KDB + สถาปัตยกรรม
Kdb + เป็นฐานข้อมูลที่มีประสิทธิภาพสูงและมีปริมาณมากซึ่งออกแบบมาตั้งแต่เริ่มแรกเพื่อจัดการกับข้อมูลจำนวนมหาศาล เป็น 64 บิตเต็มรูปแบบและมีการประมวลผลแบบมัลติคอร์และมัลติเธรดในตัว สถาปัตยกรรมเดียวกันนี้ใช้สำหรับข้อมูลเรียลไทม์และข้อมูลในอดีต ฐานข้อมูลประกอบด้วยภาษาแบบสอบถามที่มีประสิทธิภาพของตัวเองq, ดังนั้นการวิเคราะห์จึงสามารถรันบนข้อมูลได้โดยตรง
kdb+tick เป็นสถาปัตยกรรมที่ช่วยให้สามารถจับประมวลผลและสืบค้นข้อมูลแบบเรียลไทม์และในอดีต
Kdb + / ติ๊กสถาปัตยกรรม
ภาพประกอบต่อไปนี้แสดงโครงร่างทั่วไปของสถาปัตยกรรม Kdb + / tick ทั่วไปตามด้วยคำอธิบายสั้น ๆ เกี่ยวกับส่วนประกอบต่างๆและการไหลผ่านของข้อมูล
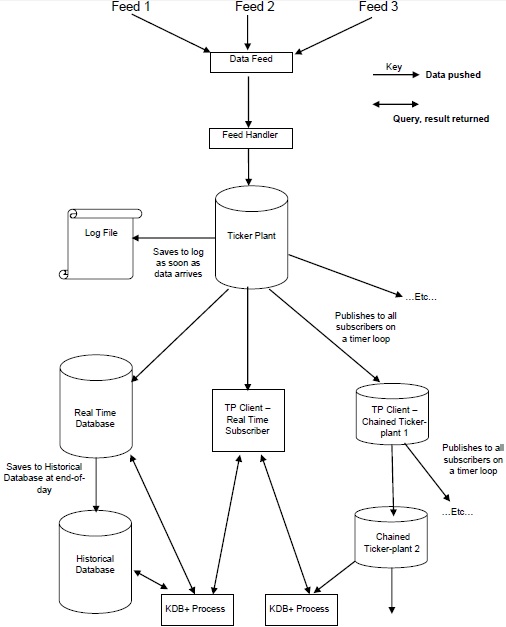
Data Feeds เป็นข้อมูลอนุกรมเวลาที่ส่วนใหญ่ให้บริการโดยผู้ให้บริการฟีดข้อมูลเช่นรอยเตอร์บลูมเบิร์กหรือโดยตรงจากการแลกเปลี่ยน
ในการรับข้อมูลที่เกี่ยวข้องข้อมูลจากฟีดข้อมูลจะถูกแยกวิเคราะห์โดยไฟล์ feed handler.
เมื่อข้อมูลถูกแยกวิเคราะห์โดยตัวจัดการฟีดข้อมูลจะไปที่ไฟล์ ticker-plant.
