คำขอ - คู่มือฉบับย่อ
คำขอเป็นไลบรารี HTTP ที่มีฟังก์ชันการทำงานที่ง่ายในการจัดการกับคำขอ / การตอบกลับ http ในเว็บแอปพลิเคชันของคุณ ไลบรารีได้รับการพัฒนาใน python
เว็บไซต์อย่างเป็นทางการของคำขอ Python ซึ่งมีอยู่ที่ https://2.python-requests.org/en/master/ กำหนดคำขอดังนี้ -
คำขอเป็นไลบรารี HTTP ที่หรูหราและเรียบง่ายสำหรับ Python ซึ่งสร้างขึ้นสำหรับมนุษย์
คุณสมบัติของคำขอ
คุณสมบัติของคำขอมีการกล่าวถึงด้านล่าง -
ขอ
ไลบรารีคำร้องขอ python มีวิธีการใช้งานที่ง่ายพร้อมใช้งานเพื่อจัดการคำขอ Http การส่งผ่านพารามิเตอร์และการจัดการประเภทคำขอเช่น GET, POST, PUT, DELETE ฯลฯ นั้นง่ายมาก
การตอบสนอง
คุณสามารถรับคำตอบในรูปแบบที่คุณต้องการและรูปแบบที่รองรับ ได้แก่ รูปแบบข้อความการตอบสนองแบบไบนารีการตอบสนอง json และการตอบกลับดิบ
ส่วนหัว
ไลบรารีช่วยให้คุณสามารถอ่านอัปเดตหรือส่งส่วนหัวใหม่ได้ตามความต้องการของคุณ
หมดเวลา
คุณสามารถเพิ่มระยะหมดเวลาลงใน URL ที่คุณขอได้อย่างง่ายดายโดยใช้ไลบรารีการร้องขอ python มันเกิดขึ้นเมื่อคุณใช้ URL ของบุคคลที่สามและรอการตอบกลับ
เป็นแนวทางปฏิบัติที่ดีเสมอในการกำหนดระยะหมดเวลาให้กับ URL เนื่องจากเราอาจต้องการให้ URL ตอบสนองภายในระยะหมดเวลานั้นด้วยการตอบสนองหรือข้อผิดพลาดที่เกิดขึ้นเนื่องจากการหมดเวลา การไม่ทำเช่นนั้นอาจทำให้ต้องรอตามคำขอนั้นไปเรื่อย ๆ
การจัดการข้อผิดพลาด
โมดูลคำขอให้การสนับสนุนสำหรับการจัดการข้อผิดพลาดและบางส่วน ได้แก่ ข้อผิดพลาดในการเชื่อมต่อข้อผิดพลาดการหมดเวลาข้อผิดพลาด TooManyRedirects ข้อผิดพลาด Response.raise_for_status เป็นต้น
คุ้กกี้
ไลบรารีอนุญาตให้คุณอ่านเขียนและอัปเดตสำหรับ URL ที่ร้องขอ
เซสชัน
ในการรักษาข้อมูลคุณต้องใช้ระหว่างคำขอที่คุณต้องการเซสชัน ดังนั้นหากโฮสต์เดียวกันถูกเรียกซ้ำแล้วซ้ำอีกคุณสามารถใช้การเชื่อมต่อ TCP ซ้ำได้ซึ่งจะช่วยปรับปรุงประสิทธิภาพ
ใบรับรอง SSL
ใบรับรอง SSL เป็นคุณลักษณะด้านความปลอดภัยที่มาพร้อมกับ URL ที่ปลอดภัย เมื่อคุณใช้คำขอนอกจากนี้ยังตรวจสอบใบรับรอง SSL สำหรับ https URL ที่ระบุ การตรวจสอบ SSL ถูกเปิดใช้งานโดยค่าเริ่มต้นในไลบรารีคำขอและจะทำให้เกิดข้อผิดพลาดหากไม่มีใบรับรอง
การรับรองความถูกต้อง
การตรวจสอบสิทธิ์ HTTP อยู่ที่ฝั่งเซิร์ฟเวอร์เพื่อขอข้อมูลการตรวจสอบสิทธิ์บางอย่างเช่นชื่อผู้ใช้รหัสผ่านเมื่อไคลเอ็นต์ร้องขอ URL นี่คือการรักษาความปลอดภัยเพิ่มเติมสำหรับคำขอและการตอบสนองที่แลกเปลี่ยนระหว่างไคลเอนต์และเซิร์ฟเวอร์
ข้อดีของการใช้ Python Request Library
ต่อไปนี้เป็นข้อดีของการใช้ Python Request Library -
ใช้งานง่ายและดึงข้อมูลจาก URL ที่กำหนด
สามารถใช้ไลบรารีคำขอเพื่อขูดข้อมูลจากเว็บไซต์
โดยใช้คำขอคุณสามารถรับโพสต์ลบอัปเดตข้อมูลสำหรับ URL ที่กำหนด
การจัดการคุกกี้และเซสชันนั้นง่ายมาก
ความปลอดภัยยังได้รับการดูแลด้วยความช่วยเหลือของการสนับสนุนโมดูลการพิสูจน์ตัวตน
ในบทนี้เราจะดำเนินการเกี่ยวกับการติดตั้งคำขอ ในการเริ่มต้นทำงานกับโมดูลคำขอเราต้องติดตั้ง Python ก่อน ดังนั้นเราจะดำเนินการต่อไป −
- ติดตั้ง Python
- ติดตั้งคำขอ
การติดตั้ง Python
ไปที่เว็บไซต์ทางการของ Python: https://www.python.org/downloads/ดังที่แสดงด้านล่างและคลิกที่เวอร์ชันล่าสุดสำหรับ Windows, Linux / Unix และ Mac OS ดาวน์โหลด Python ตามระบบปฏิบัติการ 64 หรือ 32 บิตที่มีให้กับคุณ
เมื่อคุณดาวน์โหลดแล้วให้คลิกที่ไฟล์. exe และทำตามขั้นตอนเพื่อติดตั้ง python ในระบบของคุณ
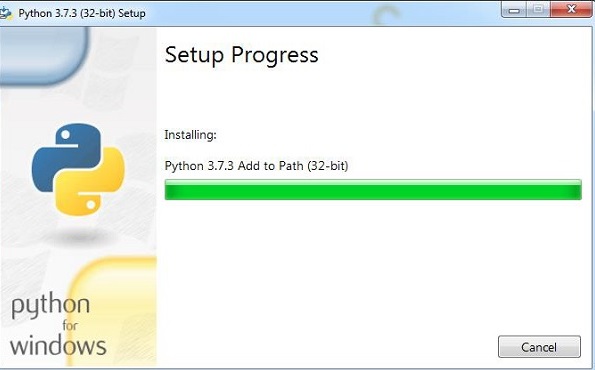
ตัวจัดการแพคเกจ python กล่าวคือ pip จะได้รับการติดตั้งตามค่าเริ่มต้นด้วยการติดตั้งด้านบน เพื่อให้ทำงานได้ทั่วโลกในระบบของคุณให้เพิ่มตำแหน่งของ python ลงในตัวแปร PATH โดยตรง สิ่งเดียวกันนี้จะแสดงเมื่อเริ่มการติดตั้งอย่าลืมทำเครื่องหมายในช่องที่ระบุว่า ADD to PATH ในกรณีที่คุณลืมตรวจสอบโปรดทำตามขั้นตอนด้านล่างเพื่อเพิ่มไปยัง PATH
ในการเพิ่มไปยัง PATH ให้ทำตามขั้นตอน
คลิกขวาที่ไอคอนคอมพิวเตอร์ของคุณและคลิกที่คุณสมบัติ> การตั้งค่าระบบขั้นสูง
จะแสดงหน้าจอดังรูปด้านล่าง -
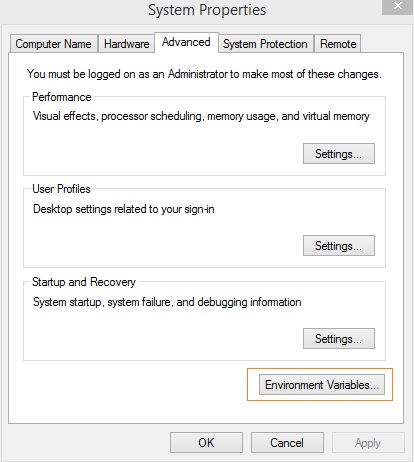
คลิกที่ Environment Variables ดังที่แสดงด้านบน จะแสดงหน้าจอดังรูปด้านล่าง -
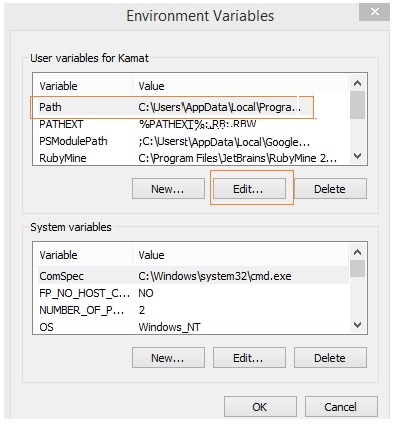
เลือกเส้นทางและคลิกที่ปุ่มแก้ไขเพิ่มเส้นทางตำแหน่งของหลามของคุณในตอนท้าย ตอนนี้ให้เราตรวจสอบเวอร์ชัน python
กำลังตรวจสอบเวอร์ชัน python
E:\prequests>python --version
Python 3.7.3ติดตั้งคำขอ
ตอนนี้เราได้ติดตั้ง python แล้วเราจะติดตั้งคำขอ
เมื่อติดตั้ง python แล้ว python package manager เช่น pip ก็จะได้รับการติดตั้งด้วย ต่อไปนี้เป็นคำสั่งเพื่อตรวจสอบเวอร์ชัน pip
E:\prequests>pip --version
pip 19.1.1 from c:\users\xxxxx\appdata\local\programs\python\python37\lib\site-p
ackages\pip (python 3.7)เราได้ติดตั้ง pip แล้วและเวอร์ชันคือ 19.1.1 ตอนนี้จะใช้ pip เพื่อติดตั้งโมดูลคำขอ
