Paralel Algoritma - Hızlı Kılavuz
Bir algorithmkullanıcıdan girdi alan ve bir miktar hesaplamadan sonra bir çıktı üreten bir dizi adımdır. Birparallel algorithm farklı işleme cihazlarında aynı anda birkaç talimatı uygulayabilen ve ardından nihai sonucu üretmek için tüm bağımsız çıktıları birleştiren bir algoritmadır.
Eşzamanlı İşleme
İnternetin büyümesiyle birlikte bilgisayarların kolay kullanılabilirliği, verileri saklama ve işleme şeklimizi değiştirdi. Verilerin bol olduğu bir çağda yaşıyoruz. Her gün karmaşık bilgi işlem gerektiren büyük hacimli verilerle ve bununla da hızlı bir şekilde ilgileniyoruz. Bazen aynı anda meydana gelen benzer veya birbiriyle ilişkili olaylardan veri almamız gerekir. Bu ihtiyacımız olan yerconcurrent processing Hızlı zamanda çıktı üretmek için karmaşık bir görevi bölebilir ve birden çok sistemde işleyebilen.
Eşzamanlı işleme, görevin büyük bir karmaşık veri yığınını işlemeyi içerdiği durumlarda önemlidir. Örnekler şunları içerir: büyük veri tabanlarına erişim, uçak testi, astronomik hesaplamalar, atomik ve nükleer fizik, biyomedikal analiz, ekonomik planlama, görüntü işleme, robotik, hava tahmini, web tabanlı hizmetler vb.
Paralellik nedir?
Parallelismbirkaç komut dizisini aynı anda işleme sürecidir. Toplam hesaplama süresini azaltır. Paralellik kullanılarak uygulanabilirparallel computers,yani birçok işlemciye sahip bir bilgisayar. Paralel bilgisayarlar, çoklu görevi destekleyen paralel algoritma, programlama dilleri, derleyiciler ve işletim sistemi gerektirir.
Bu eğitimde sadece aşağıdakileri tartışacağız: parallel algorithms. Daha fazla ilerlemeden önce, önce algoritmalar ve türleri hakkında tartışalım.
Algoritma nedir?
Bir algorithmbir sorunu çözmek için izlenen talimatlar dizisidir. Bir algoritma tasarlarken, algoritmanın çalıştırılacağı bilgisayarın mimarisini göz önünde bulundurmalıyız. Mimariye göre, iki tür bilgisayar vardır -
- Sıralı Bilgisayar
- Paralel Bilgisayar
Bilgisayarların mimarisine bağlı olarak, iki tür algoritmamız vardır -
Sequential Algorithm - Bir problemi çözmek için bazı ardışık talimat adımlarının kronolojik bir sırada yürütüldüğü bir algoritma.
Parallel Algorithm- Problem, alt problemlere bölünmüştür ve ayrı çıktılar elde etmek için paralel olarak yürütülür. Daha sonra bu bağımsız çıktılar, istenen nihai çıktıyı elde etmek için birleştirilir.
Büyük bir sorunu ikiye bölmek kolay değil. sub-problems. Alt problemler, aralarında veri bağımlılığına sahip olabilir. Bu nedenle, işlemcilerin sorunu çözmek için birbirleriyle iletişim kurması gerekir.
İşlemcilerin birbirleriyle iletişim kurarken ihtiyaç duydukları sürenin gerçek işlem süresinden daha fazla olduğu bulunmuştur. Bu nedenle, paralel bir algoritma tasarlarken, verimli bir algoritma elde etmek için uygun CPU kullanımı dikkate alınmalıdır.
Bir algoritmayı doğru bir şekilde tasarlamak için, temelde net bir fikre sahip olmalıyız model of computation paralel bir bilgisayarda.
Hesaplama Modeli
Hem sıralı hem de paralel bilgisayarlar, algoritmalar adı verilen bir dizi talimat (akışı) üzerinde çalışır. Bu talimat seti (algoritma), bilgisayara her adımda ne yapması gerektiği konusunda talimat verir.
Talimat akışına ve veri akışına bağlı olarak, bilgisayarlar dört kategoriye ayrılabilir -
- Tek Yönerge akışı, Tek Veri akışı (SISD) bilgisayarlar
- Tek Yönerge akışı, Çoklu Veri akışı (SIMD) bilgisayarlar
- Çoklu Talimat akışı, Tek Veri akışı (MISD) bilgisayarlar
- Çoklu Talimat akışı, Çoklu Veri akışı (MIMD) bilgisayarlar
SISD Bilgisayarları
SISD bilgisayarları şunları içerir: one control unit, one processing unit, ve one memory unit.

