Dağıtılmış DBMS - Hızlı Kılavuz
Herhangi bir kuruluşun düzgün çalışması için, bakımlı bir veritabanına ihtiyaç vardır. Yakın geçmişte, veritabanları doğası gereği merkezileştirilmişti. Bununla birlikte, küreselleşmenin artmasıyla birlikte, organizasyonlar dünya çapında çeşitlenme eğilimindedir. Verileri merkezi bir veritabanı yerine yerel sunucular üzerinden dağıtmayı seçebilirler. Böylece,Distributed Databases.
Bu bölüm, veritabanları ve Veritabanı Yönetim Sistemlerine (DBMS) genel bir bakış sunar. Veritabanı, ilgili verilerin sıralı bir koleksiyonudur. Bir DBMS, bir veritabanı üzerinde çalışmak için bir yazılım paketidir. Ayrıntılı bir DBMS çalışması, "DBMS Öğrenin" adlı eğiticimizde mevcuttur. Bu bölümde, DDBMS çalışmasının kolaylıkla yapılabilmesi için ana kavramları gözden geçiriyoruz. Kapsanan üç konu, veritabanı şemaları, veritabanı türleri ve veritabanları üzerindeki işlemlerdir.
Veritabanı ve Veritabanı Yönetim Sistemi
Bir databasebelirli bir amaç için oluşturulmuş, ilgili verilerin sıralı bir koleksiyonudur. Bir veri tabanı, bir tablonun gerçek dünya unsurunu veya varlığını temsil ettiği çoklu tablonun bir koleksiyonu olarak organize edilebilir. Her tablo, varlığın karakteristik özelliklerini temsil eden birkaç farklı alana sahiptir.
Örneğin, bir şirket veri tabanı projeler, çalışanlar, departmanlar, ürünler ve mali kayıtlar için tablolar içerebilir. Employee tablosundaki alanlar Name, Company_Id, Date_of_Boining vb. Olabilir.
Bir database management systembir veritabanının oluşturulmasını ve bakımını sağlayan bir program koleksiyonudur. DBMS, bir veritabanındaki verilerin tanımlanmasını, oluşturulmasını, işlenmesini ve paylaşılmasını kolaylaştıran bir yazılım paketi olarak mevcuttur. Bir veri tabanının tanımı, bir veri tabanının yapısının açıklamasını içerir. Veritabanının oluşturulması, verilerin herhangi bir depolama ortamında fiilen depolanmasını içerir. Manipülasyon, veritabanından bilgi alınması, veritabanının güncellenmesi ve raporların oluşturulması anlamına gelir. Verilerin paylaşılması, verilere farklı kullanıcılar veya programlar tarafından erişilmesini kolaylaştırır.
DBMS Uygulama Alanlarına Örnekler
- Otomatik Para Çekme Makineleri
- Tren Rezervasyon Sistemi
- Çalışan Yönetim Sistemi
- Öğrenci Bilgi Sistemi
DBMS Paketlerine Örnekler
- MySQL
- Oracle
- SQL Server
- dBASE
- FoxPro
- PostgreSQL vb.
Veritabanı Şemaları
Bir veritabanı şeması, veritabanı tasarımı sırasında belirtilen ve nadiren değişikliklere tabi olan veritabanının bir açıklamasıdır. Verilerin organizasyonunu, aralarındaki ilişkileri ve bunlarla ilişkili kısıtlamaları tanımlar.
Veritabanları genellikle şu şekilde temsil edilir: three-schema architecture veya ANSISPARC architecture. Bu mimarinin amacı, kullanıcı uygulamasını fiziksel veritabanından ayırmaktır. Üç seviye -
Internal Level having Internal Schema - Veritabanı için fiziksel yapıyı, dahili depolamanın ayrıntılarını ve erişim yollarını açıklar.
Conceptual Level having Conceptual Schema- Verilerin fiziksel olarak depolanmasının ayrıntılarını gizlerken tüm veritabanının yapısını açıklar. Bu, varlıkları, veri türleri ve kısıtlamaları ile öznitelikleri, kullanıcı işlemlerini ve ilişkilerini gösterir.
External or View Level having External Schemas or Views - Veritabanının geri kalanını gizlerken belirli bir kullanıcı veya bir kullanıcı grubu ile ilgili bir veritabanının bölümünü açıklar.
DBMS Türleri
Dört tür DBMS vardır.
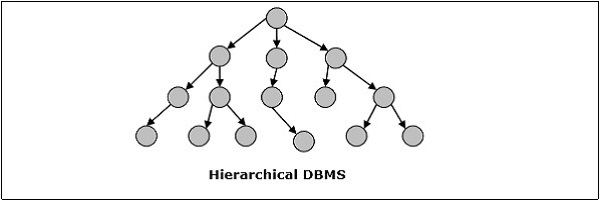
Hiyerarşik DBMS
Hiyerarşik DBMS'de, veri tabanındaki veriler arasındaki ilişkiler, bir veri elemanının diğerinin astı olarak var olacağı şekilde kurulur. Veri öğelerinin üst-alt ilişkileri vardır ve "ağaç" veri yapısı kullanılarak modellenir. Bunlar çok hızlı ve basit.
Ağ DBMS
Veritabanındaki veriler arasındaki ilişkilerin bir ağ biçiminde çoktan çoğa türünde olduğu bir ağ DBMS. Yapı, çoktan çoğa çok sayıda ilişkinin varlığı nedeniyle genellikle karmaşıktır. Ağ DBMS, "grafik" veri yapısı kullanılarak modellenmiştir.

İlişkisel DBMS
İlişkisel veritabanlarında, veritabanı ilişkiler şeklinde temsil edilir. Her ilişki bir varlığı modeller ve bir değerler tablosu olarak temsil edilir. İlişkide veya tabloda, bir satır bir demet olarak adlandırılır ve tek bir kaydı belirtir. Sütuna alan veya öznitelik adı verilir ve varlığın karakteristik bir özelliğini belirtir. RDBMS, en popüler veritabanı yönetim sistemidir.
Örneğin - Öğrenci İlişkisi -

Nesneye Yönelik DBMS
Nesne yönelimli DBMS, nesne yönelimli programlama paradigmasının modelinden türetilmiştir. Hem veritabanlarında depolanan tutarlı verilerin hem de programların yürütülmesinde bulunan geçici verilerin temsil edilmesinde yardımcı olurlar. Nesne adı verilen küçük, yeniden kullanılabilir öğeler kullanırlar. Her nesne bir veri bölümü ve veriler üzerinde çalışan bir dizi işlem içerir. Nesne ve özniteliklerine ilişkisel tablo modellerinde depolanmak yerine işaretçiler aracılığıyla erişilir.
Örneğin - Basitleştirilmiş bir Banka Hesabı nesnesine yönelik veritabanı -

Dağıtılmış DBMS
Dağıtılmış bir veritabanı, bilgisayar ağı veya internet üzerinden dağıtılan birbirine bağlı veritabanları kümesidir. Dağıtılmış Veritabanı Yönetim Sistemi (DDBMS), dağıtılmış veritabanını yönetir ve veritabanlarını kullanıcılar için şeffaf hale getirmek için mekanizmalar sağlar. Bu sistemlerde, veriler kasıtlı olarak birden çok düğüm arasında dağıtılır, böylece kuruluşun tüm bilgi işlem kaynakları en iyi şekilde kullanılabilir.
DBMS üzerinde işlemler
Veritabanındaki dört temel işlem Oluşturma, Alma, Güncelleştirme ve Silmedir.
CREATE veritabanı yapısı ve veri ile doldurun - Bir veritabanı ilişkisinin oluşturulması, depolanacak verilerin veri yapılarının, veri türlerinin ve kısıtlamalarının belirlenmesini içerir.
Example - Öğrenci tablosu oluşturmak için SQL komutu -
CREATE TABLE STUDENT (
ROLL INTEGER PRIMARY KEY,
NAME VARCHAR2(25),
YEAR INTEGER,
STREAM VARCHAR2(10)
);Veri formatı tanımlandıktan sonra, gerçek veriler formata uygun olarak bazı depolama ortamında saklanır.
Example Öğrenci tablosuna tek bir demet eklemek için SQL komutu -
INSERT INTO STUDENT ( ROLL, NAME, YEAR, STREAM)
VALUES ( 1, 'ANKIT JHA', 1, 'COMPUTER SCIENCE');RETRIEVEVeritabanından bilgi - Bilginin alınması genellikle bir tablonun alt kümesinin seçilmesini veya bazı hesaplamalar yapıldıktan sonra tablodan verilerin görüntülenmesini içerir. Tablo üzerinden sorgulama yapılarak yapılır.
Example - Bilgisayar Bilimi akışındaki tüm öğrencilerin adlarını almak için aşağıdaki SQL sorgusunun yürütülmesi gerekir -
SELECT NAME FROM STUDENT
WHERE STREAM = 'COMPUTER SCIENCE';UPDATE depolanan bilgiler ve veritabanı yapısını değiştirme - Bir tabloyu güncellemek, mevcut tablonun satırlarındaki eski değerleri yeni değerlerle değiştirmeyi içerir.
Example - Akışı Elektronikten Elektronik ve Haberleşmeye değiştirmek için SQL komutu -
UPDATE STUDENT
SET STREAM = 'ELECTRONICS AND COMMUNICATIONS'
WHERE STREAM = 'ELECTRONICS';Veritabanını değiştirmek, tablonun yapısını değiştirmek anlamına gelir. Ancak, tablonun değiştirilmesi bir takım kısıtlamalara tabidir.
Example - Yeni bir alan veya sütun eklemek için Öğrenci tablosuna adres deyin, aşağıdaki SQL komutunu kullanıyoruz -
ALTER TABLE STUDENT
ADD ( ADDRESS VARCHAR2(50) );DELETE saklanan bilgiler veya bir tablonun tamamı silinir - Belirli bilgilerin silinmesi, belirli koşulları sağlayan tablodan seçilen satırların kaldırılmasını içerir.
Example- 4'te tüm öğrencilere silmek için inci yine SQL komutunu kullanın, dışarı geçen zaman şu anda yıl -
DELETE FROM STUDENT
WHERE YEAR = 4;Alternatif olarak, tüm tablo veri tabanından kaldırılabilir.
Example - Öğrenci tablosunu tamamen kaldırmak için kullanılan SQL komutu -
DROP TABLE STUDENT;Bu bölüm DDBMS kavramını tanıtmaktadır. Dağıtılmış bir veritabanında, tüm dünyaya coğrafi olarak dağılmış olabilecek bir dizi veritabanı vardır. Dağıtılmış bir DBMS, dağıtılmış veritabanını, kullanıcılara tek bir veritabanı olarak görünecek şekilde yönetir. Bölümün sonraki kısmında, dağıtılmış veritabanlarına yol açan faktörleri, avantajlarını ve dezavantajlarını incelemeye devam edeceğiz.
Bir distributed database bir bilgisayar ağı aracılığıyla iletişim kuran çeşitli konumlara fiziksel olarak yayılan, birbirine bağlı birden çok veritabanının bir koleksiyonudur.
Özellikleri
Koleksiyondaki veritabanları mantıksal olarak birbirleriyle ilişkilidir. Genellikle tek bir mantıksal veritabanını temsil ederler.
Veriler fiziksel olarak birden çok sitede depolanır. Her sitedeki veriler, diğer sitelerden bağımsız olarak bir DBMS tarafından yönetilebilir.
Sitelerdeki işlemciler bir ağ üzerinden bağlanır. Çok işlemcili yapılandırmaları yoktur.
Dağıtılmış veritabanı, gevşek bağlanmış bir dosya sistemi değildir.
Dağıtılmış bir veritabanı, işlem sürecini içerir, ancak bir işlem işleme sistemi ile eşanlamlı değildir.
Dağıtık Veritabanı Yönetim Sistemi
Dağıtılmış bir veritabanı yönetim sistemi (DDBMS), dağıtılmış bir veritabanını, hepsi tek bir konumda depolanmış gibi yöneten merkezi bir yazılım sistemidir.
Özellikleri
Dağıtılmış veritabanları oluşturmak, almak, güncellemek ve silmek için kullanılır.
Veritabanını periyodik olarak senkronize eder ve dağıtımın kullanıcılara şeffaf hale gelmesini sağlayan erişim mekanizmaları sağlar.
Herhangi bir sitede değiştirilen verilerin evrensel olarak güncellenmesini sağlar.
Büyük hacimli verilerin aynı anda çok sayıda kullanıcı tarafından işlendiği ve erişildiği uygulama alanlarında kullanılır.
Heterojen veritabanı platformları için tasarlanmıştır.
Veritabanlarının gizliliğini ve veri bütünlüğünü korur.
DDBMS'yi Teşvik Eden Faktörler
Aşağıdaki faktörler DDBMS'ye geçmeyi teşvik eder -
Distributed Nature of Organizational Units- Mevcut zamanlarda çoğu kuruluş, fiziksel olarak dünyaya dağılmış birden çok birime bölünmüştür. Her birim kendi yerel veri setine ihtiyaç duyar. Böylece organizasyonun genel veri tabanı dağıtılır.