คำสั่งได้รับด้านล่าง
pip install requestsE:\prequests>pip install requests
Requirement already satisfied: requests in c:\users\xxxx\appdata\local\programs
\python\python37\lib\site-packages (2.22.0)
Requirement already satisfied: certifi>=2017.4.17 in c:\users\kamat\appdata\loca
l\programs\python\python37\lib\site-packages (from requests) (2019.3.9)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in c:\use
rs\xxxxx\appdata\local\programs\python\python37\lib\site-packages (from requests
) (1.25.3)
Requirement already satisfied: idna<2.9,>=2.5 in c:\users\xxxxxxx\appdata\local\pr
ograms\python\python37\lib\site-packages (from requests) (2.8)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\users\xxxxx\appdata\l
ocal\programs\python\python37\lib\site-packages (from requests) (3.0.4)เราได้ติดตั้งโมดูลไว้แล้วดังนั้นในพรอมต์คำสั่งจะระบุว่าความต้องการพอใจแล้ว หากไม่ได้ติดตั้งมันจะดาวน์โหลดแพ็คเกจที่จำเป็นสำหรับการติดตั้ง
ในการตรวจสอบรายละเอียดของโมดูลคำร้องขอที่ติดตั้งคุณสามารถใช้คำสั่งต่อไปนี้ −
pip show requests
E:\prequests>pip show requests
Name: requests
Version: 2.22.0
Summary: Python HTTP for Humans.
Home-page: http://python-requests.org
Author: Kenneth Reitz
Author-email: [email protected]
License: Apache 2.0
Location: c:\users\xxxxx\appdata\local\programs\python\python37\lib\site-package
S
Requires: certifi, idna, urllib3, chardet
Required-by:เวอร์ชันของโมดูลคำขอคือ 2.22.0
คำขอของ Python เป็นไลบรารี HTTP ที่จะช่วยให้เราแลกเปลี่ยนข้อมูลระหว่างไคลเอนต์และเซิร์ฟเวอร์ พิจารณาว่าคุณมี UI พร้อมแบบฟอร์มซึ่งคุณต้องป้อนรายละเอียดผู้ใช้ดังนั้นเมื่อคุณป้อนแล้วคุณต้องส่งข้อมูลซึ่งไม่มีอะไรเลยนอกจากคำขอ Http POST หรือ PUT จากไคลเอนต์ไปยังเซิร์ฟเวอร์เพื่อบันทึกข้อมูล
เมื่อคุณต้องการข้อมูลคุณต้องดึงข้อมูลจากเซิร์ฟเวอร์ซึ่งเป็นคำขอ Http GET อีกครั้ง การแลกเปลี่ยนข้อมูลระหว่างไคลเอนต์เมื่อร้องขอข้อมูลและเซิร์ฟเวอร์ตอบสนองด้วยข้อมูลที่ต้องการความสัมพันธ์ระหว่างไคลเอนต์และเซิร์ฟเวอร์นี้มีความสำคัญมาก
คำขอถูกส่งไปยัง URL ที่กำหนดและอาจเป็น URL ที่ปลอดภัยหรือไม่ปลอดภัย
การร้องขอไปยัง URL สามารถทำได้โดยใช้ GET, POST, PUT, DELETE วิธีที่ใช้กันมากที่สุดคือเมธอด GET ซึ่งส่วนใหญ่ใช้เมื่อคุณต้องการดึงข้อมูลจากเซิร์ฟเวอร์
คุณยังสามารถส่งข้อมูลไปยัง URL เป็นสตริงการสืบค้นได้เช่น
https://jsonplaceholder.typicode.com/users?id=9&username=Delphine
ที่นี่เรากำลังส่ง id = 9 และ username = Delphine ไปยัง URL ค่าทั้งหมดจะถูกส่งในคู่คีย์ / ค่าหลังเครื่องหมายคำถาม (?) และพารามิเตอร์หลายตัวจะถูกส่งไปยัง URL โดยคั่นด้วย &
การใช้ไลบรารีคำขอจะเรียก URL ดังต่อไปนี้โดยใช้พจนานุกรมสตริง
โดยข้อมูลไปยัง URL จะถูกส่งเป็นพจนานุกรมของสตริง หากคุณต้องการส่ง id = 9 และ username = Delphine คุณสามารถทำได้ดังนี้
payload = {'id': '9', 'username': 'Delphine'}ไลบรารีการร้องขอถูกเรียกดังนี้
res = requests.get('https://jsonplaceholder.typicode.com/users', params=payload')การใช้ POST สามารถทำได้ดังนี้
res = requests.post('https://jsonplaceholder.typicode.com/users', data = {'id':'9', 'username':'Delphine'})ใช้ PUT
res = requests.put('https://jsonplaceholder.typicode.com/users', data = {'id':'9', 'username':'Delphine'})ใช้ DELETE
res = requests.delete('https://jsonplaceholder.typicode.com/users')การตอบสนองจากคำขอ Http สามารถอยู่ในรูปแบบที่เข้ารหัสข้อความเข้ารหัสไบนารีรูปแบบ json หรือการตอบกลับดิบ รายละเอียดของคำขอและการตอบกลับจะอธิบายโดยละเอียดในบทถัดไป
ในบทนี้เราจะเข้าใจวิธีการทำงานกับโมดูลคำขอ เราจะพิจารณาสิ่งต่อไปนี้ −
- การร้องขอ HTTP
- การส่งผ่านพารามิเตอร์ไปยังคำขอ HTTP
การร้องขอ HTTP
ในการสร้างคำขอ Http เราต้องนำเข้าโมดูลคำขอก่อนตามที่แสดงด้านล่าง
import requestsตอนนี้ให้เราดูวิธีโทรไปที่ URL โดยใช้โมดูลคำขอ
ให้เราใช้ URL− https://jsonplaceholder.typicode.com/users ในรหัสเพื่อทดสอบโมดูลคำขอ
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.status_code)url− https://jsonplaceholder.typicode.com/usersถูกเรียกโดยใช้วิธีการ request.get () ออบเจ็กต์ตอบกลับของ URL ถูกเก็บไว้ในตัวแปร getdata เมื่อเราพิมพ์ตัวแปรจะให้รหัสตอบกลับ 200 ซึ่งหมายความว่าเราได้รับการตอบสนองเรียบร้อยแล้ว
เอาต์พุต
E:\prequests>python makeRequest.py
<Response [200]>ในการรับเนื้อหาจากการตอบกลับเราสามารถทำได้โดยใช้ getdata.content ดังแสดงด้านล่าง −
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)getdata.content จะพิมพ์ข้อมูลทั้งหมดที่มีอยู่ในการตอบกลับ
เอาต์พุต
