Apache Kafka - Hızlı Kılavuz
Big Data'da muazzam miktarda veri kullanılır. Verilerle ilgili olarak, iki temel zorluğumuz var: İlk zorluk, büyük hacimli verilerin nasıl toplanacağı ve ikinci zorluk, toplanan verileri analiz etmektir. Bu zorlukların üstesinden gelmek için bir mesajlaşma sistemine ihtiyacınız var.
Kafka, dağıtılmış yüksek verimli sistemler için tasarlanmıştır. Kafka, daha geleneksel bir mesaj komisyoncusu yerine çok iyi çalışma eğilimindedir. Diğer mesajlaşma sistemlerine kıyasla Kafka, daha iyi iş hacmine, yerleşik bölümlemeye, çoğaltmaya ve doğal hata toleransına sahiptir, bu da onu büyük ölçekli mesaj işleme uygulamaları için uygun hale getirir.
Mesajlaşma Sistemi nedir?
Bir Mesajlaşma Sistemi, verilerin bir uygulamadan diğerine aktarılmasından sorumludur, böylece uygulamalar verilere odaklanabilir, ancak nasıl paylaşılacağı konusunda endişelenmez. Dağıtılmış mesajlaşma, güvenilir mesaj kuyruğu kavramına dayanır. Mesajlar, istemci uygulamaları ve mesajlaşma sistemi arasında eşzamansız olarak sıraya alınır. İki tür mesajlaşma modeli mevcuttur - biri noktadan noktaya, diğeri ise yayınlama-abone olma (pub-sub) mesajlaşma sistemidir. Mesajlaşma modellerinin çoğu takip ederpub-sub.
Noktadan Noktaya Mesajlaşma Sistemi
Noktadan noktaya bir sistemde, mesajlar bir kuyrukta saklanır. Bir veya daha fazla tüketici kuyruktaki mesajları tüketebilir, ancak belirli bir mesaj yalnızca bir tüketici tarafından tüketilebilir. Bir tüketici kuyruktaki bir mesajı okuduğunda, bu kuyruktan kaybolur. Bu sistemin tipik örneği, her siparişin bir Sipariş İşlemcisi tarafından işleneceği, ancak Birden Çok Sipariş İşlemcisinin aynı anda çalışabileceği bir Sipariş İşleme Sistemidir. Aşağıdaki şema yapıyı göstermektedir.

Yayınla-Abone Ol Mesajlaşma Sistemi
Yayınlama-abone olma sisteminde, mesajlar bir konuda saklanır. Noktadan noktaya sistemin aksine, tüketiciler bir veya daha fazla konuya abone olabilir ve o konudaki tüm mesajları tüketebilir. Yayınla-Abone Ol sisteminde, mesaj üreticilerine yayıncı, mesaj tüketicilerine ise abone denir. Gerçek hayattan bir örnek, spor, film, müzik vb. Gibi farklı kanalları yayınlayan Dish TV'dir ve herkes kendi kanallarına abone olabilir ve abone olduğu kanalları kullanılabilir olduğunda bunları alabilir.

Kafka nedir?
Apache Kafka, dağıtılmış bir yayınlama-abone olma mesajlaşma sistemi ve yüksek hacimli verileri işleyebilen ve mesajları bir uç noktadan diğerine geçirmenizi sağlayan sağlam bir kuyruktur. Kafka, hem çevrimdışı hem de çevrimiçi mesaj tüketimi için uygundur. Kafka mesajları, veri kaybını önlemek için diskte saklanır ve küme içinde çoğaltılır. Kafka, ZooKeeper senkronizasyon hizmetinin üzerine inşa edilmiştir. Gerçek zamanlı veri akışı analizi için Apache Storm ve Spark ile çok iyi entegre olur.
Faydaları
Aşağıda Kafka'nın birkaç faydası vardır:
Reliability - Kafka dağıtılır, bölümlenir, çoğaltılır ve hata toleransı sağlanır.
Scalability - Kafka mesajlaşma sistemi, kesinti olmadan kolayca ölçeklenir.
Durability- Kafka,
Dağıtılmış kaydetme günlüğünü
kullanır ; bu, iletilerin diskte olabildiğince hızlı kalması, dolayısıyla dayanıklı olması anlamına gelir ..Performance- Kafka, hem mesaj yayınlamak hem de abone olmak için yüksek verimliliğe sahiptir. Birçok TB mesaj saklansa bile istikrarlı performansı korur.
Kafka çok hızlıdır ve sıfır kesinti ve sıfır veri kaybını garanti eder.
Kullanım Durumları
Kafka birçok Kullanım Durumunda kullanılabilir. Bazıları aşağıda listelenmiştir -
Metrics- Kafka genellikle operasyonel izleme verileri için kullanılır. Bu, merkezi operasyonel veri akışları üretmek için dağıtılmış uygulamalardan istatistiklerin toplanmasını içerir.
Log Aggregation Solution - Kafka, birden çok hizmetten günlükleri toplamak ve bunları standart bir biçimde birden çok tüketiciye sunmak için bir kuruluş genelinde kullanılabilir.
Stream Processing- Storm ve Spark Streaming gibi popüler çerçeveler bir konudaki verileri okur, işler ve işlenmiş verileri, kullanıcılar ve uygulamalar için kullanılabilir hale geldiği yeni bir konuya yazar. Kafka'nın güçlü dayanıklılığı, akış işleme bağlamında da çok kullanışlıdır.
Kafka ihtiyacı
Kafka, tüm gerçek zamanlı veri akışlarını işlemek için birleşik bir platformdur. Kafka, düşük gecikmeli mesaj teslimini destekler ve makine arızaları durumunda hata toleransı için garanti verir. Çok sayıda farklı tüketiciyi idare etme yeteneğine sahiptir. Kafka çok hızlıdır, 2 milyon yazma / sn yapar. Kafka tüm verileri diske kaydeder, bu da esasen tüm yazmaların OS'nin (RAM) sayfa önbelleğine gittiği anlamına gelir. Bu, verileri sayfa önbelleğinden bir ağ soketine aktarmayı çok verimli hale getirir.
Kafka'nın derinliklerine inmeden önce konular, komisyoncular, üreticiler ve tüketiciler gibi ana terminolojilerin farkında olmalısınız. Aşağıdaki şema ana terminolojileri göstermektedir ve tablo, şema bileşenlerini ayrıntılı olarak açıklamaktadır.
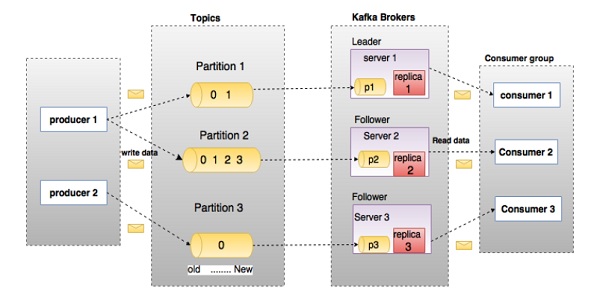
Yukarıdaki diyagramda, bir konu üç bölüm halinde yapılandırılmıştır. Bölüm 1, 0 ve 1 olmak üzere iki ofset faktörüne sahiptir. Bölüm 2'nin 0, 1, 2 ve 3 olmak üzere dört ofset faktörü vardır. Bölüm 3'ün bir ofset faktörü 0 vardır. Çoğaltmanın kimliği, onu barındıran sunucunun kimliğiyle aynıdır.
Varsayalım, konunun çoğaltma faktörü 3 olarak ayarlanmışsa, Kafka her bölümün 3 özdeş kopyasını oluşturacak ve tüm işlemleri için kullanılabilir hale getirmek için bunları kümeye yerleştirecektir. Kümedeki bir yükü dengelemek için, her aracı bu bölümlerden bir veya daha fazlasını depolar. Birden çok üretici ve tüketici aynı anda mesaj yayınlayabilir ve alabilir.
| S.No | Bileşenler ve Açıklama |
|---|---|
| 1 | Topics Belirli bir kategoriye ait bir mesaj akışına konu denir. Veriler konular içinde saklanır. Konular bölümlere ayrılmıştır. Kafka, her konu için bir bölümün küçük bir annesini tutar. Bu tür her bölüm, değişmez bir sırayla mesajlar içerir. Bir bölüm, eşit boyutlarda bir dizi bölüm dosyası olarak uygulanır. |
| 2 | Partition Konular çok sayıda bölüme sahip olabilir, bu nedenle keyfi miktarda veriyi işleyebilir. |
| 3 | Partition offset Her bölümlenmiş mesaj, |
| 4 | Replicas of partition Replikalar, bir bölümün |
| 5 | Brokers
|
| 6 | Kafka Cluster Kafka'nın birden fazla komisyoncusu olması Kafka kümesi olarak adlandırılır. Bir Kafka kümesi kesinti olmadan genişletilebilir. Bu kümeler, mesaj verilerinin kalıcılığını ve replikasyonunu yönetmek için kullanılır. |
| 7 | Producers Yapımcılar, bir veya daha fazla Kafka konusuyla ilgili mesajların yayıncısıdır. Üreticiler verileri Kafka brokerlerine gönderir. Bir yapımcı bir komisyoncuya bir mesaj yayınladığında, komisyoncu mesajı son segment dosyasına ekler. Aslında mesaj bir bölüme eklenecektir. Yapımcı ayrıca kendi seçtiği bir bölüme mesaj gönderebilir. |
| 8 | Consumers Tüketiciler, aracılardan veri okur. Tüketiciler bir veya daha fazla konuya abone olur ve brokerlardan veri çekerek yayınlanan mesajları tüketir. |
| 9 | Leader
|
| 10 | Follower Lider talimatlarını takip eden düğüme takipçi denir. Lider başarısız olursa, takipçiden biri otomatik olarak yeni lider olacaktır. Bir takipçi normal bir tüketici gibi davranır, mesajları çeker ve kendi veri deposunu günceller. |
Aşağıdaki resme bir göz atın. Kafka'nın küme diyagramını gösterir.

