DBMS - Hızlı Kılavuz
Database ilgili verilerden oluşan bir koleksiyondur ve veriler, bilgi üretmek için işlenebilecek gerçek ve rakamlardan oluşan bir koleksiyondur.
Çoğunlukla veriler kaydedilebilir gerçekleri temsil eder. Veriler, gerçeklere dayanan bilgi üretmeye yardımcı olur. Örneğin, tüm öğrenciler tarafından alınan notlarla ilgili veriye sahipsek, daha sonra toppers ve ortalama notlar hakkında sonuca varabiliriz.
Bir database management system verileri, geri alınması, işlenmesi ve üretilmesi daha kolay hale gelecek şekilde depolar.
Özellikler
Geleneksel olarak, veriler dosya formatlarında düzenlenirdi. DBMS o zamanlar yeni bir kavramdı ve geleneksel veri yönetimi tarzındaki eksikliklerin üstesinden gelmek için tüm araştırmalar yapıldı. Modern bir DBMS aşağıdaki özelliklere sahiptir -
Real-world entity- Modern bir DBMS daha gerçekçidir ve mimarisini tasarlamak için gerçek dünyadaki varlıkları kullanır. Davranışı ve nitelikleri de kullanır. Örneğin, bir okul veritabanı öğrencileri bir varlık olarak ve yaşlarını bir öznitelik olarak kullanabilir.
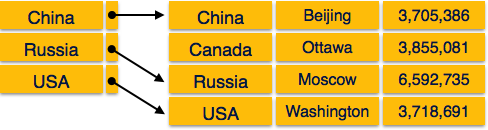
Relation-based tables- DBMS, varlıkların ve aralarındaki ilişkilerin tablolar oluşturmasına izin verir. Bir kullanıcı bir veritabanının mimarisini sadece tablo adlarına bakarak anlayabilir.
Isolation of data and application- Bir veritabanı sistemi, verilerinden tamamen farklıdır. Bir veritabanı aktif bir varlıktır, oysa verilerin üzerinde çalıştığı ve düzenlediği pasif olduğu söylenir. DBMS ayrıca kendi sürecini kolaylaştırmak için verilerle ilgili veriler olan meta verileri de depolar.
Less redundancy- DBMS, özelliklerinden herhangi biri değerlerde fazlalık olduğunda bir ilişkiyi bölen normalleştirme kurallarına uyar. Normalleştirme, veri fazlalığını azaltan matematiksel açıdan zengin ve bilimsel bir süreçtir.
Consistency- Tutarlılık, bir veritabanındaki her ilişkinin tutarlı kaldığı bir durumdur. Veritabanını tutarsız durumda bırakma girişimini tespit edebilen yöntemler ve teknikler vardır. Bir DBMS, dosya işleme sistemleri gibi daha önceki veri depolama uygulamaları formlarına kıyasla daha fazla tutarlılık sağlayabilir.
Query Language- DBMS, verileri almayı ve değiştirmeyi daha verimli hale getiren sorgu dili ile donatılmıştır. Bir kullanıcı, bir veri kümesini almak için gerektiği kadar çok ve farklı filtreleme seçeneği uygulayabilir. Geleneksel olarak dosya işleme sisteminin kullanıldığı yerlerde mümkün değildi.
ACID Properties - DBMS şu kavramları takip eder: Atomicity Ckararlılık, Içözüm ve Dişlenebilirlik (normalde ACID olarak kısaltılır). Bu kavramlar, bir veritabanındaki verileri işleyen işlemlere uygulanır. ACID özellikleri, veri tabanının çok işlemli ortamlarda ve hata durumunda sağlıklı kalmasına yardımcı olur.
Multiuser and Concurrent Access- DBMS, çok kullanıcılı ortamı destekler ve verilere paralel olarak erişmelerine ve bunları işlemelerine izin verir. Kullanıcılar aynı veri öğesini işlemeye çalıştığında işlemlerde kısıtlamalar olsa da, kullanıcılar her zaman bunlardan habersizdir.
Multiple views- DBMS, farklı kullanıcılar için birden çok görünüm sunar. Satış departmanındaki bir kullanıcı, Üretim departmanında çalışan bir kişiden farklı bir veritabanı görünümüne sahip olacaktır. Bu özellik, kullanıcıların ihtiyaçlarına göre veritabanının konsantre bir görünümüne sahip olmalarını sağlar.
Security- Çoklu görünüm gibi özellikler, kullanıcıların diğer kullanıcıların ve departmanların verilerine erişemediği durumlarda bir dereceye kadar güvenlik sağlar. DBMS, veri tabanına veri girerken ve daha sonraki bir aşamada geri alırken kısıtlamalar getirme yöntemleri sunar. DBMS, birden çok kullanıcının farklı özelliklere sahip farklı görünümlere sahip olmasını sağlayan birçok farklı güvenlik özelliği düzeyi sunar. Örneğin, Satış departmanındaki bir kullanıcı Satınalma departmanına ait verileri göremez. Ayrıca Satış departmanının ne kadar verisinin kullanıcıya gösterilmesi gerektiği de yönetilebilir. Bir DBMS, geleneksel dosya sistemleri olarak diske kaydedilmediğinden, yanlış yaratıcıların kodu kırması çok zordur.
Kullanıcılar
Tipik bir DBMS, onu farklı amaçlar için kullanan farklı haklara ve izinlere sahip kullanıcılara sahiptir. Bazı kullanıcılar verileri alır ve bazıları yedekler. Bir DBMS'nin kullanıcıları genel olarak aşağıdaki şekilde kategorize edilebilir:
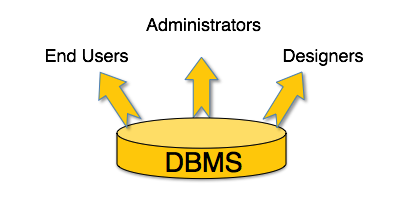
Administrators- Yöneticiler DBMS'yi korur ve veritabanının yönetiminden sorumludur. Kullanımından ve kimler tarafından kullanılması gerektiğinden sorumludurlar. Kullanıcılar için erişim profilleri oluştururlar ve izolasyonu sürdürmek ve güvenliği zorlamak için sınırlamalar uygularlar. Yöneticiler ayrıca sistem lisansı, gerekli araçlar ve diğer yazılım ve donanımla ilgili bakımlar gibi DBMS kaynaklarıyla da ilgilenir.
Designers- Tasarımcılar, veritabanının tasarım kısmında gerçekten çalışan kişilerdir. Hangi verilerin hangi formatta tutulması gerektiğini yakından izlerler. Tüm varlıkları, ilişkileri, kısıtlamaları ve görüşleri tanımlar ve tasarlarlar.
End Users- Son kullanıcılar, bir DBMS'ye sahip olmanın avantajlarından gerçekten faydalananlardır. Son kullanıcılar, günlüklere veya piyasa oranlarına dikkat eden basit izleyicilerden iş analistleri gibi sofistike kullanıcılara kadar çeşitlilik gösterebilir.
Bir DBMS'nin tasarımı mimarisine bağlıdır. Merkezi veya ademi merkeziyetçi veya hiyerarşik olabilir. Bir DBMS'nin mimarisi, tek katmanlı veya çok katmanlı olarak görülebilir. Bir n katmanlı mimari, tüm sistemi ilişkili ancak bağımsız olarak bölern bağımsız olarak değiştirilebilen, değiştirilebilen veya değiştirilebilen modüller.
1 katmanlı mimaride, DBMS, kullanıcının doğrudan DBMS'ye oturduğu ve onu kullandığı tek varlıktır. Burada yapılan herhangi bir değişiklik doğrudan DBMS'nin kendisinde yapılacaktır. Son kullanıcılar için kullanışlı araçlar sağlamaz. Veritabanı tasarımcıları ve programcıları normalde tek katmanlı mimariyi kullanmayı tercih ederler.
DBMS'nin mimarisi 2 katmanlı ise, DBMS'ye erişilebilecek bir uygulamaya sahip olması gerekir. Programcılar, bir uygulama aracılığıyla DBMS'ye eriştikleri 2 katmanlı mimari kullanır. Burada uygulama katmanı, işletim, tasarım ve programlama açısından veritabanından tamamen bağımsızdır.
3 katmanlı Mimari
3 katmanlı bir mimari, kullanıcıların karmaşıklığına ve veritabanında bulunan verileri nasıl kullandıklarına bağlı olarak katmanlarını birbirinden ayırır. Bir DBMS tasarlamak için en yaygın kullanılan mimaridir.
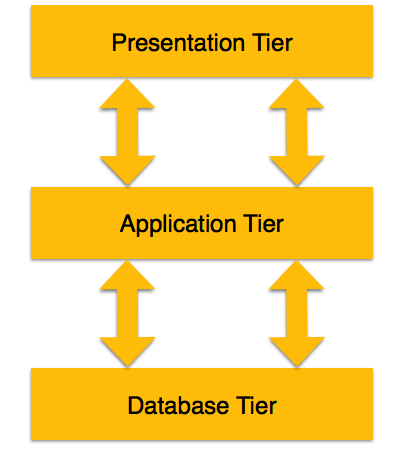
Database (Data) Tier- Bu katmanda veritabanı, sorgu işleme dilleriyle birlikte bulunur. Ayrıca bu seviyede verileri ve kısıtlamalarını tanımlayan ilişkilerimiz de var.
Application (Middle) Tier- Bu katmanda, uygulama sunucusu ve veritabanına erişen programlar bulunur. Bir kullanıcı için bu uygulama katmanı, veritabanının soyutlanmış bir görünümünü sunar. Son kullanıcılar, uygulamanın dışında veritabanının varlığından habersizdir. Diğer uçta, veritabanı katmanı, uygulama katmanının dışındaki herhangi bir kullanıcının farkında değildir. Bu nedenle, uygulama katmanı ortada oturur ve son kullanıcı ile veritabanı arasında bir aracı görevi görür.
User (Presentation) Tier- Son kullanıcılar bu katmanda çalışırlar ve bu katmanın ötesinde veritabanının varlığıyla ilgili hiçbir şey bilmezler. Bu katmanda, veritabanının birden çok görünümü uygulama tarafından sağlanabilir. Tüm görünümler, uygulama katmanında bulunan uygulamalar tarafından oluşturulur.
Hemen hemen tüm bileşenleri bağımsız olduğundan ve bağımsız olarak değiştirilebildiğinden, çok katmanlı veritabanı mimarisi oldukça değiştirilebilir.
Veri modelleri, bir veritabanının mantıksal yapısının nasıl modellendiğini tanımlar. Veri Modelleri, bir DBMS'de soyutlamayı tanıtmak için temel varlıklardır. Veri modelleri, verilerin birbirine nasıl bağlandığını ve bunların sistem içinde nasıl işlenip depolanacağını tanımlar.
İlk veri modeli, kullanılan tüm verilerin aynı düzlemde tutulacağı düz veri modelleri olabilir. Daha önceki veri modelleri o kadar bilimsel değildi, bu nedenle çok sayıda tekrarlama ve güncelleme anormallikleri ortaya koyma eğilimindeydiler.
Varlık-İlişki Modeli
Varlık-İlişki (ER) Modeli, gerçek dünya varlıkları kavramına ve aralarındaki ilişkilere dayanmaktadır. ER Modeli, gerçek dünya senaryosunu veritabanı modeline formüle ederken, varlık seti, ilişki seti, genel öznitelikler ve kısıtlamalar oluşturur.
ER Modeli, bir veritabanının kavramsal tasarımı için en iyi şekilde kullanılır.
ER Modeli şuna dayanır:
Entitiesve nitelikleri.
Relationships varlıklar arasında.
Bu kavramlar aşağıda açıklanmıştır.
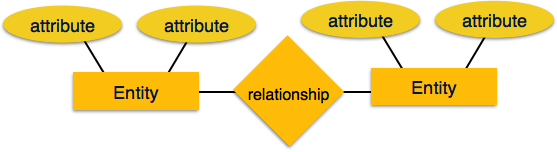
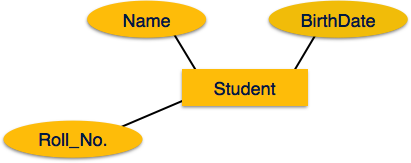
Entity - Bir ER Modelindeki bir varlık, adı verilen özelliklere sahip gerçek dünya bir varlıktır. attributes. Herattribute adı verilen değer kümesiyle tanımlanır domain. Örneğin, bir okul veritabanında, öğrenci bir varlık olarak kabul edilir. Öğrencinin adı, yaşı, sınıfı vb. Gibi çeşitli özellikleri vardır.
Relationship - Varlıklar arasındaki mantıksal ilişkiye denir relationship. İlişkiler, varlıklar ile çeşitli şekillerde eşleştirilir. Eşleme kardinaliteleri, iki varlık arasındaki ilişki sayısını tanımlar.
Değerleri Eşleme -
- bire bir
- birden çoğa
- çoktan bire
- çoktan çoğa
İlişkisel Model
DBMS'deki en popüler veri modeli İlişkisel Modeldir. Diğerlerinden daha bilimsel bir modeldir. Bu model, birinci dereceden yüklem mantığına dayanır ve bir tabloyu birn-ary relation.
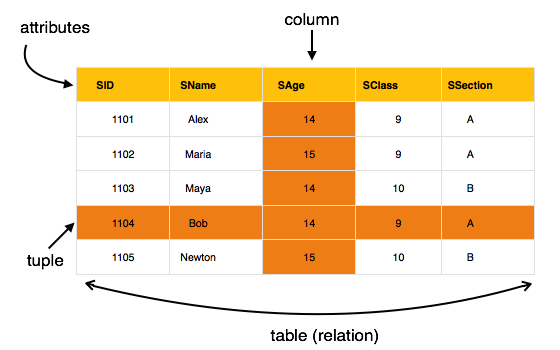
Bu modelin öne çıkan ana noktaları:
- Veriler, adı verilen tablolarda saklanır relations.
- İlişkiler normalleştirilebilir.
- Normalleştirilmiş ilişkilerde kaydedilen değerler atomik değerlerdir.
- Bir ilişkideki her satır benzersiz bir değer içerir.
- Bir ilişkideki her sütun, aynı alandaki değerleri içerir.
Veritabanı Şeması
Bir veritabanı şeması, tüm veritabanının mantıksal görünümünü temsil eden iskelet yapısıdır. Verilerin nasıl organize edildiğini ve aralarındaki ilişkilerin nasıl ilişkilendirildiğini tanımlar. Verilere uygulanacak tüm kısıtlamaları formüle eder.
Bir veritabanı şeması, varlıklarını ve aralarındaki ilişkiyi tanımlar. Şema diyagramları ile gösterilebilen veritabanının açıklayıcı bir detayını içerir. Programcıların veritabanını anlamasına ve kullanışlı hale getirmesine yardımcı olmak için şemayı tasarlayanlar veritabanı tasarımcılarıdır.
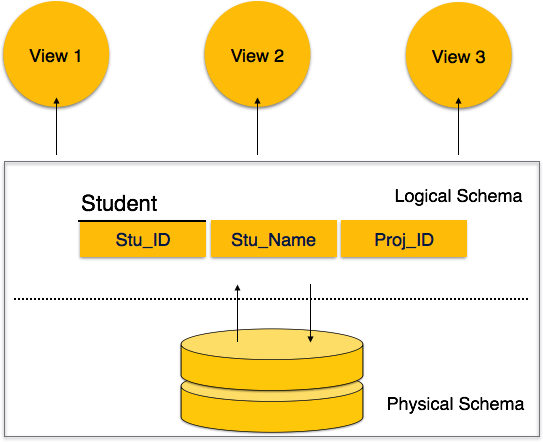
Bir veritabanı şeması genel olarak iki kategoriye ayrılabilir -
Physical Database Schema - Bu şema, verilerin gerçek depolanması ve dosyalar, indeksler, vb. Gibi depolanma biçimleri ile ilgilidir. Verilerin ikincil bir depolamada nasıl depolanacağını tanımlar.
Logical Database Schema- Bu şema, depolanan verilere uygulanması gereken tüm mantıksal kısıtlamaları tanımlar. Tabloları, görünümleri ve bütünlük kısıtlamalarını tanımlar.
Veritabanı Örneği
Bu iki terimi ayrı ayrı ayırt etmemiz önemlidir. Veritabanı şeması, veritabanının iskeletidir. Veritabanı hiç bulunmadığında tasarlanmıştır. Veritabanı çalışmaya başladığında, üzerinde herhangi bir değişiklik yapmak çok zordur. Bir veritabanı şeması herhangi bir veri veya bilgi içermez.
