Keras ile Derin Öğrenme - Hızlı Kılavuz
Derin Öğrenme, Yapay Zeka (AI) alanında son günlerde moda bir kelime haline geldi. Makinelere zeka katmak için yıllardır Makine Öğrenimini (ML) kullandık. Son günlerde, derin öğrenme, geleneksel makine öğrenimi tekniklerine kıyasla tahminlerdeki üstünlüğü nedeniyle daha popüler hale geldi.
Derin Öğrenme, esasen büyük miktarda veriyle bir Yapay Sinir Ağını (YSA) eğitmek anlamına gelir. Derin öğrenmede, ağ kendi kendine öğrenir ve bu nedenle öğrenme için muazzam verilere ihtiyaç duyar. Geleneksel makine öğrenimi esasen verileri ayrıştıran ve ondan öğrenen bir dizi algoritmadır. Daha sonra bu öğrenmeyi akıllı kararlar almak için kullandılar.
Şimdi, Keras'a gelince, uçtan uca açık kaynaklı bir makine öğrenimi platformu olan TensorFlow üzerinde çalışan üst düzey bir sinir ağları API'sidir. Keras'ı kullanarak, büyük verileriniz üzerinde deney yapmak için karmaşık YSA mimarilerini kolayca tanımlayabilirsiniz. Keras ayrıca büyük miktarda veriyi işlemek ve makine öğrenimi modelleri geliştirmek için gerekli olan GPU'yu da destekler.
Bu eğitimde, derin sinir ağları oluşturmada Keras'ın kullanımını öğreneceksiniz. Öğretim için pratik örneklere bakacağız. Eldeki sorun, derin öğrenme ile eğitilmiş bir sinir ağı kullanarak el yazısıyla yazılmış rakamları tanımaktır.
Derin öğrenmede sizi daha fazla heyecanlandırmak için, aşağıda derin öğrenmeyle ilgili Google trendlerinin bir ekran görüntüsü burada verilmiştir -

Şemadan da görebileceğiniz gibi, derin öğrenmeye olan ilgi son birkaç yıldır giderek artıyor. Derin öğrenmenin başarıyla uygulandığı bilgisayarla görme, doğal dil işleme, konuşma tanıma, biyoinformatik, ilaç tasarımı gibi birçok alan vardır. Bu eğitim, derin öğrenmeye hızlı bir şekilde başlamanızı sağlayacaktır.
Okumaya devam edin!
Girişte belirtildiği gibi, derin öğrenme, büyük miktarda veriyle yapay bir sinir ağını eğitme sürecidir. Ağ, eğitildikten sonra bize görünmeyen verilerle ilgili tahminler verebilir. Derin öğrenmenin ne olduğunu açıklamadan önce, bir sinir ağını eğitirken kullanılan bazı terimleri hızlıca gözden geçirelim.
Nöral ağlar
Yapay sinir ağı fikri beynimizdeki sinir ağlarından türetilmiştir. Tipik bir sinir ağı, aşağıdaki resimde gösterildiği gibi üç katmandan oluşur - giriş, çıkış ve gizli katman.