Aşağıdaki tablo, yukarıdaki diyagramda gösterilen bileşenlerin her birini açıklamaktadır.
| S.No | Bileşenler ve Açıklama |
|---|---|
| 1 | Broker Kafka kümesi tipik olarak yük dengesini korumak için birden çok aracıdan oluşur. Kafka aracıları devletsizdir, bu nedenle küme durumlarını korumak için ZooKeeper kullanırlar. Bir Kafka broker örneği, saniyede yüz binlerce okuma ve yazma işleyebilir ve her bir aracı, performans etkisi olmadan TBC iletiyi işleyebilir. Kafka broker lideri seçimi ZooKeeper tarafından yapılabilir. |
| 2 | ZooKeeper ZooKeeper, Kafka brokerini yönetmek ve koordine etmek için kullanılır. ZooKeeper hizmeti esas olarak üreticiyi ve tüketiciyi Kafka sisteminde herhangi bir yeni komisyoncunun varlığından veya Kafka sistemindeki komisyoncunun arızasından haberdar etmek için kullanılır. Zookeeper tarafından komisyoncunun varlığı veya başarısızlığı ile ilgili alınan bildirime göre, üretici ve tüketici karar alır ve diğer bir komisyoncu ile görevlerini koordine etmeye başlar. |
| 3 | Producers Üreticiler verileri aracılara aktarır. Yeni komisyoncu başlatıldığında, tüm üreticiler onu arar ve bu yeni komisyoncuya otomatik olarak bir mesaj gönderir. Kafka üreticisi, komisyoncunun onaylarını beklemez ve komisyoncunun yapabileceği en hızlı şekilde mesajlar gönderir. |
| 4 | Consumers Kafka aracıları devletsiz olduğundan, bu, tüketicinin bölme ofseti kullanarak kaç mesajın tüketildiğini sürdürmesi gerektiği anlamına gelir. Tüketici belirli bir mesaj ofsetini kabul ederse, bu, tüketicinin önceki tüm mesajları tükettiğini gösterir. Tüketici, kullanıma hazır bayt arabelleğine sahip olmak için aracıya zaman uyumsuz bir çekme isteği gönderir. Tüketiciler, sadece bir ofset değeri sağlayarak bir bölümdeki herhangi bir noktaya geri sarabilir veya atlayabilir. Tüketici ofset değeri ZooKeeper tarafından bildirilir. |
Şu an itibariyle Kafka'nın temel kavramlarını tartıştık. Şimdi Kafka'nın iş akışına biraz ışık tutalım.
Kafka, bir veya daha fazla bölüme ayrılmış bir konu koleksiyonudur. Bir Kafka bölümü, her bir mesajın kendi indeksiyle (ofset olarak adlandırılır) tanımlandığı doğrusal sıralı bir mesaj dizisidir. Bir Kafka kümesindeki tüm veriler, bölümlerin ayrık birleşimidir. Gelen mesajlar bir bölümün sonunda yazılır ve mesajlar tüketiciler tarafından sırayla okunur. Dayanıklılık, mesajların farklı aracılara kopyalanmasıyla sağlanır.
Kafka, hızlı, güvenilir, kalıcı, hata toleransı ve sıfır kesinti şeklinde hem pub-sub hem de kuyruk tabanlı mesajlaşma sistemi sağlar. Her iki durumda da, üreticiler mesajı bir konuya gönderir ve tüketici, ihtiyaçlarına bağlı olarak herhangi bir mesajlaşma sistemini seçebilir. Tüketicinin tercih ettiği mesajlaşma sistemini nasıl seçebileceğini anlamak için sonraki bölümdeki adımları takip edelim.
Pub-Sub Mesajlaşma İş Akışı
Aşağıda, Pub-Sub Mesajlaşma'nın adım adım iş akışı verilmiştir -
Yapımcılar düzenli aralıklarla bir konuya mesaj gönderirler.
Kafka aracısı, tüm mesajları o konu için yapılandırılmış bölümlerde saklar. Mesajların bölümler arasında eşit olarak paylaşılmasını sağlar. Üretici iki mesaj gönderirse ve iki bölüm varsa, Kafka bir mesajı ilk bölüme ve ikinci mesajı ikinci bölüme kaydedecektir.
Tüketici, belirli bir konuya abone olur.
Tüketici bir konuya abone olduktan sonra, Kafka konunun mevcut karşılığını tüketiciye sunacak ve aynı zamanda Zookeeper topluluğundaki ofseti kaydedecektir.
Tüketici, yeni mesajlar için Kafka'yı düzenli aralıklarla (100 Ms gibi) isteyecektir.
Kafka, üreticilerden gelen mesajları aldıktan sonra bu mesajları tüketicilere iletir.
Tüketici mesajı alacak ve işleyecektir.
Mesajlar işlendikten sonra, tüketici Kafka aracısına bir onay gönderecektir.
Kafka bir onay aldığında, ofseti yeni değere değiştirir ve Zookeeper'da günceller. Zookeeper'da ofsetler korunduğundan, tüketici sunucu kesintileri sırasında bile sonraki mesajı doğru bir şekilde okuyabilir.
Yukarıdaki akış, tüketici talebi durdurana kadar tekrarlanacaktır.
Tüketici, herhangi bir zamanda bir konunun istenen ofsetine geri sarma / atlama ve sonraki tüm mesajları okuma seçeneğine sahiptir.
Sıra Mesajlaşma / Tüketici Grubu İş Akışı
Tek bir tüketici yerine kuyruk mesajlaşma sisteminde, aynı Grup Kimliğine
sahip bir grup tüketici bir konuya abone olacaktır. Basit bir ifadeyle, aynı Grup Kimliğine
sahip bir konuya abone olan tüketiciler tek bir grup olarak kabul edilir ve mesajlar aralarında paylaşılır. Bu sistemin gerçek iş akışını kontrol edelim.
Yapımcılar düzenli aralıklarla bir konuya mesaj gönderirler.
Kafka, tüm mesajları önceki senaryoya benzer şekilde o konu için yapılandırılan bölümlerde depolar.
Belirli bir konuya tek tüketici abone, farz
Konu-01
ileGrup kimliği
olarakGrup-1
.Pub-Sub Mesajlaşma aynı şekilde tüketici ile Kafka etkileşimde yeni tüketici aynı konuyu, abone dek
Konu-01
ile aynıGrubu kimliği
olarakGrup-1
.Yeni tüketici geldiğinde Kafka, operasyonunu paylaşım moduna geçirir ve verileri iki tüketici arasında paylaşır. Bu paylaşım, tüketici sayısı o konu için yapılandırılan bölüm sayısına ulaşana kadar devam edecektir.
Tüketici sayısı bölüm sayısını aştığında, yeni tüketici, mevcut tüketicilerden herhangi biri aboneliğini iptal edene kadar başka bir mesaj almayacaktır. Bu senaryo, Kafka'daki her tüketiciye en az bir bölüm atanacağı ve tüm bölümler mevcut tüketicilere atandıktan sonra yeni tüketicilerin beklemesi gerekeceği için ortaya çıkar.
Bu özelliğe
Tüketici Grubu
da denir . Aynı şekilde Kafka, her iki sistemin de en iyisini çok basit ve verimli bir şekilde sağlayacaktır.
ZooKeeper'ın Rolü
Apache Kafka'nın kritik bir bağımlılığı, dağıtılmış bir yapılandırma ve senkronizasyon hizmeti olan Apache Zookeeper'dır. Zookeeper, Kafka brokerleri ve tüketiciler arasında koordinasyon arayüzü olarak hizmet eder. Kafka sunucuları, bir Zookeeper kümesi aracılığıyla bilgi paylaşır. Kafka, konular, aracılar, tüketici ofsetleri (kuyruk okuyucular) vb. Hakkında bilgiler gibi temel meta verileri Zookeeper'da depolar.
Tüm kritik bilgiler Zookeeper'da depolandığından ve normal olarak bu verileri topluluğu genelinde çoğalttığından, Kafka aracısının / Zookeeper'ın başarısızlığı Kafka kümesinin durumunu etkilemez. Zookeeper yeniden başladığında Kafka devleti geri yükleyecektir. Bu, Kafka için sıfır kesinti süresi sağlar. Kafka komisyoncusu arasındaki lider seçimi, lider başarısızlığı durumunda Zookeeper kullanılarak da yapılır.
Zookeeper hakkında daha fazla bilgi edinmek için lütfen hayvan bakıcısına başvurun
Bir sonraki bölümde makinenize Java, ZooKeeper ve Kafka'yı nasıl yükleyeceğinize devam edelim.
Makinenize Java yükleme adımları aşağıdadır.
Adım 1 - Java Kurulumunu Doğrulama
Umarım şu anda makinenize java yüklemişsinizdir, bu nedenle aşağıdaki komutu kullanarak bunu doğrulamanız yeterlidir.
$ java -versionJava, makinenize başarıyla yüklendiyse, yüklü Java'nın sürümünü görebilirsiniz.
Adım 1.1 - JDK'yı İndirin
Java indirilmemişse, lütfen aşağıdaki bağlantıyı ziyaret ederek en son JDK sürümünü indirin ve en son sürümü indirin.
http://www.oracle.com/technetwork/java/javase/downloads/index.htmlŞimdi en son sürüm JDK 8u 60 ve dosya "jdk-8u60-linux-x64.tar.gz". Lütfen dosyayı makinenize indirin.
Adım 1.2 - Dosyaları Çıkarın
Genel olarak, indirilen dosyalar indirilenler klasöründe saklanır, bunu doğrulayın ve aşağıdaki komutları kullanarak tar kurulumunu çıkarın.
$ cd /go/to/download/path
$ tar -zxf jdk-8u60-linux-x64.gzAdım 1.3 - Tercih Dizinine Taşı
Java'yı tüm kullanıcıların kullanımına açmak için, çıkarılan java içeriğini usr / local / java
/ klasörüne taşıyın .
