H2O - รันแอปพลิเคชันตัวอย่าง
คลิกที่ลิงค์ Airlines Delay Flow ในรายการตัวอย่างดังที่แสดงในภาพหน้าจอด้านล่าง -
หลังจากที่คุณยืนยันสมุดบันทึกใหม่จะถูกโหลด
การล้างผลลัพธ์ทั้งหมด
ก่อนที่เราจะอธิบายคำสั่งรหัสในสมุดบันทึกให้เราล้างผลลัพธ์ทั้งหมดแล้วเรียกใช้สมุดบันทึกค่อยๆ หากต้องการล้างผลลัพธ์ทั้งหมดให้เลือกตัวเลือกเมนูต่อไปนี้ -
Flow / Clear All Cell Contentsสิ่งนี้แสดงในภาพหน้าจอต่อไปนี้ -
เมื่อล้างเอาต์พุตทั้งหมดแล้วเราจะเรียกใช้แต่ละเซลล์ในโน้ตบุ๊กทีละเซลล์และตรวจสอบเอาต์พุต
เรียกใช้เซลล์แรก
คลิกเซลล์แรก ธงสีแดงปรากฏทางด้านซ้ายแสดงว่าเซลล์ถูกเลือก ดังที่แสดงในภาพหน้าจอด้านล่าง -

เนื้อหาของเซลล์นี้เป็นเพียงความคิดเห็นของโปรแกรมที่เขียนด้วยภาษา MarkDown (MD) เนื้อหาอธิบายว่าแอปพลิเคชันที่โหลดทำอะไร ในการเรียกใช้เซลล์ให้คลิกที่ไอคอน Run ตามที่แสดงในภาพหน้าจอด้านล่าง -

คุณจะไม่เห็นผลลัพธ์ใด ๆ ที่อยู่ใต้เซลล์เนื่องจากไม่มีโค้ดที่เรียกใช้งานได้ในเซลล์ปัจจุบัน ตอนนี้เคอร์เซอร์จะย้ายโดยอัตโนมัติไปยังเซลล์ถัดไปซึ่งพร้อมที่จะดำเนินการ
การนำเข้าข้อมูล
เซลล์ถัดไปประกอบด้วยคำสั่ง Python ต่อไปนี้ -
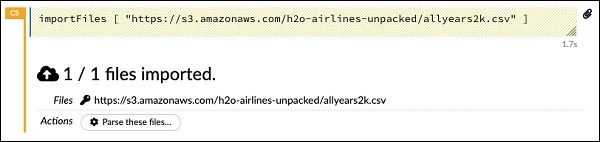
importFiles ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]คำสั่งนำเข้าไฟล์ allyears2k.csv จาก Amazon AWS เข้าสู่ระบบ เมื่อคุณเรียกใช้เซลล์จะนำเข้าไฟล์และให้ผลลัพธ์ต่อไปนี้แก่คุณ
การตั้งค่าตัวแยกวิเคราะห์ข้อมูล
ตอนนี้เราจำเป็นต้องแยกวิเคราะห์ข้อมูลและทำให้เหมาะสมกับอัลกอริทึม ML ของเรา ทำได้โดยใช้คำสั่งต่อไปนี้ -
setupParse paths: [ "https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv" ]เมื่อดำเนินการตามคำสั่งข้างต้นกล่องโต้ตอบการกำหนดค่าการตั้งค่าจะปรากฏขึ้น กล่องโต้ตอบช่วยให้คุณสามารถตั้งค่าต่างๆสำหรับการแยกวิเคราะห์ไฟล์ได้ ดังที่แสดงในภาพหน้าจอด้านล่าง -
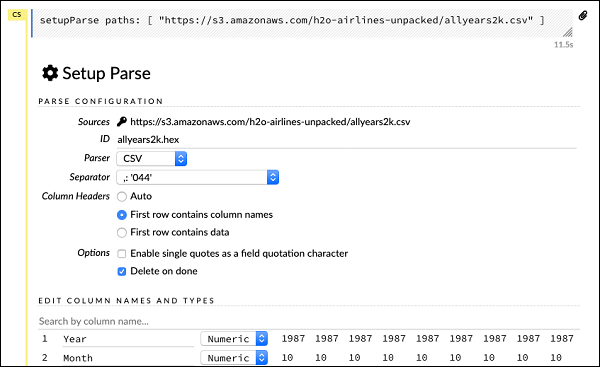
