Apache Tajo - Hızlı Kılavuz
Dağıtık Veri Ambarı Sistemi
Veri ambarı, işlem işleme yerine sorgu ve analiz için tasarlanmış ilişkisel bir veritabanıdır. Konu odaklı, entegre, zamanla değişen ve kalıcı bir veri koleksiyonudur. Bu veriler, analistlerin bir organizasyonda bilinçli kararlar almasına yardımcı olur, ancak ilişkisel veri hacimleri her geçen gün artmaktadır.
Zorlukların üstesinden gelmek için, dağıtılmış veri ambarı sistemi, Çevrimiçi Analitik İşleme (OLAP) amacıyla verileri birden çok veri havuzunda paylaşır. Her veri ambarı bir veya daha fazla kuruluşa ait olabilir. Yük dengeleme ve ölçeklenebilirlik gerçekleştirir. Meta veriler çoğaltılır ve merkezi olarak dağıtılır.
Apache Tajo, depolama katmanı olarak Hadoop Dağıtılmış Dosya Sistemi (HDFS) kullanan ve MapReduce çerçevesi yerine kendi sorgu yürütme motoruna sahip olan dağıtılmış bir veri ambarı sistemidir.
Hadoop'ta SQL'e genel bakış
Hadoop, büyük verileri dağıtılmış bir ortamda depolamaya ve işlemeye izin veren açık kaynaklı bir çerçevedir. Son derece hızlı ve güçlüdür. Ancak, Hadoop'un sınırlı sorgulama yetenekleri vardır, bu nedenle performansı Hadoop'ta SQL yardımıyla daha da iyi hale getirilebilir. Bu, kullanıcıların kolay SQL komutları aracılığıyla Hadoop ile etkileşim kurmasına olanak tanır.
Hadoop uygulamalarında SQL'in bazı örnekleri Hive, Impala, Drill, Presto, Spark, HAWQ ve Apache Tajo'dur.
Apache Tajo nedir
Apache Tajo, ilişkisel ve dağıtılmış bir veri işleme çerçevesidir. Düşük gecikme süresi ve ölçeklenebilir geçici sorgu analizi için tasarlanmıştır.
Tajo, standart SQL ve çeşitli veri formatlarını destekler. Tajo sorgularının çoğu herhangi bir değişiklik yapılmadan yürütülebilir.
Tajo'da fault-tolerance başarısız görevler ve genişletilebilir sorgu yeniden yazma motoru için bir yeniden başlatma mekanizması aracılığıyla.
Tajo gerekli olanı gerçekleştirir ETL (Extract Transform and Load process)HDFS'de depolanan büyük veri kümelerini özetlemek için işlemler. Hive / Pig'e alternatif bir seçimdir.
Tajo'nun en son sürümü, Java programlarına ve Oracle ve PostGreSQL gibi üçüncü taraf veritabanlarına daha fazla bağlanabilirliğe sahiptir.
Apache Tajo'nun Özellikleri
Apache Tajo aşağıdaki özelliklere sahiptir -
- Üstün ölçeklenebilirlik ve optimize edilmiş performans
- Düşük gecikme süresi
- Kullanıcı tanımlı işlevler
- Satır / sütunlu depolama işleme çerçevesi.
- HiveQL ve Hive MetaStore ile uyumluluk
- Basit veri akışı ve kolay bakım.
Apache Tajo'nun Faydaları
Apache Tajo aşağıdaki avantajları sunar -
- Kullanımı kolay
- Basitleştirilmiş mimari
- Maliyete dayalı sorgu optimizasyonu
- Vektörize sorgu yürütme planı
- Hızlı teslimat
- Basit G / Ç mekanizması ve çeşitli depolama türlerini destekler.
- Hata toleransı
Apache Tajo'nun Kullanım Durumları
Aşağıdakiler, Apache Tajo'nun kullanım örneklerinden bazılarıdır -
Veri depolama ve analizi
Koreli SK Telecom firması, Tajo'yu 1.7 terabayt değerinde veriye karşı çalıştırdı ve sorguları Hive veya Impala'dan daha hızlı tamamlayabildiğini gördü.
Veri keşfi
Kore müzik akışı hizmeti Melon, analitik işleme için Tajo kullanıyor. Tajo, ETL (ayıkla-dönüştür-yükle işlemi) işlerini Hive'dan 1,5 ila 10 kat daha hızlı yürütür.
Günlük analizi
Kore merkezli bir şirket olan Bluehole Studio, fantastik bir çok oyunculu çevrimiçi oyun olan TERA'yı geliştirdi. Şirket, oyun günlüğü analizi ve hizmet kalitesi kesintilerinin temel nedenlerini bulmak için Tajo kullanıyor.
Depolama ve Veri Biçimleri
Apache Tajo aşağıdaki veri formatlarını destekler -
- JSON
- Metin dosyası (CSV)
- Parquet
- Sıra Dosyası
- AVRO
- Protokol Arabelleği
- Apaçi Ork
Tajo, aşağıdaki depolama biçimlerini destekler -
- HDFS
- JDBC
- Amazon S3
- Apache HBase
- Elasticsearch
Aşağıdaki çizim Apache Tajo'nun mimarisini tasvir etmektedir.

Aşağıdaki tablo her bir bileşeni ayrıntılı olarak açıklamaktadır.
| S.No. | Bileşen Açıklaması |
|---|---|
| 1 | Client Client sonucu almak için SQL ifadelerini Tajo Master'a gönderir. |
| 2 | Master Master, ana artalan sürecidir. Sorgu planlamasından sorumludur ve işçilerin koordinatörüdür. |
| 3 | Catalog server Tabloyu ve dizin açıklamalarını korur. Ana arka plan programına gömülüdür. Katalog sunucusu, depolama katmanı olarak Apache Derby'yi kullanır ve JDBC istemcisi aracılığıyla bağlanır. |
| 4 | Worker Ana düğüm, görevi çalışan düğümlere atar. TajoWorker verileri işler. TajoWorkers sayısı arttıkça, işleme kapasitesi de doğrusal olarak artar. |
| 5 | Query Master Tajo master, sorguyu Query Master'a atar. Query Master, dağıtılmış bir yürütme planını kontrol etmekten sorumludur. TaskRunner'ı başlatır ve görevleri TaskRunner'a planlar. Sorgu Yöneticisinin ana rolü, çalışan görevleri izlemek ve bunları Ana düğüme rapor etmektir. |
| 6 | Node Managers Çalışan düğümünün kaynağını yönetir. Düğüme istekleri tahsis etmeye karar verir. |
| 7 | TaskRunner Yerel bir sorgu yürütme motoru görevi görür. Sorgu sürecini çalıştırmak ve izlemek için kullanılır. TaskRunner bir seferde bir görevi işler. Aşağıdaki üç ana özelliğe sahiptir -
|
| 8 | Query Executor Bir sorgu yürütmek için kullanılır. |
| 9 | Storage service Temel veri depolamasını Tajo'ya bağlar. |
İş akışı
Tajo, depolama katmanı olarak Hadoop Dağıtılmış Dosya Sistemi (HDFS) kullanır ve MapReduce çerçevesi yerine kendi sorgu yürütme motoruna sahiptir. Bir Tajo kümesi, bir ana düğümden ve küme düğümlerindeki birkaç çalışandan oluşur.
Kaptan, esas olarak sorgu planlamasından ve işçilerin koordinatöründen sorumludur. Master, sorguyu küçük görevlere böler ve işçilere atar. Her çalışanın, fiziksel operatörlerin yönlendirilmiş döngüsel olmayan grafiğini yürüten yerel bir sorgu motoru vardır.
Ek olarak, Tajo dağıtılmış veri akışını MapReduce'tan daha esnek bir şekilde kontrol edebilir ve indeksleme tekniklerini destekler.
Tajo'nun web tabanlı arayüzü aşağıdaki yeteneklere sahiptir -
- Gönderilen sorguların nasıl planlandığını bulma seçeneği
- Sorguların düğümler arasında nasıl dağıtıldığını bulma seçeneği
- Küme ve düğümlerin durumunu kontrol etme seçeneği
Apache Tajo'yu kurmak için, sisteminizde aşağıdaki yazılıma sahip olmalısınız -
- Hadoop sürüm 2.3 veya üstü
- Java sürüm 1.7 veya üzeri
- Linux veya Mac OS
Şimdi Tajo'yu kurmak için aşağıdaki adımlara devam edelim.
Java yüklemesini doğrulama
Umarım makinenize Java sürüm 8'i zaten yüklemişsinizdir. Şimdi, doğrulayarak devam etmeniz gerekiyor.
Doğrulamak için aşağıdaki komutu kullanın -
$ java -versionJava, makinenize başarıyla yüklendiyse, yüklü Java'nın mevcut sürümünü görebilirsiniz. Java yüklü değilse, makinenize Java 8 yüklemek için aşağıdaki adımları izleyin.
JDK'yı indirin
Aşağıdaki bağlantıyı ziyaret ederek JDK'nın en son sürümünü indirin ve ardından en son sürümü indirin.
https://www.oracle.com
En son sürüm JDK 8u 92 ve dosya “jdk-8u92-linux-x64.tar.gz”. Lütfen dosyayı makinenize indirin. Bunu takiben, dosyaları çıkarın ve belirli bir dizine taşıyın. Şimdi, Java alternatiflerini ayarlayın. Son olarak, makinenize Java yüklenir.
Hadoop Kurulumunu Doğrulama
Zaten yüklediniz Hadoopsisteminizde. Şimdi, aşağıdaki komutu kullanarak doğrulayın -
$ hadoop versionKurulumunuzda her şey yolundaysa, Hadoop sürümünü görebilirsiniz. Hadoop kurulu değilse, aşağıdaki bağlantıyı ziyaret ederek Hadoop'u indirip yükleyin -https://www.apache.org
Apache Tajo Kurulumu
Apache Tajo iki yürütme modu sağlar - yerel mod ve tamamen dağıtılmış mod. Java ve Hadoop kurulumunu doğruladıktan sonra, makinenize Tajo kümesini kurmak için aşağıdaki adımlarla devam edin. Yerel mod Tajo örneği, çok kolay yapılandırmalar gerektirir.
Aşağıdaki bağlantıyı ziyaret ederek Tajo'nun en son sürümünü indirin - https://www.apache.org/dyn/closer.cgi/tajo
Şimdi dosyayı indirebilirsiniz “tajo-0.11.3.tar.gz” makinenizden.