$ su
password: (type password of root user)
$ mkdir /opt/jdk $ mv jdk-1.8.0_60 /opt/jdk/Adım 1.4 - Yolu ayarlayın
Yol ve JAVA_HOME değişkenlerini ayarlamak için aşağıdaki komutları ~ / .bashrc dosyasına ekleyin.
export JAVA_HOME =/usr/jdk/jdk-1.8.0_60
export PATH=$PATH:$JAVA_HOME/binŞimdi tüm değişiklikleri mevcut çalışan sisteme uygulayın.
$ source ~/.bashrcAdım 1.5 - Java Alternatifleri
Java Alternatiflerini değiştirmek için aşağıdaki komutu kullanın.
update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_60/bin/java 100Step 1.6 - Adım 1'de açıklanan doğrulama komutunu (java sürümü) kullanarak java'yı şimdi doğrulayın.
Adım 2 - ZooKeeper Framework Kurulumu
Adım 2.1 - ZooKeeper'ı İndirin
ZooKeeper çerçevesini makinenize kurmak için aşağıdaki bağlantıyı ziyaret edin ve ZooKeeper'ın en son sürümünü indirin.
http://zookeeper.apache.org/releases.htmlŞu an itibariyle, ZooKeeper'ın en son sürümü 3.4.6'dır (ZooKeeper-3.4.6.tar.gz).
Adım 2.2 - tar dosyasını çıkartın
Aşağıdaki komutu kullanarak tar dosyasını çıkarın
$ cd opt/
$ tar -zxf zookeeper-3.4.6.tar.gz $ cd zookeeper-3.4.6
$ mkdir dataAdım 2.3 - Yapılandırma Dosyası Oluşturun
Vi "conf / zoo.cfg" komutunu kullanarak conf / zoo.cfg
adlı Yapılandırma Dosyasını ve aşağıdaki tüm parametreleri başlangıç noktası olarak ayarlamak için açın.
$ vi conf/zoo.cfg
tickTime=2000
dataDir=/path/to/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2Konfigürasyon dosyası başarıyla kaydedilip terminale geri döndüğünde, zookeeper sunucusunu başlatabilirsiniz.
Adım 2.4 - ZooKeeper Sunucusunu Başlatın
$ bin/zkServer.sh startBu komutu çalıştırdıktan sonra, aşağıda gösterildiği gibi bir yanıt alacaksınız -
$ JMX enabled by default
$ Using config: /Users/../zookeeper-3.4.6/bin/../conf/zoo.cfg $ Starting zookeeper ... STARTEDAdım 2.5 - CLI'yi başlatın
$ bin/zkCli.shYukarıdaki komutu yazdıktan sonra, zookeeper sunucusuna bağlanacaksınız ve aşağıdaki yanıtı alacaksınız.
Connecting to localhost:2181
................
................
................
Welcome to ZooKeeper!
................
................
WATCHER::
WatchedEvent state:SyncConnected type: None path:null
[zk: localhost:2181(CONNECTED) 0]Adım 2.6 - Zookeeper Sunucusunu Durdurun
Sunucuyu bağladıktan ve tüm işlemleri gerçekleştirdikten sonra, zookeeper sunucusunu aşağıdaki komutla durdurabilirsiniz -
$ bin/zkServer.sh stopArtık makinenize Java ve ZooKeeper'ı başarıyla yüklediniz. Apache Kafka'yı kurma adımlarını görelim.
Adım 3 - Apache Kafka Kurulumu
Kafka'yı makinenize kurmak için aşağıdaki adımlara devam edelim.
Adım 3.1 - Kafka'yı İndirin
Kafka'yı makinenize kurmak için aşağıdaki bağlantıya tıklayın -
https://www.apache.org/dyn/closer.cgi?path=/kafka/0.9.0.0/kafka_2.11-0.9.0.0.tgzŞimdi en son sürüm, yani - kafka_2.11_0.9.0.0.tgz makinenize indirilecektir.
Adım 3.2 - tar dosyasını çıkarın
Tar dosyasını aşağıdaki komutu kullanarak çıkarın -
$ cd opt/ $ tar -zxf kafka_2.11.0.9.0.0 tar.gz
$ cd kafka_2.11.0.9.0.0Şimdi Kafka'nın son sürümünü makinenize indirdiniz.
Adım 3.3 - Sunucuyu Başlatın
Aşağıdaki komutu vererek sunucuyu başlatabilirsiniz -
$ bin/kafka-server-start.sh config/server.propertiesSunucu başladıktan sonra, ekranınızda aşağıdaki yanıtı göreceksiniz -
$ bin/kafka-server-start.sh config/server.properties
[2016-01-02 15:37:30,410] INFO KafkaConfig values:
request.timeout.ms = 30000
log.roll.hours = 168
inter.broker.protocol.version = 0.9.0.X
log.preallocate = false
security.inter.broker.protocol = PLAINTEXT
…………………………………………….
…………………………………………….Adım 4 - Sunucuyu Durdurun
Tüm işlemleri yaptıktan sonra, aşağıdaki komutu kullanarak sunucuyu durdurabilirsiniz -
$ bin/kafka-server-stop.sh config/server.propertiesKafka kurulumunu daha önce tartıştığımıza göre, bir sonraki bölümde Kafka'da temel işlemleri nasıl gerçekleştireceğimizi öğrenebiliriz.
Öncelikle, tek düğümlü tek aracı
yapılandırmasını uygulamaya başlayalım ve ardından kurulumumuzu tek düğümlü birden çok aracı yapılandırmasına geçireceğiz.
Umarım şimdiye kadar makinenize Java, ZooKeeper ve Kafka'yı yüklemişsinizdir. Kafka Küme Kurulumuna geçmeden önce, önce ZooKeeper'ınızı başlatmanız gerekir çünkü Kafka Kümesi ZooKeeper'ı kullanır.
ZooKeeper'ı başlatın
Yeni bir terminal açın ve aşağıdaki komutu yazın -
bin/zookeeper-server-start.sh config/zookeeper.propertiesKafka Broker'ı başlatmak için aşağıdaki komutu yazın -
bin/kafka-server-start.sh config/server.propertiesKafka Broker'ı başlattıktan sonra , ZooKeeper terminalinde jps
komutunu yazın ve aşağıdaki yanıtı göreceksiniz -
821 QuorumPeerMain
928 Kafka
931 JpsŞimdi, QuorumPeerMain'in ZooKeeper arka plan programı ve diğerinin Kafka arka plan programı olduğu terminalde çalışan iki arka plan programı görebilirsiniz.
Tek Düğüm-Tek Broker Yapılandırması
Bu yapılandırmada, tek bir ZooKeeper ve broker kimliği örneğiniz vardır. Yapılandırma adımları aşağıdadır -
Creating a Kafka Topic- Kafka , sunucuda konular oluşturmak için kafka-topics.sh
adlı bir komut satırı aracı sağlar. Yeni terminal açın ve aşağıdaki örneği yazın.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1
--partitions 1 --topic Hello-KafkaAz önce tek bölümlü ve çoğaltma faktörlü Hello-Kafka
adlı bir konu oluşturduk . Yukarıda oluşturulan çıktı, aşağıdaki çıktıya benzer olacaktır -
Output- Hello-Kafka
konusu oluşturuldu
Konu oluşturulduktan sonra, Kafka broker terminal penceresinde bildirimi ve config / server.properties dosyasındaki "/ tmp / kafka-logs /" içinde belirtilen oluşturulan konu için günlüğü alabilirsiniz.
Konu Listesi
Kafka sunucusundaki konuların bir listesini almak için aşağıdaki komutu kullanabilirsiniz -
Syntax
bin/kafka-topics.sh --list --zookeeper localhost:2181Output
Hello-KafkaBir konu oluşturduğumuz için, sadece Hello-Kafka'yı
listeleyecek . Diyelim ki, birden fazla konu oluşturursanız, konu adlarını çıktıda alacaksınız.
Yapımcıyı Mesaj Göndermeye Başlayın
Syntax
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic-nameYukarıdaki sözdiziminden, üretici komut satırı istemcisi için iki ana parametre gereklidir -
Broker-list- Mesajları göndermek istediğimiz aracıların listesi. Bu durumda sadece bir komisyoncumuz var. Config / server.properties dosyası, aracımızın 9092 numaralı bağlantı noktasını dinlediğini bildiğimiz için aracı bağlantı noktası kimliğini içerir, böylece bunu doğrudan belirtebilirsiniz.
Konu adı - İşte konu adı için bir örnek.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Hello-KafkaÜretici stdin'den gelen girdiyi bekleyecek ve Kafka kümesine yayınlayacaktır. Varsayılan olarak, her yeni satır yeni bir mesaj olarak yayınlanır ve ardından varsayılan üretici özellikleri config / maker.properties
dosyasında belirtilir . Şimdi, terminalde aşağıda gösterildiği gibi birkaç satır mesaj yazabilirsiniz.
Output
$ bin/kafka-console-producer.sh --broker-list localhost:9092
--topic Hello-Kafka[2016-01-16 13:50:45,931]
WARN property topic is not valid (kafka.utils.Verifia-bleProperties)
Hello
My first messageMy second messageTüketiciyi Mesaj Almaya Başlayın
Üreticiye benzer şekilde, varsayılan tüketici özellikleri config / Consumer.proper-ties
dosyasında belirtilir. Yeni bir terminal açın ve mesajları tüketmek için aşağıdaki sözdizimini yazın.
Syntax
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic topic-name
--from-beginningExample
bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic Hello-Kafka
--from-beginningOutput
Hello
My first message
My second messageSon olarak, üreticinin terminalinden mesajlar girebilir ve bunların tüketicinin terminalinde göründüğünü görebilirsiniz. Şu an itibariyle, tek bir broker ile tek düğüm kümesi hakkında çok iyi bir anlayışa sahipsiniz. Şimdi çoklu broker yapılandırmasına geçelim.
Tek Düğüm-Çoklu Aracı Yapılandırması
Çoklu aracılar kümesi kurulumuna geçmeden önce, önce ZooKeeper sunucunuzu başlatın.
