Natural Language Toolkit - Hızlı Kılavuz
Doğal Dil İşleme (NLP) nedir?
İnsanların konuşabileceği, okuyabileceği ve yazabileceği yardımı ile iletişim yöntemi dildir. Başka bir deyişle, biz insanlar doğal dilimizde düşünebilir, planlar yapabilir, kararlar alabiliriz. Burada asıl soru, yapay zeka, makine öğrenimi ve derin öğrenme çağında, insanlar bilgisayarlarla / makinelerle doğal dilde iletişim kurabilir mi? NLP uygulamaları geliştirmek bizim için büyük bir zorluk çünkü bilgisayarlar yapılandırılmış veri gerektirir, ancak diğer yandan insan konuşması yapılandırılmamış ve genellikle doğası gereği belirsizdir.
Doğal dil, bilgisayar biliminin, daha özel olarak AI'nın, bilgisayarların / makinelerin insan dilini anlamasını, işlemesini ve manipüle etmesini sağlayan alt alanıdır. Basit bir deyişle, NLP, Hintçe, İngilizce, Fransızca, Hollandaca vb. Gibi doğal insan dillerini analiz etmek, anlamak ve bunlardan anlam çıkarmak için bir makine yoludur.
O nasıl çalışır?
NLP'nin çalışmasına derinlemesine dalmadan önce, insanların dili nasıl kullandığını anlamalıyız. Biz insanlar her gün yüzlerce veya binlerce kelime kullanırız ve diğer insanlar bunları yorumlar ve buna göre cevap veririz. İnsanlar için basit bir iletişim, değil mi? Ancak kelimelerin bundan çok daha derin olduğunu biliyoruz ve her zaman ne söylediğimizden ve nasıl söylediğimizden bir bağlam çıkarıyoruz. Bu nedenle, ses modülasyonuna odaklanmak yerine, NLP'nin bağlamsal modelden yararlandığını söyleyebiliriz.
Bunu bir örnekle anlayalım -
Man is to woman as king is to what?
We can interpret it easily and answer as follows:
Man relates to king, so woman can relate to queen.
Hence the answer is Queen.İnsanlar hangi kelimenin ne anlama geldiğini nasıl bilirler? Bu sorunun cevabı, deneyimlerimizle öğrenmemizdir. Peki makineler / bilgisayarlar aynı şeyi nasıl öğrenir?
Bunu aşağıdaki kolay adımlarla anlayalım -
Öncelikle, makinelerin deneyimlerden öğrenebilmesi için yeterli veriyi makinelere beslememiz gerekiyor.
Daha sonra makine, derin öğrenme algoritmalarını kullanarak, daha önce beslediğimiz verilerden ve çevresindeki verilerden kelime vektörleri oluşturacaktır.
Daha sonra bu kelime vektörleri üzerinde basit cebirsel işlemler yaparak, makine cevapları insan olarak verebilecektir.
NLP Bileşenleri
Aşağıdaki şema, doğal dil işleme (NLP) bileşenlerini temsil etmektedir -
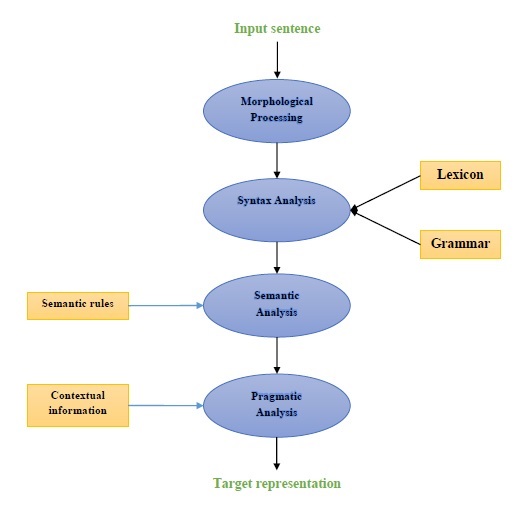
Morfolojik İşleme
Morfolojik işleme, NLP'nin ilk bileşenidir. Dil girdisi yığınlarının paragraflara, cümlelere ve kelimelere karşılık gelen simge kümelerine bölünmesini içerir. Örneğin, şöyle bir kelime“everyday” iki alt kelimeye bölünebilir “every-day”.
Sözdizimi analizi
İkinci bileşen olan Sözdizimi Analizi, NLP'nin en önemli bileşenlerinden biridir. Bu bileşenin amaçları aşağıdaki gibidir -
Bir cümlenin düzgün olup olmadığını kontrol etmek için.
Farklı kelimeler arasındaki sözdizimsel ilişkileri gösteren bir yapıya bölmek için.
Örneğin, aşağıdaki gibi cümleler “The school goes to the student” sözdizimi çözümleyicisi tarafından reddedilecektir.
Anlamsal analiz
Anlamsal Analiz, metnin anlamlılığını kontrol etmek için kullanılan NLP'nin üçüncü bileşenidir. Tam anlamın çizilmesini içerir veya metinden sözlük anlamı söyleyebiliriz. Örneğin, "Bu sıcak bir dondurma" gibi cümleler. semantik analizci tarafından atılır.
Pragmatik analiz
Pragmatik analiz, NLP'nin dördüncü bileşenidir. Her bağlamda var olan gerçek nesnelerin veya olayların, önceki bileşen, yani anlambilimsel analiz ile elde edilen nesne referansları ile uydurulmasını içerir. Örneğin, aşağıdaki gibi cümleler“Put the fruits in the basket on the table” iki anlamsal yoruma sahip olabilir, bu nedenle pragmatik analizci bu iki olasılık arasında seçim yapacaktır.
NLP Uygulamalarına Örnekler
Ortaya çıkan bir teknoloji olan NLP, bugünlerde gördüğümüz çeşitli yapay zeka biçimlerini türetiyor. Bugünün ve yarının giderek artan bilişsel uygulamaları için, insanlar ve makineler arasında kesintisiz ve etkileşimli bir arayüz oluşturmada NLP'nin kullanılması en önemli öncelik olmaya devam edecek. Aşağıda NLP'nin çok faydalı uygulamalarından bazıları verilmiştir.
Makine Çevirisi
Makine çevirisi (MT), doğal dil işlemenin en önemli uygulamalarından biridir. MT temelde bir kaynak dili veya metni başka bir dile çevirme işlemidir. Makine çeviri sistemi İki Dilli veya Çok Dilli olabilir.
Spam ile Mücadele
İstenmeyen e-postalardaki muazzam artış nedeniyle, bu soruna karşı ilk savunma hattı olduğu için spam filtreleri önem kazanmıştır. Yanlış pozitif ve yanlış negatif konularını ana konular olarak ele alarak, NLP'nin işlevselliği spam filtreleme sistemi geliştirmek için kullanılabilir.
N-gram modelleme, Kelime Stemming ve Bayesian sınıflandırması, spam filtreleme için kullanılabilen mevcut NLP modellerinden bazılarıdır.
Bilgi alma ve Web araması
Google, Yahoo, Bing, WolframAlpha, vb. Gibi arama motorlarının çoğu, makine çevirisi (MT) teknolojisini NLP derin öğrenme modellerine dayandırır. Bu tür derin öğrenme modelleri, algoritmaların web sayfasındaki metni okumasına, anlamını yorumlamasına ve başka bir dile çevirmesine izin verir.
Otomatik Metin Özetleme
Otomatik metin özetleme, daha uzun metin belgelerinin kısa ve doğru bir özetini oluşturan bir tekniktir. Dolayısıyla, alakalı bilgileri daha kısa sürede almamıza yardımcı olur. Bu dijital çağda, ciddi bir otomatik metin özetlemeye ihtiyacımız var çünkü internet üzerinden durmayacak bir bilgi akışına sahibiz. NLP ve işlevleri, otomatik bir metin özetlemesi geliştirmede önemli bir rol oynar.
Dilbilgisi Düzeltmesi
Yazım düzeltme ve dilbilgisi düzeltme, Microsoft Word gibi kelime işlemci yazılımlarının çok kullanışlı bir özelliğidir. Doğal dil işleme (NLP) bu amaç için yaygın olarak kullanılmaktadır.
Soru cevaplama
Doğal dil işlemenin (NLP) başka bir ana uygulaması olan soru cevaplama, kullanıcı tarafından gönderilen soruyu otomatik olarak kendi doğal dilinde cevaplayan sistemler oluşturmaya odaklanır.
Duygu analizi
Duygu analizi, doğal dil işlemenin (NLP) bir diğer önemli uygulamaları arasındadır. Adından da anlaşılacağı gibi, Duygu analizi şu amaçlarla kullanılır:
Birkaç gönderi arasındaki duyguları tanımlayın ve
Duyguların açıkça ifade edilmediği duyguları tanımlayın.
Amazon, ebay vb. Gibi çevrimiçi e-ticaret şirketleri, müşterilerinin çevrimiçi görüşlerini ve duygularını belirlemek için duyarlılık analizini kullanıyor. Müşterilerinin ürünleri ve hizmetleri hakkında ne düşündüklerini anlamalarına yardımcı olacaktır.
Konuşma motorları
Siri, Google Voice, Alexa gibi konuşma motorları, onlarla doğal dilimizde iletişim kurabilmemiz için NLP üzerine inşa edilmiştir.
NLP'nin Uygulanması
Yukarıda belirtilen uygulamaları oluşturmak için, dili verimli bir şekilde işlemek için büyük bir dil anlayışına ve araçlara sahip özel beceri setine sahip olmamız gerekir. Bunu başarmak için çeşitli açık kaynaklı araçlarımız var. Bazıları açık kaynaklıdır, bazıları ise kuruluşlar tarafından kendi NLP uygulamalarını oluşturmak için geliştirilmiştir. Aşağıda bazı NLP araçlarının listesi verilmiştir -
Natural Language Tool Kit (NLTK)
Mallet
GATE
NLP'yi aç
UIMA
Genism
Stanford araç seti
Bu araçların çoğu Java ile yazılmıştır.
Natural Language Tool Kit (NLTK)
Yukarıda bahsedilen NLP aracı arasında, NLTK, kullanım kolaylığı ve kavramın açıklaması söz konusu olduğunda çok yüksek puanlar almaktadır. Python'un öğrenme eğrisi çok hızlıdır ve NLTK Python'da yazılmıştır, bu nedenle NLTK ayrıca çok iyi bir öğrenme kitine sahiptir. NLTK, belirteç oluşturma, köklendirme, Lemmatizasyon, Noktalama, Karakter Sayımı ve Kelime sayımı gibi görevlerin çoğunu bünyesinde barındırmıştır. Çok zarif ve çalışması kolaydır.
NLTK'yi kurmak için bilgisayarlarımızda Python kurulu olmalıdır. Www.python.org/downloads bağlantısına gidebilir ve işletim sisteminiz için en son sürümü, yani Windows, Mac ve Linux / Unix'i seçebilirsiniz. Python ile ilgili temel eğitim için www.tutorialspoint.com/python3/index.htm bağlantısına başvurabilirsiniz .
Şimdi, Python'u bilgisayar sisteminize yükledikten sonra, NLTK'yi nasıl kurabileceğimizi anlayalım.
NLTK kurulumu
NLTK'yi çeşitli işletim sistemlerine aşağıdaki gibi kurabiliriz -
Windows'ta
NLTK'yi Windows işletim sistemine kurmak için aşağıdaki adımları izleyin -
İlk olarak, Windows komut istemini açın ve uygulamanın konumuna gidin. pip Klasör.
Ardından, NLTK'yi yüklemek için aşağıdaki komutu girin -
pip3 install nltkŞimdi, Windows Başlat Menüsünden PythonShell'i açın ve NLTK'nin kurulumunu doğrulamak için aşağıdaki komutu yazın -
Import nltkHata almazsanız, NLTK'yi Python3 içeren Windows işletim sisteminize başarıyla yüklediniz.
Mac / Linux'ta
NLTK'yi Mac / Linux OS üzerine kurmak için aşağıdaki komutu yazın -
sudo pip install -U nltkBilgisayarınızda pip kurulu değilse, ilk kurulum için aşağıda verilen talimatları izleyin. pip -
Öncelikle, aşağıdaki komutu kullanarak paket dizinini güncelleyin -
sudo apt updateŞimdi, yüklemek için aşağıdaki komutu yazın pip python 3 için -
sudo apt install python3-pipAnaconda aracılığıyla
NLTK'yi Anaconda aracılığıyla kurmak için aşağıdaki adımları izleyin -
Öncelikle Anaconda'yı kurmak için www.anaconda.com/distribution/#download-section bağlantısına gidin ve ardından kurmanız gereken Python sürümünü seçin.
Anaconda'yı bilgisayar sisteminize yükledikten sonra, komut istemine gidin ve aşağıdaki komutu yazın -
conda install -c anaconda nltk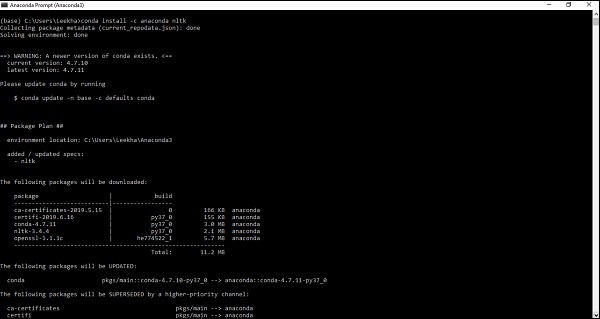
Çıktıyı gözden geçirmeniz ve 'evet' girmeniz gerekir. NLTK, Anaconda paketinize indirilecek ve yüklenecektir.
NLTK'nın Veri Kümesini ve Paketlerini İndirme
Şimdi bilgisayarlarımızda NLTK kurulu ancak onu kullanmak için içinde bulunan veri setlerini (korpus) indirmemiz gerekiyor. Mevcut önemli veri kümelerinden bazılarıstpwords, guntenberg, framenet_v15 ve bunun gibi.
Aşağıdaki komutların yardımıyla tüm NLTK veri setlerini indirebiliriz -
import nltk
nltk.download()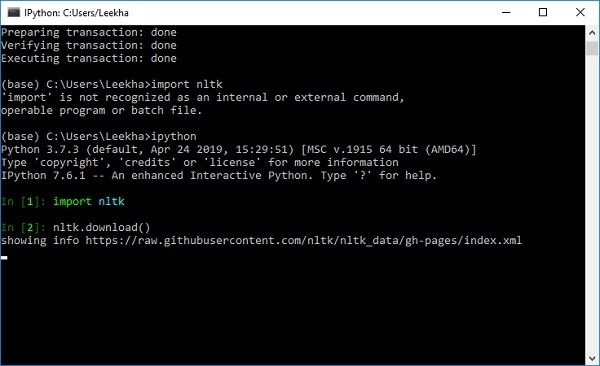
Aşağıdaki NLTK indirilen penceresini alacaksınız.
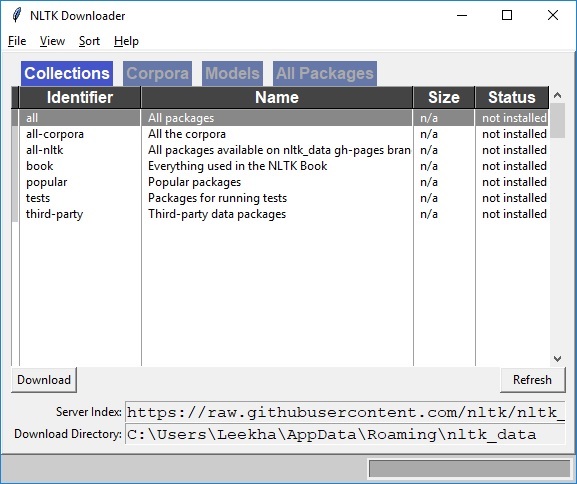
Şimdi, veri setlerini indirmek için indirme düğmesine tıklayın.
NLTK komut dosyası nasıl çalıştırılır?
Aşağıda, Porter Stemmer algoritmasını kullanarak uyguladığımız örnek yer almaktadır. PorterStemmernltk sınıfı. bu örnek ile NLTK komut dosyasının nasıl çalıştırılacağını anlayabileceksiniz.
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, PorterStemmer Porter Stemmer algoritmasını uygulamak için sınıf.
from nltk.stem import PorterStemmerArdından, aşağıdaki gibi bir Porter Stemmer sınıfı örneği oluşturun -
word_stemmer = PorterStemmer()Şimdi, kökten çıkarmak istediğiniz kelimeyi girin. -
word_stemmer.stem('writing')Çıktı
'write'word_stemmer.stem('eating')Çıktı
'eat'Tokenizing nedir?
Bir metin parçasını cümleler ve kelimeler gibi daha küçük parçalara ayırma süreci olarak tanımlanabilir. Bu daha küçük parçalara jeton adı verilir. Örneğin, bir kelime cümledeki bir simgedir ve bir cümle bir paragraftaki bir simgedir.
NLP'nin duygu analizi, QA sistemleri, dil çevirisi, akıllı sohbet robotları, ses sistemleri vb. Uygulamaları oluşturmak için kullanıldığını bildiğimiz için, bunları oluşturmak için metindeki kalıbı anlamak hayati önem taşır. Yukarıda bahsedilen belirteçler, bu kalıpları bulmada ve anlamada çok kullanışlıdır. Tokenleştirmeyi kök oluşturma ve lemmatizasyon gibi diğer tarifler için temel adım olarak düşünebiliriz.
