OpenNLP - Hızlı Kılavuz
NLP, web sayfaları ve metin belgeleri gibi doğal dil kaynaklarından anlamlı ve faydalı bilgiler elde etmek için kullanılan bir dizi araçtır.
Açık NLP nedir?
Apaçi OpenNLPdoğal dil metnini işlemek için kullanılan açık kaynaklı bir Java kitaplığıdır. Bu kitaplığı kullanarak verimli bir metin işleme hizmeti oluşturabilirsiniz.
OpenNLP, belirteçleme, cümle bölümleme, konuşma parçası etiketleme, adlandırılmış varlık çıkarma, parçalama, ayrıştırma ve ortak referans çözümleme gibi hizmetler sağlar.
OpenNLP'nin Özellikleri
OpenNLP'nin dikkate değer özellikleri şunlardır -
Named Entity Recognition (NER) - Açık NLP, sorguları işlerken bile konumların, kişilerin ve şeylerin adlarını çıkarabileceğiniz NER'i destekler.
Summarize - Kullanmak summarize özelliği, Paragrafları, makaleleri, belgeleri veya bunların koleksiyonunu NLP'de özetleyebilirsiniz.
Searching - OpenNLP'de, belirli bir arama dizesi veya eşanlamlıları, verilen kelime değiştirilmiş veya yanlış yazılmış olsa bile, verilen metinde tanımlanabilir.
Tagging (POS) - NLP'de etiketleme, metni daha fazla analiz için çeşitli dilbilgisi öğelerine bölmek için kullanılır.
Translation - Çeviri, NLP'de bir dilin diğerine çevrilmesine yardımcı olur.
Information grouping - NLP'deki bu seçenek, tıpkı konuşmanın bölümleri gibi, belge içeriğindeki metin bilgilerini gruplandırır.
Natural Language Generation - Bir veri tabanından bilgi üretmek ve hava durumu analizi veya tıbbi raporlar gibi bilgi raporlarını otomatikleştirmek için kullanılır.
Feedback Analysis - Adından da anlaşılacağı gibi, NLP tarafından ürünlerin kalplerini kazanmada ne kadar başarılı olduğunu analiz etmek için insanlardan ürünlerle ilgili çeşitli geri bildirimler toplanır.
Speech recognition - İnsan konuşmasını analiz etmek zor olsa da, NLP bu gereksinim için bazı yerleşik özelliklere sahiptir.
NLP API'sini aç
Apache OpenNLP kitaplığı, cümle algılama, belirteçleştirme, bir ad bulma, konuşma bölümlerini etiketleme, bir cümleyi parçalama, ayrıştırma, ortak referans çözümleme ve belge kategorizasyonu gibi çeşitli doğal dil işleme görevlerini gerçekleştirmek için sınıflar ve arayüzler sağlar.
Bu görevlere ek olarak, bu görevlerden herhangi biri için kendi modellerimizi de eğitebilir ve değerlendirebiliriz.
OpenNLP CLI
OpenNLP, kütüphaneye ek olarak, modelleri eğitip değerlendirebileceğimiz bir Komut Satırı Arayüzü (CLI) de sağlar. Bu eğitimin son bölümünde bu konuyu ayrıntılı olarak tartışacağız.
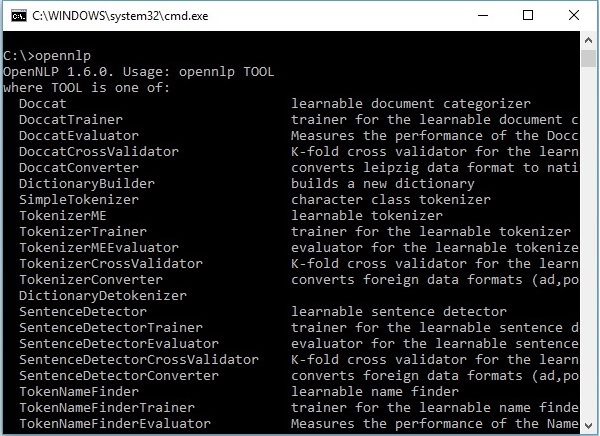
Açık NLP Modelleri
OpenNLP, çeşitli NLP görevlerini gerçekleştirmek için önceden tanımlanmış bir dizi model sağlar. Bu set, farklı diller için modeller içerir.
Modelleri indirmek
OpenNLP tarafından sağlanan önceden tanımlanmış modelleri indirmek için aşağıda verilen adımları takip edebilirsiniz.
Step 1 - Aşağıdaki bağlantıya tıklayarak OpenNLP modellerinin dizin sayfasını açın - http://opennlp.sourceforge.net/models-1.5/.

Step 2- Verilen bağlantıyı ziyaret ettiğinizde, çeşitli dillerdeki bileşenlerin bir listesini ve bunları indirmek için bağlantıları göreceksiniz. Burada, OpenNLP tarafından sağlanan tüm önceden tanımlanmış modellerin listesini alabilirsiniz.
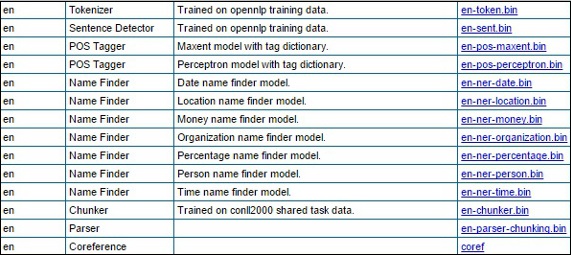
Tüm bu modelleri klasöre indirin C:/OpenNLP_models/>, ilgili bağlantılara tıklayarak. Tüm bu modeller dile bağlıdır ve bunları kullanırken model dilinin giriş metninin diliyle eşleştiğinden emin olmalısınız.
OpenNLP Tarihçesi
2010 yılında OpenNLP, Apache inkübasyonuna girdi.
2011 yılında Apache OpenNLP 1.5.2 Incubating piyasaya sürüldü ve aynı yıl üst düzey Apache projesi olarak mezun oldu.
2015 yılında OpenNLP 1.6.0 yayınlandı.
Bu bölümde, sisteminizde OpenNLP ortamını nasıl kurabileceğinizi tartışacağız. Kurulum süreciyle başlayalım.
OpenNLP'yi Yükleme
İndirme adımları aşağıdadır Apache OpenNLP library sisteminizde.
Step 1 - ana sayfasını açın Apache OpenNLP aşağıdaki bağlantıya tıklayarak - https://opennlp.apache.org/.
Step 2 - Şimdi, Downloadsbağlantı. Tıkladığınızda, sizi Apache Software Foundation Distribution dizinine yönlendirecek çeşitli yansımaları bulabileceğiniz bir sayfaya yönlendirileceksiniz.
Step 3- Bu sayfada çeşitli Apache dağıtımlarını indirmek için bağlantılar bulabilirsiniz. Bunlara göz atın ve OpenNLP dağıtımını bulun ve tıklayın.
Step 4 - Tıkladığınızda, aşağıda gösterildiği gibi OpenNLP dağıtımının dizinini görebileceğiniz dizine yönlendirileceksiniz.
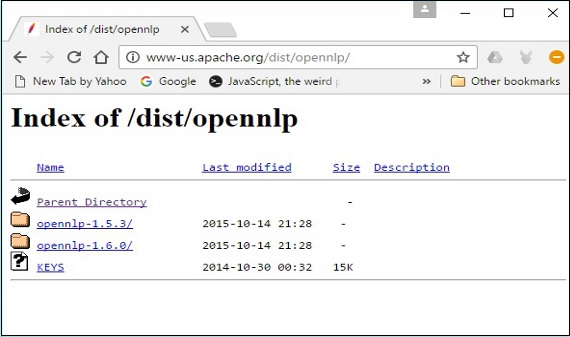
Mevcut dağıtımlardan en son sürüme tıklayın.
Step 5- Her dağıtım, çeşitli biçimlerde OpenNLP kitaplığının Kaynak ve İkili dosyalarını sağlar. Kaynak ve ikili dosyaları indirin,apache-opennlp-1.6.0-bin.zip ve apache-opennlp1.6.0-src.zip (pencereler için).

Sınıf Yolunu Ayarlama
OpenNLP kitaplığını indirdikten sonra, yolunu bindizin. OpenNLP kitaplığını sisteminizin E sürücüsüne indirdiğinizi varsayın.
Şimdi, aşağıda verilen adımları izleyin -
Step 1 - "Bilgisayarım" ı sağ tıklayın ve "Özellikler" i seçin.
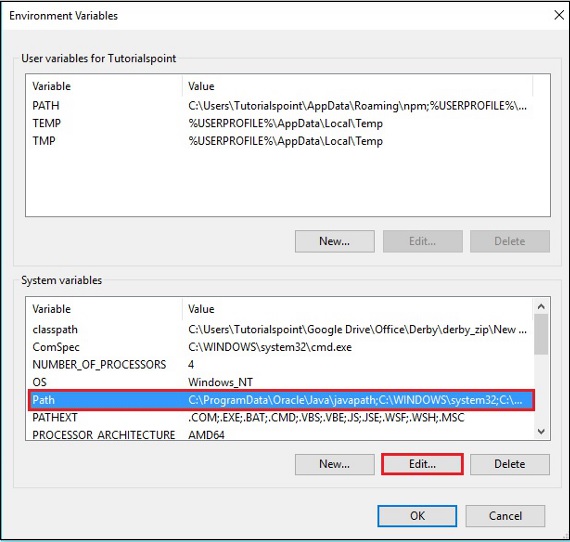
Step 2 - "Gelişmiş" sekmesinin altındaki "Ortam Değişkenleri" düğmesini tıklayın.
Step 3 - seçin path değişken ve tıklayın Edit düğmesi, aşağıdaki ekran görüntüsünde gösterildiği gibi.