Veritabanı örneği, herhangi bir zamanda veri içeren operasyonel veritabanı durumudur. Veritabanının anlık görüntüsünü içerir. Veritabanı örnekleri zamanla değişme eğilimindedir. Bir DBMS, veritabanı tasarımcılarının koyduğu tüm doğrulamaları, kısıtlamaları ve koşulları titizlikle takip ederek her örneğinin (durumunun) geçerli bir durumda olmasını sağlar.
Bir veritabanı sistemi çok katmanlı değilse, veritabanı sisteminde herhangi bir değişiklik yapmak zorlaşır. Veritabanı sistemleri, daha önce öğrendiğimiz gibi çok katmanlı olarak tasarlanmıştır.
Veri Bağımsızlığı
Bir veritabanı sistemi normalde kullanıcıların verilerine ek olarak çok fazla veri içerir. Örneğin, verileri kolayca bulmak ve almak için meta veriler olarak bilinen verilerle ilgili verileri depolar. Veritabanında depolandıktan sonra bir dizi meta veriyi değiştirmek veya güncellemek oldukça zordur. Ancak bir DBMS genişledikçe, kullanıcıların gereksinimlerini karşılamak için zamanla değişmesi gerekir. Tüm veriler bağımlıysa, sıkıcı ve oldukça karmaşık bir iş haline gelir.
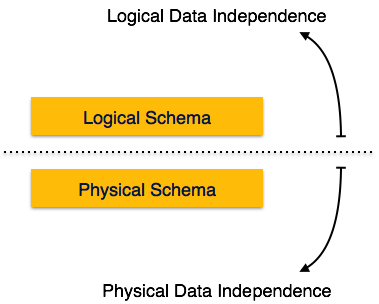
Meta verilerin kendisi katmanlı bir mimariyi takip eder, böylece bir katmandaki verileri değiştirdiğimizde, başka bir düzeydeki verileri etkilemez. Bu veriler bağımsızdır ancak birbirleriyle eşleştirilmiştir.
Mantıksal Veri Bağımsızlığı
Mantıksal veriler, veritabanıyla ilgili verilerdir, yani verilerin içinde nasıl yönetildiği hakkında bilgi depolar. Örneğin, veritabanında depolanan bir tablo (ilişki) ve bu ilişkiye uygulanan tüm kısıtlamaları.
Mantıksal veri bağımsızlığı, diskte depolanan gerçek verilerden kendisini özgürleştiren bir tür mekanizmadır. Tablo formatında bazı değişiklikler yaparsak, diskte bulunan verileri değiştirmemelidir.
Fiziksel Veri Bağımsızlığı
Tüm şemalar mantıksaldır ve gerçek veriler diskte bit formatında saklanır. Fiziksel veri bağımsızlığı, şema veya mantıksal verileri etkilemeden fiziksel verileri değiştirme gücüdür.
Örneğin, depolama sisteminin kendisini değiştirmek veya yükseltmek istememiz durumunda - sabit diskleri SSD ile değiştirmek istediğimizi varsayalım - mantıksal veriler veya şemalar üzerinde herhangi bir etkisi olmamalıdır.
ER modeli, bir veritabanının kavramsal görünümünü tanımlar. Gerçek dünyadaki varlıklar ve aralarındaki dernekler etrafında çalışır. Görünüm düzeyinde, ER modeli, veritabanları tasarlamak için iyi bir seçenek olarak kabul edilir.
Varlık
Bir varlık, canlı veya cansız, kolayca tanımlanabilen gerçek dünya nesnesi olabilir. Örneğin, bir okul veritabanında öğrenciler, öğretmenler, sınıflar ve sunulan dersler varlıklar olarak kabul edilebilir. Tüm bu varlıklar, onlara kimliklerini veren bazı niteliklere veya özelliklere sahiptir.
Bir varlık grubu, benzer türde varlıkların bir koleksiyonudur. Bir varlık grubu, benzer değerleri paylaşan özniteliğe sahip varlıklar içerebilir. Örneğin, bir Öğrenci kümesi bir okulun tüm öğrencilerini içerebilir; aynı şekilde bir Öğretmenler seti tüm fakültelerden bir okulun tüm öğretmenlerini içerebilir. Varlık kümelerinin ayrık olması gerekmez.
Öznitellikler
Varlıklar, adı verilen özellikleri aracılığıyla temsil edilir attributes. Tüm özelliklerin değerleri vardır. Örneğin, bir öğrenci varlığının öznitelikleri olarak adı, sınıfı ve yaşı olabilir.
Özniteliklere atanabilecek bir alan veya değerler aralığı vardır. Örneğin, bir öğrencinin adı sayısal bir değer olamaz. Alfabetik olmalı. Bir öğrencinin yaşı negatif olamaz vb.
Öznitelik Türleri
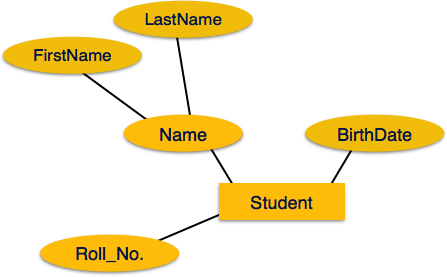
Simple attribute- Basit özellikler, daha fazla bölünemeyen atomik değerlerdir. Örneğin, bir öğrencinin telefon numarası, 10 basamaklı bir atomik değerdir.
Composite attribute- Kompozit özellikler, birden fazla basit özellikten oluşur. Örneğin, bir öğrencinin tam adı ad_adı ve soyadı olabilir.
Derived attribute- Türetilmiş öznitelikler, fiziksel veritabanında bulunmayan özniteliklerdir, ancak değerleri veritabanında bulunan diğer özniteliklerden türetilir. Örneğin, bir departmandaki ortalama_salar, doğrudan veritabanına kaydedilmemelidir, bunun yerine türetilebilir. Başka bir örnek için yaş, data_of_birth'ten türetilebilir.
Single-value attribute- Tek değerli özellikler tek bir değer içerir. Örneğin - Social_Security_Number.
Multi-value attribute- Çok değerli öznitelikler birden fazla değer içerebilir. Örneğin, bir kişinin birden fazla telefon numarası, e-posta_adresi vb. Olabilir.
Bu özellik türleri şu şekilde bir araya gelebilir:
- basit tek değerli öznitelikler
- basit çok değerli öznitelikler
- bileşik tek değerli öznitelikler
- bileşik çok değerli öznitelikler
Varlık Seti ve Anahtarlar
Anahtar, varlık kümesi arasında bir varlığı benzersiz şekilde tanımlayan bir öznitelik veya öznitelikler koleksiyonudur.
Örneğin, bir öğrencinin roll_number'ı onu öğrenciler arasında tanınabilir kılar.
Super Key - Bir varlık kümesindeki bir varlığı toplu olarak tanımlayan bir dizi öznitelik (bir veya daha fazla).
Candidate Key- Minimal bir süper anahtara aday anahtar denir. Bir varlık setinin birden fazla aday anahtarı olabilir.
Primary Key - Birincil anahtar, veritabanı tasarımcısı tarafından varlık kümesini benzersiz şekilde tanımlamak için seçilen aday anahtarlardan biridir.
İlişki
Varlıklar arasındaki ilişkiye ilişki denir. Örneğin, bir çalışanworks_at bir bölüm, bir öğrenci enrollsbir kursta. Burada Works_at ve Enrolls ilişkileri olarak adlandırılır.
İlişki Seti
Benzer türdeki bir dizi ilişki, ilişki kümesi olarak adlandırılır. Varlıklar gibi, bir ilişki de niteliklere sahip olabilir. Bu nitelikleredescriptive attributes.
İlişki Derecesi
Bir ilişkideki katılımcı varlıkların sayısı, ilişkinin derecesini tanımlar.
- İkili = derece 2
- Üçlü = derece 3
- n-ary = derece
Kardinaliteleri Haritalama
Cardinality İlişki kümesi aracılığıyla diğer kümedeki varlıkların sayısı ile ilişkilendirilebilen bir varlık kümesindeki varlıkların sayısını tanımlar.
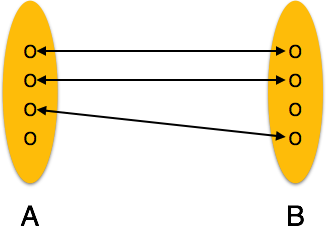
One-to-one - Varlık kümesi A'dan bir varlık, varlık kümesi B'nin en fazla bir varlığı ile ilişkilendirilebilir ve bunun tersi de geçerlidir.
One-to-many - Varlık grubu A'daki bir varlık, varlık grubu B'nin birden fazla varlığı ile ilişkilendirilebilir, ancak varlık grubu B'den bir varlık en fazla bir varlık ile ilişkilendirilebilir.
Many-to-one - Varlık grubu A'daki birden fazla varlık, varlık grubu B'nin en fazla bir varlığı ile ilişkilendirilebilir, ancak varlık grubu B'den bir varlık, varlık grubu A'dan birden fazla varlık ile ilişkilendirilebilir.
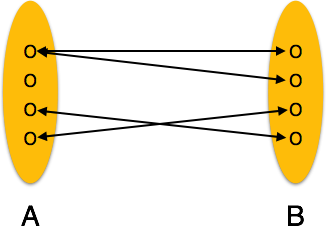
Many-to-many - A'daki bir varlık, B'deki birden fazla varlıkla ilişkilendirilebilir ve bunun tersi de geçerlidir.
Şimdi ER Modelinin bir ER diyagramıyla nasıl temsil edildiğini öğrenelim. Herhangi bir nesne, örneğin varlıklar, bir varlığın öznitelikleri, ilişki kümeleri ve ilişki kümelerinin öznitelikleri bir ER diyagramı yardımıyla temsil edilebilir.
Varlık
Varlıklar dikdörtgenler ile temsil edilir. Dikdörtgenler, temsil ettikleri varlık kümesiyle adlandırılır.

Öznitellikler
Nitelikler, varlıkların özellikleridir. Nitelikler, elipslerle temsil edilir. Her elips bir niteliği temsil eder ve doğrudan varlığına (dikdörtgen) bağlıdır.
Öznitelikler ise composite, ayrıca ağaç benzeri bir yapıya bölünürler. Her düğüm daha sonra özniteliğine bağlanır. Diğer bir deyişle, bileşik nitelikler, bir elips ile bağlantılı olan elipslerle temsil edilir.
Multivalued özellikler çift elips ile gösterilir.
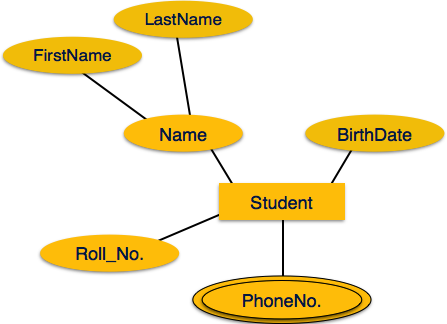
Derived öznitelikler kesikli elips ile gösterilir.
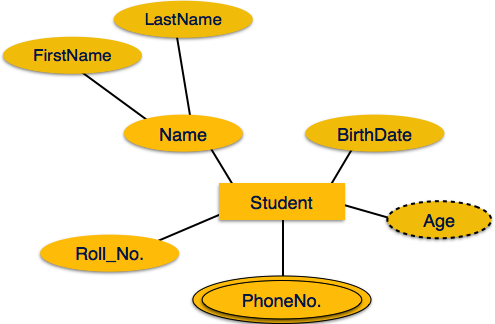
İlişki
İlişkiler, elmas şeklindeki kutuyla temsil edilir. İlişkinin adı elmas kutunun içine yazılır. Bir ilişkiye katılan tüm varlıklar (dikdörtgenler) ona bir çizgi ile bağlanır.
İkili İlişki ve Önem
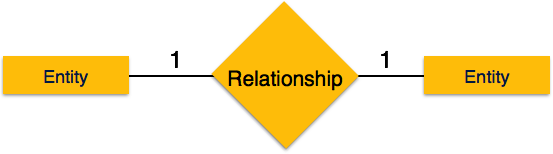
İki kuruluşun katıldığı bir ilişkiye binary relationship. Kardinalite, ilişkiyle ilişkilendirilebilen bir ilişkiden bir varlığın örnek sayısıdır.
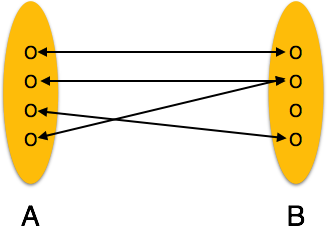
One-to-one- Bir varlığın yalnızca bir örneği ilişkiyle ilişkilendirildiğinde, "1: 1" olarak işaretlenir. Aşağıdaki görüntü, her bir varlığın yalnızca bir örneğinin ilişkiyle ilişkilendirilmesi gerektiğini yansıtmaktadır. Bire bir ilişkiyi tasvir ediyor.
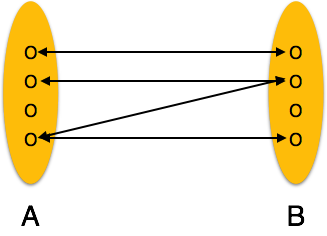
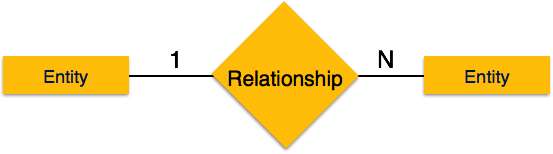
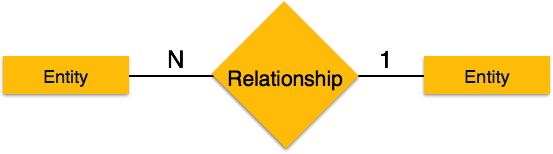
One-to-many- Bir varlığın birden fazla örneği bir ilişkiyle ilişkilendirildiğinde, "1: N" olarak işaretlenir. Aşağıdaki görüntü, soldaki yalnızca bir varlık örneğinin ve sağdaki birden fazla varlık örneğinin ilişkiyle ilişkilendirilebileceğini gösterir. Bire çok ilişkiyi tasvir ediyor.
Many-to-one- İlişkiyle birden fazla varlık örneği ilişkilendirildiğinde, "N: 1" olarak işaretlenir. Aşağıdaki görüntü, soldaki birden fazla varlık örneğinin ve sağdaki bir varlığın yalnızca bir örneğinin ilişkiyle ilişkilendirilebileceğini gösterir. Bire bir ilişkiyi tasvir ediyor.
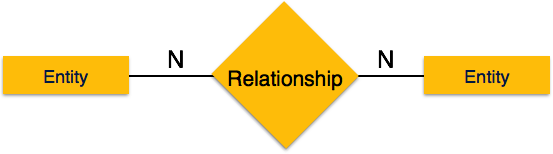
Many-to-many- Aşağıdaki görüntü, soldaki birden fazla varlık örneğinin ve sağdaki birden fazla varlık örneğinin ilişkiyle ilişkilendirilebileceğini gösterir. Çoktan çoğa ilişkiyi tasvir ediyor.
Katılım Kısıtlamaları
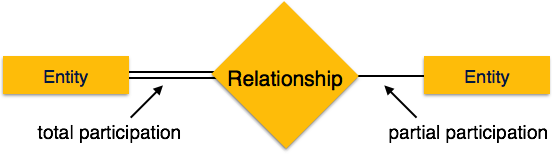
Total Participation- Her varlık ilişkiye dahil olur. Toplam katılım çift çizgilerle temsil edilmektedir.
Partial participation- İlişkiye tüm varlıklar dahil değildir. Kısmi katılım, tek satırlarla temsil edilir.
Şimdi ER Modelinin bir ER diyagramıyla nasıl temsil edildiğini öğrenelim. Herhangi bir nesne, örneğin varlıklar, bir varlığın öznitelikleri, ilişki kümeleri ve ilişki kümelerinin öznitelikleri bir ER diyagramı yardımıyla temsil edilebilir.
Varlık
Varlıklar dikdörtgenler ile temsil edilir. Dikdörtgenler, temsil ettikleri varlık kümesiyle adlandırılır.
Öznitellikler
Nitelikler, varlıkların özellikleridir. Nitelikler, elipslerle temsil edilir. Her elips bir niteliği temsil eder ve doğrudan varlığına (dikdörtgen) bağlıdır.
Öznitelikler ise composite, ayrıca ağaç benzeri bir yapıya bölünürler. Her düğüm daha sonra özniteliğine bağlanır. Diğer bir deyişle, bileşik nitelikler, bir elips ile bağlantılı olan elipslerle temsil edilir.
