HBase - คู่มือฉบับย่อ
ตั้งแต่ปี 1970 RDBMS เป็นโซลูชันสำหรับการจัดเก็บข้อมูลและปัญหาที่เกี่ยวข้องกับการบำรุงรักษา หลังจากการถือกำเนิดของข้อมูลขนาดใหญ่ บริษัท ต่างๆได้ตระหนักถึงประโยชน์ของการประมวลผลข้อมูลขนาดใหญ่และเริ่มเลือกใช้โซลูชันเช่น Hadoop
Hadoop ใช้ระบบไฟล์แบบกระจายสำหรับจัดเก็บข้อมูลขนาดใหญ่และ MapReduce เพื่อประมวลผล Hadoop มีความเชี่ยวชาญในการจัดเก็บและประมวลผลข้อมูลขนาดใหญ่ในรูปแบบต่างๆเช่นตามอำเภอใจกึ่งหรือแม้กระทั่งไม่มีโครงสร้าง
ข้อ จำกัด ของ Hadoop
Hadoop สามารถดำเนินการได้เฉพาะการประมวลผลแบบแบทช์และข้อมูลจะเข้าถึงได้เฉพาะในลักษณะตามลำดับ นั่นหมายความว่าเราต้องค้นหาชุดข้อมูลทั้งหมดแม้จะเป็นงานที่ง่ายที่สุดก็ตาม
ชุดข้อมูลขนาดใหญ่เมื่อประมวลผลแล้วจะทำให้เกิดชุดข้อมูลขนาดใหญ่อีกชุดหนึ่งซึ่งควรประมวลผลตามลำดับ ณ จุดนี้จำเป็นต้องใช้โซลูชันใหม่เพื่อเข้าถึงจุดใด ๆ ของข้อมูลในหน่วยเวลาเดียว (การเข้าถึงแบบสุ่ม)
ฐานข้อมูล Hadoop Random Access
แอปพลิเคชันเช่น HBase, Cassandra, couchDB, Dynamo และ MongoDB เป็นฐานข้อมูลบางส่วนที่จัดเก็บข้อมูลจำนวนมากและเข้าถึงข้อมูลในลักษณะสุ่ม
HBase คืออะไร?
HBase เป็นฐานข้อมูลเชิงคอลัมน์แบบกระจายที่สร้างขึ้นที่ด้านบนของระบบไฟล์ Hadoop เป็นโครงการโอเพ่นซอร์สและปรับขนาดได้ในแนวนอน
HBase เป็นรูปแบบข้อมูลที่คล้ายกับตารางขนาดใหญ่ของ Google ที่ออกแบบมาเพื่อให้เข้าถึงข้อมูลที่มีโครงสร้างจำนวนมากโดยสุ่มได้อย่างรวดเร็ว มันใช้ประโยชน์จากความทนทานต่อความผิดพลาดที่จัดเตรียมโดย Hadoop File System (HDFS)
เป็นส่วนหนึ่งของระบบนิเวศ Hadoop ที่ให้การเข้าถึงข้อมูลแบบสุ่มอ่าน / เขียนแบบเรียลไทม์ใน Hadoop File System
สามารถจัดเก็บข้อมูลใน HDFS ได้โดยตรงหรือผ่าน HBase ผู้บริโภคข้อมูลอ่าน / เข้าถึงข้อมูลใน HDFS แบบสุ่มโดยใช้ HBase HBase อยู่ด้านบนของ Hadoop File System และให้การเข้าถึงแบบอ่านและเขียน

HBase และ HDFS
| HDFS | HBase |
|---|---|
| HDFS เป็นระบบไฟล์แบบกระจายเหมาะสำหรับจัดเก็บไฟล์ขนาดใหญ่ | HBase เป็นฐานข้อมูลที่สร้างขึ้นจาก HDFS |
| HDFS ไม่รองรับการค้นหาบันทึกแต่ละรายการอย่างรวดเร็ว | HBase ให้การค้นหาอย่างรวดเร็วสำหรับตารางขนาดใหญ่ |
| ให้การประมวลผลแบทช์แฝงสูง ไม่มีแนวคิดของการประมวลผลชุดงาน | ให้การเข้าถึงแถวเดียวที่มีเวลาแฝงต่ำจากบันทึกหลายพันล้านรายการ (การเข้าถึงแบบสุ่ม) |
| ให้การเข้าถึงข้อมูลตามลำดับเท่านั้น | HBase ใช้ตาราง Hash ภายในและให้การเข้าถึงแบบสุ่มและจัดเก็บข้อมูลในไฟล์ HDFS ที่จัดทำดัชนีเพื่อการค้นหาที่เร็วขึ้น |
กลไกการจัดเก็บใน HBase
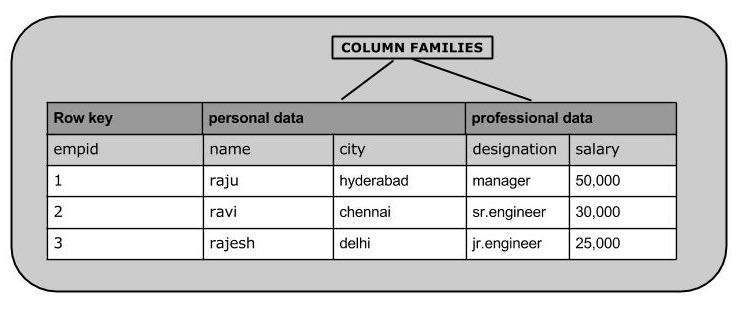
HBase คือ column-oriented databaseและตารางในนั้นจะเรียงตามแถว สคีมาของตารางกำหนดเฉพาะตระกูลคอลัมน์ซึ่งเป็นคู่คีย์ค่า ตารางมีหลายคอลัมน์และแต่ละตระกูลคอลัมน์สามารถมีคอลัมน์กี่คอลัมน์ก็ได้ ค่าคอลัมน์ที่ตามมาจะถูกจัดเก็บอย่างต่อเนื่องบนดิสก์ ค่าแต่ละเซลล์ของตารางมีการประทับเวลา ในระยะสั้นใน HBase:
- ตารางคือชุดของแถว
- Row คือชุดของตระกูลคอลัมน์
- Column family คือชุดของคอลัมน์
- คอลัมน์คือชุดของคู่ค่าคีย์
ให้ด้านล่างนี้เป็นตัวอย่างของตารางใน HBase
| Rowid | คอลัมน์ครอบครัว | คอลัมน์ครอบครัว | คอลัมน์ครอบครัว | คอลัมน์ครอบครัว | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
เชิงคอลัมน์และเชิงแถว
ฐานข้อมูลเชิงคอลัมน์คือฐานข้อมูลที่จัดเก็บตารางข้อมูลเป็นส่วนของคอลัมน์ของข้อมูลแทนที่จะเป็นแถวของข้อมูล ไม่นานพวกเขาจะมีครอบครัวคอลัมน์
| ฐานข้อมูลเชิงแถว | ฐานข้อมูลเชิงคอลัมน์ |
|---|---|
| เหมาะสำหรับ Online Transaction Process (OLTP) | เหมาะสำหรับ Online Analytical Processing (OLAP) |
| ฐานข้อมูลดังกล่าวออกแบบมาสำหรับแถวและคอลัมน์จำนวนน้อย | ฐานข้อมูลเชิงคอลัมน์ได้รับการออกแบบมาสำหรับตารางขนาดใหญ่ |
รูปภาพต่อไปนี้แสดงตระกูลคอลัมน์ในฐานข้อมูลเชิงคอลัมน์:
HBase และ RDBMS
| HBase | RDBMS |
|---|---|
| HBase เป็น schema-less ไม่มีแนวคิดของ schema คอลัมน์คงที่ กำหนดเฉพาะคอลัมน์ตระกูล | RDBMS ถูกควบคุมโดยสคีมาซึ่งอธิบายโครงสร้างทั้งหมดของตาราง |
| มันถูกสร้างขึ้นสำหรับโต๊ะกว้าง HBase สามารถปรับขนาดได้ในแนวนอน | มันบางและสร้างขึ้นสำหรับโต๊ะขนาดเล็ก ยากที่จะปรับขนาด |
| ไม่มีธุรกรรมใน HBase | RDBMS เป็นธุรกรรม |
| มีข้อมูลที่ไม่เป็นมาตรฐาน | มันจะมีข้อมูลที่ทำให้เป็นมาตรฐาน |
| เหมาะสำหรับข้อมูลกึ่งโครงสร้างและข้อมูลที่มีโครงสร้าง | เหมาะสำหรับข้อมูลที่มีโครงสร้าง |
คุณสมบัติของ HBase
- HBase สามารถปรับขนาดได้เชิงเส้น
- มีการสนับสนุนความล้มเหลวโดยอัตโนมัติ
- ให้การอ่านและเขียนที่สอดคล้องกัน
- ผสานรวมกับ Hadoop ทั้งต้นทางและปลายทาง
- มี java API ที่ง่ายสำหรับไคลเอนต์
- ให้การจำลองข้อมูลข้ามคลัสเตอร์
ใช้ HBase ได้ที่ไหน
Apache HBase ใช้เพื่อเข้าถึงข้อมูลขนาดใหญ่แบบอ่าน / เขียนแบบสุ่มแบบเรียลไทม์
มีโต๊ะขนาดใหญ่มากที่ด้านบนของกลุ่มฮาร์ดแวร์สินค้าโภคภัณฑ์
Apache HBase เป็นฐานข้อมูลที่ไม่เกี่ยวข้องซึ่งจำลองมาจาก Bigtable ของ Google Bigtable ทำงานบนระบบไฟล์ของ Google เช่นเดียวกัน Apache HBase ทำงานบน Hadoop และ HDFS
การใช้งาน HBase
- ใช้เมื่อใดก็ตามที่จำเป็นต้องเขียนแอพพลิเคชั่นหนัก ๆ
- HBase ถูกใช้เมื่อใดก็ตามที่เราต้องการให้เข้าถึงข้อมูลที่มีอยู่โดยสุ่มอย่างรวดเร็ว
- บริษัท ต่างๆเช่น Facebook, Twitter, Yahoo และ Adobe ใช้ HBase เป็นการภายใน
ประวัติ HBase
| ปี | เหตุการณ์ |
|---|---|
| พ.ย. 2549 | Google เปิดตัวกระดาษบน BigTable |
| ก.พ. 2550 | ต้นแบบ HBase เริ่มต้นถูกสร้างขึ้นเพื่อสนับสนุน Hadoop |
| ต.ค. 2550 | HBase ที่ใช้งานได้ตัวแรกพร้อมกับ Hadoop 0.15.0 ได้รับการเผยแพร่ |
| ม.ค. 2551 | HBase กลายเป็นโครงการย่อยของ Hadoop |
| ต.ค. 2551 | HBase 0.18.1 เปิดตัวแล้ว |
| ม.ค. 2552 | HBase 0.19.0 เปิดตัวแล้ว |
| ก.ย. 2552 | HBase 0.20.0 ถูกปล่อยออกมา |
| พฤษภาคม 2553 | HBase กลายเป็นโครงการระดับบนสุดของ Apache |
ใน HBase ตารางจะแบ่งออกเป็นภูมิภาคและให้บริการโดยเซิร์ฟเวอร์ภูมิภาค ภูมิภาคต่างๆแบ่งตามแนวตั้งตามตระกูลคอลัมน์เป็น "ร้านค้า" ร้านค้าจะถูกบันทึกเป็นไฟล์ใน HDFS ด้านล่างนี้คือสถาปัตยกรรมของ HBase
Note: คำว่า 'store' ใช้สำหรับภูมิภาคเพื่ออธิบายโครงสร้างการจัดเก็บ
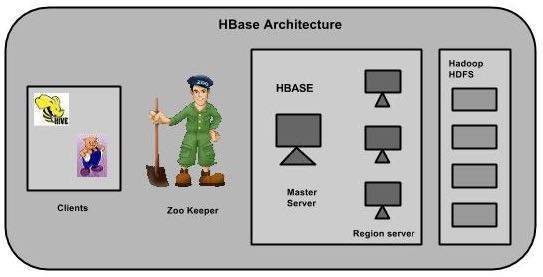
HBase มีองค์ประกอบหลักสามส่วน ได้แก่ ไลบรารีไคลเอ็นต์เซิร์ฟเวอร์หลักและเซิร์ฟเวอร์ภูมิภาค สามารถเพิ่มหรือลบเซิร์ฟเวอร์ภูมิภาคได้ตามความต้องการ
มาสเตอร์เซิร์ฟเวอร์
เซิร์ฟเวอร์หลัก -
กำหนดขอบเขตให้กับเซิร์ฟเวอร์ภูมิภาคและรับความช่วยเหลือจาก Apache ZooKeeper สำหรับงานนี้
จัดการการทำโหลดบาลานซ์ของภูมิภาคข้ามเซิร์ฟเวอร์ภูมิภาค จะยกเลิกการโหลดเซิร์ฟเวอร์ที่ไม่ว่างและเปลี่ยนภูมิภาคไปยังเซิร์ฟเวอร์ที่มีผู้ใช้น้อย
รักษาสถานะของคลัสเตอร์โดยการเจรจาการทำโหลดบาลานซ์
รับผิดชอบต่อการเปลี่ยนแปลงสคีมาและการดำเนินการข้อมูลเมตาอื่น ๆ เช่นการสร้างตารางและตระกูลคอลัมน์
ภูมิภาค
ภูมิภาคไม่ใช่อะไรนอกจากตารางที่แยกและกระจายไปทั่วเซิร์ฟเวอร์ภูมิภาค
เซิร์ฟเวอร์ภูมิภาค
เซิร์ฟเวอร์ภูมิภาคมีภูมิภาคที่ -
- สื่อสารกับลูกค้าและจัดการการดำเนินการที่เกี่ยวข้องกับข้อมูล
- จัดการคำขออ่านและเขียนสำหรับภูมิภาคทั้งหมดที่อยู่ข้างใต้
- กำหนดขนาดของพื้นที่โดยทำตามเกณฑ์ขนาดพื้นที่
เมื่อเราตรวจสอบอย่างละเอียดยิ่งขึ้นในเซิร์ฟเวอร์ภูมิภาคจะมีภูมิภาคและร้านค้าดังที่แสดงด้านล่าง:
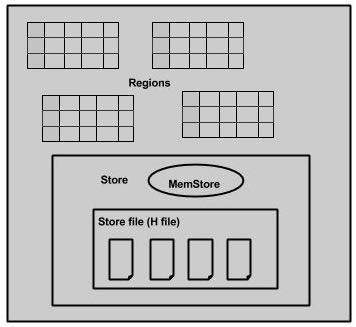
ร้านค้าประกอบด้วยที่เก็บหน่วยความจำและ HFiles Memstore ก็เหมือนกับหน่วยความจำแคช สิ่งใดก็ตามที่ป้อนลงใน HBase จะถูกเก็บไว้ที่นี่ในตอนแรก ต่อมาข้อมูลจะถูกถ่ายโอนและบันทึกใน Hfiles เป็นบล็อกและ memstore จะถูกล้าง
Zookeeper
Zookeeper เป็นโครงการโอเพ่นซอร์สที่ให้บริการต่างๆเช่นการดูแลรักษาข้อมูลการกำหนดค่าการตั้งชื่อการซิงโครไนซ์แบบกระจายเป็นต้น
Zookeeper มีโหนดชั่วคราวที่แสดงถึงเซิร์ฟเวอร์ภูมิภาคต่างๆ เซิร์ฟเวอร์หลักใช้โหนดเหล่านี้เพื่อค้นหาเซิร์ฟเวอร์ที่พร้อมใช้งาน
นอกจากความพร้อมใช้งานแล้วโหนดยังใช้เพื่อติดตามความล้มเหลวของเซิร์ฟเวอร์หรือพาร์ติชันเครือข่าย
ลูกค้าสื่อสารกับเซิร์ฟเวอร์ภูมิภาคผ่านทาง Zookeeper
ในโหมดหลอกและโหมดสแตนด์อโลน HBase เองจะดูแลผู้ดูแลสวนสัตว์
บทนี้อธิบายวิธีการติดตั้งและกำหนดค่า HBase ในเบื้องต้น Java และ Hadoop จำเป็นต้องดำเนินการกับ HBase ดังนั้นคุณต้องดาวน์โหลดและติดตั้ง java และ Hadoop ในระบบของคุณ
การตั้งค่าก่อนการติดตั้ง
ก่อนติดตั้ง Hadoop ในสภาพแวดล้อม Linux เราต้องตั้งค่า Linux โดยใช้ ssh(Secure Shell) ทำตามขั้นตอนด้านล่างเพื่อตั้งค่าสภาพแวดล้อม Linux
การสร้างผู้ใช้
ก่อนอื่นขอแนะนำให้สร้างผู้ใช้แยกต่างหากสำหรับ Hadoop เพื่อแยกระบบไฟล์ Hadoop ออกจากระบบไฟล์ Unix ทำตามขั้นตอนด้านล่างเพื่อสร้างผู้ใช้
- เปิดรูทโดยใช้คำสั่ง“ su”
- สร้างผู้ใช้จากบัญชีรูทโดยใช้คำสั่ง“ useradd username”
- ตอนนี้คุณสามารถเปิดบัญชีผู้ใช้ที่มีอยู่โดยใช้คำสั่ง“ su username”
เปิดเทอร์มินัล Linux และพิมพ์คำสั่งต่อไปนี้เพื่อสร้างผู้ใช้