Buna aynı zamanda shallowsadece bir gizli katman içerdiğinden sinir ağı. Daha karmaşık bir mimari oluşturmak için yukarıdaki mimariye daha fazla gizli katman eklersiniz.
Derin Ağlar
Aşağıdaki diyagram, dört gizli katmandan, bir giriş katmanından ve bir çıktı katmanından oluşan derin bir ağı göstermektedir.
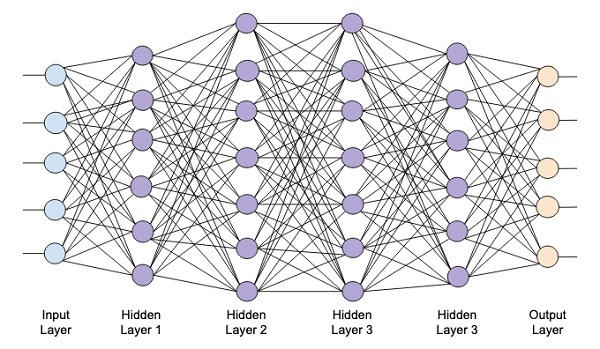
Ağa gizli katman sayısı eklendikçe, gerekli kaynaklar ve ağı tam olarak eğitmek için gereken süre açısından eğitimi daha karmaşık hale gelir.
Ağ Eğitimi
Ağ mimarisini tanımladıktan sonra, onu belirli türden tahminler yapması için eğitirsiniz. Bir ağ eğitimi, ağdaki her bağlantı için uygun ağırlıkları bulma sürecidir. Eğitim sırasında veriler, çeşitli gizli katmanlar aracılığıyla Girişten Çıkış katmanlarına akar. Veriler her zaman girişten çıkışa tek yönde hareket ettiğinden, bu ağı İleri Besleme Ağı olarak adlandırıyoruz ve veri yayılımını İleri Yayılma olarak adlandırıyoruz.
Aktivasyon Fonksiyonu
Her katmanda, ağırlıklı girdilerin toplamını hesaplıyor ve bunu bir Aktivasyon işlevine besliyoruz. Aktivasyon işlevi, ağa doğrusal olmama durumu getirir. Çıktıyı ayıran basit bir matematiksel fonksiyondur. En sık kullanılan aktivasyon fonksiyonlarından bazıları sigmoid, hiperbolik, tanjant (tanh), ReLU ve Softmax'tır.
Geri yayılım
Geri yayılım, denetimli öğrenme için bir algoritmadır. Geri yayılımda, hatalar çıktıdan giriş katmanına geriye doğru yayılır. Bir hata fonksiyonu verildiğinde, her bağlantıda atanan ağırlıklara göre hata fonksiyonunun gradyanını hesaplarız. Gradyanın hesaplanması ağ üzerinden geriye doğru ilerler. Son ağırlık katmanının eğimi önce hesaplanır ve ilk ağırlık katmanının eğimi en son hesaplanır.
Her katmanda, gradyanın kısmi hesaplamaları, önceki katman için gradyan hesaplamasında yeniden kullanılır. Buna Gradyan İniş denir.
Bu proje tabanlı öğreticide, ileri beslemeli bir derin sinir ağı tanımlayacak ve onu geri yayılım ve gradyan iniş teknikleriyle eğiteceksiniz. Neyse ki Keras, ağ mimarisini tanımlamak ve onu gradyan iniş kullanarak eğitmek için bize tüm üst düzey API'leri sağlıyor. Sonra, bunu Keras'ta nasıl yapacağınızı öğreneceksiniz.
El Yazısı Rakam Tanıma Sistemi
Bu mini projede, daha önce açıklanan teknikleri uygulayacaksınız. El yazısıyla yazılmış rakamları tanımak için eğitilecek bir derin öğrenme sinir ağı oluşturacaksınız. Herhangi bir makine öğrenimi projesinde, ilk zorluk verileri toplamaktır. Özellikle derin öğrenme ağları için çok büyük verilere ihtiyacınız var. Neyse ki, çözmeye çalıştığımız problem için, birisi eğitim için bir veri seti oluşturdu. Bu, Keras kitaplıklarının bir parçası olarak bulunan mnist olarak adlandırılır. Veri kümesi, el yazısıyla yazılmış birkaç 28x28 piksel görüntüden oluşur. Modelinizi bu veri kümesinin büyük bölümünde eğiteceksiniz ve verilerin geri kalanı eğitilmiş modelinizi doğrulamak için kullanılacaktır.
Proje Açıklaması
mnistveri seti, el yazısıyla yazılmış 70000 görüntüden oluşur. Referansınız için burada birkaç örnek resim çoğaltılmıştır

Her görüntünün boyutu 28 x 28 pikseldir ve bu da onu çeşitli gri tonlama seviyelerinde toplam 768 piksel yapar. Piksellerin çoğu siyah gölgeye doğru eğilimliyken, sadece birkaçı beyaza doğru. Bu piksellerin dağılımını bir dizi veya bir vektöre koyacağız. Örneğin, tipik bir rakam 4 ve 5 görüntüsü için piksel dağılımı aşağıdaki şekilde gösterilmektedir.
Her görüntünün boyutu 28 x 28 pikseldir ve bu da onu çeşitli gri tonlama seviyelerinde toplam 768 piksel yapar. Piksellerin çoğu siyah gölgeye doğru eğilimliyken, sadece birkaçı beyaza doğru. Bu piksellerin dağılımını bir dizi veya bir vektöre koyacağız. Örneğin, tipik bir rakam 4 ve 5 görüntüsü için piksel dağılımı aşağıdaki şekilde gösterilmektedir.

