัตถุพจนานุกรม (แผนที่) ในวิธีการเตรียม ในexecuteวิธีนี้จะตรวจสอบทูเพิลและสร้างรายการใหม่ในออบเจ็กต์พจนานุกรมสำหรับทุกค่า "การเรียก" ใหม่ในทูเปิลและตั้งค่า 1 ในออบเจ็กต์พจนานุกรม สำหรับรายการที่มีอยู่แล้วในพจนานุกรมก็แค่เพิ่มค่า กล่าวง่ายๆคือสลักเกลียวนี้จะบันทึกการโทรและจำนวนของมันในวัตถุพจนานุกรม แทนที่จะบันทึกการโทรและจำนวนครั้งในพจนานุกรมเรายังสามารถบันทึกลงในแหล่งข้อมูลได้อีกด้วย รหัสโปรแกรมที่สมบูรณ์มีดังนี้ -
การเข้ารหัส - CallLogCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class CallLogCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String call = tuple.getString(0);
Integer duration = tuple.getInteger(1);
if(!counterMap.containsKey(call)){
counterMap.put(call, 1);
}else{
Integer c = counterMap.get(call) + 1;
counterMap.put(call, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("call"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}การสร้างโทโพโลยี
โทโพโลยีแบบพายุนั้นเป็นโครงสร้างแบบ Thrift คลาส TopologyBuilder มีวิธีการที่ง่ายและสะดวกในการสร้างโทโพโลยีที่ซับซ้อน คลาส TopologyBuilder มีวิธีการตั้งค่าพวยกา(setSpout) และตั้งสลักเกลียว (setBolt). ในที่สุด TopologyBuilder ได้ createTopology เพื่อสร้างโทโพโลยี ใช้ข้อมูลโค้ดต่อไปนี้เพื่อสร้างโทโพโลยี -
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));shuffleGrouping และ fieldsGrouping วิธีการช่วยในการตั้งค่าการจัดกลุ่มสตรีมสำหรับพวยกาและสลักเกลียว
คลัสเตอร์ภายใน
เพื่อจุดประสงค์ในการพัฒนาเราสามารถสร้างคลัสเตอร์ภายในโดยใช้ออบเจ็กต์ "LocalCluster" จากนั้นส่งโทโพโลยีโดยใช้เมธอด "submitTopology" ของคลาส "LocalCluster" หนึ่งในอาร์กิวเมนต์สำหรับ "submitTopology" คืออินสแตนซ์ของคลาส "Config" คลาส "Config" ใช้เพื่อตั้งค่าตัวเลือกการกำหนดค่าก่อนที่จะส่งโทโพโลยี ตัวเลือกการกำหนดค่านี้จะรวมเข้ากับการกำหนดค่าคลัสเตอร์ในขณะทำงานและส่งไปยังงานทั้งหมด (พวยกาและสลักเกลียว) ด้วยวิธีการเตรียม เมื่อส่งโทโพโลยีไปยังคลัสเตอร์แล้วเราจะรอ 10 วินาทีเพื่อให้คลัสเตอร์คำนวณโทโพโลยีที่ส่งจากนั้นปิดคลัสเตอร์โดยใช้วิธีการ "ปิดระบบ" ของ "LocalCluster" รหัสโปรแกรมที่สมบูรณ์มีดังนี้ -
การเข้ารหัส - LogAnalyserStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
//import storm configuration packages
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
//Create main class LogAnalyserStorm submit topology.
public class LogAnalyserStorm {
public static void main(String[] args) throws Exception{
//Create Config instance for cluster configuration
Config config = new Config();
config.setDebug(true);
//
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("call-log-reader-spout", new FakeCallLogReaderSpout());
builder.setBolt("call-log-creator-bolt", new CallLogCreatorBolt())
.shuffleGrouping("call-log-reader-spout");
builder.setBolt("call-log-counter-bolt", new CallLogCounterBolt())
.fieldsGrouping("call-log-creator-bolt", new Fields("call"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("LogAnalyserStorm", config, builder.createTopology());
Thread.sleep(10000);
//Stop the topology
cluster.shutdown();
}
}การสร้างและเรียกใช้แอปพลิเคชัน
แอปพลิเคชันที่สมบูรณ์มีรหัส Java สี่ตัว พวกเขาคือ -
- FakeCallLogReaderSpout.java
- CallLogCreaterBolt.java
- CallLogCounterBolt.java
- LogAnalyerStorm.java
สามารถสร้างแอปพลิเคชันได้โดยใช้คำสั่งต่อไปนี้ -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaแอปพลิเคชันสามารถรันได้โดยใช้คำสั่งต่อไปนี้ -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserStormเอาต์พุต
เมื่อแอปพลิเคชันเริ่มทำงานแอปพลิเคชันจะแสดงรายละเอียดทั้งหมดเกี่ยวกับกระบวนการเริ่มต้นคลัสเตอร์การประมวลผลพวยกาและโบลต์และสุดท้ายคือกระบวนการปิดระบบคลัสเตอร์ ใน "CallLogCounterBolt" เราได้พิมพ์การโทรและรายละเอียดการนับ ข้อมูลนี้จะแสดงบนคอนโซลดังนี้ -
1234123402 - 1234123401 : 78
1234123402 - 1234123404 : 88
1234123402 - 1234123403 : 105
1234123401 - 1234123404 : 74
1234123401 - 1234123403 : 81
1234123401 - 1234123402 : 81
1234123403 - 1234123404 : 86
1234123404 - 1234123401 : 63
1234123404 - 1234123402 : 82
1234123403 - 1234123402 : 83
1234123404 - 1234123403 : 86
1234123403 - 1234123401 : 93ภาษาที่ไม่ใช่ JVM
