MuleSoft - คู่มือฉบับย่อ
ESB ย่อมาจาก Enterprise Service Busซึ่งโดยพื้นฐานแล้วเป็นเครื่องมือมิดเดิลแวร์สำหรับการรวมแอพพลิเคชั่นต่างๆเข้าด้วยกันผ่านโครงสร้างพื้นฐานแบบบัส โดยพื้นฐานแล้วมันเป็นสถาปัตยกรรมที่ออกแบบมาเพื่อให้มีวิธีการทำงานที่สม่ำเสมอในการใช้งานแบบบูรณาการ ด้วยวิธีนี้ด้วยความช่วยเหลือของสถาปัตยกรรม ESB เราสามารถเชื่อมต่อแอพพลิเคชั่นต่างๆผ่านบัสการสื่อสารและทำให้แอปพลิเคชั่นสื่อสารกันได้โดยไม่ต้องพึ่งพาซึ่งกันและกัน
การใช้ ESB
จุดสนใจหลักของสถาปัตยกรรม ESB คือการแยกระบบออกจากกันและอนุญาตให้สื่อสารกันได้อย่างมั่นคงและควบคุมได้ การใช้งาน ESB สามารถทำได้ด้วยความช่วยเหลือของ‘Bus’ และ ‘Adapter’ ด้วยวิธีต่อไปนี้ -
แนวคิดของ“ บัส” ซึ่งทำได้ผ่านเซิร์ฟเวอร์รับส่งข้อความเช่น JMS หรือ AMQP ใช้เพื่อแยกแอปพลิเคชันที่แตกต่างกันออกจากกัน
แนวคิดของ“ อะแดปเตอร์” ซึ่งรับผิดชอบในการสื่อสารกับแอปพลิเคชันแบ็กเอนด์และการแปลงข้อมูลจากรูปแบบแอปพลิเคชันเป็นรูปแบบบัสจะใช้ระหว่างแอปพลิเคชันและบัส
ข้อมูลหรือข้อความที่ส่งผ่านจากแอพพลิเคชั่นหนึ่งไปยังอีกแอพพลิเคชั่นผ่านบัสอยู่ในรูปแบบบัญญัติซึ่งหมายความว่าจะมีรูปแบบข้อความที่สอดคล้องกันหนึ่งรูปแบบ
อะแด็ปเตอร์ยังสามารถดำเนินกิจกรรมอื่น ๆ เช่นการรักษาความปลอดภัยการตรวจสอบการจัดการข้อผิดพลาดและการจัดการเส้นทางข้อความ
หลักการชี้นำของ ESB
เราสามารถเรียกหลักการเหล่านี้ว่าหลักการรวมหลัก มีดังนี้ -
Orchestration - การรวมบริการตั้งแต่สองบริการขึ้นไปเพื่อให้เกิดการซิงโครไนซ์ระหว่างข้อมูลและกระบวนการ
Transformation - การแปลงข้อมูลจากรูปแบบบัญญัติเป็นรูปแบบเฉพาะของแอปพลิเคชัน
Transportation - การจัดการการเจรจาโปรโตคอลระหว่างรูปแบบเช่น FTP, HTTP, JMS และอื่น ๆ
Mediation - จัดหาอินเทอร์เฟซที่หลากหลายเพื่อรองรับบริการหลายเวอร์ชัน
Non-functional consistency - จัดหากลไกในการจัดการธุรกรรมและความปลอดภัยด้วย
ความต้องการของ ESB
สถาปัตยกรรม ESB ช่วยให้เราสามารถรวมแอพพลิเคชั่นที่แตกต่างกันโดยที่แต่ละแอพพลิเคชั่นสามารถสื่อสารผ่านมันได้ ต่อไปนี้เป็นแนวทางบางประการเกี่ยวกับเวลาที่ควรใช้ ESB -
Integrating two or more applications - การใช้สถาปัตยกรรม ESB มีประโยชน์เมื่อจำเป็นต้องผสานรวมบริการหรือแอปพลิเคชันตั้งแต่สองตัวขึ้นไป
Integration of more applications in future - สมมติว่าหากเราต้องการเพิ่มบริการหรือแอพพลิเคชั่นเพิ่มเติมในอนาคตก็สามารถทำได้อย่างง่ายดายด้วยความช่วยเหลือของสถาปัตยกรรม ESB
Using multiple protocols - ในกรณีที่เราจำเป็นต้องใช้หลายโปรโตคอลเช่น HTTP, FTP, JMS เป็นต้น ESB เป็นตัวเลือกที่เหมาะสม
Message routing - เราสามารถใช้ ESB ในกรณีที่ต้องการการกำหนดเส้นทางข้อความตามเนื้อหาข้อความและพารามิเตอร์อื่น ๆ ที่คล้ายคลึงกัน
Composition and consumption - ESB สามารถใช้ได้หากเราต้องการเผยแพร่บริการสำหรับการจัดองค์ประกอบและการบริโภค
การรวม P2P เทียบกับการรวม ESB
ด้วยจำนวนแอพพลิเคชั่นที่เพิ่มขึ้นคำถามใหญ่ต่อหน้านักพัฒนาคือจะเชื่อมต่อแอพพลิเคชั่นต่างๆได้อย่างไร? สถานการณ์ได้รับการจัดการโดยการเข้ารหัสการเชื่อมต่อระหว่างแอปพลิเคชันต่างๆ นี้เรียกว่าpoint-to-point integration.
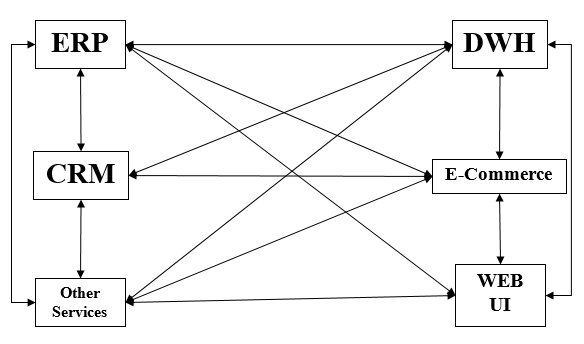
Rigidityเป็นข้อเสียเปรียบที่ชัดเจนที่สุดของการรวมจุดต่อจุด ความซับซ้อนเพิ่มขึ้นตามจำนวนการเชื่อมต่อและอินเทอร์เฟซที่เพิ่มขึ้น ข้อเสียของการรวม P-2-P ทำให้เราไปสู่การรวม ESB
ESB เป็นแนวทางที่ยืดหยุ่นกว่าในการรวมแอปพลิเคชัน มันห่อหุ้มและแสดงฟังก์ชันการทำงานของแต่ละแอปพลิเคชันเป็นชุดของความสามารถในการนำกลับมาใช้ใหม่ที่ไม่ต่อเนื่อง ไม่มีแอปพลิเคชันใดที่รวมเข้ากับโปรแกรมอื่น ๆ โดยตรง แต่จะรวมผ่าน ESB ดังที่แสดงด้านล่าง -
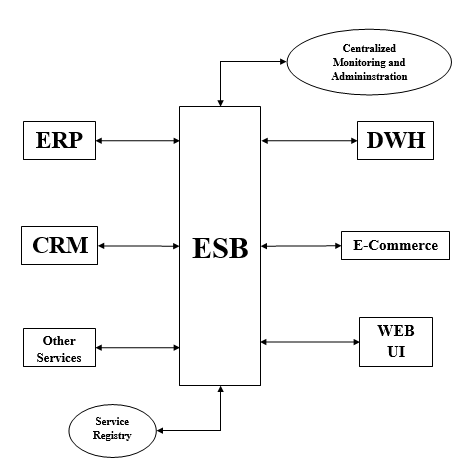
สำหรับการจัดการการรวม ESB มีสององค์ประกอบดังต่อไปนี้ -
Service Registry- Mule ESB มี Service Registry / Repository ซึ่งมีการเผยแพร่และลงทะเบียนบริการทั้งหมดที่เปิดเผยใน ESB ทำหน้าที่เป็นจุดค้นพบจากจุดที่สามารถใช้บริการและความสามารถของแอปพลิเคชันอื่น ๆ
Centralized Administration - ตามความหมายของชื่อจะให้มุมมองของขั้นตอนการทำธุรกรรมของประสิทธิภาพของการโต้ตอบที่เกิดขึ้นภายใน ESB
ESB Functionality- โดยทั่วไปแล้วตัวย่อ VETRO จะใช้เพื่อสรุปการทำงานของ ESB มีดังต่อไปนี้ -
V(ตรวจสอบความถูกต้อง) - ตามความหมายของชื่อมันจะตรวจสอบความถูกต้องของสคีมา ต้องใช้ตัวแยกวิเคราะห์ที่ตรวจสอบความถูกต้องและสคีมาที่ทันสมัย ตัวอย่างหนึ่งคือเอกสาร XML ที่ยืนยันถึงสคีมาที่เป็นปัจจุบัน
E(Enrich) - เพิ่มข้อมูลเพิ่มเติมให้กับข้อความ จุดประสงค์คือเพื่อให้ข้อความมีความหมายและเป็นประโยชน์ต่อบริการเป้าหมายมากขึ้น
T(Transform) - แปลงโครงสร้างข้อมูลเป็นรูปแบบที่ยอมรับหรือจากรูปแบบที่ยอมรับ ตัวอย่างเช่นการแปลงวันที่ / เวลาสกุลเงิน ฯลฯ
R(การกำหนดเส้นทาง) - จะกำหนดเส้นทางข้อความและทำหน้าที่เป็นผู้เฝ้าประตูปลายทางของบริการ
O(Operate) - งานหลักของฟังก์ชันนี้คือเรียกใช้บริการเป้าหมายหรือโต้ตอบกับแอปเป้าหมาย พวกเขาทำงานที่แบ็กเอนด์
รูปแบบ VETRO ให้ความยืดหยุ่นโดยรวมในการรวมและทำให้มั่นใจได้ว่าจะมีการกำหนดเส้นทางเฉพาะข้อมูลที่สอดคล้องกันและผ่านการตรวจสอบแล้วทั่วทั้ง ESB
Mule ESB คืออะไร?
Mule ESB เป็นบัสบริการระดับองค์กร (ESB) ที่ใช้ Java น้ำหนักเบาและปรับขนาดได้สูงและแพลตฟอร์มการผสานรวมที่ MuleSoft จัดหาให้ Mule ESB ช่วยให้นักพัฒนาสามารถเชื่อมต่อแอปพลิเคชันได้อย่างง่ายดายและรวดเร็ว โดยไม่คำนึงถึงเทคโนโลยีต่างๆที่ใช้โดยแอปพลิเคชัน Mule ESB ช่วยให้สามารถรวมแอปพลิเคชันได้ง่ายทำให้สามารถแลกเปลี่ยนข้อมูลได้ Mule ESB มีสองรุ่นต่อไปนี้ -
- ฉบับชุมชน
- Enterprise Edition
ข้อได้เปรียบของ Mule ESB คือเราสามารถอัปเกรดจากชุมชน Mule ESB เป็น Mule ESB enterprise ได้อย่างง่ายดายเนื่องจากทั้งสองรุ่นสร้างขึ้นจากฐานรหัสทั่วไป
คุณสมบัติและความสามารถของ Mule ESB
คุณสมบัติต่อไปนี้ถูกครอบครองโดย Mule ESB -
- มีการออกแบบกราฟิกแบบลากและวางที่เรียบง่าย
- Mule ESB สามารถทำแผนที่และแปลงข้อมูลด้วยภาพ
- ผู้ใช้จะได้รับสิ่งอำนวยความสะดวกของตัวเชื่อมต่อที่ได้รับการรับรองที่สร้างไว้ล่วงหน้า 100
- การตรวจสอบและการบริหารแบบรวมศูนย์
- มีความสามารถในการบังคับใช้ความปลอดภัยระดับองค์กรที่แข็งแกร่ง
- มีสิ่งอำนวยความสะดวกในการจัดการ API
- มีเกตเวย์ข้อมูลที่ปลอดภัยสำหรับการเชื่อมต่อบนคลาวด์ / ในองค์กร
- ให้บริการรีจิสทรีที่มีการเผยแพร่และลงทะเบียนบริการทั้งหมดที่เปิดเผยใน ESB
- ผู้ใช้สามารถควบคุมผ่านคอนโซลการจัดการบนเว็บ
- การดีบักอย่างรวดเร็วสามารถทำได้โดยใช้ตัววิเคราะห์การไหลของบริการ
แรงจูงใจที่อยู่เบื้องหลังโครงการล่อคือ -
เพื่อทำให้สิ่งต่างๆง่ายขึ้นสำหรับโปรแกรมเมอร์
ความต้องการโซลูชันที่มีน้ำหนักเบาและโมดูลาร์ที่สามารถปรับขนาดจากกรอบการส่งข้อความระดับแอปพลิเคชันไปจนถึงกรอบงานที่กระจายได้สูงทั่วทั้งองค์กร
Mule ESB ได้รับการออกแบบให้เป็นเฟรมเวิร์กที่ขับเคลื่อนด้วยเหตุการณ์เช่นเดียวกับโปรแกรม เป็นเหตุการณ์ที่ขับเคลื่อนด้วยเนื่องจากรวมกับการแสดงข้อความแบบรวมและสามารถขยายได้ด้วยโมดูลที่เสียบได้ เป็นโปรแกรมเนื่องจากโปรแกรมเมอร์สามารถปลูกฝังพฤติกรรมเพิ่มเติมบางอย่างได้อย่างง่ายดายเช่นการประมวลผลข้อความเฉพาะหรือการแปลงข้อมูลแบบกำหนดเอง
ประวัติศาสตร์
มุมมองทางประวัติศาสตร์ของโครงการล่อมีดังนี้ -
โครงการ SourceForge
โครงการ Mule เริ่มต้นในฐานะโครงการ SourceForge ในเดือนเมษายน พ.ศ. 2546 และหลังจากนั้น 2 ปีก็มีการเผยแพร่เวอร์ชันแรกและย้ายไปที่ CodeHaus Universal Message Object (UMO) API เป็นหัวใจหลักของสถาปัตยกรรม แนวคิดเบื้องหลัง UMO API คือการรวมตรรกะในขณะที่แยกพวกมันออกจากการขนส่งพื้นฐาน
เวอร์ชัน 1.0.6
ได้รับการปล่อยตัวในเดือนเมษายน 2548 ซึ่งมีการขนส่งจำนวนมาก จุดสำคัญของเวอร์ชันอื่น ๆ ตามมาด้วยคือการดีบักและเพิ่มคุณสมบัติใหม่
เวอร์ชัน 2.0 (การยอมรับ Spring 2)
Spring 2 เป็นเฟรมเวิร์กการกำหนดค่าและการเดินสายไฟถูกนำมาใช้ใน Mule 2 แต่ได้รับการพิสูจน์แล้วว่าเป็นการลากเส้นที่สำคัญเนื่องจากขาดการแสดงออกของการกำหนดค่า XML ที่จำเป็น ปัญหานี้ได้รับการแก้ไขเมื่อมีการนำการกำหนดค่าตาม XML Schema มาใช้ใน Spring 2
สร้างด้วย Maven
การปรับปรุงที่ใหญ่ที่สุดที่ทำให้การใช้งาน Mule ง่ายขึ้นทั้งในช่วงเวลาการพัฒนาและการปรับใช้คือการใช้ Maven จากเวอร์ชัน 1.3 เริ่มสร้างด้วย Maven
MuleSource
ในปี 2549 MuleSource ได้รวม "เพื่อช่วยสนับสนุนและเปิดใช้งานชุมชนที่เติบโตอย่างรวดเร็วโดยใช้ Mule ในแอปพลิเคชันระดับองค์กรที่มีภารกิจสำคัญ" ได้รับการพิสูจน์แล้วว่าเป็นก้าวสำคัญของโครงการล่อ
คู่แข่งของ Mule ESB
ต่อไปนี้เป็นคู่แข่งสำคัญของ Mule ESB -
- WSO2 ESB
- Oracle Service Bus
- WebSphere Message Broker
- แพลตฟอร์ม Aurea CX
- Fiorano ESB
- WebSphere DataPower Gateway
- กรอบกระบวนการธุรกิจในวันทำงาน
- Talend Enterprise Service Bus
- JBoss Enterprise Service Bus
- iWay ผู้จัดการฝ่ายบริการ
แนวคิดหลักของ Mule
ตามที่กล่าวไว้ Mule ESB เป็นบัสบริการสำหรับองค์กร (ESB) ที่ใช้ Java ที่มีน้ำหนักเบาและปรับขนาดได้สูงและแพลตฟอร์มการผสานรวม โดยไม่คำนึงถึงเทคโนโลยีต่างๆที่ใช้โดยแอปพลิเคชัน Mule ESB ช่วยให้สามารถรวมแอปพลิเคชันได้ง่ายทำให้สามารถแลกเปลี่ยนข้อมูลได้ ในส่วนนี้เราจะพูดถึงแนวคิดหลักของ Mule ที่เข้ามามีบทบาทเพื่อให้การบูรณาการดังกล่าวเกิดขึ้น
สำหรับสิ่งนี้เราจำเป็นต้องเข้าใจสถาปัตยกรรมของมันรวมถึงการสร้างบล็อค
สถาปัตยกรรม
สถาปัตยกรรมของ Mule ESB มีสามชั้น ได้แก่ เลเยอร์การขนส่งเลเยอร์การรวมและเลเยอร์แอปพลิเคชันดังแสดงในแผนภาพต่อไปนี้ -
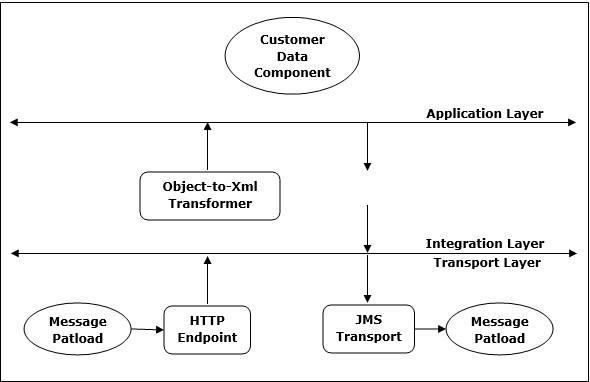
โดยทั่วไปมีงานสามประเภทดังต่อไปนี้ที่สามารถดำเนินการเพื่อกำหนดค่าและปรับแต่งการปรับใช้ Mule -
การพัฒนาส่วนประกอบบริการ
งานนี้เกี่ยวข้องกับการพัฒนาหรือการใช้ POJO ที่มีอยู่หรือ Spring Beans อีกครั้ง POJO เป็นคลาสที่มีแอตทริบิวต์ที่สร้างเมธอด get and set ตัวเชื่อมต่อระบบคลาวด์ ในทางกลับกัน Spring Beans มีตรรกะทางธุรกิจเพื่อเสริมสร้างข้อความ
การจัดระเบียบบริการ
โดยพื้นฐานแล้วงานนี้จัดเตรียมสื่อกลางการบริการที่เกี่ยวข้องกับการกำหนดค่าตัวประมวลผลข้อความเราเตอร์หม้อแปลงและตัวกรอง
บูรณาการ
งานที่สำคัญที่สุดของ Mule ESB คือการรวมแอปพลิเคชันต่างๆโดยไม่คำนึงถึงโปรโตคอลที่ใช้ เพื่อจุดประสงค์นี้ Mule มีวิธีการขนส่งที่อนุญาตให้รับและส่งข้อความบนตัวเชื่อมต่อโปรโตคอลต่างๆ Mule รองรับวิธีการขนส่งที่มีอยู่มากมายหรือเราอาจใช้วิธีการขนส่งแบบกำหนดเองก็ได้
การก่อสร้างตึก
การกำหนดค่า Mule มีโครงสร้างพื้นฐานต่อไปนี้ -
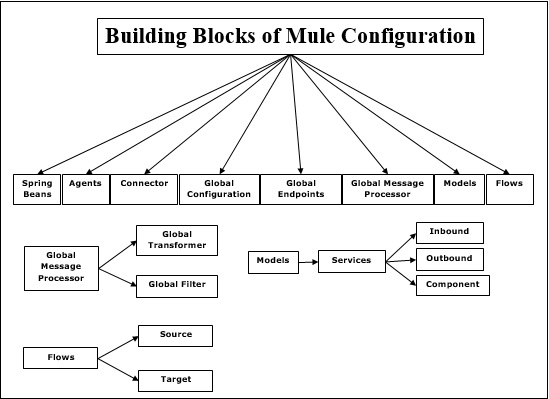
ถั่วสปริง
การใช้ถั่วสปริงเป็นหลักในการสร้างส่วนประกอบบริการ หลังจากสร้างส่วนประกอบสปริงเซอร์วิสแล้วเราสามารถกำหนดผ่านไฟล์คอนฟิกูเรชันหรือด้วยตนเองในกรณีที่คุณไม่มีไฟล์คอนฟิกูเรชัน
ตัวแทน
โดยพื้นฐานแล้วเป็นบริการที่สร้างขึ้นใน Anypoint Studio ก่อน Mule Studio เอเจนต์ถูกสร้างขึ้นเมื่อคุณเริ่มเซิร์ฟเวอร์และจะถูกทำลายเมื่อคุณหยุดเซิร์ฟเวอร์
ตัวเชื่อมต่อ
เป็นส่วนประกอบซอฟต์แวร์ที่กำหนดค่าด้วยพารามิเตอร์ที่เฉพาะเจาะจงสำหรับโปรโตคอล ส่วนใหญ่จะใช้เพื่อควบคุมการใช้โปรโตคอล ตัวอย่างเช่นตัวเชื่อมต่อ JMS ถูกกำหนดค่าด้วยไฟล์Connection และตัวเชื่อมต่อนี้จะถูกแชร์ระหว่างหน่วยงานต่างๆที่รับผิดชอบการสื่อสารจริง
การกำหนดค่าส่วนกลาง
ตามความหมายของชื่อ Building Block นี้ใช้เพื่อตั้งค่าคุณสมบัติส่วนกลางและการตั้งค่า
Global Endpoints
สามารถใช้ในแท็บ Global Elements ซึ่งสามารถใช้ได้กี่ครั้งในโฟลว์ -
Global Message Processor
ตามความหมายของชื่อจะสังเกตหรือปรับเปลี่ยนข้อความหรือโฟลว์ของข้อความ หม้อแปลงและตัวกรองเป็นตัวอย่างของ Global Message Processor
Transformers- งานหลักของหม้อแปลงคือการแปลงข้อมูลจากรูปแบบหนึ่งไปเป็นอีกรูปแบบหนึ่ง สามารถกำหนดได้ทั่วโลกและสามารถใช้ได้ในหลายโฟลว์