NLTK paketi
nltk.tokenize Tokenizasyon sürecini gerçekleştirmek için NLTK modülü tarafından sağlanan pakettir.
Cümleleri kelimelere dönüştürme
Cümleyi kelimelere bölmek veya bir dizeden bir kelime listesi oluşturmak, her metin işleme faaliyetinin önemli bir parçasıdır. Bunu, tarafından sağlanan çeşitli işlevler / modüller yardımıyla anlayalımnltk.tokenize paketi.
word_tokenize modülü
word_tokenizemodül temel kelime belirteçleri için kullanılır. Aşağıdaki örnek, bir cümleyi kelimelere ayırmak için bu modülü kullanacaktır.
Misal
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('Tutorialspoint.com provides high quality technical tutorials for free.')Çıktı
['Tutorialspoint.com', 'provides', 'high', 'quality', 'technical', 'tutorials', 'for', 'free', '.']TreebankWordTokenizer Sınıfı
word_tokenize modül, temelde tokenize () işlevini bir örnek olarak çağıran bir sarmalayıcı işlevidir. TreebankWordTokenizersınıf. Cümleleri kelimeye ayırmak için word_tokenize () modülünü kullanırken aldığımız çıktı ile aynı çıktıyı verecektir. Yukarıda uygulanan aynı örneği görelim -
Misal
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, TreebankWordTokenizer kelime belirteç algoritmasını uygulamak için sınıf -
from nltk.tokenize import TreebankWordTokenizerArdından, aşağıdaki gibi TreebankWordTokenizer sınıfının bir örneğini oluşturun -
Tokenizer_wrd = TreebankWordTokenizer()Şimdi, belirteçlere dönüştürmek istediğiniz cümleyi girin -
Tokenizer_wrd.tokenize(
'Tutorialspoint.com provides high quality technical tutorials for free.'
)Çıktı
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials', 'for', 'free', '.'
]Eksiksiz uygulama örneği
Aşağıdaki tam uygulama örneğini görelim
import nltk
from nltk.tokenize import TreebankWordTokenizer
tokenizer_wrd = TreebankWordTokenizer()
tokenizer_wrd.tokenize('Tutorialspoint.com provides high quality technical
tutorials for free.')Çıktı
[
'Tutorialspoint.com', 'provides', 'high', 'quality',
'technical', 'tutorials','for', 'free', '.'
]Bir tokenleştiricinin en önemli kuralı, kasılmaları ayırmaktır. Örneğin bu amaç için word_tokenize () modülünü kullanırsak çıktı aşağıdaki gibi verecektir -
Misal
import nltk
from nltk.tokenize import word_tokenize
word_tokenize('won’t')Çıktı
['wo', "n't"]]Bu tür bir kongre tarafından TreebankWordTokenizerkabul edilemez. Bu nedenle iki alternatif kelime belirteçimiz var:PunktWordTokenizer ve WordPunctTokenizer.
WordPunktTokenizer Sınıfı
Tüm noktalama işaretlerini ayrı belirteçlere bölen alternatif bir sözcük belirteç oluşturucu. Bunu aşağıdaki basit örnekle anlayalım -
Misal
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
tokenizer.tokenize(" I can't allow you to go home early")Çıktı
['I', 'can', "'", 't', 'allow', 'you', 'to', 'go', 'home', 'early']Metni cümlelere dönüştürme
Bu bölümde metni / paragrafı cümlelere ayıracağız. NLTK sağlarsent_tokenize bu amaç için modül.
Neden gerekli?
Aklımıza gelen açık bir soru, kelime belirteçine sahip olduğumuzda neden cümle belirtecine ihtiyacımız var veya neden metni cümleler halinde belirtmemiz gerektiğidir. Cümlelerdeki ortalama kelimeleri saymamız gerektiğini varsayalım, bunu nasıl yapabiliriz? Bu görevi başarmak için, hem cümle belirtme hem de sözcük belirtme işlemine ihtiyacımız var.
Aşağıdaki basit örnek yardımıyla cümle ve kelime belirteç arasındaki farkı anlayalım -
Misal
import nltk
from nltk.tokenize import sent_tokenize
text = "Let us understand the difference between sentence & word tokenizer.
It is going to be a simple example."
sent_tokenize(text)Çıktı
[
"Let us understand the difference between sentence & word tokenizer.",
'It is going to be a simple example.'
]Normal ifadeler kullanarak cümle belirtme
Sözcük belirtecinin çıktısının kabul edilemez olduğunu düşünüyorsanız ve metnin nasıl belirtileceğini tam olarak kontrol etmek istiyorsanız, cümle belirtme işlemi yaparken kullanılabilecek normal ifadeye sahibiz. NLTK sağlarRegexpTokenizer bunu başarmak için sınıf.
Aşağıdaki iki örnek yardımıyla kavramı anlayalım.
İlk örnekte, alfanümerik belirteçleri ve tek tırnak işaretlerini eşleştirmek için normal ifadeyi kullanacağız, böylece kısaltmaları ayırmayalım. “won’t”.
örnek 1
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
tokenizer.tokenize("won't is a contraction.")
tokenizer.tokenize("can't is a contraction.")Çıktı
["won't", 'is', 'a', 'contraction']
["can't", 'is', 'a', 'contraction']İlk örnekte, boşlukta belirtmek için normal ifadeyi kullanacağız.
Örnek 2
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = True)
tokenizer.tokenize("won't is a contraction.")Çıktı
["won't", 'is', 'a', 'contraction']Yukarıdaki çıktıdan, noktalama işaretlerinin jetonlarda kaldığını görebiliriz. Parametre boşlukları = True, modelin belirtilecek boşlukları belirleyeceği anlamına gelir. Öte yandan, gaps = False parametresini kullanırsak, aşağıdaki örnekte görülebilecek jetonları tanımlamak için desen kullanılacaktır -
import nltk
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer('/s+' , gaps = False)
tokenizer.tokenize("won't is a contraction.")Çıktı
[ ]Bize boş çıktı verecek.
Neden kendi cümle belirtecini eğitmelisiniz?
Bu çok önemli bir soru, eğer NLTK'nın varsayılan cümle belirtecine sahipsek, o zaman neden bir cümle belirteçini eğitmemiz gerekiyor? Bu sorunun cevabı, NLTK'nın varsayılan cümle belirtecinin kalitesinde yatmaktadır. NLTK'nın varsayılan belirteç oluşturucusu temelde genel amaçlı bir belirteçtir. Çok iyi çalışmasına rağmen, standart olmayan metin için, belki bizim metnimiz için iyi bir seçim olmayabilir veya benzersiz bir biçimlendirmeye sahip bir metin için. Bu tür bir metni belirtmek ve en iyi sonuçları elde etmek için kendi cümle belirteçimizi eğitmeliyiz.
Uygulama Örneği
Bu örnek için, webtext korpusunu kullanacağız. Bu külliyattan kullanacağımız metin dosyası, aşağıda gösterilen iletişim kutuları olarak biçimlendirilmiş metne sahip -
Guy: How old are you?
Hipster girl: You know, I never answer that question. Because to me, it's about
how mature you are, you know? I mean, a fourteen year old could be more mature
than a twenty-five year old, right? I'm sorry, I just never answer that question.
Guy: But, uh, you're older than eighteen, right?
Hipster girl: Oh, yeah.Bu metin dosyasını training_tokenizer adıyla kaydettik. NLTK adlı bir sınıf sağlarPunktSentenceTokenizerbunun yardımıyla özel bir cümle belirteci üretmek için ham metin üzerinde eğitim verebiliriz. Ham metni bir dosyada okuyarak veya bir NLTK derlemesinden,raw() yöntem.
Daha fazla fikir edinmek için aşağıdaki örneğe bakalım -
İlk olarak, içe aktarın PunktSentenceTokenizer sınıf nltk.tokenize paket -
from nltk.tokenize import PunktSentenceTokenizerŞimdi içe aktar webtext külliyat nltk.corpus paket
from nltk.corpus import webtextSonra, kullanarak raw() yöntem, ham metni al training_tokenizer.txt aşağıdaki gibi dosya -
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')Şimdi bir örnek oluşturun PunktSentenceTokenizer ve belirteçli cümleleri metin dosyasından aşağıdaki gibi yazdırın -
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Çıktı
White guy: So, do you have any plans for this evening?
print(sents_1[1])
Output:
Asian girl: Yeah, being angry!
print(sents_1[670])
Output:
Guy: A hundred bucks?
print(sents_1[675])
Output:
Girl: But you already have a Big Mac...Eksiksiz uygulama örneği
from nltk.tokenize import PunktSentenceTokenizer
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sent_tokenizer = PunktSentenceTokenizer(text)
sents_1 = sent_tokenizer.tokenize(text)
print(sents_1[0])Çıktı
White guy: So, do you have any plans for this evening?NLTK'nın varsayılan cümle belirteci ile kendi eğitimli cümle belirteçleştiricimiz arasındaki farkı anlamak için, aynı dosyayı varsayılan cümle belirteci yani sent_tokenize () ile belirtelim.
from nltk.tokenize import sent_tokenize
from nltk.corpus import webtext
text = webtext.raw('C://Users/Leekha/training_tokenizer.txt')
sents_2 = sent_tokenize(text)
print(sents_2[0])
Output:
White guy: So, do you have any plans for this evening?
print(sents_2[675])
Output:
Hobo: Y'know what I'd do if I was rich?Çıktıdaki farkın yardımıyla, kendi cümle belirteçimizi eğitmenin neden faydalı olduğu kavramını anlayabiliriz.
Engellenecek kelimeler nelerdir?
Metinde bulunan ancak cümlenin anlamına katkıda bulunmayan bazı yaygın kelimeler. Bu tür kelimeler, bilgi edinme veya doğal dil işleme amacıyla hiç de önemli değildir. En yaygın engellenecek kelimeler "the" ve "a" dır.
NLTK engellenecek kelimeler külliyat
Aslında, Natural Language Tool kiti, birçok dil için kelime listelerini içeren bir engellenecek kelime külliyatıyla birlikte gelir. Aşağıdaki örnek yardımıyla kullanımını anlayalım -
Öncelikle, nltk.corpus paketinden engellenecek kelimeler kopyasını içe aktarın -
from nltk.corpus import stopwordsŞimdi, İngilizce dillerinden engellenecek kelimeleri kullanacağız
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Çıktı
['I', 'writer']Eksiksiz uygulama örneği
from nltk.corpus import stopwords
english_stops = set(stopwords.words('english'))
words = ['I', 'am', 'a', 'writer']
[word for word in words if word not in english_stops]Çıktı
['I', 'writer']Desteklenen dillerin tam listesini bulma
Aşağıdaki Python komut dosyası yardımıyla, NLTK engellenecek kelimeler külliyatının desteklediği dillerin tam listesini de bulabiliriz -
from nltk.corpus import stopwords
stopwords.fileids()Çıktı
[
'arabic', 'azerbaijani', 'danish', 'dutch', 'english', 'finnish', 'french',
'german', 'greek', 'hungarian', 'indonesian', 'italian', 'kazakh', 'nepali',
'norwegian', 'portuguese', 'romanian', 'russian', 'slovene', 'spanish',
'swedish', 'tajik', 'turkish'
]Wordnet nedir?
Wordnet, Princeton tarafından oluşturulan büyük bir İngilizce sözlük veritabanıdır. NLTK külliyatının bir parçasıdır. İsimler, fiiller, sıfatlar ve zarfların tümü eşanlamlılar kümesi halinde, yani bilişsel eş anlamlılar halinde gruplandırılmıştır. Burada her bir sentez kümesi ayrı bir anlam ifade eder. Aşağıda Wordnet'in bazı kullanım örnekleri verilmiştir -
- Bir kelimenin tanımına bakmak için kullanılabilir
- Bir kelimenin eş ve zıt anlamlılarını bulabiliriz
- Kelime ilişkileri ve benzerlikler Wordnet kullanılarak keşfedilebilir
- Birden fazla kullanım ve tanıma sahip olan kelimeler için kelime anlamında belirsizlik giderme
Wordnet nasıl içe aktarılır?
Wordnet, aşağıdaki komutun yardımıyla içe aktarılabilir -
from nltk.corpus import wordnetDaha kompakt komut için aşağıdakileri kullanın -
from nltk.corpus import wordnet as wnÖrnekleri senkronize et
Eşzamanlı küme, aynı kavramı ifade eden eş anlamlı sözcük gruplarıdır. Kelimeleri aramak için Wordnet'i kullandığınızda, Synset örneklerinin bir listesini alırsınız.
wordnet.synsets (word)
Synsets'in bir listesini almak için, kullanarak Wordnet'teki herhangi bir kelimeye bakabiliriz wordnet.synsets(word). Örneğin, bir sonraki Python tarifinde, Synset'in bazı özellikleri ve yöntemleriyle birlikte 'köpek' için Synset'e bakacağız -
Misal
İlk olarak, wordnet'i aşağıdaki gibi içe aktarın -
from nltk.corpus import wordnet as wnŞimdi, Synset'e bakmak istediğiniz kelimeyi sağlayın -
syn = wn.synsets('dog')[0]Burada, doğrudan Synset'i almak için kullanılabilecek synset için benzersiz bir isim elde etmek için name () yöntemini kullanıyoruz -
syn.name()
Output:
'dog.n.01'Sonra, bize kelimenin tanımını verecek olan definition () yöntemini kullanıyoruz -
syn.definition()
Output:
'a member of the genus Canis (probably descended from the common wolf) that has
been domesticated by man since prehistoric times; occurs in many breeds'Diğer bir yöntem ise, bize - kelimesiyle ilgili örnekleri verecek olan örneklerdir ()
syn.examples()
Output:
['the dog barked all night']Eksiksiz uygulama örneği
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.name()
syn.definition()
syn.examples()Hypernyms Alma
Synsets, miras ağacı benzeri bir yapıda düzenlenir. Hypernyms daha soyutlanmış terimleri temsil ederken Hyponymsdaha spesifik terimleri temsil eder. Önemli şeylerden biri, bu ağacın bir kök hiperisine kadar izlenebilmesidir. Aşağıdaki örnek yardımıyla kavramı anlayalım -
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()Çıktı
[Synset('canine.n.02'), Synset('domestic_animal.n.01')]Burada, köpek ve evcil_hayvanın 'köpek' hiperimleri olduğunu görebiliriz.
Şimdi, 'köpek' hiponimlerini aşağıdaki gibi bulabiliriz -
syn.hypernyms()[0].hyponyms()Çıktı
[
Synset('bitch.n.04'),
Synset('dog.n.01'),
Synset('fox.n.01'),
Synset('hyena.n.01'),
Synset('jackal.n.01'),
Synset('wild_dog.n.01'),
Synset('wolf.n.01')
]Yukarıdaki çıktıdan, "köpek" in "yerli_hayvanlar" ın birçok hiponiminden yalnızca biri olduğunu görebiliriz.
Tüm bunların kökünü bulmak için aşağıdaki komutu kullanabiliriz -
syn.root_hypernyms()Çıktı
[Synset('entity.n.01')]Yukarıdaki çıktıdan sadece bir kökü olduğunu görebiliyoruz.
Eksiksiz uygulama örneği
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
syn.hypernyms()
syn.hypernyms()[0].hyponyms()
syn.root_hypernyms()Çıktı
[Synset('entity.n.01')]Wordnet'te Lemmas
Dilbilimde, bir kelimenin kanonik biçimi veya morfolojik biçimi lemma olarak adlandırılır. Bir kelimenin eşanlamlısı ve zıt anlamlılığını bulmak için WordNet'te lemaları da arayabiliriz. Nasıl olduğunu görelim.
Eşanlamlıları Bulmak
Lemma () yöntemini kullanarak bir Synset'in eşanlamlılarının sayısını bulabiliriz. Bu yöntemi 'köpek' synset'ine uygulayalım -
Misal
from nltk.corpus import wordnet as wn
syn = wn.synsets('dog')[0]
lemmas = syn.lemmas()
len(lemmas)Çıktı
3Yukarıdaki çıktı, 'köpek'in üç leması olduğunu gösterir.
İlk lemmanın adını aşağıdaki gibi almak -
lemmas[0].name()
Output:
'dog'İkinci lemmanın adını aşağıdaki gibi almak -
lemmas[1].name()
Output:
'domestic_dog'Üçüncü lemmanın adını aşağıdaki gibi almak -
lemmas[2].name()
Output:
'Canis_familiaris'Aslında, bir Synset, hepsi benzer anlama sahip bir lemma grubunu temsil ederken, bir lemma farklı bir kelime biçimini temsil eder.
Zıt Kelimeleri Bulmak
WordNet'te bazı sözcüklerin zıt anlamlıları da vardır. Örneğin, 'iyi' kelimesinin toplam 27 sentezi vardır, bunların arasında 5 tanesi zıt anlamlı sözcüklere sahiptir. Zıtlıkları bulalım ('iyi' kelimesi isim olarak ve 'iyi' kelimesi sıfat olarak kullanıldığında).
örnek 1
from nltk.corpus import wordnet as wn
syn1 = wn.synset('good.n.02')
antonym1 = syn1.lemmas()[0].antonyms()[0]
antonym1.name()Çıktı
'evil'antonym1.synset().definition()Çıktı
'the quality of being morally wrong in principle or practice'Yukarıdaki örnek, isim olarak kullanıldığında 'iyi' kelimesinin ilk zıt anlamlı 'kötü' olduğunu gösterir.
