Elasticsearch - คู่มือฉบับย่อ
Elasticsearch เป็นเซิร์ฟเวอร์การค้นหาที่ใช้ Apache Lucene ได้รับการพัฒนาโดย Shay Banon และเผยแพร่ในปี 2010 ปัจจุบันได้รับการดูแลโดย Elasticsearch BV เวอร์ชันล่าสุดคือ 7.0.0
Elasticsearch เป็นเครื่องมือค้นหาและวิเคราะห์ข้อมูลแบบเต็มรูปแบบแบบกระจายและแบบโอเพนซอร์สแบบเรียลไทม์ สามารถเข้าถึงได้จากอินเทอร์เฟซบริการเว็บ RESTful และใช้เอกสาร schema less JSON (JavaScript Object Notation) เพื่อจัดเก็บข้อมูล มันถูกสร้างขึ้นจากภาษาการเขียนโปรแกรม Java ดังนั้น Elasticsearch จึงสามารถทำงานบนแพลตฟอร์มที่แตกต่างกัน ช่วยให้ผู้ใช้สามารถสำรวจข้อมูลจำนวนมากด้วยความเร็วสูงมาก
คุณสมบัติทั่วไป
คุณสมบัติทั่วไปของ Elasticsearch มีดังนี้ -
Elasticsearch สามารถปรับขนาดได้ถึงเพตะไบต์ของข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
Elasticsearch สามารถใช้แทนที่เก็บเอกสารเช่น MongoDB และ RavenDB
Elasticsearch ใช้ denormalization เพื่อปรับปรุงประสิทธิภาพการค้นหา
Elasticsearch เป็นหนึ่งในเครื่องมือค้นหาระดับองค์กรที่ได้รับความนิยมและปัจจุบันองค์กรใหญ่ ๆ หลายแห่งใช้งานเช่น Wikipedia, The Guardian, StackOverflow, GitHub เป็นต้น
Elasticsearch เป็นโอเพ่นซอร์สและพร้อมใช้งานภายใต้ใบอนุญาต Apache เวอร์ชัน 2.0
แนวคิดหลัก
แนวคิดหลักของ Elasticsearch มีดังนี้ -
โหนด
มันหมายถึงอินสแตนซ์เดียวที่ทำงานอยู่ของ Elasticsearch เซิร์ฟเวอร์จริงและเซิร์ฟเวอร์เสมือนเดียวรองรับหลายโหนดขึ้นอยู่กับความสามารถของทรัพยากรทางกายภาพเช่น RAM หน่วยเก็บข้อมูลและพลังการประมวลผล
คลัสเตอร์
เป็นชุดของโหนดตั้งแต่หนึ่งโหนดขึ้นไป คลัสเตอร์จัดทำดัชนีแบบรวมและความสามารถในการค้นหาในโหนดทั้งหมดสำหรับข้อมูลทั้งหมด
ดัชนี
เป็นชุดเอกสารประเภทต่างๆและคุณสมบัติ ดัชนียังใช้แนวคิดของเศษเพื่อปรับปรุงประสิทธิภาพ ตัวอย่างเช่นชุดเอกสารประกอบด้วยข้อมูลของแอปพลิเคชันเครือข่ายสังคม
เอกสาร
เป็นชุดของเขตข้อมูลในลักษณะเฉพาะที่กำหนดในรูปแบบ JSON เอกสารทุกชิ้นอยู่ในประเภทและอยู่ในดัชนี เอกสารทุกฉบับเชื่อมโยงกับตัวระบุเฉพาะที่เรียกว่า UID
ชาร์ด
ดัชนีแบ่งย่อยตามแนวนอนเป็นเศษเล็กเศษน้อย ซึ่งหมายความว่าแต่ละชาร์ดมีคุณสมบัติทั้งหมดของเอกสาร แต่มีอ็อบเจ็กต์ JSON จำนวนน้อยกว่าดัชนี การแยกแนวนอนทำให้ชาร์ดเป็นโหนดอิสระซึ่งสามารถเก็บไว้ในโหนดใดก็ได้ ชาร์ดหลักคือส่วนแนวนอนดั้งเดิมของดัชนีจากนั้นเศษหลักเหล่านี้จะถูกจำลองเป็นเศษแบบจำลอง
แบบจำลอง
Elasticsearch อนุญาตให้ผู้ใช้สร้างแบบจำลองของดัชนีและเศษของพวกเขา การจำลองแบบไม่เพียง แต่ช่วยในการเพิ่มความพร้อมใช้งานของข้อมูลในกรณีที่เกิดความล้มเหลว แต่ยังช่วยเพิ่มประสิทธิภาพการค้นหาด้วยการดำเนินการค้นหาแบบขนานในแบบจำลองเหล่านี้
ข้อดี
Elasticsearch ได้รับการพัฒนาบน Java ซึ่งทำให้เข้ากันได้กับเกือบทุกแพลตฟอร์ม
Elasticsearch เป็นแบบเรียลไทม์หรืออีกนัยหนึ่งหลังจากผ่านไปหนึ่งวินาทีเอกสารที่เพิ่มจะสามารถค้นหาได้ในเอ็นจิ้นนี้
มีการแจกจ่าย Elasticsearch ซึ่งทำให้ง่ายต่อการปรับขนาดและรวมเข้ากับองค์กรขนาดใหญ่
การสร้างการสำรองข้อมูลทั้งหมดทำได้ง่ายโดยใช้แนวคิดของเกตเวย์ซึ่งมีอยู่ใน Elasticsearch
การจัดการหลายผู้เช่าทำได้ง่ายมากใน Elasticsearch เมื่อเทียบกับ Apache Solr
Elasticsearch ใช้ออบเจ็กต์ JSON เป็นการตอบสนองซึ่งทำให้สามารถเรียกใช้เซิร์ฟเวอร์ Elasticsearch ด้วยภาษาโปรแกรมต่างๆจำนวนมาก
Elasticsearch รองรับเอกสารเกือบทุกประเภทยกเว้นประเภทที่ไม่รองรับการแสดงผลข้อความ
ข้อเสีย
Elasticsearch ไม่มีการสนับสนุนหลายภาษาในแง่ของการจัดการคำขอและข้อมูลการตอบกลับ (ทำได้เฉพาะใน JSON) ซึ่งแตกต่างจาก Apache Solr ซึ่งเป็นไปได้ในรูปแบบ CSV, XML และ JSON
ในบางครั้ง Elasticsearch มีปัญหาเกี่ยวกับสถานการณ์สมองแตก
การเปรียบเทียบระหว่าง Elasticsearch และ RDBMS
ใน Elasticsearch ดัชนีจะคล้ายกับตารางใน RDBMS (Relation Database Management System) ทุกตารางเป็นชุดของแถวเช่นเดียวกับทุกดัชนีคือชุดเอกสารใน Elasticsearch
ตารางต่อไปนี้แสดงการเปรียบเทียบโดยตรงระหว่างคำศัพท์เหล่านี้
| ยางยืด | RDBMS |
|---|---|
| คลัสเตอร์ | ฐานข้อมูล |
| ชาร์ด | ชาร์ด |
| ดัชนี | ตาราง |
| ฟิลด์ | คอลัมน์ |
| เอกสาร | แถว |
ในบทนี้เราจะเข้าใจขั้นตอนการติดตั้ง Elasticsearch โดยละเอียด
ในการติดตั้ง Elasticsearch บนคอมพิวเตอร์ของคุณคุณจะต้องทำตามขั้นตอนด้านล่างนี้ -
Step 1- ตรวจสอบเวอร์ชั่นของ java ที่ติดตั้งบนคอมพิวเตอร์ของคุณ ควรเป็น java 7 หรือสูงกว่า คุณสามารถตรวจสอบได้โดยดำเนินการดังต่อไปนี้ -
ในระบบปฏิบัติการ Windows (OS) (โดยใช้พรอมต์คำสั่ง) -
> java -versionใน UNIX OS (โดยใช้ Terminal) -
$ echo $JAVA_HOMEStep 2 - ขึ้นอยู่กับระบบปฏิบัติการของคุณดาวน์โหลด Elasticsearch จาก www.elastic.co ตามที่ระบุไว้ด้านล่าง -
สำหรับ windows OS ให้ดาวน์โหลดไฟล์ ZIP
สำหรับ UNIX OS ให้ดาวน์โหลดไฟล์ TAR
สำหรับ Debian OS ให้ดาวน์โหลดไฟล์ DEB
สำหรับ Red Hat และ Linux อื่น ๆ ให้ดาวน์โหลดไฟล์ RPN
ยูทิลิตี้ APT และ Yum ยังสามารถใช้เพื่อติดตั้ง Elasticsearch ในลีนุกซ์หลายรุ่น
Step 3 - ขั้นตอนการติดตั้ง Elasticsearch นั้นง่ายมากและอธิบายไว้ด้านล่างสำหรับระบบปฏิบัติการที่แตกต่างกัน -
Windows OS- คลายซิปแพ็คเกจ zip และติดตั้ง Elasticsearch
UNIX OS- แตกไฟล์ tar ในตำแหน่งใดก็ได้และติดตั้ง Elasticsearch
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-linux-x86_64.tar.gz $tar -xzf elasticsearch-7.0.0-linux-x86_64.tar.gzUsing APT utility for Linux OS- ดาวน์โหลดและติดตั้งคีย์การลงนามสาธารณะ
$ wget -qo - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo
apt-key add -บันทึกนิยามที่เก็บดังแสดงด้านล่าง -
$ echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" |
sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listเรียกใช้การอัปเดตโดยใช้คำสั่งต่อไปนี้ -
$ sudo apt-get updateตอนนี้คุณสามารถติดตั้งโดยใช้คำสั่งต่อไปนี้ -
$ sudo apt-get install elasticsearchDownload and install the Debian package manually using the command given here −
$wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch7.0.0-amd64.deb $sudo dpkg -i elasticsearch-7.0.0-amd64.deb0Using YUM utility for Debian Linux OS
ดาวน์โหลดและติดตั้งคีย์การลงนามสาธารณะ -
$ rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchเพิ่มข้อความต่อไปนี้ในไฟล์ด้วย. repo ต่อท้ายในไดเร็กทอรี“ /etc/yum.repos.d/” ของคุณ ตัวอย่างเช่น elasticsearch.repo
elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdตอนนี้คุณสามารถติดตั้ง Elasticsearch ได้โดยใช้คำสั่งต่อไปนี้
sudo yum install elasticsearchStep 4- ไปที่ไดเร็กทอรีหลักของ Elasticsearch และภายในโฟลเดอร์ bin เรียกใช้ไฟล์ elasticsearch.bat ในกรณีของ Windows หรือคุณสามารถทำได้โดยใช้พรอมต์คำสั่งและผ่านเทอร์มินัลในกรณีของไฟล์ UNIX rum Elasticsearch
ใน Windows
> cd elasticsearch-2.1.0/bin
> elasticsearchใน Linux
$ cd elasticsearch-2.1.0/bin
$ ./elasticsearchNote - ในกรณีของ windows คุณอาจได้รับข้อผิดพลาดที่ระบุว่าไม่ได้ตั้งค่า JAVA_HOME โปรดตั้งค่าในตัวแปรสภาพแวดล้อมเป็น“ C: \ Program Files \ Java \ jre1.8.0_31” หรือตำแหน่งที่คุณติดตั้ง java
Step 5- พอร์ตเริ่มต้นสำหรับเว็บอินเตอร์เฟส Elasticsearch คือ 9200 หรือคุณสามารถเปลี่ยนได้โดยเปลี่ยน http.port ภายในไฟล์ elasticsearch.yml ที่มีอยู่ในไดเร็กทอรี bin คุณสามารถตรวจสอบว่าเซิร์ฟเวอร์ทำงานอยู่หรือไม่โดยการเรียกดูhttp://localhost:9200. มันจะส่งคืนอ็อบเจ็กต์ JSON ซึ่งมีข้อมูลเกี่ยวกับ Elasticsearch ที่ติดตั้งในลักษณะต่อไปนี้ -
{
"name" : "Brain-Child",
"cluster_name" : "elasticsearch", "version" : {
"number" : "2.1.0",
"build_hash" : "72cd1f1a3eee09505e036106146dc1949dc5dc87",
"build_timestamp" : "2015-11-18T22:40:03Z",
"build_snapshot" : false,
"lucene_version" : "5.3.1"
},
"tagline" : "You Know, for Search"
}Step 6- ในขั้นตอนนี้ให้เราติดตั้ง Kibana ปฏิบัติตามรหัสที่ระบุด้านล่างเพื่อติดตั้งบน Linux และ Windows -
For Installation on Linux −
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.0.0-linuxx86_64.tar.gz
tar -xzf kibana-7.0.0-linux-x86_64.tar.gz
cd kibana-7.0.0-linux-x86_64/
./bin/kibanaFor Installation on Windows −
ดาวน์โหลด Kibana สำหรับ Windows จาก https://www.elastic.co/products/kibana. เมื่อคุณคลิกลิงก์คุณจะพบโฮมเพจดังที่แสดงด้านล่าง -
คลายซิปและไปที่โฮมไดเร็กทอรี Kibana จากนั้นเรียกใช้
CD c:\kibana-7.0.0-windows-x86_64
.\bin\kibana.batในบทนี้ให้เราเรียนรู้วิธีการเพิ่มดัชนีการแมปและข้อมูลลงใน Elasticsearch โปรดทราบว่าข้อมูลนี้บางส่วนจะถูกใช้ในตัวอย่างที่อธิบายไว้ในบทช่วยสอนนี้
สร้างดัชนี
คุณสามารถใช้คำสั่งต่อไปนี้เพื่อสร้างดัชนี -
PUT schoolการตอบสนอง
หากสร้างดัชนีคุณสามารถดูผลลัพธ์ต่อไปนี้ -
{"acknowledged": true}เพิ่มข้อมูล
Elasticsearch จะจัดเก็บเอกสารที่เราเพิ่มลงในดัชนีดังแสดงในรหัสต่อไปนี้ เอกสารจะได้รับ ID บางส่วนที่ใช้ในการระบุเอกสาร
ร้องขอร่างกาย
POST school/_doc/10
{
"name":"Saint Paul School", "description":"ICSE Afiliation",
"street":"Dawarka", "city":"Delhi", "state":"Delhi", "zip":"110075",
"location":[28.5733056, 77.0122136], "fees":5000,
"tags":["Good Faculty", "Great Sports"], "rating":"4.5"
}การตอบสนอง
{
"_index" : "school",