ในกล่องโต้ตอบนี้คุณสามารถเลือกตัวแยกวิเคราะห์ที่ต้องการจากรายการดรอปดาวน์ที่กำหนดและตั้งค่าพารามิเตอร์อื่น ๆ เช่นตัวคั่นฟิลด์เป็นต้น
การแยกวิเคราะห์ข้อมูล
คำสั่งถัดไปซึ่งจะแยกวิเคราะห์ดาต้าไฟล์โดยใช้การกำหนดค่าข้างต้นเป็นคำสั่งที่ยาวและดังที่แสดงไว้ที่นี่ -
parseFiles
paths: ["https://s3.amazonaws.com/h2o-airlines-unpacked/allyears2k.csv"]
destination_frame: "allyears2k.hex"
parse_type: "CSV"
separator: 44
number_columns: 31
single_quotes: false
column_names: ["Year","Month","DayofMonth","DayOfWeek","DepTime","CRSDepTime",
"ArrTime","CRSArrTime","UniqueCarrier","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"Origin","Dest","Distance","TaxiIn","TaxiOut","Cancelled","CancellationCode",
"Diverted","CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed","IsDepDelayed"]
column_types: ["Enum","Enum","Enum","Enum","Numeric","Numeric","Numeric"
,"Numeric","Enum","Enum","Enum","Numeric","Numeric","Numeric","Numeric",
"Numeric","Enum","Enum","Numeric","Numeric","Numeric","Enum","Enum",
"Numeric","Numeric","Numeric","Numeric","Numeric","Numeric","Enum","Enum"]
delete_on_done: true
check_header: 1
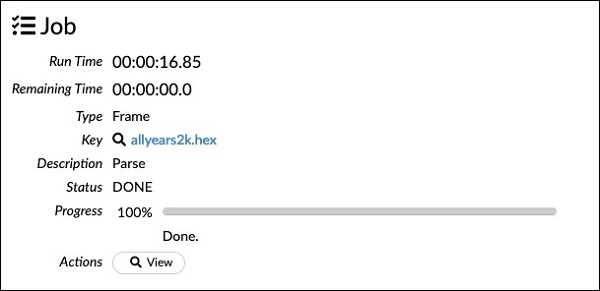
chunk_size: 4194304สังเกตว่าพารามิเตอร์ที่คุณตั้งค่าไว้ในกล่องการกำหนดค่าแสดงอยู่ในโค้ดด้านบน ตอนนี้เรียกใช้เซลล์นี้ หลังจากนั้นสักครู่การแยกวิเคราะห์จะเสร็จสิ้นและคุณจะเห็นผลลัพธ์ต่อไปนี้ -
ตรวจสอบ Dataframe
หลังจากการประมวลผลจะสร้าง dataframe ซึ่งสามารถตรวจสอบได้โดยใช้คำสั่งต่อไปนี้ -
getFrameSummary "allyears2k.hex"เมื่อดำเนินการตามคำสั่งข้างต้นคุณจะเห็นผลลัพธ์ต่อไปนี้ -
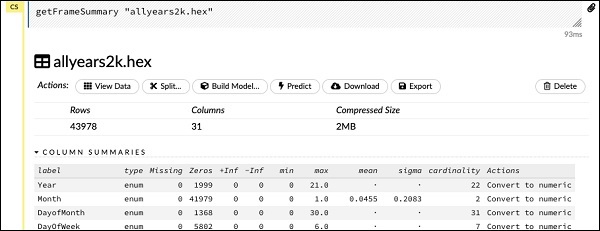
ตอนนี้ข้อมูลของคุณพร้อมที่จะป้อนเข้าสู่อัลกอริทึม Machine Learning แล้ว