Multivalued özellikler çift elips ile gösterilir.
Derived öznitelikler kesikli elips ile gösterilir.
İlişki
İlişkiler, elmas şeklindeki kutuyla temsil edilir. İlişkinin adı elmas kutunun içine yazılır. Bir ilişkiye katılan tüm varlıklar (dikdörtgenler) ona bir çizgi ile bağlanır.
İkili İlişki ve Önem
İki kuruluşun katıldığı bir ilişkiye binary relationship. Kardinalite, ilişkiyle ilişkilendirilebilen bir ilişkiden bir varlığın örnek sayısıdır.
One-to-one- Bir varlığın yalnızca bir örneği ilişkiyle ilişkilendirildiğinde, "1: 1" olarak işaretlenir. Aşağıdaki görüntü, her bir varlığın yalnızca bir örneğinin ilişkiyle ilişkilendirilmesi gerektiğini yansıtmaktadır. Bire bir ilişkiyi tasvir ediyor.
One-to-many- Bir varlığın birden fazla örneği bir ilişkiyle ilişkilendirildiğinde, "1: N" olarak işaretlenir. Aşağıdaki görüntü, soldaki yalnızca bir varlık örneğinin ve sağdaki birden fazla varlık örneğinin ilişkiyle ilişkilendirilebileceğini gösterir. Bire çok ilişkiyi tasvir ediyor.
Many-to-one- İlişkiyle birden fazla varlık örneği ilişkilendirildiğinde, "N: 1" olarak işaretlenir. Aşağıdaki görüntü, soldaki birden fazla varlık örneğinin ve sağdaki bir varlığın yalnızca bir örneğinin ilişkiyle ilişkilendirilebileceğini gösterir. Bire bir ilişkiyi tasvir ediyor.
Many-to-many- Aşağıdaki görüntü, soldaki birden fazla varlık örneğinin ve sağdaki birden fazla varlık örneğinin ilişkiyle ilişkilendirilebileceğini gösterir. Çoktan çoğa ilişkiyi tasvir ediyor.
Katılım Kısıtlamaları
Total Participation- Her varlık ilişkiye dahil olur. Toplam katılım çift çizgilerle temsil edilmektedir.
Partial participation- İlişkiye tüm varlıklar dahil değildir. Kısmi katılım, tek satırlarla temsil edilir.
ER Modeli, veritabanı varlıklarını kavramsal hiyerarşik bir şekilde ifade etme gücüne sahiptir. Hiyerarşi yükseldikçe, varlıkların bakış açısını genelleştirir ve hiyerarşinin derinliklerine gittikçe, bize dahil edilen her varlığın ayrıntılarını verir.
Bu yapıda yukarı çıkmak denir generalization, daha genel bir görüşü temsil etmek için varlıkların bir araya getirildiği yer. Örneğin, Mira adlı belirli bir öğrenci, tüm öğrencilerle birlikte genelleştirilebilir. Varlık bir öğrenci olmalı ve ayrıca öğrenci bir kişidir. Tersi denirspecialization bir kişinin öğrenci olduğu ve o öğrencinin Mira olduğu yer.
Genelleme
Yukarıda bahsedildiği gibi, genelleştirilmiş varlıkların tüm genelleştirilmiş varlıkların özelliklerini içerdiği varlıkları genelleştirme sürecine genelleme denir. Genel olarak, birkaç varlık benzer özelliklerine göre tek bir genelleştirilmiş varlık halinde bir araya getirilir. Örneğin güvercin, ev serçesi, karga ve güvercin tümü Kuşlar olarak genelleştirilebilir.

Uzmanlık
Uzmanlık, genellemenin tam tersidir. Uzmanlaşmada, bir grup varlık, özelliklerine göre alt gruplara ayrılır. Örneğin bir 'Kişi' grubunu ele alalım. Bir kişinin adı, doğum tarihi, cinsiyeti vb. Vardır. Bu özellikler tüm kişilerde, insanlarda ortaktır. Ancak bir şirkette kişiler, şirkette oynadıkları role bağlı olarak çalışan, işveren, müşteri veya satıcı olarak tanımlanabilir.
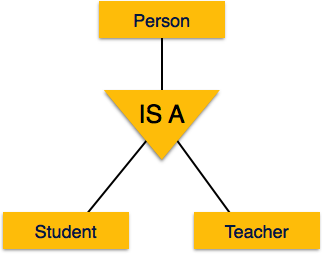
Benzer şekilde, bir okul veri tabanında, kişiler varlıklar olarak okulda oynadıkları role bağlı olarak öğretmen, öğrenci veya personel olarak uzmanlaşabilir.
Miras
Nesne yönelimli programlamada nesne sınıfları oluşturmak için ER-Model'in yukarıdaki tüm özelliklerini kullanıyoruz. Varlıkların ayrıntıları genellikle kullanıcıdan gizlenir; bu süreç olarak bilinirabstraction.
Kalıtım, Genelleme ve Uzmanlaşmanın önemli bir özelliğidir. Daha düşük seviyeli varlıkların daha yüksek seviyeli varlıkların niteliklerini devralmasına izin verir.
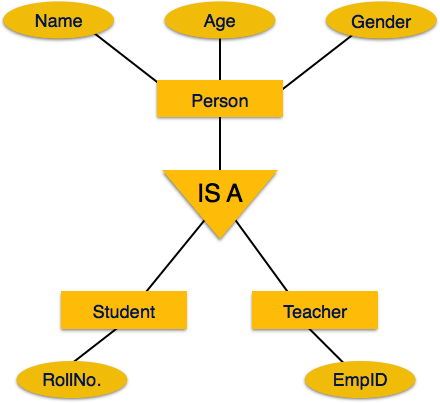
Örneğin, bir Kişi sınıfının ad, yaş ve cinsiyet gibi nitelikleri Öğrenci veya Öğretmen gibi daha düşük düzeyli varlıklar tarafından miras alınabilir.
Dr.Edgar F.
Bu kurallar, depolanan verileri yalnızca ilişkisel yeteneklerini kullanarak yöneten herhangi bir veritabanı sistemine uygulanabilir. Bu, diğer tüm kuralların temelini oluşturan bir temel kuralıdır.
Kural 1: Bilgi Kuralı
Bir veritabanında depolanan veriler, kullanıcı verileri veya meta veriler olabilir, bazı tablo hücrelerinin bir değeri olmalıdır. Veritabanındaki her şey bir tablo formatında saklanmalıdır.
Kural 2: Garantili Erişim Kuralı
Her bir veri elemanının (değer), tablo-adı, birincil-anahtar (satır değeri) ve öznitelik-adı (sütun değeri) kombinasyonuyla mantıksal olarak erişilebilir olması garanti edilir. Verilere erişmek için işaretçiler gibi başka hiçbir yöntem kullanılamaz.
Kural 3: BOŞ Değerlerin Sistematik Değerlendirilmesi
Bir veritabanındaki NULL değerlere sistematik ve tek tip bir muamele verilmelidir. Bu çok önemli bir kuraldır çünkü bir NULL aşağıdakilerden biri olarak yorumlanabilir - veri eksik, veri bilinmiyor veya veriler geçerli değil.
Kural 4: Etkin Çevrimiçi Katalog
Tüm veritabanının yapı açıklaması, şu adla bilinen çevrimiçi bir katalogda saklanmalıdır: data dictionary, yetkili kullanıcılar tarafından erişilebilir. Kullanıcılar, veritabanına erişmek için kullandıkları kataloğa erişmek için aynı sorgu dilini kullanabilir.
Kural 5: Kapsamlı Veri Alt Dil Kuralı
Bir veritabanına yalnızca veri tanımını, veri işlemeyi ve işlem yönetimi işlemlerini destekleyen doğrusal sözdizimine sahip bir dil kullanılarak erişilebilir. Bu dil doğrudan veya bazı uygulamalar aracılığıyla kullanılabilir. Veritabanı bu dilin yardımı olmadan verilere erişime izin veriyorsa, bu bir ihlal olarak kabul edilir.
Kural 6: Güncelleme Kuralını Görüntüleyin
Teorik olarak güncellenebilen bir veritabanının tüm görünümleri de sistem tarafından güncellenebilir olmalıdır.
Kural 7: Yüksek Düzeyli Ekleme, Güncelleme ve Silme Kuralı
Bir veritabanı, yüksek düzeyde ekleme, güncelleme ve silmeyi desteklemelidir. Bu, tek bir satırla sınırlı olmamalıdır, yani, veri kaydı kümeleri elde etmek için birleşim, kesişim ve eksi işlemleri de desteklemelidir.
Kural 8: Fiziksel Veri Bağımsızlığı
Bir veritabanında depolanan veriler, veritabanına erişen uygulamalardan bağımsız olmalıdır. Bir veritabanının fiziksel yapısındaki herhangi bir değişikliğin, verilere harici uygulamalar tarafından nasıl erişildiği üzerinde herhangi bir etkisi olmamalıdır.
Kural 9: Mantıksal Veri Bağımsızlığı
Bir veritabanındaki mantıksal veriler, kullanıcının görüşünden (uygulamasından) bağımsız olmalıdır. Mantıksal verilerdeki herhangi bir değişiklik, onu kullanan uygulamaları etkilememelidir. Örneğin, iki tablo birleştirilirse veya biri iki farklı tabloya bölünürse, kullanıcı uygulamasında herhangi bir etki veya değişiklik olmamalıdır. Bu, uygulanması en zor kurallardan biridir.
Kural 10: Bütünlük Bağımsızlığı
Bir veritabanı, onu kullanan uygulamadan bağımsız olmalıdır. Tüm bütünlük kısıtlamaları, uygulamada herhangi bir değişikliğe gerek kalmadan bağımsız olarak değiştirilebilir. Bu kural, bir veritabanını ön uç uygulamadan ve arayüzünden bağımsız kılar.
Kural 11: Dağıtım Bağımsızlığı
Son kullanıcı, verilerin çeşitli konumlara dağıtıldığını görememelidir. Kullanıcılar her zaman verilerin yalnızca bir sitede bulunduğu izlenimini edinmelidir. Bu kural, dağıtık veritabanı sistemlerinin temeli olarak kabul edilmiştir.
Kural 12: Yıkmama Kuralı
Bir sistemin düşük düzeyli kayıtlara erişim sağlayan bir arabirimi varsa, arabirim sistemi bozmamalı ve güvenlik ve bütünlük kısıtlamalarını atlatmamalıdır.
İlişkisel veri modeli, veri depolama ve işleme için dünya çapında yaygın olarak kullanılan birincil veri modelidir. Bu model basittir ve verileri depolama verimliliğiyle işlemek için gereken tüm özelliklere ve yeteneklere sahiptir.
Kavramlar
Tables- İlişkisel veri modelinde ilişkiler Tablolar formatında kaydedilir. Bu format, varlıklar arasındaki ilişkiyi saklar. Bir tabloda, satırların kayıtları ve sütunların öznitelikleri temsil ettiği satırlar ve sütunlar vardır.
Tuple - Bu ilişki için tek bir kayıt içeren bir tablonun tek satırına tuple denir.
Relation instance- İlişkisel veritabanı sistemindeki sonlu bir demet kümesi, ilişki örneğini temsil eder. İlişki örneklerinin yinelenen demetleri yoktur.
Relation schema - Bir ilişki şeması, ilişki adını (tablo adı), öznitelikleri ve adlarını tanımlar.
Relation key - Her satırın, ilişkideki (tablo) satırı benzersiz bir şekilde tanımlayabilen, ilişki anahtarı olarak bilinen bir veya daha fazla özelliği vardır.
Attribute domain - Her özniteliğin, öznitelik etki alanı olarak bilinen önceden tanımlanmış bir değer kapsamı vardır.
Kısıtlamalar
Her ilişkinin, geçerli bir ilişki olması için tutması gereken bazı koşulları vardır. Bu koşullaraRelational Integrity Constraints. Üç ana bütünlük kısıtlaması vardır -
- Anahtar kısıtlamalar
- Etki alanı kısıtlamaları
- Bilgi tutarlılığı kısıtlamaları
Anahtar Kısıtlamalar
İlişkide, bir demeti benzersiz bir şekilde tanımlayabilen en az bir minimum öznitelik alt kümesi olmalıdır. Bu minimal öznitelik alt kümesinekeybu ilişki için. Birden fazla bu tür minimum alt küme varsa, bunlaracandidate keys.
Anahtar kısıtlamalar bunu zorlar -
bir anahtar öznitelik ile bir ilişkide, iki demet anahtar öznitelikleri için aynı değerlere sahip olamaz.
bir anahtar özelliği NULL değerlere sahip olamaz.
Anahtar kısıtlamalara Varlık Kısıtlamaları da denir.
Etki Alanı Kısıtlamaları
Niteliklerin gerçek dünya senaryosunda belirli değerleri vardır. Örneğin, yaş yalnızca pozitif bir tam sayı olabilir. Bir ilişkinin özniteliklerine de aynı kısıtlamalar uygulanmaya çalışılmıştır. Her özniteliğin belirli bir değer aralığına sahip olması zorunludur. Örneğin, yaş sıfırdan küçük olamaz ve telefon numaraları 0-9 dışında bir rakam içeremez.
Bilgi tutarlılığı Kısıtlamaları
Referans bütünlüğü kısıtlamaları, Yabancı Anahtarlar kavramı üzerinde çalışır. Yabancı anahtar, başka bir ilişkide başvurulabilen bir ilişkinin temel bir özelliğidir.
Bilgi tutarlılığı kısıtlaması, bir ilişki farklı veya aynı ilişkinin bir anahtar niteliğine atıfta bulunuyorsa, o zaman bu anahtar öğenin var olması gerektiğini belirtir.
İlişkisel veritabanı sistemlerinin, kullanıcılarının veritabanı örneklerini sorgulamasına yardımcı olabilecek bir sorgu dili ile donatılması beklenmektedir. İki tür sorgu dili vardır - ilişkisel cebir ve ilişkisel hesap.
İlişkisel Cebir
İlişkisel cebir, ilişki örneklerini girdi olarak alan ve çıktı olarak ilişki örneklerini veren bir prosedürel sorgu dilidir. Sorgu yapmak için operatörleri kullanır. Bir operatör şunlardan biri olabilir:unary veya binary. İlişkileri girdi olarak, verim ilişkilerini çıktı olarak kabul ederler. İlişkisel cebir, bir ilişki üzerinde yinelemeli olarak gerçekleştirilir ve ara sonuçlar da ilişkiler olarak kabul edilir.
İlişkisel cebirin temel işlemleri aşağıdaki gibidir -
- Select
- Project
- Union
- Farklı ayarla
- Kartezyen ürün
- Rename
Tüm bu işlemleri ilerleyen bölümlerde tartışacağız.
İşlem Seçin (σ)
Verilen yüklemi bir ilişkiden karşılayan demetleri seçer.
Notation- σ p (r)
Nerede σ seçim koşulu anlamına gelir ve rilişki anlamına gelir. p gibi bağlayıcıları kullanabilen edat mantığı formülüdürand, or, ve not. Bu terimler - =, ≠, ≥, <,>, ≤ gibi ilişkisel operatörler kullanabilir.
For example -
σsubject="database"(Books)
Output - Konunun 'veritabanı' olduğu kitaplardan demetleri seçer.
σsubject="database" and price="450"(Books)
Output - Konunun 'veritabanı' ve 'fiyat'ın 450 olduğu kitaplardan dizileri seçer.
σsubject="database" and price < "450" or year > "2010"(Books)
Output - Konusu 'veritabanı' ve 'fiyat'ın 450 olduğu kitaplardan veya 2010'dan sonra yayınlanan kitaplardan tuple seçer.
Proje İşlemi (∏)
Belirli bir koşulu karşılayan sütunları yansıtır.
Gösterim - ∏ A 1 , A 2 , A n (r)
Burada A 1 , A 2 , A n ilişkinin öznitelik isimleridirr.
İlişki bir küme olduğundan, yinelenen satırlar otomatik olarak ortadan kaldırılır.
For example -
∏subject, author (Books)
Kitaplar ilişkisinden konu ve yazar adlı sütunları seçer ve yansıtır.
Sendika Operasyonu (∪)
Verilen iki ilişki arasında ikili birleşmeyi gerçekleştirir ve şu şekilde tanımlanır:
r ∪ s = { t | t ∈ r or t ∈ s}
Notation - r U s
Nerede r ve s veritabanı ilişkileri veya ilişki sonuç kümesidir (geçici ilişki).
Bir birleşim işleminin geçerli olması için aşağıdaki koşulların geçerli olması gerekir -
- r, ve s aynı sayıda özniteliğe sahip olmalıdır.
