Mahout - Kümeleme
Kümeleme, belirli bir koleksiyondaki öğeleri veya öğeleri, öğeler arasındaki benzerliğe göre gruplar halinde düzenleme prosedürüdür. Örneğin, çevrimiçi haber yayıncılığı ile ilgili uygulamalar, haber makalelerini kümeleme kullanarak gruplamaktadır.
Kümeleme Uygulamaları
Kümeleme, pazar araştırması, örüntü tanıma, veri analizi ve görüntü işleme gibi birçok uygulamada yaygın olarak kullanılmaktadır.
Kümeleme, pazarlamacıların müşteri bazında farklı grupları keşfetmesine yardımcı olabilir. Müşteri gruplarını satın alma modellerine göre karakterize edebilirler.
Biyoloji alanında, bitki ve hayvan taksonomilerini türetmek, benzer işlevselliğe sahip genleri kategorilere ayırmak ve popülasyonlarda bulunan yapılara ilişkin fikir edinmek için kullanılabilir.
Kümeleme, bir yer gözlem veri tabanında benzer arazi kullanımına sahip alanların belirlenmesine yardımcı olur.
Kümeleme, bilgi keşfi için web'deki belgelerin sınıflandırılmasına da yardımcı olur.
Kümeleme, kredi kartı dolandırıcılığının tespiti gibi aykırı değer tespiti uygulamalarında kullanılmaktadır.
Bir veri madenciliği işlevi olarak Küme Analizi, her bir kümenin özelliklerini gözlemlemek için verilerin dağılımına ilişkin içgörü elde etmek için bir araç görevi görür.
Mahout'u kullanarak, belirli bir veri kümesini kümeleyebiliriz. Gerekli adımlar aşağıdaki gibidir:
Algorithm Bir kümenin öğelerini gruplamak için uygun bir kümeleme algoritması seçmeniz gerekir.
Similarity and Dissimilarity Yeni karşılaşılan öğeler ile gruplardaki öğeler arasındaki benzerliği doğrulamak için bir kuralınız olması gerekir.
Stopping Condition Kümelemenin gerekli olmadığı noktayı tanımlamak için bir durdurma koşulu gereklidir.
Kümeleme Prosedürü
Verilen verileri kümelemek için yapmanız gerekenler -
Hadoop sunucusunu başlatın. Dosyaları Hadoop Dosya Sisteminde depolamak için gerekli dizinleri oluşturun. (Giriş dosyası, sıra dosyası ve gölgelik olması durumunda kümelenmiş çıktı için dizinler oluşturun).
Girdi dosyasını Unix dosya sisteminden Hadoop Dosya sistemine kopyalayın.
Sıra dosyasını giriş verilerinden hazırlayın.
Mevcut kümeleme algoritmalarından herhangi birini çalıştırın.
Kümelenmiş verileri alın.
Hadoop'u Başlatma
Mahout, Hadoop ile çalışır, bu nedenle Hadoop sunucusunun çalışır durumda olduğundan emin olun.
$ cd HADOOP_HOME/bin
$ start-all.shGirdi Dosyası Dizinlerini Hazırlama
Aşağıdaki komutu kullanarak giriş dosyasını, sıra dosyalarını ve kümelenmiş verileri depolamak için Hadoop dosya sisteminde dizinler oluşturun:
$ hadoop fs -p mkdir /mahout_data
$ hadoop fs -p mkdir /clustered_data
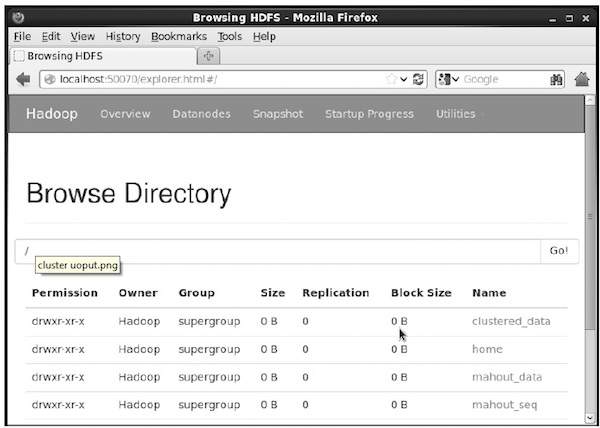
$ hadoop fs -p mkdir /mahout_seqAşağıdaki URL'de dizinin hadoop web arayüzü kullanılarak oluşturulup oluşturulmadığını doğrulayabilirsiniz - http://localhost:50070/
Size aşağıda gösterildiği gibi çıktı verir:
Giriş Dosyasını HDFS'ye Kopyalama
Şimdi, girdi veri dosyasını Linux dosya sisteminden aşağıda gösterildiği gibi Hadoop Dosya Sistemindeki mahout_data dizinine kopyalayın. Girdi dosyanızın mydata.txt olduğunu ve / home / Hadoop / data / dizininde olduğunu varsayın.