"_type" : "_doc",
"_id" : "10",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}ที่นี่เรากำลังเพิ่มเอกสารอื่นที่คล้ายกัน
POST school/_doc/16
{
"name":"Crescent School", "description":"State Board Affiliation",
"street":"Tonk Road",
"city":"Jaipur", "state":"RJ", "zip":"176114","location":[26.8535922,75.7923988],
"fees":2500, "tags":["Well equipped labs"], "rating":"4.5"
}การตอบสนอง
{
"_index" : "school",
"_type" : "_doc",
"_id" : "16",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 9,
"_primary_term" : 7
}ด้วยวิธีนี้เราจะเพิ่มข้อมูลตัวอย่างที่เราต้องการสำหรับการทำงานของเราในบทต่อ ๆ ไป
การเพิ่มข้อมูลตัวอย่างใน Kibana
Kibana เป็นเครื่องมือที่ขับเคลื่อนด้วย GUI สำหรับการเข้าถึงข้อมูลและการสร้างภาพ ในส่วนนี้ให้เราเข้าใจว่าเราจะเพิ่มข้อมูลตัวอย่างลงไปได้อย่างไร
ในโฮมเพจ Kibana ให้เลือกตัวเลือกต่อไปนี้เพื่อเพิ่มข้อมูลอีคอมเมิร์ซตัวอย่าง -
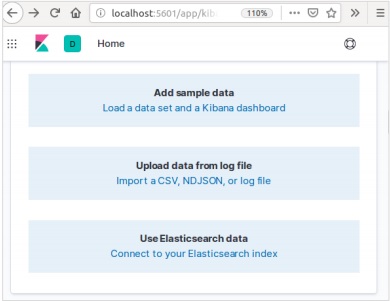
หน้าจอถัดไปจะแสดงภาพและปุ่มเพื่อเพิ่มข้อมูล -
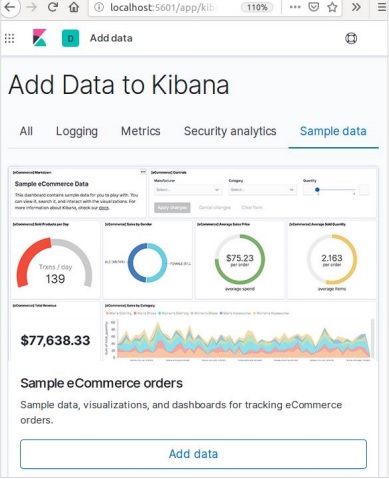
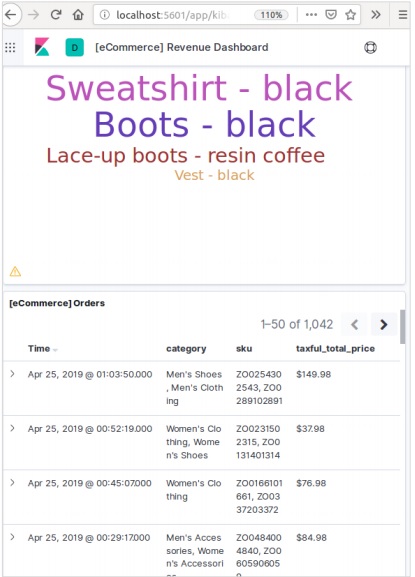
การคลิกที่เพิ่มข้อมูลจะแสดงหน้าจอต่อไปนี้ซึ่งยืนยันว่าได้เพิ่มข้อมูลลงในดัชนีชื่ออีคอมเมิร์ซแล้ว
ในระบบหรือซอฟต์แวร์ใด ๆ เมื่อเราอัปเกรดเป็นเวอร์ชันที่ใหม่กว่าเราจำเป็นต้องทำตามขั้นตอนสองสามขั้นตอนเพื่อรักษาการตั้งค่าแอปพลิเคชันการกำหนดค่าข้อมูลและสิ่งอื่น ๆ ขั้นตอนเหล่านี้จำเป็นเพื่อทำให้แอปพลิเคชันมีเสถียรภาพในระบบใหม่หรือเพื่อรักษาความสมบูรณ์ของข้อมูล (ป้องกันไม่ให้ข้อมูลเสียหาย)
คุณต้องทำตามขั้นตอนต่อไปนี้เพื่ออัพเกรด Elasticsearch -
อ่านเอกสารอัปเกรดจาก https://www.elastic.co/
ทดสอบเวอร์ชันที่อัปเกรดในสภาพแวดล้อมที่ไม่ใช่การใช้งานจริงเช่นในสภาพแวดล้อม UAT, E2E, SIT หรือ DEV
โปรดทราบว่าการย้อนกลับไปยังเวอร์ชัน Elasticsearch ก่อนหน้านั้นไม่สามารถทำได้หากไม่มีการสำรองข้อมูล ดังนั้นขอแนะนำให้สำรองข้อมูลก่อนที่จะอัปเกรดเป็นเวอร์ชันที่สูงขึ้น
เราสามารถอัปเกรดโดยใช้การรีสตาร์ทคลัสเตอร์แบบเต็มหรือการอัปเกรดแบบกลิ้ง การอัปเกรดแบบโรลลิ่งสำหรับเวอร์ชันใหม่ โปรดทราบว่าไม่มีการหยุดให้บริการเมื่อคุณใช้วิธีการอัปเกรดแบบต่อเนื่องสำหรับการย้ายข้อมูล
ขั้นตอนในการอัพเกรด
ทดสอบการอัพเกรดในสภาพแวดล้อม dev ก่อนอัพเกรดคลัสเตอร์การผลิตของคุณ
สำรองข้อมูลของคุณ คุณไม่สามารถย้อนกลับไปเป็นเวอร์ชันก่อนหน้าได้เว้นแต่คุณจะมีสแนปชอตข้อมูลของคุณ
พิจารณาปิดงานแมชชีนเลิร์นนิงก่อนเริ่มกระบวนการอัปเกรด แม้ว่างานแมชชีนเลิร์นนิงจะทำงานต่อไปได้ในระหว่างการอัปเกรดแบบต่อเนื่อง แต่จะเพิ่มค่าใช้จ่ายในคลัสเตอร์ในระหว่างกระบวนการอัปเกรด
อัปเกรดส่วนประกอบของ Elastic Stack ของคุณตามลำดับต่อไปนี้ -
- Elasticsearch
- Kibana
- Logstash
- Beats
- เซิร์ฟเวอร์ APM
การอัปเกรดจาก 6.6 ขึ้นไป
ในการอัปเกรดเป็น Elasticsearch 7.1.0 โดยตรงจากเวอร์ชัน 6.0-6.6 คุณต้องสร้างดัชนี 5.x ใด ๆ ที่คุณต้องดำเนินการต่อไปด้วยตนเองและทำการรีสตาร์ทคลัสเตอร์ทั้งหมด
รีสตาร์ทคลัสเตอร์แบบเต็ม
กระบวนการรีสตาร์ทคลัสเตอร์แบบสมบูรณ์เกี่ยวข้องกับการปิดแต่ละโหนดในคลัสเตอร์อัพเกรดแต่ละโหนดเป็น 7x แล้วรีสตาร์ทคลัสเตอร์
ต่อไปนี้เป็นขั้นตอนระดับสูงที่ต้องดำเนินการสำหรับการรีสตาร์ทคลัสเตอร์ทั้งหมด -
- ปิดใช้งานการจัดสรรชาร์ด
- หยุดการจัดทำดัชนีและทำการล้างข้อมูลที่ซิงค์
- ปิดโหนดทั้งหมด
- อัปเกรดโหนดทั้งหมด
- อัปเกรดปลั๊กอินใด ๆ
- เริ่มต้นโหนดที่อัปเกรดแต่ละโหนด
- รอให้โหนดทั้งหมดเข้าร่วมคลัสเตอร์และรายงานสถานะเป็นสีเหลือง
- เปิดใช้งานการจัดสรรอีกครั้ง
เมื่อเปิดใช้งานการจัดสรรอีกครั้งคลัสเตอร์จะเริ่มจัดสรรเศษข้อมูลจำลองให้กับโหนดข้อมูล ณ จุดนี้คุณสามารถดำเนินการจัดทำดัชนีและค้นหาต่อได้อย่างปลอดภัย แต่คลัสเตอร์ของคุณจะฟื้นตัวได้เร็วขึ้นหากคุณสามารถรอจนกว่าชิ้นส่วนหลักและส่วนจำลองทั้งหมดจะได้รับการจัดสรรสำเร็จและสถานะของโหนดทั้งหมดจะเป็นสีเขียว
Application Programming Interface (API) ในเว็บคือกลุ่มของการเรียกใช้ฟังก์ชันหรือคำสั่งการเขียนโปรแกรมอื่น ๆ เพื่อเข้าถึงส่วนประกอบซอฟต์แวร์ในเว็บแอปพลิเคชันนั้น ๆ ตัวอย่างเช่น Facebook API ช่วยให้นักพัฒนาสร้างแอปพลิเคชันโดยเข้าถึงข้อมูลหรือฟังก์ชันอื่น ๆ จาก Facebook อาจเป็นวันเดือนปีเกิดหรือการอัปเดตสถานะ
Elasticsearch จัดเตรียม REST API ซึ่งเข้าถึงโดย JSON ผ่าน HTTP Elasticsearch ใช้อนุสัญญาบางประการซึ่งเราจะพูดถึงในตอนนี้
ดัชนีหลายตัว
การดำเนินการส่วนใหญ่โดยส่วนใหญ่เป็นการค้นหาและการดำเนินการอื่น ๆ ใน API ใช้สำหรับดัชนีหนึ่งหรือมากกว่าหนึ่งดัชนี สิ่งนี้ช่วยให้ผู้ใช้ค้นหาในหลาย ๆ ที่หรือข้อมูลที่มีอยู่ทั้งหมดโดยดำเนินการค้นหาเพียงครั้งเดียว มีการใช้สัญกรณ์ที่แตกต่างกันจำนวนมากเพื่อดำเนินการในหลายดัชนี เราจะพูดถึงบางส่วนที่นี่ในบทนี้
เครื่องหมายจุลภาคคั่น
POST /index1,index2,index3/_searchร้องขอร่างกาย
{
"query":{
"query_string":{
"query":"any_string"
}
}
}การตอบสนอง
ออบเจ็กต์ JSON จาก index1, index2, index3 ที่มี any_string อยู่ในนั้น
_all คำหลักสำหรับดัชนีทั้งหมด
POST /_all/_searchร้องขอร่างกาย
{
"query":{
"query_string":{
"query":"any_string"
}
}
}การตอบสนอง
ออบเจ็กต์ JSON จากดัชนีทั้งหมดและมี any_string อยู่ในนั้น
สัญลักษณ์แทน (*, +, -)
POST /school*/_searchร้องขอร่างกาย
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}การตอบสนอง
ออบเจ็กต์ JSON จากดัชนีทั้งหมดซึ่งเริ่มต้นด้วยโรงเรียนที่มี CBSE อยู่
หรือคุณสามารถใช้รหัสต่อไปนี้ได้เช่นกัน -
POST /school*,-schools_gov /_searchร้องขอร่างกาย
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}การตอบสนอง
ออบเจ็กต์ JSON จากดัชนีทั้งหมดที่ขึ้นต้นด้วย "school" แต่ไม่ใช่จาก Schools_gov และมี CBSE อยู่
นอกจากนี้ยังมีพารามิเตอร์สตริงการสืบค้น URL -
- ignore_unavailable- จะไม่มีข้อผิดพลาดเกิดขึ้นหรือจะไม่มีการหยุดการทำงานหากไม่มีดัชนีอย่างน้อยหนึ่งรายการใน URL ตัวอย่างเช่นมีดัชนีโรงเรียน แต่ไม่มีร้านหนังสือ
POST /school*,book_shops/_searchร้องขอร่างกาย
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}ร้องขอร่างกาย
{
"error":{
"root_cause":[{
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
}],
"type":"index_not_found_exception", "reason":"no such index",
"resource.type":"index_or_alias", "resource.id":"book_shops",
"index":"book_shops"
},"status":404
}พิจารณารหัสต่อไปนี้ -
POST /school*,book_shops/_search?ignore_unavailable = trueร้องขอร่างกาย
{
"query":{
"query_string":{
"query":"CBSE"
}
}
}การตอบสนอง (ไม่มีข้อผิดพลาด)
ออบเจ็กต์ JSON จากดัชนีทั้งหมดซึ่งเริ่มต้นด้วยโรงเรียนที่มี CBSE อยู่
allow_no_indices
trueค่าของพารามิเตอร์นี้จะป้องกันข้อผิดพลาดหาก URL ที่มีสัญลักษณ์แทนส่งผลให้ไม่มีดัชนี ตัวอย่างเช่นไม่มีดัชนีที่ขึ้นต้นด้วย Schools_pri -
POST /schools_pri*/_search?allow_no_indices = trueร้องขอร่างกาย
{
"query":{
"match_all":{}
}
}การตอบสนอง (ไม่มีข้อผิดพลาด)
{
"took":1,"timed_out": false, "_shards":{"total":0, "successful":0, "failed":0},
"hits":{"total":0, "max_score":0.0, "hits":[]}
}expand_wildcards
พารามิเตอร์นี้ตัดสินว่าจำเป็นต้องขยายสัญลักษณ์แทนเป็นดัชนีเปิดหรือดัชนีปิดหรือดำเนินการทั้งสองอย่าง ค่าของพารามิเตอร์นี้สามารถเปิดและปิดหรือไม่มีและทั้งหมด
ตัวอย่างเช่นปิดโรงเรียนดัชนี -
POST /schools/_closeการตอบสนอง
{"acknowledged":true}พิจารณารหัสต่อไปนี้ -
POST /school*/_search?expand_wildcards = closedร้องขอร่างกาย
{
"query":{
"match_all":{}
}
}การตอบสนอง
{
"error":{
"root_cause":[{
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}],
"type":"index_closed_exception", "reason":"closed", "index":"schools"
}, "status":403
}วันที่รองรับคณิตศาสตร์ในชื่อดัชนี
Elasticsearch มีฟังก์ชันในการค้นหาดัชนีตามวันที่และเวลา เราจำเป็นต้องระบุวันที่และเวลาในรูปแบบเฉพาะ ตัวอย่างเช่น accountdetail-2015.12.30 ดัชนีจะจัดเก็บรายละเอียดบัญชีธนาคารของวันที่ 30 ธันวาคม 2015 การดำเนินการทางคณิตศาสตร์สามารถดำเนินการเพื่อรับรายละเอียดของวันที่เฉพาะหรือช่วงของวันที่และเวลา
รูปแบบสำหรับชื่อดัชนีคณิตศาสตร์วันที่ -
<static_name{date_math_expr{date_format|time_zone}}>
/<accountdetail-{now-2d{YYYY.MM.dd|utc}}>/_searchstatic_name เป็นส่วนหนึ่งของนิพจน์ซึ่งยังคงเหมือนเดิมในดัชนีคณิตศาสตร์ทุกวันเช่นรายละเอียดบัญชี date_math_expr มีนิพจน์ทางคณิตศาสตร์ที่กำหนดวันที่และเวลาแบบไดนามิกเช่น now-2d date_format มีรูปแบบที่เขียนวันที่ในดัชนีเช่น YYYY.MM.dd หากวันนี้คือวันที่ 30 ธันวาคม 2015 <accountdetail- {now-2d {YYYY.MM.dd}}> จะส่งคืน accountdetail-2015.12.28
| นิพจน์ | แก้ไขเป็น |
|---|---|
| <accountdetail- {now-d}> | accountdetail-2015.12.29 |
| <accountdetail- {now-M}> | accountdetail-2015.11.30 น |
| <accountdetail- {ตอนนี้ {YYYY.MM}}> | accountdetail-2015.12.2018 |
ตอนนี้เราจะเห็นตัวเลือกทั่วไปบางตัวที่มีอยู่ใน Elasticsearch ที่สามารถใช้เพื่อรับคำตอบในรูปแบบที่กำหนด
ผลลัพธ์ที่สวยงาม
เราสามารถรับการตอบสนองในออบเจ็กต์ JSON ที่มีการจัดรูปแบบไว้อย่างดีเพียงแค่ต่อท้ายพารามิเตอร์การสืบค้น URL นั่นคือ pretty = true
POST /schools/_search?pretty = trueร้องขอร่างกาย
{
"query":{
"match_all":{}
}
}การตอบสนอง
……………………..