Filters- เป็นตัวกรองที่จะตัดสินว่าข้อความล่อใดควรถูกประมวลผล โดยทั่วไปตัวกรองจะระบุเงื่อนไขที่ต้องปฏิบัติตามเพื่อให้ข้อความถูกประมวลผลและกำหนดเส้นทางไปยังบริการ
โมเดล
ตรงกันข้ามกับ Agents คือการจัดกลุ่มบริการเชิงตรรกะที่สร้างขึ้นในสตูดิโอ เรามีอิสระที่จะเริ่มและหยุดบริการทั้งหมดภายในรูปแบบเฉพาะ
Services- บริการเป็นสิ่งที่ห่อหุ้มตรรกะทางธุรกิจหรือส่วนประกอบของเรา นอกจากนี้ยังกำหนดค่าเราเตอร์ปลายทางหม้อแปลงและตัวกรองเฉพาะสำหรับบริการนั้น ๆ
Endpoints- อาจถูกกำหนดให้เป็นวัตถุที่บริการจะรับข้อความขาเข้า (รับ) และขาออก (ส่ง) บริการเชื่อมต่อผ่านจุดสิ้นสุด
ไหล
ตัวประมวลผลข้อความใช้โฟลว์เพื่อกำหนดโฟลว์ข้อความระหว่างต้นทางและเป้าหมาย
โครงสร้างข้อความล่อ
ข้อความ Mule ซึ่งรวมอยู่ภายใต้ Mule Message Object เป็นข้อมูลที่ส่งผ่านแอปพลิเคชันผ่านทาง Mule ข้อความของ Structure Mule แสดงในแผนภาพต่อไปนี้ -
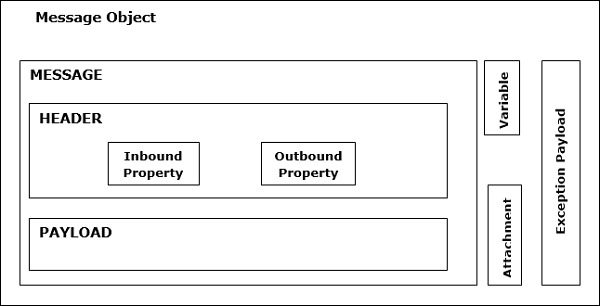
ดังที่เห็นในแผนภาพด้านบน Mule Message ประกอบด้วยสองส่วนหลัก -
หัวข้อ
ไม่มีอะไรนอกจากข้อมูลเมตาของข้อความซึ่งแสดงเพิ่มเติมจากคุณสมบัติสองประการต่อไปนี้ -
Inbound Properties- นี่คือคุณสมบัติที่กำหนดโดยแหล่งที่มาของข้อความโดยอัตโนมัติ ผู้ใช้ไม่สามารถจัดการหรือตั้งค่าได้ โดยธรรมชาติคุณสมบัติขาเข้าไม่เปลี่ยนรูป
Outbound Properties- นี่คือคุณสมบัติที่มีข้อมูลเมตาเช่นคุณสมบัติขาเข้าและสามารถตั้งค่าได้ในระหว่างขั้นตอนการไหล พวกเขาสามารถตั้งค่าโดยอัตโนมัติโดยล่อหรือด้วยตนเองโดยผู้ใช้ โดยธรรมชาติคุณสมบัติขาออกสามารถเปลี่ยนแปลงได้
คุณสมบัติขาออกกลายเป็นคุณสมบัติขาเข้าเมื่อข้อความผ่านจากจุดสิ้นสุดขาออกของโฟลว์หนึ่งไปยังปลายทางขาเข้าของโฟลว์อื่นผ่านการขนส่ง
คุณสมบัติขาออกยังคงคุณสมบัติขาออกเมื่อข้อความถูกส่งไปยังโฟลว์ใหม่ผ่านโฟลว์ ref แทนที่จะเป็นตัวเชื่อมต่อ
น้ำหนักบรรทุก
ข้อความทางธุรกิจจริงที่ดำเนินการโดยวัตถุข้อความเรียกว่า payload
ตัวแปร
อาจถูกกำหนดให้เป็นข้อมูลเมตาที่ผู้ใช้กำหนดเองเกี่ยวกับข้อความ โดยทั่วไปตัวแปรคือข้อมูลชั่วคราวเกี่ยวกับข้อความที่แอปพลิเคชันใช้ในการประมวลผล ไม่ได้หมายถึงการส่งต่อไปพร้อมกับข้อความไปยังปลายทาง มีสามประเภทตามที่ระบุด้านล่าง -
Flow variables - ตัวแปรเหล่านี้ใช้กับโฟลว์ที่มีอยู่เท่านั้น
Session variables - ตัวแปรเหล่านี้ใช้กับโฟลว์ทั้งหมดภายในแอปพลิเคชันเดียวกัน
Record variables - ตัวแปรเหล่านี้ใช้กับระเบียนที่ประมวลผลเป็นส่วนหนึ่งของชุดงานเท่านั้น
ไฟล์แนบและน้ำหนักบรรทุกพิเศษ
ต่อไปนี้เป็นข้อมูลเมตาเพิ่มเติมเกี่ยวกับส่วนของข้อความซึ่งไม่จำเป็นต้องปรากฏทุกครั้งในวัตถุข้อความ
ในบทก่อนหน้านี้เราได้เรียนรู้พื้นฐานของ Mule ESB ในบทนี้ให้เราเรียนรู้วิธีการติดตั้งและกำหนดค่า
ข้อกำหนดเบื้องต้น
เราจำเป็นต้องปฏิบัติตามข้อกำหนดเบื้องต้นต่อไปนี้ก่อนที่จะติดตั้ง Mule บนคอมพิวเตอร์ของเรา -
ชุดพัฒนา Java (JDK)
ก่อนติดตั้ง MULE ให้ตรวจสอบว่าคุณรองรับ Java เวอร์ชันบนระบบของคุณ แนะนำให้ใช้ JDK 1.8.0 เพื่อติดตั้ง Mule บนระบบของคุณให้สำเร็จ
ระบบปฏิบัติการ
ระบบปฏิบัติการต่อไปนี้รองรับโดย Mule -
- MacOS 10.11.x
- HP-UX 11iV3.0
- AIX 7.2
- เซิร์ฟเวอร์ Windows 2016
- เซิร์ฟเวอร์ Windows 2012 R2
- Windows 10
- Windows 8.1
- โซลาริส 11.3
- RHEL 7
- เซิร์ฟเวอร์ Ubuntu 18.04
- เคอร์เนลลินุกซ์ 3.13+
ฐานข้อมูล
ไม่จำเป็นต้องใช้แอ็พพลิเคชันเซิร์ฟเวอร์หรือฐานข้อมูลเนื่องจาก Mule Runtime ทำงานเป็นเซิร์ฟเวอร์แบบสแตนด์อโลน แต่ถ้าเราต้องการเข้าถึงที่เก็บข้อมูลหรือต้องการใช้แอพพลิเคชั่นเซิร์ฟเวอร์สามารถใช้แอพพลิเคชั่นเซิร์ฟเวอร์หรือฐานข้อมูลที่รองรับต่อไปนี้ได้ -
- Oracle 11g
- Oracle 12c
- MySQL 5.5+
- IBM DB2 10
- PostgreSQL 9
- ดาร์บี้ 10
- Microsoft SQL Server 2014
ความต้องการของระบบ
ก่อนที่จะติดตั้ง Mule บนระบบของคุณต้องเป็นไปตามข้อกำหนดของระบบดังต่อไปนี้ -
- CPU อย่างน้อย 2 GHz หรือ 1 CPU เสมือนในสภาพแวดล้อมเสมือน
- RAM ขั้นต่ำ 1 GB
- พื้นที่เก็บข้อมูลขั้นต่ำ 4 GB
ดาวน์โหลด Mule
หากต้องการดาวน์โหลดไฟล์ไบนารี Mule 4 ให้คลิกที่ลิงค์ https://www.mulesoft.com/lp/dl/mule-esb-enterprise และจะนำคุณไปสู่หน้าเว็บอย่างเป็นทางการของ MuleSoft ดังต่อไปนี้ -

ด้วยการให้รายละเอียดที่จำเป็นคุณจะได้รับไฟล์ไบนารี Mule 4 ในรูปแบบ Zip
ติดตั้งและเรียกใช้ Mule
หลังจากดาวน์โหลดไฟล์ไบนารี Mule 4 แล้วให้เปิดเครื่องรูดและตั้งค่าตัวแปรสภาพแวดล้อมที่เรียกว่า MULE_HOME สำหรับไดเร็กทอรี Mule ภายในโฟลเดอร์ที่แยกออกมา
ตัวอย่างเช่นตัวแปรสภาพแวดล้อมบนสภาพแวดล้อม Windows และ Linux / Unix สามารถตั้งค่าสำหรับเวอร์ชัน 4.1.5 ในไดเร็กทอรีดาวน์โหลดดังนี้ -
สภาพแวดล้อมของ Windows
$ env:MULE_HOME=C:\Downloads\mule-enterprise-standalone-4.1.5\สภาพแวดล้อม Unix / Linux
$ export MULE_HOME=~/Downloads/mule-enterprise-standalone-4.1.5/ตอนนี้สำหรับการทดสอบว่า Mule กำลังทำงานในระบบของคุณโดยไม่มีข้อผิดพลาดใด ๆ ให้ใช้คำสั่งต่อไปนี้ -
สภาพแวดล้อมของ Windows
$ $MULE_HOME\bin\mule.batสภาพแวดล้อม Unix / Linux
$ $MULE_HOME/bin/muleคำสั่งด้านบนจะเรียกใช้ Mule ในโหมดเบื้องหน้า หาก Mule กำลังทำงานอยู่เราจะไม่สามารถออกคำสั่งอื่นใดบนเทอร์มินัลได้ กดctrl-c คำสั่งในเทอร์มินัลจะหยุด Mule
เริ่มบริการล่อ
เราสามารถเริ่ม Mule เป็นบริการ Windows และเป็น Linux / Unix Daemon ได้เช่นกัน
ล่อเป็นบริการ Windows
ในการเรียกใช้ Mule เป็นบริการ Windows เราจำเป็นต้องทำตามขั้นตอนด้านล่าง -
Step 1 - ขั้นแรกให้ติดตั้งด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
$ $MULE_HOME\bin\mule.bat installStep 2 - เมื่อติดตั้งแล้วเราสามารถเรียกใช้ mule เป็นบริการ Windows ด้วยความช่วยเหลือของคำสั่งต่อไปนี้:
$ $MULE_HOME\bin\mule.bat startล่อเป็น Linux / Unix Daemon
ในการเรียกใช้ Mule เป็น Linux / Unix Daemon เราต้องทำตามขั้นตอนด้านล่าง -
Step 1 - ติดตั้งด้วยความช่วยเหลือของคำสั่งต่อไปนี้ -
$ $MULE_HOME/bin/mule installStep 2 - เมื่อติดตั้งแล้วเราสามารถเรียกใช้ mule เป็นบริการ Windows ได้โดยใช้คำสั่งต่อไปนี้ -
$ $MULE_HOME/bin/mule startExample
ตัวอย่างต่อไปนี้เริ่มต้น Mule เป็น Unix Daemon -
$ $MULE_HOME/bin/mule start
MULE_HOME is set to ~/Downloads/mule-enterprise-standalone-4.1.5
MULE_BASE is set to ~/Downloads/mule-enterprise-standalone-4.1.5
Starting Mule Enterprise Edition...
Waiting for Mule Enterprise Edition.................
running: PID:87329ปรับใช้ Mule Apps
เราสามารถปรับใช้แอพ Mule ของเราได้ด้วยความช่วยเหลือของขั้นตอนต่อไปนี้ -
Step 1 - ก่อนอื่นให้เริ่มต้นล่อ
Step 2 - เมื่อ Mule เริ่มต้นเราสามารถปรับใช้แอปพลิเคชัน Mule ของเราได้โดยย้ายไฟล์แพ็คเกจ JAR ของเราไปที่ไฟล์ apps ไดเรกทอรีใน $MULE_HOME.
หยุดบริการล่อ
เราสามารถใช้ stopคำสั่งหยุดล่อ ตัวอย่างเช่นตัวอย่างต่อไปนี้เริ่มต้น Mule เป็น Unix Daemon -
$ $MULE_HOME/bin/mule stop
MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5
MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5
Stopping Mule Enterprise Edition...
Stopped Mule Enterprise Edition.เรายังสามารถใช้ removeคำสั่งเพื่อลบ Mule Service หรือ Daemon ออกจากระบบของเรา ตัวอย่างต่อไปนี้ลบ Mule เป็น Unix Daemon -
$ $MULE_HOME/bin/mule remove
MULE_HOME is set to /Applications/mule-enterprise-standalone-4.1.5
MULE_BASE is set to /Applications/mule-enterprise-standalone-4.1.5
Detected Mac OSX:
Mule Enterprise Edition is not running.
Removing Mule Enterprise Edition daemon...Anypoint Studio ของ MuleSoft นั้นใช้งานง่าย IDE (integration development environment)ใช้สำหรับออกแบบและทดสอบแอพพลิเคชั่น Mule เป็น IDE ที่ใช้ Eclipse เราสามารถลาก Connectors จาก Mule Palette ได้อย่างง่ายดาย กล่าวอีกนัยหนึ่ง Anypoint Studio เป็น IDE ที่ใช้ Eclipse สำหรับการพัฒนาโฟลว์เป็นต้น
ข้อกำหนดเบื้องต้น
เราจำเป็นต้องปฏิบัติตามข้อกำหนดเบื้องต้นดังต่อไปนี้ก่อนที่จะติดตั้ง Mule บนระบบปฏิบัติการทั้งหมดเช่น Windows, Mac และ Linux / Unix
Java Development Kit (JDK)- ก่อนติดตั้ง Mule ให้ตรวจสอบว่าคุณรองรับ Java เวอร์ชันบนระบบของคุณแล้ว แนะนำให้ใช้ JDK 1.8.0 เพื่อติดตั้ง Anypoint บนระบบของคุณให้สำเร็จ
การดาวน์โหลดและติดตั้ง Anypoint Studio
ขั้นตอนในการดาวน์โหลดและติดตั้ง Anypoint Studio บนระบบปฏิบัติการอื่นอาจแตกต่างกันไป ต่อไปมีขั้นตอนในการดาวน์โหลดและติดตั้ง Anypoint Studio บนระบบปฏิบัติการต่างๆ -
บน Windows
ในการดาวน์โหลดและติดตั้ง Anypoint Studio บน Windows เราต้องทำตามขั้นตอนด้านล่าง -
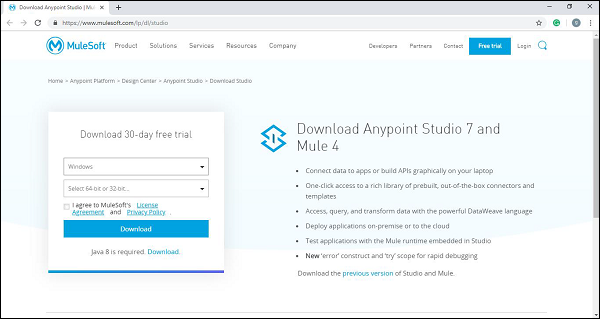
Step 1 - ขั้นแรกให้คลิกที่ลิงค์ https://www.mulesoft.com/lp/dl/studio และเลือกระบบปฏิบัติการ Windows จากรายการบนลงล่างเพื่อดาวน์โหลดสตูดิโอ
Step 2 - ตอนนี้แยกเป็นไฟล์ ‘C:\’ โฟลเดอร์รูท
Step 3 - เปิด Anypoint Studio ที่แยกออกมา
Step 4- สำหรับการยอมรับพื้นที่ทำงานเริ่มต้นให้คลิกตกลง คุณจะได้รับข้อความต้อนรับเมื่อโหลดเป็นครั้งแรก
Step 5 - ตอนนี้คลิกที่ปุ่มเริ่มต้นเพื่อใช้ Anypoint Studio
บน OS X
ในการดาวน์โหลดและติดตั้ง Anypoint Studio บน OS X เราต้องทำตามขั้นตอนด้านล่างนี้ -
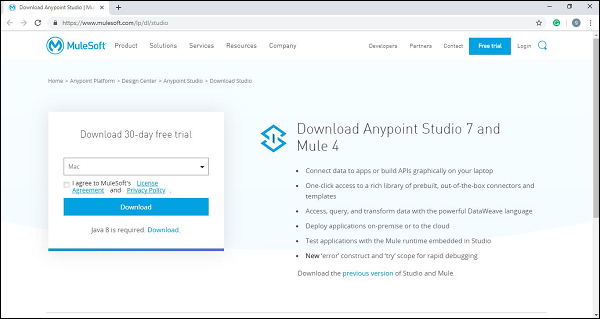
Step 1 - ขั้นแรกให้คลิกที่ลิงค์ https://www.mulesoft.com/lp/dl/studio และดาวน์โหลดสตูดิโอ
Step 2- ตอนนี้แยกมัน ในกรณีที่คุณใช้ OS เวอร์ชัน Sierra ตรวจสอบให้แน่ใจว่าได้ย้ายแอปที่แยกออกมาไปที่/Applications folder ก่อนเปิดตัว
Step 3 - เปิด Anypoint Studio ที่แยกออกมา
Step 4- สำหรับการยอมรับพื้นที่ทำงานเริ่มต้นให้คลิกตกลง คุณจะได้รับข้อความต้อนรับเมื่อโหลดเป็นครั้งแรก
Step 5 - ตอนนี้คลิกที่ Get Started ปุ่มเพื่อใช้ Anypoint Studio
หากคุณกำลังจะใช้เส้นทางที่กำหนดเองไปยังพื้นที่ทำงานของคุณโปรดทราบว่า Anypoint Studio ไม่ได้ขยายเครื่องหมาย ~ ที่ใช้ในระบบ Linux / Unix ดังนั้นขอแนะนำให้ใช้เส้นทางสัมบูรณ์ในขณะที่กำหนดพื้นที่ทำงาน
บน Linux
ในการดาวน์โหลดและติดตั้ง Anypoint Studio บน Linux เราต้องทำตามขั้นตอนด้านล่างนี้ -
Step 1 - ขั้นแรกให้คลิกที่ลิงค์ https://www.mulesoft.com/lp/dl/studio และเลือกระบบปฏิบัติการ Linux จากรายการบนลงล่างเพื่อดาวน์โหลดสตูดิโอ
Step 2 - ตอนนี้แยกมัน
Step 3 - จากนั้นเปิด Anypoint Studio ที่แยกออกมา
Step 4- สำหรับการยอมรับพื้นที่ทำงานเริ่มต้นให้คลิกตกลง คุณจะได้รับข้อความต้อนรับเมื่อโหลดเป็นครั้งแรก
Step 5 - ตอนนี้คลิกที่ปุ่มเริ่มต้นเพื่อใช้ Anypoint Studio
หากคุณกำลังจะใช้เส้นทางที่กำหนดเองไปยังพื้นที่ทำงานของคุณโปรดทราบว่า Anypoint Studio ไม่ได้ขยายเครื่องหมาย ~ ที่ใช้ในระบบ Linux / Unix ดังนั้นขอแนะนำให้ใช้เส้นทางสัมบูรณ์ในขณะที่กำหนดพื้นที่ทำงาน
ขอแนะนำให้ติดตั้ง GTK เวอร์ชัน 2 เพื่อใช้ Studio Themes ที่สมบูรณ์ใน Linux
คุณสมบัติของ Anypoint Studio
ต่อไปนี้เป็นคุณสมบัติบางอย่างของ Anypoint studio ที่ช่วยเพิ่มผลผลิตในขณะที่สร้างแอปพลิเคชัน Mule -
มีการเรียกใช้แอปพลิเคชัน Mule ทันทีภายในรันไทม์ในเครื่อง
Anypoint studio ให้เราแก้ไขภาพสำหรับการกำหนดค่าไฟล์นิยาม API และโดเมน Mule
มีกรอบการทดสอบหน่วยที่ฝังไว้เพื่อเพิ่มผลผลิต
Anypoint studio ให้การสนับสนุนในตัวเพื่อปรับใช้กับ CloudHub
มีสิ่งอำนวยความสะดวกในการทำงานร่วมกับ Exchange สำหรับการนำเข้าเทมเพลตตัวอย่างคำจำกัดความและทรัพยากรอื่น ๆ จากองค์กร Anypoint Platform อื่น ๆ
บรรณาธิการ Anypoint Studio ช่วยเราออกแบบแอปพลิเคชัน API คุณสมบัติและไฟล์การกำหนดค่า นอกจากการออกแบบแล้วยังช่วยให้เราแก้ไขได้อีกด้วย เรามีโปรแกรมแก้ไขไฟล์คอนฟิกูเรชัน Mule สำหรับวัตถุประสงค์นี้ ในการเปิดตัวแก้ไขนี้ให้ดับเบิลคลิกที่ไฟล์ XML ของแอปพลิเคชันใน/src/main/mule.