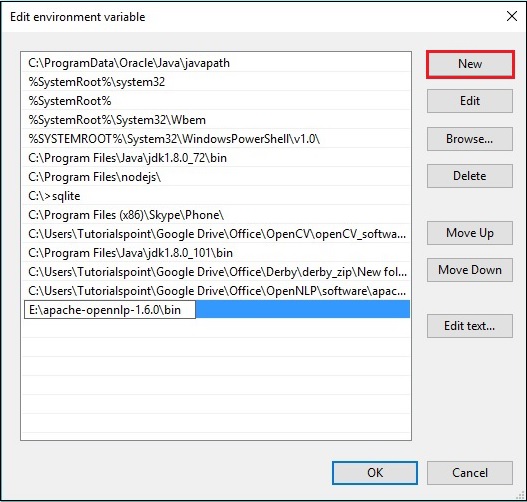
Step 4 - Ortam Değişkenini Düzenle penceresinde, New düğmesini tıklayın ve OpenNLP dizininin yolunu ekleyin E:\apache-opennlp-1.6.0\bin ve tıklayın OK düğmesi, aşağıdaki ekran görüntüsünde gösterildiği gibi.
Eclipse Kurulumu
OpenNLP kitaplığı için Eclipse ortamını, Build path JAR dosyalarına veya kullanarak pom.xml.
JAR Dosyalarının Derleme Yolunu Ayarlama
Eclipse'de OpenNLP'yi kurmak için aşağıdaki adımları izleyin -
Step 1 - Sisteminizde Eclipse ortamının kurulu olduğundan emin olun.
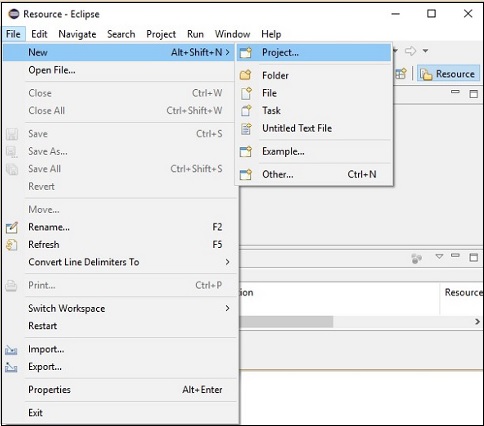
Step 2- Eclipse'i açın. Aşağıda gösterildiği gibi Dosya → Yeni → Yeni bir proje aç'ı tıklayın.
Step 3 - Alacaksın New Projectsihirbaz. Bu sihirbazda, Java projesini seçin veNext buton.
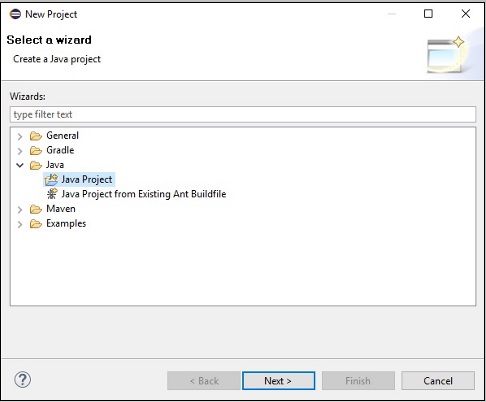
Step 4 - Sonra, alacaksın New Java Project wizard. Burada yeni bir proje oluşturmanız veNext düğmesi aşağıda gösterildiği gibi.
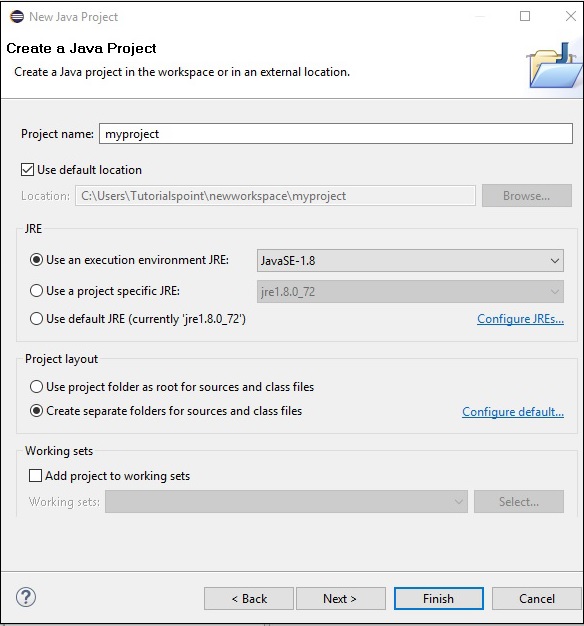
Step 5 - Yeni bir proje oluşturduktan sonra üzerine sağ tıklayın, seçin Build Path ve tıkla Configure Build Path.
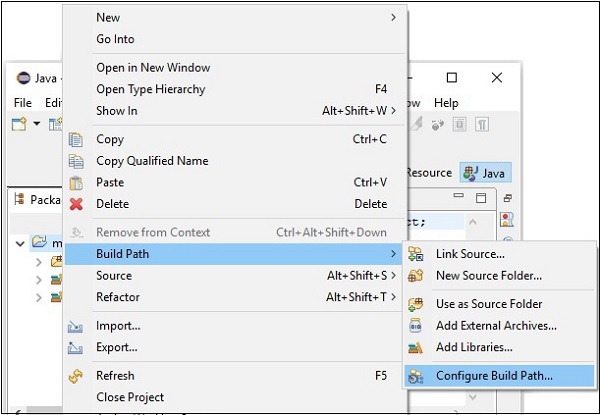
Step 6 - Sonra, alacaksın Java Build Pathsihirbaz. Buraya tıklayınAdd External JARs düğmesi aşağıda gösterildiği gibi.
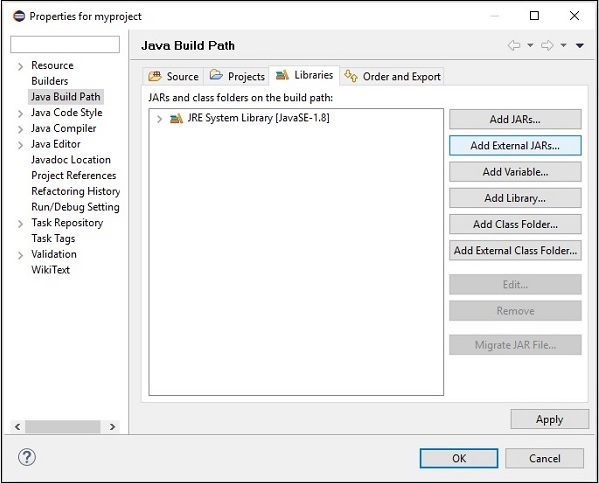
Step 7 - Jar dosyalarını seçin opennlp-tools-1.6.0.jar ve opennlp-uima-1.6.0.jar Içinde bulunan lib klasörü apache-opennlp-1.6.0 folder.
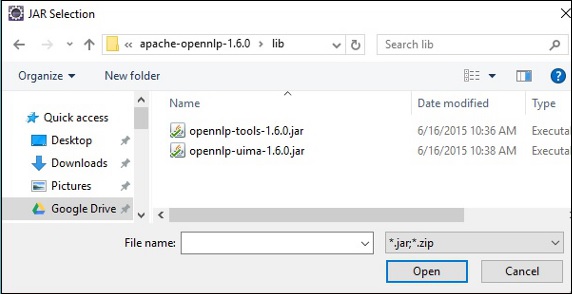
Tıklandığında Open Yukarıdaki ekranda bulunan butonuna tıkladığınızda, seçilen dosyalar kitaplığınıza eklenecektir.
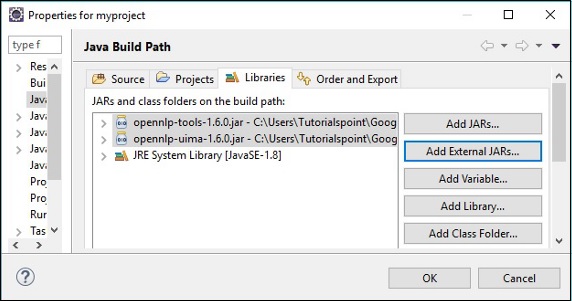
Tıklandığında OK, gerekli JAR dosyalarını mevcut projeye başarıyla ekleyeceksiniz ve aşağıda gösterildiği gibi Başvurulan Kitaplıkları genişleterek bu eklenen kitaplıkları doğrulayabilirsiniz.

Pom.xml kullanma
Projeyi bir Maven projesine dönüştürün ve aşağıdaki kodu projeye ekleyin. pom.xml.
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>myproject</groupId>
<artifactId>myproject</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-uima</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
</project>Bu bölümde, bu eğitimin sonraki bölümlerinde kullanacağımız sınıflar ve yöntemler hakkında tartışacağız.
Cümle Algılama
CümleModel sınıfı
Bu sınıf, verilen ham metindeki cümleleri tespit etmek için kullanılan önceden tanımlanmış modeli temsil eder. Bu sınıf pakete aittiropennlp.tools.sentdetect.
Bu sınıfın kurucusu bir InputStream cümle algılayıcı model dosyasının nesnesi (en-sent.bin).
CümleDetectorME sınıfı
Bu sınıf pakete aittir opennlp.tools.sentdetectve ham metni cümlelere bölmek için yöntemler içerir. Bu sınıf, cümlenin sonunu ifade edip etmediklerini belirlemek için bir dizedeki cümle sonu karakterlerini değerlendirmek için bir maksimum entropi modeli kullanır.
Bu sınıfın önemli yöntemleri aşağıdadır.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | sentDetect() Bu yöntem, kendisine aktarılan ham metindeki cümleleri tespit etmek için kullanılır. Bir String değişkenini parametre olarak kabul eder ve verilen ham metinden cümleleri tutan bir String dizisi döndürür. |
| 2 | sentPosDetect() Bu yöntem, verilen metindeki cümlelerin konumlarını tespit etmek için kullanılır. Bu yöntem, cümleyi temsil eden bir dize değişkenini kabul eder ve türdeki nesnelerin bir dizisini döndürürSpan. Adlı sınıf Span of opennlp.tools.util paketi, kümelerin başlangıç ve bitiş tam sayılarını saklamak için kullanılır. |
| 3 | getSentenceProbabilities() Bu yöntem, en son yapılan çağrılarla ilişkili olasılıkları döndürür. sentDetect() yöntem. |
Tokenizasyon
TokenizerModel sınıfı
Bu sınıf, verilen cümleyi belirtmek için kullanılan önceden tanımlanmış modeli temsil eder. Bu sınıf pakete aittiropennlp.tools.tokenizer.