Need for Sharing of Data- Birden çok kuruluş biriminin genellikle birbirleriyle iletişim kurması ve verilerini ve kaynaklarını paylaşması gerekir. Bu, senkronize bir şekilde kullanılması gereken ortak veritabanları veya çoğaltılmış veritabanları gerektirir.
Support for Both OLTP and OLAP- Çevrimiçi İşlem İşleme (OLTP) ve Çevrimiçi Analitik İşleme (OLAP), ortak verilere sahip olabilecek çeşitli sistemler üzerinde çalışır. Dağıtılmış veritabanı sistemleri, senkronize veriler sağlayarak bu iki işleme de yardımcı olur.
Database Recovery- DDBMS'de kullanılan yaygın tekniklerden biri, verilerin farklı siteler arasında kopyalanmasıdır. Herhangi bir sitedeki veritabanı hasar görmüşse, verilerin çoğaltılması otomatik olarak veri kurtarmaya yardımcı olur. Kullanıcılar, hasarlı site yeniden yapılandırılırken diğer sitelerdeki verilere erişebilir. Bu nedenle, veritabanı arızası kullanıcılar için neredeyse önemsiz hale gelebilir.
Support for Multiple Application Software- Çoğu kuruluş, her biri kendine özgü veritabanı desteğine sahip çeşitli uygulama yazılımları kullanır. DDBMS, aynı verileri farklı platformlar arasında kullanmak için tek tip bir işlevsellik sağlar.
Dağıtık Veritabanlarının Avantajları
Aşağıda, dağıtılmış veritabanlarının merkezi veritabanlarına göre avantajları verilmiştir.
Modular Development- Sistemin merkezi veri tabanı sistemlerinde yeni yerlere veya yeni birimlere genişletilmesi gerekiyorsa, eylem, mevcut işleyişte önemli çaba ve kesinti gerektirir. Bununla birlikte, dağıtılmış veri tabanlarında, iş sadece yeni bilgisayarların ve yerel verilerin yeni siteye eklenmesini ve son olarak bunların mevcut işlevlerde kesinti olmaksızın dağıtılmış sisteme bağlanmasını gerektirir.
More Reliable- Veri tabanı arızalarında, merkezi veri tabanlarının toplam sistemi durur. Bununla birlikte, dağıtılmış sistemlerde, bir bileşen arızalandığında, sistemin işleyişi devam eden düşük bir performansta olabilir. Dolayısıyla DDBMS daha güvenilirdir.
Better Response- Veriler verimli bir şekilde dağıtılırsa, kullanıcı talepleri yerel verilerin kendisinden karşılanabilir ve böylece daha hızlı yanıt sağlanır. Öte yandan, merkezi sistemlerde, tüm sorguların işlem için merkezi bilgisayardan geçmesi gerekir, bu da yanıt süresini artırır.
Lower Communication Cost- Dağıtık veritabanı sistemlerinde, veriler yerel olarak en çok kullanıldığı yerde konumlandırılmışsa, veri manipülasyonu için iletişim maliyetleri en aza indirilebilir. Bu, merkezi sistemlerde mümkün değildir.
Dağıtılmış Veritabanlarının Olumsuz Yönleri
Aşağıda, dağıtılmış veritabanları ile ilgili bazı olumsuzluklar yer almaktadır.
Need for complex and expensive software - DDBMS, çeşitli tesisler arasında veri şeffaflığı ve koordinasyonu sağlamak için karmaşık ve genellikle pahalı bir yazılım gerektirir.
Processing overhead - Basit işlemler bile, sitelerdeki verilerde tekdüzelik sağlamak için çok sayıda iletişim ve ek hesaplamalar gerektirebilir.
Data integrity - Birden çok sitedeki verileri güncelleme ihtiyacı, veri bütünlüğü sorunlarına yol açar.
Overheads for improper data distribution- Sorguların duyarlılığı büyük ölçüde doğru veri dağıtımına bağlıdır. Uygun olmayan veri dağıtımı genellikle kullanıcı isteklerine çok yavaş yanıt verilmesine neden olur.
Eğitimin bu bölümünde, dağıtılmış veritabanı ortamlarının tasarlanmasına yardımcı olan farklı yönleri inceleyeceğiz. Bu bölüm, dağıtılmış veri tabanlarının türleriyle başlar. Dağıtılmış veritabanları, başka bölümlere sahip homojen ve heterojen veritabanları olarak sınıflandırılabilir. Bu bölümün sonraki bölümü, dağıtılmış mimarileri, yani istemci - sunucu, eşler arası ve çoklu DBMS'yi tartışır. Son olarak, çoğaltma ve parçalama gibi farklı tasarım alternatifleri tanıtıldı.
Dağıtılmış Veri Tabanı Türleri
Dağıtılmış veritabanları, aşağıdaki çizimde gösterildiği gibi, her biri başka alt bölümlere sahip olan homojen ve heterojen dağıtılmış veritabanı ortamları olarak genel olarak sınıflandırılabilir.

Homojen Dağıtılmış Veritabanları
Homojen dağıtılmış bir veritabanında, tüm siteler aynı DBMS ve işletim sistemlerini kullanır. Özellikleri -
Siteler çok benzer yazılımlar kullanıyor.
Siteler, aynı satıcıya ait özdeş DBMS veya DBMS kullanır.
Her site diğer tüm sitelerden haberdardır ve kullanıcı isteklerini işlemek için diğer sitelerle işbirliği yapar.
Veritabanına tek bir veritabanı gibi tek bir arayüz üzerinden erişilir.
Homojen Dağıtılmış Veritabanı Türleri
İki tür homojen dağıtılmış veritabanı vardır -
Autonomous- Her veritabanı bağımsızdır ve kendi başına çalışır. Kontrol edici bir uygulama ile entegre edilirler ve veri güncellemelerini paylaşmak için mesaj geçişini kullanırlar.
Non-autonomous - Veriler homojen düğümler arasında dağıtılır ve merkezi veya ana DBMS, sitelerdeki veri güncellemelerini koordine eder.
Heterojen Dağıtılmış Veritabanları
Heterojen dağıtılmış bir veritabanında, farklı sitelerin farklı işletim sistemleri, DBMS ürünleri ve veri modelleri vardır. Özellikleri -
Farklı siteler, farklı şemalar ve yazılımlar kullanır.
Sistem, ilişkisel, ağ, hiyerarşik veya nesne yönelimli gibi çeşitli DBMS'lerden oluşabilir.
Farklı şemalar nedeniyle sorgu işleme karmaşıktır.
Farklı yazılımlar nedeniyle işlem işleme karmaşıktır.
Bir site diğer sitelerden haberdar olmayabilir ve bu nedenle kullanıcı isteklerini işleme koymada sınırlı işbirliği vardır.
Heterojen Dağıtılmış Veritabanlarının Türleri
Federated - Heterojen veritabanı sistemleri, doğaları gereği bağımsızdır ve tek bir veritabanı sistemi olarak işlev görmeleri için birbirine entegre edilmiştir.
Un-federated - Veritabanı sistemleri, veritabanlarına erişilen merkezi bir koordinasyon modülü kullanır.
Dağıtılmış DBMS Mimarileri
DDBMS mimarileri genellikle üç parametreye bağlı olarak geliştirilir -
Distribution - Verilerin farklı sitelerdeki fiziksel dağılımını belirtir.
Autonomy - Veritabanı sisteminin kontrol dağılımını ve her bir kurucu DBMS'nin bağımsız olarak çalışabilme derecesini gösterir.
Heterogeneity - Veri modellerinin, sistem bileşenlerinin ve veritabanlarının tekdüzeliğini veya farklılığını ifade eder.
Mimari Modeller
Yaygın mimari modellerden bazıları şunlardır:
- İstemci - DDBMS için Sunucu Mimarisi
- DDBMS için Eşler Arası Mimari
- Çoklu - DBMS Mimarisi
İstemci - DDBMS için Sunucu Mimarisi
Bu, işlevselliğin sunuculara ve istemcilere bölündüğü iki seviyeli bir mimaridir. Sunucu işlevleri temel olarak veri yönetimi, sorgu işleme, optimizasyon ve işlem yönetimini kapsar. İstemci işlevleri temel olarak kullanıcı arayüzünü içerir. Ancak, tutarlılık kontrolü ve işlem yönetimi gibi bazı işlevleri vardır.
İki farklı istemci - sunucu mimarisi -
- Tek Sunucu Çoklu İstemci
- Çoklu Sunucu Çoklu İstemci (aşağıdaki diyagramda gösterilmiştir)

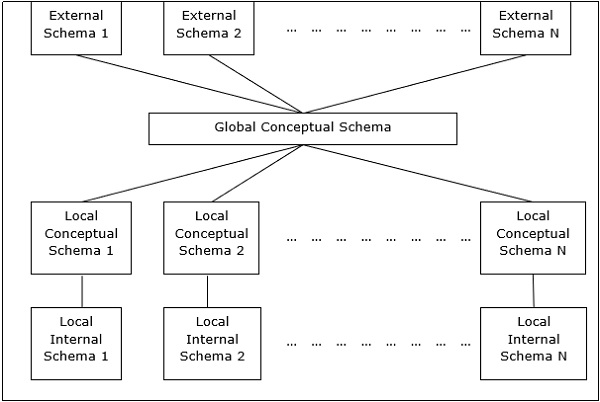
DDBMS için Eşler Arası Mimari
Bu sistemlerde, her bir eş, veritabanı hizmetlerini sağlamak için hem istemci hem de sunucu görevi görür. Akranlar kaynaklarını diğer akranlarıyla paylaşır ve faaliyetlerini koordine eder.
Bu mimarinin genellikle dört seviye şeması vardır -
Global Conceptual Schema - Verilerin genel mantıksal görünümünü gösterir.
Local Conceptual Schema - Her sitedeki mantıksal veri organizasyonunu gösterir.
Local Internal Schema - Her sitedeki fiziksel veri organizasyonunu gösterir.
External Schema - Verilerin kullanıcı görünümünü gösterir.
Çoklu - DBMS Mimarileri
Bu, iki veya daha fazla otonom veritabanı sisteminden oluşan bir koleksiyondan oluşan entegre bir veritabanı sistemidir.
Çoklu DBMS, altı şema seviyesiyle ifade edilebilir -
Multi-database View Level - Entegre dağıtılmış veritabanının alt kümelerinden oluşan birden fazla kullanıcı görünümünü gösterir.
Multi-database Conceptual Level - Global mantıksal çoklu veritabanı yapısı tanımlarından oluşan entegre çoklu veritabanını gösterir.
Multi-database Internal Level - Farklı sitelerdeki veri dağıtımını ve çoklu veritabanı ile yerel veri eşlemesini gösterir.
Local database View Level - Yerel verilerin genel görünümünü gösterir.
Local database Conceptual Level - Her sitedeki yerel veri organizasyonunu gösterir.
Local database Internal Level - Her sitedeki fiziksel veri organizasyonunu gösterir.
Çoklu DBMS için iki tasarım alternatifi vardır -
- Çoklu veritabanı kavramsal düzeyi ile modelleyin.
- Çoklu veritabanı kavramsal seviyesi olmayan model.


Tasarım Alternatifleri
Bir DDBMS'deki tablolar için dağıtım tasarım alternatifleri aşağıdaki gibidir -
- Kopyalanmamış ve parçalanmamış
- Tamamen çoğaltılmış
- Kısmen kopyalandı
- Fragmented
- Mixed
Yinelenmemiş ve Parçalanmamış
Bu tasarım alternatifinde, farklı sitelere farklı masalar yerleştirilir. Veriler, en çok kullanıldığı siteye yakın olacak şekilde yerleştirilir. Farklı sitelere yerleştirilen tablolardaki bilgileri birleştirmek için gereken sorgu yüzdesinin düşük olduğu veritabanı sistemleri için en uygun olanıdır. Uygun bir dağıtım stratejisi benimsenirse, bu tasarım alternatifi, veri işleme sırasında iletişim maliyetinin azaltılmasına yardımcı olur.
Tamamen Kopyalanmış
Bu tasarım alternatifinde, her sitede, tüm veritabanı tablolarının bir kopyası saklanır. Her site, tüm veritabanının kendi kopyasına sahip olduğundan, sorgular çok hızlıdır ve ihmal edilebilir iletişim maliyeti gerektirir. Aksine, verilerdeki muazzam artıklık, güncelleme işlemleri sırasında büyük maliyet gerektirir. Bu nedenle, bu, çok sayıda sorgunun işlenmesi gereken ve veritabanı güncellemelerinin sayısının düşük olduğu sistemler için uygundur.
Kısmen Kopyalanmış
Tabloların kopyaları veya tablo bölümleri farklı yerlerde saklanır. Tabloların dağılımı, erişim sıklığına göre yapılır. Bu, tablolara erişim sıklığının siteden siteye önemli ölçüde değiştiği gerçeğini dikkate alır. Tabloların (veya bölümlerinin) kopya sayısı, erişim sorgularının ne sıklıkla yürütüldüğüne ve erişim sorgularını oluşturan siteye bağlıdır.
Parçalanmış
Bu tasarımda, bir tablo, parçalar veya bölümler olarak adlandırılan iki veya daha fazla parçaya bölünür ve her bir parça farklı yerlerde saklanabilir. Bu, bir tabloda depolanan tüm verilerin belirli bir sitede gerekli olmasının nadiren gerçekleştiği gerçeğini dikkate alır. Dahası, parçalanma paralelliği artırır ve felaketten daha iyi kurtarma sağlar. Burada, sistemdeki her parçanın yalnızca bir kopyası vardır, yani fazlalık veri yoktur.