โทโพโลยีแบบสตอร์มถูกนำไปใช้โดยอินเทอร์เฟซ Thrift ซึ่งทำให้ง่ายต่อการส่งโทโพโลยีในภาษาใด ๆ Storm รองรับ Ruby, Python และภาษาอื่น ๆ อีกมากมาย ลองมาดูการผูกไพ ธ อน
การผูก Python
Python เป็นภาษาการเขียนโปรแกรมระดับสูงที่ตีความโต้ตอบเชิงวัตถุและระดับสูง Storm สนับสนุน Python เพื่อใช้โทโพโลยี Python สนับสนุนการเปล่งการทอดสมอการจับและการบันทึก
ดังที่คุณทราบสลักเกลียวสามารถกำหนดเป็นภาษาใดก็ได้ สลักเกลียวที่เขียนด้วยภาษาอื่นจะดำเนินการเป็นกระบวนการย่อยและ Storm สื่อสารกับกระบวนการย่อยเหล่านั้นด้วยข้อความ JSON ผ่าน stdin / stdout ก่อนอื่นให้ใช้ตัวอย่าง Bolt WordCount ที่รองรับการผูก python
public static class WordCount implements IRichBolt {
public WordSplit() {
super("python", "splitword.py");
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}ที่นี่ชั้นเรียน WordCount ใช้ IRichBoltอินเทอร์เฟซและทำงานโดยใช้ python อาร์กิวเมนต์ super method ระบุ "splitword.py" ตอนนี้สร้างการใช้งาน python ชื่อ "splitword.py"
import storm
class WordCountBolt(storm.BasicBolt):
def process(self, tup):
words = tup.values[0].split(" ")
for word in words:
storm.emit([word])
WordCountBolt().run()นี่คือตัวอย่างการใช้งาน Python ที่นับจำนวนคำในประโยคที่กำหนด ในทำนองเดียวกันคุณสามารถเชื่อมโยงกับภาษาสนับสนุนอื่น ๆ ได้เช่นกัน
ตรีศูลเป็นส่วนขยายของสตอร์ม เช่นเดียวกับ Storm Trident ก็ได้รับการพัฒนาโดย Twitter เหตุผลหลักที่อยู่เบื้องหลังการพัฒนาตรีศูลคือการให้นามธรรมระดับสูงที่ด้านบนของ Storm พร้อมกับการประมวลผลสตรีมแบบมีสถานะและการสืบค้นแบบกระจายเวลาแฝงต่ำ
Trident ใช้พวยกาและโบลต์ แต่ส่วนประกอบระดับต่ำเหล่านี้สร้างขึ้นโดยอัตโนมัติโดย Trident ก่อนดำเนินการ ตรีศูลมีฟังก์ชันตัวกรองการรวมการจัดกลุ่มและการรวม
ตรีศูลประมวลผลสตรีมเป็นชุดของแบทช์ซึ่งเรียกว่าธุรกรรม โดยทั่วไปขนาดของแบทช์เล็ก ๆ เหล่านั้นจะอยู่ในลำดับของสิ่งทอหลายพันหรือหลายล้านตัวขึ้นอยู่กับสตรีมอินพุต วิธีนี้ตรีศูลแตกต่างจาก Storm ซึ่งทำการประมวลผลแบบทูเพิล - ทูเพิล
แนวคิดการประมวลผลแบบกลุ่มมีความคล้ายคลึงกับธุรกรรมฐานข้อมูลมาก ทุกธุรกรรมจะถูกกำหนดรหัสธุรกรรม ธุรกรรมจะถือว่าสำเร็จเมื่อการประมวลผลทั้งหมดเสร็จสมบูรณ์ อย่างไรก็ตามความล้มเหลวในการประมวลผลสิ่งที่เกิดขึ้นอย่างใดอย่างหนึ่งของธุรกรรมจะทำให้ธุรกรรมทั้งหมดถูกส่งใหม่ สำหรับแต่ละแบทช์ตรีศูลจะเรียก beginCommit ที่จุดเริ่มต้นของธุรกรรมและกระทำในตอนท้ายของธุรกรรม
โทโพโลยีตรีศูล
Trident API แสดงตัวเลือกที่ง่ายในการสร้างโทโพโลยีตรีศูลโดยใช้คลาส“ TridentTopology” โดยทั่วไปโทโพโลยีตรีศูลจะรับอินพุตสตรีมจากพวยกาและทำลำดับการทำงานตามลำดับ (ตัวกรองการรวมการจัดกลุ่ม ฯลฯ ) บนสตรีม Storm Tuple ถูกแทนที่ด้วย Trident Tuple และ Bolts จะถูกแทนที่ด้วยปฏิบัติการ สามารถสร้างโทโพโลยีตรีศูลอย่างง่ายได้ดังนี้ -
TridentTopology topology = new TridentTopology();ตรีศูลทูเปิล
ตรีศูลทูเปิลเป็นรายการค่าที่ตั้งชื่อ อินเทอร์เฟซ TridentTuple เป็นแบบจำลองข้อมูลของโทโพโลยีตรีศูล อินเทอร์เฟซ TridentTuple เป็นหน่วยพื้นฐานของข้อมูลที่สามารถประมวลผลโดยโทโพโลยีตรีศูล
Trident Spout
Trident spout คล้ายกับ Storm spout พร้อมตัวเลือกเพิ่มเติมในการใช้คุณสมบัติของ Trident จริงๆแล้วเรายังสามารถใช้ IRichSpout ซึ่งเราเคยใช้ในโทโพโลยีของ Storm ได้ แต่จะไม่สามารถทำธุรกรรมได้และเราจะไม่สามารถใช้ข้อดีที่ตรีศูลให้มาได้
พวยกาพื้นฐานที่มีฟังก์ชันทั้งหมดในการใช้คุณสมบัติของ Trident คือ "ITridentSpout" สนับสนุนทั้งความหมายทรานแซคชันและทึบแสง พวยกาอื่น ๆ ได้แก่ IBatchSpout, IPartitionedTridentSpout และ IOpaquePartitionedTridentSpout
นอกเหนือจากพวยกาทั่วไปเหล่านี้ตรีศูลยังมีตัวอย่างการใช้งานพวยกาตรีศูลอีกมากมาย หนึ่งในนั้นคือ FeederBatchSpout spout ซึ่งเราสามารถใช้เพื่อส่งรายชื่อของ tuples ตรีศูลได้อย่างง่ายดายโดยไม่ต้องกังวลเกี่ยวกับการประมวลผลแบบแบทช์การขนานกัน ฯลฯ
การสร้าง FeederBatchSpout และการป้อนข้อมูลสามารถทำได้ดังภาพด้านล่าง -
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(
ImmutableList.of("fromMobileNumber", "toMobileNumber", “duration”));
topology.newStream("fixed-batch-spout", testSpout)
testSpout.feed(ImmutableList.of(new Values("1234123401", "1234123402", 20)));ตรีศูลปฏิบัติการ