Açıkça, piksellerin dağılımının (özellikle beyaz tona meyilli olanlar) farklı olduğunu görebilirsiniz, bu temsil ettikleri rakamları ayırt eder. 784 piksellik bu dağılımı girdi olarak ağımıza besleyeceğiz. Ağın çıktısı, 0 ile 9 arasındaki bir rakamı temsil eden 10 kategoriden oluşacaktır.
Ağımız 4 katmandan oluşacaktır - bir giriş katmanı, bir çıktı katmanı ve iki gizli katman. Her gizli katman 512 düğüm içerecektir. Her katman bir sonraki katmana tam olarak bağlıdır. Ağı eğittiğimizde, her bağlantı için ağırlıkları hesaplıyor olacağız. Ağı, daha önce tartıştığımız geri yayılım ve gradyan inişi uygulayarak eğitiyoruz.
Bu arka planla, şimdi projeyi oluşturmaya başlayalım.
Proje Kurmak
Kullanacağız Jupyter vasıtasıyla Anacondaprojemiz için gezgin. Projemiz TensorFlow ve Keras kullandığından, bunları Anaconda kurulumuna yüklemeniz gerekecek. Tensorflow'u kurmak için konsol pencerenizde aşağıdaki komutu çalıştırın:
>conda install -c anaconda tensorflowKeras'ı yüklemek için aşağıdaki komutu kullanın -
>conda install -c anaconda kerasArtık Jupyter'i başlatmaya hazırsınız.
Jupyter'in Başlatılması
Anaconda gezginini başlattığınızda, aşağıdaki açılış ekranını göreceksiniz.

Tıklayın ‘Jupyter’başlatmak için. Ekran, sürücünüzdeki varsa mevcut projeleri gösterecektir.
Yeni Bir Projeye Başlamak
Aşağıdaki menü seçeneğini seçerek Anaconda'da yeni bir Python 3 projesi başlatın -
File | New Notebook | Python 3Menü seçiminin ekran görüntüsü hızlı referansınız için gösterilir -

Aşağıda gösterildiği gibi ekranınızda yeni bir boş proje görünecektir -
Proje adını şu şekilde değiştirin: DeepLearningDigitRecognition varsayılan adı tıklayıp düzenleyerek “UntitledXX”.
Öncelikle projemizdeki kodun gerektirdiği çeşitli kitaplıkları içe aktarıyoruz.
Dizi Yönetimi ve Çizimi
Tipik olarak kullanıyoruz numpy dizi işleme için ve matplotlibkomplo için. Bu kütüphaneler, aşağıdakiler kullanılarak projemize aktarılırimport ifadeler
import numpy as np
import matplotlib
import matplotlib.pyplot as plotUyarıları Bastırma
Hem Tensorflow hem de Keras revize etmeye devam ettikçe, projedeki uygun sürümlerini senkronize etmezseniz, çalışma zamanında birçok uyarı hatası görürsünüz. Dikkatinizi öğrenmekten uzaklaştırdıkça, bu projedeki tüm uyarıları bastırıyor olacağız. Bu, aşağıdaki kod satırlarıyla yapılır -
# silent all warnings
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='3'
import warnings
warnings.filterwarnings('ignore')
from tensorflow.python.util import deprecation
deprecation._PRINT_DEPRECATION_WARNINGS = FalseKeras
Veri kümesini içe aktarmak için Keras kitaplıklarını kullanıyoruz. Kullanacağızmnistel yazısı rakamlar için veri kümesi. Aşağıdaki ifadeyi kullanarak gerekli paketi ithal ediyoruz
from keras.datasets import mnistDerin öğrenme sinir ağımızı Keras paketlerini kullanarak tanımlayacağız. İthal ediyoruzSequential, Dense, Dropout ve Activationağ mimarisini tanımlamak için paketler. Kullanırızload_modelmodelimizi kaydetmek ve almak için paket. Ayrıca kullanıyoruznp_utilsprojemizde ihtiyaç duyduğumuz birkaç yardımcı program için. Bu içe aktarmalar aşağıdaki program ifadeleriyle yapılır -
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utilsBu kodu çalıştırdığınızda, konsolda Keras'ın arka uçta TensorFlow kullandığını belirten bir mesaj göreceksiniz. Bu aşamadaki ekran görüntüsü burada gösterilmektedir -