คำสั่งต่อไปคือข้อคิดเห็นของโปรแกรมที่บอกว่าเราจะใช้แบบจำลองการถดถอยและระบุการกำหนดมาตรฐานที่ตั้งไว้ล่วงหน้าและค่าแลมบ์ดา
การสร้างแบบจำลอง
ต่อไปเป็นคำสั่งที่สำคัญที่สุดและนั่นคือการสร้างแบบจำลองเอง สิ่งนี้ระบุไว้ในคำสั่งต่อไปนี้ -
buildModel 'glm', {
"model_id":"glm_model","training_frame":"allyears2k.hex",
"ignored_columns":[
"DayofMonth","DepTime","CRSDepTime","ArrTime","CRSArrTime","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted","CarrierDelay",
"WeatherDelay","NASDelay","SecurityDelay","LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"response_column":"IsDepDelayed","family":"binomial",
"solver":"IRLSM","alpha":[0.5],"lambda":[0.00001],"lambda_search":false,
"standardize":true,"non_negative":false,"score_each_iteration":false,
"max_iterations":-1,"link":"family_default","intercept":true,
"objective_epsilon":0.00001,"beta_epsilon":0.0001,"gradient_epsilon":0.0001,
"prior":-1,"max_active_predictors":-1
}เราใช้ glm ซึ่งเป็นชุด Generalized Linear Model ที่มีการตั้งค่าประเภทครอบครัวเป็นทวินาม คุณสามารถดูไฮไลต์เหล่านี้ได้ในข้อความข้างต้น ในกรณีของเราผลลัพธ์ที่คาดหวังคือไบนารีและนั่นคือเหตุผลที่เราใช้ประเภททวินาม คุณสามารถตรวจสอบพารามิเตอร์อื่น ๆ ได้ด้วยตัวเอง ตัวอย่างเช่นดูอัลฟาและแลมด้าที่เราระบุไว้ก่อนหน้านี้ โปรดดูเอกสารรุ่น GLM สำหรับคำอธิบายของพารามิเตอร์ทั้งหมด
ตอนนี้เรียกใช้คำสั่งนี้ เมื่อดำเนินการผลลัพธ์ต่อไปนี้จะถูกสร้างขึ้น -

แน่นอนว่าเวลาในการดำเนินการจะแตกต่างกันไปในเครื่องของคุณ ตอนนี้เป็นส่วนที่น่าสนใจที่สุดของโค้ดตัวอย่างนี้
การตรวจสอบผลลัพธ์
เราเพียงแค่ส่งออกโมเดลที่เราสร้างขึ้นโดยใช้คำสั่งต่อไปนี้ -