ตรีศูลอาศัย“ Trident Operation” ในการประมวลผลกระแสข้อมูลของสิ่งทอตรีศูล Trident API มีการดำเนินการในตัวจำนวนมากเพื่อจัดการกับการประมวลผลสตรีมแบบง่ายถึงซับซ้อน การดำเนินการเหล่านี้มีตั้งแต่การตรวจสอบความถูกต้องอย่างง่ายไปจนถึงการจัดกลุ่มที่ซับซ้อนและการรวมตัวกันของสิ่งทอสามมิติ ให้เราดำเนินการที่สำคัญที่สุดและใช้บ่อยที่สุด
กรอง
ตัวกรองเป็นวัตถุที่ใช้ในการตรวจสอบความถูกต้องของอินพุต ตัวกรองตรีศูลรับส่วนย่อยของฟิลด์ทูเปิลตรีศูลเป็นอินพุตและส่งคืนค่าจริงหรือเท็จขึ้นอยู่กับว่าเงื่อนไขบางอย่างเป็นที่พอใจหรือไม่ หากส่งคืนค่า true ทูเปิลจะถูกเก็บไว้ในเอาต์พุตสตรีม มิฉะนั้นทูเปิลจะถูกลบออกจากสตรีม โดยพื้นฐานแล้วตัวกรองจะสืบทอดมาจากไฟล์BaseFilter คลาสและใช้ isKeepวิธี. นี่คือตัวอย่างการใช้งานตัวกรอง -
public class MyFilter extends BaseFilter {
public boolean isKeep(TridentTuple tuple) {
return tuple.getInteger(1) % 2 == 0;
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2]
[1, 4]ฟังก์ชันตัวกรองสามารถเรียกใช้ในโทโพโลยีโดยใช้วิธีการ "แต่ละ" คลาส "ฟิลด์" สามารถใช้เพื่อระบุอินพุต (เซตย่อยของทูเพิลตรีศูล) โค้ดตัวอย่างมีดังนี้ -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields("a", "b"), new MyFilter())ฟังก์ชัน
Functionเป็นวัตถุที่ใช้ในการดำเนินการอย่างง่ายกับทูเปิลตรีศูลตัวเดียว ใช้ฟิลด์ทูเปิลตรีศูลย่อยและปล่อยฟิลด์ทูเปิลตรีศูลใหม่เป็นศูนย์หรือมากกว่า
Function โดยทั่วไปจะสืบทอดมาจากไฟล์ BaseFunction ชั้นเรียนและใช้ executeวิธี. ตัวอย่างการใช้งานได้รับด้านล่าง -
public class MyFunction extends BaseFunction {
public void execute(TridentTuple tuple, TridentCollector collector) {
int a = tuple.getInteger(0);
int b = tuple.getInteger(1);
collector.emit(new Values(a + b));
}
}
input
[1, 2]
[1, 3]
[1, 4]
output
[1, 2, 3]
[1, 3, 4]
[1, 4, 5]เช่นเดียวกับการกรองการทำงานของฟังก์ชันสามารถเรียกใช้ในโทโพโลยีโดยใช้ eachวิธี. โค้ดตัวอย่างมีดังนี้ -
TridentTopology topology = new TridentTopology();
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d")));การรวม
Aggregation เป็นอ็อบเจ็กต์ที่ใช้ในการดำเนินการรวมในชุดอินพุตหรือพาร์ติชันหรือสตรีม ตรีศูลมีการรวมตัวสามประเภท มีดังนี้ -
aggregate- รวบรวมทูเปิลตรีศูลแต่ละชุดแยกกัน ในระหว่างกระบวนการรวม tuples จะถูกแบ่งพาร์ติชันในขั้นต้นโดยใช้การจัดกลุ่มส่วนกลางเพื่อรวมพาร์ติชันทั้งหมดของชุดงานเดียวกันให้เป็นพาร์ติชันเดียว
partitionAggregate- รวมแต่ละพาร์ติชันแทนที่จะเป็นกลุ่มตรีศูลทูเปิลทั้งหมด ผลลัพธ์ของการรวมพาร์ติชันจะแทนที่ทูเพิลอินพุตอย่างสมบูรณ์ ผลลัพธ์ของการรวมพาร์ติชันประกอบด้วยทูเพิลฟิลด์เดียว
persistentaggregate - รวมค่าทูเพิลตรีศูลทั้งหมดในทุกแบทช์และเก็บผลลัพธ์ไว้ในหน่วยความจำหรือฐานข้อมูล
TridentTopology topology = new TridentTopology();
// aggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.aggregate(new Count(), new Fields(“count”))
// partitionAggregate operation
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.partitionAggregate(new Count(), new Fields(“count"))
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));การดำเนินการรวมสามารถสร้างได้โดยใช้ CombinerAggregator, ReducerAggregator หรืออินเทอร์เฟซ Aggregator ทั่วไป ตัวรวบรวม "จำนวน" ที่ใช้ในตัวอย่างข้างต้นเป็นหนึ่งในตัวรวบรวมแบบบิลด์อินซึ่งใช้งานโดยใช้ "CombinerAggregator" การใช้งานมีดังนี้ -
public class Count implements CombinerAggregator<Long> {
@Override
public Long init(TridentTuple tuple) {
return 1L;
}
@Override
public Long combine(Long val1, Long val2) {
return val1 + val2;
}
@Override
public Long zero() {
return 0L;
}
}การจัดกลุ่ม
การดำเนินการจัดกลุ่มเป็นการดำเนินการที่สร้างขึ้นและสามารถเรียกใช้โดยไฟล์ groupByวิธี. เมธอด groupBy แบ่งพาร์ติชันสตรีมใหม่โดยทำ partitionBy บนฟิลด์ที่ระบุจากนั้นภายในแต่ละพาร์ติชันจะจัดกลุ่ม tuples เข้าด้วยกันซึ่งฟิลด์กลุ่มมีค่าเท่ากัน โดยปกติเราจะใช้“ groupBy” ร่วมกับ“ persistentAggregate” เพื่อรับการรวมกลุ่ม โค้ดตัวอย่างมีดังนี้ -
TridentTopology topology = new TridentTopology();
// persistentAggregate - saving the count to memory
topology.newStream("spout", spout)
.each(new Fields(“a, b"), new MyFunction(), new Fields(“d”))
.groupBy(new Fields(“d”)
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));การรวมและการเข้าร่วม