ในการทำงานกับแอปพลิเคชันของเราเรามีสามแท็บต่อไปนี้ภายใต้โปรแกรมแก้ไขไฟล์ Mule Configuration
แท็บ Flow Flow
แท็บนี้ให้การแสดงภาพของขั้นตอนการทำงาน โดยพื้นฐานแล้วจะมีผืนผ้าใบที่ช่วยให้เราตรวจสอบขั้นตอนของเราด้วยสายตา หากคุณต้องการเพิ่ม Event Processors จาก Mule Palette ลงในผืนผ้าใบให้ลากแล้วปล่อยมันจะสะท้อนในผืนผ้าใบ
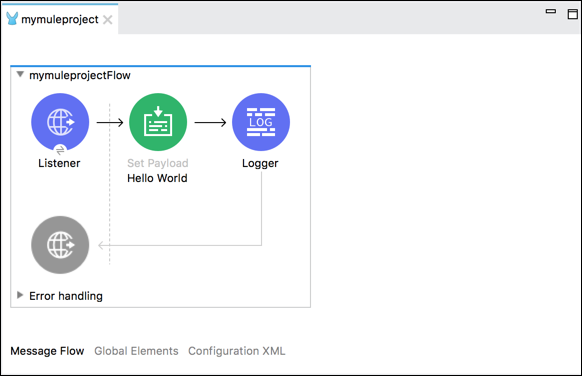
เมื่อคลิกที่ Event Processor คุณจะได้รับ Mule Properties View พร้อมแอตทริบิวต์สำหรับโปรเซสเซอร์ที่เลือก เรายังสามารถแก้ไขได้
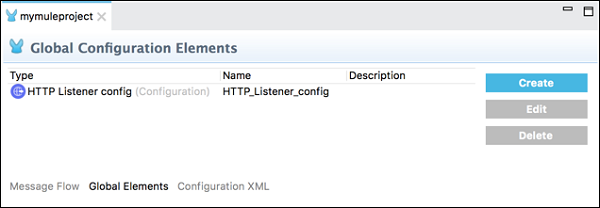
แท็บองค์ประกอบส่วนกลาง
แท็บนี้มีองค์ประกอบการกำหนดค่า Mule ส่วนกลางสำหรับโมดูล ภายใต้แท็บนี้เราสามารถสร้างแก้ไขหรือลบไฟล์คอนฟิกูเรชัน
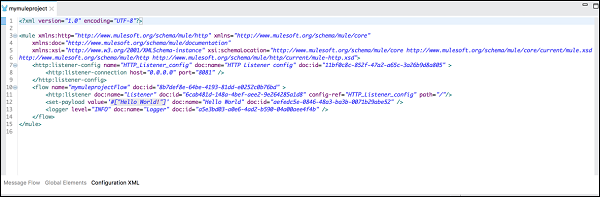
แท็บ Configuration XML
ตามความหมายของชื่อมันมี XML ที่กำหนดแอปพลิเคชัน Mule ของคุณ การเปลี่ยนแปลงทั้งหมดที่คุณทำที่นี่จะแสดงในพื้นที่รวมทั้งมุมมองคุณสมบัติของตัวประมวลผลเหตุการณ์ภายใต้แท็บโฟลวข้อความ
มุมมอง
สำหรับโปรแกรมแก้ไขที่ใช้งานอยู่ Anypoint studio ให้เราแสดงข้อมูลเมตาของโครงการของเราแบบกราฟิกคุณสมบัติด้วยความช่วยเหลือของมุมมอง ผู้ใช้สามารถย้ายปิดและเพิ่มมุมมองในโครงการ Mule ต่อไปนี้เป็นมุมมองเริ่มต้นบางส่วนใน Anypoint studio -
Package Explorer
งานหลักของมุมมอง Package Explorer คือการแสดงโฟลเดอร์โครงการและไฟล์ที่อยู่ในโครงการ Mule เราสามารถขยายหรือหดโฟลเดอร์โครงการล่อได้โดยคลิกที่ลูกศรที่อยู่ข้างๆ สามารถเปิดโฟลเดอร์หรือไฟล์ได้โดยดับเบิลคลิก ดูภาพหน้าจอ -
Mule Palette
มุมมอง Mule Palette แสดงตัวประมวลผลเหตุการณ์เช่นขอบเขตตัวกรองและเราเตอร์ควบคุมการไหลพร้อมกับโมดูลและการทำงานที่เกี่ยวข้อง ภารกิจหลักของมุมมอง Mule Palette มีดังนี้ -
- มุมมองนี้ช่วยให้เราจัดการโมดูลและตัวเชื่อมต่อในโครงการของเรา
- เรายังสามารถเพิ่มองค์ประกอบใหม่จาก Exchange
ดูภาพหน้าจอ -
คุณสมบัติล่อ
ตามความหมายของชื่อจะช่วยให้เราสามารถแก้ไขคุณสมบัติของโมดูลที่เลือกในพื้นที่ทำงานของเราได้ มุมมองคุณสมบัติล่อมีดังต่อไปนี้ -
DataSense Explorer ที่ให้ข้อมูลแบบเรียลไทม์เกี่ยวกับโครงสร้างข้อมูลของน้ำหนักบรรทุกของเรา
คุณสมบัติขาเข้าและขาออกถ้ามีหรือตัวแปร
ด้านล่างนี้คือภาพหน้าจอ -
คอนโซล
เมื่อใดก็ตามที่เราสร้างหรือเรียกใช้แอปพลิเคชัน Mule เซิร์ฟเวอร์ Mule ในตัวจะแสดงรายการของเหตุการณ์และปัญหา (ถ้ามี) ซึ่งรายงานโดย Studio มุมมองคอนโซลประกอบด้วยคอนโซลของเซิร์ฟเวอร์ Mule ที่ฝังตัวนั้น ดูภาพหน้าจอ -
มุมมองปัญหา
เราสามารถพบปัญหามากมายในขณะที่ทำงานในโครงการล่อของเรา ปัญหาทั้งหมดเหล่านั้นจะแสดงในมุมมองปัญหา ด้านล่างนี้คือภาพหน้าจอ

มุมมอง
ใน Anypoint Studio เป็นการรวบรวมมุมมองและตัวแก้ไขในการจัดเรียงที่ระบุ Anypoint Studio มีมุมมองสองแบบ -
Mule Design Perspective - เป็นมุมมองเริ่มต้นที่เราได้รับใน Studio
Mule Debug Perspective - อีกมุมมองที่จัดทำโดย Anypoint Studio คือ Mule Debug Perspective
ในทางกลับกันเรายังสามารถสร้างมุมมองของเราเองและสามารถเพิ่มหรือลบมุมมองเริ่มต้นใด ๆ
ในบทนี้เราจะสร้างแอปพลิเคชั่น Mule ตัวแรกใน Anypoint Studio ของ MuleSoft ในการสร้างก่อนอื่นเราต้องเปิด Anypoint Studio
เปิดตัว Anypoint Studio
คลิกที่ Anypoint Studio เพื่อเปิดใช้งาน หากคุณเปิดใช้งานเป็นครั้งแรกคุณจะเห็นหน้าต่างต่อไปนี้ -
ส่วนต่อประสานผู้ใช้ของ Anypoint Studio
เมื่อคุณคลิกที่ปุ่ม Go to Workspace มันจะนำคุณไปสู่ส่วนต่อประสานผู้ใช้ของ Anypoint Studio ดังต่อไปนี้ -
ขั้นตอนในการสร้าง Mule Application
ในการสร้างแอปพลิเคชัน Mule ของคุณให้ทำตามขั้นตอนด้านล่าง -
การสร้างโครงการใหม่
ขั้นตอนแรกในการสร้างแอปพลิเคชั่น Mule คือการสร้างโครงการใหม่ สามารถทำได้โดยทำตามเส้นทางFILE → NEW → Mule Project ดังแสดงด้านล่าง -
การตั้งชื่อโครงการ
หลังจากคลิกที่โครงการล่อใหม่ตามที่อธิบายไว้ข้างต้นหน้าต่างใหม่จะเปิดขึ้นเพื่อขอชื่อโครงการและข้อกำหนดอื่น ๆ ตั้งชื่อโครงการว่า 'TestAPP1'แล้วคลิกที่ปุ่มเสร็จสิ้น
เมื่อคุณคลิกที่ปุ่มเสร็จสิ้นมันจะเปิดพื้นที่ทำงานที่สร้างขึ้นสำหรับ MuleProject ของคุณคือ ‘TestAPP1’. คุณสามารถดูไฟล์Editors และ Views อธิบายไว้ในบทก่อนหน้า
การกำหนดค่าตัวเชื่อมต่อ
ที่นี่เราจะสร้างแอปพลิเคชั่น Mule ง่ายๆสำหรับ HTTP Listener สำหรับสิ่งนี้เราต้องลากตัวเชื่อมต่อ HTTP Listener จาก Mule Palette และวางลงในพื้นที่ทำงานดังที่แสดงด้านล่าง -
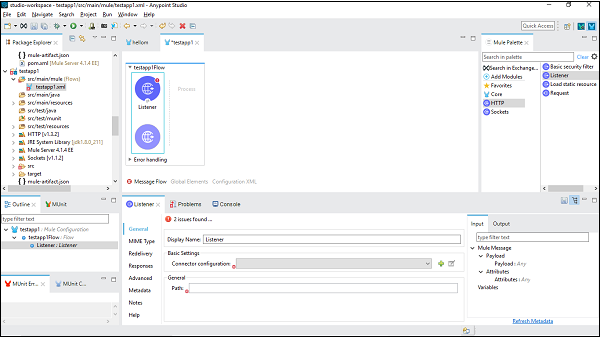
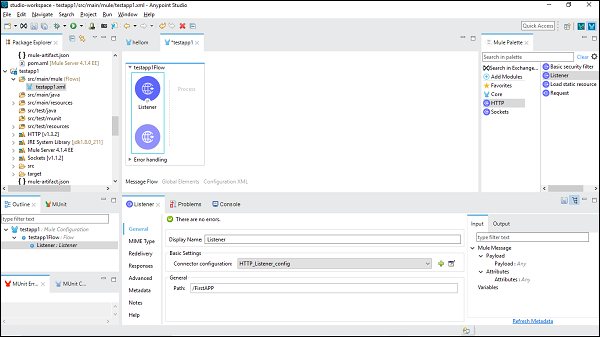
ตอนนี้เราจำเป็นต้องกำหนดค่า คลิกที่เครื่องหมาย + สีเขียวหลังจากการกำหนดค่าตัวเชื่อมต่อภายใต้การตั้งค่าพื้นฐานดังที่แสดงด้านบน

เมื่อคลิกตกลงระบบจะนำคุณกลับไปที่หน้าคุณสมบัติ HTTP Listener ตอนนี้เราต้องระบุเส้นทางภายใต้แท็บทั่วไป ในตัวอย่างนี้เราได้ให้ไว้/FirstAPP เป็นชื่อพา ธ
การกำหนดค่า Set Payload Connector
ตอนนี้เราต้องใช้ตัวเชื่อมต่อ Set Payload เราต้องให้ค่าของมันภายใต้แท็บการตั้งค่าดังนี้ -
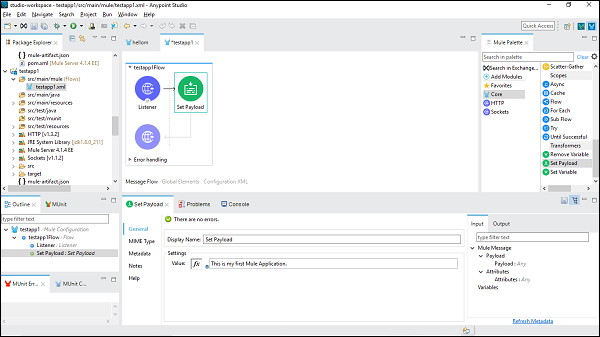
This is my first Mule Applicationเป็นชื่อที่ระบุในตัวอย่างนี้
กำลังเรียกใช้แอปพลิเคชั่นล่อ
ตอนนี้บันทึกและคลิก Run as Mule Application ดังแสดงด้านล่าง -
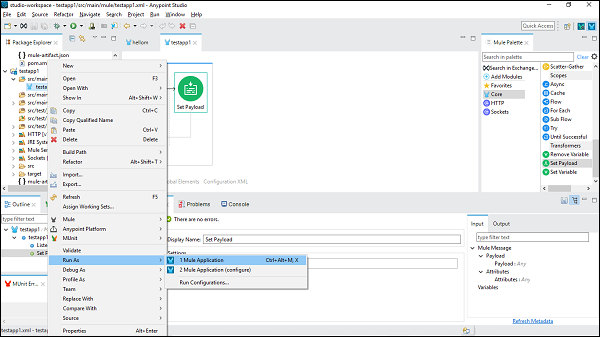
เราสามารถตรวจสอบได้ภายใต้คอนโซลซึ่งปรับใช้แอปพลิเคชันดังนี้ -
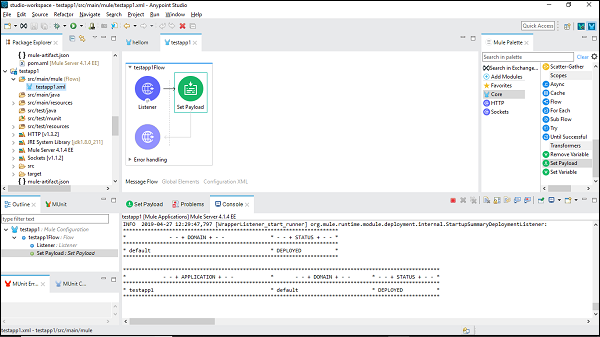
แสดงว่าคุณได้สร้าง Mule Application ตัวแรกสำเร็จแล้ว
กำลังตรวจสอบแอปพลิเคชันล่อ
ตอนนี้เราต้องทดสอบว่าแอปของเราทำงานอยู่หรือไม่ Go to POSTMANแอป Chrome และป้อน URL: http:/localhost:8081. มันแสดงข้อความที่เราให้ไว้ในขณะที่สร้างแอปพลิเคชั่น Mule ดังที่แสดงด้านล่าง -
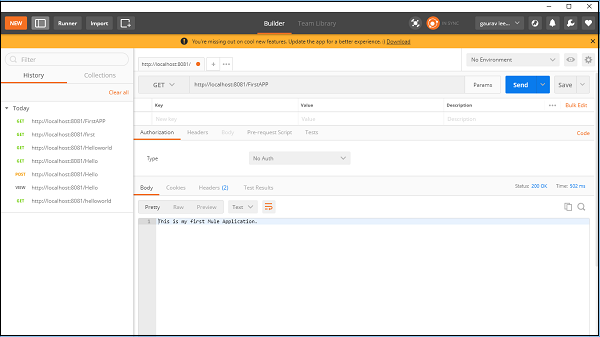
DataWeave เป็นภาษานิพจน์ MuleSoft ส่วนใหญ่จะใช้สำหรับการเข้าถึงและการแปลงข้อมูลที่ได้รับผ่านแอปพลิเคชัน Mule Mule runtime รับผิดชอบในการรันสคริปต์และนิพจน์ในแอปพลิเคชัน Mule ของเรา DataWeave ได้รับการผสานรวมกับ Mule runtime
คุณสมบัติของภาษา DataWeave
ต่อไปนี้เป็นคุณสมบัติที่สำคัญบางประการของภาษา DataWeave -
ข้อมูลสามารถเปลี่ยนจากรูปแบบหนึ่งไปเป็นอีกรูปแบบหนึ่งได้อย่างง่ายดาย ตัวอย่างเช่นเราสามารถแปลง application / json เป็น application / xml ข้อมูลการป้อนข้อมูลมีดังนี้ -
{
"title": "MuleSoft",
"author": " tutorialspoint.com ",
"year": 2019
}ต่อไปนี้เป็นรหัสใน DataWeave สำหรับการแปลง -
%dw 2.0
output application/xml
---
{
order: {
'type': 'Tutorial',
'title': payload.title,
'author': upper(payload.author),
'year': payload.year
}
}ถัดไป output น้ำหนักบรรทุกมีดังนี้ -
<?xml version = '1.0' encoding = 'UTF-8'?>
<order>
<type>Tutorial</type>
<title>MuleSoft</title>
<author>tutorialspoint.com</author>
<year>2019</year>
</order>ส่วนประกอบการแปลงสามารถใช้สำหรับการสร้างสคริปต์ที่ดำเนินการแปลงข้อมูลทั้งแบบง่ายและแบบซับซ้อน
เราสามารถเข้าถึงและใช้ฟังก์ชันหลักของ DataWeave ในบางส่วนของเหตุการณ์ Mule ที่เราต้องการเนื่องจากตัวประมวลผลข้อความ Mule ส่วนใหญ่รองรับนิพจน์ DataWeave
ข้อกำหนดเบื้องต้น
เราจำเป็นต้องปฏิบัติตามข้อกำหนดเบื้องต้นต่อไปนี้ก่อนที่จะใช้สคริปต์ DataWeave บนคอมพิวเตอร์ของเรา -
Anypoint Studio 7 จำเป็นต้องใช้สคริปต์ Dataweave
หลังจากติดตั้ง Anypoint Studio แล้วเราจำเป็นต้องตั้งค่าโปรเจ็กต์ด้วยคอมโพเนนต์ Transform Message เพื่อใช้สคริปต์ DataWeave
ขั้นตอนในการใช้ DataWeave Script พร้อมตัวอย่าง
ในการใช้ DataWeave scrip เราต้องทำตามขั้นตอนด้านล่าง -
Step 1
ขั้นแรกเราต้องตั้งค่าโครงการใหม่เช่นเดียวกับที่เราทำในบทก่อนหน้าโดยใช้ไฟล์ File → New → Mule Project.
Step 2
ต่อไปเราต้องระบุชื่อโครงการ สำหรับตัวอย่างนี้เราตั้งชื่อให้ว่าMule_test_script.
Step 3
ตอนนี้เราต้องลากไฟล์ Transform Message component จาก Mule Palette tab เป็น canvas. ดังแสดงด้านล่าง -
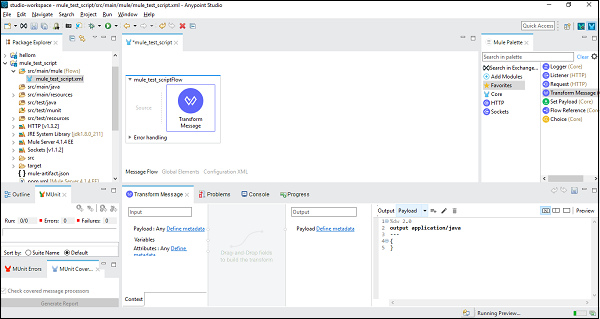
Step 4
ถัดไปใน Transform Message componentคลิกที่แสดงตัวอย่างเพื่อเปิดบานหน้าต่างแสดงตัวอย่าง เราสามารถขยายพื้นที่ซอร์สโค้ดได้โดยคลิกที่สี่เหลี่ยมว่างข้าง Preview
Step 5
ตอนนี้เราสามารถเริ่มเขียนสคริปต์ด้วยภาษา DataWeave
ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างง่ายๆของการเชื่อมสองสตริงเข้าด้วยกัน -
สคริปต์ DataWeave ข้างต้นมีคู่คีย์ - ค่า ({ myString: ("hello" ++ "World") }) ซึ่งจะเชื่อมสองสตริงเข้าด้วยกัน
โมดูลการเขียนสคริปต์อำนวยความสะดวกให้ผู้ใช้ใช้ภาษาสคริปต์ใน Mule กล่าวง่ายๆคือโมดูลการเขียนสคริปต์สามารถแลกเปลี่ยนตรรกะที่กำหนดเองซึ่งเขียนด้วยภาษาสคริปต์ สคริปต์สามารถใช้เป็น Implementations หรือ Transformers สามารถใช้สำหรับการประเมินนิพจน์เช่นสำหรับควบคุมการกำหนดเส้นทางข้อความ
Mule มีภาษาสคริปต์ที่รองรับดังต่อไปนี้ -
- Groovy
- Python
- JavaScript
- Ruby
จะติดตั้ง Scripting Modules ได้อย่างไร?
