การเชื่อมโยงแคชและการซิงโครไนซ์
ในบทนี้เราจะพูดถึงโปรโตคอลการเชื่อมโยงกันของแคชเพื่อรับมือกับปัญหาความไม่สอดคล้องกันของมัลติแคช
ปัญหาการเชื่อมโยงกันของแคช
ในระบบมัลติโปรเซสเซอร์ความไม่สอดคล้องกันของข้อมูลอาจเกิดขึ้นระหว่างระดับที่อยู่ติดกันหรืออยู่ในลำดับชั้นของหน่วยความจำระดับเดียวกัน ตัวอย่างเช่นแคชและหน่วยความจำหลักอาจมีสำเนาของวัตถุเดียวกันที่ไม่สอดคล้องกัน
เนื่องจากโปรเซสเซอร์หลายตัวทำงานแบบขนานกันและแคชหลายตัวที่เป็นอิสระอาจมีสำเนาของบล็อกหน่วยความจำเดียวกันที่แตกต่างกัน cache coherence problem. Cache coherence schemes ช่วยหลีกเลี่ยงปัญหานี้โดยการรักษาสถานะสม่ำเสมอสำหรับแต่ละบล็อกข้อมูลที่แคชไว้
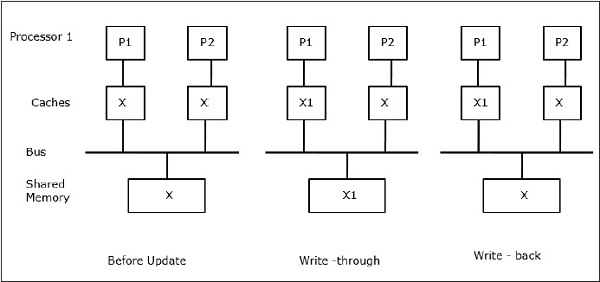
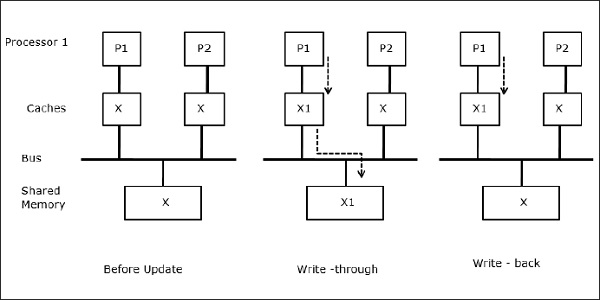
ให้ X เป็นองค์ประกอบของข้อมูลที่ใช้ร่วมกันซึ่งได้รับการอ้างอิงโดยโปรเซสเซอร์สองตัวคือ P1 และ P2 ในตอนแรกสำเนา X สามชุดมีความสอดคล้องกัน หากโปรเซสเซอร์ P1 เขียนข้อมูลใหม่ X1 ลงในแคชโดยใช้write-through policyสำเนาเดียวกันจะถูกเขียนลงในหน่วยความจำที่ใช้ร่วมกันทันที ในกรณีนี้ความไม่สอดคล้องกันจะเกิดขึ้นระหว่างหน่วยความจำแคชและหน่วยความจำหลัก เมื่อwrite-back policy ถูกใช้หน่วยความจำหลักจะได้รับการอัปเดตเมื่อข้อมูลที่แก้ไขในแคชถูกแทนที่หรือไม่ถูกต้อง
โดยทั่วไปมีสามแหล่งที่มาของปัญหาความไม่ลงรอยกัน -
- การแบ่งปันข้อมูลที่เขียนได้
- การโยกย้ายกระบวนการ
- กิจกรรม I / O
โปรโตคอล Snoopy Bus
โปรโตคอล Snoopy ทำให้เกิดความสอดคล้องของข้อมูลระหว่างหน่วยความจำแคชและหน่วยความจำที่ใช้ร่วมกันผ่านระบบหน่วยความจำแบบบัส Write-invalidate และ write-update นโยบายใช้เพื่อรักษาความสอดคล้องของแคช
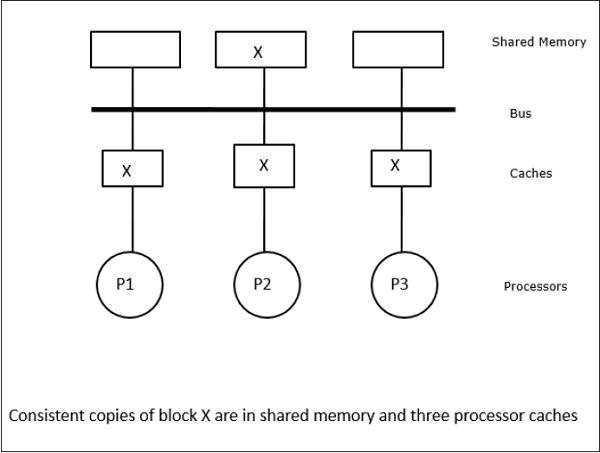
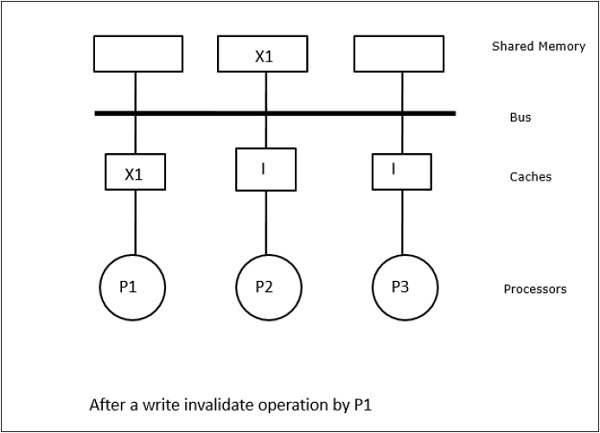
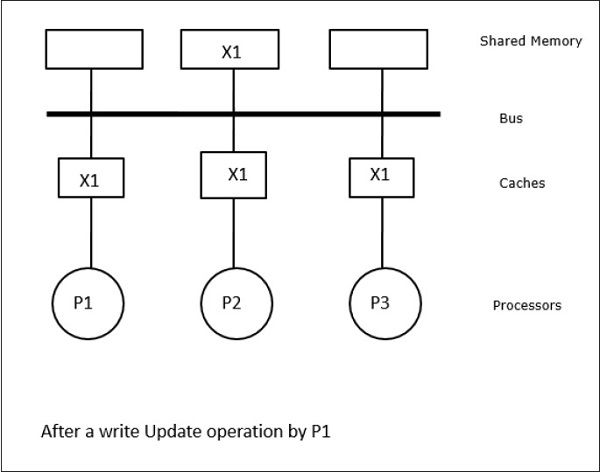