{
"_index" : "schools", "_type" : "school", "_id" : "1", "_score" : 1.0,
"_source":{
"name":"Central School", "description":"CBSE Affiliation",
"street":"Nagan", "city":"paprola", "state":"HP", "zip":"176115",
"location": [31.8955385, 76.8380405], "fees":2000,
"tags":["Senior Secondary", "beautiful campus"], "rating":"3.5"
}
}
………………….ผลลัพธ์ที่มนุษย์อ่านได้
ตัวเลือกนี้สามารถเปลี่ยนการตอบสนองทางสถิติให้อยู่ในรูปแบบที่มนุษย์อ่านได้ (ถ้ามนุษย์ = จริง) หรือรูปแบบที่อ่านได้ด้วยคอมพิวเตอร์ (ถ้ามนุษย์ = เท็จ) ตัวอย่างเช่นถ้า human = true ดังนั้น distance_kilometer = 20KM และถ้า human = false แล้ว distance_meter = 20000 เมื่อต้องใช้การตอบสนองโดยโปรแกรมคอมพิวเตอร์อื่น
การกรองการตอบสนอง
เราสามารถกรองการตอบสนองให้น้อยลงในฟิลด์โดยเพิ่มในพารามิเตอร์ field_path ตัวอย่างเช่น,
POST /schools/_search?filter_path = hits.totalร้องขอร่างกาย
{
"query":{
"match_all":{}
}
}การตอบสนอง
{"hits":{"total":3}}Elasticsearch มี API เอกสารเดียวและ API หลายเอกสารโดยที่การเรียก API กำหนดเป้าหมายเอกสารเดียวและหลายเอกสารตามลำดับ
Index API
ช่วยเพิ่มหรืออัปเดตเอกสาร JSON ในดัชนีเมื่อมีการร้องขอไปยังดัชนีที่เกี่ยวข้องด้วยการแมปเฉพาะ ตัวอย่างเช่นคำขอต่อไปนี้จะเพิ่มออบเจ็กต์ JSON เพื่อจัดทำดัชนีโรงเรียนและภายใต้การทำแผนที่โรงเรียน -
PUT schools/_doc/5
{
name":"City School", "description":"ICSE", "street":"West End",
"city":"Meerut",
"state":"UP", "zip":"250002", "location":[28.9926174, 77.692485],
"fees":3500,
"tags":["fully computerized"], "rating":"4.5"
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1
}การสร้างดัชนีอัตโนมัติ
เมื่อมีการร้องขอให้เพิ่มออบเจ็กต์ JSON ลงในดัชนีเฉพาะและหากดัชนีนั้นไม่มีอยู่ API นี้จะสร้างดัชนีนั้นโดยอัตโนมัติและการแมปพื้นฐานสำหรับออบเจ็กต์ JSON นั้นโดยอัตโนมัติ ฟังก์ชันนี้สามารถปิดใช้งานได้โดยเปลี่ยนค่าของพารามิเตอร์ต่อไปนี้เป็น false ซึ่งมีอยู่ในไฟล์ elasticsearch.yml
action.auto_create_index:false
index.mapper.dynamic:falseคุณยังสามารถ จำกัด การสร้างดัชนีโดยอัตโนมัติซึ่งอนุญาตให้ใช้เฉพาะชื่อดัชนีที่มีรูปแบบเฉพาะเท่านั้นโดยการเปลี่ยนค่าของพารามิเตอร์ต่อไปนี้ -
action.auto_create_index:+acc*,-bank*Note - ที่นี่ + แสดงว่าอนุญาตและ - แสดงว่าไม่อนุญาต
การกำหนดเวอร์ชัน
Elasticsearch ยังมีสิ่งอำนวยความสะดวกในการควบคุมเวอร์ชัน เราสามารถใช้พารามิเตอร์เคียวรีเวอร์ชันเพื่อระบุเวอร์ชันของเอกสารเฉพาะ
PUT schools/_doc/5?version=7&version_type=external
{
"name":"Central School", "description":"CBSE Affiliation", "street":"Nagan",
"city":"paprola", "state":"HP", "zip":"176115", "location":[31.8955385, 76.8380405],
"fees":2200, "tags":["Senior Secondary", "beautiful campus"], "rating":"3.3"
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 3,
"_primary_term" : 1
}การกำหนดเวอร์ชันเป็นกระบวนการแบบเรียลไทม์และไม่ได้รับผลกระทบจากการดำเนินการค้นหาแบบเรียลไทม์
การกำหนดเวอร์ชันที่สำคัญที่สุดมีสองประเภท -
การกำหนดเวอร์ชันภายใน
การกำหนดเวอร์ชันภายในเป็นเวอร์ชันเริ่มต้นที่เริ่มต้นด้วย 1 และเพิ่มขึ้นเมื่อมีการอัปเดตแต่ละครั้งรวมทั้งลบ
การกำหนดเวอร์ชันภายนอก
ใช้เมื่อการกำหนดเวอร์ชันของเอกสารถูกเก็บไว้ในระบบภายนอกเช่นระบบการกำหนดเวอร์ชันของบุคคลที่สาม ในการเปิดใช้งานฟังก์ชันนี้เราจำเป็นต้องตั้งค่า version_type เป็นภายนอก ที่นี่ Elasticsearch จะจัดเก็บหมายเลขเวอร์ชันตามที่ระบบภายนอกกำหนดและจะไม่เพิ่มขึ้นโดยอัตโนมัติ
ประเภทการทำงาน
ประเภทการดำเนินการใช้เพื่อบังคับให้สร้างการดำเนินการ ซึ่งจะช่วยหลีกเลี่ยงการเขียนทับเอกสารที่มีอยู่
PUT chapter/_doc/1?op_type=create
{
"Text":"this is chapter one"
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}การสร้าง ID อัตโนมัติ
เมื่อไม่ได้ระบุ ID ในการดำเนินการดัชนี Elasticsearch จะสร้าง id สำหรับเอกสารนั้นโดยอัตโนมัติ
POST chapter/_doc/
{
"user" : "tpoint",
"post_date" : "2018-12-25T14:12:12",
"message" : "Elasticsearch Tutorial"
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "chapter",
"_type" : "_doc",
"_id" : "PVghWGoB7LiDTeV6LSGu",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}รับ API
API ช่วยในการแยกออบเจ็กต์ JSON ประเภทโดยดำเนินการขอเอกสารเฉพาะ
pre class="prettyprint notranslate" > GET schools/_doc/5ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}การดำเนินการนี้เป็นแบบเรียลไทม์และไม่ได้รับผลกระทบจากอัตราการรีเฟรชของดัชนี
คุณยังสามารถระบุเวอร์ชันจากนั้น Elasticsearch จะดึงเอกสารเวอร์ชันนั้นเท่านั้น
คุณยังสามารถระบุ _all ในคำขอเพื่อให้ Elasticsearch ค้นหารหัสเอกสารนั้นได้ในทุกประเภทและจะส่งคืนเอกสารที่ตรงกันรายการแรก
คุณยังสามารถระบุฟิลด์ที่คุณต้องการในผลลัพธ์ของคุณจากเอกสารนั้น ๆ
GET schools/_doc/5?_source_includes=name,feesในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"fees" : 2200,
"name" : "Central School"
}
}คุณยังสามารถดึงส่วนที่มาในผลลัพธ์ของคุณได้โดยเพิ่มส่วน _source ในคำขอรับของคุณ
GET schools/_doc/5?_sourceในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "5",
"_version" : 7,
"_seq_no" : 3,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}คุณยังสามารถรีเฟรชชาร์ดก่อนดำเนินการรับโดยตั้งค่าพารามิเตอร์รีเฟรชเป็นจริง
ลบ API
คุณสามารถลบดัชนีการแมปหรือเอกสารโดยการส่งคำร้องขอ HTTP DELETE ไปยัง Elasticsearch
DELETE schools/_doc/4ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"found":true, "_index":"schools", "_type":"school", "_id":"4", "_version":2,
"_shards":{"total":2, "successful":1, "failed":0}
}สามารถระบุเวอร์ชันของเอกสารเพื่อลบเวอร์ชันนั้น ๆ สามารถระบุพารามิเตอร์การกำหนดเส้นทางเพื่อลบเอกสารจากผู้ใช้เฉพาะและการดำเนินการจะล้มเหลวหากเอกสารไม่ได้เป็นของผู้ใช้รายนั้น ในการดำเนินการนี้คุณสามารถระบุตัวเลือกการรีเฟรชและการหมดเวลาเช่นเดียวกับ GET API
อัปเดต API
สคริปต์ใช้สำหรับการดำเนินการนี้และใช้การกำหนดเวอร์ชันเพื่อให้แน่ใจว่าไม่มีการอัพเดตเกิดขึ้นระหว่างการรับและจัดทำดัชนีใหม่ ตัวอย่างเช่นคุณสามารถอัปเดตค่าธรรมเนียมของโรงเรียนโดยใช้สคริปต์ -
POST schools/_update/4
{
"script" : {
"source": "ctx._source.name = params.sname",
"lang": "painless",
"params" : {
"sname" : "City Wise School"
}
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "schools",
"_type" : "_doc",
"_id" : "4",
"_version" : 3,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 4,
"_primary_term" : 2
}คุณสามารถตรวจสอบการอัปเดตได้โดยส่งคำขอรับไปยังเอกสารที่อัปเดต
API นี้ใช้เพื่อค้นหาเนื้อหาใน Elasticsearch ผู้ใช้สามารถค้นหาได้โดยส่งคำขอ get โดยมีสตริงข้อความค้นหาเป็นพารามิเตอร์หรือสามารถโพสต์ข้อความค้นหาในเนื้อหาข้อความของคำขอโพสต์ APIS การค้นหาส่วนใหญ่เป็นแบบหลายดัชนีหลายประเภท
หลายดัชนี
Elasticsearch ช่วยให้เราค้นหาเอกสารที่มีอยู่ในดัชนีทั้งหมดหรือในดัชนีเฉพาะบางดัชนี ตัวอย่างเช่นหากเราต้องการค้นหาเอกสารทั้งหมดด้วยชื่อที่มีศูนย์กลางเราสามารถทำได้ดังที่แสดงไว้ที่นี่ -
GET /_all/_search?q=city:paprolaในการรันโค้ดด้านบนเราจะได้รับคำตอบดังต่อไปนี้ -
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 7,
"successful" : 7,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}ค้นหา URI
สามารถส่งผ่านพารามิเตอร์จำนวนมากในการดำเนินการค้นหาโดยใช้ Uniform Resource Identifier -
| ส. เลขที่ | พารามิเตอร์และคำอธิบาย |
|---|---|
| 1 | Q พารามิเตอร์นี้ใช้เพื่อระบุสตริงการสืบค้น |
| 2 | lenient พารามิเตอร์นี้ใช้เพื่อระบุสตริงการค้นหาข้อผิดพลาดที่อิงรูปแบบสามารถละเว้นได้โดยเพียงแค่ตั้งค่าพารามิเตอร์นี้เป็นจริง เป็นเท็จโดยค่าเริ่มต้น |
| 3 | fields พารามิเตอร์นี้ใช้เพื่อระบุสตริงการสืบค้น |
| 4 | sort เราสามารถรับผลลัพธ์ที่เรียงลำดับได้โดยใช้พารามิเตอร์นี้ค่าที่เป็นไปได้สำหรับพารามิเตอร์นี้คือ fieldName, fieldName: asc / fieldname: desc |
| 5 | timeout เราสามารถ จำกัด เวลาในการค้นหาได้โดยใช้พารามิเตอร์นี้และการตอบกลับจะมีเฉพาะ Hit ในเวลาที่ระบุเท่านั้น โดยค่าเริ่มต้นจะไม่มีการหมดเวลา |
| 6 | terminate_after เราสามารถ จำกัด การตอบกลับตามจำนวนเอกสารที่ระบุสำหรับแต่ละชาร์ดเมื่อถึงที่แบบสอบถามจะยุติก่อนกำหนด โดยค่าเริ่มต้นจะไม่มี terminate_after |
| 7 | from เริ่มต้นจากดัชนีของการเข้าชมที่จะกลับมา ค่าเริ่มต้นคือ 0 |
| 8 | size หมายถึงจำนวนการเข้าชมที่จะส่งคืน ค่าเริ่มต้นคือ 10 |
ขอการค้นหาร่างกาย
นอกจากนี้เรายังสามารถระบุแบบสอบถามโดยใช้แบบสอบถาม DSL ในเนื้อหาคำขอและมีตัวอย่างมากมายที่ให้ไว้แล้วในบทก่อนหน้า ตัวอย่างหนึ่งดังกล่าวได้รับที่นี่ -
POST /schools/_search
{
"query":{
"query_string":{
"query":"up"
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบดังต่อไปนี้ -
{
"took" : 11,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}เฟรมเวิร์กการรวมรวบรวมข้อมูลทั้งหมดที่เลือกโดยคำค้นหาและประกอบด้วยส่วนประกอบสำเร็จรูปจำนวนมากซึ่งช่วยในการสร้างสรุปข้อมูลที่ซับซ้อน โครงสร้างพื้นฐานของการรวมแสดงที่นี่ -
"aggregations" : {
"" : {
"" : {
}
[,"meta" : { [] } ]?
[,"aggregations" : { []+ } ]?
}
[,"" : { ... } ]*
}การรวบรวมมีหลายประเภทแต่ละประเภทมีวัตถุประสงค์ของตัวเอง พวกเขาจะกล่าวถึงรายละเอียดในบทนี้
การรวมเมตริก
การรวมเหล่านี้ช่วยในการคำนวณเมทริกซ์จากค่าของฟิลด์ของเอกสารที่รวมและบางครั้งค่าบางอย่างสามารถสร้างขึ้นจากสคริปต์
เมทริกซ์ตัวเลขอาจเป็นค่าเดียวเช่นการรวมเฉลี่ยหรือหลายค่าเช่นสถิติ
การรวมเฉลี่ย
การรวมนี้ใช้เพื่อหาค่าเฉลี่ยของฟิลด์ตัวเลขใด ๆ ที่มีอยู่ในเอกสารรวม ตัวอย่างเช่น,
POST /schools/_search
{
"aggs":{
"avg_fees":{"avg":{"field":"fees"}}
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 41,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
},
"aggregations" : {
"avg_fees" : {
"value" : 2850.0
}
}
}Cardinality Aggregation
การรวมนี้ให้จำนวนค่าที่แตกต่างกันของเขตข้อมูลหนึ่ง ๆ
POST /schools/_search?size=0
{
"aggs":{
"distinct_name_count":{"cardinality":{"field":"fees"}}
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"distinct_name_count" : {
"value" : 2
}
}
}Note - มูลค่าของคาร์ดินาลลิตี้คือ 2 เนื่องจากค่าธรรมเนียมมีสองค่าที่แตกต่างกัน
การรวมสถิติเพิ่มเติม
การรวมนี้สร้างสถิติทั้งหมดเกี่ยวกับฟิลด์ตัวเลขเฉพาะในเอกสารรวม
POST /schools/_search?size=0
{
"aggs" : {
"fees_stats" : { "extended_stats" : { "field" : "fees" } }
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"fees_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0,
"sum_of_squares" : 1.709E7,
"variance" : 422500.0,
"std_deviation" : 650.0,
"std_deviation_bounds" : {
"upper" : 4150.0,
"lower" : 1550.0
}
}
}
}การรวมสูงสุด
การรวมนี้ค้นหาค่าสูงสุดของฟิลด์ตัวเลขเฉพาะในเอกสารรวม
POST /schools/_search?size=0
{
"aggs" : {
"max_fees" : { "max" : { "field" : "fees" } }
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"max_fees" : {
"value" : 3500.0
}
}
}การรวมขั้นต่ำ
การรวมนี้ค้นหาค่าต่ำสุดของฟิลด์ตัวเลขเฉพาะในเอกสารรวม
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "min" : { "field" : "fees" } }
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"value" : 2200.0
}
}
}ผลรวมการรวม
การรวมนี้คำนวณผลรวมของฟิลด์ตัวเลขเฉพาะในเอกสารรวม
POST /schools/_search?size=0
{
"aggs" : {
"total_fees" : { "sum" : { "field" : "fees" } }
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 8,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"total_fees" : {
"value" : 5700.0
}
}
}มีการรวมเมตริกอื่น ๆ ที่ใช้ในกรณีพิเศษเช่นการรวมขอบเขตทางภูมิศาสตร์และการรวมศูนย์ภูมิศาสตร์เพื่อจุดประสงค์ในการระบุตำแหน่งทางภูมิศาสตร์
การรวมสถิติ
การรวมเมตริกหลายค่าที่คำนวณสถิติมากกว่าค่าตัวเลขที่ดึงมาจากเอกสารที่รวม
POST /schools/_search?size=0
{
"aggs" : {
"grades_stats" : { "stats" : { "field" : "fees" } }