อันที่จริง Anypoint Studio มาพร้อมกับโมดูลการเขียนสคริปต์ หากคุณไม่พบโมดูลใน Mule Palette คุณสามารถเพิ่มโมดูลได้โดยใช้+Add Module. หลังจากเพิ่มแล้วเราสามารถใช้การทำงานของโมดูลสคริปต์ในแอปพลิเคชัน Mule ของเรา
ตัวอย่างการใช้งาน
ตามที่กล่าวไว้เราจำเป็นต้องลากและวางโมดูลลงในพื้นที่ทำงานเพื่อสร้างพื้นที่ทำงานและใช้ในแอปพลิเคชันของเรา ต่อไปนี้เป็นตัวอย่างของมัน -
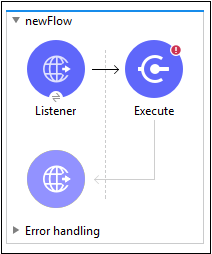
เรารู้วิธีกำหนดค่าคอมโพเนนต์ HTTP Listener แล้ว ดังนั้นเราจะพูดคุยเกี่ยวกับการกำหนดค่าโมดูลการเขียนสคริปต์ เราต้องทำตามขั้นตอนที่เขียนด้านล่างเพื่อกำหนดค่าโมดูลการเขียนสคริปต์ -
Step 1
ค้นหาโมดูล Scripting จาก Mule Palette แล้วลากไฟล์ EXECUTE การทำงานของโมดูลการเขียนสคริปต์ในโฟลว์ของคุณตามที่แสดงด้านบน
Step 2
ตอนนี้เปิดแท็บ Execute configuration โดยดับเบิลคลิกที่เดียวกัน
Step 3
ภายใต้ General เราจำเป็นต้องระบุรหัสในไฟล์ Code text window ดังแสดงด้านล่าง -
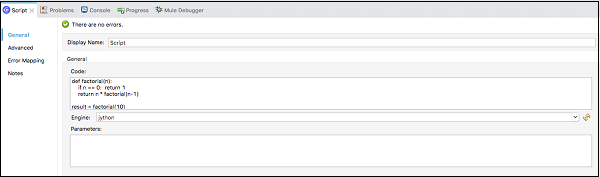
Step 4
ในที่สุดเราต้องเลือกไฟล์ Engineจากคอมโพเนนต์การดำเนินการ รายการเครื่องยนต์มีดังต่อไปนี้ -
- Groovy
- Nashorn(javaScript)
- jython(Python)
- jRuby(Ruby)
XML ของตัวอย่างการดำเนินการข้างต้นในตัวแก้ไข Configuration XML มีดังต่อไปนี้ -
<scripting:execute engine="jython" doc:name = "Script">
<scripting:code>
def factorial(n):
if n == 0: return 1
return n * factorial(n-1)
result = factorial(10)
</scripting:code>
</scripting:execute>แหล่งที่มาของข้อความ
Mule 4 มีรูปแบบที่เรียบง่ายกว่าข้อความ Mule 3 ทำให้ง่ายต่อการทำงานกับข้อมูลในลักษณะที่สอดคล้องกันระหว่างตัวเชื่อมต่อโดยไม่ต้องเขียนทับข้อมูล ในรูปแบบข้อความ Mule 4 แต่ละเหตุการณ์ Mule ประกอบด้วยสองสิ่ง:a message and variables associated with it.
ข้อความ Mule กำลังมี payload และแอตทริบิวต์โดยที่แอตทริบิวต์ส่วนใหญ่เป็นข้อมูลเมตาเช่นขนาดไฟล์
และตัวแปรจะเก็บข้อมูลผู้ใช้ตามอำเภอใจเช่นผลการดำเนินการค่าเสริมเป็นต้น
ขาเข้า
คุณสมบัติขาเข้าใน Mule 3 ตอนนี้กลายเป็นแอตทริบิวต์ใน Mule 4 ตามที่เราทราบว่าคุณสมบัติขาเข้าเก็บข้อมูลเพิ่มเติมเกี่ยวกับน้ำหนักบรรทุกที่ได้รับจากแหล่งข้อความ แต่ตอนนี้ใน Mule 4 ทำได้ด้วยความช่วยเหลือของแอตทริบิวต์ คุณสมบัติมีข้อดีดังต่อไปนี้ -
ด้วยความช่วยเหลือของแอตทริบิวต์เราสามารถดูได้อย่างง่ายดายว่ามีข้อมูลใดบ้างเนื่องจากแอตทริบิวต์ถูกพิมพ์อย่างรุนแรง
เราสามารถเข้าถึงข้อมูลที่อยู่ในแอตทริบิวต์ได้อย่างง่ายดาย
ต่อไปนี้เป็นตัวอย่างของข้อความทั่วไปใน Mule 4 -
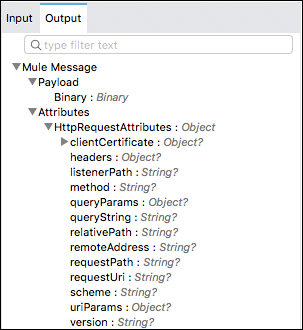
ขาออก
คุณสมบัติขาออกใน Mule 3 ต้องถูกระบุอย่างชัดเจนโดยตัวเชื่อมต่อ Mule และการขนส่งเพื่อส่งข้อมูลเพิ่มเติม แต่ใน Mule 4 แต่ละรายการสามารถตั้งค่าแยกกันได้โดยใช้นิพจน์ DataWeave สำหรับแต่ละรายการ ไม่ก่อให้เกิดผลข้างเคียงใด ๆ ในกระแสหลัก
ตัวอย่างเช่นด้านล่างนิพจน์ DataWeave จะดำเนินการร้องขอ HTTP และสร้างส่วนหัวและพารามิเตอร์การสืบค้นโดยไม่จำเป็นต้องตั้งค่าคุณสมบัติข้อความ สิ่งนี้แสดงในรหัสด้านล่าง -
<http:request path = "M_issue" config-ref="http" method = "GET">
<http:headers>#[{'path':'input/issues-list.json'}]</http:headers>
<http:query-params>#[{'provider':'memory-provider'}]</http:query-params>
</http:request>ตัวประมวลผลข้อความ
เมื่อ Mule ได้รับข้อความจากแหล่งข้อความการทำงานของตัวประมวลผลข้อความจะเริ่มขึ้น Mule ใช้ตัวประมวลผลข้อความอย่างน้อยหนึ่งตัวเพื่อประมวลผลข้อความผ่านโฟลว์ ภารกิจหลักของตัวประมวลผลข้อความคือการแปลงกรองเสริมสร้างและประมวลผลข้อความเมื่อผ่านโฟลว์ล่อ
การจัดหมวดหมู่ของ Mule Processor
ต่อไปนี้เป็นหมวดหมู่ของ Mule Processor ตามฟังก์ชัน -
Connectors- ตัวประมวลผลข้อความเหล่านี้ส่งและรับข้อมูล นอกจากนี้ยังเชื่อมต่อข้อมูลเข้ากับแหล่งข้อมูลภายนอกผ่านโปรโตคอลมาตรฐานหรือ API ของบุคคลที่สาม
Components - ตัวประมวลผลข้อความเหล่านี้มีความยืดหยุ่นตามธรรมชาติและใช้ตรรกะทางธุรกิจที่นำไปใช้ในภาษาต่างๆเช่น Java, JavaScript, Groovy, Python หรือ Ruby
Filters - พวกเขากรองข้อความและอนุญาตให้ประมวลผลเฉพาะข้อความต่อไปในขั้นตอนตามเกณฑ์ที่กำหนด
Routers - ตัวประมวลผลข้อความนี้ใช้เพื่อควบคุมการไหลของข้อความไปยังเส้นทางการเรียงลำดับใหม่หรือการแยก
Scopes - โดยทั่วไปแล้วจะห่อตัวอย่างโค้ดเพื่อจุดประสงค์ในการกำหนดพฤติกรรมที่ละเอียดภายในโฟลว์
Transformers - บทบาทของหม้อแปลงคือการแปลงประเภทน้ำหนักบรรทุกข้อความและรูปแบบข้อมูลเพื่ออำนวยความสะดวกในการสื่อสารระหว่างระบบ
Business Events - โดยทั่วไปแล้วจะจับข้อมูลที่เกี่ยวข้องกับตัวบ่งชี้ประสิทธิภาพหลัก
Exception strategies - ตัวประมวลผลข้อความเหล่านี้จัดการข้อผิดพลาดทุกประเภทที่เกิดขึ้นระหว่างการประมวลผลข้อความ
ความสามารถที่สำคัญที่สุดอย่างหนึ่งของ Mule คือสามารถทำการกำหนดเส้นทางการแปลงร่างและการประมวลผลด้วยส่วนประกอบเนื่องจากไฟล์คอนฟิกูเรชันของแอปพลิเคชัน Mule ที่รวมองค์ประกอบต่างๆมีขนาดใหญ่มาก
ต่อไปนี้เป็นประเภทของรูปแบบการกำหนดค่าที่ Mule มีให้ -
- รูปแบบการบริการที่เรียบง่าย
- Bridge
- Validator
- พร็อกซี HTTP
- พร็อกซี WS
การกำหนดค่าคอมโพเนนต์
ใน Anypoint studio เราสามารถทำตามขั้นตอนด้านล่างเพื่อกำหนดค่าส่วนประกอบ -
Step 1
เราจำเป็นต้องลากส่วนประกอบที่เราต้องการใช้ในแอปพลิเคชัน Mule ของเรา ตัวอย่างเช่นที่นี่เราใช้คอมโพเนนต์ตัวฟัง HTTP ดังนี้ -

Step 2
จากนั้นดับเบิลคลิกที่ส่วนประกอบเพื่อรับหน้าต่างการกำหนดค่า สำหรับผู้ฟัง HTTP จะแสดงด้านล่าง -
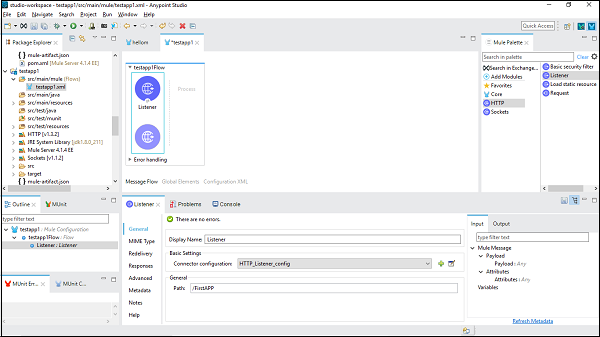
Step 3
เราสามารถกำหนดค่าส่วนประกอบตามความต้องการของโครงการของเรา ตัวอย่างเช่นเราทำกับคอมโพเนนต์ตัวฟัง HTTP -
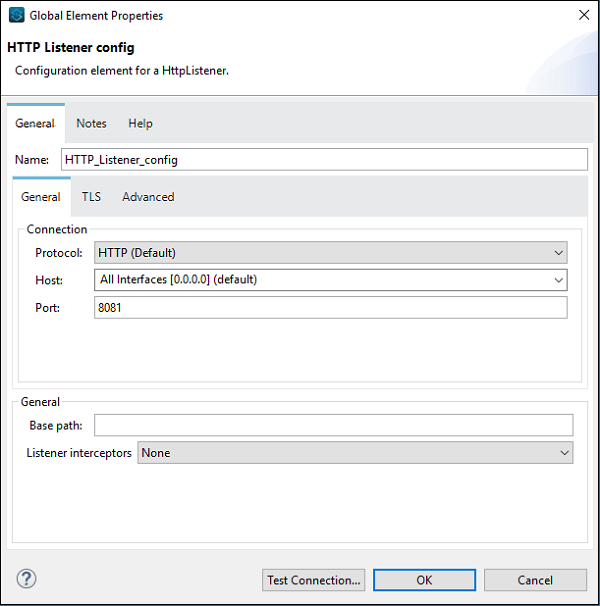
ส่วนประกอบหลักเป็นส่วนประกอบสำคัญอย่างหนึ่งของขั้นตอนการทำงานในแอป Mule ตรรกะสำหรับการประมวลผลเหตุการณ์ล่อจัดเตรียมโดยส่วนประกอบหลักเหล่านี้ ใน Anypoint studio หากต้องการเข้าถึงส่วนประกอบหลักเหล่านี้คุณสามารถคลิกที่ Core จาก Mule Palette ดังที่แสดงด้านล่าง -
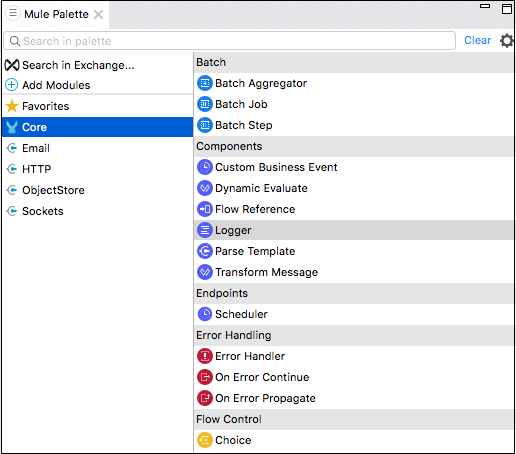
ต่อไปนี้มีหลากหลาย core components and their working in Mule 4 -
กิจกรรมทางธุรกิจที่กำหนดเอง
ส่วนประกอบหลักนี้ใช้สำหรับการรวบรวมข้อมูลเกี่ยวกับโฟลว์ตลอดจนตัวประมวลผลข้อความที่จัดการธุรกรรมทางธุรกิจในแอป Mule กล่าวอีกนัยหนึ่งเราสามารถใช้องค์ประกอบ Custom Business Event เพื่อเพิ่มสิ่งต่อไปนี้ในขั้นตอนการทำงานของเรา -
- Metadata
- ตัวบ่งชี้ประสิทธิภาพหลัก (KPI)
จะเพิ่ม KPI ได้อย่างไร?
ต่อไปนี้เป็นขั้นตอนในการเพิ่ม KPI ในโฟลว์ของเราในแอป Mule -
Step 1 - ติดตามล่อ Palette → Core → Components → Custom Business Eventเพื่อเพิ่มองค์ประกอบ Custom Business Event ในขั้นตอนการทำงานในแอป Mule ของคุณ
Step 2 - คลิกที่ส่วนประกอบเพื่อเปิด
Step 3 - ตอนนี้เราจำเป็นต้องระบุค่าสำหรับชื่อที่แสดงและชื่อเหตุการณ์
Step 4 - ในการเก็บข้อมูลจากส่วนข้อมูลข้อความให้เพิ่ม KPI ดังนี้ -
ตั้งชื่อ (คีย์) สำหรับ KPI ( การติดตาม:องค์ประกอบข้อมูลเมตา ) และค่า ชื่อนี้จะถูกใช้ในอินเทอร์เฟซการค้นหาของ Runtime Manager
ให้ค่าที่อาจเป็นนิพจน์ล่อใด ๆ
ตัวอย่าง
ตารางต่อไปนี้ประกอบด้วยรายการ KPI พร้อมชื่อและมูลค่า -
| ชื่อ | นิพจน์ / มูลค่า |
|---|---|
| โรลนักเรียน | # [เพย์โหลด ['RollNo']] |
| ชื่อนักเรียน | # [payload ['ชื่อ']] |
การประเมินแบบไดนามิก
ส่วนประกอบหลักนี้ใช้สำหรับการเลือกสคริปต์ในแอป Mule แบบไดนามิก นอกจากนี้เรายังสามารถใช้ฮาร์ดคอร์สคริปต์ผ่านคอมโพเนนต์การแปลงข้อความได้ แต่การใช้องค์ประกอบ Dynamic Evaluate เป็นวิธีที่ดีกว่า ส่วนประกอบหลักนี้ทำงานดังนี้ -
- ประการแรกจะประเมินนิพจน์ที่ควรส่งผลให้สคริปต์อื่น
- จากนั้นจะประเมินสคริปต์นั้นสำหรับผลลัพธ์สุดท้าย
ด้วยวิธีนี้จะช่วยให้เราสามารถเลือกสคริปต์ได้แบบไดนามิกแทนที่จะเข้ารหัสแบบฮาร์ดโค้ด
ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างของการเลือกสคริปต์จากฐานข้อมูลผ่านพารามิเตอร์การค้นหาและจัดเก็บ Id สคริปต์ที่ในตัวแปรชื่อMyScript ตอนนี้องค์ประกอบการประเมินแบบไดนามิกจะเข้าถึงตัวแปรเพื่อเรียกใช้สคริปต์เพื่อให้สามารถเพิ่มตัวแปรชื่อจากUName พารามิเตอร์การค้นหา
การกำหนดค่า XML ของโฟลว์ได้รับด้านล่าง -
<flow name = "DynamicE-example-flow">
<http:listener config-ref = "HTTP_Listener_Configuration" path = "/"/>
<db:select config-ref = "dbConfig" target = "myScript">
<db:sql>#["SELECT script FROM SCRIPTS WHERE ID =
$(attributes.queryParams.Id)"]
</db:sql>
</db:select>
<ee:dynamic-evaluate expression = "#[vars.myScript]">
<ee:parameters>#[{name: attributes.queryParams.UName}]</ee:parameters>
</ee:dynamic-evaluate>
</flow>สคริปต์สามารถใช้ตัวแปรบริบทเช่น message, payload, vars หรือแอตทริบิวต์ อย่างไรก็ตามหากคุณต้องการเพิ่มตัวแปรบริบทที่กำหนดเองคุณต้องระบุชุดคู่คีย์ - ค่า
การกำหนดค่าการประเมินแบบไดนามิก
ตารางต่อไปนี้แสดงวิธีกำหนดค่าองค์ประกอบการประเมินแบบไดนามิก -
| ฟิลด์ | มูลค่า | คำอธิบาย | ตัวอย่าง |
|---|---|---|---|
| นิพจน์ | นิพจน์ DataWeave | ระบุนิพจน์ที่จะประเมินเป็นสคริปต์สุดท้าย | นิพจน์ = "# [vars.generateOrderScript]" |
| พารามิเตอร์ | นิพจน์ DataWeave | ระบุคู่คีย์ - ค่า | # [{ช่างไม้: 'and', id: payload.user.id}] |
ส่วนประกอบอ้างอิงการไหล
หากคุณต้องการกำหนดเส้นทางเหตุการณ์ Mule ไปยังโฟลว์อื่นหรือโฟลว์ย่อยและกลับภายในแอพ Mule เดียวกันคอมโพเนนต์การอ้างอิงโฟลว์เป็นตัวเลือกที่ถูกต้อง
ลักษณะเฉพาะ
ต่อไปนี้เป็นลักษณะของส่วนประกอบหลักนี้ -
ส่วนประกอบหลักนี้ช่วยให้เราสามารถปฏิบัติต่อโฟลว์ที่อ้างอิงทั้งหมดได้เหมือนกับส่วนประกอบเดียวในโฟลว์ปัจจุบัน
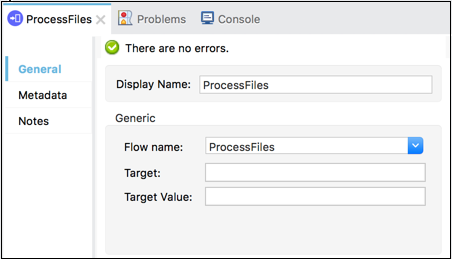
มันแบ่งแอปพลิเคชัน Mule ออกเป็นหน่วยที่ไม่ต่อเนื่องและใช้ซ้ำได้ ตัวอย่างเช่นโฟลว์กำลังแสดงรายการไฟล์เป็นประจำ อาจอ้างอิงโฟลว์อื่นที่ประมวลผลเอาต์พุตของการดำเนินการรายการ
ด้วยวิธีนี้แทนที่จะผนวกขั้นตอนการประมวลผลทั้งหมดเราสามารถผนวกการอ้างอิงโฟลว์ที่ชี้ไปยังขั้นตอนการประมวลผล ภาพหน้าจอด้านล่างแสดงให้เห็นว่า Flow Reference Core Component ชี้ไปที่โฟลว์ย่อยที่ชื่อProcessFiles.