Tar Dosyasını Çıkar
Aşağıdaki komutu kullanarak tar dosyasını çıkarın -
$ cd opt/ $ tar tajo-0.11.3.tar.gz
$ cd tajo-0.11.3Ortam Değişkenini Ayarla
Aşağıdaki değişiklikleri şuraya ekleyin: “conf/tajo-env.sh” dosya
$ cd tajo-0.11.3
$ vi conf/tajo-env.sh
# Hadoop home. Required
export HADOOP_HOME = /Users/path/to/Hadoop/hadoop-2.6.2
# The java implementation to use. Required.
export JAVA_HOME = /path/to/jdk1.8.0_92.jdk/Burada, Hadoop ve Java yolunu belirtmelisiniz. “tajo-env.sh”dosya. Değişiklikler yapıldıktan sonra dosyayı kaydedin ve terminalden çıkın.
Tajo Sunucusunu Başlatın
Tajo sunucusunu başlatmak için aşağıdaki komutu uygulayın -
$ bin/start-tajo.shAşağıdakine benzer bir yanıt alacaksınız -
Starting single TajoMaster
starting master, logging to /Users/path/to/Tajo/tajo-0.11.3/bin/../
localhost: starting worker, logging to /Users/path/toe/Tajo/tajo-0.11.3/bin/../logs/
Tajo master web UI: http://local:26080
Tajo Client Service: local:26002Şimdi, çalışan arka plan programlarını görmek için "jps" komutunu yazın.
$ jps
1010 TajoWorker
1140 Jps
933 TajoMasterTajo Shell'i (Tsql) başlatın
Tajo kabuk istemcisini başlatmak için aşağıdaki komutu kullanın -
$ bin/tsqlAşağıdaki çıktıyı alacaksınız -
welcome to
_____ ___ _____ ___
/_ _/ _ |/_ _/ /
/ // /_| |_/ // / /
/_//_/ /_/___/ \__/ 0.11.3
Try \? for help.Tajo Shell'den çıkın
Tsql'den çıkmak için aşağıdaki komutu çalıştırın -
default> \q
bye!Burada varsayılan, Tajo'daki kataloğu ifade eder.
Web kullanıcı arayüzü
Tajo web kullanıcı arayüzünü başlatmak için aşağıdaki URL'yi yazın - http://localhost:26080/
Şimdi ExecuteQuery seçeneğine benzer aşağıdaki ekranı göreceksiniz.

Tajo'yu durdur
Tajo sunucusunu durdurmak için aşağıdaki komutu kullanın -
$ bin/stop-tajo.shAşağıdaki yanıtı alacaksınız -
localhost: stopping worker
stopping masterTajo'nun yapılandırması, Hadoop'un yapılandırma sistemine dayanmaktadır. Bu bölümde Tajo yapılandırma ayarları ayrıntılı olarak açıklanmaktadır.
Temel Ayarlar
Tajo, aşağıdaki iki yapılandırma dosyasını kullanır -
- katalog-site.xml - katalog sunucusu için yapılandırma.
- tajo-site.xml - diğer Tajo modülleri için yapılandırma.
Dağıtılmış Mod Yapılandırması
Dağıtılmış mod kurulumu, Hadoop Dağıtılmış Dosya Sisteminde (HDFS) çalışır. Tajo dağıtılmış mod kurulumunu yapılandırma adımlarını takip edelim.
tajo-site.xml
Bu dosya @ /path/to/tajo/confdizin ve diğer Tajo modülleri için yapılandırma görevi görür. Tajo'ya dağıtılmış modda erişmek için aşağıdaki değişiklikleri“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://hostname:port/tajo</value>
</property>
<property>
<name>tajo.master.umbilical-rpc.address</name>
<value>hostname:26001</value>
</property>
<property>
<name>tajo.master.client-rpc.address</name>
<value>hostname:26002</value>
</property>
<property>
<name>tajo.catalog.client-rpc.address</name>
<value>hostname:26005</value>
</property>Ana Düğüm Yapılandırması
Tajo, HDFS'yi birincil depolama türü olarak kullanır. Yapılandırma aşağıdaki gibidir ve eklenmesi gerekir“tajo-site.xml”.
<property>
<name>tajo.rootdir</name>
<value>hdfs://namenode_hostname:port/path</value>
</property>Katalog Yapılandırması
Katalog hizmetini özelleştirmek istiyorsanız, $path/to/Tajo/conf/catalogsite.xml.template -e $path/to/Tajo/conf/catalog-site.xml ve aşağıdaki yapılandırmadan herhangi birini gerektiği gibi ekleyin.
Örneğin, kullanıyorsanız “Hive catalog store” Tajo'ya erişmek için, yapılandırma aşağıdaki gibi olmalıdır -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HCatalogStore</value>
</property>Saklamanız gerekiyorsa MySQL katalog, ardından aşağıdaki değişiklikleri uygulayın -
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.MySQLStore</value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.id</name>
<value><mysql user name></value>
</property>
<property>
<name>tajo.catalog.jdbc.connection.password</name>
<value><mysql user password></value>
</property>
<property>
<name>tajo.catalog.jdbc.uri</name>
<value>jdbc:mysql://<mysql host name>:<mysql port>/<database name for tajo>
?createDatabaseIfNotExist = true</value>
</property>Benzer şekilde, diğer Tajo destekli katalogları yapılandırma dosyasına kaydedebilirsiniz.
Çalışan Yapılandırması
TajoWorker varsayılan olarak geçici verileri yerel dosya sisteminde depolar. “Tajo-site.xml” dosyasında aşağıdaki gibi tanımlanır -
<property>
<name>tajo.worker.tmpdir.locations</name>
<value>/disk1/tmpdir,/disk2/tmpdir,/disk3/tmpdir</value>
</property>Her bir çalışan kaynağının görev çalıştırma kapasitesini artırmak için aşağıdaki yapılandırmayı seçin -
<property>
<name>tajo.worker.resource.cpu-cores</name>
<value>12</value>
</property>
<property>
<name>tajo.task.resource.min.memory-mb</name>
<value>2000</value>
</property>
<property>
<name>tajo.worker.resource.disks</name>
<value>4</value>
</property>Tajo çalışanının özel bir modda çalışmasını sağlamak için aşağıdaki yapılandırmayı seçin -
<property>
<name>tajo.worker.resource.dedicated</name>
<value>true</value>
</property>Bu bölümde Tajo Shell komutlarını detaylı olarak anlayacağız.
Tajo kabuk komutlarını yürütmek için, aşağıdaki komutları kullanarak Tajo sunucusunu ve Tajo kabuğunu başlatmanız gerekir -
Sunucuyu başlat
$ bin/start-tajo.shKabuğu Başlat
$ bin/tsqlYukarıdaki komutlar artık yürütülmeye hazırdır.
Meta Komutları
Şimdi tartışalım Meta Commands. Tsql meta komutları ters eğik çizgiyle başlar(‘\’).
Yardım Komutu
“\?” Komut, yardım seçeneğini göstermek için kullanılır.
Query
default> \?Result
Yukarıdaki \?Tajo'daki tüm temel kullanım seçeneklerini komut listesi. Aşağıdaki çıktıyı alacaksınız -
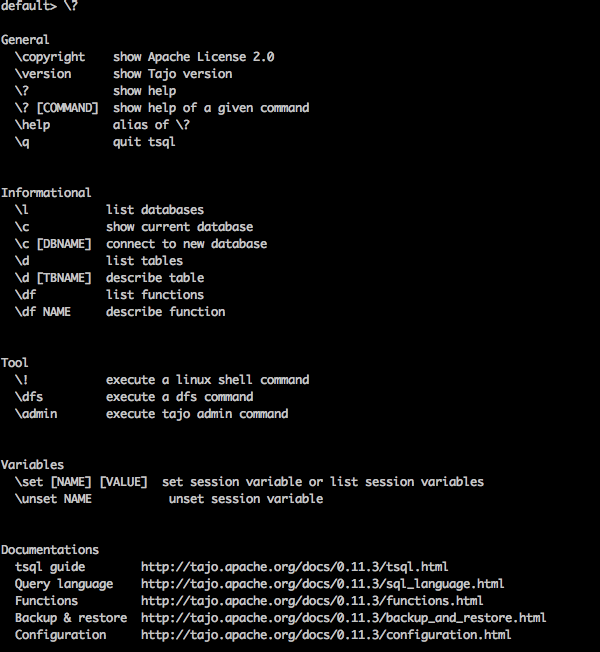
Veritabanı Listesi
Tajo'daki tüm veritabanlarını listelemek için aşağıdaki komutu kullanın -
Query
default> \lResult
Aşağıdaki çıktıyı alacaksınız -
information_schema
defaultŞu anda herhangi bir veritabanı oluşturmadık, bu nedenle iki yerleşik Tajo veritabanını gösteriyor.
Mevcut Veritabanı
\c seçeneği mevcut veritabanı adını görüntülemek için kullanılır.
Query
default> \cResult
Artık kullanıcı "kullanıcı adı" olarak "varsayılan" veritabanına bağlısınız.
Yerleşik İşlevleri listeleyin
Tüm yerleşik işlevi listelemek için sorguyu aşağıdaki gibi yazın -
Query
default> \dfResult
Aşağıdaki çıktıyı alacaksınız -

Fonksiyonu Tanımla
\df function name - Bu sorgu, verilen işlevin tam açıklamasını döndürür.
Query
default> \df sqrtResult
Aşağıdaki çıktıyı alacaksınız -

Terminalden Çık
Terminalden çıkmak için aşağıdaki sorguyu yazın -
Query
default> \qResult
Aşağıdaki çıktıyı alacaksınız -
bye!Yönetici Komutları
Tajo kabuğu sağlar \admin tüm yönetici özelliklerini listeleme seçeneği.
Query
default> \adminResult
Aşağıdaki çıktıyı alacaksınız -

Küme Bilgileri
Tajo'da küme bilgilerini görüntülemek için aşağıdaki sorguyu kullanın
Query
default> \admin -clusterResult
Aşağıdaki çıktıyı alacaksınız -

Ustayı göster
Aşağıdaki sorgu, geçerli ana bilgileri görüntüler.
Query
default> \admin -showmastersResult
localhostBenzer şekilde, diğer yönetici komutlarını deneyebilirsiniz.