Şimdi, projemizin gerektirdiği tüm ithalata sahip olduğumuzdan, Derin Öğrenme ağımızın mimarisini tanımlamaya devam edeceğiz.
Sinir ağı modelimiz doğrusal bir katman yığınından oluşacaktır. Böyle bir modeli tanımlamak için,Sequential işlev -
model = Sequential()Giriş Katmanı
Aşağıdaki program ifadesini kullanarak ağımızdaki ilk katman olan giriş katmanını tanımlıyoruz -
model.add(Dense(512, input_shape=(784,)))Bu, 784 giriş düğümü ile 512 düğüm (nöron) içeren bir katman oluşturur. Bu, aşağıdaki şekilde tasvir edilmiştir -

Tüm giriş düğümlerinin Katman 1'e tam olarak bağlı olduğuna, yani her bir giriş düğümünün Katman 1'in 512 düğümüne bağlı olduğuna dikkat edin.
Ardından, Katman 1 çıktısı için aktivasyon fonksiyonunu eklememiz gerekiyor. Aktivasyonumuz olarak ReLU kullanacağız. Aktivasyon işlevi, aşağıdaki program ifadesi kullanılarak eklenir -
model.add(Activation('relu'))Ardından, aşağıdaki ifadeyi kullanarak% 20 Bırakma ekliyoruz. Bırakma, modelin aşırı uymasını önlemek için kullanılan bir tekniktir.
model.add(Dropout(0.2))Bu noktada, girdi katmanımız tamamen tanımlanmıştır. Ardından gizli bir katman ekleyeceğiz.
Gizli Katman
Gizli katmanımız 512 düğümden oluşacaktır. Gizli katmanın girdisi, önceden tanımladığımız girdi katmanımızdan gelir. Önceki durumda olduğu gibi tüm düğümler tamamen bağlıdır. Gizli katmanın çıktısı, son ve çıktı katmanımız olacak olan ağdaki bir sonraki katmana gidecek. Önceki katmanla aynı ReLU etkinleştirmesini ve% 20'lik bir bırakmayı kullanacağız. Bu katmanı ekleme kodu burada verilmiştir -
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))Bu aşamadaki ağ aşağıdaki gibi görselleştirilebilir -

Ardından, çıkış katmanı olan son katmanı ağımıza ekleyeceğiz. Burada kullanmış olduğunuza benzer bir kod kullanarak istediğiniz sayıda gizli katman ekleyebileceğinizi unutmayın. Daha fazla katman eklemek, ağı eğitim için karmaşık hale getirir; ancak, hepsinde olmasa da çoğu durumda daha iyi sonuçlara kesin bir avantaj sağlar.
Çıktı Katmanı
Verilen görüntüleri 10 farklı basamakta sınıflandırmak istediğimiz için çıktı katmanı sadece 10 düğümden oluşur. Aşağıdaki ifadeyi kullanarak bu katmanı ekliyoruz -
model.add(Dense(10))Çıkışı 10 farklı birimde sınıflandırmak istediğimiz için softmax aktivasyonunu kullanıyoruz. ReLU durumunda, çıkış ikilidir. Aktivasyonu aşağıdaki ifadeyi kullanarak ekliyoruz -
model.add(Activation('softmax'))Bu noktada, ağımız aşağıdaki diyagramda gösterildiği gibi görselleştirilebilir -

Bu noktada, ağ modelimiz yazılımda tamamen tanımlanmıştır. Kod hücresini çalıştırın ve hata yoksa, aşağıdaki ekran görüntüsünde gösterildiği gibi ekranda bir onay mesajı alacaksınız -