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwdการตั้งค่า SSH และการสร้างคีย์
จำเป็นต้องมีการตั้งค่า SSH เพื่อดำเนินการต่างๆบนคลัสเตอร์เช่นการเริ่มต้นหยุดและการดำเนินการเชลล์ daemon แบบกระจาย ในการรับรองความถูกต้องของผู้ใช้ Hadoop ที่แตกต่างกันจำเป็นต้องให้คู่คีย์สาธารณะ / ส่วนตัวสำหรับผู้ใช้ Hadoop และแชร์กับผู้ใช้รายอื่น
คำสั่งต่อไปนี้ใช้เพื่อสร้างคู่ค่าคีย์โดยใช้ SSH คัดลอกคีย์สาธารณะในรูปแบบ id_rsa.pub ไปยัง Authorized_keys และให้สิทธิ์เจ้าของอ่านและเขียนไฟล์ Author_keys ตามลำดับ
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keysตรวจสอบ ssh
ssh localhostการติดตั้ง Java
Java เป็นข้อกำหนดเบื้องต้นหลักสำหรับ Hadoop และ HBase ก่อนอื่นคุณควรตรวจสอบการมีอยู่ของ java ในระบบของคุณโดยใช้ "java -version" ไวยากรณ์ของคำสั่งเวอร์ชัน java ได้รับด้านล่าง
$ java -versionหากทุกอย่างทำงานได้ดีจะให้ผลลัพธ์ดังต่อไปนี้
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)หากไม่ได้ติดตั้ง java ในระบบของคุณให้ทำตามขั้นตอนด้านล่างเพื่อติดตั้ง java
ขั้นตอนที่ 1
ดาวน์โหลดจาวา (JDK <เวอร์ชันล่าสุด> - X64.tar.gz) โดยไปที่ลิงก์ต่อไปนี้ของ Oracle Java
แล้ว jdk-7u71-linux-x64.tar.gz จะถูกดาวน์โหลดลงในระบบของคุณ
ขั้นตอนที่ 2
โดยทั่วไปคุณจะพบไฟล์ java ที่ดาวน์โหลดมาในโฟลเดอร์ Downloads ตรวจสอบและแตกไฟล์jdk-7u71-linux-x64.gz ไฟล์โดยใช้คำสั่งต่อไปนี้
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzขั้นตอนที่ 3
เพื่อให้ผู้ใช้ทุกคนสามารถใช้จาวาได้คุณต้องย้ายไปที่ตำแหน่ง“ / usr / local /” เปิดรูทและพิมพ์คำสั่งต่อไปนี้
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitขั้นตอนที่ 4
สำหรับการตั้งค่า PATH และ JAVA_HOME ตัวแปรเพิ่มคำสั่งต่อไปนี้ ~/.bashrc ไฟล์.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH= $PATH:$JAVA_HOME/binตอนนี้ใช้การเปลี่ยนแปลงทั้งหมดในระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 5
ใช้คำสั่งต่อไปนี้เพื่อกำหนดค่าทางเลือก java:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarตอนนี้ตรวจสอบไฟล์ java -version คำสั่งจากเทอร์มินัลตามที่อธิบายไว้ข้างต้น
กำลังดาวน์โหลด Hadoop
หลังจากติดตั้ง java คุณต้องติดตั้ง Hadoop ก่อนอื่นให้ตรวจสอบการมีอยู่ของ Hadoop โดยใช้คำสั่ง“ Hadoop version” ตามที่แสดงด้านล่าง
hadoop versionหากทุกอย่างทำงานได้ดีจะให้ผลลัพธ์ดังต่อไปนี้
Hadoop 2.6.0
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using
/home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarหากระบบของคุณไม่พบ Hadoop ให้ดาวน์โหลด Hadoop ในระบบของคุณ ทำตามคำสั่งด้านล่างเพื่อดำเนินการดังกล่าว
ดาวน์โหลดและแยกhadoop-2.6.0จาก Apache Software Foundation โดยใช้คำสั่งต่อไปนี้
$ su
password:
# cd /usr/local
# wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop-
2.6.0/hadoop-2.6.0-src.tar.gz
# tar xzf hadoop-2.6.0-src.tar.gz
# mv hadoop-2.6.0/* hadoop/
# exitการติดตั้ง Hadoop
ติดตั้ง Hadoop ในโหมดที่ต้องการ ที่นี่เรากำลังสาธิตฟังก์ชัน HBase ในโหมดกระจายหลอกดังนั้นให้ติดตั้ง Hadoop ในโหมดกระจายหลอก
ขั้นตอนต่อไปนี้ใช้สำหรับการติดตั้ง Hadoop 2.4.1.
ขั้นตอนที่ 1 - การตั้งค่า Hadoop
คุณสามารถตั้งค่าตัวแปรสภาพแวดล้อม Hadoop ได้โดยต่อท้ายคำสั่งต่อไปนี้ ~/.bashrc ไฟล์.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOMEตอนนี้ใช้การเปลี่ยนแปลงทั้งหมดในระบบที่กำลังทำงานอยู่
$ source ~/.bashrcขั้นตอนที่ 2 - การกำหนดค่า Hadoop
คุณสามารถค้นหาไฟล์การกำหนดค่า Hadoop ทั้งหมดได้ในตำแหน่ง“ $ HADOOP_HOME / etc / hadoop” คุณต้องทำการเปลี่ยนแปลงในไฟล์กำหนดค่าเหล่านั้นตามโครงสร้างพื้นฐาน Hadoop ของคุณ
$ cd $HADOOP_HOME/etc/hadoopในการพัฒนาโปรแกรม Hadoop ใน java คุณต้องรีเซ็ตตัวแปรสภาพแวดล้อม java ใน hadoop-env.sh ไฟล์โดยแทนที่ไฟล์ JAVA_HOME ค่ากับตำแหน่งของ java ในระบบของคุณ
export JAVA_HOME=/usr/local/jdk1.7.0_71คุณจะต้องแก้ไขไฟล์ต่อไปนี้เพื่อกำหนดค่า Hadoop
core-site.xml
core-site.xml ไฟล์มีข้อมูลเช่นหมายเลขพอร์ตที่ใช้สำหรับอินสแตนซ์ Hadoop หน่วยความจำที่จัดสรรสำหรับระบบไฟล์ขีด จำกัด หน่วยความจำสำหรับจัดเก็บข้อมูลและขนาดของบัฟเฟอร์อ่าน / เขียน
เปิด core-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration> และ </configuration>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
hdfs-site.xml ไฟล์มีข้อมูลเช่นค่าของข้อมูลการจำลองเส้นทาง Namenode และพา ธ datanode ของระบบไฟล์ในเครื่องของคุณซึ่งคุณต้องการจัดเก็บโครงสร้างพื้นฐาน Hadoop
ให้เราสมมติข้อมูลต่อไปนี้
dfs.replication (data replication value) = 1
(In the below given path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeเปิดไฟล์นี้และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration>, </configuration>
<configuration>
<property>
<name>dfs.replication</name >
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note: ในไฟล์ด้านบนค่าคุณสมบัติทั้งหมดจะถูกกำหนดโดยผู้ใช้และคุณสามารถเปลี่ยนแปลงได้ตามโครงสร้างพื้นฐาน Hadoop ของคุณ
yarn-site.xml
ไฟล์นี้ใช้เพื่อกำหนดค่าเส้นด้ายใน Hadoop เปิดไฟล์ yarn-site.xml และเพิ่มคุณสมบัติต่อไปนี้ระหว่าง <configuration $ gt ;, </ configuration $ gt; แท็กในไฟล์นี้
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
ไฟล์นี้ใช้เพื่อระบุเฟรมเวิร์ก MapReduce ที่เราใช้อยู่ ตามค่าเริ่มต้น Hadoop จะมีเทมเพลตของ yarn-site.xml ก่อนอื่นต้องคัดลอกไฟล์จากไฟล์mapred-site.xml.template ถึง mapred-site.xml ไฟล์โดยใช้คำสั่งต่อไปนี้
$ cp mapred-site.xml.template mapred-site.xmlเปิด mapred-site.xml ไฟล์และเพิ่มคุณสมบัติต่อไปนี้ระหว่างแท็ก <configuration> และ </configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>การตรวจสอบการติดตั้ง Hadoop
ขั้นตอนต่อไปนี้ใช้เพื่อตรวจสอบการติดตั้ง Hadoop
ขั้นตอนที่ 1 - ตั้งชื่อโหนด
ตั้งค่า Namenode โดยใช้คำสั่ง“ hdfs namenode -format” ดังต่อไปนี้
$ cd ~ $ hdfs namenode -formatผลที่คาดว่าจะได้รับมีดังนี้
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/ขั้นตอนที่ 2 - การตรวจสอบ Hadoop dfs
คำสั่งต่อไปนี้ใช้เพื่อเริ่ม dfs การดำเนินการคำสั่งนี้จะเริ่มระบบไฟล์ Hadoop ของคุณ
$ start-dfs.shผลลัพธ์ที่คาดหวังมีดังนี้
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]ขั้นตอนที่ 3 - ตรวจสอบสคริปต์เส้นด้าย
คำสั่งต่อไปนี้ใช้เพื่อเริ่มสคริปต์เส้นด้าย การดำเนินการคำสั่งนี้จะเริ่มต้นเส้นด้าย daemons ของคุณ
$ start-yarn.shผลลัพธ์ที่คาดหวังมีดังนี้
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.outขั้นตอนที่ 4 - การเข้าถึง Hadoop บนเบราว์เซอร์
หมายเลขพอร์ตเริ่มต้นในการเข้าถึง Hadoop คือ 50070 ใช้ url ต่อไปนี้เพื่อรับบริการ Hadoop บนเบราว์เซอร์ของคุณ
http://localhost:50070
ขั้นตอนที่ 5 - ตรวจสอบแอปพลิเคชันทั้งหมดของคลัสเตอร์
หมายเลขพอร์ตเริ่มต้นเพื่อเข้าถึงแอปพลิเคชันทั้งหมดของคลัสเตอร์คือ 8088 ใช้ url ต่อไปนี้เพื่อเยี่ยมชมบริการนี้
http://localhost:8088/
การติดตั้ง HBase
เราสามารถติดตั้ง HBase ในโหมดใดก็ได้จากสามโหมด: โหมดสแตนด์อโลนโหมดการกระจายหลอกและโหมดกระจายอย่างสมบูรณ์
การติดตั้ง HBase ในโหมดสแตนด์อโลน
ดาวน์โหลดแบบฟอร์ม HBase เวอร์ชันเสถียรล่าสุด http://www.interior-dsgn.com/apache/hbase/stable/โดยใช้คำสั่ง“ wget” และแยกโดยใช้คำสั่ง tar“ zxvf” ดูคำสั่งต่อไปนี้
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8-
hadoop2-bin.tar.gz
$tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gzเลื่อนไปที่โหมดผู้ใช้ขั้นสูงและย้ายโฟลเดอร์ HBase ไปที่ / usr / local ดังที่แสดงด้านล่าง
$su
$password: enter your password here
mv hbase-0.99.1/* Hbase/การกำหนดค่า HBase ในโหมดสแตนด์อโลน
ก่อนดำเนินการกับ HBase คุณต้องแก้ไขไฟล์ต่อไปนี้และกำหนดค่า HBase
hbase-env.sh
ตั้งค่า java Home สำหรับ HBase และเปิด hbase-env.shไฟล์จากโฟลเดอร์ conf แก้ไขตัวแปรสภาพแวดล้อม JAVA_HOME และเปลี่ยนเส้นทางที่มีอยู่เป็นตัวแปร JAVA_HOME ปัจจุบันของคุณดังที่แสดงด้านล่าง
cd /usr/local/Hbase/conf
gedit hbase-env.shเพื่อเปิดไฟล์ env.sh ของ HBase ตอนนี้แทนที่ไฟล์JAVA_HOME มูลค่าด้วยมูลค่าปัจจุบันของคุณตามที่แสดงด้านล่าง
export JAVA_HOME=/usr/lib/jvm/java-1.7.0hbase-site.xml
นี่คือไฟล์คอนฟิกหลักของ HBase ตั้งค่าไดเร็กทอรีข้อมูลไปยังตำแหน่งที่เหมาะสมโดยเปิดโฮมโฟลเดอร์ HBase ใน / usr / local / HBase ภายในโฟลเดอร์ conf คุณจะพบไฟล์หลายไฟล์เปิดไฟล์hbase-site.xml ไฟล์ดังที่แสดงด้านล่าง
#cd /usr/local/HBase/
#cd conf
# gedit hbase-site.xmlข้างใน hbase-site.xmlคุณจะพบแท็ก <configuration> และ </configuration> ภายในพวกเขาตั้งค่าไดเร็กทอรี HBase ภายใต้คีย์คุณสมบัติด้วยชื่อ“ hbase.rootdir” ดังที่แสดงด้านล่าง
<configuration>
//Here you have to set the path where you want HBase to store its files.