Bu tür bilgisayarlarda, işlemci kontrol biriminden tek bir talimat akışı alır ve bellek biriminden tek bir veri akışı üzerinde çalışır. Hesaplama sırasında, her adımda işlemci kontrol biriminden bir talimat alır ve bellek biriminden alınan tek bir veri üzerinde çalışır.
SIMD Bilgisayarlar
SIMD bilgisayarlar şunları içerir: one control unit, multiple processing units, ve shared memory or interconnection network.
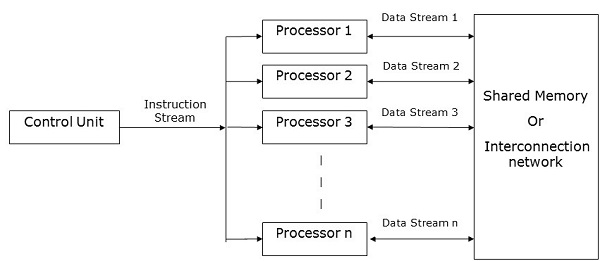
Burada, tek bir kontrol ünitesi tüm işleme birimlerine talimatlar gönderir. Hesaplama sırasında, her adımda, tüm işlemciler kontrol ünitesinden tek bir talimat seti alır ve bellek ünitesinden farklı veri seti üzerinde çalışır.
İşlem birimlerinin her biri, hem verileri hem de talimatları depolamak için kendi yerel bellek birimine sahiptir. SIMD bilgisayarlarda, işlemcilerin kendi aralarında iletişim kurması gerekir. Bu tarafından yapılırshared memory veya tarafından interconnection network.
Bazı işlemciler bir dizi talimat yürütürken, geri kalan işlemciler bir sonraki talimat dizisini bekler. Kontrol ünitesinden gelen talimatlar hangi işlemcinin olacağına karar veriractive (talimatları uygulayın) veya inactive (bir sonraki talimatı bekleyin).
MISD Bilgisayarlar
Adından da anlaşılacağı gibi, MISD bilgisayarlar şunları içerir: multiple control units, multiple processing units, ve one common memory unit.

Burada her işlemcinin kendi kontrol birimi vardır ve ortak bir bellek birimini paylaşırlar. Tüm işlemciler kendi kontrol birimlerinden ayrı ayrı talimatlar alırlar ve ilgili kontrol birimlerinden aldıkları talimatlara göre tek bir veri akışı üzerinde çalışırlar. Bu işlemci aynı anda çalışır.
MIMD Bilgisayarlar
MIMD bilgisayarlarda multiple control units, multiple processing units, ve bir shared memory veya interconnection network.

Burada her işlemcinin kendi kontrol birimi, yerel bellek birimi ve aritmetik ve mantık birimi vardır. İlgili kontrol birimlerinden farklı talimat setleri alırlar ve farklı veri setleri üzerinde çalışırlar.
Not
Ortak bir belleği paylaşan bir MIMD bilgisayar, multiprocessors, bir ara bağlantı ağı kullananlar ise multicomputers.
İşlemcilerin fiziksel mesafesine bağlı olarak, çoklu bilgisayarlar iki türdendir -
Multicomputer - Tüm işlemciler birbirine çok yakın olduğunda (örneğin aynı odada).
Distributed system - Tüm işlemciler birbirinden uzakta olduğunda (örneğin, farklı şehirlerde)
Bir algoritmanın analizi, algoritmanın yararlı olup olmadığını belirlememize yardımcı olur. Genel olarak, bir algoritma yürütme süresine göre analiz edilir(Time Complexity) ve alan miktarı (Space Complexity) gerektirir.
Makul bir maliyetle temin edilebilen gelişmiş bellek cihazlarımız olduğundan, depolama alanı artık sorun olmaktan çıktı. Bu nedenle, uzay karmaşıklığına çok fazla önem verilmiyor.
Paralel algoritmalar, bir bilgisayarın hesaplama hızını artırmak için tasarlanmıştır. Bir Paralel Algoritmayı analiz etmek için normalde aşağıdaki parametreleri dikkate alırız -
- Zaman karmaşıklığı (Yürütme Zamanı),
- Kullanılan toplam işlemci sayısı ve
- Toplam tutar.