Bu sınıfın kurucusu bir InputStream belirteç model dosyasının nesnesi (entoken.bin).
Sınıflar
Tokenizasyon gerçekleştirmek için OpenNLP kütüphanesi üç ana sınıf sağlar. Her üç sınıf da adı verilen arayüzü uygularTokenizer.
| S.No | Sınıflar ve Açıklama |
|---|---|
| 1 | SimpleTokenizer Bu sınıf, karakter sınıflarını kullanarak verilen ham metni belirteçler. |
| 2 | WhitespaceTokenizer Bu sınıf, verilen metni belirtmek için beyaz boşlukları kullanır. |
| 3 | TokenizerME Bu sınıf, ham metni ayrı belirteçlere dönüştürür. Kararlarını vermek için Maksimum Entropi kullanır. |
Bu sınıflar aşağıdaki yöntemleri içerir.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | tokenize() Bu yöntem, ham metni belirtmek için kullanılır. Bu yöntem bir String değişkenini parametre olarak kabul eder ve bir Dizeler (belirteçler) dizisi döndürür. |
| 2 | sentPosDetect() Bu yöntem, jetonların konumlarını veya aralıklarını almak için kullanılır. Dize biçiminde cümle (veya) ham metni kabul eder ve türden bir nesne dizisi döndürür.Span. |
Yukarıdaki iki yönteme ek olarak, TokenizerME sınıf var getTokenProbabilities() yöntem.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | getTokenProbabilities() Bu yöntem, en son yapılan çağrılarla ilişkili olasılıkları almak için kullanılır. tokenizePos() yöntem. |
NameEntityRecognition
TokenNameFinderModel sınıfı
Bu sınıf, verilen cümlede adlandırılan varlıkları bulmak için kullanılan önceden tanımlanmış modeli temsil eder. Bu sınıf pakete aittiropennlp.tools.namefind.
Bu sınıfın kurucusu bir InputStream ad bulucu model dosyasının nesnesi (enner-person.bin).
NameFinderME sınıfı
Sınıf pakete aittir opennlp.tools.namefindve NER görevlerini gerçekleştirmek için yöntemler içerir. Bu sınıf, verilen ham metinde adlandırılmış varlıkları bulmak için bir maksimum entropi modeli kullanır.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | find() Bu yöntem ham metindeki isimleri tespit etmek için kullanılır. Ham metni bir parametre olarak temsil eden bir String değişkenini kabul eder ve Span türünde bir dizi nesne döndürür. |
| 2 | probs() Bu yöntem, son kodu çözülen dizinin olasılıklarını elde etmek için kullanılır. |
Konuşmanın Bölümlerini Bulmak
POSModel sınıfı
Bu sınıf, verilen cümlenin konuşma bölümlerini etiketlemek için kullanılan önceden tanımlanmış modeli temsil eder. Bu sınıf pakete aittiropennlp.tools.postag.
Bu sınıfın kurucusu bir InputStream pos-tagger model dosyasının nesnesi (enpos-maxent.bin).
POSTaggerME sınıfı
Bu sınıf pakete aittir opennlp.tools.postagve verilen ham metnin konuşma bölümlerini tahmin etmek için kullanılır. Kararlarını vermek için Maksimum Entropi kullanır.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | tag() Bu yöntem, POS etiketlerinin işaretlerini atamak için kullanılır. Bu yöntem, bir dizi belirteci (String) bir parametre olarak kabul eder ve bir etiket (dizi) döndürür. |
| 2 | getSentenceProbabilities() Bu yöntem, yakın zamanda etiketlenen cümlenin her bir etiketinin olasılıklarını elde etmek için kullanılır. |
Cümlenin Ayrıştırılması
ParserModel sınıfı
Bu sınıf, verilen cümleyi ayrıştırmak için kullanılan önceden tanımlanmış modeli temsil eder. Bu sınıf pakete aittiropennlp.tools.parser.
Bu sınıfın kurucusu bir InputStream ayrıştırıcı model dosyasının nesnesi (en-parserchunking.bin).
Ayrıştırıcı Fabrika sınıfı
Bu sınıf pakete aittir opennlp.tools.parser ve ayrıştırıcılar oluşturmak için kullanılır.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | create() Bu statik bir yöntemdir ve bir ayrıştırıcı nesnesi oluşturmak için kullanılır. Bu yöntem, ayrıştırıcı model dosyasının Filestream nesnesini kabul eder. |
ParserTool sınıfı
Bu sınıf, opennlp.tools.cmdline.parser paketi ve içeriği ayrıştırmak için kullanılır.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | parseLine() Bu yöntem ParserToolsınıfı, ham metni OpenNLP'de ayrıştırmak için kullanılır. Bu yöntem kabul eder -
|
Kümeleme
ChunkerModel sınıfı
Bu sınıf, bir cümleyi daha küçük parçalara bölmek için kullanılan önceden tanımlanmış modeli temsil eder. Bu sınıf pakete aittiropennlp.tools.chunker.
Bu sınıfın kurucusu bir InputStream nesnesi chunker model dosyası (enchunker.bin).
ChunkerME sınıfı
Bu sınıf adlı pakete ait opennlp.tools.chunker ve verilen cümleyi daha küçük parçalara bölmek için kullanılır.
| S.No | Yöntemler ve Açıklama |
|---|---|
| 1 | chunk() Bu yöntem, verilen cümleyi daha küçük parçalara bölmek için kullanılır. Bir cümlenin belirteçlerini kabul eder vePsanatlar Of Sparametreler olarak peech etiketleri. |
| 2 | probs() Bu yöntem, son kodu çözülen dizinin olasılıklarını döndürür. |
Doğal bir dili işlerken cümlelerin başına ve sonuna karar vermek, ele alınması gereken sorunlardan biridir. Bu süreç olarak bilinirSgiriş Boundary Dbelirsizlik (SBD) veya basitçe cümle kırma.
Verilen metindeki cümleleri tespit etmek için kullandığımız teknikler, metnin diline bağlıdır.
Java Kullanarak Cümle Algılama
Java'da verilen metindeki cümleleri, Normal İfadeler ve bir dizi basit kural kullanarak tespit edebiliriz.
Örneğin, verilen metinde bir nokta, soru işareti veya ünlem işareti bir cümleyi bitirdiğimizi varsayalım, sonra cümleyi kullanarak cümleyi bölebiliriz. split() yöntemi Stringsınıf. Burada String formatında bir düzenli ifade geçmemiz gerekiyor.
Aşağıda, Java düzenli ifadelerini kullanarak belirli bir metindeki cümleleri belirleyen program yer almaktadır. (split method). Bu programı adıyla bir dosyaya kaydedinSentenceDetection_RE.java.
public class SentenceDetection_RE {
public static void main(String args[]){
String sentence = " Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
String simple = "[.?!]";
String[] splitString = (sentence.split(simple));
for (String string : splitString)
System.out.println(string);
}
}Kaydedilen java dosyasını aşağıdaki komutları kullanarak komut isteminden derleyin ve yürütün.
javac SentenceDetection_RE.java
java SentenceDetection_REYürütüldüğünde, yukarıdaki program aşağıdaki mesajı görüntüleyen bir PDF belgesi oluşturur.
Hi
How are you
Welcome to Tutorialspoint
We provide free tutorials on various technologiesOpenNLP Kullanarak Cümle Algılama
OpenNLP, cümleleri algılamak için önceden tanımlanmış bir model kullanır; en-sent.bin. Bu önceden tanımlanmış model, belirli bir ham metindeki cümleleri tespit etmek için eğitilmiştir.
opennlp.tools.sentdetect paketi, cümle algılama görevini gerçekleştirmek için kullanılan sınıfları ve arabirimleri içerir.
OpenNLP kitaplığını kullanarak bir cümleyi tespit etmek için yapmanız gerekenler -
Yükle en-sent.bin kullanarak model SentenceModel sınıf
Örnekleyin SentenceDetectorME sınıf.
Kullanarak cümleleri tespit edin sentDetect() bu sınıfın yöntemi.
Verilen ham metinden cümleleri tespit eden bir program yazmak için izlenecek adımlar aşağıdadır.
Adım 1: Modeli yükleme
Cümle algılama modeli, adlı sınıf tarafından temsil edilir. SentenceModelpakete ait olan opennlp.tools.sentdetect.
Bir cümle algılama modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream öğesini örnekleyin ve modelin yolunu String biçiminde yapıcısına iletin).
Örnekleyin SentenceModel sınıf ve geç InputStream (nesne), aşağıdaki kod bloğunda gösterildiği gibi yapıcısına bir parametre olarak modelin -
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/ensent.bin");
SentenceModel model = new SentenceModel(inputStream);Adım 2: CümleDetectorME sınıfını örnekleme
SentenceDetectorME paketin sınıfı opennlp.tools.sentdetectişlenmemiş metni cümlelere ayırmak için yöntemler içerir. Bu sınıf, bir dizedeki cümle sonu karakterlerini, bir cümlenin sonunu ifade edip etmediklerini belirlemek üzere değerlendirmek için Maksimum Entropi modelini kullanır.
Bu sınıfı somutlaştırın ve aşağıda gösterildiği gibi önceki adımda oluşturulan model nesnesini iletin.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);3. Adım: Cümlenin tespit edilmesi
sentDetect() yöntemi SentenceDetectorMEsınıfı, kendisine aktarılan ham metindeki cümleleri tespit etmek için kullanılır. Bu yöntem, bir String değişkenini parametre olarak kabul eder.