Örnek 2
from nltk.corpus import wordnet as wn
syn2 = wn.synset('good.a.01')
antonym2 = syn2.lemmas()[0].antonyms()[0]
antonym2.name()Çıktı
'bad'antonym2.synset().definition()Çıktı
'having undesirable or negative qualities’Yukarıdaki örnek, sıfat olarak kullanıldığında 'iyi' kelimesinin ilk zıtlığı 'kötü' olduğunu gösterir.
Stemming nedir?
Stemming, kelimelerin üzerindeki ekleri kaldırarak temel formunu çıkarmak için kullanılan bir tekniktir. Tıpkı bir ağacın dallarını saplarına kadar kesmek gibidir. Örneğin, kelimelerin köküeating, eats, eaten dır-dir eat.
Arama motorları kelimeleri indekslemek için kök ayırmayı kullanır. Bu nedenle, bir arama motoru bir kelimenin tüm biçimlerini depolamak yerine, yalnızca kökleri depolayabilir. Bu şekilde, kök oluşturma dizinin boyutunu azaltır ve alma doğruluğunu artırır.
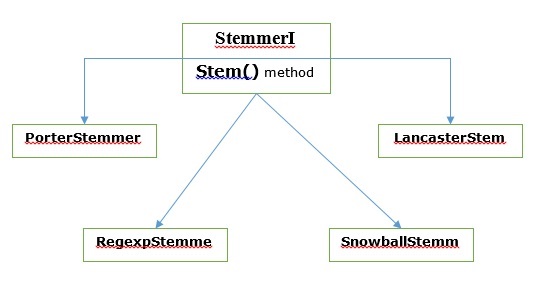
Çeşitli Stemming algoritmaları
NLTK'da, stemmerI, sahip olan stem()yöntem, arayüz, daha sonra ele alacağımız tüm saplayıcılara sahiptir. Bunu aşağıdaki diyagramla anlayalım
Porter kök belirleme algoritması
Temel olarak İngilizce kelimelerin iyi bilinen soneklerini kaldırmak ve değiştirmek için tasarlanmış en yaygın kök belirleme algoritmalarından biridir.
PorterStemmer sınıfı
NLTK, PorterStemmerkullanarak kolayca Porter Stemmer algoritmalarını uygulayabileceğimiz bir sınıf. Bu sınıf, giriş kelimesini son bir köke dönüştürebileceği birkaç normal kelime formunu ve son ekini bilir. Ortaya çıkan kök, genellikle aynı kök anlamına sahip daha kısa bir kelimedir. Bir örnek görelim -
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, PorterStemmer Porter Stemmer algoritmasını uygulamak için sınıf.
from nltk.stem import PorterStemmerArdından, aşağıdaki gibi bir Porter Stemmer sınıfı örneği oluşturun -
word_stemmer = PorterStemmer()Şimdi, kökten çıkarmak istediğiniz kelimeyi girin.
word_stemmer.stem('writing')Çıktı
'write'word_stemmer.stem('eating')Çıktı
'eat'Eksiksiz uygulama örneği
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('writing')Çıktı
'write'Lancaster kök belirleme algoritması
Lancaster Üniversitesi'nde geliştirilmiştir ve çok yaygın bir başka kök belirleme algoritmasıdır.
LancasterStemmer sınıfı
NLTK, LancasterStemmeryardımıyla kolayca köklenmesini istediğimiz kelime için Lancaster Stemmer algoritmalarını uygulayabileceğimiz bir sınıf. Bir örnek görelim -
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, LancasterStemmer Lancaster Stemmer algoritmasını uygulamak için sınıf
from nltk.stem import LancasterStemmerArdından, bir örnek oluşturun LancasterStemmer aşağıdaki gibi sınıf -
Lanc_stemmer = LancasterStemmer()Şimdi, kökten çıkarmak istediğiniz kelimeyi girin.
Lanc_stemmer.stem('eats')Çıktı
'eat'Eksiksiz uygulama örneği
import nltk
from nltk.stem import LancatserStemmer
Lanc_stemmer = LancasterStemmer()
Lanc_stemmer.stem('eats')Çıktı
'eat'Normal İfade türetme algoritması
Bu kök belirleme algoritmasının yardımıyla kendi kök oluşturucumuzu oluşturabiliriz.
RegexpStemmer sınıfı
NLTK, RegexpStemmerDüzenli İfade Stemmer algoritmalarını kolayca uygulayabileceğimiz bir sınıf. Temelde tek bir normal ifade alır ve ifadeyle eşleşen tüm önek veya son ekleri kaldırır. Bir örnek görelim -
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, RegexpStemmer Normal İfade Stemmer algoritmasını uygulamak için sınıf.
from nltk.stem import RegexpStemmerArdından, bir örnek oluşturun RegexpStemmer sınıf ve kelimeden çıkarmak istediğiniz son eki veya öneki aşağıdaki gibi sağlar -
Reg_stemmer = RegexpStemmer(‘ing’)Şimdi, kökten çıkarmak istediğiniz kelimeyi girin.
Reg_stemmer.stem('eating')Çıktı
'eat'Reg_stemmer.stem('ingeat')Çıktı
'eat'
Reg_stemmer.stem('eats')Çıktı
'eat'Eksiksiz uygulama örneği
import nltk
from nltk.stem import RegexpStemmer
Reg_stemmer = RegexpStemmer()
Reg_stemmer.stem('ingeat')Çıktı
'eat'Kartopu kök belirleme algoritması
Bir başka çok kullanışlı kök bulma algoritmasıdır.
SnowballStemmer sınıfı
NLTK, SnowballStemmerSnowball Stemmer algoritmalarını kolayca uygulayabileceğimiz bir sınıf. İngilizce olmayan 15 dili destekler. Bu buharlaştırma sınıfını kullanmak için, kullandığımız dilin adıyla bir örnek oluşturmamız ve ardından stem () yöntemini çağırmamız gerekir. Bir örnek görelim -
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, SnowballStemmer Snowball Stemmer algoritmasını uygulamak için sınıf
from nltk.stem import SnowballStemmerDesteklediği dilleri görelim -
SnowballStemmer.languagesÇıktı
(
'arabic',
'danish',
'dutch',
'english',
'finnish',
'french',
'german',
'hungarian',
'italian',
'norwegian',
'porter',
'portuguese',
'romanian',
'russian',
'spanish',
'swedish'
)Ardından, kullanmak istediğiniz dille bir SnowballStemmer sınıfı örneği oluşturun. Burada, 'Fransız' dili için kök oluşturucuyu yaratıyoruz.
French_stemmer = SnowballStemmer(‘french’)Şimdi, stem () yöntemini çağırın ve kök yapmak istediğiniz sözcüğü girin.
French_stemmer.stem (‘Bonjoura’)Çıktı
'bonjour'Eksiksiz uygulama örneği
import nltk
from nltk.stem import SnowballStemmer
French_stemmer = SnowballStemmer(‘french’)
French_stemmer.stem (‘Bonjoura’)Çıktı
'bonjour'Lemmatizasyon nedir?
Lemmatizasyon tekniği köklendirme gibidir. Tanımlamadan sonra elde edeceğimiz çıktı, kök oluşturmanın çıktısı olan kök kökten ziyade bir kök sözcük olan 'lemma' olarak adlandırılır. Konuşmadan sonra, aynı anlama gelen geçerli bir kelime alacağız.
NLTK sağlar WordNetLemmatizer etrafında ince bir paket olan sınıf wordnetkülliyat. Bu sınıf kullanırmorphy() işlevi WordNet CorpusReaderbir lemma bulmak için sınıf. Bunu bir örnekle anlayalım -
Misal
İlk olarak, doğal dil araç setini (nltk) içe aktarmamız gerekiyor.
import nltkŞimdi, WordNetLemmatizer lematizasyon tekniğini uygulamak için sınıf.
from nltk.stem import WordNetLemmatizerArdından, bir örnek oluşturun WordNetLemmatizer sınıf.
lemmatizer = WordNetLemmatizer()Şimdi, lemmatize () yöntemini çağırın ve lemmayı bulmak istediğiniz sözcüğü girin.
lemmatizer.lemmatize('eating')Çıktı
'eating'lemmatizer.lemmatize('books')Çıktı
'book'Eksiksiz uygulama örneği
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize('books')Çıktı
'book'Köklendirme ve Lemmatizasyon Arasındaki Fark
Aşağıdaki örnek yardımıyla Stemming ve Lemmatization arasındaki farkı anlayalım -
import nltk
from nltk.stem import PorterStemmer
word_stemmer = PorterStemmer()
word_stemmer.stem('believes')Çıktı
believimport nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatizer.lemmatize(' believes ')Çıktı
believHer iki programın çıktısı, köklendirme ve sözcük ayırma arasındaki temel farkı anlatır. PorterStemmersınıf, kelimedeki 'es'leri keser. Diğer yandan,WordNetLemmatizerclass geçerli bir kelime bulur. Basit bir deyişle, kök türetme tekniği yalnızca sözcüğün biçimine bakarken, sözcüklendirme tekniği sözcüğün anlamına bakar. Bu, lemmatizasyonu uyguladıktan sonra her zaman geçerli bir kelime alacağımız anlamına gelir.
Köklendirme ve lemmatizasyon bir tür dilsel sıkıştırma olarak düşünülebilir. Aynı anlamda, kelime değiştirme, metin normalleştirme veya hata düzeltme olarak düşünülebilir.
Ama neden kelime değiştirmeye ihtiyacımız vardı? Diyelim ki tokenleştirme hakkında konuşursak, o zaman kasılmalarla ilgili sorunlar yaşıyor (yapamama, yapmayacağım, vb. Bu nedenle, bu tür sorunları çözmek için kelime değiştirmeye ihtiyacımız var. Örneğin, kasılmaları genişletilmiş biçimleriyle değiştirebiliriz.
Normal ifade kullanarak kelime değiştirme
İlk olarak, normal ifadeyle eşleşen kelimeleri değiştireceğiz. Ancak bunun için normal ifadelerin yanı sıra python re modülüne ilişkin temel bir anlayışa sahip olmamız gerekir. Aşağıdaki örnekte, daraltmayı genişletilmiş biçimleriyle değiştireceğiz (örneğin, "yapamaz", "yapılamaz" ile değiştirilecektir), bunların hepsini normal ifadeler kullanarak yapacağız.
Misal
Öncelikle, normal ifadelerle çalışmak için gerekli paketi yeniden içe aktarın.
import re
from nltk.corpus import wordnetArdından, seçtiğiniz değiştirme modellerini aşağıdaki gibi tanımlayın -
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]Şimdi, kelimeleri değiştirmek için kullanılabilecek bir sınıf oluşturun -
class REReplacer(object):
def __init__(self, pattern = R_patterns):
self.pattern = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.pattern:
s = re.sub(pattern, repl, s)
return sBu python programını kaydedin (repRE.py deyin) ve python komut isteminden çalıştırın. Çalıştırdıktan sonra, kelimeleri değiştirmek istediğinizde REReplacer sınıfını içe aktarın. Nasıl olduğunu görelim.
from repRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")
Output:
'I will not do it'
rep_word.replace("I can’t do it")
Output:
'I cannot do it'Eksiksiz uygulama örneği
import re
from nltk.corpus import wordnet
R_patterns = [
(r'won\'t', 'will not'),
(r'can\'t', 'cannot'),
(r'i\'m', 'i am'),
r'(\w+)\'ll', '\g<1> will'),
(r'(\w+)n\'t', '\g<1> not'),
(r'(\w+)\'ve', '\g<1> have'),
(r'(\w+)\'s', '\g<1> is'),
(r'(\w+)\'re', '\g<1> are'),
]
class REReplacer(object):
def __init__(self, patterns=R_patterns):
self.patterns = [(re.compile(regex), repl) for (regex, repl) in patterns]
def replace(self, text):
s = text
for (pattern, repl) in self.patterns:
s = re.sub(pattern, repl, s)
return sŞimdi yukarıdaki programı kaydettikten ve çalıştırdıktan sonra, sınıfı içe aktarabilir ve aşağıdaki gibi kullanabilirsiniz -
from replacerRE import REReplacer
rep_word = REReplacer()
rep_word.replace("I won't do it")Çıktı
'I will not do it'Metin işlemeden önce değiştirme
Doğal dil işleme (NLP) ile çalışırken yaygın uygulamalardan biri, metin işlemeden önce metni temizlemektir. Bu konuda biz de kullanabilirizREReplacer önceki örnekte, metin işlemeden önceki bir ön adım olarak, yani belirteçleştirmeden önce oluşturulan sınıf.
Misal
from nltk.tokenize import word_tokenize
from replacerRE import REReplacer
rep_word = REReplacer()
word_tokenize("I won't be able to do this now")
Output:
['I', 'wo', "n't", 'be', 'able', 'to', 'do', 'this', 'now']
word_tokenize(rep_word.replace("I won't be able to do this now"))
Output:
['I', 'will', 'not', 'be', 'able', 'to', 'do', 'this', 'now']Yukarıdaki Python tarifinde, düzenli ifade değiştirme kullanmadan ve kullanmadan kelime tokenizatörünün çıktısı arasındaki farkı kolayca anlayabiliriz.
Yinelenen karakterlerin kaldırılması
Günlük dilimizde kesinlikle gramer yapıyor muyuz? Biz değiliz. Örneğin, bazen 'Merhaba' kelimesini vurgulamak için 'Hiiiiiiiiiiii Mohan' yazarız. Ancak bilgisayar sistemi, "Hiiiiiiiiiiii" nin "Merhaba" kelimesinin bir varyasyonu olduğunu bilmiyor. Aşağıdaki örnekte, adında bir sınıf oluşturacağızrep_word_removal yinelenen kelimeleri kaldırmak için kullanılabilir.
Misal
Öncelikle, normal ifadelerle çalışmak için gerekli paketi içe aktarın
import re
from nltk.corpus import wordnetŞimdi, yinelenen kelimeleri kaldırmak için kullanılabilecek bir sınıf oluşturun -
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
repl_word = self.repeat_regexp.sub(self.repl, word)
if repl_word != word:
return self.replace(repl_word)
else:
return repl_wordBu python programını kaydedin (removerepeat.py deyin) ve python komut isteminden çalıştırın. Çalıştırdıktan sonra içe aktarınRep_word_removalyinelenen kelimeleri kaldırmak istediğinizde sınıf. Bakalım nasıl?
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")
Output:
'Hi'
rep_word.replace("Hellooooooooooooooo")
Output:
'Hello'Eksiksiz uygulama örneği
import re
from nltk.corpus import wordnet
class Rep_word_removal(object):
def __init__(self):
self.repeat_regexp = re.compile(r'(\w*)(\w)\2(\w*)')
self.repl = r'\1\2\3'
def replace(self, word):
if wordnet.synsets(word):
return word
replace_word = self.repeat_regexp.sub(self.repl, word)
if replace_word != word:
return self.replace(replace_word)
else:
return replace_wordŞimdi yukarıdaki programı kaydettikten ve çalıştırdıktan sonra, sınıfı içe aktarabilir ve aşağıdaki gibi kullanabilirsiniz -
from removalrepeat import Rep_word_removal
rep_word = Rep_word_removal()
rep_word.replace ("Hiiiiiiiiiiiiiiiiiiiii")Çıktı
'Hi'Kelimeleri ortak eşanlamlılarla değiştirme
NLP ile çalışırken, özellikle frekans analizi ve metin indeksleme durumunda, kelime dağarcığını anlamını kaybetmeden sıkıştırmak her zaman faydalıdır çünkü çok fazla bellek tasarrufu sağlar. Bunu başarmak için, bir kelimenin eş anlamlıları ile eşlemesini tanımlamamız gerekir. Aşağıdaki örnekte, adında bir sınıf oluşturacağızword_syn_replacer bu, kelimeleri ortak eşanlamlılarıyla değiştirmek için kullanılabilir.
Misal
Önce gerekli paketi içe aktarın re normal ifadelerle çalışmak için.
import re
from nltk.corpus import wordnetArdından, bir kelime değiştirme eşlemesi alan sınıfı oluşturun -
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Bu python programını kaydedin (replacesyn.py deyin) ve python komut isteminden çalıştırın. Çalıştırdıktan sonra içe aktarınword_syn_replacerkelimeleri ortak eşanlamlılarla değiştirmek istediğinizde sınıf. Nasıl olduğunu görelim.
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Çıktı
'birthday'Eksiksiz uygulama örneği
import re
from nltk.corpus import wordnet
class word_syn_replacer(object):
def __init__(self, word_map):
self.word_map = word_map
def replace(self, word):
return self.word_map.get(word, word)Şimdi yukarıdaki programı kaydettikten ve çalıştırdıktan sonra, sınıfı içe aktarabilir ve aşağıdaki gibi kullanabilirsiniz -
from replacesyn import word_syn_replacer
rep_syn = word_syn_replacer ({‘bday’: ‘birthday’)
rep_syn.replace(‘bday’)Çıktı
'birthday'Yukarıdaki yöntemin dezavantajı, eş anlamlıları bir Python sözlüğünde kodlamamız gerekmesidir. CSV ve YAML dosyası şeklinde daha iyi iki alternatifimiz var. Eşanlamlı kelime dağarcığımızı yukarıda belirtilen dosyalardan herhangi birine kaydedebilir veword_maponlardan sözlük. Konsepti örnekler yardımıyla anlayalım.