การรวมและการเข้าร่วมสามารถทำได้โดยใช้วิธี "รวม" และ "เข้าร่วม" ตามลำดับ การผสานรวมสตรีมตั้งแต่หนึ่งรายการขึ้นไป การเข้าร่วมคล้ายกับการรวมยกเว้นข้อเท็จจริงที่ว่าการเข้าร่วมใช้ฟิลด์ทูเปิลตรีศูลจากทั้งสองฝ่ายเพื่อตรวจสอบและเข้าร่วมสองสตรีม ยิ่งไปกว่านั้นการเข้าร่วมจะทำงานภายใต้ระดับแบทช์เท่านั้น โค้ดตัวอย่างมีดังนี้ -
TridentTopology topology = new TridentTopology();
topology.merge(stream1, stream2, stream3);
topology.join(stream1, new Fields("key"), stream2, new Fields("x"),
new Fields("key", "a", "b", "c"));การบำรุงรักษาของรัฐ
ตรีศูลเป็นกลไกสำหรับการบำรุงรักษาสถานะ ข้อมูลสถานะสามารถจัดเก็บไว้ในโทโพโลยีเองได้มิฉะนั้นคุณสามารถจัดเก็บไว้ในฐานข้อมูลแยกต่างหากได้เช่นกัน เหตุผลคือเพื่อรักษาสถานะว่าหากทูเปิลใดล้มเหลวในระหว่างการประมวลผลทูเปิลที่ล้มเหลวจะถูกลองใหม่ สิ่งนี้สร้างปัญหาขณะอัปเดตสถานะเนื่องจากคุณไม่แน่ใจว่าสถานะของทูเปิลนี้ได้รับการอัปเดตก่อนหน้านี้หรือไม่ หากทูเปิลล้มเหลวก่อนอัปเดตสถานะการลองทูเปิลอีกครั้งจะทำให้สถานะเสถียร อย่างไรก็ตามหากทูเปิลล้มเหลวหลังจากอัปเดตสถานะแล้วการลองทูเพิลเดิมซ้ำอีกครั้งจะเพิ่มจำนวนในฐานข้อมูลและทำให้สถานะไม่เสถียร เราต้องทำตามขั้นตอนต่อไปนี้เพื่อให้แน่ใจว่าข้อความถูกประมวลผลเพียงครั้งเดียว -
ประมวลผล tuples ในแบทช์เล็ก ๆ
กำหนด ID เฉพาะให้กับแต่ละชุด หากลองชุดใหม่อีกครั้งชุดนั้นจะได้รับรหัสเฉพาะเดียวกัน
การอัปเดตสถานะจะเรียงลำดับระหว่างแบทช์ ตัวอย่างเช่นการอัปเดตสถานะของชุดที่สองจะไม่สามารถทำได้จนกว่าการอัปเดตสถานะสำหรับชุดงานแรกจะเสร็จสิ้น
RPC แบบกระจาย
RPC แบบกระจายใช้เพื่อสืบค้นและดึงผลลัพธ์จากโทโพโลยีตรีศูล Storm มีเซิร์ฟเวอร์ RPC แบบกระจายในตัว เซิร์ฟเวอร์ RPC แบบกระจายจะรับคำขอ RPC จากไคลเอนต์และส่งต่อไปยังโทโพโลยี โทโพโลยีประมวลผลคำขอและส่งผลลัพธ์ไปยังเซิร์ฟเวอร์ RPC แบบกระจายซึ่งถูกเปลี่ยนเส้นทางโดยเซิร์ฟเวอร์ RPC แบบกระจายไปยังไคลเอนต์ การสืบค้น RPC แบบกระจายของ Trident จะดำเนินการเหมือนกับการสืบค้น RPC ทั่วไปยกเว้นข้อเท็จจริงที่ว่าการสืบค้นเหล่านี้ทำงานควบคู่กันไป
ควรใช้ตรีศูลเมื่อใด
เช่นเดียวกับการใช้งานหลายกรณีหากข้อกำหนดคือการประมวลผลแบบสอบถามเพียงครั้งเดียวเราสามารถบรรลุได้โดยการเขียนโทโพโลยีในตรีศูล ในทางกลับกันการประมวลผลครั้งเดียวในกรณีของสตอร์มจะเป็นเรื่องยาก ดังนั้นตรีศูลจะเป็นประโยชน์สำหรับกรณีการใช้งานที่คุณต้องการเพียงครั้งเดียวในการประมวลผล ตรีศูลไม่ได้มีไว้สำหรับกรณีการใช้งานทั้งหมดโดยเฉพาะอย่างยิ่งกรณีการใช้งานที่มีประสิทธิภาพสูงเนื่องจากเพิ่มความซับซ้อนให้กับ Storm และจัดการสถานะ
ตัวอย่างการทำงานของตรีศูล
เรากำลังจะแปลงแอปพลิเคชันตัววิเคราะห์บันทึกการโทรของเราที่ทำในส่วนก่อนหน้านี้เป็นกรอบงานตรีศูล แอปพลิเคชั่น Trident จะค่อนข้างง่ายเมื่อเทียบกับพายุธรรมดาด้วย API ระดับสูง โดยทั่วไป Storm จะต้องดำเนินการอย่างใดอย่างหนึ่งของ Function, Filter, Aggregate, GroupBy, Join and Merge operation in Trident ในที่สุดเราจะเริ่มเซิร์ฟเวอร์ DRPC โดยใช้ไฟล์LocalDRPC คลาสและค้นหาคำหลักโดยใช้ execute วิธีการของคลาส LocalDRPC
การจัดรูปแบบข้อมูลการโทร
วัตถุประสงค์ของคลาส FormatCall คือการจัดรูปแบบข้อมูลการโทรซึ่งประกอบด้วย "หมายเลขผู้โทร" และ "หมายเลขผู้รับ" รหัสโปรแกรมที่สมบูรณ์มีดังนี้ -
การเข้ารหัส: FormatCall.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class FormatCall extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String fromMobileNumber = tuple.getString(0);
String toMobileNumber = tuple.getString(1);
collector.emit(new Values(fromMobileNumber + " - " + toMobileNumber));
}
}CSVSplit
วัตถุประสงค์ของคลาส CSVSplit คือการแยกสตริงอินพุตตาม "ลูกน้ำ (,)" และเปล่งทุกคำในสตริง ฟังก์ชันนี้ใช้เพื่อแยกวิเคราะห์อาร์กิวเมนต์อินพุตของการสืบค้นแบบกระจาย รหัสที่สมบูรณ์มีดังนี้ -
การเข้ารหัส: CSVSplit.java
import backtype.storm.tuple.Values;
import storm.trident.operation.BaseFunction;
import storm.trident.operation.TridentCollector;
import storm.trident.tuple.TridentTuple;
public class CSVSplit extends BaseFunction {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
for(String word: tuple.getString(0).split(",")) {
if(word.length() > 0) {
collector.emit(new Values(word));
}
}
}
}Log Analyzer
นี่คือแอปพลิเคชันหลัก ในขั้นต้นแอปพลิเคชันจะเริ่มต้น TridentTopology และป้อนข้อมูลผู้โทรโดยใช้FeederBatchSpout. สามารถสร้างสตรีมโทโพโลยีตรีศูลได้โดยใช้newStreamวิธีการของคลาส TridentTopology ในทำนองเดียวกันสตรีม DRPC โทโพโลยีตรีศูลสามารถสร้างได้โดยใช้newDRCPStreamวิธีการของคลาส TridentTopology สามารถสร้างเซิร์ฟเวอร์ DRCP แบบธรรมดาโดยใช้คลาส LocalDRPCLocalDRPCมีวิธีการดำเนินการเพื่อค้นหาคำหลักบางคำ รหัสที่สมบูรณ์จะได้รับด้านล่าง
