Teradata - คู่มือฉบับย่อ
Teradata คืออะไร?
Teradata เป็นหนึ่งในระบบจัดการฐานข้อมูลเชิงสัมพันธ์ที่ได้รับความนิยม เหมาะสำหรับการสร้างแอปพลิเคชันคลังข้อมูลขนาดใหญ่เป็นหลัก เทราดาทาบรรลุสิ่งนี้โดยแนวคิดเรื่องคู่ขนาน ได้รับการพัฒนาโดย บริษัท ชื่อ Teradata
ประวัติ Teradata
ต่อไปนี้เป็นข้อมูลสรุปโดยย่อเกี่ยวกับประวัติของ Teradata ซึ่งแสดงรายการเหตุการณ์สำคัญ
1979 - บริษัท Teradata ถูกรวมเข้าด้วยกัน
1984 - การเปิดตัวคอมพิวเตอร์ฐานข้อมูลเครื่องแรก DBC / 1012
1986- นิตยสารFortuneตั้งชื่อ Teradata เป็น 'Product of the Year'
1999 - ฐานข้อมูลที่ใหญ่ที่สุดในโลกโดยใช้ Teradata ที่มี 130 เทราไบต์
2002 - Teradata V2R5 เปิดตัวพร้อมกับ Partition Primary Index และการบีบอัด
2006 - เปิดตัวโซลูชันการจัดการข้อมูลหลักของ Teradata
2008 - Teradata 13.0 เปิดตัวพร้อม Active Data Warehousing
2011 - ซื้อ Teradata Aster และเข้าสู่ Advanced Analytics Space
2012 - เปิดตัว Teradata 14.0
2014 - เปิดตัว Teradata 15.0
คุณสมบัติของ Teradata
ต่อไปนี้เป็นคุณสมบัติบางอย่างของ Teradata -
Unlimited Parallelism- ระบบฐานข้อมูล Teradata ใช้สถาปัตยกรรม Massively Parallel Processing (MPP) สถาปัตยกรรม MPP แบ่งภาระงานเท่า ๆ กันทั้งระบบ ระบบ Teradata แบ่งงานระหว่างกระบวนการและรันแบบคู่ขนานเพื่อให้แน่ใจว่างานเสร็จสิ้นอย่างรวดเร็ว
Shared Nothing Architecture- สถาปัตยกรรมของ Teradata เรียกว่า Shared Nothing Architecture Teradata Nodes, Access Module Processors (AMPs) และดิสก์ที่เกี่ยวข้องกับ AMPs ทำงานแยกกัน ไม่ใช้ร่วมกับผู้อื่น
Linear Scalability- ระบบ Teradata สามารถปรับขนาดได้สูง สามารถปรับขนาดได้ถึง 2048 โหนด ตัวอย่างเช่นคุณสามารถเพิ่มความจุของระบบได้สองเท่าโดยการเพิ่มจำนวน AMP เป็นสองเท่า
Connectivity - Teradata สามารถเชื่อมต่อกับระบบที่เชื่อมต่อกับช่องสัญญาณเช่นระบบเมนเฟรมหรือระบบที่เชื่อมต่อกับเครือข่าย
Mature Optimizer- เครื่องมือเพิ่มประสิทธิภาพ Teradata เป็นหนึ่งในเครื่องมือเพิ่มประสิทธิภาพที่ครบกำหนดในตลาด ได้รับการออกแบบให้ขนานกันตั้งแต่เริ่มต้น ได้รับการปรับปรุงสำหรับแต่ละรุ่น
SQL- Teradata รองรับ SQL มาตรฐานอุตสาหกรรมเพื่อโต้ตอบกับข้อมูลที่จัดเก็บในตาราง นอกจากนี้ยังมีส่วนขยายของตัวเอง
Robust Utilities - Teradata ให้ยูทิลิตี้ที่มีประสิทธิภาพในการนำเข้า / ส่งออกข้อมูลจาก / ไปยังระบบ Teradata เช่น FastLoad, MultiLoad, FastExport และ TPT
Automatic Distribution - Teradata กระจายข้อมูลไปยังดิสก์อย่างเท่าเทียมกันโดยอัตโนมัติโดยไม่มีการแทรกแซงด้วยตนเอง
Teradata ให้บริการ Teradata express สำหรับ VMWARE ซึ่งเป็นเครื่องเสมือน Teradata ที่ใช้งานได้เต็มรูปแบบ มีพื้นที่เก็บข้อมูลสูงสุด 1 เทราไบต์ Teradata มี VMware ทั้งเวอร์ชัน 40GB และ 1TB
ข้อกำหนดเบื้องต้น
เนื่องจาก VM เป็น 64 บิต CPU ของคุณจึงต้องรองรับ 64 บิต
ขั้นตอนการติดตั้งสำหรับ Windows
Step 1 - ดาวน์โหลดเวอร์ชัน VM ที่ต้องการจากลิงค์ https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 - แตกไฟล์และระบุโฟลเดอร์เป้าหมาย
Step 3 - ดาวน์โหลดเครื่องเล่น VMWare Workstation จากลิงค์ https://my.vmware.com/web/vmware/downloads. สามารถใช้ได้ทั้ง Windows และ Linux ดาวน์โหลด VMWARE workstation player สำหรับ Windows
Step 4 - เมื่อดาวน์โหลดเสร็จแล้วให้ติดตั้งซอฟต์แวร์
Step 5 - หลังจากการติดตั้งเสร็จสิ้นให้เรียกใช้ไคลเอ็นต์ VMWARE
Step 6- เลือก 'เปิดเครื่องเสมือน' ไปที่โฟลเดอร์ Teradata VMWare ที่แยกออกมาแล้วเลือกไฟล์ที่มีนามสกุล. vmdk
Step 7- เพิ่ม Teradata VMWare ในไคลเอนต์ VMWare เลือก Teradata VMware ที่เพิ่มเข้ามาแล้วคลิก 'Play Virtual Machine'

Step 8 - หากคุณได้รับป๊อปอัปเกี่ยวกับการอัปเดตซอฟต์แวร์คุณสามารถเลือก 'เตือนฉันในภายหลัง'
Step 9 - ป้อนชื่อผู้ใช้เป็น root กดแท็บและป้อนรหัสผ่านเป็นรูทแล้วกด Enter อีกครั้ง
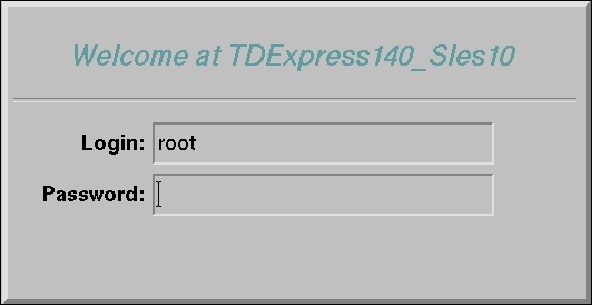
Step 10- เมื่อหน้าจอต่อไปนี้ปรากฏขึ้นบนเดสก์ท็อปให้ดับเบิลคลิกที่ 'root's home' จากนั้นดับเบิลคลิกที่ 'Genome's Terminal' เพื่อเปิดเชลล์

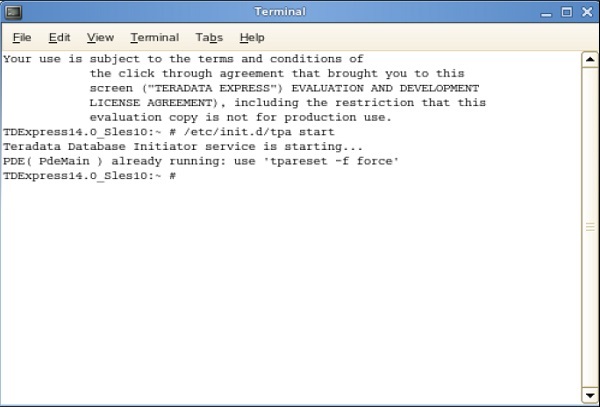
Step 11- จากเชลล์ต่อไปนี้ให้ป้อนคำสั่ง /etc/init.d/tpa start สิ่งนี้จะเริ่มต้นเซิร์ฟเวอร์ Teradata
เริ่มต้น BTEQ
ยูทิลิตี้ BTEQ ใช้เพื่อส่งแบบสอบถาม SQL แบบโต้ตอบ ต่อไปนี้เป็นขั้นตอนในการเริ่มยูทิลิตี้ BTEQ
Step 1 - ป้อนคำสั่ง / sbin / ifconfig และจดบันทึกที่อยู่ IP ของ VMWare
Step 2- รันคำสั่ง bteq ที่พรอมต์การเข้าสู่ระบบให้ป้อนคำสั่ง
เข้าสู่ระบบ <ipaddress> / dbc, dbc; และป้อนที่พรอมต์รหัสผ่านป้อนรหัสผ่านเป็น dbc;
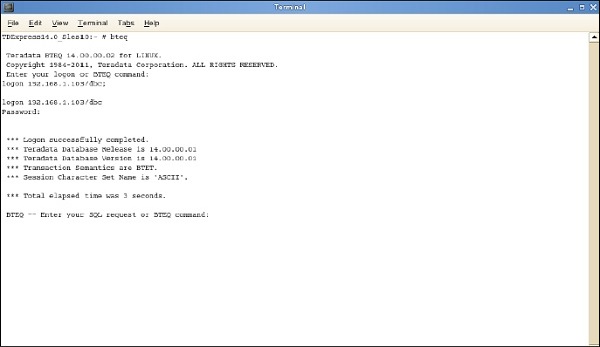
คุณสามารถเข้าสู่ระบบ Teradata โดยใช้ BTEQ และเรียกใช้แบบสอบถาม SQL ใด ๆ
สถาปัตยกรรม Teradata ใช้สถาปัตยกรรม Massively Parallel Processing (MPP) ส่วนประกอบหลักของ Teradata ได้แก่ Parsing Engine, BYNET และ Access Module Processors (AMPs) แผนภาพต่อไปนี้แสดงสถาปัตยกรรมระดับสูงของ Teradata Node
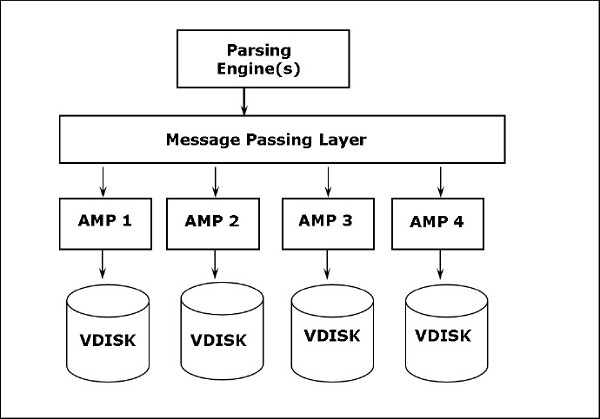
ส่วนประกอบของ Teradata
ส่วนประกอบสำคัญของ Teradata มีดังนี้ -
Node- เป็นยูนิตพื้นฐานในระบบเทราดาทา แต่ละเซิร์ฟเวอร์ในระบบ Teradata เรียกว่าโหนด โหนดประกอบด้วยระบบปฏิบัติการ CPU หน่วยความจำสำเนาซอฟต์แวร์ Teradata RDBMS และพื้นที่ดิสก์ของตัวเอง ตู้ประกอบด้วยโหนดอย่างน้อยหนึ่งโหนด
Parsing Engine- Parsing Engine มีหน้าที่รับคำถามจากลูกค้าและจัดเตรียมแผนการดำเนินการที่มีประสิทธิภาพ ความรับผิดชอบของเครื่องมือแยกวิเคราะห์คือ -
รับแบบสอบถาม SQL จากไคลเอนต์
แยกวิเคราะห์การตรวจสอบการสืบค้น SQL เพื่อหาข้อผิดพลาดทางไวยากรณ์
ตรวจสอบว่าผู้ใช้ต้องการสิทธิ์พิเศษกับวัตถุที่ใช้ในแบบสอบถาม SQL หรือไม่
ตรวจสอบว่าวัตถุที่ใช้ใน SQL มีอยู่จริงหรือไม่
เตรียมแผนการดำเนินการเพื่อดำเนินการแบบสอบถาม SQL และส่งต่อไปยัง BYNET
รับผลลัพธ์จาก AMP และส่งไปยังลูกค้า
Message Passing Layer- Message Passing Layer เรียกว่า BYNET เป็นเลเยอร์เครือข่ายในระบบ Teradata ช่วยให้การสื่อสารระหว่าง PE และ AMP และระหว่างโหนด ได้รับแผนการดำเนินการจาก Parsing Engine และส่งไปยัง AMP ในทำนองเดียวกันจะได้รับผลลัพธ์จาก AMP และส่งไปยัง Parsing Engine
Access Module Processor (AMP)- AMP ที่เรียกว่า Virtual Processors (vprocs) คือตัวที่เก็บและดึงข้อมูลมาใช้จริง AMP ได้รับข้อมูลและแผนการดำเนินการจาก Parsing Engine ทำการแปลงประเภทข้อมูลการรวมกรองการเรียงลำดับและจัดเก็บข้อมูลในดิสก์ที่เกี่ยวข้อง บันทึกจากตารางจะกระจายอย่างเท่าเทียมกันระหว่าง AMP ในระบบ AMP แต่ละตัวเชื่อมโยงกับชุดดิสก์ที่เก็บข้อมูล AMP เท่านั้นที่สามารถอ่าน / เขียนข้อมูลจากดิสก์ได้
สถาปัตยกรรมการจัดเก็บ
เมื่อไคลเอนต์รันเคียวรีเพื่อแทรกเร็กคอร์ด Parsing engine จะส่งเรกคอร์ดไปยัง BYNET BYNET ดึงข้อมูลและส่งแถวไปยัง AMP เป้าหมาย AMP เก็บบันทึกเหล่านี้ไว้ในดิสก์ แผนภาพต่อไปนี้แสดงสถาปัตยกรรมการจัดเก็บข้อมูลของ Teradata
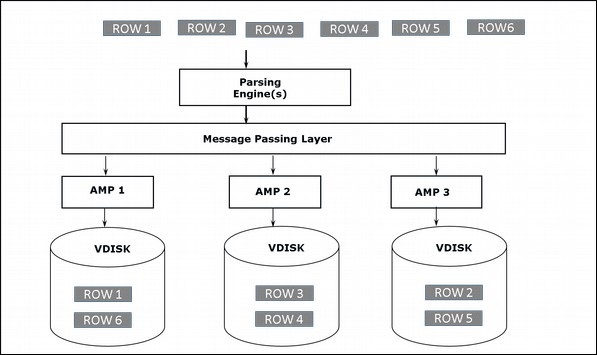
สถาปัตยกรรมการค้นคืน
เมื่อไคลเอนต์รันคิวรีเพื่อดึงเรกคอร์ดเอ็นจินการแยกวิเคราะห์จะส่งคำร้องขอไปยัง BYNET BYNET ส่งคำขอดึงข้อมูลไปยัง AMP ที่เหมาะสม จากนั้น AMP จะค้นหาดิสก์พร้อมกันและระบุระเบียนที่ต้องการแล้วส่งไปยัง BYNET BYNET จะส่งเรกคอร์ดไปยัง Parsing Engine ซึ่งจะส่งไปยังไคลเอนต์ ต่อไปนี้เป็นสถาปัตยกรรมการดึงข้อมูลของ Teradata