<property>
<name>hbase.rootdir</name>
<value>file:/home/hadoop/HBase/HFiles</value>
</property>
//Here you have to set the path where you want HBase to store its built in zookeeper files.
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zookeeper</value>
</property>
</configuration>ด้วยเหตุนี้ส่วนการติดตั้งและการกำหนดค่า HBase จึงเสร็จสมบูรณ์ เราสามารถเริ่ม HBase ได้โดยใช้start-hbase.shสคริปต์ที่อยู่ในโฟลเดอร์ bin ของ HBase สำหรับสิ่งนั้นให้เปิด HBase Home Folder และเรียกใช้สคริปต์เริ่มต้น HBase ดังที่แสดงด้านล่าง
$cd /usr/local/HBase/bin
$./start-hbase.shหากทุกอย่างเป็นไปด้วยดีเมื่อคุณพยายามเรียกใช้สคริปต์เริ่มต้น HBase ระบบจะแจ้งให้คุณทราบว่า HBase เริ่มทำงานแล้ว
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.outการติดตั้ง HBase ในโหมด Pseudo-Distributed
ตอนนี้ให้เราตรวจสอบวิธีการติดตั้ง HBase ในโหมดกระจายหลอก
การกำหนดค่า HBase
ก่อนดำเนินการกับ HBase ให้กำหนดค่า Hadoop และ HDFS บนระบบโลคัลของคุณหรือบนระบบรีโมตและตรวจสอบให้แน่ใจว่ากำลังทำงานอยู่ หยุด HBase หากกำลังทำงานอยู่
hbase-site.xml
แก้ไขไฟล์ hbase-site.xml เพื่อเพิ่มคุณสมบัติต่อไปนี้
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>จะกล่าวถึงว่าควรรัน HBase ในโหมดใด ในไฟล์เดียวกันจากระบบไฟล์ในเครื่องให้เปลี่ยน hbase.rootdir ที่อยู่อินสแตนซ์ HDFS ของคุณโดยใช้ไวยากรณ์ hdfs: //// URI เรากำลังเรียกใช้ HDFS บน localhost ที่พอร์ต 8030
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8030/hbase</value>
</property>เริ่ม HBase
หลังจากการกำหนดค่าเสร็จสิ้นให้เรียกดูโฟลเดอร์บ้าน HBase และเริ่ม HBase โดยใช้คำสั่งต่อไปนี้
$cd /usr/local/HBase
$bin/start-hbase.shNote: ก่อนเริ่ม HBase ตรวจสอบให้แน่ใจว่า Hadoop กำลังทำงานอยู่
ตรวจสอบ HBase Directory ใน HDFS
HBase สร้างไดเร็กทอรีใน HDFS หากต้องการดูไดเร็กทอรีที่สร้างขึ้นให้เรียกดู Hadoop bin และพิมพ์คำสั่งต่อไปนี้
$ ./bin/hadoop fs -ls /hbaseหากทุกอย่างเป็นไปด้วยดีมันจะให้ผลลัพธ์ดังต่อไปนี้
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALsการเริ่มต้นและการหยุดต้นแบบ
การใช้“ local-master-backup.sh” คุณสามารถเริ่มเซิร์ฟเวอร์ได้สูงสุด 10 เซิร์ฟเวอร์ เปิดโฮมโฟลเดอร์ของ HBase ต้นแบบและดำเนินการคำสั่งต่อไปนี้เพื่อเริ่มต้น
$ ./bin/local-master-backup.sh 2 4ในการฆ่าต้นแบบการสำรองข้อมูลคุณต้องมีรหัสกระบวนการซึ่งจะถูกเก็บไว้ในไฟล์ชื่อ “/tmp/hbase-USER-X-master.pid.” คุณสามารถฆ่าต้นแบบการสำรองข้อมูลโดยใช้คำสั่งต่อไปนี้
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9การเริ่มต้นและการหยุด RegionServers
คุณสามารถรันเซิร์ฟเวอร์หลายภูมิภาคจากระบบเดียวโดยใช้คำสั่งต่อไปนี้
$ .bin/local-regionservers.sh start 2 3ในการหยุดเซิร์ฟเวอร์ภูมิภาคให้ใช้คำสั่งต่อไปนี้
$ .bin/local-regionservers.sh stop 3
เริ่มต้น HBaseShell
หลังจากติดตั้ง HBase สำเร็จคุณสามารถเริ่ม HBase Shell ได้ ด้านล่างนี้เป็นลำดับของขั้นตอนที่ต้องปฏิบัติตามเพื่อเริ่มเชลล์ HBase เปิดเทอร์มินัลและเข้าสู่ระบบในฐานะผู้ใช้ขั้นสูง
เริ่มระบบไฟล์ Hadoop
เรียกดูโฟลเดอร์ Hadoop home sbin และเริ่มระบบไฟล์ Hadoop ดังที่แสดงด้านล่าง
$cd $HADOOP_HOME/sbin
$start-all.shเริ่ม HBase
เรียกดูโฟลเดอร์ bin ไดเร็กทอรีรากของ HBase และเริ่ม HBase
$cd /usr/local/HBase
$./bin/start-hbase.shเริ่ม HBase Master Server
นี่จะเป็นไดเร็กทอรีเดียวกัน เริ่มต้นตามที่แสดงด้านล่าง
$./bin/local-master-backup.sh start 2 (number signifies specific
server.)เริ่มภูมิภาค
เริ่มเซิร์ฟเวอร์ภูมิภาคดังที่แสดงด้านล่าง
$./bin/./local-regionservers.sh start 3เริ่ม HBase Shell
คุณสามารถเริ่ม HBase shell โดยใช้คำสั่งต่อไปนี้
$cd bin
$./hbase shellสิ่งนี้จะให้ HBase Shell Prompt ตามที่แสดงด้านล่าง
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation:
hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri
Nov 14 18:26:29 PST 2014
hbase(main):001:0>HBase เว็บอินเตอร์เฟส
ในการเข้าถึงเว็บอินเตอร์เฟสของ HBase ให้พิมพ์ url ต่อไปนี้ในเบราว์เซอร์
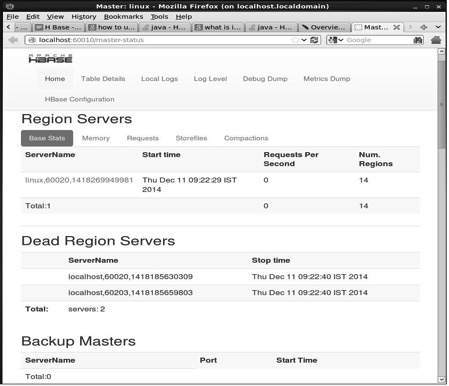
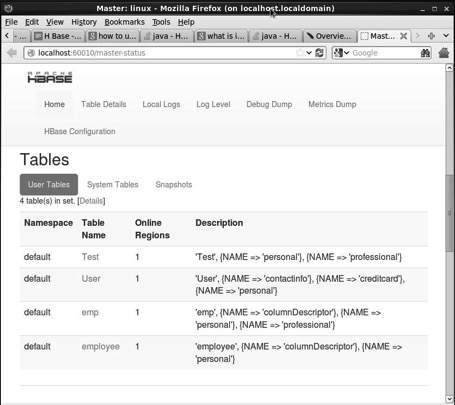
http://localhost:60010อินเทอร์เฟซนี้แสดงรายการเซิร์ฟเวอร์ภูมิภาคต้นแบบสำรองและตาราง HBase ที่กำลังทำงานอยู่
เซิร์ฟเวอร์ HBase Region และ Backup Masters
ตาราง HBase
การตั้งค่า Java Environment
นอกจากนี้เรายังสามารถสื่อสารกับ HBase โดยใช้ไลบรารี Java แต่ก่อนที่จะเข้าถึง HBase โดยใช้ Java API คุณต้องตั้งค่า classpath สำหรับไลบรารีเหล่านั้น
การตั้งค่า Classpath
ก่อนดำเนินการเขียนโปรแกรมให้ตั้งค่า classpath เป็น HBase libraries ใน .bashrcไฟล์. เปิด.bashrc ในตัวแก้ไขใด ๆ ตามที่แสดงด้านล่าง
$ gedit ~/.bashrcตั้งค่า classpath สำหรับไลบรารี HBase (โฟลเดอร์ lib ใน HBase) ตามที่แสดงด้านล่าง
export CLASSPATH = $CLASSPATH://home/hadoop/hbase/lib/*นี่เป็นการป้องกันข้อยกเว้น“ ไม่พบคลาส” ขณะเข้าถึง HBase โดยใช้ java API
บทนี้อธิบายถึงวิธีการเริ่มเชลล์โต้ตอบ HBase ที่มาพร้อมกับ HBase
HBase เชลล์
HBase มีเชลล์ที่คุณสามารถสื่อสารกับ HBase ได้ HBase ใช้ Hadoop File System เพื่อจัดเก็บข้อมูล จะมีเซิร์ฟเวอร์หลักและเซิร์ฟเวอร์ภูมิภาค การจัดเก็บข้อมูลจะอยู่ในรูปแบบของพื้นที่ (ตาราง) ภูมิภาคเหล่านี้จะถูกแยกและจัดเก็บไว้ในเซิร์ฟเวอร์ภูมิภาค
เซิร์ฟเวอร์หลักจัดการเซิร์ฟเวอร์ภูมิภาคเหล่านี้และงานทั้งหมดเหล่านี้จะเกิดขึ้นบน HDFS ด้านล่างนี้เป็นคำสั่งบางส่วนที่รองรับโดย HBase Shell
คำสั่งทั่วไป
status - ระบุสถานะของ HBase ตัวอย่างเช่นจำนวนเซิร์ฟเวอร์
version - ระบุเวอร์ชันของ HBase ที่ใช้
table_help - ให้ความช่วยเหลือสำหรับคำสั่งอ้างอิงตาราง
whoami - ให้ข้อมูลเกี่ยวกับผู้ใช้
ภาษานิยามข้อมูล
นี่คือคำสั่งที่ทำงานบนตารางใน HBase
create - สร้างตาราง
list - แสดงรายการตารางทั้งหมดใน HBase
disable - ปิดการใช้งานตาราง
is_disabled - ตรวจสอบว่าตารางถูกปิดใช้งานหรือไม่
enable - เปิดใช้งานตาราง
is_enabled - ตรวจสอบว่าตารางถูกเปิดใช้งานหรือไม่
describe - ให้คำอธิบายของตาราง
alter - ปรับเปลี่ยนตาราง
exists - ตรวจสอบว่ามีตารางอยู่หรือไม่
drop - วางตารางจาก HBase
drop_all - วางตารางที่ตรงกับ 'regex' ที่ระบุในคำสั่ง
Java Admin API- ก่อนคำสั่งทั้งหมดข้างต้น Java มี Admin API เพื่อให้บรรลุฟังก์ชัน DDL ผ่านการเขียนโปรแกรม ภายใต้org.apache.hadoop.hbase.client แพคเกจ HBaseAdmin และ HTableDescriptor เป็นสองคลาสที่สำคัญในแพ็คเกจนี้ที่มีฟังก์ชัน DDL
ภาษาการจัดการข้อมูล
put - ใส่ค่าเซลล์ที่คอลัมน์ที่ระบุในแถวที่ระบุในตารางเฉพาะ
get - ดึงเนื้อหาของแถวหรือเซลล์
delete - ลบค่าเซลล์ในตาราง
deleteall - ลบเซลล์ทั้งหมดในแถวที่กำหนด
scan - สแกนและส่งคืนข้อมูลตาราง
count - นับและส่งคืนจำนวนแถวในตาราง
truncate - ปิดใช้งานลดลงและสร้างตารางที่ระบุใหม่
Java client API - ก่อนคำสั่งทั้งหมดข้างต้น Java จัดเตรียมไคลเอนต์ API เพื่อให้บรรลุฟังก์ชัน DML CRUD (Create Retrieve Update Delete) และอื่น ๆ ผ่านการเขียนโปรแกรมภายใต้แพ็กเกจ org.apache.hadoop.hbase.client HTable Put และ Get เป็นคลาสที่สำคัญในแพ็คเกจนี้
เริ่ม HBase Shell
ในการเข้าถึง HBase เชลล์คุณต้องไปที่โฮมโฟลเดอร์ HBase
cd /usr/localhost/
cd Hbaseคุณสามารถเริ่มเชลล์โต้ตอบ HBase โดยใช้ไฟล์ “hbase shell” คำสั่งดังที่แสดงด้านล่าง
./bin/hbase shellหากคุณติดตั้ง HBase ในระบบของคุณสำเร็จแล้วระบบจะให้ HBase shell prompt ดังที่แสดงด้านล่าง
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 0.94.23, rf42302b28aceaab773b15f234aa8718fff7eea3c, Wed Aug 27
00:54:09 UTC 2014
hbase(main):001:0>หากต้องการออกจากคำสั่งเชลล์แบบโต้ตอบเมื่อใดก็ได้ให้พิมพ์ exit หรือใช้ <ctrl + c> ตรวจสอบการทำงานของเชลล์ก่อนดำเนินการต่อ ใช้list คำสั่งสำหรับวัตถุประสงค์นี้ Listเป็นคำสั่งที่ใช้เพื่อรับรายการตารางทั้งหมดใน HBase ก่อนอื่นตรวจสอบการติดตั้งและการกำหนดค่าของ HBase ในระบบของคุณโดยใช้คำสั่งนี้ดังที่แสดงด้านล่าง
hbase(main):001:0> listเมื่อคุณพิมพ์คำสั่งนี้จะให้ผลลัพธ์ดังต่อไปนี้
hbase(main):001:0> list
TABLEคำสั่งทั่วไปใน HBase ได้แก่ สถานะเวอร์ชัน table_help และ whoami บทนี้จะอธิบายคำสั่งเหล่านี้
สถานะ
คำสั่งนี้ส่งคืนสถานะของระบบรวมถึงรายละเอียดของเซิร์ฟเวอร์ที่รันบนระบบ ไวยากรณ์มีดังนี้:
hbase(main):009:0> statusหากคุณรันคำสั่งนี้จะส่งคืนผลลัพธ์ต่อไปนี้
hbase(main):009:0> status
3 servers, 0 dead, 1.3333 average loadรุ่น
คำสั่งนี้ส่งคืนเวอร์ชันของ HBase ที่ใช้ในระบบของคุณ ไวยากรณ์มีดังนี้:
hbase(main):010:0> versionหากคุณรันคำสั่งนี้จะส่งคืนผลลัพธ์ต่อไปนี้
hbase(main):009:0> version
0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14
18:26:29 PST 2014table_help
คำสั่งนี้แนะนำคุณว่าจะใช้คำสั่งอ้างอิงตารางอย่างไรและอย่างไร ด้านล่างเป็นไวยากรณ์ที่จะใช้คำสั่งนี้
hbase(main):02:0> table_helpเมื่อคุณใช้คำสั่งนี้จะแสดงหัวข้อวิธีใช้สำหรับคำสั่งที่เกี่ยวข้องกับตาราง ให้ด้านล่างนี้เป็นผลลัพธ์บางส่วนของคำสั่งนี้
hbase(main):002:0> table_help
Help for table-reference commands.