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"grades_stats" : {
"count" : 2,
"min" : 2200.0,
"max" : 3500.0,
"avg" : 2850.0,
"sum" : 5700.0
}
}
}ข้อมูลเมตาการรวม
คุณสามารถเพิ่มข้อมูลบางอย่างเกี่ยวกับการรวมในเวลาที่ร้องขอได้โดยใช้เมตาแท็กและรับข้อมูลนั้นได้
POST /schools/_search?size=0
{
"aggs" : {
"min_fees" : { "avg" : { "field" : "fees" } ,
"meta" :{
"dsc" :"Lowest Fees This Year"
}
}
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"min_fees" : {
"meta" : {
"dsc" : "Lowest Fees This Year"
},
"value" : 2850.0
}
}
}API เหล่านี้มีหน้าที่จัดการทุกแง่มุมของดัชนีเช่นการตั้งค่านามแฝงการแมปเทมเพลตดัชนี
สร้างดัชนี
API นี้ช่วยให้คุณสร้างดัชนี ดัชนีสามารถสร้างขึ้นโดยอัตโนมัติเมื่อผู้ใช้ส่งอ็อบเจ็กต์ JSON ไปยังดัชนีใด ๆ หรือสามารถสร้างขึ้นก่อนหน้านั้น ในการสร้างดัชนีคุณเพียงแค่ส่งคำขอ PUT พร้อมการตั้งค่าการแมปและนามแฝงหรือเพียงแค่คำขอธรรมดาโดยไม่มีเนื้อความ
PUT collegesในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}นอกจากนี้เรายังสามารถเพิ่มการตั้งค่าบางอย่างในคำสั่งด้านบน -
PUT colleges
{
"settings" : {
"index" : {
"number_of_shards" : 3,
"number_of_replicas" : 2
}
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "colleges"
}ลบดัชนี
API นี้ช่วยให้คุณลบดัชนีใด ๆ คุณเพียงแค่ส่งคำขอลบที่มีชื่อของดัชนีนั้น ๆ
DELETE /collegesคุณสามารถลบดัชนีทั้งหมดได้โดยใช้ _all หรือ *
รับดัชนี
API นี้สามารถเรียกได้โดยเพียงแค่ส่งคำขอ get ไปยังดัชนีหนึ่งหรือมากกว่าหนึ่งดัชนี ส่งคืนข้อมูลเกี่ยวกับดัชนี
GET collegesในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
{
"colleges" : {
"aliases" : {
"alias_1" : { },
"alias_2" : {
"filter" : {
"term" : {
"user" : "pkay"
}
},
"index_routing" : "pkay",
"search_routing" : "pkay"
}
},
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}คุณสามารถรับข้อมูลของดัชนีทั้งหมดได้โดยใช้ _all หรือ *
ดัชนีมีอยู่
การมีอยู่ของดัชนีสามารถกำหนดได้โดยเพียงแค่ส่งคำขอ get ไปยังดัชนีนั้น หากการตอบสนอง HTTP คือ 200 แสดงว่ามีอยู่ ถ้าเป็น 404 แสดงว่าไม่มีอยู่จริง
HEAD collegesในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
200-OKการตั้งค่าดัชนี
คุณสามารถรับการตั้งค่าดัชนีได้โดยการต่อท้ายคีย์เวิร์ด _settings ที่ท้าย URL
GET /colleges/_settingsในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
{
"colleges" : {
"settings" : {
"index" : {
"creation_date" : "1556245406616",
"number_of_shards" : "1",
"number_of_replicas" : "1",
"uuid" : "3ExJbdl2R1qDLssIkwDAug",
"version" : {
"created" : "7000099"
},
"provided_name" : "colleges"
}
}
}
}ดัชนีสถิติ
API นี้ช่วยคุณในการดึงข้อมูลสถิติเกี่ยวกับดัชนีเฉพาะ คุณเพียงแค่ต้องส่งคำขอรับพร้อมด้วย URL ดัชนีและคำหลัก _stats ในตอนท้าย
GET /_statsในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
………………………………………………
},
"request_cache" : {
"memory_size_in_bytes" : 849,
"evictions" : 0,
"hit_count" : 1171,
"miss_count" : 4
},
"recovery" : {
"current_as_source" : 0,
"current_as_target" : 0,
"throttle_time_in_millis" : 0
}
} ………………………………………………ฟลัช
กระบวนการล้างดัชนีทำให้แน่ใจว่าข้อมูลใด ๆ ที่ยังคงอยู่ในบันทึกธุรกรรมในขณะนี้จะยังคงอยู่ใน Lucene อย่างถาวร ซึ่งจะช่วยลดเวลาในการกู้คืนเนื่องจากข้อมูลนั้นไม่จำเป็นต้องทำดัชนีซ้ำจากบันทึกธุรกรรมหลังจากที่เปิดดัชนี Lucene แล้ว
POST colleges/_flushในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ตามที่แสดงด้านล่าง -
{
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
}
}โดยปกติผลลัพธ์จาก Elasticsearch API ต่างๆจะแสดงในรูปแบบ JSON แต่ JSON ไม่ใช่เรื่องง่ายที่จะอ่านเสมอไป ดังนั้นคุณลักษณะ cat API จึงพร้อมใช้งานใน Elasticsearch ช่วยในการดูแลรูปแบบการพิมพ์ของผลลัพธ์ให้อ่านและเข้าใจได้ง่ายขึ้น มีพารามิเตอร์ต่างๆที่ใช้ใน cat API ซึ่งเซิร์ฟเวอร์มีจุดประสงค์ที่แตกต่างกันเช่น - คำว่า V ทำให้เอาต์พุต verbose
ให้เราเรียนรู้เพิ่มเติมเกี่ยวกับ cat APIs โดยละเอียดในบทนี้
Verbose
เอาต์พุต verbose แสดงผลลัพธ์ที่ดีของคำสั่ง cat ในตัวอย่างด้านล่างเราได้รับรายละเอียดของดัชนีต่างๆที่มีอยู่ในคลัสเตอร์
GET /_cat/indices?vในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open schools RkMyEn2SQ4yUgzT6EQYuAA 1 1 2 1 21.6kb 21.6kb
yellow open index_4_analysis zVmZdM1sTV61YJYrNXf1gg 1 1 0 0 283b 283b
yellow open sensor-2018-01-01 KIrrHwABRB-ilGqTu3OaVQ 1 1 1 0 4.2kb 4.2kb
yellow open colleges 3ExJbdl2R1qDLssIkwDAug 1 1 0 0 283b 283bส่วนหัว
พารามิเตอร์ h หรือที่เรียกว่า header ใช้เพื่อแสดงเฉพาะคอลัมน์ที่กล่าวถึงในคำสั่ง
GET /_cat/nodes?h=ip,portในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
127.0.0.1 9300จัดเรียง
คำสั่ง sort ยอมรับสตริงแบบสอบถามซึ่งสามารถจัดเรียงตารางตามคอลัมน์ที่ระบุในแบบสอบถาม การเรียงลำดับเริ่มต้นคือจากน้อยไปมาก แต่สามารถเปลี่ยนแปลงได้โดยการเพิ่ม: desc ลงในคอลัมน์
ตัวอย่างด้านล่างแสดงผลลัพธ์ของเทมเพลตที่เรียงลำดับจากมากไปหาน้อยของรูปแบบดัชนีที่ยื่น
GET _cat/templates?v&s=order:desc,index_patternsในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
name index_patterns order version
.triggered_watches [.triggered_watches*] 2147483647
.watch-history-9 [.watcher-history-9*] 2147483647
.watches [.watches*] 2147483647
.kibana_task_manager [.kibana_task_manager] 0 7000099นับ
พารามิเตอร์ count ระบุจำนวนเอกสารทั้งหมดในคลัสเตอร์ทั้งหมด
GET /_cat/count?vในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
epoch timestamp count
1557633536 03:58:56 17809คลัสเตอร์ API ใช้สำหรับรับข้อมูลเกี่ยวกับคลัสเตอร์และโหนดและทำการเปลี่ยนแปลงในคลัสเตอร์ ในการเรียก API นี้เราต้องระบุชื่อโหนดที่อยู่หรือ _local
GET /_nodes/_localในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
………………………………………………
cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1",
"version" : "7.0.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "b7e28a7",
"total_indexing_buffer" : 106502553,
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
………………………………………………สุขภาพคลัสเตอร์
API นี้ใช้เพื่อรับสถานะความสมบูรณ์ของคลัสเตอร์โดยการต่อท้ายคีย์เวิร์ด 'health'
GET /_cluster/healthในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"cluster_name" : "elasticsearch",
"status" : "yellow",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 7,
"active_shards" : 7,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 4,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 63.63636363636363
}สถานะคลัสเตอร์
API นี้ใช้เพื่อรับข้อมูลสถานะเกี่ยวกับคลัสเตอร์โดยการต่อท้าย URL คำหลัก 'state' ข้อมูลสถานะประกอบด้วยเวอร์ชันโหนดหลักโหนดอื่น ๆ ตารางเส้นทางข้อมูลเมตาและบล็อก
GET /_cluster/stateในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
………………………………………………
{
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"version" : 89,
"state_uuid" : "y3BlwvspR1eUQBTo0aBjig",
"master_node" : "FKH-5blYTJmff2rJ_lQOCg",
"blocks" : { },
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"name" : "ubuntu",
"ephemeral_id" : "426kTGpITGixhEzaM-5Qyg",
"transport
}
………………………………………………สถิติคลัสเตอร์
API นี้ช่วยในการดึงข้อมูลสถิติเกี่ยวกับคลัสเตอร์โดยใช้คีย์เวิร์ด "stats" API นี้ส่งคืนหมายเลขชาร์ดขนาดที่จัดเก็บการใช้หน่วยความจำจำนวนโหนดบทบาท OS และระบบไฟล์
GET /_cluster/statsในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
………………………………………….
"cluster_name" : "elasticsearch",
"cluster_uuid" : "IzKu0OoVTQ6LxqONJnN2eQ",
"timestamp" : 1556435464704,
"status" : "yellow",
"indices" : {
"count" : 7,
"shards" : {
"total" : 7,
"primaries" : 7,
"replication" : 0.0,
"index" : {
"shards" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"primaries" : {
"min" : 1,
"max" : 1,
"avg" : 1.0
},
"replication" : {
"min" : 0.0,
"max" : 0.0,
"avg" : 0.0
}
………………………………………….การตั้งค่าการอัปเดตคลัสเตอร์
API นี้ช่วยให้คุณสามารถอัปเดตการตั้งค่าของคลัสเตอร์ได้โดยใช้คีย์เวิร์ด "settings" การตั้งค่ามีสองประเภท - ถาวร (ใช้กับการรีสตาร์ท) และชั่วคราว (ไม่สามารถรีสตาร์ทคลัสเตอร์ทั้งหมดได้)
สถิติโหนด
API นี้ใช้เพื่อดึงข้อมูลสถิติของอีกหนึ่งโหนดของคลัสเตอร์ สถิติโหนดเกือบจะเหมือนกับคลัสเตอร์
GET /_nodes/statsในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"_nodes" : {
"total" : 1,
"successful" : 1,
"failed" : 0
},
"cluster_name" : "elasticsearch",
"nodes" : {
"FKH-5blYTJmff2rJ_lQOCg" : {
"timestamp" : 1556437348653,
"name" : "ubuntu",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"roles" : [
"master",
"data",
"ingest"
],
"attributes" : {
"ml.machine_memory" : "4112797696",
"xpack.installed" : "true",
"ml.max_open_jobs" : "20"
},
………………………………………………………….โหนด hot_threads
API นี้ช่วยให้คุณดึงข้อมูลเกี่ยวกับเธรดฮอตปัจจุบันบนแต่ละโหนดในคลัสเตอร์
GET /_nodes/hot_threadsในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
:::{ubuntu}{FKH-5blYTJmff2rJ_lQOCg}{426kTGpITGixhEzaM5Qyg}{127.0.0.1}{127.0.0.1:9300}{ml.machine_memory=4112797696,
xpack.installed=true, ml.max_open_jobs=20}
Hot threads at 2019-04-28T07:43:58.265Z, interval=500ms, busiestThreads=3,
ignoreIdleThreads=true:ใน Elasticsearch การค้นหาจะดำเนินการโดยใช้แบบสอบถามตาม JSON แบบสอบถามประกอบด้วยสองประโยค -
Leaf Query Clauses - อนุประโยคเหล่านี้คือการจับคู่คำหรือช่วงซึ่งมองหาค่าเฉพาะในฟิลด์เฉพาะ
Compound Query Clauses - คำค้นหาเหล่านี้เป็นการรวมกันของประโยคการค้นหาใบไม้และการค้นหาแบบผสมอื่น ๆ เพื่อดึงข้อมูลที่ต้องการ
Elasticsearch รองรับการสืบค้นจำนวนมาก แบบสอบถามเริ่มต้นด้วยคีย์เวิร์ดเคียวรีจากนั้นมีเงื่อนไขและตัวกรองอยู่ภายในในรูปแบบของออบเจ็กต์ JSON คำค้นหาประเภทต่างๆได้อธิบายไว้ด้านล่าง
ตรงกับคำค้นหาทั้งหมด
นี่คือแบบสอบถามพื้นฐานที่สุด จะส่งคืนเนื้อหาทั้งหมดและมีคะแนน 1.0 สำหรับทุกออบเจ็กต์
POST /schools/_search
{
"query":{
"match_all":{}
}
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
},
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}ข้อความค้นหาแบบเต็ม
คำค้นหาเหล่านี้ใช้เพื่อค้นหาเนื้อหาทั้งหมดเช่นบทหรือบทความข่าว แบบสอบถามนี้ทำงานตามตัววิเคราะห์ที่เกี่ยวข้องกับดัชนีหรือเอกสารนั้น ๆ ในส่วนนี้เราจะพูดถึงการสืบค้นข้อความแบบเต็มประเภทต่างๆ
จับคู่ข้อความค้นหา
ข้อความค้นหานี้จับคู่ข้อความหรือวลีกับค่าของฟิลด์อย่างน้อยหนึ่งฟิลด์
POST /schools*/_search
{
"query":{
"match" : {
"rating":"4.5"
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 44,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.47000363,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 0.47000363,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}ข้อความค้นหาการจับคู่หลายรายการ
ข้อความค้นหานี้ตรงกับข้อความหรือวลีที่มีมากกว่าหนึ่งฟิลด์
POST /schools*/_search
{
"query":{
"multi_match" : {
"query": "paprola",
"fields": [ "city", "state" ]
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.9808292,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
"fees" : 2200,
"tags" : [
"Senior Secondary",
"beautiful campus"
],
"rating" : "3.3"
}
}
]
}
}Query String Query
คำค้นหานี้ใช้ตัวแยกวิเคราะห์คำค้นหาและคำหลัก query_string
POST /schools*/_search
{
"query":{
"query_string":{
"query":"beautiful"
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 60,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
………………………………….แบบสอบถามระดับคำศัพท์
คำค้นหาเหล่านี้ส่วนใหญ่เกี่ยวข้องกับข้อมูลที่มีโครงสร้างเช่นตัวเลขวันที่และ enums
POST /schools*/_search
{
"query":{
"term":{"zip":"176115"}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
……………………………..
hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "5",
"_score" : 0.9808292,
"_source" : {
"name" : "Central School",
"description" : "CBSE Affiliation",
"street" : "Nagan",
"city" : "paprola",
"state" : "HP",
"zip" : "176115",
"location" : [
31.8955385,
76.8380405
],
}
}
]
…………………………………………..แบบสอบถามช่วง
แบบสอบถามนี้ใช้เพื่อค้นหาวัตถุที่มีค่าระหว่างช่วงของค่าที่กำหนด สำหรับสิ่งนี้เราจำเป็นต้องใช้ตัวดำเนินการเช่น -
- gte - มากกว่าเท่ากับ
- gt - มากกว่า
- lte - น้อยกว่าเท่ากับ
- lt - น้อยกว่า
ตัวอย่างเช่นสังเกตรหัสที่ระบุด้านล่าง -
POST /schools*/_search
{
"query":{
"range":{
"rating":{
"gte":3.5
}
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 24,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "schools",
"_type" : "school",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "City Best School",
"description" : "ICSE",
"street" : "West End",
"city" : "Meerut",
"state" : "UP",
"zip" : "250002",
"location" : [
28.9926174,
77.692485
],
"fees" : 3500,
"tags" : [
"fully computerized"
],
"rating" : "4.5"
}
}
]
}
}มีแบบสอบถามระดับคำศัพท์ประเภทอื่น ๆ เช่น -
Exists query - หากฟิลด์ใดฟิลด์หนึ่งมีค่าที่ไม่ใช่ค่าว่าง
Missing query - สิ่งนี้ตรงข้ามกับคำค้นหาที่มีอยู่โดยสิ้นเชิงการค้นหานี้ค้นหาวัตถุโดยไม่มีช่องหรือเขตข้อมูลใดที่มีค่า null
Wildcard or regexp query - แบบสอบถามนี้ใช้นิพจน์ทั่วไปเพื่อค้นหารูปแบบในวัตถุ
แบบสอบถามแบบผสม
คำค้นหาเหล่านี้เป็นชุดของคำค้นหาที่แตกต่างกันที่รวมเข้าด้วยกันโดยใช้ตัวดำเนินการบูลีนเช่นและหรือไม่ใช่หรือสำหรับดัชนีที่แตกต่างกันหรือมีการเรียกใช้ฟังก์ชันเป็นต้น
POST /schools/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "state" : "UP" }
},
"filter": {
"term" : { "fees" : "2200" }
},
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 6,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 0,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
}
}แบบสอบถามภูมิศาสตร์
คำค้นหาเหล่านี้จัดการกับตำแหน่งทางภูมิศาสตร์และจุดทางภูมิศาสตร์ คำค้นหาเหล่านี้ช่วยในการค้นหาโรงเรียนหรือวัตถุทางภูมิศาสตร์อื่น ๆ ที่อยู่ใกล้กับสถานที่ใด ๆ คุณต้องใช้ประเภทข้อมูลจุดภูมิศาสตร์
PUT /geo_example
{
"mappings": {
"properties": {
"location": {
"type": "geo_shape"
}
}
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{ "acknowledged" : true,
"shards_acknowledged" : true,
"index" : "geo_example"
}ตอนนี้เราโพสต์ข้อมูลในดัชนีที่สร้างขึ้นด้านบน
POST /geo_example/_doc?refresh
{
"name": "Chapter One, London, UK",
"location": {
"type": "point",
"coordinates": [11.660544, 57.800286]
}
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
"_index" : "geo_example",
"_type" : "_doc",
"_id" : "hASWZ2oBbkdGzVfiXHKD",
"_score" : 1.0,
"_source" : {
"name" : "Chapter One, London, UK",
"location" : {
"type" : "point",
"coordinates" : [
11.660544,
57.800286
]
}
}
}
}การทำแผนที่คือโครงร่างของเอกสารที่จัดเก็บในดัชนี กำหนดประเภทข้อมูลเช่น geo_point หรือสตริงและรูปแบบของฟิลด์ที่มีอยู่ในเอกสารและกฎเพื่อควบคุมการแมปของฟิลด์ที่เพิ่มแบบไดนามิก
PUT bankaccountdetails
{
"mappings":{
"properties":{
"name": { "type":"text"}, "date":{ "type":"date"},
"balance":{ "type":"double"}, "liability":{ "type":"double"}
}
}
}เมื่อเรารันโค้ดด้านบนเราจะได้รับการตอบสนองดังที่แสดงด้านล่าง -
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "bankaccountdetails"
}ประเภทข้อมูลฟิลด์
Elasticsearch รองรับประเภทข้อมูลต่างๆสำหรับฟิลด์ในเอกสาร ชนิดข้อมูลที่ใช้ในการจัดเก็บฟิลด์ใน Elasticsearch จะกล่าวถึงโดยละเอียดที่นี่
ประเภทข้อมูลหลัก
เหล่านี้เป็นประเภทข้อมูลพื้นฐานเช่นข้อความคีย์เวิร์ดวันที่แบบยาวคู่บูลีนหรือไอพีซึ่งเกือบทุกระบบรองรับ
ประเภทข้อมูลที่ซับซ้อน
ประเภทข้อมูลเหล่านี้เป็นการรวมกันของประเภทข้อมูลหลัก ซึ่งรวมถึงอาร์เรย์ออบเจ็กต์ JSON และประเภทข้อมูลที่ซ้อนกัน ตัวอย่างประเภทข้อมูลที่ซ้อนกันแสดงอยู่ด้านล่าง & ลบ
POST /tabletennis/_doc/1
{
"group" : "players",
"user" : [
{
"first" : "dave", "last" : "jones"
},
{
"first" : "kevin", "last" : "morris"
}
]
}เมื่อเรารันโค้ดด้านบนเราจะได้รับการตอบสนองดังที่แสดงด้านล่าง -
{
"_index" : "tabletennis",
"_type" : "_doc",
"_id" : "1",
_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}โค้ดตัวอย่างอื่นแสดงไว้ด้านล่าง -
POST /accountdetails/_doc/1
{
"from_acc":"7056443341", "to_acc":"7032460534",
"date":"11/1/2016", "amount":10000
}เมื่อเรารันโค้ดด้านบนเราจะได้รับการตอบสนองดังที่แสดงด้านล่าง -
{ "_index" : "accountdetails",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}เราสามารถตรวจสอบเอกสารข้างต้นได้โดยใช้คำสั่งต่อไปนี้ -
GET /accountdetails/_mappings?include_type_name=falseการลบประเภทการทำแผนที่
ดัชนีที่สร้างใน Elasticsearch 7.0.0 ขึ้นไปจะไม่ยอมรับการแมป _default_ อีกต่อไป ดัชนีที่สร้างใน 6.x จะยังคงทำงานเหมือนเดิมใน Elasticsearch 6.x. ประเภทถูกเลิกใช้ใน API ใน 7.0
เมื่อแบบสอบถามถูกประมวลผลระหว่างการดำเนินการค้นหาเนื้อหาในดัชนีใด ๆ จะถูกวิเคราะห์โดยโมดูลการวิเคราะห์ โมดูลนี้ประกอบด้วยตัววิเคราะห์โทเค็นตัวกรองโทเค็นและตัวกรอง หากไม่มีการกำหนดตัววิเคราะห์ดังนั้นโดยค่าเริ่มต้นตัววิเคราะห์โทเค็นตัวกรองและโทเค็นในตัวจะได้รับการลงทะเบียนกับโมดูลการวิเคราะห์
ในตัวอย่างต่อไปนี้เราใช้เครื่องวิเคราะห์มาตรฐานซึ่งใช้เมื่อไม่มีการระบุตัววิเคราะห์อื่น มันจะวิเคราะห์ประโยคตามไวยากรณ์และผลิตคำที่ใช้ในประโยค
POST _analyze
{
"analyzer": "standard",
"text": "Today's weather is beautiful"
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"tokens" : [
{
"token" : "today's",
"start_offset" : 0,
"end_offset" : 7,
"type" : "",
"position" : 0
},
{
"token" : "weather",
"start_offset" : 8,
"end_offset" : 15,
"type" : "",
"position" : 1
},
{
"token" : "is",
"start_offset" : 16,
"end_offset" : 18,
"type" : "",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 19,
"end_offset" : 28,
"type" : "",
"position" : 3
}
]
}การกำหนดค่าตัววิเคราะห์มาตรฐาน
เราสามารถกำหนดค่าตัววิเคราะห์มาตรฐานด้วยพารามิเตอร์ต่างๆเพื่อให้ได้ข้อกำหนดที่กำหนดเองของเรา
ในตัวอย่างต่อไปนี้เรากำหนดค่าตัววิเคราะห์มาตรฐานให้มี max_token_length 5
สำหรับสิ่งนี้อันดับแรกเราสร้างดัชนีโดยตัววิเคราะห์ที่มีพารามิเตอร์ max_length_token
PUT index_4_analysis
{
"settings": {
"analysis": {
"analyzer": {
"my_english_analyzer": {
"type": "standard",
"max_token_length": 5,
"stopwords": "_english_"
}
}
}
}
}ต่อไปเราจะใช้เครื่องวิเคราะห์ด้วยข้อความดังที่แสดงด้านล่าง โปรดทราบว่าโทเค็นไม่ปรากฏขึ้นได้อย่างไรเนื่องจากมีช่องว่างสองช่องในจุดเริ่มต้นและสองช่องว่างในตอนท้าย สำหรับคำว่า“ คือ” จะมีช่องว่างที่จุดเริ่มต้นและเว้นวรรคท้าย เมื่อนำทั้งหมดแล้วมันจะกลายเป็นตัวอักษร 4 ตัวพร้อมช่องว่างและไม่ได้ทำให้เป็นคำ ควรมีอักขระ nonspace อย่างน้อยตอนต้นหรือตอนท้ายเพื่อให้เป็นคำที่จะนับ
POST index_4_analysis/_analyze
{
"analyzer": "my_english_analyzer",
"text": "Today's weather is beautiful"
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"tokens" : [
{
"token" : "today",
"start_offset" : 0,
"end_offset" : 5,
"type" : "",
"position" : 0
},
{
"token" : "s",
"start_offset" : 6,
"end_offset" : 7,
"type" : "",
"position" : 1
},
{
"token" : "weath",
"start_offset" : 8,
"end_offset" : 13,
"type" : "",
"position" : 2
},
{
"token" : "er",
"start_offset" : 13,
"end_offset" : 15,
"type" : "",
"position" : 3
},
{
"token" : "beaut",
"start_offset" : 19,
"end_offset" : 24,
"type" : "",
"position" : 5
},
{
"token" : "iful",
"start_offset" : 24,
"end_offset" : 28,
"type" : "",
"position" : 6
}
]
}รายชื่อเครื่องวิเคราะห์ต่างๆและคำอธิบายมีอยู่ในตารางที่แสดงด้านล่าง -
| ส. เลขที่ | เครื่องวิเคราะห์และคำอธิบาย |
|---|---|
| 1 | Standard analyzer (standard) สามารถตั้งค่าคำหยุดและ max_token_length สำหรับเครื่องวิเคราะห์นี้ได้ โดยค่าเริ่มต้นรายการคำหยุดจะว่างเปล่าและ max_token_length คือ 255 |
| 2 | Simple analyzer (simple) เครื่องวิเคราะห์นี้ประกอบด้วยโทเค็นตัวพิมพ์เล็ก |
| 3 | Whitespace analyzer (whitespace) เครื่องวิเคราะห์นี้ประกอบด้วยโทเค็นการเว้นวรรค |
| 4 | Stop analyzer (stop) สามารถกำหนดค่า stopwords และ stopwords_path ได้ โดยค่าเริ่มต้นคำหยุดเริ่มต้นเป็นคำหยุดภาษาอังกฤษและ stopwords_path มีเส้นทางไปยังไฟล์ข้อความที่มีคำหยุด |
Tokenizers
โทเค็นใช้สำหรับสร้างโทเค็นจากข้อความใน Elasticsearch ข้อความสามารถแบ่งออกเป็นโทเค็นได้โดยคำนึงถึงช่องว่างหรือเครื่องหมายวรรคตอนอื่น ๆ Elasticsearch มีโทเค็นในตัวมากมายซึ่งสามารถใช้ในตัววิเคราะห์แบบกำหนดเองได้
ตัวอย่างของโทเค็นไนเซอร์ที่แบ่งข้อความออกเป็นเงื่อนไขเมื่อใดก็ตามที่พบอักขระที่ไม่ใช่ตัวอักษร แต่จะลดขนาดของคำทั้งหมดลงด้วยแสดงไว้ด้านล่าง -
POST _analyze
{
"tokenizer": "lowercase",
"text": "It Was a Beautiful Weather 5 Days ago."
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"tokens" : [
{
"token" : "it",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "was",
"start_offset" : 3,
"end_offset" : 6,
"type" : "word",
"position" : 1
},
{
"token" : "a",
"start_offset" : 7,
"end_offset" : 8,
"type" : "word",
"position" : 2
},
{
"token" : "beautiful",
"start_offset" : 9,
"end_offset" : 18,
"type" : "word",
"position" : 3
},
{
"token" : "weather",
"start_offset" : 19,
"end_offset" : 26,
"type" : "word",
"position" : 4
},
{
"token" : "days",
"start_offset" : 29,
"end_offset" : 33,
"type" : "word",
"position" : 5
},
{
"token" : "ago",
"start_offset" : 34,
"end_offset" : 37,
"type" : "word",
"position" : 6
}
]
}รายการ Tokenizers และคำอธิบายแสดงไว้ที่นี่ในตารางด้านล่าง -
| ส. เลขที่ | Tokenizer และคำอธิบาย |
|---|---|
| 1 | Standard tokenizer (standard) สิ่งนี้สร้างขึ้นจากโทเค็นไนเซอร์ที่ใช้ไวยากรณ์และสามารถกำหนดค่า max_token_length สำหรับโทเค็นไนเซอร์นี้ได้ |
| 2 | Edge NGram tokenizer (edgeNGram) สามารถตั้งค่าเช่น min_gram, max_gram, token_chars สำหรับ tokenizer นี้ได้ |
| 3 | Keyword tokenizer (keyword) สิ่งนี้สร้างอินพุตทั้งหมดเป็นเอาต์พุตและสามารถตั้งค่า buffer_size สำหรับสิ่งนี้ |
| 4 | Letter tokenizer (letter) สิ่งนี้จะจับทั้งคำจนกว่าจะพบตัวอักษรที่ไม่ใช่ตัวอักษร |
Elasticsearch ประกอบด้วยโมดูลจำนวนมากซึ่งรับผิดชอบการทำงานของมัน โมดูลเหล่านี้มีการตั้งค่าสองประเภทดังนี้ -
Static Settings- ต้องกำหนดค่าการตั้งค่าเหล่านี้ในไฟล์ config (elasticsearch.yml) ก่อนเริ่ม Elasticsearch คุณต้องอัปเดตโหนดข้อกังวลทั้งหมดในคลัสเตอร์เพื่อแสดงการเปลี่ยนแปลงโดยการตั้งค่าเหล่านี้
Dynamic Settings - การตั้งค่าเหล่านี้สามารถตั้งค่าได้ใน Elasticsearch แบบสด
เราจะพูดถึงโมดูลต่างๆของ Elasticsearch ในส่วนต่อไปนี้ของบทนี้
การกำหนดเส้นทางระดับคลัสเตอร์และการจัดสรรชาร์ด
การตั้งค่าระดับคลัสเตอร์จะตัดสินใจการจัดสรรชาร์ดให้กับโหนดต่างๆและการจัดสรรชาร์ดใหม่เพื่อปรับสมดุลคลัสเตอร์ นี่คือการตั้งค่าต่อไปนี้เพื่อควบคุมการจัดสรรชาร์ด
การจัดสรรชาร์ดระดับคลัสเตอร์
| การตั้งค่า | ค่าที่เป็นไปได้ | คำอธิบาย |
|---|---|---|
| cluster.routing.allocation.enable | ||
| ทั้งหมด | ค่าเริ่มต้นนี้อนุญาตให้จัดสรรชาร์ดสำหรับเศษทุกชนิด | |
| ไพรมารี | สิ่งนี้อนุญาตให้มีการจัดสรรชาร์ดสำหรับเศษหลักเท่านั้น | |
| new_primaries | สิ่งนี้อนุญาตให้มีการจัดสรรชาร์ดเฉพาะสำหรับชาร์ดหลักสำหรับดัชนีใหม่ | |
| ไม่มี | สิ่งนี้ไม่อนุญาตให้มีการจัดสรรชาร์ดใด ๆ | |
| cluster.routing.allocation .node_concurrent_recoveries | ค่าตัวเลข (โดยค่าเริ่มต้น 2) | สิ่งนี้ จำกัด จำนวนการกู้คืนชาร์ดพร้อมกัน |
| cluster.routing.allocation .node_initial_primaries_recoveries | ค่าตัวเลข (โดยค่าเริ่มต้น 4) | สิ่งนี้ จำกัด จำนวนการกู้คืนหลักเริ่มต้นแบบขนาน |
| cluster.routing.allocation .same_shard.host | ค่าบูลีน (โดยค่าเริ่มต้นเท็จ) | สิ่งนี้ จำกัด การจัดสรรมากกว่าหนึ่งแบบจำลองของชาร์ดเดียวกันในโหนดทางกายภาพเดียวกัน |
| indices.recovery.concurrent _streams | ค่าตัวเลข (โดยค่าเริ่มต้น 3) | การดำเนินการนี้จะควบคุมจำนวนสตรีมเครือข่ายที่เปิดต่อโหนดในช่วงเวลาของการกู้คืนชาร์ดจากชิ้นส่วนเพียร์ |