Daha sonra modeli derlememiz gerekiyor.
Derleme, adı verilen tek bir yöntem çağrısı kullanılarak gerçekleştirilir. compile.
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')compileyöntem birkaç parametre gerektirir. Kayıp parametresi türüne sahip olacak şekilde belirtildi'categorical_crossentropy'. Metrikler parametresi şu şekilde ayarlandı:'accuracy' ve sonunda kullanıyoruz adamağı eğitmek için optimize edici. Bu aşamadaki çıktı aşağıda gösterilmiştir -

Artık verileri ağımıza aktarmaya hazırız.
Veri yükleniyor
Daha önce de belirtildiği gibi, kullanacağız mnistKeras tarafından sağlanan veri kümesi. Verileri sistemimize yüklediğimizde, onu eğitim ve test verilerine böleriz. Veriler, çağrılarak yüklenir.load_data yöntem aşağıdaki gibidir -
(X_train, y_train), (X_test, y_test) = mnist.load_data()Bu aşamadaki çıktı aşağıdaki gibi görünür -

Şimdi, yüklenen veri setinin yapısını öğreneceğiz.
Bize sağlanan veriler, her biri 0 ile 9 arasında tek bir rakam içeren 28 x 28 piksel boyutunda grafik resimlerdir. Konsolda ilk on resmi göstereceğiz. Bunu yapmak için kod aşağıda verilmiştir -
# printing first 10 images
for i in range(10):
plot.subplot(3,5,i+1)
plot.tight_layout()
plot.imshow(X_train[i], cmap='gray', interpolation='none')
plot.title("Digit: {}".format(y_train[i]))
plot.xticks([])
plot.yticks([])10 sayımlık yinelemeli bir döngüde, her yinelemede bir alt plan oluşturuyoruz ve X_trainiçindeki vektör. Her bir görüntüyü karşılık geleny_trainvektör. Unutmayın kiy_train vektör, içindeki karşılık gelen görüntünün gerçek değerlerini içerir X_trainvektör. İki yöntemi çağırarak x ve y eksen işaretlerini kaldırıyoruzxticks ve yticksboş argüman ile. Kodu çalıştırdığınızda, aşağıdaki çıktıyı görürsünüz -

Ardından, ağımıza beslemek için verileri hazırlayacağız.
Verileri ağımıza beslemeden önce, ağın gerektirdiği biçime dönüştürülmelidir. Buna ağ için veri hazırlama denir. Genellikle çok boyutlu bir girdinin tek boyutlu bir vektöre dönüştürülmesinden ve veri noktalarının normalleştirilmesinden oluşur.
Girdi Vektörünü Yeniden Şekillendirme
Veri setimizdeki görüntüler 28 x 28 pikselden oluşmaktadır. Bu, ağımıza beslemek için 28 * 28 = 784 boyutunda tek boyutlu bir vektöre dönüştürülmelidir. Bunu arayarak yapıyoruzreshape vektör yöntemi.
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)Şimdi, eğitim vektörümüz, her biri 784 boyutunda tek bir boyut vektöründen oluşan 60000 veri noktasından oluşacak. Benzer şekilde, test vektörümüz de 784 boyutunda tek boyutlu bir vektörün 10000 veri noktasından oluşacaktır.
Verileri Normalleştirme
Giriş vektörünün içerdiği veriler şu anda 0 ile 255 arasında ayrı bir değere sahiptir - gri tonlama seviyeleri. Bu piksel değerlerini 0 ile 1 arasında normalleştirmek eğitimi hızlandırmaya yardımcı olur. Stokastik gradyan inişini kullanacağımızdan, verileri normalleştirmek aynı zamanda yerel optimada takılma olasılığını azaltmaya da yardımcı olacaktır.
Verileri normalleştirmek için, onu float türü olarak temsil ederiz ve aşağıdaki kod parçacığında gösterildiği gibi 255'e böleriz -
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255Şimdi normalleştirilmiş verilerin nasıl göründüğüne bakalım.
Normalleştirilmiş Verileri İnceleme
Normalleştirilmiş verileri görüntülemek için, burada gösterildiği gibi histogram işlevini çağıracağız -
plot.hist(X_train[0])
plot.title("Digit: {}".format(y_train[0]))Burada, ilk öğenin histogramını çiziyoruz X_trainvektör. Bu veri noktasının temsil ettiği rakamı da yazdırıyoruz. Yukarıdaki kodu çalıştırmanın çıktısı burada gösterilmektedir -

