Microsoft Cognitive Toolkit - คู่มือฉบับย่อ
ในบทนี้เราจะเรียนรู้ว่า CNTK คืออะไรคุณสมบัติของมันความแตกต่างระหว่างเวอร์ชัน 1.0 และ 2.0 และไฮไลท์ที่สำคัญของเวอร์ชัน 2.7
Microsoft Cognitive Toolkit (CNTK) คืออะไร
Microsoft Cognitive Toolkit (CNTK) เดิมเรียกว่า Computational Network Toolkit เป็นชุดเครื่องมือโอเพนซอร์สเกรดเชิงพาณิชย์ที่ใช้งานง่ายฟรีที่ช่วยให้เราสามารถฝึกอัลกอริทึมการเรียนรู้เชิงลึกเพื่อเรียนรู้เช่นเดียวกับสมองของมนุษย์ ช่วยให้เราสามารถสร้างระบบการเรียนรู้เชิงลึกที่เป็นที่นิยมเช่นfeed-forward neural network time series prediction systems and Convolutional neural network (CNN) image classifiers.
เพื่อประสิทธิภาพที่ดีที่สุดฟังก์ชันของเฟรมเวิร์กจะถูกเขียนด้วย C ++ แม้ว่าเราจะสามารถเรียกใช้ฟังก์ชันโดยใช้ C ++ ได้ แต่วิธีการที่ใช้กันมากที่สุดคือการใช้โปรแกรม Python
คุณสมบัติของ CNTK
ต่อไปนี้เป็นคุณสมบัติและความสามารถบางส่วนที่นำเสนอใน Microsoft CNTK เวอร์ชันล่าสุด:
ส่วนประกอบในตัว
CNTK มีส่วนประกอบในตัวที่ได้รับการปรับแต่งอย่างดีเยี่ยมซึ่งสามารถจัดการข้อมูลที่หนาแน่นหรือกระจัดกระจายหลายมิติจาก Python, C ++ หรือ BrainScript
เราสามารถใช้ CNN, FNN, RNN, Batch Normalization และ Sequence-to-Sequence ได้ด้วยความเอาใจใส่
มีฟังก์ชันการทำงานในการเพิ่มองค์ประกอบหลักที่ผู้ใช้กำหนดใหม่บน GPU จาก Python
นอกจากนี้ยังมีการปรับแต่งไฮเปอร์พารามิเตอร์อัตโนมัติ
เราสามารถใช้การเรียนรู้แบบเสริมกำลัง Generative Adversarial Networks (GANs) ภายใต้การดูแลและการเรียนรู้ที่ไม่มีผู้ดูแล
สำหรับชุดข้อมูลขนาดใหญ่ CNTK มีโปรแกรมอ่านที่ปรับให้เหมาะสมในตัว
การใช้ทรัพยากรอย่างมีประสิทธิภาพ
CNTK ให้เราขนานกันด้วยความแม่นยำสูงบน GPU / เครื่องหลายเครื่องผ่าน SGD 1 บิต
เพื่อให้พอดีกับรุ่นที่ใหญ่ที่สุดในหน่วยความจำ GPU จะมีการแชร์หน่วยความจำและวิธีการอื่น ๆ ในตัว
แสดงเครือข่ายของเราเองได้อย่างง่ายดาย
CNTK มี API เต็มรูปแบบสำหรับการกำหนดเครือข่ายของคุณเองผู้เรียนผู้อ่านการฝึกอบรมและการประเมินผลจาก Python, C ++ และ BrainScript
เมื่อใช้ CNTK เราสามารถประเมินโมเดลด้วย Python, C ++, C # หรือ BrainScript ได้อย่างง่ายดาย
มีทั้ง API ระดับสูงและระดับต่ำ
จากข้อมูลของเราสามารถกำหนดรูปแบบการอนุมานได้โดยอัตโนมัติ
มีลูป Recurrent Neural Network (RNN) เชิงสัญลักษณ์ที่ปรับให้เหมาะสมอย่างเต็มที่
การวัดประสิทธิภาพของโมเดล
CNTK มีส่วนประกอบต่างๆเพื่อวัดประสิทธิภาพของเครือข่ายประสาทเทียมที่คุณสร้างขึ้น
สร้างข้อมูลบันทึกจากโมเดลของคุณและเครื่องมือเพิ่มประสิทธิภาพที่เกี่ยวข้องซึ่งเราสามารถใช้เพื่อตรวจสอบกระบวนการฝึกอบรม
เวอร์ชัน 1.0 เทียบกับเวอร์ชัน 2.0
ตารางต่อไปนี้เปรียบเทียบ CNTK เวอร์ชัน 1.0 และ 2.0:
| เวอร์ชัน 1.0.6 | เวอร์ชัน 2.0.2 |
|---|---|
| เปิดตัวในปี 2559 | เป็นการเขียนซ้ำอย่างมีนัยสำคัญของเวอร์ชัน 1.0 และเผยแพร่ในเดือนมิถุนายน 2017 |
| ใช้ภาษาสคริปต์ที่เป็นกรรมสิทธิ์ที่เรียกว่า BrainScript | ฟังก์ชันเฟรมเวิร์กสามารถเรียกได้โดยใช้ C ++, Python เราสามารถโหลดโมดูลของเราใน C # หรือ Java ได้อย่างง่ายดาย BrainScript ได้รับการสนับสนุนโดยเวอร์ชัน 2.0 |
| ทำงานได้ทั้งบนระบบ Windows และ Linux แต่ไม่ใช่บน Mac OS โดยตรง | นอกจากนี้ยังทำงานบนทั้ง Windows (Win 8.1, Win 10, Server 2012 R2 และใหม่กว่า) และระบบ Linux แต่ไม่ได้ทำงานบน Mac OS โดยตรง |
จุดเด่นที่สำคัญของเวอร์ชัน 2.7.2
Version 2.7เป็นเวอร์ชันหลักล่าสุดของ Microsoft Cognitive Toolkit มีการสนับสนุนอย่างเต็มที่สำหรับ ONNX 1.4.1 ต่อไปนี้เป็นไฮไลท์ที่สำคัญบางส่วนของ CNTK เวอร์ชันล่าสุดนี้
รองรับ ONNX 1.4.1 อย่างเต็มที่
รองรับ CUDA 10 สำหรับทั้งระบบ Windows และ Linux
รองรับการวนซ้ำล่วงหน้าของ Neural Networks (RNN) ล่วงหน้าในการส่งออก ONNX
สามารถส่งออกรุ่นมากกว่า 2GB ในรูปแบบ ONNX
สนับสนุน FP16 ในการดำเนินการฝึกอบรมภาษาสคริปต์ BrainScript
ที่นี่เราจะเข้าใจเกี่ยวกับการติดตั้ง CNTK บน Windows และบน Linux นอกจากนี้ในบทจะอธิบายถึงการติดตั้งแพ็คเกจ CNTK ขั้นตอนในการติดตั้ง Anaconda ไฟล์ CNTK โครงสร้างไดเร็กทอรีและองค์กรไลบรารี CNTK
ข้อกำหนดเบื้องต้น
ในการติดตั้ง CNTK เราต้องติดตั้ง Python บนคอมพิวเตอร์ของเรา คุณสามารถไปที่ลิงค์https://www.python.org/downloads/และเลือกเวอร์ชันล่าสุดสำหรับระบบปฏิบัติการของคุณเช่น Windows และ Linux / Unix สำหรับบทช่วยสอนพื้นฐานเกี่ยวกับ Python คุณสามารถอ้างอิงได้จากลิงค์https://www.tutorialspoint.com/python3/index.htm.

CNTK ได้รับการสนับสนุนสำหรับ Windows และ Linux ดังนั้นเราจะแนะนำทั้งสองอย่าง
การติดตั้งบน Windows
ในการเรียกใช้ CNTK บน Windows เราจะใช้ไฟล์ Anaconda versionของ Python เรารู้ว่าอนาคอนดาเป็นงูหลามที่แจกจ่ายต่อไป รวมถึงแพ็คเกจเพิ่มเติมเช่นScipy และScikit-learn ซึ่ง CNTK ใช้เพื่อทำการคำนวณที่เป็นประโยชน์ต่างๆ
ก่อนอื่นมาดูขั้นตอนการติดตั้ง Anaconda บนเครื่องของคุณ -
Step 1− ดาวน์โหลดไฟล์ติดตั้งจากเว็บไซต์สาธารณะก่อน https://www.anaconda.com/distribution/.
Step 2 - เมื่อคุณดาวน์โหลดไฟล์ติดตั้งแล้วให้เริ่มการติดตั้งและปฏิบัติตามคำแนะนำจากลิงค์ https://docs.anaconda.com/anaconda/install/.
Step 3- เมื่อติดตั้งแล้ว Anaconda จะติดตั้งยูทิลิตี้อื่น ๆ ด้วยซึ่งจะรวมไฟล์ปฏิบัติการของ Anaconda ทั้งหมดไว้ในตัวแปร PATH ของคอมพิวเตอร์ของคุณโดยอัตโนมัติ เราสามารถจัดการสภาพแวดล้อม Python ของเราได้จากพรอมต์นี้สามารถติดตั้งแพ็คเกจและเรียกใช้สคริปต์ Python
กำลังติดตั้งแพ็คเกจ CNTK
เมื่อติดตั้ง Anaconda เสร็จแล้วคุณสามารถใช้วิธีทั่วไปในการติดตั้งแพ็คเกจ CNTK ผ่าน pip ที่เรียกใช้งานได้โดยใช้คำสั่งต่อไปนี้ -
pip install cntkมีวิธีการอื่น ๆ อีกมากมายในการติดตั้ง Cognitive Toolkit บนเครื่องของคุณ Microsoft มีชุดเอกสารที่เป็นระเบียบซึ่งอธิบายรายละเอียดเกี่ยวกับวิธีการติดตั้งอื่น ๆ ตามลิงค์ได้เลยครับhttps://docs.microsoft.com/en-us/cognitive-toolkit/Setup-CNTK-on-your-machine.
การติดตั้งบน Linux
การติดตั้ง CNTK บน Linux นั้นแตกต่างจากการติดตั้งบน Windows เล็กน้อย ที่นี่สำหรับ Linux เราจะใช้ Anaconda เพื่อติดตั้ง CNTK แต่แทนที่จะเป็นตัวติดตั้งกราฟิกสำหรับ Anaconda เราจะใช้ตัวติดตั้งแบบเทอร์มินัลบน Linux แม้ว่าโปรแกรมติดตั้งจะทำงานร่วมกับลีนุกซ์เกือบทั้งหมด แต่เรา จำกัด คำอธิบายไว้ที่ Ubuntu
ก่อนอื่นมาดูขั้นตอนการติดตั้ง Anaconda บนเครื่องของคุณ -
ขั้นตอนในการติดตั้ง Anaconda
Step 1- ก่อนติดตั้ง Anaconda ตรวจสอบให้แน่ใจว่าระบบเป็นปัจจุบันอย่างสมบูรณ์ ในการตรวจสอบขั้นแรกให้ดำเนินการสองคำสั่งต่อไปนี้ภายในเทอร์มินัล -
sudo apt update
sudo apt upgradeStep 2 - เมื่ออัปเดตคอมพิวเตอร์แล้วให้รับ URL จากเว็บไซต์สาธารณะ https://www.anaconda.com/distribution/ สำหรับไฟล์การติดตั้ง Anaconda ล่าสุด
Step 3 - เมื่อคัดลอก URL แล้วให้เปิดหน้าต่างเทอร์มินัลและดำเนินการคำสั่งต่อไปนี้ -
wget -0 anaconda-installer.sh url SHAPE \* MERGEFORMAT
y
f
x
| }แทนที่ url ตัวยึดที่มี URL ที่คัดลอกมาจากเว็บไซต์ Anaconda
Step 4 - ถัดไปด้วยความช่วยเหลือของคำสั่งต่อไปนี้เราสามารถติดตั้ง Anaconda -
sh ./anaconda-installer.shคำสั่งดังกล่าวจะติดตั้งตามค่าเริ่มต้น Anaconda3 ภายในโฮมไดเร็กทอรีของเรา
กำลังติดตั้งแพ็คเกจ CNTK
เมื่อติดตั้ง Anaconda เสร็จแล้วคุณสามารถใช้วิธีทั่วไปในการติดตั้งแพ็คเกจ CNTK ผ่าน pip ที่เรียกใช้งานได้โดยใช้คำสั่งต่อไปนี้ -
pip install cntkการตรวจสอบไฟล์ CNTK และโครงสร้างไดเร็กทอรี
เมื่อติดตั้ง CNTK เป็นแพ็คเกจ Python แล้วเราสามารถตรวจสอบไฟล์และโครงสร้างไดเร็กทอรีได้ อยู่ที่C:\Users\

กำลังตรวจสอบการติดตั้ง CNTK
เมื่อติดตั้ง CNTK เป็นแพ็คเกจ Python แล้วคุณควรตรวจสอบว่า CNTK ได้รับการติดตั้งอย่างถูกต้อง จากเชลล์คำสั่ง Anaconda เริ่มล่าม Python โดยป้อนipython. จากนั้นนำเข้า CNTK โดยป้อนคำสั่งต่อไปนี้
import cntk as cเมื่อนำเข้าแล้วให้ตรวจสอบเวอร์ชันด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
print(c.__version__)ล่ามจะตอบกลับด้วย CNTK เวอร์ชันที่ติดตั้ง หากไม่ตอบสนองแสดงว่ามีปัญหากับการติดตั้ง
องค์กรห้องสมุด CNTK
CNTK ซึ่งเป็นแพ็คเกจ python ในทางเทคนิคถูกจัดเป็นแพ็คเกจย่อยระดับสูง 13 แพ็คเกจและแพ็คเกจย่อยที่เล็กกว่า 8 แพ็คเกจ ตารางต่อไปนี้ประกอบด้วย 10 แพ็คเกจที่ใช้บ่อยที่สุด:
| ซีเนียร์ No | ชื่อแพ็กเกจและคำอธิบาย |
|---|---|
| 1 | cntk.io ประกอบด้วยฟังก์ชันสำหรับอ่านข้อมูล ตัวอย่างเช่นnext_minibatch () |
| 2 | cntk.layers ประกอบด้วยฟังก์ชันระดับสูงสำหรับการสร้างเครือข่ายประสาทเทียม ตัวอย่างเช่น: Dense () |
| 3 | cntk.learners ประกอบด้วยฟังก์ชันสำหรับการฝึกอบรม ตัวอย่างเช่น: sgd () |
| 4 | cntk.losses ประกอบด้วยฟังก์ชันในการวัดข้อผิดพลาดในการฝึกอบรม ตัวอย่างเช่นsquared_error () |
| 5 | cntk.metrics ประกอบด้วยฟังก์ชันในการวัดข้อผิดพลาดของโมเดล ตัวอย่างเช่นclassificatoin_error |
| 6 | cntk.ops ประกอบด้วยฟังก์ชันระดับต่ำสำหรับการสร้างเครือข่ายประสาทเทียม ตัวอย่างเช่น: tanh () |
| 7 | cntk.random ประกอบด้วยฟังก์ชันในการสร้างตัวเลขสุ่ม ตัวอย่างเช่นปกติ () |
| 8 | cntk.train ประกอบด้วยฟังก์ชั่นการฝึกอบรม ตัวอย่างเช่นtrain_minibatch () |
| 9 | cntk.initializer มีตัวเริ่มต้นพารามิเตอร์โมเดล ตัวอย่างเช่นปกติ ()และเครื่องแบบ () |
| 10 | cntk.variables ประกอบด้วยโครงสร้างระดับต่ำ ตัวอย่างเช่นพารามิเตอร์ ()และตัวแปร () |
Microsoft Cognitive Toolkit มีเวอร์ชันบิวด์ที่แตกต่างกันสองเวอร์ชัน ได้แก่ CPU เท่านั้นและ GPU เท่านั้น
ซีพียูรุ่นบิวด์เท่านั้น
CNTK เวอร์ชันสร้างเฉพาะ CPU ใช้ Intel MKLML ที่ปรับให้เหมาะสมโดยที่ MKLML เป็นชุดย่อยของ MKL (Math Kernel Library) และเผยแพร่พร้อมกับ Intel MKL-DNN เป็นเวอร์ชันสิ้นสุดของ Intel MKL สำหรับ MKL-DNN
GPU เวอร์ชันบิวด์เท่านั้น
ในทางกลับกัน CNTK เวอร์ชันสร้าง GPU เท่านั้นใช้ไลบรารี NVIDIA ที่ได้รับการปรับให้เหมาะสมเช่น CUB และ cuDNN. สนับสนุนการฝึกอบรมแบบกระจายใน GPU หลายเครื่องและหลายเครื่อง สำหรับการฝึกอบรมแบบกระจายที่รวดเร็วยิ่งขึ้นใน CNTK เวอร์ชัน GPU-build ยังประกอบด้วย -
MSR พัฒนา 1 บิตเชิงปริมาณ SGD
อัลกอริธึมการฝึกแบบคู่ขนานของ Block-momentum SGD
การเปิดใช้งาน GPU ด้วย CNTK บน Windows
ในหัวข้อก่อนหน้านี้เราได้เห็นวิธีการติดตั้ง CNTK เวอร์ชันพื้นฐานเพื่อใช้กับ CPU ตอนนี้เรามาคุยกันว่าเราจะติดตั้ง CNTK เพื่อใช้กับ GPU ได้อย่างไร แต่ก่อนที่จะเจาะลึกลงไปก่อนอื่นคุณควรมีการ์ดแสดงผลที่รองรับ
ในปัจจุบัน CNTK รองรับการ์ดแสดงผล NVIDIA ที่รองรับ CUDA 3.0 เป็นอย่างน้อย เพื่อความแน่ใจคุณสามารถตรวจสอบได้ที่https://developer.nvidia.com/cuda-gpus ว่า GPU ของคุณรองรับ CUDA หรือไม่
ดังนั้นให้เราดูขั้นตอนในการเปิดใช้งาน GPU ด้วย CNTK บน Windows OS -
Step 1 - ขึ้นอยู่กับการ์ดแสดงผลที่คุณใช้อันดับแรกคุณต้องมีไดรเวอร์ GeForce หรือ Quadro ล่าสุดสำหรับการ์ดแสดงผลของคุณ
Step 2 - เมื่อคุณดาวน์โหลดไดรเวอร์แล้วคุณจะต้องติดตั้งชุดเครื่องมือ CUDA เวอร์ชัน 9.0 สำหรับ Windows จากเว็บไซต์ NVIDIA https://developer.nvidia.com/cuda-90-download-archive?target_os=Windows&target_arch=x86_64. หลังจากติดตั้งแล้วให้เรียกใช้โปรแกรมติดตั้งและปฏิบัติตามคำแนะนำ
Step 3 - ถัดไปคุณต้องติดตั้งไบนารี cuDNN จากเว็บไซต์ NVIDIA https://developer.nvidia.com/rdp/form/cudnn-download-survey. ด้วยเวอร์ชัน CUDA 9.0 cuDNN 7.4.1 จะทำงานได้ดี โดยทั่วไป cuDNN คือเลเยอร์ที่อยู่ด้านบนของ CUDA ซึ่ง CNTK ใช้
Step 4 - หลังจากดาวน์โหลดไบนารี cuDNN คุณต้องแตกไฟล์ zip ลงในโฟลเดอร์รูทของการติดตั้งชุดเครื่องมือ CUDA ของคุณ
Step 5- นี่เป็นขั้นตอนสุดท้ายที่จะเปิดใช้งานการใช้งาน GPU ภายใน CNTK ดำเนินการคำสั่งต่อไปนี้ภายในพรอมต์ Anaconda บน Windows OS -
pip install cntk-gpuการเปิดใช้งาน GPU ด้วย CNTK บน Linux
มาดูกันว่าเราจะเปิดใช้งาน GPU ด้วย CNTK บน Linux OS ได้อย่างไร -
การดาวน์โหลดชุดเครื่องมือ CUDA
ครั้งแรกที่คุณจำเป็นต้องติดตั้งเครื่องมือ CUDA จาก NVIDIA เว็บไซต์https://developer.nvidia.com/cuda-90-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1604&target_type =
เรียกใช้โปรแกรมติดตั้ง
ตอนนี้เมื่อคุณมีไบนารีบนดิสก์แล้วให้รันโปรแกรมติดตั้งโดยเปิดเทอร์มินัลและดำเนินการคำสั่งต่อไปนี้และคำแนะนำบนหน้าจอ -
sh cuda_9.0.176_384.81_linux-runแก้ไขสคริปต์โปรไฟล์ Bash
หลังจากติดตั้งชุดเครื่องมือ CUDA บนเครื่อง Linux คุณต้องแก้ไขสคริปต์โปรไฟล์ BASH ขั้นแรกให้เปิดไฟล์ $ HOME / .bashrc ในโปรแกรมแก้ไขข้อความ ในตอนท้ายของสคริปต์ให้รวมบรรทัดต่อไปนี้ -
export PATH=/usr/local/cuda-9.0/bin${PATH:+:${PATH}} export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64\ ${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
Installingการติดตั้งไลบรารี cuDNN
ในที่สุดเราต้องติดตั้งไบนารี cuDNN สามารถดาวน์โหลดได้จากเว็บไซต์ NVIDIAhttps://developer.nvidia.com/rdp/form/cudnn-download-survey. ด้วยเวอร์ชัน CUDA 9.0 cuDNN 7.4.1 จะทำงานได้ดี โดยทั่วไป cuDNN คือเลเยอร์ที่อยู่ด้านบนของ CUDA ซึ่ง CNTK ใช้
เมื่อดาวน์โหลดเวอร์ชันสำหรับ Linux แล้วให้แตกไฟล์เป็นไฟล์ /usr/local/cuda-9.0 โฟลเดอร์โดยใช้คำสั่งต่อไปนี้ -
tar xvzf -C /usr/local/cuda-9.0/ cudnn-9.0-linux-x64-v7.4.1.5.tgzเปลี่ยนเส้นทางเป็นชื่อไฟล์ตามต้องการ
ในบทนี้เราจะเรียนรู้รายละเอียดเกี่ยวกับลำดับใน CNTK และการจัดหมวดหมู่
เทนเซอร์
แนวคิดที่ CNTK ทำงานคือ tensor. โดยทั่วไปอินพุต CNTK เอาต์พุตและพารามิเตอร์จะถูกจัดเรียงเป็นtensorsซึ่งมักคิดว่าเป็นเมทริกซ์ทั่วไป ทุกเทนเซอร์มีrank -
Tensor ของอันดับ 0 เป็นสเกลาร์
Tensor ของอันดับ 1 คือเวกเตอร์
Tensor ของอันดับ 2 คือ amatrix
ในที่นี้มิติต่างๆเหล่านี้เรียกว่า axes.
แกนคงที่และแกนไดนามิก
ตามความหมายของชื่อแกนคงที่มีความยาวเท่ากันตลอดอายุของเครือข่าย ในทางกลับกันความยาวของแกนไดนามิกอาจแตกต่างกันไปในแต่ละอินสแตนซ์ ในความเป็นจริงมักไม่ทราบความยาวก่อนที่จะนำเสนอมินิแบทช์แต่ละครั้ง
แกนไดนามิกเป็นเหมือนแกนคงที่เนื่องจากยังกำหนดการจัดกลุ่มที่มีความหมายของตัวเลขที่มีอยู่ในเทนเซอร์
ตัวอย่าง
เพื่อให้ชัดเจนขึ้นเรามาดูกันว่าคลิปวิดีโอสั้น ๆ แสดงใน CNTK ได้อย่างไร สมมติว่าความละเอียดของคลิปวิดีโอคือ 640 * 480 ทั้งหมดและคลิปจะถูกถ่ายด้วยสีซึ่งโดยทั่วไปจะเข้ารหัสด้วยช่องสัญญาณสามช่อง นอกจากนี้ยังหมายความว่ามินิแบทช์ของเรามีดังต่อไปนี้ -
3 แกนคงที่ยาว 640, 480 และ 3 ตามลำดับ
แกนไดนามิกสองแกน ความยาวของวิดีโอและแกนมินิแบทช์
หมายความว่าหากมินิแบทช์มีวิดีโอ 16 รายการซึ่งแต่ละรายการมีความยาว 240 เฟรมจะแสดงเป็น 16*240*3*640*480 เทนเซอร์
การทำงานกับลำดับใน CNTK
ให้เราเข้าใจลำดับใน CNTK โดยการเรียนรู้เกี่ยวกับ Long-Short Term Memory Network ก่อน
เครือข่ายหน่วยความจำระยะยาว (LSTM)