| indices.recovery.concurrent _small_file_streams | ค่าตัวเลข (โดยค่าเริ่มต้น 2) | สิ่งนี้ควบคุมจำนวนสตรีมที่เปิดต่อโหนดสำหรับไฟล์ขนาดเล็กที่มีขนาดน้อยกว่า 5mb ในช่วงเวลาของการกู้คืนชาร์ด |
| cluster.routing.rebalance.enable | ||
| ทั้งหมด | ค่าเริ่มต้นนี้ช่วยให้สามารถปรับสมดุลสำหรับเศษทุกชนิด | |
| ไพรมารี | สิ่งนี้ช่วยให้การปรับสมดุลของชาร์ดสำหรับเศษหลักเท่านั้น | |
| แบบจำลอง | สิ่งนี้ช่วยให้การปรับสมดุลของชาร์ดสำหรับชิ้นส่วนจำลองเท่านั้น | |
| ไม่มี | สิ่งนี้ไม่อนุญาตให้มีการปรับสมดุลของชาร์ดใด ๆ | |
| cluster.routing.allocation .allow_rebalance | ||
| เสมอ | ค่าเริ่มต้นนี้อนุญาตให้ปรับสมดุลใหม่ได้เสมอ | |
| indices_primaries _active | สิ่งนี้ช่วยให้สามารถปรับสมดุลใหม่ได้เมื่อมีการจัดสรรเศษหลักทั้งหมดในคลัสเตอร์ | |
| Indices_all_active | สิ่งนี้ช่วยให้สามารถปรับสมดุลใหม่ได้เมื่อมีการจัดสรรเศษหลักและแบบจำลองทั้งหมด | |
| cluster.routing.allocation.cluster _concurrent_rebalance | ค่าตัวเลข (โดยค่าเริ่มต้น 2) | สิ่งนี้ จำกัด จำนวนของการปรับสมดุลชาร์ดพร้อมกันในคลัสเตอร์ |
| cluster.routing.allocation .balance.shard | ค่าลอย (โดยค่าเริ่มต้น 0.45f) | สิ่งนี้กำหนดปัจจัยน้ำหนักสำหรับเศษที่จัดสรรในทุกโหนด |
| cluster.routing.allocation .balance.index | ค่าลอย (โดยค่าเริ่มต้น 0.55f) | สิ่งนี้กำหนดอัตราส่วนของจำนวนชาร์ดต่อดัชนีที่จัดสรรบนโหนดเฉพาะ |
| cluster.routing.allocation .balance.threshold | ค่าลอยตัวที่ไม่ใช่ค่าลบ (โดยค่าเริ่มต้น 1.0f) | นี่คือค่าการเพิ่มประสิทธิภาพขั้นต่ำของการดำเนินการที่ควรดำเนินการ |
การจัดสรรชาร์ดบนดิสก์
| การตั้งค่า | ค่าที่เป็นไปได้ | คำอธิบาย |
|---|---|---|
| cluster.routing.allocation.disk.threshold_enabled | ค่าบูลีน (โดยค่าเริ่มต้นจริง) | สิ่งนี้เปิดใช้งานและปิดใช้งานตัวตัดสินใจการจัดสรรดิสก์ |
| cluster.routing.allocation.disk.watermark.low | ค่าสตริง (โดยค่าเริ่มต้น 85%) | นี่หมายถึงการใช้งานดิสก์สูงสุด หลังจากจุดนี้จะไม่สามารถจัดสรรชาร์ดอื่นให้กับดิสก์นั้นได้ |
| cluster.routing.allocation.disk.watermark.high | ค่าสตริง (โดยค่าเริ่มต้น 90%) | นี่หมายถึงการใช้งานสูงสุด ณ เวลาที่จัดสรร หากถึงจุดนี้ในช่วงเวลาของการจัดสรร Elasticsearch จะจัดสรรชาร์ดนั้นไปยังดิสก์อื่น |
| cluster.info.update.interval | ค่าสตริง (โดยค่าเริ่มต้น 30 วินาที) | นี่คือช่วงเวลาระหว่างการตรวจสอบการใช้งานดิสก์ |
| cluster.routing.allocation.disk.include_relocations | ค่าบูลีน (โดยค่าเริ่มต้นจริง) | สิ่งนี้จะตัดสินใจว่าจะพิจารณาชิ้นส่วนที่กำลังจัดสรรอยู่หรือไม่ในขณะที่คำนวณการใช้ดิสก์ |
การค้นพบ
โมดูลนี้ช่วยให้คลัสเตอร์ค้นหาและรักษาสถานะของโหนดทั้งหมดในนั้น สถานะของคลัสเตอร์จะเปลี่ยนไปเมื่อมีการเพิ่มหรือลบโหนดออกจากโหนด การตั้งค่าชื่อคลัสเตอร์ถูกใช้เพื่อสร้างความแตกต่างทางตรรกะระหว่างคลัสเตอร์ต่างๆ มีโมดูลบางอย่างที่ช่วยให้คุณใช้ API ที่ผู้ให้บริการคลาวด์จัดเตรียมไว้ให้และมีดังที่ระบุด้านล่าง -
- การค้นพบ Azure
- การค้นพบ EC2
- Google compute engine discovery
- การค้นพบเซน
ประตู
โมดูลนี้รักษาสถานะคลัสเตอร์และข้อมูลชาร์ดในคลัสเตอร์แบบเต็มจะรีสตาร์ท ต่อไปนี้เป็นการตั้งค่าคงที่ของโมดูลนี้ -
| การตั้งค่า | ค่าที่เป็นไปได้ | คำอธิบาย |
|---|---|---|
| gateway. expected_nodes | ค่าตัวเลข (โดยค่าเริ่มต้น 0) | จำนวนโหนดที่คาดว่าจะอยู่ในคลัสเตอร์สำหรับการกู้คืนชาร์ดโลคัล |
| gateway. expected_master_nodes | ค่าตัวเลข (โดยค่าเริ่มต้น 0) | จำนวนโหนดหลักที่คาดว่าจะอยู่ในคลัสเตอร์ก่อนเริ่มการกู้คืน |
| gateway. expected_data_nodes | ค่าตัวเลข (โดยค่าเริ่มต้น 0) | จำนวนโหนดข้อมูลที่คาดหวังในคลัสเตอร์ก่อนเริ่มการกู้คืน |
| gateway.recover_after_time | ค่าสตริง (โดยค่าเริ่มต้น 5m) | นี่คือช่วงเวลาระหว่างการตรวจสอบการใช้งานดิสก์ |
| cluster.routing.allocation disk.include_relocations | ค่าบูลีน (โดยค่าเริ่มต้นจริง) | ค่านี้ระบุเวลาที่กระบวนการกู้คืนจะรอเพื่อเริ่มต้นโดยไม่คำนึงถึงจำนวนโหนดที่เข้าร่วมในคลัสเตอร์ gateway.recover_ after_nodes |
HTTP
โมดูลนี้จัดการการสื่อสารระหว่างไคลเอ็นต์ HTTP และ Elasticsearch API โมดูลนี้สามารถปิดใช้งานได้โดยเปลี่ยนค่าของ http.enabled เป็น false
ต่อไปนี้คือการตั้งค่า (กำหนดค่าใน elasticsearch.yml) เพื่อควบคุมโมดูลนี้ -
| ส. เลขที่ | การตั้งค่าและคำอธิบาย |
|---|---|
| 1 | http.port นี่คือพอร์ตสำหรับเข้าถึง Elasticsearch และมีตั้งแต่ 9200-9300 |
| 2 | http.publish_port พอร์ตนี้มีไว้สำหรับไคลเอ็นต์ http และยังมีประโยชน์ในกรณีของไฟร์วอลล์ |
| 3 | http.bind_host นี่คือที่อยู่โฮสต์สำหรับบริการ http |
| 4 | http.publish_host นี่คือที่อยู่โฮสต์สำหรับไคลเอ็นต์ http |
| 5 | http.max_content_length นี่คือขนาดสูงสุดของเนื้อหาในคำขอ http ค่าเริ่มต้นคือ 100mb |
| 6 | http.max_initial_line_length นี่คือขนาดสูงสุดของ URL และค่าเริ่มต้นคือ 4kb |
| 7 | http.max_header_size นี่คือขนาดส่วนหัว http สูงสุดและค่าเริ่มต้นคือ 8kb |
| 8 | http.compression สิ่งนี้เปิดใช้งานหรือปิดใช้งานการสนับสนุนสำหรับการบีบอัดและค่าเริ่มต้นเป็นเท็จ |
| 9 | http.pipelinig สิ่งนี้เปิดหรือปิดใช้งานการไปป์ไลน์ HTTP |
| 10 | http.pipelining.max_events ซึ่งจะ จำกัด จำนวนเหตุการณ์ที่จะจัดคิวก่อนปิดคำขอ HTTP |
ดัชนี
โมดูลนี้รักษาการตั้งค่าซึ่งกำหนดไว้ทั่วโลกสำหรับทุกดัชนี การตั้งค่าต่อไปนี้เกี่ยวข้องกับการใช้หน่วยความจำเป็นหลัก -
เบรกเกอร์
ใช้เพื่อป้องกันการดำเนินการไม่ให้เกิด OutOfMemroyError การตั้งค่านี้ จำกัด ขนาดฮีพ JVM เป็นหลัก ตัวอย่างเช่นการตั้งค่า indices.breaker.total.limit ซึ่งมีค่าเริ่มต้นเป็น 70% ของฮีป JVM
แคช Fielddata
ส่วนใหญ่จะใช้เมื่อรวมในเขตข้อมูล ขอแนะนำให้มีหน่วยความจำเพียงพอที่จะจัดสรรได้ จำนวนหน่วยความจำที่ใช้สำหรับแคชข้อมูลฟิลด์สามารถควบคุมได้โดยใช้การตั้งค่า indices.fielddata.cache.size
Node Query Cache
หน่วยความจำนี้ใช้สำหรับการแคชผลลัพธ์คิวรี แคชนี้ใช้นโยบายการขับไล่อย่างน้อยที่สุดที่ใช้ (LRU) การตั้งค่า Indices.queries.cahce.size ควบคุมขนาดหน่วยความจำของแคชนี้
บัฟเฟอร์การจัดทำดัชนี
บัฟเฟอร์นี้จะจัดเก็บเอกสารที่สร้างขึ้นใหม่ในดัชนีและจะล้างข้อมูลเมื่อบัฟเฟอร์เต็ม การตั้งค่าเช่น indices.memory.index_buffer_size ควบคุมจำนวนฮีปที่จัดสรรสำหรับบัฟเฟอร์นี้
แคชคำขอชาร์ด
แคชนี้ใช้เพื่อจัดเก็บข้อมูลการค้นหาในเครื่องสำหรับทุกชาร์ด สามารถเปิดใช้งานแคชระหว่างการสร้างดัชนีหรือปิดใช้งานได้โดยการส่งพารามิเตอร์ URL
Disable cache - ?request_cache = true
Enable cache "index.requests.cache.enable": trueการกู้คืนดัชนี
ควบคุมทรัพยากรในระหว่างกระบวนการกู้คืน ต่อไปนี้คือการตั้งค่า -
| การตั้งค่า | ค่าเริ่มต้น |
|---|---|
| indices.recovery.concurrent_streams | 3 |
| indices.recovery.concurrent_small_file_streams | 2 |
| indices.recovery.file_chunk_size | 512kb |
| indices.recovery.translog_ops | 1,000 |
| indices.recovery.translog_size | 512kb |
| indices.recovery.compress | จริง |
| indices.recovery.max_bytes_per_sec | 40mb |
ช่วง TTL
ช่วง Time to Live (TTL) กำหนดเวลาของเอกสารหลังจากนั้นเอกสารจะถูกลบ ต่อไปนี้คือการตั้งค่าไดนามิกสำหรับการควบคุมกระบวนการนี้ -
| การตั้งค่า | ค่าเริ่มต้น |
|---|---|
| indices.ttl.interval | ยุค 60 |
| indices.ttl.bulk_size | 1,000 |
โหนด
แต่ละโหนดมีตัวเลือกว่าจะเป็นโหนดข้อมูลหรือไม่ คุณสามารถเปลี่ยนคุณสมบัตินี้ได้โดยการเปลี่ยนnode.dataการตั้งค่า. การตั้งค่าเป็นfalse กำหนดว่าโหนดไม่ใช่โหนดข้อมูล
นี่คือโมดูลที่สร้างขึ้นสำหรับทุกดัชนีและควบคุมการตั้งค่าและพฤติกรรมของดัชนี ตัวอย่างเช่นจำนวนชาร์ดที่ดัชนีสามารถใช้ได้หรือจำนวนของแบบจำลองที่ชาร์ดหลักสามารถมีได้สำหรับดัชนีนั้นเป็นต้นการตั้งค่าดัชนีมีสองประเภท -
- Static - สามารถตั้งค่าได้เฉพาะในเวลาสร้างดัชนีหรือในดัชนีปิด
- Dynamic - สิ่งเหล่านี้สามารถเปลี่ยนแปลงได้ในดัชนีสด
การตั้งค่าดัชนีคงที่
ตารางต่อไปนี้แสดงรายการการตั้งค่าดัชนีคงที่ -
| การตั้งค่า | ค่าที่เป็นไปได้ | คำอธิบาย |
|---|---|---|
| index.number_of_shards | ค่าเริ่มต้นคือ 5 สูงสุด 1024 | จำนวนชิ้นส่วนหลักที่ดัชนีควรมี |
| index.shard.check_on_startup | ค่าเริ่มต้นเป็นเท็จ สามารถเป็น True | ควรตรวจสอบความเสียหายก่อนเปิดหรือไม่ |
| index.codec | การบีบอัด LZ4 | ประเภทการบีบอัดที่ใช้ในการจัดเก็บข้อมูล |
| index.routing_partition_size | 1 | จำนวนชาร์ดที่ค่าการกำหนดเส้นทางที่กำหนดเองสามารถไปได้ |
| index.load_fixed_bitset_filters_eagerly | เท็จ | ระบุว่ามีการโหลดตัวกรองแคชไว้ล่วงหน้าสำหรับเคียวรีที่ซ้อนกันหรือไม่ |
การตั้งค่าดัชนีไดนามิก
ตารางต่อไปนี้แสดงรายการการตั้งค่าดัชนีไดนามิก -
| การตั้งค่า | ค่าที่เป็นไปได้ | คำอธิบาย |
|---|---|---|
| index.number_of_replicas | ค่าเริ่มต้นคือ 1 | จำนวนการจำลองแต่ละชาร์ดหลักมี |
| index.auto_expand_replicas | เส้นประคั่นขอบล่างและบน (0-5) | ขยายจำนวนแบบจำลองโดยอัตโนมัติตามจำนวนโหนดข้อมูลในคลัสเตอร์ |
| index.search.idle.after | 30 วินาที | ระยะเวลาที่ชาร์ดไม่สามารถรับการค้นหาหรือรับคำขอจนกว่าจะถือว่าไม่ได้ใช้งานการค้นหา |
| index.refresh_interval | 1 วินาที | ความถี่ในการดำเนินการรีเฟรชซึ่งทำให้การเปลี่ยนแปลงล่าสุดในดัชนีสามารถค้นหาได้ |
| index.blocks.read_only | 1 จริง / เท็จ | ตั้งค่าเป็น true เพื่อให้ข้อมูลเมตาของดัชนีและดัชนีเป็นแบบอ่านอย่างเดียวเป็นเท็จเพื่ออนุญาตให้เขียนและเปลี่ยนแปลงข้อมูลเมตา |
บางครั้งเราจำเป็นต้องแปลงเอกสารก่อนที่จะจัดทำดัชนี ตัวอย่างเช่นเราต้องการลบเขตข้อมูลออกจากเอกสารหรือเปลี่ยนชื่อเขตข้อมูลแล้วจัดทำดัชนี สิ่งนี้จัดการโดย Ingest node
ทุกโหนดในคลัสเตอร์มีความสามารถในการนำเข้า แต่ยังสามารถปรับแต่งให้ประมวลผลโดยโหนดเฉพาะได้
ขั้นตอนที่เกี่ยวข้อง
มีสองขั้นตอนที่เกี่ยวข้องในการทำงานของโหนดการนำเข้า -
- การสร้างไปป์ไลน์
- การสร้างเอกสาร
สร้างไปป์ไลน์
ขั้นแรกให้สร้างไปป์ไลน์ที่มีโปรเซสเซอร์จากนั้นดำเนินการไปป์ไลน์ดังที่แสดงด้านล่าง -
PUT _ingest/pipeline/int-converter
{
"description": "converts the content of the seq field to an integer",
"processors" : [
{
"convert" : {
"field" : "seq",
"type": "integer"
}
}
]
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"acknowledged" : true
}สร้างเอกสาร
ต่อไปเราจะสร้างเอกสารโดยใช้ตัวแปลงไปป์ไลน์
PUT /logs/_doc/1?pipeline=int-converter
{
"seq":"21",
"name":"Tutorialspoint",
"Addrs":"Hyderabad"
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}ต่อไปเราจะค้นหาเอกสารที่สร้างขึ้นด้านบนโดยใช้คำสั่ง GET ดังที่แสดงด้านล่าง -
GET /logs/_doc/1ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"Addrs" : "Hyderabad",
"name" : "Tutorialspoint",
"seq" : 21
}
}คุณจะเห็นด้านบนว่า 21 กลายเป็นจำนวนเต็ม
ไม่มีท่อ
ตอนนี้เราสร้างเอกสารโดยไม่ต้องใช้ไปป์ไลน์
PUT /logs/_doc/2
{
"seq":"11",
"name":"Tutorix",
"Addrs":"Secunderabad"
}
GET /logs/_doc/2ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "logs",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"seq" : "11",
"name" : "Tutorix",
"Addrs" : "Secunderabad"
}
}คุณจะเห็นด้านบนว่า 11 เป็นสตริงที่ไม่มีการใช้ไปป์ไลน์
การจัดการวงจรชีวิตของดัชนีเกี่ยวข้องกับการดำเนินการจัดการตามปัจจัยต่างๆเช่นขนาดของชิ้นส่วนและข้อกำหนดด้านประสิทธิภาพ API การจัดการวงจรชีวิตของดัชนี (ILM) ช่วยให้คุณสามารถจัดการดัชนีของคุณได้โดยอัตโนมัติเมื่อเวลาผ่านไป
บทนี้แสดงรายการ ILM API และการใช้งาน
API การจัดการนโยบาย
| ชื่อ API | วัตถุประสงค์ | ตัวอย่าง |
|---|---|---|
| สร้างนโยบายวงจรการใช้งาน | สร้างนโยบายวงจรชีวิต หากมีนโยบายที่ระบุนโยบายจะถูกแทนที่และเวอร์ชันของนโยบายจะเพิ่มขึ้น | PUT_ilm / policy / policy_id |
| รับนโยบายวงจรการใช้งาน | ส่งกลับข้อกำหนดนโยบายที่ระบุ รวมเวอร์ชันของนโยบายและวันที่แก้ไขล่าสุด หากไม่ได้ระบุนโยบายจะส่งคืนนโยบายที่กำหนดไว้ทั้งหมด | GET_ilm / policy / policy_id |
| ลบนโยบายวงจรการใช้งาน | ลบข้อกำหนดนโยบายวงจรการใช้งานที่ระบุ คุณไม่สามารถลบนโยบายที่ใช้อยู่ในปัจจุบันได้ หากกำลังใช้นโยบายเพื่อจัดการดัชนีใด ๆ คำขอจะล้มเหลวและส่งกลับข้อผิดพลาด | DELETE_ilm / policy / policy_id |
API การจัดการดัชนี
| ชื่อ API | วัตถุประสงค์ | ตัวอย่าง |
|---|---|---|
| ย้ายไปที่ Lifecycle step API | ย้ายดัชนีด้วยตนเองไปยังขั้นตอนที่ระบุและดำเนินการขั้นตอนนั้น | POST_ilm / move / index |
