อิมพาลา - สถาปัตยกรรม
Impala เป็นเอ็นจิ้นการดำเนินการสืบค้น MPP (Massive Parallel Processing) ที่ทำงานบนระบบต่างๆในคลัสเตอร์ Hadoop อิมพาลาแตกต่างจากระบบจัดเก็บข้อมูลแบบดั้งเดิมอิมพาลาถูกแยกออกจากระบบจัดเก็บข้อมูล มันมีองค์ประกอบหลักสามส่วน ได้แก่ Impala daemon (Impalad) , Impala Statestore และ Impala metadata หรือ metastore
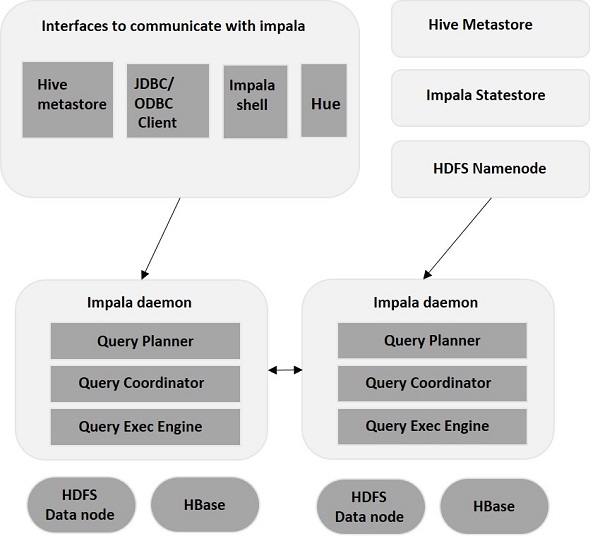
ภูตอิมพาลา ( Impalad )
Impala daemon (หรือที่เรียกว่า impalad) ทำงานบนแต่ละโหนดที่ติดตั้ง Impala ยอมรับการสืบค้นจากอินเทอร์เฟซต่างๆเช่นอิมพาลาเชลล์เว้เบราว์เซอร์ ฯลฯ ... และประมวลผล
เมื่อใดก็ตามที่ส่งแบบสอบถามไปยัง impalad บนโหนดใดโหนดหนึ่งโหนดนั้นจะทำหน้าที่เป็น "coordinator node” สำหรับข้อความค้นหานั้น Impaladให้บริการหลายคิวรีที่รันบนโหนดอื่นเช่นกัน หลังจากยอมรับการสืบค้นแล้วImpaladจะอ่านและเขียนไปยังไฟล์ข้อมูลและปรับเปลี่ยนคิวรีโดยกระจายงานไปยังโหนด Impala อื่นในคลัสเตอร์ Impala เมื่อคิวรีกำลังประมวลผลอินสแตนซ์ Impaladต่าง ๆทั้งหมดจะส่งคืนผลลัพธ์ไปยังโหนดการประสานงานกลาง
ขึ้นอยู่กับความต้องการแบบสอบถามสามารถส่งไปยังImpaladเฉพาะหรือในลักษณะโหลดบาลานซ์ไปยังImpaladอื่นในคลัสเตอร์ของคุณ
ร้านค้ารัฐอิมพาลา
Impala มีองค์ประกอบที่สำคัญอีกอย่างหนึ่งที่เรียกว่า Impala State store ซึ่งมีหน้าที่ในการตรวจสอบความสมบูรณ์ของImpaladแต่ละตัวจากนั้นจึงถ่ายทอดสุขภาพของ Impala daemon แต่ละตัวไปยังภูตตัวอื่นบ่อยๆ สิ่งนี้สามารถทำงานบนโหนดเดียวกันกับที่เซิร์ฟเวอร์ Impala หรือโหนดอื่น ๆ ภายในคลัสเตอร์กำลังทำงานอยู่
ชื่อของกระบวนการจัดเก็บภูตรัฐ Impala เป็นรัฐที่เก็บไว้ Impaladรายงานสถานะสุขภาพของตนที่ร้านภูตรัฐ Impala คือรัฐที่เก็บไว้
ในกรณีที่โหนดล้มเหลวเนื่องจากสาเหตุใดก็ตามStatestore จะอัปเดตโหนดอื่น ๆ ทั้งหมดเกี่ยวกับความล้มเหลวนี้และเมื่อการแจ้งเตือนดังกล่าวพร้อมใช้งานสำหรับอิมพาลาดอื่น ๆแล้วจะไม่มี Impala daemon ตัวอื่นที่กำหนดเคียวรีเพิ่มเติมให้กับโหนดที่ได้รับผลกระทบ
Impala Metadata & Meta Store
ข้อมูลเมตาและเมตาของ Impala เป็นอีกหนึ่งองค์ประกอบที่สำคัญ Impala ใช้ฐานข้อมูล MySQL หรือ PostgreSQL แบบดั้งเดิมในการจัดเก็บคำจำกัดความของตาราง รายละเอียดที่สำคัญเช่นข้อมูลตารางและคอลัมน์และคำจำกัดความของตารางจะถูกเก็บไว้ในฐานข้อมูลส่วนกลางที่เรียกว่า meta store