You can either create a table via 'create' and then manipulate the table
via commands like 'put', 'get', etc.
See the standard help information for how to use each of these commands.
However, as of 0.96, you can also get a reference to a table, on which
you can invoke commands.
For instance, you can get create a table and keep around a reference to
it via:
hbase> t = create 't', 'cf'…...ฉันเป็นใคร
คำสั่งนี้ส่งคืนรายละเอียดผู้ใช้ของ HBase หากคุณรันคำสั่งนี้ให้ส่งคืนผู้ใช้ HBase ปัจจุบันดังที่แสดงด้านล่าง
hbase(main):008:0> whoami
hadoop (auth:SIMPLE)
groups: hadoopHBase เขียนด้วย java ดังนั้นจึงมี java API เพื่อสื่อสารกับ HBase Java API เป็นวิธีที่เร็วที่สุดในการสื่อสารกับ HBase ด้านล่างนี้คือ java Admin API ที่อ้างอิงซึ่งครอบคลุมงานที่ใช้ในการจัดการตาราง
คลาส HBaseAdmin
HBaseAdminเป็นคลาสที่เป็นตัวแทนของผู้ดูแลระบบ คลาสนี้เป็นของorg.apache.hadoop.hbase.clientแพ็คเกจ เมื่อใช้คลาสนี้คุณสามารถทำงานของผู้ดูแลระบบได้ คุณสามารถรับอินสแตนซ์ของผู้ดูแลระบบโดยใช้Connection.getAdmin() วิธี.
วิธีการและคำอธิบาย
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | void createTable(HTableDescriptor desc) สร้างตารางใหม่ |
| 2 | void createTable(HTableDescriptor desc, byte[][] splitKeys) สร้างตารางใหม่ด้วยชุดเริ่มต้นของพื้นที่ว่างที่กำหนดโดยคีย์แยกที่ระบุ |
| 3 | void deleteColumn(byte[] tableName, String columnName) ลบคอลัมน์จากตาราง |
| 4 | void deleteColumn(String tableName, String columnName) ลบคอลัมน์จากตาราง |
| 5 | void deleteTable(String tableName) ลบตาราง |
Class Descriptor
คลาสนี้มีรายละเอียดเกี่ยวกับตาราง HBase เช่น:
- ตัวบ่งชี้ของตระกูลคอลัมน์ทั้งหมด
- ถ้าตารางเป็นตารางแค็ตตาล็อก
- ถ้าตารางเป็นแบบอ่านอย่างเดียว
- ขนาดสูงสุดของที่เก็บ mem
- เมื่อเกิดการแยกภูมิภาค
- โปรเซสเซอร์ร่วมที่เกี่ยวข้อง ฯลฯ
ตัวสร้าง
| ส. | ตัวสร้างและสรุป |
|---|---|
| 1 | HTableDescriptor(TableName name) สร้างตัวอธิบายตารางที่ระบุอ็อบเจ็กต์ TableName |
วิธีการและคำอธิบาย
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | HTableDescriptor addFamily(HColumnDescriptor family) เพิ่มตระกูลคอลัมน์ให้กับตัวอธิบายที่กำหนด |
การสร้างตารางโดยใช้ HBase Shell
คุณสามารถสร้างตารางโดยใช้ไฟล์ createคุณต้องระบุชื่อตารางและชื่อตระกูลคอลัมน์ที่นี่ syntax เพื่อสร้างตารางใน HBase shell ดังแสดงด้านล่าง
create ‘<table name>’,’<column family>’ตัวอย่าง
ด้านล่างนี้เป็นสคีมาตัวอย่างของตารางชื่อ emp มีคอลัมน์สองตระกูล ได้แก่ "ข้อมูลส่วนบุคคล" และ "ข้อมูลระดับมืออาชีพ"
| คีย์แถว | ข้อมูลส่วนบุคคล | ข้อมูลระดับมืออาชีพ |
|---|---|---|
คุณสามารถสร้างตารางนี้ใน HBase shell ดังที่แสดงด้านล่าง
hbase(main):002:0> create 'emp', 'personal data', 'professional data'และจะให้ผลลัพธ์ดังต่อไปนี้
0 row(s) in 1.1300 seconds
=> Hbase::Table - empการยืนยัน
คุณสามารถตรวจสอบได้ว่าสร้างตารางโดยใช้ไฟล์ listคำสั่งดังที่แสดงด้านล่าง ที่นี่คุณสามารถสังเกตตาราง emp ที่สร้างขึ้น
hbase(main):002:0> list
TABLE
emp
2 row(s) in 0.0340 secondsการสร้างตารางโดยใช้ java API
คุณสามารถสร้างตารางใน HBase โดยใช้ไฟล์ createTable() วิธีการของ HBaseAdminชั้นเรียน. คลาสนี้เป็นของorg.apache.hadoop.hbase.clientแพ็คเกจ ด้านล่างนี้เป็นขั้นตอนในการสร้างตารางใน HBase โดยใช้ java API
ขั้นที่ 1: สร้างอินสแตนซ์ HBaseAdmin
คลาสนี้ต้องการอ็อบเจ็กต์คอนฟิกูเรชันเป็นพารามิเตอร์ดังนั้นในขั้นต้นจึงสร้างอินสแตนซ์คลาสคอนฟิกูเรชันและส่งอินสแตนซ์นี้ไปยัง HBaseAdmin
Configuration conf = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2: สร้าง TableDescriptor
HTableDescriptor เป็นคลาสที่เป็นของ org.apache.hadoop.hbaseชั้นเรียน. คลาสนี้เป็นเหมือนที่เก็บของชื่อตารางและตระกูลคอลัมน์
//creating table descriptor
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//creating column family descriptor
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//adding coloumn family to HTable
table.addFamily(family);ขั้นตอนที่ 3: ดำเนินการผ่านผู้ดูแลระบบ
ใช้ createTable() วิธีการของ HBaseAdmin คลาสคุณสามารถเรียกใช้ตารางที่สร้างขึ้นในโหมดผู้ดูแลระบบ
admin.createTable(table);ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการสร้างตารางผ่านทางผู้ดูแลระบบ
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.conf.Configuration;
public class CreateTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration con = HBaseConfiguration.create();
// Instantiating HbaseAdmin class
HBaseAdmin admin = new HBaseAdmin(con);
// Instantiating table descriptor class
HTableDescriptor tableDescriptor = new
HTableDescriptor(TableName.valueOf("emp"));
// Adding column families to table descriptor
tableDescriptor.addFamily(new HColumnDescriptor("personal"));
tableDescriptor.addFamily(new HColumnDescriptor("professional"));
// Execute the table through admin
admin.createTable(tableDescriptor);
System.out.println(" Table created ");
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac CreateTable.java
$java CreateTableสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
Table createdรายการตารางโดยใช้ HBase Shell
list คือคำสั่งที่ใช้เพื่อแสดงรายการตารางทั้งหมดใน HBase ด้านล่างนี้เป็นไวยากรณ์ของคำสั่งรายการ
hbase(main):001:0 > listเมื่อคุณพิมพ์คำสั่งนี้และดำเนินการใน HBase prompt มันจะแสดงรายการตารางทั้งหมดใน HBase ดังที่แสดงด้านล่าง
hbase(main):001:0> list
TABLE
empที่นี่คุณสามารถสังเกตตารางชื่อ emp
รายการตารางโดยใช้ Java API
ทำตามขั้นตอนด้านล่างเพื่อรับรายการตารางจาก HBase โดยใช้ java API
ขั้นตอนที่ 1
คุณมีวิธีการที่เรียกว่า listTables() ในห้องเรียน HBaseAdminเพื่อรับรายชื่อตารางทั้งหมดใน HBase วิธีนี้ส่งคืนอาร์เรย์ของHTableDescriptor วัตถุ
//creating a configuration object
Configuration conf = HBaseConfiguration.create();
//Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);
//Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();ขั้นตอนที่ 2
คุณสามารถรับความยาวของไฟล์ HTableDescriptor[] อาร์เรย์โดยใช้ตัวแปรความยาวของ HTableDescriptorชั้นเรียน. รับชื่อของตารางจากวัตถุนี้โดยใช้getNameAsString()วิธี. เรียกใช้ลูป 'for' โดยใช้สิ่งเหล่านี้และรับรายการตารางใน HBase
ด้านล่างนี้เป็นโปรแกรมสำหรับแสดงรายการตารางทั้งหมดใน HBase โดยใช้ Java API
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ListTables {
public static void main(String args[])throws MasterNotRunningException, IOException{
// Instantiating a configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Getting all the list of tables using HBaseAdmin object
HTableDescriptor[] tableDescriptor = admin.listTables();
// printing all the table names.
for (int i=0; i<tableDescriptor.length;i++ ){
System.out.println(tableDescriptor[i].getNameAsString());
}
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac ListTables.java
$java ListTablesสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
User
empการปิดใช้งานตารางโดยใช้ HBase Shell
หากต้องการลบตารางหรือเปลี่ยนการตั้งค่าคุณต้องปิดใช้งานตารางก่อนโดยใช้คำสั่งปิดใช้งาน คุณสามารถเปิดใช้งานใหม่ได้โดยใช้คำสั่งเปิดใช้งาน
ด้านล่างเป็นไวยากรณ์เพื่อปิดใช้งานตาราง:
disable ‘emp’ตัวอย่าง
ด้านล่างเป็นตัวอย่างที่แสดงวิธีปิดใช้งานตาราง
hbase(main):025:0> disable 'emp'
0 row(s) in 1.2760 secondsการยืนยัน
หลังจากปิดใช้งานตารางคุณยังสามารถสัมผัสได้ถึงการมีอยู่ของตาราง list และ existsคำสั่ง คุณไม่สามารถสแกนได้ จะทำให้คุณมีข้อผิดพลาดต่อไปนี้
hbase(main):028:0> scan 'emp'
ROW COLUMN + CELL
ERROR: emp is disabled.ถูกปิดใช้งาน
คำสั่งนี้ใช้เพื่อค้นหาว่าตารางถูกปิดใช้งานหรือไม่ ไวยากรณ์เป็นดังนี้
hbase> is_disabled 'table name'ตัวอย่างต่อไปนี้ตรวจสอบว่าตารางที่ชื่อ emp ถูกปิดใช้งานหรือไม่ หากปิดใช้งานจะส่งคืนค่า true และหากไม่เป็นเช่นนั้นก็จะส่งคืนเป็นเท็จ
hbase(main):031:0> is_disabled 'emp'
true
0 row(s) in 0.0440 secondsdisable_all
คำสั่งนี้ใช้เพื่อปิดใช้งานตารางทั้งหมดที่ตรงกับ regex ที่กำหนด ไวยากรณ์สำหรับdisable_all ได้รับคำสั่งด้านล่าง
hbase> disable_all 'r.*'สมมติว่ามี 5 ตารางใน HBase ได้แก่ ราชาราชานีราเจนดราราชาและราจู รหัสต่อไปนี้จะปิดใช้งานตารางทั้งหมดที่ขึ้นต้นด้วยraj.