ในการกู้คืนข้อมูลจากความล้มเหลวใด ๆ ทิกเกอร์ - แพลนท์จะอัปเดต / จัดเก็บข้อมูลใหม่ลงในล็อกไฟล์จากนั้นอัปเดตตารางของตนเอง
หลังจากอัปเดตตารางภายในและไฟล์บันทึกข้อมูลลูปตรงเวลาจะถูกส่ง / เผยแพร่ไปยังฐานข้อมูลแบบเรียลไทม์อย่างต่อเนื่องและสมาชิกที่ถูกล่ามโซ่ทั้งหมดที่ร้องขอข้อมูล
เมื่อสิ้นสุดวันทำการไฟล์บันทึกจะถูกลบไฟล์ใหม่ที่สร้างขึ้นและฐานข้อมูลแบบเรียลไทม์จะถูกบันทึกลงในฐานข้อมูลประวัติ เมื่อข้อมูลทั้งหมดถูกบันทึกลงในฐานข้อมูลประวัติฐานข้อมูลแบบเรียลไทม์จะล้างตาราง
ส่วนประกอบของ Kdb + Tick Architecture
ฟีดข้อมูล
ฟีดข้อมูลอาจเป็นข้อมูลตลาดหรือข้อมูลอนุกรมเวลาอื่น ๆ พิจารณาฟีดข้อมูลเป็นอินพุตดิบของตัวจัดการฟีด ฟีดได้โดยตรงจากการแลกเปลี่ยน (ข้อมูลสตรีมสด) จากผู้ให้บริการข่าว / ข้อมูลเช่น Thomson-Reuters, Bloomberg หรือหน่วยงานภายนอกอื่น ๆ
ตัวจัดการฟีด
ตัวจัดการฟีดจะแปลงสตรีมข้อมูลให้อยู่ในรูปแบบที่เหมาะสมสำหรับการเขียนลงใน kdb + เชื่อมต่อกับฟีดข้อมูลและดึงและแปลงข้อมูลจากรูปแบบเฉพาะฟีดเป็นข้อความ Kdb + ซึ่งเผยแพร่ไปยังกระบวนการทิกเกอร์ - แพลนท์ โดยทั่วไปจะใช้ตัวจัดการฟีดเพื่อดำเนินการดังต่อไปนี้ -
- เก็บข้อมูลตามชุดของกฎ
- แปล (/ enrich) ข้อมูลนั้นจากรูปแบบหนึ่งไปยังอีกรูปแบบหนึ่ง
- จับค่าล่าสุด
โรงงานทิกเกอร์
Ticker Plant เป็นส่วนประกอบที่สำคัญที่สุดของสถาปัตยกรรม KDB + เป็นโรงงานสัญลักษณ์ที่มีการเชื่อมต่อฐานข้อมูลแบบเรียลไทม์หรือสมาชิกโดยตรง (ไคลเอนต์) เพื่อเข้าถึงข้อมูลทางการเงิน มันทำงานในpublish and subscribeกลไก. เมื่อคุณได้รับการสมัครสมาชิก (ใบอนุญาต) จะมีการกำหนดเครื่องหมายติ๊ก (เป็นประจำ) สิ่งพิมพ์จากผู้จัดพิมพ์ (โรงงานสัญลักษณ์) ดำเนินการดังต่อไปนี้ -
รับข้อมูลจากตัวจัดการฟีด
ทันทีหลังจากโรงงานทิกเกอร์ได้รับข้อมูลจะจัดเก็บสำเนาเป็นไฟล์บันทึกและอัปเดตเมื่อโรงงานสัญลักษณ์ได้รับการอัปเดตดังนั้นในกรณีที่เกิดความล้มเหลวเราไม่ควรมีข้อมูลสูญหาย
ลูกค้า (ผู้สมัครสมาชิกแบบเรียลไทม์) สามารถสมัครสมาชิกกับโรงงานที่เป็นสัญลักษณ์ได้โดยตรง
ในตอนท้ายของแต่ละวันทำการกล่าวคือเมื่อฐานข้อมูลเรียลไทม์ได้รับข้อความสุดท้ายจะจัดเก็บข้อมูลทั้งหมดของวันนี้ไว้ในฐานข้อมูลประวัติและส่งข้อมูลเดียวกันนี้ไปยังสมาชิกทั้งหมดที่สมัครรับข้อมูลวันนี้ จากนั้นจะรีเซ็ตตารางทั้งหมด นอกจากนี้ไฟล์บันทึกจะถูกลบเมื่อข้อมูลถูกเก็บไว้ในฐานข้อมูลประวัติหรือสมาชิกที่เชื่อมโยงโดยตรงกับฐานข้อมูลเรียลไทม์ (rtdb)