$ hadoop fs -put /home/Hadoop/data/mydata.txt /mahout_data/Sıra Dosyasını Hazırlama
Mahout, verilen girdi dosyasını bir sıra dosyası formatına dönüştürmek için bir yardımcı program sağlar. Bu yardımcı program iki parametre gerektirir.
- Orijinal verilerin bulunduğu girdi dosyası dizini.
- Kümelenmiş verilerin depolanacağı çıktı dosyası dizini.
Mahout'un yardım istemi aşağıda verilmiştir seqdirectory Yarar.
Step 1:Mahout ana dizinine gidin. Yardımcı programdan aşağıda gösterildiği gibi yardım alabilirsiniz:
[Hadoop@localhost bin]$ ./mahout seqdirectory --help
Job-Specific Options:
--input (-i) input Path to job input directory.
--output (-o) output The directory pathname for output.
--overwrite (-ow) If present, overwrite the output directoryAşağıdaki sözdizimini kullanarak yardımcı programı kullanarak sıra dosyasını oluşturun:
mahout seqdirectory -i <input file path> -o <output directory>Example
mahout seqdirectory
-i hdfs://localhost:9000/mahout_seq/
-o hdfs://localhost:9000/clustered_data/Kümeleme Algoritmaları
Mahout, kümeleme için iki ana algoritmayı destekler:
- Gölgelik kümeleme
- K-kümeleme anlamına gelir
Gölgelik Kümeleme
Kanopi kümeleme, Mahout tarafından kümeleme amacıyla kullanılan basit ve hızlı bir tekniktir. Nesneler düz bir alanda noktalar olarak ele alınacaktır. Bu teknik genellikle k-ortalamalı kümeleme gibi diğer kümeleme tekniklerinde bir ilk adım olarak kullanılır. Aşağıdaki sözdizimini kullanarak bir Canopy işini çalıştırabilirsiniz:
mahout canopy -i <input vectors directory>
-o <output directory>
-t1 <threshold value 1>
-t2 <threshold value 2>Canopy işi, sıra dosyası içeren bir girdi dosyası dizini ve kümelenmiş verilerin depolanacağı bir çıktı dizini gerektirir.
Example
mahout canopy -i hdfs://localhost:9000/mahout_seq/mydata.seq
-o hdfs://localhost:9000/clustered_data
-t1 20
-t2 30Verilen çıktı dizininde oluşturulan kümelenmiş verileri alacaksınız.
K-anlamına gelir Kümeleme
K-ortalama kümeleme, önemli bir kümeleme algoritmasıdır. K in k-ortalamalı kümeleme algoritması, verilerin bölüneceği küme sayısını temsil eder. Örneğin bu algoritmaya belirtilen k değeri 3 olarak seçilir, algoritma veriyi 3 kümeye bölecektir.
Her nesne uzayda vektör olarak temsil edilecektir. Başlangıçta k noktası algoritma tarafından rastgele seçilecek ve merkezler olarak değerlendirilecek, her merkeze en yakın her nesne kümelenecek. Mesafe ölçümü için birkaç algoritma vardır ve kullanıcı gerekli olanı seçmelidir.
Creating Vector Files
Canopy algoritmasından farklı olarak, k-ortalamaları algoritması giriş olarak vektör dosyaları gerektirir, bu nedenle vektör dosyaları oluşturmanız gerekir.
Mahout, sıra dosyası formatından vektör dosyaları oluşturmak için seq2parse Yarar.
Aşağıda verilen seçeneklerden bazıları verilmiştir seq2parseYarar. Bu seçenekleri kullanarak vektör dosyaları oluşturun.
$MAHOUT_HOME/bin/mahout seq2sparse
--analyzerName (-a) analyzerName The class name of the analyzer
--chunkSize (-chunk) chunkSize The chunkSize in MegaBytes.
--output (-o) output The directory pathname for o/p
--input (-i) input Path to job input directory.Vektörler oluşturduktan sonra, k-ortalama algoritması ile devam edin. K-anlamına gelen işi çalıştırmak için sözdizimi aşağıdaki gibidir:
mahout kmeans -i <input vectors directory>
-c <input clusters directory>
-o <output working directory>
-dm <Distance Measure technique>
-x <maximum number of iterations>
-k <number of initial clusters>K-ortalamalı kümeleme işi, girdi vektör dizini, çıktı kümeleri dizini, mesafe ölçüsü, gerçekleştirilecek maksimum yineleme sayısı ve girdi verilerinin bölüneceği küme sayısını temsil eden bir tam sayı değerini gerektirir.