Üç parçalama tekniği:
- Dikey parçalanma
- Yatay parçalanma
- Hibrit parçalanma
Karışık Dağıtım
Bu, parçalanma ve kısmi tekrarlamaların bir kombinasyonudur. Burada, tablolar başlangıçta herhangi bir biçimde (yatay veya dikey) parçalara ayrılır ve daha sonra bu parçalar, parçalara erişim sıklığına göre farklı siteler boyunca kısmen kopyalanır.
Son bölümde farklı tasarım alternatiflerini tanıtmıştık. Bu bölümde, tasarımları benimsemeye yardımcı olan stratejileri inceleyeceğiz. Stratejiler genel olarak çoğaltma ve parçalanmaya ayrılabilir. Bununla birlikte, çoğu durumda, ikisinin bir kombinasyonu kullanılır.
Veri Çoğaltma
Veri çoğaltma, veritabanının ayrı kopyalarını iki veya daha fazla sitede saklama işlemidir. Dağıtılmış veritabanlarının popüler bir hata tolerans tekniğidir.
Veri Çoğaltmanın Avantajları
Reliability - Herhangi bir sitenin arızalanması durumunda, bir kopyası başka site (ler) de mevcut olduğu için veritabanı sistemi çalışmaya devam eder.
Reduction in Network Load- Verilerin yerel kopyaları mevcut olduğundan, sorgu işleme, özellikle birincil saatlerde daha az ağ kullanımıyla yapılabilir. Veri güncellemesi asıl olmayan saatlerde yapılabilir.
Quicker Response - Yerel veri kopyalarının kullanılabilirliği, hızlı sorgu işleme ve dolayısıyla hızlı yanıt süresi sağlar.
Simpler Transactions- İşlemler, farklı yerlerde bulunan tabloların daha az sayıda birleştirilmesini ve ağ üzerinde minimum koordinasyonun olmasını gerektirir. Böylece doğada daha basit hale gelirler.
Veri Çoğaltmanın Dezavantajları
Increased Storage Requirements- Birden çok veri kopyasının korunması, artan depolama maliyetleri ile ilişkilidir. Gerekli depolama alanı, merkezi bir sistem için gereken depolamanın katları kadardır.
Increased Cost and Complexity of Data Updating- Bir veri öğesi her güncellendiğinde, güncellemenin farklı sitelerdeki verilerin tüm kopyalarına yansıtılması gerekir. Bu, karmaşık senkronizasyon teknikleri ve protokolleri gerektirir.
Undesirable Application – Database coupling- Karmaşık güncelleme mekanizmaları kullanılmıyorsa, veri tutarsızlığını ortadan kaldırmak, uygulama düzeyinde karmaşık koordinasyon gerektirir. Bu, istenmeyen uygulama - veritabanı bağlantısına neden olur.
Yaygın olarak kullanılan bazı çoğaltma teknikleri şunlardır:
- Anlık görüntü çoğaltma
- Neredeyse gerçek zamanlı çoğaltma
- Çoğaltma çekin
Parçalanma
Parçalanma, bir tabloyu daha küçük tablolara bölme görevidir. Tablonun alt kümeleri denirfragments. Parçalanma üç tipte olabilir: yatay, dikey ve hibrit (yatay ve dikey kombinasyonu). Yatay parçalanma ayrıca iki teknik olarak sınıflandırılabilir: birincil yatay parçalama ve türetilmiş yatay parçalama.
Parçalanma, orijinal tablonun parçalardan yeniden oluşturulabileceği şekilde yapılmalıdır. Bu, orijinal tablonun gerektiğinde parçalardan yeniden oluşturulabilmesi için gereklidir. Bu gereksinime "yeniden yapılandırılabilirlik" denir.
Parçalanmanın Avantajları
Veriler kullanım sahasına yakın depolandığı için veritabanı sisteminin verimliliği artırılmıştır.
Veriler yerel olarak mevcut olduğundan, yerel sorgu optimizasyon teknikleri çoğu sorgu için yeterlidir.
Sitelerde ilgisiz veriler bulunmadığından veritabanı sisteminin güvenliği ve gizliliği sağlanabilmektedir.
Parçalanmanın Dezavantajları
Farklı parçalardan veriler gerektiğinde, erişim hızları çok yüksek olabilir.
Yinelemeli parçalanmalar durumunda, yeniden yapılandırma işi pahalı tekniklere ihtiyaç duyacaktır.
Farklı sitelerdeki verilerin yedek kopyalarının olmaması, bir sitenin arızalanması durumunda veritabanını etkisiz hale getirebilir.
Dikey Parçalanma
Dikey parçalamada, bir tablonun alanları veya sütunları parçalar halinde gruplanır. Yeniden yapılandırılabilirliği korumak için, her parça tablonun birincil anahtar alanlarını içermelidir. Dikey parçalama, verilerin gizliliğini sağlamak için kullanılabilir.
Örneğin, bir Üniversite veritabanının aşağıdaki şemaya sahip bir Öğrenci tablosundaki tüm kayıtlı öğrencilerin kayıtlarını tuttuğunu düşünelim.
ÖĞRENCİ
| Regd_No | İsim | Ders | Adres | Dönem | Ücretler | İşaretler |
Şimdi, ücret detayları hesaplar bölümünde tutulmaktadır. Bu durumda, tasarımcı veritabanını aşağıdaki gibi parçalayacaktır -
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;Yatay Parçalanma
Yatay parçalama, bir tablonun demetlerini bir veya daha fazla alanın değerlerine göre gruplandırır. Yatay parçalanma, yeniden yapılandırılabilirlik kuralını da doğrulamalıdır. Her yatay parça, orijinal temel tablonun tüm sütunlarına sahip olmalıdır.
Örneğin, öğrenci şemasında, Bilgisayar Bilimleri Kursu'ndaki tüm öğrencilerin ayrıntılarının Bilgisayar Bilimleri Fakültesi'nde muhafaza edilmesi gerekiyorsa, tasarımcı veritabanını aşağıdaki gibi yatay olarak parçalara ayıracaktır -
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";Hibrit Parçalanma
Hibrit parçalamada, yatay ve dikey parçalama tekniklerinin bir kombinasyonu kullanılır. Bu, minimum gereksiz bilgi içeren parçalar ürettiği için en esnek parçalama tekniğidir. Bununla birlikte, orijinal tablonun yeniden yapılandırılması genellikle pahalı bir iştir.
Hibrit parçalama iki alternatif yolla yapılabilir -
İlk önce, bir dizi yatay parça oluşturun; daha sonra bir veya daha fazla yatay parçadan dikey parçalar oluşturun.
İlk önce, bir dizi dikey parça oluşturun; daha sonra bir veya daha fazla dikey parçadan yatay parçalar oluşturun.
Dağıtım şeffaflığı, dağıtımın dahili ayrıntılarının kullanıcılardan gizlenmesi nedeniyle dağıtılmış veritabanlarının özelliğidir. DDBMS tasarımcısı tabloları parçalamayı, parçaları çoğaltmayı ve farklı yerlerde depolamayı seçebilir. Bununla birlikte, kullanıcılar bu ayrıntılardan habersiz olduklarından, dağıtılmış veritabanını herhangi bir merkezi veritabanı gibi kullanımı kolay buluyorlar.
Dağıtım şeffaflığının üç boyutu:
- Konum şeffaflığı
- Parçalanma şeffaflığı
- Çoğaltma şeffaflığı
Konum Şeffaflığı
Konum şeffaflığı, kullanıcının herhangi bir tabloyu veya bir tablonun parçasını, kullanıcının sitesinde yerel olarak depolanmış gibi sorgulayabilmesini sağlar. Tablonun veya parçalarının dağıtılmış veritabanı sisteminde uzak bir sitede saklanması gerçeği, son kullanıcı için tamamen habersiz olmalıdır. Uzak sitelerin adresi ve erişim mekanizmaları tamamen gizlidir.
Konum şeffaflığını dahil etmek için DDBMS, güncellenmiş ve doğru veri sözlüğüne ve verilerin konumlarının ayrıntılarını içeren DDBMS dizinine erişime sahip olmalıdır.
Parçalanma Şeffaflığı
Parçalanma şeffaflığı, kullanıcıların herhangi bir tabloyu sanki parçalanmamış gibi sorgulamasını sağlar. Böylece, kullanıcının sorguladığı tablonun aslında bazı parçaların bir parçası veya birleşimi olduğu gerçeğini gizler. Ayrıca, parçaların farklı yerlerde bulunduğu gerçeğini de gizler.
Bu, kullanıcının tablonun kendisi yerine bir tablo görünümünü kullandıklarını bilmeyebileceği SQL görünümleri kullanıcılarına biraz benzer.
Çoğaltma Şeffaflığı
Replikasyon şeffaflığı, veritabanlarının replikasyonunun kullanıcılardan gizlenmesini sağlar. Kullanıcıların bir tablo üzerinde, tablonun yalnızca tek bir kopyası varmış gibi sorgulama yapmasını sağlar.
Çoğaltma şeffaflığı, eşzamanlılık şeffaflığı ve hata şeffaflığı ile ilişkilidir. Bir kullanıcı bir veri öğesini güncellediğinde, güncelleme tablonun tüm kopyalarına yansıtılır. Ancak bu işlem kullanıcı tarafından bilinmemelidir. Bu eşzamanlılık şeffaflığıdır. Ayrıca, bir sitenin arızalanması durumunda, kullanıcı, herhangi bir arıza bilgisi olmaksızın, çoğaltılmış kopyaları kullanarak sorgularına devam edebilir. Bu, başarısızlık şeffaflığıdır.
Asetat Kombinasyonu
Herhangi bir dağıtılmış veritabanı sisteminde, tasarımcı belirtilen tüm asetatların önemli ölçüde muhafaza edilmesini sağlamalıdır. Tasarımcı tabloları parçalamayı, çoğaltmayı ve farklı yerlerde depolamayı seçebilir; hepsi son kullanıcıya habersiz. Bununla birlikte, tam dağıtım şeffaflığı zor bir görevdir ve önemli tasarım çabaları gerektirir.
Veritabanı kontrolü, bir veritabanının gerçek kullanıcılarına ve uygulamalarına doğru verileri sağlamak için düzenlemeleri uygulama görevini ifade eder. Kullanıcılara doğru verilerin sunulması için, tüm verilerin veri tabanında tanımlanan bütünlük kısıtlamalarına uygun olması gerekir. Ayrıca, veri tabanının güvenliğini ve gizliliğini korumak için veriler yetkisiz kullanıcılardan uzak tutulmalıdır. Veritabanı kontrolü, veritabanı yöneticisinin (DBA) birincil görevlerinden biridir.
Veritabanı kontrolünün üç boyutu:
- Authentication
- Erişim hakları
- Bütünlük kısıtlamaları
Doğrulama
Dağıtılmış bir veritabanı sisteminde, kimlik doğrulama, yalnızca yasal kullanıcıların veri kaynaklarına erişim sağlayabildiği süreçtir.
Kimlik doğrulama iki düzeyde zorlanabilir -
Controlling Access to Client Computer- Bu düzeyde, veritabanı sunucusuna kullanıcı arabirimi sağlayan istemci bilgisayarda oturum açarken kullanıcı erişimi kısıtlanır. En yaygın yöntem bir kullanıcı adı / şifre kombinasyonudur. Bununla birlikte, yüksek güvenlikli veriler için biyometrik kimlik doğrulama gibi daha karmaşık yöntemler kullanılabilir.
Controlling Access to the Database Software- Bu düzeyde, veritabanı yazılımı / yöneticisi kullanıcıya bazı kimlik bilgileri atar. Kullanıcı bu kimlik bilgilerini kullanarak veritabanına erişim kazanır. Yöntemlerden biri, veritabanı sunucusu içinde bir oturum açma hesabı oluşturmaktır.
Erişim Hakları
Bir kullanıcının erişim hakları, bir tablo oluşturma, bir tablo bırakma, bir tabloya kayıt ekleme / silme / güncelleme hakları veya tablo üzerindeki sorgu gibi DBMS işlemleriyle ilgili olarak kullanıcıya verilen ayrıcalıkları ifade eder.
Dağıtılmış ortamlarda, çok sayıda tablo ve yine de çok sayıda kullanıcı olduğundan, kullanıcılara bireysel erişim hakları atamak mümkün değildir. Dolayısıyla, DDBMS belirli rolleri tanımlar. Rol, bir veritabanı sistemi içinde belirli ayrıcalıklara sahip bir yapıdır. Farklı roller tanımlandıktan sonra, bireysel kullanıcılara bu rollerden biri atanır. Genellikle, kuruluşun yetki ve sorumluluk hiyerarşisine göre bir roller hiyerarşisi tanımlanır.
Örneğin, aşağıdaki SQL ifadeleri bir "Muhasebeci" rolü oluşturur ve ardından bu rolü "ABC" kullanıcısına atar.