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "[email protected]",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n }การส่งผ่านพารามิเตอร์ไปยังคำขอ HTTP
เพียงแค่ขอ URL นั้นไม่เพียงพอเราจำเป็นต้องส่งพารามิเตอร์ไปยัง URL ด้วย
พารามิเตอร์ส่วนใหญ่จะถูกส่งผ่านเป็นคู่คีย์ / ค่าตัวอย่างเช่น
https://jsonplaceholder.typicode.com/users?id=9&username=Delphineดังนั้นเราจึงมี id = 9 และ username = Delphine ตอนนี้จะดูวิธีส่งข้อมูลดังกล่าวเพื่อขอโมดูล Http
ตัวอย่าง
import requests
payload = {'id': 9, 'username': 'Delphine'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users', params=payload)
print(getdata.content)รายละเอียดจะถูกเก็บไว้ในส่วนของวัตถุในคู่คีย์ / ค่าและส่งผ่านไปยัง params ภายในเมธอด get ()
เอาต์พุต
E:\prequests>python makeRequest.py
b'[\n {\n "id": 9,\n "name": "Glenna Reichert",\n "username": "Delphin
e",\n "email": "[email protected]",\n "address": {\n "street":
"Dayna Park",\n "suite": "Suite 449",\n "city": "Bartholomebury",\n
"zipcode": "76495-3109",\n "geo": {\n "lat": "24.6463",\n
"lng": "-168.8889"\n }\n },\n "phone": "(775)976-6794 x41206",\n "
website": "conrad.com",\n "company": {\n "name": "Yost and Sons",\n
"catchPhrase": "Switchable contextually-based project",\n "bs": "aggregate
real-time technologies"\n }\n }\n]'ขณะนี้เราได้รับรายละเอียดของ id = 9 และ username = Delphine รายละเอียดในการตอบกลับ
หากคุณต้องการดูว่า URL มีลักษณะอย่างไรหลังจากส่งผ่านพารามิเตอร์โดยใช้ออบเจ็กต์ตอบกลับไปยัง URL
ตัวอย่าง
import requests
payload = {'id': 9, 'username': 'Delphine'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users', params=payload)
print(getdata.url)เอาต์พุต
E:\prequests>python makeRequest.py
https://jsonplaceholder.typicode.com/users?id=9&username=Delphineในบทนี้เราจะลงรายละเอียดเพิ่มเติมเกี่ยวกับการตอบกลับที่ได้รับจากโมดูลคำขอ เราจะพูดถึงรายละเอียดต่อไปนี้
- รับการตอบสนอง
- การตอบสนอง JSON
- การตอบสนอง RAW
- การตอบสนองแบบไบนารี
รับการตอบสนอง
เราจะทำการร้องขอไปยัง URL โดยใช้เมธอด request.get ()
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users');getdata มีวัตถุตอบสนอง มันมีรายละเอียดทั้งหมดของการตอบสนอง เราสามารถรับคำตอบได้ 2 วิธีโดยใช้ (. text ) และ (. content ) การใช้ response.text จะให้ข้อมูลกลับมาในรูปแบบข้อความดังที่แสดงด้านล่าง
ตัวอย่าง
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
},คุณจะเห็นการตอบสนองเหมือนเดิมเช่นเดียวกับที่จะปรากฏในเบราว์เซอร์เมื่อคุณดูแหล่งที่มาของ URL ดังที่แสดงด้านล่าง
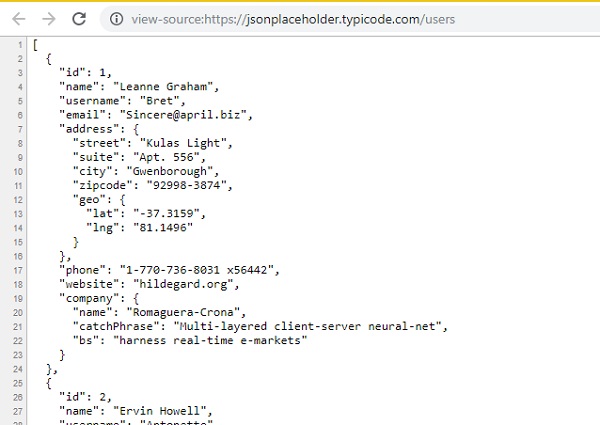
คุณยังสามารถลองใช้. html URL และดูเนื้อหาโดยใช้ response.text ซึ่งจะเหมือนกับเนื้อหาที่มาของมุมมองสำหรับ URL. html ในเบราว์เซอร์
ตอนนี้ให้เราลอง response.content สำหรับ URL เดียวกันและดูผลลัพธ์
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)เอาต์พุต
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "[email protected]",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n },\n {\n "id": 2,\n "name": "Ervin Howell",\n "us
ername": "Antonette",\n "email": "[email protected]",\n "address": {\n
"street": "Victor Plains",\n "suite": "Suite 879",\n "city": "Wisoky
burgh",\n "zipcode": "90566-7771",\n "geo": {\n "lat": "-43.950
9",\n "lng": "-34.4618"\n }\n },\n "phone": "010-692-6593 x091
25",\n "website": "anastasia.net",\n "company": {\n "name": "Deckow-C
rist",\n "catchPhrase": "Proactive didactic contingency",\n "bs": "syn
ergize scalable supply-chains"\n }\n },\n {\n "id": 3,\n "name": "Cle
mentine Bauch",\n "username": "Samantha",\n "email":
"[email protected]",
\n "address": {\n "street": "Douglas Extension",\n "suite": "Suite
847",\n "city": "McKenziehaven",\n "zipcode": "59590-4157",\n "ge
o": {\n "lat": "-68.6102",\n "lng": "-47.0653"\n }\n },\nการตอบสนองจะได้รับเป็นไบต์ คุณจะได้รับจดหมายbเมื่อเริ่มต้นการตอบกลับ ด้วยโมดูลคำขอคุณสามารถรับการเข้ารหัสที่ใช้และเปลี่ยนการเข้ารหัสได้หากจำเป็น ตัวอย่างเช่นในการรับการเข้ารหัสคุณสามารถใช้ response.encoding
print(getdata.encoding)เอาต์พุต
utf-8คุณสามารถเปลี่ยนการเข้ารหัสได้ดังนี้คุณสามารถใช้การเข้ารหัสที่คุณเลือกได้
getdata.encoding = 'ISO-8859-1'การตอบสนอง JSON
คุณยังสามารถรับการตอบสนองสำหรับคำขอ Http ในรูปแบบ json โดยใช้วิธี response.json () ดังต่อไปนี้
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.json())เอาต์พุต
E:\prequests>python makeRequest.py
[{'id': 1, 'name': 'Leanne Graham', 'username': 'Bret', 'email': 'Sincere@april.
