Scikit Learn - สนับสนุนเครื่องเวกเตอร์
บทนี้เกี่ยวกับวิธีการเรียนรู้ของเครื่องที่เรียกว่า Support Vector Machines (SVMs)
บทนำ
Support vector Machines (SVM) เป็นวิธีการเรียนรู้ของเครื่องที่มีประสิทธิภาพ แต่มีความยืดหยุ่นซึ่งใช้สำหรับการจำแนกการถดถอยและการตรวจจับค่าผิดปกติ SVM มีประสิทธิภาพมากในช่องว่างมิติสูงและโดยทั่วไปจะใช้ในปัญหาการจำแนกประเภท SVM เป็นที่นิยมและหน่วยความจำมีประสิทธิภาพเนื่องจากใช้จุดฝึกอบรมย่อยในฟังก์ชันการตัดสินใจ
เป้าหมายหลักของ SVM คือการแบ่งชุดข้อมูลออกเป็นจำนวนชั้นเรียนเพื่อค้นหาไฟล์ maximum marginal hyperplane (MMH) ซึ่งสามารถทำได้ในสองขั้นตอนต่อไปนี้ -
Support Vector Machines ก่อนอื่นจะสร้างไฮเปอร์เพลนซ้ำ ๆ เพื่อแยกคลาสออกจากกันด้วยวิธีที่ดีที่สุด
หลังจากนั้นจะเลือกไฮเปอร์เพลนที่แยกชั้นเรียนอย่างถูกต้อง
แนวคิดที่สำคัญบางประการใน SVM มีดังนี้ -
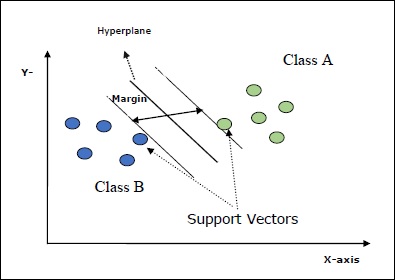
Support Vectors- อาจถูกกำหนดให้เป็นจุดข้อมูลที่อยู่ใกล้กับไฮเปอร์เพลนมากที่สุด เวกเตอร์สนับสนุนช่วยในการตัดสินใจเลือกเส้นคั่น
Hyperplane - ระนาบการตัดสินใจหรือช่องว่างที่แบ่งชุดของวัตถุที่มีคลาสต่างๆ
Margin - ช่องว่างระหว่างสองบรรทัดบนจุดข้อมูลตู้เสื้อผ้าของคลาสต่างๆเรียกว่าระยะขอบ
แผนภาพต่อไปนี้จะให้ข้อมูลเชิงลึกเกี่ยวกับแนวคิด SVM เหล่านี้ -
SVM ใน Scikit-learn รองรับทั้งเวกเตอร์ตัวอย่างแบบเบาบางและหนาแน่นเป็นอินพุต
การจำแนกประเภทของ SVM
Scikit-learn มีสามคลาส ได้แก่ SVC, NuSVC และ LinearSVC ซึ่งสามารถทำการจำแนกหลายคลาสได้
SVC
มันคือการจำแนกเวกเตอร์สนับสนุน C ซึ่งมีการนำไปใช้งาน libsvm. โมดูลที่ใช้โดย scikit-learn คือsklearn.svm.SVC. คลาสนี้จัดการการสนับสนุนหลายคลาสตามแบบแผนหนึ่งต่อหนึ่ง
พารามิเตอร์
ตารางต่อไปนี้ประกอบด้วยพารามิเตอร์ที่ใช้โดย sklearn.svm.SVC ชั้นเรียน -
| ซีเนียร์ No | พารามิเตอร์และคำอธิบาย |
|---|---|
| 1 | C - ลอยไม่จำเป็นค่าเริ่มต้น = 1.0 เป็นพารามิเตอร์การลงโทษของข้อผิดพลาด |
| 2 | kernel - สตริงตัวเลือกค่าเริ่มต้น = 'rbf' พารามิเตอร์นี้ระบุชนิดของเคอร์เนลที่จะใช้ในอัลกอริทึม เราสามารถเลือกคนใดคนหนึ่งจาก‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’. ค่าเริ่มต้นของเคอร์เนลจะเป็น‘rbf’. |
| 3 | degree - int, ทางเลือก, ค่าเริ่มต้น = 3 แสดงถึงระดับของฟังก์ชันเคอร์เนล 'poly' และเมล็ดอื่น ๆ จะถูกละเว้น |