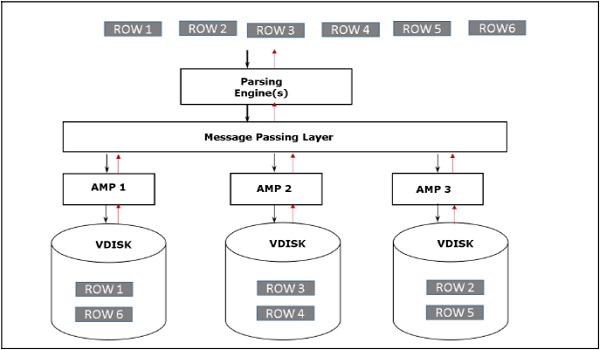
Relational Database Management System (RDBMS) เป็นซอฟต์แวร์ DBMS ที่ช่วยในการโต้ตอบกับฐานข้อมูล พวกเขาใช้ Structured Query Language (SQL) เพื่อโต้ตอบกับข้อมูลที่จัดเก็บในตาราง
ฐานข้อมูล
ฐานข้อมูลคือการรวบรวมข้อมูลที่เกี่ยวข้องกับเหตุผล เข้าถึงได้โดยผู้ใช้หลายคนเพื่อวัตถุประสงค์ที่แตกต่างกัน ตัวอย่างเช่นฐานข้อมูลการขายมีข้อมูลทั้งหมดเกี่ยวกับการขายซึ่งจัดเก็บไว้ในหลายตาราง
ตาราง
ตารางเป็นหน่วยพื้นฐานใน RDBMS ที่เก็บข้อมูล ตารางคือชุดของแถวและคอลัมน์ ต่อไปนี้เป็นตัวอย่างตารางพนักงาน
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เกิด |
|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 1/5/1980 |
| 104 | อเล็กซ์ | สจวร์ต | 11/6/1984 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 5/3/1983 |
| 105 | โรเบิร์ต | เจมส์ | 1/12/1984 |
| 103 | ปีเตอร์ | พอล | 1/1/2553 |
คอลัมน์
คอลัมน์มีข้อมูลที่คล้ายกัน ตัวอย่างเช่นคอลัมน์วันเกิดในตารางพนักงานมีข้อมูลวันเกิดสำหรับพนักงานทุกคน
| วันที่เกิด |
|---|
| 1/5/1980 |
| 11/6/1984 |
| 5/3/1983 |
| 1/12/1984 |
| 1/1/2553 |
แถว
แถวเป็นหนึ่งในคอลัมน์ทั้งหมด ตัวอย่างเช่นในตารางพนักงานหนึ่งแถวมีข้อมูลเกี่ยวกับพนักงานคนเดียว
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เกิด |
|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 1/5/1980 |
คีย์หลัก
คีย์หลักใช้เพื่อระบุแถวในตารางโดยไม่ซ้ำกัน ไม่อนุญาตให้มีค่าที่ซ้ำกันในคอลัมน์คีย์หลักและไม่สามารถยอมรับค่า NULL ได้ เป็นฟิลด์บังคับในตาราง
คีย์ต่างประเทศ
คีย์ต่างประเทศใช้เพื่อสร้างความสัมพันธ์ระหว่างตาราง คีย์ภายนอกในตารางลูกถูกกำหนดให้เป็นคีย์หลักในตารางหลัก ตารางสามารถมีคีย์ต่างประเทศได้มากกว่าหนึ่งคีย์ สามารถรับค่าที่ซ้ำกันและค่า null ได้ คีย์ต่างประเทศเป็นทางเลือกในตาราง
แต่ละคอลัมน์ในตารางเชื่อมโยงกับชนิดข้อมูล ชนิดข้อมูลระบุชนิดของค่าที่จะจัดเก็บในคอลัมน์ Teradata รองรับข้อมูลหลายประเภท ต่อไปนี้เป็นประเภทข้อมูลที่ใช้บ่อย
| ประเภทข้อมูล | ความยาว (ไบต์) | ช่วงของค่า |
|---|---|---|
| BYTEINT | 1 | -128 ถึง +127 |
| SMALLINT | 2 | -32768 ถึง +32767 |
| จำนวนเต็ม | 4 | -2,147,483,648 ถึง +2147,483,647 |
| ใหญ่ | 8 | -9,233,372,036,854,775,80 8 ถึง +9,233,372,036,854,775,8 07 |
| ทศนิยม | 1-16 | |
| NUMERIC | 1-16 | |
| ลอย | 8 | รูปแบบ IEEE |
| CHAR | รูปแบบคงที่ | 1-64,000 |
| VARCHAR | ตัวแปร | 1-64,000 |
| วันที่ | 4 | ปปปปปปปปปปป |
| เวลา | 6 หรือ 8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| TIMESTAMP | 10 หรือ 12 | YYMMDDHHMMSS.nnnnnn or YYMMDDHHMMSS.nnnnnn + HHMM |
ตารางในโมเดลเชิงสัมพันธ์ถูกกำหนดให้เป็นการรวบรวมข้อมูล แสดงเป็นแถวและคอลัมน์
ประเภทตาราง
ประเภท Teradata รองรับตารางประเภทต่างๆ
Permanent Table - นี่คือตารางเริ่มต้นและมีข้อมูลแทรกโดยผู้ใช้และจัดเก็บข้อมูลอย่างถาวร
Volatile Table- ข้อมูลที่แทรกลงในตารางระเหยจะถูกเก็บไว้ในช่วงเซสชันของผู้ใช้เท่านั้น ตารางและข้อมูลจะหายไปเมื่อสิ้นสุดเซสชัน ตารางเหล่านี้ส่วนใหญ่ใช้เพื่อเก็บข้อมูลระดับกลางระหว่างการแปลงข้อมูล
Global Temporary Table - คำจำกัดความของตารางชั่วคราวส่วนกลางยังคงอยู่ แต่ข้อมูลในตารางจะถูกลบเมื่อสิ้นสุดเซสชันผู้ใช้
Derived Table- ตารางที่ได้รับจะเก็บผลลัพธ์ระดับกลางในแบบสอบถาม อายุการใช้งานของพวกเขาอยู่ในแบบสอบถามที่สร้างขึ้นใช้และทิ้ง
ตั้งค่า Versus Multiset
Teradata จัดประเภทตารางเป็นตาราง SET หรือ MULTISET ตามวิธีการจัดการระเบียนที่ซ้ำกัน ตารางที่กำหนดเป็นตาราง SET จะไม่เก็บระเบียนที่ซ้ำกันในขณะที่ตาราง MULTISET สามารถจัดเก็บระเบียนที่ซ้ำกันได้
| ซีเนียร์ No | คำสั่งตารางและคำอธิบาย |
|---|---|
| 1 | สร้างตาราง คำสั่ง CREATE TABLE ใช้เพื่อสร้างตารางใน Teradata |
| 2 | เปลี่ยนแปลงตาราง คำสั่ง ALTER TABLE ใช้เพื่อเพิ่มหรือวางคอลัมน์จากตารางที่มีอยู่ |
| 3 | วางตาราง คำสั่ง DROP TABLE ใช้เพื่อวางตาราง |
บทนี้จะแนะนำคำสั่ง SQL ที่ใช้ในการจัดการข้อมูลที่จัดเก็บในตาราง Teradata
แทรกบันทึก
คำสั่ง INSERT INTO ใช้เพื่อแทรกระเบียนลงในตาราง
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปสำหรับ INSERT INTO
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);ตัวอย่าง
ตัวอย่างต่อไปนี้แทรกระเบียนลงในตารางพนักงาน
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);เมื่อแทรกแบบสอบถามด้านบนแล้วคุณสามารถใช้คำสั่ง SELECT เพื่อดูบันทึกจากตารางได้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เข้าร่วม | แผนก | วันที่เกิด |
|---|---|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 27/3/2548 | 1 | 1/5/1980 |
แทรกจากตารางอื่น
คำสั่ง INSERT SELECT ใช้เพื่อแทรกระเบียนจากตารางอื่น
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปสำหรับ INSERT INTO
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;ตัวอย่าง
ตัวอย่างต่อไปนี้แทรกระเบียนลงในตารางพนักงาน สร้างตารางชื่อ Employee_Bkup โดยใช้คำจำกัดความคอลัมน์เดียวกับตารางพนักงานก่อนที่จะเรียกใช้แบบสอบถามแทรกต่อไปนี้
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;เมื่อดำเนินการค้นหาข้างต้นจะแทรกระเบียนทั้งหมดจากตารางพนักงานลงในตาราง staff_bkup
กฎ
จำนวนคอลัมน์ที่ระบุในรายการ VALUES ควรตรงกับคอลัมน์ที่ระบุในส่วนคำสั่ง INSERT INTO
ค่าจำเป็นสำหรับคอลัมน์ NOT NULL
หากไม่ได้ระบุค่า NULL จะถูกแทรกสำหรับช่องว่าง
ชนิดข้อมูลของคอลัมน์ที่ระบุในส่วนคำสั่ง VALUES ควรเข้ากันได้กับชนิดข้อมูลของคอลัมน์ในส่วนคำสั่ง INSERT
อัปเดตบันทึก
คำสั่ง UPDATE ใช้เพื่ออัปเดตเรกคอร์ดจากตาราง
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปสำหรับ UPDATE
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];ตัวอย่าง
ตัวอย่างต่อไปนี้จะอัปเดตแผนกของพนักงานเป็น 03 สำหรับพนักงาน 101
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;ในผลลัพธ์ต่อไปนี้คุณจะเห็นว่า DepartmentNo ได้รับการอัปเดตจาก 1 เป็น 3 สำหรับ EmployeeNo 101
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3กฎ
คุณสามารถอัปเดตค่าของตารางได้ตั้งแต่หนึ่งค่าขึ้นไป
หากไม่ได้ระบุเงื่อนไข WHERE แถวทั้งหมดของตารางจะได้รับผลกระทบ
คุณสามารถอัปเดตตารางด้วยค่าจากตารางอื่น
ลบบันทึก
คำสั่ง DELETE FROM ใช้เพื่ออัปเดตเรกคอร์ดจากตาราง
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปสำหรับ DELETE FROM
DELETE FROM <tablename>
[WHERE condition];ตัวอย่าง
ตัวอย่างต่อไปนี้ลบพนักงาน 101 จากพนักงานโต๊ะ
DELETE FROM Employee
WHERE EmployeeNo = 101;ในผลลัพธ์ต่อไปนี้คุณจะเห็นว่าพนักงาน 101 ถูกลบออกจากตาราง
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.กฎ
คุณสามารถอัปเดตระเบียนของตารางได้ตั้งแต่หนึ่งรายการขึ้นไป
หากไม่ได้ระบุเงื่อนไข WHERE แถวทั้งหมดของตารางจะถูกลบ
คุณสามารถอัปเดตตารางด้วยค่าจากตารางอื่น
คำสั่ง SELECT ใช้เพื่อดึงข้อมูลจากตาราง
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานของคำสั่ง SELECT
SELECT
column 1, column 2, .....