biz', 'address': {'street': 'Kulas Light', 'suite': 'Apt. 556', 'city': 'Gwenbor
ough', 'zipcode': '92998-3874', 'geo': {'lat': '-37.3159', 'lng': '81.1496'}},
'
phone': '1-770-736-8031 x56442', 'website': 'hildegard.org', 'company': {'name':
'Romaguera-Crona', 'catchPhrase': 'Multi-layered client-server neural-net', 'bs
': 'harness real-time e-markets'}}]การตอบสนอง RAW
ในกรณีที่คุณต้องการการตอบกลับดิบสำหรับ Http URL คุณสามารถใช้ response.raw เพิ่มได้ด้วย stream=True ภายในวิธีรับดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', stream=True)
print(getdata.raw)เอาต์พุต
E:\prequests>python makeRequest.py
<urllib3.response.HTTPResponse object at 0x000000A8833D7B70>หากต้องการอ่านเนื้อหาเพิ่มเติมจากข้อมูลดิบคุณสามารถทำได้ดังนี้
print(getdata.raw.read(50))เอาต์พุต
E:\prequests>python makeRequest.py
b'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03\x95\x98[o\xe38\x12\x85\xdf\xe7W\x10y\
xda\x01F\x82.\xd4m\x9f\xdc\x9dd\xba\xb7\x93\xf4\x06q\xef4\x06\x83A@K\x15\x89m'การตอบสนองแบบไบนารี
ในการรับการตอบสนองแบบไบนารีเราสามารถใช้ response.content
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)เอาต์พุต
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "[email protected]",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n },\n {\n "id": 2,\n "name": "Ervin Howell",\n "us
ername": "Antonette",\n "email": "[email protected]",\n "address": {\n
"street": "Victor Plains",\n "suite": "Suite 879",\n "city": "Wisoky
burgh",\n "zipcode": "90566-7771",\n "geo": {\n "lat": "-43.950
9",\n "lng": "-34.4618"\n }\n },\n "phone": "010-692-6593 x091
25",\n "website": "anastasia.net",\n "company": {\n "name": "Deckow-C
rist",\n "catchPhrase": "Proactive didactic contingency",\n "bs": "syn
ergize scalable supply-chains"\n }\n },\n {\n "id": 3,\n "name": "Cle
mentine Bauch",\n "username": "Samantha",\n "email": "[email protected]",
\n "address": {\n "street": "Douglas Extension",\n "suite": "Suite
847",\n "city": "McKenziehaven",\n "zipcode": "59590-4157",\n "ge
o": {\n "lat": "-68.6102",\n "lng": "-47.0653"\n }\n },\nการตอบสนองจะได้รับเป็นไบต์ คุณจะได้รับจดหมายbเมื่อเริ่มต้นการตอบกลับ การตอบสนองแบบไบนารีส่วนใหญ่จะใช้สำหรับคำขอที่ไม่ใช่ข้อความ
คำขอ - ส่วนหัวคำขอ HTTP
ในบทที่แล้วเราได้เห็นวิธีการร้องขอและได้รับการตอบสนอง บทนี้จะสำรวจเพิ่มเติมเล็กน้อยเกี่ยวกับส่วนหัวของ URL ดังนั้นเราจะพิจารณาสิ่งต่อไปนี้
- ทำความเข้าใจกับส่วนหัวของคำขอ
- ส่วนหัวที่กำหนดเอง
- ส่วนหัวการตอบกลับ
ทำความเข้าใจกับส่วนหัวของคำขอ
กด URL ใดก็ได้ในเบราว์เซอร์ตรวจสอบและตรวจสอบในแท็บเครือข่ายเครื่องมือสำหรับนักพัฒนาซอฟต์แวร์
คุณจะได้รับส่วนหัวการตอบกลับส่วนหัวของคำขอน้ำหนักบรรทุก ฯลฯ
ตัวอย่างเช่นพิจารณา URL ต่อไปนี้
https://jsonplaceholder.typicode.com/users
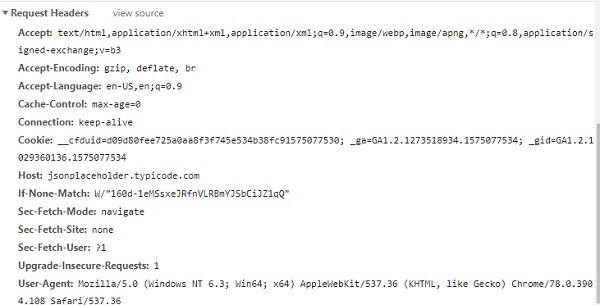
คุณสามารถรับรายละเอียดส่วนหัวได้ดังนี้
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', stream=True)
print(getdata.headers)เอาต์พุต
E:\prequests>python makeRequest.py
{'Date': 'Sat, 30 Nov 2019 05:15:00 GMT', 'Content-Type': 'application/json; cha
rset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Set-Co
okie': '__cfduid=d2b84ccf43c40e18b95122b0b49f5cf091575090900; expires=Mon, 30-De
c-19 05:15:00 GMT; path=/; domain=.typicode.com; HttpOnly', 'X-Powered-By': 'Exp
ress', 'Vary': 'Origin, Accept-Encoding', 'Access-Control-Allow-Credentials': 't
rue', 'Cache-Control': 'max-age=14400', 'Pragma': 'no-cache', 'Expires': '-1', '
X-Content-Type-Options': 'nosniff', 'Etag': 'W/"160d-1eMSsxeJRfnVLRBmYJSbCiJZ1qQ
"', 'Content-Encoding': 'gzip', 'Via': '1.1 vegur', 'CF-Cache-Status': 'HIT', 'A
ge': '2271', 'Expect-CT': 'max-age=604800, report-uri="https://report-uri.cloudf
lare.com/cdn-cgi/beacon/expect-ct"', 'Server': 'cloudflare', 'CF-RAY': '53da574f
f99fc331-SIN'}หากต้องการอ่านส่วนหัว http คุณสามารถทำได้ดังนี้ as
getdata.headers["Content-Encoding"] // gzipส่วนหัวที่กำหนดเอง
คุณยังสามารถส่งส่วนหัวไปยัง URL ที่ถูกเรียกได้ดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
headers = {'x-user': 'test123'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users', headers=headers)ส่วนหัวที่ส่งจะต้องเป็นรูปแบบสตริงบายเทสต์หรือ Unicode ลักษณะการทำงานของคำขอจะไม่เปลี่ยนแปลงตามส่วนหัวที่กำหนดเองที่ส่งผ่าน
ส่วนหัวการตอบกลับ
ส่วนหัวการตอบกลับมีลักษณะดังนี้เมื่อคุณตรวจสอบ URL ในเครื่องมือสำหรับนักพัฒนาเบราว์เซอร์แท็บเครือข่าย −
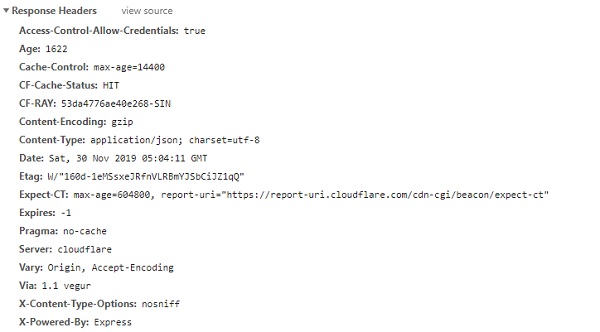
เพื่อรับรายละเอียดของส่วนหัวจากโมดูลคำขอให้ใช้ Response.headers ดังแสดงด้านล่าง −
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.headers)เอาต์พุต
E:\prequests>python makeRequest.py
{'Date': 'Sat, 30 Nov 2019 06:08:10 GMT', 'Content-Type': 'application/json; cha
rset=utf-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Set-Co
okie': '__cfduid=de1158f1a5116f3754c2c353055694e0d1575094090; expires=Mon, 30-De
c-19 06:08:10 GMT; path=/; domain=.typicode.com; HttpOnly', 'X-Powered-By': 'Exp
ress', 'Vary': 'Origin, Accept-Encoding', 'Access-Control-Allow-Credentials': 't
rue', 'Cache-Control': 'max-age=14400', 'Pragma': 'no-cache', 'Expires': '-1', '
X-Content-Type-Options': 'nosniff', 'Etag': 'W/"160d-1eMSsxeJRfnVLRBmYJSbCiJZ1qQ
"', 'Content-Encoding': 'gzip', 'Via': '1.1 vegur', 'CF-Cache-Status': 'HIT', 'A
ge': '5461', 'Expect-CT': 'max-age=604800, report-uri="https://report-uri.cloudf
lare.com/cdn-cgi/beacon/expect-ct"', 'Server': 'cloudflare', 'CF-RAY': '53daa52f
3b7ec395-SIN'}คุณสามารถรับส่วนหัวเฉพาะที่คุณต้องการดังต่อไปนี้ −
print(getdata.headers["Expect-CT"])เอาต์พุต
max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/exp
ect-ctYou can also get the header details by using the get() method.
