Python Data Persistence - ไดรเวอร์ Cassandra
Cassandra เป็นฐานข้อมูล NoSQL ยอดนิยมอีกตัว ความสามารถในการปรับขนาดความสม่ำเสมอและความทนทานต่อความผิดพลาดสูง - นี่คือคุณสมบัติที่สำคัญบางประการของ Cassandra นี่คือColumn storeฐานข้อมูล. ข้อมูลจะถูกเก็บไว้ในเซิร์ฟเวอร์สินค้าจำนวนมาก เป็นผลให้ข้อมูลพร้อมใช้งานสูง
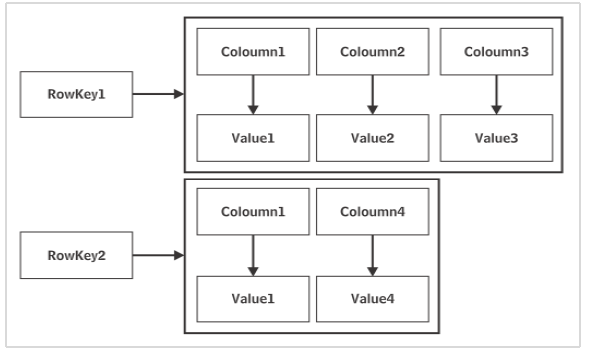
Cassandra เป็นผลิตภัณฑ์จาก Apache Software foundation ข้อมูลจะถูกจัดเก็บในลักษณะกระจายในหลาย ๆ โหนด แต่ละโหนดเป็นเซิร์ฟเวอร์เดียวที่ประกอบด้วยคีย์สเปซ โครงสร้างพื้นฐานของฐานข้อมูล Cassandra คือkeyspace ซึ่งสามารถพิจารณาได้ว่าคล้ายคลึงกับฐานข้อมูล
ข้อมูลในโหนดหนึ่งของ Cassandra ถูกจำลองแบบในโหนดอื่น ๆ บนเครือข่ายโหนดแบบเพียร์ทูเพียร์ นั่นทำให้ Cassandra เป็นฐานข้อมูลที่เข้าใจผิดได้ เครือข่ายเรียกว่าศูนย์ข้อมูล อาจมีการเชื่อมต่อศูนย์ข้อมูลหลายแห่งเพื่อสร้างคลัสเตอร์ ลักษณะของการจำลองแบบได้รับการกำหนดค่าโดยการตั้งค่ากลยุทธ์การจำลองและปัจจัยการจำลองขณะที่สร้างคีย์สเปซ
หนึ่งคีย์สเปซอาจมีมากกว่าหนึ่งตระกูลคอลัมน์เช่นเดียวกับที่ฐานข้อมูลเดียวอาจมีหลายตาราง คีย์สเปซของ Cassandra ไม่มีสคีมาที่กำหนดไว้ล่วงหน้า เป็นไปได้ว่าแต่ละแถวในตาราง Cassandra อาจมีคอลัมน์ที่มีชื่อแตกต่างกันและมีตัวเลขตัวแปร
ซอฟต์แวร์ Cassandra มีให้เลือกสองเวอร์ชัน: ชุมชนและองค์กร Cassandra เวอร์ชันล่าสุดสำหรับองค์กรสามารถดาวน์โหลดได้ที่https://cassandra.apache.org/download/. พบฉบับชุมชนที่https://academy.datastax.com/planet-cassandra/cassandra.