ในกรณีนี้เรามีโปรเซสเซอร์ P1, P2 และ P3 สามตัวที่มีสำเนาขององค์ประกอบข้อมูล 'X' ที่สอดคล้องกันในหน่วยความจำแคชภายในเครื่องและในหน่วยความจำที่ใช้ร่วมกัน (รูปที่ a) โปรเซสเซอร์ P1 เขียน X1 ในหน่วยความจำแคชโดยใช้write-invalidate protocol. ดังนั้นสำเนาอื่น ๆ ทั้งหมดจะไม่ถูกต้องผ่านทางรถบัส แสดงโดย 'I' (รูป -b) บล็อกที่ไม่ถูกต้องเรียกอีกอย่างว่าdirtyกล่าวคือไม่ควรใช้ write-update protocolอัปเดตสำเนาแคชทั้งหมดผ่านทางบัส โดยใช้write back cacheสำเนาหน่วยความจำจะได้รับการอัพเดตด้วย (รูป -c)
เหตุการณ์แคชและการดำเนินการ
เหตุการณ์และการกระทำต่อไปนี้เกิดขึ้นกับการเรียกใช้คำสั่งการเข้าถึงหน่วยความจำและการยกเลิกการใช้งาน -
Read-miss- เมื่อโปรเซสเซอร์ต้องการอ่านบล็อกและไม่ได้อยู่ในแคชการอ่านพลาดจะเกิดขึ้น สิ่งนี้เริ่มต้นไฟล์bus-readการดำเนินการ. หากไม่มีสำเนาสกปรกหน่วยความจำหลักที่มีสำเนาสม่ำเสมอจะส่งสำเนาไปยังหน่วยความจำแคชที่ร้องขอ หากมีสำเนาสกปรกอยู่ในหน่วยความจำแคชระยะไกลแคชนั้นจะ จำกัด หน่วยความจำหลักและส่งสำเนาไปยังหน่วยความจำแคชที่ร้องขอ ในทั้งสองกรณีสำเนาแคชจะเข้าสู่สถานะที่ถูกต้องหลังจากอ่านพลาด
Write-hit - หากสำเนาสกปรกหรือ reservedรัฐเขียนเสร็จในพื้นที่และสถานะใหม่สกปรก หากสถานะใหม่ถูกต้องคำสั่ง write-invalidate จะถูกกระจายไปยังแคชทั้งหมดทำให้สำเนาของพวกเขาไม่ถูกต้อง เมื่อเขียนหน่วยความจำแบบแบ่งใช้สถานะผลลัพธ์จะถูกสงวนไว้หลังจากการเขียนครั้งแรกนี้
Write-miss- หากโปรเซสเซอร์ไม่สามารถเขียนลงในหน่วยความจำแคชภายในเครื่องสำเนาจะต้องมาจากหน่วยความจำหลักหรือจากหน่วยความจำแคชระยะไกลที่มีบล็อกสกปรก ทำได้โดยการส่งไฟล์read-invalidateซึ่งจะทำให้สำเนาแคชทั้งหมดเป็นโมฆะ จากนั้นสำเนาภายในเครื่องจะถูกอัพเดตด้วยสถานะสกปรก
Read-hit - Read-hit จะดำเนินการในหน่วยความจำแคชภายในเครื่องเสมอโดยไม่ทำให้เกิดการเปลี่ยนสถานะหรือใช้สนูปปี้บัสเพื่อทำให้ไม่ถูกต้อง
Block replacement- เมื่อสำเนาสกปรกจะต้องเขียนกลับไปยังหน่วยความจำหลักโดยวิธีการแทนที่บล็อก อย่างไรก็ตามเมื่อสำเนาอยู่ในสถานะที่ถูกต้องหรือสงวนไว้หรือไม่ถูกต้องจะไม่มีการแทนที่