Oturum Değişkenleri
Tajo istemcisi, Master'a benzersiz bir oturum kimliği aracılığıyla bağlanır. Oturum, müşterinin bağlantısı kesilene veya süresi dolana kadar canlıdır.
Aşağıdaki komut, tüm oturum değişkenlerini listelemek için kullanılır.
Query
default> \setResult
'SESSION_LAST_ACCESS_TIME' = '1470206387146'
'CURRENT_DATABASE' = 'default'
‘USERNAME’ = 'user'
'SESSION_ID' = 'c60c9b20-dfba-404a-822f-182bc95d6c7c'
'TIMEZONE' = 'Asia/Kolkata'
'FETCH_ROWNUM' = '200'
‘COMPRESSED_RESULT_TRANSFER' = 'false'\set key val adlı oturum değişkenini ayarlayacak key değeri ile val. Örneğin,
Query
default> \set ‘current_database’='default'Result
usage: \set [[NAME] VALUE]Burada, anahtar ve değeri atayabilirsiniz. \setkomut. Değişiklikleri geri almanız gerekiyorsa,\unset komut.
Bir Tajo kabuğunda bir sorgu yürütmek için, terminalinizi açın ve Tajo kurulu dizinine gidin ve ardından aşağıdaki komutu yazın -
$ bin/tsqlŞimdi aşağıdaki programda gösterildiği gibi yanıtı göreceksiniz -
default>Artık sorgularınızı yürütebilirsiniz. Aksi takdirde, sorgularınızı web konsolu uygulaması aracılığıyla aşağıdaki URL'ye çalıştırabilirsiniz -http://localhost:26080/
İlkel Veri Türleri
Apache Tajo, aşağıdaki ilkel veri türleri listesini destekler -
| S.No. | Veri türü ve Açıklama |
|---|---|
| 1 | integer Tamsayı değerini 4 bayt depolamayla depolamak için kullanılır. |
| 2 | tinyint Küçük tam sayı değeri 1 bayttır |
| 3 | smallint Küçük boyutlu tamsayı 2 bayt değerini saklamak için kullanılır. |
| 4 | bigint Büyük aralıklı tamsayı değerinde 8 baytlık depolama alanı vardır. |
| 5 | boolean Doğru / yanlış döndürür. |
| 6 | real Gerçek değeri saklamak için kullanılır. Boyut 4 bayttır. |
| 7 | float 4 veya 8 bayt depolama alanına sahip kayan nokta hassas değeri. |
| 8 | double 8 bayt olarak saklanan çift nokta kesinlik değeri. |
| 9 | char[(n)] Karakter değeri. |
| 10 | varchar[(n)] Değişken uzunluklu Unicode olmayan veriler. |
| 11 | number Ondalık değerler. |
| 12 | binary İkili değerler. |
| 13 | date Takvim tarihi (yıl, ay, gün). Example - TARİH '2016-08-22' |
| 14 | time Saat dilimi olmadan günün saati (saat, dakika, saniye, milisaniye). Bu türdeki değerler, oturum saat diliminde ayrıştırılır ve işlenir. |
| 15 | timezone Saat dilimi ile günün saati (saat, dakika, saniye, milisaniye). Bu türdeki değerler, değerden saat dilimi kullanılarak oluşturulur. Example - SAAT '01: 02: 03.456 Asya / kolkata ' |
| 16 | timestamp Saat dilimi olmadan günün tarih ve saatini içeren anlık. Example - TIMESTAMP '2016-08-22 03: 04: 05.321' |
| 17 | text Değişken uzunluklu Unicode metin. |
Tajo'da istenen işlemleri gerçekleştirmek için aşağıdaki operatörler kullanılır.
| S.No. | Operatör ve Açıklama |
|---|---|
| 1 | Aritmetik operatörler Presto, +, -, *, /,% gibi aritmetik operatörleri destekler. |
| 2 | İlişkisel operatörler <,>, <=,> =, =, <> |
| 3 | Mantıksal operatörler VE, VEYA, DEĞİL |
| 4 | Dize operatörleri '||' operatör, dize birleştirme gerçekleştirir. |
| 5 | Menzil operatörleri Aralık operatörü, belirli bir aralıktaki değeri test etmek için kullanılır. Tajo BETWEEN, IS NULL, IS NOT NULL operatörlerini destekler. |
Şu an itibariyle, Tajo'da basit temel sorgular çalıştırmanın farkındaydınız. Sonraki birkaç bölümde, aşağıdaki SQL işlevlerini tartışacağız -
- Matematik Fonksiyonları
- String Fonksiyonları
- DateTime İşlevleri
- JSON İşlevleri
Matematik fonksiyonları matematiksel formüllerle çalışır. Aşağıdaki tablo, işlevlerin listesini ayrıntılı olarak açıklamaktadır.
| S.No. | İşlev ve Açıklama |
|---|---|
| 1 | abs (x) X'in mutlak değerini döndürür. |
| 2 | cbrt (x) X'in küp kökünü döndürür. |
| 3 | tavan (x) En yakın tam sayıya yuvarlanmış x değerini döndürür. |
| 4 | kat (x) X'i en yakın tam sayıya yuvarlayarak döndürür. |
| 5 | pi () Pi değerini döndürür. Sonuç çift değer olarak döndürülecektir. |
| 6 | radyan (x) x açısını radyan derece cinsinden dönüştürür. |
| 7 | derece (x) X için derece değerini verir. |
| 8 | pow (x, p) 'P' değerinin gücünü x değerine döndürür. |
| 9 | div (x, y) Verilen iki x, y tamsayı değeri için bölme sonucunu döndürür. |
| 10 | exp (x) Euler'in numarasını verir e bir sayının gücüne yükseltildi. |
| 11 | sqrt (x) X'in karekökünü verir. |
| 12 | işaret (x) X'in işaret işlevini verir, yani -
|
| 13 | mod (n, m) N bölü m modülünü (kalan) verir. |
| 14 | yuvarlak (x) X için yuvarlanmış değeri döndürür. |
| 15 | çünkü (x) Kosinüs değerini (x) verir. |
| 16 | asin (x) Ters sinüs değerini (x) verir. |
| 17 | acos (x) Ters kosinüs değerini (x) verir. |
| 18 | atan (x) Ters tanjant değerini (x) verir. |
| 19 | atan2 (y, x) Ters tanjant değerini (y / x) verir. |
Veri Türü İşlevleri
Aşağıdaki tablo, Apache Tajo'da bulunan veri türü işlevlerini listeler.
| S.No. | İşlev ve Açıklama |
|---|---|
| 1 | to_bin (x) Tamsayının ikili temsilini döndürür. |
| 2 | to_char (int, metin) Tamsayıyı dizeye dönüştürür. |
| 3 | to_hex (x) X değerini onaltılık tabana dönüştürür. |
Aşağıdaki tablo, Tajo'daki dizi işlevlerini listeler.
| S.No. | İşlev ve Açıklama |
|---|---|
| 1 | concat (dize1, ..., dizeN) Verilen dizeleri birleştirin. |
| 2 | uzunluk (dize) Verilen dizenin uzunluğunu döndürür. |
| 3 | alt (dize) Dize için küçük harf biçimini döndürür. |
| 4 | üst (dize) Verilen dizge için büyük harf biçimini döndürür. |
| 5 | ascii (dize metni) Metnin ilk karakterinin ASCII kodunu döndürür. |
| 6 | bit_length (dize metni) Bir dizedeki bit sayısını döndürür. |
| 7 | char_length (dize metni) Bir dizedeki karakter sayısını verir. |
| 8 | octet_length (dize metni) Bir dizedeki bayt sayısını döndürür. |
| 9 | özet (giriş metni, yöntem metni) Hesaplar Digestdize karması. Burada ikinci arg yöntemi hash yöntemini ifade eder. |
| 10 | initcap (dize metni) Her sözcüğün ilk harfini büyük harfe dönüştürür. |
| 11 | md5 (dize metni) Hesaplar MD5 dize karması. |
| 12 | left (string text, int size) Dizedeki ilk n karakteri döndürür. |
| 13 | right (string text, int size) Dizedeki son n karakteri döndürür. |
| 14 | locate (kaynak metin, hedef metin, başlangıç_indisi) Belirtilen alt dizenin konumunu döndürür. |
| 15 | strposb (kaynak metin, hedef metin) Belirtilen alt dizenin ikili konumunu döndürür. |
| 16 | substr (kaynak metin, başlangıç dizini, uzunluk) Belirtilen uzunluk için alt dizeyi döndürür. |
| 17 | kırpma (dize metni [, karakter metni]) Dizenin başından / sonundan / her iki ucundan karakterleri (varsayılan olarak bir boşluk) kaldırır. |
| 18 | split_part (dize metni, ayırıcı metin, alan int) Sınırlayıcıda bir dizeyi böler ve verilen alanı döndürür (birden sayarak). |
| 19 | regexp_replace (dize metni, desen metni, değiştirme metni) Belirli bir normal ifade modeliyle eşleşen alt dizeleri değiştirir. |
| 20 | ters (dize) Dizi için ters işlem gerçekleştirildi. |
Apache Tajo, aşağıdaki DateTime işlevlerini destekler.