Sıfıra yakın değere sahip kalın bir nokta yoğunluğu göreceksiniz. Bunlar, görüntünün büyük bir kısmı olduğu açık olan görüntüdeki siyah nokta noktalarıdır. Beyaz renge yakın olan gri tonlama noktalarının geri kalanı rakamı temsil eder. Başka bir rakam için piksel dağılımını kontrol edebilirsiniz. Aşağıdaki kod, eğitim veri kümesindeki 2 dizinindeki bir hanenin histogramını yazdırır.
plot.hist(X_train[2])
plot.title("Digit: {}".format(y_train[2])Yukarıdaki kodu çalıştırmanın çıktısı aşağıda gösterilmiştir -

Yukarıdaki iki şekli karşılaştırdığınızda, iki görüntüdeki beyaz piksel dağılımının farklı bir rakamın - yukarıdaki iki resimdeki "5" ve "4" rakamlarının temsilini göstererek farklı olduğunu fark edeceksiniz.
Daha sonra, tam eğitim veri setimizdeki verilerin dağılımını inceleyeceğiz.
Veri Dağıtımının İncelenmesi
Makine öğrenimi modelimizi veri kümemiz üzerinde eğitmeden önce, veri kümemizdeki benzersiz basamakların dağılımını bilmeliyiz. Görüntülerimiz 0 ile 9 arasında değişen 10 farklı haneyi temsil etmektedir. Veri setimizdeki 0, 1 vb. Basamakların sayısını bilmek istiyoruz. Bu bilgileri kullanarak elde edebiliriz.unique Numpy yöntemi.
Benzersiz değerlerin sayısını ve her birinin oluşum sayısını yazdırmak için aşağıdaki komutu kullanın
print(np.unique(y_train, return_counts=True))Yukarıdaki komutu çalıştırdığınızda, aşağıdaki çıktıyı göreceksiniz -
(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([5923, 6742, 5958, 6131, 5842, 5421, 5918, 6265, 5851, 5949]))0'dan 9'a kadar 10 farklı değer olduğunu gösterir. 5923 basamak 0, 6742 basamak 1, vb. Vardır. Çıktının ekran görüntüsü burada gösterilmektedir -

Veri hazırlamanın son adımı olarak verilerimizi kodlamamız gerekiyor.
Kodlama Verileri
Veri setimizde on kategorimiz var. Böylece çıktımızı tek sıcak kodlama kullanarak bu on kategoride kodlayacağız. Kodlamayı gerçekleştirmek için Numpy yardımcı programlarının to_categorial yöntemini kullanıyoruz. Çıktı verileri kodlandıktan sonra, her veri noktası 10 büyüklüğünde tek boyutlu bir vektöre dönüştürülür. Örneğin, basamak 5 artık [0,0,0,0,0,1,0,0,0 olarak gösterilecektir. , 0].
Verileri aşağıdaki kod parçasını kullanarak kodlayın -
n_classes = 10
Y_train = np_utils.to_categorical(y_train, n_classes)Kategorize edilmiş Y_train vektörünün ilk 5 elemanını yazdırarak kodlamanın sonucunu kontrol edebilirsiniz.
İlk 5 vektörü yazdırmak için aşağıdaki kodu kullanın -
for i in range(5):
print (Y_train[i])Aşağıdaki çıktıyı göreceksiniz -
[0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]
[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 0. 0. 1.]İlk eleman 5 rakamını, ikincisi 0 rakamını temsil eder ve bu böyle devam eder.
Son olarak, aşağıdaki ifadeyi kullanarak test verilerini de sınıflandırmanız gerekecek -
Y_test = np_utils.to_categorical(y_test, n_classes)Bu aşamada, verileriniz ağa beslenmek için tamamen hazırlanır.
Daha sonra, en önemli kısım geliyor ve bu, ağ modelimizi eğitmektir.
Model eğitimi, aşağıdaki kodda görüldüğü gibi birkaç parametre alan uygun adında tek bir yöntem çağrısında yapılır -
history = model.fit(X_train, Y_train,
batch_size=128, epochs=20,
verbose=2,
validation_data=(X_test, Y_test)))Uyum yönteminin ilk iki parametresi, eğitim veri setinin özelliklerini ve çıktısını belirtir.
epochs20'ye ayarlanmıştır; eğitimin en fazla 20 dönemde - yinelemelerde - yakınsadığını varsayıyoruz. Eğitilen model, son parametrede belirtildiği gibi test verileri üzerinde doğrulanır.
Yukarıdaki komutu çalıştırmanın kısmi çıkışı burada gösterilmektedir -
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
- 9s - loss: 0.2488 - acc: 0.9252 - val_loss: 0.1059 - val_acc: 0.9665
Epoch 2/20
- 9s - loss: 0.1004 - acc: 0.9688 - val_loss: 0.0850 - val_acc: 0.9715
Epoch 3/20
- 9s - loss: 0.0723 - acc: 0.9773 - val_loss: 0.0717 - val_acc: 0.9765
Epoch 4/20
- 9s - loss: 0.0532 - acc: 0.9826 - val_loss: 0.0665 - val_acc: 0.9795
Epoch 5/20
- 9s - loss: 0.0457 - acc: 0.9856 - val_loss: 0.0695 - val_acc: 0.9792Hızlı referansınız için çıktının ekran görüntüsü aşağıda verilmiştir -