โปรโตคอลตามไดเรกทอรี
ด้วยการใช้เครือข่ายหลายขั้นตอนเพื่อสร้างโปรเซสเซอร์หลายตัวขนาดใหญ่ที่มีตัวประมวลผลหลายร้อยตัวจำเป็นต้องแก้ไขโปรโตคอลของสนูปปี้แคชให้เหมาะสมกับความสามารถของเครือข่าย การกระจายเสียงมีราคาแพงมากในการดำเนินการในเครือข่ายหลายขั้นตอนคำสั่งความสอดคล้องจะถูกส่งไปยังแคชที่เก็บสำเนาของบล็อกไว้เท่านั้น นี่คือเหตุผลของการพัฒนาโปรโตคอลแบบไดเร็กทอรีสำหรับมัลติโปรเซสเซอร์ที่เชื่อมต่อกับเครือข่าย
ในระบบโปรโตคอลแบบใช้ไดเร็กทอรีข้อมูลที่จะแชร์จะถูกวางไว้ในไดเร็กทอรีทั่วไปที่รักษาการเชื่อมโยงระหว่างแคช ที่นี่ไดเร็กทอรีทำหน้าที่เป็นตัวกรองที่โปรเซสเซอร์ขออนุญาตโหลดรายการจากหน่วยความจำหลักไปยังหน่วยความจำแคช หากรายการถูกเปลี่ยนไดเร็กทอรีจะอัพเดตหรือทำให้แคชอื่นที่มีรายการนั้นเป็นโมฆะ
กลไกการซิงโครไนซ์ฮาร์ดแวร์
การซิงโครไนซ์เป็นรูปแบบการสื่อสารพิเศษที่แทนที่จะเป็นการควบคุมข้อมูลข้อมูลจะถูกแลกเปลี่ยนระหว่างกระบวนการสื่อสารที่อยู่ในโปรเซสเซอร์เดียวกันหรือต่างกัน
ระบบมัลติโปรเซสเซอร์ใช้กลไกฮาร์ดแวร์เพื่อดำเนินการซิงโครไนซ์ระดับต่ำ ตัวประมวลผลหลายตัวส่วนใหญ่มีกลไกฮาร์ดแวร์ในการกำหนดการดำเนินการเกี่ยวกับอะตอมเช่นหน่วยความจำอ่านเขียนหรืออ่าน - แก้ไข - เขียนเพื่อใช้งานพื้นฐานการซิงโครไนซ์ นอกเหนือจากการทำงานของหน่วยความจำปรมาณูแล้วอินเตอร์รัปต์ระหว่างตัวประมวลผลบางตัวยังใช้เพื่อวัตถุประสงค์ในการซิงโครไนซ์
Cache Coherency ในเครื่องหน่วยความจำที่ใช้ร่วมกัน
การรักษาความสอดคล้องกันของแคชเป็นปัญหาในระบบมัลติโปรเซสเซอร์เมื่อโปรเซสเซอร์มีหน่วยความจำแคชภายใน ความไม่สอดคล้องกันของข้อมูลระหว่างแคชต่างๆเกิดขึ้นได้ง่ายในระบบนี้
ประเด็นสำคัญคือ -
- การแบ่งปันข้อมูลที่เขียนได้
- การโยกย้ายกระบวนการ
- กิจกรรม I / O
การแบ่งปันข้อมูลที่เขียนได้
เมื่อตัวประมวลผลสองตัว (P1 และ P2) มีองค์ประกอบข้อมูล (X) เดียวกันในแคชภายในเครื่องและกระบวนการหนึ่ง (P1) เขียนไปยังองค์ประกอบข้อมูล (X) เนื่องจากแคชเขียนผ่านแคชในเครื่องของ P1 หน่วยความจำหลักคือ อัพเดทด้วย ตอนนี้เมื่อ P2 พยายามอ่านองค์ประกอบข้อมูล (X) ไม่พบ X เนื่องจากองค์ประกอบข้อมูลในแคชของ P2 ล้าสมัยแล้ว