hbase(main):002:07> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledปิดการใช้งานตารางโดยใช้ Java API
ในการตรวจสอบว่าตารางถูกปิดใช้งานหรือไม่ isTableDisabled() ใช้วิธีการและปิดใช้งานตาราง disableTable()ใช้วิธีการ วิธีการเหล่านี้เป็นของHBaseAdminชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อปิดใช้งานตาราง
ขั้นตอนที่ 1
ทันที HBaseAdmin คลาสดังที่แสดงด้านล่าง
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
ตรวจสอบว่าตารางถูกปิดใช้งานโดยใช้ isTableDisabled() วิธีการดังแสดงด้านล่าง
Boolean b = admin.isTableDisabled("emp");ขั้นตอนที่ 3
หากตารางไม่ได้ปิดใช้งานให้ปิดการใช้งานดังที่แสดงด้านล่าง
if(!b){
admin.disableTable("emp");
System.out.println("Table disabled");
}ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์เพื่อตรวจสอบว่าตารางถูกปิดใช้งานหรือไม่ ถ้าไม่วิธีปิดการใช้งาน
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DisableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying weather the table is disabled
Boolean bool = admin.isTableDisabled("emp");
System.out.println(bool);
// Disabling the table using HBaseAdmin object
if(!bool){
admin.disableTable("emp");
System.out.println("Table disabled");
}
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac DisableTable.java
$java DsiableTableสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
false
Table disabledการเปิดใช้งานตารางโดยใช้ HBase Shell
ไวยากรณ์เพื่อเปิดใช้งานตาราง:
enable ‘emp’ตัวอย่าง
ด้านล่างเป็นตัวอย่างในการเปิดใช้งานตาราง
hbase(main):005:0> enable 'emp'
0 row(s) in 0.4580 secondsการยืนยัน
หลังจากเปิดใช้งานตารางแล้วให้สแกน หากคุณเห็นสคีมาแสดงว่าตารางของคุณเปิดใช้งานสำเร็จแล้ว
hbase(main):006:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417516501, value = hyderabad
1 column = personal data:name, timestamp = 1417525058, value = ramu
1 column = professional data:designation, timestamp = 1417532601, value = manager
1 column = professional data:salary, timestamp = 1417524244109, value = 50000
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 14175292204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 14175246987, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000
3 row(s) in 0.0400 secondsเปิดใช้งาน
คำสั่งนี้ใช้เพื่อค้นหาว่าเปิดใช้งานตารางหรือไม่ ไวยากรณ์มีดังนี้:
hbase> is_enabled 'table name'รหัสต่อไปนี้จะตรวจสอบว่าตารางชื่อ empเปิดใช้งาน. หากเปิดใช้งานจะส่งคืนค่าจริงและหากไม่เป็นเช่นนั้นก็จะส่งคืนเป็นเท็จ
hbase(main):031:0> is_enabled 'emp'
true
0 row(s) in 0.0440 secondsเปิดใช้งานตารางโดยใช้ Java API
ในการตรวจสอบว่าตารางถูกเปิดใช้งานหรือไม่ isTableEnabled()ใช้วิธีการ; และเพื่อเปิดใช้งานตารางenableTable()ใช้วิธีการ วิธีการเหล่านี้เป็นของHBaseAdminชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อเปิดใช้งานตาราง
ขั้นตอนที่ 1
ทันที HBaseAdmin คลาสดังที่แสดงด้านล่าง
// Creating configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
ตรวจสอบว่าตารางเปิดใช้งานโดยใช้ isTableEnabled() วิธีการดังแสดงด้านล่าง
Boolean bool = admin.isTableEnabled("emp");ขั้นตอนที่ 3
หากตารางไม่ได้ปิดใช้งานให้ปิดการใช้งานดังที่แสดงด้านล่าง
if(!bool){
admin.enableTable("emp");
System.out.println("Table enabled");
}ให้ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์เพื่อตรวจสอบว่าตารางเปิดใช้งานอยู่หรือไม่และหากไม่ใช่ให้เปิดใช้งานอย่างไร
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class EnableTable{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying whether the table is disabled
Boolean bool = admin.isTableEnabled("emp");
System.out.println(bool);
// Enabling the table using HBaseAdmin object
if(!bool){
admin.enableTable("emp");
System.out.println("Table Enabled");
}
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac EnableTable.java
$java EnableTableสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
false
Table Enabledอธิบาย
คำสั่งนี้ส่งคืนคำอธิบายของตาราง ไวยากรณ์มีดังนี้:
hbase> describe 'table name'ด้านล่างเป็นผลลัพธ์ของคำสั่งอธิบายบนไฟล์ emp ตาราง.
hbase(main):006:0> describe 'emp'
DESCRIPTION
ENABLED
'emp', {NAME ⇒ 'READONLY', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER
⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒ 'NONE', VERSIONS ⇒
'1', TTL true
⇒ 'FOREVER', MIN_VERSIONS ⇒ '0', KEEP_DELETED_CELLS ⇒ 'false',
BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME
⇒ 'personal
data', DATA_BLOCK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW',
REPLICATION_SCOPE ⇒ '0', VERSIONS ⇒ '5', COMPRESSION ⇒ 'NONE',
MIN_VERSIONS ⇒ '0', TTL
⇒ 'FOREVER', KEEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536',
IN_MEMORY ⇒ 'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'professional
data', DATA_BLO
CK_ENCODING ⇒ 'NONE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0',
VERSIONS ⇒ '1', COMPRESSION ⇒ 'NONE', MIN_VERSIONS ⇒ '0', TTL ⇒
'FOREVER', K
EEP_DELETED_CELLS ⇒ 'false', BLOCKSIZE ⇒ '65536', IN_MEMORY ⇒
'false', BLOCKCACHE ⇒ 'true'}, {NAME ⇒ 'table_att_unset',
DATA_BLOCK_ENCODING ⇒ 'NO
NE', BLOOMFILTER ⇒ 'ROW', REPLICATION_SCOPE ⇒ '0', COMPRESSION ⇒
'NONE', VERSIONS ⇒ '1', TTL ⇒ 'FOREVER', MIN_VERSIONS ⇒ '0',
KEEP_DELETED_CELLS
⇒ 'false', BLOCKSIZE ⇒ '6เปลี่ยนแปลง
Alter เป็นคำสั่งที่ใช้ในการเปลี่ยนแปลงตารางที่มีอยู่ เมื่อใช้คำสั่งนี้คุณสามารถเปลี่ยนจำนวนเซลล์สูงสุดของตระกูลคอลัมน์ตั้งค่าและลบตัวดำเนินการขอบเขตตารางและลบตระกูลคอลัมน์ออกจากตารางได้
การเปลี่ยนจำนวนเซลล์สูงสุดของตระกูลคอลัมน์
ด้านล่างนี้คือไวยากรณ์สำหรับเปลี่ยนจำนวนเซลล์สูงสุดของตระกูลคอลัมน์
hbase> alter 't1', NAME ⇒ 'f1', VERSIONS ⇒ 5ในตัวอย่างต่อไปนี้จำนวนเซลล์สูงสุดถูกตั้งค่าเป็น 5
hbase(main):003:0> alter 'emp', NAME ⇒ 'personal data', VERSIONS ⇒ 5
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.3050 secondsตัวดำเนินการขอบเขตตาราง
เมื่อใช้การเปลี่ยนแปลงคุณสามารถตั้งค่าและลบตัวดำเนินการขอบเขตตารางเช่น MAX_FILESIZE, READONLY, MEMSTORE_FLUSHSIZE, DEFERRED_LOG_FLUSH เป็นต้น
การตั้งค่าอ่านอย่างเดียว
ด้านล่างนี้เป็นไวยากรณ์เพื่อให้ตารางอ่านอย่างเดียว
hbase>alter 't1', READONLY(option)ในตัวอย่างต่อไปนี้เราได้สร้างไฟล์ emp ตารางอ่านอย่างเดียว
hbase(main):006:0> alter 'emp', READONLY
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2140 secondsการลบตัวดำเนินการขอบเขตตาราง
เรายังสามารถลบตัวดำเนินการขอบเขตตาราง ด้านล่างนี้เป็นไวยากรณ์สำหรับลบ 'MAX_FILESIZE' จากตาราง emp
hbase> alter 't1', METHOD ⇒ 'table_att_unset', NAME ⇒ 'MAX_FILESIZE'การลบตระกูลคอลัมน์
คุณยังสามารถลบตระกูลคอลัมน์ได้ด้วยการใช้การเปลี่ยนแปลง ให้ด้านล่างนี้คือไวยากรณ์สำหรับลบตระกูลคอลัมน์โดยใช้การเปลี่ยนแปลง
hbase> alter ‘ table name ’, ‘delete’ ⇒ ‘ column family ’ให้ด้านล่างเป็นตัวอย่างในการลบตระกูลคอลัมน์จากตาราง 'emp'
สมมติว่ามีตารางชื่อพนักงานใน HBase ประกอบด้วยข้อมูลต่อไปนี้:
hbase(main):006:0> scan 'employee'
ROW COLUMN+CELL
row1 column = personal:city, timestamp = 1418193767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
row1 column = professional:designation, timestamp = 1418193767, value = manager
row1 column = professional:salary, timestamp = 1418193806767, value = 50000
1 row(s) in 0.0160 secondsตอนนี้ให้เราลบตระกูลคอลัมน์ที่ชื่อ professional โดยใช้คำสั่ง alter
hbase(main):007:0> alter 'employee','delete'⇒'professional'
Updating all regions with the new schema...
0/1 regions updated.
1/1 regions updated.
Done.
0 row(s) in 2.2380 secondsตอนนี้ตรวจสอบข้อมูลในตารางหลังจากการเปลี่ยนแปลง สังเกตคอลัมน์ตระกูล 'มืออาชีพ' ไม่มีอีกแล้วเนื่องจากเราลบไปแล้ว
hbase(main):003:0> scan 'employee'
ROW COLUMN + CELL
row1 column = personal:city, timestamp = 14181936767, value = hyderabad
row1 column = personal:name, timestamp = 1418193806767, value = raju
1 row(s) in 0.0830 secondsการเพิ่มตระกูลคอลัมน์โดยใช้ Java API
คุณสามารถเพิ่มตระกูลคอลัมน์ลงในตารางโดยใช้วิธีการ addColumn() ของ HBAseAdminชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อเพิ่มตระกูลคอลัมน์ลงในตาราง
ขั้นตอนที่ 1
เริ่มต้นไฟล์ HBaseAdmin ชั้นเรียน.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
addColumn() วิธีการต้องใช้ชื่อตารางและวัตถุของ HColumnDescriptorชั้นเรียน. ดังนั้นจึงสร้างHColumnDescriptorชั้นเรียน. ตัวสร้างของHColumnDescriptorในทางกลับกันต้องใช้ชื่อสกุลของคอลัมน์ที่จะเพิ่ม ที่นี่เรากำลังเพิ่มกลุ่มคอลัมน์ชื่อ“ contactDetails” ลงในตาราง“ พนักงาน” ที่มีอยู่
// Instantiating columnDescriptor object
HColumnDescriptor columnDescriptor = new
HColumnDescriptor("contactDetails");ขั้นตอนที่ 3
เพิ่มตระกูลคอลัมน์โดยใช้ addColumnวิธี. ส่งชื่อตารางและHColumnDescriptor คลาสอ็อบเจ็กต์เป็นพารามิเตอร์สำหรับวิธีนี้
// Adding column family
admin.addColumn("employee", new HColumnDescriptor("columnDescriptor"));ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการเพิ่มตระกูลคอลัมน์ลงในตารางที่มีอยู่
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class AddColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Instantiating columnDescriptor class
HColumnDescriptor columnDescriptor = new HColumnDescriptor("contactDetails");
// Adding column family
admin.addColumn("employee", columnDescriptor);
System.out.println("coloumn added");
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac AddColumn.java
$java AddColumnการคอมไพล์ข้างต้นจะใช้ได้ก็ต่อเมื่อคุณตั้งค่า classpath ไว้ใน“ .bashrc”. หากคุณยังไม่ได้ทำให้ทำตามขั้นตอนด้านล่างเพื่อรวบรวมไฟล์. java ของคุณ
//if "/home/home/hadoop/hbase " is your Hbase home folder then.
$javac -cp /home/hadoop/hbase/lib/*: Demo.javaหากทุกอย่างเป็นไปด้วยดีมันจะให้ผลลัพธ์ดังต่อไปนี้:
column addedการลบตระกูลคอลัมน์โดยใช้ Java API
คุณสามารถลบตระกูลคอลัมน์ออกจากตารางโดยใช้วิธีการ deleteColumn() ของ HBAseAdminชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อเพิ่มตระกูลคอลัมน์ลงในตาราง
ขั้นตอนที่ 1
เริ่มต้นไฟล์ HBaseAdmin ชั้นเรียน.