FROM
tablename;ตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เข้าร่วม | แผนก | วันที่เกิด |
|---|---|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 27/3/2548 | 1 | 1/5/1980 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 25/4/2550 | 2 | 5/3/1983 |
| 103 | ปีเตอร์ | พอล | 21/3/2550 | 2 | 1/1/2553 |
| 104 | อเล็กซ์ | สจวร์ต | 1/2/2561 | 2 | 11/6/1984 |
| 105 | โรเบิร์ต | เจมส์ | 1/4/2561 | 3 | 1/12/1984 |
ต่อไปนี้เป็นตัวอย่างของคำสั่ง SELECT
SELECT EmployeeNo,FirstName,LastName
FROM Employee;เมื่อเรียกใช้แบบสอบถามนี้จะดึงคอลัมน์ EmployeeNo, FirstName และ LastName จากตารางพนักงาน
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter Paulหากคุณต้องการดึงคอลัมน์ทั้งหมดจากตารางคุณสามารถใช้คำสั่งต่อไปนี้แทนการลงรายการคอลัมน์ทั้งหมด
SELECT * FROM Employee;แบบสอบถามข้างต้นจะดึงบันทึกทั้งหมดจากตารางพนักงาน
WHERE ข้อ
คำสั่ง WHERE ใช้เพื่อกรองระเบียนที่ส่งคืนโดยคำสั่ง SELECT เงื่อนไขเกี่ยวข้องกับ WHERE clause เฉพาะระเบียนที่ตรงตามเงื่อนไขในส่วนคำสั่ง WHERE เท่านั้นที่จะถูกส่งกลับ
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง SELECT ที่มีส่วนคำสั่ง WHERE
SELECT * FROM tablename
WHERE[condition];ตัวอย่าง
แบบสอบถามต่อไปนี้ดึงข้อมูลโดยที่ EmployeeNo คือ 101
SELECT * FROM Employee
WHERE EmployeeNo = 101;เมื่อเรียกใช้แบบสอบถามนี้จะส่งคืนระเบียนต่อไปนี้
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike Jamesสั่งโดย
เมื่อดำเนินการคำสั่ง SELECT แถวที่ส่งคืนจะไม่อยู่ในลำดับใด ๆ ORDER BY clause ใช้เพื่อจัดเรียงระเบียนจากน้อยไปมาก / มากไปหาน้อยในคอลัมน์ใด ๆ
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง SELECT ที่มีคำสั่ง ORDER BY
SELECT * FROM tablename
ORDER BY column 1, column 2..;ตัวอย่าง
แบบสอบถามต่อไปนี้ดึงข้อมูลจากตารางพนักงานและจัดลำดับผลลัพธ์โดย FirstName
SELECT * FROM Employee
ORDER BY FirstName;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesGROUP BY
GROUP BY clause ใช้กับคำสั่ง SELECT และจัดเรียงระเบียนที่คล้ายกันเป็นกลุ่ม
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง SELECT ที่มีคำสั่ง GROUP BY
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;ตัวอย่าง
ตัวอย่างต่อไปนี้จัดกลุ่มระเบียนตามคอลัมน์ DepartmentNo และระบุจำนวนรวมจากแต่ละแผนก
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradata สนับสนุนตัวดำเนินการทางตรรกะและเงื่อนไขต่อไปนี้ ตัวดำเนินการเหล่านี้ใช้เพื่อทำการเปรียบเทียบและรวมหลายเงื่อนไข
| ไวยากรณ์ | ความหมาย |
|---|---|
| > | มากกว่า |
| < | น้อยกว่า |
| >= | มากกว่าหรือเท่ากับ |
| <= | น้อยกว่าหรือเท่ากับ |
| = | เท่ากับ |
| BETWEEN | ถ้าค่าอยู่ในช่วง |
| IN | ถ้าค่าใน <expression> |
| NOT IN | หากค่าไม่อยู่ใน <expression> |
| IS NULL | ถ้าค่าเป็นโมฆะ |
| IS NOT NULL | ถ้าค่าไม่เป็นโมฆะ |
| AND | รวมหลายเงื่อนไข ประเมินเป็นจริงก็ต่อเมื่อตรงตามเงื่อนไขทั้งหมด |
| OR | รวมหลายเงื่อนไข ประเมินเป็นจริงก็ต่อเมื่อตรงตามเงื่อนไขข้อใดข้อหนึ่ง |
| NOT | กลับความหมายของเงื่อนไข |
ระหว่าง
คำสั่ง BETWEEN ใช้เพื่อตรวจสอบว่าค่าอยู่ในช่วงของค่าหรือไม่
ตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เข้าร่วม | แผนก | วันที่เกิด |
|---|---|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 27/3/2548 | 1 | 1/5/1980 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 25/4/2550 | 2 | 5/3/1983 |
| 103 | ปีเตอร์ | พอล | 21/3/2550 | 2 | 1/1/2553 |
| 104 | อเล็กซ์ | สจวร์ต | 1/2/2561 | 2 | 11/6/1984 |
| 105 | โรเบิร์ต | เจมส์ | 1/4/2561 | 3 | 1/12/1984 |
ตัวอย่างต่อไปนี้ดึงข้อมูลที่มีหมายเลขพนักงานอยู่ในช่วงระหว่าง 101,102 ถึง 103
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;เมื่อดำเนินการค้นหาข้างต้นจะส่งคืนระเบียนพนักงานโดยมีพนักงานไม่อยู่ระหว่าง 101 ถึง 103
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 Peterใน
คำสั่ง IN ใช้เพื่อตรวจสอบค่ากับรายการค่าที่กำหนด
ตัวอย่าง
ตัวอย่างต่อไปนี้ดึงข้อมูลที่มีหมายเลขพนักงานใน 101, 102 และ 103
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);แบบสอบถามข้างต้นส่งคืนระเบียนต่อไปนี้
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 Peterไม่ได้อยู่ใน
คำสั่ง NOT IN ย้อนกลับผลลัพธ์ของคำสั่ง IN จะดึงข้อมูลที่มีค่าที่ไม่ตรงกับรายการที่กำหนด
ตัวอย่าง
ตัวอย่างต่อไปนี้ดึงข้อมูลที่มีหมายเลขพนักงานไม่อยู่ใน 101, 102 และ 103
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);แบบสอบถามข้างต้นส่งคืนระเบียนต่อไปนี้
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert Jamesตัวดำเนินการ SET รวมผลลัพธ์จากคำสั่ง SELECT หลายคำสั่ง สิ่งนี้อาจมีลักษณะคล้ายกับการเข้าร่วม แต่การรวมจะรวมคอลัมน์จากหลายตารางในขณะที่ตัวดำเนินการ SET รวมแถวจากหลายแถว
กฎ
จำนวนคอลัมน์จากแต่ละคำสั่ง SELECT ควรเท่ากัน
ชนิดข้อมูลจากแต่ละ SELECT ต้องเข้ากันได้
ORDER BY ควรรวมไว้ในคำสั่ง SELECT สุดท้ายเท่านั้น
ยูเนี่ยน
คำสั่ง UNION ใช้เพื่อรวมผลลัพธ์จากคำสั่ง SELECT หลายรายการ จะละเว้นรายการที่ซ้ำกัน
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานของคำสั่ง UNION
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];ตัวอย่าง
พิจารณาตารางพนักงานและตารางเงินเดือนต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เข้าร่วม | แผนก | วันที่เกิด |
|---|---|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 27/3/2548 | 1 | 1/5/1980 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 25/4/2550 | 2 | 5/3/1983 |
| 103 | ปีเตอร์ | พอล | 21/3/2550 | 2 | 1/1/2553 |
| 104 | อเล็กซ์ | สจวร์ต | 1/2/2561 | 2 | 11/6/1984 |
| 105 | โรเบิร์ต | เจมส์ | 1/4/2561 | 3 | 1/12/1984 |
| พนักงาน | ขั้นต้น | การหักเงิน | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
แบบสอบถาม UNION ต่อไปนี้รวมค่า EmployeeNo จากทั้งตาราง Employee และ Salary
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;เมื่อเรียกใช้แบบสอบถามจะสร้างผลลัพธ์ต่อไปนี้
EmployeeNo
-----------
101
102
103
104
105ยูเนี่ยนทั้งหมด
คำสั่ง UNION ALL คล้ายกับ UNION ซึ่งรวมผลลัพธ์จากหลายตารางรวมทั้งแถวที่ซ้ำกัน
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานของคำสั่ง UNION ALL
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างสำหรับคำสั่ง UNION ALL
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้ คุณจะเห็นว่ามันส่งคืนรายการที่ซ้ำกันด้วย
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103ตัด
คำสั่ง INTERSECT ยังใช้เพื่อรวมผลลัพธ์จากคำสั่ง SELECT หลายคำสั่ง ส่งคืนแถวจากคำสั่ง SELECT แรกที่ตรงกันในคำสั่ง SELECT ที่สอง กล่าวอีกนัยหนึ่งคือส่งคืนแถวที่มีอยู่ในคำสั่ง SELECT ทั้งสอง
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานของคำสั่ง INTERSECT
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างของคำสั่ง INTERSECT ส่งคืนค่า EmployeeNo ที่มีอยู่ในทั้งสองตาราง
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;เมื่อดำเนินการค้นหาข้างต้นจะส่งคืนระเบียนต่อไปนี้ EmployeeNo 105 ถูกแยกออกเนื่องจากไม่มีอยู่ในตาราง SALARY
EmployeeNo
-----------
101
104
102
103ลบ / ยกเว้น
คำสั่ง MINUS / EXCEPT รวมแถวจากหลายตารางและส่งกลับแถวที่อยู่ใน SELECT แรก แต่ไม่อยู่ใน SELECT ที่สอง ทั้งสองให้ผลลัพธ์เหมือนกัน
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานของคำสั่ง MINUS
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างของคำสั่ง MINUS
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;เมื่อเรียกใช้แบบสอบถามนี้จะส่งคืนระเบียนต่อไปนี้
EmployeeNo
-----------
105Teradata มีฟังก์ชันหลายอย่างในการจัดการกับสตริง ฟังก์ชันเหล่านี้เข้ากันได้กับมาตรฐาน ANSI
| ซีเนียร์ No | ฟังก์ชันสตริงและคำอธิบาย |
|---|---|
| 1 | || เชื่อมสตริงเข้าด้วยกัน |
| 2 | SUBSTR แยกส่วนของสตริง (นามสกุล Teradata) |
| 3 | SUBSTRING แยกส่วนของสตริง (มาตรฐาน ANSI) |
| 4 | INDEX ค้นหาตำแหน่งของอักขระในสตริง (ส่วนขยาย Teradata) |
| 5 | POSITION ค้นหาตำแหน่งของอักขระในสตริง (มาตรฐาน ANSI) |
| 6 | TRIM จดจ้องช่องว่างจากสตริง |
| 7 | UPPER แปลงสตริงเป็นตัวพิมพ์ใหญ่ |
| 8 | LOWER แปลงสตริงเป็นตัวพิมพ์เล็ก |
ตัวอย่าง
ตารางต่อไปนี้แสดงรายการฟังก์ชันสตริงบางส่วนพร้อมผลลัพธ์
| ฟังก์ชันสตริง | ผลลัพธ์ |
|---|---|
| เลือก SUBSTRING ('warehouse' จาก 1 เป็น 4) | เครื่อง |
| เลือก SUBSTR ('warehouse', 1,4) | เครื่อง |
| เลือก 'ข้อมูล' || '' || 'คลังสินค้า' | คลังข้อมูล |
| เลือก UPPER ('data') | ข้อมูล |
| เลือก LOWER ('DATA') | ข้อมูล |
บทนี้กล่าวถึงฟังก์ชันวันที่ / เวลาที่มีอยู่ใน Teradata
วันที่จัดเก็บ
วันที่จะถูกจัดเก็บเป็นจำนวนเต็มภายในโดยใช้สูตรต่อไปนี้
((YEAR - 1900) * 10000) + (MONTH * 100) + DAYคุณสามารถใช้แบบสอบถามต่อไปนี้เพื่อตรวจสอบวิธีการจัดเก็บวันที่
SELECT CAST(CURRENT_DATE AS INTEGER);เนื่องจากวันที่ถูกจัดเก็บเป็นจำนวนเต็มคุณจึงสามารถดำเนินการทางคณิตศาสตร์ได้ Teradata จัดเตรียมฟังก์ชันเพื่อดำเนินการเหล่านี้
สารสกัด
ฟังก์ชัน EXTRACT จะแยกส่วนของวันเดือนและปีจากค่า DATE ฟังก์ชันนี้ยังใช้เพื่อแยกชั่วโมงนาทีและวินาทีจากค่า TIME / TIMESTAMP
ตัวอย่าง
ตัวอย่างต่อไปนี้แสดงวิธีแยกค่าปีเดือนวันที่ชั่วโมงนาทีและวินาทีจากค่าวันที่และเวลา
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000ช่วงเวลา
Teradata มีฟังก์ชัน INTERVAL เพื่อดำเนินการทางคณิตศาสตร์ในค่า DATE และ TIME ฟังก์ชัน INTERVAL มีสองประเภท
ช่วงปี - เดือน
- YEAR
- ปีต่อเดือน
- MONTH
ช่วงวัน - เวลา
- DAY
- วันต่อชั่วโมง
- วันต่อนาที
- วันถึงวินาที
- HOUR
- ชั่วโมงต่อนาที
- ชั่วโมงถึงวินาที
- MINUTE
- นาทีถึงวินาที
- SECOND
ตัวอย่าง
ตัวอย่างต่อไปนี้จะเพิ่ม 3 ปีในวันที่ปัจจุบัน
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01ตัวอย่างต่อไปนี้จะเพิ่ม 3 ปีและ 01 เดือนในวันที่ปัจจุบัน
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01ตัวอย่างต่อไปนี้จะเพิ่มเวลา 01 วัน 05 ชั่วโมง 10 นาทีในการประทับเวลาปัจจุบัน
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradata มีฟังก์ชันในตัวซึ่งเป็นส่วนขยายของ SQL ต่อไปนี้เป็นฟังก์ชันทั่วไปในตัว
| ฟังก์ชัน | ผลลัพธ์ |
|---|---|
| เลือกวันที่; | วันที่ -------- 16/01/01 |
| เลือก CURRENT_DATE; | วันที่ -------- 16/01/01 |
| เลือกเวลา; | เวลา -------- 04:50:29 น |
| เลือก CURRENT_TIME; | เวลา -------- 04:50:29 น |
| เลือก CURRENT_TIMESTAMP; | TimeStamp ปัจจุบัน (6) -------------------------------- 2016-01-01 04: 51: 06.990000 + 00: 00 |
| เลือกฐานข้อมูล | ฐานข้อมูล ------------------------------ TDUSER |
Teradata รองรับฟังก์ชันการรวมทั่วไป สามารถใช้กับคำสั่ง SELECT
COUNT - นับแถว
SUM - สรุปค่าของคอลัมน์ที่ระบุ
MAX - ส่งกลับค่าขนาดใหญ่ของคอลัมน์ที่ระบุ
MIN - ส่งกลับค่าต่ำสุดของคอลัมน์ที่ระบุ
AVG - ส่งกลับค่าเฉลี่ยของคอลัมน์ที่ระบุ
ตัวอย่าง
พิจารณาตารางเงินเดือนต่อไปนี้
| พนักงาน | ขั้นต้น | การหักเงิน | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 104 | 75,000 | 5,000 | 70,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 105 | 70,000 | 4,000 | 66,000 |
| 103 | 90,000 | 7,000 | 83,000 |
นับ
ตัวอย่างต่อไปนี้นับจำนวนระเบียนในตารางเงินเดือน
SELECT count(*) from Salary;
Count(*)
-----------
5MAX
ตัวอย่างต่อไปนี้ส่งคืนมูลค่าเงินเดือนสุทธิของพนักงานสูงสุด
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000นาที
ตัวอย่างต่อไปนี้ส่งคืนมูลค่าเงินเดือนสุทธิขั้นต่ำของพนักงานจากตารางเงินเดือน
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000AVG
ตัวอย่างต่อไปนี้ส่งคืนค่าเฉลี่ยของมูลค่าเงินเดือนสุทธิของพนักงานจากตาราง
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800SUM
ตัวอย่างต่อไปนี้คำนวณผลรวมของเงินเดือนสุทธิของพนักงานจากบันทึกทั้งหมดของตารางเงินเดือน
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000บทนี้จะอธิบายถึงฟังก์ชัน CASE และ COALESCE ของ Teradata
นิพจน์กรณี
นิพจน์ CASE ประเมินแต่ละแถวเทียบกับเงื่อนไขหรือ WHEN clause และส่งกลับผลลัพธ์ของการจับคู่ครั้งแรก หากไม่มีการจับคู่ผลลัพธ์จากส่วน ELSE ที่ส่งกลับ
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของนิพจน์ CASE
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
ENDตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เข้าร่วม | แผนก | วันที่เกิด |
|---|---|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 27/3/2548 | 1 | 1/5/1980 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 25/4/2550 | 2 | 5/3/1983 |
| 103 | ปีเตอร์ | พอล | 21/3/2550 | 2 | 1/1/2553 |
| 104 | อเล็กซ์ | สจวร์ต | 1/2/2561 | 2 | 11/6/1984 |
| 105 | โรเบิร์ต | เจมส์ | 1/4/2561 | 3 | 1/12/1984 |
ตัวอย่างต่อไปนี้จะประเมินคอลัมน์ DepartmentNo และส่งกลับค่าเป็น 1 ถ้าหมายเลขแผนกคือ 1 ส่งคืน 2 ถ้าหมายเลขแผนกคือ 3; มิฉะนั้นจะคืนค่าเป็นแผนกที่ไม่ถูกต้อง
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 ITนอกจากนี้นิพจน์ CASE ข้างต้นสามารถเขียนในรูปแบบต่อไปนี้ซึ่งจะให้ผลลัพธ์เช่นเดียวกับด้านบน
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;COALESCE
COALESCE เป็นคำสั่งที่ส่งกลับค่าที่ไม่ใช่ค่าว่างแรกของนิพจน์ จะคืนค่า NULL หากอาร์กิวเมนต์ทั้งหมดของนิพจน์ประเมินเป็น NULL ต่อไปนี้เป็นไวยากรณ์
ไวยากรณ์
COALESCE(expression 1, expression 2, ....)ตัวอย่าง
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
คำสั่ง NULLIF ส่งคืนค่า NULL ถ้าอาร์กิวเมนต์เท่ากัน
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง NULLIF
NULLIF(expression 1, expression 2)ตัวอย่าง
ตัวอย่างต่อไปนี้จะคืนค่า NULL ถ้า DepartmentNo เท่ากับ 3 มิฉะนั้นจะส่งคืนค่า DepartmentNo
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;แบบสอบถามข้างต้นส่งคืนระเบียนต่อไปนี้ คุณสามารถเห็นพนักงานคนนั้น 105 มีแผนกเลขที่ เป็น NULL
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2ดัชนีหลักใช้เพื่อระบุตำแหน่งของข้อมูลใน Teradata ใช้เพื่อระบุว่า AMP ใดรับแถวข้อมูล แต่ละตารางใน Teradata จะต้องมีดัชนีหลักที่กำหนดไว้ หากไม่ได้กำหนดดัชนีหลัก Teradata จะกำหนดดัชนีหลักโดยอัตโนมัติ ดัชนีหลักเป็นวิธีที่เร็วที่สุดในการเข้าถึงข้อมูล คอลัมน์หลักอาจมีได้สูงสุด 64 คอลัมน์
ดัชนีหลักถูกกำหนดในขณะที่สร้างตาราง ดัชนีหลักมี 2 ประเภท
- ดัชนีหลักที่ไม่ซ้ำกัน (UPI)
- ดัชนีหลักที่ไม่ซ้ำกัน (NUPI)
ดัชนีหลักที่ไม่ซ้ำกัน (UPI)
หากตารางถูกกำหนดให้มี UPI คอลัมน์ที่ถือว่าเป็น UPI ไม่ควรมีค่าที่ซ้ำกัน หากใส่ค่าที่ซ้ำกันค่านั้นจะถูกปฏิเสธ
สร้างดัชนีหลักที่ไม่ซ้ำกัน
ตัวอย่างต่อไปนี้สร้างตารางเงินเดือนที่มีคอลัมน์ EmployeeNo เป็นดัชนีหลักที่ไม่ซ้ำกัน
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);ดัชนีหลักที่ไม่ซ้ำกัน (NUPI)
หากตารางถูกกำหนดให้มี NUPI คอลัมน์ที่ถือว่าเป็น UPI สามารถยอมรับค่าที่ซ้ำกันได้
Create Non Unique Primary Index
The following example creates the employee accounts table with column EmployeeNo as Non Unique Primary Index. EmployeeNo is defined as Non Unique Primary Index since an employee can have multiple accounts in the table; one for salary account and another one for reimbursement account.