CREATE ROLE ACCOUNTANT;
GRANT SELECT, INSERT, UPDATE ON EMP_SAL TO ACCOUNTANT;
GRANT INSERT, UPDATE, DELETE ON TENDER TO ACCOUNTANT;
GRANT INSERT, SELECT ON EXPENSE TO ACCOUNTANT;
COMMIT;
GRANT ACCOUNTANT TO ABC;
COMMIT;Anlamsal Bütünlük Kontrolü
Anlamsal bütünlük kontrolü, veritabanı sisteminin bütünlük kısıtlamalarını tanımlar ve uygular.
Bütünlük kısıtlamaları aşağıdaki gibidir -
- Veri türü bütünlük kısıtlaması
- Varlık bütünlüğü kısıtlaması
- Bilgi tutarlılığı kısıtlaması
Veri Türü Bütünlüğü Kısıtlaması
Bir veri türü kısıtlaması, belirtilen veri türüne sahip alana uygulanabilecek değer aralığını ve işlem türünü kısıtlar.
Örneğin, bir "HOSTEL" tablosunun üç alana sahip olduğunu düşünelim - pansiyon numarası, pansiyon adı ve kapasite. Pansiyon numarası büyük harf "H" ile başlamalı ve NULL olamaz ve kapasite 150'den fazla olmamalıdır. Veri tanımı için aşağıdaki SQL komutu kullanılabilir -
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) NOT NULL,
H_NAME VARCHAR2(15),
CAPACITY INTEGER,
CHECK ( H_NO LIKE 'H%'),
CHECK ( CAPACITY <= 150)
);Varlık Bütünlük Kontrolü
Varlık bütünlüğü denetimi, kuralları uygular, böylece her bir demet diğer kayıtlardan benzersiz bir şekilde tanımlanabilir. Bunun için birincil anahtar tanımlanır. Birincil anahtar, bir demeti benzersiz bir şekilde tanımlayabilen bir minimum alan kümesidir. Varlık bütünlüğü kısıtlaması, bir tablodaki iki tablonun birincil anahtarlar için aynı değerlere sahip olamayacağını ve birincil anahtarın parçası olan hiçbir alanın NULL değerine sahip olamayacağını belirtir.
Örneğin, yukarıdaki hostel tablosunda, hostel numarası aşağıdaki SQL ifadesi aracılığıyla birincil anahtar olarak atanabilir (kontroller göz ardı edilerek) -
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) PRIMARY KEY,
H_NAME VARCHAR2(15),
CAPACITY INTEGER
);Bilgi Bütünlüğü Kısıtlaması
Bilgi tutarlılığı kısıtlaması, yabancı anahtarların kurallarını belirler. Yabancı anahtar, ilgili tablonun birincil anahtarı olan veri tablosundaki bir alandır. Referans bütünlük kısıtlaması, yabancı anahtar alanının değerinin başvurulan tablonun birincil anahtarının değerleri arasında olması veya tamamen NULL olması gerektiği kuralını ortaya koyar.
Örneğin, bir öğrencinin pansiyonda yaşamayı tercih edebileceği bir öğrenci masası düşünelim. Bunu dahil etmek için, pansiyon tablosunun birincil anahtarı öğrenci tablosuna yabancı anahtar olarak dahil edilmelidir. Aşağıdaki SQL ifadesi bunu içerir -
CREATE TABLE STUDENT (
S_ROLL INTEGER PRIMARY KEY,
S_NAME VARCHAR2(25) NOT NULL,
S_COURSE VARCHAR2(10),
S_HOSTEL VARCHAR2(5) REFERENCES HOSTEL
);Bir sorgu yerleştirildiğinde, önce taranır, ayrıştırılır ve doğrulanır. Daha sonra sorgu ağacı veya sorgu grafiği gibi sorgunun dahili bir temsili oluşturulur. Daha sonra, veritabanı tablolarından sonuçların alınması için alternatif yürütme stratejileri tasarlanır. Sorgu işleme için en uygun yürütme stratejisini seçme sürecine sorgu optimizasyonu denir.
DDBMS'de Sorgu Optimizasyonu Sorunları
DDBMS'de sorgu optimizasyonu çok önemli bir görevdir. Aşağıdaki faktörler nedeniyle alternatif stratejilerin sayısı katlanarak artabileceğinden karmaşıklık yüksektir -
- Bir dizi parçanın varlığı.
- Parçaların veya tabloların çeşitli sitelere dağılımı.
- İletişim bağlantılarının hızı.
- Yerel işleme yeteneklerinde eşitsizlik.
Bu nedenle, dağıtılmış bir sistemde hedef genellikle en iyisinden ziyade sorgu işleme için iyi bir yürütme stratejisi bulmaktır. Bir sorguyu yürütme süresi aşağıdakilerin toplamıdır -
- Veritabanlarına sorgu iletme zamanı.
- Yerel sorgu parçalarını yürütme zamanı.
- Farklı sitelerden veri toplama zamanı.
- Sonuçları uygulamaya görüntüleme zamanı.
Sorgu İşleme
Sorgu işleme, sorgu yerleştirmeden başlayarak sorgunun sonuçlarını görüntülemeye kadar tüm etkinlikler kümesidir. Adımlar aşağıdaki şemada gösterildiği gibidir -

İlişkisel Cebir
İlişkisel cebir, ilişkisel veritabanı modelinin temel işlemlerini tanımlar. Bir dizi ilişkisel cebir işlemleri, ilişkisel bir cebir ifadesi oluşturur. Bu ifadenin sonucu, bir veritabanı sorgusunun sonucunu temsil eder.
Temel işlemler -
- Projection
- Selection
- Union
- Intersection
- Minus
- Join
Projeksiyon
Projeksiyon işlemi, bir tablonun alanlarının bir alt kümesini görüntüler. Bu, tablonun dikey bir bölümünü verir.
Syntax in Relational Algebra
$$ \ pi _ {<{AttributeList}>} {(<{Tablo Adı}>)} $$
Örneğin, aşağıdaki Öğrenci veritabanını ele alalım -
|
|
||||
| Roll_No | Name | Course | Semester | Gender |
| 2 | Amit Prasad | BCA | 1 | Erkek |
| 4 | Varsha Tiwari | BCA | 1 | Kadın |
| 5 | Asıf Ali | MCA | 2 | Erkek |
| 6 | Joe Wallace | MCA | 1 | Erkek |
| 8 | Shivani Iyengar | BCA | 1 | Kadın |
Tüm öğrencilerin isimlerini ve derslerini göstermek istiyorsak, aşağıdaki ilişkisel cebir ifadesini kullanacağız -
$$\pi_{Name,Course}{(STUDENT)}$$
Seçimi
Seçim işlemi, belirli koşulları sağlayan bir tablonun tuple alt kümesini görüntüler. Bu, tablonun yatay bir bölümünü verir.
Syntax in Relational Algebra
$$ \ sigma _ {<{Koşullar}>} {(<{Tablo Adı}>)} $$
Örneğin, Öğrenci tablosunda, MCA kursunu seçen tüm öğrencilerin ayrıntılarını görüntülemek istiyorsak, aşağıdaki ilişkisel cebir ifadesini kullanacağız -
$$\sigma_{Course} = {\small "BCA"}^{(STUDENT)}$$
Projeksiyon ve Seçim İşlemlerinin Kombinasyonu
Çoğu sorgu için, projeksiyon ve seçim işlemlerinin bir kombinasyonuna ihtiyacımız var. Bu ifadeleri yazmanın iki yolu vardır -
- Projeksiyon dizisini ve seçim işlemlerini kullanma.
- Ara sonuçlar oluşturmak için yeniden adlandırma işlemini kullanma.
Örneğin, BCA kursundaki tüm kız öğrencilerin adlarını görüntülemek için -
- Projeksiyon dizisi ve seçim işlemleri kullanarak ilişkisel cebir ifadesi
$$\pi_{Name}(\sigma_{Gender = \small "Female" AND \: Course = \small "BCA"}{(STUDENT)})$$
- Ara sonuçlar oluşturmak için yeniden adlandırma işlemini kullanan ilişkisel cebir ifadesi
$$FemaleBCAStudent \leftarrow \sigma_{Gender = \small "Female" AND \: Course = \small "BCA"} {(STUDENT)}$$
$$Result \leftarrow \pi_{Name}{(FemaleBCAStudent)}$$
Birlik
P bir işlemin sonucuysa ve Q başka bir işlemin sonucuysa, P ve Q'nun birleşimi ($p \cup Q$) P veya Q veya her ikisinde de yinelenmeyen tüm tuplelar kümesidir.
Örneğin, 1. Dönemde olan veya BCA kursunda olan tüm öğrencileri görüntülemek için -
$$Sem1Student \leftarrow \sigma_{Semester = 1}{(STUDENT)}$$
$$BCAStudent \leftarrow \sigma_{Course = \small "BCA"}{(STUDENT)}$$
$$Result \leftarrow Sem1Student \cup BCAStudent$$
Kavşak
P bir işlemin sonucuysa ve Q başka bir işlemin sonucuysa, P ve Q'nun kesişimi ( $p \cap Q$ ) her ikisi de P ve Q'da olan tüm tuplelar kümesidir.
Örneğin, aşağıdaki iki şema verildiğinde -
EMPLOYEE
| EmpID | İsim | Kent | Bölüm | Maaş |
PROJECT
| PId | Kent | Bölüm | Durum |
Bir projenin bulunduğu ve aynı zamanda bir çalışanın ikamet ettiği tüm şehirlerin adlarını görüntülemek için -
$$CityEmp \leftarrow \pi_{City}{(EMPLOYEE)}$$
$$CityProject \leftarrow \pi_{City}{(PROJECT)}$$
$$Result \leftarrow CityEmp \cap CityProject$$
Eksi
P bir işlemin sonucuysa ve Q başka bir işlemin sonucuysa, P - Q, Q'da değil P'de olan tüm tuplelar kümesidir.
Örneğin, devam eden bir projesi olmayan tüm departmanları listelemek için (durumu = devam eden projeler) -
$$AllDept \leftarrow \pi_{Department}{(EMPLOYEE)}$$
$$ProjectDept \leftarrow \pi_{Department} (\sigma_{Status = \small "ongoing"}{(PROJECT)})$$
$$Result \leftarrow AllDept - ProjectDept$$
Katılmak
Birleştirme işlemi, iki farklı tablonun ilgili tupl'larını (sorguların sonuçları) tek bir tabloda birleştirir.
Örneğin, aşağıdaki gibi bir Banka veritabanındaki Müşteri ve Şube olmak üzere iki şema düşünün -
CUSTOMER
| Müşteri Kimliği | AccNo | TypeOfAc | BranchID | DateOfOpening |
BRANCH
| BranchID | BranchName | IFSC kodu | Adres |
Çalışan ayrıntılarını şube ayrıntılarıyla birlikte listelemek için -
$$Result \leftarrow CUSTOMER \bowtie_{Customer.BranchID=Branch.BranchID}{BRANCH}$$
SQL Sorgularını İlişkisel Cebire Çevirme
SQL sorguları, optimizasyondan önce eşdeğer ilişkisel cebir ifadelerine çevrilir. Bir sorgu ilk başta daha küçük sorgu bloklarına ayrıştırılır. Bu bloklar eşdeğer ilişkisel cebir ifadelerine çevrilir. Optimizasyon, her bloğun optimizasyonunu ve ardından sorgunun bir bütün olarak optimizasyonunu içerir.
Örnekler
Aşağıdaki şemaları ele alalım -
ÇALIŞAN
| EmpID | İsim | Kent | Bölüm | Maaş |
PROJE
| PId | Kent | Bölüm | Durum |
İŞLER
| EmpID | PID | Saatler |
örnek 1
Ortalama maaştan DAHA AZ maaş kazanan tüm çalışanların ayrıntılarını görüntülemek için SQL sorgusunu yazıyoruz -
SELECT * FROM EMPLOYEE
WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;Bu sorgu, iç içe geçmiş bir alt sorgu içerir. Yani, bu iki bloğa bölünebilir.
İç blok -
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;Bu sorgunun sonucu AvgSal ise, dış blok -
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;İç blok için ilişkisel cebir ifadesi -
$$AvgSal \leftarrow \Im_{AVERAGE(Salary)}{EMPLOYEE}$$
Dış blok için ilişkisel cebir ifadesi -
$$ \ sigma_ {Salary <{AvgSal}>} {EMPLOYEE} $$
Örnek 2
Çalışan 'Arun Kumar' ın tüm projelerinin proje kimliğini ve durumunu görüntülemek için SQL sorgusunu yazıyoruz -
SELECT PID, STATUS FROM PROJECT
WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE
WHERE NAME = 'ARUN KUMAR'));Bu sorgu, iç içe geçmiş iki alt sorgu içerir. Böylece, aşağıdaki gibi üç bloğa ayrılabilir -
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR';
SELECT PID FROM WORKS WHERE EMPID = ArunEmpID;
SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;(Burada ArunEmpID ve ArunPID, iç sorguların sonuçlarıdır)
Üç blok için ilişkisel cebir ifadeleri:
$$ArunEmpID \leftarrow \pi_{EmpID}(\sigma_{Name = \small "Arun Kumar"} {(EMPLOYEE)})$$
$$ArunPID \leftarrow \pi_{PID}(\sigma_{EmpID = \small "ArunEmpID"} {(WORKS)})$$
$$Result \leftarrow \pi_{PID, Status}(\sigma_{PID = \small "ArunPID"} {(PROJECT)})$$
İlişkisel Cebir Operatörlerinin Hesaplanması
İlişkisel cebir operatörlerinin hesaplanması birçok farklı şekilde yapılabilir ve her alternatife bir access path.