Create Multiple Kafka Brokers- con-fig / server.properties dosyasında zaten bir Kafka broker örneğimiz var. Şimdi birden fazla aracı örneğine ihtiyacımız var, bu nedenle mevcut server.prop-erties dosyasını iki yeni yapılandırma dosyasına kopyalayın ve onu server-one.properties ve server-two.prop-erties olarak yeniden adlandırın. Ardından her iki yeni dosyayı düzenleyin ve aşağıdaki değişiklikleri atayın -
config / server-one.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
# The port the socket server listens on
port=9093
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-1config / server-two.properties
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=2
# The port the socket server listens on
port=9094
# A comma seperated list of directories under which to store log files
log.dirs=/tmp/kafka-logs-2Start Multiple Brokers- Üç sunucuda tüm değişiklikler yapıldıktan sonra, her aracıyı tek tek başlatmak için üç yeni terminal açın.
Broker1
bin/kafka-server-start.sh config/server.properties
Broker2
bin/kafka-server-start.sh config/server-one.properties
Broker3
bin/kafka-server-start.sh config/server-two.propertiesŞimdi makinede çalışan üç farklı brokerimiz var. Yazarak tüm artalan süreçleri kontrol etmeyi kendiniz deneyinjps ZooKeeper terminalinde, yanıtı görürsünüz.
Konu Oluşturmak
Bu konu için çoğaltma faktörü değerini üç olarak atayalım çünkü çalışan üç farklı aracımız var. İki aracınız varsa, atanan kopya değeri iki olacaktır.
Syntax
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic topic-nameExample
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3
-partitions 1 --topic MultibrokerapplicationOutput
created topic “Multibrokerapplication”Açıklayın
komutu aşağıda gösterildiği gibi akım yarattı konuda dinlediği komisyoncu kontrol etmek için kullanılır -
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cationOutput
bin/kafka-topics.sh --describe --zookeeper localhost:2181
--topic Multibrokerappli-cation
Topic:Multibrokerapplication PartitionCount:1
ReplicationFactor:3 Configs:
Topic:Multibrokerapplication Partition:0 Leader:0
Replicas:0,2,1 Isr:0,2,1Yukarıdaki çıktıdan, ilk satırın, konu adını, bölüm sayısını ve daha önce seçmiş olduğumuz çoğaltma faktörünü gösteren tüm bölümlerin bir özetini verdiği sonucuna varabiliriz. İkinci satırda, her bir düğüm, bölümlerin rastgele seçilen bir kısmı için lider olacaktır.
Bizim durumumuzda, ilk brokerimizin (broker.id 0 ile) lider olduğunu görüyoruz. O zaman Kopyalar: 0,2,1, tüm aracıların konuyu çoğalttığı anlamına gelir ve nihayet Isr
, eşzamanlı
çoğaltma kümesidir . Bu, şu anda hayatta olan ve lider tarafından yakalanan kopyaların alt kümesidir.
Yapımcıyı Mesaj Göndermeye Başlayın
Bu prosedür, tek aracı kuruluşundakiyle aynı kalır.
Example
bin/kafka-console-producer.sh --broker-list localhost:9092
--topic MultibrokerapplicationOutput
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic Multibrokerapplication
[2016-01-20 19:27:21,045] WARN Property topic is not valid (kafka.utils.Verifia-bleProperties)
This is single node-multi broker demo
This is the second messageTüketiciyi Mesaj Almaya Başlayın
Bu yordam, tek aracı kuruluşunda gösterilenle aynı kalır.
Example
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion --from-beginningOutput
bin/kafka-console-consumer.sh --zookeeper localhost:2181
—topic Multibrokerapplica-tion —from-beginning
This is single node-multi broker demo
This is the second messageTemel Konu İşlemleri
Bu bölümde çeşitli temel konu işlemlerini tartışacağız.
Bir Konuyu Değiştirme
Kafka Kümesi'nde nasıl konu oluşturulacağını zaten anladığınız gibi. Şimdi oluşturulmuş bir konuyu aşağıdaki komutu kullanarak değiştirelim
Syntax
bin/kafka-topics.sh —zookeeper localhost:2181 --alter --topic topic_name
--parti-tions countExample
We have already created a topic “Hello-Kafka” with single partition count and one replica factor.
Now using “alter” command we have changed the partition count.
bin/kafka-topics.sh --zookeeper localhost:2181
--alter --topic Hello-kafka --parti-tions 2Output
WARNING: If partitions are increased for a topic that has a key,
the partition logic or ordering of the messages will be affected
Adding partitions succeeded!Bir Konuyu Silme
Bir konuyu silmek için aşağıdaki sözdizimini kullanabilirsiniz.
Syntax
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic topic_nameExample
bin/kafka-topics.sh --zookeeper localhost:2181 --delete --topic Hello-kafkaOutput
> Topic Hello-kafka marked for deletionNote −Bunun hiçbir etkisi olmayacak, eğer delete.topic.enable doğru olarak ayarlanmadı
Java istemcisi kullanarak mesajları yayınlamak ve tüketmek için bir uygulama oluşturalım. Kafka üretici istemcisi aşağıdaki API'lerden oluşur.
KafkaProducer API
Bu bölümdeki en önemli Kafka üretici API kümesini anlayalım. KafkaProducer API'nin merkezi kısmı, KafkaProducer
sınıfıdır. KafkaProducer sınıfı, yapıcısındaki bir Kafka aracısını aşağıdaki yöntemlerle bağlama seçeneği sağlar.
KafkaProducer sınıfı, iletileri bir konuya eşzamansız olarak göndermek için gönderme yöntemi sağlar. Send () imzası aşağıdaki gibidir
producer.send(new ProducerRecord<byte[],byte[]>(topic,
partition, key1, value1) , callback);ProducerRecord - Üretici gönderilmeyi bekleyen bir kayıt tamponunu yönetir.
Callback - Kayıt sunucu tarafından onaylandığında yürütülecek kullanıcı tarafından sağlanan bir geri arama (boş, geri arama olmadığını gösterir).
KafkaProducer sınıfı, önceden gönderilen tüm iletilerin gerçekten tamamlandığından emin olmak için bir temizleme yöntemi sağlar. Flush yönteminin sözdizimi aşağıdaki gibidir -
public void flush()KafkaProducer sınıfı, belirli bir konu için bölüm meta verilerini elde etmeye yardımcı olan partitionFor yöntemini sağlar. Bu, özel bölümleme için kullanılabilir. Bu yöntemin imzası aşağıdaki gibidir -
public Map metrics()Üretici tarafından tutulan dahili ölçümlerin haritasını döndürür.
public void close () - KafkaProducer sınıfı, önceden gönderilen tüm istekler tamamlanıncaya kadar yakın yöntem blokları sağlar.
Üretici API'si
Producer API'nin merkezi kısmı, Üretici
sınıfıdır. Üretici sınıfı, aşağıdaki yöntemlerle yapıcısındaki Kafka aracısını bağlama seçeneği sunar.
Üretici Sınıfı
Üretici sınıfı, send Aşağıdaki imzaları kullanarak tek veya birden çok konuya mesaj gönderebilirsiniz.
public void send(KeyedMessaget<k,v> message)
- sends the data to a single topic,par-titioned by key using either sync or async producer.
public void send(List<KeyedMessage<k,v>>messages)
- sends data to multiple topics.
Properties prop = new Properties();
prop.put(producer.type,”async”)
ProducerConfig config = new ProducerConfig(prop);İki tür üretici vardır - Sync ve Async.
Aynı API yapılandırması, Sync
üreticisi için de geçerlidir . Aralarındaki fark, bir senkronizasyon üreticisinin mesajları doğrudan göndermesi, ancak mesajları arka planda göndermesidir. Daha yüksek bir iş hacmi istediğinizde zaman uyumsuz üretici tercih edilir. 0.8 gibi önceki sürümlerde, zaman uyumsuz bir üreticinin hata işleyicileri kaydetmek için send () için bir geri araması yoktur. Bu yalnızca mevcut 0.9 sürümünde mevcuttur.
public void close ()
Üretici sınıfı sağlar close tüm Kafka brokerlerine üretici havuzu bağlantılarını kapatma yöntemi.
Yapılandırma ayarları
Daha iyi anlaşılması için Producer API'nin ana yapılandırma ayarları aşağıdaki tabloda listelenmiştir -
| S.No | Yapılandırma Ayarları ve Açıklama |
|---|---|
| 1 | client.id üretici uygulamasını tanımlar |
| 2 | producer.type eşzamanlı veya eşzamansız |
| 3 | acks Acks yapılandırması, üretici talepleri altındaki kriterlerin eksiksiz olarak kabul edilir. |
| 4 | retries Üretici talebi başarısız olursa, otomatik olarak belirli bir değerle yeniden deneyin. |
| 5 | bootstrap.servers aracıların önyükleme listesi. |
| 6 | linger.ms istek sayısını azaltmak istiyorsanız, linger.ms'yi belirli bir değerden daha büyük bir değere ayarlayabilirsiniz. |
| 7 | key.serializer Serileştirici arabirimi anahtarı. |
| 8 | value.serializer serileştirici arabirimi için değer. |
| 9 | batch.size Tampon boyutu. |
| 10 | buffer.memory üreticinin arabellekleme için kullanabileceği toplam bellek miktarını kontrol eder. |
ProducerRecord API
ProducerRecord, aşağıdaki imzayı kullanarak bölüm, anahtar ve değer çiftleri ile bir kayıt oluşturmak için Kafka cluster.ProducerRecord sınıf yapıcısına gönderilen bir anahtar / değer çiftidir.
public ProducerRecord (string topic, int partition, k key, v value)Topic - kayda eklenecek kullanıcı tanımlı konu adı.
Partition - bölüm sayısı
Key - Kayda dahil edilecek anahtar.
- Value - İçeriği kaydedin
public ProducerRecord (string topic, k key, v value)ProducerRecord sınıf yapıcısı, anahtarlı, değer çiftli ve bölümsüz bir kayıt oluşturmak için kullanılır.
Topic - Kayıt atamak için bir konu oluşturun.
Key - kaydın anahtarı.
Value - içeriği kaydedin.
public ProducerRecord (string topic, v value)ProducerRecord sınıfı, bölüm ve anahtarsız bir kayıt oluşturur.