- Öznitelik alanları uyumlu olmalıdır.
- Yinelenen demetler otomatik olarak ortadan kaldırılır.
∏ author (Books) ∪ ∏ author (Articles)
Output - Bir kitap veya makale veya her ikisini birden yazan yazarların adlarını yansıtır.
Farkı Ayarla (-)
Küme farkı işleminin sonucu, bir ilişkide bulunan ancak ikinci ilişkide olmayan tuplelardır.
Notation - r - s
Mevcut tüm tupleları bulur r ama içinde değil s.
∏ author (Books) − ∏ author (Articles)
Output - Kitap yazmış ancak makale yazmamış yazarların adını verir.
Kartezyen Ürün (Χ)
İki farklı ilişkinin bilgilerini tek bir yerde birleştirir.
Notation - r Χ s
Nerede r ve s ilişkilerdir ve çıktıları şu şekilde tanımlanacaktır:
r Χ s = {qt | q ∈ r ve t ∈ s}
∏ author = 'tutorialspoint'(Books Χ Articles)
Output - Tutorialspoint tarafından yazılan tüm kitapları ve makaleleri gösteren bir ilişki verir.
İşlemi Yeniden Adlandır (ρ)
İlişkisel cebirin sonuçları da ilişkilerdir, ancak herhangi bir isim yoktur. Yeniden adlandırma işlemi, çıktı ilişkisini yeniden adlandırmamızı sağlar. 'yeniden adlandırma' işlemi küçük Yunan harfiyle belirtilirrho ρ .
Notation- ρ x (E)
İfadenin sonucu nerede E adıyla kaydedildi x.
Ek işlemler -
- Kavşağı ayarla
- Assignment
- Doğal birleşim
İlişkisel Hesap
İlişkisel Cebirin aksine, İlişkisel Hesaplama prosedürel olmayan bir sorgu dilidir, yani ne yapılacağını söyler ama nasıl yapılacağını asla açıklamaz.
İlişkisel hesap iki şekilde bulunur -
Tuple İlişkisel Hesap (TRC)
Değişken aralıkları tuples üzerinden filtreleme
Notation- {T | Durum}
Bir koşulu karşılayan tüm T tuplelarını döndürür.
For example -
{ T.name | Author(T) AND T.article = 'database' }Output - 'Veritabanı' üzerine makale yazan Yazardan 'adı' olan demetleri döndürür.
TRC ölçülebilir. Varoluşsal (∃) ve Evrensel Niceleyicileri (∀) kullanabiliriz.
For example -
{ R| ∃T ∈ Authors(T.article='database' AND R.name=T.name)}Output - Yukarıdaki sorgu, öncekiyle aynı sonucu verecektir.
Etki Alanı İlişkisel Hesabı (DRC)
DRC'de, filtreleme değişkeni, tüm tuple değerleri yerine özniteliklerin alanını kullanır (yukarıda belirtildiği gibi TRC'de yapıldığı gibi).
Notation -
{bir 1 , bir 2 , bir 3 , ..., bir n | P (bir 1 , bir 2 , bir 3 , ..., bir n )}
Burada a1, a2 özniteliklerdir ve P iç özelliklerle oluşturulmuş formülleri temsil eder.
For example -
{< article, page, subject > |
∈ TutorialsPoint ∧ subject = 'database'}
Output - Konu veritabanı olan TutorialsPoint ilişkisinden Makale, Sayfa ve Konu verir.
Tıpkı TRC gibi, DRC de varoluşsal ve evrensel niceleyiciler kullanılarak yazılabilir. DRC ayrıca ilişkisel operatörleri de içerir.
Tuple Relation Calculus ve Domain Relation Calculus'un ifade gücü İlişkisel Cebire eşdeğerdir.
ER Modeli, diyagramlar halinde kavramsallaştırıldığında, anlaşılması daha kolay olan, varlık-ilişkisine iyi bir genel bakış sağlar. ER diyagramları ilişkisel şema ile eşleştirilebilir, yani ER diyagramı kullanılarak ilişkisel şema oluşturmak mümkündür. Tüm ER kısıtlamalarını ilişkisel modele aktaramayız, ancak yaklaşık bir şema oluşturulabilir.
ER Diyagramlarını İlişkisel Şemaya dönüştürmek için kullanılabilen birkaç işlem ve algoritma vardır. Bazıları otomatik, bazıları manuel. Burada, ilişkisel temellerle eşleme diyagramı içeriklerine odaklanabiliriz.
ER diyagramları esas olarak aşağıdakilerden oluşur:
- Varlık ve öznitelikleri
- Varlıklar arasında ilişki olan ilişki.
Eşleme Varlığı
Bir varlık, bazı niteliklere sahip gerçek dünya nesnesidir.
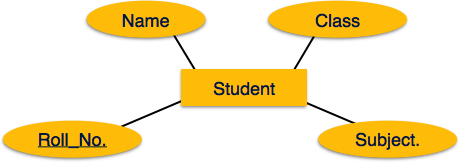
Haritalama Süreci (Algoritma)
- Her varlık için tablo oluşturun.
- Varlığın öznitelikleri, ilgili veri türleriyle tablo alanları haline gelmelidir.
- Birincil anahtarı bildirin.
Eşleme İlişkisi
Bir ilişki, varlıklar arasındaki bir ilişkidir.
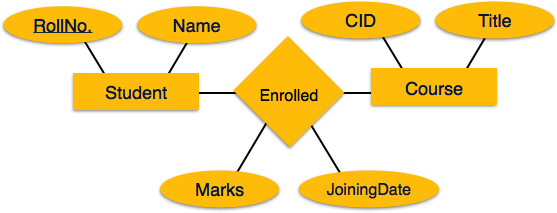
Haritalama Süreci
- Bir ilişki için tablo oluşturun.
- Tüm katılımcı Varlıkların birincil anahtarlarını ilgili veri türleriyle birlikte tablo alanları olarak ekleyin.
- İlişkinin herhangi bir özelliği varsa, her bir özelliği tablo alanı olarak ekleyin.
- Katılımcı varlıkların tüm birincil anahtarlarını oluşturan bir birincil anahtar bildirin.
- Tüm yabancı anahtar kısıtlamalarını bildirin.
Zayıf Varlık Kümelerini Eşleme
Zayıf bir varlık kümesi, kendisiyle ilişkili herhangi bir birincil anahtara sahip olmayan bir varlık kümesidir.
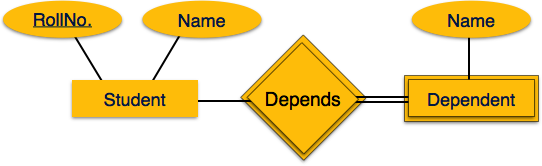
Haritalama Süreci
- Zayıf varlık kümesi için tablo oluşturun.
- Tüm özelliklerini tabloya alan olarak ekleyin.
- Varlık kümesini tanımlayan birincil anahtarı ekleyin.
- Tüm yabancı anahtar kısıtlamalarını bildirin.
Hiyerarşik Varlıkları Eşleme
ER uzmanlığı veya genellemesi, hiyerarşik varlık kümeleri biçiminde gelir.
Haritalama Süreci
Tüm üst düzey varlıklar için tablolar oluşturun.
Daha düşük seviyeli varlıklar için tablolar oluşturun.
Daha düşük seviyeli varlıklar tablosuna daha yüksek seviyeli varlıkların birincil anahtarlarını ekleyin.
Alt düzey tablolarda, alt düzey varlıkların diğer tüm özniteliklerini ekleyin.
Üst düzey tablonun birincil anahtarını ve daha düşük düzeyli tablonun birincil anahtarını bildirin.
Yabancı anahtar kısıtlamalarını bildirin.
SQL, İlişkisel Veritabanları için bir programlama dilidir. İlişkisel cebir ve tuple ilişkisel hesap üzerinden tasarlanmıştır. SQL, RDBMS'nin tüm ana dağıtımlarını içeren bir paket olarak gelir.
SQL, hem veri tanımlama hem de veri işleme dillerini içerir. SQL'in veri tanımlama özelliklerini kullanarak veritabanı şeması tasarlanabilir ve değiştirilebilir, oysa veri işleme özellikleri SQL'in veritabanından verileri depolamasına ve almasına izin verir.
Veri Tanımlama Dili
SQL, veritabanı şemasını tanımlamak için aşağıdaki komut setini kullanır -
OLUŞTURMAK
RDBMS'den yeni veritabanları, tablolar ve görünümler oluşturur.
For example -
Create database tutorialspoint;
Create table article;
Create view for_students;DÜŞÜRMEK
RDBMS'den komutları, görünümleri, tabloları ve veritabanlarını düşürür.
For example-
Drop object_type object_name;
Drop database tutorialspoint;
Drop table article;
Drop view for_students;DEĞİŞTİR
Veritabanı şemasını değiştirir.
Alter object_type object_name parameters;For example-
Alter table article add subject varchar;Bu komut, ilişkiye bir öznitelik ekler article isimle subject dize türü.
Veri işleme dili
SQL, veri işleme dili (DML) ile donatılmıştır. DML, verilerini ekleyerek, güncelleyerek ve silerek veritabanı örneğini değiştirir. DML, bir veritabanındaki tüm form veri modifikasyonundan sorumludur. SQL, DML bölümünde aşağıdaki komut kümesini içerir -
- SELECT/FROM/WHERE
- INSERT IN / VALUES
- UPDATE/SET/WHERE
- / NEREDEN SİL
Bu temel yapılar, veritabanı programcılarının ve kullanıcıların veri ve bilgileri veritabanına girmesine ve bir dizi filtre seçeneği kullanarak verimli bir şekilde geri almasına izin verir.
SEÇİM / NEREDEN / NEREDE
SELECT- Bu, SQL'in temel sorgu komutlarından biridir. İlişkisel cebirin projeksiyon işlemine benzer. WHERE yan tümcesi tarafından açıklanan koşula göre öznitelikleri seçer.
FROM- Bu madde, özniteliklerin seçileceği / yansıtılacağı bağımsız değişken olarak bir ilişki adını alır. Birden fazla ilişki adı verilmesi durumunda, bu madde Kartezyen çarpıma karşılık gelir.
WHERE - Bu madde, öngörülen öznitelikleri nitelemek için eşleşmesi gereken koşulu veya koşulu tanımlar.
For example -
Select author_name
From book_author
Where age > 50;Bu komut, ilişkiden yazarların isimlerini verecektir. book_author yaşı 50'den büyük olan.
INSERT IN / VALUES
Bu komut, bir tablonun (ilişki) satırlarına değerler eklemek için kullanılır.
Syntax-
INSERT INTO table (column1 [, column2, column3 ... ]) VALUES (value1 [, value2, value3 ... ])Veya
INSERT INTO table VALUES (value1, [value2, ... ])For example -
INSERT INTO tutorialspoint (Author, Subject) VALUES ("anonymous", "computers");GÜNCELLE / AYARLA / NEREDE
Bu komut, bir tablodaki (ilişki) sütunların değerlerini güncellemek veya değiştirmek için kullanılır.
Syntax -
UPDATE table_name SET column_name = value [, column_name = value ...] [WHERE condition]For example -
UPDATE tutorialspoint SET Author="webmaster" WHERE Author="anonymous";DELETE / FROM / WHERE
Bu komut, bir tablodan (ilişkiden) bir veya daha fazla satırı kaldırmak için kullanılır.
Syntax -
DELETE FROM table_name [WHERE condition];For example -
DELETE FROM tutorialspoints
WHERE Author="unknown";İşlevsel Bağımlılık
İşlevsel bağımlılık (FD), bir ilişkideki iki öznitelik arasındaki bir dizi kısıtlamadır. İşlevsel bağımlılık, iki demet A1, A2, ..., An öznitelikleri için aynı değerlere sahipse, bu iki dizinin B1, B2, ..., Bn öznitelikleri için aynı değerlere sahip olması gerektiğini söyler.
Fonksiyonel bağımlılık bir ok işareti (→), yani X → Y ile temsil edilir, burada X fonksiyonel olarak Y'yi belirler. Sol taraftaki özellikler, sağ taraftaki özelliklerin değerlerini belirler.
Armstrong Aksiyomları
F, bir dizi işlevsel bağımlılık ise, F + olarak belirtilen kapanış, F'nin mantıksal olarak ima ettiği tüm işlevsel bağımlılıklar kümesidir. .
Reflexive rule - Alfa bir özellik kümesiyse ve beta, alfa is_subset_of ise, alfa betayı tutar.
Augmentation rule- Eğer a → b tutarsa ve y öznitelik kümesiyse, o zaman ay → by de tutar. Yani bağımlılıklara nitelik eklemek, temel bağımlılıkları değiştirmez.
Transitivity rule- Cebirdeki geçiş kuralıyla aynı, eğer a → b ve b → c tutarsa, o zaman a → c de tutar. a → b, b'yi belirleyen işlevsel olarak adlandırılır.
Önemsiz İşlevsel Bağımlılık
Trivial- Y'nin X'in bir alt kümesi olduğu bir işlevsel bağımlılık (FD) X → Y tutarsa, buna önemsiz bir FD denir. Önemsiz FD'ler her zaman geçerlidir.
Non-trivial - Y'nin X'in bir alt kümesi olmadığı FD X → Y tutarsa, buna önemsiz olmayan FD denir.
Completely non-trivial - X'in Y = Φ ile kesiştiği bir FD X → Y tutarsa, bunun tamamen önemsiz olmayan bir FD olduğu söylenir.
Normalleştirme
Bir veritabanı tasarımı mükemmel değilse, herhangi bir veritabanı yöneticisi için kötü bir rüya gibi olan anormallikler içerebilir. Anormallikler içeren bir veritabanını yönetmek neredeyse imkansızdır.
Update anomalies- Veri öğeleri dağınıksa ve birbirine doğru şekilde bağlanmazsa, garip durumlara yol açabilir. Örneğin, kopyaları birkaç yere dağılmış bir veri öğesini güncellemeye çalıştığımızda, birkaç örnek düzgün bir şekilde güncellenirken, diğer birkaç örnek eski değerlerle bırakılır. Bu tür örnekler, veritabanını tutarsız bir durumda bırakır.
Deletion anomalies - Bir kaydı silmeye çalıştık, ancak bazı kısımları bilinçsizlik nedeniyle silinmeden kaldı, veriler de başka bir yere kaydedildi.
Insert anomalies - Hiç olmayan bir kayda veri eklemeye çalıştık.
Normalleştirme, tüm bu anormallikleri ortadan kaldırmak ve veritabanını tutarlı bir duruma getirmek için kullanılan bir yöntemdir.
Birincil normal form
İlk Normal Form, ilişkilerin (tabloların) tanımında tanımlanır. Bu kural, bir ilişkideki tüm niteliklerin atomik alanlara sahip olması gerektiğini tanımlar. Atomik bir alandaki değerler bölünemez birimlerdir.

İlişkiyi (tabloyu) Birinci Normal Biçime dönüştürmek için aşağıdaki gibi yeniden düzenledik.
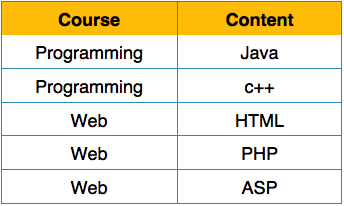
Her öznitelik, önceden tanımlanmış etki alanından yalnızca tek bir değer içermelidir.
İkinci Normal Form
İkinci normal formu öğrenmeden önce, aşağıdakileri anlamamız gerekir -
Prime attribute - Aday anahtarın bir parçası olan öznitelik, ana öznitelik olarak bilinir.
Non-prime attribute - Prime-key'in parçası olmayan bir özniteliğin asal olmayan bir öznitelik olduğu söylenir.
İkinci normal biçimi izlersek, o zaman her asal olmayan öznitelik tamamen işlevsel olarak birincil anahtar özniteliğine bağlı olmalıdır. Yani, X → A tutarsa, o zaman X'in Y → A'nın da doğru olduğu herhangi bir uygun Y alt kümesi olmamalıdır.

Burada Student_Project ilişkisinde asal anahtar özniteliklerinin Stu_ID ve Proj_ID olduğunu görüyoruz. Kurala göre, anahtar olmayan öznitelikler, yani Stu_Name ve Proj_Name, her ikisine de bağlı olmalıdır ve tek tek hiçbir ana anahtar özniteliğine bağlı olmamalıdır. Ancak Stu_Name'in Stu_ID ile tanımlanabileceğini ve Proj_Name'in Proj_ID tarafından bağımsız olarak tanımlanabileceğini bulduk. Bu denirpartial dependencyİkinci Normal Formda buna izin verilmez.