CSV dosyasını kullanma
CSV dosyasını bu amaçla kullanabilmek için dosyanın iki sütun içermesi, birinci sütun word'den ve ikinci sütun onun yerini alacak eşanlamlılardan oluşmalıdır. Bu dosyayı olarak kaydedelimsyn.csv. Aşağıdaki örnekte, adında bir sınıf oluşturacağız CSVword_syn_replacer hangisi genişleyecek word_syn_replacer içinde replacesyn.py dosyasını oluşturmak için kullanılacaktır. word_map dan sözlük syn.csv dosya.
Misal
Önce gerekli paketleri içe aktarın.
import csvArdından, bir kelime değiştirme eşlemesi alan sınıfı oluşturun -
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Çalıştırdıktan sonra içe aktarın CSVword_syn_replacerkelimeleri ortak eşanlamlılarla değiştirmek istediğinizde sınıf. Bakalım nasıl?
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Çıktı
'birthday'Eksiksiz uygulama örneği
import csv
class CSVword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = {}
for line in csv.reader(open(fname)):
word, syn = line
word_map[word] = syn
super(Csvword_syn_replacer, self).__init__(word_map)Şimdi yukarıdaki programı kaydettikten ve çalıştırdıktan sonra, sınıfı içe aktarabilir ve aşağıdaki gibi kullanabilirsiniz -
from replacesyn import CSVword_syn_replacer
rep_syn = CSVword_syn_replacer (‘syn.csv’)
rep_syn.replace(‘bday’)Çıktı
'birthday'YAML dosyasını kullanma
CSV dosyasını kullandığımız için, bu amaçla YAML dosyasını da kullanabiliriz (PyYAML'in kurulu olması gerekir). Dosyayı şu şekilde kaydedelim:syn.yaml. Aşağıdaki örnekte, adında bir sınıf oluşturacağız YAMLword_syn_replacer hangisi genişleyecek word_syn_replacer içinde replacesyn.py dosyasını oluşturmak için kullanılacaktır. word_map dan sözlük syn.yaml dosya.
Misal
Önce gerekli paketleri içe aktarın.
import yamlArdından, bir kelime değiştirme eşlemesi alan sınıfı oluşturun -
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Çalıştırdıktan sonra içe aktarın YAMLword_syn_replacerkelimeleri ortak eşanlamlılarla değiştirmek istediğinizde sınıf. Bakalım nasıl?
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Çıktı
'birthday'Eksiksiz uygulama örneği
import yaml
class YAMLword_syn_replacer(word_syn_replacer):
def __init__(self, fname):
word_map = yaml.load(open(fname))
super(YamlWordReplacer, self).__init__(word_map)Şimdi yukarıdaki programı kaydettikten ve çalıştırdıktan sonra, sınıfı içe aktarabilir ve aşağıdaki gibi kullanabilirsiniz -
from replacesyn import YAMLword_syn_replacer
rep_syn = YAMLword_syn_replacer (‘syn.yaml’)
rep_syn.replace(‘bday’)Çıktı
'birthday'Antonym değiştirme
Bir zıt sözcüğün başka bir sözcüğün zıt anlamını taşıyan bir sözcük olduğunu bildiğimiz gibi ve eşanlamlı değiştirmenin zıttı zıt sözcük değiştirme olarak adlandırılır. Bu bölümde, zıt anlamlı sözcüklerin yerini alacağız, yani sözcükleri kesin zıt anlamlı sözcüklerle WordNet kullanarak değiştireceğiz. Aşağıdaki örnekte, adında bir sınıf oluşturacağızword_antonym_replacer Biri sözcüğü değiştirmek, diğeri olumsuzları kaldırmak için olmak üzere iki yöntemi vardır.
Misal
Önce gerekli paketleri içe aktarın.
from nltk.corpus import wordnetArdından, adlı sınıfı oluşturun word_antonym_replacer -
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsBu python programını kaydedin (replaceantonym.py deyin) ve python komut isteminden çalıştırın. Çalıştırdıktan sonra içe aktarınword_antonym_replacerkelimeleri açık ve net zıt anlamlıları ile değiştirmek istediğinizde sınıf. Nasıl olduğunu görelim.
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)Çıktı
['beautify'']
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Çıktı
["Let us", 'beautify', 'our', 'country']Eksiksiz uygulama örneği
nltk.corpus import wordnet
class word_antonym_replacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsŞimdi yukarıdaki programı kaydettikten ve çalıştırdıktan sonra, sınıfı içe aktarabilir ve aşağıdaki gibi kullanabilirsiniz -
from replacerantonym import word_antonym_replacer
rep_antonym = word_antonym_replacer ()
rep_antonym.replace(‘uglify’)
sentence = ["Let us", 'not', 'uglify', 'our', 'country']
rep_antonym.replace _negations(sentence)Çıktı
["Let us", 'beautify', 'our', 'country']Bir külliyat nedir?
Bir külliyat, doğal bir iletişim ortamında üretilmiş, makine tarafından okunabilir metinlerin yapılandırılmış biçimde geniş bir koleksiyonudur. Corpora kelimesi, Corpus'un çoğuludur. Derlem aşağıdaki gibi birçok şekilde türetilebilir -
- Orijinal olarak elektronik olan metinden
- Konuşulan dilin transkriptlerinden
- Optik karakter tanımadan vb.
Derlem temsilciliği, Derlem Dengesi, Örnekleme, Derlem Büyüklüğü, derlemi tasarlarken önemli rol oynayan unsurlardır. NLP görevleri için en popüler külliyatlardan bazıları TreeBank, PropBank, VarbNet ve WordNet'tir.
Özel korpus nasıl oluşturulur?
NLTK'yi indirirken, NLTK veri paketini de kurduk. Yani, zaten bilgisayarımızda NLTK veri paketi kurulu. Windows hakkında konuşursak, bu veri paketinin şu adrese yüklendiğini varsayacağız:C:\natural_language_toolkit_data Linux, Unix ve Mac OS X hakkında konuşursak, bu veri paketinin şu adrese yüklendiğini varsayacağız: /usr/share/natural_language_toolkit_data.
Aşağıdaki Python tarifinde, NLTK tarafından tanımlanan yollardan biri içinde olması gereken özel corpora oluşturacağız. Öyle çünkü NLTK tarafından bulunabilir. Resmi NLTK veri paketiyle çakışmayı önlemek için, ana dizinimizde özel bir doğal_dil_toolkit_data dizini oluşturalım.
import os, os.path
path = os.path.expanduser('~/natural_language_toolkit_data')
if not os.path.exists(path):
os.mkdir(path)
os.path.exists(path)Çıktı
TrueŞimdi, ana dizininizde natural_language_toolkit_data dizinimiz olup olmadığını kontrol edelim -
import nltk.data
path in nltk.data.pathÇıktı
TrueTrue çıktısına sahip olduğumuz için, nltk_data ana dizinimizdeki dizin.
Şimdi adlı bir wordlist dosyası yapacağız. wordfile.txt ve bunu korpus adlı bir klasöre koyun nltk_data dizin (~/nltk_data/corpus/wordfile.txt) ve kullanarak yükleyecek nltk.data.load -
import nltk.data
nltk.data.load(‘corpus/wordfile.txt’, format = ‘raw’)Çıktı
b’tutorialspoint\n’Derlem okuyucuları
NLTK, çeşitli CorpusReader sınıfları sağlar. Bunları aşağıdaki piton tariflerinde ele alacağız
Kelime listesi külliyatının oluşturulması
NLTK, WordListCorpusReaderkelime listesi içeren dosyaya erişim sağlayan sınıf. Aşağıdaki Python tarifi için CSV veya normal metin dosyası olabilen bir wordlist dosyası oluşturmamız gerekiyor. Örneğin, aşağıdaki verileri içeren 'liste' adlı bir dosya oluşturduk -
tutorialspoint
Online
Free
TutorialsŞimdi bir örnekleyelim WordListCorpusReader Oluşturduğumuz dosyadan kelime listesini üreten sınıf ‘list’.
from nltk.corpus.reader import WordListCorpusReader
reader_corpus = WordListCorpusReader('.', ['list'])
reader_corpus.words()Çıktı
['tutorialspoint', 'Online', 'Free', 'Tutorials']POS etiketli kelime külliyatı oluşturma
NLTK, TaggedCorpusReaderPOS etiketli bir kelime korpusu oluşturabileceğimiz bir sınıf. Aslında, POS etiketleme, bir kelime için konuşma parçası etiketini tanımlama işlemidir.
Etiketli bir külliyat için en basit biçimlerden biri, kahverengi külliyattan alınan alıntıdan sonra gelen 'kelime / etiket' biçimindedir -
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber
astronomical/jj ./.Yukarıdaki alıntıda, her kelimenin POS'unu gösteren bir etiketi vardır. Örneğin,vb bir fiil anlamına gelir.
Şimdi bir örnekleyelim TaggedCorpusReadersınıf üreten POS etiketli kelimeleri dosyadan oluşturur ‘list.pos’, yukarıdaki alıntıya sahip.
from nltk.corpus.reader import TaggedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.pos')
reader_corpus.tagged_words()Çıktı
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]Yığınlanmış kelime öbeği korpusu oluşturma
NLTK, ChnkedCorpusReaderyardımıyla bir Chunked ifade külliyatını oluşturabileceğimiz sınıf. Aslında yığın, cümledeki kısa bir ifadedir.
Örneğin, etiketli aşağıdaki alıntıya sahibiz: treebank külliyat -
[Earlier/JJR staff-reduction/NN moves/NNS] have/VBP trimmed/VBN about/
IN [300/CD jobs/NNS] ,/, [the/DT spokesman/NN] said/VBD ./.Yukarıdaki alıntıda, her yığın bir isim tümcecikidir ancak parantez içinde olmayan sözcükler cümle ağacının bir parçasıdır ve herhangi bir isim tümcesi alt ağacının parçası değildir.
Şimdi bir örnekleyelim ChunkedCorpusReader dosyadan öbeklenmiş öbek üreten sınıf ‘list.chunk’, yukarıdaki alıntıya sahip.
from nltk.corpus.reader import ChunkedCorpusReader
reader_corpus = TaggedCorpusReader('.', r'.*\.chunk')
reader_corpus.chunked_words()Çıktı
[
Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'), ('moves', 'NNS')]),
('have', 'VBP'), ...
]Kategorize Edilmiş Metin Külliyatı Oluşturma
NLTK, CategorizedPlaintextCorpusReaderyardımıyla kategorize edilmiş bir metin külliyatını oluşturabileceğimiz sınıf. Büyük bir metin külliyatına sahip olduğumuz ve bunu ayrı bölümlere ayırmak istediğimiz durumlarda çok kullanışlıdır.
Örneğin, kahverengi külliyatın birkaç farklı kategorisi vardır. Bunları Python kodunu takip ederek bulalım -
from nltk.corpus import brown^M
brown.categories()Çıktı
[
'adventure', 'belles_lettres', 'editorial', 'fiction', 'government',
'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion',
'reviews', 'romance', 'science_fiction'
]Bir külliyatı kategorize etmenin en kolay yollarından biri, her kategori için bir dosyaya sahip olmaktır. Örneğin, şu iki alıntıya bakalım:movie_reviews külliyat -
movie_pos.txt
İnce kırmızı çizgi kusurlu ama kışkırtıyor.
movie_neg.txt
Büyük bütçeli ve gösterişli bir yapım, televizyon şovlarına nüfuz eden kendiliğindenlik eksikliğini telafi edemez.
Yani, yukarıdaki iki dosyadan iki kategorimiz var: pos ve neg.
Şimdi bir örnekleyelim CategorizedPlaintextCorpusReader sınıf.
from nltk.corpus.reader import CategorizedPlaintextCorpusReader
reader_corpus = CategorizedPlaintextCorpusReader('.', r'movie_.*\.txt',
cat_pattern = r'movie_(\w+)\.txt')
reader_corpus.categories()
reader_corpus.fileids(categories = [‘neg’])
reader_corpus.fileids(categories = [‘pos’])Çıktı
['neg', 'pos']
['movie_neg.txt']
['movie_pos.txt']POS etiketlemesi nedir?
Bir tür sınıflandırma olan etiketleme, belirteçlerin açıklamasının otomatik olarak atanmasıdır. Tanımlayıcının konuşma bölümlerinden birini (isimler, fiil, zarflar, sıfatlar, zamirler, bağlaçlar ve bunların alt kategorileri), anlamsal bilgi ve benzerlerini temsil eden 'etiketi' olarak adlandırıyoruz.
Öte yandan, Konuşma Parçası (POS) etiketlemesinden bahsedecek olursak, bir kelime listesi biçimindeki bir cümleyi bir demet listesine dönüştürme işlemi olarak tanımlanabilir. Burada demetler (kelime, etiket) biçimindedir. POS etiketlemeyi, konuşma bölümlerinden birini verilen kelimeye atama işlemini de adlandırabiliriz.
Aşağıdaki tablo, Penn Treebank külliyatında en sık kullanılan POS bildirimini göstermektedir -
| Sr.No | Etiket | Açıklama |
|---|---|---|
| 1 | NNP | Uygun isim, tekil |
| 2 | NNPS | Özel isim, çoğul |
| 3 | Pasifik yaz saati | Ön belirleyici |
| 4 | POS | İyelik sonu |
| 5 | PRP | Şahıs zamiri |
| 6 | PRP $ | İyelik zamiri |
| 7 | RB | Zarf |
| 8 | RBR | Zarf, karşılaştırmalı |
| 9 | RBS | Zarf, en üstün |
| 10 | RP | Parçacık |
| 11 | SYM | Sembol (matematiksel veya bilimsel) |
| 12 | KİME | -e |
| 13 | UH | Ünlem |
| 14 | VB | Fiil, temel biçim |
| 15 | VBD | Fiil, geçmiş zaman |
| 16 | VBG | Fiil, ulaç / şimdiki zaman ortacı |
| 17 | VBN | Fiil, geçmiş |
| 18 | WP | Wh zamiri |
| 19 | WP $ | İyelik wh-zamiri |
| 20 | WRB | Wh-zarf |
| 21 | # | Diyez işareti |
| 22 | $ | Dolar işareti |
| 23 | . | Cümle sonu noktalama |
| 24 | , | Virgül |
| 25 | : | Kolon, noktalı virgül |
| 26 | ( | Sol ayraç karakteri |
| 27 | ) | Sağ köşeli ayraç karakteri |
| 28 | " | Düz çift tırnak |
| 29 | ' | Sol açık tek alıntı |
| 30 | " | Sol açık çift tırnak |
| 31 | ' | Sağdan yakın tek tırnak |
| 32 | " | Sağa açık çift tırnak |
Misal
Bunu bir Python deneyiyle anlayalım -
import nltk
from nltk import word_tokenize
sentence = "I am going to school"
print (nltk.pos_tag(word_tokenize(sentence)))Çıktı
[('I', 'PRP'), ('am', 'VBP'), ('going', 'VBG'), ('to', 'TO'), ('school', 'NN')]Neden POS etiketlemesi?
POS etiketleme, NLP'nin önemli bir parçasıdır çünkü aşağıdaki gibi daha fazla NLP analizi için ön koşul olarak çalışır -
- Chunking
- Sözdizimi Ayrıştırma
- Bilgi çıkarma
- Makine Çevirisi
- Duygu Analizi
- Dilbilgisi analizi ve kelime anlamında belirsizlik giderme
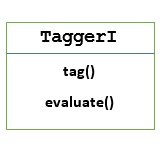
TaggerI - Temel sınıf
Tüm etiketleyiciler NLTK'nın nltk.tag paketinde bulunur. Bu etiketleyicilerin temel sınıfıTaggerI, tüm etiketleyicilerin bu sınıftan miras aldığı anlamına gelir.
Methods - TaggerI sınıfı, tüm alt sınıfları tarafından uygulanması gereken aşağıdaki iki yönteme sahiptir -
tag() method - Adından da anlaşılacağı gibi, bu yöntem girdi olarak bir sözcük listesi alır ve çıktı olarak etiketlenmiş sözcüklerin bir listesini döndürür.
evaluate() method - Bu yöntem sayesinde etiketleyicinin doğruluğunu değerlendirebiliriz.
POS Etiketlemenin Temelleri
POS etiketlemesinin temeli veya temel adımı, Default Tagging, NLTK'nin DefaultTagger sınıfı kullanılarak gerçekleştirilebilir. Varsayılan etiketleme, aynı POS etiketini her jetona atar. Varsayılan etiketleme ayrıca doğruluk iyileştirmelerini ölçmek için bir temel sağlar.
DefaultTagger sınıfı
Varsayılan etiketleme kullanılarak gerçekleştirilir DefaultTagging sınıf, tek bağımsız değişkeni, yani uygulamak istediğimiz etiketi alan.
O nasıl çalışır?