Topic - bir konu oluşturun.
Value - içeriği kaydedin.
ProducerRecord sınıfı yöntemleri aşağıdaki tabloda listelenmiştir -
| S.No | Sınıf Yöntemleri ve Açıklama |
|---|---|
| 1 | public string topic() Konu kayda eklenecek. |
| 2 | public K key() Kayda dahil edilecek anahtar. Böyle bir anahtar yoksa, burada null yeniden döndürülecektir. |
| 3 | public V value() İçeriği kaydedin. |
| 4 | partition() Kayıt için bölüm sayısı |
SimpleProducer uygulaması
Uygulamayı oluşturmadan önce, önce ZooKeeper ve Kafka broker'ı başlatın, ardından create topic komutunu kullanarak Kafka broker'da kendi konunuzu oluşturun. Bundan sonra Sim-pleProducer.java
adında bir java sınıfı oluşturun ve aşağıdaki kodlamayı yazın.
//import util.properties packages
import java.util.Properties;
//import simple producer packages
import org.apache.kafka.clients.producer.Producer;
//import KafkaProducer packages
import org.apache.kafka.clients.producer.KafkaProducer;
//import ProducerRecord packages
import org.apache.kafka.clients.producer.ProducerRecord;
//Create java class named “SimpleProducer”
public class SimpleProducer {
public static void main(String[] args) throws Exception{
// Check arguments length value
if(args.length == 0){
System.out.println("Enter topic name”);
return;
}
//Assign topicName to string variable
String topicName = args[0].toString();
// create instance for properties to access producer configs
Properties props = new Properties();
//Assign localhost id
props.put("bootstrap.servers", “localhost:9092");
//Set acknowledgements for producer requests.
props.put("acks", “all");
//If the request fails, the producer can automatically retry,
props.put("retries", 0);
//Specify buffer size in config
props.put("batch.size", 16384);
//Reduce the no of requests less than 0
props.put("linger.ms", 1);
//The buffer.memory controls the total amount of memory available to the producer for buffering.
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer
<String, String>(props);
for(int i = 0; i < 10; i++)
producer.send(new ProducerRecord<String, String>(topicName,
Integer.toString(i), Integer.toString(i)));
System.out.println(“Message sent successfully”);
producer.close();
}
}Compilation - Uygulama aşağıdaki komut kullanılarak derlenebilir.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution - Uygulama aşağıdaki komut kullanılarak yürütülebilir.
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleProducer <topic-name>Output
Message sent successfully
To check the above output open new terminal and type Consumer CLI command to receive messages.
>> bin/kafka-console-consumer.sh --zookeeper localhost:2181 —topic <topic-name> —from-beginning
1
2
3
4
5
6
7
8
9
10Basit Tüketici Örneği
Şu an itibariyle Kafka kümesine mesaj gönderecek bir üretici oluşturduk. Şimdi Kafka kümesinden gelen mesajları tüketecek bir tüketici oluşturalım. KafkaConsumer API, Kafka kümesinden gelen mesajları tüketmek için kullanılır. KafkaConsumer sınıfı yapıcısı aşağıda tanımlanmıştır.
public KafkaConsumer(java.util.Map<java.lang.String,java.lang.Object> configs)configs - Tüketici yapılandırmalarının bir haritasını döndürür.
KafkaConsumer sınıfı, aşağıdaki tabloda listelenen aşağıdaki önemli yöntemlere sahiptir.
| S.No | Yöntem ve Açıklama |
|---|---|
| 1 | public java.util.Set<TopicPar-tition> assignment() Tüketici tarafından şu anda atanan bölüm kümesini alın. |
| 2 | public string subscription() Dinamik olarak imzalanmış bölümler almak için verilen konu listesine abone olun. |
| 3 | public void sub-scribe(java.util.List<java.lang.String> topics, ConsumerRe-balanceListener listener) Dinamik olarak imzalanmış bölümler almak için verilen konu listesine abone olun. |
| 4 | public void unsubscribe() Verilen bölümler listesindeki konuların aboneliğini kaldırın. |
| 5 | public void sub-scribe(java.util.List<java.lang.String> topics) Dinamik olarak imzalanmış bölümler almak için verilen konu listesine abone olun. Verilen konu listesi boşsa, unsubscribe () ile aynı şekilde değerlendirilir. |
| 6 | public void sub-scribe(java.util.regex.Pattern pattern, ConsumerRebalanceLis-tener listener) Argüman modeli, düzenli ifade formatındaki abone modeline atıfta bulunur ve dinleyici argümanı abone modelinden bildirimler alır. |
| 7 | public void as-sign(java.util.List<TopicParti-tion> partitions) Müşteriye manuel olarak bölüm listesi atayın. |
| 8 | poll() Abone olma / atama API'lerinden birini kullanarak belirtilen konular veya bölümler için verileri alın. Veri yoklamasından önce konular abone olunmazsa bu hata verir. |
| 9 | public void commitSync() Konuların ve bölümlerin tüm alt karalanmış listesi için son ankette () döndürülen kaydetme ofsetleri. Aynı işlem commitAsyn () için de uygulanır. |
| 10 | public void seek(TopicPartition partition, long offset) Tüketicinin bir sonraki anket () yönteminde kullanacağı mevcut göreli konum değerini getir. |
| 11 | public void resume() Duraklatılan bölümleri devam ettirin. |
| 12 | public void wakeup() Tüketiciyi uyandırın. |
ConsumerRecord API
ConsumerRecord API, Kafka kümesinden kayıtları almak için kullanılır. Bu API, kaydın alındığı bir konu adı, bölüm numarası ve bir Kafka bölümündeki kayda işaret eden bir ofsetten oluşur. ConsumerRecord sınıfı, belirli konu adı, bölüm sayısı ve <anahtar, değer> çiftleriyle bir tüketici kaydı oluşturmak için kullanılır. Aşağıdaki imzaya sahiptir.
public ConsumerRecord(string topic,int partition, long offset,K key, V value)Topic - Kafka kümesinden alınan tüketici kaydı için konu adı.
Partition - Konu için bölüm.
Key - Anahtar yoksa, kaydın anahtarı boş döndürülür.
Value - İçeriği kaydedin.
ConsumerRecords API
ConsumerRecords API, ConsumerRecord için bir kapsayıcı görevi görür. Bu API, belirli bir konu için bölüm başına Tüketici Kaydı listesini tutmak için kullanılır. Yapıcısı aşağıda tanımlanmıştır.
public ConsumerRecords(java.util.Map<TopicPartition,java.util.List
<Consumer-Record>K,V>>> records)TopicPartition - Belirli bir konu için bir bölüm haritası döndürür.
Records - ConsumerRecord'un iade listesi.
ConsumerRecords sınıfı aşağıdaki yöntemlere sahiptir.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | public int count() Tüm konular için kayıt sayısı. |
| 2 | public Set partitions() Bu kayıt kümesindeki verilere sahip bölümler kümesi (veri döndürülmediyse küme boştur). |
| 3 | public Iterator iterator() Yineleyici, bir koleksiyonda gezinmenizi, öğeleri elde etmenizi veya yeniden hareket ettirmenizi sağlar. |
| 4 | public List records() Verilen bölüm için kayıtların listesini alın. |
Yapılandırma ayarları
Tüketici istemcisi API ana yapılandırma ayarları için yapılandırma ayarları aşağıda listelenmiştir -
| S.No | Ayarlar ve Açıklama |
|---|---|
| 1 | bootstrap.servers Aracıların önyükleme listesi. |
| 2 | group.id Bireysel bir tüketiciyi bir gruba atar. |
| 3 | enable.auto.commit Değer doğruysa, aksi takdirde taahhüt edilmemişse ofsetler için otomatik kesinlemeyi etkinleştirin. |
| 4 | auto.commit.interval.ms ZooKeeper'a ne sıklıkla güncellenen tüketilen ofsetlerin yazıldığını döndürür. |
| 5 | session.timeout.ms Mesajları bırakmadan ve tüketmeye devam etmeden önce Kafka'nın ZooKeeper'ın bir isteğe yanıt vermesini (okuma veya yazma) kaç milisaniye bekleyeceğini belirtir. |
SimpleConsumer Uygulaması
Üretici başvuru adımları burada aynı kalır. İlk önce ZooKeeper ve Kafka brokerınızı başlatın. Sonra oluşturmak SimpleConsumer
adlı java sınıfı ile uygulamayı SimpleCon-sumer.java
ve aşağıdaki kodu yazın.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class SimpleConsumer {
public static void main(String[] args) throws Exception {
if(args.length == 0){
System.out.println("Enter topic name");
return;
}
//Kafka consumer configuration settings
String topicName = args[0].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer
<String, String>(props);
//Kafka Consumer subscribes list of topics here.
consumer.subscribe(Arrays.asList(topicName))
//print the topic name
System.out.println("Subscribed to topic " + topicName);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = con-sumer.poll(100);
for (ConsumerRecord<String, String> record : records)
// print the offset,key and value for the consumer records.
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Compilation - Uygulama aşağıdaki komut kullanılarak derlenebilir.
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*” *.javaExecution − Uygulama aşağıdaki komut kullanılarak yürütülebilir
java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/lib/*”:. SimpleConsumer <topic-name>Input- Üretici CLI'yi açın ve konuya bazı mesajlar gönderin. Smple girişini 'Merhaba Tüketici' olarak koyabilirsiniz.
Output - Aşağıdakiler çıktı olacaktır.
Subscribed to topic Hello-Kafka
offset = 3, key = null, value = Hello ConsumerTüketici grubu, Kafka konularından çok iş parçacıklı veya çok makineli bir tüketimdir.
Tüketici Grubu
Tüketiciler, aynı
group.id adresini
kullanarak bir gruba katılabilir.
Bir grubun maksimum paralelliği, gruptaki tüketici sayısı ← bölüm sayısıdır.
Kafka, bir konunun bölümlerini bir gruptaki tüketiciye atar, böylece her bölüm gruptaki tam olarak bir tüketici tarafından tüketilir.
Kafka, bir mesajın yalnızca gruptaki tek bir tüketici tarafından okunacağını garanti eder.
