Lucene - Endeksleme Süreci
Endeksleme süreci, Lucene tarafından sağlanan temel işlevlerden biridir. Aşağıdaki şema indeksleme sürecini ve sınıfların kullanımını göstermektedir. IndexWriter, indeksleme sürecinin en önemli ve temel bileşenidir.
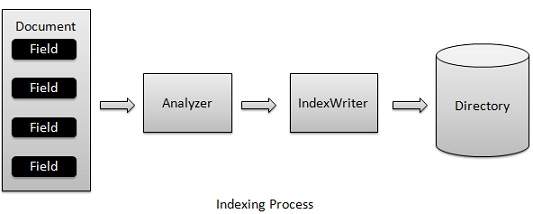
Biz eklemek Belge (ler) içeren Saha (lar) kullanılarak Belgesi (ler) analizleri IndexWriter için Analyzer ve sonra oluşturur açık / / düzenle gerektiği gibi endeksler ve mağaza / a bunları güncellemek Directory . IndexWriter , dizinleri güncellemek veya oluşturmak için kullanılır. Dizinleri okumak için kullanılmaz.
Şimdi, temel bir örnek kullanarak indeksleme sürecini anlamaya başlamak için size adım adım bir işlem göstereceğiz.
Bir belge oluşturun
Bir metin dosyasından lucene bir belge almak için bir yöntem oluşturun.
Ad olarak anahtarlar ve dizine eklenecek içerik olarak değerler içeren anahtar değer çiftleri olan çeşitli türlerde alanlar oluşturun.
Analiz edilecek veya edilmeyecek alanı ayarlayın. Bizim durumumuzda, arama işlemlerinde gerekli olmayan a, am, are, vb gibi verileri içerebileceğinden sadece içerikler analiz edilmelidir.
Yeni oluşturulan alanları belge nesnesine ekleyin ve arayan yöntemine geri döndürün.
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}IndexWriter oluşturun
IndexWriter sınıfı, indeksleme işlemi sırasında indeksleri oluşturan / güncelleyen temel bir bileşen olarak hareket eder. Bir IndexWriter oluşturmak için şu adımları izleyin -
Step 1 - IndexWriter nesnesini oluşturun.
Step 2 - Dizinlerin saklanacağı yeri göstermesi gereken bir Lucene dizini oluşturun.
Step 3 - Sürüm bilgisi ve diğer gerekli / isteğe bağlı parametrelere sahip standart bir analizör olan dizin diziniyle oluşturulan IndexWriter nesnesini başlatın.
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}Endeksleme İşlemini Başlat
Aşağıdaki program bir indeksleme işleminin nasıl başlatılacağını göstermektedir -
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}Örnek Uygulama
İndeksleme sürecini test etmek için bir Lucene uygulama testi oluşturmamız gerekiyor.
| Adım | Açıklama |
|---|---|
| 1 | Lucene - İlk Uygulama bölümünde açıklandığı gibi com.tutorialspoint.lucene paketinin altında LuceneFirstApplication adıyla bir proje oluşturun . İndeksleme sürecini anlamak için bu bölüm için Lucene - İlk Uygulama bölümünde oluşturulan projeyi de kullanabilirsiniz . |
| 2 | Lucene - İlk Uygulama bölümünde açıklandığı gibi LuceneConstants.java, TextFileFilter.java ve Indexer.java'yı oluşturun . Dosyaların geri kalanını değiştirmeyin. |
| 3 | Create LuceneTester.java aşağıda belirtildiği gibi. |
| 4 | İş mantığının gereksinimlere göre çalıştığından emin olmak için uygulamayı temizleyin ve oluşturun. |
LuceneConstants.java
Bu sınıf, örnek uygulamada kullanılacak çeşitli sabitler sağlamak için kullanılır.
package com.tutorialspoint.lucene;
public class LuceneConstants {
public static final String CONTENTS = "contents";
public static final String FILE_NAME = "filename";
public static final String FILE_PATH = "filepath";
public static final int MAX_SEARCH = 10;
}TextFileFilter.java
Bu sınıf bir .txt dosya filtresi.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
public class TextFileFilter implements FileFilter {
@Override
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}Indexer.java
Bu sınıf ham verileri indekslemek için kullanılır, böylece Lucene kütüphanesini kullanarak aranabilir hale getirebiliriz.