Cümlenin String biçimini bu yönteme ileterek bu yöntemi çağırın.
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);Example
Aşağıda verilen ham metindeki cümleleri tespit eden program yer almaktadır. Bu programı isimli bir dosyaya kaydedin.SentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionME {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac SentenceDetectorME.java
java SentenceDetectorMEYürütüldüğünde, yukarıdaki program verilen String'i okur ve içindeki cümleleri algılar ve aşağıdaki çıktıyı görüntüler.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesCümlelerin Konumlarını Tespit Etmek
Ayrıca cümlelerin konumlarını sentPosDetect () yöntemini kullanarak tespit edebiliriz. SentenceDetectorME class.
Verilen ham metinden cümlelerin konumlarını tespit eden bir program yazmak için izlenecek adımlar aşağıdadır.
Adım 1: Modeli yükleme
Cümle algılama modeli, adlı sınıf tarafından temsil edilir. SentenceModelpakete ait olan opennlp.tools.sentdetect.
Bir cümle algılama modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream öğesini örnekleyin ve modelin yolunu String biçiminde yapıcısına iletin).
Örnekleyin SentenceModel sınıf ve geç InputStream (nesne) modelinin yapıcısına bir parametre olarak aşağıdaki kod bloğunda gösterildiği gibi.
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);Adım 2: CümleDetectorME sınıfını örnekleme
SentenceDetectorME paketin sınıfı opennlp.tools.sentdetectişlenmemiş metni cümlelere ayırmak için yöntemler içerir. Bu sınıf, bir dizedeki cümle sonu karakterlerini, bir cümlenin sonunu ifade edip etmediklerini belirlemek üzere değerlendirmek için Maksimum Entropi modelini kullanır.
Bu sınıfı örnekleyin ve önceki adımda oluşturulan model nesnesini iletin.
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);3. Adım: Cümlenin konumunu tespit etmek
sentPosDetect() yöntemi SentenceDetectorMEsınıfı, kendisine aktarılan ham metindeki cümlelerin konumlarını tespit etmek için kullanılır. Bu yöntem, bir String değişkenini parametre olarak kabul eder.
Cümlenin String biçimini bir parametre olarak bu yönteme ileterek bu yöntemi çağırın.
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sentence);Adım 4: Cümlelerin aralıklarını yazdırma
sentPosDetect() yöntemi SentenceDetectorME sınıf, türdeki nesnelerin bir dizisini döndürür Span. Span adlı sınıfopennlp.tools.util paketi, kümelerin başlangıç ve bitiş tam sayılarını saklamak için kullanılır.
Tarafından döndürülen aralıkları saklayabilirsiniz. sentPosDetect() yöntemini Span dizisine ekleyin ve aşağıdaki kod bloğunda gösterildiği gibi yazdırın.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);Example
Aşağıda verilen ham metindeki cümleleri tespit eden program yer almaktadır. Bu programı isimli bir dosyaya kaydedin.SentenceDetectionME.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencePosDetection {
public static void main(String args[]) throws Exception {
String paragraph = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the raw text
Span spans[] = detector.sentPosDetect(paragraph);
//Printing the spans of the sentences in the paragraph
for (Span span : spans)
System.out.println(span);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac SentencePosDetection.java
java SentencePosDetectionYürütüldüğünde, yukarıdaki program verilen String'i okur ve içindeki cümleleri algılar ve aşağıdaki çıktıyı görüntüler.
[0..16)
[17..43)
[44..93)Pozisyonları ile birlikte cümleler
substring() String sınıfının yöntemi, begin ve end offsetsve ilgili dizeyi döndürür. Aşağıdaki kod bloğunda gösterildiği gibi, cümleleri ve bunların aralıklarını (konumlarını) birlikte yazdırmak için bu yöntemi kullanabiliriz.
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);Aşağıda verilen ham metinden cümleleri tespit etme ve konumlarıyla birlikte görüntüleme programı verilmiştir. Bu programı adıyla bir dosyaya kaydedinSentencesAndPosDetection.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
import opennlp.tools.util.Span;
public class SentencesAndPosDetection {
public static void main(String args[]) throws Exception {
String sen = "Hi. How are you? Welcome to Tutorialspoint."
+ " We provide free tutorials on various technologies";
//Loading a sentence model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the position of the sentences in the paragraph
Span[] spans = detector.sentPosDetect(sen);
//Printing the sentences and their spans of a paragraph
for (Span span : spans)
System.out.println(sen.substring(span.getStart(), span.getEnd())+" "+ span);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac SentencesAndPosDetection.java
java SentencesAndPosDetectionYürütüldüğünde, yukarıdaki program verilen dizgeyi okur ve cümleleri konumlarıyla birlikte algılar ve aşağıdaki çıktıyı görüntüler.
Hi. How are you? [0..16)
Welcome to Tutorialspoint. [17..43)
We provide free tutorials on various technologies [44..93)Cümle Olasılık Tespiti
getSentenceProbabilities() yöntemi SentenceDetectorME sınıfı, sentDetect () yöntemine yapılan en son çağrılarla ilişkili olasılıkları döndürür.
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();SentDetect () yöntemine yapılan çağrılarla ilişkili olasılıkları yazdırmak için program aşağıdadır. Bu programı adıyla bir dosyaya kaydedinSentenceDetectionMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.sentdetect.SentenceDetectorME;
import opennlp.tools.sentdetect.SentenceModel;
public class SentenceDetectionMEProbs {
public static void main(String args[]) throws Exception {
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading sentence detector model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-sent.bin");
SentenceModel model = new SentenceModel(inputStream);
//Instantiating the SentenceDetectorME class
SentenceDetectorME detector = new SentenceDetectorME(model);
//Detecting the sentence
String sentences[] = detector.sentDetect(sentence);
//Printing the sentences
for(String sent : sentences)
System.out.println(sent);
//Getting the probabilities of the last decoded sequence
double[] probs = detector.getSentenceProbabilities();
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac SentenceDetectionMEProbs.java
java SentenceDetectionMEProbsYürütüldüğünde, yukarıdaki program verilen dizgeyi okur ve cümleleri algılar ve yazdırır. Ek olarak, aşağıda gösterildiği gibi sentDetect () yöntemine yapılan en son çağrılarla ilişkili olasılıkları da döndürür.
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologies
0.9240246995179983
0.9957680129995953
1.0Verilen cümleyi daha küçük parçalara (jetonlara) bölme süreci şu şekilde bilinir: tokenization. Genel olarak, verilen işlenmemiş metin bir dizi sınırlayıcıya (çoğunlukla beyaz boşluklar) dayalı olarak belirtilir.
Tokenizasyon, yazım denetimi, aramaları işleme, konuşma bölümlerini tanımlama, cümle algılama, belgelerin belge sınıflandırması vb. Gibi görevlerde kullanılır.
OpenNLP kullanarak kodlama
opennlp.tools.tokenize paketi, belirteçleştirmeyi gerçekleştirmek için kullanılan sınıfları ve arabirimleri içerir.
Verilen cümleleri daha basit parçalar halinde belirtmek için, OpenNLP kitaplığı üç farklı sınıf sağlar -
SimpleTokenizer - Bu sınıf, karakter sınıflarını kullanarak verilen ham metni belirteçler.
WhitespaceTokenizer - Bu sınıf, verilen metni belirtmek için beyaz boşlukları kullanır.
TokenizerME- Bu sınıf, ham metni ayrı belirteçlere dönüştürür. Kararlarını vermek için Maksimum Entropi kullanır.
SimpleTokenizer
Kullanarak bir cümleyi belirtmek için SimpleTokenizer sınıf, yapmanız gereken -
İlgili sınıfın bir nesnesini oluşturun.
Cümleyi kullanarak cümleyi şifreleyin tokenize() yöntem.
Jetonları yazdırın.
Verilen ham metni belirteçlere ayıran bir program yazmak için izlenecek adımlar aşağıdadır.
Step 1 - İlgili sınıfı örneklemek
Her iki sınıfta da, onları başlatacak yapıcılar yoktur. Bu nedenle, statik değişkeni kullanarak bu sınıfların nesnelerini oluşturmamız gerekir.INSTANCE.
SimpleTokenizer tokenizer = SimpleTokenizer.INSTANCE;Step 2 - Cümleleri şifreleyin
Her iki sınıf da adında bir yöntem içerir tokenize(). Bu yöntem, String formatında bir ham metni kabul eder. Çağrıldığında, verilen String'i jetonlaştırır ve bir Dizeler (jetonlar) dizisi döndürür.
Cümleyi kullanarak cümleyi şifreleyin tokenizer() yöntemi aşağıda gösterildiği gibi.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - Jetonları yazdırın
Cümleyi belirtdikten sonra, belirteçleri kullanarak yazdırabilirsiniz. for loop, Aşağıda gösterildiği gibi.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Aşağıda verilen cümleyi SimpleTokenizer sınıfını kullanarak belirteç yapan program yer almaktadır. Bu programı adıyla bir dosyaya kaydedinSimpleTokenizerExample.java.
import opennlp.tools.tokenize.SimpleTokenizer;
public class SimpleTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Tokenizing the given sentence
String tokens[] = simpleTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens) {
System.out.println(token);
}
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac SimpleTokenizerExample.java
java SimpleTokenizerExampleYürütüldüğünde, yukarıdaki program verilen String'i (ham metin) okur, onu tokenize eder ve aşağıdaki çıktıyı görüntüler -
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologiesWhitespaceTokenizer
Kullanarak bir cümleyi belirtmek için WhitespaceTokenizer sınıf, yapmanız gereken -
İlgili sınıfın bir nesnesini oluşturun.
Cümleyi kullanarak cümleyi şifreleyin tokenize() yöntem.
Jetonları yazdırın.
Verilen ham metni belirteçlere ayıran bir program yazmak için izlenecek adımlar aşağıdadır.
Step 1 - İlgili sınıfı örneklemek
Her iki sınıfta da, onları başlatacak yapıcılar yoktur. Bu nedenle, statik değişkeni kullanarak bu sınıfların nesnelerini oluşturmamız gerekir.INSTANCE.