Tüketiciler, mesajı günlükte saklandıkları sırayla görebilirler.
Bir Tüketicinin Yeniden Dengelenmesi
Daha fazla süreç / iş parçacığı eklemek Kafka'nın yeniden dengelenmesine neden olacaktır. Herhangi bir tüketici veya komisyoncu ZooKeeper'a sinyal gönderemezse, Kafka kümesi aracılığıyla yeniden yapılandırılabilir. Bu yeniden dengeleme sırasında Kafka, mevcut bölümleri mevcut iş parçacıkları için atayacak ve muhtemelen bir bölümü başka bir işleme taşıyacaktır.
import java.util.Properties;
import java.util.Arrays;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class ConsumerGroup {
public static void main(String[] args) throws Exception {
if(args.length < 2){
System.out.println("Usage: consumer <topic> <groupname>");
return;
}
String topic = args[0].toString();
String group = args[1].toString();
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", group);
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.ByteArraySerializer");
props.put("value.deserializer",
"org.apache.kafka.common.serializa-tion.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topic));
System.out.println("Subscribed to topic " + topic);
int i = 0;
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s\n",
record.offset(), record.key(), record.value());
}
}
}Derleme
javac -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*" ConsumerGroup.javaYürütme
>>java -cp “/path/to/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-group
>>java -cp "/home/bala/Workspace/kafka/kafka_2.11-0.9.0.0/libs/*":.
ConsumerGroup <topic-name> my-groupBurada , iki tüketicili my-group
olarak bir örnek grup adı oluşturduk . Benzer şekilde, grubunuzu ve gruptaki tüketici sayısını oluşturabilirsiniz.
Giriş
Üretici CLI'yi açın ve aşağıdakiler gibi bazı mesajlar gönderin:
Test consumer group 01
Test consumer group 02İlk İşlemin Çıktısı
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 01İkinci Sürecin Çıktısı
Subscribed to topic Hello-kafka
offset = 3, key = null, value = Test consumer group 02Şimdi umarım SimpleConsumer ve ConsumeGroup'u Java istemci demosunu kullanarak anlamışsınızdır. Artık bir Java istemcisi kullanarak nasıl mesaj gönderip alacağınız hakkında bir fikriniz var. Bir sonraki bölümde büyük veri teknolojileri ile Kafka entegrasyonuna devam edelim.
Bu bölümde Kafka'yı Apache Storm ile nasıl entegre edeceğimizi öğreneceğiz.
Storm hakkında
Storm, başlangıçta Nathan Marz ve BackType ekibi tarafından oluşturuldu. Kısa sürede Apache Storm, büyük hacimli verileri işlemenizi sağlayan dağıtılmış gerçek zamanlı işleme sistemi için bir standart haline geldi. Fırtına çok hızlı ve bir kıyaslama, düğüm başına saniyede işlenen bir milyondan fazla tuple saat hızına ulaştı. Apache Storm, yapılandırılmış kaynaklardan (Spouts) gelen verileri tüketerek sürekli çalışır ve verileri işleme hattından (Cıvatalar) geçirir. Kombine, Musluklar ve Cıvatalar bir Topoloji oluşturur.
Storm ile entegrasyon
Kafka ve Storm doğal olarak birbirini tamamlar ve güçlü işbirliği, hızlı hareket eden büyük veriler için gerçek zamanlı akış analitiği sağlar. Kafka ve Storm entegrasyonu, geliştiricilerin Storm topolojilerinden veri akışlarını almasını ve yayınlamasını kolaylaştırmak içindir.
Kavramsal akış
Bir musluk, bir akış kaynağıdır. Örneğin, bir ağzı bir Kafka Konusundaki tupl'leri okuyabilir ve bunları bir akış olarak yayınlayabilir. Bir cıvata, giriş akışlarını tüketir, işler ve muhtemelen yeni akışlar yayar. Cıvatalar, çalışan işlevlerden, tuple'ları filtrelemeye, akış toplama işlemlerine, akışa katılmalara, veritabanlarıyla konuşmaya ve daha fazlasına kadar her şeyi yapabilir. Bir Storm topolojisindeki her düğüm paralel olarak çalışır. Bir topoloji, siz onu sonlandırana kadar süresiz olarak çalışır. Storm, başarısız olan tüm görevleri otomatik olarak yeniden atayacaktır. Ek olarak Storm, makineler çökse ve mesajlar atılsa bile veri kaybı olmayacağını garanti ediyor.
Kafka-Storm entegrasyon API'lerini detaylı olarak inceleyelim. Kafka'yı Storm ile entegre etmek için üç ana sınıf vardır. Bunlar aşağıdaki gibidir -
BrokerHosts - ZkHosts & StaticHosts
BrokerHosts bir arayüzdür ve ZkHosts ve StaticHosts iki ana uygulamasıdır. ZkHosts, ZooKeeper'daki ayrıntıları koruyarak Kafka brokerlerini dinamik olarak izlemek için kullanılırken, StaticHosts Kafka brokerlerini ve ayrıntılarını manuel / statik olarak ayarlamak için kullanılır. ZkHosts, Kafka brokerine erişmenin basit ve hızlı yoludur.
ZkHosts'un imzası aşağıdaki gibidir -
public ZkHosts(String brokerZkStr, String brokerZkPath)
public ZkHosts(String brokerZkStr)BrokerZkStr'in ZooKeeper ana bilgisayarı ve broker olduğu durumlarda, ZkPath, Kafka broker ayrıntılarını korumak için ZooKeeper yoludur.
KafkaConfig API
Bu API, Kafka kümesinin yapılandırma ayarlarını tanımlamak için kullanılır. Kafka Con-fig imzası şu şekilde tanımlanır
public KafkaConfig(BrokerHosts hosts, string topic)Hosts - BrokerHosts, ZkHosts / StaticHosts olabilir.
Topic - konu adı.
SpoutConfig API
Spoutconfig, ek ZooKeeper bilgilerini destekleyen KafkaConfig'in bir uzantısıdır.
public SpoutConfig(BrokerHosts hosts, string topic, string zkRoot, string id)Hosts - BrokerHosts, BrokerHosts arayüzünün herhangi bir uygulaması olabilir
Topic - konu adı.
zkRoot - ZooKeeper kök yolu.
id −Çıkış ucu Zookeeper'da tüketilen ofsetlerin durumunu depolar. Kimlik, ağzınızı benzersiz şekilde tanımlamalıdır.
SchemeAsMultiScheme
SchemeAsMultiScheme, Kafka'dan tüketilen ByteBuffer'ın nasıl bir fırtına demetine dönüştürüldüğünü belirleyen bir arabirimdir. MultiScheme'den türetilmiştir ve Scheme sınıfının uygulanmasını kabul eder. Scheme sınıfının birçok uygulaması vardır ve böyle bir uygulama, baytı basit bir dizge olarak ayrıştıran StringScheme'dir. Ayrıca çıktı alanınızın adlandırılmasını da kontrol eder. İmza aşağıdaki gibi tanımlanır.
public SchemeAsMultiScheme(Scheme scheme)Scheme - kafka'dan tüketilen bayt arabelleği.
KafkaSpout API
KafkaSpout, Storm ile entegre olacak emzik uygulamamızdır. Kafka konusundan mesajları alıp Storm ekosistemine tuple olarak yayar. KafkaSpout yapılandırma ayrıntılarını SpoutConfig'den alır.
Aşağıda basit bir Kafka ağzı oluşturmak için örnek bir kod verilmiştir.
// ZooKeeper connection string
BrokerHosts hosts = new ZkHosts(zkConnString);
//Creating SpoutConfig Object
SpoutConfig spoutConfig = new SpoutConfig(hosts,
topicName, "/" + topicName UUID.randomUUID().toString());
//convert the ByteBuffer to String.
spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
//Assign SpoutConfig to KafkaSpout.
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);Bolt Oluşturma
Bolt, tuple'ları girdi olarak alan, tuple'ı işleyen ve çıktı olarak yeni tuples üreten bir bileşendir. Cıvatalar IRichBolt arayüzünü uygulayacaktır. Bu programda işlemleri gerçekleştirmek için WordSplitter-Bolt ve WordCounterBolt olmak üzere iki cıvata sınıfı kullanılmaktadır.
IRichBolt arayüzü aşağıdaki yöntemlere sahiptir -
Prepare- Cıvataya uygulanacak bir ortam sağlar. Uygulayıcılar, musluğu başlatmak için bu yöntemi çalıştıracaktır.
Execute - Tek bir giriş demeti işleyin.
Cleanup - Bir cıvata kapanacağı zaman çağrılır.
declareOutputFields - Demetin çıktı şemasını bildirir.
Bir cümleyi kelimelere ayırma mantığını uygulayan SplitBolt.java'yı ve benzersiz kelimeleri ayırmak ve oluşumlarını saymak için mantığı uygulayan CountBolt.java'yı oluşturalım.
SplitBolt.java
import java.util.Map;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class SplitBolt implements IRichBolt {
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for(String word: words) {
word = word.trim();
if(!word.isEmpty()) {
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
collector.ack(input);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
@Override
public void cleanup() {}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}CountBolt.java
import java.util.Map;
import java.util.HashMap;
import backtype.storm.tuple.Tuple;
import backtype.storm.task.OutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.IRichBolt;
import backtype.storm.task.TopologyContext;
public class CountBolt implements IRichBolt{
Map<String, Integer> counters;
private OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.counters = new HashMap<String, Integer>();
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String str = input.getString(0);
if(!counters.containsKey(str)){
counters.put(str, 1);
}else {
Integer c = counters.get(str) +1;
counters.put(str, c);
}
collector.ack(input);
}
@Override
public void cleanup() {
for(Map.Entry<String, Integer> entry:counters.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}Topolojiye Gönderme
Fırtına topolojisi temelde bir Thrift yapısıdır. TopologyBuilder sınıfı, karmaşık topolojiler oluşturmak için basit ve kolay yöntemler sağlar. TopologyBuilder sınıfı, musluğu (setSpout) ve cıvatayı (setBolt) ayarlama yöntemlerine sahiptir. Son olarak, TopologyBuilder, to-pology oluşturmak için createTopology'ye sahiptir. shuffleGrouping ve FieldsGrouping yöntemleri, ağız ve cıvatalar için akış gruplamasının ayarlanmasına yardımcı olur.