Zaman Karmaşıklığı
Paralel algoritmalar geliştirmenin arkasındaki ana neden, bir algoritmanın hesaplama süresini azaltmaktı. Bu nedenle, bir algoritmanın yürütme süresinin değerlendirilmesi, verimliliğini analiz etmede son derece önemlidir.
Yürütme süresi, algoritmanın bir sorunu çözmek için harcadığı süreye göre ölçülür. Toplam yürütme süresi, algoritmanın çalışmaya başladığı andan durduğu ana kadar hesaplanır. Tüm işlemciler aynı anda yürütmeyi başlatmaz veya bitirmezse, algoritmanın toplam yürütme süresi, ilk işlemcinin yürütmeye başladığı andan son işlemcinin yürütmeyi durdurduğu ana kadardır.
Bir algoritmanın zaman karmaşıklığı üç kategoriye ayrılabilir−
Worst-case complexity - Belirli bir girdi için bir algoritmanın gerektirdiği zaman miktarı maximum.
Average-case complexity - Belirli bir girdi için bir algoritmanın gerektirdiği zaman miktarı average.
Best-case complexity - Belirli bir girdi için bir algoritmanın gerektirdiği zaman miktarı minimum.
Asimptotik Analiz
Bir algoritmanın karmaşıklığı veya verimliliği, istenen çıktıyı elde etmek için algoritma tarafından yürütülen adımların sayısıdır. Asimptotik analiz, teorik analizinde bir algoritmanın karmaşıklığını hesaplamak için yapılır. Asimptotik analizde, algoritmanın karmaşıklık fonksiyonunu hesaplamak için büyük uzunlukta girdi kullanılır.
Note - Asymptoticbir çizginin bir eğriyi karşılama eğiliminde olduğu, ancak kesişmediği bir durumdur. Burada çizgi ve eğri birbirine asimptotiktir.
Asimptotik gösterim, hızda yüksek sınırlar ve düşük sınırlar kullanan bir algoritma için mümkün olan en hızlı ve en yavaş yürütme süresini tanımlamanın en kolay yoludur. Bunun için aşağıdaki gösterimleri kullanıyoruz -
- Büyük O gösterimi
- Omega notasyonu
- Teta gösterimi
Büyük O gösterimi
Matematikte, Big O notasyonu, fonksiyonların asimptotik özelliklerini temsil etmek için kullanılır. Basit ve doğru bir yöntemde büyük girdiler için bir işlevin davranışını temsil eder. Bir algoritmanın yürütme süresinin üst sınırını temsil eden bir yöntemdir. Algoritmanın yürütülmesini tamamlaması için alabileceği en uzun süreyi temsil eder. Fonksiyon -
f (n) = O (g (n))
pozitif sabitler varsa c ve n0 öyle ki f(n) ≤ c * g(n) hepsi için n nerede n ≥ n0.
Omega notasyonu
Omega gösterimi, bir algoritmanın yürütme süresinin alt sınırını temsil eden bir yöntemdir. Fonksiyon -
f (n) = Ω (g (n))
pozitif sabitler varsa c ve n0 öyle ki f(n) ≥ c * g(n) hepsi için n nerede n ≥ n0.
Theta Notasyonu
Teta gösterimi, bir algoritmanın yürütme süresinin hem alt sınırını hem de üst sınırını temsil eden bir yöntemdir. Fonksiyon -
f (n) = θ (g (n))
pozitif sabitler varsa c1, c2, ve n0 öyle ki c1 * g (n) ≤ f (n) ≤ c2 * g (n) hepsi için n nerede n ≥ n0.
Bir Algoritmanın Hızlandırılması
Paralel bir algoritmanın performansı hesaplanarak belirlenir. speedup. Hızlandırma, belirli bir problem için bilinen en hızlı sıralı algoritmanın en kötü durum yürütme süresinin paralel algoritmanın en kötü durum yürütme süresine oranı olarak tanımlanır.
Kullanılan İşlemci Sayısı
Paralel bir algoritmanın verimliliğini analiz etmede kullanılan işlemci sayısı önemli bir faktördür. Bilgisayarları satın alma, bakım ve çalıştırma maliyetleri hesaplanır. Bir algoritma tarafından bir problemi çözmek için kullanılan işlemci sayısı ne kadar fazlaysa, elde edilen sonuç o kadar maliyetli olur.