WhitespaceTokenizer tokenizer = WhitespaceTokenizer.INSTANCE;Step 2 - Cümleleri şifreleyin
Her iki sınıf da adında bir yöntem içerir tokenize(). Bu yöntem, String formatında bir ham metni kabul eder. Çağrıldığında, verilen String'i jetonlaştırır ve bir Dizeler (jetonlar) dizisi döndürür.
Cümleyi kullanarak cümleyi şifreleyin tokenizer() yöntemi aşağıda gösterildiği gibi.
//Tokenizing the given sentence
String tokens[] = tokenizer.tokenize(sentence);Step 3 - Jetonları yazdırın
Cümleyi belirtdikten sonra, belirteçleri kullanarak yazdırabilirsiniz. for loop, Aşağıda gösterildiği gibi.
//Printing the tokens
for(String token : tokens)
System.out.println(token);Example
Aşağıda, verilen cümleyi kullanarak jetonlaştıran programdır. WhitespaceTokenizersınıf. Bu programı adıyla bir dosyaya kaydedinWhitespaceTokenizerExample.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class WhitespaceTokenizerExample {
public static void main(String args[]){
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating whitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Tokenizing the given paragraph
String tokens[] = whitespaceTokenizer.tokenize(sentence);
//Printing the tokens
for(String token : tokens)
System.out.println(token);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac WhitespaceTokenizerExample.java
java WhitespaceTokenizerExampleYürütüldüğünde, yukarıdaki program verilen String'i (ham metin) okur, onu tokenize eder ve aşağıdaki çıktıyı görüntüler.
Hi.
How
are
you?
Welcome
to
Tutorialspoint.
We
provide
free
tutorials
on
various
technologiesTokenizerME sınıfı
OpenNLP ayrıca cümleleri belirtmek için önceden tanımlanmış bir model, de-token.bin adlı bir dosya kullanır. Belirli bir ham metindeki cümleleri belirtmek için eğitilmiştir.
TokenizerME sınıfı opennlp.tools.tokenizerpaketi, bu modeli yüklemek ve verilen ham metni OpenNLP kitaplığını kullanarak belirtmek için kullanılır. Bunu yapmak için yapmanız gerekenler -
Yükle en-token.bin kullanarak model TokenizerModel sınıf.
Örnekleyin TokenizerME sınıf.
Cümleleri kullanarak şifreleyin tokenize() bu sınıfın yöntemi.
Aşağıdaki adımları kullanarak verilen ham metinden cümleleri dizgeye dönüştüren bir program yazmak için izlenecek adımlar verilmiştir. TokenizerME sınıf.
Step 1 - Modeli yükleme
Simgeleştirme modeli, adlı sınıf tarafından temsil edilir. TokenizerModelpakete ait olan opennlp.tools.tokenize.
Bir jetonlaştırıcı modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream öğesini örnekleyin ve modelin yolunu String biçiminde yapıcısına iletin).
Örnekleyin TokenizerModel sınıf ve geç InputStream (nesne) modelinin yapıcısına bir parametre olarak aşağıdaki kod bloğunda gösterildiği gibi.
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);Step 2 - TokenizerME sınıfını örnekleme
TokenizerME paketin sınıfı opennlp.tools.tokenizeişlenmemiş metni daha küçük parçalara (jetonlar) ayırmak için yöntemler içerir. Kararlarını vermek için Maksimum Entropi kullanır.
Bu sınıfı somutlaştırın ve önceki adımda oluşturulan model nesnesini aşağıda gösterildiği gibi iletin.
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);Step 3 - Cümlenin simge haline getirilmesi
tokenize() yöntemi TokenizerMEsınıfı, kendisine iletilen ham metni belirtmek için kullanılır. Bu yöntem bir String değişkenini parametre olarak kabul eder ve bir Dizeler (belirteçler) dizisi döndürür.
Aşağıdaki gibi, cümlenin String biçimini bu yönteme ileterek bu yöntemi çağırın.
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(paragraph);Example
Aşağıda verilen ham metni tokenize eden program yer almaktadır. Bu programı adıyla bir dosyaya kaydedinTokenizerMEExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
public class TokenizerMEExample {
public static void main(String args[]) throws Exception{
String sentence = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the given raw text
String tokens[] = tokenizer.tokenize(sentence);
//Printing the tokens
for (String a : tokens)
System.out.println(a);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac TokenizerMEExample.java
java TokenizerMEExampleYürütüldüğünde, yukarıdaki program verilen String'i okur ve içindeki cümleleri algılar ve aşağıdaki çıktıyı görüntüler -
Hi
.
How
are
you
?
Welcome
to
Tutorialspoint
.
We
provide
free
tutorials
on
various
technologieJetonların Konumlarını Geri Alma
Pozisyonları da alabiliriz veya spans token'ların tokenizePos()yöntem. Bu, paketin Tokenizer arayüzünün yöntemidiropennlp.tools.tokenize. Tüm (üç) Tokenizer sınıfı bu arayüzü uyguladığından, bu yöntemi hepsinde bulabilirsiniz.
Bu yöntem cümleyi veya ham metni bir dize biçiminde kabul eder ve türdeki nesnelerin bir dizisini döndürür Span.
Tokenların pozisyonlarını şurayı kullanarak alabilirsiniz: tokenizePos() yöntem, aşağıdaki gibi -
//Retrieving the tokens
tokenizer.tokenizePos(sentence);Pozisyonları (aralıkları) yazdırma
Adlı sınıf Span of opennlp.tools.util paketi, kümelerin başlangıç ve bitiş tam sayılarını saklamak için kullanılır.
Tarafından döndürülen aralıkları saklayabilirsiniz. tokenizePos() yöntemini Span dizisine ekleyin ve aşağıdaki kod bloğunda gösterildiği gibi yazdırın.
//Retrieving the tokens
Span[] tokens = tokenizer.tokenizePos(sentence);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token);Jetonları ve konumlarını birlikte yazdırma
substring() String sınıfının yöntemi, begin ve endofsetler ve ilgili dizeyi döndürür. Aşağıdaki kod bloğunda gösterildiği gibi, bu yöntemi tokenleri ve bunların aralıklarını (konumlarını) birlikte yazdırmak için kullanabiliriz.
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));Example(SimpleTokenizer)
Aşağıda, ham metnin belirteç aralıklarını kullanarak SimpleTokenizersınıf. Ayrıca, jetonları konumlarıyla birlikte yazdırır. Bu programı isimli bir dosyaya kaydedin.SimpleTokenizerSpans.java.
import opennlp.tools.tokenize.SimpleTokenizer;
import opennlp.tools.util.Span;
public class SimpleTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
SimpleTokenizer simpleTokenizer = SimpleTokenizer.INSTANCE;
//Retrieving the boundaries of the tokens
Span[] tokens = simpleTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac SimpleTokenizerSpans.java
java SimpleTokenizerSpansYürütüldüğünde, yukarıdaki program verilen String'i (ham metin) okur, onu tokenize eder ve aşağıdaki çıktıyı görüntüler -
[0..2) Hi
[2..3) .
[4..7) How
[8..11) are
[12..15) you
[15..16) ?
[17..24) Welcome
[25..27) to
[28..42) Tutorialspoint
[42..43) .
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (WhitespaceTokenizer)
Aşağıda, ham metnin belirteç aralıklarını kullanarak WhitespaceTokenizersınıf. Ayrıca, jetonları konumlarıyla birlikte yazdırır. Bu programı adıyla bir dosyaya kaydedinWhitespaceTokenizerSpans.java.
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class WhitespaceTokenizerSpans {
public static void main(String args[]){
String sent = "Hi. How are you? Welcome to Tutorialspoint. "
+ "We provide free tutorials on various technologies";
//Instantiating SimpleTokenizer class
WhitespaceTokenizer whitespaceTokenizer = WhitespaceTokenizer.INSTANCE;
//Retrieving the tokens
Span[] tokens = whitespaceTokenizer.tokenizePos(sent);
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
}
}Kaydedilen java dosyasını aşağıdaki komutları kullanarak komut isteminden derleyin ve yürütün
javac WhitespaceTokenizerSpans.java
java WhitespaceTokenizerSpansYürütüldüğünde, yukarıdaki program verilen String'i (ham metin) okur, onu tokenize eder ve aşağıdaki çıktıyı görüntüler.
[0..3) Hi.
[4..7) How
[8..11) are
[12..16) you?
[17..24) Welcome
[25..27) to
[28..43) Tutorialspoint.
[44..46) We
[47..54) provide
[55..59) free
[60..69) tutorials
[70..72) on
[73..80) various
[81..93) technologiesExample (TokenizerME)
Aşağıda, ham metnin belirteç aralıklarını kullanarak TokenizerMEsınıf. Ayrıca, jetonları konumlarıyla birlikte yazdırır. Bu programı adıyla bir dosyaya kaydedinTokenizerMESpans.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMESpans {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac TokenizerMESpans.java
java TokenizerMESpansYürütüldüğünde, yukarıdaki program verilen String'i (ham metin) okur, onu tokenize eder ve aşağıdaki çıktıyı görüntüler -
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) TutorialspointTokenizatör Olasılığı
TokenizerME sınıfının getTokenProbabilities () yöntemi, tokenizePos () yöntemine yapılan en son çağrılarla ilişkili olasılıkları almak için kullanılır.
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Aşağıdaki program, tokenizePos () yöntemine yapılan çağrılarla ilişkili olasılıkları yazdırmaktır. Bu programı adıyla bir dosyaya kaydedinTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for(Span token : tokens)
System.out.println(token +" "+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac TokenizerMEProbs.java
java TokenizerMEProbsYürütüldüğünde, yukarıdaki program verilen dizgeyi okur ve cümleleri belirtip, yazdırır. Ek olarak, tokenizerPos () yöntemine yapılan en son çağrılarla ilişkili olasılıkları da döndürür.