Hesaplama alternatifi üç ana faktöre bağlıdır -
- Operatör tipi
- Kullanılabilir hafıza
- Disk yapıları
İlişkisel bir cebir işleminin yürütülmesi için gereken süre -
- Demetleri işleme zamanı.
- Tablonun demetlerini diskten belleğe alma zamanı.
Bir demeti işleme süresi, özellikle dağıtılmış bir sistemde, kaydı depodan getirme süresinden çok daha kısa olduğundan, disk erişimi genellikle ilişkisel ifade maliyetini hesaplamak için bir ölçü olarak kabul edilir.
Seçimin Hesaplanması
Seçim işleminin hesaplanması, seçim koşulunun karmaşıklığına ve tablonun öznitelikleri üzerindeki dizinlerin mevcudiyetine bağlıdır.
Aşağıda indekslere bağlı olarak hesaplama alternatifleri verilmiştir -
No Index- Tablo sıralanmamışsa ve dizini yoksa, seçim işlemi tablonun tüm disk bloklarının taranmasını içerir. Her blok belleğe getirilir ve bloktaki her bir tuple, seçim koşulunu karşılayıp karşılamadığını görmek için incelenir. Koşul yerine getirilirse, çıktı olarak görüntülenir. Bu, her demet hafızaya getirildiği ve her bir demet işlendiği için en maliyetli yaklaşımdır.
B+ Tree Index- Çoğu veritabanı sistemi B + Ağaç indeksi üzerine inşa edilmiştir. Seçim koşulu, bu B + Ağaç indeksinin anahtarı olan alana dayanıyorsa, bu indeks sonuçların alınması için kullanılır. Ancak, karmaşık koşullara sahip seçim ifadelerinin işlenmesi, daha fazla sayıda disk bloğu erişimini ve bazı durumlarda tablonun tam olarak taranmasını içerebilir.
Hash Index- Karma dizinler kullanılıyorsa ve anahtar alanı seçim koşulunda kullanılıyorsa, karma dizini kullanarak tupleları almak basit bir işlem haline gelir. Bir karma dizini, karma değerine karşılık gelen anahtar değerinin depolandığı bir paketin adresini bulmak için bir karma işlevi kullanır. Dizinde bir anahtar değeri bulmak için, karma işlevi çalıştırılır ve paket adresi bulunur. Paket içindeki anahtar değerleri aranır. Bir eşleşme bulunursa, gerçek kayıt disk bloğundan belleğe alınır.
Birleşmelerin Hesaplanması
İki tabloyu birleştirmek istediğimizde, örneğin P ve Q, P'deki her bir demet, birleştirme koşulunun karşılanıp karşılanmadığını test etmek için Q'daki her bir demet ile karşılaştırılmalıdır. Koşul yerine getirilirse, karşılık gelen kayıtlar birleştirilir, yinelenen alanlar ortadan kaldırılır ve sonuç ilişkisine eklenir. Sonuç olarak, bu en pahalı işlemdir.
Bilgi işlem birleştirmeleri için yaygın yaklaşımlar şunlardır:
İç içe döngü Yaklaşımı
Bu, geleneksel birleştirme yaklaşımıdır. Aşağıdaki sözde kodla gösterilebilir (Tablolar P ve Q, tuple_p ve tuple_q ve birleştirme niteliği a ile) -
For each tuple_p in P
For each tuple_q in Q
If tuple_p.a = tuple_q.a Then
Concatenate tuple_p and tuple_q and append to Result
End If
Next tuple_q
Next tuple-pSırala-birleştirme Yaklaşımı
Bu yaklaşımda, iki tablo birleştirme özniteliğine göre ayrı ayrı sıralanır ve ardından sıralanan tablolar birleştirilir. Kayıtların sayısı çok yüksek olduğundan ve hafızaya alınamadığından harici sıralama teknikleri benimsenmiştir. Tek tek tablolar sıralandıktan sonra, sıralanan tabloların her biri bir sayfa belleğe getirilir, birleştirme özelliğine göre birleştirilir ve birleştirilen tuplelar yazılır.
Hash-Join Yaklaşımı
Bu yaklaşım iki aşamadan oluşur: bölümleme aşaması ve araştırma aşaması. Bölümleme aşamasında, P ve Q tabloları iki ayrık bölüm kümesine ayrılır. Ortak bir hash fonksiyonuna karar verilir. Bu hash işlevi, tuple'ları bölümlere atamak için kullanılır. Araştırma aşamasında, P'nin bir bölümündeki tuplelar, karşılık gelen Q bölümünün tuplelarıyla karşılaştırılır. Eğer eşleşirlerse, yazılırlar.
Bir ilişkisel cebir ifadesinin hesaplanması için alternatif erişim yolları türetildiğinde, optimum erişim yolu belirlenir. Bu bölümde, merkezi sistemde sorgu optimizasyonunu inceleyeceğiz, sonraki bölümde ise dağıtılmış bir sistemde sorgu optimizasyonunu inceleyeceğiz.
Merkezi bir sistemde, sorgu işleme şu amaçla yapılır -
Sorgunun yanıt süresinin en aza indirilmesi (sonuçları kullanıcının sorgusuna üretmek için geçen süre).
Sistem verimini en üst düzeye çıkarın (belirli bir süre içinde işlenen istek sayısı).
İşleme için gereken bellek ve depolama miktarını azaltın.
Paralelliği artırın.
Sorgu Ayrıştırma ve Çeviri
Başlangıçta SQL sorgusu taranır. Daha sonra sözdizimsel hataları ve veri türlerinin doğruluğunu aramak için ayrıştırılır. Sorgu bu adımı geçerse, sorgu daha küçük sorgu bloklarına ayrılır. Her blok daha sonra eşdeğer ilişkisel cebir ifadesine çevrilir.
Sorgu Optimizasyonu için Adımlar
Sorgu optimizasyonu, sorgu ağacı oluşturma, plan oluşturma ve sorgu planı kodu oluşturma olmak üzere üç adımı içerir.
Step 1 − Query Tree Generation
Bir sorgu ağacı, ilişkisel bir cebir ifadesini temsil eden bir ağaç veri yapısıdır. Sorgu tabloları yaprak düğümler olarak temsil edilir. İlişkisel cebir işlemleri, iç düğümler olarak temsil edilir. Kök, sorguyu bir bütün olarak temsil eder.
Yürütme sırasında, işlenen tabloları mevcut olduğunda bir dahili düğüm çalıştırılır. Düğüm daha sonra sonuç tablosu ile değiştirilir. Bu işlem, kök düğüm yürütülene ve sonuç tablosu ile değiştirilene kadar tüm dahili düğümler için devam eder.
Örneğin, aşağıdaki şemaları ele alalım -
ÇALIŞAN
| EmpID | Ad | Maaş | DeptNo | Katılım tarihi |
BÖLÜM
| DNo | İsim | Location |
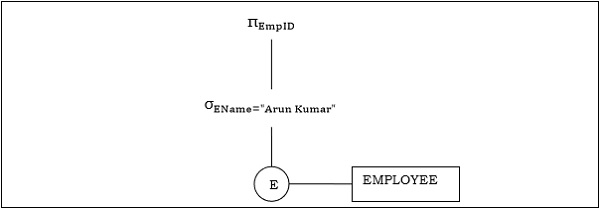
Example 1
Let us consider the query as the following.
$$\pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)})$$
The corresponding query tree will be −
Example 2
Let us consider another query involving a join.
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
Following is the query tree for the above query.

Step 2 − Query Plan Generation
After the query tree is generated, a query plan is made. A query plan is an extended query tree that includes access paths for all operations in the query tree. Access paths specify how the relational operations in the tree should be performed. For example, a selection operation can have an access path that gives details about the use of B+ tree index for selection.
Besides, a query plan also states how the intermediate tables should be passed from one operator to the next, how temporary tables should be used and how operations should be pipelined/combined.
Step 3− Code Generation
Code generation is the final step in query optimization. It is the executable form of the query, whose form depends upon the type of the underlying operating system. Once the query code is generated, the Execution Manager runs it and produces the results.
Approaches to Query Optimization
Among the approaches for query optimization, exhaustive search and heuristics-based algorithms are mostly used.
Exhaustive Search Optimization
In these techniques, for a query, all possible query plans are initially generated and then the best plan is selected. Though these techniques provide the best solution, it has an exponential time and space complexity owing to the large solution space. For example, dynamic programming technique.
Heuristic Based Optimization
Heuristic based optimization uses rule-based optimization approaches for query optimization. These algorithms have polynomial time and space complexity, which is lower than the exponential complexity of exhaustive search-based algorithms. However, these algorithms do not necessarily produce the best query plan.
Some of the common heuristic rules are −
Perform select and project operations before join operations. This is done by moving the select and project operations down the query tree. This reduces the number of tuples available for join.
Perform the most restrictive select/project operations at first before the other operations.
Avoid cross-product operation since they result in very large-sized intermediate tables.
This chapter discusses query optimization in distributed database system.
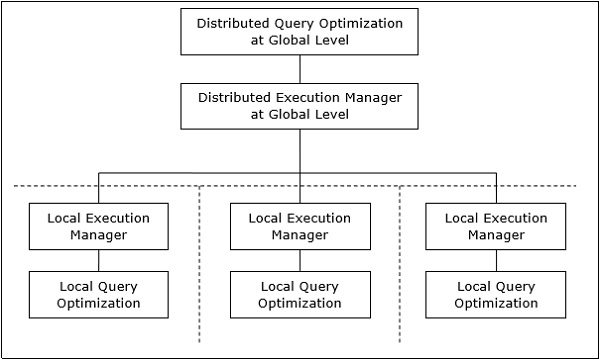
Distributed Query Processing Architecture
In a distributed database system, processing a query comprises of optimization at both the global and the local level. The query enters the database system at the client or controlling site. Here, the user is validated, the query is checked, translated, and optimized at a global level.
The architecture can be represented as −
Mapping Global Queries into Local Queries
The process of mapping global queries to local ones can be realized as follows −
The tables required in a global query have fragments distributed across multiple sites. The local databases have information only about local data. The controlling site uses the global data dictionary to gather information about the distribution and reconstructs the global view from the fragments.
If there is no replication, the global optimizer runs local queries at the sites where the fragments are stored. If there is replication, the global optimizer selects the site based upon communication cost, workload, and server speed.
The global optimizer generates a distributed execution plan so that least amount of data transfer occurs across the sites. The plan states the location of the fragments, order in which query steps needs to be executed and the processes involved in transferring intermediate results.
The local queries are optimized by the local database servers. Finally, the local query results are merged together through union operation in case of horizontal fragments and join operation for vertical fragments.
For example, let us consider that the following Project schema is horizontally fragmented according to City, the cities being New Delhi, Kolkata and Hyderabad.
PROJECT
| PId | City | Department | Status |
Suppose there is a query to retrieve details of all projects whose status is “Ongoing”.
The global query will be &inus;
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
Query in New Delhi’s server will be −
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
Query in Kolkata’s server will be −
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
Query in Hyderabad’s server will be −
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
In order to get the overall result, we need to union the results of the three queries as follows −
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
Distributed Query Optimization
Distributed query optimization requires evaluation of a large number of query trees each of which produce the required results of a query. This is primarily due to the presence of large amount of replicated and fragmented data. Hence, the target is to find an optimal solution instead of the best solution.
The main issues for distributed query optimization are −
- Optimal utilization of resources in the distributed system.
- Query trading.
- Reduction of solution space of the query.
Optimal Utilization of Resources in the Distributed System
A distributed system has a number of database servers in the various sites to perform the operations pertaining to a query. Following are the approaches for optimal resource utilization −
Operation Shipping − In operation shipping, the operation is run at the site where the data is stored and not at the client site. The results are then transferred to the client site. This is appropriate for operations where the operands are available at the same site. Example: Select and Project operations.
Data Shipping − In data shipping, the data fragments are transferred to the database server, where the operations are executed. This is used in operations where the operands are distributed at different sites. This is also appropriate in systems where the communication costs are low, and local processors are much slower than the client server.
Hybrid Shipping − This is a combination of data and operation shipping. Here, data fragments are transferred to the high-speed processors, where the operation runs. The results are then sent to the client site.

Query Trading
In query trading algorithm for distributed database systems, the controlling/client site for a distributed query is called the buyer and the sites where the local queries execute are called sellers. The buyer formulates a number of alternatives for choosing sellers and for reconstructing the global results. The target of the buyer is to achieve the optimal cost.
The algorithm starts with the buyer assigning sub-queries to the seller sites. The optimal plan is created from local optimized query plans proposed by the sellers combined with the communication cost for reconstructing the final result. Once the global optimal plan is formulated, the query is executed.
Reduction of Solution Space of the Query
Optimal solution generally involves reduction of solution space so that the cost of query and data transfer is reduced. This can be achieved through a set of heuristic rules, just as heuristics in centralized systems.
Following are some of the rules −
Perform selection and projection operations as early as possible. This reduces the data flow over communication network.