เครือข่ายหน่วยความจำระยะสั้น (LSTMs) ได้รับการแนะนำโดย Hochreiter & Schmidhuber มันแก้ปัญหาในการรับเลเยอร์ซ้ำขั้นพื้นฐานเพื่อจดจำสิ่งต่างๆเป็นเวลานาน สถาปัตยกรรมของ LSTM แสดงไว้ด้านบนในแผนภาพ อย่างที่เราเห็นมันมีเซลล์ประสาทอินพุตเซลล์ความจำและเซลล์ประสาทเอาท์พุต เพื่อต่อสู้กับปัญหาการไล่ระดับสีที่หายไปเครือข่ายหน่วยความจำระยะยาวจะใช้เซลล์หน่วยความจำที่ชัดเจน (เก็บค่าก่อนหน้านี้) และประตูต่อไปนี้ -
Forget gate- ตามความหมายของชื่อจะบอกให้เซลล์หน่วยความจำลืมค่าก่อนหน้านี้ เซลล์หน่วยความจำจะเก็บค่าไว้จนกว่าเกตคือ 'forget gate' จะบอกให้ลืม
Input gate - ตามความหมายของชื่อมันจะเพิ่มสิ่งใหม่ ๆ ให้กับเซลล์
Output gate - ตามความหมายของชื่อประตูเอาต์พุตจะตัดสินใจว่าเมื่อใดที่จะส่งต่อเวกเตอร์จากเซลล์ไปยังสถานะที่ซ่อนอยู่ถัดไป
มันง่ายมากที่จะทำงานกับลำดับใน CNTK มาดูกันด้วยความช่วยเหลือของตัวอย่างต่อไปนี้ -
import sys
import os
from cntk import Trainer, Axis
from cntk.io import MinibatchSource, CTFDeserializer, StreamDef, StreamDefs,\
INFINITELY_REPEAT
from cntk.learners import sgd, learning_parameter_schedule_per_sample
from cntk import input_variable, cross_entropy_with_softmax, \
classification_error, sequence
from cntk.logging import ProgressPrinter
from cntk.layers import Sequential, Embedding, Recurrence, LSTM, Dense
def create_reader(path, is_training, input_dim, label_dim):
return MinibatchSource(CTFDeserializer(path, StreamDefs(
features=StreamDef(field='x', shape=input_dim, is_sparse=True),
labels=StreamDef(field='y', shape=label_dim, is_sparse=False)
)), randomize=is_training,
max_sweeps=INFINITELY_REPEAT if is_training else 1)
def LSTM_sequence_classifier_net(input, num_output_classes, embedding_dim,
LSTM_dim, cell_dim):
lstm_classifier = Sequential([Embedding(embedding_dim),
Recurrence(LSTM(LSTM_dim, cell_dim)),
sequence.last,
Dense(num_output_classes)])
return lstm_classifier(input)
def train_sequence_classifier():
input_dim = 2000
cell_dim = 25
hidden_dim = 25
embedding_dim = 50
num_output_classes = 5
features = sequence.input_variable(shape=input_dim, is_sparse=True)
label = input_variable(num_output_classes)
classifier_output = LSTM_sequence_classifier_net(
features, num_output_classes, embedding_dim, hidden_dim, cell_dim)
ce = cross_entropy_with_softmax(classifier_output, label)
pe = classification_error(classifier_output, label)
rel_path = ("../../../Tests/EndToEndTests/Text/" +
"SequenceClassification/Data/Train.ctf")
path = os.path.join(os.path.dirname(os.path.abspath(__file__)), rel_path)
reader = create_reader(path, True, input_dim, num_output_classes)
input_map = {
features: reader.streams.features,
label: reader.streams.labels
}
lr_per_sample = learning_parameter_schedule_per_sample(0.0005)
progress_printer = ProgressPrinter(0)
trainer = Trainer(classifier_output, (ce, pe),
sgd(classifier_output.parameters, lr=lr_per_sample),progress_printer)
minibatch_size = 200
for i in range(255):
mb = reader.next_minibatch(minibatch_size, input_map=input_map)
trainer.train_minibatch(mb)
evaluation_average = float(trainer.previous_minibatch_evaluation_average)
loss_average = float(trainer.previous_minibatch_loss_average)
return evaluation_average, loss_average
if __name__ == '__main__':
error, _ = train_sequence_classifier()
print(" error: %f" % error)average since average since examples
loss last metric last
------------------------------------------------------
1.61 1.61 0.886 0.886 44
1.61 1.6 0.714 0.629 133
1.6 1.59 0.56 0.448 316
1.57 1.55 0.479 0.41 682
1.53 1.5 0.464 0.449 1379
1.46 1.4 0.453 0.441 2813
1.37 1.28 0.45 0.447 5679
1.3 1.23 0.448 0.447 11365
error: 0.333333คำอธิบายโดยละเอียดของโปรแกรมข้างต้นจะกล่าวถึงในส่วนถัดไปโดยเฉพาะอย่างยิ่งเมื่อเราจะสร้าง Recurrent Neural networks
บทนี้เกี่ยวข้องกับการสร้างแบบจำลองการถดถอยโลจิสติกใน CNTK
พื้นฐานของแบบจำลอง Logistic Regression
Logistic Regression ซึ่งเป็นหนึ่งในเทคนิค ML ที่ง่ายที่สุดเป็นเทคนิคเฉพาะสำหรับการจำแนกไบนารี กล่าวอีกนัยหนึ่งคือในการสร้างแบบจำลองการคาดการณ์ในสถานการณ์ที่ค่าของตัวแปรที่จะทำนายอาจเป็นค่าเชิงหมวดหมู่หนึ่งในสองค่า หนึ่งในตัวอย่างที่ง่ายที่สุดของ Logistic Regression คือการทำนายว่าบุคคลนั้นเป็นชายหรือหญิงโดยพิจารณาจากอายุเสียงเส้นผมและอื่น ๆ
ตัวอย่าง
มาทำความเข้าใจกับแนวคิดของ Logistic Regression ทางคณิตศาสตร์ด้วยความช่วยเหลือของตัวอย่างอื่น -
สมมติว่าเราต้องการทำนายความน่าเชื่อถือของการขอสินเชื่อ 0 หมายถึงปฏิเสธและ 1 หมายถึงอนุมัติตามผู้สมัครdebt , income และ credit rating. เราเป็นตัวแทนหนี้ด้วย X1 รายได้กับ X2 และอันดับเครดิตด้วย X3
ใน Logistic Regression เรากำหนดค่าน้ำหนักซึ่งแสดงโดย wสำหรับทุกคุณลักษณะและค่าอคติเดียวแสดงโดย b.
สมมติว่า
X1 = 3.0
X2 = -2.0
X3 = 1.0และสมมติว่าเรากำหนดน้ำหนักและความลำเอียงดังนี้ -
W1 = 0.65, W2 = 1.75, W3 = 2.05 and b = 0.33ตอนนี้สำหรับการทำนายคลาสเราจำเป็นต้องใช้สูตรต่อไปนี้ -
Z = (X1*W1)+(X2*W2)+(X3+W3)+b
i.e. Z = (3.0)*(0.65) + (-2.0)*(1.75) + (1.0)*(2.05) + 0.33
= 0.83ต่อไปเราต้องคำนวณ P = 1.0/(1.0 + exp(-Z)). ในที่นี้ฟังก์ชัน exp () คือหมายเลขของออยเลอร์
P = 1.0/(1.0 + exp(-0.83)
= 0.6963ค่า P สามารถตีความได้ว่าเป็นความน่าจะเป็นที่คลาสคือ 1 ถ้า P <0.5 การทำนายคือ class = 0 else การทำนาย (P> = 0.5) คือ class = 1
ในการกำหนดค่าของน้ำหนักและอคติเราต้องได้รับชุดข้อมูลการฝึกอบรมที่มีค่าตัวทำนายการป้อนข้อมูลที่ทราบและทราบค่าป้ายกำกับชั้นเรียนที่ถูกต้อง หลังจากนั้นเราสามารถใช้อัลกอริทึมโดยทั่วไปคือ Gradient Descent เพื่อค้นหาค่าของน้ำหนักและอคติ
ตัวอย่างการใช้งานโมเดล LR
สำหรับรุ่น LR นี้เราจะใช้ชุดข้อมูลต่อไปนี้ -
1.0, 2.0, 0
3.0, 4.0, 0
5.0, 2.0, 0
6.0, 3.0, 0
8.0, 1.0, 0
9.0, 2.0, 0
1.0, 4.0, 1
2.0, 5.0, 1
4.0, 6.0, 1
6.0, 5.0, 1
7.0, 3.0, 1
8.0, 5.0, 1ในการเริ่มใช้งานโมเดล LR นี้ใน CNTK เราต้องนำเข้าแพ็คเกจต่อไปนี้ก่อน -
import numpy as np
import cntk as Cโปรแกรมมีโครงสร้างด้วยฟังก์ชัน main () ดังนี้ -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")ตอนนี้เราต้องโหลดข้อมูลการฝึกอบรมลงในหน่วยความจำดังนี้ -
data_file = ".\\dataLRmodel.txt"
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)ตอนนี้เราจะสร้างโปรแกรมการฝึกอบรมที่สร้างแบบจำลองการถดถอยโลจิสติกซึ่งเข้ากันได้กับข้อมูลการฝึกอบรม -
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = pตอนนี้เราต้องสร้าง Lerner และ trainer ดังนี้ -
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000การฝึกอบรมโมเดล LR
เมื่อเราสร้างแบบจำลอง LR แล้วต่อไปก็ถึงเวลาเริ่มกระบวนการฝึกอบรม -
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)ตอนนี้ด้วยความช่วยเหลือของรหัสต่อไปนี้เราสามารถพิมพ์น้ำหนักและอคติของโมเดล -
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
print("")
if __name__ == "__main__":
main()การฝึกโมเดล Logistic Regression - ตัวอย่างที่สมบูรณ์
import numpy as np
import cntk as C
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
print("Loading data from " + data_file + "\n")
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[0,1])
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",", skiprows=0, usecols=[2], ndmin=2)
features_dim = 2
labels_dim = 1
X = C.ops.input_variable(features_dim, np.float32)
y = C.input_variable(labels_dim, np.float32)
W = C.parameter(shape=(features_dim, 1)) # trainable cntk.Parameter
b = C.parameter(shape=(labels_dim))
z = C.times(X, W) + b
p = 1.0 / (1.0 + C.exp(-z))
model = p
ce_error = C.binary_cross_entropy(model, y) # CE a bit more principled for LR
fixed_lr = 0.010
learner = C.sgd(model.parameters, fixed_lr)
trainer = C.Trainer(model, (ce_error), [learner])
max_iterations = 4000
np.random.seed(4)
N = len(features_mat)
for i in range(0, max_iterations):
row = np.random.choice(N,1) # pick a random row from training items
trainer.train_minibatch({ X: features_mat[row], y: labels_mat[row] })
if i % 1000 == 0 and i > 0:
mcee = trainer.previous_minibatch_loss_average
print(str(i) + " Cross-entropy error on curr item = %0.4f " % mcee)
np.set_printoptions(precision=4, suppress=True)
print("Model weights: ")
print(W.value)
print("Model bias:")
print(b.value)
if __name__ == "__main__":
main()เอาต์พุต
Using CNTK version = 2.7
1000 cross entropy error on curr item = 0.1941
2000 cross entropy error on curr item = 0.1746
3000 cross entropy error on curr item = 0.0563
Model weights:
[-0.2049]
[0.9666]]
Model bias:
[-2.2846]การทำนายโดยใช้โมเดล LR ที่ได้รับการฝึกฝน
เมื่อโมเดล LR ได้รับการฝึกฝนแล้วเราสามารถใช้เพื่อการทำนายได้ดังนี้ -
ก่อนอื่นโปรแกรมการประเมินของเราจะนำเข้าแพ็คเกจ numpy และโหลดข้อมูลการฝึกอบรมลงในเมทริกซ์คุณลักษณะและเมทริกซ์ป้ายชื่อชั้นเรียนในลักษณะเดียวกับโปรแกรมการฝึกอบรมที่เราใช้ข้างต้น -
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)ต่อไปก็ถึงเวลากำหนดค่าของน้ำหนักและอคติที่กำหนดโดยโปรแกรมการฝึกของเรา -
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2ต่อไปโปรแกรมการประเมินของเราจะคำนวณความน่าจะเป็นของการถดถอยโลจิสติกส์โดยพิจารณาตามแต่ละรายการฝึกอบรมดังนี้ -
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))ตอนนี้ให้เราสาธิตวิธีการทำนาย -
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")โปรแกรมการประเมินผลการทำนายที่สมบูรณ์
import numpy as np
def main():
data_file = ".\\dataLRmodel.txt" # provide the name and the location of data file
features_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=(0,1))
labels_mat = np.loadtxt(data_file, dtype=np.float32, delimiter=",",
skiprows=0, usecols=[2], ndmin=2)
print("Setting weights and bias values \n")
weights = np.array([0.0925, 1.1722], dtype=np.float32)
bias = np.array([-4.5400], dtype=np.float32)
N = len(features_mat)
features_dim = 2
print("item pred_prob pred_label act_label result")
for i in range(0, N): # each item
x = features_mat[i]
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
pred_prob = 1.0 / (1.0 + np.exp(-z))
pred_label = 0 if pred_prob < 0.5 else 1
act_label = labels_mat[i]
pred_str = ‘correct’ if np.absolute(pred_label - act_label) < 1.0e-5 \
else ‘WRONG’
print("%2d %0.4f %0.0f %0.0f %s" % \ (i, pred_prob, pred_label, act_label, pred_str))
x = np.array([9.5, 4.5], dtype=np.float32)
print("\nPredicting class for age, education = ")
print(x)
z = 0.0
for j in range(0, features_dim):
z += x[j] * weights[j]
z += bias[0]
p = 1.0 / (1.0 + np.exp(-z))
print("Predicted p = " + str(p))
if p < 0.5: print("Predicted class = 0")
else: print("Predicted class = 1")
if __name__ == "__main__":
main()เอาต์พุต
การตั้งค่าน้ำหนักและค่าอคติ
Item pred_prob pred_label act_label result
0 0.3640 0 0 correct
1 0.7254 1 0 WRONG
2 0.2019 0 0 correct
3 0.3562 0 0 correct
4 0.0493 0 0 correct
5 0.1005 0 0 correct
6 0.7892 1 1 correct
7 0.8564 1 1 correct
8 0.9654 1 1 correct
9 0.7587 1 1 correct
10 0.3040 0 1 WRONG
11 0.7129 1 1 correct
Predicting class for age, education =
[9.5 4.5]
Predicting p = 0.526487952
Predicting class = 1บทนี้เกี่ยวข้องกับแนวคิดของ Neural Network เกี่ยวกับ CNTK
อย่างที่เราทราบกันดีว่าเซลล์ประสาทหลายชั้นถูกใช้ในการสร้างเครือข่ายประสาท แต่คำถามเกิดขึ้นใน CNTK ว่าเราจะสร้างแบบจำลองเลเยอร์ของ NN ได้อย่างไร? สามารถทำได้ด้วยความช่วยเหลือของฟังก์ชันเลเยอร์ที่กำหนดไว้ในโมดูลเลเยอร์
ฟังก์ชันเลเยอร์
จริงๆแล้วใน CNTK การทำงานกับเลเยอร์มีความรู้สึกในการเขียนโปรแกรมเชิงฟังก์ชันที่แตกต่างออกไป ฟังก์ชันเลเยอร์ดูเหมือนฟังก์ชันปกติและสร้างฟังก์ชันทางคณิตศาสตร์พร้อมชุดพารามิเตอร์ที่กำหนดไว้ล่วงหน้า มาดูกันว่าเราจะสร้างประเภทเลเยอร์พื้นฐานที่สุด Dense ได้อย่างไรด้วยความช่วยเหลือของฟังก์ชันเลเยอร์
ตัวอย่าง
ด้วยความช่วยเหลือของขั้นตอนพื้นฐานต่อไปนี้เราสามารถสร้างประเภทเลเยอร์พื้นฐานที่สุด -
Step 1 - ขั้นแรกเราต้องนำเข้าฟังก์ชันเลเยอร์หนาแน่นจากแพ็คเกจเลเยอร์ของ CNTK
from cntk.layers import DenseStep 2 - ถัดจากแพ็กเกจราก CNTK เราต้องนำเข้าฟังก์ชัน input_variable
from cntk import input_variableStep 3- ตอนนี้เราต้องสร้างตัวแปรอินพุตใหม่โดยใช้ฟังก์ชัน input_variable เราต้องระบุขนาดของมันด้วย
feature = input_variable(100)Step 4 - ในที่สุดเราจะสร้างเลเยอร์ใหม่โดยใช้ฟังก์ชัน Dense ควบคู่ไปกับการระบุจำนวนเซลล์ประสาทที่เราต้องการ
layer = Dense(40)(feature)ตอนนี้เราสามารถเรียกใช้ฟังก์ชันเลเยอร์ Dense ที่กำหนดค่าไว้เพื่อเชื่อมต่อเลเยอร์ Dense กับอินพุต
ตัวอย่างการใช้งานที่สมบูรณ์
from cntk.layers import Dense
from cntk import input_variable
feature= input_variable(100)
layer = Dense(40)(feature)การปรับแต่งเลเยอร์
ดังที่เราได้เห็น CNTK มีชุดค่าเริ่มต้นที่ดีสำหรับการสร้าง NN ขึ้นอยู่กับactivationฟังก์ชันและการตั้งค่าอื่น ๆ ที่เราเลือกพฤติกรรมและประสิทธิภาพของ NN นั้นแตกต่างกัน เป็นอีกหนึ่งอัลกอริธึมการตัดต้นกำเนิดที่มีประโยชน์มาก นั่นคือเหตุผลที่ควรทำความเข้าใจว่าเราสามารถกำหนดค่าอะไรได้บ้าง
ขั้นตอนในการกำหนดค่าเลเยอร์หนาแน่น
แต่ละเลเยอร์ใน NN มีตัวเลือกการกำหนดค่าที่ไม่ซ้ำกันและเมื่อเราพูดถึงเลเยอร์ Dense เรามีการตั้งค่าที่สำคัญต่อไปนี้เพื่อกำหนด -
shape - ตามความหมายของชื่อจะกำหนดรูปร่างผลลัพธ์ของชั้นซึ่งจะกำหนดจำนวนเซลล์ประสาทในชั้นนั้น ๆ
activation - กำหนดฟังก์ชันการเปิดใช้งานของเลเยอร์นั้นดังนั้นจึงสามารถแปลงข้อมูลอินพุตได้
init- เป็นการกำหนดฟังก์ชันการเริ่มต้นของเลเยอร์นั้น มันจะเริ่มต้นพารามิเตอร์ของเลเยอร์เมื่อเราเริ่มฝึก NN
มาดูขั้นตอนด้วยความช่วยเหลือซึ่งเราสามารถกำหนดค่าไฟล์ Dense ชั้น -
Step1 - ขั้นแรกเราต้องนำเข้าไฟล์ Dense ฟังก์ชันเลเยอร์จากแพ็คเกจเลเยอร์ของ CNTK
from cntk.layers import DenseStep2 - ถัดจากแพ็คเกจ CNTK ops เราต้องนำเข้าไฟล์ sigmoid operator. จะถูกใช้เพื่อกำหนดค่าเป็นฟังก์ชันการเปิดใช้งาน
from cntk.ops import sigmoidStep3 - ตอนนี้จากแพ็คเกจ initializer เราจำเป็นต้องนำเข้าไฟล์ glorot_uniform initializer.
from cntk.initializer import glorot_uniformStep4 - ในที่สุดเราจะสร้างเลเยอร์ใหม่โดยใช้ฟังก์ชัน Dense พร้อมกับการระบุจำนวนเซลล์ประสาทเป็นอาร์กิวเมนต์แรก นอกจากนี้ยังให้ไฟล์sigmoid ตัวดำเนินการเป็น activation ฟังก์ชันและ glorot_uniform เป็น init ฟังก์ชันสำหรับเลเยอร์
layer = Dense(50, activation = sigmoid, init = glorot_uniform)ตัวอย่างการใช้งานที่สมบูรณ์ -
from cntk.layers import Dense
from cntk.ops import sigmoid
from cntk.initializer import glorot_uniform
layer = Dense(50, activation = sigmoid, init = glorot_uniform)การปรับพารามิเตอร์ให้เหมาะสม
จนถึงตอนนี้เราได้เห็นวิธีสร้างโครงสร้างของ NN และวิธีกำหนดการตั้งค่าต่างๆ เราจะมาดูกันว่าเราจะปรับพารามิเตอร์ของ NN ให้เหมาะสมได้อย่างไร ด้วยความช่วยเหลือของการรวมกันของสององค์ประกอบคือlearners และ trainersเราสามารถเพิ่มประสิทธิภาพพารามิเตอร์ของ NN
ส่วนประกอบผู้ฝึกสอน
ส่วนประกอบแรกที่ใช้ในการปรับพารามิเตอร์ของ NN ให้เหมาะสมคือ trainerส่วนประกอบ. โดยทั่วไปจะใช้กระบวนการ backpropagation ถ้าเราพูดถึงการทำงานมันจะส่งผ่านข้อมูลผ่าน NN เพื่อรับคำทำนาย
หลังจากนั้นจะใช้ส่วนประกอบอื่นที่เรียกว่าผู้เรียนเพื่อให้ได้ค่าใหม่สำหรับพารามิเตอร์ใน NN เมื่อได้รับค่าใหม่แล้วจะใช้ค่าใหม่เหล่านี้และทำซ้ำขั้นตอนจนกว่าจะตรงตามเกณฑ์การออก
องค์ประกอบของผู้เรียน
องค์ประกอบที่สองที่ใช้เพื่อปรับพารามิเตอร์ของ NN ให้เหมาะสมคือ learner คอมโพเนนต์ซึ่งโดยพื้นฐานแล้วรับผิดชอบในการดำเนินการอัลกอริทึมการไล่ระดับสี
ผู้เรียนรวมอยู่ในห้องสมุด CNTK
ต่อไปนี้เป็นรายชื่อผู้เรียนที่น่าสนใจบางส่วนที่รวมอยู่ในห้องสมุด CNTK -
Stochastic Gradient Descent (SGD) - ผู้เรียนนี้แสดงถึงการสืบเชื้อสายการไล่ระดับสีสุ่มขั้นพื้นฐานโดยไม่มีสิ่งพิเศษใด ๆ
Momentum Stochastic Gradient Descent (MomentumSGD) - ด้วย SGD ผู้เรียนคนนี้ใช้แรงผลักดันเพื่อเอาชนะปัญหาของ maxima ในท้องถิ่น
RMSProp - ผู้เรียนคนนี้เพื่อควบคุมอัตราการสืบเชื้อสายใช้อัตราการเรียนรู้ที่ลดลง
Adam - ผู้เรียนคนนี้เพื่อลดอัตราการสืบเชื้อสายเมื่อเวลาผ่านไปใช้โมเมนตัมที่สลายตัว
Adagrad - ผู้เรียนรายนี้สำหรับคุณลักษณะที่เกิดขึ้นบ่อยและไม่บ่อยนักจะใช้อัตราการเรียนรู้ที่แตกต่างกัน
CNTK - การสร้างเครือข่ายประสาทเทียมครั้งแรก
บทนี้จะอธิบายรายละเอียดเกี่ยวกับการสร้างเครือข่ายประสาทเทียมใน CNTK
สร้างโครงสร้างเครือข่าย
เพื่อที่จะใช้แนวคิด CNTK ในการสร้าง NN แรกของเราเราจะใช้ NN เพื่อจำแนกชนิดของดอกไอริสตามคุณสมบัติทางกายภาพของความกว้างและความยาวกลีบเลี้ยงและความกว้างและความยาวของกลีบดอก ชุดข้อมูลที่เราจะใช้ชุดข้อมูลไอริสที่อธิบายคุณสมบัติทางกายภาพของดอกไอริสพันธุ์ต่างๆ -
- ความยาวกลีบเลี้ยง
- ความกว้าง Sepal
- ความยาวกลีบดอก
- ความกว้างของกลีบดอก
- Class คือ iris setosa หรือ iris versicolor หรือ iris virginica
ที่นี่เราจะสร้าง NN ปกติที่เรียกว่า NN feedforward ให้เราดูขั้นตอนการใช้งานเพื่อสร้างโครงสร้างของ NN -
Step 1 - ขั้นแรกเราจะนำเข้าส่วนประกอบที่จำเป็นเช่นประเภทเลเยอร์ของเราฟังก์ชันการเปิดใช้งานและฟังก์ชันที่อนุญาตให้เรากำหนดตัวแปรอินพุตสำหรับ NN ของเราจากไลบรารี CNTK
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, reluStep 2- หลังจากนั้นเราจะสร้างโมเดลของเราโดยใช้ฟังก์ชันลำดับ เมื่อสร้างแล้วเราจะป้อนด้วยเลเยอร์ที่เราต้องการ ที่นี่เราจะสร้างเลเยอร์ที่แตกต่างกันสองชั้นใน NN ของเรา หนึ่งเซลล์มีสี่เซลล์และอีกเซลล์หนึ่งมีเซลล์ประสาทสามเซลล์
model = Sequential([Dense(4, activation=relu), Dense(3, activation=log_sogtmax)])Step 3- ในที่สุดเพื่อรวบรวม NN เราจะผูกเครือข่ายกับตัวแปรอินพุต มีชั้นอินพุตที่มีเซลล์ประสาทสี่เซลล์และชั้นเอาต์พุตที่มีเซลล์ประสาทสามเซลล์
feature= input_variable(4)
z = model(feature)การใช้ฟังก์ชันการเปิดใช้งาน
มีฟังก์ชั่นการเปิดใช้งานมากมายให้เลือกและการเลือกฟังก์ชั่นการเปิดใช้งานที่เหมาะสมจะสร้างความแตกต่างอย่างมากว่าโมเดลการเรียนรู้เชิงลึกของเราจะทำงานได้ดีเพียงใด
ที่เลเยอร์เอาต์พุต
การเลือกไฟล์ activation ฟังก์ชันที่เลเยอร์เอาต์พุตจะขึ้นอยู่กับประเภทของปัญหาที่เรากำลังจะแก้ไขด้วยโมเดลของเรา
สำหรับปัญหาการถดถอยเราควรใช้ไฟล์ linear activation function บนเลเยอร์เอาต์พุต
สำหรับปัญหาการจัดประเภทไบนารีเราควรใช้ไฟล์ sigmoid activation function บนเลเยอร์เอาต์พุต
สำหรับปัญหาการจำแนกหลายชั้นเราควรใช้ไฟล์ softmax activation function บนเลเยอร์เอาต์พุต
ที่นี่เราจะสร้างแบบจำลองสำหรับทำนายหนึ่งในสามคลาส หมายความว่าเราจำเป็นต้องใช้softmax activation function ที่ชั้นเอาต์พุต
ที่เลเยอร์ที่ซ่อนอยู่
การเลือกไฟล์ activation ฟังก์ชันที่เลเยอร์ที่ซ่อนอยู่จำเป็นต้องมีการทดลองบางอย่างเพื่อตรวจสอบประสิทธิภาพเพื่อดูว่าฟังก์ชันการเปิดใช้งานใดทำงานได้ดี
ในปัญหาการจำแนกประเภทเราจำเป็นต้องคาดการณ์ความน่าจะเป็นที่ตัวอย่างเป็นของคลาสเฉพาะ นั่นเป็นเหตุผลที่เราต้องการไฟล์activation functionนั่นทำให้เรามีค่าความน่าจะเป็น เพื่อบรรลุเป้าหมายนี้sigmoid activation function สามารถช่วยเราได้
ปัญหาสำคัญอย่างหนึ่งที่เกี่ยวข้องกับฟังก์ชัน sigmoid คือการหายไปจากปัญหาการไล่ระดับสี เพื่อเอาชนะปัญหาดังกล่าวเราสามารถใช้ReLU activation function ซึ่งครอบคลุมค่าลบทั้งหมดเป็นศูนย์และทำงานเป็นตัวกรองแบบพาสทรูสำหรับค่าบวก
เลือกฟังก์ชั่นการสูญเสีย
เมื่อเรามีโครงสร้างสำหรับโมเดล NN ของเราแล้วเราต้องปรับให้เหมาะสม สำหรับการเพิ่มประสิทธิภาพเราจำเป็นต้องมีloss function. ไม่เหมือนactivation functionsเรามีฟังก์ชันการสูญเสียน้อยมากให้เลือก อย่างไรก็ตามการเลือกฟังก์ชันการสูญเสียจะขึ้นอยู่กับประเภทของปัญหาที่เรากำลังจะแก้ไขด้วยแบบจำลองของเรา
ตัวอย่างเช่นในปัญหาการจัดหมวดหมู่เราควรใช้ฟังก์ชันการสูญเสียที่สามารถวัดความแตกต่างระหว่างคลาสที่คาดคะเนและคลาสจริง
ฟังก์ชั่นการสูญเสีย
สำหรับปัญหาการจำแนกประเภทเราจะแก้ปัญหาด้วยโมเดล NN ของเรา categorical cross entropyฟังก์ชันการสูญเสียเป็นตัวเลือกที่ดีที่สุด ใน CNTK จะดำเนินการเป็นไฟล์cross_entropy_with_softmax ซึ่งสามารถนำเข้าจาก cntk.losses แพคเกจดังต่อไปนี้
label= input_variable(3)
loss = cross_entropy_with_softmax(z, label)เมตริก
ด้วยการมีโครงสร้างสำหรับโมเดล NN ของเราและฟังก์ชันการสูญเสียที่จะนำไปใช้เราจึงมีส่วนผสมทั้งหมดเพื่อเริ่มสร้างสูตรสำหรับการปรับโมเดลการเรียนรู้เชิงลึกให้เหมาะสมที่สุด แต่ก่อนที่จะเจาะลึกเรื่องนี้เราควรเรียนรู้เกี่ยวกับเมตริก
cntk.metricsCNTK มีชื่อแพคเกจ cntk.metricsซึ่งเราสามารถนำเข้าเมตริกที่เรากำลังจะใช้ ในขณะที่เรากำลังสร้างแบบจำลองการจำแนกประเภทเราจะใช้classification_error เมทริกที่จะสร้างตัวเลขระหว่าง 0 ถึง 1 จำนวนระหว่าง 0 ถึง 1 แสดงเปอร์เซ็นต์ของตัวอย่างที่ทำนายได้อย่างถูกต้อง -
ขั้นแรกเราต้องนำเข้าเมตริกจาก cntk.metrics แพ็คเกจ -
from cntk.metrics import classification_error
error_rate = classification_error(z, label)ฟังก์ชันข้างต้นต้องการเอาต์พุตของ NN และเลเบลที่คาดไว้เป็นอินพุต
CNTK - ฝึกอบรม Neural Network
ในที่นี้เราจะทำความเข้าใจเกี่ยวกับการฝึก Neural Network ใน CNTK
ฝึกอบรมนางแบบใน CNTK
ในส่วนก่อนหน้านี้เราได้กำหนดองค์ประกอบทั้งหมดสำหรับโมเดลการเรียนรู้เชิงลึก ตอนนี้มันเป็นเวลาที่จะฝึกมัน ดังที่เราได้กล่าวไว้ก่อนหน้านี้เราสามารถฝึกโมเดล NN ใน CNTK โดยใช้การรวมกันของlearner และ trainer.
การเลือกผู้เรียนและการตั้งค่าการฝึกอบรม
ในส่วนนี้เราจะกำหนดไฟล์ learner. CNTK ให้หลาย ๆlearnersให้เลือก สำหรับโมเดลของเราซึ่งกำหนดไว้ในส่วนก่อนหน้านี้เราจะใช้Stochastic Gradient Descent (SGD) learner.
ในการฝึกอบรมเครือข่ายประสาทให้เรากำหนดค่า learner และ trainer ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
Step 1 - ก่อนอื่นเราต้องนำเข้า sgd ฟังก์ชันจาก cntk.lerners แพ็คเกจ
from cntk.learners import sgdStep 2 - ต่อไปเราต้องนำเข้า Trainer ฟังก์ชันจาก cntk.trainแพ็คเกจ. trainer.
from cntk.train.trainer import TrainerStep 3 - ตอนนี้เราต้องสร้างไฟล์ learner. สามารถสร้างได้โดยการเรียกใช้sgd ฟังก์ชั่นพร้อมกับการระบุพารามิเตอร์ของโมเดลและค่าสำหรับอัตราการเรียนรู้
learner = sgd(z.parametrs, 0.01)Step 4 - ในที่สุดเราต้องเริ่มต้นไฟล์ trainer. จะต้องมีการจัดเตรียมเครือข่ายการรวมกันของloss และ metric พร้อมกับ learner.
trainer = Trainer(z, (loss, error_rate), [learner])อัตราการเรียนรู้ที่ควบคุมความเร็วของการปรับให้เหมาะสมควรมีค่าน้อยระหว่าง 0.1 ถึง 0.001
การเลือกผู้เรียนและการตั้งค่าการฝึกอบรม - ตัวอย่างที่สมบูรณ์
from cntk.learners import sgd
from cntk.train.trainer import Trainer
learner = sgd(z.parametrs, 0.01)
trainer = Trainer(z, (loss, error_rate), [learner])ป้อนข้อมูลลงในเทรนเนอร์
เมื่อเราเลือกและกำหนดค่าเทรนเนอร์แล้วก็ถึงเวลาโหลดชุดข้อมูล เราได้บันทึกไฟล์iris ชุดข้อมูลเป็น.CSV และเราจะใช้แพ็คเกจการโต้เถียงข้อมูลชื่อ pandas เพื่อโหลดชุดข้อมูล
ขั้นตอนในการโหลดชุดข้อมูลจากไฟล์. CSV
Step 1 - ขั้นแรกเราต้องนำเข้าไฟล์ pandas แพ็คเกจ
from import pandas as pdStep 2 - ตอนนี้เราต้องเรียกใช้ฟังก์ชันที่ชื่อ read_csv เพื่อโหลดไฟล์. csv จากดิสก์
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, index_col=False)เมื่อเราโหลดชุดข้อมูลแล้วเราจำเป็นต้องแยกออกเป็นชุดของคุณลักษณะและป้ายกำกับ
ขั้นตอนในการแยกชุดข้อมูลออกเป็นฟีเจอร์และป้ายกำกับ
Step 1- ขั้นแรกเราต้องเลือกแถวทั้งหมดและสี่คอลัมน์แรกจากชุดข้อมูล สามารถทำได้โดยใช้iloc ฟังก์ชัน
x = df_source.iloc[:, :4].valuesStep 2- ต่อไปเราต้องเลือกคอลัมน์สายพันธุ์จากชุดข้อมูลไอริส เราจะใช้คุณสมบัติค่าในการเข้าถึงพื้นฐานnumpy อาร์เรย์
x = df_source[‘species’].valuesขั้นตอนในการเข้ารหัสคอลัมน์สายพันธุ์เป็นการแสดงเวกเตอร์ที่เป็นตัวเลข
ดังที่เราได้กล่าวไปก่อนหน้านี้โมเดลของเราขึ้นอยู่กับการจำแนกประเภทซึ่งต้องใช้ค่าที่ป้อนเป็นตัวเลข ดังนั้นในที่นี้เราจำเป็นต้องเข้ารหัสคอลัมน์สปีชีส์เป็นการแสดงเวกเตอร์ที่เป็นตัวเลข มาดูขั้นตอนกันเลย -
Step 1- ขั้นแรกเราต้องสร้างนิพจน์รายการเพื่อวนซ้ำองค์ประกอบทั้งหมดในอาร์เรย์ จากนั้นทำการค้นหาในพจนานุกรม label_mapping สำหรับแต่ละค่า
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 2- จากนั้นแปลงค่าตัวเลขที่แปลงแล้วนี้เป็นเวกเตอร์ที่เข้ารหัสแบบร้อนแรง เราจะใช้one_hot ฟังก์ชันดังต่อไปนี้ -
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultStep 3 - ในที่สุดเราต้องเปลี่ยนรายการที่แปลงแล้วนี้เป็นไฟล์ numpy อาร์เรย์
y = np.array([one_hot(label_mapping[v], 3) for v in y])ขั้นตอนในการตรวจจับการติดตั้งมากเกินไป
สถานการณ์เมื่อโมเดลของคุณจำตัวอย่างได้ แต่ไม่สามารถสรุปกฎจากตัวอย่างการฝึกอบรมได้ ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้เราสามารถตรวจจับการติดตั้งมากเกินไปในแบบจำลองของเรา -
Step 1 - อันดับแรกจาก sklearn นำเข้าไฟล์ train_test_split ฟังก์ชั่นจาก model_selection โมดูล.
from sklearn.model_selection import train_test_splitStep 2 - ต่อไปเราต้องเรียกใช้ฟังก์ชัน train_test_split ด้วยคุณสมบัติ x และป้ายกำกับ y ดังนี้ -
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2,
stratify=y)เราระบุขนาดการทดสอบ 0.2 เพื่อกันไว้ 20% ของข้อมูลทั้งหมด
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}ขั้นตอนในการป้อนชุดการฝึกและการตรวจสอบความถูกต้องให้กับโมเดลของเรา
Step 1 - ในการฝึกโมเดลของเราก่อนอื่นเราจะเรียกใช้ไฟล์ train_minibatchวิธี. จากนั้นให้พจนานุกรมที่จับคู่ข้อมูลอินพุตกับตัวแปรอินพุตที่เราใช้เพื่อกำหนด NN และฟังก์ชันการสูญเสียที่เกี่ยวข้อง
trainer.train_minibatch({ features: X_train, label: y_train})Step 2 - ต่อไปโทร train_minibatch โดยใช้สิ่งต่อไปนี้สำหรับลูป -
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))ป้อนข้อมูลลงในเทรนเนอร์ - ตัวอย่างที่สมบูรณ์
from import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, index_col=False)
x = df_source.iloc[:, :4].values
x = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
y = np.array([one_hot(label_mapping[v], 3) for v in y])
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0-2, stratify=y)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
trainer.train_minibatch({ features: X_train, label: y_train})
for _epoch in range(10):
trainer.train_minbatch ({ feature: X_train, label: y_train})
print(‘Loss: {}, Acc: {}’.format(
trainer.previous_minibatch_loss_average,
trainer.previous_minibatch_evaluation_average))การวัดประสิทธิภาพของ NN
เพื่อเพิ่มประสิทธิภาพโมเดล NN ของเราเมื่อใดก็ตามที่เราส่งข้อมูลผ่านเทรนเนอร์มันจะวัดประสิทธิภาพของโมเดลผ่านเมตริกที่เรากำหนดค่าสำหรับเทรนเนอร์ การวัดประสิทธิภาพของแบบจำลอง NN ในระหว่างการฝึกอบรมอยู่บนข้อมูลการฝึกอบรม แต่ในทางกลับกันสำหรับการวิเคราะห์ประสิทธิภาพของโมเดลอย่างสมบูรณ์เราจำเป็นต้องใช้ข้อมูลการทดสอบด้วยเช่นกัน
ดังนั้นในการวัดประสิทธิภาพของโมเดลโดยใช้ข้อมูลการทดสอบเราสามารถเรียกใช้ไฟล์ test_minibatch วิธีการบน trainer ดังต่อไปนี้ -
trainer.test_minibatch({ features: X_test, label: y_test})การทำนายด้วย NN
เมื่อคุณได้ฝึกฝนรูปแบบการเรียนรู้เชิงลึกแล้วสิ่งที่สำคัญที่สุดคือการคาดเดาโดยใช้สิ่งนั้น เพื่อทำการทำนายจาก NN ที่ได้รับการฝึกฝนข้างต้นเราสามารถทำตามขั้นตอนที่กำหนด
Step 1 - ก่อนอื่นเราต้องเลือกสุ่มไอเทมจากชุดทดสอบโดยใช้ฟังก์ชันต่อไปนี้ -
np.random.choiceStep 2 - ต่อไปเราต้องเลือกข้อมูลตัวอย่างจากชุดทดสอบโดยใช้ sample_index.
Step 3 - ตอนนี้ในการแปลงเอาต์พุตตัวเลขเป็น NN เป็นฉลากจริงให้สร้างการแมปแบบกลับด้าน
Step 4 - ตอนนี้ใช้สิ่งที่เลือก sampleข้อมูล. ทำการทำนายโดยเรียกใช้ NN z เป็นฟังก์ชัน
Step 5- ตอนนี้เมื่อคุณได้ผลลัพธ์ที่ทำนายแล้วให้นำดัชนีของเซลล์ประสาทที่มีค่าสูงสุดเป็นค่าที่คาดการณ์ไว้ สามารถทำได้โดยใช้ไฟล์np.argmax ฟังก์ชั่นจาก numpy แพ็คเกจ
Step 6 - ในที่สุดให้แปลงค่าดัชนีเป็นฉลากจริงโดยใช้ inverted_mapping.
การทำนายด้วย NN - ตัวอย่างที่สมบูรณ์
sample_index = np.random.choice(X_test.shape[0])
sample = X_test[sample_index]
inverted_mapping = {
1:’Iris-setosa’,
2:’Iris-versicolor’,
3:’Iris-virginica’
}
prediction = z(sample)
predicted_label = inverted_mapping[np.argmax(prediction)]
print(predicted_label)เอาต์พุต
หลังจากฝึกรูปแบบการเรียนรู้เชิงลึกข้างต้นและเรียกใช้แล้วคุณจะได้ผลลัพธ์ดังต่อไปนี้ -
Iris-versicolorCNTK - ในหน่วยความจำและชุดข้อมูลขนาดใหญ่
ในบทนี้เราจะเรียนรู้เกี่ยวกับวิธีการทำงานกับในหน่วยความจำและชุดข้อมูลขนาดใหญ่ใน CNTK
การฝึกอบรมด้วยชุดข้อมูลหน่วยความจำขนาดเล็ก
เมื่อเราพูดถึงการป้อนข้อมูลลงในเทรนเนอร์ CNTK อาจมีหลายวิธี แต่จะขึ้นอยู่กับขนาดของชุดข้อมูลและรูปแบบของข้อมูล ชุดข้อมูลอาจเป็นชุดข้อมูลขนาดเล็กในหน่วยความจำหรือชุดข้อมูลขนาดใหญ่
ในส่วนนี้เราจะทำงานกับชุดข้อมูลในหน่วยความจำ สำหรับสิ่งนี้เราจะใช้สองกรอบต่อไปนี้ -
- Numpy
- Pandas
การใช้อาร์เรย์ Numpy
ที่นี่เราจะทำงานกับชุดข้อมูลที่สร้างขึ้นแบบสุ่มตามจำนวนใน CNTK ในตัวอย่างนี้เราจะจำลองข้อมูลสำหรับปัญหาการจำแนกไบนารี สมมติว่าเรามีชุดการสังเกตที่มีคุณลักษณะ 4 ประการและต้องการคาดเดาป้ายกำกับที่เป็นไปได้ 2 รายการด้วยโมเดลการเรียนรู้เชิงลึกของเรา
ตัวอย่างการใช้งาน
สำหรับสิ่งนี้อันดับแรกเราต้องสร้างชุดของป้ายกำกับที่มีการแสดงเวกเตอร์แบบฮ็อตเดียวของป้ายกำกับซึ่งเราต้องการคาดการณ์ สามารถทำได้ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
Step 1 - นำเข้าไฟล์ numpy แพคเกจดังนี้ -
import numpy as np
num_samples = 20000Step 2 - จากนั้นสร้างการแมปฉลากโดยใช้ np.eye ฟังก์ชันดังต่อไปนี้ -
label_mapping = np.eye(2)Step 3 - ตอนนี้โดยใช้ np.random.choice ฟังก์ชั่นรวบรวม 20000 ตัวอย่างสุ่มดังต่อไปนี้ -
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)Step 4 - ในที่สุดโดยใช้ฟังก์ชัน np.random.random สร้างอาร์เรย์ของค่าทศนิยมแบบสุ่มดังนี้ -
x = np.random.random(size=(num_samples, 4)).astype(np.float32)เมื่อเราสร้างอาร์เรย์ของค่าทศนิยมแบบสุ่มเราจำเป็นต้องแปลงเป็นตัวเลขทศนิยม 32 บิตเพื่อให้สามารถจับคู่กับรูปแบบที่ CNTK คาดไว้ได้ ทำตามขั้นตอนด้านล่างเพื่อทำสิ่งนี้ -
Step 5 - นำเข้าฟังก์ชันเลเยอร์หนาแน่นและตามลำดับจากโมดูล cntk.layers ดังนี้ -
from cntk.layers import Dense, SequentialStep 6- ตอนนี้เราต้องนำเข้าฟังก์ชันการเปิดใช้งานสำหรับเลเยอร์ในเครือข่าย ให้เรานำเข้าไฟล์sigmoid เป็นฟังก์ชันการเปิดใช้งาน -
from cntk import input_variable, default_options
from cntk.ops import sigmoidStep 7- ตอนนี้เราจำเป็นต้องนำเข้าฟังก์ชั่นการสูญเสียเพื่อฝึกอบรมเครือข่าย ให้เรานำเข้าbinary_cross_entropy เป็นฟังก์ชันการสูญเสีย -
from cntk.losses import binary_cross_entropyStep 8- ต่อไปเราต้องกำหนดตัวเลือกเริ่มต้นสำหรับเครือข่าย ที่นี่เราจะให้บริการsigmoidฟังก์ชันการเปิดใช้งานเป็นการตั้งค่าเริ่มต้น สร้างโมเดลโดยใช้ฟังก์ชัน Sequential Layer ดังนี้ -
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])Step 9 - ถัดไปเริ่มต้นไฟล์ input_variable ด้วยคุณสมบัติการป้อนข้อมูล 4 แบบที่ทำหน้าที่เป็นอินพุตสำหรับเครือข่าย
features = input_variable(4)Step 10 - ตอนนี้เพื่อให้เสร็จสมบูรณ์เราจำเป็นต้องเชื่อมต่อตัวแปรคุณสมบัติกับ NN
z = model(features)ดังนั้นตอนนี้เรามี NN แล้วด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ให้เราฝึกมันโดยใช้ชุดข้อมูลในหน่วยความจำ -
Step 11 - ในการฝึกอบรม NN นี้อันดับแรกเราต้องนำเข้าผู้เรียนจาก cntk.learnersโมดูล. เราจะนำเข้าsgd ผู้เรียนดังนี้ -
from cntk.learners import sgdStep 12 - พร้อมกับการนำเข้าไฟล์ ProgressPrinter จาก cntk.logging โมดูลด้วย
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 13 - จากนั้นกำหนดตัวแปรอินพุตใหม่สำหรับป้ายกำกับดังนี้ -
labels = input_variable(2)Step 14 - ในการฝึกโมเดล NN ต่อไปเราต้องกำหนดการสูญเสียโดยใช้ binary_cross_entropyฟังก์ชัน นอกจากนี้ให้ระบุโมเดล z และตัวแปรเลเบล
loss = binary_cross_entropy(z, labels)Step 15 - ถัดไปเริ่มต้น sgd ผู้เรียนดังนี้ -
learner = sgd(z.parameters, lr=0.1)Step 16- ในที่สุดเรียกวิธีการรถไฟในฟังก์ชั่นการสูญเสีย นอกจากนี้ให้ใส่ข้อมูลอินพุตไฟล์sgd ผู้เรียนและ progress_printer.−
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])ตัวอย่างการใช้งานที่สมบูรณ์
import numpy as np
num_samples = 20000
label_mapping = np.eye(2)
y = label_mapping[np.random.choice(2,num_samples)].astype(np.float32)
x = np.random.random(size=(num_samples, 4)).astype(np.float32)
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid
from cntk.losses import binary_cross_entropy
with default_options(activation=sigmoid):
model = Sequential([Dense(6),Dense(2)])
features = input_variable(4)
z = model(features)
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(2)
loss = binary_cross_entropy(z, labels)
learner = sgd(z.parameters, lr=0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer])เอาต์พุต
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.52 1.52 0 0 32
1.51 1.51 0 0 96
1.48 1.46 0 0 224
1.45 1.42 0 0 480
1.42 1.4 0 0 992
1.41 1.39 0 0 2016
1.4 1.39 0 0 4064
1.39 1.39 0 0 8160
1.39 1.39 0 0 16352การใช้ Pandas DataFrames
อาร์เรย์ Numpy มีข้อ จำกัด อย่างมากในสิ่งที่สามารถบรรจุได้และเป็นวิธีการจัดเก็บข้อมูลขั้นพื้นฐานที่สุดวิธีหนึ่ง ตัวอย่างเช่นอาร์เรย์ n มิติเดียวสามารถมีข้อมูลประเภทข้อมูลเดียวได้ แต่ในทางกลับกันสำหรับกรณีต่างๆในโลกแห่งความเป็นจริงเราต้องการไลบรารีที่สามารถจัดการข้อมูลมากกว่าหนึ่งประเภทในชุดข้อมูลเดียว
หนึ่งในไลบรารี Python ที่เรียกว่า Pandas ช่วยให้ทำงานกับชุดข้อมูลประเภทนี้ได้ง่ายขึ้น แนะนำแนวคิดของ DataFrame (DF) และช่วยให้เราโหลดชุดข้อมูลจากดิสก์ที่จัดเก็บในรูปแบบต่างๆเป็น DF ตัวอย่างเช่นเราสามารถอ่าน DF ที่จัดเก็บเป็น CSV, JSON, Excel เป็นต้น
คุณสามารถเรียนรู้ไลบรารี Python Pandas โดยละเอียดได้ที่ https://www.tutorialspoint.com/python_pandas/index.htm.
ตัวอย่างการใช้งาน
ในตัวอย่างนี้เราจะใช้ตัวอย่างการจำแนกชนิดของดอกไอริสที่เป็นไปได้สามชนิดตามคุณสมบัติสี่ประการ เราได้สร้างรูปแบบการเรียนรู้เชิงลึกนี้ในส่วนก่อนหน้านี้ด้วย โมเดลมีดังนี้ -
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)แบบจำลองด้านบนประกอบด้วยเลเยอร์ที่ซ่อนอยู่หนึ่งชั้นและชั้นเอาต์พุตที่มีเซลล์ประสาทสามเซลล์เพื่อให้ตรงกับจำนวนชั้นเรียนที่เราสามารถคาดเดาได้
ต่อไปเราจะใช้ไฟล์ train วิธีการและ lossฟังก์ชั่นในการฝึกอบรมเครือข่าย สำหรับสิ่งนี้อันดับแรกเราต้องโหลดและประมวลผลชุดข้อมูลม่านตาล่วงหน้าเพื่อให้ตรงกับรูปแบบและรูปแบบข้อมูลที่คาดไว้สำหรับ NN สามารถทำได้ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
Step 1 - นำเข้าไฟล์ numpy และ Pandas แพคเกจดังนี้ -
import numpy as np
import pandas as pdStep 2 - ถัดไปใช้ read_csv ฟังก์ชั่นโหลดชุดข้อมูลลงในหน่วยความจำ -
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’,
‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 - ตอนนี้เราจำเป็นต้องสร้างพจนานุกรมที่จะทำแผนที่ป้ายกำกับในชุดข้อมูลด้วยการแสดงตัวเลขที่สอดคล้องกัน
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 4 - ตอนนี้โดยใช้ iloc ตัวทำดัชนีบน DataFrameเลือกสี่คอลัมน์แรกดังนี้ -
x = df_source.iloc[:, :4].valuesStep 5− ถัดไปเราต้องเลือกคอลัมน์สายพันธุ์เป็นป้ายกำกับสำหรับชุดข้อมูล สามารถทำได้ดังนี้ -
y = df_source[‘species’].valuesStep 6 - ตอนนี้เราต้องแมปป้ายกำกับในชุดข้อมูลซึ่งสามารถทำได้โดยใช้ label_mapping. นอกจากนี้ให้ใช้one_hot การเข้ารหัสเพื่อแปลงเป็นอาร์เรย์การเข้ารหัสแบบร้อนเดียว
y = np.array([one_hot(label_mapping[v], 3) for v in y])Step 7 - ถัดไปในการใช้คุณสมบัติและป้ายกำกับที่แมปกับ CNTK เราจำเป็นต้องแปลงทั้งคู่เป็นลอย -
x= x.astype(np.float32)
y= y.astype(np.float32)ดังที่เราทราบดีว่าเลเบลจะถูกเก็บไว้ในชุดข้อมูลเป็นสตริงและ CNTK ไม่สามารถทำงานกับสตริงเหล่านี้ได้ นั่นเป็นเหตุผลว่าทำไมจึงต้องใช้เวกเตอร์ที่เข้ารหัสแบบร้อนเดียวซึ่งแสดงถึงป้ายกำกับ สำหรับสิ่งนี้เราสามารถกำหนดฟังก์ชันพูดได้one_hot ดังต่อไปนี้ -
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return resultตอนนี้เรามีอาร์เรย์ numpy ในรูปแบบที่ถูกต้องด้วยความช่วยเหลือของขั้นตอนต่อไปนี้เราสามารถใช้มันเพื่อฝึกโมเดลของเรา -
Step 8- ก่อนอื่นเราต้องนำเข้าฟังก์ชันการสูญเสียเพื่อฝึกอบรมเครือข่าย ให้เรานำเข้าbinary_cross_entropy_with_softmax เป็นฟังก์ชันการสูญเสีย -
from cntk.losses import binary_cross_entropy_with_softmaxStep 9 - ในการฝึกอบรม NN นี้เราจำเป็นต้องนำเข้าผู้เรียนจาก cntk.learnersโมดูล. เราจะนำเข้าsgd ผู้เรียนดังนี้ -
from cntk.learners import sgdStep 10 - พร้อมกับการนำเข้าไฟล์ ProgressPrinter จาก cntk.logging โมดูลด้วย
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)Step 11 - จากนั้นกำหนดตัวแปรอินพุตใหม่สำหรับป้ายกำกับดังนี้ -
labels = input_variable(3)Step 12 - ในการฝึกโมเดล NN ต่อไปเราต้องกำหนดการสูญเสียโดยใช้ binary_cross_entropy_with_softmaxฟังก์ชัน ระบุโมเดล z และตัวแปรเลเบลด้วย
loss = binary_cross_entropy_with_softmax (z, labels)Step 13 - ถัดไปเริ่มต้น sgd ผู้เรียนดังนี้ -
learner = sgd(z.parameters, 0.1)Step 14- ในที่สุดเรียกวิธีการรถไฟในฟังก์ชั่นการสูญเสีย นอกจากนี้ให้ใส่ข้อมูลอินพุตไฟล์sgd ผู้เรียนและ progress_printer.
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=
[progress_writer],minibatch_size=16,max_epochs=5)ตัวอย่างการใช้งานที่สมบูรณ์
from cntk.layers import Dense, Sequential
from cntk import input_variable, default_options
from cntk.ops import sigmoid, log_softmax
from cntk.losses import binary_cross_entropy
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
z = model(features)
import numpy as np
import pandas as pd
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
x = df_source.iloc[:, :4].values
y = df_source[‘species’].values
y = np.array([one_hot(label_mapping[v], 3) for v in y])
x= x.astype(np.float32)
y= y.astype(np.float32)
def one_hot(index, length):
result = np.zeros(length)
result[index] = index
return result
from cntk.losses import binary_cross_entropy_with_softmax
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_writer = ProgressPrinter(0)
labels = input_variable(3)
loss = binary_cross_entropy_with_softmax (z, labels)
learner = sgd(z.parameters, 0.1)
training_summary=loss.train((x,y),parameter_learners=[learner],callbacks=[progress_writer],minibatch_size=16,max_epochs=5)เอาต์พุต
Build info:
Built time: *** ** **** 21:40:10
Last modified date: *** *** ** 21:08:46 2019
Build type: Release
Build target: CPU-only
With ASGD: yes
Math lib: mkl
Build Branch: HEAD
Build SHA1:ae9c9c7c5f9e6072cc9c94c254f816dbdc1c5be6 (modified)
MPI distribution: Microsoft MPI
MPI version: 7.0.12437.6
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.1 1.1 0 0 16
0.835 0.704 0 0 32
1.993 1.11 0 0 48
1.14 1.14 0 0 112
[………]การฝึกอบรมกับชุดข้อมูลขนาดใหญ่
ในส่วนก่อนหน้าเราทำงานกับชุดข้อมูลในหน่วยความจำขนาดเล็กโดยใช้ Numpy และ pandas แต่ชุดข้อมูลทั้งหมดไม่ได้มีขนาดเล็กมาก โดยเฉพาะชุดข้อมูลที่มีรูปภาพวิดีโอตัวอย่างเสียงมีขนาดใหญ่MinibatchSourceเป็นคอมโพเนนต์ที่สามารถโหลดข้อมูลเป็นชิ้น ๆ ซึ่ง CNTK จัดหาให้เพื่อทำงานกับชุดข้อมูลขนาดใหญ่ดังกล่าว คุณสมบัติบางอย่างของMinibatchSource ส่วนประกอบมีดังนี้ -
MinibatchSource สามารถป้องกันไม่ให้ NN เกินพอดีโดยสุ่มตัวอย่างโดยอัตโนมัติที่อ่านจากแหล่งข้อมูล
มีท่อส่งการแปลงในตัวซึ่งสามารถใช้เพื่อเพิ่มข้อมูลได้
โหลดข้อมูลบนเธรดพื้นหลังแยกต่างหากจากกระบวนการฝึกอบรม
ในส่วนต่อไปนี้เราจะสำรวจวิธีใช้แหล่งข้อมูลมินิแบทช์ที่มีข้อมูลไม่อยู่ในหน่วยความจำเพื่อทำงานกับชุดข้อมูลขนาดใหญ่ นอกจากนี้เราจะสำรวจว่าเราจะใช้มันเพื่อฝึกอบรม NN ได้อย่างไร
การสร้างอินสแตนซ์ MinibatchSource
ในส่วนก่อนหน้านี้เราได้ใช้ตัวอย่างดอกไอริสและทำงานกับชุดข้อมูลในหน่วยความจำขนาดเล็กโดยใช้ Pandas DataFrames ที่นี่เราจะแทนที่โค้ดที่ใช้ข้อมูลจากแพนด้า DF ด้วยMinibatchSource. ขั้นแรกเราต้องสร้างอินสแตนซ์ของMinibatchSource ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
ตัวอย่างการใช้งาน
Step 1 - อันดับแรกจาก cntk.io โมดูลนำเข้าส่วนประกอบสำหรับมินิแบทช์ซอร์สดังนี้ -
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 - ตอนนี้โดยใช้ StreamDef คลาสสร้างนิยามสตรีมสำหรับป้ายกำกับ
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 3 - จากนั้นสร้างเพื่ออ่านคุณสมบัติที่ยื่นจากไฟล์อินพุตสร้างอินสแตนซ์อื่นของ StreamDef ดังต่อไปนี้.
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 4 - ตอนนี้เราจำเป็นต้องให้ iris.ctf ไฟล์เป็นอินพุตและเริ่มต้นไฟล์ deserializer ดังต่อไปนี้ -
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=
label_stream, features=features_stream)Step 5 - ในที่สุดเราต้องสร้างอินสแตนซ์ของ minisourceBatch โดยใช้ deserializer ดังต่อไปนี้ -
Minibatch_source = MinibatchSource(deserializer, randomize=True)การสร้างอินสแตนซ์ MinibatchSource - ตัวอย่างการใช้งานที่สมบูรณ์
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(‘iris.ctf’, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True)การสร้างไฟล์ MCTF
ดังที่คุณได้เห็นข้างต้นเรากำลังนำข้อมูลจากไฟล์ 'iris.ctf' มีรูปแบบไฟล์ที่เรียกว่า CNTK Text Format (CTF) จำเป็นต้องสร้างไฟล์ CTF เพื่อรับข้อมูลสำหรับไฟล์MinibatchSourceอินสแตนซ์ที่เราสร้างไว้ข้างต้น มาดูกันว่าเราจะสร้างไฟล์ CTF ได้อย่างไร
ตัวอย่างการใช้งาน
Step 1 - ก่อนอื่นเราต้องนำเข้าแพนด้าและแพคเกจ numpy ดังนี้ -
import pandas as pd
import numpy as npStep 2- ต่อไปเราต้องโหลดไฟล์ข้อมูลของเราคือ iris.csv ลงในหน่วยความจำ จากนั้นเก็บไว้ในไฟล์df_source ตัวแปร.
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)Step 3 - ตอนนี้โดยใช้ ilocตัวทำดัชนีเป็นคุณสมบัตินำเนื้อหาของสี่คอลัมน์แรก ใช้ข้อมูลจากคอลัมน์สายพันธุ์ดังนี้ -
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].valuesStep 4- ต่อไปเราต้องสร้างการจับคู่ระหว่างชื่อป้ายกำกับและการแสดงตัวเลข สามารถทำได้โดยการสร้างlabel_mapping ดังต่อไปนี้ -
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}Step 5 - ตอนนี้ให้แปลงป้ายกำกับเป็นชุดเวกเตอร์ที่เข้ารหัสแบบร้อนเดียวดังนี้ -
labels = [one_hot(label_mapping[v], 3) for v in labels]ตอนนี้อย่างที่เราเคยทำมาก่อนสร้างฟังก์ชันยูทิลิตี้ที่เรียกว่า one_hotเพื่อเข้ารหัสฉลาก สามารถทำได้ดังนี้ -
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return resultเนื่องจากเราได้โหลดและประมวลผลข้อมูลล่วงหน้าถึงเวลาเก็บไว้ในดิสก์ในรูปแบบไฟล์ CTF เราสามารถทำได้ด้วยความช่วยเหลือของการทำตามรหัส Python -
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))การสร้างไฟล์ MCTF - ตัวอย่างการใช้งานที่สมบูรณ์
import pandas as pd
import numpy as np
df_source = pd.read_csv(‘iris.csv’, names = [‘sepal_length’, ‘sepal_width’, ‘petal_length’, ‘petal_width’, ‘species’], index_col=False)
features = df_source.iloc[: , :4].values
labels = df_source[‘species’].values
label_mapping = {‘Iris-Setosa’ : 0, ‘Iris-Versicolor’ : 1, ‘Iris-Virginica’ : 2}
labels = [one_hot(label_mapping[v], 3) for v in labels]
def one_hot(index, length):
result = np.zeros(length)
result[index] = 1
return result
With open(‘iris.ctf’, ‘w’) as output_file:
for index in range(0, feature.shape[0]):
feature_values = ‘ ‘.join([str(x) for x in np.nditer(features[index])])
label_values = ‘ ‘.join([str(x) for x in np.nditer(labels[index])])
output_file.write(‘features {} | labels {} \n’.format(feature_values, label_values))การป้อนข้อมูล
เมื่อคุณสร้าง MinibatchSource,เช่นเราต้องฝึกมัน เราสามารถใช้ตรรกะการฝึกแบบเดียวกับที่ใช้เมื่อเราทำงานกับชุดข้อมูลขนาดเล็กในหน่วยความจำ ที่นี่เราจะใช้MinibatchSource อินสแตนซ์เป็นอินพุตสำหรับเมธอดรถไฟในฟังก์ชันการสูญเสียดังต่อไปนี้ -
ตัวอย่างการใช้งาน
Step 1 - ในการบันทึกผลลัพธ์ของเซสชันการฝึกอบรมขั้นแรกให้นำเข้า ProgressPrinter จาก cntk.logging โมดูลดังนี้ -
from cntk.logging import ProgressPrinterStep 2 - ถัดไปในการตั้งค่าเซสชันการฝึกอบรมให้นำเข้าไฟล์ trainer และ training_session จาก cntk.train โมดูลดังนี้ -
from cntk.train import Trainer,Step 3 - ตอนนี้เราต้องกำหนดชุดค่าคงที่เช่น minibatch_size, samples_per_epoch และ num_epochs ดังต่อไปนี้ -
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30Step 4 - ถัดไปเพื่อที่จะทราบว่า CNTK จะอ่านข้อมูลอย่างไรในระหว่างการฝึกอบรมเราจำเป็นต้องกำหนดการแมประหว่างตัวแปรอินพุตสำหรับเครือข่ายและสตรีมในแหล่งมินิแบทช์
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}Step 5 - ถัดไปในการบันทึกผลลัพธ์ของกระบวนการฝึกอบรมให้เริ่มต้นไฟล์ progress_printer ตัวแปรด้วยไฟล์ ProgressPrinter อินสแตนซ์ดังนี้ -
progress_writer = ProgressPrinter(0)Step 6 - ในที่สุดเราต้องเรียกใช้วิธีการรถไฟในการสูญเสียดังต่อไปนี้ -
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)การป้อนข้อมูล - ตัวอย่างการใช้งานที่สมบูรณ์
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
input_map = {
features: minibatch.source.streams.features,
labels: minibatch.source.streams.features
}
progress_writer = ProgressPrinter(0)
train_history = loss.train(minibatch_source,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer],
epoch_size=samples_per_epoch,
max_epochs=num_epochs)เอาต์พุต
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.21 1.21 0 0 32
1.15 0.12 0 0 96
[………]CNTK - การวัดประสิทธิภาพ
บทนี้จะอธิบายวิธีการวัดประสิทธิภาพของโมเดลใน CNKT
กลยุทธ์ในการตรวจสอบประสิทธิภาพของโมเดล
หลังจากสร้างแบบจำลอง ML เราใช้ในการฝึกอบรมโดยใช้ชุดตัวอย่างข้อมูล เนื่องจากการฝึกอบรมนี้แบบจำลอง ML ของเราเรียนรู้และได้รับกฎทั่วไปบางประการ ประสิทธิภาพของแบบจำลอง ML มีความสำคัญเมื่อเราป้อนตัวอย่างใหม่กล่าวคือตัวอย่างที่แตกต่างจากที่ให้ไว้ในขณะฝึกอบรมไปยังโมเดล โมเดลจะทำงานแตกต่างกันในกรณีนั้น มันอาจจะแย่กว่าในการคาดการณ์ที่ดีสำหรับตัวอย่างใหม่เหล่านั้น
แต่แบบจำลองจะต้องทำงานได้ดีสำหรับตัวอย่างใหม่เช่นกันเนื่องจากในสภาพแวดล้อมการผลิตเราจะได้รับข้อมูลที่แตกต่างจากที่เราใช้ข้อมูลตัวอย่างเพื่อการฝึกอบรม นั่นเป็นเหตุผลที่เราควรตรวจสอบความถูกต้องของแบบจำลอง ML โดยใช้ชุดตัวอย่างที่แตกต่างจากตัวอย่างที่เราใช้ในการฝึกอบรม ในที่นี้เราจะพูดถึงเทคนิคสองอย่างในการสร้างชุดข้อมูลสำหรับการตรวจสอบความถูกต้องของ NN
ชุดข้อมูลระงับ
เป็นวิธีที่ง่ายที่สุดวิธีหนึ่งในการสร้างชุดข้อมูลเพื่อตรวจสอบความถูกต้องของ NN ตามความหมายของชื่อในวิธีนี้เราจะระงับตัวอย่างหนึ่งชุดจากการฝึกอบรม (พูด 20%) และใช้เพื่อทดสอบประสิทธิภาพของโมเดล ML ของเรา แผนภาพต่อไปนี้แสดงอัตราส่วนระหว่างตัวอย่างการฝึกอบรมและการตรวจสอบความถูกต้อง -