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0Belirli bir metinden isimleri, kişileri, yerleri ve diğer varlıkları bulma süreci, Named Entity Rtanıma (NER). Bu bölümde, OpenNLP kitaplığını kullanarak Java programı aracılığıyla NER'in nasıl gerçekleştirileceğini tartışacağız.
Açık NLP kullanarak Adlandırılmış Varlık Tanıma
OpenNLP, çeşitli NER görevlerini gerçekleştirmek için önceden tanımlanmış farklı modeller kullanır: en-nerdate.bn, en-ner-location.bin, en-ner-organization.bin, en-ner-person.bin ve en-ner-time. çöp Kutusu. Tüm bu dosyalar, belirli bir ham metindeki ilgili varlıkları tespit etmek için eğitilmiş önceden tanımlanmış modellerdir.
opennlp.tools.namefindpaketi, NER görevini gerçekleştirmek için kullanılan sınıfları ve arabirimleri içerir. OpenNLP kitaplığını kullanarak NER görevini gerçekleştirmek için yapmanız gerekenler -
Kullanarak ilgili modeli yükleyin TokenNameFinderModel sınıf.
Örnekleyin NameFinder sınıf.
İsimleri bulun ve yazdırın.
Belirli bir ham metinden isim varlıklarını algılayan bir program yazmak için izlenecek adımlar aşağıdadır.
Adım 1: Modeli yükleme
Cümle algılama modeli, adlı sınıf tarafından temsil edilir. TokenNameFinderModelpakete ait olan opennlp.tools.namefind.
Bir NER modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream'i somutlaştırın ve uygun NER modelinin yolunu String biçiminde yapıcısına iletin).
Örnekleyin TokenNameFinderModel sınıf ve geç InputStream (nesne) modelinin yapıcısına bir parametre olarak aşağıdaki kod bloğunda gösterildiği gibi.
//Loading the NER-person model
InputStream inputStreamNameFinder = new FileInputStream(".../en-nerperson.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);2. Adım: NameFinderME sınıfının örneğini oluşturma
NameFinderME paketin sınıfı opennlp.tools.namefindNER görevlerini gerçekleştirmek için yöntemler içerir. Bu sınıf, verilen ham metinde adlandırılmış varlıkları bulmak için Maksimum Entropy modelini kullanır.
Bu sınıfı örnekleyin ve önceki adımda oluşturulan model nesnesini aşağıda gösterildiği gibi iletin -
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);3. Adım: Cümledeki isimleri bulmak
find() yöntemi NameFinderMEsınıfı, kendisine aktarılan ham metindeki isimleri tespit etmek için kullanılır. Bu yöntem, bir String değişkenini parametre olarak kabul eder.
Cümlenin String biçimini bu yönteme ileterek bu yöntemi çağırın.
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);Adım 4: Cümledeki adların aralıklarını yazdırma
find() yöntemi NameFinderMEclass, Span türünde bir dizi nesne döndürür. Span adlı sınıfopennlp.tools.util paketi saklamak için kullanılır start ve end kümelerin tamsayısı.
Tarafından döndürülen aralıkları saklayabilirsiniz. find() yöntemini Span dizisine ekleyin ve aşağıdaki kod bloğunda gösterildiği gibi yazdırın.
//Printing the sentences and their spans of a sentence
for (Span span : spans)
System.out.println(paragraph.substring(span);NER Example
Aşağıda verilen cümleyi okuyan ve içindeki kişilerin isimlerinin açıklıklarını tanıyan programdır. Bu programı adıyla bir dosyaya kaydedinNameFinderME_Example.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.util.Span;
public class NameFinderME_Example {
public static void main(String args[]) throws Exception{
/Loading the NER - Person model InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-ner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStream);
//Instantiating the NameFinder class
NameFinderME nameFinder = new NameFinderME(model);
//Getting the sentence in the form of String array
String [] sentence = new String[]{
"Mike",
"and",
"Smith",
"are",
"good",
"friends"
};
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(sentence);
//Printing the spans of the names in the sentence
for(Span s: nameSpans)
System.out.println(s.toString());
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac NameFinderME_Example.java
java NameFinderME_ExampleYürütüldüğünde, yukarıdaki program verilen Dizgeyi (ham metin) okur, içindeki kişilerin adlarını algılar ve aşağıda gösterildiği gibi konumlarını (aralıkları) görüntüler.
[0..1) person
[2..3) personİsimler ve Pozisyonları
substring() String sınıfının yöntemi, begin ve end offsetsve ilgili dizeyi döndürür. Bu yöntemi, aşağıdaki kod bloğunda gösterildiği gibi adları ve açıklıklarını (konumlarını) birlikte yazdırmak için kullanabiliriz.
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);Aşağıda verilen ham metinden isimleri tespit etmek ve konumlarıyla birlikte görüntülemek için program yer almaktadır. Bu programı adıyla bir dosyaya kaydedinNameFinderSentences.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class NameFinderSentences {
public static void main(String args[]) throws Exception{
//Loading the tokenizer model
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Tokenizing the sentence in to a string array
String sentence = "Mike is senior programming
manager and Rama is a clerk both are working at
Tutorialspoint";
String tokens[] = tokenizer.tokenize(sentence);
//Loading the NER-person model
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/enner-person.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names in the sentence
Span nameSpans[] = nameFinder.find(tokens);
//Printing the names and their spans in a sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac NameFinderSentences.java
java NameFinderSentencesYürütüldüğünde, yukarıdaki program verilen Dizgeyi (ham metin) okur, içindeki kişilerin adlarını algılar ve aşağıda gösterildiği gibi konumlarını (aralıklarını) görüntüler.
[0..1) person MikeKonumun Adlarını Bulmak
Çeşitli modeller yükleyerek, çeşitli adlandırılmış varlıkları tespit edebilirsiniz. Aşağıdakileri yükleyen bir Java programıen-ner-location.binverilen cümlede yer adlarını modelleyip algılar. Bu programı adıyla bir dosyaya kaydedinLocationFinder.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.namefind.NameFinderME;
import opennlp.tools.namefind.TokenNameFinderModel;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class LocationFinder {
public static void main(String args[]) throws Exception{
InputStream inputStreamTokenizer = new
FileInputStream("C:/OpenNLP_models/entoken.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStreamTokenizer);
//String paragraph = "Mike and Smith are classmates";
String paragraph = "Tutorialspoint is located in Hyderabad";
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
String tokens[] = tokenizer.tokenize(paragraph);
//Loading the NER-location moodel
InputStream inputStreamNameFinder = new
FileInputStream("C:/OpenNLP_models/en- ner-location.bin");
TokenNameFinderModel model = new TokenNameFinderModel(inputStreamNameFinder);
//Instantiating the NameFinderME class
NameFinderME nameFinder = new NameFinderME(model);
//Finding the names of a location
Span nameSpans[] = nameFinder.find(tokens);
//Printing the spans of the locations in the sentence
for(Span s: nameSpans)
System.out.println(s.toString()+" "+tokens[s.getStart()]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac LocationFinder.java
java LocationFinderYürütüldüğünde, yukarıdaki program verilen Dizgeyi (ham metin) okur, içindeki kişilerin adlarını algılar ve aşağıda gösterildiği gibi konumlarını (aralıkları) görüntüler.
[4..5) location HyderabadAd Bulucu Olasılığı
probs()yöntemi NameFinderME sınıfı, son kodu çözülen dizinin olasılıklarını elde etmek için kullanılır.
double[] probs = nameFinder.probs();Olasılıkları yazdırmak için program aşağıdadır. Bu programı adıyla bir dosyaya kaydedinTokenizerMEProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.tokenize.TokenizerME;
import opennlp.tools.tokenize.TokenizerModel;
import opennlp.tools.util.Span;
public class TokenizerMEProbs {
public static void main(String args[]) throws Exception{
String sent = "Hello John how are you welcome to Tutorialspoint";
//Loading the Tokenizer model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-token.bin");
TokenizerModel tokenModel = new TokenizerModel(inputStream);
//Instantiating the TokenizerME class
TokenizerME tokenizer = new TokenizerME(tokenModel);
//Retrieving the positions of the tokens
Span tokens[] = tokenizer.tokenizePos(sent);
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = tokenizer.getTokenProbabilities();
//Printing the spans of tokens
for( Span token : tokens)
System.out.println(token +"
"+sent.substring(token.getStart(), token.getEnd()));
System.out.println(" ");
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac TokenizerMEProbs.java
java TokenizerMEProbsYürütüldüğünde, yukarıdaki program verilen String'i okur, cümleleri belirteçler ve yazdırır. Ek olarak, aşağıda gösterildiği gibi, son kodu çözülen dizinin olasılıklarını da döndürür.
[0..5) Hello
[6..10) John
[11..14) how
[15..18) are
[19..22) you
[23..30) welcome
[31..33) to
[34..48) Tutorialspoint
1.0
1.0
1.0
1.0
1.0
1.0
1.0
1.0OpenNLP'yi kullanarak, belirli bir cümlenin Konuşma Bölümlerini de algılayabilir ve bunları yazdırabilirsiniz. OpenNLP, konuşma bölümlerinin tam adı yerine, her konuşma bölümünün kısa biçimlerini kullanır. Aşağıdaki tablo OpenNLP tarafından algılanan çeşitli konuşma bölümlerini ve anlamlarını gösterir.
| Konuşmanın Bölümleri | Konuşma bölümlerinin anlamı |
|---|---|
| NN | İsim, tekil veya kitle |
| DT | Belirleyici |
| VB | Fiil, temel biçim |
| VBD | Fiil, geçmiş zaman |
| VBZ | Fiil, üçüncü tekil şahıs şimdiki zaman |
| İÇİNDE | Edat veya ikincil bağlaç |
| NNP | Uygun isim, tekil |
| KİME | -e |
| JJ | Sıfat |
Konuşma Bölümlerini Etiketleme
OpenNLP, bir cümlenin konuşma bölümlerini etiketlemek için bir model, adında bir dosya kullanır. en-posmaxent.bin. Bu, verilen ham metnin konuşma bölümlerini etiketlemek için eğitilmiş önceden tanımlanmış bir modeldir.