| 4 | gamma - {'scale', 'auto'} หรือลอย เป็นค่าสัมประสิทธิ์เคอร์เนลสำหรับเมล็ด 'rbf', 'poly' และ 'sigmoid' |
| 5 | optinal default - = 'มาตราส่วน' หากคุณเลือกค่าเริ่มต้นคือ gamma = 'scale' ค่าของแกมมาที่ SVC จะใช้คือ 1 / (_ ∗. ()) ในทางกลับกันถ้า gamma = 'auto' จะใช้ 1 / _ |
| 6 | coef0 - ลอยไม่จำเป็นค่าเริ่มต้น = 0.0 คำศัพท์อิสระในฟังก์ชันเคอร์เนลซึ่งมีความสำคัญเฉพาะใน 'poly' และ 'sigmoid' |
| 7 | tol - ลอยตัวเลือกเริ่มต้น = 1.e-3 พารามิเตอร์นี้แสดงถึงเกณฑ์การหยุดสำหรับการทำซ้ำ |
| 8 | shrinking - บูลีนทางเลือกค่าเริ่มต้น = True พารามิเตอร์นี้แสดงว่าเราต้องการใช้ฮิวริสติกที่หดตัวหรือไม่ |
| 9 | verbose - บูลีนค่าเริ่มต้น: เท็จ เปิดหรือปิดการใช้งานเอาต์พุต verbose ค่าเริ่มต้นเป็นเท็จ |
| 10 | probability - บูลีนทางเลือกค่าเริ่มต้น = จริง พารามิเตอร์นี้เปิดใช้งานหรือปิดใช้งานการประมาณความน่าจะเป็น ค่าเริ่มต้นเป็นเท็จ แต่ต้องเปิดใช้งานก่อนที่เราจะเรียกว่า fit |
| 11 | max_iter - int, ทางเลือก, ค่าเริ่มต้น = -1 ตามที่แนะนำชื่อหมายถึงจำนวนการทำซ้ำสูงสุดภายในตัวแก้ ค่า -1 หมายถึงไม่มีการ จำกัด จำนวนการทำซ้ำ |
| 12 | cache_size - ลอยไม่จำเป็น พารามิเตอร์นี้จะระบุขนาดของเคอร์เนลแคช ค่าจะอยู่ในหน่วย MB (MegaBytes) |
| 13 | random_state - int, RandomState instance หรือ None, optional, default = none พารามิเตอร์นี้แสดงถึงจุดเริ่มต้นของหมายเลขสุ่มหลอกที่สร้างขึ้นซึ่งใช้ในขณะที่สับข้อมูล ตัวเลือกดังต่อไปนี้ -
|
| 14 | class_weight - {dict, 'balanced'} หรือไม่ก็ได้ พารามิเตอร์นี้จะตั้งค่าพารามิเตอร์ C ของคลาส j เป็น_ℎ [] ∗ สำหรับ SVC ถ้าเราใช้ตัวเลือกเริ่มต้นหมายความว่าทุกชั้นเรียนควรมีน้ำหนัก ในทางกลับกันถ้าคุณเลือกclass_weight:balancedมันจะใช้ค่าของ y เพื่อปรับน้ำหนักโดยอัตโนมัติ |
| 15 | decision_function_shape - ovo ',' ovr ', ค่าเริ่มต้น =' ovr ' พารามิเตอร์นี้จะตัดสินว่าอัลกอริทึมจะกลับมาหรือไม่ ‘ovr’ (one-vs-rest) ฟังก์ชั่นการตัดสินใจของรูปร่างเป็นตัวแยกประเภทอื่น ๆ ทั้งหมดหรือแบบดั้งเดิม ovo(one-vs-one) ฟังก์ชันการตัดสินใจของ libsvm |
| 16 | break_ties - บูลีนทางเลือกค่าเริ่มต้น = เท็จ True - การทำนายจะทำลายความสัมพันธ์ตามค่าความเชื่อมั่นของฟังก์ชันการตัดสินใจ False - การทำนายจะส่งคืนคลาสแรกในคลาสที่ผูกไว้ |