การเข้ารหัส: LogAnalyserTrident.java
import java.util.*;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.LocalDRPC;
import backtype.storm.utils.DRPCClient;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.tuple.TridentTuple;
import storm.trident.operation.builtin.FilterNull;
import storm.trident.operation.builtin.Count;
import storm.trident.operation.builtin.Sum;
import storm.trident.operation.builtin.MapGet;
import storm.trident.operation.builtin.Debug;
import storm.trident.operation.BaseFilter;
import storm.trident.testing.FixedBatchSpout;
import storm.trident.testing.FeederBatchSpout;
import storm.trident.testing.Split;
import storm.trident.testing.MemoryMapState;
import com.google.common.collect.ImmutableList;
public class LogAnalyserTrident {
public static void main(String[] args) throws Exception {
System.out.println("Log Analyser Trident");
TridentTopology topology = new TridentTopology();
FeederBatchSpout testSpout = new FeederBatchSpout(ImmutableList.of("fromMobileNumber",
"toMobileNumber", "duration"));
TridentState callCounts = topology
.newStream("fixed-batch-spout", testSpout)
.each(new Fields("fromMobileNumber", "toMobileNumber"),
new FormatCall(), new Fields("call"))
.groupBy(new Fields("call"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(),
new Fields("count"));
LocalDRPC drpc = new LocalDRPC();
topology.newDRPCStream("call_count", drpc)
.stateQuery(callCounts, new Fields("args"), new MapGet(), new Fields("count"));
topology.newDRPCStream("multiple_call_count", drpc)
.each(new Fields("args"), new CSVSplit(), new Fields("call"))
.groupBy(new Fields("call"))
.stateQuery(callCounts, new Fields("call"), new MapGet(),
new Fields("count"))
.each(new Fields("call", "count"), new Debug())
.each(new Fields("count"), new FilterNull())
.aggregate(new Fields("count"), new Sum(), new Fields("sum"));
Config conf = new Config();
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("trident", conf, topology.build());
Random randomGenerator = new Random();
int idx = 0;
while(idx < 10) {
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123402", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123403", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123401",
"1234123404", randomGenerator.nextInt(60))));
testSpout.feed(ImmutableList.of(new Values("1234123402",
"1234123403", randomGenerator.nextInt(60))));
idx = idx + 1;
}
System.out.println("DRPC : Query starts");
System.out.println(drpc.execute("call_count","1234123401 - 1234123402"));
System.out.println(drpc.execute("multiple_call_count", "1234123401 -
1234123402,1234123401 - 1234123403"));
System.out.println("DRPC : Query ends");
cluster.shutdown();
drpc.shutdown();
// DRPCClient client = new DRPCClient("drpc.server.location", 3772);
}
}การสร้างและเรียกใช้แอปพลิเคชัน
แอปพลิเคชันที่สมบูรณ์มีรหัส Java สามรหัส มีดังนี้ -
- FormatCall.java
- CSVSplit.java
- LogAnalyerTrident.java
สามารถสร้างแอปพลิเคชันได้โดยใช้คำสั่งต่อไปนี้ -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*” *.javaแอปพลิเคชันสามารถทำงานได้โดยใช้คำสั่งต่อไปนี้ -
java -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:. LogAnalyserTridentเอาต์พุต
เมื่อแอปพลิเคชันเริ่มทำงานแอปพลิเคชันจะแสดงรายละเอียดทั้งหมดเกี่ยวกับกระบวนการเริ่มต้นคลัสเตอร์การประมวลผลการดำเนินงานเซิร์ฟเวอร์ DRPC และข้อมูลไคลเอ็นต์และสุดท้ายคือกระบวนการปิดระบบคลัสเตอร์ เอาต์พุตนี้จะแสดงบนคอนโซลดังที่แสดงด้านล่าง
DRPC : Query starts
[["1234123401 - 1234123402",10]]
DEBUG: [1234123401 - 1234123402, 10]
DEBUG: [1234123401 - 1234123403, 10]
[[20]]
DRPC : Query endsในบทนี้เราจะพูดถึงการใช้งาน Apache Storm แบบเรียลไทม์ เราจะมาดูกันว่า Storm ใช้อย่างไรใน Twitter
ทวิตเตอร์