Daha önce de belirtildiği gibi, tüm etiketleyiciler TaggerIsınıf. DefaultTagger miras kaldı SequentialBackoffTagger alt sınıfı olan TaggerI class. Bunu aşağıdaki diyagramla anlayalım -
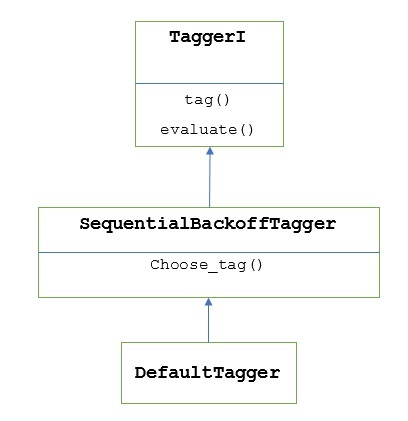
Parçası olarak SeuentialBackoffTagger, DefaultTagger Aşağıdaki üç argümanı alan select_tag () yöntemini uygulamalıdır.
- Jeton listesi
- Mevcut jeton dizini
- Önceki jeton listesi, yani geçmiş
Misal
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag(['Tutorials','Point'])Çıktı
[('Tutorials', 'NN'), ('Point', 'NN')]Bu örnekte, en yaygın kelime türleri olduğu için bir isim etiketi seçtik. Dahası,DefaultTagger en yaygın POS etiketini seçtiğimizde de en kullanışlıdır.
Doğruluk değerlendirmesi
DefaultTaggerayrıca etiketleyicilerin doğruluğunu değerlendirmek için temeldir. Onu birlikte kullanabilmemizin nedeni budur.evaluate()doğruluğu ölçme yöntemi. evaluate() yöntemi etiketleyiciyi değerlendirmek için altın standart olarak etiketlenmiş belirteçlerin bir listesini alır.
Aşağıda, adlı varsayılan etiketleyicimizi kullandığımız bir örnek yer almaktadır. exptagger, bir alt kümesinin doğruluğunu değerlendirmek için yukarıda oluşturulmuştur treebank corpus etiketli cümleler -
Misal
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
from nltk.corpus import treebank
testsentences = treebank.tagged_sents() [1000:]
exptagger.evaluate (testsentences)Çıktı
0.13198749536374715Yukarıdaki çıktı şunu gösterir: NN Her etiket için, 1000 girişte yaklaşık% 13 doğruluk testi gerçekleştirebiliriz. treebank külliyat.
Bir cümle listesini etiketleme
Tek bir cümleyi etiketlemek yerine, NLTK'lar TaggerI sınıf ayrıca bize bir tag_sents()yardımı ile bir cümle listesini etiketleyebileceğimiz yöntem. İki basit cümleyi etiketlediğimiz örnek aşağıdadır
Misal
import nltk
from nltk.tag import DefaultTagger
exptagger = DefaultTagger('NN')
exptagger.tag_sents([['Hi', ','], ['How', 'are', 'you', '?']])Çıktı
[
[
('Hi', 'NN'),
(',', 'NN')
],
[
('How', 'NN'),
('are', 'NN'),
('you', 'NN'),
('?', 'NN')
]
]Yukarıdaki örnekte, daha önce oluşturduğumuz varsayılan etiketleyicimizi kullandık. exptagger.
Bir cümlenin etiketini kaldırma
Ayrıca bir cümlenin etiketini kaldırabiliriz. NLTK, bu amaç için nltk.tag.untag () yöntemini sağlar. Giriş olarak etiketli bir cümle alacak ve etiketsiz kelimelerin bir listesini sağlayacaktır. Bir örnek görelim -
Misal
import nltk
from nltk.tag import untag
untag([('Tutorials', 'NN'), ('Point', 'NN')])Çıktı
['Tutorials', 'Point']Unigram Etiketleyici nedir?
Adından da anlaşılacağı gibi, unigram etiketleyici, POS (Konuşma Kısmı) etiketini belirlemek için bağlam olarak yalnızca tek bir kelimeyi kullanan bir etiketleyicidir. Basit bir deyişle, Unigram Tagger, bağlamı tek bir kelime, yani Unigram olan bağlam tabanlı bir etiketleyicidir.
O nasıl çalışır?
NLTK adlı bir modül sağlar UnigramTaggerbu amaç için. Ancak çalışmasına derinlemesine dalmadan önce, aşağıdaki diyagramın yardımıyla hiyerarşiyi anlayalım -
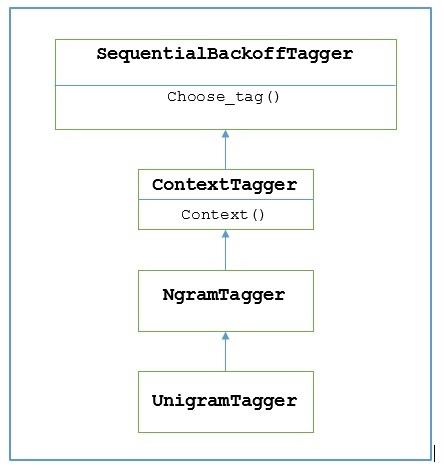
Yukarıdaki diyagramdan anlaşılmaktadır ki UnigramTagger miras kaldı NgramTagger alt sınıfı olan ContextTaggermiras alan SequentialBackoffTagger.
Çalışma UnigramTagger aşağıdaki adımların yardımı ile açıklanmaktadır -
Gördüğümüz gibi, UnigramTagger miras alır ContextTagger, bir context()yöntem. Bucontext() yöntem aynı üç argümanı alır choose_tag() yöntem.
Sonucu context()yöntem, modeli oluşturmak için daha sonra kullanılan kelime simgesi olacaktır. Model oluşturulduktan sonra, simge simgesi de en iyi etiketi aramak için kullanılır.
Böylece, UnigramTagger etiketli cümleler listesinden bir bağlam modeli oluşturacaktır.
Unigram Etiketleyici Eğitimi
NLTK'lar UnigramTaggerbaşlatma sırasında etiketli cümlelerin bir listesi sağlanarak eğitilebilir. Aşağıdaki örnekte, treebank külliyatının etiketli cümlelerini kullanacağız. Bu külliyattan ilk 2500 cümleyi kullanacağız.
Misal
Önce UniframTagger modülünü nltk'den içe aktarın -
from nltk.tag import UnigramTaggerArdından, kullanmak istediğiniz külliyatı içe aktarın. Burada treebank corpus kullanıyoruz -
from nltk.corpus import treebankŞimdi, eğitim amaçlı cümleleri alın. Eğitim amaçlı ilk 2500 cümleyi alıyoruz ve etiketleyeceğiz -
train_sentences = treebank.tagged_sents()[:2500]Ardından, eğitim amacıyla kullanılan cümlelere UnigramTagger uygulayın -
Uni_tagger = UnigramTagger(train_sentences)Test amacıyla eğitim amacıyla, yani 2500'e eşit veya daha az alınmış bazı cümleler alın. Burada test amacıyla ilk 1500'ü alıyoruz -
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sents)Çıktı
0.8942306156033808Burada, POS etiketini belirlemek için tek kelime arama kullanan bir etiketleyici için yaklaşık yüzde 89 doğruluk elde ettik.
Eksiksiz uygulama örneği
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Çıktı
0.8942306156033808Bağlam modelini geçersiz kılmak
İçin hiyerarşiyi gösteren yukarıdaki diyagramdan UnigramTaggermiras alan tüm etiketleyicileri biliyoruz ContextTaggerkendi eğitmek yerine, önceden oluşturulmuş bir model alabilir. Bu önceden oluşturulmuş model, bir etikete bağlam anahtarının Python sözlüğü eşlemesidir. Ve içinUnigramTaggerbağlam anahtarları tek tek kelimelerdir, diğerleri içinse NgramTagger alt sınıflar, tuple olacaktır.
Bu bağlam modelini, başka bir basit modeli UnigramTaggereğitim setini geçmek yerine sınıf. Bunu aşağıdaki kolay bir örnek yardımıyla anlayalım -
Misal
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
Override_tagger = UnigramTagger(model = {‘Vinken’ : ‘NN’})
Override_tagger.tag(treebank.sents()[0])Çıktı
[
('Pierre', None),
('Vinken', 'NN'),
(',', None),
('61', None),
('years', None),
('old', None),
(',', None),
('will', None),
('join', None),
('the', None),
('board', None),
('as', None),
('a', None),
('nonexecutive', None),
('director', None),
('Nov.', None),
('29', None),
('.', None)
]Modelimiz tek bağlam anahtarı olarak 'Vinken'i içerdiğinden, yukarıdaki çıktıdan sadece bu kelimenin etiketi olduğunu ve diğer her kelimenin etiket olarak Hiçbiri olmadığını görebilirsiniz.
Minimum frekans eşiği ayarlama
Belirli bir bağlam için hangi etiketin en olası olduğuna karar vermek için, ContextTaggersınıf, oluşum sıklığını kullanır. Bağlam kelimesi ve etiketi yalnızca bir kez geçse bile bunu varsayılan olarak yapacaktır, ancak bir minimum frekans eşiği ayarlayabiliriz.cutoff değeri UnigramTaggersınıf. Aşağıdaki örnekte, UnigramTagger'ı eğittiğimiz önceki tarifte kesme değerini geçiyoruz -
Misal
from nltk.tag import UnigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Uni_tagger = UnigramTagger(train_sentences, cutoff = 4)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Çıktı
0.7357651629613641Etiketleyicileri Birleştirme
Etiketleyicileri veya zincirleme etiketleyicileri birbiriyle birleştirmek, NLTK'nın önemli özelliklerinden biridir. Etiketleyicileri birleştirmenin arkasındaki ana kavram, bir etiketleyicinin bir kelimeyi nasıl etiketleyeceğini bilmemesi durumunda, zincirleme etiketleyiciye aktarılacağıdır. Bu amaca ulaşmak için,SequentialBackoffTagger bize sağlar Backoff tagging özelliği.
Backoff Etiketleme
Daha önce de belirtildiği gibi, geri çekilme etiketlemesi, önemli özelliklerinden biridir. SequentialBackoffTaggerBu, etiketleyicileri, bir etiketleyici bir kelimeyi nasıl etiketleyeceğini bilmiyorsa, kelime bir sonraki etiketleyiciye aktarılacak ve kontrol edilecek geri çekilme etiketleyicileri kalmayana kadar bu şekilde birleştirmemize olanak tanır.
O nasıl çalışır?
Aslında, her alt sınıfı SequentialBackoffTaggerbir 'geri çekilme' anahtar kelime argümanı alabilir. Bu anahtar kelime bağımsız değişkeninin değeri, başka birSequentialBackoffTagger. Şimdi ne zaman buSequentialBackoffTaggersınıf başlatıldığında, geri çekilme etiketleyicilerinin dahili bir listesi (kendisi ilk öğe olarak) oluşturulacaktır. Ayrıca, bir geri çekilme etiketleyicisi verilirse, bu geri çekilme etiketleyicilerin dahili listesi eklenecektir.
Aşağıdaki örnekte, alıyoruz DefaulTagger yukarıdaki Python tarifinde geri çekilme etiketleyicisi olarak UnigramTagger.
Misal
Bu örnekte, kullanıyoruz DefaulTaggergeri çekilme etiketleyicisi olarak. Ne zamanUnigramTagger bir kelimeyi etiketleyemiyor, geri çekilme etiketleyicisi, yani DefaulTaggerbizim durumumuzda onu 'NN' ile etiketleyecektir.
from nltk.tag import UnigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Uni_tagger = UnigramTagger(train_sentences, backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Uni_tagger.evaluate(test_sentences)Çıktı
0.9061975746536931Yukarıdaki çıktıdan, bir geri çekilme etiketleyicisi ekleyerek doğruluğun yaklaşık% 2 oranında arttığını gözlemleyebilirsiniz.
Etiketleyicileri turşu ile kaydetme
Bir etiketleyiciyi eğitmenin çok zahmetli olduğunu ve aynı zamanda zaman aldığını gördüğümüz gibi. Zaman kazanmak için, daha sonra kullanmak üzere eğitimli bir etiketleyiciyi seçebiliriz. Aşağıdaki örnekte, bunu, adlı önceden eğitilmiş etiketleyicimize yapacağız.‘Uni_tagger’.
Misal
import pickle
f = open('Uni_tagger.pickle','wb')
pickle.dump(Uni_tagger, f)
f.close()
f = open('Uni_tagger.pickle','rb')
Uni_tagger = pickle.load(f)NgramTagger Sınıfı
Önceki ünitede tartışılan hiyerarşi diyagramından, UnigramTagger miras kaldı NgarmTagger sınıf ama iki alt sınıfımız daha var NgarmTagger sınıf -
BigramTagger alt sınıfı
Aslında bir ngram, n öğeden oluşan bir alt dizidir, dolayısıyla adından da anlaşılacağı gibi, BigramTaggeralt sınıf iki öğeye bakar. İlk öğe, önceki etiketlenmiş sözcüktür ve ikinci öğe, geçerli etiketlenmiş sözcüktür.
TrigramTagger alt sınıfı
Aynı notta BigramTagger, TrigramTagger alt sınıf, üç öğeye bakar, yani iki önceki etiketli kelime ve bir geçerli etiketlenmiş kelime.
Pratik olarak uygularsak BigramTagger ve TrigramTaggerUnigramTagger alt sınıfında yaptığımız gibi alt sınıflar tek tek, ikisi de çok kötü performans gösteriyor. Aşağıdaki örneklerde görelim:
BigramTagger Alt Sınıfını Kullanma
from nltk.tag import BigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Bi_tagger = BigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Bi_tagger.evaluate(test_sentences)Çıktı
0.44669191071913594TrigramTagger Alt Sınıfını Kullanma
from nltk.tag import TrigramTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Tri_tagger = TrigramTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Tri_tagger.evaluate(test_sentences)Çıktı
0.41949863394526193Daha önce kullandığımız (yaklaşık% 89 doğruluk verdi) UnigramTagger'ın performansını BigramTagger (yaklaşık% 44 doğruluk sağladı) ve TrigramTagger (yaklaşık% 41 doğruluk verdi) ile karşılaştırabilirsiniz. Bunun nedeni, Bigram ve Trigram etiketleyicilerinin cümledeki ilk sözcük (ler) den bağlamı öğrenememesidir. Öte yandan, UnigramTagger sınıfı önceki bağlamı önemsemez ve her kelime için en yaygın etiketi tahmin eder, bu nedenle yüksek temel doğruluğa sahip olabilir.
Ngram etiketleyicileri birleştirmek
Yukarıdaki örneklerde olduğu gibi, Bigram ve Trigram etiketleyicilerinin, onları geri çekilme etiketlemeyle birleştirdiğimizde katkıda bulunabileceği açıktır. Aşağıdaki örnekte Unigram, Bigram ve Trigram etiketleyicileri geri çekilme etiketleme ile birleştiriyoruz. UnigramTagger'ı backoff tagger ile birleştirirken konsept önceki tarifle aynıdır. Tek fark, geri çekilme işlemi için aşağıda verilen tagger_util.py'deki backoff_tagger () adlı işlevi kullanıyor olmamızdır.
def backoff_tagger(train_sentences, tagger_classes, backoff=None):
for cls in tagger_classes:
backoff = cls(train_sentences, backoff=backoff)
return backoffMisal
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Çıktı
0.9234530029238365Yukarıdaki çıktıdan doğruluğu yaklaşık% 3 artırdığını görebiliriz.
Ek Etiketleyici
ContextTagger alt sınıfının bir diğer önemli sınıfı, AffixTagger'dır. AffixTagger sınıfında, bağlam, bir sözcüğün öneki ya da sonekidir. AffixTagger sınıfının, bir kelimenin başındaki veya sonundaki sabit uzunluktaki alt dizelere dayalı olarak etiketleri öğrenmesinin nedeni budur.
O nasıl çalışır?
Çalışması, önek veya sonekin uzunluğunu belirten affix_length adlı argümana bağlıdır. Varsayılan değer 3'tür. Fakat AffixTagger sınıfının kelimenin önekini veya sonekini öğrenip öğrenmediğini nasıl ayırt eder?
affix_length=positive - affix_lenght değeri pozitifse bu, AffixTagger sınıfının kelimenin öneklerini öğreneceği anlamına gelir.
affix_length=negative - affix_lenght değeri negatifse bu, AffixTagger sınıfının kelimenin soneklerini öğreneceği anlamına gelir.
Daha açık hale getirmek için, aşağıdaki örnekte, etiketli treebank cümlelerinde AffixTagger sınıfını kullanacağız.
Misal
Bu örnekte, AffixTagger sözcüğün önekini öğrenecek çünkü affix_length bağımsız değişkeni için herhangi bir değer belirtmiyoruz. Bağımsız değişken varsayılan 3 değerini alacaktır -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Çıktı
0.2800492099250667Aşağıdaki örnekte, affix_length argümanına 4 değerini verdiğimizde doğruluğun ne olacağını görelim -
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Prefix_tagger = AffixTagger(train_sentences, affix_length=4 )
test_sentences = treebank.tagged_sents()[1500:]
Prefix_tagger.evaluate(test_sentences)Çıktı
0.18154947354966527Misal
Bu örnekte, AffixTagger kelimenin sonekini öğrenecek çünkü affix_length bağımsız değişkeni için negatif bir değer belirleyeceğiz.
from nltk.tag import AffixTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
Suffix_tagger = AffixTagger(train_sentences, affix_length = -3)
test_sentences = treebank.tagged_sents()[1500:]
Suffix_tagger.evaluate(test_sentences)Çıktı
0.2800492099250667Brill Etiketleyici
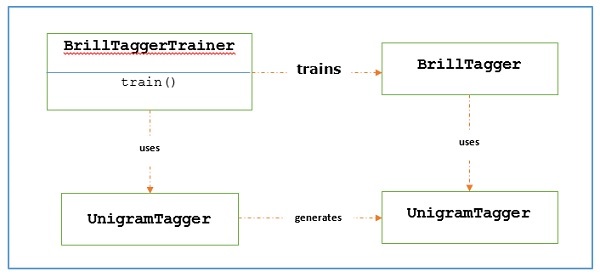
Brill Tagger, dönüşüm tabanlı bir etiketleyicidir. NLTK sağlarBrillTagger alt sınıfı olmayan ilk etiketleyici olan sınıf SequentialBackoffTagger. Bunun karşısında, ilk etiketleyicinin sonuçlarını düzeltmek için bir dizi kural kullanılır.BrillTagger.