POSTaggerME sınıfı opennlp.tools.postagpaketi, bu modeli yüklemek ve OpenNLP kitaplığını kullanarak verilen ham metnin konuşma bölümlerini etiketlemek için kullanılır. Bunu yapmak için yapmanız gerekenler -
Yükle en-pos-maxent.bin kullanarak model POSModel sınıf.
Örnekleyin POSTaggerME sınıf.
Cümleyi şifreleyin.
Kullanarak etiketleri oluşturun tag() yöntem.
Belirteçleri ve etiketleri kullanarak yazdırın POSSample sınıf.
Aşağıdaki ham metinde konuşmanın bölümlerini kullanarak etiketleyen bir program yazmak için izlenecek adımlar aşağıdadır. POSTaggerME sınıf.
Adım 1: Modeli yükleyin
POS etiketleme modeli, adlı sınıf tarafından temsil edilir. POSModelpakete ait olan opennlp.tools.postag.
Bir jetonlaştırıcı modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream öğesini örnekleyin ve modelin yolunu String biçiminde yapıcısına iletin).
Örnekleyin POSModel sınıf ve geç InputStream (nesne), aşağıdaki kod bloğunda gösterildiği gibi yapıcısına bir parametre olarak modelin -
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);Adım 2: POSTaggerME sınıfını örnekleme
POSTaggerME paketin sınıfı opennlp.tools.postagverilen ham metnin konuşma bölümlerini tahmin etmek için kullanılır. Kararlarını vermek için Maksimum Entropi kullanır.
Bu sınıfı örnekleyin ve aşağıda gösterildiği gibi önceki adımda oluşturulan model nesnesini iletin -
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);3. Adım: Cümlenin şifrelenmesi
tokenize() yöntemi whitespaceTokenizersınıfı, kendisine iletilen ham metni belirtmek için kullanılır. Bu yöntem bir String değişkenini parametre olarak kabul eder ve bir Dizeler (belirteçler) dizisi döndürür.
Örnekleyin whitespaceTokenizer sınıfı ve cümlenin String biçimini bu yönteme ileterek bu yöntemi çağırın.
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);4. Adım: Etiketleri oluşturma
tag() yöntemi whitespaceTokenizerclass, POS etiketlerini jetonların cümlesine atar. Bu yöntem bir dizi belirteci (String) bir parametre olarak kabul eder ve tag (dizi) döndürür.
Çağırın tag() yöntem, önceki adımda oluşturulan jetonları ona geçirerek.
//Generating tags
String[] tags = tagger.tag(tokens);Adım 5: Jetonları ve etiketleri yazdırma
POSSamplesınıf, POS etiketli cümleyi temsil eder. Bu sınıfı somutlaştırmak için, bir dizi (metin) ve bir etiket dizisi gerekir.
toString()bu sınıfın yöntemi etiketli cümleyi döndürür. Önceki adımlarda oluşturulan belirteci ve etiket dizilerini ileterek bu sınıfı somutlaştırın vetoString() yöntem, aşağıdaki kod bloğunda gösterildiği gibi.
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());Example
Aşağıda, belirli bir ham metinde konuşma bölümlerini etiketleyen program verilmiştir. Bu programı adıyla bir dosyaya kaydedinPosTaggerExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerExample {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
String sentence = "Hi welcome to Tutorialspoint";
//Tokenizing the sentence using WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac PosTaggerExample.java
java PosTaggerExampleYürütüldüğünde, yukarıdaki program verilen metni okur ve bu cümlelerin konuşma bölümlerini tespit eder ve aşağıda gösterildiği gibi görüntüler.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VBPOS Etiketleyici Performansı
Aşağıda, belirli bir ham metnin konuşma bölümlerini etiketleyen program verilmiştir. Ayrıca, performansı izler ve etiketleyicinin performansını gösterir. Bu programı adıyla bir dosyaya kaydedinPosTagger_Performance.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTagger_Performance {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Monitoring the performance of POS tagger
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
perfMon.start();
perfMon.incrementCounter();
perfMon.stopAndPrintFinalResult();
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac PosTaggerExample.java
java PosTaggerExampleYürütüldüğünde, yukarıdaki program verilen metni okur ve bu cümlelerin konuşma bölümlerini etiketler ve görüntüler. Ek olarak, POS etiketleyicinin performansını da izler ve görüntüler.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
Average: 0.0 sent/s
Total: 1 sent
Runtime: 0.0sPOS Etiketleyici Olasılığı
probs() yöntemi POSTaggerME sınıfı, yakın zamanda etiketlenen cümlenin her bir etiketinin olasılıklarını bulmak için kullanılır.
//Getting the probabilities of the recent calls to tokenizePos() method
double[] probs = detector.getSentenceProbabilities();Aşağıda, etiketlenen son cümlenin her bir etiketi için olasılıkları gösteren program yer almaktadır. Bu programı adıyla bir dosyaya kaydedinPosTaggerProbs.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class PosTaggerProbs {
public static void main(String args[]) throws Exception{
//Loading Parts of speech-maxent model
InputStream inputStream = new FileInputStream("C:/OpenNLP_mdl/en-pos-maxent.bin");
POSModel model = new POSModel(inputStream);
//Creating an object of WhitespaceTokenizer class
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Instantiating POSTaggerME class
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags
String[] tags = tagger.tag(tokens);
//Instantiating the POSSample class
POSSample sample = new POSSample(tokens, tags);
System.out.println(sample.toString());
//Probabilities for each tag of the last tagged sentence.
double [] probs = tagger.probs();
System.out.println(" ");
//Printing the probabilities
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac TokenizerMEProbs.java
java TokenizerMEProbsYürütüldüğünde, yukarıdaki program verilen ham metni okur, içindeki her simgenin konuşma bölümlerini etiketler ve bunları görüntüler. Ek olarak, aşağıda gösterildiği gibi, verilen cümledeki her bir kelime parçası için olasılıkları da gösterir.
Hi_NNP welcome_JJ to_TO Tutorialspoint_VB
0.6416834779738033
0.42983612874819177
0.8584513635863117
0.4394784478206072OpenNLP API kullanarak verilen cümleleri ayrıştırabilirsiniz. Bu bölümde, OpenNLP API kullanılarak ham metnin nasıl ayrıştırılacağını tartışacağız.
OpenNLP Kitaplığını Kullanarak Ham Metni Ayrıştırma
Cümleleri algılamak için, OpenNLP önceden tanımlanmış bir model kullanır; en-parserchunking.bin. Bu, verilen ham metni ayrıştırmak için eğitilmiş önceden tanımlanmış bir modeldir.
Parser sınıfı opennlp.tools.Parser paket ayrıştırma bileşenlerini tutmak için kullanılır ve ParserTool sınıfı opennlp.tools.cmdline.parser paket içeriği ayrıştırmak için kullanılır.
Aşağıda, verilen ham metni kullanarak ayrıştıran bir program yazmak için izlenecek adımlar verilmiştir. ParserTool sınıf.
Adım 1: Modeli yükleme
Metni ayrıştırma modeli, adlı sınıf tarafından temsil edilir. ParserModelpakete ait olan opennlp.tools.parser.
Bir jetonlaştırıcı modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream öğesini örnekleyin ve modelin yolunu String biçiminde yapıcısına iletin).
Örnekleyin ParserModel sınıf ve geç InputStream (nesne) modelinin yapıcısına bir parametre olarak aşağıdaki kod bloğunda gösterildiği gibi.
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);Adım 2: Parser sınıfının bir nesnesini oluşturma
Parser paketin sınıfı opennlp.tools.parserayrıştırma bileşenlerini tutmak için bir veri yapısını temsil eder. Statik kullanarak bu sınıfın bir nesnesini oluşturabilirsiniz.create() yöntemi ParserFactory sınıf.
Çağırın create() yöntemi ParserFactory önceki adımda oluşturulan model nesnesini aşağıda gösterildiği gibi ileterek -
//Creating a parser Parser parser = ParserFactory.create(model);3. Adım: Cümlenin ayrıştırılması
parseLine() yöntemi ParserToolsınıfı, ham metni OpenNLP'de ayrıştırmak için kullanılır. Bu yöntem kabul eder -
ayrıştırılacak metni temsil eden bir String değişkeni.
ayrıştırıcı nesnesi.
gerçekleştirilecek ayrıştırma sayısını temsil eden bir tam sayı.
Aşağıdaki parametreleri cümleyi ileterek bu yöntemi çağırın: önceki adımlarda oluşturulan ayrıştırma nesnesi ve yürütülecek gerekli çözümleme sayısını temsil eden bir tam sayı.
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);Example
Verilen ham metni ayrıştıran program aşağıdadır. Bu programı adıyla bir dosyaya kaydedinParserExample.java.
import java.io.FileInputStream;
import java.io.InputStream;
import opennlp.tools.cmdline.parser.ParserTool;
import opennlp.tools.parser.Parse;
import opennlp.tools.parser.Parser;
import opennlp.tools.parser.ParserFactory;
import opennlp.tools.parser.ParserModel;
public class ParserExample {
public static void main(String args[]) throws Exception{
//Loading parser model
InputStream inputStream = new FileInputStream(".../en-parserchunking.bin");
ParserModel model = new ParserModel(inputStream);
//Creating a parser
Parser parser = ParserFactory.create(model);
//Parsing the sentence
String sentence = "Tutorialspoint is the largest tutorial library.";
Parse topParses[] = ParserTool.parseLine(sentence, parser, 1);
for (Parse p : topParses)
p.show();
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac ParserExample.java
java ParserExampleYürütüldüğünde, yukarıdaki program verilen ham metni okur, ayrıştırır ve aşağıdaki çıktıyı görüntüler -
(TOP (S (NP (NN Tutorialspoint)) (VP (VBZ is) (NP (DT the) (JJS largest) (NN
tutorial) (NN library.)))))Bir cümleyi parçalamak, bir cümleyi kelime grupları ve fiil grupları gibi kelimelerin parçalarına ayırmak / bölmek anlamına gelir.