การโยกย้ายกระบวนการ
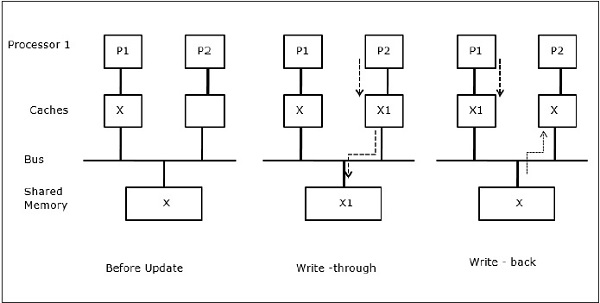
ในขั้นแรกแคชของ P1 มีองค์ประกอบข้อมูล X ในขณะที่ P2 ไม่มีอะไรเลย กระบวนการบน P2 จะเขียนบน X ก่อนแล้วจึงย้ายไปที่ P1 ตอนนี้กระบวนการเริ่มอ่านองค์ประกอบข้อมูล X แต่เนื่องจากโปรเซสเซอร์ P1 มีข้อมูลที่ล้าสมัยกระบวนการจึงไม่สามารถอ่านได้ ดังนั้นกระบวนการบน P1 จึงเขียนไปยังองค์ประกอบข้อมูล X จากนั้นย้ายไปที่ P2 หลังจากการย้ายข้อมูลกระบวนการบน P2 จะเริ่มอ่านองค์ประกอบข้อมูล X แต่พบว่าเวอร์ชัน X ที่ล้าสมัยในหน่วยความจำหลัก
กิจกรรม I / O
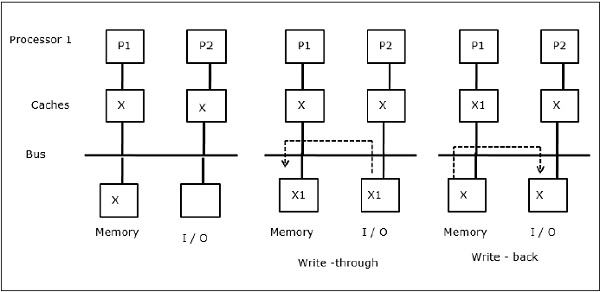
ดังที่แสดงในรูปอุปกรณ์ I / O จะถูกเพิ่มลงในบัสในสถาปัตยกรรมมัลติโปรเซสเซอร์สองตัวประมวลผล ในตอนแรกแคชทั้งสองมีองค์ประกอบข้อมูล X เมื่ออุปกรณ์ I / O ได้รับองค์ประกอบ X ใหม่จะเก็บองค์ประกอบใหม่ไว้ในหน่วยความจำหลักโดยตรง ตอนนี้เมื่อ P1 หรือ P2 (สมมติว่า P1) พยายามอ่านองค์ประกอบ X จะได้รับสำเนาที่ล้าสมัย ดังนั้น P1 จึงเขียนไปยังองค์ประกอบ X ตอนนี้หากอุปกรณ์ I / O พยายามส่ง X จะได้รับสำเนาที่ล้าสมัย
การเข้าถึงหน่วยความจำแบบสม่ำเสมอ (UMA)
สถาปัตยกรรม Uniform Memory Access (UMA) หมายถึงหน่วยความจำแบบแบ่งใช้เหมือนกันสำหรับโปรเซสเซอร์ทั้งหมดในระบบ คลาสยอดนิยมของเครื่อง UMA ซึ่งโดยทั่วไปใช้สำหรับเซิร์ฟเวอร์ (file-) คือสิ่งที่เรียกว่า Symmetric Multiprocessors (SMPs) ใน SMP ทรัพยากรระบบทั้งหมดเช่นหน่วยความจำดิสก์อุปกรณ์ I / O อื่น ๆ สามารถเข้าถึงได้โดยโปรเซสเซอร์ในลักษณะเดียวกัน
การเข้าถึงหน่วยความจำแบบไม่สม่ำเสมอ (NUMA)
ในสถาปัตยกรรม NUMA มีคลัสเตอร์ SMP หลายคลัสเตอร์ที่มีเครือข่ายทางอ้อม / แชร์ภายในซึ่งเชื่อมต่อในเครือข่ายการส่งข้อความที่ปรับขนาดได้ ดังนั้นสถาปัตยกรรม NUMA จึงเป็นสถาปัตยกรรมหน่วยความจำแบบกระจายทางกายภาพที่ใช้ร่วมกันในเชิงตรรกะ