กำลังทำงาน
การทำงานของส่วนประกอบ Flow Ref สามารถเข้าใจได้ด้วยความช่วยเหลือของแผนภาพต่อไปนี้ -

แผนภาพแสดงลำดับการประมวลผลในแอปพลิเคชัน Mule เมื่อโฟลว์หนึ่งอ้างอิงโฟลว์อื่นในแอ็พพลิเคชันเดียวกัน เมื่อขั้นตอนการทำงานหลักในแอปพลิเคชัน Mule ถูกทริกเกอร์เหตุการณ์ Mule จะเดินทางผ่านทั้งหมดและดำเนินการโฟลว์จนกว่าเหตุการณ์ Mule จะถึง Flow Reference
หลังจากถึง Flow Reference เหตุการณ์ Mule จะรันโฟลว์ที่อ้างอิงตั้งแต่ต้นจนจบ เมื่อเหตุการณ์ Mule เสร็จสิ้นการเรียกใช้ Ref Flow มันจะกลับไปที่โฟลว์หลัก
ตัวอย่าง
เพื่อความเข้าใจที่ดีขึ้น let us use this component in Anypoint Studio. ในตัวอย่างนี้เรากำลังรับฟัง HTTP เพื่อรับข้อความเหมือนที่เราทำในบทที่แล้ว ดังนั้นเราสามารถลากและวางส่วนประกอบและกำหนดค่าได้ แต่สำหรับตัวอย่างนี้เราจำเป็นต้องเพิ่ม Sub-flow component และตั้งค่าส่วนประกอบ Payload ตามที่แสดงด้านล่าง -
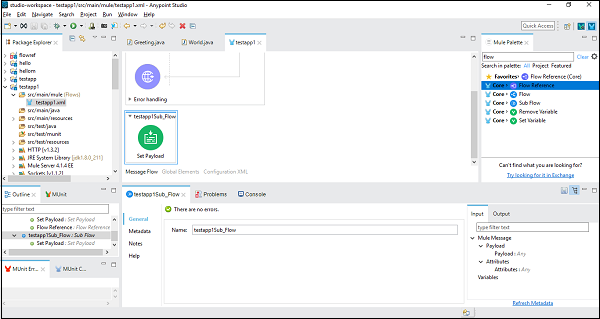
ต่อไปเราต้องกำหนดค่า Set Payloadโดยดับเบิลคลิกที่มัน ในที่นี้เรากำลังให้ค่า "Sub flow ที่ดำเนินการ" ดังที่แสดงด้านล่าง -
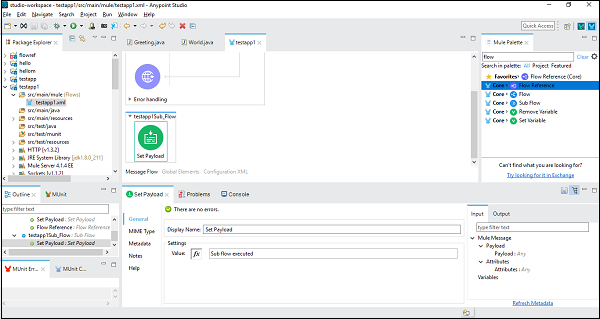
เมื่อกำหนดค่าส่วนประกอบของโฟลว์ย่อยสำเร็จแล้วเราต้องใช้ Flow Reference Component เพื่อตั้งค่าหลังจาก Set Payload ของโฟลว์หลักซึ่งเราสามารถลากและวางจาก Mule Palette ดังที่แสดงด้านล่าง -
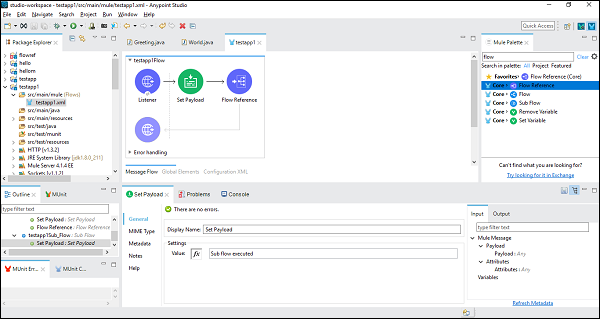
ถัดไปในขณะที่กำหนดค่าส่วนประกอบอ้างอิงโฟลว์เราจำเป็นต้องเลือกชื่อโฟลว์ภายใต้แท็บทั่วไปดังที่แสดงด้านล่าง -
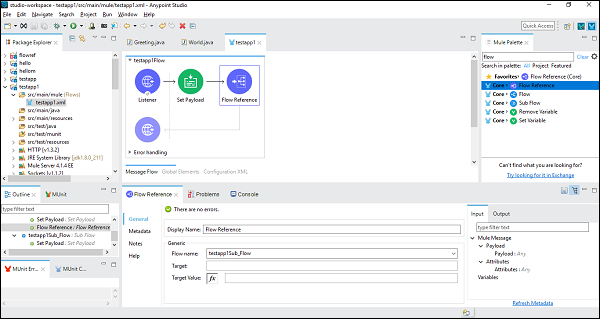
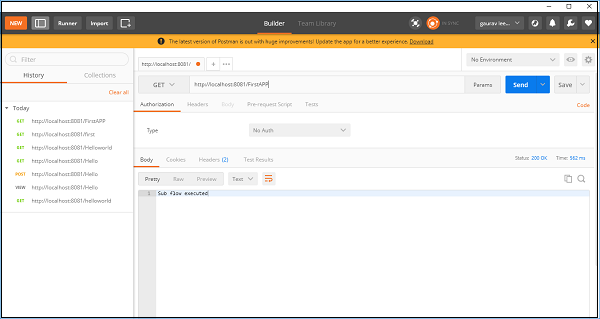
ตอนนี้บันทึกและเรียกใช้แอปพลิเคชันนี้ ในการทดสอบสิ่งนี้ไปที่ POSTMAN แล้วพิมพ์http:/localhost:8181/FirstAPP ในแถบ URL และคุณจะได้รับข้อความ Sub flow ดำเนินการ
ส่วนประกอบ Logger
ส่วนประกอบหลักที่เรียกว่าคนตัดไม้ช่วยให้เราตรวจสอบและแก้ไขข้อบกพร่องของแอปพลิเคชัน Mule ของเราโดยบันทึกข้อมูลสำคัญเช่นข้อความแสดงข้อผิดพลาดการแจ้งเตือนสถานะน้ำหนักบรรทุก ฯลฯ ใน AnyPoint studio จะปรากฏใน Console.
ข้อดี
ต่อไปนี้เป็นข้อดีบางประการของ Logger Component -
- เราสามารถเพิ่มส่วนประกอบหลักนี้ได้ทุกที่ในขั้นตอนการทำงาน
- เราสามารถกำหนดค่าให้บันทึกสตริงที่เราระบุ
- เราสามารถกำหนดค่าให้เป็นผลลัพธ์ของนิพจน์ DataWeave ที่เขียนโดยเรา
- นอกจากนี้เรายังสามารถกำหนดค่าให้รวมกันของสตริงและนิพจน์
ตัวอย่าง
ตัวอย่างด้านล่างแสดงข้อความ“ Hello World” ใน Set Payload ในเบราว์เซอร์และบันทึกข้อความด้วย
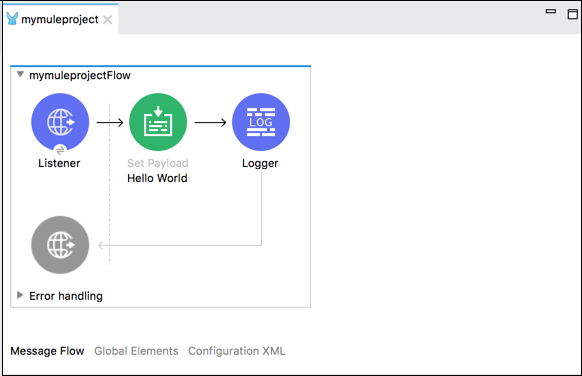
ต่อไปนี้คือการกำหนดค่า XML ของโฟลว์ในตัวอย่างด้านบน -
<http:listener-config name = "HTTP_Listener_Configuration" host = "localhost" port = "8081"/>
<flow name = "mymuleprojectFlow">
<http:listener config-ref="HTTP_Listener_Configuration" path="/"/>
<set-payload value="Hello World"/>
<logger message = "#[payload]" level = "INFO"/>
</flow>โอนส่วนประกอบข้อความ
Transform Message Component หรือที่เรียกว่า Transfer component ช่วยให้เราสามารถแปลงข้อมูลอินพุตเป็นรูปแบบเอาต์พุตใหม่
วิธีการสร้างการเปลี่ยนแปลง
เราสามารถสร้างการเปลี่ยนแปลงของเราได้ด้วยความช่วยเหลือของสองวิธีต่อไปนี้ -
Drag-and-Drop Editor (Graphical View)- นี่เป็นวิธีแรกและใช้มากที่สุดในการสร้างการเปลี่ยนแปลงของเรา ในวิธีนี้เราสามารถใช้วิชวลแมปเปอร์ของคอมโพเนนต์นี้เพื่อลากและวางองค์ประกอบของโครงสร้างข้อมูลขาเข้า ตัวอย่างเช่นในแผนภาพต่อไปนี้มุมมองต้นไม้สองมุมมองแสดงโครงสร้างข้อมูลเมตาที่คาดไว้ของอินพุตและเอาต์พุต เส้นที่เชื่อมต่ออินพุตกับฟิลด์เอาต์พุตแสดงถึงการแมประหว่างมุมมองแบบต้นไม้สองมุมมอง
Script View- การทำแผนที่ภาพของการแปลงยังสามารถแสดงด้วยความช่วยเหลือของ DataWeave ซึ่งเป็นภาษาสำหรับรหัสล่อ เราสามารถทำการเข้ารหัสสำหรับการเปลี่ยนแปลงขั้นสูงบางอย่างเช่นการรวมการทำให้เป็นมาตรฐานการจัดกลุ่มการรวมการแบ่งพาร์ติชันการหมุนและการกรอง ตัวอย่างได้รับด้านล่าง -
ส่วนประกอบหลักนี้โดยทั่วไปยอมรับข้อมูลเมตาของอินพุตและเอาต์พุตสำหรับตัวแปรแอตทริบิวต์หรือเพย์โหลดข้อความ เราสามารถจัดหาทรัพยากรเฉพาะรูปแบบสำหรับสิ่งต่อไปนี้ -
- CSV
- Schema
- สคีมาไฟล์แบบแบน
- JSON
- คลาสออบเจ็กต์
- ประเภทธรรมดา
- สคีมา XML
- ชื่อและประเภทคอลัมน์ Excel
- ชื่อและประเภทคอลัมน์ความกว้างคงที่
จุดสิ้นสุดโดยทั่วไปจะรวมส่วนประกอบเหล่านั้นที่ทริกเกอร์หรือเริ่มต้นการประมวลผลในขั้นตอนการทำงานของแอปพลิเคชัน Mule พวกเขาเรียกว่าSource ใน Anypoint Studio และ Triggersในศูนย์การออกแบบของ Mule จุดสิ้นสุดที่สำคัญอย่างหนึ่งใน Mule 4 คือScheduler component.
ปลายทางของเครื่องมือจัดกำหนดการ
ส่วนประกอบนี้ทำงานบนเงื่อนไขตามเวลาซึ่งหมายความว่าช่วยให้เราสามารถทริกเกอร์โฟลว์เมื่อใดก็ตามที่ตรงตามเงื่อนไขตามเวลา ตัวอย่างเช่นตัวกำหนดตารางเวลาสามารถทริกเกอร์เหตุการณ์เพื่อเริ่มขั้นตอนการทำงานของ Mule ทุกๆ 10 วินาที นอกจากนี้เรายังสามารถใช้นิพจน์ Cron ที่ยืดหยุ่นเพื่อทริกเกอร์ปลายทางของเครื่องมือจัดกำหนดการ
ประเด็นสำคัญเกี่ยวกับเครื่องมือจัดกำหนดการ
ในขณะที่ใช้งาน Scheduler เราจำเป็นต้องดูแลประเด็นสำคัญบางประการตามที่ระบุไว้ด้านล่าง -
Scheduler Endpoint ตามโซนเวลาของเครื่องที่ Mule รันไทม์กำลังทำงานอยู่
สมมติว่าหากแอปพลิเคชัน Mule ทำงานใน CloudHub ตัวกำหนดเวลาจะทำตามเขตเวลาของภูมิภาคที่ผู้ปฏิบัติงาน CloudHub ทำงานอยู่
ในช่วงเวลาใดก็ตามสามารถใช้งานได้เพียงหนึ่งโฟลว์ที่ถูกเรียกโดยจุดสิ้นสุดของเครื่องมือจัดกำหนดการเท่านั้น
ในคลัสเตอร์รันไทม์ Mule จุดสิ้นสุดของ Scheduler จะรันหรือทริกเกอร์บนโหนดหลักเท่านั้น
วิธีกำหนดค่าเครื่องมือจัดกำหนดการ
ดังที่ได้กล่าวไว้ข้างต้นเราสามารถกำหนดค่าจุดสิ้นสุดของตัวกำหนดตารางเวลาที่จะเรียกใช้ในช่วงเวลาที่กำหนดหรือเรายังสามารถให้นิพจน์ Cron
พารามิเตอร์ในการกำหนดค่าเครื่องมือจัดกำหนดการ (สำหรับช่วงเวลาคงที่)
ต่อไปนี้เป็นพารามิเตอร์ในการตั้งค่าตัวกำหนดตารางเวลาเพื่อทริกเกอร์โฟลว์ในช่วงเวลาปกติ -
Frequency- โดยพื้นฐานแล้วจะอธิบายว่าความถี่ใดที่จุดสิ้นสุดของตัวกำหนดเวลาจะทำให้เกิดการไหลของล่อ หน่วยเวลาสำหรับสิ่งนี้สามารถเลือกได้จากฟิลด์หน่วยเวลา ในกรณีที่คุณไม่ได้ระบุค่าใด ๆ สำหรับสิ่งนี้จะใช้ค่าเริ่มต้นซึ่งก็คือ 1000 ในอีกด้านหนึ่งหากคุณระบุ 0 หรือค่าเป็นลบก็จะใช้ค่าเริ่มต้นด้วย
Start Delay- เป็นระยะเวลาที่เราต้องรอก่อนที่จะเรียกใช้ขั้นตอนล่อเป็นครั้งแรกเมื่อแอปพลิเคชันเริ่มทำงาน ค่าของการหน่วงเวลาเริ่มแสดงเป็นหน่วยเวลาเดียวกันกับความถี่ ค่าเริ่มต้นคือ 0
Time Unit- อธิบายหน่วยเวลาทั้งความถี่และความล่าช้าในการเริ่มต้น ค่าที่เป็นไปได้ของหน่วยเวลาคือมิลลิวินาทีวินาทีนาทีชั่วโมงวัน ค่าเริ่มต้นคือมิลลิวินาที
พารามิเตอร์เพื่อกำหนดค่าตัวกำหนดตารางเวลา (สำหรับ Cron Expression)
จริงๆแล้ว Cron เป็นมาตรฐานที่ใช้สำหรับอธิบายข้อมูลเวลาและวันที่ ในกรณีที่คุณใช้นิพจน์ Cron ที่ยืดหยุ่นเพื่อสร้างทริกเกอร์ตัวกำหนดตารางเวลาปลายทางของตารางจะติดตามทุกวินาทีและสร้างเหตุการณ์ล่อเมื่อใดก็ตามที่นิพจน์ Quartz Cron ตรงกับการตั้งค่าวันที่เวลา ด้วยนิพจน์ Cron เหตุการณ์สามารถถูกทริกเกอร์เพียงครั้งเดียวหรือในช่วงเวลาปกติ
ตารางต่อไปนี้แสดงการแสดงวันที่ - เวลาของการตั้งค่าที่จำเป็นหกแบบ -
| แอตทริบิวต์ | มูลค่า |
|---|---|
| วินาที | 0-59 |
| นาที | 0-59 |
| ชั่วโมง | 0-23 |
| วันของเดือน | 1-31 |
| เดือน | 1-12 หรือ ม.ค. - ธ.ค. |
| วันของสัปดาห์ | 1-7 หรือ SUN-SAT |
ตัวอย่างบางส่วนของนิพจน์ Quartz Cron ที่สนับสนุนโดย Scheduler Endpoint มีดังต่อไปนี้ -
½ * * * * ? - หมายความว่าตัวกำหนดตารางเวลาทำงานทุกๆ 2 วินาทีของวันทุกวัน
0 0/5 16 ** ? - หมายความว่ากำหนดการทำงานทุกๆ 5 นาทีเริ่มเวลา 16.00 น. และสิ้นสุดเวลา 16:55 น. ทุกวัน
1 1 1 1, 5 * ? - หมายถึงกำหนดการทำงานในวันแรกของเดือนมกราคมและวันแรกของเดือนเมษายนของทุกปี
ตัวอย่าง
รหัสต่อไปนี้จะบันทึกข้อความ“ สวัสดี” ทุกวินาที -
<flow name = "cronFlow" doc:id = "ae257a5d-6b4f-4006-80c8-e7c76d2f67a0">
<doc:name = "Scheduler" doc:id = "e7b6scheduler8ccb-c6d8-4567-87af-aa7904a50359">
<scheduling-strategy>
<cron expression = "* * * * * ?" timeZone = "America/Los_Angeles"/>
</scheduling-strategy>
</scheduler>
<logger level = "INFO" doc:name = "Logger"
doc:id = "e2626dbb-54a9-4791-8ffa-b7c9a23e88a1" message = '"hi"'/>
</flow>การควบคุมการไหล (เราเตอร์)
ภารกิจหลักขององค์ประกอบ Flow Control คือการรับเหตุการณ์ Mule อินพุตและกำหนดเส้นทางไปยังลำดับส่วนประกอบที่แยกจากกันอย่างน้อยหนึ่งลำดับ โดยทั่วไปเป็นการกำหนดเส้นทางเหตุการณ์ Mule อินพุตไปยังลำดับอื่น ๆ ของส่วนประกอบ ดังนั้นจึงเรียกอีกอย่างว่าเราเตอร์ เราเตอร์ Choice และ Scatter-Gather เป็นเราเตอร์ที่ใช้มากที่สุดภายใต้ส่วนประกอบ Flow Control
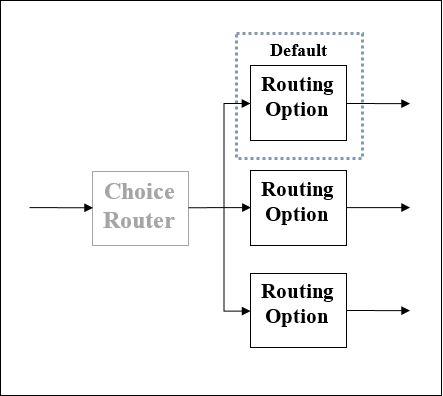
เราเตอร์ตัวเลือก
ตามชื่อที่แนะนำเราเตอร์นี้ใช้ตรรกะ DataWeave เพื่อเลือกหนึ่งในสองเส้นทางขึ้นไป ตามที่กล่าวไว้ก่อนหน้านี้แต่ละเส้นทางเป็นลำดับแยกกันของตัวประมวลผลเหตุการณ์ล่อ เราสามารถกำหนดเราเตอร์ตัวเลือกเป็นเราเตอร์ที่กำหนดเส้นทางข้อความผ่านโฟลว์แบบไดนามิกตามชุดนิพจน์ DataWeave ที่ใช้ประเมินเนื้อหาข้อความ
แผนผังของ Choice Router
ผลของการใช้เราเตอร์ Choice ก็เหมือนกับการเพิ่มการประมวลผลแบบมีเงื่อนไขลงในโฟลว์หรือไฟล์ if/then/elseบล็อกรหัสในภาษาโปรแกรมส่วนใหญ่ ต่อไปนี้เป็นแผนผังของ Choice Router ซึ่งมีสามตัวเลือก หนึ่งในนั้นคือเราเตอร์เริ่มต้น
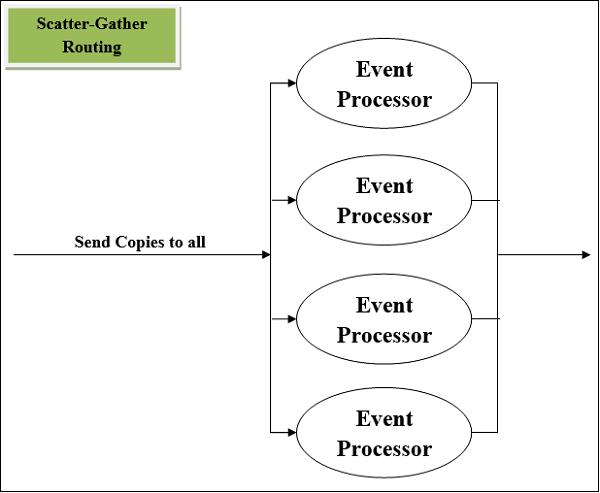
Scatter-Gather Router
ตัวประมวลผลเหตุการณ์การกำหนดเส้นทางที่ใช้มากที่สุดอีกตัวหนึ่งคือ Scatter-Gather component. ตามความหมายของชื่อมันทำงานบนพื้นฐานของ scatters (สำเนา) และ Gather (Consolidates) เราสามารถเข้าใจว่ามันทำงานได้ด้วยความช่วยเหลือของสองประเด็นต่อไปนี้ -
ขั้นแรกเราเตอร์นี้จะคัดลอก (Scatter) เหตุการณ์ล่อไปยังเส้นทางขนานสองเส้นทางขึ้นไป เงื่อนไขคือแต่ละเส้นทางต้องเป็นลำดับของตัวประมวลผลเหตุการณ์ตั้งแต่หนึ่งตัวขึ้นไปซึ่งเปรียบเสมือนโฟลว์ย่อย แต่ละเส้นทางในกรณีนี้จะสร้างเหตุการณ์ Mule โดยใช้เธรดแยกกัน ทุกเหตุการณ์ Mule จะมี payload แอตทริบิวต์และตัวแปรของตัวเอง
จากนั้นเราเตอร์นี้จะรวบรวมเหตุการณ์ Mule ที่สร้างขึ้นจากแต่ละเส้นทางจากนั้นรวมเข้าด้วยกันเป็นเหตุการณ์ Mule ใหม่ หลังจากนี้จะส่งเหตุการณ์ Mule ที่รวมไว้นี้ไปยังตัวประมวลผลเหตุการณ์ถัดไป เงื่อนไขคือเราเตอร์ SG จะส่งเหตุการณ์ Mule รวมไปยังตัวประมวลผลเหตุการณ์ถัดไปก็ต่อเมื่อทุกเส้นทางเสร็จสมบูรณ์
แผนผังของ Scatter-Gather Router
ต่อไปนี้เป็นแผนผังของ Scatter-Gather Router ที่มีตัวประมวลผลเหตุการณ์สี่ตัว มันดำเนินการทุกเส้นทางแบบขนานและไม่เรียงตามลำดับ
การจัดการข้อผิดพลาดโดย Scatter-Gather Router
อันดับแรกเราต้องมีความรู้เกี่ยวกับประเภทของข้อผิดพลาดที่สามารถสร้างขึ้นภายในองค์ประกอบ Scatter-Gather ข้อผิดพลาดใด ๆ อาจถูกสร้างขึ้นภายในตัวประมวลผลเหตุการณ์ที่ทำให้ส่วนประกอบ Scatter-Gather แสดงข้อผิดพลาดประเภทMule: COMPOSITE_ERROR. ข้อผิดพลาดนี้จะถูกส่งโดยส่วนประกอบ SG หลังจากที่ทุกเส้นทางล้มเหลวหรือเสร็จสิ้น
ในการจัดการข้อผิดพลาดประเภทนี้ a try scopeสามารถใช้ได้ในแต่ละเส้นทางของส่วนประกอบ Scatter-Gather หากข้อผิดพลาดถูกจัดการโดยtry scopeจากนั้นเส้นทางจะสามารถสร้างเหตุการณ์ล่อได้อย่างแน่นอน
หม้อแปลงไฟฟ้า
สมมติว่าเราต้องการตั้งค่าหรือลบส่วนหนึ่งของเหตุการณ์ Mule ใด ๆ ส่วนประกอบ Transformer เป็นตัวเลือกที่ดีที่สุด ส่วนประกอบหม้อแปลงมีประเภทต่อไปนี้ -
ถอดหม้อแปลงตัวแปร
ตามความหมายของชื่อคอมโพเนนต์นี้รับชื่อตัวแปรและลบตัวแปรนั้นออกจากเหตุการณ์ Mule
การกำหนดค่าการถอดหม้อแปลงตัวแปร
ตารางด้านล่างแสดงชื่อของเขตข้อมูลและคำอธิบายที่จะพิจารณาในขณะกำหนดค่าการถอดหม้อแปลงตัวแปร -
| ซีเนียร์ No | ฟิลด์และคำอธิบาย |
|---|---|
| 1 | Display Name (doc:name) เราสามารถปรับแต่งค่านี้เพื่อแสดงชื่อเฉพาะสำหรับส่วนประกอบนี้ในขั้นตอนการทำงานของ Mule |
| 2 | Name (variableName) แสดงถึงชื่อของตัวแปรที่ต้องการลบ |
ตั้งหม้อแปลงน้ำหนักบรรทุก
ด้วยความช่วยเหลือของ set-payloadเราสามารถอัปเดตเพย์โหลดซึ่งอาจเป็นสตริงตัวอักษรหรือนิพจน์ DataWeave ของข้อความ ไม่แนะนำให้ใช้ส่วนประกอบนี้สำหรับนิพจน์หรือการแปลงที่ซับซ้อน สามารถใช้สำหรับคนง่ายๆเช่นselections.