ด้วยเหตุนี้จึงทำให้ฐานข้อมูลแบบเรียลไทม์และฐานข้อมูลในอดีตสามารถทำงานได้ตลอด 24 ชั่วโมงทุกวัน
เนื่องจาก Ticker-plant เป็นแอปพลิเคชัน Kdb + จึงสามารถสอบถามตารางได้โดยใช้ qเช่นเดียวกับฐานข้อมูล Kdb + อื่น ๆ ลูกค้าที่เป็น บริษัท ขายตั๋วทั้งหมดควรเข้าถึงฐานข้อมูลในฐานะสมาชิกเท่านั้น
ฐานข้อมูลแบบเรียลไทม์
ฐานข้อมูลแบบเรียลไทม์ (rdb) เก็บข้อมูลของวันนี้ เชื่อมต่อโดยตรงกับโรงงานผลิตสัญลักษณ์ โดยปกติแล้วจะถูกเก็บไว้ในหน่วยความจำในช่วงเวลาทำการของตลาด (หนึ่งวัน) และเขียนลงในฐานข้อมูลประวัติ (hdb) ในตอนท้ายของวัน เนื่องจากข้อมูล (ข้อมูล rdb) ถูกเก็บไว้ในหน่วยความจำการประมวลผลจึงรวดเร็วมาก
เนื่องจาก kdb + แนะนำให้มีขนาด RAM ที่มากกว่าขนาดข้อมูลที่คาดไว้สี่เท่าต่อวันแบบสอบถามที่ทำงานบน rdb จึงเร็วมากและให้ประสิทธิภาพที่เหนือกว่า เนื่องจากฐานข้อมูลแบบเรียลไทม์มีเฉพาะข้อมูลของวันนี้จึงไม่จำเป็นต้องใช้คอลัมน์วันที่ (พารามิเตอร์)
ตัวอย่างเช่นเราสามารถมีแบบสอบถาม rdb เช่น
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100ฐานข้อมูลประวัติศาสตร์
หากเราต้องคำนวณค่าประมาณของ บริษัท เราจำเป็นต้องมีข้อมูลประวัติของ บริษัท ฐานข้อมูลย้อนหลัง (hdb) เก็บข้อมูลธุรกรรมที่ทำในอดีต บันทึกของแต่ละวันใหม่จะถูกเพิ่มลงใน hdb ในตอนท้ายของวัน ตารางขนาดใหญ่ใน hdb จะถูกจัดเก็บแบบแยกส่วน (แต่ละคอลัมน์จะถูกเก็บไว้ในไฟล์ของตัวเอง) หรือจะถูกจัดเก็บแบ่งพาร์ติชันโดยข้อมูลชั่วคราว นอกจากนี้ฐานข้อมูลขนาดใหญ่บางส่วนอาจถูกแบ่งพาร์ติชันเพิ่มเติมโดยใช้par.txt (ไฟล์).
กลยุทธ์การจัดเก็บข้อมูลเหล่านี้ (แยกส่วนแบ่งพาร์ติชัน ฯลฯ ) มีประสิทธิภาพในขณะค้นหาหรือเข้าถึงข้อมูลจากตารางขนาดใหญ่
นอกจากนี้ยังสามารถใช้ฐานข้อมูลประวัติเพื่อวัตถุประสงค์ในการรายงานภายในและภายนอกเช่นสำหรับการวิเคราะห์ ตัวอย่างเช่นสมมติว่าเราต้องการรับ บริษัท การค้าของ IBM ในวันใดวันหนึ่งจากชื่อตารางการค้า (หรือใด ๆ ) เราจำเป็นต้องเขียนแบบสอบถามดังนี้ -
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - เราจะเขียนข้อความค้นหาดังกล่าวทั้งหมดเมื่อเราได้รับภาพรวมของไฟล์ q ภาษา.