คุณลักษณะ
ตารางต่อไปนี้ประกอบด้วยแอตทริบิวต์ที่ใช้โดย sklearn.svm.SVC ชั้นเรียน -
| ซีเนียร์ No | คุณสมบัติและคำอธิบาย |
|---|---|
| 1 | support_ - คล้ายอาร์เรย์รูปร่าง = [n_SV] ส่งคืนดัชนีของเวกเตอร์สนับสนุน |
| 2 | support_vectors_ - คล้ายอาร์เรย์รูปร่าง = [n_SV, n_features] มันส่งคืนเวกเตอร์สนับสนุน |
| 3 | n_support_ - เหมือนอาร์เรย์, dtype = int32, shape = [n_class] แสดงจำนวนเวกเตอร์สนับสนุนสำหรับแต่ละคลาส |
| 4 | dual_coef_ - อาร์เรย์รูปร่าง = [n_class-1, n_SV] นี่คือค่าสัมประสิทธิ์ของเวกเตอร์สนับสนุนในฟังก์ชันการตัดสินใจ |
| 5 | coef_ - อาร์เรย์รูปร่าง = [n_class * (n_class-1) / 2, n_features] แอตทริบิวต์นี้มีให้เฉพาะในกรณีของเคอร์เนลเชิงเส้นเท่านั้นที่ให้น้ำหนักที่กำหนดให้กับคุณลักษณะ |
| 6 | intercept_ - อาร์เรย์รูปร่าง = [n_class * (n_class-1) / 2] มันแสดงถึงระยะอิสระ (ค่าคงที่) ในฟังก์ชันการตัดสินใจ |
| 7 | fit_status_ - int ผลลัพธ์จะเป็น 0 หากติดตั้งอย่างถูกต้อง ผลลัพธ์จะเป็น 1 หากติดตั้งไม่ถูกต้อง |
| 8 | classes_ - อาร์เรย์ของรูปร่าง = [n_classes] จะให้ป้ายกำกับของชั้นเรียน |
Implementation Example
เช่นเดียวกับตัวแยกประเภทอื่น ๆ SVC จะต้องติดตั้งอาร์เรย์สองอาร์เรย์ต่อไปนี้ -
อาร์เรย์ Xถือตัวอย่างการฝึกอบรม มีขนาด [n_samples, n_features]
อาร์เรย์ Yถือค่าเป้าหมายเช่นป้ายชื่อคลาสสำหรับตัวอย่างการฝึกอบรม มีขนาด [n_samples]
ใช้สคริปต์ Python ต่อไปนี้ sklearn.svm.SVC ชั้นเรียน -
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import SVC
SVCClf = SVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
SVCClf.fit(X, y)Output
SVC(C = 1.0, cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, probability = False, random_state = None, shrinking = False,
tol = 0.001, verbose = False)Example
ตอนนี้เมื่อติดตั้งแล้วเราจะได้เวกเตอร์น้ำหนักด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
SVCClf.coef_Output
array([[0.5, 0.5]])Example
ในทำนองเดียวกันเราสามารถรับค่าของคุณสมบัติอื่น ๆ ได้ดังนี้ -
SVCClf.predict([[-0.5,-0.8]])Output
array([1])Example
SVCClf.n_support_Output
array([1, 1])Example
SVCClf.support_vectors_Output
array(
[
[-1., -1.],
[ 1., 1.]
