Apache Flume - Twitter Verilerini Almak
Flume'u kullanarak çeşitli hizmetlerden veri alabilir ve bunları merkezi mağazalara (HDFS ve HBase) taşıyabiliriz. Bu bölüm, Twitter hizmetinden verilerin nasıl alınacağını ve Apache Flume kullanılarak HDFS'de nasıl saklanacağını açıklar.
Flume Architecture'da tartışıldığı gibi, bir web sunucusu günlük verilerini üretir ve bu veriler Flume'daki bir aracı tarafından toplanır. Kanal, bu verileri bir havuzda arabelleğe alır ve bu da sonunda onları merkezi mağazalara iter.
Bu bölümde verilen örnekte, Apache Flume tarafından sağlanan deneysel twitter kaynağını kullanarak bir uygulama oluşturacak ve ondan tweetleri alacağız. Bu tweet'leri tamponlamak için bellek kanalını ve bu tweet'leri HDFS'ye göndermek için HDFS havuzunu kullanacağız.

Twitter verilerini almak için aşağıda verilen adımları izlememiz gerekecek -
- Twitter Uygulaması Oluşturun
- HDFS'yi Kur / Başlat
- Flume'u Yapılandır
Twitter Uygulaması Oluşturma
Twitter'dan tweetleri alabilmek için bir Twitter uygulaması oluşturulması gerekiyor. Bir Twitter uygulaması oluşturmak için aşağıdaki adımları izleyin.
Aşama 1
Bir Twitter uygulaması oluşturmak için aşağıdaki bağlantıya tıklayın https://apps.twitter.com/. Twitter hesabınızda oturum açın. Twitter Uygulamaları oluşturabileceğiniz, silebileceğiniz ve yönetebileceğiniz bir Twitter Uygulama Yönetimi penceresine sahip olacaksınız.
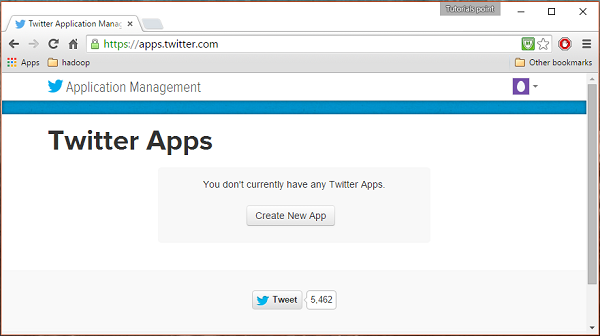
Adım 2
Tıkla Create New Appbuton. Uygulamayı oluşturmak için bilgilerinizi doldurmanız gereken bir başvuru formu alacağınız bir pencereye yönlendirileceksiniz. Web sitesi adresini doldururken, örneğin tam URL modelini verin,http://example.com.
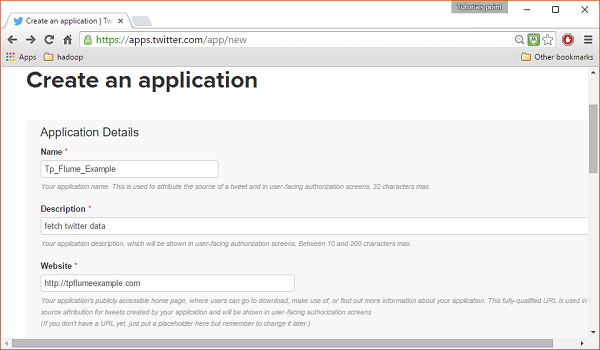
Aşama 3
Ayrıntıları doldurun, kabul edin Developer Agreement bittiğinde, tıklayın Create your Twitter application buttonbu sayfanın alt kısmındadır. Her şey yolunda giderse, aşağıda gösterildiği gibi verilen ayrıntılarla bir Uygulama oluşturulacaktır.
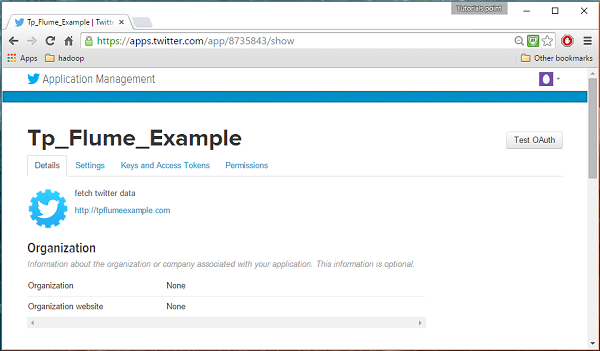
4. adım
Altında keys and Access Tokens sekmesinde, sayfanın altındaki bir düğme görebilirsiniz. Create my access token. Erişim belirtecini oluşturmak için üzerine tıklayın.