ตารางด้านล่างแสดงชื่อของเขตข้อมูลและคำอธิบายที่จะพิจารณาในขณะกำหนดค่าหม้อแปลงน้ำหนักบรรทุกชุด -
| ฟิลด์ | การใช้งาน | คำอธิบาย |
|---|---|---|
| มูลค่า (มูลค่า) | บังคับ | ค่าที่ยื่นเป็นสิ่งจำเป็นสำหรับการตั้งค่าน้ำหนักบรรทุก จะยอมรับสตริงตัวอักษรหรือนิพจน์ DataWeave ซึ่งกำหนดวิธีการตั้งค่าเพย์โหลด ตัวอย่างเช่น "สตริงบาง" |
| ประเภทละครใบ้ (mimeType) | ไม่จำเป็น | เป็นทางเลือก แต่แสดงถึงประเภท mime ของค่าที่กำหนดให้กับ payload ของข้อความ ตัวอย่างเช่นข้อความ / ธรรมดา |
| การเข้ารหัส (การเข้ารหัส) | ไม่จำเป็น | นอกจากนี้ยังเป็นทางเลือก แต่แสดงถึงการเข้ารหัสของค่าที่กำหนดให้กับส่วนข้อมูลของข้อความ ตัวอย่างเช่น UTF-8 |
เราสามารถตั้งค่า payload ผ่านโค้ดการกำหนดค่า XML -
With Static Content - โค้ดคอนฟิกูเรชัน XML ต่อไปนี้จะตั้งค่าเพย์โหลดโดยใช้เนื้อหาคงที่ -
<set-payload value = "{ 'name' : 'Gaurav', 'Id' : '2510' }"
mimeType = "application/json" encoding = "UTF-8"/>With Expression Content - โค้ดคอนฟิกูเรชัน XML ต่อไปนี้จะตั้งค่าเพย์โหลดโดยใช้เนื้อหา Expression -
<set-payload value = "#['Hi' ++ ' Today is ' ++ now()]"/>ตัวอย่างข้างต้นจะต่อท้ายวันที่ของวันนี้ด้วยเพย์โหลดข้อความ“ สวัสดี”
ตั้งค่า Variable Transformer
ด้วยความช่วยเหลือของ set variableคอมโพเนนต์เราสามารถสร้างหรืออัปเดตตัวแปรเพื่อเก็บค่าซึ่งอาจเป็นค่าตามตัวอักษรง่ายๆเช่นสตริงเพย์โหลดข้อความหรืออ็อบเจ็กต์แอตทริบิวต์เพื่อใช้ภายในโฟลว์ของแอปพลิเคชัน Mule ไม่แนะนำให้ใช้ส่วนประกอบนี้สำหรับนิพจน์หรือการแปลงที่ซับซ้อน สามารถใช้สำหรับคนง่ายๆเช่นselections.
การกำหนดค่าหม้อแปลงตัวแปรชุด
ตารางด้านล่างแสดงชื่อของเขตข้อมูลและคำอธิบายที่จะพิจารณาในขณะกำหนดค่าหม้อแปลงน้ำหนักบรรทุกชุด -
| ฟิลด์ | การใช้งาน | คำอธิบาย |
|---|---|---|
| ชื่อตัวแปร (variableName) | บังคับ | จำเป็นต้องยื่นและแสดงชื่อของตัวแปร ในขณะตั้งชื่อให้ทำตามหลักการตั้งชื่อเช่นต้องมีตัวเลขอักขระและขีดล่าง |
| มูลค่า (มูลค่า) | บังคับ | ค่าที่ยื่นเป็นสิ่งจำเป็นสำหรับการตั้งค่าตัวแปร จะยอมรับสตริงตัวอักษรหรือนิพจน์ DataWeave |
| ประเภทละครใบ้ (mimeType) | ไม่จำเป็น | เป็นทางเลือก แต่แสดงถึงประเภท mime ของตัวแปร ตัวอย่างเช่นข้อความ / ธรรมดา |
| การเข้ารหัส (การเข้ารหัส) | ไม่จำเป็น | นอกจากนี้ยังเป็นทางเลือก แต่แสดงถึงการเข้ารหัสของตัวแปร ตัวอย่างเช่น ISO 10646 / Unicode (UTF-8) |
ตัวอย่าง
ตัวอย่างด้านล่างนี้จะตั้งค่าตัวแปรเป็น payload ข้อความ -
Variable Name = msg_var
Value = payload in Design center and #[payload] in Anypoint Studioในทำนองเดียวกันตัวอย่างด้านล่างจะตั้งค่าตัวแปรเป็น payload ข้อความ -
Variable Name = msg_var
Value = attributes in Design center and #[attributes] in Anypoint Studio.บริการเว็บ REST
REST รูปแบบเต็มคือการถ่ายโอนสถานะตัวแทนซึ่งเชื่อมโยงกับ HTTP ดังนั้นหากคุณต้องการออกแบบแอปพลิเคชันเพื่อใช้เฉพาะบนเว็บ REST จึงเป็นตัวเลือกที่ดีที่สุด
การใช้บริการเว็บ RESTful
ในตัวอย่างต่อไปนี้เราจะใช้คอมโพเนนต์ REST และหนึ่งบริการ RESTful สาธารณะที่ให้บริการโดย Mule Soft เรียกว่ารายละเอียดเที่ยวบินอเมริกัน มีรายละเอียดต่าง ๆ แต่เราจะใช้ GET:http://training-american-ws.cloudhub.io/api/flightsซึ่งจะส่งคืนรายละเอียดเที่ยวบินทั้งหมด ดังที่ได้กล่าวไว้ก่อนหน้านี้ REST เชื่อมโยงกับ HTTP ดังนั้นเราจึงต้องการส่วนประกอบ HTTP สองส่วน - หนึ่งคือ Listener และอื่น ๆ คือคำขอสำหรับแอปพลิเคชันนี้ด้วย ภาพหน้าจอด้านล่างแสดงการกำหนดค่าสำหรับผู้ฟัง HTTP -
การกำหนดค่าและส่งผ่านอาร์กิวเมนต์
การกำหนดค่าสำหรับคำขอ HTTP มีให้ด้านล่าง -
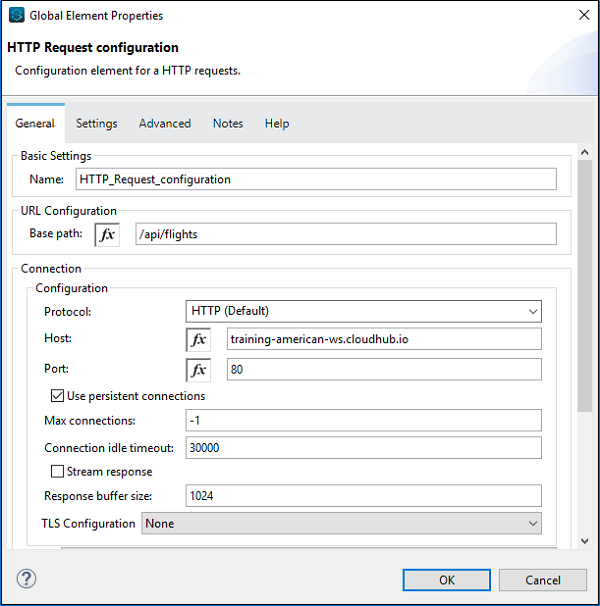
ตอนนี้ตามขั้นตอนการทำงานของเราเราได้ใช้คนตัดไม้เพื่อให้สามารถกำหนดค่าได้ดังต่อไปนี้ -
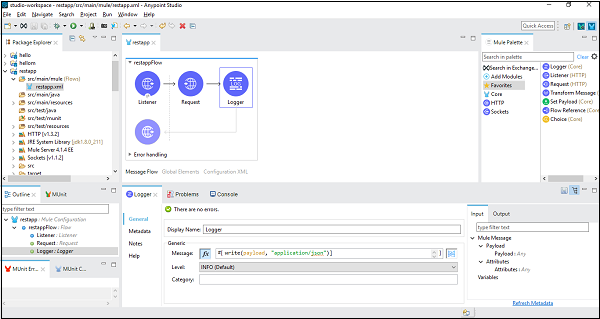
ในแท็บข้อความเราเขียนโค้ดเพื่อแปลงเพย์โหลดเป็นสตริง
การทดสอบแอปพลิเคชัน
ตอนนี้บันทึกและเรียกใช้แอปพลิเคชันและไปที่ POSTMAN เพื่อตรวจสอบผลลัพธ์สุดท้ายตามที่แสดงด้านล่าง -
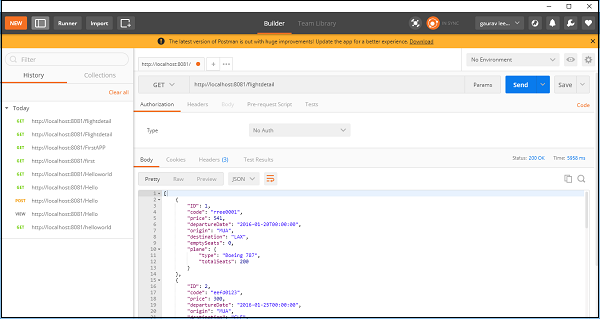
คุณสามารถดูรายละเอียดเที่ยวบินโดยใช้องค์ประกอบ REST
ส่วนประกอบสบู่
SOAP เต็มรูปแบบคือ Simple Object Access Protocol. โดยพื้นฐานแล้วเป็นข้อกำหนดโปรโตคอลการส่งข้อความสำหรับการแลกเปลี่ยนข้อมูลในการใช้บริการเว็บ ต่อไปเราจะใช้ SOAP API ใน Anypoint Studio เพื่อเข้าถึงข้อมูลโดยใช้บริการเว็บ
การใช้บริการเว็บที่ใช้ SOAP
สำหรับตัวอย่างนี้เราจะใช้บริการ SOAP สาธารณะที่มีชื่อว่า Country Info Service ซึ่งจะเก็บรักษาบริการที่เกี่ยวข้องกับข้อมูลของประเทศ ที่อยู่ WSDL คือ:http://www.oorsprong.org/websamples.countryinfo/countryinfoservice.wso?WSDL
ขั้นแรกเราต้องลาก SOAP ที่ใช้ในผืนผ้าใบของเราจาก Mule Palette ดังที่แสดงด้านล่าง -
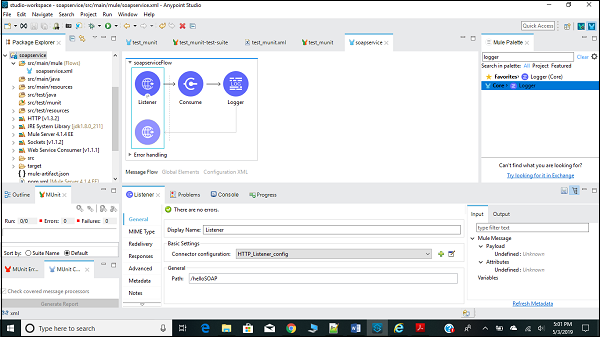
การกำหนดค่าและการส่งผ่านอาร์กิวเมนต์
ต่อไปเราต้องกำหนดค่าคำขอ HTTP ตามตัวอย่างด้านบนตามที่ระบุด้านล่าง -
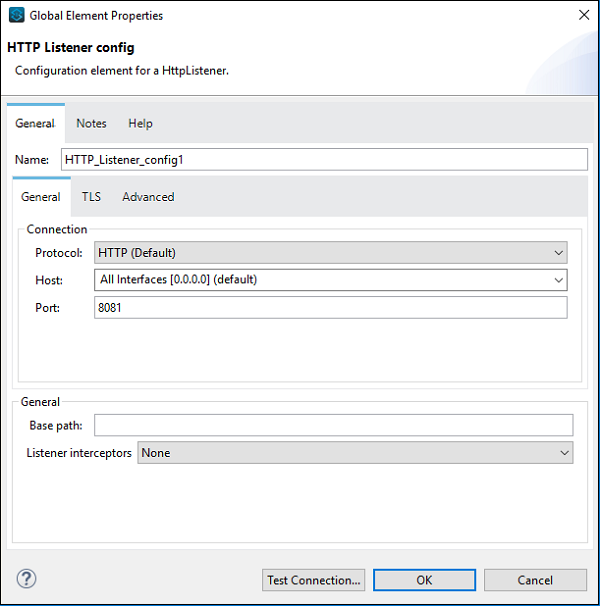
ตอนนี้เราต้องกำหนดค่า Web Service Consumer ดังที่แสดงด้านล่าง -
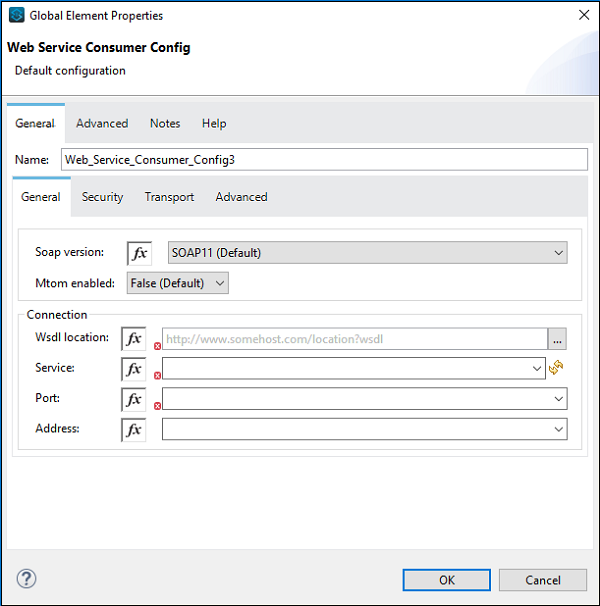
ที่ตำแหน่งของ WSDL เราจำเป็นต้องระบุที่อยู่เว็บของ WSDL ซึ่งระบุไว้ด้านบน (สำหรับตัวอย่างนี้) เมื่อคุณให้ที่อยู่เว็บแล้ว Studio จะค้นหาบริการพอร์ตและที่อยู่ด้วยตัวเอง คุณไม่จำเป็นต้องจัดหาด้วยตนเอง
การตอบสนองการโอนจาก Web Service
สำหรับสิ่งนี้เราจำเป็นต้องเพิ่มคนตัดไม้ในขั้นตอนล่อและกำหนดค่าเพื่อให้น้ำหนักบรรทุกดังที่แสดงด้านล่าง -
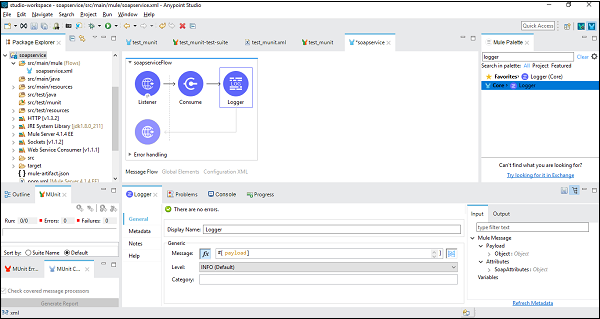
การทดสอบแอปพลิเคชัน
บันทึกและเรียกใช้แอปพลิเคชันและไปที่ Google Chrome เพื่อตรวจสอบผลลัพธ์สุดท้าย ประเภทhttp://localhist:8081/helloSOAP (สำหรับตัวอย่างนี้) และจะแสดงชื่อประเทศตามรหัสดังที่แสดงในภาพหน้าจอด้านล่าง -

การจัดการข้อผิดพลาด Mule ใหม่เป็นหนึ่งในการเปลี่ยนแปลงที่ใหญ่ที่สุดและสำคัญใน Mule 4 การส่งข้อผิดพลาดใหม่อาจดูซับซ้อน แต่จะดีกว่าและมีประสิทธิภาพมากกว่า ในบทนี้เราจะพูดถึงส่วนประกอบของ Mule error ประเภท Error ประเภทของ Mule error และส่วนประกอบสำหรับจัดการ Mule error
ส่วนประกอบของ Mule Error
ข้อผิดพลาด Mule เป็นผลมาจากความล้มเหลวของข้อยกเว้น Mule มีองค์ประกอบดังต่อไปนี้ -
คำอธิบาย
เป็นส่วนประกอบที่สำคัญของข้อผิดพลาด Mule ซึ่งจะให้คำอธิบายเกี่ยวกับปัญหา การแสดงออกมีดังนี้ -
#[error.description]ประเภท
ส่วนประกอบ Type ของข้อผิดพลาด Mule ใช้เพื่อกำหนดลักษณะของปัญหา นอกจากนี้ยังอนุญาตให้กำหนดเส้นทางภายในตัวจัดการข้อผิดพลาด การแสดงออกมีดังนี้ -
#[error.errorType]สาเหตุ
คอมโพเนนต์สาเหตุของข้อผิดพลาด Mule ให้ java throwable ที่เป็นสาเหตุของความล้มเหลว การแสดงออกมีดังนี้ -
#[error.cause]ข้อความ
ข้อความส่วนประกอบของข้อผิดพลาดล่อแสดงข้อความเพิ่มเติมเกี่ยวกับข้อผิดพลาด การแสดงออกมีดังนี้ -
#[error.errorMessage]ข้อผิดพลาดของเด็ก
ข้อผิดพลาดเด็กส่วนประกอบของข้อผิดพลาดล่อให้คอลเลกชันที่ไม่จำเป็นของข้อผิดพลาดภายใน ข้อผิดพลาดภายในเหล่านี้ส่วนใหญ่จะใช้โดยองค์ประกอบเช่น Scatter-Gather เพื่อให้ข้อผิดพลาดรวมของเส้นทาง การแสดงออกมีดังนี้ -
#[error.childErrors]ตัวอย่าง
ในกรณีที่คำขอ HTTP ล้มเหลวด้วยรหัสสถานะ 401 ข้อผิดพลาด Mule มีดังต่อไปนี้ -
Description: HTTP GET on resource ‘http://localhost:8181/TestApp’
failed: unauthorized (401)
Type: HTTP:UNAUTHORIZED
Cause: a ResponseValidatorTypedException instance
Error Message: { "message" : "Could not authorize the user." }| ส.น.น. | ประเภทข้อผิดพลาดและคำอธิบาย |
|---|---|
| 1 | TRANSFORMATION ประเภทข้อผิดพลาดนี้ระบุว่ามีข้อผิดพลาดเกิดขึ้นขณะแปลงค่า การแปลงเป็นการแปลงภายใน Mule Runtime ไม่ใช่การแปลง DataWeave |
| 2 | EXPRESSION ชนิดของข้อผิดพลาดนี้บ่งชี้ข้อผิดพลาดที่เกิดขึ้นขณะประเมินนิพจน์ |
| 3 | VALIDATION ประเภทข้อผิดพลาดนี้บ่งชี้ว่าเกิดข้อผิดพลาดในการตรวจสอบความถูกต้อง |
| 4 | DUPLICATE_MESSAGE ข้อผิดพลาดในการตรวจสอบความถูกต้องซึ่งเกิดขึ้นเมื่อมีการประมวลผลข้อความสองครั้ง |
| 5 | REDELIVERY_EXHAUSTED ประเภทข้อผิดพลาดนี้เกิดขึ้นเมื่อความพยายามสูงสุดในการประมวลผลข้อความจากแหล่งที่มาใหม่หมดลง |
| 6 | CONNECTIVITY ประเภทข้อผิดพลาดนี้บ่งชี้ปัญหาขณะสร้างการเชื่อมต่อ |
| 7 | ROUTING ประเภทข้อผิดพลาดนี้ระบุว่ามีข้อผิดพลาดเกิดขึ้นขณะกำหนดเส้นทางข้อความ |
| 8 | SECURITY ประเภทข้อผิดพลาดนี้ระบุว่าเกิดข้อผิดพลาดด้านความปลอดภัย ตัวอย่างเช่นได้รับข้อมูลรับรองที่ไม่ถูกต้อง |
| 9 | STREAM_MAXIMUM_SIZE_EXCEEDED ประเภทข้อผิดพลาดนี้เกิดขึ้นเมื่อขนาดสูงสุดที่อนุญาตสำหรับสตรีมหมดลง |
| 10 | TIMEOUT บ่งชี้การหมดเวลาขณะประมวลผลข้อความ |
| 11 | UNKNOWN ประเภทข้อผิดพลาดนี้บ่งชี้ข้อผิดพลาดที่ไม่คาดคิดเกิดขึ้น |
| 12 | SOURCE แสดงถึงการเกิดข้อผิดพลาดในแหล่งที่มาของการไหล |
| 13 | SOURCE_RESPONSE แสดงถึงการเกิดข้อผิดพลาดในแหล่งที่มาของโฟลว์ขณะประมวลผลการตอบสนองที่ประสบความสำเร็จ |
ในตัวอย่างข้างต้นคุณจะเห็นส่วนประกอบข้อความของข้อผิดพลาดล่อ
ประเภทข้อผิดพลาด
ให้เราเข้าใจประเภทข้อผิดพลาดด้วยความช่วยเหลือของลักษณะ -
ลักษณะแรกของ Mule Error types คือประกอบด้วยทั้งสองอย่าง a namespace and an identifier. สิ่งนี้ช่วยให้เราสามารถแยกแยะประเภทต่างๆตามโดเมนได้ ในตัวอย่างข้างต้นประเภทข้อผิดพลาดคือHTTP: UNAUTHORIZED.