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
เพิ่มตระกูลคอลัมน์โดยใช้ deleteColumn()วิธี. ส่งชื่อตารางและชื่อตระกูลคอลัมน์เป็นพารามิเตอร์ไปยังวิธีนี้
// Deleting column family
admin.deleteColumn("employee", "contactDetails");ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการลบตระกูลคอลัมน์จากตารางที่มีอยู่
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteColoumn{
public static void main(String args[]) throws MasterNotRunningException, IOException{
// Instantiating configuration class.
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class.
HBaseAdmin admin = new HBaseAdmin(conf);
// Deleting a column family
admin.deleteColumn("employee","contactDetails");
System.out.println("coloumn deleted");
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac DeleteColumn.java $java DeleteColumnสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
column deletedการมีอยู่ของตารางโดยใช้ HBase Shell
คุณสามารถตรวจสอบการมีอยู่ของตารางโดยใช้ไฟล์ existsคำสั่ง ตัวอย่างต่อไปนี้แสดงวิธีใช้คำสั่งนี้
hbase(main):024:0> exists 'emp'
Table emp does exist
0 row(s) in 0.0750 seconds
==================================================================
hbase(main):015:0> exists 'student'
Table student does not exist
0 row(s) in 0.0480 secondsการตรวจสอบการมีอยู่ของตารางโดยใช้ Java API
คุณสามารถตรวจสอบการมีอยู่ของตารางใน HBase โดยใช้ไฟล์ tableExists() วิธีการของ HBaseAdmin ชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อตรวจสอบการมีอยู่ของตารางใน HBase
ขั้นตอนที่ 1
Instantiate the HBaseAdimn class
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
ตรวจสอบการมีอยู่ของตารางโดยใช้ tableExists( ) วิธี.
ด้านล่างนี้เป็นโปรแกรม java เพื่อทดสอบการมีอยู่ของตารางใน HBase โดยใช้ java API
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class TableExists{
public static void main(String args[])throws IOException{
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Verifying the existance of the table
boolean bool = admin.tableExists("emp");
System.out.println( bool);
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac TableExists.java $java TableExistsสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
trueวางตารางโดยใช้ HBase Shell
ใช้ dropคำสั่งคุณสามารถลบตาราง ก่อนวางตารางคุณต้องปิดการใช้งาน
hbase(main):018:0> disable 'emp'
0 row(s) in 1.4580 seconds
hbase(main):019:0> drop 'emp'
0 row(s) in 0.3060 secondsตรวจสอบว่าตารางถูกลบโดยใช้คำสั่งที่มีอยู่หรือไม่
hbase(main):020:07gt; exists 'emp'
Table emp does not exist
0 row(s) in 0.0730 secondsdrop_all
คำสั่งนี้ใช้เพื่อวางตารางที่ตรงกับ "regex" ที่กำหนดในคำสั่ง ไวยากรณ์มีดังนี้:
hbase> drop_all ‘t.*’Note: ก่อนวางตารางคุณต้องปิดการใช้งาน
ตัวอย่าง
สมมติว่ามีตารางชื่อราชาราชานีราเจนดราราชเดชและราจู
hbase(main):017:0> list
TABLE
raja
rajani
rajendra
rajesh
raju
9 row(s) in 0.0270 secondsตารางทั้งหมดนี้เริ่มต้นด้วยตัวอักษร raj. ก่อนอื่นให้เราปิดการใช้งานตารางเหล่านี้ทั้งหมดโดยใช้ไฟล์disable_all คำสั่งดังที่แสดงด้านล่าง
hbase(main):002:0> disable_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Disable the above 5 tables (y/n)?
y
5 tables successfully disabledตอนนี้คุณสามารถลบทั้งหมดได้โดยใช้ไฟล์ drop_all คำสั่งตามที่ระบุด้านล่าง
hbase(main):018:0> drop_all 'raj.*'
raja
rajani
rajendra
rajesh
raju
Drop the above 5 tables (y/n)?
y
5 tables successfully droppedการลบตารางโดยใช้ Java API
คุณสามารถลบตารางโดยใช้ไฟล์ deleteTable() วิธีการใน HBaseAdminชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อลบตารางโดยใช้ java API
ขั้นตอนที่ 1
สร้างอินสแตนซ์คลาส HBaseAdmin
// creating a configuration object
Configuration conf = HBaseConfiguration.create();
// Creating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
ปิดการใช้งานตารางโดยใช้ disableTable() วิธีการของ HBaseAdmin ชั้นเรียน.
admin.disableTable("emp1");ขั้นตอนที่ 3
ตอนนี้ลบตารางโดยใช้ deleteTable() วิธีการของ HBaseAdmin ชั้นเรียน.
admin.deleteTable("emp12");ด้านล่างเป็นโปรแกรม java ที่สมบูรณ์เพื่อลบตารางใน HBase
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class DeleteTable {
public static void main(String[] args) throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// disabling table named emp
admin.disableTable("emp12");
// Deleting emp
admin.deleteTable("emp12");
System.out.println("Table deleted");
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac DeleteTable.java $java DeleteTableสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
Table deletedทางออก
คุณออกจากเชลล์โดยพิมพ์ exit คำสั่ง
hbase(main):021:0> exitกำลังหยุด HBase
ในการหยุด HBase ให้เรียกดูโฮมโฟลเดอร์ HBase แล้วพิมพ์คำสั่งต่อไปนี้
./bin/stop-hbase.shการหยุด HBase โดยใช้ Java API
คุณสามารถปิด HBase โดยใช้ไฟล์ shutdown() วิธีการของ HBaseAdminชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อปิด HBase:
ขั้นตอนที่ 1
สร้างอินสแตนซ์คลาส HbaseAdmin
// Instantiating configuration object
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin object
HBaseAdmin admin = new HBaseAdmin(conf);ขั้นตอนที่ 2
ปิด HBase โดยใช้ shutdown() วิธีการของ HBaseAdmin ชั้นเรียน.
admin.shutdown();ด้านล่างคือโปรแกรมหยุด HBase
import java.io.IOException;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.HBaseAdmin;
public class ShutDownHbase{
public static void main(String args[])throws IOException {
// Instantiating configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HBaseAdmin class
HBaseAdmin admin = new HBaseAdmin(conf);
// Shutting down HBase
System.out.println("Shutting down hbase");
admin.shutdown();
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac ShutDownHbase.java $java ShutDownHbaseสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
Shutting down hbaseบทนี้อธิบาย java client API สำหรับ HBase ที่ใช้ในการดำเนินการ CRUDการดำเนินการบนตาราง HBase HBase เขียนด้วย Java และมี Java Native API ดังนั้นจึงให้การเข้าถึงแบบเป็นโปรแกรมไปยัง Data Manipulation Language (DML)
การกำหนดค่าคลาส HBase
เพิ่มไฟล์คอนฟิกูเรชัน HBase ไปยัง Configuration คลาสนี้เป็นของorg.apache.hadoop.hbase แพ็คเกจ
วิธีการและคำอธิบาย
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | static org.apache.hadoop.conf.Configuration create() วิธีนี้สร้างการกำหนดค่าด้วยทรัพยากร HBase |
คลาส HTable
HTable เป็นคลาสภายใน HBase ที่แสดงถึงตาราง HBase เป็นการนำตารางที่ใช้สื่อสารกับตาราง HBase เดียว คลาสนี้เป็นของorg.apache.hadoop.hbase.client ชั้นเรียน.
ตัวสร้าง
| ส. | ตัวสร้างและคำอธิบาย |
|---|---|
| 1 | HTable() |
| 2 | HTable(TableName tableName, ClusterConnection connection, ExecutorService pool) การใช้ตัวสร้างนี้คุณสามารถสร้างวัตถุเพื่อเข้าถึงตาราง HBase |
วิธีการและคำอธิบาย
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | void close() เผยแพร่ทรัพยากรทั้งหมดของ HTable |
| 2 | void delete(Delete delete) ลบเซลล์ / แถวที่ระบุ |
| 3 | boolean exists(Get get) เมื่อใช้วิธีนี้คุณสามารถทดสอบการมีอยู่ของคอลัมน์ในตารางตามที่ Get ระบุ |
| 4 | Result get(Get get) ดึงเซลล์บางเซลล์จากแถวที่กำหนด |
| 5 | org.apache.hadoop.conf.Configuration getConfiguration() ส่งคืนวัตถุ Configuration ที่อินสแตนซ์นี้ใช้ |
| 6 | TableName getName() ส่งคืนอินสแตนซ์ชื่อตารางของตารางนี้ |
| 7 | HTableDescriptor getTableDescriptor() ส่งกลับตัวอธิบายตารางสำหรับตารางนี้ |
| 8 | byte[] getTableName() ส่งคืนชื่อของตารางนี้ |
| 9 | void put(Put put) เมื่อใช้วิธีนี้คุณสามารถแทรกข้อมูลลงในตารางได้ |
คลาสใส่
คลาสนี้ใช้เพื่อดำเนินการใส่สำหรับแถวเดียว มันเป็นของorg.apache.hadoop.hbase.client แพ็คเกจ
ตัวสร้าง
| ส. | ตัวสร้างและคำอธิบาย |
|---|---|
| 1 | Put(byte[] row) เมื่อใช้ตัวสร้างนี้คุณสามารถสร้างการดำเนินการใส่สำหรับแถวที่ระบุ |
| 2 | Put(byte[] rowArray, int rowOffset, int rowLength) เมื่อใช้ตัวสร้างนี้คุณสามารถทำสำเนาของคีย์แถวที่ส่งผ่านเพื่อเก็บไว้ในเครื่อง |
| 3 | Put(byte[] rowArray, int rowOffset, int rowLength, long ts) เมื่อใช้ตัวสร้างนี้คุณสามารถทำสำเนาของคีย์แถวที่ส่งผ่านเพื่อเก็บไว้ในเครื่อง |
| 4 | Put(byte[] row, long ts) การใช้ตัวสร้างนี้เราสามารถสร้างการดำเนินการใส่สำหรับแถวที่ระบุโดยใช้การประทับเวลาที่กำหนด |
วิธีการ
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | Put add(byte[] family, byte[] qualifier, byte[] value) เพิ่มคอลัมน์และค่าที่ระบุให้กับการดำเนินการ Put นี้ |
| 2 | Put add(byte[] family, byte[] qualifier, long ts, byte[] value) เพิ่มคอลัมน์และค่าที่ระบุพร้อมเวลาประทับที่ระบุเป็นเวอร์ชันในการดำเนินการ Put นี้ |
| 3 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) เพิ่มคอลัมน์และค่าที่ระบุพร้อมเวลาประทับที่ระบุเป็นเวอร์ชันในการดำเนินการ Put นี้ |
| 4 | Put add(byte[] family, ByteBuffer qualifier, long ts, ByteBuffer value) เพิ่มคอลัมน์และค่าที่ระบุพร้อมเวลาประทับที่ระบุเป็นเวอร์ชันในการดำเนินการ Put นี้ |
คลาสรับ
คลาสนี้ใช้เพื่อดำเนินการ Get บนแถวเดียว คลาสนี้เป็นของorg.apache.hadoop.hbase.client แพ็คเกจ
ตัวสร้าง
| ส. | ตัวสร้างและคำอธิบาย |
|---|---|
| 1 | Get(byte[] row) เมื่อใช้ตัวสร้างนี้คุณสามารถสร้างการดำเนินการรับสำหรับแถวที่ระบุ |
| 2 | Get(Get get) |
วิธีการ
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | Get addColumn(byte[] family, byte[] qualifier) ดึงข้อมูลคอลัมน์จากตระกูลเฉพาะที่มีคุณสมบัติที่ระบุ |
| 2 | Get addFamily(byte[] family) ดึงข้อมูลคอลัมน์ทั้งหมดจากตระกูลที่ระบุ |
ลบคลาส
คลาสนี้ใช้เพื่อดำเนินการลบบนแถวเดียว ในการลบทั้งแถวให้สร้างอินสแตนซ์ของวัตถุ Delete กับแถวที่จะลบ คลาสนี้เป็นของorg.apache.hadoop.hbase.client แพ็คเกจ
ตัวสร้าง
| ส. | ตัวสร้างและคำอธิบาย |
|---|---|
| 1 | Delete(byte[] row) สร้างการดำเนินการลบสำหรับแถวที่ระบุ |
| 2 | Delete(byte[] rowArray, int rowOffset, int rowLength) สร้างการดำเนินการลบสำหรับแถวและการประทับเวลาที่ระบุ |
| 3 | Delete(byte[] rowArray, int rowOffset, int rowLength, long ts) สร้างการดำเนินการลบสำหรับแถวและการประทับเวลาที่ระบุ |
| 4 | Delete(byte[] row, long timestamp) สร้างการดำเนินการลบสำหรับแถวและการประทับเวลาที่ระบุ |
วิธีการ
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | Delete addColumn(byte[] family, byte[] qualifier) ลบเวอร์ชันล่าสุดของคอลัมน์ที่ระบุ |
| 2 | Delete addColumns(byte[] family, byte[] qualifier, long timestamp) ลบทุกเวอร์ชันของคอลัมน์ที่ระบุโดยมีการประทับเวลาน้อยกว่าหรือเท่ากับการประทับเวลาที่ระบุ |
| 3 | Delete addFamily(byte[] family) ลบทุกเวอร์ชันของคอลัมน์ทั้งหมดของตระกูลที่ระบุ |
| 4 | Delete addFamily(byte[] family, long timestamp) ลบคอลัมน์ทั้งหมดของตระกูลที่ระบุโดยมีการประทับเวลาน้อยกว่าหรือเท่ากับการประทับเวลาที่ระบุ |
ผลการเรียน
คลาสนี้ใช้เพื่อรับผลลัพธ์แถวเดียวของคิวรี Get หรือ Scan
ตัวสร้าง
| ส. | ตัวสร้าง |
|---|---|
| 1 | Result() การใช้ตัวสร้างนี้คุณสามารถสร้างผลลัพธ์ที่ว่างเปล่าโดยไม่มีเพย์โหลด KeyValue ส่งคืนค่าว่างถ้าคุณเรียกเซลล์ดิบ () |
วิธีการ
| ส. | วิธีการและคำอธิบาย |
|---|---|
| 1 | byte[] getValue(byte[] family, byte[] qualifier) วิธีนี้ใช้เพื่อรับเวอร์ชันล่าสุดของคอลัมน์ที่ระบุ |
| 2 | byte[] getRow() วิธีนี้ใช้เพื่อดึงคีย์แถวที่ตรงกับแถวที่สร้างผลลัพธ์นี้ |
การแทรกข้อมูลโดยใช้ HBase Shell
บทนี้สาธิตวิธีการสร้างข้อมูลในตาราง HBase ในการสร้างข้อมูลในตาราง HBase จะใช้คำสั่งและวิธีการต่อไปนี้:
put คำสั่ง
add() วิธีการของ Put ชั้นเรียนและ
put() วิธีการของ HTable ชั้นเรียน.