Simplify operations on horizontal fragments by eliminating selection conditions which are not relevant to a particular site.
In case of join and union operations comprising of fragments located in multiple sites, transfer fragmented data to the site where most of the data is present and perform operation there.
Use semi-join operation to qualify tuples that are to be joined. This reduces the amount of data transfer which in turn reduces communication cost.
Merge the common leaves and sub-trees in a distributed query tree.
This chapter discusses the various aspects of transaction processing. We’ll also study the low level tasks included in a transaction, the transaction states and properties of a transaction. In the last portion, we will look over schedules and serializability of schedules.
Transactions
A transaction is a program including a collection of database operations, executed as a logical unit of data processing. The operations performed in a transaction include one or more of database operations like insert, delete, update or retrieve data. It is an atomic process that is either performed into completion entirely or is not performed at all. A transaction involving only data retrieval without any data update is called read-only transaction.
Each high level operation can be divided into a number of low level tasks or operations. For example, a data update operation can be divided into three tasks −
read_item() − reads data item from storage to main memory.
modify_item() − change value of item in the main memory.
write_item() − write the modified value from main memory to storage.
Database access is restricted to read_item() and write_item() operations. Likewise, for all transactions, read and write forms the basic database operations.
Transaction Operations
The low level operations performed in a transaction are −
begin_transaction − A marker that specifies start of transaction execution.
read_item or write_item − Database operations that may be interleaved with main memory operations as a part of transaction.
end_transaction − A marker that specifies end of transaction.
commit − A signal to specify that the transaction has been successfully completed in its entirety and will not be undone.
rollback − A signal to specify that the transaction has been unsuccessful and so all temporary changes in the database are undone. A committed transaction cannot be rolled back.
Transaction States
A transaction may go through a subset of five states, active, partially committed, committed, failed and aborted.
Active − The initial state where the transaction enters is the active state. The transaction remains in this state while it is executing read, write or other operations.
Partially Committed − The transaction enters this state after the last statement of the transaction has been executed.
Committed − The transaction enters this state after successful completion of the transaction and system checks have issued commit signal.
Failed − The transaction goes from partially committed state or active state to failed state when it is discovered that normal execution can no longer proceed or system checks fail.
Aborted − This is the state after the transaction has been rolled back after failure and the database has been restored to its state that was before the transaction began.
The following state transition diagram depicts the states in the transaction and the low level transaction operations that causes change in states.
Desirable Properties of Transactions
Any transaction must maintain the ACID properties, viz. Atomicity, Consistency, Isolation, and Durability.
Atomicity − This property states that a transaction is an atomic unit of processing, that is, either it is performed in its entirety or not performed at all. No partial update should exist.
Consistency − A transaction should take the database from one consistent state to another consistent state. It should not adversely affect any data item in the database.
Isolation − A transaction should be executed as if it is the only one in the system. There should not be any interference from the other concurrent transactions that are simultaneously running.
Durability − If a committed transaction brings about a change, that change should be durable in the database and not lost in case of any failure.
Schedules and Conflicts
In a system with a number of simultaneous transactions, a schedule is the total order of execution of operations. Given a schedule S comprising of n transactions, say T1, T2, T3………..Tn; for any transaction Ti, the operations in Ti must execute as laid down in the schedule S.
Types of Schedules
There are two types of schedules −
Serial Schedules − In a serial schedule, at any point of time, only one transaction is active, i.e. there is no overlapping of transactions. This is depicted in the following graph −

Parallel Schedules − In parallel schedules, more than one transactions are active simultaneously, i.e. the transactions contain operations that overlap at time. This is depicted in the following graph −

Conflicts in Schedules
In a schedule comprising of multiple transactions, a conflict occurs when two active transactions perform non-compatible operations. Two operations are said to be in conflict, when all of the following three conditions exists simultaneously −
The two operations are parts of different transactions.
Both the operations access the same data item.
At least one of the operations is a write_item() operation, i.e. it tries to modify the data item.
Serializability
A serializable schedule of ‘n’ transactions is a parallel schedule which is equivalent to a serial schedule comprising of the same ‘n’ transactions. A serializable schedule contains the correctness of serial schedule while ascertaining better CPU utilization of parallel schedule.
Equivalence of Schedules
Equivalence of two schedules can be of the following types −
Result equivalence − Two schedules producing identical results are said to be result equivalent.
View equivalence − Two schedules that perform similar action in a similar manner are said to be view equivalent.
Conflict equivalence − Two schedules are said to be conflict equivalent if both contain the same set of transactions and has the same order of conflicting pairs of operations.
Concurrency controlling techniques ensure that multiple transactions are executed simultaneously while maintaining the ACID properties of the transactions and serializability in the schedules.
In this chapter, we will study the various approaches for concurrency control.
Locking Based Concurrency Control Protocols
Locking-based concurrency control protocols use the concept of locking data items. A lock is a variable associated with a data item that determines whether read/write operations can be performed on that data item. Generally, a lock compatibility matrix is used which states whether a data item can be locked by two transactions at the same time.
Locking-based concurrency control systems can use either one-phase or two-phase locking protocols.
One-phase Locking Protocol
In this method, each transaction locks an item before use and releases the lock as soon as it has finished using it. This locking method provides for maximum concurrency but does not always enforce serializability.
Two-phase Locking Protocol
In this method, all locking operations precede the first lock-release or unlock operation. The transaction comprise of two phases. In the first phase, a transaction only acquires all the locks it needs and do not release any lock. This is called the expanding or the growing phase. In the second phase, the transaction releases the locks and cannot request any new locks. This is called the shrinking phase.
Every transaction that follows two-phase locking protocol is guaranteed to be serializable. However, this approach provides low parallelism between two conflicting transactions.
Timestamp Concurrency Control Algorithms
Timestamp-based concurrency control algorithms use a transaction’s timestamp to coordinate concurrent access to a data item to ensure serializability. A timestamp is a unique identifier given by DBMS to a transaction that represents the transaction’s start time.
These algorithms ensure that transactions commit in the order dictated by their timestamps. An older transaction should commit before a younger transaction, since the older transaction enters the system before the younger one.
Timestamp-based concurrency control techniques generate serializable schedules such that the equivalent serial schedule is arranged in order of the age of the participating transactions.
Some of timestamp based concurrency control algorithms are −
- Basic timestamp ordering algorithm.
- Conservative timestamp ordering algorithm.
- Multiversion algorithm based upon timestamp ordering.
Timestamp based ordering follow three rules to enforce serializability −
Access Rule − When two transactions try to access the same data item simultaneously, for conflicting operations, priority is given to the older transaction. This causes the younger transaction to wait for the older transaction to commit first.
Late Transaction Rule − If a younger transaction has written a data item, then an older transaction is not allowed to read or write that data item. This rule prevents the older transaction from committing after the younger transaction has already committed.
Younger Transaction Rule − A younger transaction can read or write a data item that has already been written by an older transaction.
Optimistic Concurrency Control Algorithm
In systems with low conflict rates, the task of validating every transaction for serializability may lower performance. In these cases, the test for serializability is postponed to just before commit. Since the conflict rate is low, the probability of aborting transactions which are not serializable is also low. This approach is called optimistic concurrency control technique.
In this approach, a transaction’s life cycle is divided into the following three phases −
Execution Phase − A transaction fetches data items to memory and performs operations upon them.
Validation Phase − A transaction performs checks to ensure that committing its changes to the database passes serializability test.
Commit Phase − A transaction writes back modified data item in memory to the disk.
This algorithm uses three rules to enforce serializability in validation phase −
Rule 1 − Given two transactions Ti and Tj, if Ti is reading the data item which Tj is writing, then Ti’s execution phase cannot overlap with Tj’s commit phase. Tj can commit only after Ti has finished execution.
Rule 2 − Given two transactions Ti and Tj, if Ti is writing the data item that Tj is reading, then Ti’s commit phase cannot overlap with Tj’s execution phase. Tj can start executing only after Ti has already committed.
Rule 3 − Given two transactions Ti and Tj, if Ti is writing the data item which Tj is also writing, then Ti’s commit phase cannot overlap with Tj’s commit phase. Tj can start to commit only after Ti has already committed.
Concurrency Control in Distributed Systems
In this section, we will see how the above techniques are implemented in a distributed database system.
Distributed Two-phase Locking Algorithm
The basic principle of distributed two-phase locking is same as the basic two-phase locking protocol. However, in a distributed system there are sites designated as lock managers. A lock manager controls lock acquisition requests from transaction monitors. In order to enforce co-ordination between the lock managers in various sites, at least one site is given the authority to see all transactions and detect lock conflicts.
Depending upon the number of sites who can detect lock conflicts, distributed two-phase locking approaches can be of three types −
Centralized two-phase locking − In this approach, one site is designated as the central lock manager. All the sites in the environment know the location of the central lock manager and obtain lock from it during transactions.
Primary copy two-phase locking − In this approach, a number of sites are designated as lock control centers. Each of these sites has the responsibility of managing a defined set of locks. All the sites know which lock control center is responsible for managing lock of which data table/fragment item.
Distributed two-phase locking − In this approach, there are a number of lock managers, where each lock manager controls locks of data items stored at its local site. The location of the lock manager is based upon data distribution and replication.
Distributed Timestamp Concurrency Control
In a centralized system, timestamp of any transaction is determined by the physical clock reading. But, in a distributed system, any site’s local physical/logical clock readings cannot be used as global timestamps, since they are not globally unique. So, a timestamp comprises of a combination of site ID and that site’s clock reading.
For implementing timestamp ordering algorithms, each site has a scheduler that maintains a separate queue for each transaction manager. During transaction, a transaction manager sends a lock request to the site’s scheduler. The scheduler puts the request to the corresponding queue in increasing timestamp order. Requests are processed from the front of the queues in the order of their timestamps, i.e. the oldest first.
Conflict Graphs
Another method is to create conflict graphs. For this transaction classes are defined. A transaction class contains two set of data items called read set and write set. A transaction belongs to a particular class if the transaction’s read set is a subset of the class’ read set and the transaction’s write set is a subset of the class’ write set. In the read phase, each transaction issues its read requests for the data items in its read set. In the write phase, each transaction issues its write requests.
A conflict graph is created for the classes to which active transactions belong. This contains a set of vertical, horizontal, and diagonal edges. A vertical edge connects two nodes within a class and denotes conflicts within the class. A horizontal edge connects two nodes across two classes and denotes a write-write conflict among different classes. A diagonal edge connects two nodes across two classes and denotes a write-read or a read-write conflict among two classes.
The conflict graphs are analyzed to ascertain whether two transactions within the same class or across two different classes can be run in parallel.
Distributed Optimistic Concurrency Control Algorithm
Distributed optimistic concurrency control algorithm extends optimistic concurrency control algorithm. For this extension, two rules are applied −
Rule 1 − According to this rule, a transaction must be validated locally at all sites when it executes. If a transaction is found to be invalid at any site, it is aborted. Local validation guarantees that the transaction maintains serializability at the sites where it has been executed. After a transaction passes local validation test, it is globally validated.
Rule 2 − According to this rule, after a transaction passes local validation test, it should be globally validated. Global validation ensures that if two conflicting transactions run together at more than one site, they should commit in the same relative order at all the sites they run together. This may require a transaction to wait for the other conflicting transaction, after validation before commit. This requirement makes the algorithm less optimistic since a transaction may not be able to commit as soon as it is validated at a site.
This chapter overviews deadlock handling mechanisms in database systems. We’ll study the deadlock handling mechanisms in both centralized and distributed database system.
What are Deadlocks?
Deadlock is a state of a database system having two or more transactions, when each transaction is waiting for a data item that is being locked by some other transaction. A deadlock can be indicated by a cycle in the wait-for-graph. This is a directed graph in which the vertices denote transactions and the edges denote waits for data items.
For example, in the following wait-for-graph, transaction T1 is waiting for data item X which is locked by T3. T3 is waiting for Y which is locked by T2 and T2 is waiting for Z which is locked by T1. Hence, a waiting cycle is formed, and none of the transactions can proceed executing.

Deadlock Handling in Centralized Systems
There are three classical approaches for deadlock handling, namely −
- Deadlock prevention.
- Deadlock avoidance.
- Deadlock detection and removal.
All of the three approaches can be incorporated in both a centralized and a distributed database system.
Deadlock Prevention
The deadlock prevention approach does not allow any transaction to acquire locks that will lead to deadlocks. The convention is that when more than one transactions request for locking the same data item, only one of them is granted the lock.
One of the most popular deadlock prevention methods is pre-acquisition of all the locks. In this method, a transaction acquires all the locks before starting to execute and retains the locks for the entire duration of transaction. If another transaction needs any of the already acquired locks, it has to wait until all the locks it needs are available. Using this approach, the system is prevented from being deadlocked since none of the waiting transactions are holding any lock.
Deadlock Avoidance
The deadlock avoidance approach handles deadlocks before they occur. It analyzes the transactions and the locks to determine whether or not waiting leads to a deadlock.
The method can be briefly stated as follows. Transactions start executing and request data items that they need to lock. The lock manager checks whether the lock is available. If it is available, the lock manager allocates the data item and the transaction acquires the lock. However, if the item is locked by some other transaction in incompatible mode, the lock manager runs an algorithm to test whether keeping the transaction in waiting state will cause a deadlock or not. Accordingly, the algorithm decides whether the transaction can wait or one of the transactions should be aborted.