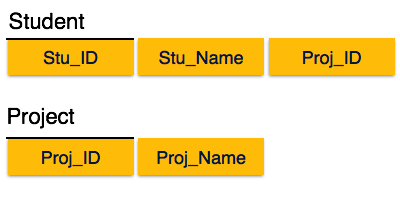
Yukarıdaki resimde gösterildiği gibi ilişkiyi ikiye böldük. Dolayısıyla kısmi bağımlılık yoktur.
Üçüncü Normal Form
Bir ilişkinin Üçüncü Normal Formda olması için, İkinci Normal formda olması ve aşağıdakilerin sağlaması gerekir:
- Asal olmayan hiçbir öznitelik geçişli olarak birincil anahtar özniteliğine bağlı değildir.
- Önemsiz olmayan herhangi bir işlevsel bağımlılık için, X → A, sonra ya -
-
X bir süpererkidir veya
- A, asal niteliktir.

Yukarıdaki Student_detail ilişkisinde Stu_ID'nin anahtar ve tek asal anahtar niteliği olduğunu görüyoruz. Şehrin Stu_ID ile ve Zip'in kendisi tarafından tanımlanabileceğini bulduk. Ne Zip bir süper kahraman ne de City bir ana özelliktir. Ek olarak, Stu_ID → Zip → Şehir, böylece vartransitive dependency.
Bu ilişkiyi üçüncü normal forma getirmek için, ilişkiyi aşağıdaki gibi iki ilişkiye ayırıyoruz:
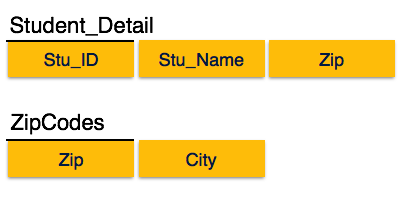
Boyce-Codd Normal Formu
Boyce-Codd Normal Form (BCNF), Üçüncü Normal Form'un katı şartlarda bir uzantısıdır. BCNF şunu belirtir -
- Önemsiz olmayan herhangi bir işlevsel bağımlılık için, X → A, X bir süper anahtar olmalıdır.
Yukarıdaki görüntüde Stu_ID, Student_Detail ilişkisindeki süper anahtardır ve Zip, ZipCodes ilişkisindeki süper anahtardır. Yani,
Stu_ID → Stu_Name, Zip
ve
Zip → Şehir
Bu, her iki ilişkinin de BCNF'de olduğunu doğrular.
İki ilişkinin Kartezyen çarpımını almanın faydalarını anlıyoruz, bu bize birlikte eşleştirilmiş tüm olası tupl'ları verir. Ancak bazı durumlarda, hatırı sayılır sayıda niteliğe sahip binlerce demet ile büyük ilişkilerle karşılaştığımız bir Kartezyen ürünü almak bizim için mümkün olmayabilir.
Joinbir Kartezyen ürünü ve ardından bir seçim sürecinin birleşimidir. Bir Birleştirme işlemi, farklı ilişkilerden iki demeti eşler, ancak ve ancak belirli bir birleştirme koşulu sağlanırsa.
Aşağıdaki bölümlerde çeşitli birleştirme türlerini kısaca açıklayacağız.
Theta (θ) Birleştir
Teta birleştirme, teta koşulunu sağlamaları koşuluyla, farklı ilişkilerden tuple'ları birleştirir. Birleştirme koşulu, sembolü ile gösterilirθ.
Gösterim
R1 ⋈θ R2R1 ve R2, özniteliklere (A1, A2, .., An) ve (B1, B2, .., Bn) sahip ilişkilerdir, öyle ki özniteliklerin ortak bir yanı yoktur, yani R1 ∩ R2 = Φ.
Theta join, her türlü karşılaştırma işlecini kullanabilir.
Öğrenci SID İsim Std 101 Alex 10 102 Maria 11 Konular Sınıf Konu 10 Matematik 10 ingilizce 11 Müzik 11 Spor Dalları Student_Detail =
STUDENT ⋈Student.Std = Subject.Class SUBJECTStudent_detail SID İsim Std Sınıf Konu 101 Alex 10 10 Matematik 101 Alex 10 10 ingilizce 102 Maria 11 11 Müzik 102 Maria 11 11 Spor Dalları Equijoin
Theta birleştirme yalnızca kullandığında equalitykarşılaştırma operatörü, equijoin olduğu söylenir. Yukarıdaki örnek equijoin'e karşılık gelir.
Doğal Birleştirme ( ⋈ )
Doğal birleştirme herhangi bir karşılaştırma operatörü kullanmaz. Kartezyen bir ürünün yaptığı gibi birleştirmez. Yalnızca iki ilişki arasında var olan en az bir ortak özellik varsa Doğal Birleştirme gerçekleştirebiliriz. Ek olarak, özniteliklerin aynı ada ve alana sahip olması gerekir.
Doğal birleştirme, her iki ilişkideki özniteliklerin değerlerinin aynı olduğu eşleşen özniteliklere etki eder.
Dersler CID Ders Bölüm CS01 Veri tabanı CS ME01 Mekanik BEN Mİ EE01 Elektronik EE HoD Bölüm Kafa CS Alex BEN Mİ Maya EE Mira Dersler ⋈ HoD Bölüm CID Ders Kafa CS CS01 Veri tabanı Alex BEN Mİ ME01 Mekanik Maya EE EE01 Elektronik Mira Dış Birleşimler
Theta Join, Equijoin ve Natural Join iç birleşimler olarak adlandırılır. Bir iç birleşim, yalnızca eşleşen özniteliklere sahip tuple'ları içerir ve geri kalanlar ortaya çıkan ilişkide atılır. Bu nedenle, ortaya çıkan ilişkiye katılan ilişkilerden gelen tüm demetleri dahil etmek için dış birleşimleri kullanmamız gerekir. Üç tür dış birleşim vardır - sol dış birleşim, sağ dış birleşim ve tam dış birleşim.
Sol Dış Birleşim (R
S)
Sol ilişkideki tüm tuplelar, ortaya çıkan ilişkiye dahil edilir. Sağ bağıntısında S herhangi bir eşleşen tuple olmadan R'de tuplelar varsa, ortaya çıkan ilişkinin S öznitelikleri NULL yapılır.
Ayrıldı Bir B 100 Veri tabanı 101 Mekanik 102 Elektronik Sağ Bir B 100 Alex 102 Maya 104 Mira Dersler HoD
Bir B C D 100 Veri tabanı 100 Alex 101 Mekanik --- --- 102 Elektronik 102 Maya Sağ Dış Birleşim: (R
S)
Sağ bağıntısından gelen tüm tuplelar, ortaya çıkan ilişkiye dahil edilir. S'de R'de eşleşen herhangi bir tuple olmayan tuplelar varsa, sonuçta ortaya çıkan ilişkinin R nitelikleri NULL yapılır.
Dersler HoD
Bir B C D 100 Veri tabanı 100 Alex 102 Elektronik 102 Maya --- --- 104 Mira Tam Dış Birleşim: (R
S)
Her iki katılımcı ilişkiden gelen tüm demetler ortaya çıkan ilişkiye dahil edilir. Her iki ilişki için eşleşen tuple yoksa, ilgili eşleşmeyen öznitelikleri NULL yapılır.
Dersler HoD
Bir B C D 100 Veri tabanı 100 Alex 101 Mekanik --- --- 102 Elektronik 102 Maya --- --- 104 Mira Veritabanları, kayıtları içeren dosya formatlarında saklanır. Fiziksel düzeyde, gerçek veriler bazı cihazlarda elektromanyetik formatta saklanır. Bu depolama aygıtları genel olarak üç türe ayrılabilir -

Primary Storage- CPU tarafından doğrudan erişilebilen bellek deposu bu kategoriye girer. CPU'nun dahili belleği (kayıtları), hızlı belleği (önbellek) ve ana belleğine (RAM), tümü ana karta veya CPU yonga setine yerleştirildikleri için doğrudan CPU tarafından erişilebilir. Bu depolama alanı tipik olarak çok küçük, çok hızlı ve geçicidir. Birincil depolama, durumunu korumak için sürekli güç kaynağı gerektirir. Elektrik kesintisi durumunda tüm verileri kaybolur.
Secondary Storage- İkincil depolama cihazları, verileri ileride kullanmak üzere veya yedekleme amacıyla depolamak için kullanılır. İkincil depolama, CPU yonga setinin veya ana kartın bir parçası olmayan bellek aygıtlarını, örneğin manyetik diskleri, optik diskleri (DVD, CD, vb.), Sabit diskleri, flash sürücüleri ve manyetik bantları içerir.
Tertiary Storage- Üçüncül depolama, büyük hacimli verileri depolamak için kullanılır. Bu tür depolama aygıtları bilgisayar sisteminin dışında olduğundan, hızları en düşük olanlardır. Bu depolama aygıtları çoğunlukla tüm sistemin yedeğini almak için kullanılır. Optik diskler ve manyetik bantlar, üçüncül depolama olarak yaygın şekilde kullanılmaktadır.
Bellek Hiyerarşisi
Bir bilgisayar sistemi, iyi tanımlanmış bir bellek hiyerarşisine sahiptir. Bir CPU'nun ana belleğine ve dahili kayıtlarına doğrudan erişimi vardır. Ana belleğin erişim süresi açıkça CPU hızından daha azdır. Bu hız uyumsuzluğunu en aza indirmek için önbellek tanıtıldı. Önbellek, en hızlı erişim süresini sağlar ve CPU tarafından en sık erişilen verileri içerir.
En hızlı erişime sahip bellek, en pahalı olandır. Daha büyük depolama aygıtları düşük hız sunar ve daha ucuzdur, ancak CPU kayıtları veya önbellekle karşılaştırıldığında çok büyük miktarlarda veri depolayabilirler.
Manyetik Diskler
Sabit disk sürücüleri, mevcut bilgisayar sistemlerindeki en yaygın ikincil depolama aygıtlarıdır. Bunlara manyetik diskler denir çünkü bilgiyi depolamak için manyetizasyon kavramını kullanırlar. Sabit diskler, mıknatıslanabilir malzeme ile kaplanmış metal disklerden oluşur. Bu diskler bir mil üzerine dikey olarak yerleştirilir. Bir okuma / yazma kafası diskler arasında hareket eder ve altındaki noktayı mıknatıslamak veya manyetikliğini gidermek için kullanılır. Mıknatıslanmış bir nokta 0 (sıfır) veya 1 (bir) olarak tanınabilir.
Sabit diskler, verileri verimli bir şekilde depolamak için iyi tanımlanmış bir sırayla biçimlendirilir. Bir sabit disk plakasının üzerinde birçok eşmerkezli daire vardır.tracks. Her parça daha da ayrılmıştırsectors. Sabit diskteki bir sektör tipik olarak 512 bayt veri depolar.
RAID
RAID, Rbol Aöfke Ibağımsız Disks, birden çok ikincil depolama cihazını birbirine bağlayan ve bunları tek bir depolama ortamı olarak kullanan bir teknoloji.
RAID, farklı hedeflere ulaşmak için birden çok diskin birbirine bağlandığı bir disk dizisinden oluşur. RAID seviyeleri, disk dizilerinin kullanımını tanımlar.
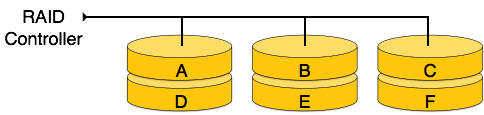
RAID 0- Bu düzeyde, şeritli bir disk dizisi uygulanır. Veriler bloklara bölünür ve bloklar diskler arasında dağıtılır. Her disk, paralel olarak yazmak / okumak için bir veri bloğu alır. Depolama cihazının hızını ve performansını artırır. Seviye 0'da eşlik ve yedekleme yoktur.
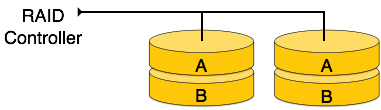
RAID 1- RAID 1, aynalama tekniklerini kullanır. Veriler bir RAID denetleyicisine gönderildiğinde, dizideki tüm disklere verilerin bir kopyasını gönderir. RAID seviye 1 aynı zamandamirroring ve arıza durumunda% 100 yedeklilik sağlar.
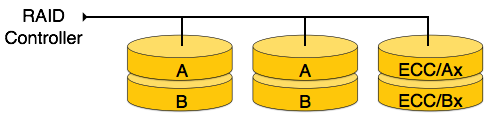
RAID 2- RAID 2, verileri için Hamming mesafesini kullanarak, farklı disklerde şeritlenen Hata Düzeltme Kodunu kaydeder. Seviye 0 gibi, bir kelimedeki her veri biti ayrı bir diske kaydedilir ve veri kelimelerinin ECC kodları farklı bir disk setinde saklanır. Karmaşık yapısı ve yüksek maliyeti nedeniyle, RAID 2 ticari olarak mevcut değildir.
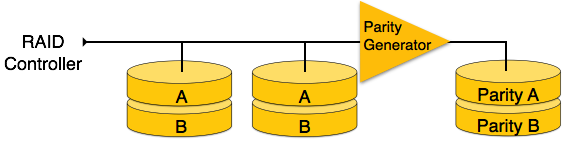
RAID 3- RAID 3, verileri birden çok diske aktarır. Veri sözcüğü için oluşturulan eşlik biti farklı bir diskte saklanır. Bu teknik, tek disk arızalarının üstesinden gelmesini sağlar.
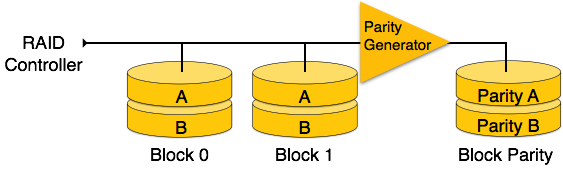
RAID 4- Bu seviyede, tüm bir veri bloğu veri disklerine yazılır ve ardından eşlik oluşturulur ve farklı bir diskte saklanır. Seviye 3'ün bayt seviyesinde şeritleme kullandığını, seviye 4'ün ise blok seviyesinde şeritleme kullandığını unutmayın. Hem seviye 3 hem de seviye 4, RAID uygulamak için en az üç disk gerektirir.
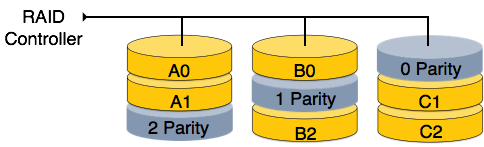
RAID 5 - RAID 5, tüm veri bloklarını farklı disklere yazar, ancak veri bloğu şeridi için üretilen eşlik bitleri, farklı bir ayrılmış diskte saklamak yerine tüm veri diskleri arasında dağıtılır.
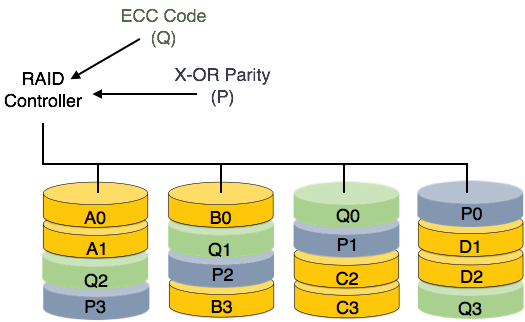
RAID 6- RAID 6, seviye 5'in bir uzantısıdır. Bu seviyede, iki bağımsız eşlik oluşturulur ve birden çok disk arasında dağıtılmış şekilde depolanır. İki eşlik, ek hata toleransı sağlar. Bu seviye, RAID uygulamak için en az dört disk sürücüsü gerektirir.
Göreceli veriler ve bilgiler toplu olarak dosya formatlarında saklanır. Dosya, ikili biçimde saklanan kayıt dizisidir. Bir disk sürücüsü, kayıtları saklayabilen birkaç blok halinde biçimlendirilir. Dosya kayıtları bu disk bloklarıyla eşleştirilir.
Dosya Organizasyonu
Dosya Organizasyonu, dosya kayıtlarının disk bloklarıyla nasıl eşleneceğini tanımlar. Dosya kayıtlarını düzenlemek için dört tür Dosya Organizasyonumuz var -
Yığın Dosyası Organizasyonu
Yığın Dosya Organizasyonu kullanılarak bir dosya oluşturulduğunda, İşletim Sistemi bellek alanını herhangi bir hesaplama detayı olmadan bu dosyaya tahsis eder. Dosya kayıtları o hafıza alanında herhangi bir yere yerleştirilebilir. Kayıtların yönetimi yazılımın sorumluluğundadır. Yığın Dosyası kendi başına herhangi bir sıralama, sıralama veya indekslemeyi desteklemez.