Cassandra มีภาษาสืบค้นของตัวเองที่เรียกว่า Cassandra Query Language (CQL). แบบสอบถาม CQL สามารถดำเนินการจากภายในเชลล์ CQLASH - คล้ายกับ MySQL หรือ SQLite เชลล์ ไวยากรณ์ CQL ดูเหมือนกับ SQL มาตรฐาน
Datastax community edition ยังมาพร้อมกับ Develcenter IDE ที่แสดงในรูปต่อไปนี้ -
เรียกว่าโมดูล Python สำหรับทำงานกับฐานข้อมูล Cassandra Cassandra Driver. นอกจากนี้ยังพัฒนาโดยมูลนิธิ Apache โมดูลนี้ประกอบด้วย ORM API เช่นเดียวกับ API หลักที่คล้ายคลึงกับ DB-API สำหรับฐานข้อมูลเชิงสัมพันธ์
การติดตั้งไดรเวอร์ Cassandra ทำได้อย่างง่ายดายโดยใช้ pip utility.
pip3 install cassandra-driverการโต้ตอบกับฐานข้อมูล Cassandra ทำได้ผ่านวัตถุคลัสเตอร์ โมดูล Cassandra.cluster กำหนดคลาสคลัสเตอร์ ก่อนอื่นเราต้องประกาศวัตถุคลัสเตอร์
from cassandra.cluster import Cluster
clstr=Cluster()ธุรกรรมทั้งหมดเช่นแทรก / อัปเดต ฯลฯ จะดำเนินการโดยเริ่มเซสชันด้วยคีย์สเปซ
session=clstr.connect()ในการสร้างคีย์สเปซใหม่ให้ใช้ execute()วิธีการของวัตถุเซสชัน เมธอด execute () ใช้อาร์กิวเมนต์สตริงซึ่งต้องเป็นสตริงเคียวรี CQL มีคำสั่ง CREATE KEYSPACE ดังนี้ รหัสที่สมบูรณ์มีดังต่อไปนี้ -
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect()
session.execute(“create keyspace mykeyspace with replication={
'class': 'SimpleStrategy', 'replication_factor' : 3
};”ที่นี่ SimpleStrategy เป็นค่าสำหรับ replication strategy และ replication factorถูกตั้งค่าเป็น 3 ตามที่กล่าวไว้ก่อนหน้านี้คีย์สเปซประกอบด้วยตารางอย่างน้อยหนึ่งตาราง แต่ละตารางมีลักษณะข้อมูลประเภท IT ประเภทข้อมูล Python จะถูกแยกวิเคราะห์โดยอัตโนมัติด้วยประเภทข้อมูล CQL ที่เกี่ยวข้องตามตารางต่อไปนี้ -
| ประเภท Python | ประเภท CQL |
|---|---|
| ไม่มี | NULL |
| บูล | บูลีน |
| ลอย | ลอยสองครั้ง |
| int ยาว | int, bigint, varint, smallint, tinyint, counter |
| ทศนิยมทศนิยม | ทศนิยม |
| str, Unicode | ascii, varchar, ข้อความ |
| บัฟเฟอร์ bytearray | หยด |
| วันที่ | วันที่ |
| วันเวลา | การประทับเวลา |
| เวลา | เวลา |
| รายการทูเพิลเครื่องกำเนิดไฟฟ้า | รายการ |
| ชุด Frozenset | ชุด |
| คำสั่งสั่งซื้อ | แผนที่ |
| uuid.UUID | timeuuid, uuid |
ในการสร้างตารางให้ใช้วัตถุเซสชันเพื่อเรียกใช้แบบสอบถาม CQL สำหรับสร้างตาราง
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
qry= '''
create table students (
studentID int,
name text,
age int,
marks int,
primary key(studentID)
);'''
session.execute(qry)คีย์สเปซที่สร้างขึ้นสามารถใช้เพิ่มเติมเพื่อแทรกแถวได้ แบบสอบถาม INSERT รุ่น CQL คล้ายกับคำสั่ง SQL Insert โค้ดต่อไปนี้แทรกแถวในตารางนักเรียน
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