]
)Example
SVCClf.support_Output
array([0, 2])Example
SVCClf.intercept_Output
array([-0.])Example
SVCClf.fit_status_Output
0NuSVC
NuSVC คือ Nu Support Vector Classification เป็นอีกคลาสที่จัดทำโดย scikit-learn ซึ่งสามารถทำการจำแนกหลายคลาสได้ เหมือนกับ SVC แต่ NuSVC ยอมรับชุดพารามิเตอร์ที่แตกต่างกันเล็กน้อย พารามิเตอร์ที่แตกต่างจาก SVC มีดังนี้ -
nu - ลอยตัวเลือกเริ่มต้น = 0.5
แสดงขอบเขตบนของเศษส่วนของข้อผิดพลาดในการฝึกอบรมและขอบเขตล่างของเศษส่วนของเวกเตอร์สนับสนุน ค่าควรอยู่ในช่วงเวลา (o, 1]
พารามิเตอร์และแอตทริบิวต์ที่เหลือเหมือนกับ SVC
ตัวอย่างการใช้งาน
เราสามารถใช้ตัวอย่างเดียวกันโดยใช้ sklearn.svm.NuSVC ชั้นเรียนด้วย
import numpy as np
X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])
y = np.array([1, 1, 2, 2])
from sklearn.svm import NuSVC
NuSVCClf = NuSVC(kernel = 'linear',gamma = 'scale', shrinking = False,)
NuSVCClf.fit(X, y)เอาต์พุต
NuSVC(cache_size = 200, class_weight = None, coef0 = 0.0,
decision_function_shape = 'ovr', degree = 3, gamma = 'scale', kernel = 'linear',
max_iter = -1, nu = 0.5, probability = False, random_state = None,
shrinking = False, tol = 0.001, verbose = False)เราสามารถรับเอาต์พุตของคุณลักษณะที่เหลือได้เช่นเดียวกับในกรณีของ SVC
LinearSVC
เป็น Linear Support Vector Classification คล้ายกับ SVC ที่มี kernel = 'linear' ความแตกต่างระหว่างพวกเขาก็คือLinearSVC ดำเนินการในแง่ของ liblinear ในขณะที่ SVC ถูกนำมาใช้ libsvm. นั่นคือเหตุผลLinearSVCมีความยืดหยุ่นมากขึ้นในการเลือกบทลงโทษและฟังก์ชันการสูญเสีย นอกจากนี้ยังปรับขนาดได้ดีกว่าสำหรับกลุ่มตัวอย่างจำนวนมาก
หากเราพูดถึงพารามิเตอร์และคุณลักษณะนั้นจะไม่รองรับ ‘kernel’ เนื่องจากถือว่าเป็นเชิงเส้นและยังขาดคุณลักษณะบางอย่างเช่น support_, support_vectors_, n_support_, fit_status_ และ, dual_coef_.
อย่างไรก็ตามมันรองรับ penalty และ loss พารามิเตอร์ดังนี้ -
penalty − string, L1 or L2(default = ‘L2’)
พารามิเตอร์นี้ใช้เพื่อระบุบรรทัดฐาน (L1 หรือ L2) ที่ใช้ในการลงโทษ (การทำให้เป็นมาตรฐาน)
loss − string, hinge, squared_hinge (default = squared_hinge)
มันแสดงถึงฟังก์ชันการสูญเสียโดยที่ 'บานพับ' คือการสูญเสีย SVM มาตรฐานและ 'squared_hinge' คือกำลังสองของการสูญเสียบานพับ
ตัวอย่างการใช้งาน
ใช้สคริปต์ Python ต่อไปนี้ sklearn.svm.LinearSVC ชั้นเรียน -
from sklearn.svm import LinearSVC
from sklearn.datasets import make_classification
X, y = make_classification(n_features = 4, random_state = 0)
LSVCClf = LinearSVC(dual = False, random_state = 0, penalty = 'l1',tol = 1e-5)
LSVCClf.fit(X, y)เอาต์พุต
LinearSVC(C = 1.0, class_weight = None, dual = False, fit_intercept = True,
intercept_scaling = 1, loss = 'squared_hinge', max_iter = 1000,