print(getdata.headers.get("Expect-CT"))เอาต์พุต
max-age=604800, report-uri="https://report-uri.cloudflare.com/cdn-cgi/beacon/exp
ect-ctคำขอ - การจัดการรับคำขอ
บทนี้จะเน้นไปที่คำขอ GET ซึ่งเป็นเรื่องปกติและใช้บ่อยมาก การทำงานของ GET ในโมดูลการร้องขอนั้นง่ายมาก นี่คือตัวอย่างง่ายๆเกี่ยวกับการทำงานกับ URL โดยใช้เมธอด GET
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.content)
getdata.content, will print all the data available in the response.เอาต์พุต
E:\prequests>python makeRequest.py
b'[\n {\n "id": 1,\n "name": "Leanne Graham",\n "username": "Bret",\n
"email": "[email protected]",\n "address": {\n "street": "Kulas Light
",\n "suite": "Apt. 556",\n "city": "Gwenborough",\n "zipcode": "
92998-3874",\n "geo": {\n "lat": "-37.3159",\n "lng": "81.149
6"\n }\n },\n "phone": "1-770-736-8031 x56442",\n "website": "hild
egard.org",\n "company": {\n "name": "Romaguera-Crona",\n "catchPhr
ase": "Multi-layered client-server neural-net",\n "bs": "harness real-time
e-markets"\n }\n }คุณยังสามารถส่งผ่านพารามิเตอร์ไปยังเมธอด get โดยใช้พารามิเตอร์พารามิเตอร์ดังที่แสดงด้านล่าง
import requests
payload = {'id': 9, 'username': 'Delphine'}
getdata = requests.get('https://jsonplaceholder.typicode.com/users',
params=payload)
print(getdata.content)รายละเอียดจะถูกเก็บไว้ในส่วนของวัตถุในคู่คีย์ / ค่าและส่งผ่านไปยัง params ภายในเมธอด get ()
เอาต์พุต
E:\prequests>python makeRequest.py
b'[\n {\n "id": 9,\n "name": "Glenna Reichert",\n "username": "Delphin
e",\n "email": "[email protected]",\n "address": {\n "street":
"Dayna Park",\n "suite": "Suite 449",\n "city": "Bartholomebury",\n
"zipcode": "76495-3109",\n "geo": {\n "lat": "24.6463",\n
"lng": "-168.8889"\n }\n },\n "phone": "(775)976-6794 x41206",\n "
website": "conrad.com",\n "company": {\n "name": "Yost and Sons",\n
"catchPhrase": "Switchable contextually-based project",\n "bs": "aggregate
real-time technologies"\n }\n }\n]'การจัดการคำขอ POST, PUT, PATCH และ DELETE
ในบทนี้เราจะเข้าใจวิธีใช้เมธอด POST โดยใช้ไลบรารีคำขอและส่งผ่านพารามิเตอร์ไปยัง URL
การใช้ POST
สำหรับคำร้องขอ PUT ไลบรารีคำร้องขอมีเมธอด request.post () ดังตัวอย่างที่แสดงด้านล่าง:
คำขอนำเข้า
myurl = 'https://postman-echo.com/post'
myparams = {'name': 'ABC', 'email':'[email protected]'}
res = requests.post(myurl, data=myparams)
print(res.text)เอาต์พุต
E:\prequests>python makeRequest.py
{"args":{},"data":"","files":{},"form":{"name":"ABC","email":"[email protected]"},"headers":{"x-forwarded-proto":"https","host":"postman-echo.com","content-length":"30","accept":"*/*","accept-encoding":"gzip,deflate","content-type":"application/x-www-form-urlencoded","user-agent":"python-requests/2.22.0","x-forwarded-port":"443"},"json":{"name":"ABC","email":"[email protected]"},"url":"https://postman-echo.com/post"}ในตัวอย่างที่แสดงด้านบนคุณสามารถส่งข้อมูลแบบฟอร์มเป็นคู่คีย์ - ค่าไปยังพารามิเตอร์ข้อมูลภายใน request.post () นอกจากนี้เราจะดูวิธีการทำงานกับ PUT, PATCH และ DELETE ในโมดูลคำขอ
ใช้ PUT
สำหรับคำร้องขอ PUT ไลบรารีคำร้องขอมีเมธอด request.put () ดังตัวอย่างที่แสดงด้านล่าง
import requests
myurl = 'https://postman-echo.com/put'
myparams = {'name': 'ABC', 'email':'[email protected]'}
res = requests.put(myurl, data=myparams)
print(res.text)เอาต์พุต
E:\prequests>python makeRequest.py
{"args":{},"data":"","files":{},"form":{"name":"ABC","email":"[email protected]"},"h
eaders":{"x-forwarded-proto":"https","host":"postman-echo.com","content-length":
"30","accept":"*/*","accept-encoding":"gzip, deflate","content-type":"applicatio
n/x-www-form-urlencoded","user-agent":"python-requests/2.22.0","x-forwarded-port
":"443"},"json":{"name":"ABC","email":"[email protected]"},"url":"https://postman-ec ho.com/put"}การใช้ PATCH
สำหรับคำร้องขอ PATCH ไลบรารีคำร้องขอมีเมธอด request.patch () ดังตัวอย่างที่แสดงด้านล่าง
import requests
myurl = https://postman-echo.com/patch'
res = requests.patch(myurl, data="testing patch")
print(res.text)เอาต์พุต
E:\prequests>python makeRequest.py
{"args":{},"data":{},"files":{},"form":{},"headers":{"x-forwarded-proto":"https"
,"host":"postman-echo.com","content-length":"13","accept":"*/*","accept-encoding
":"gzip, deflate","user-agent":"python-requests/2.22.0","x-forwarded-port":"443"
},"json":null,"url":"https://postman-echo.com/patch"}ใช้ DELETE
สำหรับคำร้องขอ DELETE ไลบรารีคำร้องขอมีเมธอด request.delete () ดังตัวอย่างที่แสดงด้านล่าง
import requests
myurl = 'https://postman-echo.com/delete'
res = requests.delete(myurl, data="testing delete")
print(res.text)เอาต์พุต
E:\prequests>python makeRequest.py
{"args":{},"data":{},"files":{},"form":{},"headers":{"x-forwarded-proto":"https"
,"host":"postman-echo.com","content-length":"14","accept":"*/*","accept-encoding
":"gzip, deflate","user-agent":"python-requests/2.22.0","x-forwarded-port":"443"
},"json":null,"url":"https://postman-echo.com/delete"}คำขอ - อัปโหลดไฟล์
ในบทนี้เราจะอัปโหลดไฟล์โดยใช้คำขอและอ่านเนื้อหาของไฟล์ที่อัปโหลด เราสามารถทำได้โดยใช้ไฟล์files param ดังที่แสดงในตัวอย่างด้านล่าง
เราจะใช้ไฟล์ http://httpbin.org/โพสต์เพื่ออัปโหลดไฟล์
ตัวอย่าง
import requests
myurl = 'https://httpbin.org/post'
files = {'file': open('test.txt', 'rb')}
getdata = requests.post(myurl, files=files)
print(getdata.text)Test.txt
File upload test using Requestsตัวอย่าง
var total = [0, 1, 2, 3].reduceRight(function(a, b){ return a + b; });
console.log("total is : " + total );เอาต์พุต
E:\prequests>python makeRequest.py
{
"args": {},
"data": "",
"files": {
"file": "File upload test using Requests"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "175",
"Content-Type": "multipart/form-data;
boundary=28aee3a9d15a3571fb80d4d2a94bf
d33",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0"
},
"json": null,
"origin": "117.223.63.135, 117.223.63.135",
"url": "https://httpbin.org/post"
}นอกจากนี้ยังสามารถส่งเนื้อหาของไฟล์ดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
myurl = 'https://httpbin.org/post'
files = {'file': ('test1.txt', 'Welcome to TutorialsPoint')}
getdata = requests.post(myurl, files=files)
print(getdata.text)เอาต์พุต
E:\prequests>python makeRequest.py