แบบจำลองชุดข้อมูลที่ระงับไว้ช่วยให้มั่นใจได้ว่าเรามีข้อมูลเพียงพอที่จะฝึกโมเดล ML ของเราและในเวลาเดียวกันเราจะมีตัวอย่างจำนวนพอสมควรเพื่อให้ได้การวัดประสิทธิภาพของโมเดลที่ดี
เพื่อที่จะรวมไว้ในชุดฝึกและชุดทดสอบควรเลือกตัวอย่างแบบสุ่มจากชุดข้อมูลหลัก ช่วยให้มั่นใจได้ว่ามีการกระจายอย่างสม่ำเสมอระหว่างชุดฝึกและชุดทดสอบ
ต่อไปนี้เป็นตัวอย่างที่เรากำลังสร้างชุดข้อมูลแบบระงับเองโดยใช้ train_test_split ฟังก์ชั่นจาก scikit-learn ห้องสมุด.
ตัวอย่าง
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# Here above test_size = 0.2 represents that we provided 20% of the data as test data.
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
classifier_knn = KNeighborsClassifier(n_neighbors=3)
classifier_knn.fit(X_train, y_train)
y_pred = classifier_knn.predict(X_test)
# Providing sample data and the model will make prediction out of that data
sample = [[5, 5, 3, 2], [2, 4, 3, 5]]
preds = classifier_knn.predict(sample)
pred_species = [iris.target_names[p] for p in preds] print("Predictions:", pred_species)เอาต์พุต
Predictions: ['versicolor', 'virginica']ในขณะที่ใช้ CNTK เราจำเป็นต้องสุ่มลำดับของชุดข้อมูลของเราทุกครั้งที่เราฝึกโมเดลของเราเพราะ -
อัลกอริทึมการเรียนรู้เชิงลึกได้รับอิทธิพลอย่างมากจากตัวสร้างตัวเลขสุ่ม
ลำดับที่เราส่งตัวอย่างไปยัง NN ระหว่างการฝึกอบรมมีผลต่อประสิทธิภาพอย่างมาก
ข้อเสียที่สำคัญของการใช้เทคนิคชุดข้อมูลแบบระงับคือไม่น่าเชื่อถือเพราะบางครั้งเราได้ผลลัพธ์ที่ดีมาก แต่บางครั้งเราก็ได้ผลลัพธ์ที่ไม่ดี
K-fold cross validation
เพื่อให้แบบจำลอง ML ของเรามีความน่าเชื่อถือมากขึ้นมีเทคนิคที่เรียกว่า K-fold cross validation โดยธรรมชาติแล้วเทคนิค K-fold cross validation นั้นเหมือนกับเทคนิคก่อนหน้านี้ แต่จะทำซ้ำหลาย ๆ ครั้งโดยปกติจะใช้เวลาประมาณ 5 ถึง 10 ครั้ง แผนภาพต่อไปนี้แสดงถึงแนวคิด -