ตัวอย่างเช่นเราจะสร้างตารางต่อไปนี้ใน HBase
การใช้ putคุณสามารถแทรกแถวลงในตารางได้ ไวยากรณ์มีดังนี้:
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’การแทรกแถวแรก
ให้เราแทรกค่าแถวแรกลงในตาราง emp ดังภาพด้านล่าง
hbase(main):005:0> put 'emp','1','personal data:name','raju'
0 row(s) in 0.6600 seconds
hbase(main):006:0> put 'emp','1','personal data:city','hyderabad'
0 row(s) in 0.0410 seconds
hbase(main):007:0> put 'emp','1','professional
data:designation','manager'
0 row(s) in 0.0240 seconds
hbase(main):007:0> put 'emp','1','professional data:salary','50000'
0 row(s) in 0.0240 secondsแทรกแถวที่เหลือโดยใช้คำสั่ง put ในลักษณะเดียวกัน หากคุณแทรกทั้งตารางคุณจะได้ผลลัพธ์ต่อไปนี้
hbase(main):022:0> scan 'emp'
ROW COLUMN+CELL
1 column=personal data:city, timestamp=1417524216501, value=hyderabad
1 column=personal data:name, timestamp=1417524185058, value=ramu
1 column=professional data:designation, timestamp=1417524232601,
value=manager
1 column=professional data:salary, timestamp=1417524244109, value=50000
2 column=personal data:city, timestamp=1417524574905, value=chennai
2 column=personal data:name, timestamp=1417524556125, value=ravi
2 column=professional data:designation, timestamp=1417524592204,
value=sr:engg
2 column=professional data:salary, timestamp=1417524604221, value=30000
3 column=personal data:city, timestamp=1417524681780, value=delhi
3 column=personal data:name, timestamp=1417524672067, value=rajesh
3 column=professional data:designation, timestamp=1417524693187,
value=jr:engg
3 column=professional data:salary, timestamp=1417524702514,
value=25000การแทรกข้อมูลโดยใช้ Java API
คุณสามารถแทรกข้อมูลลงใน Hbase โดยใช้ไฟล์ add() วิธีการของ Putชั้นเรียน. คุณสามารถบันทึกโดยใช้ไฟล์put() วิธีการของ HTableชั้นเรียน. ชั้นเรียนเหล่านี้เป็นของorg.apache.hadoop.hbase.clientแพ็คเกจ ด้านล่างนี้เป็นขั้นตอนในการสร้างข้อมูลในตาราง HBase
ขั้นตอนที่ 1: สร้างอินสแตนซ์คลาสการกำหนดค่า
Configurationคลาสเพิ่มไฟล์คอนฟิกูเรชัน HBase ให้กับอ็อบเจ็กต์ คุณสามารถสร้างวัตถุการกำหนดค่าโดยใช้ไฟล์create() วิธีการของ HbaseConfiguration คลาสดังที่แสดงด้านล่าง
Configuration conf = HbaseConfiguration.create();ขั้นตอนที่ 2: สร้างคลาส HTable
คุณมีคลาสที่เรียกว่า HTableการใช้งาน Table ใน HBase คลาสนี้ใช้เพื่อสื่อสารกับตาราง HBase เดียว ในขณะที่สร้างอินสแตนซ์คลาสนี้จะยอมรับออบเจ็กต์การกำหนดค่าและชื่อตารางเป็นพารามิเตอร์ คุณสามารถสร้างอินสแตนซ์คลาส HTable ได้ดังที่แสดงด้านล่าง
HTable hTable = new HTable(conf, tableName);ขั้นตอนที่ 3: เริ่มต้น PutClass
ในการแทรกข้อมูลลงในตาราง HBase ไฟล์ add()ใช้วิธีการและรูปแบบต่างๆ วิธีนี้เป็นของPutดังนั้นจึงสร้างอินสแตนซ์คลาสใส่ คลาสนี้ต้องการชื่อแถวที่คุณต้องการแทรกข้อมูลในรูปแบบสตริง คุณสามารถสร้างอินสแตนซ์ไฟล์Put คลาสดังที่แสดงด้านล่าง
Put p = new Put(Bytes.toBytes("row1"));ขั้นตอนที่ 4: InsertData
add() วิธีการของ Putคลาสใช้เพื่อแทรกข้อมูล ต้องใช้อาร์เรย์ 3 ไบต์ที่แสดงถึงตระกูลคอลัมน์ตัวระบุคอลัมน์ (ชื่อคอลัมน์) และค่าที่จะแทรกตามลำดับ แทรกข้อมูลลงในตาราง HBase โดยใช้เมธอด add () ดังที่แสดงด้านล่าง
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));ขั้นตอนที่ 5: บันทึกข้อมูลในตาราง
หลังจากแทรกแถวที่ต้องการแล้วให้บันทึกการเปลี่ยนแปลงโดยเพิ่มอินสแตนซ์ใส่ลงในไฟล์ put() วิธีการของคลาส HTable ดังแสดงด้านล่าง
hTable.put(p);ขั้นตอนที่ 6: ปิดอินสแตนซ์ HTable
หลังจากสร้างข้อมูลในตาราง HBase แล้วให้ปิดไฟล์ HTable อินสแตนซ์โดยใช้ไฟล์ close() วิธีการดังแสดงด้านล่าง
hTable.close();ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการสร้างข้อมูลในตาราง HBase
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class InsertData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
// accepts a row name.
Put p = new Put(Bytes.toBytes("row1"));
// adding values using add() method
// accepts column family name, qualifier/row name ,value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("name"),Bytes.toBytes("raju"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("hyderabad"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("designation"),
Bytes.toBytes("manager"));
p.add(Bytes.toBytes("professional"),Bytes.toBytes("salary"),
Bytes.toBytes("50000"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data inserted");
// closing HTable
hTable.close();
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac InsertData.java $java InsertDataสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
data insertedการอัปเดตข้อมูลโดยใช้ HBase Shell
คุณสามารถอัปเดตค่าเซลล์ที่มีอยู่โดยใช้ไฟล์ putคำสั่ง ในการทำเช่นนั้นเพียงทำตามไวยากรณ์เดียวกันและระบุค่าใหม่ของคุณดังที่แสดงด้านล่าง
put ‘table name’,’row ’,'Column family:column name',’new value’ค่าที่กำหนดใหม่จะแทนที่ค่าที่มีอยู่โดยอัปเดตแถว
ตัวอย่าง
สมมติว่ามีตารางใน HBase เรียกว่า emp ด้วยข้อมูลต่อไปนี้
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418051555, value = raju
row1 column = personal:city, timestamp = 1418275907, value = Hyderabad
row1 column = professional:designation, timestamp = 14180555,value = manager
row1 column = professional:salary, timestamp = 1418035791555,value = 50000
1 row(s) in 0.0100 secondsคำสั่งต่อไปนี้จะอัปเดตค่าเมืองของพนักงานชื่อ 'Raju' เป็นเดลี
hbase(main):002:0> put 'emp','row1','personal:city','Delhi'
0 row(s) in 0.0400 secondsตารางที่อัปเดตมีลักษณะดังต่อไปนี้ซึ่งคุณสามารถสังเกตเห็นเมืองราจูได้เปลี่ยนเป็น 'เดลี'
hbase(main):003:0> scan 'emp'
ROW COLUMN + CELL
row1 column = personal:name, timestamp = 1418035791555, value = raju
row1 column = personal:city, timestamp = 1418274645907, value = Delhi
row1 column = professional:designation, timestamp = 141857555,value = manager
row1 column = professional:salary, timestamp = 1418039555, value = 50000
1 row(s) in 0.0100 secondsการอัปเดตข้อมูลโดยใช้ Java API
คุณสามารถอัปเดตข้อมูลในเซลล์ใดเซลล์หนึ่งโดยใช้ไฟล์ put()วิธี. ทำตามขั้นตอนด้านล่างเพื่ออัปเดตค่าเซลล์ที่มีอยู่ของตาราง
ขั้นตอนที่ 1: สร้างอินสแตนซ์คลาสการกำหนดค่า
Configurationคลาสเพิ่มไฟล์คอนฟิกูเรชัน HBase ให้กับอ็อบเจ็กต์ คุณสามารถสร้างวัตถุการกำหนดค่าโดยใช้ไฟล์create() วิธีการของ HbaseConfiguration คลาสดังที่แสดงด้านล่าง
Configuration conf = HbaseConfiguration.create();ขั้นตอนที่ 2: สร้างคลาส HTable
คุณมีคลาสที่เรียกว่า HTableการใช้งาน Table ใน HBase คลาสนี้ใช้เพื่อสื่อสารกับตาราง HBase เดียว ในขณะที่สร้างอินสแตนซ์คลาสนี้จะยอมรับอ็อบเจ็กต์คอนฟิกูเรชันและชื่อตารางเป็นพารามิเตอร์ คุณสามารถสร้างอินสแตนซ์คลาส HTable ได้ดังที่แสดงด้านล่าง
HTable hTable = new HTable(conf, tableName);ขั้นตอนที่ 3: สร้างคลาส Put
ในการแทรกข้อมูลลงในตาราง HBase ไฟล์ add()ใช้วิธีการและรูปแบบต่างๆ วิธีนี้เป็นของPutดังนั้นจึงสร้างตัวอย่างไฟล์ putชั้นเรียน. คลาสนี้ต้องการชื่อแถวที่คุณต้องการแทรกข้อมูลในรูปแบบสตริง คุณสามารถสร้างอินสแตนซ์ไฟล์Put คลาสดังที่แสดงด้านล่าง
Put p = new Put(Bytes.toBytes("row1"));ขั้นตอนที่ 4: อัปเดตเซลล์ที่มีอยู่
add() วิธีการของ Putคลาสใช้เพื่อแทรกข้อมูล ต้องใช้อาร์เรย์ 3 ไบต์ที่แสดงถึงตระกูลคอลัมน์คุณสมบัติคอลัมน์ (ชื่อคอลัมน์) และค่าที่จะแทรกตามลำดับ แทรกข้อมูลลงในตาราง HBase โดยใช้add() วิธีการดังแสดงด้านล่าง
p.add(Bytes.toBytes("coloumn family "), Bytes.toBytes("column
name"),Bytes.toBytes("value"));
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));ขั้นตอนที่ 5: บันทึกข้อมูลในตาราง
หลังจากแทรกแถวที่ต้องการแล้วให้บันทึกการเปลี่ยนแปลงโดยเพิ่มอินสแตนซ์ใส่ลงในไฟล์ put() วิธีการของคลาส HTable ดังแสดงด้านล่าง
hTable.put(p);ขั้นตอนที่ 6: ปิดอินสแตนซ์ HTable
หลังจากสร้างข้อมูลในตาราง HBase แล้วให้ปิดไฟล์ HTable อินสแตนซ์โดยใช้เมธอด close () ดังที่แสดงด้านล่าง
hTable.close();ด้านล่างนี้เป็นโปรแกรมที่สมบูรณ์ในการอัปเดตข้อมูลในตารางเฉพาะ
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.util.Bytes;
public class UpdateData{
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable hTable = new HTable(config, "emp");
// Instantiating Put class
//accepts a row name
Put p = new Put(Bytes.toBytes("row1"));
// Updating a cell value
p.add(Bytes.toBytes("personal"),
Bytes.toBytes("city"),Bytes.toBytes("Delih"));
// Saving the put Instance to the HTable.
hTable.put(p);
System.out.println("data Updated");
// closing HTable
hTable.close();
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac UpdateData.java $java UpdateDataสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
data Updatedการอ่านข้อมูลโดยใช้ HBase Shell
get คำสั่งและ get() วิธีการของ HTableคลาสใช้อ่านข้อมูลจากตารางใน HBase การใช้getคำสั่งคุณจะได้รับข้อมูลทีละแถว ไวยากรณ์มีดังนี้:
get ’<table name>’,’row1’ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงวิธีใช้คำสั่ง get ให้เราสแกนแถวแรกของไฟล์emp ตาราง.
hbase(main):012:0> get 'emp', '1'
COLUMN CELL
personal : city timestamp = 1417521848375, value = hyderabad
personal : name timestamp = 1417521785385, value = ramu
professional: designation timestamp = 1417521885277, value = manager
professional: salary timestamp = 1417521903862, value = 50000
4 row(s) in 0.0270 secondsการอ่านคอลัมน์เฉพาะ
ให้ด้านล่างเป็นไวยากรณ์สำหรับอ่านคอลัมน์เฉพาะโดยใช้ get วิธี.