{
"args": {},
"data": "",
"files": {
"file": "Welcome to TutorialsPoint"
},
"form": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "170",
"Content-Type": "multipart/form-data; boundary=f2837238286fe40e32080aa7e172b
e4f",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.22.0"
},
"json": null,
"origin": "117.223.63.135, 117.223.63.135",
"url": "https://httpbin.org/post"
}คำขอ - การทำงานกับคุกกี้
บทนี้จะกล่าวถึงวิธีจัดการกับคุกกี้ คุณสามารถรับคุกกี้และส่งคุกกี้ของคุณขณะเรียก URL โดยใช้ไลบรารีคำขอ
URL, https://jsonplaceholder.typicode.com/users เมื่อเข้ามาในเบราว์เซอร์เราจะได้รับรายละเอียดของคุกกี้ดังที่แสดงด้านล่าง
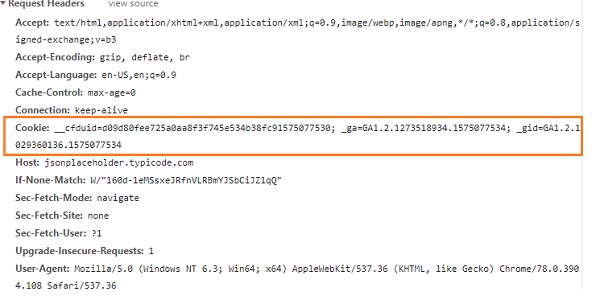
คุณสามารถอ่านคุกกี้ดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users')
print(getdata.cookies["__cfduid"])เอาต์พุต
E:\prequests>python makeRequest.py
d1733467caa1e3431fb7f768fa79ed3741575094848คุณยังสามารถส่งคุกกี้ได้เมื่อเราทำการร้องขอ
ตัวอย่าง
import requests
cookies = dict(test='test123')
getdata = requests.get('https://httpbin.org/cookies',cookies=cookies)
print(getdata.text)เอาต์พุต
E:\prequests>python makeRequest.py
{
"cookies": {
"test": "test123"
}
}คำขอ - การทำงานกับข้อผิดพลาด
บทนี้จะกล่าวถึงวิธีจัดการกับข้อผิดพลาดที่เกิดขึ้นเมื่อทำงานกับไลบรารีคำขอ Http การจัดการข้อผิดพลาดในทุกกรณีเป็นแนวทางปฏิบัติที่ดีเสมอ
ข้อยกเว้นข้อผิดพลาด
โมดูลการร้องขอมีข้อผิดพลาดประเภทต่อไปนี้
ConnectionError- สิ่งนี้จะเพิ่มขึ้นหากมีข้อผิดพลาดในการเชื่อมต่อ ตัวอย่างเช่นเครือข่ายล้มเหลว DNS เกิดข้อผิดพลาดดังนั้นไลบรารีคำขอจะเพิ่มข้อยกเว้น ConnectionError
Response.raise_for_status()- ตามรหัสสถานะเช่น 401, 404 จะเพิ่ม HTTPError สำหรับ url ที่ร้องขอ
HTTPError- ข้อผิดพลาดนี้จะเพิ่มขึ้นสำหรับการตอบกลับที่ไม่ถูกต้องสำหรับคำขอที่ทำขึ้น
Timeout- เกิดข้อผิดพลาดในการหมดเวลาสำหรับ URL ที่ร้องขอ
TooManyRedirects- หากขีด จำกัด สำหรับการเปลี่ยนเส้นทางสูงสุดเกินจะทำให้เกิดข้อผิดพลาด TooManyRedirects
ตัวอย่าง
นี่คือตัวอย่างข้อผิดพลาดที่แสดงสำหรับการหมดเวลา −
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=0.001)
print(getdata.text)เอาต์พุต
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='jsonplaceholder.ty
picode.com', port=443): Max retries exceeded with url: /users (Caused by Connect
TimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at
0x000000B02AD
E76A0>, 'Connection to jsonplaceholder.typicode.com timed out. (connect timeout= 0.001)'))คำขอ - การจัดการการหมดเวลา
สามารถเพิ่มการหมดเวลาลงใน URL ที่คุณขอได้อย่างง่ายดาย มันเป็นไปได้ว่าคุณกำลังใช้ URL ของบุคคลที่สามและกำลังรอการตอบกลับ เป็นแนวทางปฏิบัติที่ดีเสมอในการกำหนดระยะหมดเวลาให้กับ URL เนื่องจากเราอาจต้องการให้ URL ตอบสนองภายในช่วงเวลาที่มีการตอบสนองหรือข้อผิดพลาด หากไม่ทำเช่นนั้นอาจทำให้ต้องรอคำขอนั้นไปเรื่อย ๆ
เราสามารถกำหนดระยะหมดเวลาให้กับ URL ได้โดยใช้พารามิเตอร์การหมดเวลาและค่าจะถูกส่งผ่านเป็นวินาทีดังที่แสดงในตัวอย่างด้านล่าง
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=0.001)
print(getdata.text)เอาต์พุต
raise ConnectTimeout(e, request=request)
requests.exceptions.ConnectTimeout: HTTPSConnectionPool(host='jsonplaceholder.ty
picode.com', port=443): Max retries exceeded with url: /users (Caused by Connect
TimeoutError(<urllib3.connection.VerifiedHTTPSConnection object at 0x000000B02AD
E76A0>, 'Connection to jsonplaceholder.typicode.com timed out. (connect timeout=
0.001)'))ระยะหมดเวลาที่กำหนดมีดังนี้
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=0.001)การดำเนินการแสดงข้อผิดพลาดการหมดเวลาการเชื่อมต่อดังที่แสดงในเอาต์พุต การหมดเวลาที่กำหนดคือ 0.001 ซึ่งเป็นไปไม่ได้สำหรับการร้องขอเพื่อเรียกคืนการตอบกลับและแสดงข้อผิดพลาด ตอนนี้เราจะเพิ่มระยะหมดเวลาและตรวจสอบ
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users',timeout=1.000)
print(getdata.text)เอาต์พุต
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}เมื่อหมดเวลา 1 วินาทีเราจะได้รับคำตอบสำหรับ URL ที่ร้องขอ
คำขอ - การจัดการการเปลี่ยนเส้นทาง
บทนี้จะดูว่าไลบรารีคำขอจัดการกับกรณีการเปลี่ยนเส้นทาง URL อย่างไร
ตัวอย่าง
import requests
getdata = requests.get('http://google.com/')
print(getdata.status_code)
print(getdata.history)url− http://google.com จะถูกเปลี่ยนเส้นทางโดยใช้รหัสสถานะ 301 (ย้ายถาวร) ไปที่ https://www.google.com/. การเปลี่ยนเส้นทางจะถูกบันทึกไว้ในประวัติ
เอาต์พุต
เมื่อดำเนินการโค้ดด้านบนเราจะได้ผลลัพธ์ดังต่อไปนี้
E:\prequests>python makeRequest.py
200
[<Response [301]>]คุณสามารถหยุดการเปลี่ยนเส้นทาง URL โดยใช้ allow_redirects=False. สามารถทำได้บนวิธี GET, POST, OPTIONS, PUT, DELETE, PATCH ที่ใช้
ตัวอย่าง
นี่คือตัวอย่างในเรื่องเดียวกันimport requests
getdata = requests.get('http://google.com/', allow_redirects=False)
print(getdata.status_code)
print(getdata.history)
print(getdata.text)ตอนนี้ถ้าคุณตรวจสอบผลลัพธ์การเปลี่ยนเส้นทางจะไม่ได้รับอนุญาตและจะได้รับรหัสสถานะ 301
เอาต์พุต
E:\prequests>python makeRequest.py
301
[]
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
<TITLE>301 Moved</TITLE></HEAD><BODY>
<H1>301 Moved</H1>
The document has moved
<A HREF="http://www.google.com/">here</A>.
</BODY></HTML>คำขอ - ประวัติการจัดการ
คุณสามารถรับประวัติของ URL ที่กำหนดได้โดยใช้ response.history. หาก URL ที่ระบุมีการเปลี่ยนเส้นทางใด ๆ URL เดียวกันจะถูกเก็บไว้ในประวัติ
สำหรับประวัติศาสตร์
import requests
getdata = requests.get('http://google.com/')
print(getdata.status_code)
print(getdata.history)เอาต์พุต
E:\prequests>python makeRequest.py
200
[<Response [301]>]response.historyคุณสมบัติจะมีรายละเอียดของอ็อบเจ็กต์การตอบกลับที่ทำตามคำขอ ค่าที่แสดงจะเรียงลำดับจากค่าเก่าสุดไปหาค่าใหม่ล่าสุด response.history คุณสมบัติติดตามการเปลี่ยนเส้นทางทั้งหมดที่ทำบน URL ที่ร้องขอ
คำขอ - การจัดการเซสชัน
ในการรักษาข้อมูลระหว่างคำขอคุณต้องมีเซสชัน ดังนั้นหากโฮสต์เดียวกันถูกเรียกซ้ำแล้วซ้ำอีกคุณสามารถใช้การเชื่อมต่อ TCP ซ้ำซึ่งจะช่วยปรับปรุงประสิทธิภาพได้ ตอนนี้ให้เราดูวิธีการรักษาคุกกี้ในคำขอที่ทำโดยใช้เซสชัน
การเพิ่มคุกกี้โดยใช้เซสชัน
import requests
req = requests.Session()
cookies = dict(test='test123')
getdata = req.get('https://httpbin.org/cookies',cookies=cookies)
print(getdata.text)เอาต์พุต
E:\prequests>python makeRequest.py
{
"cookies": {
"test": "test123"
}