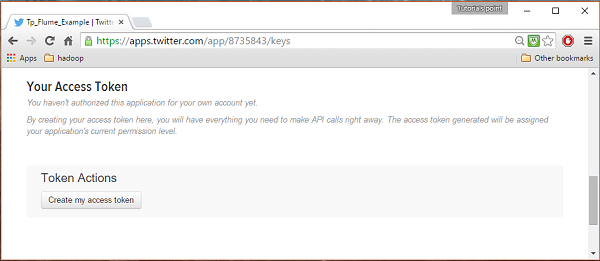
Adım 5
Son olarak, Test OAuthsayfanın sağ üst tarafında bulunan buton. Bu, sizi görüntüleyen bir sayfaya götürür.Consumer key, Consumer secret, Access token, ve Access token secret. Bu ayrıntıları kopyalayın. Bunlar, ajanı Flume'da yapılandırmak için kullanışlıdır.

HDFS'yi başlatma
Verileri HDFS'de sakladığımız için, Hadoop'u kurmamız / doğrulamamız gerekiyor. Hadoop'u başlatın ve Flume verilerini depolamak için içinde bir klasör oluşturun. Flume'u yapılandırmadan önce aşağıda verilen adımları izleyin.
1. Adım: Hadoop'u Kurun / Doğrulayın
Hadoop'u yükleyin . Hadoop sisteminize zaten kuruluysa, aşağıda gösterildiği gibi Hadoop sürüm komutunu kullanarak kurulumu doğrulayın.
$ hadoop versionSisteminiz Hadoop içeriyorsa ve yol değişkenini ayarladıysanız, aşağıdaki çıktıyı alırsınız -
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar2. Adım: Hadoop'u Başlatma
Göz atın sbin Hadoop dizini ve start ipliği ve Hadoop dfs (dağıtılmış dosya sistemi) aşağıda gösterildiği gibi.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.out3. Adım: HDFS'de Dizin Oluşturun
Hadoop DFS'de şu komutu kullanarak dizinler oluşturabilirsiniz. mkdir. İçinde gezinin ve adıyla bir dizin oluşturuntwitter_data aşağıda gösterildiği gibi gerekli yolda.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataFlume'u Yapılandırma
Kaynak, kanal ve havuzu, içindeki yapılandırma dosyasını kullanarak yapılandırmamız gerekir. confKlasör. Bu bölümde verilen örnek, Apache Flume tarafından sağlanan deneysel bir kaynağı kullanır.Twitter 1% Firehose Bellek kanalı ve HDFS havuzu.
Twitter% 1 Firehose Kaynağı
Bu kaynak oldukça deneyseldir. Akış API'sini kullanarak% 1'lik örnek Twitter Firehose'a bağlanır ve sürekli olarak tweet'ler indirir, bunları Avro formatına dönüştürür ve Avro olaylarını aşağı akışlı bir Flume havuzuna gönderir.
Bu kaynağı Flume kurulumuyla birlikte varsayılan olarak alacağız. jar bu kaynağa karşılık gelen dosyalar şurada bulunabilir: lib klasörü aşağıda gösterildiği gibi.

Sınıf yolunu ayarlama
Yı kur classpath değişken lib Flume klasörü Flume-env.sh dosya aşağıda gösterildiği gibi.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*Bu kaynağın aşağıdaki gibi ayrıntılara ihtiyacı var Consumer key, Consumer secret, Access token, ve Access token secretBir Twitter uygulamasının. Bu kaynağı yapılandırırken, aşağıdaki özelliklere değer sağlamanız gerekir -
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - OAuth tüketici anahtarı
consumerSecret - OAuth tüketici sırrı
accessToken - OAuth erişim belirteci
accessTokenSecret - OAuth jetonunun sırrı
maxBatchSize- Bir twitter grubunda olması gereken maksimum twitter mesajı sayısı. Varsayılan değer 1000'dir (isteğe bağlı).
maxBatchDurationMillis- Bir grubu kapatmadan önce beklenecek maksimum milisaniye sayısı. Varsayılan değer 1000'dir (isteğe bağlı).
Kanal
Hafıza kanalını kullanıyoruz. Bellek kanalını yapılandırmak için , kanalın türüne değer sağlamanız gerekir .
type- Kanalın türünü tutar. Örneğimizde türMemChannel.