| ลองใช้นโยบายอีกครั้ง | ตั้งค่านโยบายกลับไปที่ขั้นตอนที่เกิดข้อผิดพลาดและดำเนินการตามขั้นตอน | POST ดัชนี / _ilm / ลองใหม่ |
| ลบนโยบายจากการแก้ไขดัชนี API | ลบนโยบายวงจรการใช้งานที่กำหนดและหยุดการจัดการดัชนีที่ระบุ หากระบุรูปแบบดัชนีให้ลบนโยบายที่กำหนดออกจากดัชนีที่ตรงกันทั้งหมด | ดัชนี POST / _ilm / ลบ |
API การจัดการการดำเนินงาน
| ชื่อ API | วัตถุประสงค์ | ตัวอย่าง |
|---|---|---|
| รับ API สถานะการจัดการอายุการใช้งานดัชนี | ส่งคืนสถานะของปลั๊กอิน ILM ฟิลด์ operation_mode ในการตอบกลับจะแสดงสถานะหนึ่งในสามสถานะ: STARTED, STOPPING หรือ STOPPED | รับ / _ilm / สถานะ |
| เริ่ม API การจัดการวงจรชีวิตของดัชนี | เริ่มต้นปลั๊กอิน ILM หากหยุดทำงานในขณะนี้ ILM เริ่มต้นโดยอัตโนมัติเมื่อคลัสเตอร์ถูกสร้างขึ้น | POST / _ilm / เริ่ม |
| หยุด API การจัดการวงจรชีวิตดัชนี | หยุดการดำเนินการจัดการอายุการใช้งานทั้งหมดและหยุดปลั๊กอิน ILM สิ่งนี้มีประโยชน์เมื่อคุณดำเนินการบำรุงรักษาบนคลัสเตอร์และจำเป็นต้องป้องกันไม่ให้ ILM ดำเนินการใด ๆ กับดัชนีของคุณ | POST / _ilm / หยุด |
| อธิบายอายุการใช้งาน API | ดึงข้อมูลเกี่ยวกับสถานะวงจรชีวิตปัจจุบันของดัชนีเช่นเฟสการดำเนินการการดำเนินการและขั้นตอนในปัจจุบัน แสดงเมื่อดัชนีเข้าสู่แต่ละรายการนิยามของเฟสการทำงานและข้อมูลเกี่ยวกับความล้มเหลวใด ๆ | รับดัชนี / _ilm / อธิบาย |
เป็นคอมโพเนนต์ที่ช่วยให้การสืบค้นแบบ SQL ดำเนินการแบบเรียลไทม์กับ Elasticsearch คุณสามารถนึกถึง Elasticsearch SQL เป็นตัวแปลซึ่งเข้าใจทั้ง SQL และ Elasticsearch และทำให้ง่ายต่อการอ่านและประมวลผลข้อมูลแบบเรียลไทม์ในระดับขนาดโดยใช้ประโยชน์จากความสามารถของ Elasticsearch
ข้อดีของ Elasticsearch SQL
It has native integration - การสืบค้นแต่ละรายการจะถูกดำเนินการอย่างมีประสิทธิภาพกับโหนดที่เกี่ยวข้องตามที่เก็บข้อมูลพื้นฐาน
No external parts - ไม่จำเป็นต้องใช้ฮาร์ดแวร์กระบวนการรันไทม์หรือไลบรารีเพิ่มเติมเพื่อค้นหา Elasticsearch
Lightweight and efficient - มันรวบรวมและเปิดเผย SQL เพื่อให้สามารถค้นหาข้อความแบบเต็มได้อย่างเหมาะสมแบบเรียลไทม์
ตัวอย่าง
PUT /schoollist/_bulk?refresh
{"index":{"_id": "CBSE"}}
{"name": "GleanDale", "Address": "JR. Court Lane", "start_date": "2011-06-02",
"student_count": 561}
{"index":{"_id": "ICSE"}}
{"name": "Top-Notch", "Address": "Gachibowli Main Road", "start_date": "1989-
05-26", "student_count": 482}
{"index":{"_id": "State Board"}}
{"name": "Sunshine", "Address": "Main Street", "start_date": "1965-06-01",
"student_count": 604}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
{
"took" : 277,
"errors" : false,
"items" : [
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "CBSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "ICSE",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1,
"status" : 201
}
},
{
"index" : {
"_index" : "schoollist",
"_type" : "_doc",
"_id" : "State Board",
"_version" : 1,
"result" : "created",
"forced_refresh" : true,
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 2,
"_primary_term" : 1,
"status" : 201
}
}
]
}แบบสอบถาม SQL
ตัวอย่างต่อไปนี้แสดงให้เห็นว่าเราจัดกรอบแบบสอบถาม SQL อย่างไร -
POST /_sql?format=txt
{
"query": "SELECT * FROM schoollist WHERE start_date < '2000-01-01'"
}ในการรันโค้ดด้านบนเราจะได้รับคำตอบตามที่แสดงด้านล่าง -
Address | name | start_date | student_count
--------------------+---------------+------------------------+---------------
Gachibowli Main Road|Top-Notch |1989-05-26T00:00:00.000Z|482
Main Street |Sunshine |1965-06-01T00:00:00.000Z|604Note - โดยการเปลี่ยนแบบสอบถาม SQL ด้านบนคุณจะได้รับชุดผลลัพธ์ที่แตกต่างกัน
เพื่อตรวจสอบความสมบูรณ์ของคลัสเตอร์คุณลักษณะการมอนิเตอร์จะรวบรวมเมตริกจากแต่ละโหนดและจัดเก็บไว้ใน Elasticsearch Indices การตั้งค่าทั้งหมดที่เกี่ยวข้องกับการมอนิเตอร์ใน Elasticsearch ต้องตั้งค่าในไฟล์ elasticsearch.yml สำหรับแต่ละโหนดหรือหากเป็นไปได้ในการตั้งค่าคลัสเตอร์แบบไดนามิก
ในการเริ่มการตรวจสอบเราต้องตรวจสอบการตั้งค่าคลัสเตอร์ซึ่งสามารถทำได้ด้วยวิธีต่อไปนี้ -
GET _cluster/settings
{
"persistent" : { },
"transient" : { }
}แต่ละองค์ประกอบในสแต็กมีหน้าที่ตรวจสอบตัวเองจากนั้นส่งต่อเอกสารเหล่านั้นไปยังคลัสเตอร์การผลิต Elasticsearch สำหรับทั้งการกำหนดเส้นทางและการจัดทำดัชนี (ที่เก็บข้อมูล) กระบวนการกำหนดเส้นทางและการจัดทำดัชนีใน Elasticsearch ได้รับการจัดการโดยสิ่งที่เรียกว่าผู้รวบรวมและผู้ส่งออก
นักสะสม
Collector รันหนึ่งครั้งต่อแต่ละช่วงการรวบรวมเพื่อรับข้อมูลจาก API สาธารณะใน Elasticsearch ที่เลือกมอนิเตอร์ เมื่อการรวบรวมข้อมูลเสร็จสิ้นข้อมูลจะถูกส่งจำนวนมากไปยังผู้ส่งออกเพื่อส่งไปยังคลัสเตอร์การตรวจสอบ
มีเพียงหนึ่งตัวรวบรวมต่อชนิดข้อมูลที่รวบรวม ตัวรวบรวมแต่ละตัวสามารถสร้างเอกสารการมอนิเตอร์เป็นศูนย์หรือมากกว่า
ผู้ส่งออก
ผู้ส่งออกนำข้อมูลที่รวบรวมจากแหล่งที่มาของ Elastic Stack และกำหนดเส้นทางไปยังคลัสเตอร์การมอนิเตอร์ เป็นไปได้ที่จะกำหนดค่าผู้ส่งออกมากกว่าหนึ่งราย แต่การตั้งค่าทั่วไปและค่าเริ่มต้นคือการใช้ผู้ส่งออกรายเดียว ผู้ส่งออกสามารถกำหนดค่าได้ทั้งในระดับโหนดและคลัสเตอร์
มีผู้ส่งออกสองประเภทใน Elasticsearch -
local - ผู้ส่งออกรายนี้กำหนดเส้นทางข้อมูลกลับเข้าสู่คลัสเตอร์เดียวกัน
http - ผู้ส่งออกที่ต้องการซึ่งคุณสามารถใช้เพื่อกำหนดเส้นทางข้อมูลไปยังคลัสเตอร์ Elasticsearch ที่รองรับซึ่งเข้าถึงได้ผ่าน HTTP
ก่อนที่ผู้ส่งออกจะกำหนดเส้นทางข้อมูลการตรวจสอบได้พวกเขาต้องตั้งค่าทรัพยากร Elasticsearch บางอย่าง ทรัพยากรเหล่านี้รวมถึงแม่แบบและท่อนำเข้า
งานรวบรวมเป็นงานตามระยะเวลาที่สรุปข้อมูลจากดัชนีที่ระบุโดยรูปแบบดัชนีและรวบรวมเป็นดัชนีใหม่ ในตัวอย่างต่อไปนี้เราสร้างดัชนีชื่อเซ็นเซอร์ที่มีการประทับวันที่ที่แตกต่างกัน จากนั้นเราจะสร้างงานรวบรวมเพื่อรวบรวมข้อมูลจากดัชนีเหล่านี้เป็นระยะโดยใช้งาน cron
PUT /sensor/_doc/1
{
"timestamp": 1516729294000,
"temperature": 200,
"voltage": 5.2,
"node": "a"
}ในการรันโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้ -
{
"_index" : "sensor",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}ตอนนี้เพิ่มเอกสารที่สองและอื่น ๆ สำหรับเอกสารอื่น ๆ ด้วย
PUT /sensor-2018-01-01/_doc/2
{
"timestamp": 1413729294000,
"temperature": 201,
"voltage": 5.9,
"node": "a"
}สร้างงาน Rollup
PUT _rollup/job/sensor
{
"index_pattern": "sensor-*",
"rollup_index": "sensor_rollup",
"cron": "*/30 * * * * ?",
"page_size" :1000,
"groups" : {
"date_histogram": {
"field": "timestamp",
"interval": "60m"
},
"terms": {
"fields": ["node"]
}
},
"metrics": [
{
"field": "temperature",
"metrics": ["min", "max", "sum"]
},
{
"field": "voltage",
"metrics": ["avg"]
}
]
}พารามิเตอร์ cron ควบคุมเวลาและความถี่ที่งานเปิดใช้งาน เมื่อกำหนดเวลา cron ของงานแบบรวบรวมจะเริ่มต้นขึ้นจากจุดที่ค้างไว้หลังจากการเปิดใช้งานครั้งสุดท้าย
หลังจากงานรันและประมวลผลข้อมูลบางส่วนแล้วเราสามารถใช้ DSL Query เพื่อทำการค้นหาบางอย่างได้
GET /sensor_rollup/_rollup_search
{
"size": 0,
"aggregations": {
"max_temperature": {
"max": {
"field": "temperature"
}
}
}
}ดัชนีที่ค้นหาบ่อยจะถูกเก็บไว้ในหน่วยความจำเนื่องจากต้องใช้เวลาในการสร้างดัชนีใหม่และช่วยในการค้นหาที่มีประสิทธิภาพ ในทางกลับกันอาจมีดัชนีที่เราไม่ค่อยเข้าถึง ดัชนีเหล่านั้นไม่จำเป็นต้องใช้หน่วยความจำและสามารถสร้างขึ้นใหม่ได้เมื่อจำเป็น ดัชนีดังกล่าวเรียกว่าดัชนีแช่แข็ง
Elasticsearch สร้างโครงสร้างข้อมูลชั่วคราวของแต่ละชิ้นส่วนของดัชนีที่ถูกแช่แข็งทุกครั้งที่มีการค้นหาชิ้นส่วนและทิ้งโครงสร้างข้อมูลเหล่านี้ทันทีที่การค้นหาเสร็จสมบูรณ์ เนื่องจาก Elasticsearch ไม่ได้รักษาโครงสร้างข้อมูลชั่วคราวเหล่านี้ไว้ในหน่วยความจำดัชนีที่ถูกแช่แข็งจะใช้ฮีปน้อยกว่าดัชนีปกติมาก สิ่งนี้ช่วยให้มีอัตราส่วนดิสก์ต่อฮีพสูงกว่าที่จะเป็นไปได้
ตัวอย่างสำหรับการแช่แข็งและการคลายน้ำแข็ง
ตัวอย่างต่อไปนี้ค้างและคลายดัชนี -
POST /index_name/_freeze
POST /index_name/_unfreezeการค้นหาดัชนีที่หยุดนิ่งคาดว่าจะดำเนินการช้า ดัชนีที่หยุดนิ่งไม่ได้มีไว้สำหรับการค้นหาที่สูง เป็นไปได้ว่าการค้นหาดัชนีที่หยุดนิ่งอาจใช้เวลาเป็นวินาทีหรือนาทีในการดำเนินการแม้ว่าการค้นหาเดียวกันจะเสร็จสมบูรณ์ในมิลลิวินาทีเมื่อดัชนีไม่ได้หยุดนิ่ง
ค้นหา Frozen Index
จำนวนดัชนีที่ตรึงพร้อมกันที่โหลดพร้อมกันต่อโหนดถูก จำกัด โดยจำนวนเธรดในเธรดพูล search_throttled ซึ่งเป็น 1 โดยดีฟอลต์ ในการรวมดัชนีที่ตรึงไว้การร้องขอการค้นหาจะต้องดำเนินการโดยใช้พารามิเตอร์การค้นหา - Ignore_throttled = false
GET /index_name/_search?q=user:tpoint&ignore_throttled=falseการตรวจสอบดัชนีที่ถูกแช่แข็ง
ดัชนีแช่แข็งเป็นดัชนีธรรมดาที่ใช้การควบคุมปริมาณการค้นหาและการใช้งานส่วนแบ่งหน่วยความจำที่มีประสิทธิภาพ
GET /_cat/indices/index_name?v&h=i,sthElasticsearch มีไฟล์ jar ซึ่งสามารถเพิ่มลงใน java IDE ใด ๆ และสามารถใช้เพื่อทดสอบโค้ดที่เกี่ยวข้องกับ Elasticsearch การทดสอบต่างๆสามารถทำได้โดยใช้กรอบการทำงานที่ Elasticsearch จัดเตรียมไว้ให้ ในบทนี้เราจะพูดถึงการทดสอบเหล่านี้โดยละเอียด -
- การทดสอบหน่วย
- การทดสอบการผสานรวม
- การทดสอบแบบสุ่ม
ข้อกำหนดเบื้องต้น
ในการเริ่มต้นการทดสอบคุณต้องเพิ่มการพึ่งพาการทดสอบ Elasticsearch ในโปรแกรมของคุณ คุณสามารถใช้ maven เพื่อจุดประสงค์นี้และสามารถเพิ่มสิ่งต่อไปนี้ใน pom.xml
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>2.1.0</version>
</dependency>EsSetup ได้รับการเตรียมใช้งานเพื่อเริ่มต้นและหยุดโหนด Elasticsearch และเพื่อสร้างดัชนี
EsSetup esSetup = new EsSetup();esSetup.execute () ฟังก์ชันด้วย createIndex จะสร้างดัชนีคุณต้องระบุการตั้งค่าประเภทและข้อมูล
การทดสอบหน่วย
การทดสอบหน่วยดำเนินการโดยใช้กรอบการทดสอบ JUnit และ Elasticsearch โหนดและดัชนีสามารถสร้างได้โดยใช้คลาส Elasticsearch และในวิธีการทดสอบสามารถใช้เพื่อทำการทดสอบได้ ใช้คลาส ESTestCase และ ESTokenStreamTestCase สำหรับการทดสอบนี้
การทดสอบการผสานรวม
การทดสอบการรวมใช้หลายโหนดในคลัสเตอร์ คลาส ESIntegTestCase ใช้สำหรับการทดสอบนี้ มีหลายวิธีที่ทำให้งานเตรียมกรณีทดสอบง่ายขึ้น
| ส. เลขที่ | วิธีการและคำอธิบาย |
|---|---|
| 1 | refresh() ดัชนีทั้งหมดในคลัสเตอร์จะถูกรีเฟรช |
| 2 | ensureGreen() ตรวจสอบสถานะคลัสเตอร์สุขภาพสีเขียว |
| 3 | ensureYellow() ตรวจสอบสถานะคลัสเตอร์สุขภาพสีเหลือง |
| 4 | createIndex(name) สร้างดัชนีด้วยชื่อที่ส่งไปยังเมธอดนี้ |
| 5 | flush() ดัชนีทั้งหมดในคลัสเตอร์จะถูกล้าง |
| 6 | flushAndRefresh() ล้าง () และรีเฟรช () |
| 7 | indexExists(name) ตรวจสอบการมีอยู่ของดัชนีที่ระบุ |
| 8 | clusterService() ส่งคืนคลาส Java ของคลัสเตอร์เซอร์วิส |
| 9 | cluster() ส่งคืนคลาสคลัสเตอร์ทดสอบ |
วิธีทดสอบคลัสเตอร์
| ส. เลขที่ | วิธีการและคำอธิบาย |
|---|---|
| 1 | ensureAtLeastNumNodes(n) ตรวจสอบให้แน่ใจว่าจำนวนโหนดขั้นต่ำในคลัสเตอร์มากกว่าหรือเท่ากับจำนวนที่ระบุ |
| 2 | ensureAtMostNumNodes(n) ตรวจสอบให้แน่ใจว่าจำนวนโหนดสูงสุดในคลัสเตอร์น้อยกว่าหรือเท่ากับจำนวนที่ระบุ |
| 3 | stopRandomNode() เพื่อหยุดโหนดสุ่มในคลัสเตอร์ |
| 4 | stopCurrentMasterNode() เพื่อหยุดโหนดหลัก |
| 5 | stopRandomNonMaster() เพื่อหยุดโหนดสุ่มในคลัสเตอร์ซึ่งไม่ใช่โหนดหลัก |
| 6 | buildNode() สร้างโหนดใหม่ |
| 7 | startNode(settings) เริ่มโหนดใหม่ |
| 8 | nodeSettings() แทนที่วิธีนี้สำหรับการเปลี่ยนการตั้งค่าโหนด |
การเข้าถึงลูกค้า
ไคลเอ็นต์ใช้เพื่อเข้าถึงโหนดต่างๆในคลัสเตอร์และดำเนินการบางอย่าง วิธี ESIntegTestCase.client () ใช้สำหรับรับไคลเอ็นต์แบบสุ่ม Elasticsearch เสนอวิธีการอื่น ๆ ในการเข้าถึงไคลเอนต์และวิธีการเหล่านั้นสามารถเข้าถึงได้โดยใช้เมธอด ESIntegTestCase.internalCluster ()
| S.No | Method & Description |
|---|---|
| 1 | iterator() This helps you to access all the available clients. |
| 2 | masterClient() This returns a client, which is communicating with master node. |
| 3 | nonMasterClient() This returns a client, which is not communicating with master node. |
| 4 | clientNodeClient() This returns a client currently up on client node. |
Randomized Testing
This testing is used to test the user’s code with every possible data, so that there will be no failure in future with any type of data. Random data is the best option to carry out this testing.