}การใช้เซสชันคุณสามารถเก็บรักษาข้อมูลคุกกี้ในคำขอต่างๆ นอกจากนี้ยังสามารถส่งผ่านข้อมูลส่วนหัวโดยใช้เซสชันดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
req = requests.Session()
req.headers.update({'x-user1': 'ABC'})
headers = {'x-user2': 'XYZ'}
getdata = req.get('https://httpbin.org/headers', headers=headers)
print(getdata.headers)คำขอ - การรับรอง SSL
ใบรับรอง SSL เป็นคุณลักษณะด้านความปลอดภัยที่มาพร้อมกับ URL ที่ปลอดภัย เมื่อคุณใช้ไลบรารีคำขอนอกจากนี้ยังตรวจสอบใบรับรอง SSL สำหรับ https URL ที่กำหนด การยืนยัน SSL ถูกเปิดใช้งานโดยค่าเริ่มต้นในโมดูลคำขอและจะทำให้เกิดข้อผิดพลาดหากไม่มีใบรับรอง
ทำงานกับ URL ที่ปลอดภัย
ต่อไปนี้เป็นตัวอย่างการทำงานกับ URL ที่ปลอดภัย −
import requests
getdata = requests.get(https://jsonplaceholder.typicode.com/users)
print(getdata.text)เอาต์พุต
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]เราได้รับคำตอบอย่างง่ายดายจาก https URL ด้านบนและเป็นเพราะโมดูลคำขอสามารถตรวจสอบใบรับรอง SSL ได้
คุณสามารถปิดใช้งานการตรวจสอบ SSL ได้โดยเพียงแค่เพิ่ม Verify = False ดังที่แสดงในตัวอย่างด้านล่าง
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', verify=False)
print(getdata.text)คุณจะได้รับผลลัพธ์ แต่จะมีข้อความเตือนด้วยว่าใบรับรอง SSL ไม่ได้รับการตรวจสอบและแนะนำให้เพิ่มการตรวจสอบใบรับรอง
เอาต์พุต
E:\prequests>python makeRequest.py
connectionpool.py:851: InsecureRequestWarning: Unverified HTTPS request is being
made. Adding certificate verification is strongly advised. See: https://urllib3
.readthedocs.io/en/latest/advanced-usage.htm l#ssl-warnings
InsecureRequestWarning)
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]คุณยังสามารถตรวจสอบใบรับรอง SSL ได้โดยโฮสต์ไว้ที่ส่วนท้ายของคุณและระบุเส้นทางโดยใช้ verify param ดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
getdata = requests.get('https://jsonplaceholder.typicode.com/users', verify='C:\Users\AppData\Local\certificate.txt')
print(getdata.text)เอาต์พุต
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]คำขอ - การรับรองความถูกต้อง
บทนี้จะกล่าวถึงประเภทของการพิสูจน์ตัวตนที่มีอยู่ในโมดูลคำขอ
เราจะกล่าวถึงต่อไปนี้
การทำงานของการพิสูจน์ตัวตนในคำขอ HTTP
การรับรองความถูกต้องขั้นพื้นฐาน
การรับรองความถูกต้องของไดเจสต์
การตรวจสอบสิทธิ์ OAuth2
การทำงานของการพิสูจน์ตัวตนในคำขอ HTTP
การตรวจสอบสิทธิ์ HTTP อยู่ที่ฝั่งเซิร์ฟเวอร์เพื่อขอข้อมูลการตรวจสอบสิทธิ์บางอย่างเช่นชื่อผู้ใช้รหัสผ่านเมื่อไคลเอ็นต์ร้องขอ URL นี่คือการรักษาความปลอดภัยเพิ่มเติมสำหรับคำขอและการตอบสนองที่แลกเปลี่ยนระหว่างไคลเอนต์และเซิร์ฟเวอร์
จากฝั่งไคลเอ็นต์ข้อมูลการตรวจสอบความถูกต้องเพิ่มเติมเหล่านี้เช่นชื่อผู้ใช้และรหัสผ่านสามารถส่งไปที่ส่วนหัวซึ่งในภายหลังทางฝั่งเซิร์ฟเวอร์จะได้รับการตรวจสอบ การตอบกลับจะถูกส่งจากฝั่งเซิร์ฟเวอร์ก็ต่อเมื่อการพิสูจน์ตัวตนถูกต้อง
ไลบรารีคำขอมีการพิสูจน์ตัวตนที่ใช้บ่อยที่สุดในrequest.authซึ่ง ได้แก่ การพิสูจน์ตัวตนพื้นฐาน ( HTTPBasicAuth ) และการพิสูจน์ตัวตนแบบแยกย่อย ( HTTPDigestAuth )
การรับรองความถูกต้องขั้นพื้นฐาน
นี่เป็นรูปแบบที่ง่ายที่สุดในการตรวจสอบสิทธิ์เซิร์ฟเวอร์ ในการทำงานกับการพิสูจน์ตัวตนขั้นพื้นฐานเราจะใช้คลาส HTTPBasicAuth ที่มีอยู่ในไลบรารีคำขอ
ตัวอย่าง
นี่คือตัวอย่างการใช้งานของวิธีการใช้งาน
import requests
from requests.auth import HTTPBasicAuth
response_data = requests.get('httpbin.org/basic-auth/admin/admin123', auth=HTTPDigestAuth('admin', 'admin123'))
print(response_data.text)เรากำลังเรียก url https://httpbin.org/basic-auth/admin/admin123ที่มีผู้ใช้เป็นผู้ดูแลระบบและรหัสผ่านเป็นadmin123
ดังนั้น URL นี้จะไม่ทำงานหากไม่มีการตรวจสอบความถูกต้องนั่นคือผู้ใช้และรหัสผ่าน เมื่อคุณให้การรับรองความถูกต้องโดยใช้พารามิเตอร์รับรองความถูกต้องแล้วเซิร์ฟเวอร์เท่านั้นที่จะตอบกลับ
เอาต์พุต
E:\prequests>python makeRequest.py
{
"authenticated": true,
"user": "admin"
}การรับรองความถูกต้องของไดเจสต์
นี่คือรูปแบบการตรวจสอบสิทธิ์อีกรูปแบบหนึ่งที่สามารถใช้ได้กับคำขอ เราจะใช้ประโยชน์จากคลาส HTTPDigestAuth จากคำขอ
ตัวอย่าง
import requests
from requests.auth import HTTPDigestAuth
response_data = requests.get('https://httpbin.org/digest-auth/auth/admin/admin123>, auth=HTTPDigestAuth('admin', 'admin123'))
print(response_data.text)เอาต์พุต
E:\prequests>python makeRequest.py
{
"authenticated": true,
"user": "admin"
}การตรวจสอบสิทธิ์ OAuth2
ในการใช้ OAuth2 Authentication เราต้องมีไลบรารี“ request_oauth2” ในการติดตั้ง“ request_oauth2” ให้ทำดังต่อไปนี้
pip install requests_oauth2การแสดงผลในเทอร์มินัลของคุณขณะติดตั้งจะเป็นอย่างที่แสดงด้านล่าง
E:\prequests>pip install requests_oauth2
Collecting requests_oauth2
Downloading https://files.pythonhosted.org/packages/52/dc/01c3c75e6e7341a2c7a9
71d111d7105df230ddb74b5d4e10a3dabb61750c/requests-oauth2-0.3.0.tar.gz
Requirement already satisfied: requests in c:\users\xyz\appdata\local\programs
\python\python37\lib\site-packages (from requests_oauth2) (2.22.0)
Requirement already satisfied: six in c:\users\xyz\appdata\local\programs\pyth
on\python37\lib\site-packages (from requests_oauth2) (1.12.0)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in c:\use
rs\xyz\appdata\local\programs\python\python37\lib\site-packages (from requests
->requests_oauth2) (1.25.3)
Requirement already satisfied: certifi>=2017.4.17 in c:\users\xyz\appdata\loca
l\programs\python\python37\lib\site-packages (from requests->requests_oauth2) (2
019.3.9)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\users\xyz\appdata\l
ocal\programs\python\python37\lib\site-packages (from requests->requests_oauth2)
(3.0.4)
Requirement already satisfied: idna<2.9,>=2.5 in c:\users\xyz\appdata\local\pr
ograms\python\python37\lib\site-packages (from requests->requests_oauth2) (2.8)
Building wheels for collected packages: requests-oauth2
Building wheel for requests-oauth2 (setup.py) ... done
Stored in directory: C:\Users\xyz\AppData\Local\pip\Cache\wheels\90\ef\b4\43
3743cbbc488463491da7df510d41c4e5aa28213caeedd586
Successfully built requests-oauth2เราติดตั้ง“ request-oauth2” เสร็จเรียบร้อยแล้ว ในการใช้ API ของ Google Twitter เราต้องได้รับความยินยอมและทำได้เช่นเดียวกันโดยใช้การตรวจสอบสิทธิ์ OAuth2
สำหรับการตรวจสอบสิทธิ์ OAuth2 เราจะต้องมีรหัสไคลเอ็นต์และรหัสลับ รายละเอียดวิธีการรับมีกล่าวถึงhttps://developers.google.com/identity/protocols/OAuth2.