There are two algorithms for this purpose, namely wait-die and wound-wait. Let us assume that there are two transactions, T1 and T2, where T1 tries to lock a data item which is already locked by T2. The algorithms are as follows −
Wait-Die − If T1 is older than T2, T1 is allowed to wait. Otherwise, if T1 is younger than T2, T1 is aborted and later restarted.
Wound-Wait − If T1 is older than T2, T2 is aborted and later restarted. Otherwise, if T1 is younger than T2, T1 is allowed to wait.
Deadlock Detection and Removal
The deadlock detection and removal approach runs a deadlock detection algorithm periodically and removes deadlock in case there is one. It does not check for deadlock when a transaction places a request for a lock. When a transaction requests a lock, the lock manager checks whether it is available. If it is available, the transaction is allowed to lock the data item; otherwise the transaction is allowed to wait.
Since there are no precautions while granting lock requests, some of the transactions may be deadlocked. To detect deadlocks, the lock manager periodically checks if the wait-forgraph has cycles. If the system is deadlocked, the lock manager chooses a victim transaction from each cycle. The victim is aborted and rolled back; and then restarted later. Some of the methods used for victim selection are −
- Choose the youngest transaction.
- Choose the transaction with fewest data items.
- Choose the transaction that has performed least number of updates.
- Choose the transaction having least restart overhead.
- Choose the transaction which is common to two or more cycles.
This approach is primarily suited for systems having transactions low and where fast response to lock requests is needed.
Deadlock Handling in Distributed Systems
Transaction processing in a distributed database system is also distributed, i.e. the same transaction may be processing at more than one site. The two main deadlock handling concerns in a distributed database system that are not present in a centralized system are transaction location and transaction control. Once these concerns are addressed, deadlocks are handled through any of deadlock prevention, deadlock avoidance or deadlock detection and removal.
Transaction Location
Transactions in a distributed database system are processed in multiple sites and use data items in multiple sites. The amount of data processing is not uniformly distributed among these sites. The time period of processing also varies. Thus the same transaction may be active at some sites and inactive at others. When two conflicting transactions are located in a site, it may happen that one of them is in inactive state. This condition does not arise in a centralized system. This concern is called transaction location issue.
This concern may be addressed by Daisy Chain model. In this model, a transaction carries certain details when it moves from one site to another. Some of the details are the list of tables required, the list of sites required, the list of visited tables and sites, the list of tables and sites that are yet to be visited and the list of acquired locks with types. After a transaction terminates by either commit or abort, the information should be sent to all the concerned sites.
Transaction Control
Transaction control is concerned with designating and controlling the sites required for processing a transaction in a distributed database system. There are many options regarding the choice of where to process the transaction and how to designate the center of control, like −
- One server may be selected as the center of control.
- The center of control may travel from one server to another.
- The responsibility of controlling may be shared by a number of servers.
Distributed Deadlock Prevention
Just like in centralized deadlock prevention, in distributed deadlock prevention approach, a transaction should acquire all the locks before starting to execute. This prevents deadlocks.
The site where the transaction enters is designated as the controlling site. The controlling site sends messages to the sites where the data items are located to lock the items. Then it waits for confirmation. When all the sites have confirmed that they have locked the data items, transaction starts. If any site or communication link fails, the transaction has to wait until they have been repaired.
Though the implementation is simple, this approach has some drawbacks −
Pre-acquisition of locks requires a long time for communication delays. This increases the time required for transaction.
In case of site or link failure, a transaction has to wait for a long time so that the sites recover. Meanwhile, in the running sites, the items are locked. This may prevent other transactions from executing.
If the controlling site fails, it cannot communicate with the other sites. These sites continue to keep the locked data items in their locked state, thus resulting in blocking.
Distributed Deadlock Avoidance
As in centralized system, distributed deadlock avoidance handles deadlock prior to occurrence. Additionally, in distributed systems, transaction location and transaction control issues needs to be addressed. Due to the distributed nature of the transaction, the following conflicts may occur −
- Conflict between two transactions in the same site.
- Conflict between two transactions in different sites.
In case of conflict, one of the transactions may be aborted or allowed to wait as per distributed wait-die or distributed wound-wait algorithms.
Let us assume that there are two transactions, T1 and T2. T1 arrives at Site P and tries to lock a data item which is already locked by T2 at that site. Hence, there is a conflict at Site P. The algorithms are as follows −
Distributed Wound-Die
If T1 is older than T2, T1 is allowed to wait. T1 can resume execution after Site P receives a message that T2 has either committed or aborted successfully at all sites.
If T1 is younger than T2, T1 is aborted. The concurrency control at Site P sends a message to all sites where T1 has visited to abort T1. The controlling site notifies the user when T1 has been successfully aborted in all the sites.
Distributed Wait-Wait
If T1 is older than T2, T2 needs to be aborted. If T2 is active at Site P, Site P aborts and rolls back T2 and then broadcasts this message to other relevant sites. If T2 has left Site P but is active at Site Q, Site P broadcasts that T2 has been aborted; Site L then aborts and rolls back T2 and sends this message to all sites.
If T1 is younger than T1, T1 is allowed to wait. T1 can resume execution after Site P receives a message that T2 has completed processing.
Distributed Deadlock Detection
Just like centralized deadlock detection approach, deadlocks are allowed to occur and are removed if detected. The system does not perform any checks when a transaction places a lock request. For implementation, global wait-for-graphs are created. Existence of a cycle in the global wait-for-graph indicates deadlocks. However, it is difficult to spot deadlocks since transaction waits for resources across the network.
Alternatively, deadlock detection algorithms can use timers. Each transaction is associated with a timer which is set to a time period in which a transaction is expected to finish. If a transaction does not finish within this time period, the timer goes off, indicating a possible deadlock.
Another tool used for deadlock handling is a deadlock detector. In a centralized system, there is one deadlock detector. In a distributed system, there can be more than one deadlock detectors. A deadlock detector can find deadlocks for the sites under its control. There are three alternatives for deadlock detection in a distributed system, namely.
Centralized Deadlock Detector − One site is designated as the central deadlock detector.
Hierarchical Deadlock Detector − A number of deadlock detectors are arranged in hierarchy.
Distributed Deadlock Detector − All the sites participate in detecting deadlocks and removing them.
This chapter looks into replication control, which is required to maintain consistent data in all sites. We will study the replication control techniques and the algorithms required for replication control.
As discussed earlier, replication is a technique used in distributed databases to store multiple copies of a data table at different sites. The problem with having multiple copies in multiple sites is the overhead of maintaining data consistency, particularly during update operations.
In order to maintain mutually consistent data in all sites, replication control techniques need to be adopted. There are two approaches for replication control, namely −
- Synchronous Replication Control
- Asynchronous Replication Control
Synchronous Replication Control
In synchronous replication approach, the database is synchronized so that all the replications always have the same value. A transaction requesting a data item will have access to the same value in all the sites. To ensure this uniformity, a transaction that updates a data item is expanded so that it makes the update in all the copies of the data item. Generally, two-phase commit protocol is used for the purpose.
For example, let us consider a data table PROJECT(PId, PName, PLocation). We need to run a transaction T1 that updates PLocation to ‘Mumbai’, if PLocation is ‘Bombay’. If no replications are there, the operations in transaction T1 will be −
Begin T1:
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1;If the data table has two replicas in Site A and Site B, T1 needs to spawn two children T1A and T1B corresponding to the two sites. The expanded transaction T1 will be −
Begin T1:
Begin T1A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1A;
Begin T2A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T2A;
End T1;Asynchronous Replication Control
In asynchronous replication approach, the replicas do not always maintain the same value. One or more replicas may store an outdated value, and a transaction can see the different values. The process of bringing all the replicas to the current value is called synchronization.
A popular method of synchronization is store and forward method. In this method, one site is designated as the primary site and the other sites are secondary sites. The primary site always contains updated values. All the transactions first enter the primary site. These transactions are then queued for application in the secondary sites. The secondary sites are updated using rollout method only when a transaction is scheduled to execute on it.
Replication Control Algorithms
Some of the replication control algorithms are −
- Master-slave replication control algorithm.
- Distributed voting algorithm.
- Majority consensus algorithm.
- Circulating token algorithm.
Master-Slave Replication Control Algorithm
There is one master site and ‘N’ slave sites. A master algorithm runs at the master site to detect conflicts. A copy of slave algorithm runs at each slave site. The overall algorithm executes in the following two phases −
Transaction acceptance/rejection phase − When a transaction enters the transaction monitor of a slave site, the slave site sends a request to the master site. The master site checks for conflicts. If there aren’t any conflicts, the master sends an “ACK+” message to the slave site which then starts the transaction application phase. Otherwise, the master sends an “ACK-” message to the slave which then rejects the transaction.
Transaction application phase − Upon entering this phase, the slave site where transaction has entered broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it sends a “DONE” message to the master site. The master understands that the transaction has been completed and removes it from the pending queue.
Distributed Voting Algorithm
This comprises of ‘N’ peer sites, all of whom must “OK” a transaction before it starts executing. Following are the two phases of this algorithm −
Distributed transaction acceptance phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site resolves conflicts using priority based voting rules. If all the peer sites are “OK” with the transaction, the requesting site starts application phase. If any of the peer sites does not “OK” a transaction, the requesting site rejects the transaction.
Distributed transaction application phase − Upon entering this phase, the site where the transaction has entered, broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” message to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it lets the transaction manager know that the transaction has been completed.
Majority Consensus Algorithm
This is a variation from the distributed voting algorithm, where a transaction is allowed to execute when a majority of the peers “OK” a transaction. This is divided into three phases −
Voting phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site tests for conflicts using voting rules and keeps the conflicting transactions, if any, in pending queue. Then, it sends either an “OK” or a “NOT OK” message.
Transaction acceptance/rejection phase − If the requesting site receives a majority “OK” on the transaction, it accepts the transaction and broadcasts “ACCEPT” to all the sites. Otherwise, it broadcasts “REJECT” to all the sites and rejects the transaction.
Transaction application phase − When a peer site receives a “REJECT” message, it removes this transaction from its pending list and reconsiders all deferred transactions. When a peer site receives an “ACCEPT” message, it applies the transaction and rejects all the deferred transactions in the pending queue which are in conflict with this transaction. It sends an “ACK” to the requesting slave on completion.
Circulating Token Algorithm
In this approach the transactions in the system are serialized using a circulating token and executed accordingly against every replica of the database. Thus, all the transactions are accepted, i.e. none is rejected. This has two phases −
Transaction serialization phase − In this phase, all transactions are scheduled to run in a serialization order. Each transaction in each site is assigned a unique ticket from a sequential series, indicating the order of transaction. Once a transaction has been assigned a ticket, it is broadcasted to all the sites.
Transaction application phase − When a site receives a transaction along with its ticket, it places the transaction for execution according to its ticket. After the transaction has finished execution, this site broadcasts an appropriate message. A transaction ends when it has completed execution in all the sites.
A database management system is susceptible to a number of failures. In this chapter we will study the failure types and commit protocols. In a distributed database system, failures can be broadly categorized into soft failures, hard failures and network failures.
Soft Failure
Soft failure is the type of failure that causes the loss in volatile memory of the computer and not in the persistent storage. Here, the information stored in the non-persistent storage like main memory, buffers, caches or registers, is lost. They are also known as system crash. The various types of soft failures are as follows −
- Operating system failure.
- Main memory crash.
- Transaction failure or abortion.
- System generated error like integer overflow or divide-by-zero error.
- Failure of supporting software.
- Power failure.
Hard Failure
A hard failure is the type of failure that causes loss of data in the persistent or non-volatile storage like disk. Disk failure may cause corruption of data in some disk blocks or failure of the total disk. The causes of a hard failure are −
- Power failure.
- Faults in media.
- Read-write malfunction.
- Corruption of information on the disk.
- Read/write head crash of disk.
Recovery from disk failures can be short, if there is a new, formatted, and ready-to-use disk on reserve. Otherwise, duration includes the time it takes to get a purchase order, buy the disk, and prepare it.
Network Failure
Network failures are prevalent in distributed or network databases. These comprises of the errors induced in the database system due to the distributed nature of the data and transferring data over the network. The causes of network failure are as follows −
- Communication link failure.
- Network congestion.
- Information corruption during transfer.
- Site failures.
- Network partitioning.
Commit Protocols
Any database system should guarantee that the desirable properties of a transaction are maintained even after failures. If a failure occurs during the execution of a transaction, it may happen that all the changes brought about by the transaction are not committed. This makes the database inconsistent. Commit protocols prevent this scenario using either transaction undo (rollback) or transaction redo (roll forward).
Commit Point
The point of time at which the decision is made whether to commit or abort a transaction, is known as commit point. Following are the properties of a commit point.
It is a point of time when the database is consistent.
At this point, the modifications brought about by the database can be seen by the other transactions. All transactions can have a consistent view of the database.
At this point, all the operations of transaction have been successfully executed and their effects have been recorded in transaction log.
At this point, a transaction can be safely undone, if required.
At this point, a transaction releases all the locks held by it.
Transaction Undo
The process of undoing all the changes made to a database by a transaction is called transaction undo or transaction rollback. This is mostly applied in case of soft failure.