session.execute("insert into students (studentID, name, age, marks) values
(1, 'Juhi',20, 200);"ตามที่คุณคาดหวังคำสั่ง SELECT ยังใช้กับ Cassandra ในกรณีของ execute () method ที่มีสตริงเคียวรี SELECT จะส่งคืนอ็อบเจ็กต์ชุดผลลัพธ์ซึ่งสามารถข้ามผ่านโดยใช้ลูป
from cassandra.cluster import Cluster
clstr=Cluster()
session=clstr.connect('mykeyspace')
rows=session.execute("select * from students;")
for row in rows:
print (StudentID: {} Name:{} Age:{} price:{} Marks:{}'
.format(row[0],row[1], row[2], row[3]))แบบสอบถาม SELECT ของ Cassandra สนับสนุนการใช้คำสั่ง WHERE เพื่อใช้ตัวกรองกับชุดผลลัพธ์ที่จะดึงข้อมูล ตัวดำเนินการทางตรรกะแบบดั้งเดิมเช่น <,> == เป็นต้นได้รับการยอมรับ ในการดึงข้อมูลเฉพาะแถวเหล่านั้นจากตารางนักเรียนสำหรับชื่อที่มีอายุ> 20 สตริงเคียวรีในเมธอด execute () ควรเป็นดังนี้ -
rows=session.execute("select * from students WHERE age>20 allow filtering;")หมายเหตุการใช้ ALLOW FILTERING. ส่วนอนุญาตการกรองของคำสั่งนี้อนุญาตอย่างชัดเจน (บางส่วน) การสืบค้นที่ต้องการการกรอง
API ไดรเวอร์ Cassandra กำหนดประเภทของ Statement ต่อไปนี้ในโมดูล cassendra.query
SimpleStatement
แบบสอบถาม CQL แบบง่ายที่ไม่ได้เตรียมไว้ในสตริงแบบสอบถาม ตัวอย่างทั้งหมดข้างต้นเป็นตัวอย่างของ SimpleStatement
BatchStatement
การสืบค้นข้อมูลหลายรายการ (เช่น INSERT, UPDATE และ DELETE) จะรวมอยู่ในชุดและดำเนินการพร้อมกัน แต่ละแถวจะถูกแปลงเป็น SimpleStatement ก่อนจากนั้นจึงเพิ่มในชุดงาน
ให้เราใส่แถวที่จะเพิ่มในตารางนักเรียนในรูปแบบของรายการสิ่งต่อไปนี้:
studentlist=[(1,'Juhi',20,100), ('2,'dilip',20, 110),(3,'jeevan',24,145)]หากต้องการเพิ่มแถวด้านบนโดยใช้ BathStatement ให้เรียกใช้สคริปต์ต่อไปนี้ -
from cassandra.query import SimpleStatement, BatchStatement
batch=BatchStatement()
for student in studentlist:
batch.add(SimpleStatement("INSERT INTO students
(studentID, name, age, marks) VALUES
(%s, %s, %s %s)"), (student[0], student[1],student[2], student[3]))
session.execute(batch)เตรียมพร้อม
คำสั่งที่เตรียมไว้ก็เหมือนกับคิวรีที่กำหนดพารามิเตอร์ใน DB-API Cassandra บันทึกสตริงการสืบค้นไว้เพื่อใช้ในภายหลัง วิธี Session.prepare () ส่งคืนอินสแตนซ์ PreparedStatement
สำหรับตารางนักเรียนของเราแบบสอบถาม PreparedStatement สำหรับ INSERT มีดังนี้ -
stmt=session.prepare("INSERT INTO students (studentID, name, age, marks) VALUES (?,?,?)")จากนั้นจะต้องส่งค่าของพารามิเตอร์เพื่อผูกเท่านั้น ตัวอย่างเช่น -
qry=stmt.bind([1,'Ram', 23,175])สุดท้ายดำเนินการคำสั่งผูกไว้ข้างต้น
session.execute(qry)ซึ่งจะช่วยลดปริมาณการใช้งานเครือข่ายและการใช้งาน CPU เนื่องจาก Cassandra ไม่ต้องแยกวิเคราะห์คำค้นหาใหม่ทุกครั้ง