Twitter เป็นบริการเครือข่ายสังคมออนไลน์ที่มีแพลตฟอร์มในการส่งและรับทวีตของผู้ใช้ ผู้ใช้ที่ลงทะเบียนสามารถอ่านและโพสต์ทวีตได้ แต่ผู้ใช้ที่ไม่ได้ลงทะเบียนสามารถอ่านทวีตได้เท่านั้น แฮชแท็กใช้ในการจัดหมวดหมู่ทวีตตามคีย์เวิร์ดโดยต่อท้าย # ก่อนคีย์เวิร์ดที่เกี่ยวข้อง ตอนนี้ให้เราใช้สถานการณ์แบบเรียลไทม์เพื่อค้นหาแฮชแท็กที่ใช้บ่อยที่สุดตามหัวข้อ
การสร้างรางน้ำ
จุดประสงค์ของพวยกาคือการรับทวีตที่ส่งโดยผู้คนโดยเร็วที่สุด Twitter มี“ Twitter Streaming API” ซึ่งเป็นเครื่องมือที่ใช้บริการบนเว็บเพื่อดึงทวีตที่ส่งโดยผู้คนแบบเรียลไทม์ Twitter Streaming API สามารถเข้าถึงได้ในภาษาโปรแกรมใดก็ได้
twitter4j เป็นไลบรารี Java แบบโอเพ่นซอร์สที่ไม่เป็นทางการซึ่งมีโมดูลที่ใช้ Java เพื่อเข้าถึง Twitter Streaming API ได้อย่างง่ายดาย twitter4jจัดเตรียมเฟรมเวิร์กสำหรับผู้ฟังเพื่อเข้าถึงทวีต ในการเข้าถึง Twitter Streaming API เราต้องลงชื่อเข้าใช้บัญชีผู้พัฒนา Twitter และควรได้รับรายละเอียดการตรวจสอบสิทธิ์ OAuth ดังต่อไปนี้
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Storm ให้ Twitter พวยกา TwitterSampleSpout,ในชุดเริ่มต้น เราจะใช้มันเพื่อดึงทวีต พวยกาต้องการรายละเอียดการตรวจสอบสิทธิ์ OAuth และอย่างน้อยคำหลัก พวยกาจะส่งเสียงทวีตตามเวลาจริงตามคำสำคัญ รหัสโปรแกรมที่สมบูรณ์จะได้รับด้านล่าง
การเข้ารหัส: TwitterSampleSpout.java
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.FilterQuery;
import twitter4j.StallWarning;
import twitter4j.Status;
import twitter4j.StatusDeletionNotice;
import twitter4j.StatusListener;
import twitter4j.TwitterStream;
import twitter4j.TwitterStreamFactory;
import twitter4j.auth.AccessToken;
import twitter4j.conf.ConfigurationBuilder;
import backtype.storm.Config;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.utils.Utils;
@SuppressWarnings("serial")
public class TwitterSampleSpout extends BaseRichSpout {
SpoutOutputCollector _collector;
LinkedBlockingQueue<Status> queue = null;
TwitterStream _twitterStream;
String consumerKey;
String consumerSecret;
String accessToken;
String accessTokenSecret;
String[] keyWords;
public TwitterSampleSpout(String consumerKey, String consumerSecret,
String accessToken, String accessTokenSecret, String[] keyWords) {
this.consumerKey = consumerKey;
this.consumerSecret = consumerSecret;
this.accessToken = accessToken;
this.accessTokenSecret = accessTokenSecret;
this.keyWords = keyWords;
}
public TwitterSampleSpout() {
// TODO Auto-generated constructor stub
}
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
queue = new LinkedBlockingQueue<Status>(1000);
_collector = collector;
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
}
@Override
public void onDeletionNotice(StatusDeletionNotice sdn) {}
@Override
public void onTrackLimitationNotice(int i) {}
@Override
public void onScrubGeo(long l, long l1) {}
@Override
public void onException(Exception ex) {}
@Override
public void onStallWarning(StallWarning arg0) {
// TODO Auto-generated method stub
}
};
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
_twitterStream = new TwitterStreamFactory(cb.build()).getInstance();
_twitterStream.addListener(listener);
if (keyWords.length == 0) {
_twitterStream.sample();
}else {
FilterQuery query = new FilterQuery().track(keyWords);
_twitterStream.filter(query);
}
}
@Override
public void nextTuple() {
Status ret = queue.poll();
if (ret == null) {
Utils.sleep(50);
} else {
_collector.emit(new Values(ret));
}
}
@Override
public void close() {
_twitterStream.shutdown();
}
@Override
public Map<String, Object> getComponentConfiguration() {
Config ret = new Config();
ret.setMaxTaskParallelism(1);
return ret;
}
@Override
public void ack(Object id) {}
@Override
public void fail(Object id) {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("tweet"));
}
}Hashtag Reader Bolt
ทวีตที่ปล่อยออกมาโดยพวยกาจะถูกส่งต่อไปยัง HashtagReaderBoltซึ่งจะประมวลผลทวีตและปล่อยแฮชแท็กทั้งหมดที่มี HashtagReaderBolt ใช้getHashTagEntitiesวิธีการให้โดย twitter4j getHashTagEntities อ่านทวีตและส่งคืนรายการแฮชแท็ก รหัสโปรแกรมที่สมบูรณ์มีดังนี้ -
การเข้ารหัส: HashtagReaderBolt.java
import java.util.HashMap;
import java.util.Map;
import twitter4j.*;