multi_class = 'ovr', penalty = 'l1', random_state = 0, tol = 1e-05, verbose = 0)ตัวอย่าง
เมื่อติดตั้งแล้วแบบจำลองสามารถทำนายค่าใหม่ได้ดังนี้ -
LSVCClf.predict([[0,0,0,0]])เอาต์พุต
[1]ตัวอย่าง
สำหรับตัวอย่างข้างต้นเราสามารถรับเวกเตอร์น้ำหนักได้ด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
LSVCClf.coef_เอาต์พุต
[[0. 0. 0.91214955 0.22630686]]ตัวอย่าง
ในทำนองเดียวกันเราสามารถรับค่าของการสกัดกั้นด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
LSVCClf.intercept_เอาต์พุต
[0.26860518]การถดถอยด้วย SVM
ตามที่กล่าวไว้ก่อนหน้านี้ SVM ใช้สำหรับทั้งการจำแนกประเภทและปัญหาการถดถอย วิธีการของ Scikit-learn ในการสนับสนุน Vector Classification (SVC) สามารถขยายเพื่อแก้ปัญหาการถดถอยได้เช่นกัน วิธีการขยายนั้นเรียกว่า Support Vector Regression (SVR)
ความคล้ายคลึงกันพื้นฐานระหว่าง SVM และ SVR
แบบจำลองที่สร้างโดย SVC ขึ้นอยู่กับข้อมูลการฝึกอบรมบางส่วนเท่านั้น ทำไม? เนื่องจากฟังก์ชันต้นทุนสำหรับการสร้างโมเดลไม่สนใจจุดข้อมูลการฝึกอบรมที่อยู่นอกขอบ
ในขณะที่แบบจำลองที่ผลิตโดย SVR (Support Vector Regression) ยังขึ้นอยู่กับข้อมูลการฝึกบางส่วนเท่านั้น ทำไม? เนื่องจากฟังก์ชันต้นทุนสำหรับการสร้างโมเดลจะไม่สนใจจุดข้อมูลการฝึกอบรมใด ๆ ที่ใกล้เคียงกับการคาดคะเนโมเดล
Scikit-learn มีสามคลาส ได้แก่ SVR, NuSVR and LinearSVR เป็นการนำ SVR ไปใช้งานที่แตกต่างกันสามแบบ
SVR
มันคือการถดถอยเวกเตอร์ที่สนับสนุนเอปไซลอนซึ่งการใช้งานอยู่บนพื้นฐานของ libsvm. ตรงข้ามกับSVC มีพารามิเตอร์ฟรีสองตัวในแบบจำลอง ได้แก่ ‘C’ และ ‘epsilon’.
epsilon - ลอยไม่จำเป็นค่าเริ่มต้น = 0.1
มันแสดงถึง epsilon ในแบบจำลอง epsilon-SVR และระบุ epsilon-tube ที่ไม่มีการลงโทษใด ๆ ในฟังก์ชันการสูญเสียการฝึกอบรมด้วยคะแนนที่ทำนายภายในระยะ epsilon จากค่าจริง
พารามิเตอร์และแอตทริบิวต์ที่เหลือคล้ายกับที่เราใช้ SVC.
ตัวอย่างการใช้งาน
ใช้สคริปต์ Python ต่อไปนี้ sklearn.svm.SVR ชั้นเรียน -
from sklearn import svm
X = [[1, 1], [2, 2]]
y = [1, 2]
SVRReg = svm.SVR(kernel = ’linear’, gamma = ’auto’)
SVRReg.fit(X, y)เอาต์พุต
SVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, epsilon = 0.1, gamma = 'auto',
kernel = 'linear', max_iter = -1, shrinking = True, tol = 0.001, verbose = False)ตัวอย่าง
ตอนนี้เมื่อติดตั้งแล้วเราจะได้เวกเตอร์น้ำหนักด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
SVRReg.coef_เอาต์พุต
array([[0.4, 0.4]])ตัวอย่าง
ในทำนองเดียวกันเราสามารถรับค่าของคุณสมบัติอื่น ๆ ได้ดังนี้ -
SVRReg.predict([[1,1]])เอาต์พุต
array([1.1])ในทำนองเดียวกันเราสามารถรับค่าของคุณลักษณะอื่น ๆ ได้เช่นกัน
NuSVR
NuSVR คือ Nu Support Vector Regression เหมือนกับ NuSVC แต่ NuSVR ใช้พารามิเตอร์nuเพื่อควบคุมจำนวนเวกเตอร์สนับสนุน และยิ่งไปกว่านั้นไม่เหมือน NuSVC ตรงไหนnu แทนที่พารามิเตอร์ C ที่นี่จะแทนที่ epsilon.