Capacity- Kanalda saklanan maksimum olay sayısıdır. Varsayılan değeri 100'dür (isteğe bağlı).
TransactionCapacity- Kanalın kabul ettiği veya gönderdiği maksimum olay sayısıdır. Varsayılan değeri 100'dür (isteğe bağlı).
HDFS Lavabo
Bu havuz, verileri HDFS'ye yazar. Bu havuzu yapılandırmak için aşağıdaki ayrıntıları sağlamanız gerekir .
Channel
type - hdfs
hdfs.path - HDFS'deki verilerin depolanacağı dizinin yolu.
Ve senaryoya bağlı olarak bazı isteğe bağlı değerler sağlayabiliriz. Aşağıda, uygulamamızda yapılandırdığımız HDFS havuzunun isteğe bağlı özellikleri verilmiştir.
fileType - Bu, HDFS dosyamız için gerekli dosya formatıdır. SequenceFile, DataStream ve CompressedStreambu akışta kullanılabilen üç tür vardır. Örneğimizde, kullanıyoruzDataStream.
writeFormat - Yazılı veya yazılabilir olabilir.
batchSize- Bir dosyaya HDFS'ye yüklenmeden önce yazılan olayların sayısıdır. Varsayılan değeri 100'dür.
rollsize- Bir ruloyu tetikleyen dosya boyutudur. Varsayılan değer 100'dür.
rollCount- Dosyaya aktarılmadan önce yazılan olayların sayısıdır. Varsayılan değeri 10'dur.
Örnek - Yapılandırma Dosyası
Aşağıda, yapılandırma dosyası için bir örnek verilmiştir. Bu içeriği kopyalayın ve farklı kaydedintwitter.conf Flume'un conf klasöründe.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelYürütme
Flume ana dizinine göz atın ve aşağıda gösterildiği gibi uygulamayı çalıştırın.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentHer şey yolunda giderse, tweetlerin HDFS'ye akışı başlayacaktır. Aşağıda, tweetleri getirirken komut istemi penceresinin anlık görüntüsü verilmiştir.
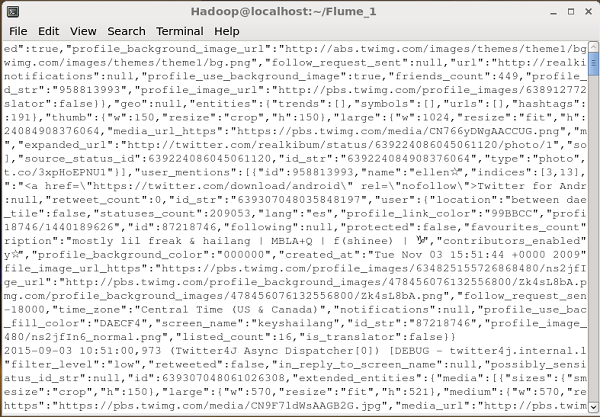
HDFS'yi doğrulama
Hadoop Yönetimi Web Kullanıcı Arayüzüne aşağıda verilen URL'yi kullanarak erişebilirsiniz.
http://localhost:50070/Adlı açılır menüye tıklayın Utilitiessayfanın sağ tarafında. Aşağıda verilen anlık görüntüde gösterildiği gibi iki seçenek görebilirsiniz.
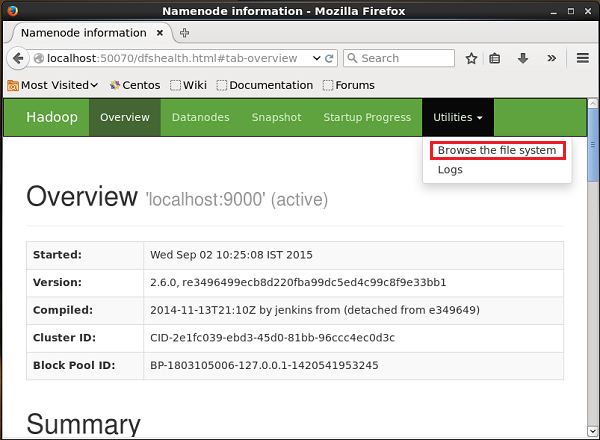
Tıklamak Browse the file systemve tweet'leri sakladığınız HDFS dizininin yolunu girin. Örneğimizde yol olacak/user/Hadoop/twitter_data/. Ardından, aşağıda verildiği gibi HDFS'de depolanan twitter günlük dosyalarının listesini görebilirsiniz.
