PyBrain - โมดูลการเรียนรู้การเสริมแรง
Reinforcement Learning (RL) เป็นส่วนสำคัญใน Machine Learning การเรียนรู้แบบเสริมกำลังทำให้ตัวแทนเรียนรู้พฤติกรรมของมันโดยอาศัยปัจจัยนำเข้าจากสิ่งแวดล้อม
ส่วนประกอบที่โต้ตอบกันระหว่างการเสริมแรงมีดังนี้ -
- Environment
- Agent
- Task
- Experiment
เค้าโครงของการเรียนรู้การเสริมแรงมีให้ด้านล่าง -
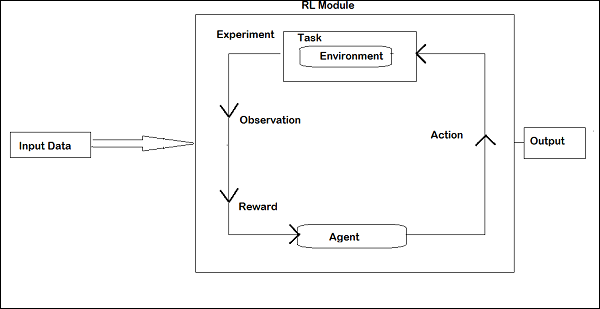
ใน RL ตัวแทนจะพูดคุยกับสิ่งแวดล้อมในการทำซ้ำ ในการทำซ้ำแต่ละครั้งตัวแทนจะได้รับการสังเกตซึ่งมีรางวัล จากนั้นเลือกการกระทำและส่งไปยังสิ่งแวดล้อม สภาพแวดล้อมในการทำซ้ำแต่ละครั้งจะย้ายไปสู่สถานะใหม่และรางวัลที่ได้รับในแต่ละครั้งจะถูกบันทึกไว้
เป้าหมายของตัวแทน RL คือการรวบรวมรางวัลให้ได้มากที่สุด ในระหว่างการทำซ้ำประสิทธิภาพของตัวแทนจะถูกเปรียบเทียบกับของตัวแทนที่ทำหน้าที่ในทางที่ดีและความแตกต่างของประสิทธิภาพก่อให้เกิดรางวัลหรือความล้มเหลว โดยทั่วไปแล้ว RL จะใช้ในการแก้ปัญหาเช่นการควบคุมหุ่นยนต์ลิฟต์โทรคมนาคมเกมเป็นต้น
ลองมาดูวิธีการทำงานกับ RL ใน Pybrain
เรากำลังจะทำงานในเขาวงกต environmentซึ่งจะแสดงโดยใช้อาร์เรย์ numpy 2 มิติโดยที่ 1 คือกำแพงและ 0 คือฟิลด์ว่าง ความรับผิดชอบของตัวแทนคือการเคลื่อนย้ายไปยังสนามว่างและค้นหาจุดเป้าหมาย
นี่คือขั้นตอนการทำงานกับสภาพแวดล้อมเขาวงกตทีละขั้นตอน
ขั้นตอนที่ 1
นำเข้าแพ็คเกจที่เราต้องการด้วยรหัสด้านล่าง -
from scipy import *
import sys, time
import matplotlib.pyplot as pylab # for visualization we are using mathplotlib
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Taskขั้นตอนที่ 2
สร้างสภาพแวดล้อมเขาวงกตโดยใช้รหัสด้านล่าง -
# create the maze with walls as 1 and 0 is a free field
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7)) # create the environment, the first parameter is the
maze array and second one is the goal field tupleขั้นตอนที่ 3
ขั้นตอนต่อไปคือการสร้าง Agent
ตัวแทนมีบทบาทสำคัญใน RL มันจะโต้ตอบกับสภาพแวดล้อมเขาวงกตโดยใช้เมธอด getAction () และ integrateObservation ()
ตัวแทนมีตัวควบคุม (ซึ่งจะแมปสถานะกับการกระทำ) และผู้เรียน
คอนโทรลเลอร์ใน PyBrain เป็นเหมือนโมดูลที่อินพุตเป็นสถานะและแปลงเป็นการกระทำ
controller = ActionValueTable(81, 4)
controller.initialize(1.)ActionValueTableต้องการปัจจัยการผลิต 2 รายการกล่าวคือจำนวนสถานะและการดำเนินการ สภาพแวดล้อมเขาวงกตมาตรฐานมี 4 การกระทำ: เหนือใต้ตะวันออกตะวันตก
ตอนนี้เราจะสร้างผู้เรียน เราจะใช้อัลกอริทึมการเรียนรู้ SARSA () สำหรับผู้เรียนที่จะใช้กับตัวแทน
learner = SARSA()
agent = LearningAgent(controller, learner)ขั้นตอนที่ 4
ขั้นตอนนี้กำลังเพิ่ม Agent ให้กับ Environment
