Güzel Çorba - Sayfayı Sarmak
Önceki kod örneğinde, bir dize yöntemi kullanarak belgeyi güzel bir kurucu aracılığıyla ayrıştırıyoruz. Başka bir yol da belgeyi açık dosya tanıtıcısından geçirmektir.
from bs4 import BeautifulSoup
with open("example.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")Önce belge Unicode'a dönüştürülür ve HTML varlıkları Unicode karakterlere dönüştürülür: </p>
import bs4
html = '''<b>tutorialspoint</b>, <i>&web scraping &data science;</i>'''
soup = bs4.BeautifulSoup(html, 'lxml')
print(soup)Çıktı
<html><body><b>tutorialspoint</b>, <i>&web scraping &data science;</i></body></html>BeautifulSoup daha sonra verileri HTML ayrıştırıcı kullanarak ayrıştırır veya siz ona açıkça bir XML ayrıştırıcı kullanarak ayrıştırmasını söylersiniz.
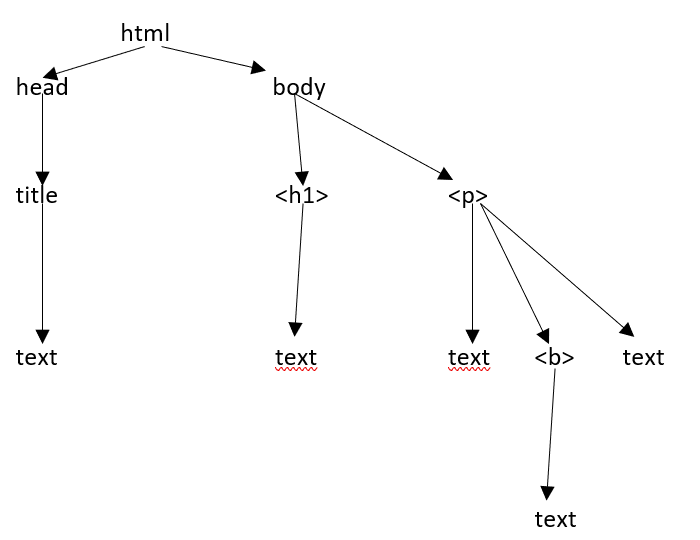
HTML ağaç Yapısı
Bir HTML sayfasının farklı bileşenlerine bakmadan önce, önce HTML ağaç yapısını anlayalım.
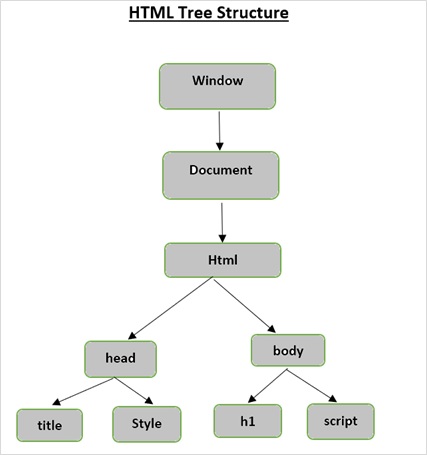
Belge ağacındaki kök öğe, ebeveynlere, çocuklara ve kardeşlere sahip olabilen html'dir ve bu, ağaç yapısındaki konumu ile belirlenir. HTML öğeleri, nitelikleri ve metin arasında hareket etmek için ağaç yapınızdaki düğümler arasında hareket etmeniz gerekir.
Web sayfasının aşağıda gösterildiği gibi olduğunu varsayalım -
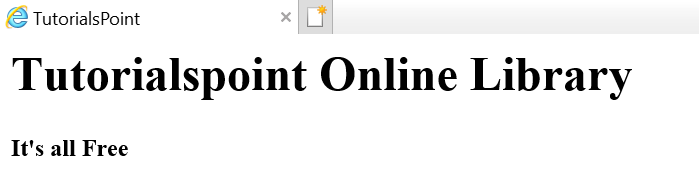
Aşağıdaki gibi bir html belgesine çevrilen -
<html><head><title>TutorialsPoint</title></head><h1>Tutorialspoint Online Library</h1><p<<b>It's all Free</b></p></body></html>Bu basitçe, yukarıdaki html belgesi için aşağıdaki gibi bir html ağaç yapımız olduğu anlamına gelir -