Apache Flink - Mimari
Apache Flink, Kappa mimarisi üzerinde çalışır. Kappa mimarisinde, tüm girdileri akış olarak ele alan ve akış motoru verileri gerçek zamanlı olarak işleyen tek bir işlemci akışına sahiptir. Kappa mimarisindeki toplu veri, özel bir akış durumudur.
Aşağıdaki şema, Apache Flink Architecture.
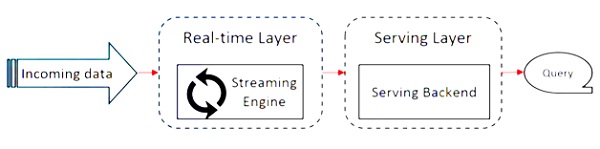
Kappa mimarisindeki temel fikir, hem toplu hem de gerçek zamanlı verileri tek bir akış işleme motoru aracılığıyla işlemektir.
Çoğu büyük veri çerçevesi, toplu iş ve akış verileri için ayrı işlemcilere sahip Lambda mimarisi üzerinde çalışır. Lambda mimarisinde, toplu iş ve akış görünümleri için ayrı kod tabanlarınız vardır. Sorgulamak ve sonucu almak için kod tabanlarının birleştirilmesi gerekir. Ayrı kod tabanlarını / görünümleri korumamak ve bunları birleştirmek bir acıdır, ancak Kappa mimarisi bu sorunu tek bir görünüme sahip olduğu için çözer - gerçek zamanlı, dolayısıyla kod tabanının birleştirilmesi gerekmez.
Bu, Kappa mimarisinin Lambda mimarisinin yerini aldığı anlamına gelmez, tamamen kullanım durumuna ve hangi mimarinin tercih edileceğine karar veren uygulamaya bağlıdır.
Aşağıdaki diyagram Apache Flink iş yürütme mimarisini göstermektedir.

Program
Flink Kümesi üzerinde çalıştırdığınız bir kod parçasıdır.
Müşteri
Kod (program) almaktan ve iş veri akışı grafiğini oluşturmaktan ve ardından bunu JobManager'a iletmekten sorumludur. Ayrıca İş sonuçlarını da alır.
JobManager
Müşteriden Job Dataflow Grafiğini aldıktan sonra, yürütme grafiğini oluşturmaktan sorumludur. İşi kümedeki TaskManager'lara atar ve işin yürütülmesini denetler.
Görev Yöneticisi
JobManager tarafından atanan tüm görevleri yürütmekten sorumludur. Tüm TaskManager'lar görevleri ayrı yuvalarında belirtilen paralellikte çalıştırır. Görevlerin durumunu JobManager'a göndermek sorumludur.
Apache Flink'in Özellikleri
Apache Flink'in özellikleri aşağıdaki gibidir -
Hem toplu hem de akış programlarını çalıştırabilen bir akış işlemcisine sahiptir.
Verileri yıldırım hızında işleyebilir.
API'ler Java, Scala ve Python'da mevcuttur.
Programcıların kullanması çok kolay olan tüm genel işlemler için API'ler sağlar.
Verileri düşük gecikme (nanosaniye) ve yüksek verimle işler.
Hataya dayanıklıdır. Bir düğüm, uygulama veya donanım arızalanırsa, kümeyi etkilemez.
Apache Hadoop, Apache MapReduce, Apache Spark, HBase ve diğer büyük veri araçlarıyla kolayca entegre edilebilir.
Bellek içi yönetim, daha iyi hesaplama için özelleştirilebilir.
Oldukça ölçeklenebilir ve bir kümede binlerce düğüme kadar ölçeklenebilir.
Apache Flink'te pencereleme çok esnektir.
Grafik İşleme, Makine Öğrenimi, Karmaşık Olay İşleme kütüphaneleri sağlar.