O nasıl çalışır?
Eğitmek için BrillTagger sınıf kullanıyor BrillTaggerTrainer aşağıdaki işlevi tanımlıyoruz -
def train_brill_tagger(initial_tagger, train_sentences, **kwargs) -
templates = [
brill.Template(brill.Pos([-1])),
brill.Template(brill.Pos([1])),
brill.Template(brill.Pos([-2])),
brill.Template(brill.Pos([2])),
brill.Template(brill.Pos([-2, -1])),
brill.Template(brill.Pos([1, 2])),
brill.Template(brill.Pos([-3, -2, -1])),
brill.Template(brill.Pos([1, 2, 3])),
brill.Template(brill.Pos([-1]), brill.Pos([1])),
brill.Template(brill.Word([-1])),
brill.Template(brill.Word([1])),
brill.Template(brill.Word([-2])),
brill.Template(brill.Word([2])),
brill.Template(brill.Word([-2, -1])),
brill.Template(brill.Word([1, 2])),
brill.Template(brill.Word([-3, -2, -1])),
brill.Template(brill.Word([1, 2, 3])),
brill.Template(brill.Word([-1]), brill.Word([1])),
]
trainer = brill_trainer.BrillTaggerTrainer(initial_tagger, templates, deterministic=True)
return trainer.train(train_sentences, **kwargs)Gördüğümüz gibi, bu işlev şunu gerektirir: initial_tagger ve train_sentences. Bir alırinitial_tagger bağımsız değişken ve bir şablon listesi, BrillTemplatearayüz. BrillTemplate arayüzü şurada bulunur: nltk.tbl.templatemodül. Bu tür uygulamalardan biribrill.Template sınıf.
Dönüşüm tabanlı etiketleyicinin ana rolü, ilk etiketleyicinin çıktısını eğitim cümleleri ile daha uyumlu olacak şekilde düzelten dönüşüm kuralları oluşturmaktır. İş akışını aşağıda görelim -
Misal
Bu örnek için kullanacağız combine_tagger (önceki tarifte) etiketleyicileri tararken oluşturduğumuz, geri çekilme zincirinden NgramTagger sınıflar olarak initial_tagger. Önce sonucu şu şekilde değerlendirelim:Combine.tagger ve sonra bunu olarak kullan initial_tagger brill tagger yetiştirmek için.
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(
train_sentences, [UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger
)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)Çıktı
0.9234530029238365Şimdi değerlendirme sonucuna bakalım. Combine_tagger Olarak kullanılır initial_tagger brill tagger'ı eğitmek -
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Çıktı
0.9246832510505041Bunu fark edebiliriz BrillTagger sınıfının biraz daha yüksek doğruluğu vardır. Combine_tagger.
Eksiksiz uygulama örneği
from tagger_util import backoff_tagger
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
from nltk.tag import DefaultTagger
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
back_tagger = DefaultTagger('NN')
Combine_tagger = backoff_tagger(train_sentences,
[UnigramTagger, BigramTagger, TrigramTagger], backoff = back_tagger)
test_sentences = treebank.tagged_sents()[1500:]
Combine_tagger.evaluate(test_sentences)
from tagger_util import train_brill_tagger
brill_tagger = train_brill_tagger(combine_tagger, train_sentences)
brill_tagger.evaluate(test_sentences)Çıktı
0.9234530029238365
0.9246832510505041TnT Etiketleyici
TnT Tagger, Trigrams'nTags'in kısaltmasıdır ve ikinci derece Markov modellerine dayanan istatistiksel bir etiketleyicidir.
O nasıl çalışır?
Aşağıdaki adımlar yardımıyla TnT etiketleyicinin çalışmasını anlayabiliriz -
İlk olarak eğitim verilerine dayalı olarak, TnT tegger birkaç dahili FreqDist ve ConditionalFreqDist örnekler.
Bundan sonra unigramlar, bigramlar ve trigramlar bu frekans dağılımları tarafından sayılacaktır.
Şimdi, etiketleme sırasında, frekansları kullanarak, her kelime için olası etiketlerin olasılıklarını hesaplayacaktır.
Bu nedenle, NgramTagger'ın geri çekilme zincirini oluşturmak yerine, her kelime için en iyi etiketi seçmek için tüm ngram modellerini birlikte kullanır. Aşağıdaki örnekte doğruluğu TnT etiketleyici ile değerlendirelim -
from nltk.tag import tnt
from nltk.corpus import treebank
train_sentences = treebank.tagged_sents()[:2500]
tnt_tagger = tnt.TnT()
tnt_tagger.train(train_sentences)
test_sentences = treebank.tagged_sents()[1500:]
tnt_tagger.evaluate(test_sentences)Çıktı
0.9165508316157791Brill Tagger ile elde ettiğimizden biraz daha az doğruluğa sahibiz.
Lütfen aramamız gerektiğini unutmayın train() önce evaluate() aksi takdirde% 0 doğruluk elde ederiz.
Ayrıştırma ve NLP'deki alaka düzeyi
Kökeni Latince kelimeden gelen 'Ayrıştırma' kelimesi ‘pars’ (yani ‘part’), metinden tam anlam veya sözlük anlamını çıkarmak için kullanılır. Sözdizimi analizi veya sözdizimi analizi olarak da adlandırılır. Biçimsel gramer kurallarını karşılaştıran sözdizimi analizi, metnin anlamlı olup olmadığını kontrol eder. Örneğin, "Bana sıcak dondurma ver" gibi cümle ayrıştırıcı veya sözdizimsel çözümleyici tarafından reddedilir.
Bu anlamda, ayrıştırma veya sözdizimsel analizi veya sözdizimi analizini şu şekilde tanımlayabiliriz -
Biçimsel dilbilgisi kurallarına uygun olarak sembol dizilerinin doğal dilde analiz edilmesi süreci olarak tanımlanabilir.
Aşağıdaki noktaların yardımıyla NLP'de ayrıştırmanın uygunluğunu anlayabiliriz -
Ayrıştırıcı, herhangi bir sözdizimi hatasını bildirmek için kullanılır.
Programın geri kalanının işlenmesine devam edilebilmesi için yaygın olarak meydana gelen hatalardan kurtulmaya yardımcı olur.
Ayrıştırma ağacı bir ayrıştırıcı yardımı ile oluşturulur.
Ayrıştırıcı, NLP'de önemli bir rol oynayan sembol tablosu oluşturmak için kullanılır.
Ayrıştırıcı ayrıca ara gösterimler (IR) üretmek için de kullanılır.
Derin ve Sığ Ayrıştırma
| Derin Ayrıştırma | Sığ Ayrıştırma |
|---|---|
| Derin ayrıştırmada, arama stratejisi bir cümleye tam bir sözdizimsel yapı verecektir. | Verilen görevdeki sözdizimsel bilginin sınırlı bir bölümünü ayrıştırma görevidir. |
| Karmaşık NLP uygulamaları için uygundur. | Daha az karmaşık NLP uygulamaları için kullanılabilir. |
| Diyalog sistemleri ve özetleme, derin ayrıştırmanın kullanıldığı NLP uygulamalarının örnekleridir. | Bilgi çıkarma ve metin madenciliği, derin ayrıştırmanın kullanıldığı NLP uygulamalarının örnekleridir. |
| Tam ayrıştırma olarak da adlandırılır. | Aynı zamanda yığınlama olarak da adlandırılır. |
Çeşitli ayrıştırıcı türleri
Tartışıldığı gibi, ayrıştırıcı temelde dilbilgisinin prosedürel bir yorumudur. Çeşitli ağaçların arasında arama yaptıktan sonra verilen cümle için en uygun ağacı bulur. Aşağıda mevcut ayrıştırıcılardan bazılarını görelim -
Yinelemeli iniş ayrıştırıcı
Özyinelemeli iniş ayrıştırma, ayrıştırmanın en basit biçimlerinden biridir. Aşağıda yinelemeli iniş ayrıştırıcısı hakkında bazı önemli noktalar verilmiştir -
Yukarıdan aşağıya bir süreci takip eder.
Giriş akışının sözdiziminin doğru olup olmadığını doğrulamaya çalışır.
Giriş cümlesini soldan sağa okur.
Özyinelemeli iniş ayrıştırıcısı için gerekli bir işlem, giriş akışından karakterleri okumak ve bunları dilbilgisindeki uçbirimlerle eşleştirmektir.
Shift-azaltma ayrıştırıcı
Shift-azaltma ayrıştırıcısı hakkında bazı önemli noktalar aşağıdadır -
Basit bir aşağıdan yukarıya süreci izler.
Bir gramer üretiminin sağ tarafına karşılık gelen ve bunları üretimin sol tarafıyla değiştiren bir dizi kelime ve kelime öbeği bulmaya çalışır.
Yukarıdaki bir kelime dizisi bulma girişimi, tüm cümle azalıncaya kadar devam eder.
Diğer basit bir deyişle, kaydırma-azaltma ayrıştırıcısı, giriş sembolüyle başlar ve ayrıştırıcı ağacını başlangıç sembolüne kadar oluşturmaya çalışır.
Grafik ayrıştırıcı
Aşağıda, grafik ayrıştırıcıyla ilgili bazı önemli noktalar verilmiştir -
Esas olarak, doğal dillerin gramerleri dahil, belirsiz gramerler için yararlı veya uygundur.
Çözümleme problemlerine dinamik programlama uygular.
Dinamik programlamadan dolayı, kısmi varsayılmış sonuçlar 'grafik' adı verilen bir yapıda saklanır.
'Grafik' de yeniden kullanılabilir.
Regexp ayrıştırıcı
Regexp ayrıştırma, en çok kullanılan ayrıştırma tekniklerinden biridir. Aşağıda, Regexp ayrıştırıcısı hakkında bazı önemli noktalar verilmiştir -
Adından da anlaşılacağı gibi, POS etiketli bir dizenin üstünde gramer biçiminde tanımlanan normal bir ifade kullanır.
Temel olarak bu düzenli ifadeleri girdi cümlelerini ayrıştırmak ve bundan bir ayrıştırma ağacı oluşturmak için kullanır.
Misal
Aşağıda, Regexp Parser'ın çalışan bir örneği verilmiştir -
import nltk
sentence = [
("a", "DT"),
("clever", "JJ"),
("fox","NN"),
("was","VBP"),
("jumping","VBP"),
("over","IN"),
("the","DT"),
("wall","NN")
]
grammar = "NP:{<DT>?<JJ>*<NN>}"
Reg_parser = nltk.RegexpParser(grammar)
Reg_parser.parse(sentence)
Output = Reg_parser.parse(sentence)
Output.draw()Çıktı
Bağımlılık Ayrıştırma
Bağımlılık Ayrıştırma (DP), modern bir çözümleme mekanizması olup, ana kavramı her dil biriminin, yani kelimelerin doğrudan bir bağlantıyla birbiriyle ilişkili olmasıdır. Bu doğrudan bağlantılar aslında‘dependencies’dilbilimsel olarak. Örneğin, aşağıdaki diyagram cümle için bağımlılık dilbilgisini gösterir.“John can hit the ball”.

NLTK Paketi
NLTK ile bağımlılık ayrıştırması yapmanın iki yolunu takip ediyoruz -
Olasılıklı, projektif bağımlılık ayrıştırıcı
Bu, NLTK ile bağımlılık ayrıştırmasını yapmanın ilk yoludur. Ancak bu ayrıştırıcı, sınırlı bir eğitim verisi kümesiyle eğitim kısıtlamasına sahiptir.
Stanford ayrıştırıcı
Bu, NLTK ile bağımlılık ayrıştırmasını yapabileceğimiz başka bir yoldur. Stanford ayrıştırıcısı, son teknoloji ürünü bir bağımlılık ayrıştırıcısıdır. NLTK'nın etrafında bir sarmalayıcı var. Kullanmak için aşağıdaki iki şeyi indirmemiz gerekiyor -
Stanford CoreNLP ayrıştırıcı .
İstenilen dil için dil modeli . Örneğin, İngilizce dil modeli.
Misal
Modeli indirdikten sonra NLTK üzerinden şu şekilde kullanabiliriz -
from nltk.parse.stanford import StanfordDependencyParser
path_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser.jar'
path_models_jar = 'path_to/stanford-parser-full-2014-08-27/stanford-parser-3.4.1-models.jar'
dep_parser = StanfordDependencyParser(
path_to_jar = path_jar, path_to_models_jar = path_models_jar
)
result = dep_parser.raw_parse('I shot an elephant in my sleep')
depndency = result.next()
list(dependency.triples())Çıktı
[
((u'shot', u'VBD'), u'nsubj', (u'I', u'PRP')),
((u'shot', u'VBD'), u'dobj', (u'elephant', u'NN')),
((u'elephant', u'NN'), u'det', (u'an', u'DT')),
((u'shot', u'VBD'), u'prep', (u'in', u'IN')),
((u'in', u'IN'), u'pobj', (u'sleep', u'NN')),
((u'sleep', u'NN'), u'poss', (u'my', u'PRP$'))
]Chunking nedir?
Doğal dil işlemede önemli süreçlerden biri olan parçalama, konuşma bölümlerini (POS) ve kısa cümleleri tanımlamak için kullanılır. Başka bir deyişle, öbekleme ile cümlenin yapısını elde edebiliriz. Aynı zamandapartial parsing.
Yığın desenler ve oyuklar
Chunk patternsNe tür kelimelerin bir yığın oluşturduğunu tanımlayan konuşma bölümü (POS) etiketlerinin kalıplarıdır. Değiştirilmiş düzenli ifadeler yardımıyla yığın kalıpları tanımlayabiliriz.
Dahası, ne tür kelimelerin bir yığın halinde olmaması gerektiği için kalıplar da tanımlayabiliriz ve bu parçalanmamış kelimeler olarak bilinir. chinks.
Uygulama örneği
Aşağıdaki örnekte, cümlenin ayrıştırılmasının sonucu ile birlikte “the book has many chapters”, hem bir yığın hem de bir çentik desenini birleştiren isim cümleleri için bir gramer vardır -
import nltk
sentence = [
("the", "DT"),
("book", "NN"),
("has","VBZ"),
("many","JJ"),
("chapters","NNS")
]
chunker = nltk.RegexpParser(
r'''
NP:{<DT><NN.*><.*>*<NN.*>}
}<VB.*>{
'''
)
chunker.parse(sentence)
Output = chunker.parse(sentence)
Output.draw()Çıktı
Yukarıda görüldüğü gibi, bir yığın belirtme modeli aşağıdaki gibi kaşlı ayraçlar kullanmaktır -
{<DT><NN>}Ve bir boşluk belirtmek için, aşağıdaki gibi parantezleri çevirebiliriz -
}<VB>{.Şimdi, belirli bir kelime öbeği türü için, bu kurallar bir dilbilgisinde birleştirilebilir.
Bilgi Çıkarma
Bilgi çıkarma motoru oluşturmak için kullanılabilecek etiketleyicilerden ve ayrıştırıcılardan geçtik. Temel bir bilgi çıkarma boru hattı görelim -
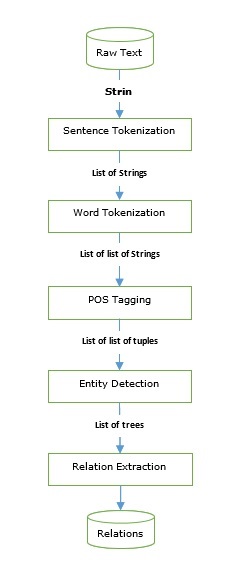
Bilgi çıkarmanın aşağıdakiler dahil birçok uygulaması vardır:
- İş zekası
- Hasat etmeye devam et
- Medya analizi
- Duygu algılama
- Patent araştırması
- E-posta taraması
Adlandırılmış varlık tanıma (NER)
Adlandırılmış varlık tanıma (NER) aslında adlar, kuruluşlar, konum vb. Gibi en yaygın varlıklardan bazılarını çıkarmanın bir yoludur. Cümle belirtme, POS etiketleme, yığın oluşturma, NER, ve yukarıdaki şekilde verilen boru hattını takip eder.
Misal
Import nltk
file = open (
# provide here the absolute path for the file of text for which we want NER
)
data_text = file.read()
sentences = nltk.sent_tokenize(data_text)
tokenized_sentences = [nltk.word_tokenize(sentence) for sentence in sentences]
tagged_sentences = [nltk.pos_tag(sentence) for sentence in tokenized_sentences]
for sent in tagged_sentences:
print nltk.ne_chunk(sent)Bazı değiştirilmiş Adlandırılmış varlık tanıma (NER), ürün adları, biyo-tıbbi varlıklar, marka adı ve çok daha fazlası gibi varlıkları çıkarmak için de kullanılabilir.