Transaction Redo
The process of reapplying the changes made to a database by a transaction is called transaction redo or transaction roll forward. This is mostly applied for recovery from a hard failure.
Transaction Log
A transaction log is a sequential file that keeps track of transaction operations on database items. As the log is sequential in nature, it is processed sequentially either from the beginning or from the end.
Purposes of a transaction log −
- To support commit protocols to commit or support transactions.
- To aid database recovery after failure.
A transaction log is usually kept on the disk, so that it is not affected by soft failures. Additionally, the log is periodically backed up to an archival storage like magnetic tape to protect it from disk failures as well.
Lists in Transaction Logs
The transaction log maintains five types of lists depending upon the status of the transaction. This list aids the recovery manager to ascertain the status of a transaction. The status and the corresponding lists are as follows −
A transaction that has a transaction start record and a transaction commit record, is a committed transaction – maintained in commit list.
A transaction that has a transaction start record and a transaction failed record but not a transaction abort record, is a failed transaction – maintained in failed list.
A transaction that has a transaction start record and a transaction abort record is an aborted transaction – maintained in abort list.
A transaction that has a transaction start record and a transaction before-commit record is a before-commit transaction, i.e. a transaction where all the operations have been executed but not committed – maintained in before-commit list.
A transaction that has a transaction start record but no records of before-commit, commit, abort or failed, is an active transaction – maintained in active list.
Immediate Update and Deferred Update
Immediate Update and Deferred Update are two methods for maintaining transaction logs.
In immediate update mode, when a transaction executes, the updates made by the transaction are written directly onto the disk. The old values and the updates values are written onto the log before writing to the database in disk. On commit, the changes made to the disk are made permanent. On rollback, changes made by the transaction in the database are discarded and the old values are restored into the database from the old values stored in the log.
In deferred update mode, when a transaction executes, the updates made to the database by the transaction are recorded in the log file. On commit, the changes in the log are written onto the disk. On rollback, the changes in the log are discarded and no changes are applied to the database.
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
Transactions which are in active list and failed list are undone and written on the abort list.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
In case of deferred update mode, the recovery manager takes the following actions −
Transactions which are in the active list and failed list are written onto the abort list. No undo operations are required since the changes have not been written to the disk yet.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
The transactions in the commit list and before-commit list are redone and written onto the commit list in the transaction log.
The transactions in the active list and failed list are undone and written onto the abort list in the transaction log.
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
- Consistent checkpointing
- Fuzzy checkpointing
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and needn’t be processed again. The actions taken for checkpointing are −
- The active transactions are suspended temporarily.
- All changes in main-memory buffers are written onto the disk.
- A “checkpoint” record is written in the transaction log.
- The transaction log is written to the disk.
- The suspended transactions are resumed.
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
Ta commits before checkpoint.
Tb starts before checkpoint and commits before system crash.
Tc starts after checkpoint and commits before system crash.
Td starts after checkpoint and was active at the time of system crash.
The situation is depicted in the following diagram −
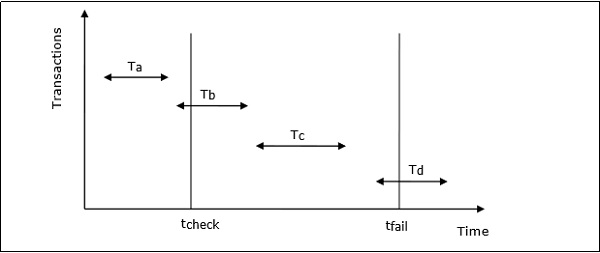
The actions that are taken by the recovery manager are −
- Nothing is done with Ta.
- Transaction redo is performed for Tb and Tc.
- Transaction undo is performed for Td.
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
UNDO all faulty transactions and transactions that may be affected by the faulty transactions.
REDO all transactions that are not faulty but have been undone due to the faulty transactions.
Steps for the UNDO operation are −
If the faulty transaction has done INSERT, the recovery manager deletes the data item(s) inserted.
If the faulty transaction has done DELETE, the recovery manager inserts the deleted data item(s) from the log.
If the faulty transaction has done UPDATE, the recovery manager eliminates the value by writing the before-update value from the log.
Steps for the REDO operation are −
If the transaction has done INSERT, the recovery manager generates an insert from the log.
If the transaction has done DELETE, the recovery manager generates a delete from the log.
If the transaction has done UPDATE, the recovery manager generates an update from the log.
In a local database system, for committing a transaction, the transaction manager has to only convey the decision to commit to the recovery manager. However, in a distributed system, the transaction manager should convey the decision to commit to all the servers in the various sites where the transaction is being executed and uniformly enforce the decision. When processing is complete at each site, it reaches the partially committed transaction state and waits for all other transactions to reach their partially committed states. When it receives the message that all the sites are ready to commit, it starts to commit. In a distributed system, either all sites commit or none of them does.
The different distributed commit protocols are −
- One-phase commit
- Two-phase commit
- Three-phase commit
Distributed One-phase Commit
Distributed one-phase commit is the simplest commit protocol. Let us consider that there is a controlling site and a number of slave sites where the transaction is being executed. The steps in distributed commit are −
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site.
The slaves wait for “Commit” or “Abort” message from the controlling site. This waiting time is called window of vulnerability.
When the controlling site receives “DONE” message from each slave, it makes a decision to commit or abort. This is called the commit point. Then, it sends this message to all the slaves.
On receiving this message, a slave either commits or aborts and then sends an acknowledgement message to the controlling site.
Distributed Two-phase Commit
Distributed two-phase commit reduces the vulnerability of one-phase commit protocols. The steps performed in the two phases are as follows −
Phase 1: Prepare Phase
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site. When the controlling site has received “DONE” message from all slaves, it sends a “Prepare” message to the slaves.
The slaves vote on whether they still want to commit or not. If a slave wants to commit, it sends a “Ready” message.
A slave that does not want to commit sends a “Not Ready” message. This may happen when the slave has conflicting concurrent transactions or there is a timeout.
Phase 2: Commit/Abort Phase
After the controlling site has received “Ready” message from all the slaves −
The controlling site sends a “Global Commit” message to the slaves.
The slaves apply the transaction and send a “Commit ACK” message to the controlling site.
When the controlling site receives “Commit ACK” message from all the slaves, it considers the transaction as committed.
After the controlling site has received the first “Not Ready” message from any slave −
The controlling site sends a “Global Abort” message to the slaves.
The slaves abort the transaction and send a “Abort ACK” message to the controlling site.
When the controlling site receives “Abort ACK” message from all the slaves, it considers the transaction as aborted.
Distributed Three-phase Commit
The steps in distributed three-phase commit are as follows −
Phase 1: Prepare Phase
The steps are same as in distributed two-phase commit.
Phase 2: Prepare to Commit Phase
- The controlling site issues an “Enter Prepared State” broadcast message.
- The slave sites vote “OK” in response.
Phase 3: Commit / Abort Phase
The steps are same as two-phase commit except that “Commit ACK”/”Abort ACK” message is not required.
In this chapter, we will look into the threats that a database system faces and the measures of control. We will also study cryptography as a security tool.
Database Security and Threats
Data security is an imperative aspect of any database system. It is of particular importance in distributed systems because of large number of users, fragmented and replicated data, multiple sites and distributed control.
Threats in a Database
Availability loss − Availability loss refers to non-availability of database objects by legitimate users.
Integrity loss − Integrity loss occurs when unacceptable operations are performed upon the database either accidentally or maliciously. This may happen while creating, inserting, updating or deleting data. It results in corrupted data leading to incorrect decisions.
Confidentiality loss − Confidentiality loss occurs due to unauthorized or unintentional disclosure of confidential information. It may result in illegal actions, security threats and loss in public confidence.
Measures of Control
The measures of control can be broadly divided into the following categories −
Access Control − Access control includes security mechanisms in a database management system to protect against unauthorized access. A user can gain access to the database after clearing the login process through only valid user accounts. Each user account is password protected.
Flow Control − Distributed systems encompass a lot of data flow from one site to another and also within a site. Flow control prevents data from being transferred in such a way that it can be accessed by unauthorized agents. A flow policy lists out the channels through which information can flow. It also defines security classes for data as well as transactions.
Data Encryption − Data encryption refers to coding data when sensitive data is to be communicated over public channels. Even if an unauthorized agent gains access of the data, he cannot understand it since it is in an incomprehensible format.
What is Cryptography?
Cryptography is the science of encoding information before sending via unreliable communication paths so that only an authorized receiver can decode and use it.
The coded message is called cipher text and the original message is called plain text. The process of converting plain text to cipher text by the sender is called encoding or encryption. The process of converting cipher text to plain text by the receiver is called decoding or decryption.
The entire procedure of communicating using cryptography can be illustrated through the following diagram −

Conventional Encryption Methods
In conventional cryptography, the encryption and decryption is done using the same secret key. Here, the sender encrypts the message with an encryption algorithm using a copy of the secret key. The encrypted message is then send over public communication channels. On receiving the encrypted message, the receiver decrypts it with a corresponding decryption algorithm using the same secret key.
Security in conventional cryptography depends on two factors −
A sound algorithm which is known to all.
A randomly generated, preferably long secret key known only by the sender and the receiver.
The most famous conventional cryptography algorithm is Data Encryption Standard or DES.
The advantage of this method is its easy applicability. However, the greatest problem of conventional cryptography is sharing the secret key between the communicating parties. The ways to send the key are cumbersome and highly susceptible to eavesdropping.
Public Key Cryptography
In contrast to conventional cryptography, public key cryptography uses two different keys, referred to as public key and the private key. Each user generates the pair of public key and private key. The user then puts the public key in an accessible place. When a sender wants to sends a message, he encrypts it using the public key of the receiver. On receiving the encrypted message, the receiver decrypts it using his private key. Since the private key is not known to anyone but the receiver, no other person who receives the message can decrypt it.
The most popular public key cryptography algorithms are RSA algorithm and Diffie– Hellman algorithm. This method is very secure to send private messages. However, the problem is, it involves a lot of computations and so proves to be inefficient for long messages.
The solution is to use a combination of conventional and public key cryptography. The secret key is encrypted using public key cryptography before sharing between the communicating parties. Then, the message is send using conventional cryptography with the aid of the shared secret key.
Digital Signatures
A Digital Signature (DS) is an authentication technique based on public key cryptography used in e-commerce applications. It associates a unique mark to an individual within the body of his message. This helps others to authenticate valid senders of messages.
Typically, a user’s digital signature varies from message to message in order to provide security against counterfeiting. The method is as follows −
The sender takes a message, calculates the message digest of the message and signs it digest with a private key.
The sender then appends the signed digest along with the plaintext message.
The message is sent over communication channel.
The receiver removes the appended signed digest and verifies the digest using the corresponding public key.
The receiver then takes the plaintext message and runs it through the same message digest algorithm.
If the results of step 4 and step 5 match, then the receiver knows that the message has integrity and authentic.
A distributed system needs additional security measures than centralized system, since there are many users, diversified data, multiple sites and distributed control. In this chapter, we will look into the various facets of distributed database security.
In distributed communication systems, there are two types of intruders −
Passive eavesdroppers − They monitor the messages and get hold of private information.
Active attackers − They not only monitor the messages but also corrupt data by inserting new data or modifying existing data.
Security measures encompass security in communications, security in data and data auditing.
Communications Security
In a distributed database, a lot of data communication takes place owing to the diversified location of data, users and transactions. So, it demands secure communication between users and databases and between the different database environments.
Security in communication encompasses the following −
Data should not be corrupt during transfer.
The communication channel should be protected against both passive eavesdroppers and active attackers.
In order to achieve the above stated requirements, well-defined security algorithms and protocols should be adopted.
Two popular, consistent technologies for achieving end-to-end secure communications are −
- Secure Socket Layer Protocol or Transport Layer Security Protocol.
- Virtual Private Networks (VPN).
Data Security
In distributed systems, it is imperative to adopt measure to secure data apart from communications. The data security measures are −
Authentication and authorization − These are the access control measures adopted to ensure that only authentic users can use the database. To provide authentication digital certificates are used. Besides, login is restricted through username/password combination.
Data encryption − The two approaches for data encryption in distributed systems are −
Internal to distributed database approach: The user applications encrypt the data and then store the encrypted data in the database. For using the stored data, the applications fetch the encrypted data from the database and then decrypt it.
External to distributed database: The distributed database system has its own encryption capabilities. The user applications store data and retrieve them without realizing that the data is stored in an encrypted form in the database.
Validated input − In this security measure, the user application checks for each input before it can be used for updating the database. An un-validated input can cause a wide range of exploits like buffer overrun, command injection, cross-site scripting and corruption in data.
Data Auditing
A database security system needs to detect and monitor security violations, in order to ascertain the security measures it should adopt. It is often very difficult to detect breach of security at the time of occurrences. One method to identify security violations is to examine audit logs. Audit logs contain information such as −
- Date, time and site of failed access attempts.
- Details of successful access attempts.
- Vital modifications in the database system.
- Access of huge amounts of data, particularly from databases in multiple sites.
All the above information gives an insight of the activities in the database. A periodical analysis of the log helps to identify any unnatural activity along with its site and time of occurrence. This log is ideally stored in a separate server so that it is inaccessible to attackers.