Toplam tutar
Paralel bir algoritmanın toplam maliyeti, zaman karmaşıklığının ve o belirli algoritmada kullanılan işlemci sayısının ürünüdür.
Toplam Maliyet = Zaman karmaşıklığı × Kullanılan işlemci sayısı
bu yüzden efficiency paralel bir algoritmanın -
Paralel bir algoritma modeli, verileri ve işleme yöntemini bölmek için bir strateji düşünülerek ve etkileşimleri azaltmak için uygun bir strateji uygulanarak geliştirilir. Bu bölümde, aşağıdaki Paralel Algoritma Modellerini tartışacağız -
- Veri paralel modeli
- Görev grafiği modeli
- Çalışma havuzu modeli
- Ana köle modeli
- Üretici tüketici veya satış hattı modeli
- Hibrit model
Veri Paralel
Veri paralel modelinde, görevler süreçlere atanır ve her görev farklı veriler üzerinde benzer türde işlemler gerçekleştirir. Data parallelism birden çok veri öğesine uygulanan tek işlemlerin bir sonucudur.
Veri paralel modeli, paylaşılan adres alanlarına ve mesaj geçirme paradigmalarına uygulanabilir. Veri-paralel modelde, etkileşim ek yükleri, ayrıştırmayı koruyan bir yerellik seçerek, optimize edilmiş toplu etkileşim rutinleri kullanarak veya örtüşen hesaplama ve etkileşim yoluyla azaltılabilir.
Veri paralel model problemlerinin temel özelliği, problemin boyutuyla birlikte veri paralelliğinin yoğunluğunun artması ve bu da daha büyük problemleri çözmek için daha fazla işlemin kullanılmasını mümkün kılmasıdır.
Example - Yoğun matris çarpımı.

Görev Grafik Modeli
Görev grafiği modelinde, paralellik bir task graph. Bir görev grafiği ya önemsiz ya da önemsiz olabilir. Bu modelde, görevler arasındaki korelasyon, yerelliği teşvik etmek veya etkileşim maliyetlerini en aza indirmek için kullanılır. Bu model, görevlerle ilişkili veri miktarının kendileriyle ilişkili hesaplama sayısına kıyasla çok büyük olduğu sorunları çözmek için uygulanır. Görevler, görevler arasında veri hareketinin maliyetini iyileştirmeye yardımcı olmak için atanır.
Examples - Paralel hızlı sıralama, seyrek matris çarpanlara ayırma ve böl ve yönet yaklaşımıyla türetilen paralel algoritmalar.
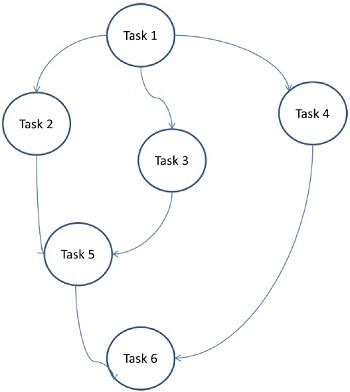
Burada problemler atomik görevlere bölünür ve grafik olarak uygulanır. Her görev, bir veya daha fazla öncül göreve bağımlılığı olan bağımsız bir iş birimidir. Bir görevin tamamlanmasından sonra, bir önceki görevin çıktısı bağımlı göreve geçirilir. Öncül göreve sahip bir görev, yalnızca önceki görevin tamamı tamamlandığında yürütülmeye başlar. Grafiğin son çıktısı, son bağımlı görev tamamlandığında alınır (yukarıdaki şekilde Görev 6).
Çalışma Havuzu Modeli
İş havuzu modelinde, yükün dengelenmesi için görevler dinamik olarak süreçlere atanır. Bu nedenle, herhangi bir işlem potansiyel olarak herhangi bir görevi yürütebilir. Bu model, görevlerle ilişkili veri miktarı, görevlerle ilişkili hesaplamadan nispeten daha küçük olduğunda kullanılır.
Süreçlere istenen görevlerin önceden atanması yoktur. Görevlerin atanması merkezileştirilmiş veya dağıtılmıştır. Görevlere yönelik işaretçiler, fiziksel olarak paylaşılan bir listeye, bir öncelik kuyruğuna veya bir karma tablo veya ağaçta kaydedilir veya fiziksel olarak dağıtılmış bir veri yapısına kaydedilebilir.