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);Join is used to combine records from more than one table. Tables are joined based on the common columns/values from these tables.
There are different types of Joins available.
- Inner Join
- Left Outer Join
- Right Outer Join
- Full Outer Join
- Self Join
- Cross Join
- Cartesian Production Join
INNER JOIN
Inner Join combines records from multiple tables and returns the values that exist in both the tables.
Syntax
Following is the syntax of the INNER JOIN statement.
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Example
Consider the following employee table and salary table.
| EmployeeNo | FirstName | LastName | JoinedDate | DepartmentNo | BirthDate |
|---|---|---|---|---|---|
| 101 | Mike | James | 3/27/2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 4/25/2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 3/21/2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
| EmployeeNo | Gross | Deduction | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
The following query joins the Employee table and Salary table on the common column EmployeeNo. Each table is assigned an alias A & B and the columns are referenced with the correct alias.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);When the above query is executed, it returns the following records. Employee 105 is not included in the result since it doesn’t have matching records in the Salary table.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000OUTER JOIN
LEFT OUTER JOIN and RIGHT OUTER JOIN also combine the results from multiple table.
LEFT OUTER JOIN returns all the records from the left table and returns only the matching records from the right table.
RIGHT OUTER JOIN returns all the records from the right table and returns only matching rows from the left table.
FULL OUTER JOIN combines the results from both LEFT OUTER and RIGHT OUTER JOINS. It returns both matching and non-matching rows from the joined tables.
Syntax
Following is the syntax of the OUTER JOIN statement. You need to use one of the options from LEFT OUTER JOIN, RIGHT OUTER JOIN or FULL OUTER JOIN.
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Example
Consider the following example of the LEFT OUTER JOIN query. It returns all the records from Employee table and matching records from Salary table.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;When the above query is executed, it produces the following output. For employee 105, NetPay value is NULL, since it doesn’t have matching records in Salary table.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?CROSS JOIN
Cross Join joins every row from the left table to every row from the right table.
Syntax
Following is the syntax of the CROSS JOIN statement.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;When the above query is executed, it produces the following output. Employee No 101 from Employee table is joined with each and every record from Salary Table.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000A subquery returns records from one table based on the values from another table. It is a SELECT query within another query. The SELECT query called as inner query is executed first and the result is used by the outer query. Some of its salient features are −
A query can have multiple subqueries and subqueries may contain another subquery.
Subqueries doesn't return duplicate records.
If subquery returns only one value, you can use = operator to use it with the outer query. If it returns multiple values you can use IN or NOT IN.
Syntax
Following is the generic syntax of subqueries.
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);Example
Consider the following Salary table.
| EmployeeNo | Gross | Deduction | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
The following query identifies the employee number with highest salary. The inner SELECT performs the aggregation function to return the maximum NetPay value and the outer SELECT query uses this value to return the employee record with this value.
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);เมื่อเรียกใช้แบบสอบถามนี้จะสร้างผลลัพธ์ต่อไปนี้
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradata รองรับตารางประเภทต่อไปนี้เพื่อเก็บข้อมูลชั่วคราว
- ตารางที่ได้มา
- ตารางระเหย
- ตารางชั่วคราวส่วนกลาง
ตารางที่ได้มา
ตารางที่ได้มาจะถูกสร้างใช้และลดลงภายในแบบสอบถาม สิ่งเหล่านี้ใช้เพื่อจัดเก็บผลลัพธ์ระดับกลางภายในแบบสอบถาม
ตัวอย่าง
ตัวอย่างต่อไปนี้สร้าง EmpSal ตารางที่ได้รับมาพร้อมกับบันทึกของพนักงานที่มีเงินเดือนมากกว่า 75000
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;เมื่อดำเนินการค้นหาข้างต้นจะส่งคืนพนักงานที่มีเงินเดือนมากกว่า 75000
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000ตารางระเหย
ตารางระเหยถูกสร้างใช้และลดลงภายในเซสชันผู้ใช้ คำจำกัดความไม่ได้เก็บไว้ในพจนานุกรมข้อมูล พวกเขาเก็บข้อมูลระดับกลางของแบบสอบถามที่ใช้บ่อย ต่อไปนี้เป็นไวยากรณ์
ไวยากรณ์
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWSตัวอย่าง
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
*** Table has been created.
*** Total elapsed time was 1 second.ตารางชั่วคราวส่วนกลาง
คำจำกัดความของตารางชั่วคราวส่วนกลางจะถูกเก็บไว้ในพจนานุกรมข้อมูลและผู้ใช้ / เซสชันจำนวนมากสามารถใช้ได้ แต่ข้อมูลที่โหลดลงในตารางชั่วคราวส่วนกลางจะถูกเก็บไว้ในระหว่างเซสชันเท่านั้น คุณสามารถสร้างตารางชั่วคราวส่วนกลางได้มากถึง 2,000 ตารางต่อเซสชัน ต่อไปนี้เป็นไวยากรณ์
ไวยากรณ์
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>ตัวอย่าง
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
*** Table has been created.
*** Total elapsed time was 1 second.Teradata มีช่องว่างสามประเภท
พื้นที่ถาวร
พื้นที่ถาวรคือจำนวนพื้นที่สูงสุดที่ผู้ใช้ / ฐานข้อมูลสามารถเก็บแถวข้อมูลได้ ตารางถาวรวารสารตารางทางเลือกและตารางย่อยดัชนีรองใช้พื้นที่ถาวร
พื้นที่ถาวรไม่ได้ถูกจัดสรรไว้ล่วงหน้าสำหรับฐานข้อมูล / ผู้ใช้ พวกเขากำหนดให้เป็นจำนวนพื้นที่สูงสุดที่ฐานข้อมูล / ผู้ใช้สามารถใช้ได้ จำนวนพื้นที่ถาวรหารด้วยจำนวน AMP เมื่อใดก็ตามที่เกินขีด จำกัด AMP ต่อไประบบจะสร้างข้อความแสดงข้อผิดพลาด
Spool Space
Spool space คือพื้นที่ถาวรที่ไม่ได้ใช้ซึ่งระบบใช้เพื่อเก็บผลลัพธ์ระดับกลางของแบบสอบถาม SQL ผู้ใช้ที่ไม่มีพื้นที่สปูลไม่สามารถดำเนินการสืบค้นใด ๆ
เช่นเดียวกับพื้นที่ถาวร Spool Space กำหนดจำนวนพื้นที่สูงสุดที่ผู้ใช้สามารถใช้ได้ พื้นที่สปูลหารด้วยจำนวน AMP เมื่อใดก็ตามที่เกินขีด จำกัด AMP ผู้ใช้จะได้รับข้อผิดพลาดเกี่ยวกับ Spool Space
พื้นที่ชั่วคราว
Temp space คือพื้นที่ถาวรที่ไม่ได้ใช้งานซึ่งใช้โดย Global Temporary tables พื้นที่ชั่วคราวยังหารด้วยจำนวน AMP
ตารางสามารถมีดัชนีหลักได้เพียงดัชนีเดียว บ่อยขึ้นคุณจะเจอสถานการณ์ที่ตารางมีคอลัมน์อื่น ๆ ซึ่งใช้ข้อมูลนี้ถูกเข้าถึงบ่อยครั้ง Teradata จะทำการสแกนแบบเต็มตารางสำหรับคำค้นหาเหล่านั้น ดัชนีรองช่วยแก้ปัญหานี้
ดัชนีรองเป็นเส้นทางอื่นในการเข้าถึงข้อมูล มีความแตกต่างบางประการระหว่างดัชนีหลักและดัชนีรอง
ดัชนีทุติยภูมิไม่เกี่ยวข้องกับการกระจายข้อมูล
ค่าดัชนีรองจะถูกเก็บไว้ในตารางย่อย ตารางเหล่านี้สร้างขึ้นใน AMP ทั้งหมด
ดัชนีรองเป็นทางเลือก
สามารถสร้างได้ในระหว่างการสร้างตารางหรือหลังจากสร้างตาราง
พวกเขาใช้พื้นที่เพิ่มเติมเนื่องจากสร้างตารางย่อยและยังต้องการการบำรุงรักษาเนื่องจากตารางย่อยต้องได้รับการอัปเดตสำหรับแต่ละแถวใหม่
ดัชนีทุติยภูมิมีสองประเภท -
- ดัชนีรองเฉพาะ (USI)
- ดัชนีรองที่ไม่ซ้ำกัน (NUSI)
ดัชนีรองเฉพาะ (USI)
ดัชนีรองที่ไม่ซ้ำกันอนุญาตเฉพาะค่าที่ไม่ซ้ำกันสำหรับคอลัมน์ที่กำหนดเป็น USI การเข้าถึงแถวโดย USI เป็นการดำเนินการสองแอมป์
สร้างดัชนีรองเฉพาะ
ตัวอย่างต่อไปนี้สร้าง USI ในคอลัมน์ EmployeeNo ของตารางพนักงาน
CREATE UNIQUE INDEX(EmployeeNo) on employee;ดัชนีรองที่ไม่ซ้ำกัน (NUSI)
ดัชนีรองที่ไม่ซ้ำกันอนุญาตให้สร้างค่าที่ซ้ำกันสำหรับคอลัมน์ที่กำหนดเป็น NUSI การเข้าถึงแถวโดย NUSI เป็นการดำเนินการทั้งหมด
สร้างดัชนีรองที่ไม่ซ้ำกัน
ตัวอย่างต่อไปนี้สร้าง NUSI ในคอลัมน์ FirstName ของตารางพนักงาน
CREATE INDEX(FirstName) on Employee;เครื่องมือเพิ่มประสิทธิภาพ Teradata มาพร้อมกับกลยุทธ์การดำเนินการสำหรับทุกแบบสอบถาม SQL กลยุทธ์การดำเนินการนี้ขึ้นอยู่กับสถิติที่รวบรวมบนตารางที่ใช้ภายในแบบสอบถาม SQL สถิติบนตารางถูกรวบรวมโดยใช้คำสั่ง COLLECT STATISTICS เครื่องมือเพิ่มประสิทธิภาพต้องการข้อมูลสภาพแวดล้อมและข้อมูลประชากรเพื่อสร้างกลยุทธ์การดำเนินการที่เหมาะสมที่สุด
ข้อมูลสิ่งแวดล้อม
- จำนวนโหนดแอมป์และซีพียู
- จำนวนหน่วยความจำ
ข้อมูลประชากร
- จำนวนแถว
- ขนาดแถว
- ช่วงของค่าในตาราง
- จำนวนแถวต่อค่า
- จำนวน Nulls
มีสามวิธีในการรวบรวมสถิติบนโต๊ะ
- การสุ่มตัวอย่าง AMP
- การรวบรวมสถิติแบบเต็ม
- ใช้ตัวเลือก SAMPLE
การรวบรวมสถิติ
คำสั่ง COLLECT STATISTICS ใช้เพื่อรวบรวมสถิติบนตาราง
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานในการรวบรวมสถิติบนตาราง
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;ตัวอย่าง
ตัวอย่างต่อไปนี้รวบรวมสถิติในคอลัมน์ EmployeeNo ของตารางพนักงาน
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.การดูสถิติ
คุณสามารถดูสถิติที่รวบรวมได้โดยใช้คำสั่ง HELP STATISTICS
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์เพื่อดูสถิติที่รวบรวม
HELP STATISTICS <tablename>;ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างเพื่อดูสถิติที่รวบรวมในตารางพนักงาน
HELP STATISTICS employee;เมื่อดำเนินการค้นหาข้างต้นจะให้ผลลัพธ์ดังต่อไปนี้
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNoการบีบอัดใช้เพื่อลดพื้นที่จัดเก็บที่ใช้โดยตาราง ใน Teradata การบีบอัดสามารถบีบอัดค่าที่แตกต่างกันได้ถึง 255 ค่ารวมทั้ง NULL เนื่องจากพื้นที่จัดเก็บลดลง Teradata จึงสามารถจัดเก็บบันทึกได้มากขึ้นในบล็อก ส่งผลให้เวลาตอบสนองของแบบสอบถามดีขึ้นเนื่องจากการดำเนินการ I / O ใด ๆ สามารถประมวลผลแถวต่อบล็อกได้มากขึ้น สามารถเพิ่มการบีบอัดในการสร้างตารางโดยใช้ CREATE TABLE หรือหลังการสร้างตารางโดยใช้คำสั่ง ALTER TABLE
ข้อ จำกัด
- สามารถบีบอัดได้เพียง 255 ค่าต่อคอลัมน์
- ไม่สามารถบีบอัดคอลัมน์ดัชนีหลัก
- ไม่สามารถบีบอัดตารางระเหยได้
การบีบอัดหลายค่า (MVC)
ตารางต่อไปนี้บีบอัด DepatmentNo ของเขตข้อมูลสำหรับค่า 1, 2 และ 3 เมื่อใช้การบีบอัดบนคอลัมน์ค่าสำหรับคอลัมน์นี้จะไม่ถูกเก็บไว้กับแถว แต่ค่าจะถูกเก็บไว้ในส่วนหัวของตารางในแต่ละ AMP และจะเพิ่มเฉพาะบิตแสดงตนในแถวเพื่อระบุค่า
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);การบีบอัดแบบหลายค่าสามารถใช้ได้เมื่อคุณมีคอลัมน์ในตารางขนาดใหญ่ที่มีค่า จำกัด