import twitter4j.conf.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagReaderBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
Status tweet = (Status) tuple.getValueByField("tweet");
for(HashtagEntity hashtage : tweet.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
this.collector.emit(new Values(hashtage.getText()));
}
}
@Override
public void cleanup() {}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Hashtag Counter Bolt
แฮชแท็กที่ปล่อยออกมาจะถูกส่งต่อไปยัง HashtagCounterBolt. สายฟ้านี้จะประมวลผลแฮชแท็กทั้งหมดและบันทึกแต่ละแฮชแท็กและจำนวนในหน่วยความจำโดยใช้วัตถุ Java Map รหัสโปรแกรมที่สมบูรณ์จะได้รับด้านล่าง
การเข้ารหัส: HashtagCounterBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class HashtagCounterBolt implements IRichBolt {
Map<String, Integer> counterMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.counterMap = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String key = tuple.getString(0);
if(!counterMap.containsKey(key)){
counterMap.put(key, 1);
}else{
Integer c = counterMap.get(key) + 1;
counterMap.put(key, c);
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counterMap.entrySet()){
System.out.println("Result: " + entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("hashtag"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}การส่งโทโพโลยี
การส่งโทโพโลยีเป็นแอปพลิเคชันหลัก โทโพโลยีของ Twitter ประกอบด้วยTwitterSampleSpout, HashtagReaderBoltและ HashtagCounterBolt. รหัสโปรแกรมต่อไปนี้แสดงวิธีการส่งโทโพโลยี
การเข้ารหัส: TwitterHashtagStorm.java
import java.util.*;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class TwitterHashtagStorm {
public static void main(String[] args) throws Exception{
String consumerKey = args[0];
String consumerSecret = args[1];
String accessToken = args[2];
String accessTokenSecret = args[3];
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 4, arguments.length);
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("twitter-spout", new TwitterSampleSpout(consumerKey,
consumerSecret, accessToken, accessTokenSecret, keyWords));
builder.setBolt("twitter-hashtag-reader-bolt", new HashtagReaderBolt())
.shuffleGrouping("twitter-spout");
builder.setBolt("twitter-hashtag-counter-bolt", new HashtagCounterBolt())
.fieldsGrouping("twitter-hashtag-reader-bolt", new Fields("hashtag"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("TwitterHashtagStorm", config,
builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}การสร้างและเรียกใช้แอปพลิเคชัน
แอปพลิเคชันที่สมบูรณ์มีรหัส Java สี่ตัว มีดังนี้ -
- TwitterSampleSpout.java
- HashtagReaderBolt.java
- HashtagCounterBolt.java
- TwitterHashtagStorm.java
คุณสามารถคอมไพล์แอปพลิเคชันโดยใช้คำสั่งต่อไปนี้ -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*” *.javaดำเนินการแอปพลิเคชันโดยใช้คำสั่งต่อไปนี้ -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/twitter4j/lib/*”:.
TwitterHashtagStorm <customerkey> <customersecret> <accesstoken> <accesstokensecret>
<keyword1> <keyword2> … <keywordN>เอาต์พุต
แอปพลิเคชันจะพิมพ์แฮชแท็กที่มีอยู่ในปัจจุบันและจำนวนของมัน ผลลัพธ์ควรคล้ายกับสิ่งต่อไปนี้ -
Result: jazztastic : 1
Result: foodie : 1
Result: Redskins : 1
Result: Recipe : 1
Result: cook : 1
Result: android : 1
Result: food : 2
Result: NoToxicHorseMeat : 1
Result: Purrs4Peace : 1
Result: livemusic : 1
Result: VIPremium : 1
Result: Frome : 1
Result: SundayRoast : 1
Result: Millennials : 1
Result: HealthWithKier : 1
Result: LPs30DaysofGratitude : 1
Result: cooking : 1
Result: gameinsight : 1
Result: Countryfile : 1
Result: androidgames : 1Yahoo! Finance เป็นเว็บไซต์ข่าวธุรกิจและข้อมูลทางการเงินชั้นนำของอินเทอร์เน็ต เป็นส่วนหนึ่งของ Yahoo! และให้ข้อมูลเกี่ยวกับข่าวการเงินสถิติการตลาดข้อมูลตลาดต่างประเทศและข้อมูลอื่น ๆ เกี่ยวกับแหล่งข้อมูลทางการเงินที่ทุกคนสามารถเข้าถึงได้
หากคุณลงทะเบียน Yahoo! จากนั้นคุณสามารถปรับแต่ง Yahoo! การเงินเพื่อใช้ประโยชน์จากข้อเสนอบางอย่าง Yahoo! Finance API ใช้เพื่อสืบค้นข้อมูลทางการเงินจาก Yahoo!