Local Cluster- Geliştirme amacıyla, LocalCluster
nesnesini kullanarak yerel bir küme oluşturabilir ve ardından LocalCluster
sınıfının submitTopology
yöntemini kullanarak topolojiyi sunabiliriz .
KafkaStormSample.java
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import backtype.storm.spout.SchemeAsMultiScheme;
import storm.kafka.trident.GlobalPartitionInformation;
import storm.kafka.ZkHosts;
import storm.kafka.Broker;
import storm.kafka.StaticHosts;
import storm.kafka.BrokerHosts;
import storm.kafka.SpoutConfig;
import storm.kafka.KafkaConfig;
import storm.kafka.KafkaSpout;
import storm.kafka.StringScheme;
public class KafkaStormSample {
public static void main(String[] args) throws Exception{
Config config = new Config();
config.setDebug(true);
config.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
String zkConnString = "localhost:2181";
String topic = "my-first-topic";
BrokerHosts hosts = new ZkHosts(zkConnString);
SpoutConfig kafkaSpoutConfig = new SpoutConfig (hosts, topic, "/" + topic,
UUID.randomUUID().toString());
kafkaSpoutConfig.bufferSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.fetchSizeBytes = 1024 * 1024 * 4;
kafkaSpoutConfig.forceFromStart = true;
kafkaSpoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("kafka-spout", new KafkaSpout(kafkaSpoutCon-fig));
builder.setBolt("word-spitter", new SplitBolt()).shuffleGroup-ing("kafka-spout");
builder.setBolt("word-counter", new CountBolt()).shuffleGroup-ing("word-spitter");
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("KafkaStormSample", config, builder.create-Topology());
Thread.sleep(10000);
cluster.shutdown();
}
}Derlemeyi taşımadan önce, Kakfa-Storm entegrasyonunun küratör ZooKeeper istemci java kitaplığına ihtiyacı vardır. Küratör sürüm 2.9.1, Apache Storm sürüm 0.9.5'i destekler (bu eğiticide kullandığımız). Aşağıda belirtilen jar dosyalarını indirin ve java sınıf yoluna yerleştirin.
- curator-client-2.9.1.jar
- curator-framework-2.9.1.jar
Bağımlılık dosyalarını ekledikten sonra, aşağıdaki komutu kullanarak programı derleyin,
javac -cp "/path/to/Kafka/apache-storm-0.9.5/lib/*" *.javaYürütme
Kafka Producer CLI'yi başlatın (önceki bölümde açıklanmıştır), my-first-topic
adında yeni bir konu oluşturun ve aşağıda gösterildiği gibi bazı örnek mesajlar sağlayın -
hello
kafka
storm
spark
test message
another test messageŞimdi aşağıdaki komutu kullanarak uygulamayı çalıştırın -
java -cp “/path/to/Kafka/apache-storm-0.9.5/lib/*”:. KafkaStormSampleBu uygulamanın örnek çıktısı aşağıda belirtilmiştir -
storm : 1
test : 2
spark : 1
another : 1
kafka : 1
hello : 1
message : 2Bu bölümde Apache Kafka'nın Spark Streaming API ile nasıl entegre edileceğini tartışacağız.
Spark hakkında
Spark Streaming API, canlı veri akışlarının ölçeklenebilir, yüksek verimli, hataya dayanıklı akış işlemesini sağlar. Veriler Kafka, Flume, Twitter vb. Birçok kaynaktan alınabilir ve harita, azaltma, birleştirme ve pencere gibi üst düzey işlevler gibi karmaşık algoritmalar kullanılarak işlenebilir. Son olarak, işlenen veriler dosya sistemlerine, veri tabanlarına ve canlı gösterge panolarına gönderilebilir. Esnek Dağıtılmış Veri Kümeleri (RDD), Spark'ın temel bir veri yapısıdır. Değişmez dağıtılmış nesneler koleksiyonudur. RDD'deki her veri kümesi, kümenin farklı düğümlerinde hesaplanabilen mantıksal bölümlere bölünmüştür.
Spark ile entegrasyon
Kafka, Spark akışı için potansiyel bir mesajlaşma ve entegrasyon platformudur. Kafka, gerçek zamanlı veri akışları için merkezi bir merkez görevi görür ve Spark Streaming'de karmaşık algoritmalar kullanılarak işlenir. Veriler işlendikten sonra, Spark Streaming sonuçları başka bir Kafka konusunda yayınlıyor olabilir veya HDFS'de, veritabanlarında veya kontrol panellerinde depolayabilir. Aşağıdaki şema kavramsal akışı göstermektedir.

Şimdi Kafka-Spark API'lerini detaylı olarak inceleyelim.
SparkConf API
Bir Spark uygulaması için yapılandırmayı temsil eder. Çeşitli Spark parametrelerini anahtar-değer çiftleri olarak ayarlamak için kullanılır.
SparkConf
sınıfı aşağıdaki yöntemlere sahiptir -
set(string key, string value) - yapılandırma değişkenini ayarlayın.
remove(string key) - anahtarı yapılandırmadan çıkarın.
setAppName(string name) - uygulamanız için uygulama adını ayarlayın.
get(string key) - anahtarı al
StreamingContext API
Bu, Spark işlevselliği için ana giriş noktasıdır. SparkContext, bir Spark kümesine olan bağlantıyı temsil eder ve kümede RDD'ler, toplayıcılar ve yayın değişkenleri oluşturmak için kullanılabilir. İmza aşağıda gösterildiği gibi tanımlanır.
public StreamingContext(String master, String appName, Duration batchDuration,
String sparkHome, scala.collection.Seq<String> jars,
scala.collection.Map<String,String> environment)master - bağlanılacak küme URL'si (ör. Mesos: // ana bilgisayar: bağlantı noktası, kıvılcım: // ana bilgisayar: bağlantı noktası, yerel [4]).
appName - küme web kullanıcı arayüzünde görüntülenecek, işinizin adı
batchDuration - akış verilerinin gruplara bölüneceği zaman aralığı
public StreamingContext(SparkConf conf, Duration batchDuration)Yeni bir SparkContext için gerekli yapılandırmayı sağlayarak bir StreamingContext oluşturun.
conf - Kıvılcım parametreleri
batchDuration - akış verilerinin gruplara bölüneceği zaman aralığı
KafkaUtils API
KafkaUtils API, Kafka kümesini Spark akışına bağlamak için kullanılır. Bu API, aşağıdaki gibi tanımlanan createStream
imzasının önemli yöntemine sahiptir
.
public static ReceiverInputDStream<scala.Tuple2<String,String>> createStream(
StreamingContext ssc, String zkQuorum, String groupId,
scala.collection.immutable.Map<String,Object> topics, StorageLevel storageLevel)Yukarıda gösterilen yöntem, Kafka Brokers'tan mesajları çeken bir giriş akışı oluşturmak için kullanılır.
ssc - StreamingContext nesnesi.
zkQuorum - Hayvan bakıcısı yeter sayısı.
groupId - Bu tüketicinin grup kimliği.
topics - tüketilecek konuların bir haritasını döndürür.
storageLevel - Alınan nesneleri saklamak için kullanılacak depolama seviyesi.
KafkaUtils API, herhangi bir alıcı kullanmadan Kafka Brokers'tan mesajları doğrudan çeken bir giriş akışı oluşturmak için kullanılan başka bir createDirectStream yöntemine sahiptir. Bu akış, Kafka'dan gelen her mesajın dönüşümlere tam olarak bir kez dahil edilmesini garanti edebilir.
Örnek uygulama Scala'da yapılmıştır. Uygulamayı derlemek için lütfen sbt
, scala build tool ( maven'e
benzer) indirip kurun . Ana uygulama kodu aşağıda sunulmuştur.
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, Produc-erRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum><group> <topics> <numThreads>")
System.exit(1)
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}Komut Dosyası Oluştur
Kıvılcım-kafka entegrasyonu kıvılcım, kıvılcım akışı ve kıvılcım Kafka entegrasyon kavanozuna bağlıdır. Yeni bir build.sbt
dosyası oluşturun
ve uygulama ayrıntılarını ve bağımlılığını belirtin. Sbt
derleme ve uygulama paketleme sırasında gerekli kavanoz indirecektir.
name := "Spark Kafka Project"
version := "1.0"
scalaVersion := "2.10.5"
libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "1.6.0"
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka" % "1.6.0"Derleme / Paketleme
Uygulamanın jar dosyasını derlemek ve paketlemek için aşağıdaki komutu çalıştırın. Uygulamayı çalıştırmak için jar dosyasını spark konsoluna göndermemiz gerekiyor.
sbt packageSpark'a gönderiliyor
Kafka Producer CLI'yi başlatın (önceki bölümde açıklanmıştır), my-first-topic
adlı yeni bir konu oluşturun ve aşağıda gösterildiği gibi bazı örnek mesajlar sağlayın.
Another spark test messageUygulamayı spark console'a göndermek için aşağıdaki komutu çalıştırın.
/usr/local/spark/bin/spark-submit --packages org.apache.spark:spark-streaming
-kafka_2.10:1.6.0 --class "KafkaWordCount" --master local[4] target/scala-2.10/spark
-kafka-project_2.10-1.0.jar localhost:2181 <group name> <topic name> <number of threads>Bu uygulamanın örnek çıktısı aşağıda gösterilmiştir.
spark console messages ..
(Test,1)
(spark,1)
(another,1)
(message,1)
spark console message ..En son twitter beslemelerini ve hashtag'lerini almak için gerçek zamanlı bir uygulamayı analiz edelim. Daha önce Storm ve Spark'ın Kafka ile entegrasyonunu görmüştük. Her iki senaryoda da, Kafka ekosistemine mesaj göndermek için bir Kafka Yapımcısı (cli kullanarak) oluşturduk. Ardından, fırtına ve kıvılcım entegrasyonu, Kafka tüketicisini kullanarak mesajları okur ve sırasıyla fırtına ve kıvılcım ekosistemine enjekte eder. Yani, pratik olarak bir Kafka Yapımcısı yaratmalıyız ki bu -
- Twitter akışlarını "Twitter Akış API" kullanarak okuyun,
- Beslemeleri işleyin,
- HashTag'leri ayıklayın ve
- Kafka'ya gönder.