ลักษณะที่สองและสำคัญคือประเภทของข้อผิดพลาดอาจมีประเภทหลัก ตัวอย่างเช่นประเภทข้อผิดพลาดHTTP: UNAUTHORIZED มี MULE:CLIENT_SECURITY ในฐานะผู้ปกครองซึ่งในทางกลับกันก็มีชื่อผู้ปกครอง MULE:SECURITY. คุณลักษณะนี้กำหนดประเภทข้อผิดพลาดเป็นข้อกำหนดของรายการส่วนกลางเพิ่มเติม
ชนิดของประเภทข้อผิดพลาด
ต่อไปนี้เป็นหมวดหมู่ที่ข้อผิดพลาดทั้งหมดอยู่ -
ใด ๆ
ข้อผิดพลาดในหมวดหมู่นี้เป็นข้อผิดพลาดที่อาจเกิดขึ้นในโฟลว์ ไม่รุนแรงและสามารถจัดการได้ง่าย
วิกฤต
ข้อผิดพลาดในหมวดหมู่นี้เป็นข้อผิดพลาดร้ายแรงที่ไม่สามารถจัดการได้ ต่อไปนี้เป็นรายการประเภทข้อผิดพลาดในหมวดหมู่นี้ -
| ส.น.น. | ประเภทข้อผิดพลาดและคำอธิบาย |
|---|---|
| 1 | OVERLOAD ประเภทข้อผิดพลาดนี้ระบุว่ามีข้อผิดพลาดเกิดขึ้นเนื่องจากปัญหาการโอเวอร์โหลด ในกรณีนี้การดำเนินการจะถูกปฏิเสธ |
| 2 | FATAL_JVM_ERROR ประเภทของข้อผิดพลาดนี้บ่งชี้ถึงการเกิดข้อผิดพลาดร้ายแรง ตัวอย่างเช่น stack overflow |
ประเภทข้อผิดพลาด CUSTOM
CUSTOM Error types คือข้อผิดพลาดที่กำหนดโดยเรา สามารถกำหนดได้เมื่อทำการแมปหรือเมื่อเพิ่มข้อผิดพลาด เราต้องกำหนดเนมสเปซที่กำหนดเองเฉพาะให้กับประเภทข้อผิดพลาดเหล่านี้เพื่อแยกความแตกต่างจากประเภทข้อผิดพลาดอื่น ๆ ที่มีอยู่ภายในแอปพลิเคชัน Mule ตัวอย่างเช่นในแอปพลิเคชัน Mule โดยใช้ HTTP เราไม่สามารถใช้ HTTP เป็นประเภทข้อผิดพลาดที่กำหนดเองได้
หมวดหมู่ของ Mule Error
ในแง่กว้างข้อผิดพลาดใน Mule สามารถแบ่งออกเป็นสองประเภท ได้แก่ Messaging Errors and System Errors.
ข้อผิดพลาดในการรับส่งข้อความ
ข้อผิดพลาด Mule ประเภทนี้เกี่ยวข้องกับขั้นตอนการล่อ เมื่อใดก็ตามที่เกิดปัญหาขึ้นภายในขั้นตอนของ Mule Mule จะแสดงข้อผิดพลาดในการส่งข้อความ เราสามารถตั้งค่าOn Error ส่วนประกอบภายในคอมโพเนนต์ตัวจัดการข้อผิดพลาดเพื่อจัดการกับข้อผิดพลาด Mule เหล่านี้
ระบบผิดพลาด
ข้อผิดพลาดของระบบบ่งชี้ข้อยกเว้นที่เกิดขึ้นที่ระดับระบบ หากไม่มีเหตุการณ์ Mule ข้อผิดพลาดของระบบจะถูกจัดการโดยตัวจัดการข้อผิดพลาดของระบบ ประเภทของข้อยกเว้นต่อไปนี้จัดการโดยตัวจัดการข้อผิดพลาดของระบบ -
- ข้อยกเว้นที่เกิดขึ้นระหว่างการเริ่มต้นแอปพลิเคชัน
- ข้อยกเว้นที่เกิดขึ้นเมื่อการเชื่อมต่อกับระบบภายนอกล้มเหลว
ในกรณีที่ระบบเกิดข้อผิดพลาด Mule จะส่งการแจ้งเตือนข้อผิดพลาดไปยังผู้ฟังที่ลงทะเบียนไว้ นอกจากนี้ยังบันทึกข้อผิดพลาด ในทางกลับกัน Mule เรียกใช้กลยุทธ์การเชื่อมต่อใหม่หากข้อผิดพลาดเกิดจากความล้มเหลวในการเชื่อมต่อ
การจัดการข้อผิดพลาดล่อ
Mule มีตัวจัดการข้อผิดพลาดสองตัวต่อไปนี้เพื่อจัดการข้อผิดพลาด -
On-Error Error Handlers
ตัวจัดการข้อผิดพลาด Mule ตัวแรกคือคอมโพเนนต์ On-Error ซึ่งกำหนดประเภทของข้อผิดพลาดที่สามารถจัดการได้ ตามที่กล่าวไว้ก่อนหน้านี้เราสามารถกำหนดค่าคอมโพเนนต์ On-Error ภายในคอมโพเนนต์ตัวจัดการข้อผิดพลาดแบบขอบเขต โฟลว์ Mule แต่ละตัวมีตัวจัดการข้อผิดพลาดเพียงตัวเดียว แต่ตัวจัดการข้อผิดพลาดนี้สามารถมีขอบเขต On-Error ได้มากเท่าที่เราต้องการ ขั้นตอนในการจัดการข้อผิดพลาด Mule ภายในโฟลว์ด้วยความช่วยเหลือของคอมโพเนนต์ On-Error มีดังนี้ -
ขั้นแรกเมื่อใดก็ตามที่ Mule flow เกิดข้อผิดพลาดการดำเนินการโฟลว์ปกติจะหยุดลง
จากนั้นกระบวนการจะถูกโอนไปยังไฟล์ Error Handler Component ที่มีอยู่แล้ว On Error component เพื่อจับคู่ประเภทข้อผิดพลาดและนิพจน์
ในที่สุดคอมโพเนนต์ตัวจัดการข้อผิดพลาดจะกำหนดเส้นทางข้อผิดพลาดไปยังส่วนแรก On Error scope ที่ตรงกับข้อผิดพลาด

ต่อไปนี้เป็นส่วนประกอบ On-Error สองประเภทที่ Mule สนับสนุน -
On-Error Propagate
On-Error Propagate component เรียกทำงาน แต่เผยแพร่ข้อผิดพลาดไปยังระดับถัดไปและหยุดการดำเนินการของเจ้าของ ธุรกรรมจะถูกย้อนกลับหากได้รับการจัดการโดยOn Error Propagate ส่วนประกอบ.
On-Error ดำเนินการต่อ
เช่นเดียวกับคอมโพเนนต์ On-Error Propagate คอมโพเนนต์ On-Error Continue ยังดำเนินธุรกรรม เงื่อนไขเดียวคือถ้าเจ้าของทำการดำเนินการสำเร็จแล้วคอมโพเนนต์นี้จะใช้ผลลัพธ์ของการดำเนินการซึ่งเป็นผลลัพธ์ของเจ้าของ ธุรกรรมจะถูกคอมมิตหากจัดการโดยคอมโพเนนต์ On-Error Continue
ลองใช้ Scope Component
Try Scope เป็นหนึ่งในคุณสมบัติใหม่มากมายที่มีอยู่ใน Mule 4 ซึ่งทำงานคล้ายกับการลองบล็อกของ JAVA ที่เราใช้ในการใส่โค้ดที่มีความเป็นไปได้ที่จะเป็นข้อยกเว้นเพื่อให้สามารถจัดการได้โดยไม่ทำลายโค้ดทั้งหมด
เราสามารถรวมตัวประมวลผลเหตุการณ์ Mule หนึ่งตัวขึ้นไปใน Try Scope และหลังจากนั้นขอบเขตการลองจะจับและจัดการข้อยกเว้นใด ๆ ที่เกิดขึ้นจากตัวประมวลผลเหตุการณ์เหล่านี้ การทำงานหลักของขอบเขตการลองใช้กลยุทธ์การจัดการข้อผิดพลาดของตัวเองซึ่งสนับสนุนการจัดการข้อผิดพลาดในส่วนประกอบภายในแทนที่จะเป็นโฟลว์ทั้งหมด นั่นคือเหตุผลที่เราไม่จำเป็นต้องแยกกระแสออกเป็นโฟลว์แยก
Example
ต่อไปนี้เป็นตัวอย่างของการใช้ขอบเขตการลอง -
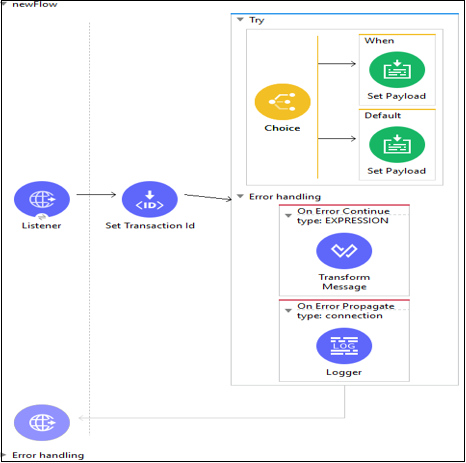
การกำหนดค่าขอบเขตการลองสำหรับการจัดการธุรกรรม
อย่างที่เราทราบกันดีว่าธุรกรรมคือชุดของการดำเนินการที่ไม่ควรดำเนินการบางส่วน การดำเนินการทั้งหมดภายในขอบเขตของธุรกรรมจะดำเนินการในเธรดเดียวกันและหากเกิดข้อผิดพลาดขึ้นควรนำไปสู่การย้อนกลับหรือการคอมมิต เราสามารถกำหนดค่าขอบเขตการลองในลักษณะต่อไปนี้เพื่อให้ถือว่าการดำเนินการย่อยเป็นธุรกรรม
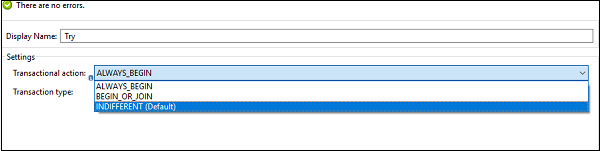
INDIFFERENT [Default]- หากเราเลือกการกำหนดค่านี้ใน try block การกระทำของลูกจะไม่ถือเป็นธุรกรรม ในกรณีนี้ข้อผิดพลาดไม่ทำให้เกิดการย้อนกลับหรือคอมมิต
ALWAYS_BEGIN - ระบุว่าธุรกรรมใหม่จะเริ่มต้นทุกครั้งที่ดำเนินการขอบเขต
BEGIN_OR_JOIN- ระบุว่าหากการประมวลผลปัจจุบันของโฟลว์เริ่มต้นธุรกรรมแล้วให้เข้าร่วม มิฉะนั้นเริ่มต้นใหม่
ในกรณีของทุกโครงการข้อเท็จจริงเกี่ยวกับข้อยกเว้นคือสิ่งที่ผูกพันที่จะเกิดขึ้น นั่นคือเหตุผลที่การจับแยกประเภทและจัดการข้อยกเว้นจึงเป็นสิ่งสำคัญเพื่อไม่ให้ระบบ / แอปพลิเคชันอยู่ในสถานะที่ไม่สอดคล้องกัน มีกลยุทธ์การยกเว้นเริ่มต้นซึ่งใช้กับแอปพลิเคชัน Mule ทั้งหมดโดยปริยาย การย้อนกลับธุรกรรมที่รอดำเนินการโดยอัตโนมัติเป็นกลยุทธ์การยกเว้นเริ่มต้น
ข้อยกเว้นใน Mule
ก่อนที่จะดำน้ำลึกลงไปในการจัดการที่ยอดเยี่ยมเราควรทำความเข้าใจว่าข้อยกเว้นประเภทใดที่สามารถเกิดขึ้นได้พร้อมกับคำถามพื้นฐานสามข้อที่นักพัฒนาต้องมีในขณะออกแบบตัวจัดการข้อยกเว้น
ขนส่งไหนสำคัญ?
คำถามนี้มีความเกี่ยวข้องเพียงพอก่อนที่จะออกแบบตัวจัดการข้อยกเว้นเนื่องจากการขนส่งทั้งหมดไม่รองรับการข้ามชาติ
File หรือ HTTPไม่รองรับการทำธุรกรรม นั่นคือเหตุผลว่าทำไมหากมีข้อยกเว้นเกิดขึ้นในกรณีเหล่านี้เราต้องจัดการด้วยตนเอง
Databasesรองรับการทำธุรกรรม ในขณะที่ออกแบบตัวจัดการข้อยกเว้นในกรณีนี้เราต้องจำไว้ว่าธุรกรรมฐานข้อมูลสามารถย้อนกลับได้โดยอัตโนมัติ (หากจำเป็น)
ในกรณีที่ REST APIsเราควรทราบว่าควรส่งคืนรหัสสถานะ HTTP ที่ถูกต้อง ตัวอย่างเช่น 404 สำหรับทรัพยากรไม่พบ
จะใช้รูปแบบการแลกเปลี่ยนข้อความแบบใด
ในขณะที่ออกแบบตัวจัดการข้อยกเว้นเราต้องดูแลเกี่ยวกับรูปแบบการแลกเปลี่ยนข้อความ อาจมีรูปแบบข้อความซิงโครนัส (ขอ - ตอบกลับ) หรืออะซิงโครนัส (ลืมไฟ)
Synchronous message pattern ขึ้นอยู่กับรูปแบบการตอบกลับคำขอซึ่งหมายความว่ารูปแบบนี้จะคาดหวังการตอบกลับและจะถูกบล็อกจนกว่าจะมีการตอบกลับหรือหมดเวลา
Asynchronous message pattern ขึ้นอยู่กับรูปแบบ fire-forget ซึ่งหมายความว่ารูปแบบนี้ถือว่าคำขอจะได้รับการดำเนินการในที่สุด
เป็นข้อยกเว้นประเภทใด
กฎง่ายๆคือคุณจะจัดการกับข้อยกเว้นตามประเภท เป็นสิ่งสำคัญมากที่จะต้องทราบว่าข้อยกเว้นนั้นเกิดจากปัญหาของระบบ / ทางเทคนิคหรือปัญหาทางธุรกิจหรือไม่?
เกิดข้อยกเว้นโดย system/technical issue (เช่นเครือข่ายขัดข้อง) ควรจัดการโดยอัตโนมัติโดยกลไกการลองใหม่
ในทางกลับกันเกิดข้อยกเว้น by a business issue (เช่นข้อมูลที่ไม่ถูกต้อง) ไม่ควรแก้ไขโดยใช้กลไกการลองใหม่เนื่องจากไม่มีประโยชน์ที่จะลองใหม่โดยไม่แก้ไขสาเหตุที่แท้จริง
ทำไมต้องจัดหมวดหมู่ข้อยกเว้น?