İlişki çıkarma
Yaygın olarak kullanılan bir başka bilgi çıkarma işlemi olan ilişki çıkarma, çeşitli varlıklar arasındaki farklı ilişkileri çıkarma işlemidir. Tanımı bilgi ihtiyacına bağlı olan kalıtım, eşanlamlılar, benzerlik vb. Gibi farklı ilişkiler olabilir. Örneğin, bir kitabın yazısını aramak istiyorsak, yazarın yazar adı ile kitap adı arasındaki bir ilişki olacağını varsayalım.
Misal
Aşağıdaki örnekte, yukarıdaki diyagramda gösterildiği gibi, Adlandırılmış varlık ilişkisine (NER) kadar kullandığımız IE işlem hattını kullanıyoruz ve bunu NER etiketlerine dayalı bir ilişki modeli ile genişletiyoruz.
import nltk
import re
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus = 'ieer',
pattern = IN):
print(nltk.sem.rtuple(rel))Çıktı
[ORG: 'WHYY'] 'in' [LOC: 'Philadelphia']
[ORG: 'McGlashan & Sarrail'] 'firm in' [LOC: 'San Mateo']
[ORG: 'Freedom Forum'] 'in' [LOC: 'Arlington']
[ORG: 'Brookings Institution'] ', the research group in' [LOC: 'Washington']
[ORG: 'Idealab'] ', a self-described business incubator based in' [LOC: 'Los Angeles']
[ORG: 'Open Text'] ', based in' [LOC: 'Waterloo']
[ORG: 'WGBH'] 'in' [LOC: 'Boston']
[ORG: 'Bastille Opera'] 'in' [LOC: 'Paris']
[ORG: 'Omnicom'] 'in' [LOC: 'New York']
[ORG: 'DDB Needham'] 'in' [LOC: 'New York']
[ORG: 'Kaplan Thaler Group'] 'in' [LOC: 'New York']
[ORG: 'BBDO South'] 'in' [LOC: 'Atlanta']
[ORG: 'Georgia-Pacific'] 'in' [LOC: 'Atlanta']Yukarıdaki kodda, ieer adlı dahili bir külliyat kullandık. Bu külliyatta, cümleler Adlandırılmış varlık ilişkisine (NER) kadar etiketlenmiştir. Burada sadece istediğimiz ilişki modelini ve ilişkinin tanımlamasını istediğimiz NER türünü belirtmemiz gerekiyor. Örneğimizde, bir kuruluş ve bir konum arasındaki ilişkiyi tanımladık. Bu modellerin tüm kombinasyonlarını çıkardık.
Neden Chunks'u dönüştürüyoruz?
Şimdiye kadar cümlelerden parçalar veya cümleler var ama onlarla ne yapmamız gerekiyor? Önemli görevlerden biri onları dönüştürmektir. Ama neden? Aşağıdakileri yapmaktır -
- dilbilgisi düzeltmesi ve
- ifadeleri yeniden düzenlemek
Önemsiz / işe yaramaz kelimeleri filtreleme
Bir cümlenin anlamını yargılamak istiyorsanız, 'the', 'a' gibi yaygın olarak kullanılan birçok kelimenin önemsiz veya yararsız olduğunu varsayalım. Örneğin, şu ifadeye bakın -
'Film güzeldi'.
Burada en anlamlı kelimeler 'film' ve 'iyi'. Diğer sözcükler, "the" ve "was" her ikisi de işe yaramaz veya önemsizdir. Bunun nedeni, onlar olmadan da ifadenin aynı anlamını alabilmemizdir. 'İyi film'.
Aşağıdaki python tarifinde, POS etiketleri yardımıyla gereksiz / önemsiz kelimelerin nasıl kaldırılacağını ve anlamlı kelimelerin nasıl saklanacağını öğreneceğiz.
Misal
Önce, bakarak treebankEngellenecek kelimeler için külliyat, hangi konuşma parçası etiketlerinin önemli, hangilerinin önemli olmadığına karar vermemiz gerekir. Önemsiz kelimelerin ve etiketlerin aşağıdaki tablosunu görelim -
| Kelime | Etiket |
|---|---|
| a | DT |
| Herşey | Pasifik yaz saati |
| Bir | DT |
| Ve | CC |
| Veya | CC |
| Bu | WDT |
| The | DT |
Yukarıdaki tablodan CC haricinde görebiliriz, diğer tüm etiketler DT ile biter, bu da önemsiz kelimeleri etiketin son ekine bakarak filtreleyebileceğimiz anlamına gelir.
Bu örnek için, adlı bir fonksiyon kullanacağız. filter()tek bir yığın alır ve önemsiz etiketlenmiş kelimeler olmadan yeni bir yığın döndürür. Bu işlev, DT veya CC ile biten tüm etiketleri filtreler.
Misal
import nltk
def filter(chunk, tag_suffixes=['DT', 'CC']):
significant = []
for word, tag in chunk:
ok = True
for suffix in tag_suffixes:
if tag.endswith(suffix):
ok = False
break
if ok:
significant.append((word, tag))
return (significant)Şimdi, önemsiz kelimeleri silmek için Python tarifimizde bu fonksiyon filtresini () kullanalım -
from chunk_parse import filter
filter([('the', 'DT'),('good', 'JJ'),('movie', 'NN')])Çıktı
[('good', 'JJ'), ('movie', 'NN')]Fiil Düzeltme
Çoğu zaman, gerçek dünya dilinde yanlış fiil formları görürüz. Örneğin, 'iyi misin?' Doğru değil. Bu cümlede fiil formu doğru değil. Cümle 'iyi misin?' Olmalıdır. NLTK, fiil düzeltme eşlemeleri oluşturarak bu tür hataları düzeltmemiz için bize bir yol sağlar. Bu düzeltme eşlemeleri, öbekte çoğul veya tekil bir isim olmasına bağlı olarak kullanılır.
Misal
Python tarifini uygulamak için önce fiil düzeltme eşlemelerini tanımlamamız gerekir. Aşağıdaki gibi iki eşleme oluşturalım -
Plural to Singular mappings
plural= {
('is', 'VBZ'): ('are', 'VBP'),
('was', 'VBD'): ('were', 'VBD')
}Singular to Plural mappings
singular = {
('are', 'VBP'): ('is', 'VBZ'),
('were', 'VBD'): ('was', 'VBD')
}Yukarıda görüldüğü gibi, her eşlemede başka bir etiketli fiil ile eşleşen etiketli bir fiil vardır. Örneğimizdeki ilk eşlemeler, eşlemelerin temelini kapsaris to are, was to wereve tam tersi.
Sonra, adında bir fonksiyon tanımlayacağız verbs(), yanlış fiil biçimine sahip bir boşluktan geçebilir ve düzeltilmiş bir yığın geri alırsınız. Bitirmek için,verb() işlev adlı bir yardımcı işlev kullanır index_chunk() bu, ilk etiketlenen kelimenin konumu için yığın arayacaktır.
Bu işlevleri görelim -
def index_chunk(chunk, pred, start = 0, step = 1):
l = len(chunk)
end = l if step > 0 else -1
for i in range(start, end, step):
if pred(chunk[i]):
return i
return None
def tag_startswith(prefix):
def f(wt):
return wt[1].startswith(prefix)
return f
def verbs(chunk):
vbidx = index_chunk(chunk, tag_startswith('VB'))
if vbidx is None:
return chunk
verb, vbtag = chunk[vbidx]
nnpred = tag_startswith('NN')
nnidx = index_chunk(chunk, nnpred, start = vbidx+1)
if nnidx is None:
nnidx = index_chunk(chunk, nnpred, start = vbidx-1, step = -1)
if nnidx is None:
return chunk
noun, nntag = chunk[nnidx]
if nntag.endswith('S'):
chunk[vbidx] = plural.get((verb, vbtag), (verb, vbtag))
else:
chunk[vbidx] = singular.get((verb, vbtag), (verb, vbtag))
return chunkBu işlevleri Python veya Anaconda'nın kurulu olduğu yerel dizininizdeki bir Python dosyasına kaydedin ve çalıştırın. Olarak kaydettimverbcorrect.py.
Şimdi arayalım verbs() etiketli bir POS üzerinde işlev is you fine yığın -
from verbcorrect import verbs
verbs([('is', 'VBZ'), ('you', 'PRP$'), ('fine', 'VBG')])Çıktı
[('are', 'VBP'), ('you', 'PRP$'), ('fine','VBG')]Pasif sesi ifadelerden çıkarmak
Bir başka yararlı görev, pasif sesi ifadelerden çıkarmaktır. Bu, bir fiilin etrafındaki kelimelerin değiş tokuşu ile yapılabilir. Örneğin,‘the tutorial was great’ dönüştürülebilir ‘the great tutorial’.
Misal
Bunu başarmak için adlı bir fonksiyon tanımlıyoruz eliminate_passive()Bu, pivot noktası olarak fiili kullanarak yığının sağ tarafını sol tarafla değiştirecektir. Dönecek fiili bulmak için, aynı zamandaindex_chunk() yukarıda tanımlanan işlev.
def eliminate_passive(chunk):
def vbpred(wt):
word, tag = wt
return tag != 'VBG' and tag.startswith('VB') and len(tag) > 2
vbidx = index_chunk(chunk, vbpred)
if vbidx is None:
return chunk
return chunk[vbidx+1:] + chunk[:vbidx]Şimdi arayalım eliminate_passive() etiketli bir POS üzerinde işlev the tutorial was great yığın -
from passiveverb import eliminate_passive
eliminate_passive(
[
('the', 'DT'), ('tutorial', 'NN'), ('was', 'VBD'), ('great', 'JJ')
]
)Çıktı
[('great', 'JJ'), ('the', 'DT'), ('tutorial', 'NN')]İsim kardinallerinin değiştirilmesi
Bildiğimiz gibi, 5 gibi önemli bir kelime, bir yığın halinde CD olarak etiketlenir. Bu temel sözcükler genellikle bir isimden önce veya sonra ortaya çıkar, ancak normalleştirme amacıyla onları her zaman ismin önüne koymak yararlıdır. Örneğin tarihJanuary 5 olarak yazılabilir 5 January. Bunu aşağıdaki örnekle anlayalım.
Misal
Bunu başarmak için adlı bir fonksiyon tanımlıyoruz swapping_cardinals()bu, isimden hemen sonra ortaya çıkan herhangi bir kardinali isimle değiştirecektir. Bununla kardinal, isimden hemen önce ortaya çıkacaktır. Verilen etiketle eşitlik karşılaştırması yapmak için, adını verdiğimiz bir yardımcı işlevi kullanır.tag_eql().
def tag_eql(tag):
def f(wt):
return wt[1] == tag
return fŞimdi swapping_cardinals () tanımlayabiliriz -
def swapping_cardinals (chunk):
cdidx = index_chunk(chunk, tag_eql('CD'))
if not cdidx or not chunk[cdidx-1][1].startswith('NN'):
return chunk
noun, nntag = chunk[cdidx-1]
chunk[cdidx-1] = chunk[cdidx]
chunk[cdidx] = noun, nntag
return chunkŞimdi arayalım swapping_cardinals() bir tarihte işlev “January 5” -
from Cardinals import swapping_cardinals()
swapping_cardinals([('Janaury', 'NNP'), ('5', 'CD')])Çıktı
[('10', 'CD'), ('January', 'NNP')]
10 JanuaryAğaçları dönüştürmenin iki nedeni aşağıdadır:
- Derin ayrıştırma ağacını değiştirmek için ve
- Derin ayrıştırılmış ağaçları düzleştirmek için
Ağacı veya Alt Ağacı Cümleye Dönüştürme
Burada tartışacağımız ilk tarif, bir Ağacı veya alt ağacı bir cümle veya yığın dizesine geri dönüştürmektir. Bu çok basit, aşağıdaki örnekte görelim -
Misal
from nltk.corpus import treebank_chunk
tree = treebank_chunk.chunked_sents()[2]
' '.join([w for w, t in tree.leaves()])Çıktı
'Rudolph Agnew , 55 years old and former chairman of Consolidated Gold Fields
PLC , was named a nonexecutive director of this British industrial
conglomerate .'Derin ağaç düzleştirme
İç içe geçmiş cümlelerin derin ağaçları bir yığın eğitmek için kullanılamaz, bu yüzden kullanmadan önce onları düzleştirmeliyiz. Aşağıdaki örnekte, derin iç içe geçmiş ifadeler ağacı olan 3. çözümlenmiş cümleyi kullanacağız.treebank külliyat.
Misal
Bunu başarmak için adında bir fonksiyon tanımlıyoruz deeptree_flat()tek bir Ağacı alacak ve sadece en düşük seviyedeki ağaçları tutan yeni bir Ağaç döndürecektir. İşin çoğunu yapmak için, adını verdiğimiz bir yardımcı işlevi kullanır.childtree_flat().
from nltk.tree import Tree
def childtree_flat(trees):
children = []
for t in trees:
if t.height() < 3:
children.extend(t.pos())
elif t.height() == 3:
children.append(Tree(t.label(), t.pos()))
else:
children.extend(flatten_childtrees([c for c in t]))
return children
def deeptree_flat(tree):
return Tree(tree.label(), flatten_childtrees([c for c in tree]))Şimdi arayalım deeptree_flat() derin iç içe geçmiş ifadeler ağacı olan 3. ayrıştırılmış cümle üzerinde işlev, treebankkülliyat. Bu işlevleri deeptree.py adlı bir dosyaya kaydettik.
from deeptree import deeptree_flat
from nltk.corpus import treebank
deeptree_flat(treebank.parsed_sents()[2])Çıktı
Tree('S', [Tree('NP', [('Rudolph', 'NNP'), ('Agnew', 'NNP')]),
(',', ','), Tree('NP', [('55', 'CD'),
('years', 'NNS')]), ('old', 'JJ'), ('and', 'CC'),
Tree('NP', [('former', 'JJ'),
('chairman', 'NN')]), ('of', 'IN'), Tree('NP', [('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC',
'NNP')]), (',', ','), ('was', 'VBD'),
('named', 'VBN'), Tree('NP-SBJ', [('*-1', '-NONE-')]),
Tree('NP', [('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN')]),
('of', 'IN'), Tree('NP',
[('this', 'DT'), ('British', 'JJ'),
('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Sığ ağaç inşa etmek
Önceki bölümde, derin bir iç içe geçmiş ifadeler ağacını yalnızca en düşük seviyedeki alt ağaçları tutarak düzleştirdik. Bu bölümde, sadece en yüksek seviyedeki alt ağaçları tutacağız, yani sığ ağacı inşa edeceğiz. Aşağıdaki örnekte, derin iç içe geçmiş ifadeler ağacı olan 3. ayrıştırılmış cümleyi kullanacağız.treebank külliyat.
Misal
Bunu başarmak için adında bir fonksiyon tanımlıyoruz tree_shallow() bu, yalnızca en üstteki alt ağaç etiketlerini tutarak tüm iç içe geçmiş alt ağaçları ortadan kaldıracaktır.
from nltk.tree import Tree
def tree_shallow(tree):
children = []
for t in tree:
if t.height() < 3:
children.extend(t.pos())
else:
children.append(Tree(t.label(), t.pos()))
return Tree(tree.label(), children)Şimdi arayalım tree_shallow()derin iç içe geçmiş ifadeler ağacı olan 3. ayrıştırılmış cümle üzerinde işlev ,treebankkülliyat. Bu işlevleri sığ ağaç.py adlı bir dosyaya kaydettik.
from shallowtree import shallow_tree
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2])Çıktı
Tree('S', [Tree('NP-SBJ-1', [('Rudolph', 'NNP'), ('Agnew', 'NNP'), (',', ','),
('55', 'CD'), ('years', 'NNS'), ('old', 'JJ'), ('and', 'CC'),
('former', 'JJ'), ('chairman', 'NN'), ('of', 'IN'), ('Consolidated', 'NNP'),
('Gold', 'NNP'), ('Fields', 'NNP'), ('PLC', 'NNP'), (',', ',')]),
Tree('VP', [('was', 'VBD'), ('named', 'VBN'), ('*-1', '-NONE-'), ('a', 'DT'),
('nonexecutive', 'JJ'), ('director', 'NN'), ('of', 'IN'), ('this', 'DT'),
('British', 'JJ'), ('industrial', 'JJ'), ('conglomerate', 'NN')]), ('.', '.')])Ağaçların yüksekliğini elde etmenin yardımı ile farkı görebiliriz -
from nltk.corpus import treebank
tree_shallow(treebank.parsed_sents()[2]).height()Çıktı
3from nltk.corpus import treebank
treebank.parsed_sents()[2].height()Çıktı
9Ağaç etiketleri dönüşümü
Ayrıştırma ağaçlarında çeşitli Treeyığın ağaçlarda bulunmayan etiket türleri. Ancak bir yığın eğitmek için ayrıştırma ağacını kullanırken, bazı Ağaç etiketlerini daha yaygın etiket türlerine dönüştürerek bu çeşitliliği azaltmak istiyoruz. Örneğin, NP-SBL ve NP-TMP olmak üzere iki alternatif NP alt ağacımız var. İkisini de NP'ye dönüştürebiliriz. Aşağıdaki örnekte nasıl yapılacağını görelim.