Bir kez Hashtag'ler
Kafka, Fırtına tarafından alınır / Kıvılcım entegrasyon bulu-mation almak ve Fırtına / Kıvılcım ekosistem gönderin.
Twitter Akış API'si
"Twitter Streaming API" herhangi bir programlama dilinde erişilebilir. “Twitter4j”, “Twitter Streaming API” ye kolayca erişmek için Java tabanlı bir modül sağlayan açık kaynaklı, resmi olmayan bir Java kitaplığıdır. "Twitter4j", tweet'lere erişmek için dinleyici tabanlı bir çerçeve sağlar. "Twitter Streaming API" ye erişmek için, Twitter geliştirici hesabına giriş yapmalı ve aşağıdakileri almalıyızOAuth kimlik doğrulama ayrıntıları.
- Customerkey
- CustomerSecret
- AccessToken
- AccessTookenSecret
Geliştirici hesabı oluşturulduktan sonra, "twitter4j" jar dosyalarını indirin ve java sınıf yoluna yerleştirin.
Tam Twitter Kafka yapımcı kodlaması (KafkaTwitterProducer.java) aşağıda listelenmiştir -
import java.util.Arrays;
import java.util.Properties;
import java.util.concurrent.LinkedBlockingQueue;
import twitter4j.*;
import twitter4j.conf.*;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class KafkaTwitterProducer {
public static void main(String[] args) throws Exception {
LinkedBlockingQueue<Status> queue = new LinkedBlockingQueue<Sta-tus>(1000);
if(args.length < 5){
System.out.println(
"Usage: KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret> <twitter-access-token>
<twitter-access-token-secret>
<topic-name> <twitter-search-keywords>");
return;
}
String consumerKey = args[0].toString();
String consumerSecret = args[1].toString();
String accessToken = args[2].toString();
String accessTokenSecret = args[3].toString();
String topicName = args[4].toString();
String[] arguments = args.clone();
String[] keyWords = Arrays.copyOfRange(arguments, 5, arguments.length);
ConfigurationBuilder cb = new ConfigurationBuilder();
cb.setDebugEnabled(true)
.setOAuthConsumerKey(consumerKey)
.setOAuthConsumerSecret(consumerSecret)
.setOAuthAccessToken(accessToken)
.setOAuthAccessTokenSecret(accessTokenSecret);
TwitterStream twitterStream = new TwitterStreamFactory(cb.build()).get-Instance();
StatusListener listener = new StatusListener() {
@Override
public void onStatus(Status status) {
queue.offer(status);
// System.out.println("@" + status.getUser().getScreenName()
+ " - " + status.getText());
// System.out.println("@" + status.getUser().getScreen-Name());
/*for(URLEntity urle : status.getURLEntities()) {
System.out.println(urle.getDisplayURL());
}*/
/*for(HashtagEntity hashtage : status.getHashtagEntities()) {
System.out.println(hashtage.getText());
}*/
}
@Override
public void onDeletionNotice(StatusDeletionNotice statusDeletion-Notice) {
// System.out.println("Got a status deletion notice id:"
+ statusDeletionNotice.getStatusId());
}
@Override
public void onTrackLimitationNotice(int numberOfLimitedStatuses) {
// System.out.println("Got track limitation notice:" +
num-berOfLimitedStatuses);
}
@Override
public void onScrubGeo(long userId, long upToStatusId) {
// System.out.println("Got scrub_geo event userId:" + userId +
"upToStatusId:" + upToStatusId);
}
@Override
public void onStallWarning(StallWarning warning) {
// System.out.println("Got stall warning:" + warning);
}
@Override
public void onException(Exception ex) {
ex.printStackTrace();
}
};
twitterStream.addListener(listener);
FilterQuery query = new FilterQuery().track(keyWords);
twitterStream.filter(query);
Thread.sleep(5000);
//Add Kafka producer config settings
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serializa-tion.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
int i = 0;
int j = 0;
while(i < 10) {
Status ret = queue.poll();
if (ret == null) {
Thread.sleep(100);
i++;
}else {
for(HashtagEntity hashtage : ret.getHashtagEntities()) {
System.out.println("Hashtag: " + hashtage.getText());
producer.send(new ProducerRecord<String, String>(
top-icName, Integer.toString(j++), hashtage.getText()));
}
}
}
producer.close();
Thread.sleep(5000);
twitterStream.shutdown();
}
}Derleme
Aşağıdaki komutu kullanarak uygulamayı derleyin -
javac -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:. KafkaTwitterProducer.javaYürütme
İki konsol açın. Yukarıda derlenen uygulamayı aşağıda gösterildiği gibi bir konsolda çalıştırın.
java -cp “/path/to/kafka/libs/*”:”/path/to/twitter4j/lib/*”:
. KafkaTwitterProducer <twitter-consumer-key>
<twitter-consumer-secret>
<twitter-access-token>
<twitter-ac-cess-token-secret>
my-first-topic foodÖnceki bölümde başka bir win-dow'da açıklanan Spark / Storm uygulamasından herhangi birini çalıştırın. Dikkat edilmesi gereken en önemli nokta, kullanılan konunun her iki durumda da aynı olması gerektiğidir. Burada konu adı olarak “ilk-konu” kullandık.
Çıktı
Bu uygulamanın çıktısı, anahtar kelimelere ve twitter'ın mevcut beslemesine bağlı olacaktır. Aşağıda örnek bir çıktı belirtilmiştir (fırtına entegrasyonu).
. . .
food : 1
foodie : 2
burger : 1
. . .Kafka Aracı “org.apache.kafka.tools. * Altında paketlenmiştir. Araçlar, sistem araçları ve çoğaltma araçları olarak kategorize edilir.
Sistem Araçları
Sistem araçları, çalıştırma sınıfı betiği kullanılarak komut satırından çalıştırılabilir. Sözdizimi aşağıdaki gibidir -
bin/kafka-run-class.sh package.class - - optionsSistem araçlarından bazıları aşağıda belirtilmiştir -
Kafka Migration Tool - Bu araç, bir aracıyı bir sürümden diğerine geçirmek için kullanılır.
Mirror Maker - Bu araç, bir Kafka kümesinin diğerine yansıtılmasını sağlamak için kullanılır.
Consumer Offset Checker - Bu araç, belirtilen Konular ve Tüketici Grubu için Tüketici Grubu, Konu, Bölümler, Off-set, logSize, Owner gösterir.
Çoğaltma Aracı
Kafka replikasyonu, üst düzey bir tasarım aracıdır. Çoğaltma aracı eklemenin amacı, daha güçlü dayanıklılık ve daha yüksek kullanılabilirlik içindir. Çoğaltma araçlarından bazıları aşağıda belirtilmiştir -
Create Topic Tool - Bu, varsayılan sayıda bölüm ve çoğaltma faktörüne sahip bir konu oluşturur ve çoğaltma ataması yapmak için Kafka'nın varsayılan şemasını kullanır.
List Topic Tool- Bu araç, belirli bir konu listesi için bilgileri listeler. Komut satırında hiçbir konu sağlanmadıysa, araç tüm konuları almak için Zookeeper'ı sorgular ve bunlara ilişkin bilgileri listeler. Aracın görüntülediği alanlar konu adı, bölüm, lider, eşlemeler, isr'dir.
Add Partition Tool- Bir konunun oluşturulması, konu için bölüm sayısı belirtilmelidir. Daha sonra konunun hacmi artacağı zaman konu için daha fazla bölüme ihtiyaç duyulabilir. Bu araç, belirli bir konu için daha fazla bölüm eklemeye yardımcı olur ve ayrıca eklenen bölümlerin manuel eşleme atamasına izin verir.
Kafka, günümüzün en iyi endüstriyel uygulamalarının çoğunu desteklemektedir. Bu bölümde Kafka'nın en dikkate değer uygulamalarının bazılarına çok kısa bir genel bakış sunacağız.
Twitter, kullanıcı tweetleri gönderip almak için bir platform sağlayan çevrimiçi bir sosyal ağ hizmetidir. Kayıtlı kullanıcılar tweet okuyabilir ve gönderebilir ancak kayıtsız kullanıcılar yalnızca tweet okuyabilir. Twitter, akış işleme altyapısının bir parçası olarak Storm-Kafka'yı kullanıyor.
Apache Kafka, LinkedIn'de etkinlik akışı verileri ve operasyonel ölçümler için kullanılır. Kafka mesajlaşma sistemi, LinkedIn'e çevrimiçi mesaj tüketimi için LinkedIn Newsfeed, LinkedIn Today gibi çeşitli ürünler ve Hadoop gibi çevrimdışı analiz sistemleriyle yardımcı olur. Kafka'nın güçlü dayanıklılığı da LinkedIn ile bağlantılı temel faktörlerden biridir.
Netflix
Netflix, Amerikan çok uluslu, isteğe bağlı İnternet akış medyası sağlayıcısıdır. Netflix, gerçek zamanlı izleme ve olay işleme için Kafka'yı kullanır.
Mozilla
Mozilla, 1998 yılında Netscape üyeleri tarafından oluşturulan bir özgür yazılım topluluğudur. Kafka yakında, Telemetri, Test Pilotu vb. Projeler için son kullanıcının tarayıcısından performans ve kullanım verilerini toplamak üzere Mozilla'nın mevcut üretim sisteminin bir parçasını değiştirecek.
Oracle
Oracle, geliştiricilerin aşamalı veri ardışık düzenlerini uygulamak için OSB yerleşik arabuluculuk yeteneklerinden yararlanmasına olanak tanıyan OSB (Oracle Service Bus) adlı Enterprise Service Bus ürününden Kafka'ya yerel bağlantı sağlar.