Şimdi model eğitim verilerimize göre eğitilirken performansını değerlendireceğiz.
Model performansını değerlendirmek için diyoruz evaluate yöntem aşağıdaki gibidir -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)Model performansını değerlendirmek için diyoruz evaluate yöntem aşağıdaki gibidir -
loss_and_metrics = model.evaluate(X_test, Y_test, verbose=2)Kaybı ve doğruluğu aşağıdaki iki ifadeyi kullanarak yazdıracağız -
print("Test Loss", loss_and_metrics[0])
print("Test Accuracy", loss_and_metrics[1])Yukarıdaki ifadeleri çalıştırdığınızda, aşağıdaki çıktıyı görürsünüz -
Test Loss 0.08041584826191042
Test Accuracy 0.9837Bu, bizim için kabul edilebilir olması gereken% 98'lik bir test doğruluğunu gösterir. Vakaların% 2'sinde el yazısıyla yazılan rakamların doğru sınıflandırılmaması bizim için ne anlama geliyor? Modelin test verileri üzerinde nasıl performans gösterdiğini görmek için doğruluk ve kayıp ölçümlerini de planlayacağız.
Doğruluk Metriklerinin Grafiklendirilmesi
Kaydedilenleri kullanıyoruz historyeğitimimiz sırasında doğruluk ölçümlerinin bir taslağını elde etmek için. Aşağıdaki kod, her çağın doğruluğunu çizecektir. Çizim için eğitim veri doğruluğunu ("acc") ve doğrulama veri doğruluğunu ("val_acc") alıyoruz.
plot.subplot(2,1,1)
plot.plot(history.history['acc'])
plot.plot(history.history['val_acc'])
plot.title('model accuracy')
plot.ylabel('accuracy')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='lower right')Çıktı grafiği aşağıda gösterilmiştir -

Diyagramda görebileceğiniz gibi, doğruluk ilk iki çağda hızla artarak ağın hızlı bir şekilde öğrendiğini gösterir. Daha sonra eğri düzleşir ve modeli daha fazla eğitmek için çok fazla döneme gerek olmadığını gösterir. Genel olarak, doğrulama verilerinin doğruluğu ("val_acc") kötüleşirken eğitim verilerinin doğruluğu ("acc") artmaya devam ederse, aşırı uyumla karşılaşıyorsunuz demektir. Modelin verileri ezberlemeye başladığını gösterir.
Modelimizin performansını kontrol etmek için kayıp ölçümlerini de planlayacağız.
Kayıp Metriklerinin Grafiklendirilmesi
Yine, kaybı hem eğitim ("kayıp") hem de test ("değer_kaybı") verileri üzerine çiziyoruz. Bu, aşağıdaki kod kullanılarak yapılır -
plot.subplot(2,1,2)
plot.plot(history.history['loss'])
plot.plot(history.history['val_loss'])
plot.title('model loss')
plot.ylabel('loss')
plot.xlabel('epoch')
plot.legend(['train', 'test'], loc='upper right')Bu kodun çıktısı aşağıda gösterilmiştir -