ในการเชื่อมต่อตัวแทนกับสภาพแวดล้อมเราจำเป็นต้องมีองค์ประกอบพิเศษที่เรียกว่างาน บทบาทของกtask คือการมองหาเป้าหมายในสิ่งแวดล้อมและวิธีที่ตัวแทนได้รับผลตอบแทนจากการกระทำ
สภาพแวดล้อมมีงานของตัวเอง สภาพแวดล้อมเขาวงกตที่เราใช้มีงาน MDPMazeTask MDP ย่อมาจาก“markov decision process”ซึ่งหมายความว่าตัวแทนรู้ตำแหน่งในเขาวงกต สภาพแวดล้อมจะเป็นพารามิเตอร์ของงาน
task = MDPMazeTask(env)ขั้นตอนที่ 5
ขั้นตอนต่อไปหลังจากเพิ่มตัวแทนในสภาพแวดล้อมคือการสร้างการทดสอบ
ตอนนี้เราจำเป็นต้องสร้างการทดสอบเพื่อที่เราจะได้มีงานและตัวแทนประสานงานซึ่งกันและกัน
experiment = Experiment(task, agent)ตอนนี้เราจะทำการทดลอง 1,000 ครั้งดังที่แสดงด้านล่าง -
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()สภาพแวดล้อมจะทำงาน 100 ครั้งระหว่างเอเจนต์และงานเมื่อโค้ดต่อไปนี้ถูกเรียกใช้งาน -
experiment.doInteractions(100)หลังจากการทำซ้ำแต่ละครั้งจะให้สถานะใหม่แก่งานซึ่งจะตัดสินว่าควรส่งข้อมูลและรางวัลใดให้กับตัวแทน เรากำลังจะวางตารางใหม่หลังจากเรียนรู้และรีเซ็ตเอเจนต์ภายใน for loop
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(table.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")นี่คือรหัสเต็ม -
ตัวอย่าง
maze.py
from scipy import *
import sys, time
import matplotlib.pyplot as pylab
from pybrain.rl.environments.mazes import Maze, MDPMazeTask
from pybrain.rl.learners.valuebased import ActionValueTable
from pybrain.rl.agents import LearningAgent
from pybrain.rl.learners import Q, QLambda, SARSA #@UnusedImport
from pybrain.rl.explorers import BoltzmannExplorer #@UnusedImport
from pybrain.rl.experiments import Experiment
from pybrain.rl.environments import Task
# create maze array
mazearray = array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7))
# create task
task = MDPMazeTask(env)
#controller in PyBrain is like a module, for which the input is states and
convert them into actions.
controller = ActionValueTable(81, 4)
controller.initialize(1.)
# create agent with controller and learner - using SARSA()
learner = SARSA()
# create agent
agent = LearningAgent(controller, learner)
# create experiment
experiment = Experiment(task, agent)
# prepare plotting
pylab.gray()
pylab.ion()
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
pylab.pcolor(controller.params.reshape(81,4).max(1).reshape(9,9))
pylab.savefig("test.png")เอาต์พุต
python maze.py
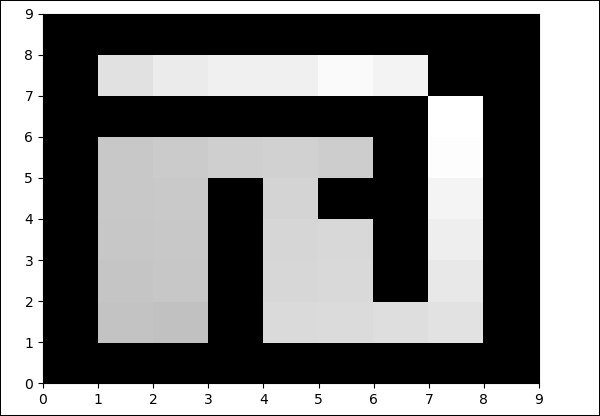
สีในช่องว่างจะเปลี่ยนไปในการทำซ้ำแต่ละครั้ง