การทำงานของ K-fold cross validation
การทำงานของ K-fold cross validation สามารถเข้าใจได้ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
Step 1- เช่นเดียวกับในเทคนิค Hand-out dataset ในเทคนิค K-fold cross validation ก่อนอื่นเราต้องแยกชุดข้อมูลออกเป็นชุดฝึกและชุดทดสอบ ตามหลักการแล้วอัตราส่วนคือ 80-20 คือ 80% ของชุดฝึกและ 20% ของชุดทดสอบ
Step 2 - ต่อไปเราต้องฝึกโมเดลของเราโดยใช้ชุดฝึก
Step 3สุดท้ายนี้เราจะใช้ชุดทดสอบเพื่อวัดประสิทธิภาพของโมเดลของเรา ข้อแตกต่างเพียงอย่างเดียวระหว่างเทคนิค Hold-out dataset และเทคนิค k-cross validation คือกระบวนการข้างต้นมักจะทำซ้ำเป็นเวลา 5 ถึง 10 ครั้งและในตอนท้ายค่าเฉลี่ยจะถูกคำนวณจากเมตริกประสิทธิภาพทั้งหมด ค่าเฉลี่ยดังกล่าวจะเป็นตัวชี้วัดประสิทธิภาพขั้นสุดท้าย
ให้เราดูตัวอย่างด้วยชุดข้อมูลขนาดเล็ก -
ตัวอย่าง
from numpy import array
from sklearn.model_selection import KFold
data = array([0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0])
kfold = KFold(5, True, 1)
for train, test in kfold.split(data):
print('train: %s, test: %s' % (data[train],(data[test]))เอาต์พุต
train: [0.1 0.2 0.4 0.5 0.6 0.7 0.8 0.9], test: [0.3 1. ]
train: [0.1 0.2 0.3 0.4 0.6 0.8 0.9 1. ], test: [0.5 0.7]
train: [0.2 0.3 0.5 0.6 0.7 0.8 0.9 1. ], test: [0.1 0.4]
train: [0.1 0.3 0.4 0.5 0.6 0.7 0.9 1. ], test: [0.2 0.8]
train: [0.1 0.2 0.3 0.4 0.5 0.7 0.8 1. ], test: [0.6 0.9]อย่างที่เราเห็นเนื่องจากการใช้สถานการณ์การฝึกอบรมและการทดสอบที่เป็นจริงมากขึ้นเทคนิคการตรวจสอบความถูกต้องข้ามแบบ k-fold ทำให้เราสามารถวัดประสิทธิภาพได้อย่างมีเสถียรภาพมากขึ้น แต่ในทางกลับกันก็ต้องใช้เวลามากในการตรวจสอบโมเดลการเรียนรู้เชิงลึก
CNTK ไม่รองรับการตรวจสอบความถูกต้อง k-cross ดังนั้นเราจึงต้องเขียนสคริปต์ของเราเองเพื่อดำเนินการดังกล่าว
ตรวจจับ underfitting และ overfitting
ไม่ว่าเราจะใช้ Hand-out dataset หรือ k-fold cross-validation ก็ตามเราจะพบว่าผลลัพธ์สำหรับเมตริกจะแตกต่างกันสำหรับชุดข้อมูลที่ใช้สำหรับการฝึกอบรมและชุดข้อมูลที่ใช้สำหรับการตรวจสอบความถูกต้อง
ตรวจจับการติดตั้งมากเกินไป
ปรากฏการณ์ที่เรียกว่า overfitting เป็นสถานการณ์ที่แบบจำลอง ML ของเราสร้างแบบจำลองข้อมูลการฝึกอบรมได้ดีเป็นพิเศษ แต่ไม่สามารถทำงานได้ดีกับข้อมูลการทดสอบกล่าวคือไม่สามารถทำนายข้อมูลการทดสอบได้
เกิดขึ้นเมื่อแบบจำลอง ML เรียนรู้รูปแบบเฉพาะและเสียงรบกวนจากข้อมูลการฝึกอบรมในระดับดังกล่าวซึ่งส่งผลเสียต่อความสามารถของโมเดลนั้นในการสรุปข้อมูลทั่วไปจากข้อมูลการฝึกอบรมไปสู่ข้อมูลใหม่นั่นคือข้อมูลที่มองไม่เห็น เสียงรบกวนคือข้อมูลที่ไม่เกี่ยวข้องหรือการสุ่มในชุดข้อมูล
ต่อไปนี้เป็นสองวิธีด้วยความช่วยเหลือที่เราสามารถตรวจจับสภาพอากาศแบบจำลองของเราว่าเกินหรือไม่ -
แบบจำลองโอเวอร์ฟิตจะทำงานได้ดีกับตัวอย่างเดียวกับที่เราใช้ในการฝึก แต่จะให้ผลไม่ดีกับตัวอย่างใหม่กล่าวคือตัวอย่างที่แตกต่างจากการฝึกอบรม
แบบจำลองนี้เกินกำลังในระหว่างการตรวจสอบความถูกต้องหากเมตริกในชุดทดสอบต่ำกว่าเมตริกเดียวกันเราจะใช้กับชุดการฝึกของเรา
ตรวจจับ underfitting
อีกสถานการณ์หนึ่งที่อาจเกิดขึ้นใน ML ของเรานั้นไม่เหมาะสม นี่เป็นสถานการณ์ที่แบบจำลอง ML ของเราไม่ได้จำลองข้อมูลการฝึกอบรมที่ดีและไม่สามารถคาดการณ์ผลลัพธ์ที่เป็นประโยชน์ได้ เมื่อเราเริ่มฝึกยุคแรกแบบจำลองของเราจะไม่เหมาะสม แต่จะน้อยลงตามความคืบหน้าของการฝึกอบรม
วิธีหนึ่งในการตรวจจับว่าแบบจำลองของเราเหมาะสมหรือไม่คือการดูเมตริกสำหรับชุดการฝึกอบรมและชุดทดสอบ แบบจำลองของเราจะอยู่ภายใต้ความเหมาะสมหากเมตริกในชุดทดสอบสูงกว่าเมตริกในชุดการฝึก
CNTK - การจำแนกเครือข่ายประสาท
ในบทนี้เราจะศึกษาวิธีการจำแนกเครือข่ายประสาทเทียมโดยใช้ CNTK
บทนำ
การจำแนกประเภทอาจถูกกำหนดให้เป็นกระบวนการในการทำนายป้ายกำกับเอาต์พุตประเภทหรือการตอบสนองสำหรับข้อมูลอินพุตที่กำหนด ผลลัพธ์ที่จัดหมวดหมู่ซึ่งจะขึ้นอยู่กับสิ่งที่โมเดลได้เรียนรู้ในขั้นตอนการฝึกอบรมอาจมีรูปแบบเช่น "ดำ" หรือ "ขาว" หรือ "สแปม" หรือ "ไม่มีสแปม"
ในทางกลับกันในทางคณิตศาสตร์มันเป็นหน้าที่ของการประมาณฟังก์ชันการทำแผนที่พูด f จากตัวแปรอินพุตพูดว่า X ถึงตัวแปรเอาต์พุตบอกว่า Y
ตัวอย่างคลาสสิกของปัญหาการจัดประเภทอาจเป็นการตรวจจับสแปมในอีเมล เห็นได้ชัดว่าเอาต์พุตมีได้เพียง 2 ประเภทคือ "สแปม" และ "ไม่มีสแปม"
ในการใช้การจัดประเภทดังกล่าวก่อนอื่นเราต้องทำการฝึกอบรมตัวแยกประเภทซึ่งจะใช้อีเมล "สแปม" และ "ไม่มีสแปม" เป็นข้อมูลการฝึกอบรม เมื่อลักษณนามได้รับการฝึกฝนเรียบร้อยแล้วก็สามารถใช้ตรวจหาอีเมลที่ไม่รู้จักได้
ที่นี่เราจะสร้าง 4-5-3 NN โดยใช้ชุดข้อมูลดอกไอริสโดยมีดังต่อไปนี้ -
โหนดอินพุต 4 โหนด (หนึ่งโหนดสำหรับค่าตัวทำนายแต่ละค่า)
5 โหนดการประมวลผลที่ซ่อนอยู่
โหนด 3 เอาต์พุต (เนื่องจากมีสามชนิดที่เป็นไปได้ในชุดข้อมูลไอริส)
กำลังโหลดชุดข้อมูล
เราจะใช้ชุดข้อมูลดอกไอริสซึ่งเราต้องการจำแนกชนิดของดอกไอริสตามคุณสมบัติทางกายภาพของความกว้างและความยาวกลีบเลี้ยงและความกว้างและความยาวของกลีบดอก ชุดข้อมูลอธิบายคุณสมบัติทางกายภาพของดอกไอริสพันธุ์ต่างๆ -
ความยาวกลีบเลี้ยง
ความกว้าง Sepal
ความยาวกลีบดอก
ความกว้างของกลีบดอก
Class คือ iris setosa หรือ iris versicolor หรือ iris virginica
เรามี iris.CSVไฟล์ที่เราใช้มาก่อนในบทก่อนหน้านี้ด้วย สามารถโหลดได้ด้วยความช่วยเหลือของPandasห้องสมุด. แต่ก่อนที่จะใช้หรือโหลดสำหรับลักษณนามของเราเราจำเป็นต้องเตรียมไฟล์การฝึกอบรมและการทดสอบเพื่อให้สามารถใช้กับ CNTK ได้อย่างง่ายดาย
การเตรียมไฟล์การฝึกอบรมและการทดสอบ
ชุดข้อมูล Iris เป็นหนึ่งในชุดข้อมูลยอดนิยมสำหรับโครงการ ML มีรายการข้อมูล 150 รายการและข้อมูลดิบมีลักษณะดังนี้ -
5.1 3.5 1.4 0.2 setosa
4.9 3.0 1.4 0.2 setosa
…
7.0 3.2 4.7 1.4 versicolor
6.4 3.2 4.5 1.5 versicolor
…
6.3 3.3 6.0 2.5 virginica
5.8 2.7 5.1 1.9 virginicaอย่างที่บอกไปก่อนหน้านี้ค่าสี่ค่าแรกในแต่ละบรรทัดจะอธิบายถึงคุณสมบัติทางกายภาพของพันธุ์ที่แตกต่างกัน ได้แก่ ความยาวกลีบเลี้ยงความกว้างกลีบเลี้ยงความยาวกลีบดอกความกว้างกลีบดอกของดอกไอริส
แต่เราควรจะต้องแปลงข้อมูลในรูปแบบที่ CNTK สามารถใช้งานได้ง่ายและรูปแบบนั้นคือไฟล์. ctf (เราสร้าง iris.ctf หนึ่งอันในส่วนก่อนหน้านี้ด้วย) จะมีลักษณะดังนี้ -
|attribs 5.1 3.5 1.4 0.2|species 1 0 0
|attribs 4.9 3.0 1.4 0.2|species 1 0 0
…
|attribs 7.0 3.2 4.7 1.4|species 0 1 0
|attribs 6.4 3.2 4.5 1.5|species 0 1 0
…
|attribs 6.3 3.3 6.0 2.5|species 0 0 1
|attribs 5.8 2.7 5.1 1.9|species 0 0 1ในข้อมูลข้างต้นแท็ก | attribs จะทำเครื่องหมายจุดเริ่มต้นของค่าคุณลักษณะและแท็ก | species เป็นค่าเลเบลคลาส นอกจากนี้เรายังสามารถใช้ชื่อแท็กอื่น ๆ ตามความปรารถนาของเราได้แม้ว่าเราจะเพิ่มรหัสไอเท็มได้เช่นกัน ตัวอย่างเช่นดูข้อมูลต่อไปนี้ -
|ID 001 |attribs 5.1 3.5 1.4 0.2|species 1 0 0 |#setosa
|ID 002 |attribs 4.9 3.0 1.4 0.2|species 1 0 0 |#setosa
…
|ID 051 |attribs 7.0 3.2 4.7 1.4|species 0 1 0 |#versicolor
|ID 052 |attribs 6.4 3.2 4.5 1.5|species 0 1 0 |#versicolor
…มีรายการข้อมูลทั้งหมด 150 รายการในชุดข้อมูลม่านตาและสำหรับตัวอย่างนี้เราจะใช้กฎชุดข้อมูลที่ระงับ 80-20 รายการเช่นรายการข้อมูล 80% (120 รายการ) เพื่อวัตถุประสงค์ในการฝึกอบรมและรายการข้อมูลที่เหลืออีก 20% (30 รายการ) สำหรับการทดสอบ วัตถุประสงค์.
การสร้างแบบจำลองการจำแนกประเภท
ขั้นแรกเราต้องประมวลผลไฟล์ข้อมูลในรูปแบบ CNTK และเราจะใช้ฟังก์ชันตัวช่วยที่ชื่อ create_reader ดังต่อไปนี้ -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcตอนนี้เราต้องตั้งค่าอาร์กิวเมนต์สถาปัตยกรรมสำหรับ NN ของเราและระบุตำแหน่งของไฟล์ข้อมูลด้วย สามารถทำได้ด้วยความช่วยเหลือของรหัส python ต่อไปนี้ -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)ตอนนี้ด้วยความช่วยเหลือของบรรทัดรหัสต่อไปนี้โปรแกรมของเราจะสร้าง NN ที่ไม่ได้รับการฝึกฝน -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)ตอนนี้เมื่อเราสร้างโมเดลที่ไม่ได้รับการฝึกฝนมาแล้วเราจำเป็นต้องตั้งค่าออบเจ็กต์อัลกอริทึมของผู้เรียนจากนั้นจึงใช้เพื่อสร้างอ็อบเจ็กต์การฝึกเทรนเนอร์ เราจะใช้ผู้เรียน SGD และcross_entropy_with_softmax ฟังก์ชันการสูญเสีย -
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])รหัสอัลกอริทึมการเรียนรู้ดังนี้ -
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])ตอนนี้เมื่อเราใช้วัตถุ Trainer เสร็จแล้วเราจำเป็นต้องสร้างฟังก์ชันตัวอ่านเพื่ออ่านข้อมูลการฝึกอบรม training
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }ตอนนี้ถึงเวลาฝึกโมเดล NN ของเราแล้ว
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))เมื่อเราทำการฝึกอบรมเสร็จแล้วเรามาประเมินแบบจำลองโดยใช้รายการข้อมูลการทดสอบ -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)หลังจากประเมินความแม่นยำของแบบจำลอง NN ที่ได้รับการฝึกฝนแล้วเราจะใช้มันเพื่อทำการคาดคะเนข้อมูลที่มองไม่เห็น -
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[6.4, 3.2, 4.5, 1.5]], dtype=np.float32)
print("\nPredicting Iris species for input features: ")
print(unknown[0]) pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])รูปแบบการจำแนกที่สมบูรณ์
Import numpy as np
Import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='attribs', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='species', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 5
output_dim = 3
train_file = ".\\...\\" #provide the name of the training file(120 data items)
test_file = ".\\...\\" #provide the name of the test file(30 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 2000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
max_iter = 2000
batch_size = 10
lr_schedule = C.learning_parameter_schedule_per_sample([(1000, 0.05), (1, 0.01)])
mom_sch = C.momentum_schedule([(100, 0.99), (0, 0.95)], batch_size)
learner = C.fsadagrad(nnet.parameters, lr=lr_schedule, momentum=mom_sch)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
iris_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 30
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])
if __name__== ”__main__”:
main()เอาต์พุต
Using CNTK version = 2.7
batch 0: mean loss = 1.0986, mean accuracy = 40.00%
batch 500: mean loss = 0.6677, mean accuracy = 80.00%
batch 1000: mean loss = 0.5332, mean accuracy = 70.00%
batch 1500: mean loss = 0.2408, mean accuracy = 100.00%
Evaluating test data
Classification accuracy = 94.58%
Predicting species for input features:
[7.0 3.2 4.7 1.4]
Prediction probabilities:
[0.0847 0.736 0.113]บันทึกโมเดลที่ได้รับการฝึกฝน
ชุดข้อมูล Iris นี้มีรายการข้อมูลเพียง 150 รายการดังนั้นจึงต้องใช้เวลาเพียงไม่กี่วินาทีในการฝึกโมเดลตัวจำแนก NN แต่การฝึกชุดข้อมูลขนาดใหญ่ที่มีรายการข้อมูลเป็นแสนรายการอาจใช้เวลาหลายชั่วโมงหรือหลายวัน
เราสามารถบันทึกโมเดลของเราเพื่อที่เราจะได้ไม่ต้องเก็บมันไว้ตั้งแต่ต้น ด้วยความช่วยเหลือในการทำตามรหัส Python เราสามารถบันทึก NN ที่ได้รับการฝึกฝนของเรา -
nn_classifier = “.\\neuralclassifier.model” #provide the name of the file
model.save(nn_classifier, format=C.ModelFormat.CNTKv2)ต่อไปนี้เป็นข้อโต้แย้งของ save() ฟังก์ชันที่ใช้ข้างต้น -
ชื่อไฟล์เป็นอาร์กิวเมนต์แรกของ save()ฟังก์ชัน นอกจากนี้ยังสามารถเขียนพร้อมกับเส้นทางของไฟล์
พารามิเตอร์อื่นคือไฟล์ format พารามิเตอร์ซึ่งมีค่าเริ่มต้น C.ModelFormat.CNTKv2.
กำลังโหลดแบบจำลองที่ผ่านการฝึกอบรม
เมื่อคุณบันทึกโมเดลที่ฝึกแล้วการโหลดโมเดลนั้นทำได้ง่ายมาก เราจำเป็นต้องใช้ไฟล์load ()ฟังก์ชัน ลองตรวจสอบสิ่งนี้ในตัวอย่างต่อไปนี้ -
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralclassifier.model”)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[7.0, 3.2, 4.7, 1.4]], dtype=np.float32)
print("\nPredicting species for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities: ")
print(pred_prob[0])ข้อดีของโมเดลที่บันทึกไว้คือเมื่อคุณโหลดโมเดลที่บันทึกไว้แล้วโมเดลนั้นจะสามารถใช้งานได้เหมือนกับว่าโมเดลนั้นเพิ่งได้รับการฝึกฝนมา
CNTK - การจำแนกไบนารีเครือข่ายประสาท
ให้เราเข้าใจว่าการจำแนกไบนารีของเครือข่ายประสาทเทียมโดยใช้ CNTK คืออะไรในบทนี้
การจำแนกไบนารีโดยใช้ NN ก็เหมือนกับการจำแนกหลายชั้นสิ่งเดียวคือมีโหนดเอาต์พุตเพียงสองโหนดแทนที่จะเป็นสามโหนดขึ้นไป ที่นี่เราจะทำการจำแนกไบนารีโดยใช้เครือข่ายประสาทโดยใช้สองเทคนิคคือหนึ่งโหนดและเทคนิคสองโหนด เทคนิคหนึ่งโหนดเป็นเรื่องปกติมากกว่าเทคนิคสองโหนด
กำลังโหลดชุดข้อมูล
สำหรับเทคนิคทั้งสองนี้ในการนำไปใช้โดยใช้ NN เราจะใช้ชุดข้อมูลธนบัตร สามารถดาวน์โหลดชุดข้อมูลได้จาก UCI Machine Learning Repository ซึ่งมีอยู่ที่https://archive.ics.uci.edu/ml/datasets/banknote+authentication.
ตัวอย่างของเราเราจะใช้รายการข้อมูลแท้ 50 รายการที่มีการปลอมแปลงคลาส = 0 และรายการปลอม 50 รายการแรกที่มีการปลอมแปลงคลาส = 1
การเตรียมไฟล์การฝึกอบรมและการทดสอบ
มีรายการข้อมูล 1372 รายการในชุดข้อมูลทั้งหมด ชุดข้อมูลดิบมีลักษณะดังนี้ -
3.6216, 8.6661, -2.8076, -0.44699, 0
4.5459, 8.1674, -2.4586, -1.4621, 0
…
-1.3971, 3.3191, -1.3927, -1.9948, 1
0.39012, -0.14279, -0.031994, 0.35084, 1ตอนนี้ก่อนอื่นเราต้องแปลงข้อมูลดิบนี้เป็นรูปแบบ CNTK สองโหนดซึ่งจะเป็นดังนี้ -
|stats 3.62160000 8.66610000 -2.80730000 -0.44699000 |forgery 0 1 |# authentic
|stats 4.54590000 8.16740000 -2.45860000 -1.46210000 |forgery 0 1 |# authentic
. . .
|stats -1.39710000 3.31910000 -1.39270000 -1.99480000 |forgery 1 0 |# fake
|stats 0.39012000 -0.14279000 -0.03199400 0.35084000 |forgery 1 0 |# fakeคุณสามารถใช้โปรแกรม python ต่อไปนี้เพื่อสร้างข้อมูลรูปแบบ CNTK จากข้อมูลดิบ -
fin = open(".\\...", "r") #provide the location of saved dataset text file.
for line in fin:
line = line.strip()
tokens = line.split(",")
if tokens[4] == "0":
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 0 1 |# authentic" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
else:
print("|stats %12.8f %12.8f %12.8f %12.8f |forgery 1 0 |# fake" % \
(float(tokens[0]), float(tokens[1]), float(tokens[2]), float(tokens[3])) )
fin.close()แบบจำลองการจำแนกไบนารีสองโหนด
มีความแตกต่างน้อยมากระหว่างการจำแนกแบบสองโหนดและการจำแนกแบบหลายคลาส ก่อนอื่นเราต้องประมวลผลไฟล์ข้อมูลในรูปแบบ CNTK และเราจะใช้ฟังก์ชันตัวช่วยที่ชื่อcreate_reader ดังต่อไปนี้ -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcตอนนี้เราต้องตั้งค่าอาร์กิวเมนต์สถาปัตยกรรมสำหรับ NN ของเราและระบุตำแหน่งของไฟล์ข้อมูลด้วย สามารถทำได้ด้วยความช่วยเหลือของรหัส python ต่อไปนี้ -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test fileตอนนี้ด้วยความช่วยเหลือของบรรทัดรหัสต่อไปนี้โปรแกรมของเราจะสร้าง NN ที่ไม่ได้รับการฝึกฝน -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)ตอนนี้เมื่อเราสร้างโมเดลที่ไม่ได้รับการฝึกฝนมาแล้วเราจำเป็นต้องตั้งค่าออบเจ็กต์อัลกอริทึมของผู้เรียนจากนั้นจึงใช้เพื่อสร้างอ็อบเจ็กต์การฝึกเทรนเนอร์ เราจะใช้ SGD learner และ cross_entropy_with_softmax loss function -
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])ตอนนี้เมื่อเราเสร็จสิ้นกับ Trainer object แล้วเราจำเป็นต้องสร้างฟังก์ชัน reader เพื่ออ่านข้อมูลการฝึก -
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }ตอนนี้ได้เวลาฝึกโมเดล NN ของเราแล้ว -
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))เมื่อการฝึกอบรมเสร็จสิ้นให้เราประเมินแบบจำลองโดยใช้รายการข้อมูลการทดสอบ -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)หลังจากประเมินความแม่นยำของแบบจำลอง NN ที่ได้รับการฝึกฝนแล้วเราจะใช้มันเพื่อทำการคาดคะเนข้อมูลที่มองไม่เห็น -
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)ทำแบบจำลองการจำแนกสองโหนดให้สมบูรณ์
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 2
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
withC.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
nnet = oLayer
model = C.ops.softmax(nnet)
tr_loss = C.cross_entropy_with_softmax(nnet, Y)
tr_clas = C.classification_error(nnet, Y)
max_iter = 500
batch_size = 10
learn_rate = 0.01
learner = C.sgd(nnet.parameters, learn_rate)
trainer = C.Trainer(nnet, (tr_loss, tr_clas), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 500 == 0:
mcee = trainer.previous_minibatch_loss_average
macc = (1.0 - trainer.previous_minibatch_evaluation_average) * 100
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, macc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map) acc = (1.0 - trainer.test_minibatch(all_test)) * 100
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval(unknown)
np.set_printoptions(precision = 4, suppress=True)
print("Prediction probabilities are: ")
print(pred_prob[0])
if pred_prob[0,0] < pred_prob[0,1]:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()เอาต์พุต
Using CNTK version = 2.7
batch 0: mean loss = 0.6928, accuracy = 80.00%
batch 50: mean loss = 0.6877, accuracy = 70.00%
batch 100: mean loss = 0.6432, accuracy = 80.00%
batch 150: mean loss = 0.4978, accuracy = 80.00%
batch 200: mean loss = 0.4551, accuracy = 90.00%
batch 250: mean loss = 0.3755, accuracy = 90.00%
batch 300: mean loss = 0.2295, accuracy = 100.00%
batch 350: mean loss = 0.1542, accuracy = 100.00%
batch 400: mean loss = 0.1581, accuracy = 100.00%
batch 450: mean loss = 0.1499, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.58%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probabilities are:
[0.7847 0.2536]
Prediction: fakeโมเดลการจำแนกไบนารีแบบโหนดเดียว
โปรแกรมการนำไปใช้เกือบจะเหมือนกับที่เราได้ทำไว้ข้างต้นสำหรับการจำแนกสองโหนด การเปลี่ยนแปลงหลักคือเมื่อใช้เทคนิคการจำแนกสองโหนด
เราสามารถใช้ฟังก์ชัน CNTK built-in Classification_error () ได้ แต่ในกรณีของการจำแนกประเภทโหนดเดียว CNTK ไม่รองรับฟังก์ชันการจำแนกประเภท _error () นั่นเป็นเหตุผลที่เราต้องใช้ฟังก์ชันที่โปรแกรมกำหนดไว้ดังนี้ -
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)ด้วยการเปลี่ยนแปลงดังกล่าวเรามาดูตัวอย่างการจำแนกโหนดเดียวที่สมบูรณ์ -
สร้างโมเดลการจำแนกโหนดเดียวให้สมบูรณ์
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='stats', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='forgery', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def class_acc(mb, x_var, y_var, model):
num_correct = 0; num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
p = model.eval(x_mat[i]
y = y_mat[i]
if p[0,0] < 0.5 and y[0,0] == 0.0 or p[0,0] >= 0.5 and y[0,0] == 1.0:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 4
hidden_dim = 10
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file
test_file = ".\\...\\" #provide the name of the test file
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = oLayer
tr_loss = C.cross_entropy_with_softmax(model, Y)
max_iter = 1000
batch_size = 10
learn_rate = 0.01
learner = C.sgd(model.parameters, learn_rate)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
banknote_input_map = {X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=iris_input_map) trainer.train_minibatch(curr_batch)
if i % 100 == 0:
mcee=trainer.previous_minibatch_loss_average
ca = class_acc(curr_batch, X,Y, model)
print("batch %4d: mean loss = %0.4f, accuracy = %0.2f%% " \ % (i, mcee, ca))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
banknote_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=iris_input_map)
acc = class_acc(all_test, X,Y, model)
print("Classification accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 1, suppress=True)
unknown = np.array([[0.6, 1.9, -3.3, -0.3]], dtype=np.float32)
print("\nPredicting Banknote authenticity for input features: ")
print(unknown[0])
pred_prob = model.eval({X:unknown})
print("Prediction probability: ")
print(“%0.4f” % pred_prob[0,0])
if pred_prob[0,0] < 0.5:
print(“Prediction: authentic”)
else:
print(“Prediction: fake”)
if __name__== ”__main__”:
main()เอาต์พุต
Using CNTK version = 2.7
batch 0: mean loss = 0.6936, accuracy = 10.00%
batch 100: mean loss = 0.6882, accuracy = 70.00%
batch 200: mean loss = 0.6597, accuracy = 50.00%
batch 300: mean loss = 0.5298, accuracy = 70.00%
batch 400: mean loss = 0.4090, accuracy = 100.00%
batch 500: mean loss = 0.3790, accuracy = 90.00%
batch 600: mean loss = 0.1852, accuracy = 100.00%
batch 700: mean loss = 0.1135, accuracy = 100.00%
batch 800: mean loss = 0.1285, accuracy = 100.00%
batch 900: mean loss = 0.1054, accuracy = 100.00%
Evaluating test data
Classification accuracy = 84.00%
Predicting banknote authenticity for input features:
[0.6 1.9 -3.3 -0.3]
Prediction probability:
0.8846
Prediction: fakeCNTK - การถดถอยเครือข่ายประสาท
บทนี้จะช่วยให้คุณเข้าใจการถดถอยของโครงข่ายประสาทที่เกี่ยวข้องกับ CNTK
บทนำ
อย่างที่เราทราบกันดีว่าในการทำนายค่าตัวเลขจากตัวแปรทำนายหนึ่งตัวหรือมากกว่านั้นเราใช้การถดถอย ลองมาดูตัวอย่างการทำนายค่ากลางของบ้านในหนึ่งใน 100 เมือง ในการทำเช่นนั้นเรามีข้อมูลที่ประกอบด้วย -
สถิติอาชญากรรมของแต่ละเมือง
อายุของบ้านในแต่ละเมือง
การวัดระยะทางจากแต่ละเมืองไปยังสถานที่สำคัญ
อัตราส่วนนักเรียนต่อครูในแต่ละเมือง
สถิติประชากรทางเชื้อชาติของแต่ละเมือง
มูลค่าบ้านเฉลี่ยในแต่ละเมือง
จากตัวแปรตัวทำนายทั้งห้านี้เราต้องการทำนายมูลค่าบ้านเฉลี่ย และสำหรับสิ่งนี้เราสามารถสร้างแบบจำลองการถดถอยเชิงเส้นตามเส้นของ
Y = a0+a1(crime)+a2(house-age)+(a3)(distance)+(a4)(ratio)+(a5)(racial)ในสมการข้างต้น -
Y คือค่ากลางที่คาดการณ์ไว้
a0 คือค่าคงที่และ
a1 ถึง a5 ทั้งหมดเป็นค่าคงที่ที่เกี่ยวข้องกับตัวทำนายทั้งห้าที่เรากล่าวถึงข้างต้น
นอกจากนี้เรายังมีวิธีอื่นในการใช้เครือข่ายประสาทเทียม มันจะสร้างแบบจำลองการทำนายที่แม่นยำยิ่งขึ้น
ที่นี่เราจะสร้างแบบจำลองการถดถอยของเครือข่ายประสาทโดยใช้ CNTK
กำลังโหลดชุดข้อมูล
ในการใช้การถดถอยของเครือข่ายประสาทโดยใช้ CNTK เราจะใช้ชุดข้อมูลค่าบ้านของพื้นที่บอสตัน สามารถดาวน์โหลดชุดข้อมูลได้จาก UCI Machine Learning Repository ซึ่งมีอยู่ที่https://archive.ics.uci.edu/ml/machine-learning-databases/housing/. ชุดข้อมูลนี้มีทั้งหมด 14 ตัวแปรและ 506 อินสแตนซ์
แต่สำหรับโปรแกรมการติดตั้งของเราเราจะใช้ตัวแปร 6 ตัวจาก 14 ตัวและ 100 อินสแตนซ์ จาก 6, 5 เป็นตัวทำนายและอีกหนึ่งค่าเป็นตัวทำนาย จาก 100 อินสแตนซ์เราจะใช้ 80 สำหรับการฝึกอบรมและ 20 สำหรับการทดสอบ มูลค่าที่เราต้องการทำนายคือราคาบ้านเฉลี่ยในเมือง มาดูตัวทำนายห้าตัวที่เราจะใช้ -
Crime per capita in the town - เราคาดว่าค่าที่น้อยกว่าจะเชื่อมโยงกับตัวทำนายนี้
Proportion of owner - ยูนิตที่ถูกครอบครองซึ่งสร้างขึ้นก่อนปี 1940 - เราคาดว่าค่าที่น้อยกว่าจะเชื่อมโยงกับตัวทำนายนี้เนื่องจากค่าที่มากกว่าหมายถึงบ้านที่มีอายุ
Weighed distance of the town to five Boston employment centers.
Area school pupil-to-teacher ratio.
An indirect metric of the proportion of black residents in the town.
การเตรียมไฟล์การฝึกอบรมและการทดสอบ
อย่างที่เคยทำมาก่อนอื่นเราต้องแปลงข้อมูลดิบเป็นรูปแบบ CNTK เราจะใช้ข้อมูล 80 รายการแรกเพื่อจุดประสงค์ในการฝึกอบรมดังนั้นรูปแบบ CNTK ที่คั่นด้วยแท็บจึงเป็นดังนี้ -
|predictors 1.612820 96.90 3.76 21.00 248.31 |medval 13.50
|predictors 0.064170 68.20 3.36 19.20 396.90 |medval 18.90
|predictors 0.097440 61.40 3.38 19.20 377.56 |medval 20.00
. . .อีก 20 รายการถัดไปซึ่งแปลงเป็นรูปแบบ CNTK จะใช้เพื่อการทดสอบ
การสร้างแบบจำลองการถดถอย
ขั้นแรกเราต้องประมวลผลไฟล์ข้อมูลในรูปแบบ CNTK และสำหรับสิ่งนั้นเราจะใช้ฟังก์ชันตัวช่วยที่ชื่อ create_reader ดังต่อไปนี้ -
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_srcต่อไปเราต้องสร้างฟังก์ชันตัวช่วยที่ยอมรับ CNTK mini-batch object และคำนวณเมตริกความแม่นยำที่กำหนดเอง
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)ตอนนี้เราต้องตั้งค่าอาร์กิวเมนต์สถาปัตยกรรมสำหรับ NN ของเราและระบุตำแหน่งของไฟล์ข้อมูลด้วย สามารถทำได้ด้วยความช่วยเหลือของรหัส python ต่อไปนี้ -
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)ตอนนี้ด้วยความช่วยเหลือของบรรทัดรหัสต่อไปนี้โปรแกรมของเราจะสร้าง NN ที่ไม่ได้รับการฝึกฝน -
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)ตอนนี้เมื่อเราสร้างโมเดลที่ไม่ได้รับการฝึกฝนมาแล้วเราจำเป็นต้องตั้งค่าวัตถุอัลกอริทึมของผู้เรียน เราจะใช้ผู้เรียน SGD และsquared_error ฟังก์ชันการสูญเสีย -
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch=C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])ตอนนี้เมื่อเราเรียนรู้อัลกอริทึมออบเจ็กต์เสร็จแล้วเราจำเป็นต้องสร้างฟังก์ชันผู้อ่านเพื่ออ่านข้อมูลการฝึกอบรม -
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }ตอนนี้ถึงเวลาฝึกโมเดล NN ของเรา -
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))เมื่อเราฝึกอบรมเสร็จแล้วให้ประเมินแบบจำลองโดยใช้รายการข้อมูลการทดสอบ -
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)หลังจากประเมินความแม่นยำของแบบจำลอง NN ที่ได้รับการฝึกฝนแล้วเราจะใช้มันเพื่อทำการคาดคะเนข้อมูลที่มองไม่เห็น -
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])แบบจำลองการถดถอยที่สมบูรณ์
import numpy as np
import cntk as C
def create_reader(path, input_dim, output_dim, rnd_order, sweeps):
x_strm = C.io.StreamDef(field='predictors', shape=input_dim, is_sparse=False)
y_strm = C.io.StreamDef(field='medval', shape=output_dim, is_sparse=False)
streams = C.io.StreamDefs(x_src=x_strm, y_src=y_strm)
deserial = C.io.CTFDeserializer(path, streams)
mb_src = C.io.MinibatchSource(deserial, randomize=rnd_order, max_sweeps=sweeps)
return mb_src
def mb_accuracy(mb, x_var, y_var, model, delta):
num_correct = 0
num_wrong = 0
x_mat = mb[x_var].asarray()
y_mat = mb[y_var].asarray()
for i in range(mb[x_var].shape[0]):
v = model.eval(x_mat[i])
y = y_mat[i]
if np.abs(v[0,0] – y[0,0]) < delta:
num_correct += 1
else:
num_wrong += 1
return (num_correct * 100.0)/(num_correct + num_wrong)
def main():
print("Using CNTK version = " + str(C.__version__) + "\n")
input_dim = 5
hidden_dim = 20
output_dim = 1
train_file = ".\\...\\" #provide the name of the training file(80 data items)
test_file = ".\\...\\" #provide the name of the test file(20 data items)
X = C.ops.input_variable(input_dim, np.float32)
Y = C.ops.input_variable(output_dim, np.float32)
with C.layers.default_options(init=C.initializer.uniform(scale=0.01, seed=1)):
hLayer = C.layers.Dense(hidden_dim, activation=C.ops.tanh, name='hidLayer')(X)
oLayer = C.layers.Dense(output_dim, activation=None, name='outLayer')(hLayer)
model = C.ops.alias(oLayer)
tr_loss = C.squared_error(model, Y)
max_iter = 3000
batch_size = 5
base_learn_rate = 0.02
sch = C.learning_parameter_schedule([base_learn_rate, base_learn_rate/2], minibatch_size=batch_size, epoch_size=int((max_iter*batch_size)/2))
learner = C.sgd(model.parameters, sch)
trainer = C.Trainer(model, (tr_loss), [learner])
rdr = create_reader(train_file, input_dim, output_dim, rnd_order=True, sweeps=C.io.INFINITELY_REPEAT)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
for i in range(0, max_iter):
curr_batch = rdr.next_minibatch(batch_size, input_map=boston_input_map) trainer.train_minibatch(curr_batch)
if i % int(max_iter/10) == 0:
mcee = trainer.previous_minibatch_loss_average
acc = mb_accuracy(curr_batch, X, Y, model, delta=3.00)
print("batch %4d: mean squared error = %8.4f, accuracy = %5.2f%% " \ % (i, mcee, acc))
print("\nEvaluating test data \n")
rdr = create_reader(test_file, input_dim, output_dim, rnd_order=False, sweeps=1)
boston_input_map = { X : rdr.streams.x_src, Y : rdr.streams.y_src }
num_test = 20
all_test = rdr.next_minibatch(num_test, input_map=boston_input_map)
acc = mb_accuracy(all_test, X, Y, model, delta=3.00)
print("Prediction accuracy = %0.2f%%" % acc)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])
if __name__== ”__main__”:
main()เอาต์พุต
Using CNTK version = 2.7
batch 0: mean squared error = 385.6727, accuracy = 0.00%
batch 300: mean squared error = 41.6229, accuracy = 20.00%
batch 600: mean squared error = 28.7667, accuracy = 40.00%
batch 900: mean squared error = 48.6435, accuracy = 40.00%
batch 1200: mean squared error = 77.9562, accuracy = 80.00%
batch 1500: mean squared error = 7.8342, accuracy = 60.00%
batch 1800: mean squared error = 47.7062, accuracy = 60.00%
batch 2100: mean squared error = 40.5068, accuracy = 40.00%
batch 2400: mean squared error = 46.5023, accuracy = 40.00%
batch 2700: mean squared error = 15.6235, accuracy = 60.00%
Evaluating test data
Prediction accuracy = 64.00%
Predicting median home value for feature/predictor values:
[0.09 50. 4.5 17. 350.]
Predicted value is:
$21.02(x1000)บันทึกโมเดลที่ได้รับการฝึกฝน
ชุดข้อมูลค่าบ้านบอสตันนี้มีข้อมูลเพียง 506 รายการ (ซึ่งเราฟ้องเพียง 100 รายการ) ดังนั้นจะใช้เวลาเพียงไม่กี่วินาทีในการฝึกแบบจำลองตัวปรับแรงดัน NN แต่การฝึกชุดข้อมูลขนาดใหญ่ที่มีรายการข้อมูลนับแสนรายการอาจใช้เวลาหลายชั่วโมงหรือหลายวัน
เราสามารถบันทึกโมเดลของเราเพื่อที่เราจะได้ไม่ต้องเก็บมันไว้ตั้งแต่ต้น ด้วยความช่วยเหลือในการทำตามรหัส Python เราสามารถบันทึก NN ที่ได้รับการฝึกฝนของเรา -
nn_regressor = “.\\neuralregressor.model” #provide the name of the file
model.save(nn_regressor, format=C.ModelFormat.CNTKv2)ต่อไปนี้เป็นอาร์กิวเมนต์ของฟังก์ชัน save () ที่ใช้ด้านบน -
ชื่อไฟล์เป็นอาร์กิวเมนต์แรกของ save()ฟังก์ชัน นอกจากนี้ยังสามารถเขียนพร้อมกับเส้นทางของไฟล์
พารามิเตอร์อื่นคือไฟล์ format พารามิเตอร์ซึ่งมีค่าเริ่มต้น C.ModelFormat.CNTKv2.
กำลังโหลดแบบจำลองที่ผ่านการฝึกอบรม
เมื่อคุณบันทึกโมเดลที่ฝึกแล้วการโหลดโมเดลนั้นทำได้ง่ายมาก เราต้องใช้ฟังก์ชัน load () เท่านั้น ลองตรวจสอบสิ่งนี้ในตัวอย่างต่อไปนี้ -
import numpy as np
import cntk as C
model = C.ops.functions.Function.load(“.\\neuralregressor.model”)
np.set_printoptions(precision = 2, suppress=True)
unknown = np.array([[0.09, 50.00, 4.5, 17.00, 350.00], dtype=np.float32)
print("\nPredicting area median home value for feature/predictor values: ")
print(unknown[0])
pred_prob = model.eval({X: unknown)
print("\nPredicted value is: ")
print(“$%0.2f (x1000)” %pred_value[0,0])ข้อดีของโมเดลที่บันทึกไว้คือเมื่อคุณโหลดโมเดลที่บันทึกไว้แล้วจะสามารถใช้งานได้เหมือนกับว่าโมเดลนั้นเพิ่งได้รับการฝึกฝนมา
CNTK - รูปแบบการจำแนกประเภท
บทนี้จะช่วยให้คุณเข้าใจวิธีการวัดประสิทธิภาพของรูปแบบการจำแนกใน CNTK เริ่มต้นด้วยเมทริกซ์ความสับสน
เมทริกซ์ความสับสน
เมทริกซ์ความสับสน - ตารางที่มีผลลัพธ์ที่คาดการณ์ไว้เทียบกับผลลัพธ์ที่คาดไว้เป็นวิธีที่ง่ายที่สุดในการวัดประสิทธิภาพของปัญหาการจำแนกประเภทโดยที่ผลลัพธ์อาจเป็นประเภทสองประเภทขึ้นไป
เพื่อให้เข้าใจถึงวิธีการทำงานเราจะสร้างเมทริกซ์ความสับสนสำหรับรูปแบบการจำแนกไบนารีที่คาดการณ์ว่าธุรกรรมบัตรเครดิตเป็นเรื่องปกติหรือเป็นการฉ้อโกง ดังต่อไปนี้ -
| การฉ้อโกงที่เกิดขึ้นจริง | ปกติจริง | |
|---|---|---|
| Predicted fraud |
บวกจริง |
บวกเท็จ |
| Predicted normal |
ลบเท็จ |
ลบจริง |
ดังที่เราเห็นเมทริกซ์ความสับสนตัวอย่างข้างต้นมี 2 คอลัมน์คอลัมน์หนึ่งสำหรับการฉ้อโกงคลาสและอื่น ๆ สำหรับคลาสปกติ ในทำนองเดียวกันเรามี 2 แถวแถวหนึ่งถูกเพิ่มสำหรับการฉ้อโกงคลาสและอื่น ๆ จะถูกเพิ่มสำหรับคลาสปกติ ต่อไปนี้เป็นคำอธิบายของคำศัพท์ที่เกี่ยวข้องกับเมทริกซ์ความสับสน -
True Positives - เมื่อทั้งคลาสจริงและคลาสของจุดข้อมูลที่คาดการณ์ไว้คือ 1
True Negatives - เมื่อทั้งคลาสจริงและคลาสที่คาดการณ์ไว้ของจุดข้อมูลเป็น 0
False Positives - เมื่อคลาสจริงของจุดข้อมูลคือ 0 และคลาสของจุดข้อมูลที่คาดการณ์ไว้คือ 1
False Negatives - เมื่อคลาสจริงของจุดข้อมูลคือ 1 และคลาสของจุดข้อมูลที่คาดการณ์ไว้คือ 0
มาดูกันว่าเราจะคำนวณจำนวนสิ่งต่าง ๆ จากเมทริกซ์ความสับสนได้อย่างไร -
Accuracy- เป็นจำนวนการคาดคะเนที่ถูกต้องซึ่งทำโดยรูปแบบการจำแนก ML ของเรา สามารถคำนวณได้ด้วยความช่วยเหลือของสูตรต่อไปนี้ -
Precision− บอกให้เราทราบว่ามีตัวอย่างจำนวนเท่าใดที่ทำนายได้อย่างถูกต้องจากตัวอย่างทั้งหมดที่เราคาดการณ์ไว้ สามารถคำนวณได้ด้วยความช่วยเหลือของสูตรต่อไปนี้ -
Recall or Sensitivity- การเรียกคืนคือจำนวนผลบวกที่ส่งคืนโดยรูปแบบการจำแนก ML ของเรา กล่าวอีกนัยหนึ่งก็คือจะบอกให้เราทราบว่าโมเดลนั้นตรวจพบการฉ้อโกงในชุดข้อมูลได้กี่กรณี สามารถคำนวณได้ด้วยความช่วยเหลือของสูตรต่อไปนี้ -
Specificity- ตรงข้ามกับการเรียกคืนจะให้จำนวนเชิงลบที่ส่งคืนโดยรูปแบบการจำแนก ML ของเรา สามารถคำนวณได้ด้วยความช่วยเหลือของสูตรต่อไปนี้ -