Sıralı Dosya Organizasyonu
Her dosya kaydı, o kaydı benzersiz şekilde tanımlamak için bir veri alanı (öznitelik) içerir. Sıralı dosya organizasyonunda, kayıtlar dosyaya benzersiz anahtar alanına veya arama anahtarına göre sıralı bir sırayla yerleştirilir. Pratik olarak tüm kayıtları fiziksel formda sıralı olarak saklamak mümkün değildir.
Hash Dosyası Organizasyonu
Karma Dosya Organizasyonu, kayıtların bazı alanlarında Hash işlevi hesaplamasını kullanır. Karma işlevinin çıktısı, kayıtların yerleştirileceği disk bloğunun konumunu belirler.
Kümelenmiş Dosya Organizasyonu
Kümelenmiş dosya organizasyonu, büyük veritabanları için iyi kabul edilmez. Bu mekanizmada, bir veya daha fazla ilişkiden ilgili kayıtlar aynı disk bloğunda tutulur, yani kayıtların sıralaması birincil anahtara veya arama anahtarına dayanmaz.
Dosya İşlemleri
Veritabanı dosyalarındaki işlemler genel olarak iki kategoriye ayrılabilir -
Update Operations
Retrieval Operations
Güncelleme işlemleri, veri değerlerini ekleme, silme veya güncelleme yoluyla değiştirir. Öte yandan, geri alma işlemleri verileri değiştirmez, isteğe bağlı koşullu filtrelemeden sonra geri alır. Her iki işlem türünde de seçim önemli bir rol oynar. Bir dosyanın oluşturulması ve silinmesi dışında, dosyalarda yapılabilecek birkaç işlem olabilir.
Open - İki moddan birinde bir dosya açılabilir, read mode veya write mode. Okuma modunda, işletim sistemi kimsenin verileri değiştirmesine izin vermez. Diğer bir deyişle, veriler salt okunurdur. Okuma modunda açılan dosyalar birkaç varlık arasında paylaşılabilir. Yazma modu veri değişikliğine izin verir. Yazma modunda açılan dosyalar okunabilir ancak paylaşılamaz.
Locate- Her dosyanın, verilerin okunacağı veya yazılacağı mevcut konumu söyleyen bir dosya işaretçisi vardır. Bu işaretçi buna göre ayarlanabilir. Bul (arama) işlemini kullanarak ileri veya geri hareket ettirilebilir.
Read- Varsayılan olarak, dosyalar okuma modunda açıldığında, dosya işaretçisi dosyanın başlangıcını gösterir. Kullanıcının, bir dosyayı açarken işletim sistemine dosya işaretçisini nerede bulacağını söyleyebileceği seçenekler vardır. Dosya işaretçisine sonraki veriler okunur.
Write- Kullanıcı bir dosyayı yazma modunda açmayı seçebilir, bu da içeriğini düzenlemesine olanak tanır. Silme, ekleme veya değiştirme olabilir. Dosya işaretçisi, açılış anında bulunabilir veya işletim sistemi izin verirse dinamik olarak değiştirilebilir.
Close- Bu, işletim sistemi açısından en önemli işlemdir. Bir dosyayı kapatma isteği oluşturulduğunda, işletim sistemi
- tüm kilitleri kaldırır (paylaşımlı moddaysa),
- verileri (değiştirilmişse) ikincil depolama ortamına kaydeder ve
- dosyayla ilişkili tüm arabellekleri ve dosya işleyicilerini serbest bırakır.
Bir dosya içindeki verilerin organizasyonu burada önemli bir rol oynar. Kayıtların sıralı olarak mı yoksa kümelenmiş mi olduğuna bağlı olarak, dosya işaretçisini bir dosya içinde istenen bir kayda yerleştirme işlemi.
Verilerin kayıt şeklinde saklandığını biliyoruz. Her kaydın benzersiz bir şekilde tanınmasına yardımcı olan bir anahtar alanı vardır.
İndeksleme, indekslemenin yapıldığı bazı özniteliklere dayalı olarak veritabanı dosyalarından kayıtları verimli bir şekilde almak için bir veri yapısı tekniğidir. Veritabanı sistemlerinde indeksleme, kitaplarda gördüğümüze benzer.
İndeksleme, indeksleme niteliklerine göre tanımlanır. İndeksleme aşağıdaki türlerde olabilir -
Primary Index- Birincil dizin, sıralı bir veri dosyasında tanımlanır. Veri dosyası birkey field. Anahtar alan genellikle ilişkinin birincil anahtarıdır.
Secondary Index - İkincil dizin, bir aday anahtar olan ve her kayıtta benzersiz bir değere sahip olan bir alandan veya yinelenen değerlere sahip bir anahtar olmayan bir alandan üretilebilir.
Clustering Index- Kümeleme indeksi, sıralı bir veri dosyasında tanımlanır. Veri dosyası, anahtarsız bir alanda sıralanır.
Sıralı Dizine Ekleme iki türdendir -
- Yoğun Endeksi
- Seyrek İndeks
Yoğun Endeksi
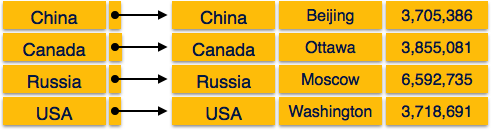
Yoğun indekste, veritabanındaki her arama anahtarı değeri için bir indeks kaydı vardır. Bu, aramayı daha hızlı hale getirir ancak dizin kayıtlarını depolamak için daha fazla alan gerektirir. Dizin kayıtları, arama anahtarı değeri ve diskteki gerçek kayda bir işaretçi içerir.
Seyrek İndeks
Seyrek dizinde, her arama anahtarı için dizin kayıtları oluşturulmaz. Buradaki bir dizin kaydı, bir arama anahtarı ve diskteki verilere gerçek bir işaretçi içerir. Bir kaydı aramak için önce indeks kaydı ile ilerliyoruz ve verinin gerçek konumuna ulaşıyoruz. Eğer aradığımız veri indeksi takip ederek direkt olarak ulaştığımız yerde değilse, sistem istenen veri bulunana kadar sıralı aramaya başlar.
Çok Düzeyli Dizin
Dizin kayıtları, arama anahtarı değerleri ve veri işaretçilerinden oluşur. Çok düzeyli dizin, gerçek veritabanı dosyalarıyla birlikte diskte saklanır. Veritabanının boyutu büyüdükçe, endekslerin boyutu da büyür. Arama işlemlerini hızlandırmak için dizin kayıtlarını ana bellekte tutmaya büyük bir ihtiyaç vardır. Tek düzeyli dizin kullanılıyorsa, büyük boyutlu bir dizin bellekte tutulamaz ve bu da birden çok disk erişimine yol açar.
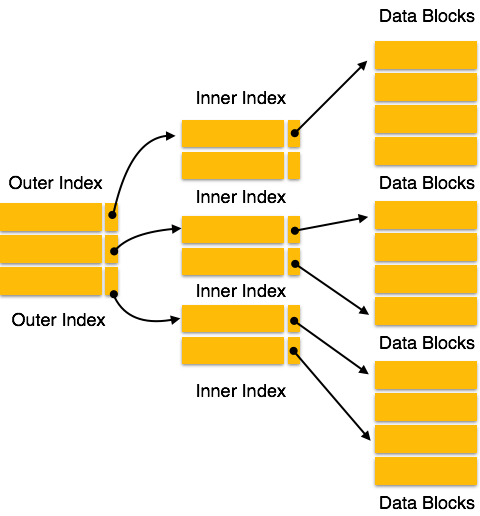
Çok Düzeyli Dizin, en dıştaki düzeyi, ana bellekte herhangi bir yere kolayca yerleştirilebilecek tek bir disk bloğuna kaydedilebilecek kadar küçük hale getirmek için dizinin birkaç küçük dizine bölünmesine yardımcı olur.
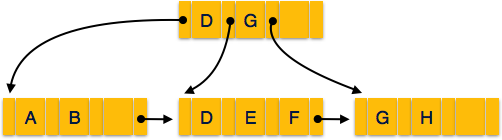
B + Ağaç
AB + ağaç, çok seviyeli bir dizin biçimini izleyen dengeli bir ikili arama ağacıdır. Bir B + ağacının yaprak düğümleri, gerçek veri işaretçilerini gösterir. B + ağacı, tüm yaprak düğümlerinin aynı yükseklikte ve dolayısıyla dengeli kalmasını sağlar. Ek olarak, yaprak düğümler bir bağlantı listesi kullanılarak bağlanır; bu nedenle, bir B + ağacı sıralı erişimin yanı sıra rastgele erişimi de destekleyebilir.
B + Ağacının Yapısı
Her yaprak düğüm, kök düğümden eşit uzaklıktadır. AB + ağacı sıraya gören nerede nher B + ağacı için sabittir .
Internal nodes -
- Dahili (yaprak olmayan) düğümler, kök düğüm dışında en az ⌈n / 2⌉ işaretçiler içerir.
- En fazla, bir dahili düğüm içerebilir n işaretçiler.
Leaf nodes -
- Yaprak düğümler en az ⌈n / 2⌉ kayıt işaretçileri ve ⌈n / 2⌉ anahtar değerleri içerir.
- En fazla bir yaprak düğümü şunları içerebilir: n rekor işaretçileri ve n anahtar değerler.
- Her yaprak düğümü bir blok işaretçisi içerir P sonraki yaprak düğüme işaret etmek ve bağlantılı bir liste oluşturmak için.
B + Ağaç Ekleme
B + ağaçları alttan doldurulur ve her giriş yaprak düğümünde yapılır.
- Bir yaprak düğümü taşarsa -
Düğümü iki parçaya ayırın.
Bölme i = ⌊(m+1)/2⌋.
İlk i girişler bir düğümde saklanır.
Girişlerin geri kalanı (i + 1 sonrası) yeni bir düğüme taşınır.
ith anahtar yaprağın üst kısmında çoğaltılır.
Yaprak olmayan bir düğüm taşarsa -
Düğümü iki parçaya ayırın.
Düğümü bölümlere ayır i = ⌈(m+1)/2⌉.
Girişler i tek düğümde tutulur.
Girişlerin geri kalanı yeni bir düğüme taşınır.
B + Ağaç Silme
B + ağaç girişleri, yaprak düğümlerinde silinir.
Hedef giriş aranır ve silinir.
Dahili bir düğüm ise, silin ve sol pozisyondaki girişle değiştirin.
Silme işleminden sonra alt akış test edilir,
Alt taşma meydana gelirse, girdileri kendisine bırakılan düğümlerden dağıtın.
Soldan dağıtım mümkün değilse, o zaman
Düğümlerden ona doğru dağıtın.
Soldan veya sağdan dağıtım mümkün değilse, o zaman
Düğümü sol ve sağ ile birleştirin.
Büyük bir veritabanı yapısı için, tüm dizin değerlerini tüm seviyelerinde aramak ve ardından istenen veriyi almak için hedef veri bloğuna ulaşmak neredeyse imkansız olabilir. Hashing, dizin yapısını kullanmadan bir veri kaydının disk üzerindeki doğrudan konumunu hesaplamak için etkili bir tekniktir.
Hashing, bir veri kaydının adresini oluşturmak için parametre olarak arama anahtarlarıyla birlikte karma işlevler kullanır.
Hash Organizasyonu
Bucket- Bir hash dosyası, verileri paket biçiminde depolar. Kova, bir depolama birimi olarak kabul edilir. Bir kova tipik olarak bir tam disk bloğunu depolar ve bu da bir veya daha fazla kaydı depolayabilir.
Hash Function - Bir hash işlevi, h, tüm arama tuşları kümesini eşleyen bir eşleme işlevidir Kgerçek kayıtların yerleştirildiği adrese. Arama anahtarlarından paket adreslerine kadar bir işlevdir.
Statik Hashing
Statik karmada, bir arama anahtarı değeri sağlandığında, karma işlevi her zaman aynı adresi hesaplar. Örneğin mod-4 hash fonksiyonu kullanılıyorsa, sadece 5 değer üretecektir. Çıkış adresi, bu işlev için her zaman aynı olacaktır. Sağlanan paketlerin sayısı her zaman değişmeden kalır.
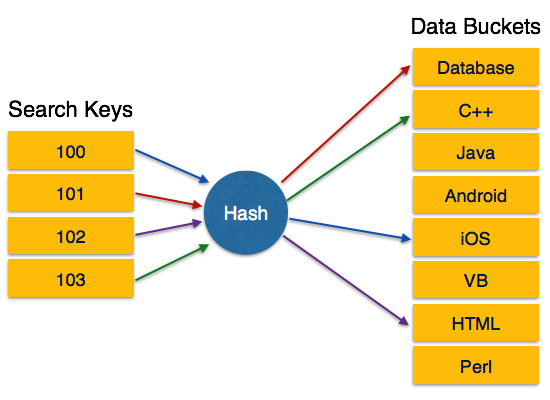
Operasyon
Insertion - Statik karma kullanılarak bir kaydın girilmesi gerektiğinde, karma işlevi h arama anahtarı için paket adresini hesaplar K, kaydın depolanacağı yer.
Paket adresi = h (K)
Search - Bir kaydın alınması gerektiğinde, verilerin depolandığı paketin adresini almak için aynı karma işlevi kullanılabilir.
Delete - Bu basitçe bir arama ve ardından silme işlemidir.
Kova Taşması
Kova taşması durumu şu şekilde bilinir: collision. Bu, herhangi bir statik hash işlevi için ölümcül bir durumdur. Bu durumda taşma zincirleme kullanılabilir.
Overflow Chaining- Paketler dolduğunda, aynı hash sonucu için yeni bir paket ayrılır ve öncekinden sonra bağlanır. Bu mekanizmayaClosed Hashing.
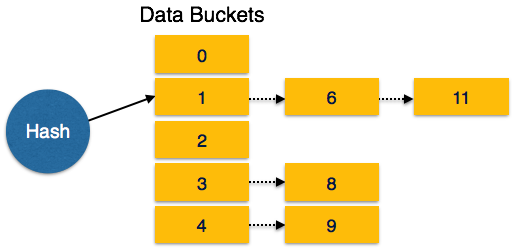
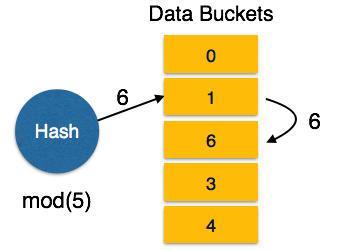
Linear Probing- Bir karma işlevi, verilerin halihazırda depolandığı bir adres oluşturduğunda, bir sonraki boş paket ona tahsis edilir. Bu mekanizmayaOpen Hashing.
Dinamik Hashing
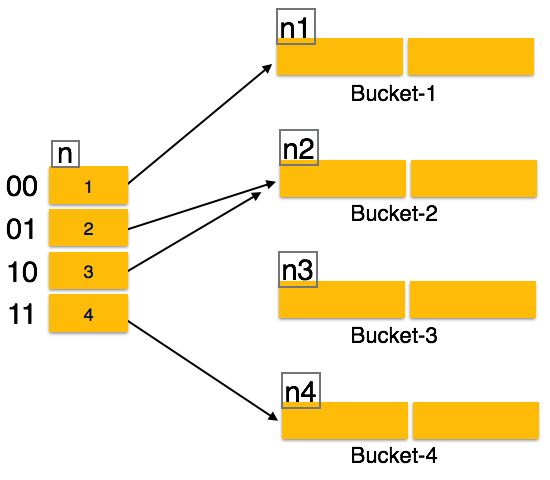
Statik karma ile ilgili sorun, veritabanının boyutu büyüdükçe veya küçüldükçe dinamik olarak genişlememesi veya küçülmemesidir. Dinamik hashing, veri paketlerinin dinamik olarak ve isteğe bağlı olarak eklendiği ve kaldırıldığı bir mekanizma sağlar. Dinamik hashing, aynı zamandaextended hashing.
Dinamik hashing işleminde hash fonksiyonu, çok sayıda değer üretmek için yapılır ve başlangıçta yalnızca birkaçı kullanılır.
Organizasyon
Tüm bir hash değerinin öneki, bir hash indeksi olarak alınır. Paket adreslerini hesaplamak için karma değerinin yalnızca bir kısmı kullanılır. Her hash indeksinin, bir hash fonksiyonunu hesaplamak için kaç bit kullanıldığını gösteren bir derinlik değeri vardır. Bu bitler 2n kova adresleyebilir. Tüm bu bitler tüketildiğinde - yani, tüm kepçeler dolduğunda - derinlik değeri doğrusal olarak artırılır ve bölmelerin iki katı tahsis edilir.
