Gensim - Kelime Gömme Geliştirme
Bu bölüm, Gensim'de gelişmekte olan kelime gömülmesini anlamamıza yardımcı olacaktır.
Kelime gömme, kelime ve belgeyi temsil etme yaklaşımı, aynı anlama sahip kelimelerin benzer bir temsiline sahip olduğu metin için yoğun bir vektör temsilidir. Aşağıda kelime yerleştirmenin bazı özellikleri verilmiştir -
Tek tek sözcükleri önceden tanımlanmış bir vektör uzayında gerçek değerli vektörler olarak temsil eden bir teknik sınıfıdır.
Bu teknik genellikle DL (derin öğrenme) alanında toplanır çünkü her kelime bir vektöre eşlenir ve vektör değerleri bir NN'nin (Sinir Ağları) yaptığı gibi öğrenilir.
Kelime gömme tekniğinin temel yaklaşımı, her kelime için yoğun dağıtılmış bir temsildir.
Farklı Kelime Gömme Yöntemleri / Algoritmaları
Yukarıda tartışıldığı gibi, kelime gömme yöntemleri / algoritmaları, bir metin külliyatından gerçek değerli bir vektör temsilini öğrenir. Bu öğrenme süreci, belge sınıflandırması gibi görevlerde NN modeliyle birlikte kullanılabilir veya belge istatistikleri gibi denetimsiz bir süreçtir. Burada, metinden gömülen bir kelimeyi öğrenmek için kullanılabilecek iki yöntemi / algoritmayı tartışacağız -
Google'dan Word2Vec
Word2Vec, Tomas Mikolov ve diğerleri tarafından geliştirilmiştir. al. 2013'te Google'da, metin derlemesinden bir kelimeyi gömmeyi verimli bir şekilde öğrenmek için istatistiksel bir yöntemdir. Aslında NN tabanlı kelime gömme eğitimini daha verimli hale getirmek için bir yanıt olarak geliştirilmiştir. Kelime yerleştirmenin fiili standardı haline geldi.
Word2Vec tarafından kelime gömme, öğrenilen vektörlerin analizinin yanı sıra kelimelerin temsili üzerinde vektör matematiğinin araştırılmasını içerir. Aşağıda, Word2Vec yönteminin bir parçası olarak kullanılabilecek iki farklı öğrenme yöntemi verilmiştir -
- CBoW (Sürekli Kelime Çantası) Modeli
- Sürekli Skip-Gram Modeli
GloVe by Standford
GloVe (Kelime Gösterimi için Global Vektörler), Word2Vec yönteminin bir uzantısıdır. Pennington ve diğerleri tarafından geliştirilmiştir. Stanford'da. GloVe algoritması her ikisinin bir karışımıdır -
- LSA (Gizli Anlamsal Analiz) gibi matris çarpanlarına ayırma tekniklerinin küresel istatistikleri
- Word2Vec'de yerel bağlama dayalı öğrenme.
Çalışması hakkında konuşursak, yerel bağlamı tanımlamak için bir pencere kullanmak yerine, GloVe tüm metin külliyatındaki istatistikleri kullanarak açık bir kelime birlikte oluşum matrisi oluşturur.
Word2Vec Gömme Geliştirme
Burada, Gensim kullanarak Word2Vec katıştırmayı geliştireceğiz. Bir Word2Vec modeliyle çalışmak için Gensim bizeWord2Vec ithal edilebilecek sınıf models.word2vec. Word2vec uygulaması için çok sayıda metin, örneğin tüm Amazon inceleme külliyatı gerektirir. Ancak burada, bu prensibi hafızası küçük metinlere uygulayacağız.
Uygulama Örneği
Öncelikle Word2Vec sınıfını gensim.models'den aşağıdaki gibi içe aktarmamız gerekiyor -
from gensim.models import Word2VecDaha sonra eğitim verilerini tanımlamamız gerekiyor. Büyük metin dosyası almaktansa, bu prensibi uygulamak için bazı cümleler kullanıyoruz.
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]Eğitim verileri sağlandıktan sonra modeli eğitmemiz gerekir. şu şekilde yapılabilir -
model = Word2Vec(sentences, min_count=1)Modeli şu şekilde özetleyebiliriz -;
print(model)Kelime dağarcığını şu şekilde özetleyebiliriz -
words = list(model.wv.vocab)
print(words)Sonra, bir kelime için vektöre erişelim. Bunu 'öğretici' kelimesi için yapıyoruz.
print(model['tutorial'])Ardından, modeli kaydetmemiz gerekiyor -
model.save('model.bin')Ardından, modeli yüklememiz gerekiyor -
new_model = Word2Vec.load('model.bin')Son olarak, kaydedilen modeli aşağıdaki gibi yazdırın -
print(new_model)Eksiksiz Uygulama Örneği
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)Çıktı
Word2Vec(vocab=20, size=100, alpha=0.025)
[
'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint',
'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are',
'implementing', 'word2vec', 'learn', 'full'
]
[
-2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03
-1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03
-1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03
3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03
-2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03
-4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03
9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03
4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03
1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04
4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03
4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03
6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03
-2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03
7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03
4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03
-3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03
3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04
-3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03
-3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03
2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03
-3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03
1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03
3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04
3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03
-1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03
]
Word2Vec(vocab=20, size=100, alpha=0.025)Kelime Gömmeyi Görselleştirme
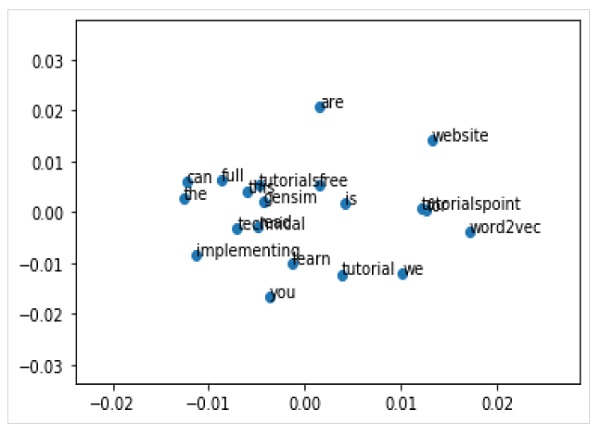
Görselleştirme ile kelime yerleştirmeyi de keşfedebiliriz. Yüksek boyutlu kelime vektörlerini 2 boyutlu grafiklere indirmek için klasik bir projeksiyon yöntemi (PCA gibi) kullanılarak yapılabilir. Azaltıldıktan sonra, onları grafiğe çizebiliriz.
PCA Kullanarak Kelime Vektörlerini Çizme
İlk olarak, tüm vektörleri eğitimli bir modelden aşağıdaki gibi almamız gerekir -
Z = model[model.wv.vocab]Daha sonra, aşağıdaki gibi PCA sınıfını kullanarak 2-D PCA kelime vektörleri modeli oluşturmamız gerekiyor -
pca = PCA(n_components=2)
result = pca.fit_transform(Z)Şimdi matplotlib kullanarak ortaya çıkan projeksiyonu aşağıdaki gibi grafiklendirebiliriz -
Pyplot.scatter(result[:,0],result[:,1])Grafikteki noktalara kelimelerin kendisiyle de açıklama ekleyebiliriz. Matplotlib kullanarak ortaya çıkan projeksiyonu aşağıdaki gibi çizin -
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))Eksiksiz Uygulama Örneği
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()Çıktı