Şemadan da görebileceğiniz gibi, eğitim setindeki kayıp ilk iki dönem için hızla azalmaktadır. Test seti için, kayıp eğitim setiyle aynı oranda azalmaz, ancak birden çok dönem için neredeyse sabit kalır. Bu, modelimizin görünmeyen verilere iyi bir şekilde genellediği anlamına gelir.
Şimdi, test verilerimizdeki basamakları tahmin etmek için eğitimli modelimizi kullanacağız.
Görünmeyen bir verideki rakamları tahmin etmek çok kolaydır. Aramanız yeterlidir.predict_classes yöntemi model bilinmeyen veri noktalarınızdan oluşan bir vektöre aktararak.
predictions = model.predict_classes(X_test)Yöntem çağrısı, gerçek değerlere karşı 0'lar ve 1'ler için test edilebilen bir vektördeki tahminleri döndürür. Bu, aşağıdaki iki ifade kullanılarak yapılır -
correct_predictions = np.nonzero(predictions == y_test)[0]
incorrect_predictions = np.nonzero(predictions != y_test)[0]Son olarak, aşağıdaki iki program ifadesini kullanarak doğru ve yanlış tahminlerin sayısını yazdıracağız -
print(len(correct_predictions)," classified correctly")
print(len(incorrect_predictions)," classified incorrectly")Kodu çalıştırdığınızda, aşağıdaki çıktıyı alacaksınız -
9837 classified correctly
163 classified incorrectlyŞimdi, modeli tatmin edici bir şekilde eğittiğiniz için, onu ileride kullanmak üzere saklayacağız.
Eğitilmiş modeli yerel sürücümüzde mevcut çalışma dizinimizdeki modeller klasörüne kaydedeceğiz. Modeli kaydetmek için aşağıdaki kodu çalıştırın -
directory = "./models/"
name = 'handwrittendigitrecognition.h5'
path = os.path.join(save_dir, name)
model.save(path)
print('Saved trained model at %s ' % path)Kodu çalıştırdıktan sonraki çıktı aşağıda gösterilmiştir -

Şimdi, eğitimli bir modeli kaydettiğiniz için, onu daha sonra bilinmeyen verilerinizi işlemek için kullanabilirsiniz.
Görünmeyen verileri tahmin etmek için, önce eğitilmiş modeli belleğe yüklemeniz gerekir. Bu, aşağıdaki komut kullanılarak yapılır -
model = load_model ('./models/handwrittendigitrecognition.h5')Sadece .h5 dosyasını belleğe yüklediğimizi unutmayın. Bu, her katmana atanan ağırlıklarla birlikte tüm sinir ağını bellekte kurar.
Şimdi, görünmeyen veriler üzerinde tahminlerinizi yapmak için verileri hafızaya yükleyin, bir veya daha fazla öğe olsun. Yukarıdaki eğitim ve test verilerinizde yaptığınız gibi modelimizin giriş gereksinimlerini karşılamak için verileri önceden işleyin. Ön işlemeden sonra ağınıza besleyin. Model tahminini çıkaracaktır.
Keras, derin sinir ağı oluşturmak için yüksek düzeyde bir API sağlar. Bu eğitimde, el yazısı metindeki rakamları bulmak için eğitilmiş derin bir sinir ağı oluşturmayı öğrendiniz. Bu amaçla çok katmanlı bir ağ oluşturuldu. Keras, her katmanda seçtiğiniz bir etkinleştirme işlevini tanımlamanıza olanak tanır. Gradyan inişi kullanılarak ağ, eğitim verileri konusunda eğitildi. Eğitimli ağın görünmeyen verileri tahmin etmedeki doğruluğu test verileri üzerinde test edildi. Doğruluk ve hata ölçümlerini planlamayı öğrendiniz. Ağ tam olarak eğitildikten sonra, ağ modelini ileride kullanmak üzere kaydettiniz.