Operasyon
Querying - Karma dizininin derinlik değerine bakın ve bu bitleri paket adresini hesaplamak için kullanın.
Update - Yukarıdaki gibi bir sorgulama yapın ve verileri güncelleyin.
Deletion - İstenen verileri bulmak ve bunları silmek için bir sorgu gerçekleştirin.
Insertion - Paketin adresini hesaplayın
- Kova zaten doluysa.
- Daha fazla kova ekleyin.
- Karma değerine ek bitler ekleyin.
- Karma işlevini yeniden hesaplayın.
- Başka
- Pakete veri ekleyin,
- Tüm kovalar doluysa, statik hashing çözümlerini uygulayın.
- Kova zaten doluysa.
Veriler bazı sıralamalarda düzenlendiğinde ve sorgular bir dizi veri gerektirdiğinde, karma oluşturma uygun değildir. Veriler ayrık ve rastgele olduğunda, hash en iyi sonucu verir.
Karma algoritmalar, indekslemeden daha karmaşıktır. Tüm hash işlemleri sabit zamanda yapılır.
Bir işlem, bir görevler grubu olarak tanımlanabilir. Tek bir görev, daha fazla bölünemeyen minimum işlem birimidir.
Basit bir işlem örneğini ele alalım. Bir banka çalışanının A'nın hesabından B'nin hesabına 500 Rs aktardığını varsayalım. Bu çok basit ve küçük işlem, birkaç düşük seviyeli görevi içerir.
A’s Account
Open_Account(A) Old_Balance = A.balance New_Balance = Old_Balance - 500 A.balance = New_Balance Close_Account(A)B’s Account
Open_Account(B) Old_Balance = B.balance New_Balance = Old_Balance + 500 B.balance = New_Balance Close_Account(B)ACID Özellikleri
İşlem, bir programın çok küçük bir birimidir ve birkaç düşük düzeyli görev içerebilir. Bir veritabanı sistemindeki bir işleminAtomicity Ckararlılık, Içözüm ve Ddoğruluk, eksiksizlik ve veri bütünlüğünü sağlamak için yaygın olarak ACID özellikleri olarak bilinen uygulanabilirlik.
Atomicity- Bu özellik, bir işlemin bir atomik birim olarak ele alınması gerektiğini, yani tüm işlemlerinin yürütüldüğünü veya hiçbirinin yapılmadığını belirtir. Bir işlemin kısmen tamamlanmış olarak bırakıldığı bir veritabanında hiçbir durum olmamalıdır. Durumlar, işlemin yürütülmesinden önce veya işlemin yürütülmesinden / durdurulmasından / başarısız olmasından sonra tanımlanmalıdır.
Consistency- Veritabanı herhangi bir işlemden sonra tutarlı bir durumda kalmalıdır. Veritabanında bulunan veriler üzerinde hiçbir işlemin olumsuz etkisi olmamalıdır. Veritabanı, bir işlemin yürütülmesinden önce tutarlı bir durumda ise, işlemin yürütülmesinden sonra da tutarlı kalması gerekir.
Durability- Veritabanı, sistem başarısız olsa veya yeniden başlatılsa bile en son güncellemelerini tutacak kadar dayanıklı olmalıdır. Bir işlem bir veri tabanındaki bir veri yığınını güncellerse ve işlem yaparsa, veri tabanı değiştirilen verileri tutacaktır. Bir işlem tamamlanırsa ancak veriler diske yazılmadan önce sistem başarısız olursa, sistem yeniden harekete geçtiğinde bu veriler güncellenecektir.
Isolation- Birden fazla işlemin aynı anda ve paralel olarak yürütüldüğü bir veri tabanı sisteminde izolasyon özelliği, tüm işlemlerin sistemdeki tek işlemmiş gibi yürütüleceğini ve yürütüleceğini belirtir. Hiçbir işlem, başka herhangi bir işlemin varlığını etkilemez.
Seri hale getirilebilirlik
Çoklu programlama ortamında işletim sistemi tarafından birden fazla işlem yürütüldüğünde, bir işlemin talimatlarının başka bir işlemle karıştırılması olasılığı vardır.
Schedule- Bir işlemin kronolojik yürütme sırasına çizelge denir. Bir programda, her biri bir dizi talimat / görevden oluşan birçok işlem bulunabilir.
Serial Schedule- İşlemlerin, önce bir işlemin gerçekleştirileceği şekilde hizalandığı bir çizelgedir. İlk işlem döngüsünü tamamladığında, sonraki işlem yürütülür. İşlemler birbiri ardına sıralanır. İşlemler seri bir şekilde yürütüldüğünden, bu tür çizelgeleme seri çizelge olarak adlandırılır.
Çok işlemli bir ortamda, seri programlar bir kıyaslama olarak kabul edilir. Bir işlemdeki bir talimatın yürütme sırası değiştirilemez, ancak iki işlemin talimatları rastgele bir şekilde çalıştırılabilir. Bu yürütme, iki işlem karşılıklı olarak bağımsızsa ve farklı veri segmentleri üzerinde çalışıyorsa hiçbir zarar vermez; ancak bu iki işlemin aynı veriler üzerinde çalışması durumunda sonuçlar değişebilir. Bu sürekli değişen sonuç, veritabanını tutarsız bir duruma getirebilir.
Bu sorunu çözmek için, işlemleri serileştirilebilirse veya aralarında bazı denklik ilişkisine sahipse, bir işlem planının paralel yürütülmesine izin veriyoruz.
Eşdeğerlik Çizelgeleri
Bir denklik programı aşağıdaki türlerde olabilir -
Sonuç Eşdeğeri
İki program yürütmeden sonra aynı sonucu verirse, sonuç eşdeğer olduğu söylenir. Bazı değerler için aynı sonucu ve başka bir değerler kümesi için farklı sonuçlar verebilirler. Bu nedenle, bu eşdeğerlik genel olarak önemli görülmez.
Eşitliği Görüntüle
Her iki çizelgedeki işlemler benzer eylemleri benzer şekilde gerçekleştirirse, iki çizelge görünüm eşdeğerliği olacaktır.
Örneğin -
T, S1'deki ilk veriyi okursa, o zaman S2'deki ilk verileri de okur.
T, J tarafından S1'de yazılan değeri okursa, o zaman S2'de J tarafından yazılan değeri de okur.
T, S1'deki veri değeri üzerinde son yazmayı gerçekleştirirse, o zaman S2'deki veri değeri üzerinde son yazmayı da gerçekleştirir.
Çatışma Eşdeğeri
Aşağıdaki özelliklere sahiplerse iki program birbiriyle çelişir:
- Her ikisi de ayrı işlemlere aittir.
- Her ikisi de aynı veri öğesine erişir.
- Bunlardan en az biri "yazma" işlemi.
Çakışan işlemlere sahip birden fazla işlem içeren iki programın, ancak ve ancak aşağıdaki durumlarda çakışmaya eşdeğer olduğu söylenir:
- Her iki program da aynı İşlem setini içerir.
- Çakışan işlem çiftlerinin sırası her iki programda da korunur.
Note- Eşdeğer çizelgeleri görüntüleyin, seri hale getirilebilir ve çakışmaya eşdeğer çizelgeler çakışma serileştirilebilirdir. Çakışma serileştirilebilir tüm programlar da serileştirilebilir olarak görüntülenebilir.
İşlem Durumları
Veritabanındaki bir işlem aşağıdaki durumlardan birinde olabilir -
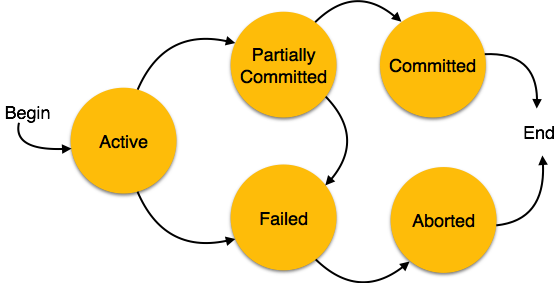
Active- Bu durumda, işlem yürütülüyor. Bu, her işlemin başlangıç durumudur.
Partially Committed - Bir işlem son işlemini gerçekleştirdiğinde, kısmen taahhüt edilmiş durumda olduğu söylenir.
Failed- Veritabanı kurtarma sistemi tarafından yapılan kontrollerden herhangi biri başarısız olursa, işlemin başarısız durumda olduğu söylenir. Başarısız bir işlem artık daha fazla ilerleyemez.
Aborted- Kontrollerden herhangi biri başarısız olursa ve işlem başarısız bir duruma ulaştıysa, kurtarma yöneticisi, veritabanını işlemin yürütülmesinden önceki orijinal durumuna geri getirmek için veritabanındaki tüm yazma işlemlerini geri alır. Bu durumdaki işlemler iptal edildi olarak adlandırılır. Veritabanı kurtarma modülü, bir işlem iptal edildikten sonra iki işlemden birini seçebilir -
- İşlemi yeniden başlatın
- İşlemi sonlandırın
Committed- Bir işlem tüm işlemlerini başarılı bir şekilde gerçekleştirirse, taahhüt edildiği söylenir. Tüm etkileri artık kalıcı olarak veritabanı sistemi üzerinde kurulmaktadır.
Birden çok işlemin aynı anda yürütülebildiği bir çoklu programlama ortamında, işlemlerin eşzamanlılığını kontrol etmek son derece önemlidir. Eşzamanlı işlemlerin atomikliğini, izolasyonunu ve serileştirilebilirliğini sağlamak için eşzamanlılık kontrol protokollerine sahibiz. Eşzamanlılık kontrol protokolleri genel olarak iki kategoriye ayrılabilir -
- Temel protokolleri kilitle
- Zaman damgası tabanlı protokoller
Kilit tabanlı Protokoller
Kilit tabanlı protokollerle donatılmış veritabanı sistemleri, üzerinde uygun bir kilit elde edene kadar herhangi bir işlemin verileri okuyup yazamayacağı bir mekanizma kullanır. Kilitler iki çeşittir -
Binary Locks- Bir veri öğesindeki kilit iki durumda olabilir; ya kilitli ya da kilidi açılmıştır.
Shared/exclusive- Bu tip kilitleme mekanizması, kilitleri kullanımlarına göre farklılaştırır. Bir yazma işlemi gerçekleştirmek için bir veri öğesi üzerinde bir kilit elde edilirse, bu bir özel kilittir. Aynı veri maddesine birden fazla işlemin yazılmasına izin vermek, veri tabanını tutarsız bir duruma sürükleyecektir. Veri değeri değiştirilmediğinden okuma kilitleri paylaşılır.
Dört tür kilit protokolü mevcuttur -
Basit Kilit Protokolü
Basit kilit tabanlı protokoller, işlemlerin bir 'yazma' işlemi gerçekleştirilmeden önce her nesne üzerinde bir kilit elde etmesine izin verir. İşlemler, 'yazma' işlemini tamamladıktan sonra veri öğesinin kilidini açabilir.
Ön talep Kilit Protokolü
Ön talep protokolleri, işlemlerini değerlendirir ve kilitlere ihtiyaç duydukları veri öğelerinin bir listesini oluşturur. Bir işlem başlatmadan önce, işlem sistemden ihtiyaç duyduğu tüm kilitleri önceden talep eder. Tüm kilitler verilirse, işlem tüm işlemleri bittiğinde tüm kilitleri çalıştırır ve serbest bırakır. Tüm kilitler verilmemişse, işlem geri alınır ve tüm kilitler verilinceye kadar bekler.
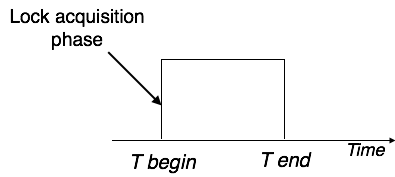
İki Fazlı Kilitleme 2PL
Bu kilitleme protokolü, bir işlemin yürütme aşamasını üç bölüme ayırır. Birinci kısımda işlem gerçekleşmeye başladığında ihtiyaç duyduğu kilitler için izin arar. İkinci bölüm, işlemin tüm kilitleri aldığı yerdir. İşlem ilk kilidini açar açmaz üçüncü aşama başlar. Bu aşamada işlem yeni kilit talep edemez; yalnızca edinilen kilitleri serbest bırakır.

İki fazlı kilitlemenin iki fazı vardır, biri growingtüm kilitlerin işlem tarafından alındığı yer; ve ikinci aşama küçülüyor, burada işlem tarafından tutulan kilitler serbest bırakılıyor.
Özel (yazma) bir kilit talep etmek için, bir işlemin önce paylaşılan (okuma) bir kilit alması ve ardından bunu özel bir kilide yükseltmesi gerekir.
Sıkı İki Fazlı Kilitleme
Strict-2PL'nin ilk aşaması 2PL ile aynıdır. İlk aşamada tüm kilitler alındıktan sonra işlem normal şekilde devam eder. Ancak 2PL'nin aksine, Strict-2PL, kullandıktan sonra bir kilidi açmaz. Strict-2PL, kesinleştirme noktasına kadar tüm kilitleri tutar ve bir seferde tüm kilitleri serbest bırakır.
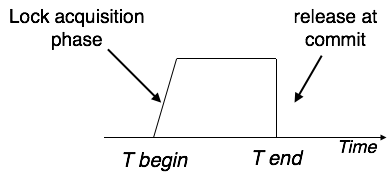
Strict-2PL, 2PL'de olduğu gibi basamaklı durdurmaya sahip değildir.
Zaman damgası tabanlı Protokoller
En yaygın kullanılan eşzamanlılık protokolü, zaman damgası tabanlı protokoldür. Bu protokol, zaman damgası olarak sistem saatini veya mantıksal sayacı kullanır.
Kilit tabanlı protokoller, yürütme sırasında işlemler arasındaki çakışan çiftler arasındaki sırayı yönetirken, zaman damgası tabanlı protokoller bir işlem oluşturulur oluşturulmaz çalışmaya başlar.
Her işlemin kendisiyle ilişkili bir zaman damgası vardır ve sipariş, işlemin yaşına göre belirlenir. 0002 saat zamanında oluşturulan bir işlem, ondan sonra gelen diğer tüm işlemlerden daha eski olacaktır. Örneğin, sisteme 0004'te giren herhangi bir 'y' işlemi iki saniye daha gençtir ve öncelik eskisine verilecektir.
Ek olarak, her veri öğesine en son okuma ve yazma zaman damgası verilir. Bu, sistemin veri öğesi üzerinde en son 'okuma ve yazma' işleminin ne zaman yapıldığını bilmesini sağlar.
Zaman Damgası Sıralama Protokolü
Zaman damgası sipariş protokolü, çakışan okuma ve yazma işlemlerinde işlemler arasında serileştirilebilirliği sağlar. Bu, birbiriyle çakışan görev çiftlerinin işlemlerin zaman damgası değerlerine göre yürütülmesi gerektiği protokol sisteminin sorumluluğudur.
- İşlem T zaman damgası i TS (T olarak gösterilir i ).
- Veri öğesi X'in okuma zaman damgası, R zaman damgası (X) ile gösterilir.
- Veri öğesi X'in yazma zaman damgası W-zaman damgası (X) ile gösterilir.
Zaman damgası sipariş protokolü aşağıdaki gibi çalışır -
If a transaction Ti issues a read(X) operation −
- TS (Ti) <W-zaman damgası (X) ise
- İşlem reddedildi.
- TS (Ti)> = W-zaman damgası (X) ise
- İşlem gerçekleştirildi.
- Tüm veri öğesi zaman damgaları güncellendi.
If a transaction Ti issues a write(X) operation −
- TS (Ti) <R-zaman damgası (X) ise
- İşlem reddedildi.
- TS (Ti) <W-zaman damgası (X) ise
- İşlem reddedildi ve Ti geri döndü.
- Aksi takdirde işlem yürütülür.
Thomas'ın Yazma Kuralı
Bu kural TS (Ti) <W-zaman damgası (X) ise, işlem reddedilir ve T i geri alınır.
Zaman damgası sipariş kuralları, çizelge görünümünü serileştirilebilir hale getirmek için değiştirilebilir.
T i'yi geri almak yerine , 'yazma' işleminin kendisi göz ardı edilir.
Çok işlemli bir sistemde kilitlenme, bir sürecin başka bir işlem tarafından tutulan bir kaynağı süresiz olarak beklediği paylaşılan bir kaynak ortamında ortaya çıkan istenmeyen bir durumdur.