F- วัด
เราสามารถใช้ F-measure เป็นอีกทางเลือกหนึ่งของ Confusion matrix เหตุผลหลักเบื้องหลังนี้เราไม่สามารถเพิ่มการเรียกคืนและความแม่นยำสูงสุดในเวลาเดียวกันได้ เมตริกเหล่านี้มีความสัมพันธ์ที่แน่นแฟ้นมากและสามารถเข้าใจได้ด้วยความช่วยเหลือของตัวอย่างต่อไปนี้ -
สมมติว่าเราต้องการใช้แบบจำลอง DL เพื่อจำแนกตัวอย่างเซลล์ว่าเป็นมะเร็งหรือปกติ ที่นี่เพื่อให้ได้ความแม่นยำสูงสุดเราจำเป็นต้องลดจำนวนการคาดการณ์ลงเหลือ 1 แม้ว่าสิ่งนี้จะช่วยให้เราเข้าถึงความแม่นยำได้ประมาณ 100 เปอร์เซ็นต์ แต่การเรียกคืนจะต่ำมาก
ในทางกลับกันหากเราต้องการเรียกคืนสูงสุดเราจำเป็นต้องคาดการณ์ให้ได้มากที่สุด แม้ว่าสิ่งนี้จะช่วยให้เราจำได้ประมาณ 100 เปอร์เซ็นต์ แต่ความแม่นยำจะต่ำมาก
ในทางปฏิบัติเราต้องหาวิธีที่สมดุลระหว่างความแม่นยำและความจำ เมตริกการวัดค่า F ช่วยให้เราสามารถทำได้เนื่องจากเป็นการแสดงค่าเฉลี่ยฮาร์มอนิกระหว่างความแม่นยำและการเรียกคืน