ดังที่เราทราบดีว่าข้อยกเว้นทั้งหมดไม่เหมือนกันการจัดหมวดหมู่ข้อยกเว้นจึงเป็นเรื่องสำคัญมาก ในระดับสูงข้อยกเว้นสามารถแบ่งออกเป็นสองประเภทต่อไปนี้ -
ข้อยกเว้นทางธุรกิจ
สาเหตุหลักของการเกิดข้อยกเว้นทางธุรกิจคือข้อมูลที่ไม่ถูกต้องหรือขั้นตอนกระบวนการไม่ถูกต้อง โดยทั่วไปแล้วข้อยกเว้นประเภทนี้จะไม่สามารถดึงกลับได้ตามธรรมชาติดังนั้นการกำหนดค่าไฟล์rollback. แม้กระทั่งการสมัครretryกลไกจะไม่สมเหตุสมผลเพราะไม่มีประโยชน์ที่จะลองใหม่โดยไม่แก้ไขสาเหตุที่แท้จริง ในการจัดการกับข้อยกเว้นดังกล่าวการประมวลผลควรหยุดลงทันทีและข้อยกเว้นจะถูกส่งกลับเป็นการตอบกลับไปยังคิวจดหมายตาย ควรส่งการแจ้งเตือนไปยังฝ่ายปฏิบัติการด้วย
ข้อยกเว้นที่ไม่ใช่ธุรกิจ
สาเหตุหลักของการเกิดข้อยกเว้นที่ไม่ใช่ธุรกิจคือปัญหาของระบบหรือปัญหาทางเทคนิค ข้อยกเว้นประเภทนี้สามารถเรียกคืนได้ตามธรรมชาติและด้วยเหตุนี้จึงเป็นการดีที่จะกำหนดค่าไฟล์retry กลไกเพื่อแก้ไขข้อยกเว้นเหล่านี้
กลยุทธ์การจัดการข้อยกเว้น
Mule มีกลยุทธ์การจัดการข้อยกเว้นห้าประการต่อไปนี้ -
กลยุทธ์การยกเว้นเริ่มต้น
Mule ใช้กลยุทธ์นี้กับกระแสของ Mule โดยปริยาย สามารถจัดการข้อยกเว้นทั้งหมดในโฟลว์ของเราได้ แต่ยังสามารถลบล้างได้ด้วยการเพิ่มกลยุทธ์ข้อยกเว้นการจับตัวเลือกหรือการย้อนกลับ กลยุทธ์ข้อยกเว้นนี้จะย้อนกลับธุรกรรมที่รอดำเนินการและบันทึกข้อยกเว้นด้วย ลักษณะสำคัญของกลยุทธ์การยกเว้นนี้คือจะบันทึกข้อยกเว้นด้วยหากไม่มีธุรกรรม
เนื่องจากเป็นกลยุทธ์เริ่มต้น Mule จะใช้สิ่งนี้เมื่อเกิดข้อผิดพลาดใด ๆ ในโฟลว์ เราไม่สามารถกำหนดค่าใน AnyPoint studio
กลยุทธ์การยกเว้นย้อนกลับ
สมมติว่าหากไม่มีวิธีแก้ไขที่เป็นไปได้ในการแก้ไขข้อผิดพลาดจะทำอย่างไร? วิธีแก้ปัญหาคือใช้กลยุทธ์ Rollback Exception ซึ่งจะย้อนกลับธุรกรรมพร้อมกับการส่งข้อความไปยังตัวเชื่อมต่อขาเข้าของโฟลว์พาเรนต์เพื่อประมวลผลข้อความอีกครั้ง กลยุทธ์นี้ยังมีประโยชน์มากเมื่อเราต้องการประมวลผลข้อความอีกครั้ง
Example
กลยุทธ์นี้สามารถนำไปใช้กับธุรกรรมธนาคารที่มีการฝากเงินเข้าบัญชีเงินฝากออมทรัพย์ เราสามารถกำหนดค่ากลยุทธ์การยกเว้นการย้อนกลับได้ที่นี่เพราะในกรณีที่เกิดข้อผิดพลาดระหว่างการทำธุรกรรมกลยุทธ์นี้จะย้อนข้อความกลับไปที่จุดเริ่มต้นของขั้นตอนเพื่อพยายามประมวลผลใหม่
จับกลยุทธ์ข้อยกเว้น
กลยุทธ์นี้จับข้อยกเว้นทั้งหมดที่เกิดขึ้นภายในโฟลว์พาเรนต์ มันจะลบล้างกลยุทธ์การยกเว้นเริ่มต้นของ Mule โดยการประมวลผลข้อยกเว้นทั้งหมดที่เกิดจากโฟลว์พาเรนต์ เราสามารถใช้กลยุทธ์ข้อยกเว้นการจับเพื่อหลีกเลี่ยงการเผยแพร่ข้อยกเว้นไปยังตัวเชื่อมต่อขาเข้าและโฟลว์พาเรนต์ได้เช่นกัน
กลยุทธ์นี้ยังช่วยให้มั่นใจได้ว่าธุรกรรมที่ประมวลผลโดยโฟลว์จะไม่ย้อนกลับเมื่อเกิดข้อยกเว้น
Example
กลยุทธ์นี้สามารถใช้ได้กับระบบการจองเที่ยวบินที่เรามีขั้นตอนในการประมวลผลข้อความจากคิว ข้อความที่เพิ่มขึ้นจะเพิ่มคุณสมบัติในข้อความสำหรับการกำหนดที่นั่งแล้วส่งข้อความไปยังคิวอื่น
ตอนนี้หากมีข้อผิดพลาดเกิดขึ้นในขั้นตอนนี้ข้อความจะแสดงข้อยกเว้น ที่นี่กลยุทธ์การยกเว้นการจับของเราสามารถเพิ่มส่วนหัวที่มีข้อความที่เหมาะสมและสามารถผลักดันข้อความนั้นออกจากขั้นตอนไปยังคิวถัดไป
กลยุทธ์การยกเว้นทางเลือก
ในกรณีที่คุณต้องการจัดการข้อยกเว้นตามเนื้อหาข้อความดังนั้นกลยุทธ์การยกเว้นตัวเลือกจะเป็นทางเลือกที่ดีที่สุด การทำงานของกลยุทธ์ข้อยกเว้นนี้จะเป็นดังนี้ -
- ขั้นแรกจะตรวจจับข้อยกเว้นทั้งหมดที่เกิดขึ้นภายในโฟลว์พาเรนต์
- จากนั้นจะตรวจสอบเนื้อหาข้อความและประเภทข้อยกเว้น
- และสุดท้ายจะกำหนดเส้นทางข้อความไปยังกลยุทธ์ข้อยกเว้นที่เหมาะสม
จะมีกลยุทธ์ข้อยกเว้นมากกว่าหนึ่งอย่างเช่น Catch หรือ Rollback ซึ่งกำหนดไว้ในกลยุทธ์การยกเว้นตัวเลือก ในกรณีที่ไม่มีกลยุทธ์ที่กำหนดไว้ภายใต้กลยุทธ์ข้อยกเว้นนี้ระบบจะกำหนดเส้นทางข้อความไปยังกลยุทธ์ข้อยกเว้นเริ่มต้น จะไม่ดำเนินการกระทำหรือย้อนกลับหรือใช้กิจกรรมใด ๆ
กลยุทธ์การยกเว้นการอ้างอิง
นี่หมายถึงกลยุทธ์ข้อยกเว้นทั่วไปที่กำหนดไว้ในไฟล์คอนฟิกูเรชันแยกต่างหาก ในกรณีที่ข้อความแสดงข้อยกเว้นกลยุทธ์การยกเว้นนี้จะอ้างถึงพารามิเตอร์การจัดการข้อผิดพลาดที่กำหนดไว้ในกลยุทธ์การจับการย้อนกลับหรือการยกเว้นทางเลือกทั่วโลก เช่นเดียวกับกลยุทธ์การยกเว้นทางเลือกจะไม่ทำการกระทำหรือย้อนกลับหรือใช้กิจกรรมใด ๆ ด้วย
เราเข้าใจว่าการทดสอบหน่วยเป็นวิธีการที่สามารถทดสอบซอร์สโค้ดแต่ละหน่วยเพื่อพิจารณาว่าเหมาะสมกับการใช้งานหรือไม่ โปรแกรมเมอร์ Java สามารถใช้ Junit framework เพื่อเขียนกรณีทดสอบ ในทำนองเดียวกัน MuleSoft ยังมีกรอบที่เรียกว่า MUnit ซึ่งช่วยให้เราสามารถเขียนกรณีทดสอบอัตโนมัติสำหรับ API และการผสานรวมของเราได้ เหมาะอย่างยิ่งสำหรับสภาพแวดล้อมการรวม / การปรับใช้อย่างต่อเนื่อง ข้อดีอย่างหนึ่งของ MUnit framework คือเราสามารถรวมเข้ากับ Maven และ Surefire ได้
คุณสมบัติของ MUnit
ต่อไปนี้เป็นคุณสมบัติที่มีประโยชน์บางประการของกรอบการทดสอบ Mule MUnit -
ใน MUnit framework เราสามารถสร้าง Mule test ได้โดยใช้ Mule code และ Java code
เราสามารถออกแบบและทดสอบแอป Mule และ API ของเราทั้งในรูปแบบกราฟิกหรือแบบ XML ภายใน Anypoint Studio
MUnit ช่วยให้เราสามารถรวมการทดสอบเข้ากับกระบวนการ CI / CD ที่มีอยู่ได้อย่างง่ายดาย
มีการทดสอบและรายงานความครอบคลุมที่สร้างขึ้นโดยอัตโนมัติ ดังนั้นการทำงานด้วยตนเองจึงมีน้อย
นอกจากนี้เรายังสามารถใช้เซิร์ฟเวอร์ DB / FTP / เมลในเครื่องเพื่อทำการทดสอบแบบพกพามากขึ้นผ่านกระบวนการ CI
ช่วยให้เราสามารถเปิดหรือปิดการทดสอบได้
เรายังสามารถขยายกรอบ MUnit ด้วยปลั๊กอิน
ช่วยให้เราตรวจสอบการเรียกใช้ตัวประมวลผลข้อความ
ด้วยความช่วยเหลือของกรอบการทดสอบ MUnit เราสามารถปิดการใช้งานตัวเชื่อมต่อปลายทางและจุดสิ้นสุดขาเข้า
เราสามารถตรวจสอบรายงานข้อผิดพลาดด้วย Mule stack trace
รุ่นล่าสุดของ Mule MUnit Testing Framework
MUnit 2.1.4 เป็นเฟรมเวิร์กการทดสอบ Mule MUnit รุ่นล่าสุด ต้องทำตามข้อกำหนดฮาร์ดแวร์และซอฟต์แวร์ -
- MS Windows 8+
- Apple Mac OS X 10.10+
- Linux
- จาวา 8
- Maven 3.3.3, 3.3.9, 3.5.4, 3.6.0
เข้ากันได้กับ Mule 4.1.4 และ Anypoint Studio 7.3.0
MUnit และ Anypoint Studio
ตามที่กล่าวไว้ MUnit ได้รับการผสานรวมอย่างสมบูรณ์ใน Anypoint studio และเราสามารถออกแบบและทดสอบแอป Mule และ API ของเราแบบกราฟิกหรือใน XML ภายใน Anypoint studio กล่าวอีกนัยหนึ่งเราสามารถใช้อินเทอร์เฟซแบบกราฟิกของ Anypoint Studio เพื่อทำสิ่งต่อไปนี้ -
- สำหรับการสร้างและออกแบบการทดสอบ MUnit
- สำหรับการดำเนินการทดสอบของเรา
- สำหรับการดูผลการทดสอบและรายงานความครอบคลุม
- สำหรับการดีบักการทดสอบ
ดังนั้นให้เราเริ่มคุยกันทีละงาน
การสร้างและออกแบบการทดสอบ MUnit
เมื่อคุณเริ่มโปรเจ็กต์ใหม่มันจะเพิ่มโฟลเดอร์ใหม่โดยอัตโนมัติคือ src/test/munitกับโครงการของเรา ตัวอย่างเช่นเราเริ่มโครงการ Mule ใหม่คือtest_munitคุณจะเห็นในภาพด้านล่างซึ่งจะเพิ่มโฟลเดอร์ดังกล่าวข้างต้นภายใต้โครงการของเรา
ตอนนี้เมื่อคุณเริ่มโครงการใหม่มีสองวิธีพื้นฐานในการสร้างการทดสอบ MUnit ใหม่ใน Anypoint Studio -
By Right-Clicking the Flow - ในวิธีนี้เราต้องคลิกขวาที่โฟลว์เฉพาะและเลือก MUnit จากเมนูแบบเลื่อนลง
By Using the Wizard- ในวิธีนี้เราต้องใช้ตัวช่วยสร้างแบบทดสอบ ช่วยให้เราสร้างการทดสอบสำหรับโฟลว์ใด ๆ ในพื้นที่ทำงาน
เราจะใช้วิธี 'คลิกขวาที่โฟลว์' เพื่อสร้างการทดสอบสำหรับโฟลว์เฉพาะ
ขั้นแรกเราต้องสร้างโฟลว์ในพื้นที่ทำงานดังนี้ -
ตอนนี้คลิกขวาที่โฟลว์นี้แล้วเลือก MUnit เพื่อสร้างการทดสอบสำหรับโฟลว์นี้ดังที่แสดงด้านล่าง -
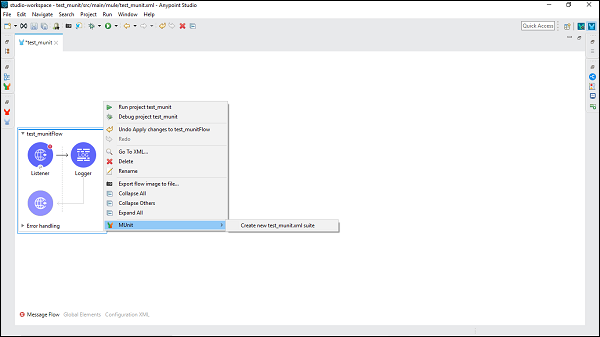
จะสร้างชุดทดสอบใหม่ที่ตั้งชื่อตามไฟล์ XML ที่โฟลว์อยู่ ในกรณีนี้,test_munit-test-suite คือชื่อของชุดทดสอบใหม่ดังที่แสดงด้านล่าง -
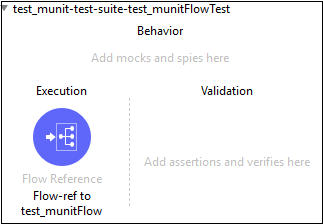
ต่อไปนี้เป็นตัวแก้ไข XML สำหรับโฟลว์ข้อความด้านบน -
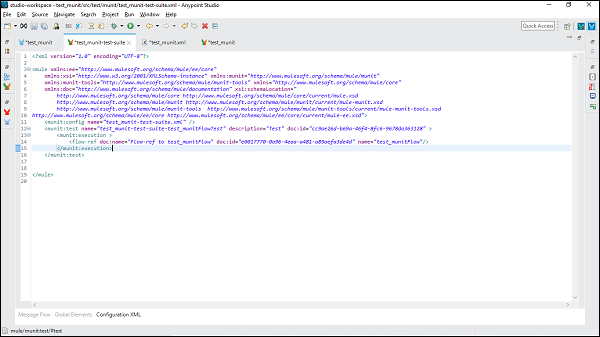
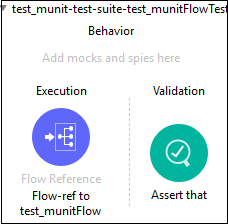
ตอนนี้เราสามารถเพิ่มไฟล์ MUnit ตัวประมวลผลข้อความไปยังชุดทดสอบโดยลากจาก Mule Palette
หากคุณต้องการสร้างการทดสอบผ่านตัวช่วยสร้างให้ทำตาม File → New → MUnit และจะนำคุณไปสู่ชุดทดสอบ MUnit ต่อไปนี้ -
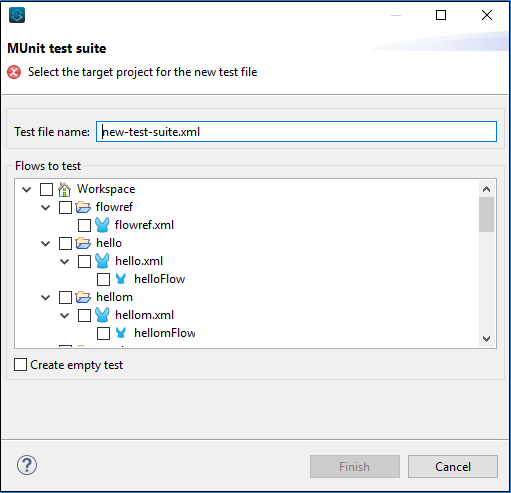
การกำหนดค่าการทดสอบ
ใน Mule 4 เรามีสองส่วนใหม่ ได้แก่ MUnit และ MUnit Toolsโดยรวมมีตัวประมวลผลข้อความ MUnit ทั้งหมด คุณสามารถลากตัวประมวลผลข้อความใดก็ได้ในพื้นที่ทดสอบ MUnit ของคุณ มันแสดงในภาพหน้าจอด้านล่าง -
ตอนนี้หากคุณต้องการแก้ไขการกำหนดค่าสำหรับชุดสูทของคุณหรือทดสอบใน Anypoint Studio คุณต้องทำตามขั้นตอนด้านล่าง -
Step 1
ไปที่ไฟล์ Package Explorer และคลิกขวาที่ไฟล์ .xml fileสำหรับห้องชุดหรือการทดสอบของคุณ จากนั้นเลือกไฟล์Properties.
Step 2
ตอนนี้ในหน้าต่าง Properties เราต้องคลิก Run/Debug Settings. หลังจากนี้คลิกNew.
Step 3
ในขั้นตอนสุดท้ายคลิก MUnit ภายใต้ Select Configuration Type หน้าต่างแล้วคลิก OK.
เรียกใช้การทดสอบ
เราสามารถเรียกใช้ชุดทดสอบเช่นเดียวกับการทดสอบ ขั้นแรกเราจะดูวิธีเรียกใช้ชุดทดสอบ
การเรียกใช้ชุดทดสอบ
สำหรับการเรียกใช้ชุดทดสอบให้คลิกขวาที่ส่วนว่างของ Mule Canvas ที่ชุดทดสอบของคุณอยู่ จะเปิดเมนูที่ขยายลงมา ตอนนี้คลิกที่ไฟล์Run MUnit suite ดังแสดงด้านล่าง -
ต่อมาเราจะเห็นผลลัพธ์ในคอนโซล
ทำการทดสอบ
ในการเรียกใช้การทดสอบเฉพาะเราจำเป็นต้องเลือกการทดสอบที่เฉพาะเจาะจงและคลิกขวาที่สิ่งนั้น เราจะได้รับเมนูแบบเลื่อนลงเช่นเดียวกับที่เราได้รับในขณะที่เรียกใช้ชุดทดสอบ ตอนนี้คลิกที่ไฟล์Run MUnit Test ตัวเลือกที่แสดงด้านล่าง -

หลังจากผลลัพธ์สามารถเห็นได้ในคอนโซล
การดูและวิเคราะห์ผลการทดสอบ
Anypoint studio แสดงผลการทดสอบ MUnit ในไฟล์ MUnit tabของบานหน้าต่างนักสำรวจด้านซ้าย คุณสามารถค้นหาการทดสอบที่ประสบความสำเร็จเป็นสีเขียวและการทดสอบที่ล้มเหลวเป็นสีแดงดังที่แสดงด้านล่าง -
เราสามารถวิเคราะห์ผลการทดสอบของเราได้โดยดูรายงานความครอบคลุม คุณสมบัติหลักของรายงานความครอบคลุมคือการให้ตัวชี้วัดว่าแอปพลิเคชัน Mule ดำเนินการได้สำเร็จมากน้อยเพียงใดโดยชุดการทดสอบ MUnit การครอบคลุม MUnit นั้นโดยพื้นฐานแล้วขึ้นอยู่กับจำนวนของตัวประมวลผลข้อความ MUnit ที่ดำเนินการ รายงานความครอบคลุมของ MUnit ให้เมตริกดังต่อไปนี้ -
- ความครอบคลุมโดยรวมของแอปพลิเคชัน
- ความครอบคลุมของทรัพยากร
- ความครอบคลุมการไหล
หากต้องการรับรายงานความครอบคลุมเราต้องคลิกที่ 'สร้างรายงาน' ใต้แท็บ MUnit ดังที่แสดงด้านล่าง -
การดีบักการทดสอบ
เราสามารถดีบักชุดทดสอบและชุดทดสอบ ขั้นแรกเราจะดูวิธีการดีบักชุดทดสอบ
การดีบักชุดทดสอบ
สำหรับการดีบักชุดทดสอบให้คลิกขวาที่ส่วนว่างของ Mule Canvas ที่ชุดทดสอบของคุณอยู่ จะเปิดเมนูที่ขยายลงมา ตอนนี้คลิกที่ไฟล์Debug MUnit Suite ดังแสดงในภาพด้านล่าง -
จากนั้นเราจะเห็นผลลัพธ์ในคอนโซล
การแก้จุดบกพร่องของการทดสอบ
ในการแก้ไขข้อบกพร่องของการทดสอบที่เฉพาะเจาะจงเราจำเป็นต้องเลือกการทดสอบเฉพาะและคลิกขวาที่สิ่งนั้น เราจะได้รับเมนูแบบเลื่อนลงเช่นเดียวกับที่เราได้รับในขณะที่แก้ไขข้อบกพร่องชุดทดสอบ ตอนนี้คลิกที่ไฟล์Debug MUnit Testตัวเลือก จะแสดงในภาพหน้าจอด้านล่าง