คำสั่ง EXPLAIN ส่งคืนแผนการดำเนินการของเอ็นจินการแยกวิเคราะห์เป็นภาษาอังกฤษ สามารถใช้กับคำสั่ง SQL ใดก็ได้ยกเว้นคำสั่ง EXPLAIN อื่น เมื่อข้อความค้นหาขึ้นหน้าด้วยคำสั่ง EXPLAIN แผนการดำเนินการของ Parsing Engine จะถูกส่งกลับไปยังผู้ใช้แทน AMP
ตัวอย่างของ EXPLAIN
พิจารณาตารางพนักงานด้วยคำจำกัดความต่อไปนี้
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );ตัวอย่างบางส่วนของแผน EXPLAIN มีให้ด้านล่าง
การสแกนแบบเต็มตาราง (FTS)
เมื่อไม่มีการระบุเงื่อนไขใด ๆ ในคำสั่ง SELECT เครื่องมือเพิ่มประสิทธิภาพอาจเลือกใช้ Full Table Scan โดยที่แต่ละแถวและทุกแถวของตารางสามารถเข้าถึงได้
ตัวอย่าง
ต่อไปนี้เป็นแบบสอบถามตัวอย่างที่เครื่องมือเพิ่มประสิทธิภาพอาจเลือก FTS
EXPLAIN SELECT * FROM employee;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้ ดังจะเห็นได้ว่าเครื่องมือเพิ่มประสิทธิภาพเลือกที่จะเข้าถึง AMP ทั้งหมดและทุกแถวภายใน AMP
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.ดัชนีหลักที่ไม่ซ้ำกัน
เมื่อเข้าถึงแถวโดยใช้ดัชนีหลักที่ไม่ซ้ำกันจะเป็นการดำเนินการ AMP อย่างหนึ่ง
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้ ดังที่เห็นได้ว่าเป็นการดึง AMP เพียงครั้งเดียวและเครื่องมือเพิ่มประสิทธิภาพกำลังใช้ดัชนีหลักที่ไม่ซ้ำกันเพื่อเข้าถึงแถว
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.ดัชนีรองที่ไม่ซ้ำกัน
เมื่อเข้าถึงแถวโดยใช้ Unique Secondary Index จะเป็นการดำเนินการสองแอมป์
ตัวอย่าง
พิจารณาตารางเงินเดือนด้วยคำจำกัดความต่อไปนี้
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);พิจารณาคำสั่ง SELECT ต่อไปนี้
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้ ดังที่เห็นได้ว่าเครื่องมือเพิ่มประสิทธิภาพจะดึงแถวในการดำเนินการสองแอมป์โดยใช้ดัชนีรองที่ไม่ซ้ำกัน
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.ข้อกำหนดเพิ่มเติม
ต่อไปนี้เป็นรายการคำศัพท์ที่พบเห็นได้ทั่วไปในแผน EXPLAIN
... (Last Use) …
ไม่จำเป็นต้องใช้ไฟล์เก็บพักอีกต่อไปและจะถูกปล่อยออกมาเมื่อขั้นตอนนี้เสร็จสิ้น
... with no residual conditions …
เงื่อนไขที่เกี่ยวข้องทั้งหมดถูกนำไปใช้กับแถวแล้ว
... END TRANSACTION …
ล็อกธุรกรรมจะถูกปลดล็อกและมีการเปลี่ยนแปลง
... eliminating duplicate rows ...
แถวที่ซ้ำกันมีอยู่ในไฟล์สปูลเท่านั้นไม่ได้ตั้งค่าตาราง การดำเนินการ DISTINCT
... by way of a traversal of index #n extracting row ids only …
ไฟล์สปูลถูกสร้างขึ้นโดยมีรหัสแถวที่พบในดัชนีรอง (ดัชนี #n)
... we do a SMS (set manipulation step) …
การรวมแถวโดยใช้ตัวดำเนินการ UNION, MINUS หรือ INTERSECT
... which is redistributed by hash code to all AMPs.
แจกจ่ายข้อมูลเพื่อเตรียมเข้าร่วม
... which is duplicated on all AMPs.
การทำสำเนาข้อมูลจากตารางขนาดเล็ก (ในแง่ของ SPOOL) เพื่อเตรียมการเข้าร่วม
... (one_AMP) or (group_AMPs)
ระบุว่าจะใช้ AMP 1 รายการหรือ AMP ชุดย่อยแทน AMP ทั้งหมด
มีการกำหนดแถวให้กับ AMP หนึ่ง ๆ ตามค่าดัชนีหลัก Teradata ใช้อัลกอริทึมการแฮชเพื่อกำหนดว่า AMP ใดรับแถวนั้น
ต่อไปนี้เป็นแผนภาพระดับสูงเกี่ยวกับอัลกอริทึมการแฮช

ต่อไปนี้เป็นขั้นตอนในการแทรกข้อมูล
ลูกค้าส่งคำถาม
ตัวแยกวิเคราะห์จะรับแบบสอบถามและส่งผ่านค่า PI ของเรกคอร์ดไปยังอัลกอริทึมการแฮช
อัลกอริทึมการแฮชแฮชค่าดัชนีหลักและส่งกลับตัวเลข 32 บิตเรียกว่า Row Hash
บิตลำดับที่สูงกว่าของแฮชแถว (16 บิตแรก) ถูกใช้เพื่อระบุรายการแม็พแฮช แฮชแมปมีหนึ่ง AMP # Hash map คืออาร์เรย์ของที่เก็บข้อมูลซึ่งมี AMP # ที่เฉพาะเจาะจง
BYNET ส่งข้อมูลไปยัง AMP ที่ระบุ
AMP ใช้แฮช Row 32 บิตเพื่อค้นหาแถวภายในดิสก์
หากมีเร็กคอร์ดใด ๆ ที่มีแฮชแถวเดียวกันก็จะเพิ่มรหัสเฉพาะซึ่งเป็นตัวเลข 32 บิต สำหรับแฮชแถวใหม่ ID เฉพาะจะถูกกำหนดเป็น 1 และจะเพิ่มขึ้นเมื่อใดก็ตามที่มีการแทรกเร็กคอร์ดที่มีแฮชแถวเดียวกัน
การรวมกันของ Row hash และ Uniqueness ID เรียกว่า Row ID
Row ID นำหน้าแต่ละระเบียนในดิสก์
แต่ละแถวของตารางใน AMP จะเรียงลำดับตามเหตุผลตามรหัสแถว
วิธีจัดเก็บตาราง
ตารางจะจัดเรียงตามรหัสแถว (แฮชแถว + รหัสเฉพาะ) จากนั้นจัดเก็บไว้ใน AMP รหัสแถวจะถูกเก็บไว้กับแถวข้อมูลแต่ละแถว
| แถวแฮช | รหัสเอกลักษณ์ | พนักงาน | ชื่อจริง | นามสกุล |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | ไมค์ | เจมส์ |
| 2A01 2612 | 0000 0001 | 104 | อเล็กซ์ | สจวร์ต |
| 2A01 2613 | 0000 0001 | 102 | โรเบิร์ต | วิลเลียมส์ |
| 2A01 2614 | 0000 0001 | 105 | โรเบิร์ต | เจมส์ |
| 2A01 2615 | 0000 0001 | 103 | ปีเตอร์ | พอล |
JOIN INDEX เป็นมุมมองที่เป็นรูปธรรม คำจำกัดความจะถูกจัดเก็บอย่างถาวรและข้อมูลจะถูกอัพเดตเมื่อใดก็ตามที่มีการอัพเดตตารางพื้นฐานที่อ้างถึงในดัชนีการรวม JOIN INDEX อาจมีตารางอย่างน้อยหนึ่งตารางและยังมีข้อมูลที่รวบรวมไว้ล่วงหน้า ดัชนีการเข้าร่วมส่วนใหญ่จะใช้เพื่อปรับปรุงประสิทธิภาพ
มีดัชนีการเข้าร่วมประเภทต่างๆ
- ดัชนีการเข้าร่วมตารางเดียว (STJI)
- ดัชนีการเข้าร่วมหลายตาราง (MTJI)
- ดัชนีการเข้าร่วมรวม (AJI)
ดัชนีการเข้าร่วมตารางเดียว
ดัชนีการเข้าร่วมตารางเดียวอนุญาตให้แบ่งตารางขนาดใหญ่โดยยึดตามคอลัมน์ดัชนีหลักที่แตกต่างจากตารางฐาน
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของ JOIN INDEX
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;ตัวอย่าง
พิจารณาตารางพนักงานและเงินเดือนต่อไปนี้
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);ต่อไปนี้เป็นตัวอย่างที่สร้างดัชนีเข้าร่วมชื่อ Employee_JI บนตารางพนักงาน
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);หากผู้ใช้ส่งแบบสอบถามที่มีส่วนคำสั่ง WHERE ใน EmployeeNo ระบบจะสอบถามตารางพนักงานโดยใช้ดัชนีหลักที่ไม่ซ้ำกัน หากผู้ใช้สอบถามตารางพนักงานโดยใช้ชื่อพนักงานระบบอาจเข้าถึงดัชนีการรวม Employee_JI โดยใช้ชื่อพนักงาน แถวของดัชนีการรวมถูกแฮชในคอลัมน์ชื่อพนักงาน หากไม่ได้กำหนดดัชนีการเข้าร่วมและชื่อพนักงานไม่ได้กำหนดเป็นดัชนีรองระบบจะทำการสแกนแบบเต็มตารางเพื่อเข้าถึงแถวที่ใช้เวลานาน
คุณสามารถเรียกใช้แผน EXPLAIN ต่อไปนี้และตรวจสอบแผนเครื่องมือเพิ่มประสิทธิภาพ ในตัวอย่างต่อไปนี้คุณจะเห็นว่าเครื่องมือเพิ่มประสิทธิภาพกำลังใช้ Join Index แทนตารางพนักงานพื้นฐานเมื่อตารางสอบถามโดยใช้คอลัมน์ Employee_Name
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.ดัชนีการเข้าร่วมหลายตาราง
ดัชนีการรวมแบบหลายตารางถูกสร้างขึ้นโดยการเข้าร่วมมากกว่าหนึ่งตาราง ดัชนีการรวมหลายตารางสามารถใช้เพื่อจัดเก็บชุดผลลัพธ์ของตารางที่เข้าร่วมบ่อยเพื่อปรับปรุงประสิทธิภาพ
ตัวอย่าง
ตัวอย่างต่อไปนี้สร้าง JOIN INDEX ชื่อ Employee_Salary_JI โดยการเข้าร่วมตารางพนักงานและเงินเดือน
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);เมื่อใดก็ตามที่มีการอัปเดตตารางพื้นฐานของพนักงานหรือเงินเดือนดัชนีการเข้าร่วม Employee_Salary_JI จะได้รับการอัปเดตโดยอัตโนมัติเช่นกัน หากคุณกำลังเรียกใช้แบบสอบถามที่เข้าร่วมตารางพนักงานและเงินเดือนเครื่องมือเพิ่มประสิทธิภาพอาจเลือกที่จะเข้าถึงข้อมูลจาก Employee_Salary_JI โดยตรงแทนที่จะเข้าร่วมตาราง แผน EXPLAIN ในแบบสอบถามสามารถใช้เพื่อตรวจสอบว่าเครื่องมือเพิ่มประสิทธิภาพจะเลือกตารางพื้นฐานหรือดัชนีเข้าร่วม
ดัชนีการเข้าร่วมโดยรวม
หากตารางรวมอยู่ในคอลัมน์บางคอลัมน์อย่างสม่ำเสมอคุณสามารถกำหนดดัชนีการรวมรวมบนตารางเพื่อปรับปรุงประสิทธิภาพได้ ข้อ จำกัด อย่างหนึ่งของดัชนีการรวมแบบรวมคือรองรับฟังก์ชัน SUM และ COUNT เท่านั้น
ตัวอย่าง
ในตัวอย่างต่อไปนี้พนักงานและเงินเดือนจะถูกรวมเข้าด้วยกันเพื่อระบุเงินเดือนรวมต่อแผนก
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);มุมมองคือวัตถุฐานข้อมูลที่สร้างขึ้นโดยแบบสอบถาม มุมมองสามารถสร้างขึ้นโดยใช้ตารางเดียวหรือหลายตารางโดยการเข้าร่วม คำจำกัดความของพวกเขาจะถูกเก็บไว้อย่างถาวรในพจนานุกรมข้อมูล แต่จะไม่จัดเก็บสำเนาของข้อมูล ข้อมูลสำหรับมุมมองถูกสร้างขึ้นแบบไดนามิก
มุมมองอาจมีชุดย่อยของแถวของตารางหรือส่วนย่อยของคอลัมน์ของตาราง
สร้างมุมมอง
มุมมองถูกสร้างขึ้นโดยใช้คำสั่ง CREATE VIEW
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์สำหรับการสร้างมุมมอง
CREATE/REPLACE VIEW <viewname>
AS
<select query>;ตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เกิด |
|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 1/5/1980 |
| 104 | อเล็กซ์ | สจวร์ต | 11/6/1984 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 5/3/1983 |
| 105 | โรเบิร์ต | เจมส์ | 1/12/1984 |
| 103 | ปีเตอร์ | พอล | 1/1/2553 |
ตัวอย่างต่อไปนี้สร้างมุมมองบนตารางพนักงาน
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;การใช้มุมมอง
คุณสามารถใช้คำสั่ง SELECT ปกติเพื่อดึงข้อมูลจาก Views
ตัวอย่าง
ตัวอย่างต่อไปนี้ดึงข้อมูลจาก Employee_View;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter Paulการแก้ไขมุมมอง
มุมมองที่มีอยู่สามารถแก้ไขได้โดยใช้คำสั่ง REPLACE VIEW
ต่อไปนี้เป็นไวยากรณ์ในการแก้ไขมุมมอง
REPLACE VIEW <viewname>
AS
<select query>;ตัวอย่าง
ตัวอย่างต่อไปนี้ปรับเปลี่ยนมุมมอง Employee_View สำหรับการเพิ่มคอลัมน์เพิ่มเติม
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;Drop View
มุมมองที่มีอยู่สามารถทิ้งได้โดยใช้คำสั่ง DROP VIEW
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของ DROP VIEW
DROP VIEW <viewname>;ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างในการลดมุมมอง Employee_View
DROP VIEW Employee_View;ข้อดีของมุมมอง
มุมมองให้ระดับความปลอดภัยเพิ่มเติมโดยการ จำกัด แถวหรือคอลัมน์ของตาราง
ผู้ใช้สามารถให้สิทธิ์เข้าถึงเฉพาะมุมมองแทนตารางฐาน
ลดความยุ่งยากในการใช้ตารางหลายตารางโดยการรวมตารางล่วงหน้าโดยใช้ Views
Macro คือชุดคำสั่ง SQL ที่จัดเก็บและดำเนินการโดยเรียกชื่อมาโคร คำจำกัดความของมาโครจะถูกเก็บไว้ในพจนานุกรมข้อมูล ผู้ใช้ต้องการสิทธิ์ EXEC เท่านั้นในการเรียกใช้งาน Macro ผู้ใช้ไม่จำเป็นต้องมีสิทธิ์แยกต่างหากในวัตถุฐานข้อมูลที่ใช้ในมาโคร คำสั่งแมโครจะดำเนินการเป็นธุรกรรมเดียว ถ้าหนึ่งในคำสั่ง SQL ในมาโครล้มเหลวคำสั่งทั้งหมดจะถูกย้อนกลับ มาโครสามารถรับพารามิเตอร์ได้ มาโครสามารถมีคำสั่ง DDL ได้ แต่ควรเป็นคำสั่งสุดท้ายใน Macro
สร้างมาโคร
มาโครถูกสร้างขึ้นโดยใช้คำสั่ง CREATE MACRO
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปของคำสั่ง CREATE MACRO
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);ตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เกิด |
|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 1/5/1980 |
| 104 | อเล็กซ์ | สจวร์ต | 11/6/1984 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 5/3/1983 |
| 105 | โรเบิร์ต | เจมส์ | 1/12/1984 |
| 103 | ปีเตอร์ | พอล | 1/1/2553 |
ตัวอย่างต่อไปนี้สร้างมาโครชื่อ Get_Emp ประกอบด้วยคำสั่งเลือกเพื่อดึงข้อมูลจากตารางพนักงาน
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);การเรียกใช้มาโคร
แมโครถูกดำเนินการโดยใช้คำสั่ง EXEC
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง EXECUTE MACRO
EXEC <macroname>;ตัวอย่าง
ตัวอย่างต่อไปนี้เรียกใช้ชื่อมาโคร Get_Emp; เมื่อดำเนินการคำสั่งต่อไปนี้คำสั่งจะดึงข้อมูลทั้งหมดจากตารางพนักงาน
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert Jamesมาโครที่กำหนดพารามิเตอร์
Teradata Macros สามารถรับพารามิเตอร์ได้ ภายในมาโครพารามิเตอร์เหล่านี้อ้างอิงด้วย; (อัฒภาค).