สูตรนี้เรียกว่า F1-measure โดยคำพิเศษที่เรียกว่า B ถูกตั้งค่าเป็น 1 เพื่อให้ได้อัตราส่วนความแม่นยำและการเรียกคืนที่เท่ากัน เพื่อเน้นย้ำถึงการระลึกถึงเราสามารถตั้งค่าปัจจัย B เป็น 2 ในทางกลับกันเพื่อเน้นความแม่นยำเราสามารถตั้งค่าปัจจัย B เป็น 0.5
ใช้ CNTK เพื่อวัดประสิทธิภาพการจัดหมวดหมู่
ในส่วนก่อนหน้านี้เราได้สร้างแบบจำลองการจำแนกโดยใช้ชุดข้อมูลดอกไอริส ที่นี่เราจะวัดประสิทธิภาพโดยใช้เมทริกซ์ความสับสนและเมตริกการวัดค่า F
การสร้างเมทริกซ์ความสับสน
เราได้สร้างแบบจำลองแล้วดังนั้นเราจึงสามารถเริ่มกระบวนการตรวจสอบความถูกต้องซึ่งรวมถึง confusion matrixในขณะเดียวกัน ขั้นแรกเราจะสร้างเมทริกซ์ความสับสนด้วยความช่วยเหลือของconfusion_matrix ฟังก์ชันจาก scikit-learn. สำหรับสิ่งนี้เราจำเป็นต้องมีฉลากจริงสำหรับตัวอย่างทดสอบของเราและฉลากที่คาดการณ์ไว้สำหรับตัวอย่างทดสอบเดียวกัน
ลองคำนวณเมทริกซ์ความสับสนโดยใช้รหัส python ต่อไปนี้ -
from sklearn.metrics import confusion_matrix
y_true = np.argmax(y_test, axis=1)
y_pred = np.argmax(z(X_test), axis=1)
matrix = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(matrix)เอาต์พุต
[[10 0 0]
[ 0 1 9]
[ 0 0 10]]นอกจากนี้เรายังสามารถใช้ฟังก์ชันแผนที่ความร้อนเพื่อแสดงภาพเมทริกซ์ความสับสนได้ดังนี้ -
import seaborn as sns
import matplotlib.pyplot as plt
g = sns.heatmap(matrix,
annot=True,
xticklabels=label_encoder.classes_.tolist(),
yticklabels=label_encoder.classes_.tolist(),
cmap='Blues')
g.set_yticklabels(g.get_yticklabels(), rotation=0)
plt.show()
เราควรมีหมายเลขประสิทธิภาพเดียวที่เราสามารถใช้เพื่อเปรียบเทียบรุ่นได้ สำหรับสิ่งนี้เราจำเป็นต้องคำนวณข้อผิดพลาดในการจำแนกโดยใช้classification_error จากแพ็กเกจเมตริกใน CNTK เมื่อเสร็จสิ้นขณะสร้างโมเดลการจำแนก
ตอนนี้ในการคำนวณข้อผิดพลาดในการจำแนกให้ดำเนินการวิธีการทดสอบกับฟังก์ชันการสูญเสียด้วยชุดข้อมูล หลังจากนั้น CNTK จะนำตัวอย่างที่เราให้ไว้เป็นอินพุตสำหรับฟังก์ชันนี้และทำการคาดคะเนตามคุณสมบัติการป้อนข้อมูล X_test.
loss.test([X_test, y_test])เอาต์พุต
{'metric': 0.36666666666, 'samples': 30}การใช้มาตรการ F
สำหรับการใช้ F-Measures CNTK ยังมีฟังก์ชันที่เรียกว่า fmeasures เราสามารถใช้ฟังก์ชันนี้ในขณะที่ฝึก NN โดยการแทนที่เซลล์cntk.metrics.classification_errorพร้อมโทร cntk.losses.fmeasure เมื่อกำหนดฟังก์ชันโรงงานเกณฑ์ดังนี้ -
import cntk
@cntk.Function
def criterion_factory(output, target):
loss = cntk.losses.cross_entropy_with_softmax(output, target)
metric = cntk.losses.fmeasure(output, target)
return loss, metricหลังจากใช้ฟังก์ชัน cntk.losses.fmeasure เราจะได้ผลลัพธ์ที่แตกต่างกันสำหรับไฟล์ loss.test เรียกวิธีการดังต่อไปนี้ -
loss.test([X_test, y_test])เอาต์พุต
{'metric': 0.83101488749, 'samples': 30}CNTK - แบบจำลองการถดถอย
ในที่นี้เราจะศึกษาเกี่ยวกับการวัดประสิทธิภาพเกี่ยวกับแบบจำลองการถดถอย
พื้นฐานของการตรวจสอบความถูกต้องของแบบจำลองการถดถอย
ดังที่เราทราบว่าแบบจำลองการถดถอยแตกต่างจากแบบจำลองการจำแนกประเภทในแง่ที่ว่าไม่มีการวัดแบบไบนารีว่าถูกหรือผิดสำหรับตัวอย่างของแต่ละบุคคล ในแบบจำลองการถดถอยเราต้องการวัดว่าการทำนายนั้นใกล้เคียงกับค่าจริงมากเพียงใด ยิ่งค่าการทำนายใกล้เคียงกับผลลัพธ์ที่คาดหวังมากเท่าใดโมเดลก็จะทำงานได้ดีขึ้นเท่านั้น
ในที่นี้เราจะวัดประสิทธิภาพของ NN ที่ใช้สำหรับการถดถอยโดยใช้ฟังก์ชันอัตราความผิดพลาดที่แตกต่างกัน
กำลังคำนวณขอบข้อผิดพลาด
ดังที่ได้กล่าวไว้ก่อนหน้านี้ในขณะที่ตรวจสอบความถูกต้องของแบบจำลองการถดถอยเราไม่สามารถบอกได้ว่าการคาดคะเนถูกหรือผิด เราต้องการให้การทำนายของเราใกล้เคียงกับมูลค่าที่แท้จริงมากที่สุด แต่ข้อผิดพลาดเล็กน้อยสามารถยอมรับได้ที่นี่
สูตรคำนวณระยะขอบข้อผิดพลาดมีดังนี้ -

ที่นี่
Predicted value = ระบุ y ด้วยหมวก
Real value = ทำนายโดย y
ขั้นแรกเราต้องคำนวณระยะห่างระหว่างค่าที่คาดการณ์และมูลค่าจริง จากนั้นเพื่อให้ได้อัตราความผิดพลาดโดยรวมเราต้องรวมระยะทางกำลังสองเหล่านี้และคำนวณค่าเฉลี่ย นี้เรียกว่าmean squared ฟังก์ชันข้อผิดพลาด
แต่ถ้าเราต้องการตัวเลขประสิทธิภาพที่แสดงความคลาดเคลื่อนเราจำเป็นต้องมีสูตรที่แสดงถึงข้อผิดพลาดที่แน่นอน สูตรสำหรับmean absolute ฟังก์ชันข้อผิดพลาดมีดังนี้ -