Örneğin, bir dizi işlemi {T 0 , T 1 , T 2 , ..., T n } varsayalım . T 0 , görevini tamamlamak için X kaynağına ihtiyaç duyar. Kaynak X, T 1 tarafından tutulur ve T 1 , T 2 tarafından tutulan bir Y kaynağını bekler . T 2 , T 0 tarafından tutulan Z kaynağını bekliyor . Böylece, tüm süreçler birbirlerinin kaynakları serbest bırakmasını bekler. Bu durumda, işlemlerin hiçbiri görevlerini tamamlayamaz. Bu durum bir çıkmaz olarak bilinir.
Kilitlenmeler bir sistem için sağlıklı değildir. Bir sistemin kilitlenme durumunda kalması durumunda, kilitlenmeye dahil olan işlemler ya geri alınır ya da yeniden başlatılır.
Kilitlenme Önleme
Sistemdeki herhangi bir kilitlenme durumunu önlemek için, DBMS işlemlerin yürütüleceği tüm işlemleri agresif bir şekilde denetler. DBMS, operasyonları denetler ve bir kilitlenme durumu yaratabileceklerini analiz eder. Bir kilitlenme durumunun ortaya çıkabileceğini tespit ederse, bu işlemin yürütülmesine asla izin verilmez.
Bir kilitlenme durumunu önceden belirlemek için işlemlerin zaman damgası sıralama mekanizmasını kullanan kilitlenme önleme planları vardır.
Bekle-Öl Şeması
Bu şemada, bir işlem, başka bir işlem tarafından zaten çakışan bir kilitle tutulan bir kaynağı (veri öğesini) kilitlemek isterse, iki olasılıktan biri ortaya çıkabilir -
Eğer TS (T i ) <TS (T j ) - T olduğunu ben bir çakışan kilidi, T daha yaşlıdır istiyor, j sonra T - i veri maddelik kullanılabilir kadar beklemek izin verilir.
Eğer TS (T i )> TS (t j ) - yani T i , T j'den daha gençse - o zaman T i ölür. T i daha sonra rastgele bir gecikmeyle ancak aynı zaman damgasıyla yeniden başlatılır.
Bu şema, eski işlemin beklemesine izin verir, ancak daha genç olanı öldürür.
Wound-Wait Şeması
Bu şemada, bir işlem, başka bir işlem tarafından zaten çakışan kilitle tutulan bir kaynağı (veri öğesini) kilitleme talebinde bulunursa, iki olasılıktan biri ortaya çıkabilir -
TS (T i ) <TS (T j ) ise, o zaman T i T j'yi geri alınmaya zorlar - yani T i yaraları T j'dir . T j daha sonra rastgele bir gecikmeyle ancak aynı zaman damgasıyla yeniden başlatılır.
TS (T i )> TS (T j ) ise, T i kaynak kullanılabilir olana kadar beklemek zorunda kalır.
Bu şema, daha genç olan işlemin beklemesini sağlar; ancak daha eski bir işlem, daha genç bir işlemin tuttuğu bir öğeyi talep ettiğinde, eski işlem, küçük olanı öğeyi iptal etmeye ve serbest bırakmaya zorlar.
Her iki durumda da sisteme daha sonraki bir aşamada giren işlem iptal edilir.
Kilitlenme Önleme
Bir işlemi iptal etmek her zaman pratik bir yaklaşım değildir. Bunun yerine, herhangi bir kilitlenme durumunu önceden tespit etmek için kilitlenme önleme mekanizmaları kullanılabilir. "Bekleme grafiği" gibi yöntemler mevcuttur, ancak bunlar yalnızca işlemlerin hafif olduğu ve daha az kaynak örneğine sahip sistemler için uygundur. Hacimli bir sistemde, kilitlenme önleme teknikleri işe yarayabilir.
Bekleme Grafiği
Bu, herhangi bir kilitlenme durumunun ortaya çıkıp çıkmayacağını izlemek için kullanılabilen basit bir yöntemdir. Sisteme giren her işlem için bir düğüm oluşturulur. Bir işlem T zaman ben bir öğe üzerinde bir kilit için istekleri, diğer bazı işlem T tarafından düzenlenen X söylemek j , yönlendirilmiş kenar T oluşturulur i T j . T j , X öğesini serbest bırakırsa , aralarındaki kenar düşer ve T i veri öğesini kilitler.
Sistem, başkaları tarafından tutulan bazı veri maddelerini bekleyen her işlem için bu bekleme grafiğini korur. Sistem, grafikte herhangi bir döngü olup olmadığını kontrol etmeye devam eder.
Burada, aşağıdaki iki yaklaşımdan herhangi birini kullanabiliriz -
İlk olarak, başka bir işlem tarafından zaten kilitlenmiş olan bir öğe için herhangi bir talebe izin vermeyin. Bu her zaman mümkün değildir ve bir işlemin süresiz olarak bir veri öğesini beklediği ve asla elde edemediği açlıktan ölmeye neden olabilir.
İkinci seçenek, işlemlerden birini geri almaktır. Eski işlemden daha önemli olabileceğinden, genç işlemi geri almak her zaman mümkün değildir. Bazı göreceli algoritmaların yardımıyla, iptal edilecek bir işlem seçilir. Bu işlem olarak bilinirvictim ve süreç olarak bilinir victim selection.
Uçucu Depolama Kaybı
RAM gibi uçucu bir depolama, tüm etkin günlükleri, disk arabelleklerini ve ilgili verileri depolar. Ek olarak, şu anda yürütülmekte olan tüm işlemleri saklar. Böyle uçucu bir depolama aniden çökerse ne olur? Açıkça, veritabanının tüm günlüklerini ve etkin kopyalarını alacaktır. Verileri kurtarmak için gereken her şey kaybolduğu için kurtarmayı neredeyse imkansız hale getirir.
Uçucu depolamanın kaybolması durumunda aşağıdaki teknikler benimsenebilir -
Sahip olabiliriz checkpoints Veritabanının içeriğini periyodik olarak kaydetmek için birden çok aşamada.
Geçici bellekteki aktif veritabanı durumu periyodik olarak olabilir dumped günlükleri ve aktif işlemleri ve arabellek bloklarını da içerebilen kararlı bir depolama alanına.
<dump>, veritabanı içeriği geçici olmayan bir bellekten kararlı bir belleğe atıldığında bir günlük dosyasında işaretlenebilir.
Kurtarma
Sistem bir arızadan kurtulursa, en son dökümü geri yükleyebilir.
Kontrol noktaları olarak bir yineleme listesi ve bir geri alma listesi tutabilir.
Son kontrol noktasına kadar tüm işlemlerin durumunu geri yüklemek için geri alma-yineleme listelerine başvurarak sistemi kurtarabilir.
Yıkıcı Arızadan Veritabanı Yedekleme ve Kurtarma
Yıkıcı bir arıza, kararlı, ikincil bir depolama cihazının bozulduğu bir arızadır. Depolama cihazı ile, içinde depolanan tüm değerli veriler kaybolur. Böylesine yıkıcı bir arızadan veri kurtarmak için iki farklı stratejimiz var -
Uzaktan yedekleme & minu; Burada veritabanının bir yedek kopyası, bir felaket durumunda geri yüklenebileceği uzak bir konumda saklanır.
Alternatif olarak, veritabanı yedekleri manyetik bantlara alınabilir ve daha güvenli bir yerde saklanabilir. Bu yedekleme daha sonra, yedekleme noktasına getirmek için yeni kurulmuş bir veritabanına aktarılabilir.
Yetişkin veritabanları sık sık yedeklenemeyecek kadar büyüktür. Bu gibi durumlarda, bir veritabanını sadece günlüklerine bakarak geri yükleyebileceğimiz tekniklere sahibiz. Yani, burada tek yapmamız gereken, sık aralıklarla tüm günlüklerin yedeğini almak. Veritabanı haftada bir yedeklenebilir ve çok küçük olan günlükler her gün veya olabildiğince sık yedeklenebilir.
Uzaktan Yedekleme
Uzaktan yedekleme, veritabanının bulunduğu birincil konumun yok edilmesi durumunda bir güvenlik hissi sağlar. Uzaktan yedekleme çevrimdışı, gerçek zamanlı veya çevrimiçi olabilir. Çevrimdışı olması durumunda, manuel olarak bakımı yapılır.
Çevrimiçi yedekleme sistemleri, veritabanı yöneticileri ve yatırımcıları için daha gerçek zamanlı ve hayat kurtarıcıdır. Çevrimiçi yedekleme sistemi, gerçek zamanlı verilerin her bir bitinin aynı anda iki uzak yerde yedeklendiği bir mekanizmadır. Biri doğrudan sisteme bağlı, diğeri ise yedek olarak uzak bir yerde tutuluyor.
Birincil veritabanı depolaması başarısız olur olmaz, yedekleme sistemi hatayı algılar ve kullanıcı sistemini uzak depolamaya geçirir. Bazen bu o kadar anlık olur ki kullanıcılar bir başarısızlığın farkına bile varamazlar.
Crash Recovery
DBMS, her saniye yüzlerce işlemin gerçekleştirildiği oldukça karmaşık bir sistemdir. Bir DBMS'nin dayanıklılığı ve sağlamlığı, karmaşık mimarisine ve temelindeki donanım ve sistem yazılımına bağlıdır. İşlemler sırasında başarısız olursa veya çökerse, sistemin kayıp verileri kurtarmak için bir çeşit algoritma veya teknik izlemesi beklenir.
Arıza Sınıflandırması
Sorunun nerede oluştuğunu görmek için, aşağıdaki gibi bir arızayı çeşitli kategorilere ayırıyoruz -
İşlem hatası
Bir işlem yürütülemediğinde veya daha ileri gidemeyeceği bir noktaya ulaştığında iptal edilmelidir. Bu, yalnızca birkaç işlemin veya işlemin zarar gördüğü işlem hatası olarak adlandırılır.
Bir işlem başarısızlığının nedenleri şunlar olabilir:
Logical errors - Bazı kod hataları veya herhangi bir dahili hata durumu olduğu için işlemin tamamlanamadığı durumlarda.
System errors- Veritabanı sisteminin kendisinin etkin bir işlemi DBMS yürütemediği için veya bazı sistem koşulları nedeniyle durması gerektiği için sonlandırması. Örneğin, kilitlenme veya kaynak kullanılamaması durumunda, sistem aktif bir işlemi iptal eder.
Sistem çökmesi
Sistemin haricinde, sistemin aniden durmasına ve sistemin çökmesine neden olabilecek sorunlar vardır. Örneğin, güç kaynağındaki kesintiler, temelde yatan donanım veya yazılım arızasına neden olabilir.
Örnekler işletim sistemi hatalarını içerebilir.
Disk Hatası
Teknoloji evriminin ilk günlerinde, sabit disk sürücülerinin veya depolama sürücülerinin sık sık arızalanması yaygın bir sorundu.
Disk arızaları, bozuk kesimlerin oluşumunu, diske erişilememeyi, disk kafasının çökmesini veya disk depolamasının tamamını veya bir kısmını yok eden başka bir arızayı içerir.
Depolama Yapısı
Depolama sistemini zaten tanımlamıştık. Kısaca, depolama yapısı iki kategoriye ayrılabilir -
Volatile storage- Adından da anlaşılacağı gibi, geçici bir depolama, sistem çökmelerinden kurtulamaz. Uçucu depolama aygıtları CPU'nun çok yakınına yerleştirilir; normalde yonga setinin üzerine gömülürler. Örneğin, ana bellek ve önbellek, geçici depolama örnekleridir. Hızlıdırlar ancak çok az miktarda bilgi depolayabilirler.
Non-volatile storage- Bu anılar, sistem çökmelerinden kurtulmak için yapılmıştır. Veri depolama kapasitesi açısından çok büyüktür, ancak erişilebilirlik açısından daha yavaştır. Örnekler arasında sabit diskler, manyetik bantlar, flash bellek ve uçucu olmayan (pil yedeklemeli) RAM bulunabilir.
Kurtarma ve Atomiklik
Bir sistem çöktüğünde, çeşitli işlemler yürütülebilir ve veri öğelerini değiştirmek için çeşitli dosyalar açılabilir. İşlemler, doğası gereği atomik olan çeşitli işlemlerden oluşur. Ancak DBMS'nin ACID özelliklerine göre, işlemlerin bir bütün olarak atomikliği korunmalıdır, yani, tüm işlemler yürütülür veya hiçbiri yapılmaz.
Bir DBMS bir çökmeden kurtardığında, aşağıdakileri korumalıdır -
Yürütülen tüm işlemlerin durumlarını kontrol etmelidir.
Bir işlem, bazı işlemlerin ortasında olabilir; DBMS, bu durumda işlemin atomikliğini sağlamalıdır.
İşlemin şimdi tamamlanıp tamamlanamayacağını veya geri alınması gerekip gerekmediğini kontrol etmelidir.
Hiçbir işlemin DBMS'yi tutarsız bir durumda bırakmasına izin verilmez.
Bir DBMS'ye bir işlemin atomikliğini korumanın yanı sıra kurtarmada da yardımcı olabilecek iki tür teknik vardır -
Her işlemin günlüklerini tutmak ve veritabanını fiilen değiştirmeden önce bunları sabit bir depolama alanına yazmak.
Değişikliklerin geçici bir bellekte yapıldığı gölge sayfalamanın sürdürülmesi ve daha sonra gerçek veritabanı güncellenir.
Günlük Tabanlı Kurtarma
Günlük, bir işlem tarafından gerçekleştirilen eylemlerin kayıtlarını tutan bir kayıt dizisidir. Günlüklerin fiili değişiklikten önce yazılması ve arızasız olan kararlı bir depolama ortamında depolanması önemlidir.
Günlük tabanlı kurtarma şu şekilde çalışır -
Günlük dosyası, sabit bir depolama ortamında tutulur.
Bir işlem sisteme girdiğinde ve çalışmaya başladığında, bununla ilgili bir günlük yazar.
<Tn, Start>İşlem bir X öğesini değiştirdiğinde, günlükleri aşağıdaki gibi yazar -
<Tn, X, V1, V2>T n'nin X'in değerini V 1'den V 2'ye değiştirdiğini okur .
- İşlem bittiğinde, günlüğe kaydedilir -
<Tn, commit>Veritabanı iki yaklaşım kullanılarak değiştirilebilir -
Deferred database modification - Tüm günlükler kararlı depolamaya yazılır ve bir işlem gerçekleştirildiğinde veritabanı güncellenir.
Immediate database modification- Her günlük, gerçek bir veritabanı değişikliğini izler. Yani, veritabanı her işlemden hemen sonra değiştirilir.
Eş Zamanlı İşlemlerle Kurtarma
Birden fazla işlem paralel olarak yürütüldüğünde, günlükler araya eklenir. Kurtarma sırasında, kurtarma sisteminin tüm günlükleri geri izlemesi ve ardından kurtarmaya başlaması zorlaşır. Bu durumu kolaylaştırmak için, çoğu modern DBMS 'kontrol noktaları' kavramını kullanır.
Kontrol noktası
Günlükleri gerçek zamanlı ve gerçek ortamda tutmak ve muhafaza etmek, sistemdeki mevcut tüm bellek alanını doldurabilir. Zaman geçtikçe, günlük dosyası ele alınamayacak kadar büyüyebilir. Kontrol noktası, önceki tüm günlüklerin sistemden kaldırıldığı ve kalıcı olarak bir depolama diskinde depolandığı bir mekanizmadır. Kontrol noktası, DBMS'nin tutarlı durumda olduğu ve tüm işlemlerin gerçekleştirildiği bir noktayı bildirir.
Kurtarma
Eşzamanlı işlemlere sahip bir sistem çöktüğünde ve kurtarıldığında, aşağıdaki şekilde davranır -

Kurtarma sistemi, günlükleri sondan son kontrol noktasına kadar geriye doğru okur.
Bir geri alma listesi ve bir yineleme listesi olmak üzere iki liste tutar.
Kurtarma sistemi <T n , Start> ve <T n , Commit> veya yalnızca <T n , Commit> içeren bir günlük görürse , işlemi tekrar listesine koyar.
Kurtarma sistemi <T n , Start> içeren bir günlük görürse ancak herhangi bir tamamlama veya iptal günlüğü bulunmazsa, işlemi geri alma listesine koyar.
Geri alma listesindeki tüm işlemler daha sonra geri alınır ve günlükleri kaldırılır. Yeniden listedeki tüm işlemler ve önceki günlükleri kaldırılır ve ardından günlüklerini kaydetmeden önce yeniden yapılır.