OpenNLP Kullanarak Cümle Oluşturma
Cümleleri algılamak için OpenNLP, bir model, adında bir dosya kullanır. en-chunker.bin. Bu, verilen ham metindeki cümleleri parçalamak için eğitilmiş önceden tanımlanmış bir modeldir.
opennlp.tools.chunker paketi, isim öbekleri gibi özyinelemeli olmayan sözdizimsel ek açıklamaları bulmak için kullanılan sınıfları ve arabirimleri içerir.
Yöntemi kullanarak bir cümleyi parçalayabilirsiniz chunk() of ChunkerMEsınıf. Bu yöntem, bir cümlenin simgelerini ve POS etiketlerini parametre olarak kabul eder. Bu nedenle, parçalama sürecine başlamadan önce, öncelikle cümleyi şifrelemeniz ve bölümlerinin POS etiketlerini oluşturmanız gerekir.
OpenNLP kitaplığını kullanarak bir cümleyi parçalamak için yapmanız gerekenler -
Cümleyi şifreleyin.
Bunun için POS etiketleri oluşturun.
Yükle en-chunker.bin kullanarak model ChunkerModel sınıf
Örnekleyin ChunkerME sınıf.
Kullanarak cümleleri parçalara ayırın chunk() bu sınıfın yöntemi.
Verilen ham metinden cümleleri parçalamak için bir program yazmak için izlenecek adımlar aşağıdadır.
Adım 1: Cümlenin şifrelenmesi
Cümleleri kullanarak şifreleyin tokenize() yöntemi whitespaceTokenizer aşağıdaki kod bloğunda gösterildiği gibi.
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);Adım 2: POS etiketlerinin oluşturulması
Cümlenin POS etiketlerini kullanarak tag() yöntemi POSTaggerME aşağıdaki kod bloğunda gösterildiği gibi.
//Generating the POS tags
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);3. Adım: Modeli yükleme
Bir cümleyi parçalama modeli, adlı sınıf tarafından temsil edilir. ChunkerModelpakete ait olan opennlp.tools.chunker.
Bir cümle algılama modeli yüklemek için -
Oluşturduğunuz bir InputStream modelin nesnesi (FileInputStream öğesini örnekleyin ve modelin yolunu String biçiminde yapıcısına iletin).
Örnekleyin ChunkerModel sınıf ve geç InputStream (nesne), aşağıdaki kod bloğunda gösterildiği gibi yapıcısına bir parametre olarak modelin -
//Loading the chunker model
InputStream inputStream = new FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);Adım 4: chunkerME sınıfını örnekleme
chunkerME paketin sınıfı opennlp.tools.chunkercümleleri parçalamak için yöntemler içerir. Bu, maksimum entropi tabanlı bir parçalayıcıdır.
Bu sınıfı örnekleyin ve önceki adımda oluşturulan model nesnesini iletin.
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);Adım 5: Cümlenin parçalanması
chunk() yöntemi ChunkerMEsınıfı, kendisine aktarılan ham metindeki cümleleri parçalara ayırmak için kullanılır. Bu yöntem, belirteçleri ve etiketleri parametreler olarak temsil eden iki String dizisini kabul eder.
Önceki adımlarda oluşturulan belirteç dizisini ve etiket dizisini parametre olarak ileterek bu yöntemi çağırın.
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);Example
Aşağıda, verilen ham metindeki cümleleri parçalama programı verilmiştir. Bu programı adıyla bir dosyaya kaydedinChunkerExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerExample{
public static void main(String args[]) throws IOException {
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating the POS tags
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
//Instantiate the ChunkerME class
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the chunks
String result[] = chunkerME.chunk(tokens, tags);
for (String s : result)
System.out.println(s);
}
}Kaydedilen Java dosyasını aşağıdaki komutu kullanarak Komut isteminden derleyin ve yürütün -
javac ChunkerExample.java
java ChunkerExampleYürütüldüğünde, yukarıdaki program verilen String'i okur ve içindeki cümleleri parçalar ve aşağıda gösterildiği gibi görüntüler.
Loading POS Tagger model ... done (1.040s)
B-NP
I-NP
B-VP
I-VPJetonların Konumlarının Tespiti
Ayrıca parçaların konumlarını veya aralıklarını da chunkAsSpans() yöntemi ChunkerMEsınıf. Bu yöntem, Span türünde bir dizi nesne döndürür. Span adlı sınıfopennlp.tools.util paketi saklamak için kullanılır start ve end kümelerin tamsayısı.
Tarafından döndürülen aralıkları saklayabilirsiniz. chunkAsSpans() yöntemini Span dizisine ekleyin ve aşağıdaki kod bloğunda gösterildiği gibi yazdırın.
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());Example
Aşağıda verilen ham metindeki cümleleri tespit eden program yer almaktadır. Bu programı adıyla bir dosyaya kaydedinChunkerSpansEample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.Span;
public class ChunkerSpansEample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel chunkerModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(chunkerModel);
//Generating the tagged chunk spans
Span[] span = chunkerME.chunkAsSpans(tokens, tags);
for (Span s : span)
System.out.println(s.toString());
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac ChunkerSpansEample.java
java ChunkerSpansEampleYürütüldüğünde, yukarıdaki program verilen String'i ve içindeki parçaların aralıklarını okur ve aşağıdaki çıktıyı görüntüler -
Loading POS Tagger model ... done (1.059s)
[0..2) NP
[2..4) VPChunker Olasılık Algılama
probs() yöntemi ChunkerME sınıfı, son kodu çözülen dizinin olasılıklarını döndürür.
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();Aşağıda, son kodu çözülen dizinin olasılıklarını, chunker. Bu programı adıyla bir dosyaya kaydedinChunkerProbsExample.java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import opennlp.tools.chunker.ChunkerME;
import opennlp.tools.chunker.ChunkerModel;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
public class ChunkerProbsExample{
public static void main(String args[]) throws IOException {
//Load the parts of speech model
File file = new File("C:/OpenNLP_models/en-pos-maxent.bin");
POSModel model = new POSModelLoader().load(file);
//Constructing the tagger
POSTaggerME tagger = new POSTaggerME(model);
//Tokenizing the sentence
String sentence = "Hi welcome to Tutorialspoint";
WhitespaceTokenizer whitespaceTokenizer= WhitespaceTokenizer.INSTANCE;
String[] tokens = whitespaceTokenizer.tokenize(sentence);
//Generating tags from the tokens
String[] tags = tagger.tag(tokens);
//Loading the chunker model
InputStream inputStream = new
FileInputStream("C:/OpenNLP_models/en-chunker.bin");
ChunkerModel cModel = new ChunkerModel(inputStream);
ChunkerME chunkerME = new ChunkerME(cModel);
//Generating the chunk tags
chunkerME.chunk(tokens, tags);
//Getting the probabilities of the last decoded sequence
double[] probs = chunkerME.probs();
for(int i = 0; i<probs.length; i++)
System.out.println(probs[i]);
}
}Kaydedilen Java dosyasını aşağıdaki komutları kullanarak Komut isteminden derleyin ve yürütün -
javac ChunkerProbsExample.java
java ChunkerProbsExampleYürütüldüğünde, yukarıdaki program verilen String'i okur, parçalara ayırır ve son kodu çözülen dizinin olasılıklarını yazdırır.
0.9592746040797778
0.6883933131241501
0.8830563473996004
0.8951150529746051OpenNLP, komut satırı üzerinden farklı işlemler gerçekleştirmek için bir Komut Satırı Arayüzü (CLI) sağlar. Bu bölümde, OpenNLP Komut Satırı Arayüzünü nasıl kullanabileceğimizi göstermek için bazı örnekler alacağız.
Tokenleştirme
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSözdizimi
> opennlp TokenizerME path_for_models../en-token.bin <inputfile..> outputfile..komut
C:\> opennlp TokenizerME C:\OpenNLP_models/en-token.bin <input.txt >output.txtçıktı
Loading Tokenizer model ... done (0.207s)
Average: 214.3 sent/s
Total: 3 sent
Runtime: 0.014soutput.txt
Hi . How are you ? Welcome to Tutorialspoint . We provide free tutorials on various technologiesCümle Algılama
input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSözdizimi
> opennlp SentenceDetector path_for_models../en-token.bin <inputfile..> outputfile..komut
C:\> opennlp SentenceDetector C:\OpenNLP_models/en-sent.bin <input.txt > output_sendet.txtÇıktı
Loading Sentence Detector model ... done (0.067s)
Average: 750.0 sent/s
Total: 3 sent
Runtime: 0.004sOutput_sendet.txt
Hi. How are you?
Welcome to Tutorialspoint.
We provide free tutorials on various technologiesAdlandırılmış Varlık Tanıma
input.txt
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at TutorialspointSözdizimi
> opennlp TokenNameFinder path_for_models../en-token.bin <inputfile..Komut
C:\>opennlp TokenNameFinder C:\OpenNLP_models\en-ner-person.bin <input_namefinder.txtÇıktı
Loading Token Name Finder model ... done (0.730s)
<START:person> <START:person> Mike <END> <END> is senior programming manager and
<START:person> Rama <END> is a clerk both are working at Tutorialspoint
Average: 55.6 sent/s
Total: 1 sent
Runtime: 0.018sKonuşma Etiketlemenin Parçaları
Input.txt
Hi. How are you? Welcome to Tutorialspoint. We provide free tutorials on various technologiesSözdizimi
> opennlp POSTagger path_for_models../en-token.bin <inputfile..Komut
C:\>opennlp POSTagger C:\OpenNLP_models/en-pos-maxent.bin < input.txtÇıktı
Loading POS Tagger model ... done (1.315s)
Hi._NNP How_WRB are_VBP you?_JJ Welcome_NNP to_TO Tutorialspoint._NNP We_PRP
provide_VBP free_JJ tutorials_NNS on_IN various_JJ technologies_NNS
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s