สูตรข้างต้นใช้ระยะห่างสัมบูรณ์ระหว่างค่าที่คาดการณ์และมูลค่าจริง
ใช้ CNTK เพื่อวัดประสิทธิภาพการถดถอย
ที่นี่เราจะดูวิธีการใช้เมตริกต่างๆที่เราพูดถึงร่วมกับ CNTK เราจะใช้แบบจำลองการถดถอยซึ่งทำนายไมล์ต่อแกลลอนสำหรับรถยนต์โดยใช้ขั้นตอนที่ระบุด้านล่าง
ขั้นตอนการดำเนินการ
Step 1 - ขั้นแรกเราต้องนำเข้าส่วนประกอบที่จำเป็นจาก cntk แพคเกจดังนี้ -
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import reluStep 2 - ต่อไปเราต้องกำหนดฟังก์ชันการเปิดใช้งานเริ่มต้นโดยใช้ไฟล์ default_optionsฟังก์ชั่น. จากนั้นสร้างชุดเลเยอร์ตามลำดับใหม่และจัดเตรียมเลเยอร์หนาแน่นสองชั้นพร้อมเซลล์ประสาท 64 เซลล์ จากนั้นเพิ่มเลเยอร์ Dense เพิ่มเติม (ซึ่งจะทำหน้าที่เป็นเลเยอร์เอาต์พุต) ให้กับชุดเลเยอร์ลำดับและให้ 1 เซลล์ประสาทโดยไม่มีการกระตุ้นดังนี้ -
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])Step 3- เมื่อสร้างเครือข่ายแล้วเราจำเป็นต้องสร้างคุณสมบัติการป้อนข้อมูล เราต้องแน่ใจว่ามันมีรูปร่างเหมือนกับคุณสมบัติที่เรากำลังจะใช้ในการฝึก
features = input_variable(X.shape[1])Step 4 - ตอนนี้เราต้องสร้างใหม่ input_variable ที่มีขนาด 1 จะใช้เพื่อเก็บค่าที่คาดไว้สำหรับ NN
target = input_variable(1)
z = model(features)ตอนนี้เราจำเป็นต้องฝึกโมเดลและเพื่อที่จะทำเช่นนั้นเราจะแยกชุดข้อมูลและดำเนินการก่อนการประมวลผลโดยใช้ขั้นตอนการใช้งานต่อไปนี้ -
Step 5− ขั้นแรกให้นำเข้า StandardScaler จาก sklearn.preprocessing เพื่อรับค่าระหว่าง -1 ถึง +1 สิ่งนี้จะช่วยเราในการป้องกันปัญหาการไล่ระดับสีใน NN
from sklearn.preprocessing import StandardScalarStep 6 - จากนั้นนำเข้า train_test_split จาก sklearn.model_selection ดังต่อไปนี้
from sklearn.model_selection import train_test_splitStep 7 - วางไฟล์ mpg คอลัมน์จากชุดข้อมูลโดยใช้ dropวิธี. ในที่สุดแยกชุดข้อมูลออกเป็นชุดการฝึกอบรมและการตรวจสอบความถูกต้องโดยใช้train_test_split ฟังก์ชันดังต่อไปนี้ -
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)Step 8 - ตอนนี้เราจำเป็นต้องสร้าง input_variable อื่นที่มีขนาด 1 ซึ่งจะใช้เพื่อเก็บค่าที่คาดไว้สำหรับ NN
target = input_variable(1)
z = model(features)เราได้แยกและประมวลผลข้อมูลล่วงหน้าแล้วตอนนี้เราต้องฝึก NN เช่นเดียวกับในส่วนก่อนหน้าในขณะที่สร้างแบบจำลองการถดถอยเราจำเป็นต้องกำหนดการรวมกันของการสูญเสียและmetric ฟังก์ชั่นในการฝึกโมเดล
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metricตอนนี้เรามาดูวิธีใช้แบบจำลองที่ได้รับการฝึกฝน สำหรับแบบจำลองของเราเราจะใช้เกณฑ์การผลิตเป็นเกณฑ์การสูญเสียและเมตริก
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)ตัวอย่างการใช้งานที่สมบูรณ์
from cntk import default_option, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import relu
with default_options(activation=relu):
model = Sequential([Dense(64),Dense(64),Dense(1,activation=None)])
features = input_variable(X.shape[1])
target = input_variable(1)
z = model(features)
from sklearn.preprocessing import StandardScalar
from sklearn.model_selection import train_test_split
x = df_cars.drop(columns=[‘mpg’]).values.astype(np.float32)
y=df_cars.iloc[: , 0].values.reshape(-1, 1).astype(np.float32)
scaler = StandardScaler()
X = scaler.fit_transform(x)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
target = input_variable(1)
z = model(features)
import cntk
def absolute_error(output, target):
return cntk.ops.reduce_mean(cntk.ops.abs(output – target))
@ cntk.Function
def criterion_factory(output, target):
loss = squared_error(output, target)
metric = absolute_error(output, target)
return loss, metric
from cntk.losses import squared_error
from cntk.learners import sgd
from cntk.logging import ProgressPrinter
progress_printer = ProgressPrinter(0)
loss = criterion_factory (z, target)
learner = sgd(z.parameters, 0.001)
training_summary=loss.train((x_train,y_train),parameter_learners=[learner],callbacks=[progress_printer],minibatch_size=16,max_epochs=10)เอาต์พุต
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.001
690 690 24.9 24.9 16
654 636 24.1 23.7 48
[………]ในการตรวจสอบความถูกต้องของแบบจำลองการถดถอยของเราเราจำเป็นต้องตรวจสอบให้แน่ใจว่าแบบจำลองจัดการข้อมูลใหม่เช่นเดียวกับที่ทำกับข้อมูลการฝึกอบรม สำหรับสิ่งนี้เราต้องเรียกใช้ไฟล์test วิธีการ loss และ metric รวมกับข้อมูลการทดสอบดังนี้ -
loss.test([X_test, y_test])เอาต์พุต
{'metric': 1.89679785619, 'samples': 79}CNTK - ชุดข้อมูลหน่วยความจำไม่เพียงพอ
ในบทนี้จะอธิบายวิธีการวัดประสิทธิภาพของชุดข้อมูลที่ไม่อยู่ในหน่วยความจำ
ในส่วนก่อนหน้านี้เราได้พูดถึงวิธีการต่างๆในการตรวจสอบประสิทธิภาพของ NN ของเรา แต่วิธีการที่เราได้กล่าวถึงนั้นเป็นวิธีการที่เกี่ยวข้องกับชุดข้อมูลที่พอดีกับหน่วยความจำ
ที่นี่คำถามคืออะไรเกี่ยวกับชุดข้อมูลหน่วยความจำที่ไม่อยู่ในหน่วยความจำเนื่องจากในสถานการณ์การผลิตเราต้องการข้อมูลจำนวนมากเพื่อฝึกอบรม NN. ในส่วนนี้เราจะพูดถึงวิธีการวัดประสิทธิภาพเมื่อทำงานกับแหล่งมินิแบทช์และลูปมินิแบทช์ด้วยตนเอง
แหล่งที่มาของมินิแบทช์
ในขณะที่ทำงานกับชุดข้อมูลที่ไม่อยู่ในหน่วยความจำเช่นแหล่งที่มาของมินิแบทช์เราต้องการการตั้งค่าสำหรับการสูญเสียและเมตริกที่แตกต่างกันเล็กน้อยกว่าการตั้งค่าที่เราใช้ในขณะที่ทำงานกับชุดข้อมูลขนาดเล็กเช่นชุดข้อมูลในหน่วยความจำ ขั้นแรกเราจะดูวิธีการตั้งค่าวิธีป้อนข้อมูลไปยังผู้ฝึกสอนของโมเดล NN
ต่อไปนี้เป็นขั้นตอนการติดตั้ง
Step 1 - อันดับแรกจาก cntk.โมดูล io นำเข้าส่วนประกอบสำหรับสร้างแหล่งมินิแบทช์ดังต่อไปนี้ −
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer,
INFINITY_REPEATStep 2 - จากนั้นสร้างฟังก์ชันใหม่ชื่อ say create_datasource. ฟังก์ชันนี้จะมีสองพารามิเตอร์คือชื่อไฟล์และขีด จำกัด โดยมีค่าเริ่มต้นเป็นINFINITELY_REPEAT.
def create_datasource(filename, limit =INFINITELY_REPEAT)Step 3 - ตอนนี้ภายในฟังก์ชั่นโดยใช้ StreamDefคลาสสร้างนิยามสตรีมสำหรับเลเบลที่อ่านจากฟิลด์เลเบลที่มีคุณสมบัติสามอย่าง เราต้องตั้งค่าด้วยis_sparse ถึง False ดังต่อไปนี้
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)Step 4 - จากนั้นสร้างเพื่ออ่านคุณสมบัติที่ยื่นจากไฟล์อินพุตสร้างอินสแตนซ์อื่นของ StreamDef ดังต่อไปนี้.
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)Step 5 - ตอนนี้เริ่มต้น CTFDeserializerคลาสอินสแตนซ์ ระบุชื่อไฟล์และสตรีมที่เราต้องการเพื่อยกเลิกการกำหนดค่าตามลำดับดังนี้ -
deserializer = CTFDeserializer(filename, StreamDefs(labels=
label_stream, features=features_stream)Step 6 - ต่อไปเราต้องสร้างอินสแตนซ์ของ minisourceBatch โดยใช้ deserializer ดังนี้ -
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_sourceStep 7- ในที่สุดเราจำเป็นต้องจัดหาแหล่งฝึกอบรมและทดสอบซึ่งเราได้สร้างไว้ในส่วนก่อนหน้านี้ด้วย เราใช้ชุดข้อมูลดอกไอริส
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)เมื่อคุณสร้าง MinibatchSourceเช่นเราต้องฝึกมัน เราสามารถใช้ตรรกะการฝึกแบบเดียวกับที่ใช้เมื่อเราทำงานกับชุดข้อมูลในหน่วยความจำขนาดเล็ก ที่นี่เราจะใช้MinibatchSource เช่นเป็นอินพุตสำหรับวิธีการรถไฟในฟังก์ชันการสูญเสียดังต่อไปนี้ -
ต่อไปนี้เป็นขั้นตอนการติดตั้ง
Step 1 - ในการบันทึกผลลัพธ์ของเซสชันการฝึกอบรมขั้นแรกให้นำเข้าไฟล์ ProgressPrinter จาก cntk.logging โมดูลดังนี้ -
from cntk.logging import ProgressPrinterStep 2 - ถัดไปในการตั้งค่าเซสชันการฝึกอบรมให้นำเข้าไฟล์ trainer และ training_session จาก cntk.train โมดูลดังนี้
from cntk.train import Trainer, training_sessionStep 3 - ตอนนี้เราต้องกำหนดชุดค่าคงที่เช่น minibatch_size, samples_per_epoch และ num_epochs ดังต่อไปนี้
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochsStep 4 - ถัดไปเพื่อที่จะทราบวิธีการอ่านข้อมูลระหว่างการฝึกอบรมใน CNTK เราจำเป็นต้องกำหนดการแมประหว่างตัวแปรอินพุตสำหรับเครือข่ายและสตรีมในแหล่งมินิแบทช์
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}Step 5 - ถัดจากบันทึกผลลัพธ์ของกระบวนการฝึกอบรมให้เริ่มต้นไฟล์ progress_printer ตัวแปรด้วยไฟล์ ProgressPrinterตัวอย่าง. นอกจากนี้ให้เริ่มต้นไฟล์trainer และระบุรุ่นดังต่อไปนี้
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labelsStep 6 - ในที่สุดเพื่อเริ่มกระบวนการฝึกอบรมเราจำเป็นต้องเรียกใช้ไฟล์ training_session ฟังก์ชันดังต่อไปนี้ -
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()เมื่อเราฝึกโมเดลแล้วเราสามารถเพิ่มการตรวจสอบความถูกต้องให้กับการตั้งค่านี้ได้โดยใช้ไฟล์ TestConfig วัตถุและกำหนดให้กับไฟล์ test_config อาร์กิวเมนต์คำหลักของ train_session ฟังก์ชัน
ต่อไปนี้เป็นขั้นตอนการติดตั้ง
Step 1 - ขั้นแรกเราต้องนำเข้าไฟล์ TestConfig คลาสจากโมดูล cntk.train ดังต่อไปนี้
from cntk.train import TestConfigStep 2 - ตอนนี้เราจำเป็นต้องสร้างอินสแตนซ์ใหม่ของไฟล์ TestConfig กับ test_source เป็นอินพุต
Test_config = TestConfig(test_source)ตัวอย่างที่สมบูรณ์
from cntk.io import StreamDef, StreamDefs, MinibatchSource, CTFDeserializer, INFINITY_REPEAT
def create_datasource(filename, limit =INFINITELY_REPEAT)
labels_stream = StreamDef(field=’labels’, shape=3, is_sparse=False)
feature_stream = StreamDef(field=’features’, shape=4, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(labels=label_stream, features=features_stream)
Minibatch_source = MinibatchSource(deserializer, randomize=True, max_sweeps=limit)
return minibatch_source
training_source = create_datasource(‘Iris_train.ctf’)
test_source = create_datasource(‘Iris_test.ctf’, limit=1)
from cntk.logging import ProgressPrinter
from cntk.train import Trainer, training_session
minbatch_size = 16
samples_per_epoch = 150
num_epochs = 30
max_samples = samples_per_epoch * num_epochs
input_map = {
features: training_source.streams.features,
labels: training_source.streams.labels
}
progress_writer = ProgressPrinter(0)
trainer: training_source.streams.labels
session = training_session(trainer,
mb_source=training_source,
mb_size=minibatch_size,
model_inputs_to_streams=input_map,
max_samples=max_samples,
test_config=test_config)
session.train()
from cntk.train import TestConfig
Test_config = TestConfig(test_source)เอาต์พุต
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.57 1.57 0.214 0.214 16
1.38 1.28 0.264 0.289 48
[………]
Finished Evaluation [1]: Minibatch[1-1]:metric = 69.65*30;ห่วงมินิแบทช์ด้วยตนเอง
ดังที่เราเห็นข้างต้นการวัดประสิทธิภาพของแบบจำลอง NN ของเราในระหว่างและหลังการฝึกอบรมทำได้ง่ายโดยใช้เมตริกเมื่อฝึกกับ API ปกติใน CNTK แต่ในอีกด้านหนึ่งสิ่งต่างๆจะไม่ง่ายอย่างนั้นในขณะที่ทำงานกับมินิแบทช์แบบแมนนวล
ที่นี่เรากำลังใช้โมเดลที่ระบุด้านล่างโดยมี 4 อินพุตและ 3 เอาต์พุตจากชุดข้อมูล Iris Flower ซึ่งสร้างขึ้นในส่วนก่อนหน้านี้ด้วย
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)จากนั้นการสูญเสียสำหรับแบบจำลองจะถูกกำหนดเป็นการรวมกันของฟังก์ชันการสูญเสียเอนโทรปีและเมตริกการวัดค่า F ตามที่ใช้ในส่วนก่อนหน้า เราจะใช้ไฟล์criterion_factory ยูทิลิตี้เพื่อสร้างสิ่งนี้เป็นวัตถุฟังก์ชัน CNTK ดังที่แสดงด้านล่าง
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}ตอนนี้เมื่อเราได้กำหนดฟังก์ชันการสูญเสียแล้วเราจะดูว่าเราจะใช้มันในเทรนเนอร์ได้อย่างไรเพื่อตั้งค่าเซสชั่นการฝึกด้วยตนเอง
ต่อไปนี้เป็นขั้นตอนการติดตั้ง -
Step 1 - ขั้นแรกเราต้องนำเข้าแพ็คเกจที่จำเป็นเช่น numpy และ pandas เพื่อโหลดและประมวลผลข้อมูลล่วงหน้า
import pandas as pd
import numpy as npStep 2 - ถัดไปในการบันทึกข้อมูลระหว่างการฝึกอบรมให้นำเข้าไฟล์ ProgressPrinter class ดังนี้
from cntk.logging import ProgressPrinterStep 3 - จากนั้นเราต้องนำเข้าโมดูลเทรนเนอร์จากโมดูล cntk.train ดังนี้ -
from cntk.train import TrainerStep 4 - จากนั้นสร้างอินสแตนซ์ใหม่ของ ProgressPrinter ดังต่อไปนี้ -
progress_writer = ProgressPrinter(0)Step 5 - ตอนนี้เราจำเป็นต้องเริ่มต้นผู้ฝึกสอนด้วยพารามิเตอร์การสูญเสียผู้เรียนและ progress_writer ดังต่อไปนี้ -
trainer = Trainer(z, loss, learner, progress_writer)Step 6− ต่อไปเพื่อฝึกโมเดลเราจะสร้างลูปที่จะวนซ้ำชุดข้อมูล 30 ครั้ง นี่จะเป็นห่วงการฝึกด้านนอก
for _ in range(0,30):Step 7- ตอนนี้เราต้องโหลดข้อมูลจากดิสก์โดยใช้แพนด้า จากนั้นเพื่อโหลดชุดข้อมูลในmini-batches, ตั้งค่า chunksize อาร์กิวเมนต์คำหลักถึง 16
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)Step 8 - ตอนนี้สร้างการฝึกอบรมภายในสำหรับการวนซ้ำเพื่อวนซ้ำในแต่ละครั้ง mini-batches.
for df_batch in input_data:Step 9 - ตอนนี้อยู่ในลูปนี้อ่านสี่คอลัมน์แรกโดยใช้ iloc ดัชนีเป็นไฟล์ features เพื่อฝึกจากและแปลงเป็น float32 -
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)Step 10 - ตอนนี้อ่านคอลัมน์สุดท้ายเป็นป้ายกำกับที่จะฝึกดังนี้ -
label_values = df_batch.iloc[:,-1]Step 11 - ต่อไปเราจะใช้เวกเตอร์แบบ one-hot เพื่อแปลงสตริงป้ายกำกับเป็นการนำเสนอตัวเลขดังนี้ -
label_values = label_values.map(lambda x: label_mapping[x])Step 12- หลังจากนั้นนำเสนอป้ายกำกับเป็นตัวเลข จากนั้นแปลงเป็นอาร์เรย์ numpy ดังนั้นจึงง่ายต่อการทำงานกับพวกเขาดังนี้ -
label_values = label_values.valuesStep 13 - ตอนนี้เราจำเป็นต้องสร้างอาร์เรย์จำนวนใหม่ที่มีจำนวนแถวเท่ากับค่าป้ายกำกับที่เราแปลง
encoded_labels = np.zeros((label_values.shape[0], 3))Step 14 - ตอนนี้ในการสร้างป้ายที่เข้ารหัสแบบร้อนเดียวให้เลือกคอลัมน์ตามค่าป้ายกำกับตัวเลข
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.Step 15 - ในที่สุดเราต้องเรียกใช้ไฟล์ train_minibatch วิธีการบนเทรนเนอร์และจัดเตรียมคุณสมบัติและป้ายกำกับสำหรับมินิแบทช์
trainer.train_minibatch({features: feature_values, labels: encoded_labels})ตัวอย่างที่สมบูรณ์
from cntk import default_options, input_variable
from cntk.layers import Dense, Sequential
from cntk.ops import log_softmax, relu, sigmoid
from cntk.learners import sgd
model = Sequential([
Dense(4, activation=sigmoid),
Dense(3, activation=log_softmax)
])
features = input_variable(4)
labels = input_variable(3)
z = model(features)
import cntk
from cntk.losses import cross_entropy_with_softmax, fmeasure
@cntk.Function
def criterion_factory(outputs, targets):
loss = cross_entropy_with_softmax(outputs, targets)
metric = fmeasure(outputs, targets, beta=1)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, 0.1)
label_mapping = {
'Iris-setosa': 0,
'Iris-versicolor': 1,
'Iris-virginica': 2
}
import pandas as pd
import numpy as np
from cntk.logging import ProgressPrinter
from cntk.train import Trainer
progress_writer = ProgressPrinter(0)
trainer = Trainer(z, loss, learner, progress_writer)
for _ in range(0,30):
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]),
label_values] = 1.
trainer.train_minibatch({features: feature_values, labels: encoded_labels})เอาต์พุต
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]ในผลลัพธ์ข้างต้นเราได้รับทั้งผลลัพธ์สำหรับการสูญเสียและเมตริกระหว่างการฝึกอบรม เป็นเพราะเรารวมเมตริกและการสูญเสียไว้ในอ็อบเจ็กต์ฟังก์ชันและใช้เครื่องพิมพ์ความคืบหน้าในการกำหนดค่าเทรนเนอร์
ในการประเมินประสิทธิภาพของโมเดลเราจำเป็นต้องปฏิบัติงานเช่นเดียวกับการฝึกโมเดล แต่คราวนี้เราต้องใช้ Evaluatorอินสแตนซ์เพื่อทดสอบโมเดล จะแสดงในโค้ด Python ต่อไปนี้
from cntk import Evaluator
evaluator = Evaluator(loss.outputs[1], [progress_writer])
input_data = pd.read_csv('iris.csv',
names=['sepal_length', 'sepal_width','petal_length','petal_width', 'species'],
index_col=False, chunksize=16)
for df_batch in input_data:
feature_values = df_batch.iloc[:,:4].values
feature_values = feature_values.astype(np.float32)
label_values = df_batch.iloc[:,-1]
label_values = label_values.map(lambda x: label_mapping[x])
label_values = label_values.values
encoded_labels = np.zeros((label_values.shape[0], 3))
encoded_labels[np.arange(label_values.shape[0]), label_values] = 1.
evaluator.test_minibatch({ features: feature_values, labels:
encoded_labels})
evaluator.summarize_test_progress()ตอนนี้เราจะได้ผลลัพธ์ดังนี้ like
เอาต์พุต
Finished Evaluation [1]: Minibatch[1-11]:metric = 74.62*143;CNTK - การตรวจสอบโมเดล
ในบทนี้เราจะเข้าใจวิธีการตรวจสอบโมเดลใน CNTK
บทนำ
ในส่วนก่อนหน้านี้เราได้ทำการตรวจสอบความถูกต้องของโมเดล NN ของเราแล้ว แต่จำเป็นและเป็นไปได้หรือไม่ที่จะตรวจสอบโมเดลของเราในระหว่างการฝึกอบรม
ใช่เราได้ใช้แล้ว ProgressWriterชั้นเรียนเพื่อตรวจสอบโมเดลของเราและยังมีอีกหลายวิธีที่จะทำเช่นนั้น ก่อนที่จะเจาะลึกถึงวิธีต่างๆก่อนอื่นเรามาดูกันว่าการตรวจสอบใน CNTK ทำงานอย่างไรและเราจะใช้มันเพื่อตรวจหาปัญหาในแบบจำลอง NN ของเราได้อย่างไร
การโทรกลับใน CNTK
จริงๆแล้วในระหว่างการฝึกอบรมและการตรวจสอบความถูกต้อง CNTK ช่วยให้เราระบุการเรียกกลับในหลาย ๆ จุดใน API ก่อนอื่นเรามาดูอย่างละเอียดยิ่งขึ้นเมื่อ CNTK เรียกใช้การโทรกลับ
เมื่อ CNTK เรียกใช้การโทรกลับ?
CNTK จะเรียกใช้การโทรกลับในช่วงเวลาการฝึกอบรมและการทดสอบเมื่อ −
รถสองแถวเสร็จสมบูรณ์
การกวาดล้างชุดข้อมูลทั้งหมดเสร็จสิ้นในระหว่างการฝึกอบรม
การทดสอบมินิแบทช์เสร็จสมบูรณ์
การกวาดล้างชุดข้อมูลทั้งหมดเสร็จสมบูรณ์ในระหว่างการทดสอบ
การระบุการโทรกลับ
ในขณะที่ทำงานกับ CNTK เราสามารถระบุการเรียกกลับได้หลายจุดใน API ตัวอย่างเช่น
เมื่อโทรฝึกฟังก์ชั่นการสูญเสีย?
ที่นี่เมื่อเราเรียกใช้ train ในฟังก์ชั่นการสูญเสียเราสามารถระบุชุดของการโทรกลับผ่านอาร์กิวเมนต์การเรียกกลับได้ดังนี้ −
training_summary=loss.train((x_train,y_train),
parameter_learners=[learner],
callbacks=[progress_writer]),
minibatch_size=16, max_epochs=15)เมื่อทำงานกับแหล่งที่มาของมินิแบทช์หรือใช้ห่วงมินิแบทช์ด้วยตนเอง
ในกรณีนี้เราสามารถระบุการเรียกกลับเพื่อตรวจสอบจุดประสงค์ในขณะที่สร้างไฟล์ Trainer ดังต่อไปนี้
from cntk.logging import ProgressPrinter
callbacks = [
ProgressPrinter(0)
]
Trainer = Trainer(z, (loss, metric), learner, [callbacks])เครื่องมือตรวจสอบต่างๆ
ให้เราศึกษาเกี่ยวกับเครื่องมือตรวจสอบต่างๆ
ProgressPrinter
ขณะอ่านบทแนะนำนี้คุณจะพบ ProgressPrinterเป็นเครื่องมือตรวจสอบที่ใช้มากที่สุด ลักษณะบางอย่างของProgressPrinter เครื่องมือตรวจสอบคือ
ProgressPrinterคลาสใช้การบันทึกบนคอนโซลพื้นฐานเพื่อตรวจสอบโมเดลของเรา มันสามารถเข้าสู่ดิสก์ที่เราต้องการได้
มีประโยชน์อย่างยิ่งในขณะที่ทำงานในสถานการณ์การฝึกอบรมแบบกระจาย
นอกจากนี้ยังมีประโยชน์มากในขณะที่ทำงานในสถานการณ์ที่เราไม่สามารถเข้าสู่ระบบบนคอนโซลเพื่อดูผลลัพธ์ของโปรแกรม Python ของเรา
ด้วยความช่วยเหลือของรหัสต่อไปนี้เราสามารถสร้างอินสแตนซ์ของ ProgressPrinter-
ProgressPrinter(0, log_to_file=’test.txt’)เราจะได้ผลลัพธ์บางอย่างที่เราได้เห็นในส่วนก่อนหน้านี้
Test.txt
CNTKCommandTrainInfo: train : 300
CNTKCommandTrainInfo: CNTKNoMoreCommands_Total : 300
CNTKCommandTrainBegin: train
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.1
1.45 1.45 -0.189 -0.189 16
1.24 1.13 -0.0382 0.0371 48
[………]TensorBoard
ข้อเสียอย่างหนึ่งของการใช้ ProgressPrinter คือเราไม่สามารถเข้าใจได้ดีว่าการสูญเสียและความคืบหน้าของเมตริกเมื่อเวลาผ่านไปนั้นยากเพียงใด TensorBoardProgressWriter เป็นทางเลือกที่ยอดเยี่ยมสำหรับคลาส ProgressPrinter ใน CNTK
ก่อนใช้งานเราต้องติดตั้งก่อนด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
pip install tensorboardตอนนี้เพื่อที่จะใช้ TensorBoard เราจำเป็นต้องตั้งค่า TensorBoardProgressWriter ในรหัสการฝึกอบรมของเราดังนี้
import time
from cntk.logging import TensorBoardProgressWriter
tensorbrd_writer = TensorBoardProgressWriter(log_dir=’logs/{}’.format(time.time()),freq=1,model=z)เป็นแนวทางปฏิบัติที่ดีในการเรียกใช้วิธีการปิด TensorBoardProgressWriter หลังจากเสร็จสิ้นด้วยการฝึกอบรมของ NNแบบ.
เราสามารถเห็นภาพไฟล์ TensorBoard บันทึกข้อมูลด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
Tensorboard –logdir logsCNTK - Convolutional Neural Network
ในบทนี้ให้เราศึกษาวิธีสร้าง Convolutional Neural Network (CNN) ใน CNTK
บทนำ
Convolutional Neural Network (CNN) ยังประกอบด้วยเซลล์ประสาทซึ่งมีน้ำหนักและอคติที่เรียนรู้ได้ ด้วยเหตุนี้จึงเหมือนกับโครงข่ายประสาทเทียมทั่วไป (NNs)
ถ้าเราจำการทำงานของ NN ธรรมดาเซลล์ประสาททุกเซลล์จะได้รับอินพุตตั้งแต่หนึ่งตัวขึ้นไปรับผลรวมถ่วงน้ำหนักและส่งผ่านฟังก์ชันกระตุ้นเพื่อสร้างผลลัพธ์สุดท้าย ที่นี่คำถามเกิดขึ้นว่าถ้า CNN และ NN ธรรมดามีความคล้ายคลึงกันมากมายอะไรที่ทำให้เครือข่ายทั้งสองนี้แตกต่างกัน?
สิ่งที่ทำให้แตกต่างกันคือการจัดการข้อมูลอินพุตและประเภทของเลเยอร์ โครงสร้างของข้อมูลอินพุตจะถูกละเว้นใน NN ธรรมดาและข้อมูลทั้งหมดจะถูกแปลงเป็นอาร์เรย์ 1-D ก่อนที่จะป้อนเข้าสู่เครือข่าย
แต่สถาปัตยกรรม Convolutional Neural Network สามารถพิจารณาโครงสร้าง 2 มิติของภาพประมวลผลและอนุญาตให้ดึงคุณสมบัติที่เฉพาะเจาะจงสำหรับภาพออกมาได้ ยิ่งไปกว่านั้น CNN ยังมีข้อได้เปรียบในการมีเลเยอร์ Convolutional อย่างน้อยหนึ่งเลเยอร์และเลเยอร์พูลซึ่งเป็นส่วนประกอบหลักของ CNN
เลเยอร์เหล่านี้ตามด้วยเลเยอร์ที่เชื่อมต่อกันอย่างเต็มที่อย่างน้อยหนึ่งเลเยอร์เช่นเดียวกับ NN หลายชั้นมาตรฐาน ดังนั้นเราสามารถนึกถึง CNN เป็นกรณีพิเศษของเครือข่ายที่เชื่อมต่ออย่างสมบูรณ์
สถาปัตยกรรม Convolutional Neural Network (CNN)
สถาปัตยกรรมของ CNN โดยพื้นฐานแล้วเป็นรายการของเลเยอร์ที่เปลี่ยน 3 มิติ ได้แก่ ความกว้างความสูงและความลึกของปริมาณภาพให้เป็นปริมาณเอาต์พุต 3 มิติ ประเด็นสำคัญอย่างหนึ่งที่ควรทราบก็คือเซลล์ประสาททุกเซลล์ในชั้นปัจจุบันจะเชื่อมต่อกับส่วนเล็ก ๆ ของเอาต์พุตจากเลเยอร์ก่อนหน้าซึ่งเหมือนกับการซ้อนทับฟิลเตอร์ N * N บนภาพอินพุต
ใช้ฟิลเตอร์ M ซึ่งโดยพื้นฐานแล้วเป็นตัวแยกคุณสมบัติที่ดึงคุณสมบัติเช่นขอบมุมและอื่น ๆ ต่อไปนี้เป็นเลเยอร์ [INPUT-CONV-RELU-POOL-FC] ที่ใช้ในการสร้าง Convolutional neural networks (CNNs) -
INPUT- ตามความหมายของชื่อเลเยอร์นี้เก็บค่าพิกเซลดิบ ค่าพิกเซลดิบหมายถึงข้อมูลของรูปภาพตามที่เป็นจริง ตัวอย่างเช่น INPUT [64 × 64 × 3] คือภาพ RGB แบบ 3 ช่องที่มีความกว้าง -64, สูง -64 และความลึก -3
CONV- เลเยอร์นี้เป็นหนึ่งในส่วนประกอบสำคัญของ CNN เนื่องจากการคำนวณส่วนใหญ่เสร็จสิ้นในเลเยอร์นี้ ตัวอย่าง - ถ้าเราใช้ 6 ฟิลเตอร์กับ INPUT ที่กล่าวมาข้างต้น [64 × 64 × 3] อาจส่งผลให้โวลุ่ม [64 × 64 × 6]
RELU− เรียกอีกอย่างว่าเลเยอร์หน่วยเชิงเส้นแก้ไขซึ่งใช้ฟังก์ชันการเปิดใช้งานกับเอาต์พุตของเลเยอร์ก่อนหน้า ในอีกลักษณะหนึ่งจะเพิ่มความไม่เป็นเชิงเส้นลงในเครือข่ายโดย RELU
POOL- เลเยอร์นี้เช่น Pooling layer เป็นกลุ่มอาคารอื่น ๆ ของ CNN งานหลักของเลเยอร์นี้คือการสุ่มตัวอย่างแบบลงซึ่งหมายความว่ามันทำงานอย่างอิสระในทุกส่วนของอินพุตและปรับขนาดเชิงพื้นที่
FC- เรียกว่าเลเยอร์ที่เชื่อมต่ออย่างเต็มที่หรือโดยเฉพาะเลเยอร์เอาต์พุต ใช้ในการคำนวณคะแนนคลาสเอาต์พุตและผลลัพธ์ที่ได้คือปริมาตรของขนาด 1 * 1 * Lโดย L คือตัวเลขที่ตรงกับคะแนนชั้นเรียน
แผนภาพด้านล่างแสดงถึงสถาปัตยกรรมทั่วไปของ CNNs−