package com.tutorialspoint.lucene;
import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.CorruptIndexException;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
public class Indexer {
private IndexWriter writer;
public Indexer(String indexDirectoryPath) throws IOException {
//this directory will contain the indexes
Directory indexDirectory =
FSDirectory.open(new File(indexDirectoryPath));
//create the indexer
writer = new IndexWriter(indexDirectory,
new StandardAnalyzer(Version.LUCENE_36),true,
IndexWriter.MaxFieldLength.UNLIMITED);
}
public void close() throws CorruptIndexException, IOException {
writer.close();
}
private Document getDocument(File file) throws IOException {
Document document = new Document();
//index file contents
Field contentField = new Field(LuceneConstants.CONTENTS,
new FileReader(file));
//index file name
Field fileNameField = new Field(LuceneConstants.FILE_NAME,
file.getName(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
//index file path
Field filePathField = new Field(LuceneConstants.FILE_PATH,
file.getCanonicalPath(),
Field.Store.YES,Field.Index.NOT_ANALYZED);
document.add(contentField);
document.add(fileNameField);
document.add(filePathField);
return document;
}
private void indexFile(File file) throws IOException {
System.out.println("Indexing "+file.getCanonicalPath());
Document document = getDocument(file);
writer.addDocument(document);
}
public int createIndex(String dataDirPath, FileFilter filter)
throws IOException {
//get all files in the data directory
File[] files = new File(dataDirPath).listFiles();
for (File file : files) {
if(!file.isDirectory()
&& !file.isHidden()
&& file.exists()
&& file.canRead()
&& filter.accept(file)
){
indexFile(file);
}
}
return writer.numDocs();
}
}LuceneTester.java
Bu sınıf, Lucene kütüphanesinin indeksleme kabiliyetini test etmek için kullanılır.
package com.tutorialspoint.lucene;
import java.io.IOException;
public class LuceneTester {
String indexDir = "E:\\Lucene\\Index";
String dataDir = "E:\\Lucene\\Data";
Indexer indexer;
public static void main(String[] args) {
LuceneTester tester;
try {
tester = new LuceneTester();
tester.createIndex();
} catch (IOException e) {
e.printStackTrace();
}
}
private void createIndex() throws IOException {
indexer = new Indexer(indexDir);
int numIndexed;
long startTime = System.currentTimeMillis();
numIndexed = indexer.createIndex(dataDir, new TextFileFilter());
long endTime = System.currentTimeMillis();
indexer.close();
System.out.println(numIndexed+" File indexed, time taken: "
+(endTime-startTime)+" ms");
}
}Veri ve Dizin Dizini Oluşturma
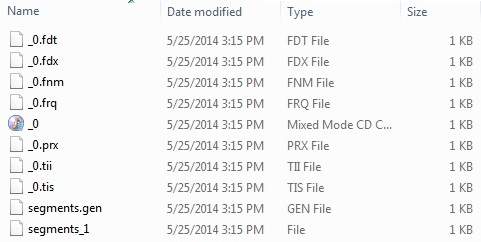
Kayıt1.txt'den record10.txt'ye kadar öğrencilerin isimlerini ve diğer detaylarını içeren 10 adet metin dosyası kullandık ve dizine koyduk E:\Lucene\Data. Test Verileri . Bir dizin dizin yolu şu şekilde oluşturulmalıdır:E:\Lucene\Index. Bu programı çalıştırdıktan sonra, o klasörde oluşturulan indeks dosyalarının listesini görebilirsiniz.
Programı Çalıştırmak
Kaynak, ham veri, veri dizini ve indeks dizini oluşturmayı tamamladığınızda, programınızı derleyip çalıştırarak devam edebilirsiniz. Bunu yapmak için, LuceneTester.Java dosyası sekmesini aktif tutun veRun Eclipse IDE'de mevcut seçenek veya kullanım Ctrl + F11 derlemek ve çalıştırmak için LuceneTesteruygulama. Uygulamanız başarılı bir şekilde çalışırsa, Eclipse IDE'nin konsolunda aşağıdaki mesajı yazdıracaktır -
Indexing E:\Lucene\Data\record1.txt
Indexing E:\Lucene\Data\record10.txt
Indexing E:\Lucene\Data\record2.txt
Indexing E:\Lucene\Data\record3.txt
Indexing E:\Lucene\Data\record4.txt
Indexing E:\Lucene\Data\record5.txt
Indexing E:\Lucene\Data\record6.txt
Indexing E:\Lucene\Data\record7.txt
Indexing E:\Lucene\Data\record8.txt
Indexing E:\Lucene\Data\record9.txt
10 File indexed, time taken: 109 msProgramı başarıyla çalıştırdıktan sonra, aşağıdaki içeriğe sahip olacaksınız. index directory −