getModel "glm_model"โปรดทราบว่า glm_model คือ ID โมเดลที่เราระบุเป็นพารามิเตอร์ model_id ในขณะที่สร้างโมเดลในคำสั่งก่อนหน้า สิ่งนี้ทำให้เราได้ผลลัพธ์ขนาดใหญ่ที่มีรายละเอียดผลลัพธ์พร้อมพารามิเตอร์ที่แตกต่างกัน ผลลัพธ์บางส่วนของรายงานจะแสดงในภาพหน้าจอด้านล่าง -
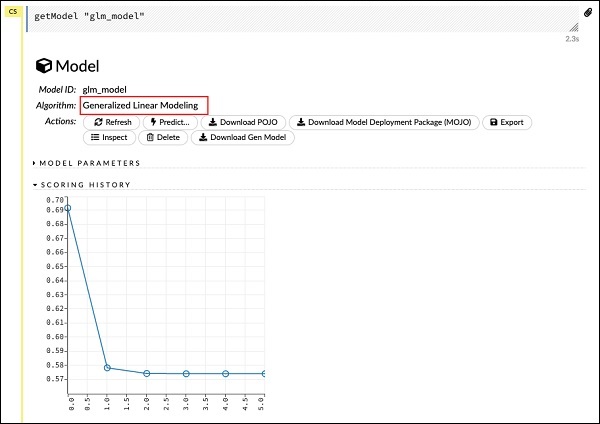
ดังที่คุณเห็นในผลลัพธ์มันบอกว่านี่เป็นผลมาจากการเรียกใช้อัลกอริทึมการสร้างแบบจำลองเชิงเส้นทั่วไปบนชุดข้อมูลของคุณ
เหนือประวัติการให้คะแนนคุณจะเห็นแท็ก MODEL PARAMETERS ขยายและคุณจะเห็นรายการพารามิเตอร์ทั้งหมดที่ใช้ในขณะสร้างโมเดล สิ่งนี้แสดงในภาพหน้าจอด้านล่าง
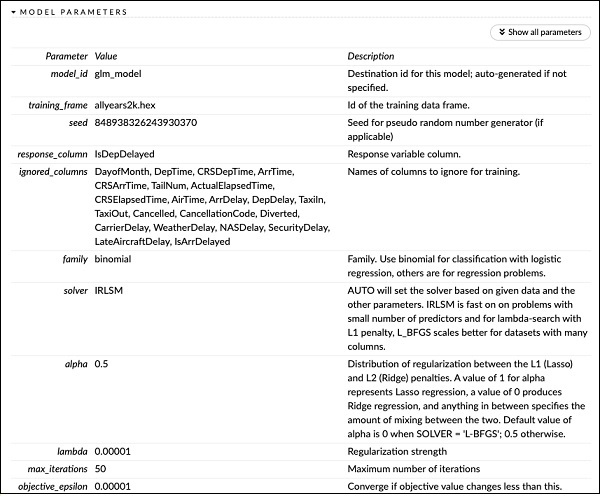
ในทำนองเดียวกันแต่ละแท็กจะแสดงผลลัพธ์โดยละเอียดของประเภทเฉพาะ ขยายแท็กต่างๆด้วยตัวคุณเองเพื่อศึกษาผลลัพธ์ของประเภทต่างๆ
การสร้างแบบจำลองอื่น
ต่อไปเราจะสร้างโมเดล Deep Learning บนดาต้าเฟรมของเรา คำสั่งถัดไปในโค้ดตัวอย่างเป็นเพียงข้อคิดเห็นของโปรแกรม คำสั่งต่อไปนี้เป็นคำสั่งสร้างโมเดล ดังที่แสดงไว้ที่นี่ -
buildModel 'deeplearning', {
"model_id":"deeplearning_model","training_frame":"allyear
s2k.hex","ignored_columns":[
"DepTime","CRSDepTime","ArrTime","CRSArrTime","FlightNum","TailNum",
"ActualElapsedTime","CRSElapsedTime","AirTime","ArrDelay","DepDelay",
"TaxiIn","TaxiOut","Cancelled","CancellationCode","Diverted",
"CarrierDelay","WeatherDelay","NASDelay","SecurityDelay",
"LateAircraftDelay","IsArrDelayed"],
"ignore_const_cols":true,"res ponse_column":"IsDepDelayed",
"activation":"Rectifier","hidden":[200,200],"epochs":"100",
"variable_importances":false,"balance_classes":false,
"checkpoint":"","use_all_factor_levels":true,
"train_samples_per_iteration":-2,"adaptive_rate":true,
"input_dropout_ratio":0,"l1":0,"l2":0,"loss":"Automatic","score_interval":5,
"score_training_samples":10000,"score_duty_cycle":0.1,"autoencoder":false,
"overwrite_with_best_model":true,"target_ratio_comm_to_comp":0.02,