ในเครื่อง NUMA ตัวควบคุมแคชของโปรเซสเซอร์จะพิจารณาว่าการอ้างอิงหน่วยความจำอยู่ภายในหน่วยความจำของ SMP หรือเป็นรีโมต เพื่อลดจำนวนการเข้าถึงหน่วยความจำระยะไกลโดยปกติสถาปัตยกรรม NUMA จะใช้ตัวประมวลผลการแคชที่สามารถแคชข้อมูลระยะไกลได้ แต่เมื่อเกี่ยวข้องกับแคชจำเป็นต้องรักษาความสอดคล้องกันของแคช ดังนั้นระบบเหล่านี้จึงเรียกอีกอย่างว่า CC-NUMA (Cache Coherent NUMA)
สถาปัตยกรรมหน่วยความจำแคชเท่านั้น (COMA)
เครื่อง COMA นั้นคล้ายกับเครื่อง NUMA โดยมีข้อแตกต่างเพียงประการเดียวที่ความทรงจำหลักของเครื่อง COMA ทำหน้าที่เป็นแคชแบบแมปโดยตรงหรือชุดเชื่อมโยง บล็อกข้อมูลจะถูกแฮชไปยังตำแหน่งในแคช DRAM ตามที่อยู่ ข้อมูลที่เรียกจากระยะไกลจะถูกเก็บไว้ในหน่วยความจำหลักภายในเครื่อง ยิ่งไปกว่านั้นบล็อกข้อมูลไม่มีตำแหน่งบ้านที่แน่นอนพวกเขาสามารถเคลื่อนย้ายได้อย่างอิสระทั่วทั้งระบบ
สถาปัตยกรรม COMA ส่วนใหญ่มีเครือข่ายการส่งผ่านข้อความตามลำดับชั้น สวิตช์ในทรีดังกล่าวมีไดเร็กทอรีที่มีองค์ประกอบข้อมูลเป็นแผนผังย่อย เนื่องจากข้อมูลไม่มีตำแหน่งบ้านจึงต้องค้นหาอย่างชัดเจน ซึ่งหมายความว่าการเข้าถึงระยะไกลต้องใช้การข้ามผ่านสวิตช์ในแผนผังเพื่อค้นหาไดเร็กทอรีสำหรับข้อมูลที่ต้องการ ดังนั้นหากสวิตช์ในเครือข่ายได้รับคำขอหลายรายการจากแผนผังย่อยสำหรับข้อมูลเดียวกันจะรวมเข้าด้วยกันเป็นคำขอเดียวซึ่งจะถูกส่งไปยังแม่ของสวิตช์ เมื่อข้อมูลที่ร้องขอกลับมาสวิตช์จะส่งสำเนาหลายชุดไปตามทรีย่อยของมัน
COMA กับ CC-NUMA
ต่อไปนี้คือความแตกต่างระหว่าง COMA และ CC-NUMA
COMA มีแนวโน้มที่จะยืดหยุ่นกว่า CC-NUMA เนื่องจาก COMA สนับสนุนการโยกย้ายและจำลองข้อมูลอย่างโปร่งใสโดยไม่จำเป็นต้องใช้ระบบปฏิบัติการ
เครื่อง COMA มีราคาแพงและซับซ้อนในการสร้างเนื่องจากต้องการฮาร์ดแวร์การจัดการหน่วยความจำที่ไม่ได้มาตรฐานและโปรโตคอล Coherency นั้นยากที่จะนำไปใช้
การเข้าถึงระยะไกลใน COMA มักจะช้ากว่าใน CC-NUMA เนื่องจากเครือข่ายแบบทรีจะต้องมีการข้ามเพื่อค้นหาข้อมูล