API นี้แสดงข้อมูลที่ล่าช้า 15 นาทีจากเวลาจริงและอัปเดตฐานข้อมูลทุกๆ 1 นาทีเพื่อเข้าถึงข้อมูลที่เกี่ยวข้องกับสต็อกในปัจจุบัน ตอนนี้ให้เราใช้สถานการณ์แบบเรียลไทม์ของ บริษัท และดูวิธีแจ้งเตือนเมื่อมูลค่าหุ้นต่ำกว่า 100
การสร้างรางน้ำ
จุดประสงค์ของพวยกาคือการรับรายละเอียดของ บริษัท และแสดงราคาให้กับสลักเกลียว คุณสามารถใช้โค้ดโปรแกรมต่อไปนี้เพื่อสร้างพวยกา
การเข้ารหัส: YahooFinanceSpout.java
import java.util.*;
import java.io.*;
import java.math.BigDecimal;
//import yahoofinace packages
import yahoofinance.YahooFinance;
import yahoofinance.Stock;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.topology.IRichSpout;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
public class YahooFinanceSpout implements IRichSpout {
private SpoutOutputCollector collector;
private boolean completed = false;
private TopologyContext context;
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector){
this.context = context;
this.collector = collector;
}
@Override
public void nextTuple() {
try {
Stock stock = YahooFinance.get("INTC");
BigDecimal price = stock.getQuote().getPrice();
this.collector.emit(new Values("INTC", price.doubleValue()));
stock = YahooFinance.get("GOOGL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("GOOGL", price.doubleValue()));
stock = YahooFinance.get("AAPL");
price = stock.getQuote().getPrice();
this.collector.emit(new Values("AAPL", price.doubleValue()));
} catch(Exception e) {}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("company", "price"));
}
@Override
public void close() {}
public boolean isDistributed() {
return false;
}
@Override
public void activate() {}
@Override
public void deactivate() {}
@Override
public void ack(Object msgId) {}
@Override
public void fail(Object msgId) {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}การสร้างกลอน
จุดประสงค์ของโบลต์คือการประมวลผลราคาของ บริษัท ที่กำหนดเมื่อราคาต่ำกว่า 100 โดยใช้วัตถุ Java Map เพื่อตั้งค่าการแจ้งเตือนขีด จำกัด ราคาตัดเป็น trueเมื่อราคาหุ้นลดลงต่ำกว่า 100 มิฉะนั้นเท็จ รหัสโปรแกรมที่สมบูรณ์มีดังนี้ -
การเข้ารหัส: PriceCutOffBolt.java
import java.util.HashMap;
import java.util.Map;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.IRichBolt;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.tuple.Tuple;
public class PriceCutOffBolt implements IRichBolt {
Map<String, Integer> cutOffMap;
Map<String, Boolean> resultMap;
private OutputCollector collector;
@Override
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.cutOffMap = new HashMap <String, Integer>();
this.cutOffMap.put("INTC", 100);
this.cutOffMap.put("AAPL", 100);
this.cutOffMap.put("GOOGL", 100);
this.resultMap = new HashMap<String, Boolean>();
this.collector = collector;
}
@Override
public void execute(Tuple tuple) {
String company = tuple.getString(0);
Double price = tuple.getDouble(1);
if(this.cutOffMap.containsKey(company)){
Integer cutOffPrice = this.cutOffMap.get(company);
if(price < cutOffPrice) {
this.resultMap.put(company, true);
} else {
this.resultMap.put(company, false);
}
}
collector.ack(tuple);
}
@Override
public void cleanup() {
for(Map.Entry<String, Boolean> entry:resultMap.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("cut_off_price"));
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}การส่งโทโพโลยี
นี่เป็นแอปพลิเคชันหลักที่ YahooFinanceSpout.java และ PriceCutOffBolt.java เชื่อมต่อเข้าด้วยกันและสร้างโทโพโลยี รหัสโปรแกรมต่อไปนี้แสดงวิธีการส่งโทโพโลยี
การเข้ารหัส: YahooFinanceStorm.java
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
public class YahooFinanceStorm {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("yahoo-finance-spout", new YahooFinanceSpout());
builder.setBolt("price-cutoff-bolt", new PriceCutOffBolt())
.fieldsGrouping("yahoo-finance-spout", new Fields("company"));
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("YahooFinanceStorm", config, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}การสร้างและเรียกใช้แอปพลิเคชัน
แอปพลิเคชันที่สมบูรณ์มีรหัส Java สามรหัส มีดังนี้ -
- YahooFinanceSpout.java
- PriceCutOffBolt.java
- YahooFinanceStorm.java
สามารถสร้างแอปพลิเคชันได้โดยใช้คำสั่งต่อไปนี้ -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*” *.javaแอปพลิเคชันสามารถรันได้โดยใช้คำสั่งต่อไปนี้ -
javac -cp “/path/to/storm/apache-storm-0.9.5/lib/*”:”/path/to/yahoofinance/lib/*”:.
YahooFinanceStormเอาต์พุต
ผลลัพธ์จะคล้ายกับสิ่งต่อไปนี้ -
GOOGL : false
AAPL : false
INTC : trueApache Storm framework รองรับแอพพลิเคชั่นอุตสาหกรรมที่ดีที่สุดในปัจจุบันมากมาย เราจะให้ภาพรวมคร่าวๆของแอพพลิเคชั่น Storm ที่โดดเด่นที่สุดในบทนี้
Klout
Klout เป็นแอปพลิเคชันที่ใช้การวิเคราะห์โซเชียลมีเดียเพื่อจัดอันดับผู้ใช้ตามอิทธิพลทางสังคมออนไลน์ผ่าน Klout Scoreซึ่งเป็นค่าตัวเลขระหว่าง 1 ถึง 100 Klout ใช้นามธรรม Trident ในตัวของ Apache Storm เพื่อสร้างโทโพโลยีที่ซับซ้อนที่สตรีมข้อมูล
ช่องอากาศ
Weather Channel ใช้โทโพโลยี Storm เพื่อนำเข้าข้อมูลสภาพอากาศ ได้เชื่อมโยงกับ Twitter เพื่อเปิดใช้งานการโฆษณาตามสภาพอากาศบน Twitter และแอปพลิเคชันบนมือถือOpenSignal เป็น บริษัท ที่เชี่ยวชาญในการทำแผนที่ครอบคลุมพื้นที่ไร้สาย StormTag และ WeatherSignalเป็นโครงการตามสภาพอากาศที่สร้างโดย OpenSignal StormTag คือสถานีตรวจอากาศบลูทู ธ ที่ติดพวงกุญแจ ข้อมูลสภาพอากาศที่เก็บรวบรวมโดยอุปกรณ์จะถูกส่งไปยังแอป WeatherSignal และเซิร์ฟเวอร์ OpenSignal
อุตสาหกรรมโทรคมนาคม
ผู้ให้บริการโทรคมนาคมประมวลผลการโทรหลายล้านครั้งต่อวินาที พวกเขาดำเนินการทางนิติวิทยาศาสตร์เกี่ยวกับสายที่หลุดและคุณภาพเสียงที่ไม่ดี บันทึกรายละเอียดการโทรไหลเข้าด้วยอัตราล้านต่อวินาทีและ Apache Storm ประมวลผลแบบเรียลไทม์และระบุรูปแบบที่เป็นปัญหา การวิเคราะห์พายุสามารถใช้เพื่อปรับปรุงคุณภาพการโทรได้อย่างต่อเนื่อง