ตัวอย่างการใช้งาน
ใช้สคริปต์ Python ต่อไปนี้ sklearn.svm.SVR ชั้นเรียน -
from sklearn.svm import NuSVR
import numpy as np
n_samples, n_features = 20, 15
np.random.seed(0)
y = np.random.randn(n_samples)
X = np.random.randn(n_samples, n_features)
NuSVRReg = NuSVR(kernel = 'linear', gamma = 'auto',C = 1.0, nu = 0.1)^M
NuSVRReg.fit(X, y)เอาต์พุต
NuSVR(C = 1.0, cache_size = 200, coef0 = 0.0, degree = 3, gamma = 'auto',
kernel = 'linear', max_iter = -1, nu = 0.1, shrinking = True, tol = 0.001,
verbose = False)ตัวอย่าง
ตอนนี้เมื่อติดตั้งแล้วเราจะได้เวกเตอร์น้ำหนักด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
NuSVRReg.coef_เอาต์พุต
array(
[
[-0.14904483, 0.04596145, 0.22605216, -0.08125403, 0.06564533,
0.01104285, 0.04068767, 0.2918337 , -0.13473211, 0.36006765,
-0.2185713 , -0.31836476, -0.03048429, 0.16102126, -0.29317051]
]
)ในทำนองเดียวกันเราสามารถรับค่าของคุณลักษณะอื่น ๆ ได้เช่นกัน
LinearSVR
มันคือ Linear Support Vector Regression คล้ายกับ SVR ที่มี kernel = 'linear' ความแตกต่างระหว่างพวกเขาก็คือLinearSVR ดำเนินการในแง่ของ liblinearในขณะที่ SVC ดำเนินการใน libsvm. นั่นคือเหตุผลLinearSVRมีความยืดหยุ่นมากขึ้นในการเลือกบทลงโทษและฟังก์ชันการสูญเสีย นอกจากนี้ยังปรับขนาดได้ดีกว่าสำหรับกลุ่มตัวอย่างจำนวนมาก
หากเราพูดถึงพารามิเตอร์และคุณลักษณะนั้นจะไม่รองรับ ‘kernel’ เนื่องจากถือว่าเป็นเชิงเส้นและยังขาดคุณลักษณะบางอย่างเช่น support_, support_vectors_, n_support_, fit_status_ และ, dual_coef_.
อย่างไรก็ตามสนับสนุนพารามิเตอร์ 'การสูญเสีย' ดังนี้ -
loss - สตริงทางเลือกค่าเริ่มต้น = 'epsilon_insensitive'
มันแสดงถึงฟังก์ชันการสูญเสียโดยที่การสูญเสีย epsilon_insensitive คือการสูญเสีย L1 และการสูญเสียที่ไม่ไวต่อเอปไซลอนกำลังสองคือการสูญเสีย L2
ตัวอย่างการใช้งาน
ใช้สคริปต์ Python ต่อไปนี้ sklearn.svm.LinearSVR ชั้นเรียน -
from sklearn.svm import LinearSVR
from sklearn.datasets import make_regression
X, y = make_regression(n_features = 4, random_state = 0)
LSVRReg = LinearSVR(dual = False, random_state = 0,
loss = 'squared_epsilon_insensitive',tol = 1e-5)
LSVRReg.fit(X, y)เอาต์พุต
LinearSVR(
C=1.0, dual=False, epsilon=0.0, fit_intercept=True,
intercept_scaling=1.0, loss='squared_epsilon_insensitive',
max_iter=1000, random_state=0, tol=1e-05, verbose=0
)ตัวอย่าง
เมื่อติดตั้งแล้วแบบจำลองสามารถทำนายค่าใหม่ได้ดังนี้ -
LSRReg.predict([[0,0,0,0]])เอาต์พุต
array([-0.01041416])ตัวอย่าง
สำหรับตัวอย่างข้างต้นเราสามารถรับเวกเตอร์น้ำหนักได้ด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
LSRReg.coef_เอาต์พุต
array([20.47354746, 34.08619401, 67.23189022, 87.47017787])ตัวอย่าง
ในทำนองเดียวกันเราสามารถรับค่าของการสกัดกั้นด้วยความช่วยเหลือของสคริปต์ python ต่อไปนี้ -
LSRReg.intercept_เอาต์พุต
array([-0.01041416])