hbase> get 'table name', ‘rowid’, {COLUMN ⇒ ‘column family:column name ’}ตัวอย่าง
ให้ด้านล่างเป็นตัวอย่างในการอ่านคอลัมน์เฉพาะในตาราง HBase
hbase(main):015:0> get 'emp', 'row1', {COLUMN ⇒ 'personal:name'}
COLUMN CELL
personal:name timestamp = 1418035791555, value = raju
1 row(s) in 0.0080 secondsการอ่านข้อมูลโดยใช้ Java API
หากต้องการอ่านข้อมูลจากตาราง HBase ให้ใช้ไฟล์ get()วิธีการของคลาส HTable วิธีนี้ต้องการอินสแตนซ์ของไฟล์Getชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อดึงข้อมูลจากตาราง HBase
ขั้นตอนที่ 1: สร้างอินสแตนซ์คลาสการกำหนดค่า
Configurationคลาสเพิ่มไฟล์คอนฟิกูเรชัน HBase ให้กับอ็อบเจ็กต์ คุณสามารถสร้างวัตถุการกำหนดค่าโดยใช้ไฟล์create() วิธีการของ HbaseConfiguration คลาสดังที่แสดงด้านล่าง
Configuration conf = HbaseConfiguration.create();ขั้นตอนที่ 2: สร้างคลาส HTable
คุณมีคลาสที่เรียกว่า HTableการใช้งาน Table ใน HBase คลาสนี้ใช้เพื่อสื่อสารกับตาราง HBase เดียว ในขณะที่สร้างอินสแตนซ์คลาสนี้จะยอมรับอ็อบเจ็กต์คอนฟิกูเรชันและชื่อตารางเป็นพารามิเตอร์ คุณสามารถสร้างอินสแตนซ์คลาส HTable ได้ดังที่แสดงด้านล่าง
HTable hTable = new HTable(conf, tableName);ขั้นตอนที่ 3: สร้างอินสแตนซ์รับคลาส
คุณสามารถดึงข้อมูลจากตาราง HBase โดยใช้ไฟล์ get() วิธีการของ HTableชั้นเรียน. วิธีนี้แยกเซลล์จากแถวที่กำหนด ต้องใช้ไฟล์Getคลาสอ็อบเจ็กต์เป็นพารามิเตอร์ สร้างตามที่แสดงด้านล่าง
Get get = new Get(toBytes("row1"));ขั้นตอนที่ 4: อ่านข้อมูล
ในขณะที่ดึงข้อมูลคุณสามารถรับแถวเดียวโดยใช้ id หรือรับชุดของแถวตามชุดรหัสแถวหรือสแกนทั้งตารางหรือชุดย่อยของแถว
คุณสามารถดึงข้อมูลตาราง HBase โดยใช้ตัวแปรวิธีการเพิ่มใน Get ชั้นเรียน.
หากต้องการรับคอลัมน์เฉพาะจากกลุ่มคอลัมน์เฉพาะให้ใช้วิธีการต่อไปนี้
get.addFamily(personal)หากต้องการรับคอลัมน์ทั้งหมดจากกลุ่มคอลัมน์เฉพาะให้ใช้วิธีการต่อไปนี้
get.addColumn(personal, name)ขั้นตอนที่ 5: รับผลลัพธ์
Get the result by passing your Get class instance to the get method of the HTable class. This method returns the Result class object, which holds the requested result. Given below is the usage of get() method.
Result result = table.get(g);Step 6: Reading Values from the Result Instance
The Result class provides the getValue() method to read the values from its instance. Use it as shown below to read the values from the Result instance.
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));Given below is the complete program to read values from an HBase table.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.util.Bytes;
public class RetriveData{
public static void main(String[] args) throws IOException, Exception{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating Get class
Get g = new Get(Bytes.toBytes("row1"));
// Reading the data
Result result = table.get(g);
// Reading values from Result class object
byte [] value = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("name"));
byte [] value1 = result.getValue(Bytes.toBytes("personal"),Bytes.toBytes("city"));
// Printing the values
String name = Bytes.toString(value);
String city = Bytes.toString(value1);
System.out.println("name: " + name + " city: " + city);
}
}Compile and execute the above program as shown below.
$javac RetriveData.java $java RetriveDataThe following should be the output:
name: Raju city: DelhiDeleting a Specific Cell in a Table
Using the delete command, you can delete a specific cell in a table. The syntax of delete command is as follows:
delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’Example
Here is an example to delete a specific cell. Here we are deleting the salary.
hbase(main):006:0> delete 'emp', '1', 'personal data:city',
1417521848375
0 row(s) in 0.0060 secondsDeleting All Cells in a Table
Using the “deleteall” command, you can delete all the cells in a row. Given below is the syntax of deleteall command.
deleteall ‘<table name>’, ‘<row>’,Example
Here is an example of “deleteall” command, where we are deleting all the cells of row1 of emp table.
hbase(main):007:0> deleteall 'emp','1'
0 row(s) in 0.0240 secondsตรวจสอบตารางโดยใช้ scanคำสั่ง ภาพรวมของตารางหลังจากลบตารางจะได้รับด้านล่าง
hbase(main):022:0> scan 'emp'
ROW COLUMN + CELL
2 column = personal data:city, timestamp = 1417524574905, value = chennai
2 column = personal data:name, timestamp = 1417524556125, value = ravi
2 column = professional data:designation, timestamp = 1417524204, value = sr:engg
2 column = professional data:salary, timestamp = 1417524604221, value = 30000
3 column = personal data:city, timestamp = 1417524681780, value = delhi
3 column = personal data:name, timestamp = 1417524672067, value = rajesh
3 column = professional data:designation, timestamp = 1417523187, value = jr:engg
3 column = professional data:salary, timestamp = 1417524702514, value = 25000การลบข้อมูลโดยใช้ Java API
คุณสามารถลบข้อมูลจากตาราง HBase โดยใช้ไฟล์ delete() วิธีการของ HTableชั้นเรียน. ทำตามขั้นตอนด้านล่างเพื่อลบข้อมูลออกจากตาราง
ขั้นตอนที่ 1: สร้างอินสแตนซ์คลาสการกำหนดค่า
Configurationคลาสเพิ่มไฟล์คอนฟิกูเรชัน HBase ให้กับอ็อบเจ็กต์ คุณสามารถสร้างวัตถุการกำหนดค่าโดยใช้ไฟล์create() วิธีการของ HbaseConfiguration คลาสดังที่แสดงด้านล่าง
Configuration conf = HbaseConfiguration.create();ขั้นตอนที่ 2: สร้างคลาส HTable
คุณมีคลาสที่เรียกว่า HTableการใช้งาน Table ใน HBase คลาสนี้ใช้เพื่อสื่อสารกับตาราง HBase เดียว ในขณะที่สร้างอินสแตนซ์คลาสนี้จะยอมรับอ็อบเจ็กต์คอนฟิกูเรชันและชื่อตารางเป็นพารามิเตอร์ คุณสามารถสร้างอินสแตนซ์คลาส HTable ได้ดังที่แสดงด้านล่าง
HTable hTable = new HTable(conf, tableName);ขั้นตอนที่ 3: สร้างขั้นตอนการลบคลาส
เริ่มต้นไฟล์ Deleteคลาสโดยส่ง rowid ของแถวที่จะลบในรูปแบบไบต์อาร์เรย์ คุณยังสามารถส่งการประทับเวลาและ Rowlock ไปยังตัวสร้างนี้ได้
Delete delete = new Delete(toBytes("row1"));ขั้นตอนที่ 4: เลือกข้อมูลที่จะลบ
คุณสามารถลบข้อมูลโดยใช้วิธีการลบของไฟล์ Deleteชั้นเรียน. คลาสนี้มีวิธีการลบต่างๆ เลือกคอลัมน์หรือตระกูลคอลัมน์ที่จะลบโดยใช้วิธีการเหล่านั้น ดูตัวอย่างต่อไปนี้ที่แสดงการใช้เมธอด Delete class
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));ขั้นตอนที่ 5: ลบข้อมูล
ลบข้อมูลที่เลือกโดยส่งไฟล์ delete อินสแตนซ์ไปยังไฟล์ delete() วิธีการของ HTable คลาสดังที่แสดงด้านล่าง
table.delete(delete);ขั้นตอนที่ 6: ปิด HTableInstance
หลังจากลบข้อมูลแล้วให้ปิดไฟล์ HTable ตัวอย่าง.
table.close();ด้านล่างเป็นโปรแกรมที่สมบูรณ์ในการลบข้อมูลจากตาราง HBase
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.util.Bytes;
public class DeleteData {
public static void main(String[] args) throws IOException {
// Instantiating Configuration class
Configuration conf = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(conf, "employee");
// Instantiating Delete class
Delete delete = new Delete(Bytes.toBytes("row1"));
delete.deleteColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
delete.deleteFamily(Bytes.toBytes("professional"));
// deleting the data
table.delete(delete);
// closing the HTable object
table.close();
System.out.println("data deleted.....");
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac Deletedata.java $java DeleteDataสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
data deletedการสแกนโดยใช้ HBase Shell
scanคำสั่งใช้เพื่อดูข้อมูลใน HTable ใช้คำสั่ง scan คุณจะได้รับข้อมูลตาราง ไวยากรณ์มีดังนี้:
scan ‘<table name>’ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงวิธีการอ่านข้อมูลจากตารางโดยใช้คำสั่ง scan ที่นี่เรากำลังอ่านไฟล์emp ตาราง.
hbase(main):010:0> scan 'emp'
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417521848375, value = hyderabad
1 column = personal data:name, timestamp = 1417521785385, value = ramu
1 column = professional data:designation, timestamp = 1417585277,value = manager
1 column = professional data:salary, timestamp = 1417521903862, value = 50000
1 row(s) in 0.0370 secondsการสแกนโดยใช้ Java API
โปรแกรมที่สมบูรณ์ในการสแกนข้อมูลตารางทั้งหมดโดยใช้ java API มีดังนี้
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
public class ScanTable{
public static void main(String args[]) throws IOException{
// Instantiating Configuration class
Configuration config = HBaseConfiguration.create();
// Instantiating HTable class
HTable table = new HTable(config, "emp");
// Instantiating the Scan class
Scan scan = new Scan();
// Scanning the required columns
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("name"));
scan.addColumn(Bytes.toBytes("personal"), Bytes.toBytes("city"));
// Getting the scan result
ResultScanner scanner = table.getScanner(scan);
// Reading values from scan result
for (Result result = scanner.next(); result != null; result = Scanner.next())
System.out.println("Found row : " + result);
//closing the scanner
scanner.close();
}
}คอมไพล์และรันโปรแกรมข้างต้นตามที่แสดงด้านล่าง
$javac ScanTable.java $java ScanTableสิ่งต่อไปนี้ควรเป็นผลลัพธ์:
Found row :
keyvalues={row1/personal:city/1418275612888/Put/vlen=5/mvcc=0,
row1/personal:name/1418035791555/Put/vlen=4/mvcc=0}นับ
คุณสามารถนับจำนวนแถวของตารางโดยใช้ countคำสั่ง ไวยากรณ์มีดังนี้:
count ‘<table name>’หลังจากลบแถวแรกตาราง emp จะมีสองแถว ตรวจสอบตามที่แสดงด้านล่าง
hbase(main):023:0> count 'emp'
2 row(s) in 0.090 seconds
⇒ 2ตัด
คำสั่งนี้ปิดใช้งานการดร็อปและสร้างตารางใหม่ ไวยากรณ์ของtruncate มีดังนี้:
hbase> truncate 'table name'ตัวอย่าง
ด้านล่างเป็นตัวอย่างของคำสั่งตัดทอน ที่นี่เราได้ตัดทอนไฟล์emp ตาราง.
hbase(main):011:0> truncate 'emp'
Truncating 'one' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.5950 secondsหลังจากตัดตารางให้ใช้คำสั่ง scan เพื่อตรวจสอบ คุณจะได้ตารางที่มีแถวศูนย์
hbase(main):017:0> scan ‘emp’
ROW COLUMN + CELL
0 row(s) in 0.3110 secondsเราสามารถให้สิทธิ์และเพิกถอนสิทธิ์แก่ผู้ใช้ใน HBase คำสั่งเพื่อความปลอดภัยมีสามคำสั่ง: ให้สิทธิ์เพิกถอนและ user_permission
ให้
grantคำสั่งให้สิทธิ์เฉพาะเช่นอ่านเขียนดำเนินการและผู้ดูแลระบบบนตารางแก่ผู้ใช้บางราย ไวยากรณ์ของคำสั่ง Grant มีดังนี้:
hbase> grant <user> <permissions> [<table> [<column family> [<column; qualifier>]]เราสามารถให้สิทธิ์เป็นศูนย์หรือมากกว่าแก่ผู้ใช้จากชุดของ RWXCA โดยที่
- R - แสดงถึงสิทธิ์ในการอ่าน
- W - แสดงถึงสิทธิ์ในการเขียน
- X - แสดงถึงสิทธิ์ในการดำเนินการ
- C - แสดงถึงสิทธิ์ในการสร้าง
- A - แสดงถึงสิทธิ์ของผู้ดูแลระบบ
ด้านล่างนี้เป็นตัวอย่างที่ให้สิทธิ์ทั้งหมดแก่ผู้ใช้ชื่อ 'Tutorialspoint'
hbase(main):018:0> grant 'Tutorialspoint', 'RWXCA'ถอน
revokeคำสั่งใช้เพื่อเพิกถอนสิทธิ์การเข้าถึงตารางของผู้ใช้ ไวยากรณ์มีดังนี้:
hbase> revoke <user>รหัสต่อไปนี้จะเพิกถอนสิทธิ์ทั้งหมดจากผู้ใช้ชื่อ 'Tutorialspoint'
hbase(main):006:0> revoke 'Tutorialspoint'user_permission
คำสั่งนี้ใช้เพื่อแสดงรายการสิทธิ์ทั้งหมดสำหรับตารางเฉพาะ ไวยากรณ์ของuser_permission มีดังนี้:
hbase>user_permission ‘tablename’รหัสต่อไปนี้แสดงรายการสิทธิ์ผู้ใช้ทั้งหมดของตาราง 'emp'
hbase(main):013:0> user_permission 'emp'