Misal
Bunu başarmak için adlı bir fonksiyon tanımlıyoruz tree_convert() aşağıdaki iki argümanı alır -
- Dönüştürülecek ağaç
- Bir etiket dönüştürme eşlemesi
Bu işlev, eşlemedeki değerlere bağlı olarak tüm eşleşen etiketlerin değiştirildiği yeni bir Ağaç döndürür.
from nltk.tree import Tree
def tree_convert(tree, mapping):
children = []
for t in tree:
if isinstance(t, Tree):
children.append(convert_tree_labels(t, mapping))
else:
children.append(t)
label = mapping.get(tree.label(), tree.label())
return Tree(label, children)Şimdi arayalım tree_convert() derin iç içe geçmiş ifadeler ağacı olan 3. ayrıştırılmış cümle üzerinde işlev, treebankkülliyat. Bu işlevleri adlı bir dosyaya kaydettik.converttree.py.
from converttree import tree_convert
from nltk.corpus import treebank
mapping = {'NP-SBJ': 'NP', 'NP-TMP': 'NP'}
convert_tree_labels(treebank.parsed_sents()[2], mapping)Çıktı
Tree('S', [Tree('NP-SBJ-1', [Tree('NP', [Tree('NNP', ['Rudolph']),
Tree('NNP', ['Agnew'])]), Tree(',', [',']),
Tree('UCP', [Tree('ADJP', [Tree('NP', [Tree('CD', ['55']),
Tree('NNS', ['years'])]),
Tree('JJ', ['old'])]), Tree('CC', ['and']),
Tree('NP', [Tree('NP', [Tree('JJ', ['former']),
Tree('NN', ['chairman'])]), Tree('PP', [Tree('IN', ['of']),
Tree('NP', [Tree('NNP', ['Consolidated']),
Tree('NNP', ['Gold']), Tree('NNP', ['Fields']),
Tree('NNP', ['PLC'])])])])]), Tree(',', [','])]),
Tree('VP', [Tree('VBD', ['was']),Tree('VP', [Tree('VBN', ['named']),
Tree('S', [Tree('NP', [Tree('-NONE-', ['*-1'])]),
Tree('NP-PRD', [Tree('NP', [Tree('DT', ['a']),
Tree('JJ', ['nonexecutive']), Tree('NN', ['director'])]),
Tree('PP', [Tree('IN', ['of']), Tree('NP',
[Tree('DT', ['this']), Tree('JJ', ['British']), Tree('JJ', ['industrial']),
Tree('NN', ['conglomerate'])])])])])])]), Tree('.', ['.'])])Metin sınıflandırması nedir?
Adından da anlaşılacağı gibi metin sınıflandırması, metin veya belge parçalarını kategorize etmenin yoludur. Ancak burada, neden metin sınıflandırıcıları kullanmamız gerektiği sorusu ortaya çıkıyor. Bir belgede veya bir metin parçasında kelime kullanımını inceledikten sonra, sınıflandırıcılar ona hangi sınıf etiketinin atanması gerektiğine karar verebilecekler.
İkili Sınıflandırıcı
Adından da anlaşılacağı gibi, ikili sınıflandırıcı iki etiket arasında karar verecektir. Örneğin, olumlu ya da olumsuz. Bunda metin parçası veya belge bir etiket veya başka bir etiket olabilir, ancak ikisi birden olamaz.
Çok etiketli Sınıflandırıcı
İkili sınıflandırıcının tersine, çok etiketli sınıflandırıcı bir metin veya belgeye bir veya daha fazla etiket atayabilir.
Etiketli Vs Etiketsiz Özellik kümesi
Özellik adlarının özellik değerleriyle anahtar / değer eşlemesine özellik kümesi denir. Etiketli özellik kümeleri veya eğitim verileri, daha sonra etiketlenmemiş özellik kümesini sınıflandırabilmesi için sınıflandırma eğitimi için çok önemlidir.
| Etiketli Özellik Kümesi | Etiketsiz Özellik Kümesi |
|---|---|
| Bu (feat, label) gibi görünen bir demettir. | Bu başlı başına bir başarıdır. |
| Bilinen bir sınıf etiketine sahip bir örnektir. | İlişkili etiket olmadan buna örnek diyebiliriz. |
| Bir sınıflandırma algoritmasını eğitmek için kullanılır. | Sınıflandırma algoritması eğitildikten sonra, etiketlenmemiş bir özellik kümesini sınıflandırabilir. |
Metin Özelliği Çıkarma
Metin özelliği çıkarma, adından da anlaşılacağı gibi, bir sözcük listesini bir sınıflandırıcı tarafından kullanılabilen bir özellik kümesine dönüştürme işlemidir. Metnimizi dönüştürmeliyiz‘dict’ stil özelliği setleri, çünkü Natural Language Tool Kit (NLTK) ‘dict’ stil özellik setleri.
Kelime Çantası (BoW) modeli
NLP'deki en basit modellerden biri olan BoW, makine öğrenimi algoritmalarında olacak şekilde modellemede kullanılabilmesi için metin veya belgeden özellikleri çıkarmak için kullanılır. Temel olarak, bir örneğin tüm sözcüklerinden bir sözcük varlığı özelliği kümesi oluşturur. Bu yöntemin arkasındaki kavram, bir kelimenin kaç kez geçtiğini veya kelimelerin sırasını önemsememesi, yalnızca kelimenin bir kelime listesinde bulunup bulunmadığıyla ilgilenmesidir.
Misal
Bu örnek için bow () adında bir fonksiyon tanımlayacağız -
def bow(words):
return dict([(word, True) for word in words])Şimdi arayalım bow()kelimeler üzerinde işlev. Bu işlevleri bagwords.py adlı bir dosyaya kaydettik.
from bagwords import bow
bow(['we', 'are', 'using', 'tutorialspoint'])Çıktı
{'we': True, 'are': True, 'using': True, 'tutorialspoint': True}Eğitim sınıflandırıcılar
Önceki bölümlerde, metinden özelliklerin nasıl çıkarılacağını öğrendik. Şimdi bir sınıflandırıcı eğitebiliriz. İlk ve en kolay sınıflandırıcıNaiveBayesClassifier sınıf.
Naïve Bayes Sınıflandırıcı
Belirli bir özellik setinin belirli bir etikete ait olma olasılığını tahmin etmek için Bayes teoremini kullanır. Bayes teoreminin formülü aşağıdaki gibidir.
$$P(A|B)=\frac{P(B|A)P(A)}{P(B)}$$Buraya,
P(A|B) - Aynı zamanda, son olasılık, yani birinci olayın olasılığı, yani ikinci olayın, yani B'nin meydana gelmesi durumunda A'nın meydana gelme olasılığı da denir.
P(B|A) - İkinci olayın, yani B'nin ilk olaydan sonra, yani A'nın meydana gelme olasılığıdır.
P(A), P(B) - Aynı zamanda önceki olasılık, yani ilk olayın olasılığı, yani A veya ikinci olayın, yani B'nin meydana gelme olasılığı olarak da adlandırılır.
Naïve Bayes sınıflandırıcısını eğitmek için, movie_reviewsNLTK'dan külliyat. Bu külliyatın iki kategorisi vardır, yani:pos ve neg. Bu kategoriler, kendileri için eğitilmiş bir sınıflandırıcıyı bir ikili sınıflandırıcı yapar. Derlemedeki her dosya ikiden oluşur; biri olumlu film incelemesi ve diğeri olumsuz film incelemesidir. Örneğimizde, her bir dosyayı sınıflandırıcıyı hem eğitmek hem de test etmek için tek bir örnek olarak kullanacağız.
Misal
Sınıflandırıcı eğitimi için, [(featureset, label)]. İştefeatureset değişken bir dict ve etiket, için bilinen sınıf etiketidir. featureset. Adlı bir fonksiyon oluşturacağızlabel_corpus() adlı bir külliyat alacak movie_reviewsve ayrıca adlı bir işlev feature_detectorvarsayılan olan bag of words. {Label: [featureset]} formunun bir eşlemesini oluşturur ve döndürür. Bundan sonra, bu eşlemeyi, etiketli eğitim örneklerinin ve test örneklerinin bir listesini oluşturmak için kullanacağız.
import collections
def label_corpus(corp, feature_detector=bow):
label_feats = collections.defaultdict(list)
for label in corp.categories():
for fileid in corp.fileids(categories=[label]):
feats = feature_detector(corp.words(fileids=[fileid]))
label_feats[label].append(feats)
return label_featsYukarıdaki fonksiyonun yardımıyla bir eşleme elde edeceğiz {label:fetaureset}. Şimdi adında bir fonksiyon daha tanımlayacağızsplit geri dönen bir eşleme alacak label_corpus() işlev ve her özellik grubu listesini etiketli eğitime ve ayrıca test örneklerine böler.
def split(lfeats, split=0.75):
train_feats = []
test_feats = []
for label, feats in lfeats.items():
cutoff = int(len(feats) * split)
train_feats.extend([(feat, label) for feat in feats[:cutoff]])
test_feats.extend([(feat, label) for feat in feats[cutoff:]])
return train_feats, test_featsŞimdi, bu işlevleri külliyatımızda kullanalım, yani film
from nltk.corpus import movie_reviews
from featx import label_feats_from_corpus, split_label_feats
movie_reviews.categories()Çıktı
['neg', 'pos']Misal
lfeats = label_feats_from_corpus(movie_reviews)
lfeats.keys()Çıktı
dict_keys(['neg', 'pos'])Misal
train_feats, test_feats = split_label_feats(lfeats, split = 0.75)
len(train_feats)Çıktı
1500Misal
len(test_feats)Çıktı
500Biz gördük movie_reviewskülliyatta 1000 pos dosyası ve 1000 neg dosyası vardır. Ayrıca 1500 etiketli eğitim örneği ve 500 etiketli test örneği elde ediyoruz.
Şimdi eğitelim NaïveBayesClassifier kullanarak train() sınıf yöntemi -
from nltk.classify import NaiveBayesClassifier
NBC = NaiveBayesClassifier.train(train_feats)
NBC.labels()Çıktı
['neg', 'pos']Karar Ağacı Sınıflandırıcısı
Diğer bir önemli sınıflandırıcı, karar ağacı sınıflandırıcıdır. Onu eğitmek için buradaDecisionTreeClassifiersınıf bir ağaç yapısı oluşturacaktır. Bu ağaç yapısında her düğüm bir özellik adına karşılık gelir ve dallar özellik değerlerine karşılık gelir. Ve dalların aşağısında ağacın yapraklarına, yani sınıflandırma etiketlerine ulaşacağız.
Karar ağacı sınıflandırıcısını eğitmek için aynı eğitim ve test özelliklerini kullanacağız, örn. train_feats ve test_featsyarattığımız değişkenler movie_reviews külliyat.
Misal
Bu sınıflandırıcıyı eğitmek için arayacağız DecisionTreeClassifier.train() aşağıdaki gibi sınıf yöntemi -
from nltk.classify import DecisionTreeClassifier
decisiont_classifier = DecisionTreeClassifier.train(
train_feats, binary = True, entropy_cutoff = 0.8,
depth_cutoff = 5, support_cutoff = 30
)
accuracy(decisiont_classifier, test_feats)Çıktı
0.725Maksimum Entropi Sınıflandırıcısı
Diğer bir önemli sınıflandırıcı MaxentClassifier olarak da bilinen conditional exponential classifier veya logistic regression classifier. Onu eğitmek için burada,MaxentClassifier sınıfı, kodlamayı kullanarak etiketli özellik kümelerini vektöre dönüştürür.
Karar ağacı sınıflandırıcısını eğitmek için aynı eğitim ve test özelliklerini kullanacağız, örn. train_featsve test_featsyarattığımız değişkenler movie_reviews külliyat.
Misal
Bu sınıflandırıcıyı eğitmek için arayacağız MaxentClassifier.train() aşağıdaki gibi sınıf yöntemi -
from nltk.classify import MaxentClassifier
maxent_classifier = MaxentClassifier
.train(train_feats,algorithm = 'gis', trace = 0, max_iter = 10, min_lldelta = 0.5)
accuracy(maxent_classifier, test_feats)Çıktı
0.786Scikit-learn Sınıflandırıcı
En iyi makine öğrenimi (ML) kitaplıklarından biri Scikit-learn'dür. Aslında çeşitli amaçlar için her türden makine öğrenimi algoritmasını içerir, ancak hepsi aşağıdaki gibi aynı uyum tasarım modeline sahiptir -
- Modeli verilere uydurma
- Ve tahmin yapmak için bu modeli kullanın
Scikit-learn modellerine doğrudan erişmek yerine, burada NLTK'ları kullanacağız SklearnClassifiersınıf. Bu sınıf, NLTK'nın Sınıflandırıcı arayüzüne uyması için bir scikit-learn modelinin etrafındaki bir sarmalayıcı sınıftır.
Bir eğitmek için aşağıdaki adımları izleyeceğiz SklearnClassifier sınıf -
Step 1 - Önce önceki tariflerde yaptığımız gibi eğitim özellikleri oluşturacağız.
Step 2 - Şimdi, bir Scikit-öğrenme algoritması seçin ve içe aktarın.
Step 3 - Sonra, bir SklearnClassifier Seçilen algoritma ile sınıf.
Step 4 - Son olarak antrenman yapacağız SklearnClassifier eğitim özelliklerimizle sınıf.
Bu adımları aşağıdaki Python tarifine uygulayalım -
from nltk.classify.scikitlearn import SklearnClassifier
from sklearn.naive_bayes import MultinomialNB
sklearn_classifier = SklearnClassifier(MultinomialNB())
sklearn_classifier.train(train_feats)
<SklearnClassifier(MultinomialNB(alpha = 1.0,class_prior = None,fit_prior = True))>
accuracy(sk_classifier, test_feats)Çıktı
0.885Hassasiyet ve geri çağırma ölçümü
Çeşitli sınıflandırıcıları eğitirken bunların doğruluğunu da ölçtük. Ancak doğruluktan ayrı olarak sınıflandırıcıları değerlendirmek için kullanılan çok sayıda başka ölçüt vardır. Bu ölçümlerden ikisiprecision ve recall.
Misal
Bu örnekte, daha önce eğittiğimiz NaiveBayesClassifier sınıfının hassasiyetini ve geri çağrılmasını hesaplayacağız. Bunu başarmak için, biri eğitimli sınıflandırıcı ve diğeri etiketli test özellikleri olmak üzere iki bağımsız değişken alacak olan metrics_PR () adlı bir işlev oluşturacağız. Her iki argüman da sınıflandırıcıların doğruluğunu hesaplarken geçirdiğimizle aynıdır -
import collections
from nltk import metrics
def metrics_PR(classifier, testfeats):
refsets = collections.defaultdict(set)
testsets = collections.defaultdict(set)
for i, (feats, label) in enumerate(testfeats):
refsets[label].add(i)
observed = classifier.classify(feats)
testsets[observed].add(i)
precisions = {}
recalls = {}
for label in classifier.labels():
precisions[label] = metrics.precision(refsets[label],testsets[label])
recalls[label] = metrics.recall(refsets[label], testsets[label])
return precisions, recallsKesinliği bulmak ve geri çağırmak için bu işlevi arayalım -
from metrics_classification import metrics_PR
nb_precisions, nb_recalls = metrics_PR(nb_classifier,test_feats)
nb_precisions['pos']Çıktı
0.6713532466435213Misal
nb_precisions['neg']Çıktı
0.9676271186440678Misal
nb_recalls['pos']Çıktı
0.96Misal
nb_recalls['neg']Çıktı
0.478Sınıflandırıcı ve oylamanın kombinasyonu
Sınıflandırıcıları birleştirmek, sınıflandırma performansını iyileştirmenin en iyi yollarından biridir. Ve oylama, birden çok sınıflandırıcıyı birleştirmenin en iyi yollarından biridir. Oylama için tek sayıda sınıflandırıcıya ihtiyacımız var. Aşağıdaki Python tarifinde NaiveBayesClassifier sınıfı, DecisionTreeClassifier sınıfı ve MaxentClassifier sınıfı olmak üzere üç sınıflandırıcıyı birleştireceğiz.
Bunu başarmak için, aşağıdaki gibi voting_classifiers () adında bir işlev tanımlayacağız.
import itertools
from nltk.classify import ClassifierI
from nltk.probability import FreqDist
class Voting_classifiers(ClassifierI):
def __init__(self, *classifiers):
self._classifiers = classifiers
self._labels = sorted(set(itertools.chain(*[c.labels() for c in classifiers])))
def labels(self):
return self._labels
def classify(self, feats):
counts = FreqDist()
for classifier in self._classifiers:
counts[classifier.classify(feats)] += 1
return counts.max()Üç sınıflandırıcıyı birleştirmek ve doğruluğu bulmak için bu işlevi arayalım -
from vote_classification import Voting_classifiers
combined_classifier = Voting_classifiers(NBC, decisiont_classifier, maxent_classifier)
combined_classifier.labels()Çıktı
['neg', 'pos']Misal
accuracy(combined_classifier, test_feats)Çıktı
0.948Yukarıdaki çıktıdan, birleşik sınıflandırıcıların tek tek sınıflandırıcılardan en yüksek doğruluğu elde ettiğini görebiliriz.