Görev başlangıçta mevcut olabilir veya dinamik olarak oluşturulabilir. Görev dinamik olarak oluşturulursa ve merkezi olmayan bir görev ataması yapılırsa, tüm işlemlerin tüm programın tamamlandığını gerçekten algılayabilmesi ve daha fazla görev aramayı bırakabilmesi için bir sonlandırma algılama algoritması gerekir.
Example - Paralel ağaç araması

Master-Slave Modeli
Master-slave modelinde, bir veya daha fazla master proses görevi üretir ve onu slave proseslerine tahsis eder. Aşağıdaki durumlarda görevler önceden tahsis edilebilir:
- usta, görevlerin hacmini tahmin edebilir veya
- rastgele bir atama, yükü dengelemek için tatmin edici bir iş yapabilir veya
- kölelere farklı zamanlarda daha küçük görevler atanır.
Bu model genel olarak eşit derecede uygundur shared-address-space veya message-passing paradigms, çünkü etkileşim doğal olarak iki yol.
Bazı durumlarda, bir görevin aşamalar halinde tamamlanması gerekebilir ve sonraki aşamalardaki görev oluşturulmadan önce her aşamadaki görevin tamamlanması gerekir. Master-slave modeli şu şekilde genelleştirilebilir:hierarchical veya multi-level master-slave model burada üst düzey yönetici, görevlerin büyük bölümünü, görevleri kendi yardımcıları arasında daha fazla alt bölümlere ayıran ve görevin bir bölümünü kendi başına gerçekleştirebilen ikinci düzey yöneticiye besler.
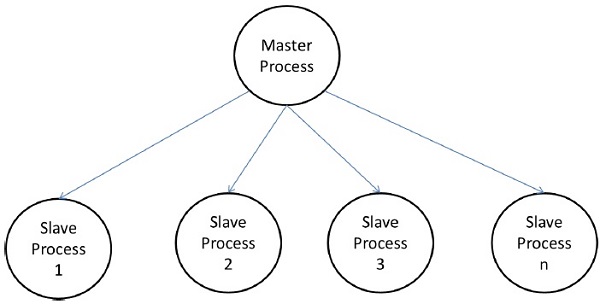
Master-slave modelinin kullanımıyla ilgili önlemler
Ustanın bir tıkanıklık noktası olmamasını sağlamak için özen gösterilmelidir. Görevler çok küçükse veya çalışanlar nispeten hızlıysa bu gerçekleşebilir.
Görevler, bir görevi yerine getirme maliyeti iletişim maliyetine ve senkronizasyon maliyetine hakim olacak şekilde seçilmelidir.
Eşzamansız etkileşim, üst üste gelen etkileşimin ve iş üretimiyle ilişkili hesaplamanın usta tarafından yapılmasına yardımcı olabilir.
Boru Hattı Modeli
Aynı zamanda producer-consumer model. Burada bir dizi veri, her biri üzerinde bazı görevler gerçekleştiren bir dizi işlemden geçirilir. Burada, yeni verilerin gelmesi, kuyruktaki bir işlem tarafından yeni bir görevin yürütülmesini oluşturur. Süreçler, doğrusal veya çok boyutlu diziler, ağaçlar veya döngüleri olan veya olmayan genel grafikler şeklinde bir kuyruk oluşturabilir.
Bu model bir üretici ve tüketici zinciridir. Kuyruktaki her işlem, kuyrukta kendisinden önce gelen işlem için bir dizi veri öğesinin tüketicisi ve kuyrukta onu izleyen işlem için bir veri üreticisi olarak kabul edilebilir. Kuyruğun doğrusal bir zincir olması gerekmez; yönlendirilmiş bir grafik olabilir. Bu modele uygulanabilen en yaygın etkileşim minimizasyon tekniği, hesaplama ile örtüşen etkileşimdir.
Example - Paralel LU çarpanlara ayırma algoritması.

Hibrit Modeller
Bir problemi çözmek için birden fazla modele ihtiyaç duyulduğunda bir hibrit algoritma modeli gereklidir.
Bir hibrit model, hiyerarşik olarak uygulanan birden çok modelden veya paralel bir algoritmanın farklı aşamalarına sırayla uygulanan birden çok modelden oluşabilir.
Example - Paralel hızlı sıralama
Parallel Random Access Machines (PRAM)paralel algoritmaların çoğu için düşünülen bir modeldir. Burada, birden çok işlemci tek bir bellek bloğuna eklenir. Bir PRAM modeli şunları içerir:
Bir dizi benzer işlemci türü.