การสร้างโครงสร้าง CNN
เราได้เห็นสถาปัตยกรรมและพื้นฐานของ CNN แล้วตอนนี้เรากำลังจะสร้างเครือข่าย Convolutional โดยใช้ CNTK ที่นี่ก่อนอื่นเราจะดูวิธีการรวมโครงสร้างของ CNN จากนั้นเราจะดูวิธีฝึกพารามิเตอร์ของมัน
ในที่สุดเราจะมาดูกันว่าเราจะปรับปรุงโครงข่ายประสาทเทียมได้อย่างไรโดยการเปลี่ยนโครงสร้างด้วยการตั้งค่าเลเยอร์ต่างๆ เราจะใช้ชุดข้อมูลภาพ MNIST
ก่อนอื่นมาสร้างโครงสร้าง CNN โดยทั่วไปเมื่อเราสร้าง CNN เพื่อจดจำรูปแบบในรูปภาพเราจะทำสิ่งต่อไปนี้
เราใช้การรวมกันของเลเยอร์การแปลงและการรวมกัน
เลเยอร์ที่ซ่อนอยู่อย่างน้อยหนึ่งชั้นที่ส่วนท้ายของเครือข่าย
ในที่สุดเราก็เสร็จสิ้นเครือข่ายด้วยชั้น softmax เพื่อการจำแนกประเภท
ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้เราสามารถสร้างโครงสร้างเครือข่าย
Step 1- ขั้นแรกเราต้องนำเข้าเลเยอร์ที่จำเป็นสำหรับ CNN
from cntk.layers import Convolution2D, Sequential, Dense, MaxPoolingStep 2- ต่อไปเราต้องนำเข้าฟังก์ชันการเปิดใช้งานสำหรับ CNN
from cntk.ops import log_softmax, reluStep 3- หลังจากนั้นในการเริ่มต้นเลเยอร์คอนโวลูชั่นในภายหลังเราจำเป็นต้องนำเข้าไฟล์ glorot_uniform_initializer ดังต่อไปนี้
from cntk.initializer import glorot_uniformStep 4- ถัดไปในการสร้างตัวแปรอินพุตนำเข้าไฟล์ input_variableฟังก์ชัน และนำเข้าdefault_option เพื่อให้การกำหนดค่า NN ง่ายขึ้นเล็กน้อย
from cntk import input_variable, default_optionsStep 5- ตอนนี้ในการจัดเก็บภาพอินพุตสร้างไฟล์ input_variable. มันจะมีสามช่องคือสีแดงสีเขียวและสีน้ำเงิน จะมีขนาด 28 x 28 พิกเซล
features = input_variable((3,28,28))Step 6− ต่อไปเราต้องสร้างใหม่ input_variable เพื่อจัดเก็บป้ายกำกับเพื่อทำนาย
labels = input_variable(10)Step 7- ตอนนี้เราต้องสร้างไฟล์ default_optionสำหรับ NN และเราจำเป็นต้องใช้ไฟล์glorot_uniform เป็นฟังก์ชันเริ่มต้น
with default_options(initialization=glorot_uniform, activation=relu):Step 8- ถัดไปในการกำหนดโครงสร้างของ NN เราต้องสร้างไฟล์ Sequential ชุดชั้น
Step 9- ตอนนี้เราต้องเพิ่มไฟล์ Convolutional2D เลเยอร์ด้วย filter_shape ของ 5 และ a strides การตั้งค่าของ 1, ภายใน Sequentialชุดชั้น นอกจากนี้ให้เปิดใช้งานช่องว่างภายในเพื่อให้ภาพมีการปรับขนาดเพื่อคงขนาดเดิมไว้
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),Step 10- ตอนนี้ได้เวลาเพิ่มไฟล์ MaxPooling เลเยอร์ด้วย filter_shape จาก 2 และก strides การตั้งค่า 2 เพื่อบีบอัดภาพลงครึ่งหนึ่ง
MaxPooling(filter_shape=(2,2), strides=(2,2)),Step 11- ตอนนี้ตามที่เราทำในขั้นตอนที่ 9 เราต้องเพิ่มอีก Convolutional2D เลเยอร์ด้วย filter_shape ของ 5 และ a stridesการตั้งค่า 1 ใช้ 16 ตัวกรอง นอกจากนี้ให้เปิดใช้งานการขยายเพื่อให้คงขนาดของรูปภาพที่สร้างโดยเลเยอร์การรวมกลุ่มก่อนหน้านี้
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),Step 12- ตอนนี้ตามที่เราทำในขั้นตอนที่ 10 ให้เพิ่มอีกอัน MaxPooling เลเยอร์ด้วย filter_shape ของ 3 และ a strides การตั้งค่า 3 เพื่อลดภาพเป็นหนึ่งในสาม
MaxPooling(filter_shape=(3,3), strides=(3,3)),Step 13- ในที่สุดเพิ่มเลเยอร์หนาแน่นด้วยเซลล์ประสาทสิบเซลล์สำหรับ 10 คลาสที่เป็นไปได้เครือข่ายสามารถทำนายได้ ในการเปลี่ยนเครือข่ายให้เป็นรูปแบบการจำแนกประเภทให้ใช้ไฟล์log_siftmax ฟังก์ชั่นการเปิดใช้งาน
Dense(10, activation=log_softmax)
])ตัวอย่างที่สมบูรณ์สำหรับการสร้างโครงสร้าง CNN
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)ฝึกอบรม CNN ด้วยภาพ
เมื่อเราสร้างโครงสร้างของเครือข่ายแล้วก็ถึงเวลาฝึกอบรมเครือข่าย แต่ก่อนที่จะเริ่มการฝึกอบรมเครือข่ายของเราเราจำเป็นต้องตั้งค่าแหล่งที่มาของมินิแบทช์เนื่องจากการฝึก NN ที่ทำงานกับรูปภาพต้องใช้หน่วยความจำมากกว่าที่คอมพิวเตอร์ส่วนใหญ่มี
เราได้สร้างแหล่งที่มาของมินิแบทช์แล้วในส่วนก่อนหน้านี้ ต่อไปนี้เป็นรหัส Python เพื่อตั้งค่ามินิแบทช์สองแหล่ง -
อย่างที่เรามี create_datasource ขณะนี้เราสามารถสร้างแหล่งข้อมูลแยกกันสองแหล่ง (การฝึกอบรมและการทดสอบหนึ่ง) เพื่อฝึกโมเดล
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)ตอนนี้เมื่อเราเตรียมภาพแล้วเราสามารถเริ่มฝึก NN ของเราได้ ดังที่เราทำในส่วนก่อนหน้านี้เราสามารถใช้วิธีการฝึกกับฟังก์ชันการสูญเสียเพื่อเริ่มการฝึกอบรม ต่อไปนี้เป็นรหัสสำหรับสิ่งนี้ -
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)ด้วยความช่วยเหลือของรหัสก่อนหน้านี้เราได้ตั้งค่าการสูญเสียและผู้เรียนสำหรับ NN รหัสต่อไปนี้จะฝึกและตรวจสอบความถูกต้องของ NN−
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])ตัวอย่างการใช้งานที่สมบูรณ์
from cntk.layers import Convolution2D, Sequential, Dense, MaxPooling
from cntk.ops import log_softmax, relu
from cntk.initializer import glorot_uniform
from cntk import input_variable, default_options
features = input_variable((3,28,28))
labels = input_variable(10)
with default_options(initialization=glorot_uniform, activation=relu):
model = Sequential([
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=8, pad=True),
MaxPooling(filter_shape=(2,2), strides=(2,2)),
Convolution2D(filter_shape=(5,5), strides=(1,1), num_filters=16, pad=True),
MaxPooling(filter_shape=(3,3), strides=(3,3)),
Dense(10, activation=log_softmax)
])
z = model(features)
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)
train_datasource = create_datasource('mnist_train')
test_datasource = create_datasource('mnist_test', max_sweeps=1, train=False)
from cntk import Function
from cntk.losses import cross_entropy_with_softmax
from cntk.metrics import classification_error
from cntk.learners import sgd
@Function
def criterion_factory(output, targets):
loss = cross_entropy_with_softmax(output, targets)
metric = classification_error(output, targets)
return loss, metric
loss = criterion_factory(z, labels)
learner = sgd(z.parameters, lr=0.2)
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
labels: train_datasource.streams.labels
}
loss.train(train_datasource,
max_epochs=10,
minibatch_size=64,
epoch_size=60000,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config])เอาต์พุต
-------------------------------------------------------------------
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.2
142 142 0.922 0.922 64
1.35e+06 1.51e+07 0.896 0.883 192
[………]การแปลงภาพ
ดังที่เราได้เห็นแล้วการฝึก NN ที่ใช้ในการจดจำภาพเป็นเรื่องยากและต้องใช้ข้อมูลจำนวนมากเพื่อฝึกอบรมด้วย อีกปัญหาหนึ่งคือพวกเขามักจะใส่รูปภาพที่ใช้ระหว่างการฝึกมากเกินไป ลองดูตัวอย่างเมื่อเรามีรูปถ่ายใบหน้าในตำแหน่งตั้งตรงนางแบบของเราจะมีปัญหาในการจดจำใบหน้าที่หมุนไปในทิศทางอื่น
เพื่อเอาชนะปัญหาดังกล่าวเราสามารถใช้การเพิ่มรูปภาพและ CNTK รองรับการแปลงเฉพาะเมื่อสร้างแหล่งที่มาของมินิแบทช์สำหรับรูปภาพ เราสามารถใช้การแปลงได้หลายรูปแบบดังนี้
เราสามารถสุ่มครอบตัดรูปภาพที่ใช้ในการฝึกอบรมโดยใช้โค้ดเพียงไม่กี่บรรทัด
เราสามารถใช้สเกลและสีได้ด้วย
มาดูความช่วยเหลือของโค้ด Python ต่อไปนี้ว่าเราจะเปลี่ยนรายการการแปลงได้อย่างไรโดยรวมการแปลงการปลูกพืชไว้ในฟังก์ชันที่ใช้ในการสร้างแหล่งมินิแบทช์ก่อนหน้านี้
import os
from cntk.io import MinibatchSource, StreamDef, StreamDefs, ImageDeserializer, INFINITELY_REPEAT
import cntk.io.transforms as xforms
def create_datasource(folder, train=True, max_sweeps=INFINITELY_REPEAT):
mapping_file = os.path.join(folder, 'mapping.bin')
image_transforms = []
if train:
image_transforms += [
xforms.crop(crop_type='randomside', side_ratio=0.8),
xforms.scale(width=28, height=28, channels=3, interpolations='linear')
]
stream_definitions = StreamDefs(
features=StreamDef(field='image', transforms=image_transforms),
labels=StreamDef(field='label', shape=10)
)
deserializer = ImageDeserializer(mapping_file, stream_definitions)
return MinibatchSource(deserializer, max_sweeps=max_sweeps)ด้วยความช่วยเหลือของโค้ดด้านบนเราสามารถปรับปรุงฟังก์ชั่นเพื่อรวมชุดการแปลงรูปภาพดังนั้นเมื่อเราจะฝึกอบรมเราสามารถครอบตัดรูปภาพแบบสุ่มดังนั้นเราจึงได้รูปแบบต่างๆของรูปภาพมากขึ้น
CNTK - เครือข่ายประสาทที่เกิดซ้ำ
ตอนนี้ให้เราเข้าใจวิธีสร้าง Recurrent Neural Network (RNN) ใน CNTK
บทนำ
เราได้เรียนรู้วิธีการจัดประเภทภาพด้วยโครงข่ายประสาทเทียมและเป็นงานที่โดดเด่นอย่างหนึ่งในการเรียนรู้เชิงลึก แต่อีกพื้นที่หนึ่งที่เครือข่ายประสาทเทียมมีความเชี่ยวชาญและมีงานวิจัยเกิดขึ้นมากมายคือ Recurrent Neural Networks (RNN) ที่นี่เราจะได้ทราบว่า RNN คืออะไรและสามารถใช้ในสถานการณ์ที่เราต้องจัดการกับข้อมูลอนุกรมเวลาได้อย่างไร
Recurrent Neural Network คืออะไร?
เครือข่ายประสาทที่เกิดซ้ำ (RNNs) อาจถูกกำหนดให้เป็นสายพันธุ์พิเศษของ NN ที่สามารถให้เหตุผลได้ตลอดเวลา RNN ส่วนใหญ่จะใช้ในสถานการณ์ที่เราต้องจัดการกับค่าที่เปลี่ยนแปลงตลอดเวลานั่นคือข้อมูลอนุกรมเวลา เพื่อที่จะเข้าใจมันในทางที่ดีขึ้นเรามาเปรียบเทียบกันเล็กน้อยระหว่างเครือข่ายประสาทเทียมปกติและเครือข่ายประสาทที่เกิดซ้ำ -
ดังที่เราทราบดีว่าในโครงข่ายประสาทเทียมปกติเราสามารถป้อนข้อมูลได้เพียงรายการเดียว ซึ่งจะ จำกัด ผลการทำนายเพียงครั้งเดียว เพื่อเป็นตัวอย่างเราสามารถแปลงานข้อความได้โดยใช้โครงข่ายประสาทเทียมปกติ
ในทางกลับกันในเครือข่ายประสาทที่เกิดซ้ำเราสามารถจัดเตรียมลำดับของตัวอย่างที่ทำให้เกิดการคาดคะเนเพียงครั้งเดียว กล่าวอีกนัยหนึ่งคือการใช้ RNNs เราสามารถทำนายลำดับเอาต์พุตตามลำดับอินพุต ตัวอย่างเช่นมีการทดลองกับ RNN ในงานแปลที่ประสบความสำเร็จค่อนข้างน้อย
การใช้โครงข่ายประสาทที่เกิดซ้ำ
RNN สามารถใช้ได้หลายวิธี บางส่วนมีดังนี้ -
การคาดการณ์ผลลัพธ์เดียว
ก่อนที่จะลงลึกในขั้นตอนต่างๆว่า RNN สามารถทำนายผลลัพธ์เดียวตามลำดับได้อย่างไรมาดูกันว่า RNN พื้นฐานมีลักษณะอย่างไร

ดังที่เราทำได้ในแผนภาพด้านบน RNN มีการเชื่อมต่อแบบย้อนกลับไปยังอินพุตและเมื่อใดก็ตามที่เราป้อนลำดับของค่ามันจะประมวลผลแต่ละองค์ประกอบตามลำดับเป็นขั้นตอนเวลา
ยิ่งไปกว่านั้นเนื่องจากการเชื่อมต่อแบบย้อนกลับ RNN สามารถรวมเอาท์พุทที่สร้างขึ้นกับอินพุตสำหรับองค์ประกอบถัดไปในลำดับ ด้วยวิธีนี้ RNN จะสร้างหน่วยความจำในลำดับทั้งหมดซึ่งสามารถใช้ในการทำนายได้
ในการทำนายด้วย RNN เราสามารถดำเนินการตามขั้นตอนต่อไปนี้
ขั้นแรกในการสร้างสถานะที่ซ่อนเริ่มต้นเราต้องป้อนองค์ประกอบแรกของลำดับการป้อนข้อมูล
หลังจากนั้นในการสร้างสถานะที่ซ่อนไว้ที่อัปเดตเราจำเป็นต้องใช้สถานะที่ซ่อนเริ่มต้นและรวมเข้ากับองค์ประกอบที่สองในลำดับอินพุต
ในที่สุดเพื่อสร้างสถานะสุดท้ายที่ซ่อนอยู่และเพื่อทำนายผลลัพธ์สำหรับ RNN เราจำเป็นต้องใช้องค์ประกอบสุดท้ายในลำดับอินพุต
ด้วยวิธีนี้ด้วยความช่วยเหลือของการเชื่อมต่อแบบย้อนกลับนี้เราสามารถสอน RNN ให้รู้จักรูปแบบที่เกิดขึ้นเมื่อเวลาผ่านไป
การทำนายลำดับ
โมเดลพื้นฐานที่กล่าวถึงข้างต้นของ RNN สามารถขยายไปยังกรณีการใช้งานอื่น ๆ ได้เช่นกัน ตัวอย่างเช่นเราสามารถใช้เพื่อทำนายลำดับของค่าตามอินพุตเดียว ในสถานการณ์นี้เพื่อทำการทำนายด้วย RNN เราสามารถดำเนินการตามขั้นตอนต่อไปนี้ -
ขั้นแรกในการสร้างสถานะที่ซ่อนอยู่เริ่มต้นและทำนายองค์ประกอบแรกในลำดับเอาต์พุตเราจำเป็นต้องป้อนตัวอย่างอินพุตเข้าไปในโครงข่ายประสาทเทียม
หลังจากนั้นในการสร้างสถานะที่ซ่อนไว้ที่อัปเดตและองค์ประกอบที่สองในลำดับเอาต์พุตเราจำเป็นต้องรวมสถานะที่ซ่อนไว้เริ่มต้นกับตัวอย่างเดียวกัน
ในที่สุดเพื่ออัปเดตสถานะที่ซ่อนอีกครั้งและทำนายองค์ประกอบสุดท้ายในลำดับเอาต์พุตเราจะป้อนตัวอย่างอีกครั้ง
ลำดับการทำนาย
ดังที่เราได้เห็นวิธีการทำนายค่าเดียวตามลำดับและวิธีทำนายลำดับตามค่าเดียว ตอนนี้เรามาดูกันว่าเราสามารถทำนายลำดับของลำดับได้อย่างไร ในสถานการณ์นี้เพื่อทำการทำนายด้วย RNN เราสามารถดำเนินการตามขั้นตอนต่อไปนี้ -
ขั้นแรกในการสร้างสถานะที่ซ่อนไว้เริ่มต้นและทำนายองค์ประกอบแรกในลำดับเอาต์พุตเราจำเป็นต้องใช้องค์ประกอบแรกในลำดับอินพุต
หลังจากนั้นในการอัปเดตสถานะที่ซ่อนอยู่และทำนายองค์ประกอบที่สองในลำดับเอาต์พุตเราจำเป็นต้องใช้สถานะที่ซ่อนอยู่เริ่มต้น
ในที่สุดในการทำนายองค์ประกอบสุดท้ายในลำดับเอาต์พุตเราจำเป็นต้องใช้สถานะที่ซ่อนอยู่ที่อัปเดตและองค์ประกอบสุดท้ายในลำดับอินพุต
การทำงานของ RNN
เพื่อให้เข้าใจถึงการทำงานของเครือข่ายประสาทที่เกิดซ้ำ (RNN) ก่อนอื่นเราต้องเข้าใจว่าเลเยอร์ที่เกิดซ้ำในเครือข่ายทำงานอย่างไร ก่อนอื่นเรามาดูกันว่า e สามารถทำนายผลลัพธ์ด้วยเลเยอร์ซ้ำมาตรฐานได้อย่างไร
การคาดการณ์ผลลัพธ์ด้วยเลเยอร์ RNN มาตรฐาน
ดังที่เราได้กล่าวไปก่อนหน้านี้ว่าเลเยอร์พื้นฐานใน RNN นั้นค่อนข้างแตกต่างจากเลเยอร์ปกติในโครงข่ายประสาทเทียม ในส่วนก่อนหน้านี้เราได้แสดงให้เห็นในแผนภาพสถาปัตยกรรมพื้นฐานของ RNN ในการอัปเดตสถานะที่ซ่อนอยู่สำหรับลำดับขั้นตอนในครั้งแรกเราสามารถใช้สูตรต่อไปนี้ -

ในสมการข้างต้นเราคำนวณสถานะใหม่ที่ซ่อนอยู่โดยการคำนวณผลิตภัณฑ์ดอทระหว่างสถานะที่ซ่อนเริ่มต้นและชุดของน้ำหนัก
ตอนนี้สำหรับขั้นตอนต่อไปสถานะที่ซ่อนอยู่สำหรับขั้นตอนเวลาปัจจุบันจะถูกใช้เป็นสถานะที่ซ่อนไว้เริ่มต้นสำหรับขั้นตอนถัดไปในลำดับ นั่นเป็นเหตุผลว่าทำไมในการอัปเดตสถานะที่ซ่อนอยู่สำหรับขั้นตอนที่สองเราสามารถทำซ้ำการคำนวณที่ทำในขั้นตอนแรกได้ดังนี้ -
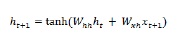
จากนั้นเราสามารถทำซ้ำขั้นตอนการอัปเดตสถานะที่ซ่อนอยู่สำหรับขั้นตอนที่สามและขั้นสุดท้ายตามลำดับดังนี้ -

และเมื่อเราประมวลผลขั้นตอนข้างต้นตามลำดับทั้งหมดแล้วเราสามารถคำนวณผลลัพธ์ได้ดังนี้ -

สำหรับสูตรข้างต้นเราได้ใช้ชุดที่สามของน้ำหนักและสถานะที่ซ่อนอยู่จากขั้นตอนสุดท้าย
หน่วยกำเริบขั้นสูง
ปัญหาหลักของเลเยอร์ที่เกิดซ้ำขั้นพื้นฐานคือการหายไปจากปัญหาการไล่ระดับสีและด้วยเหตุนี้การเรียนรู้ความสัมพันธ์ในระยะยาวจึงไม่ดีนัก พูดง่ายๆว่าเลเยอร์กำเริบขั้นพื้นฐานไม่สามารถจัดการลำดับที่ยาวได้เป็นอย่างดี นั่นเป็นเหตุผลที่บางประเภทของเลเยอร์ที่เกิดซ้ำซึ่งเหมาะสำหรับการทำงานกับลำดับที่ยาวขึ้นมีดังนี้ -
หน่วยความจำระยะยาว (LSTM)

เครือข่ายหน่วยความจำระยะสั้น (LSTMs) ได้รับการแนะนำโดย Hochreiter & Schmidhuber มันแก้ปัญหาในการรับเลเยอร์ซ้ำขั้นพื้นฐานเพื่อจดจำสิ่งต่างๆเป็นเวลานาน สถาปัตยกรรมของ LSTM แสดงไว้ด้านบนในแผนภาพ อย่างที่เราเห็นมันมีเซลล์ประสาทอินพุตเซลล์ความจำและเซลล์ประสาทเอาท์พุต เพื่อต่อสู้กับปัญหาการไล่ระดับสีที่หายไปเครือข่ายหน่วยความจำระยะยาวจะใช้เซลล์หน่วยความจำที่ชัดเจน (เก็บค่าก่อนหน้านี้) และประตูต่อไปนี้ -
Forget gate- ตามความหมายของชื่อจะบอกให้เซลล์หน่วยความจำลืมค่าก่อนหน้านี้ เซลล์หน่วยความจำจะเก็บค่าไว้จนกว่าเกตคือ 'forget gate' จะบอกให้ลืม
Input gate- ตามความหมายของชื่อมันจะเพิ่มสิ่งใหม่ ๆ ให้กับเซลล์
Output gate- ตามความหมายของชื่อประตูเอาต์พุตจะตัดสินใจว่าเมื่อใดที่จะส่งต่อเวกเตอร์จากเซลล์ไปยังสถานะที่ซ่อนอยู่ถัดไป
Gated Recurrent Units (GRU)

Gradient recurrent units(GRUs) เป็นเครือข่าย LSTM ที่มีความแตกต่างกันเล็กน้อย มีประตูน้อยกว่าหนึ่งประตูและมีสายแตกต่างจาก LSTM เล็กน้อย สถาปัตยกรรมของมันแสดงไว้ในแผนภาพด้านบน มันมีเซลล์ประสาทอินพุตเซลล์หน่วยความจำที่มีรั้วรอบขอบชิดและเซลล์ประสาทที่ส่งออก เครือข่าย Gated Recurrent Units มีสองประตูดังต่อไปนี้ -
Update gate- กำหนดสองสิ่งต่อไปนี้
ข้อมูลจำนวนเท่าใดที่ควรเก็บรักษาไว้จากสถานะสุดท้าย?
ควรปล่อยให้ข้อมูลจำนวนเท่าใดจากเลเยอร์ก่อนหน้านี้
Reset gate- การทำงานของ reset gate เหมือนกับของ forget gate ของเครือข่าย LSTMs ข้อแตกต่างเพียงอย่างเดียวคือตั้งอยู่แตกต่างกันเล็กน้อย
ตรงกันข้ามกับเครือข่ายหน่วยความจำระยะสั้นเครือข่าย Gated Recurrent Unit จะเร็วกว่าและทำงานง่ายกว่าเล็กน้อย
การสร้างโครงสร้าง RNN
ก่อนที่เราจะเริ่มทำการทำนายเกี่ยวกับผลลัพธ์จากแหล่งข้อมูลใด ๆ ของเราเราต้องสร้าง RNN ก่อนและการสร้าง RNN นั้นค่อนข้างเหมือนกับที่เราสร้างเครือข่ายประสาทเทียมในส่วนก่อนหน้านี้ ต่อไปนี้เป็นรหัสสำหรับสร้างหนึ่ง
from cntk.losses import squared_error
from cntk.io import CTFDeserializer, MinibatchSource, INFINITELY_REPEAT, StreamDefs, StreamDef
from cntk.learners import adam
from cntk.logging import ProgressPrinter
from cntk.train import TestConfig
BATCH_SIZE = 14 * 10
EPOCH_SIZE = 12434
EPOCHS = 10การจับคู่หลายชั้น
นอกจากนี้เรายังสามารถซ้อนเลเยอร์ที่เกิดซ้ำหลาย ๆ ชั้นใน CNTK ตัวอย่างเช่นเราสามารถใช้การรวมกันของเลเยอร์ต่อไปนี้
from cntk import sequence, default_options, input_variable
from cntk.layers import Recurrence, LSTM, Dropout, Dense, Sequential, Fold
features = sequence.input_variable(1)
with default_options(initial_state = 0.1):
model = Sequential([
Fold(LSTM(15)),
Dense(1)
])(features)
target = input_variable(1, dynamic_axes=model.dynamic_axes)ดังที่เราเห็นในโค้ดด้านบนเรามีสองวิธีต่อไปนี้ที่เราสามารถสร้างแบบจำลอง RNN ใน CNTK -
ขั้นแรกหากเราต้องการเพียงผลลัพธ์สุดท้ายของเลเยอร์ที่เกิดซ้ำเราสามารถใช้ไฟล์ Fold เลเยอร์ร่วมกับเลเยอร์ที่เกิดซ้ำเช่น GRU, LSTM หรือแม้แต่ RNNStep
ประการที่สองเราสามารถใช้ไฟล์ Recurrence บล็อก.
การฝึกอบรม RNN ด้วยข้อมูลอนุกรมเวลา
เมื่อเราสร้างโมเดลแล้วมาดูกันว่าเราจะฝึก RNN ใน CNTK ได้อย่างไร -
from cntk import Function
@Function
def criterion_factory(z, t):
loss = squared_error(z, t)
metric = squared_error(z, t)
return loss, metric
loss = criterion_factory(model, target)
learner = adam(model.parameters, lr=0.005, momentum=0.9)ตอนนี้ในการโหลดข้อมูลลงในกระบวนการฝึกอบรมเราต้องทำการ deserialize ลำดับจากชุดไฟล์ CTF รหัสต่อไปนี้มีนามสกุลcreate_datasource ฟังก์ชันซึ่งเป็นฟังก์ชันยูทิลิตี้ที่มีประโยชน์ในการสร้างทั้งแหล่งข้อมูลการฝึกอบรมและการทดสอบ
target_stream = StreamDef(field='target', shape=1, is_sparse=False)
features_stream = StreamDef(field='features', shape=1, is_sparse=False)
deserializer = CTFDeserializer(filename, StreamDefs(features=features_stream, target=target_stream))
datasource = MinibatchSource(deserializer, randomize=True, max_sweeps=sweeps)
return datasource
train_datasource = create_datasource('Training data filename.ctf')#we need to provide the location of training file we created from our dataset.
test_datasource = create_datasource('Test filename.ctf', sweeps=1) #we need to provide the location of testing file we created from our dataset.ตอนนี้เมื่อเราได้ตั้งค่าแหล่งข้อมูลแบบจำลองและฟังก์ชันการสูญเสียแล้วเราสามารถเริ่มกระบวนการฝึกอบรมได้ ค่อนข้างคล้ายกับที่เราทำในส่วนก่อนหน้านี้กับโครงข่ายใยประสาทพื้นฐาน
progress_writer = ProgressPrinter(0)
test_config = TestConfig(test_datasource)
input_map = {
features: train_datasource.streams.features,
target: train_datasource.streams.target
}
history = loss.train(
train_datasource,
epoch_size=EPOCH_SIZE,
parameter_learners=[learner],
model_inputs_to_streams=input_map,
callbacks=[progress_writer, test_config],
minibatch_size=BATCH_SIZE,
max_epochs=EPOCHS
)เราจะได้ผลลัพธ์ที่คล้ายกันดังนี้ -
เอาต์พุต
average since average since examples
loss last metric last
------------------------------------------------------
Learning rate per minibatch: 0.005
0.4 0.4 0.4 0.4 19
0.4 0.4 0.4 0.4 59
0.452 0.495 0.452 0.495 129
[…]กำลังตรวจสอบโมเดล
จริงๆแล้วการคาดเดาด้วย RNN นั้นค่อนข้างคล้ายกับการคาดคะเนด้วยโมเดล CNK อื่น ๆ ข้อแตกต่างเพียงอย่างเดียวคือเราต้องจัดเตรียมลำดับมากกว่าตัวอย่างเดียว
ตอนนี้เมื่อ RNN ของเราเสร็จสิ้นในการฝึกอบรมแล้วเราสามารถตรวจสอบความถูกต้องของโมเดลได้โดยการทดสอบโดยใช้ลำดับตัวอย่างสองสามลำดับดังนี้ -
import pickle
with open('test_samples.pkl', 'rb') as test_file:
test_samples = pickle.load(test_file)
model(test_samples) * NORMALIZEเอาต์พุต
array([[ 8081.7905],
[16597.693 ],
[13335.17 ],
...,
[11275.804 ],
[15621.697 ],
[16875.555 ]], dtype=float32)