| S.No. | İşlev ve Açıklama |
|---|---|
| 1 | add_days (tarih tarihi veya zaman damgası, int gün Verilen gün değerine göre eklenen tarihi döndürür. |
| 2 | add_months (tarih tarihi veya zaman damgası, int ay) Verilen ay değerine göre eklenen tarihi döndürür. |
| 3 | Geçerli tarih() Bugünün tarihini döndürür. |
| 4 | şimdiki zaman() Bugünün saatini döndürür. |
| 5 | ayıklamak (tarihten / zaman damgasından itibaren yüzyıl) Yüzyılı, verilen parametreden çıkarır. |
| 6 | ayıkla (tarihten / zaman damgasından itibaren gün) Verilen parametreden günü çıkarır. |
| 7 | ayıklamak (tarih / zaman damgasından itibaren on yıl) Verilen parametreden on yılı çıkarır. |
| 8 | ayıklamak (gün dow tarihi / zaman damgası) Verilen parametreden haftanın gününü çıkarır. |
| 9 | ayıklamak (tarih / zaman damgasından gelen doy) Verilen parametreden yılın gününü çıkarır. |
| 10 | ayıklamayı seçin (zaman damgasından itibaren saat) Verilen parametreden saati çıkarır. |
| 11 | ayıklamayı seçin (zaman damgasından izdüşüm) Verilen parametreden haftanın gününü çıkarır. Bu, Pazar günü dışında dow ile aynıdır. Bu, ISO 8601 haftanın gün numaralandırmasıyla eşleşir. |
| 12 | özü seçin (tarihten itibaren izoyear) ISO yılını belirtilen tarihten çıkarır. ISO yılı miladi yıldan farklı olabilir. |
| 13 | özüt (zamandan mikrosaniye) Verilen parametreden mikrosaniyeleri alır. Kesirli kısımları içeren saniye alanı 1.000.000 ile çarpılır; |
| 14 | ayıklamak (zaman damgasından milenyum) Verilen parametreden milenyumu çıkarır. Bir milenyum, 1000 yıla karşılık gelir. Bu nedenle, üçüncü milenyum 1 Ocak 2001'de başladı. |
| 15 | ayıklamak (zamandan milisaniye) Verilen parametreden milisaniyeleri çıkarır. |
| 16 | ayıklamak (zaman damgasından dakika) Verilen parametreden dakikayı çıkarır. |
| 17 | ayıkla (zaman damgasından çeyrek) Verilen parametreden yılın çeyreğini (1-4) çıkarır. |
| 18 | tarih_bölüm (alan metni, kaynak tarih veya zaman damgası veya saat) Metinden tarih alanını çıkarır. |
| 19 | şimdi () Geçerli zaman damgasını döndürür. |
| 20 | to_char (zaman damgası, biçim metni) Zaman damgasını metne dönüştürür. |
| 21 | to_date (src metni, metni biçimlendir) Metni tarihe dönüştürür. |
| 22 | to_timestamp (src metni, metni biçimlendir) Metni zaman damgasına dönüştürür. |
JSON işlevleri aşağıdaki tabloda listelenmiştir -
| S.No. | İşlev ve Açıklama |
|---|---|
| 1 | json_extract_path_text (metin üzerinde js, json_path metni) JSON dizesini belirtilen json yoluna göre bir JSON dizesinden ayıklar. |
| 2 | json_array_get (json_array metni, dizin int4) Belirtilen dizindeki öğeyi JSON dizisine döndürür. |
| 3 | json_array_contains (json_ dizi metni, herhangi bir değer) Verilen değerin JSON dizisinde olup olmadığını belirleyin. |
| 4 | json_array_length (json_ar ışın metni) Json dizisinin uzunluğunu döndürür. |
Bu bölüm Tajo DDL komutlarını açıklamaktadır. Tajo'nun adında yerleşik bir veritabanı vardırdefault.
Veritabanı İfadesi Oluşturun
Create DatabaseTajo'da bir veritabanı oluşturmak için kullanılan bir ifadedir. Bu ifadenin sözdizimi aşağıdaki gibidir -
CREATE DATABASE [IF NOT EXISTS] <database_name>Sorgu
default> default> create database if not exists test;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
OKVeritabanı, Tajo'daki ad alanıdır. Bir veritabanı, benzersiz bir ada sahip birden çok tablo içerebilir.
Mevcut Veritabanını Göster
Mevcut veritabanı adını kontrol etmek için aşağıdaki komutu verin -
Sorgu
default> \cSonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
You are now connected to database "default" as user “user1".
default>Veritabanına Bağlan
Şu an itibariyle "test" adında bir veritabanı oluşturdunuz. Aşağıdaki sözdizimi, "test" veritabanını bağlamak için kullanılır.
\c <database name>Sorgu
default> \c testSonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
You are now connected to database "test" as user “user1”.
test>Artık varsayılan veritabanından test veritabanına geçiş değişikliklerini görebilirsiniz.
Veritabanını Bırak
Bir veritabanını bırakmak için aşağıdaki sözdizimini kullanın -
DROP DATABASE <database-name>Sorgu
test> \c default
You are now connected to database "default" as user “user1".
default> drop database test;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
OKTablo, bir veri kaynağının mantıksal görünümüdür. Mantıksal bir şema, bölümler, URL ve çeşitli özelliklerden oluşur. Bir Tajo tablosu, HDFS'de bir dizin, tek bir dosya, bir HBase tablosu veya bir RDBMS tablosu olabilir.
Tajo, aşağıdaki iki tür tabloyu destekler -
- dış tablo
- iç tablo
Dış Tablo
Dış tablo, tablo oluşturulduğunda konum özelliğine ihtiyaç duyar. Örneğin, verileriniz Metin / JSON dosyaları veya HBase tablosu olarak zaten oradaysa, onu Tajo harici tablosu olarak kaydedebilirsiniz.
Aşağıdaki sorgu, harici tablo oluşturmanın bir örneğidir.
create external table sample(col1 int,col2 text,col3 int) location ‘hdfs://path/to/table';Buraya,
External keyword- Bu, harici bir tablo oluşturmak için kullanılır. Bu, belirtilen konumda bir tablo oluşturmaya yardımcı olur.
Örnek, tablo adını ifade eder.
Location- HDFS, Amazon S3, HBase veya yerel dosya sistemi için bir dizindir. Dizinler için bir konum özelliği atamak için aşağıdaki URI örneklerini kullanın -
HDFS - hdfs: // localhost: bağlantı noktası / yol / / tablo
Amazon S3 - s3: // paket adı / tablo
local file system - dosya: /// yol / tablo
Openstack Swift - swift: // kova-adı / tablo
Tablo Özellikleri
Harici bir tablo aşağıdaki özelliklere sahiptir -
TimeZone - Kullanıcılar bir tabloyu okumak veya yazmak için bir saat dilimi belirleyebilir.
Compression format- Veri boyutunu sıkıştırmak için kullanılır. Örneğin, text / json dosyası şunu kullanır:compression.codec Emlak.
İç Tablo
Dahili tablo aynı zamanda Managed Table. Tablo alanı adı verilen önceden tanımlanmış bir fiziksel konumda oluşturulur.
Sözdizimi
create table table1(col1 int,col2 text);Tajo, varsayılan olarak "conf / tajo-site.xml" içinde bulunan "tajo.warehouse.directory" dosyasını kullanır. Tabloya yeni konum atamak için, Tablo Alanı yapılandırmasını kullanabilirsiniz.
Tablo alanı
Tablo alanı, depolama sistemindeki konumları tanımlamak için kullanılır. Yalnızca dahili tablolar için desteklenir. Tablo alanlarına isimleriyle erişebilirsiniz. Her tablo alanı farklı bir depolama türü kullanabilir. Tablo alanları belirtmezseniz, Tajo kök dizinde varsayılan tablo alanını kullanır.
Tablo Alanı Yapılandırması
Var “conf/tajo-site.xml.template”Tajo'da. Dosyayı kopyalayın ve şu şekilde yeniden adlandırın:“storagesite.json”. Bu dosya, Tablo alanları için bir konfigürasyon görevi görecek. Tajo veri biçimleri aşağıdaki yapılandırmayı kullanır -
HDFS Yapılandırması
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}HBase Yapılandırması
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
"uri": “hbase:zk://quorum1:port,quorum2:port/"
}
}
}Metin Dosyası Yapılandırması
$ vi conf/storage-site.json { "spaces": { "${tablespace_name}": {
“uri”: “hdfs://localhost:9000/path/to/Tajo”
}
}
}Tablo Alanı Oluşturma
Tajo'nun dahili tablo kayıtlarına yalnızca başka bir tablodan erişilebilir. Tablo alanı ile yapılandırabilirsiniz.
Sözdizimi
CREATE TABLE [IF NOT EXISTS] <table_name> [(column_list)] [TABLESPACE tablespace_name]
[using <storage_type> [with (<key> = <value>, ...)]] [AS <select_statement>]Buraya,
IF NOT EXISTS - Bu, aynı tablo önceden oluşturulmamışsa bir hatayı önler.
TABLESPACE - Bu madde, tablo alanı adını atamak için kullanılır.
Storage type - Tajo verileri metin, JSON, HBase, Parquet, Sequencefile ve ORC gibi formatları destekler.
AS select statement - Başka bir tablodan kayıtları seçin.
Tablo Alanını Yapılandır
Hadoop hizmetlerinizi başlatın ve dosyayı açın “conf/storage-site.json”, ardından aşağıdaki değişiklikleri ekleyin -
$ vi conf/storage-site.json {
"spaces": {
“space1”: {
"uri": “hdfs://localhost:9000/path/to/Tajo"
}
}
}Burada Tajo, HDFS konumundan alınan verilere atıfta bulunacak ve space1tablo alanı adıdır. Hadoop hizmetlerini başlatmazsanız, tablo alanını kaydedemezsiniz.
Sorgu
default> create table table1(num1 int,num2 text,num3 float) tablespace space1;Yukarıdaki sorgu, "tablo1" adlı bir tablo oluşturur ve "boşluk1", tablo alanı adını ifade eder.
Veri formatları
Tajo, veri formatlarını destekler. Her bir formatı tek tek ayrıntılı olarak inceleyelim.
Metin
Karakterle ayrılmış değerlerin düz metin dosyası, satırlar ve sütunlardan oluşan tablo şeklinde bir veri kümesini temsil eder. Her satır bir düz metin satırıdır.
Tablo Oluşturuluyor
default> create external table customer(id int,name text,address text,age int)
using text with('text.delimiter'=',') location ‘file:/Users/workspace/Tajo/customers.csv’;Buraya, “customers.csv” dosyası, Tajo kurulum dizininde bulunan virgülle ayrılmış bir değer dosyasını ifade eder.
Metin biçimini kullanarak dahili tablo oluşturmak için aşağıdaki sorguyu kullanın -
default> create table customer(id int,name text,address text,age int) using text;Yukarıdaki sorguda, herhangi bir tablo alanı atamadınız, bu nedenle Tajo'nun varsayılan tablo alanını alacaktır.
Özellikleri
Bir metin dosyası formatı aşağıdaki özelliklere sahiptir -
text.delimiter- Bu bir sınırlayıcı karakterdir. Varsayılan '|' dir.
compression.codec- Bu bir sıkıştırma formatıdır. Varsayılan olarak devre dışıdır. ayarları belirtilen algoritmayı kullanarak değiştirebilirsiniz.
timezone - Okuma veya yazma için kullanılan tablo.
text.error-tolerance.max-num - Maksimum tolerans seviyesi sayısı.
text.skip.headerlines - Atlanan başlık satırlarının sayısı.
text.serde - Bu serileştirme özelliğidir.