Tüm işlemciler ortak bir bellek birimini paylaşır. İşlemciler kendi aralarında yalnızca paylaşılan bellek aracılığıyla iletişim kurabilirler.
Bir bellek erişim birimi (MAU), işlemcileri tek paylaşılan bellekle bağlar.

Buraya, n işlemci sayısı üzerinde bağımsız işlemler gerçekleştirebilir nbelirli bir zaman birimindeki veri sayısı. Bu, farklı işlemciler tarafından aynı bellek konumuna eşzamanlı erişimle sonuçlanabilir.
Bu sorunu çözmek için, PRAM modeline aşağıdaki kısıtlamalar getirilmiştir -
Exclusive Read Exclusive Write (EREW) - Burada iki işlemcinin aynı anda aynı bellek konumundan okuma veya yazma izni yoktur.
Exclusive Read Concurrent Write (ERCW) - Burada iki işlemcinin aynı anda aynı bellek konumundan okumasına izin verilmez, ancak aynı anda aynı bellek konumuna yazmalarına izin verilir.
Concurrent Read Exclusive Write (CREW) - Burada tüm işlemcilerin aynı anda aynı bellek konumundan okumasına izin verilir, ancak aynı anda aynı bellek konumuna yazmalarına izin verilmez.
Concurrent Read Concurrent Write (CRCW) - Tüm işlemcilerin aynı anda aynı bellek konumundan okumasına veya bu konuma yazmasına izin verilir.
PRAM modelini uygulamak için birçok yöntem vardır, ancak en önemlileri şunlardır:
- Paylaşılan bellek modeli
- Mesaj geçen model
- Veri paralel modeli
Paylaşılan Bellek Modeli
Paylaşılan hafıza, control parallelism Üzerinde data parallelism. Paylaşılan bellek modelinde, birden çok işlem farklı işlemciler üzerinde bağımsız olarak yürütülür, ancak ortak bir bellek alanını paylaşırlar. Herhangi bir işlemci faaliyeti nedeniyle, herhangi bir bellek konumunda herhangi bir değişiklik olması durumunda, bu, işlemcilerin geri kalanı tarafından görülebilir.
Birden fazla işlemci aynı bellek konumuna erişirken, belirli bir zamanda birden fazla işlemci aynı bellek konumuna erişiyor olabilir. Birinin o yeri okuduğunu ve diğerinin o konuma yazdığını varsayalım. Kafa karışıklığı yaratabilir. Bundan kaçınmak için bazı kontrol mekanizmalarılock / semaphore, karşılıklı dışlamayı sağlamak için uygulanmaktadır.

Paylaşılan bellek programlama aşağıda uygulanmıştır -
Thread libraries- İş parçacığı kitaplığı, aynı bellek konumunda aynı anda çalışan birden çok denetim iş parçacığına izin verir. İş parçacığı kitaplığı, bir alt yordam kitaplığı aracılığıyla çoklu okumayı destekleyen bir arabirim sağlar. İçin alt yordamlar içerir
- Konu oluşturma ve yok etme
- İş parçacığının yürütülmesini planlama
- diziler arasında veri ve mesaj geçirme
- iş parçacığı bağlamlarını kaydetme ve geri yükleme
İş parçacığı kitaplıklarının örnekleri şunları içerir - Solaris için SolarisTM iş parçacıkları, Linux'ta uygulanan POSIX iş parçacıkları, Windows NT ve Windows 2000'de bulunan Win32 iş parçacıkları ve standart JavaTM Geliştirme Kitinin (JDK) bir parçası olarak JavaTM iş parçacıkları.
Distributed Shared Memory (DSM) Systems- DSM sistemleri, donanım desteği olmadan paylaşılan bellek programlamasını uygulamak için gevşek bağlı mimaride paylaşılan bellek soyutlaması oluşturur. Standart kitaplıkları uygularlar ve modern işletim sistemlerinde bulunan gelişmiş kullanıcı düzeyinde bellek yönetimi özelliklerini kullanırlar. Örnekler arasında Sırt İşaretleri Sistemi, Munin, IVY, Shasta, Brazos ve Kaşmir bulunur.
Program Annotation Packages- Bu, tek tip bellek erişim özelliklerine sahip mimarilerde uygulanır. Program açıklama paketlerinin en dikkate değer örneği OpenMP'dir. OpenMP, işlevsel paralellik uygular. Esas olarak döngülerin paralelleştirilmesine odaklanır.