Generating Random Data
In this testing, the Random class is instantiated by the instance provided by RandomizedTest and offers many methods for getting different types of data.
| Method | Return value |
|---|---|
| getRandom() | Instance of random class |
| randomBoolean() | Random boolean |
| randomByte() | Random byte |
| randomShort() | Random short |
| randomInt() | Random integer |
| randomLong() | Random long |
| randomFloat() | Random float |
| randomDouble() | Random double |
| randomLocale() | Random locale |
| randomTimeZone() | Random time zone |
| randomFrom() | Random element from array |
Assertions
ElasticsearchAssertions and ElasticsearchGeoAssertions classes contain assertions, which are used for performing some common checks at the time of testing. For example, observe the code given here −
SearchResponse seearchResponse = client().prepareSearch();
assertHitCount(searchResponse, 6);
assertFirstHit(searchResponse, hasId("6"));
assertSearchHits(searchResponse, "1", "2", "3", "4",”5”,”6”);A Kibana dashboard is a collection of visualizations and searches. You can arrange, resize, and edit the dashboard content and then save the dashboard so you can share it. In this chapter, we will see how to create and edit a dashboard.
Dashboard Creation
From the Kibana Homepage, select the dashboard option from the left control bars as shown below. This will prompt you to create a new dashboard.
To Add visualizations to the dashboard, we choose the menu Add and the select from the pre-built visualizations available. We chose the following visualization options from the list.
On selecting the above visualizations, we get the dashboard as shown here. We can later add and edit the dashboard for changing the elements and adding the new elements.
Inspecting Elements
We can inspect the Dashboard elements by choosing the visualizations panel menu and selecting Inspect. This will bring out the data behind the element which also can be downloaded.
Sharing Dashboard
We can share the dashboard by choosing the share menu and selecting the option to get a hyperlink as shown below −

The discover functionality available in Kibana home page allows us to explore the data sets from various angles. You can search and filter data for the selected index patterns. The data is usually available in form of distribution of values over a period of time.
To explore the ecommerce data sample, we click on the Discover icon as shown in the picture below. This will bring up the data along with the chart.
Filtering by Time
To filter out data by specific time interval we use the time filter option as shown below. By default, the filter is set at 15 minutes.
Filtering by Fields
The data set can also be filtered by fields using the Add Filter option as shown below. Here we add one or more fields and get the corresponding result after the filters are applied. In our example we choose the field day_of_week and then the operator for that field as is and value as Sunday.
Next, we click Save with above filter conditions. The result set containing the filter conditions applied is shown below.
The data table is type of visualization that is used to display the raw data of a composed aggregation. There are various types of aggregations that are presented by using Data tables. In order to create a Data Table, we should go through the steps that are discussed here in detail.
Visualize
In Kibana Home screen we find the option name Visualize which allows us to create visualization and aggregations from the indices stored in Elasticsearch. The following image shows the option.
Select Data Table
Next, we select the Data Table option from among the various visualization options available. The option is shown in the following image &miuns;
Select Metrics
We then select the metrics needed for creating the data table visualization. This choice decides the type of aggregation we are going to use. We select the specific fields shown below from the ecommerce data set for this.
On running the above configuration for Data Table, we get the result as shown in the image here −
Region Maps show metrics on a geographic Map. It is useful in looking at the data anchored to different geographic regions with varying intensity. The darker shades usually indicate higher values and the lighter shades indicate lower values.
The steps to create this visualization are as explained in detail as follows −
Visualize
In this step we go to the visualize button available in the left bar of the Kibana Home screen and then choosing the option to add a new Visualization.
The following screen shows how we choose the region Map option.
Choose the Metrics
The next screen prompts us for choosing the metrics which will be used in creating the Region Map. Here we choose the Average price as the metric and country_iso_code as the field in the bucket which will be used in creating the visualization.
The final result below shows the Region Map once we apply the selection. Please note the shades of the colour and their values mentioned in the label.
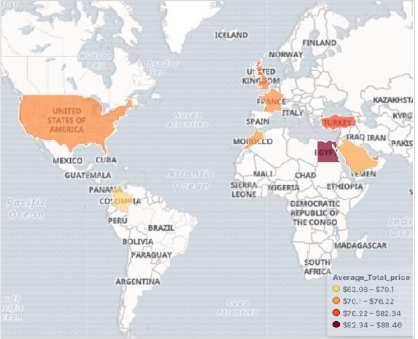
Pie charts are one of the simplest and famous visualization tools. It represents the data as slices of a circle each coloured differently. The labels along with the percentage data values can be presented along with the circle. The circle can also take the shape of a donut.
Visualize
In Kibana Home screen, we find the option name Visualize which allows us to create visualization and aggregations from the indices stored in Elasticsearch. We choose to add a new visualization and select pie chart as the option shown below.
Choose the Metrics
The next screen prompts us for choosing the metrics which will be used in creating the Pie Chart. Here we choose the count of base unit price as the metric and Bucket Aggregation as histogram. Also, the minimum interval is chosen as 20. So, the prices will be displayed as blocks of values with 20 as a range.
The result below shows the pie chart after we apply the selection. Please note the shades of the colour and their values mentioned in the label.

Pie Chart Options
On moving to the options tab under pie chart we can see various configuration options to change the look as well as the arrangement of data display in the pie chart. In the following example, the pie chart appears as donut and the labels appear at the top.
An area chart is an extension of line chart where the area between the line chart and the axes is highlighted with some colours. A bar chart represents data organized into a range of values and then plotted against the axes. It can consist of either horizontal bars or vertical bars.
In this chapter we will see all these three types of graphs that is created using Kibana. As discussed in earlier chapters we will continue to use the data in the ecommerce index.
Area Chart
In Kibana Home screen, we find the option name Visualize which allows us to create visualization and aggregations from the indices stored in Elasticsearch. We choose to add a new visualization and select Area Chart as the option shown in the image given below.
Choose the Metrics
The next screen prompts us for choosing the metrics which will be used in creating the Area Chart. Here we choose the sum as the type of aggregation metric. Then we choose total_quantity field as the field to be used as metric. On the X-axis, we chose the order_date field and split the series with the given metric in a size of 5.

On running the above configuration, we get the following area chart as the output −
Horizontal Bar Chart
Similarly, for the Horizontal bar chart we choose new visualization from Kibana Home screen and choose the option for Horizontal Bar. Then we choose the metrics as shown in the image below. Here we choose Sum as the aggregation for the filed named product quantity. Then we choose buckets with date histogram for the field order date.
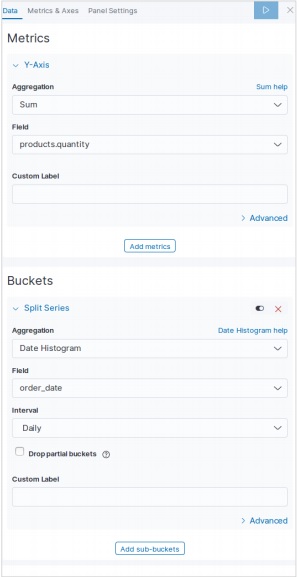
On running the above configuration, we can see a horizontal bar chart as shown below −
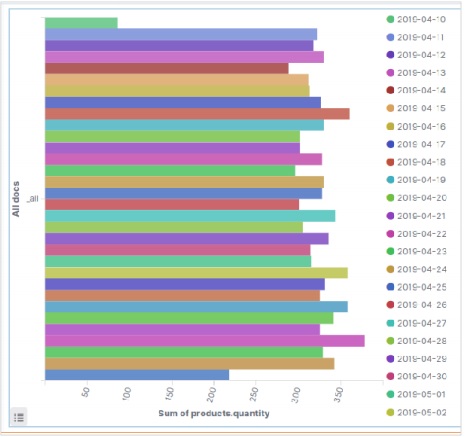
Vertical Bar Chart
For the vertical bar chart, we choose new visualization from Kibana Home screen and choose the option for Vertical Bar. Then we choose the metrics as shown in the image below.
Here we choose Sum as the aggregation for the field named product quantity. Then we choose buckets with date histogram for the field order date with a weekly interval.
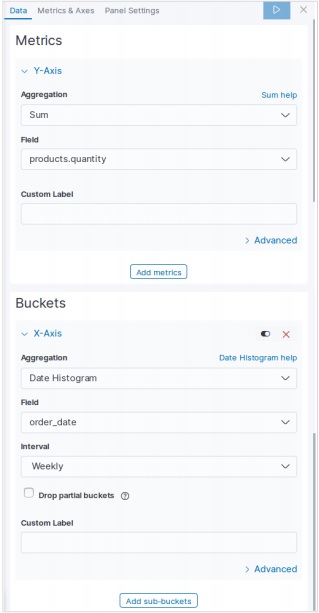
On running the above configuration, a chart will be generated as shown below −
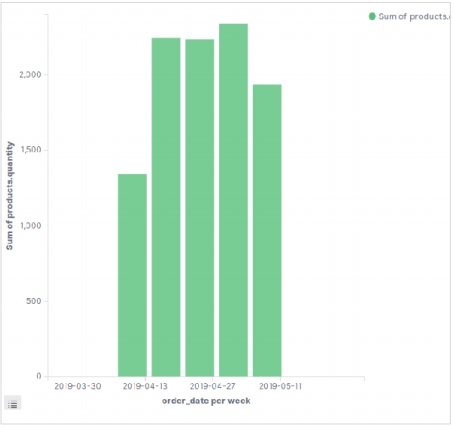
Time series is a representation of sequence of data in a specific time sequence. For example, the data for each day starting from first day of the month to the last day. The interval between the data points remains constant. Any data set which has a time component in it can be represented as a time series.
In this chapter, we will use the sample e-commerce data set and plot the count of the number of orders for each day to create a time series.
Choose Metrics
First, we choose the index pattern, data field and interval which will be used for creating the time series. From the sample ecommerce data set we choose order_date as the field and 1d as the interval. We use the Panel Options tab to make these choices. Also we leave the other values in this tab as default to get a default colour and format for the time series.
In the Data tab, we choose count as the aggregation option, group by option as everything and put a label for the time series chart.
Result
The final result of this configuration appears as follows. Please note that we are using a time period of Month to Date for this graph. Different time periods will give different results.
A tag cloud represents text which are mostly keywords and metadata in a visually appealing form. They are aligned in different angles and represented in different colours and font sizes. It helps in finding out the most prominent terms in the data. The prominence can be decided by one or more factors like frequency of the term, uniquness of the tag or based on some weightage attached to specific terms etc. Below we see the steps to create a Tag Cloud.
Visualize
In Kibana Home screen, we find the option name Visualize which allows us to create visualization and aggregations from the indices stored in Elasticsearch. We choose to add a new visualization and select Tag Cloud as the option shown below −
Choose the Metrics
The next screen prompts us for choosing the metrics which will be used in creating the Tag Cloud. Here we choose the count as the type of aggregation metric. Then we choose productname field as the keyword to be used as tags.
The result shown here shows the pie chart after we apply the selection. Please note the shades of the colour and their values mentioned in the label.

Tag Cloud Options
On moving to the options tab under Tag Cloud we can see various configuration options to change the look as well as the arrangement of data display in the Tag Cloud. In the below example the Tag Cloud appears with tags spread across both horizontal and vertical directions.
Heat map is a type of visualization in which different shades of colour represent different areas in the graph. The values may be continuously varying and hence the colour r shades of a colour vary along with the values. They are very useful to represent both the continuously varying data as well as discrete data.
In this chapter we will use the data set named sample_data_flights to build a heatmap chart. In it we consider the variables named origin country and destination country of flights and take a count.
In Kibana Home screen, we find the option name Visualize which allows us to create visualization and aggregations from the indices stored in Elasticsearch. We choose to add a new visualization and select Heat Map as the option shown below &mimus;
Choose the Metrics
The next screen prompts us for choosing the metrics which will be used in creating the Heat Map Chart. Here we choose the count as the type of aggregation metric. Then for the buckets in Y-Axis, we choose Terms as the aggregation for the field OriginCountry. For the X-Axis, we choose the same aggregation but DestCountry as the field to be used. In both the cases, we choose the size of the bucket as 5.

On running the above shown configuration, we get the heat map chart generated as follows.
Note − You have to allow the date range as This Year so that the graph gathers data for a year to produce an effective heat map chart.
Canvas application is a part of Kibana which allows us to create dynamic, multi-page and pixel perfect data displays. Its ability to create infographics and not just charts and metrices is what makes it unique and appealing. In this chapter we will see various features of canvas and how to use the canvas work pads.
Opening a Canvas
Go to the Kibana homepage and select the option as shown in the below diagram. It opens up the list of canvas work pads you have. We choose the ecommerce Revenue tracking for our study.
Cloning A Workpad
We clone the [eCommerce] Revenue Tracking workpad to be used in our study. To clone it, we highlight the row with the name of this workpad and then use the clone button as shown in the diagram below −
As a result of the above clone, we will get a new work pad named as [eCommerce] Revenue Tracking – Copy which on opening will show the below infographics.
It describes the total sales and Revenue by category along with nice pictures and charts.
Modifying the Workpad
We can change the style and figures in the workpad by using the options available in the right hand side tab. Here we aim to change the background colour of the workpad by choosing a different colour as shown in the diagram below. The colour selection comes into effect immediately and we get the result as shown below −

Kibana can also help in visualizing log data from various sources. Logs are important sources of analysis for infrastructure health, performance needs and security breach analysis etc. Kibana can connect to various logs like web server logs, elasticsearch logs and cloudwatch logs etc.
Logstash Logs
In Kibana, we can connect to logstash logs for visualization. First we choose the Logs button from the Kibana home screen as shown below −
Then we choose the option Change Source Configuration which brings us the option to choose Logstash as a source. The below screen also shows other types of options we have as a log source.
You can stream data for live log tailing or pause streaming to focus on historical log data. When you are streaming logs, the most recent log appears at the bottom on the console.
For further reference, you can refer to our Logstash tutorial.