JSON
Apache Tajo, verileri sorgulamak için JSON formatını destekler. Tajo, bir JSON nesnesini SQL kaydı olarak değerlendirir. Bir Tajo tablosundaki bir nesne bir satıra eşittir. "Array.json" u aşağıdaki gibi ele alalım -
$ hdfs dfs -cat /json/array.json {
"num1" : 10,
"num2" : "simple json array",
"num3" : 50.5
}Bu dosyayı oluşturduktan sonra, Tajo kabuğuna geçin ve JSON formatını kullanarak bir tablo oluşturmak için aşağıdaki sorguyu yazın.
Sorgu
default> create external table sample (num1 int,num2 text,num3 float)
using json location ‘json/array.json’;Dosya verilerinin tablo şemasıyla eşleşmesi gerektiğini daima unutmayın. Aksi takdirde, sütun adlarını atlayabilir ve sütun listesi gerektirmeyen * kullanabilirsiniz.
Dahili bir tablo oluşturmak için aşağıdaki sorguyu kullanın -
default> create table sample (num1 int,num2 text,num3 float) using json;Parke
Parke, sütunlu bir depolama formatıdır. Tajo, kolay, hızlı ve verimli erişim için Parquet formatını kullanır.
Tablo oluşturma
Aşağıdaki sorgu, tablo oluşturma için bir örnektir -
CREATE TABLE parquet (num1 int,num2 text,num3 float) USING PARQUET;Parke dosya formatı aşağıdaki özelliklere sahiptir -
parquet.block.size - bellekte arabelleğe alınan bir satır grubunun boyutu.
parquet.page.size - Sayfa boyutu sıkıştırma içindir.
parquet.compression - Sayfaları sıkıştırmak için kullanılan sıkıştırma algoritması.
parquet.enable.dictionary - Boole değeri, sözlük kodlamasını etkinleştirmek / devre dışı bırakmak içindir.
RCFile
RCFile, Kayıt Sütun Dosyasıdır. İkili anahtar / değer çiftlerinden oluşur.
Tablo oluşturma
Aşağıdaki sorgu, tablo oluşturma için bir örnektir -
CREATE TABLE Record(num1 int,num2 text,num3 float) USING RCFILE;RCFile aşağıdaki özelliklere sahiptir -
rcfile.serde - özel seri çözümleyici sınıfı.
compression.codec - sıkıştırma algoritması.
rcfile.null - BOŞ karakter.
Sıra Dosyası
SequenceFile, Hadoop'ta anahtar / değer çiftlerinden oluşan temel bir dosya biçimidir.
Tablo oluşturma
Aşağıdaki sorgu, tablo oluşturma için bir örnektir -
CREATE TABLE seq(num1 int,num2 text,num3 float) USING sequencefile;Bu sıra dosyası Hive uyumluluğuna sahiptir. Bu, Hive'da şu şekilde yazılabilir:
CREATE TABLE table1 (id int, name string, score float, type string)
STORED AS sequencefile;ORC
ORC (Optimize Edilmiş Satır Sütunu), Hive'dan bir sütun depolama formatıdır.
Tablo oluşturma
Aşağıdaki sorgu, tablo oluşturma için bir örnektir -
CREATE TABLE optimized(num1 int,num2 text,num3 float) USING ORC;ORC formatı aşağıdaki özelliklere sahiptir -
orc.max.merge.distance - ORC dosyası okunur, mesafe azaldığında birleşir.
orc.stripe.size - Bu, her şeridin boyutu.
orc.buffer.size - Varsayılan 256 KB'dir.
orc.rowindex.stride - Bu, sıra sayısındaki ORC indeksi adımdır.
Önceki bölümde, Tajo'da nasıl tablo oluşturacağınızı anladınız. Bu bölüm, Tajo'daki SQL ifadesini açıklar.
Tablo İfadesi Oluştur
Bir tablo oluşturmaya geçmeden önce, aşağıdaki gibi Tajo kurulum dizini yolunda bir metin dosyası "student.csv" oluşturun -
students.csv
| İD | İsim | Adres | Yaş | İşaretler |
|---|---|---|---|---|
| 1 | Adam | 23 Yeni Sokak | 21 | 90 |
| 2 | Amit | 12 Eski Sokak | 13 | 95 |
| 3 | Bob | 10 Cross Street | 12 | 80 |
| 4 | David | 15 Ekspres Caddesi | 12 | 85 |
| 5 | Esha | 20 Garden Street | 13 | 50 |
| 6 | Ganga | 25 Kuzey Caddesi | 12 | 55 |
| 7 | Jack | 2 Park Street | 12 | 60 |
| 8 | Leena | 24 South Street | 12 | 70 |
| 9 | Mary | 5 West Street | 12 | 75 |
| 10 | Peter | 16 Park Avenue | 12 | 95 |
Dosya oluşturulduktan sonra terminale gidin ve Tajo sunucusunu ve kabuğu birer birer başlatın.
Veritabanı yarat
Aşağıdaki komutu kullanarak yeni bir veritabanı oluşturun -
Sorgu
default> create database sampledb;
OKŞimdi oluşturulan "sampledb" veritabanına bağlanın.
default> \c sampledb
You are now connected to database "sampledb" as user “user1”.Ardından, "sampledb" içinde aşağıdaki gibi bir tablo oluşturun -
Sorgu
sampledb> create external table mytable(id int,name text,address text,age int,mark int)
using text with('text.delimiter' = ',') location ‘file:/Users/workspace/Tajo/students.csv’;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
OKBurada dış tablo oluşturulur. Şimdi, sadece dosya konumunu girmeniz gerekiyor. Tabloyu hdfs'den atamanız gerekiyorsa, dosya yerine hdfs kullanın.
Sonra, “students.csv”dosya virgülle ayrılmış değerler içeriyor. text.delimiter field is assigned with ‘,’.
You have now created “mytable” successfully in “sampledb”.
Show Table
To show tables in Tajo, use the following query.
Query
sampledb> \d
mytable
sampledb> \d mytableResult
The above query will generate the following result.
table name: sampledb.mytable
table uri: file:/Users/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 261 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4List table
To fetch all the records in the table, type the following query −
Query
sampledb> select * from mytable;Result
The above query will generate the following result.

Insert Table Statement
Tajo uses the following syntax to insert records in table.
Syntax
create table table1 (col1 int8, col2 text, col3 text);
--schema should be same for target table schema
Insert overwrite into table1 select * from table2;
(or)
Insert overwrite into LOCATION '/dir/subdir' select * from table;Tajo’s insert statement is similar to the INSERT INTO SELECT statement of SQL.
Query
Let’s create a table to overwrite table data of an existing table.
sampledb> create table test(sno int,name text,addr text,age int,mark int);
OK
sampledb> \dResult
The above query will generate the following result.
mytable
testInsert Records
To insert records in the “test” table, type the following query.
Query
sampledb> insert overwrite into test select * from mytable;Result
The above query will generate the following result.
Progress: 100%, response time: 0.518 secHere, “mytable" records overwrite the “test” table. If you don’t want to create the “test” table, then straight away assign the physical path location as mentioned in an alternative option for insert query.
Fetch records
Use the following query to list out all the records in the “test” table −
Query
sampledb> select * from test;Result
The above query will generate the following result.

This statement is used to add, remove or modify columns of an existing table.
To rename the table use the following syntax −
Alter table table1 RENAME TO table2;Query
sampledb> alter table test rename to students;Result
The above query will generate the following result.
OKTo check the changed table name, use the following query.
sampledb> \d
mytable
studentsNow the table “test” is changed to “students” table.
Add Column
To insert new column in the “students” table, type the following syntax −
Alter table <table_name> ADD COLUMN <column_name> <data_type>Query
sampledb> alter table students add column grade text;Result
The above query will generate the following result.
OKSet Property
This property is used to change the table’s property.
Query
sampledb> ALTER TABLE students SET PROPERTY 'compression.type' = 'RECORD',
'compression.codec' = 'org.apache.hadoop.io.compress.Snappy Codec' ;
OKHere, compression type and codec properties are assigned.
To change the text delimiter property, use the following −
Query
ALTER TABLE students SET PROPERTY ‘text.delimiter'=',';
OKResult
The above query will generate the following result.
sampledb> \d students
table name: sampledb.students
table uri: file:/tmp/tajo-user1/warehouse/sampledb/students
store type: TEXT
number of rows: 10
volume: 228 B
Options:
'compression.type' = 'RECORD'
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'compression.codec' = 'org.apache.hadoop.io.compress.SnappyCodec'
'text.delimiter' = ','
schema:
id INT4
name TEXT
addr TEXT
age INT4
mark INT4
grade TEXTThe above result shows that the table’s properties are changed using the “SET” property.
Select Statement
The SELECT statement is used to select data from a database.
The syntax for the Select statement is as follows −
SELECT [distinct [all]] * | <expression> [[AS] <alias>] [, ...]
[FROM <table reference> [[AS] <table alias name>] [, ...]]
[WHERE <condition>]
[GROUP BY <expression> [, ...]]
[HAVING <condition>]
[ORDER BY <expression> [ASC|DESC] [NULLS (FIRST|LAST)] [, …]]Madde nerede
Where cümlesi, tablodaki kayıtları filtrelemek için kullanılır.
Sorgu
sampledb> select * from mytable where id > 5;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
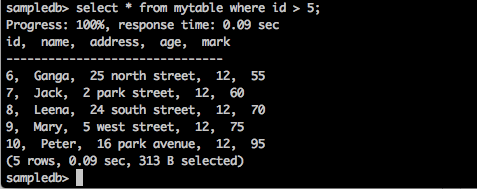
Sorgu, kimliği 5'ten büyük olan öğrencilerin kayıtlarını döndürür.
Sorgu
sampledb> select * from mytable where name = ‘Peter’;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
Progress: 100%, response time: 0.117 sec
id, name, address, age
-------------------------------
10, Peter, 16 park avenue , 12Sonuç yalnızca Peter'ın kayıtlarını filtreler.
Ayırt Edici Madde
Bir tablo sütunu, yinelenen değerler içerebilir. DISTINCT anahtar sözcüğü yalnızca farklı (farklı) değerler döndürmek için kullanılabilir.