"seed":6765686131094811000,"rho":0.99,"epsilon":1e-8,"max_w2":"Infinity",
"initial_weight_distribution":"UniformAdaptive","classification_stop":0,
"diagnostics":true,"fast_mode":true,"force_load_balance":true,
"single_node_mode":false,"shuffle_training_data":false,"missing_values_handling":
"MeanImputation","quiet_mode":false,"sparse":false,"col_major":false,
"average_activation":0,"sparsity_beta":0,"max_categorical_features":2147483647,
"reproducible":false,"export_weights_and_biases":false
}ดังที่คุณเห็นในโค้ดด้านบนเราระบุ deeplearning สำหรับการสร้างโมเดลโดยมีพารามิเตอร์หลายตัวที่กำหนดเป็นค่าที่เหมาะสมตามที่ระบุไว้ในเอกสารของโมเดล deeplearning เมื่อคุณเรียกใช้คำสั่งนี้จะใช้เวลานานกว่าการสร้างแบบจำลอง GLM คุณจะเห็นผลลัพธ์ต่อไปนี้เมื่อการสร้างแบบจำลองเสร็จสมบูรณ์แม้ว่าจะมีการกำหนดเวลาที่แตกต่างกัน

การตรวจสอบผลลัพธ์ของโมเดลการเรียนรู้เชิงลึก
สิ่งนี้จะสร้างชนิดของเอาต์พุตซึ่งสามารถตรวจสอบได้โดยใช้คำสั่งต่อไปนี้เช่นเดียวกับในกรณีก่อนหน้านี้
getModel "deeplearning_model"เราจะพิจารณาผลลัพธ์ของเส้นโค้ง ROC ดังที่แสดงด้านล่างเพื่อการอ้างอิงอย่างรวดเร็ว
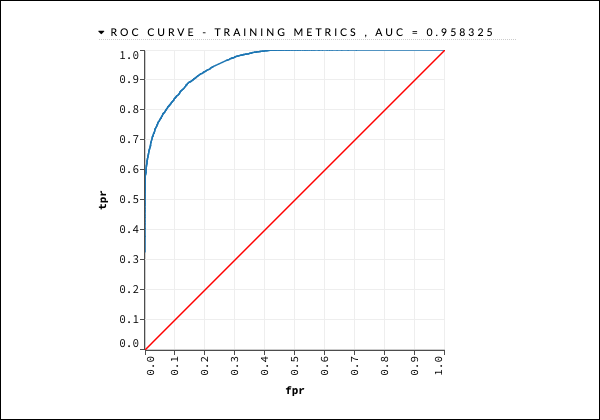
เช่นเดียวกับในกรณีก่อนหน้านี้ให้ขยายแท็บต่างๆและศึกษาผลลัพธ์ที่แตกต่างกัน
กำลังบันทึกโมเดล
หลังจากที่คุณศึกษาผลลัพธ์ของโมเดลต่างๆแล้วคุณจะตัดสินใจใช้หนึ่งในโมเดลเหล่านั้นในสภาพแวดล้อมการผลิตของคุณ H20 อนุญาตให้คุณบันทึกโมเดลนี้เป็น POJO (Plain Old Java Object)
ขยายแท็กสุดท้าย PREVIEW POJO ในเอาต์พุตและคุณจะเห็นโค้ด Java สำหรับโมเดลที่ปรับแต่งแล้วของคุณ ใช้สิ่งนี้ในสภาพแวดล้อมการผลิตของคุณ
ต่อไปเราจะเรียนรู้เกี่ยวกับคุณสมบัติที่น่าตื่นเต้นของ H2O เราจะเรียนรู้วิธีใช้ AutoML เพื่อทดสอบและจัดอันดับอัลกอริทึมต่างๆตามประสิทธิภาพ