ต่อไปนี้เป็นตัวอย่างของมาโครที่รับพารามิเตอร์
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);การเรียกใช้แมโครพารามิเตอร์
แมโครถูกดำเนินการโดยใช้คำสั่ง EXEC คุณต้องมีสิทธิ์ EXEC เพื่อดำเนินการมาโคร
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง EXECUTE MACRO
EXEC <macroname>(value);ตัวอย่าง
ตัวอย่างต่อไปนี้เรียกใช้ชื่อมาโคร Get_Emp; ยอมรับหมายเลขพนักงานเป็นพารามิเตอร์และแยกบันทึกจากตารางพนักงานสำหรับพนักงานนั้น
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000กระบวนงานที่จัดเก็บประกอบด้วยชุดคำสั่ง SQL และคำสั่งขั้นตอน อาจมีเพียงคำชี้แจงขั้นตอน คำจำกัดความของกระบวนงานที่จัดเก็บจะถูกเก็บไว้ในฐานข้อมูลและพารามิเตอร์จะถูกเก็บไว้ในตารางพจนานุกรมข้อมูล
ข้อดี
โพรซีเดอร์ที่จัดเก็บไว้ลดภาระเครือข่ายระหว่างไคลเอนต์และเซิร์ฟเวอร์
ให้ความปลอดภัยที่ดีขึ้นเนื่องจากข้อมูลถูกเข้าถึงผ่านโพรซีเดอร์ที่จัดเก็บไว้แทนที่จะเข้าถึงโดยตรง
ให้การบำรุงรักษาที่ดีขึ้นเนื่องจากตรรกะทางธุรกิจได้รับการทดสอบและจัดเก็บไว้ในเซิร์ฟเวอร์
การสร้างขั้นตอน
กระบวนงานที่เก็บไว้ถูกสร้างขึ้นโดยใช้คำสั่ง CREATE PROCEDURE
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปของคำสั่ง CREATE PROCEDURE
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;ตัวอย่าง
พิจารณาตารางเงินเดือนต่อไปนี้
| พนักงาน | ขั้นต้น | การหักเงิน | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
ตัวอย่างต่อไปนี้สร้างกระบวนงานที่จัดเก็บชื่อ InsertSalary เพื่อยอมรับค่าและแทรกลงในตารางเงินเดือน
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;การดำเนินการตามขั้นตอน
กระบวนงานที่จัดเก็บจะดำเนินการโดยใช้คำสั่ง CALL
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปของคำสั่ง CALL
CALL <procedure name> [(parameter values)];ตัวอย่าง
ตัวอย่างต่อไปนี้เรียกกระบวนงานที่เก็บไว้ว่า InsertSalary และแทรกระเบียนไปยังตารางเงินเดือน
CALL InsertSalary(105,20000,2000,18000);เมื่อดำเนินการค้นหาข้างต้นแล้วจะสร้างผลลัพธ์ต่อไปนี้และคุณจะเห็นแถวที่แทรกในตารางเงินเดือน
| พนักงาน | ขั้นต้น | การหักเงิน | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
| 105 | 20,000 | 2,000 | 18,000 |
บทนี้จะกล่าวถึงกลยุทธ์การเข้าร่วมต่างๆที่มีใน Teradata
เข้าร่วมวิธีการ
Teradata ใช้วิธีการเข้าร่วมที่แตกต่างกันเพื่อดำเนินการเข้าร่วม วิธีการเข้าร่วมที่ใช้กันทั่วไป ได้แก่
- รวมเข้าร่วม
- การเข้าร่วมที่ซ้อนกัน
- เข้าร่วมผลิตภัณฑ์
รวมเข้าร่วม
เมธอด Merge Join เกิดขึ้นเมื่อการเข้าร่วมเป็นไปตามเงื่อนไขความเท่าเทียมกัน Merge Join กำหนดให้แถวการรวมอยู่ใน AMP เดียวกัน แถวจะรวมตามแฮชแถว Merge Join ใช้กลยุทธ์การเข้าร่วมที่แตกต่างกันเพื่อนำแถวไปยัง AMP เดียวกัน
กลยุทธ์ # 1
หากคอลัมน์การรวมเป็นดัชนีหลักของตารางที่เกี่ยวข้องแถวการรวมจะอยู่ใน AMP เดียวกันแล้ว ในกรณีนี้ไม่จำเป็นต้องมีการแจกจ่าย
พิจารณาตารางพนักงานและเงินเดือนต่อไปนี้
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);เมื่อสองตารางนี้รวมเข้ากับคอลัมน์ EmployeeNo จะไม่มีการแจกจ่ายซ้ำเนื่องจาก EmployeeNo เป็นดัชนีหลักของทั้งสองตารางที่กำลังถูกรวมเข้าด้วยกัน
กลยุทธ์ # 2
พิจารณาตารางพนักงานและแผนกต่อไปนี้
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );ถ้าตารางทั้งสองนี้รวมอยู่ในคอลัมน์ DeparmentNo ดังนั้นแถวจะต้องถูกแจกจ่ายใหม่เนื่องจาก DepartmentNo เป็นดัชนีหลักในตารางเดียวและไม่ใช่ดัชนีหลักในตารางอื่น ในสถานการณ์นี้การรวมแถวอาจไม่อยู่ใน AMP เดียวกัน ในกรณีเช่นนี้ Teradata อาจแจกจ่ายตารางพนักงานในคอลัมน์ DepartmentNo อีกครั้ง
กลยุทธ์ # 3
สำหรับตารางพนักงานและแผนกข้างต้น Teradata อาจทำซ้ำตาราง Department ใน AMP ทั้งหมดหากขนาดของตาราง Department มีขนาดเล็ก
การเข้าร่วมที่ซ้อนกัน
Nested Join ไม่ได้ใช้ AMP ทั้งหมด เพื่อให้การเข้าร่วมแบบซ้อนเกิดขึ้นเงื่อนไขข้อใดข้อหนึ่งควรมีความเท่าเทียมกันในดัชนีหลักที่ไม่ซ้ำกันของตารางหนึ่งจากนั้นจึงรวมคอลัมน์นี้เข้ากับดัชนีใด ๆ ในตารางอื่น
ในสถานการณ์สมมตินี้ระบบจะดึงข้อมูลหนึ่งแถวโดยใช้ดัชนีหลักที่ไม่ซ้ำกันของตารางหนึ่งและใช้แฮชแถวนั้นเพื่อดึงระเบียนที่ตรงกันจากตารางอื่น การเข้าร่วมแบบซ้อนเป็นวิธีการเข้าร่วมที่มีประสิทธิภาพมากที่สุด
เข้าร่วมผลิตภัณฑ์
การเข้าร่วมผลิตภัณฑ์จะเปรียบเทียบแถวที่มีคุณสมบัติแต่ละแถวจากตารางหนึ่งกับแต่ละแถวที่มีคุณสมบัติจากตารางอื่น การเข้าร่วมผลิตภัณฑ์อาจเกิดขึ้นเนื่องจากปัจจัยต่อไปนี้ -
- สภาพหายไปไหน.