Sözdizimi
SELECT DISTINCT column1,column2 FROM table_name;Sorgu
sampledb> select distinct age from mytable;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
Progress: 100%, response time: 0.216 sec
age
-------------------------------
13
12Sorgu, öğrencinin farklı yaşını döndürür mytable.
Maddeye Göre Gruplama
GROUP BY yan tümcesi, aynı verileri gruplar halinde düzenlemek için SELECT deyimiyle birlikte kullanılır.
Sözdizimi
SELECT column1, column2 FROM table_name WHERE [ conditions ] GROUP BY column1, column2;Sorgu
select age,sum(mark) as sumofmarks from mytable group by age;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
age, sumofmarks
-------------------------------
13, 145
12, 610Burada, "mytable" sütununun iki tür yaşı vardır - 12 ve 13. Şimdi sorgu, kayıtları yaşa göre gruplandırır ve öğrencilerin karşılık gelen yaşları için toplam puanları üretir.
Maddeye Sahip Olmak
HAVING yan tümcesi, nihai sonuçlarda hangi grup sonuçlarının görüneceğini filtreleyen koşulları belirlemenizi sağlar. WHERE yan tümcesi koşulları seçili sütunlara yerleştirirken HAVING yan tümcesi, koşulları GROUP BY yan tümcesi tarafından oluşturulan gruplara yerleştirir.
Sözdizimi
SELECT column1, column2 FROM table1 GROUP BY column HAVING [ conditions ]Sorgu
sampledb> select age from mytable group by age having sum(mark) > 200;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
age
-------------------------------
12Sorgu, kayıtları yaşa göre gruplar ve koşul sonucu toplamı (işaret)> 200 olduğunda yaşı döndürür.
Maddeye Göre Sırala
ORDER BY yan tümcesi, verileri bir veya daha fazla sütuna göre artan veya azalan düzende sıralamak için kullanılır. Tajo veritabanı, sorgu sonuçlarını varsayılan olarak artan sırada sıralar.
Sözdizimi
SELECT column-list FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];Sorgu
sampledb> select * from mytable where mark > 60 order by name desc;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.

Sorgu, işaretleri 60'tan büyük olan öğrencilerin adlarını azalan sırayla döndürür.
Dizin İfadesi Oluşturun
CREATE INDEX ifadesi, tablolarda dizin oluşturmak için kullanılır. Dizin, verilerin hızlı bir şekilde alınması için kullanılır. Mevcut sürüm, yalnızca HDFS'de depolanan düz TEXT biçimleri için dizini destekler.
Sözdizimi
CREATE INDEX [ name ] ON table_name ( { column_name | ( expression ) }Sorgu
create index student_index on mytable(id);Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
id
———————————————Sütuna atanmış dizini görüntülemek için aşağıdaki sorguyu yazın.
default> \d mytable
table name: default.mytable
table uri: file:/Users/deiva/workspace/Tajo/students.csv
store type: TEXT
number of rows: unknown
volume: 307 B
Options:
'timezone' = 'Asia/Kolkata'
'text.null' = '\\N'
'text.delimiter' = ','
schema:
id INT4
name TEXT
address TEXT
age INT4
mark INT4
Indexes:
"student_index" TWO_LEVEL_BIN_TREE (id ASC NULLS LAST )Burada, Tajo'da varsayılan olarak TWO_LEVEL_BIN_TREE yöntemi kullanılır.
Drop Table Statement
Drop Table Statement, veritabanından bir tabloyu bırakmak için kullanılır.
Sözdizimi
drop table table name;Sorgu
sampledb> drop table mytable;Tablonun tablodan çıkarılıp kaldırılmadığını kontrol etmek için aşağıdaki sorguyu yazın.
sampledb> \d mytable;Sonuç
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
ERROR: relation 'mytable' does not existMevcut Tajo tablolarını listelemek için "\ d" komutunu kullanarak da sorguyu kontrol edebilirsiniz.
Bu bölüm toplama ve pencere işlevlerini ayrıntılı olarak açıklamaktadır.
Toplama İşlevleri
Toplama işlevleri, bir dizi girdi değerinden tek bir sonuç üretir. Aşağıdaki tablo, toplama işlevlerinin listesini ayrıntılı olarak açıklamaktadır.
| S.No. | İşlev ve Açıklama |
|---|---|
| 1 | AVG (exp) Bir veri kaynağındaki tüm kayıtların bir sütununun ortalamasını alır. |
| 2 | CORR (ifade1; ifade2) Bir dizi sayı çifti arasındaki korelasyon katsayısını verir. |
| 3 | MİKTAR() Sayı satırlarını döndürür. |
| 4 | MAX (ifade) Seçili sütunun en büyük değerini döndürür. |
| 5 | MIN (ifade) Seçili sütunun en küçük değerini döndürür. |
| 6 | SUM (ifade) Verilen sütunun toplamını döndürür. |
| 7 | LAST_VALUE (ifade) Verilen sütunun son değerini döndürür. |
Pencere Fonksiyonu
Pencere işlevleri bir dizi satırda yürütülür ve sorgudan her satır için tek bir değer döndürür. Pencere terimi, işlev için satır kümesi anlamına gelir.
Sorgudaki Window işlevi, OVER () yan tümcesini kullanarak pencereyi tanımlar.
OVER() fıkra aşağıdaki yeteneklere sahiptir -
- Satır grupları oluşturmak için pencere bölümlerini tanımlar. (PARTITION BY maddesi)
- Bir bölüm içindeki satırları sıralar. (ORDER BY maddesi)
Aşağıdaki tablo, pencere işlevlerini ayrıntılı olarak açıklamaktadır.
| Fonksiyon | Dönüş türü | Açıklama |
|---|---|---|
| sıra () | int | Boşluklarla birlikte geçerli satırın sıralamasını döndürür. |
| satır_sayısı () | int | 1'den sayarak bölümü içindeki geçerli satırı döndürür. |
| olası satış (değer [, tam sayı [, varsayılan herhangi]]) | Giriş türü ile aynı | Bölüm içinde geçerli satırdan sonraki satırlardan uzak olan satırda değerlendirilen değeri döndürür. Böyle bir satır yoksa, varsayılan değer döndürülür. |
| gecikme (değer [, tam sayı [, varsayılan herhangi biri]]) | Giriş türü ile aynı | Bölüm içinde geçerli satırdan önceki satırlardan uzak olan satırda değerlendirilen değeri döndürür. |
| ilk_değer (değer) | Giriş türü ile aynı | Giriş satırlarının ilk değerini döndürür. |
| last_value (değer) | Giriş türü ile aynı | Giriş satırlarının son değerini döndürür. |
Bu bölümde aşağıdaki önemli Sorgular açıklanmaktadır.
- Predicates
- Explain
- Join
Devam edelim ve sorguları gerçekleştirelim.
Dayanaklar
Dayanak, doğru / yanlış değerleri ve BİLİNMEYEN değerleri değerlendirmek için kullanılan bir ifadedir. Dayanaklar, WHERE yan tümcelerinin ve HAVING yan tümcelerinin ve Boolean değerinin gerekli olduğu diğer yapıların arama koşulunda kullanılır.
IN yüklem
Test edilecek ifade değerinin alt sorgudaki veya listedeki herhangi bir değerle eşleşip eşleşmediğini belirler. Alt sorgu, bir sütun ve bir veya daha fazla satırdan oluşan bir sonuç kümesine sahip sıradan bir SELECT ifadesidir. Bu sütun veya listedeki tüm ifadeler, test edilecek ifadeyle aynı veri türüne sahip olmalıdır.
Syntax
IN::=
<expression to test> [NOT] IN (<subquery>)
| (<expression1>,...)Query
select id,name,address from mytable where id in(2,3,4);Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
id, name, address
-------------------------------
2, Amit, 12 old street
3, Bob, 10 cross street
4, David, 15 express avenueSorgu, mytable 2,3 ve 4 numaralı öğrenciler için.
Query
select id,name,address from mytable where id not in(2,3,4);Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
id, name, address
-------------------------------
1, Adam, 23 new street
5, Esha, 20 garden street
6, Ganga, 25 north street
7, Jack, 2 park street
8, Leena, 24 south street
9, Mary, 5 west street
10, Peter, 16 park avenueYukarıdaki sorgu, mytable öğrencilerin 2,3 ve 4'te olmadığı yer.
Predicate gibi
LIKE koşulu, test edilecek bir değer olarak adlandırılan dize değerini hesaplamak için birinci ifadede belirtilen dizeyi, dize değerini hesaplamak için ikinci ifadede tanımlanan modelle karşılaştırır.
Kalıp, aşağıdaki gibi joker karakterlerin herhangi bir kombinasyonunu içerebilir:
Test edilecek değerdeki herhangi bir tek karakter yerine kullanılabilen altını çiz sembol (_).
Yüzde işareti (%), test edilecek değerdeki herhangi bir sıfır veya daha fazla karakter dizisinin yerine geçer.
Syntax
LIKE::=
<expression for calculating the string value>
[NOT] LIKE
<expression for calculating the string value>
[ESCAPE <symbol>]Query
select * from mytable where name like ‘A%';Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
id, name, address, age, mark
-------------------------------
1, Adam, 23 new street, 12, 90
2, Amit, 12 old street, 13, 95Sorgu, adları 'A' ile başlayan öğrencilerin mytable kayıtlarını döndürür.
Query
select * from mytable where name like ‘_a%';Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
id, name, address, age, mark
——————————————————————————————————————-
4, David, 15 express avenue, 12, 85
6, Ganga, 25 north street, 12, 55
7, Jack, 2 park street, 12, 60
9, Mary, 5 west street, 12, 75Sorgu, mytable isimleri ikinci karakter olarak 'a' ile başlayan öğrencilerden.
Arama Koşullarında BOŞ Değer Kullanma
Şimdi arama koşullarında NULL Değerinin nasıl kullanılacağını anlayalım.
Syntax
Predicate
IS [NOT] NULLQuery
select name from mytable where name is not null;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
name
-------------------------------
Adam
Amit
Bob
David
Esha
Ganga
Jack
Leena
Mary
Peter
(10 rows, 0.076 sec, 163 B selected)Burada sonuç doğrudur, bu nedenle tablodaki tüm isimleri döndürür.