Paylaşılan bellek kavramı, paylaşılan bellek sisteminin düşük seviyeli kontrolünü sağlar, ancak sıkıcı ve hatalı olma eğilimindedir. Sistem programlaması için uygulama programlamasından daha uygundur.
Paylaşılan Bellek Programlamanın Özellikleri
Global adres alanı, belleğe kullanıcı dostu bir programlama yaklaşımı sağlar.
Belleğin CPU'ya yakınlığı nedeniyle, işlemler arasında veri paylaşımı hızlı ve tek tiptir.
Süreçler arasında veri iletişimini açıkça belirtmeye gerek yoktur.
Süreç-iletişim ek yükü ihmal edilebilir düzeydedir.
Öğrenmesi çok kolay.
Paylaşılan Bellek Programlamanın Zorlukları
- Taşınabilir değildir.
- Veri yerelliğini yönetmek çok zordur.
Mesaj Aktarma Modeli
Mesaj geçirme, dağıtılmış bellek sistemlerinde en yaygın kullanılan paralel programlama yaklaşımıdır. Burada programcı paralelliği belirlemelidir. Bu modelde, tüm işlemcilerin kendi yerel bellek birimleri vardır ve bir iletişim ağı üzerinden veri alışverişi yaparlar.

İşlemciler, kendi aralarında iletişim kurmak için mesaj geçiren kitaplıkları kullanır. Gönderilen verilerle birlikte, mesaj aşağıdaki bileşenleri içerir -
Mesajın gönderildiği işlemcinin adresi;
Gönderen işlemcideki verilerin hafıza yerinin başlangıç adresi;
Gönderilen verinin veri türü;
Gönderen verinin veri boyutu;
Mesajın gönderildiği işlemcinin adresi;
Alıcı işlemcideki veriler için hafıza konumunun başlangıç adresi.
İşlemciler birbirleriyle aşağıdaki yöntemlerden herhangi biri ile iletişim kurabilir -
- Noktadan Noktaya İletişim
- Toplu İletişim
- Mesaj Geçiş Arayüzü
Noktadan Noktaya İletişim
Noktadan noktaya iletişim, mesaj geçişinin en basit şeklidir. Burada, aşağıdaki aktarım modlarından herhangi biri ile gönderen işlemciden alıcı işlemciye bir mesaj gönderilebilir -
Synchronous mode - Bir sonraki mesaj, mesajın sırasını korumak için, yalnızca önceki mesajının teslim edildiğine dair bir onay alındıktan sonra gönderilir.
Asynchronous mode - Bir sonraki mesajı göndermek için, önceki mesajın alındığına dair onay alınması gerekli değildir.
Toplu İletişim
Toplu iletişim, mesaj geçişi için ikiden fazla işlemci içerir. Aşağıdaki modlar toplu iletişime izin verir -
Barrier - Bariyer modu, iletişimdeki tüm işlemciler belirli bir bock'u çalıştırırsa mümkündür ( barrier block) mesaj geçişi için.
Broadcast - Yayın iki türdendir -
One-to-all - Burada tek işlemli bir işlemci diğer tüm işlemcilere aynı mesajı gönderir.
All-to-all - Burada tüm işlemciler diğer tüm işlemcilere mesaj gönderir.
Yayınlanan mesajlar üç türde olabilir -
Personalized - Diğer tüm hedef işlemcilere benzersiz mesajlar gönderilir.
Non-personalized - Tüm hedef işlemciler aynı mesajı alır.
Reduction - İndirgeme yayınında, grubun bir işlemcisi gruptaki diğer tüm işlemcilerden gelen tüm mesajları toplar ve bunları gruptaki diğer tüm işlemcilerin erişebileceği tek bir mesajda birleştirir.
Mesaj Aktarmanın Esasları
- Paralellik için düşük seviyeli kontrol sağlar;
- Portatiftir;
- Daha az hata eğilimi;
- Paralel senkronizasyon ve veri dağıtımında daha az ek yük.
Mesaj Aktarmanın Zorlukları
Paralel paylaşımlı bellek koduyla karşılaştırıldığında, mesaj geçiren kod genellikle daha fazla yazılım ek yüküne ihtiyaç duyar.