- เงื่อนไขการเข้าร่วมไม่ได้ขึ้นอยู่กับเงื่อนไขความเท่าเทียมกัน
- ชื่อแทนตารางไม่ถูกต้อง
- เงื่อนไขการเข้าร่วมหลายรายการ
Partitioned Primary Index (PPI) เป็นกลไกการสร้างดัชนีที่มีประโยชน์ในการปรับปรุงประสิทธิภาพของคำค้นหาบางคำ เมื่อแทรกแถวลงในตารางแถวนั้นจะถูกเก็บไว้ใน AMP และจัดเรียงตามลำดับแฮชของแถว เมื่อกำหนดตารางด้วย PPI แถวจะเรียงตามหมายเลขพาร์ติชัน ภายในแต่ละพาร์ติชันจะจัดเรียงตามแฮชแถว แถวถูกกำหนดให้กับพาร์ติชันตามนิพจน์พาร์ติชันที่กำหนด
ข้อดี
หลีกเลี่ยงการสแกนแบบเต็มตารางสำหรับข้อความค้นหาบางรายการ
หลีกเลี่ยงการใช้ดัชนีรองที่ต้องการโครงสร้างทางกายภาพเพิ่มเติมและการบำรุงรักษา I / O เพิ่มเติม
เข้าถึงชุดย่อยของตารางขนาดใหญ่ได้อย่างรวดเร็ว
วางข้อมูลเก่าอย่างรวดเร็วและเพิ่มข้อมูลใหม่
ตัวอย่าง
พิจารณาตารางคำสั่งซื้อต่อไปนี้พร้อมดัชนีหลักใน OrderNo
| ไม่มีการจัดเก็บ | ลำดับที่ | วันสั่ง | OrderTotal |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1,200 |
| 102 | 7503 | 2015-10-02 | 3,000 |
| 102 | 7504 | 2015-10-03 | 2,454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2,454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
สมมติว่ามีการกระจายระเบียนระหว่าง AMP ดังแสดงในตารางต่อไปนี้ บันทึกจะถูกเก็บไว้ใน AMP โดยเรียงตามแฮชแถว
| RowHash | ลำดับที่ | วันสั่ง |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | ลำดับที่ | วันสั่ง |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
หากคุณเรียกใช้การสืบค้นเพื่อแยกคำสั่งซื้อสำหรับวันใดวันหนึ่งเครื่องมือเพิ่มประสิทธิภาพอาจเลือกใช้การสแกนแบบเต็มตารางจากนั้นอาจเข้าถึงบันทึกทั้งหมดภายใน AMP ได้ เพื่อหลีกเลี่ยงปัญหานี้คุณสามารถกำหนดวันที่สั่งซื้อเป็นดัชนีหลักแบบแบ่งพาร์ติชัน เมื่อแทรกแถวในตารางคำสั่งซื้อจะถูกแบ่งตามวันที่สั่งซื้อ ภายในแต่ละพาร์ติชันจะเรียงลำดับตามแฮชแถว
ข้อมูลต่อไปนี้จะแสดงวิธีจัดเก็บระเบียนใน AMP หากมีการแบ่งพาร์ติชันตามวันที่สั่งซื้อ ถ้ามีการเรียกใช้แบบสอบถามเพื่อเข้าถึงระเบียนตามวันที่สั่งซื้อจะมีการเข้าถึงเฉพาะพาร์ติชันที่มีระเบียนสำหรับคำสั่งนั้น
| พาร์ทิชัน | RowHash | ลำดับที่ | วันสั่ง |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| พาร์ทิชัน | RowHash | ลำดับที่ | วันสั่ง |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
ต่อไปนี้เป็นตัวอย่างการสร้างตารางที่มีดัชนีหลักของพาร์ติชัน PARTITION BY clause ใช้เพื่อกำหนดพาร์ติชัน
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);ในตัวอย่างข้างต้นตารางจะแบ่งตามคอลัมน์ OrderDate จะมีพาร์ทิชั่นแยกต่างหากสำหรับแต่ละวัน
ฟังก์ชัน OLAP คล้ายกับฟังก์ชันการรวมยกเว้นว่าฟังก์ชันการรวมจะส่งคืนค่าเพียงค่าเดียวในขณะที่ฟังก์ชัน OLAP จะให้แต่ละแถวนอกเหนือจากการรวม
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปของฟังก์ชัน OLAP
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)ฟังก์ชันการรวมสามารถเป็น SUM, COUNT, MAX, MIN, AVG
ตัวอย่าง
พิจารณาตารางเงินเดือนต่อไปนี้
| พนักงาน | ขั้นต้น | การหักเงิน | NetPay |
|---|---|---|---|
| 101 | 40,000 | 4,000 | 36,000 |
| 102 | 80,000 | 6,000 | 74,000 |
| 103 | 90,000 | 7,000 | 83,000 |
| 104 | 75,000 | 5,000 | 70,000 |
ต่อไปนี้เป็นตัวอย่างในการค้นหาผลรวมสะสมหรือยอดรวมของ NetPay บนตารางเงินเดือน เร็กคอร์ดถูกจัดเรียงตาม EmployeeNo และผลรวมสะสมจะคำนวณในคอลัมน์ NetPay
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000อันดับ
ฟังก์ชัน RANK จะเรียงลำดับระเบียนตามคอลัมน์ที่ให้ไว้ ฟังก์ชัน RANK ยังสามารถกรองจำนวนระเบียนที่ส่งคืนตามอันดับ
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ทั่วไปในการใช้ฟังก์ชัน RANK
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])ตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เข้าร่วม | DepartmentID | วันที่เกิด |
|---|---|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 27/3/2548 | 1 | 1/5/1980 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 25/4/2550 | 2 | 5/3/1983 |
| 103 | ปีเตอร์ | พอล | 21/3/2550 | 2 | 1/1/2553 |
| 104 | อเล็กซ์ | สจวร์ต | 1/2/2561 | 2 | 11/6/1984 |
| 105 | โรเบิร์ต | เจมส์ | 1/4/2561 | 3 | 1/12/1984 |
การสืบค้นต่อไปนี้จะสั่งให้บันทึกตารางพนักงานตามวันที่เข้าร่วมและกำหนดการจัดอันดับในวันที่เข้าร่วม
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5PARTITION BY clause จัดกลุ่มข้อมูลตามคอลัมน์ที่กำหนดในส่วนคำสั่ง PARTITION BY และดำเนินการฟังก์ชัน OLAP ภายในแต่ละกลุ่ม ต่อไปนี้เป็นตัวอย่างของแบบสอบถามที่ใช้คำสั่ง PARTITION BY
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;เมื่อดำเนินการค้นหาข้างต้นจะสร้างผลลัพธ์ต่อไปนี้ คุณจะเห็นได้ว่าอันดับจะถูกรีเซ็ตสำหรับแต่ละแผนก
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1บทนี้กล่าวถึงคุณสมบัติที่มีให้สำหรับการปกป้องข้อมูลใน Teradata
วารสารชั่วคราว
Teradata ใช้ Transient Journal เพื่อป้องกันข้อมูลจากความล้มเหลวของธุรกรรม เมื่อใดก็ตามที่มีการเรียกใช้ธุรกรรมสมุดรายวันชั่วคราวจะเก็บสำเนาของรูปภาพก่อนหน้าของแถวที่ได้รับผลกระทบจนกว่าธุรกรรมจะสำเร็จหรือย้อนกลับได้สำเร็จ จากนั้นภาพก่อนหน้าจะถูกทิ้ง บันทึกชั่วคราวจะถูกเก็บไว้ในแต่ละ AMP เป็นกระบวนการอัตโนมัติและไม่สามารถปิดใช้งานได้
รั้งท้าย
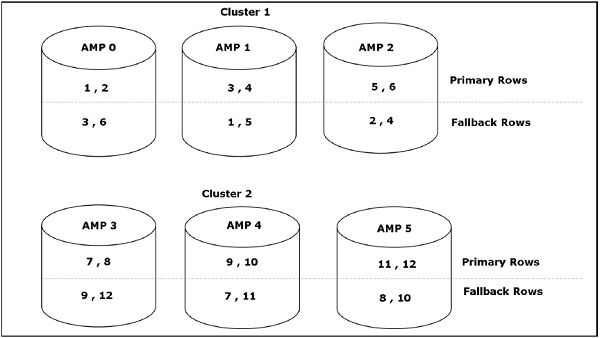
ทางเลือกปกป้องข้อมูลตารางโดยการจัดเก็บสำเนาที่สองของแถวของตารางใน AMP อื่นที่เรียกว่า AMP สำรอง หาก AMP หนึ่งรายการล้มเหลวระบบจะเข้าถึงแถวสำรอง ด้วยเหตุนี้แม้ว่า AMP หนึ่งรายการจะล้มเหลว แต่ข้อมูลยังคงมีอยู่ผ่านทาง AMP สำรอง สามารถใช้ตัวเลือกทางเลือกในการสร้างตารางหรือหลังการสร้างตาราง ทางเลือกช่วยให้แน่ใจว่าสำเนาที่สองของแถวของตารางจะถูกเก็บไว้ใน AMP อื่นเสมอเพื่อป้องกันข้อมูลจาก AMP ล้มเหลว อย่างไรก็ตามทางเลือกใช้พื้นที่เก็บข้อมูลสองเท่าและ I / O สำหรับแทรก / ลบ / อัปเดต
แผนภาพต่อไปนี้แสดงวิธีจัดเก็บสำเนาสำรองของแถวใน AMP อื่น
ลง AMP Recovery Journal
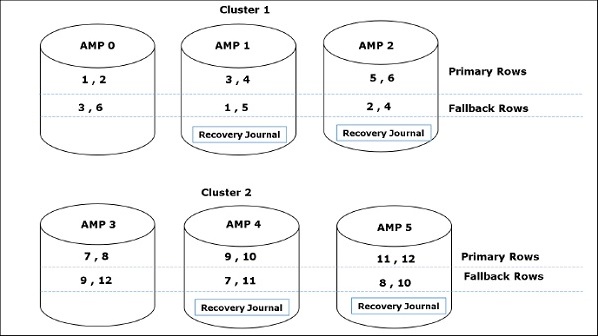
สมุดรายวันการกู้คืน AMP Down จะเปิดใช้งานเมื่อ AMP ล้มเหลวและตารางได้รับการป้องกันทางเลือก วารสารนี้ติดตามการเปลี่ยนแปลงทั้งหมดในข้อมูลของ AMP ที่ล้มเหลว สมุดรายวันเปิดใช้งานใน AMP ที่เหลือในคลัสเตอร์ เป็นกระบวนการอัตโนมัติและไม่สามารถปิดใช้งานได้ เมื่อ AMP ที่ล้มเหลวใช้งานได้จริงข้อมูลจากสมุดรายวันการกู้คืน Down AMP จะซิงโครไนซ์กับ AMP เมื่อเสร็จแล้ววารสารจะถูกทิ้ง
Cliques
Clique เป็นกลไกที่ Teradata ใช้เพื่อปกป้องข้อมูลจากความล้มเหลวของโหนด กลุ่มคืออะไรนอกจากชุดของโหนด Teradata ที่ใช้ชุดของ Disk Arrays ร่วมกัน เมื่อโหนดล้มเหลว vprocs จากโหนดที่ล้มเหลวจะย้ายไปยังโหนดอื่นในกลุ่มและเข้าถึงดิสก์อาร์เรย์ต่อไป
ฮอตสแตนด์บายโหนด
Hot Standby Node คือโหนดที่ไม่มีส่วนร่วมในสภาพแวดล้อมการผลิต หากโหนดล้มเหลว vprocs จากโหนดที่ล้มเหลวจะโอนย้ายไปยังโหนดฮอตสแตนบาย เมื่อกู้คืนโหนดที่ล้มเหลวแล้วจะกลายเป็นโหนดฮอตสแตนบาย โหนด Hot Standby ใช้เพื่อรักษาประสิทธิภาพในกรณีที่โหนดล้มเหลว
RAID
Redundant Array of Independent Disks (RAID) เป็นกลไกที่ใช้ในการปกป้องข้อมูลจาก Disk Failures Disk Array ประกอบด้วยชุดของดิสก์ซึ่งจัดกลุ่มเป็นหน่วยลอจิคัล หน่วยนี้อาจดูเหมือนหน่วยเดียวสำหรับผู้ใช้ แต่อาจกระจายไปทั่วดิสก์หลายแผ่น
RAID 1 มักใช้ใน Teradata ใน RAID 1 ดิสก์แต่ละตัวเชื่อมโยงกับมิเรอร์ดิสก์ การเปลี่ยนแปลงข้อมูลในดิสก์หลักจะแสดงในสำเนามิเรอร์ด้วย หากดิสก์หลักล้มเหลวข้อมูลจากมิเรอร์ดิสก์จะสามารถเข้าถึงได้

บทนี้จะกล่าวถึงกลยุทธ์ต่างๆของการจัดการผู้ใช้ใน Teradata
ผู้ใช้
ผู้ใช้ถูกสร้างขึ้นโดยใช้คำสั่ง CREATE USER ใน Teradata ผู้ใช้ก็คล้ายกับฐานข้อมูลเช่นกัน ทั้งสองสามารถกำหนดพื้นที่และมีวัตถุฐานข้อมูลยกเว้นว่าผู้ใช้จะได้รับการกำหนดรหัสผ่าน
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์สำหรับ CREATE USER
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;ในขณะที่สร้างผู้ใช้ค่าสำหรับชื่อผู้ใช้พื้นที่ถาวรและรหัสผ่านเป็นสิ่งจำเป็น ช่องอื่นเป็นทางเลือก
ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างในการสร้างผู้ใช้ TD01
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;บัญชี
ในขณะที่สร้างผู้ใช้ใหม่ผู้ใช้อาจถูกกำหนดให้กับบัญชี ตัวเลือกบัญชีในสร้างผู้ใช้ใช้เพื่อกำหนดบัญชี ผู้ใช้อาจถูกกำหนดให้กับหลายบัญชี
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์สำหรับ CREATE USER with account option
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountidตัวอย่าง
ตัวอย่างต่อไปนี้สร้างผู้ใช้ TD02 และกำหนดบัญชีเป็น IT และ Admin
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);ผู้ใช้สามารถระบุรหัสบัญชีขณะล็อกอินเข้าสู่ระบบ Teradata หรือหลังจากล็อกอินเข้าสู่ระบบโดยใช้คำสั่ง SET SESSION
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountidให้สิทธิ์
คำสั่ง GRANT ใช้เพื่อกำหนดสิทธิ์อย่างน้อยหนึ่งสิทธิ์บนวัตถุฐานข้อมูลให้กับผู้ใช้หรือฐานข้อมูล
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์ของคำสั่ง GRANT
GRANT privileges ON objectname TO username;สิทธิพิเศษสามารถ INSERT, SELECT, UPDATE, REFERENCES
ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างของคำสั่ง GRANT
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;เพิกถอนสิทธิ์
คำสั่ง REVOKE ลบสิทธิพิเศษจากผู้ใช้หรือฐานข้อมูล คำสั่ง REVOKE สามารถลบสิทธิ์ที่ชัดเจนเท่านั้น
ไวยากรณ์
ต่อไปนี้เป็นไวยากรณ์พื้นฐานสำหรับคำสั่ง REVOKE
REVOKE [ALL|privileges] ON objectname FROM username;ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างของคำสั่ง REVOKE
REVOKE INSERT,SELECT ON Employee FROM TD01;บทนี้จะกล่าวถึงขั้นตอนของการปรับแต่งประสิทธิภาพใน Teradata
อธิบาย
ขั้นตอนแรกในการปรับแต่งประสิทธิภาพคือการใช้ EXPLAIN ในแบบสอบถามของคุณ แผน EXPLAIN ให้รายละเอียดว่าเครื่องมือเพิ่มประสิทธิภาพจะดำเนินการค้นหาของคุณอย่างไร ในแผนอธิบายให้ตรวจสอบคีย์เวิร์ดเช่นระดับความเชื่อมั่นกลยุทธ์การเข้าร่วมที่ใช้ขนาดไฟล์สปูลการแจกจ่ายซ้ำ ฯลฯ