Query
Şimdi sorguyu NULL koşuluyla kontrol edelim.
default> select name from mytable where name is null;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
name
-------------------------------
(0 rows, 0.068 sec, 0 B selected)Açıklamak
Explainbir sorgu yürütme planı elde etmek için kullanılır. Bir ifadenin mantıksal ve küresel bir plan uygulamasını gösterir.
Mantıksal Plan Sorgusu
explain select * from mytable;
explain
-------------------------------
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.

Sorgu sonucu, verilen tablo için mantıksal bir plan formatı gösterir. Mantıksal plan aşağıdaki üç sonucu verir -
- Hedef listesi
- Out şeması
- Şemada
Global Plan Sorgusu
explain global select * from mytable;
explain
-------------------------------
-------------------------------------------------------------------------------
Execution Block Graph (TERMINAL - eb_0000000000000_0000_000002)
-------------------------------------------------------------------------------
|-eb_0000000000000_0000_000002
|-eb_0000000000000_0000_000001
-------------------------------------------------------------------------------
Order of Execution
-------------------------------------------------------------------------------
1: eb_0000000000000_0000_000001
2: eb_0000000000000_0000_000002
-------------------------------------------------------------------------------
=======================================================
Block Id: eb_0000000000000_0000_000001 [ROOT]
=======================================================
SCAN(0) on default.mytable
=> target list: default.mytable.id (INT4), default.mytable.name (TEXT),
default.mytable.address (TEXT), default.mytable.age (INT4), default.mytable.mark (INT4)
=> out schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT),default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=> in schema: {
(5) default.mytable.id (INT4), default.mytable.name (TEXT), default.mytable.address (TEXT),
default.mytable.age (INT4), default.mytable.mark (INT4)
}
=======================================================
Block Id: eb_0000000000000_0000_000002 [TERMINAL]
=======================================================
(24 rows, 0.065 sec, 0 B selected)Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.

Burada Global plan, yürütme bloğu kimliğini, yürütme sırasını ve bilgilerini gösterir.
Katılır
SQL birleştirmeleri, iki veya daha fazla tablodan satırları birleştirmek için kullanılır. Aşağıdakiler farklı SQL Birleştirme türleridir -
- İç birleşim
- {SOL | SAĞ | FULL} OUTER JOIN
- Çapraz birleşim
- Kendi kendine katıl
- Doğal birleşim
Birleştirme işlemlerini gerçekleştirmek için aşağıdaki iki tabloyu inceleyin.
Tablo1 - Müşteriler
| İD | İsim | Adres | Yaş |
|---|---|---|---|
| 1 | Müşteri 1 | 23 Eski Sokak | 21 |
| 2 | Müşteri 2 | 12 Yeni Sokak | 23 |
| 3 | Müşteri 3 | 10 Ekspres Caddesi | 22 |
| 4 | Müşteri 4 | 15 Ekspres Caddesi | 22 |
| 5 | Müşteri 5 | 20 Garden Street | 33 |
| 6 | Müşteri 6 | 21 Kuzey Caddesi | 25 |
Tablo2 - müşteri_siparişi
| İD | Sipariş Kimliği | Emp Id |
|---|---|---|
| 1 | 1 | 101 |
| 2 | 2 | 102 |
| 3 | 3 | 103 |
| 4 | 4 | 104 |
| 5 | 5 | 105 |
Şimdi devam edelim ve yukarıdaki iki tablodaki SQL birleştirme işlemlerini gerçekleştirelim.
İç birleşim
İç birleşim, her iki tablodaki sütunlar arasında bir eşleşme olduğunda her iki tablodan tüm satırları seçer.
Syntax
SELECT column_name(s) FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;Query
default> select c.age,c1.empid from customers c inner join customer_order c1 on c.id = c1.id;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
age, empid
-------------------------------
21, 101
23, 102
22, 103
22, 104
33, 105Sorgu, her iki tablodan beş satırla eşleşir. Bu nedenle, eşleşen satırları ilk tablodan yaş olarak döndürür.
Sol dış katılma
Sol dış birleştirme, "sağ" tabloda eşleşen bir satır olup olmadığına bakılmaksızın "sol" tablonun tüm satırlarını tutar.
Query
select c.name,c1.empid from customers c left outer join customer_order c1 on c.id = c1.id;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105
customer6,Burada, sol dış birleştirme, müşteri (sol) tablosundan ad sütun satırlarını ve müşteri_sırası (sağ) tablosundan boş sütun eşleşen satırları döndürür.
Sağ Dış Birleştirme
Sağ dış birleşim, "sol" tabloda eşleşen bir satır olup olmadığına bakılmaksızın "sağ" tablonun tüm satırlarını tutar.
Query
select c.name,c1.empid from customers c right outer join customer_order c1 on c.id = c1.id;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
name, empid
-------------------------------
customer1, 101
customer2, 102
customer3, 103
customer4, 104
customer5, 105Burada, Sağ Dış Birleştirme, customer_order (sağ) tablosundan boşluk satırlarını ve müşteri tablosundaki ad sütunu eşleşen satırları döndürür.
Tam Dış Birleştirme
Tam Dış Birleştirme, hem sol hem de sağ tablodaki tüm satırları tutar.
Query
select * from customers c full outer join customer_order c1 on c.id = c1.id;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.

Sorgu, hem müşterilerden hem de müşteri siparişi tablolarından eşleşen ve eşleşmeyen tüm satırları döndürür.
Çapraz Birleşim
Bu, iki veya daha fazla birleştirilmiş tablodan kayıt kümelerinin Kartezyen çarpımını döndürür.
Syntax
SELECT * FROM table1 CROSS JOIN table2;Query
select orderid,name,address from customers,customer_order;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
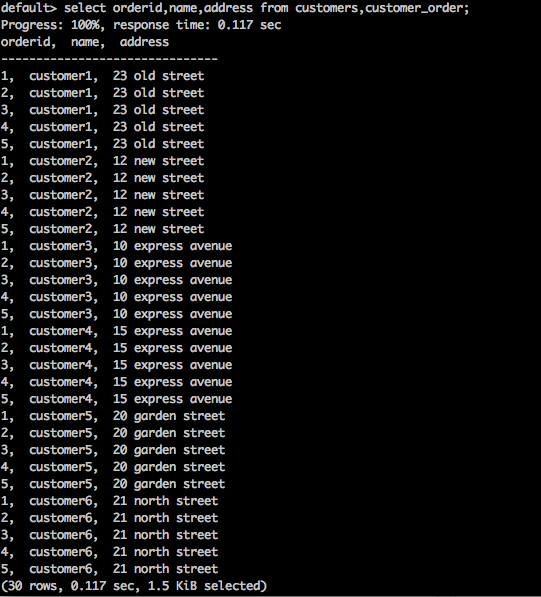
Yukarıdaki sorgu, tablonun Kartezyen çarpımını döndürür.
Doğal Birleştirme
Natural Join herhangi bir karşılaştırma operatörü kullanmaz. Kartezyen bir ürünün yaptığı gibi birleştirmez. Yalnızca iki ilişki arasında en az bir ortak özellik varsa bir Doğal Birleştirme gerçekleştirebiliriz.
Syntax
SELECT * FROM table1 NATURAL JOIN table2;Query
select * from customers natural join customer_order;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.

Burada, iki tablo arasında bulunan bir ortak sütun kimliği vardır. Bu ortak sütunu kullanarak,Natural Join her iki masaya katılır.
Kendinden Katılma
SQL SELF JOIN, bir tabloyu, tablo iki tablodaymış gibi kendisine birleştirmek için kullanılır, SQL deyimindeki en az bir tabloyu geçici olarak yeniden adlandırır.
Syntax
SELECT a.column_name, b.column_name...
FROM table1 a, table1 b
WHERE a.common_filed = b.common_fieldQuery
default> select c.id,c1.name from customers c, customers c1 where c.id = c1.id;Result
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
id, name
-------------------------------
1, customer1
2, customer2
3, customer3
4, customer4
5, customer5
6, customer6Sorgu, bir müşteri tablosunu kendisine katar.
Tajo, çeşitli depolama formatlarını destekler. Depolama eklentisi konfigürasyonunu kaydetmek için, değişiklikleri “storage-site.json” konfigürasyon dosyasına eklemelisiniz.
storage-site.json
Yapı aşağıdaki gibi tanımlanmıştır -
{
"storages": {
“storage plugin name“: {
"handler": "${class name}”, "default-format": “plugin name"
}
}
}Her depolama örneği URI ile tanımlanır.
PostgreSQL Depolama İşleyicisi
Tajo, PostgreSQL depolama işleyicisini destekler. Kullanıcı sorgularının PostgreSQL'deki veritabanı nesnelerine erişmesini sağlar. Tajo'daki varsayılan depolama işleyicisidir, böylece onu kolayca yapılandırabilirsiniz.
konfigürasyon
{
"spaces": {
"postgre": {
"uri": "jdbc:postgresql://hostname:port/database1"
"configs": {
"mapped_database": “sampledb”
"connection_properties": {
"user":“tajo", "password": "pwd"
}
}
}
}
}Buraya, “database1” ifade eder postgreSQL veritabanına eşlenen veritabanı “sampledb” Tajo'da.
Apache Tajo, HBase entegrasyonunu destekler. Bu, Tajo'daki HBase tablolarına erişmemizi sağlar. HBase, Hadoop dosya sisteminin üzerine inşa edilmiş, dağıtılmış bir sütun yönelimli veritabanıdır. Hadoop Dosya Sistemindeki verilere rastgele gerçek zamanlı okuma / yazma erişimi sağlayan Hadoop ekosisteminin bir parçasıdır. HBase entegrasyonunu yapılandırmak için aşağıdaki adımlar gereklidir.
Ortam Değişkenini Ayarla
Aşağıdaki değişiklikleri "conf / tajo-env.sh" dosyasına ekleyin.
$ vi conf/tajo-env.sh
# HBase home directory. It is opitional but is required mandatorily to use HBase.
# export HBASE_HOME = path/to/HBaseHBase yolunu dahil ettikten sonra, Tajo, HBase kitaplık dosyasını sınıf yoluna ayarlayacaktır.
Harici Tablo Oluşturun
Aşağıdaki sözdizimini kullanarak harici bir tablo oluşturun -
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] <table_name> [(<column_name> <data_type>, ... )]
USING hbase WITH ('table' = '<hbase_table_name>'
, 'columns' = ':key,<column_family_name>:<qualifier_name>, ...'