หลังจากนั้นให้เข้าสู่ระบบคอนโซล Google API ซึ่งมีให้ที่ https://console.developers.google.com/และรับรหัสลูกค้าและรหัสลับ
ตัวอย่าง
นี่คือตัวอย่างวิธีการใช้ "request-oauth2"
import requests
from requests_oauth2.services import GoogleClient
google_auth = GoogleClient(
client_id="xxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com",
redirect_uri="http://localhost/auth/success.html",
)
a = google_auth.authorize_url(
scope=["profile", "email"],
response_type="code",
)
res = requests.get(a)
print(res.url)เราจะไม่สามารถเปลี่ยนเส้นทางไปยัง URL ที่ระบุได้เนื่องจากจำเป็นต้องลงชื่อเข้าใช้บัญชี Gmail แต่ที่นี่คุณจะเห็นจากตัวอย่างว่า google_auth ทำงานได้และได้รับ URL ที่ได้รับอนุญาต
เอาต์พุต
E:\prequests>python oauthRequest.py
https://accounts.google.com/o/oauth2/auth?redirect_uri=
http%3A%2F%2Flocalhost%2Fauth%2Fsuccess.html&
client_id=xxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com&
scope=profile+email&response_type=codeคำขอ - ตะขอเกี่ยวเหตุการณ์
เราสามารถเพิ่มเหตุการณ์ให้กับ URL ที่ร้องขอโดยใช้ event hooks ในตัวอย่างด้านล่างเราจะเพิ่มฟังก์ชันการโทรกลับที่จะเรียกเมื่อมีการตอบกลับ
ตัวอย่าง
ในการเพิ่มการโทรกลับเราจำเป็นต้องใช้ hooks param ดังที่แสดงในตัวอย่างด้านล่าง
mport requests
def printData(r, *args, **kwargs):
print(r.url)
print(r.text)
getdata = requests.get('https://jsonplaceholder.typicode.com/users',
hooks={'response': printData})เอาต์พุต
E:\prequests>python makeRequest.py
https://jsonplaceholder.typicode.com/users
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]คุณยังสามารถเรียกใช้ฟังก์ชันโทรกลับได้หลายรายการดังที่แสดงด้านล่าง −
ตัวอย่าง
import requests
def printRequestedUrl(r, *args, **kwargs):
print(r.url)
def printData(r, *args, **kwargs):
print(r.text)
getdata = requests.get('https://jsonplaceholder.typicode.com/users', hooks={'response': [printRequestedUrl, printData]})เอาต์พุต
E:\prequests>python makeRequest.py
https://jsonplaceholder.typicode.com/users
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]คุณยังสามารถเพิ่มเบ็ดในเซสชันที่สร้างขึ้นดังที่แสดงด้านล่าง −
ตัวอย่าง
import requests
def printData(r, *args, **kwargs):
print(r.text)
s = requests.Session()
s.hooks['response'].append(printData)
s.get('https://jsonplaceholder.typicode.com/users')เอาต์พุต
E:\prequests>python makeRequest.py
[
{
"id": 1,
"name": "Leanne Graham",
"username": "Bret",
"email": "[email protected]",
"address": {
"street": "Kulas Light",
"suite": "Apt. 556",
"city": "Gwenborough",
"zipcode": "92998-3874",
"geo": {
"lat": "-37.3159",
"lng": "81.1496"
}
},
"phone": "1-770-736-8031 x56442",
"website": "hildegard.org",
"company": {
"name": "Romaguera-Crona",
"catchPhrase": "Multi-layered client-server neural-net",
"bs": "harness real-time e-markets"
}
}
]คำขอ - พร็อกซี
จนถึงขณะนี้เราได้เห็นลูกค้าเชื่อมต่อและพูดคุยกับเซิร์ฟเวอร์โดยตรง การใช้พร็อกซีการโต้ตอบจะเกิดขึ้นดังนี้
ไคลเอนต์ส่งคำขอไปยังพร็อกซี
พร็อกซีส่งคำขอไปยังเซิร์ฟเวอร์
เซิร์ฟเวอร์ส่งการตอบกลับไปยังพร็อกซี
พร็อกซีจะส่งคำตอบกลับไปยังไคลเอนต์
การใช้ Http-proxy เป็นการรักษาความปลอดภัยเพิ่มเติมที่กำหนดให้จัดการการแลกเปลี่ยนข้อมูลระหว่างไคลเอนต์และเซิร์ฟเวอร์ ไลบรารีคำร้องขอยังมีข้อกำหนดในการจัดการพร็อกซีโดยใช้พร็อกซีพารามิเตอร์ดังที่แสดงด้านล่าง
ตัวอย่าง
import requests
proxies = {
'http': 'http://localhost:8080'
}
res = requests.get('http://httpbin.org/', proxies=proxies)
print(res.status_code)คำขอจะกำหนดเส้นทางไปยัง ('http://localhost:8080 URL
เอาต์พุต
200คำขอ - การขูดเว็บโดยใช้คำขอ
เราได้เห็นแล้วว่าเราสามารถรับข้อมูลจาก URL ที่กำหนดโดยใช้ไลบรารีคำขอ python ได้อย่างไร เราจะพยายามดึงข้อมูลจากเว็บไซต์ของTutorialspoint ซึ่งมีอยู่ที่ https://www.tutorialspoint.com/tutorialslibrary.htm โดยใช้สิ่งต่อไปนี้
ขอไลบรารี
ไลบรารีซุปสวยจากหลาม
เราได้ติดตั้งไลบรารีคำขอแล้วให้เราติดตั้งแพ็คเกจ Beautiful soup นี่คือเว็บไซต์อย่างเป็นทางการสำหรับbeautiful soup สามารถดูได้ที่ https://www.crummy.com/software/BeautifulSoup/bs4/doc/ ในกรณีที่คุณต้องการสำรวจฟังก์ชั่นอื่น ๆ ของซุปที่สวยงาม
การติดตั้ง Beautifulsoup
เราจะมาดูวิธีการติดตั้ง Beautiful Soup ด้านล่าง
E:\prequests>pip install beautifulsoup4
Collecting beautifulsoup4
Downloading https://files.pythonhosted.org/packages/3b/c8/a55eb6ea11cd7e5ac4ba
cdf92bac4693b90d3ba79268be16527555e186f0/beautifulsoup4-4.8.1-py3-none-any.whl (
101kB)
|████████████████████████████████| 102kB 22kB/s
Collecting soupsieve>=1.2 (from beautifulsoup4)
Downloading https://files.pythonhosted.org/packages/81/94/03c0f04471fc245d08d0
a99f7946ac228ca98da4fa75796c507f61e688c2/soupsieve-1.9.5-py2.py3-none-any.whl
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.8.1 soupsieve-1.9.5ตอนนี้เรามีไลบรารีคำขอหลามและซุปที่สวยงามติดตั้งแล้ว
ตอนนี้ให้เราเขียนโค้ดซึ่งจะดึงข้อมูลจาก URL ที่กำหนด
การขูดเว็บ
import requests
from bs4 import BeautifulSoup
res = requests.get('https://www.tutorialspoint.com/tutorialslibrary.htm')
print("The status code is ", res.status_code)
print("\n")
soup_data = BeautifulSoup(res.text, 'html.parser')
print(soup_data.title)
print("\n")
print(soup_data.find_all('h4'))การใช้ไลบรารีคำขอเราสามารถดึงเนื้อหาจาก URL ที่กำหนดและไลบรารีซุปที่สวยงามช่วยในการแยกวิเคราะห์และดึงรายละเอียดตามที่เราต้องการ
คุณสามารถใช้ไลบรารีซุปที่สวยงามเพื่อดึงข้อมูลโดยใช้แท็ก Html, คลาส, id, ตัวเลือก css และวิธีอื่น ๆ อีกมากมาย ต่อไปนี้เป็นผลลัพธ์ที่เราได้รับจากนั้นเราได้พิมพ์ชื่อของหน้าและแท็ก h4 ทั้งหมดบนหน้า
เอาต์พุต
E:\prequests>python makeRequest.py
The status code is 200
<title>Free Online Tutorials and Courses</title>
[<h4>Academic</h4>, <h4>Computer Science</h4>, <h4>Digital Marketing</h4>, <h4>M
onuments</h4>,<h4>Machine Learning</h4>, <h4>Mathematics</h4>, <h4>Mobile Devel
opment</h4>,<h4>SAP</h4>, <h4>Software Quality</h4>, <h4>Big Data & Analyti
cs</h4>, <h4>Databases</h4>, <h4>Engineering Tutorials</h4>, <h4>Mainframe Devel
opment</h4>, <h4>Microsoft Technologies</h4>, <h4>Java Technologies</h4>,<h4>XM
L Technologies</h4>, <h4>Python Technologies</h4>, <h4>Sports</h4>, <h4>Computer
Programming</h4>,<h4>DevOps</h4>, <h4>Latest Technologies</h4>, <h4>Telecom</h4>, <h4>Exams Syllabus</h4>, <h4>UPSC IAS Exams</h4>, <h4>Web Development</h4>,
<h4>Scripts</h4>, <h4>Management</h4>,<h4>Soft Skills</h4>, <h4>Selected Readin
g</h4>, <h4>Misc</h4>]