รวบรวมสถิติ
เครื่องมือเพิ่มประสิทธิภาพใช้ข้อมูลประชากรเพื่อสร้างกลยุทธ์การดำเนินการที่มีประสิทธิภาพ คำสั่ง COLLECT STATISTICS ใช้เพื่อรวบรวมข้อมูลประชากรของตาราง ตรวจสอบให้แน่ใจว่าสถิติที่รวบรวมในคอลัมน์เป็นข้อมูลล่าสุด
รวบรวมสถิติเกี่ยวกับคอลัมน์ที่ใช้ในส่วนคำสั่ง WHERE และคอลัมน์ที่ใช้ในเงื่อนไขการรวม
รวบรวมสถิติในคอลัมน์ดัชนีหลักที่ไม่ซ้ำกัน
รวบรวมสถิติในคอลัมน์ดัชนีรองที่ไม่ซ้ำกัน Optimizer จะตัดสินใจว่าสามารถใช้ NUSI หรือ Full Table Scan ได้หรือไม่
รวบรวมสถิติในดัชนีเข้าร่วมแม้ว่าจะมีการรวบรวมสถิติบนตารางฐาน
รวบรวมสถิติเกี่ยวกับคอลัมน์การแบ่งพาร์ติชัน
ประเภทข้อมูล
ตรวจสอบให้แน่ใจว่ามีการใช้ประเภทข้อมูลที่เหมาะสม วิธีนี้จะหลีกเลี่ยงการใช้พื้นที่เก็บข้อมูลมากเกินความจำเป็น
การแปลง
ตรวจสอบให้แน่ใจว่าชนิดข้อมูลของคอลัมน์ที่ใช้ในเงื่อนไขการรวมเข้ากันได้เพื่อหลีกเลี่ยงการแปลงข้อมูลที่โจ่งแจ้ง
จัดเรียง
ลบคำสั่ง ORDER BY ที่ไม่จำเป็นออกเว้นแต่จำเป็น
ปัญหาเกี่ยวกับ Spool Space
ข้อผิดพลาดของ Spool space จะถูกสร้างขึ้นหากการค้นหาเกินขีด จำกัด พื้นที่ spool ของ AMP สำหรับผู้ใช้นั้น ตรวจสอบแผนการอธิบายและระบุขั้นตอนที่ใช้พื้นที่สปูลมากขึ้น แบบสอบถามระดับกลางเหล่านี้สามารถแยกและวางแยกกันเพื่อสร้างตารางชั่วคราว
ดัชนีหลัก
ตรวจสอบให้แน่ใจว่าดัชนีหลักถูกกำหนดไว้อย่างถูกต้องสำหรับตาราง คอลัมน์ดัชนีหลักควรกระจายข้อมูลอย่างเท่าเทียมกันและควรใช้บ่อยครั้งเพื่อเข้าถึงข้อมูล
ตาราง SET
หากคุณกำหนดตาราง SET เครื่องมือเพิ่มประสิทธิภาพจะตรวจสอบว่าระเบียนนั้นซ้ำกันสำหรับแต่ละระเบียนหรือไม่ หากต้องการลบเงื่อนไขการตรวจสอบที่ซ้ำกันคุณสามารถกำหนดดัชนีรองเฉพาะสำหรับตารางได้
อัปเดตบนโต๊ะขนาดใหญ่
การอัปเดตตารางขนาดใหญ่จะใช้เวลานาน แทนที่จะอัปเดตตารางคุณสามารถลบระเบียนและแทรกระเบียนด้วยแถวที่แก้ไขได้
การวางตารางชั่วคราว
วางตารางชั่วคราว (ตารางการจัดเตรียม) และ volatiles หากไม่จำเป็นอีกต่อไป สิ่งนี้จะเพิ่มพื้นที่ว่างถาวรและพื้นที่สปูล
ตาราง MULTISET
หากคุณแน่ใจว่าระเบียนอินพุตจะไม่มีระเบียนที่ซ้ำกันคุณสามารถกำหนดตารางเป้าหมายเป็นตาราง MULTISET เพื่อหลีกเลี่ยงการตรวจสอบแถวที่ซ้ำกันซึ่งใช้โดยตาราง SET
ยูทิลิตี้ FastLoad ใช้เพื่อโหลดข้อมูลลงในตารางเปล่า เนื่องจากไม่ใช้วารสารชั่วคราวจึงสามารถโหลดข้อมูลได้อย่างรวดเร็ว ไม่โหลดแถวที่ซ้ำกันแม้ว่าตารางเป้าหมายจะเป็นตาราง MULTISET ก็ตาม
ข้อ จำกัด
ตารางเป้าหมายไม่ควรมีดัชนีรองดัชนีเข้าร่วมและการอ้างอิงคีย์ต่างประเทศ
FastLoad ทำงานอย่างไร
FastLoad ดำเนินการในสองขั้นตอน
ขั้นตอนที่ 1
เอ็นจินการแยกวิเคราะห์จะอ่านบันทึกจากไฟล์อินพุตและส่งบล็อกไปยัง AMP แต่ละรายการ
AMP แต่ละตัวจะจัดเก็บบล็อกของระเบียน
จากนั้น AMP จะแฮชแต่ละระเบียนและแจกจ่ายซ้ำไปยัง AMP ที่ถูกต้อง
ในตอนท้ายของเฟส 1 AMP แต่ละแถวจะมีแถว แต่ไม่อยู่ในลำดับแฮชของแถว
ระยะที่ 2
เฟส 2 เริ่มต้นเมื่อ FastLoad ได้รับคำสั่ง END LOADING
AMP แต่ละรายการจะเรียงลำดับระเบียนในแฮชแถวและเขียนลงในดิสก์
ล็อกบนตารางเป้าหมายจะถูกปลดล็อกและตารางข้อผิดพลาดจะหลุดออก
ตัวอย่าง
สร้างไฟล์ข้อความด้วยเร็กคอร์ดต่อไปนี้และตั้งชื่อไฟล์เป็น staff.txt
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3ต่อไปนี้เป็นสคริปต์ FastLoad ตัวอย่างเพื่อโหลดไฟล์ด้านบนลงในตาราง Employee_Stg
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;การเรียกใช้สคริปต์ FastLoad
เมื่อสร้างไฟล์อินพุต Employ.txt และสคริปต์ FastLoad ตั้งชื่อเป็น EmployeeLoad.fl คุณสามารถรันสคริปต์ FastLoad โดยใช้คำสั่งต่อไปนี้ใน UNIX และ Windows
FastLoad < EmployeeLoad.fl;เมื่อคำสั่งดังกล่าวถูกเรียกใช้สคริปต์ FastLoad จะทำงานและสร้างบันทึก ในบันทึกคุณสามารถดูจำนวนระเบียนที่ประมวลผลโดย FastLoad และรหัสสถานะ
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsข้อกำหนด FastLoad
ต่อไปนี้เป็นรายการคำศัพท์ทั่วไปที่ใช้ในสคริปต์ FastLoad
LOGON - เข้าสู่ระบบ Teradata และเริ่มเซสชันอย่างน้อยหนึ่งครั้ง
DATABASE - ตั้งค่าฐานข้อมูลเริ่มต้น
BEGIN LOADING - ระบุตารางที่จะโหลด
ERRORFILES - ระบุตารางข้อผิดพลาด 2 ตารางที่ต้องสร้าง / อัปเดต
CHECKPOINT - กำหนดเวลาที่จะตรวจสอบ
SET RECORD - ระบุว่ารูปแบบไฟล์อินพุตเป็นรูปแบบไบนารีข้อความหรือไม่ได้จัดรูปแบบ
DEFINE - กำหนดรูปแบบไฟล์อินพุต
FILE - ระบุชื่อไฟล์อินพุตและพา ธ
INSERT - แทรกบันทึกจากไฟล์อินพุตลงในตารางเป้าหมาย
END LOADING- เริ่มเฟส 2 ของ FastLoad แจกจ่ายระเบียนลงในตารางเป้าหมาย
LOGOFF - สิ้นสุดเซสชันทั้งหมดและยกเลิก FastLoad
MultiLoad สามารถโหลดตารางได้หลายตารางและยังสามารถทำงานประเภทต่างๆเช่น INSERT, DELETE, UPDATE และ UPSERT สามารถโหลดได้สูงสุด 5 ตารางในแต่ละครั้งและดำเนินการ DML ได้ถึง 20 รายการในสคริปต์ ตารางเป้าหมายไม่จำเป็นสำหรับ MultiLoad
MultiLoad รองรับสองโหมด -
- IMPORT
- DELETE
MultiLoad ต้องการตารางงานตารางบันทึกและตารางข้อผิดพลาดสองตารางนอกเหนือจากตารางเป้าหมาย
Log Table - ใช้เพื่อรักษาจุดตรวจที่เกิดขึ้นระหว่างการโหลดซึ่งจะใช้สำหรับการรีสตาร์ท
Error Tables- ตารางเหล่านี้จะถูกแทรกระหว่างการโหลดเมื่อเกิดข้อผิดพลาด ตารางข้อผิดพลาดแรกจัดเก็บข้อผิดพลาดในการแปลงในขณะที่ตารางข้อผิดพลาดที่สองเก็บบันทึกที่ซ้ำกัน
Log Table - รักษาผลลัพธ์จากแต่ละเฟสของ MultiLoad เพื่อการรีสตาร์ท
Work table- สคริปต์ MultiLoad สร้างตารางงานหนึ่งตารางต่อตารางเป้าหมาย ตารางงานใช้เพื่อเก็บงาน DML และข้อมูลอินพุต
ข้อ จำกัด
MultiLoad มีข้อ จำกัด บางประการ
- ไม่รองรับดัชนีรองเฉพาะในตารางเป้าหมาย
- ไม่รองรับความสมบูรณ์ของการอ้างอิง
- ไม่รองรับทริกเกอร์
MultiLoad ทำงานอย่างไร
การนำเข้า MultiLoad มีห้าขั้นตอน -
Phase 1 - ขั้นตอนเบื้องต้น - ดำเนินกิจกรรมการตั้งค่าพื้นฐาน
Phase 2 - DML Transaction Phase - ตรวจสอบไวยากรณ์ของคำสั่ง DML และนำไปยังระบบ Teradata
Phase 3 - Acquisition Phase - นำข้อมูลเข้ามาในตารางงานและล็อกตาราง
Phase 4 - Application Phase - ใช้การดำเนินการ DML ทั้งหมด
Phase 5 - Cleanup Phase - ปลดล็อคตาราง
ขั้นตอนที่เกี่ยวข้องกับสคริปต์ MultiLoad ได้แก่ -
Step 1 - ตั้งค่าตารางบันทึก
Step 2 - เข้าสู่ระบบ Teradata
Step 3 - ระบุตารางเป้าหมายงานและข้อผิดพลาด
Step 4 - กำหนดรูปแบบไฟล์ INPUT
Step 5 - กำหนดแบบสอบถาม DML
Step 6 - ตั้งชื่อไฟล์นำเข้า
Step 7 - ระบุ LAYOUT ที่จะใช้
Step 8 - เริ่มการโหลด
Step 9 - เสร็จสิ้นการโหลดและยุติเซสชัน
ตัวอย่าง
สร้างไฟล์ข้อความด้วยเร็กคอร์ดต่อไปนี้และตั้งชื่อไฟล์เป็น staff.txt
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3ตัวอย่างต่อไปนี้เป็นสคริปต์ MultiLoad ที่อ่านเรกคอร์ดจากตารางพนักงานและโหลดลงในตาราง Employee_Stg
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;การเรียกใช้สคริปต์ MultiLoad
เมื่อสร้างไฟล์อินพุต Employ.txt และสคริปต์หลายโหลดถูกตั้งชื่อเป็น EmployeeLoad.ml คุณสามารถรันสคริปต์ Multiload โดยใช้คำสั่งต่อไปนี้ใน UNIX และ Windows
Multiload < EmployeeLoad.ml;ยูทิลิตี้ FastExport ใช้เพื่อส่งออกข้อมูลจากตาราง Teradata ไปยังไฟล์แบบแบน นอกจากนี้ยังสามารถสร้างข้อมูลในรูปแบบรายงาน สามารถดึงข้อมูลจากตารางอย่างน้อยหนึ่งตารางโดยใช้เข้าร่วม เนื่องจาก FastExport ส่งออกข้อมูลในบล็อก 64K จึงมีประโยชน์สำหรับการแยกข้อมูลจำนวนมาก
ตัวอย่าง
พิจารณาตารางพนักงานต่อไปนี้
| พนักงาน | ชื่อจริง | นามสกุล | วันที่เกิด |
|---|---|---|---|
| 101 | ไมค์ | เจมส์ | 1/5/1980 |
| 104 | อเล็กซ์ | สจวร์ต | 11/6/1984 |
| 102 | โรเบิร์ต | วิลเลียมส์ | 5/3/1983 |
| 105 | โรเบิร์ต | เจมส์ | 1/12/1984 |
| 103 | ปีเตอร์ | พอล | 1/1/2553 |
ต่อไปนี้เป็นตัวอย่างของสคริปต์ FastExport ส่งออกข้อมูลจากตารางพนักงานและเขียนลงในไฟล์ Employeedata.txt
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;การเรียกใช้สคริปต์ FastExport
เมื่อสคริปต์ถูกเขียนและตั้งชื่อเป็น staff.fx คุณสามารถใช้คำสั่งต่อไปนี้เพื่อเรียกใช้สคริปต์
fexp < employee.fxหลังจากดำเนินการคำสั่งข้างต้นคุณจะได้รับผลลัพธ์ต่อไปนี้ในไฟล์ Employeedata.txt
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06ข้อกำหนด FastExport
ต่อไปนี้เป็นรายการคำศัพท์ที่ใช้กันทั่วไปในสคริปต์ FastExport
LOGTABLE - ระบุตารางบันทึกสำหรับการรีสตาร์ท
LOGON - เข้าสู่ระบบ Teradata และเริ่มเซสชันอย่างน้อยหนึ่งครั้ง
DATABASE - ตั้งค่าฐานข้อมูลเริ่มต้น
BEGIN EXPORT - ระบุจุดเริ่มต้นของการส่งออก
EXPORT - ระบุไฟล์เป้าหมายและรูปแบบการส่งออก
SELECT - ระบุคิวรีเลือกเพื่อส่งออกข้อมูล
END EXPORT - ระบุจุดสิ้นสุดของ FastExport
LOGOFF - สิ้นสุดเซสชันทั้งหมดและยกเลิก FastExport
ยูทิลิตี้ BTEQ เป็นยูทิลิตี้ที่มีประสิทธิภาพใน Teradata ซึ่งสามารถใช้ได้ทั้งในโหมดแบตช์และโหมดโต้ตอบ สามารถใช้เพื่อรันคำสั่ง DDL, คำสั่ง DML, สร้างมาโครและโพรซีเดอร์ที่เก็บไว้ BTEQ สามารถใช้เพื่อนำเข้าข้อมูลลงในตาราง Teradata จากไฟล์แบบแฟลตและยังสามารถใช้เพื่อดึงข้อมูลจากตารางลงในไฟล์หรือรายงาน
ข้อกำหนด BTEQ
ต่อไปนี้เป็นรายการคำศัพท์ที่ใช้กันทั่วไปในสคริปต์ BTEQ
LOGON - ใช้เพื่อเข้าสู่ระบบ Teradata
ACTIVITYCOUNT - ส่งคืนจำนวนแถวที่ได้รับผลกระทบจากแบบสอบถามก่อนหน้า
ERRORCODE - ส่งคืนรหัสสถานะของแบบสอบถามก่อนหน้า
DATABASE - ตั้งค่าฐานข้อมูลเริ่มต้น
LABEL - กำหนดเลเบลให้กับชุดคำสั่ง SQL
RUN FILE - ดำเนินการค้นหาที่อยู่ในไฟล์
GOTO - การควบคุมการถ่ายโอนไปยังฉลาก
LOGOFF - ออกจากฐานข้อมูลและยกเลิกเซสชันทั้งหมด
IMPORT - ระบุพา ธ ไฟล์อินพุต
EXPORT - ระบุพา ธ ไฟล์เอาต์พุตและเริ่มการเอ็กซ์พอร์ต
ตัวอย่าง
ต่อไปนี้เป็นตัวอย่างสคริปต์ BTEQ
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;สคริปต์ข้างต้นทำหน้าที่ต่อไปนี้
เข้าสู่ระบบ Teradata
ตั้งค่าฐานข้อมูลเริ่มต้น
สร้างตารางที่เรียกว่าพนักงาน_bkup
เลือกหนึ่งระเบียนจากตารางพนักงานเพื่อตรวจสอบว่าตารางมีระเบียนใด ๆ หรือไม่
วางตาราง staff_bkup หากตารางว่างเปล่า
ถ่ายโอนการควบคุมไปยัง Label InsertEmployee ซึ่งแทรกเร็กคอร์ดลงในตาราง staff_bkup
ตรวจสอบ ERRORCODE เพื่อให้แน่ใจว่าคำสั่งนั้นสำเร็จตามคำสั่ง SQL แต่ละคำสั่ง
ACTIVITYCOUNT ส่งคืนจำนวนระเบียนที่เลือก / ได้รับผลกระทบจากแบบสอบถาม SQL ก่อนหน้า