, 'hbase.zookeeper.quorum' = '<zookeeper_address>'
, 'hbase.zookeeper.property.clientPort' = '<zookeeper_client_port>')
[LOCATION 'hbase:zk://<hostname>:<port>/'] ;HBase tablolarına erişmek için, tablo alanı konumunu yapılandırmanız gerekir.
Buraya,
Table- Hbase orijin tablosu adını ayarlayın. Harici bir tablo oluşturmak istiyorsanız, tablonun HBase'de bulunması gerekir.
Columns- Anahtar, HBase satır anahtarını ifade eder. Sütun sayısı girişi, Tajo tablo sütunlarının sayısına eşit olmalıdır.
hbase.zookeeper.quorum - Hayvan bakıcısı yetersayı adresini ayarlayın.
hbase.zookeeper.property.clientPort - Hayvan bekçisi istemci bağlantı noktasını ayarlayın.
Query
CREATE EXTERNAL TABLE students (rowkey text,id int,name text)
USING hbase WITH ('table' = 'students', 'columns' = ':key,info:id,content:name')
LOCATION 'hbase:zk://<hostname>:<port>/';Burada, Konum yolu alanı, zookeeper istemci bağlantı noktası kimliğini ayarlar. Bağlantı noktasını ayarlamazsanız, Tajo hbase-site.xml dosyasının özelliğine başvurur.
HBase'de Tablo Oluştur
Aşağıdaki sorguda gösterildiği gibi “hbase shell” komutunu kullanarak HBase etkileşimli kabuğunu başlatabilirsiniz.
Query
/bin/hbase shellResult
Yukarıdaki sorgu aşağıdaki sonucu oluşturacaktır.
hbase(main):001:0>HBase'i Sorgulama Adımları
HBase'i sorgulamak için aşağıdaki adımları tamamlamalısınız -
Step 1 - Bir "öğretici" tablo oluşturmak için aşağıdaki komutları HBase kabuğuna aktarın.
Query
hbase(main):001:0> create ‘students’,{NAME => ’info’},{NAME => ’content’}
put 'students', ‘row-01', 'content:name', 'Adam'
put 'students', ‘row-01', 'info:id', '001'
put 'students', ‘row-02', 'content:name', 'Amit'
put 'students', ‘row-02', 'info:id', '002'
put 'students', ‘row-03', 'content:name', 'Bob'
put 'students', ‘row-03', 'info:id', ‘003'Step 2 - Şimdi, verileri bir tabloya yüklemek için hbase kabuğunda aşağıdaki komutu çalıştırın.
main):001:0> cat ../hbase/hbase-students.txt | bin/hbase shellStep 3 - Şimdi, Tajo kabuğuna dönün ve tablonun meta verilerini görüntülemek için aşağıdaki komutu çalıştırın -
default> \d students;
table name: default.students
table path:
store type: HBASE
number of rows: unknown
volume: 0 B
Options:
'columns' = ':key,info:id,content:name'
'table' = 'students'
schema:
rowkey TEXT
id INT4
name TEXTStep 4 - Tablodan sonuçları almak için aşağıdaki sorguyu kullanın -
Query
default> select * from studentsResult
Yukarıdaki sorgu aşağıdaki sonucu getirecektir -
rowkey, id, name
-------------------------------
row-01, 001, Adam
row-02, 002, Amit
row-03 003, BobTajo, Apache Hive ile entegre olmak için HiveCatalogStore'u destekler. Bu entegrasyon, Tajo'nun Apache Hive'daki tablolara erişmesine izin verir.
Ortam Değişkenini Ayarla
Aşağıdaki değişiklikleri "conf / tajo-env.sh" dosyasına ekleyin.
$ vi conf/tajo-env.sh
export HIVE_HOME = /path/to/hiveHive yolunu ekledikten sonra, Tajo, Hive kitaplık dosyasını sınıf yoluna ayarlayacaktır.
Katalog Yapılandırması
Aşağıdaki değişiklikleri "conf / catalog-site.xml" dosyasına ekleyin.
$ vi conf/catalog-site.xml
<property>
<name>tajo.catalog.store.class</name>
<value>org.apache.tajo.catalog.store.HiveCatalogStore</value>
</property>HiveCatalogStore yapılandırıldıktan sonra, Tajo'da Hive'ın tablosuna erişebilirsiniz.
Swift, dağıtılmış ve tutarlı bir nesne / blob deposudur. Swift, çok sayıda veriyi basit bir API ile depolayıp geri alabilmeniz için bulut depolama yazılımı sunar. Tajo, Swift entegrasyonunu destekler.
Aşağıdakiler Swift Entegrasyonunun önkoşullarıdır -
- Swift
- Hadoop
Core-site.xml
Hadoop “core-site.xml” dosyasına aşağıdaki değişiklikleri ekleyin -
<property>
<name>fs.swift.impl</name>
<value>org.apache.hadoop.fs.swift.snative.SwiftNativeFileSystem</value>
<description>File system implementation for Swift</description>
</property>
<property>
<name>fs.swift.blocksize</name>
<value>131072</value>
<description>Split size in KB</description>
</property>Bu, Hadoop'un Swift nesnelerine erişmesi için kullanılacaktır. Tüm değişiklikleri yaptıktan sonra Swift ortam değişkenini ayarlamak için Tajo dizinine gidin.
conf / tajo-env.h
Tajo yapılandırma dosyasını açın ve ortam değişkenini aşağıdaki gibi ayarlayın -
$ vi conf/tajo-env.h export TAJO_CLASSPATH = $HADOOP_HOME/share/hadoop/tools/lib/hadoop-openstack-x.x.x.jarArtık Tajo, Swift kullanarak verileri sorgulayabilecek.
Tablo Oluştur
Tajo'da Swift nesnelerine erişmek için aşağıdaki gibi harici bir tablo oluşturalım -
default> create external table swift(num1 int, num2 text, num3 float)
using text with ('text.delimiter' = '|') location 'swift://bucket-name/table1';Tablo oluşturulduktan sonra SQL sorgularını çalıştırabilirsiniz.
Apache Tajo, sorguları bağlamak ve yürütmek için JDBC arayüzü sağlar. Tajo'yu Java tabanlı uygulamamızdan bağlamak için aynı JDBC arayüzünü kullanabiliriz. Şimdi Tajo'yu nasıl bağlayacağımızı ve bu bölümde JDBC arayüzünü kullanarak örnek Java uygulamamızdaki komutları nasıl çalıştıracağımızı anlayalım.
JDBC Sürücüsünü İndirin
Aşağıdaki bağlantıyı ziyaret ederek JDBC sürücüsünü indirin - http://apache.org/dyn/closer.cgi/tajo/tajo-0.11.3/tajo-jdbc-0.11.3.jar.
Artık “tajo-jdbc-0.11.3.jar” dosyası makinenize indirilmiştir.
Sınıf Yolunu Ayarla
Programınızda JDBC sürücüsünü kullanmak için, sınıf yolunu aşağıdaki gibi ayarlayın -
CLASSPATH = path/to/tajo-jdbc-0.11.3.jar:$CLASSPATHTajo'ya bağlanın
Apache Tajo, tek bir jar dosyası olarak bir JDBC sürücüsü sağlar ve kullanılabilir @ /path/to/tajo/share/jdbc-dist/tajo-jdbc-0.11.3.jar.
Apache Tajo'yu bağlamak için bağlantı dizesi aşağıdaki biçimdedir -
jdbc:tajo://host/
jdbc:tajo://host/database
jdbc:tajo://host:port/
jdbc:tajo://host:port/databaseBuraya,
host - TajoMaster'ın ana bilgisayar adı.
port- Sunucunun dinlediği bağlantı noktası numarası. Varsayılan bağlantı noktası numarası 26002'dir.
database- Veritabanı adı. Varsayılan veritabanı adı varsayılandır.
Java Uygulaması
Şimdi Java uygulamasını anlayalım.
Kodlama
import java.sql.*;
import org.apache.tajo.jdbc.TajoDriver;
public class TajoJdbcSample {
public static void main(String[] args) {
Connection connection = null;
Statement statement = null;
try {
Class.forName("org.apache.tajo.jdbc.TajoDriver");
connection = DriverManager.getConnection(“jdbc:tajo://localhost/default");
statement = connection.createStatement();
String sql;
sql = "select * from mytable”;
// fetch records from mytable.
ResultSet resultSet = statement.executeQuery(sql);
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
System.out.print("ID: " + id + ";\nName: " + name + "\n");
}
resultSet.close();
statement.close();
connection.close();
}catch(SQLException sqlException){
sqlException.printStackTrace();
}catch(Exception exception){
exception.printStackTrace();
}
}
}Uygulama aşağıdaki komutlar kullanılarak derlenebilir ve çalıştırılabilir.
Derleme
javac -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSample.javaYürütme
java -cp /path/to/tajo-jdbc-0.11.3.jar:. TajoJdbcSampleSonuç
Yukarıdaki komutlar aşağıdaki sonucu üretecektir -
ID: 1;
Name: Adam
ID: 2;
Name: Amit
ID: 3;
Name: Bob
ID: 4;
Name: David
ID: 5;
Name: Esha
ID: 6;
Name: Ganga
ID: 7;
Name: Jack
ID: 8;
Name: Leena
ID: 9;
Name: Mary
ID: 10;
Name: PeterApache Tajo, özel / kullanıcı tanımlı işlevleri (UDF'ler) destekler. Özel işlevler python'da oluşturulabilir.
Özel işlevler, dekoratörlü düz python işlevleridir “@output_type(<tajo sql datatype>)” aşağıdaki gibi -
@ouput_type(“integer”)
def sum_py(a, b):
return a + b;UDF'lere sahip python komut dosyaları, aşağıdaki yapılandırma eklenerek kaydedilebilir. “tajosite.xml”.
<property>
<name>tajo.function.python.code-dir</name>
<value>file:///path/to/script1.py,file:///path/to/script2.py</value>
</property>Komut dosyaları kaydedildikten sonra, kümeyi yeniden başlatın ve UDF'ler aşağıdaki gibi SQL sorgusunda kullanılabilir olacaktır -
select sum_py(10, 10) as pyfn;Apache Tajo, kullanıcı tanımlı toplama işlevlerini de destekler ancak kullanıcı tanımlı pencere işlevlerini desteklemez.