โหนด Impala แต่ละโหนดจะเก็บข้อมูลเมตาทั้งหมดไว้ในเครื่อง เมื่อต้องจัดการกับข้อมูลจำนวนมากและ / หรือหลายพาร์ติชันการรับข้อมูลเมตาเฉพาะของตารางอาจใช้เวลานานมาก ดังนั้นแคชข้อมูลเมตาที่จัดเก็บไว้ในเครื่องจะช่วยในการให้ข้อมูลดังกล่าวได้ทันที
เมื่อมีการอัปเดตข้อกำหนดตารางหรือข้อมูลตาราง Impala daemons อื่น ๆ จะต้องอัปเดตแคชข้อมูลเมตาของตนโดยการดึงข้อมูลเมตาล่าสุดก่อนที่จะออกแบบสอบถามใหม่กับตารางที่เป็นปัญหา
อินเตอร์เฟซการประมวลผลการสืบค้น
ในการประมวลผลคำค้นหา Impala มีอินเทอร์เฟซสามแบบตามรายการด้านล่าง
Impala-shell - หลังจากตั้งค่า Impala โดยใช้ Cloudera VM คุณสามารถเริ่มอิมพาลาเชลล์ได้โดยพิมพ์คำสั่ง impala-shellในตัวแก้ไข เราจะพูดคุยเพิ่มเติมเกี่ยวกับเปลือกอิมพาลาในบทต่อ ๆ ไป
Hue interface- คุณสามารถประมวลผลการสืบค้นของ Impala โดยใช้เบราว์เซอร์ Hue ในเบราว์เซอร์ Hue คุณมีตัวแก้ไขแบบสอบถาม Impala ที่คุณสามารถพิมพ์และดำเนินการสืบค้นอิมพาลาได้ ในการเข้าถึงโปรแกรมแก้ไขนี้ก่อนอื่นคุณต้องเข้าสู่ระบบเบราว์เซอร์ Hue
ODBC/JDBC drivers- เช่นเดียวกับฐานข้อมูลอื่น ๆ Impala มีไดรเวอร์ ODBC / JDBC เมื่อใช้ไดรเวอร์เหล่านี้คุณสามารถเชื่อมต่อกับอิมพาลาผ่านภาษาโปรแกรมที่รองรับไดรเวอร์เหล่านี้และสร้างแอปพลิเคชันที่ประมวลผลการสืบค้นในอิมพาลาโดยใช้ภาษาโปรแกรมเหล่านั้น
ขั้นตอนการดำเนินการสืบค้น
เมื่อใดก็ตามที่ผู้ใช้ส่งแบบสอบถามโดยใช้อินเทอร์เฟซใด ๆ ที่ให้มาสิ่งนี้จะถูกยอมรับโดย Impalads ตัวใดตัวหนึ่งในคลัสเตอร์ Impalad นี้ถือว่าเป็นผู้ประสานงานสำหรับข้อความค้นหานั้น ๆ
หลังจากได้รับคำถามแล้วผู้ประสานงานการสืบค้นจะตรวจสอบว่าแบบสอบถามนั้นเหมาะสมหรือไม่โดยใช้ Table Schemaจาก Hive meta store หลังจากนั้นจะรวบรวมข้อมูลเกี่ยวกับตำแหน่งของข้อมูลที่จำเป็นในการดำเนินการสืบค้นจากโหนดชื่อ HDFS และส่งข้อมูลนี้ไปยังอิมพาลาดอื่น ๆ เพื่อดำเนินการสืบค้น
Impala daemons อื่น ๆ ทั้งหมดอ่านบล็อกข้อมูลที่ระบุและประมวลผลแบบสอบถาม ทันทีที่ภูตทั้งหมดทำงานเสร็จผู้ประสานงานคิวรีจะรวบรวมผลลัพธ์กลับมาและส่งมอบให้กับผู้ใช้