Mesaj Gönderme Kitaplıkları
Birçok ileti aktaran kitaplık vardır. Burada, en çok kullanılan mesaj geçiren kitaplıklardan ikisini tartışacağız -
- Mesaj Geçiş Arayüzü (MPI)
- Paralel Sanal Makine (PVM)
Mesaj Geçiş Arayüzü (MPI)
Dağıtılmış bir bellek sistemindeki tüm eşzamanlı süreçler arasında iletişim sağlamak evrensel bir standarttır. Yaygın olarak kullanılan paralel hesaplama platformlarının çoğu, mesaj geçirme arayüzünün en az bir uygulamasını sağlar. Adı verilen önceden tanımlanmış işlevlerin bir koleksiyonu olarak uygulanmıştır.library ve C, C ++, Fortran, vb. gibi dillerden çağrılabilir. MPI'ler, diğer ileti geçiren kitaplıklara kıyasla hem hızlı hem de taşınabilirdir.
Merits of Message Passing Interface
Yalnızca paylaşılan bellek mimarilerinde veya dağıtılmış bellek mimarilerinde çalışır;
Her işlemcinin kendi yerel değişkenleri vardır;
Büyük paylaşımlı bellekli bilgisayarlarla karşılaştırıldığında, dağıtılmış bellekli bilgisayarlar daha ucuzdur.
Demerits of Message Passing Interface
- Paralel algoritma için daha fazla programlama değişikliği gereklidir;
- Bazen hata ayıklamak zordur; ve
- Düğümler arasındaki iletişim ağında iyi performans göstermez.
Paralel Sanal Makine (PVM)
PVM, tek bir sanal makine oluşturmak üzere ayrı heterojen ana makineleri bağlamak için tasarlanmış taşınabilir bir mesaj geçirme sistemidir. Yönetilebilir tek bir paralel bilgi işlem kaynağıdır. Süperiletkenlik çalışmaları, moleküler dinamik simülasyonları ve matris algoritmaları gibi büyük hesaplama sorunları, birçok bilgisayarın belleği ve toplam gücü kullanılarak daha uygun maliyetli bir şekilde çözülebilir. Uyumsuz bilgisayar mimarileri ağındaki tüm mesaj yönlendirmesini, veri dönüşümünü, görev planlamasını yönetir.
Features of PVM
- Kurulumu ve yapılandırması çok kolay;
- Birden çok kullanıcı aynı anda PVM'yi kullanabilir;
- Bir kullanıcı birden çok uygulamayı çalıştırabilir;
- Küçük bir paket;
- C, C ++, Fortran;
- Bir PVM programının belirli bir çalışması için, kullanıcılar makine grubunu seçebilir;
- Mesaj ileten bir modeldir,
- Süreç tabanlı hesaplama;
- Heterojen mimariyi destekler.
Veri Paralel Programlama
Veri paralel programlama modelinin ana odak noktası, bir veri kümesi üzerinde aynı anda işlem yapmaktır. Veri kümesi, dizi, hiperküp, vb. Gibi bazı yapılarda düzenlenir. İşlemciler, işlemleri aynı veri yapısı üzerinde toplu olarak gerçekleştirir. Her görev, aynı veri yapısının farklı bir bölümünde gerçekleştirilir.
Tüm algoritmalar veri paralelliği açısından belirlenemediği için kısıtlayıcıdır. Veri paralelliğinin evrensel olmamasının nedeni budur.
Veri paralel dilleri, veri ayrıştırma ve işlemcilerle eşleştirmenin belirlenmesine yardımcı olur. Ayrıca, programcının veri üzerinde kontrol sahibi olmasına izin veren veri dağıtım ifadelerini de içerir - örneğin, hangi verilerin hangi işlemciye gideceği - işlemcilerdeki iletişim miktarını azaltmak için.
Herhangi bir algoritmayı doğru bir şekilde uygulamak için, uygun bir veri yapısı seçmeniz çok önemlidir. Bunun nedeni, bir veri yapısı üzerinde gerçekleştirilen belirli bir işlemin, başka bir veri yapısı üzerinde gerçekleştirilen aynı işleme kıyasla daha fazla zaman alabilmesidir.
Example- Bir dizi kullanarak bir kümedeki i'inci öğeye erişmek sabit bir süre alabilir, ancak bağlantılı bir liste kullanarak, aynı işlemi gerçekleştirmek için gereken süre bir polinom olabilir.
Bu nedenle, bir veri yapısının seçimi, yapılacak işlemlerin mimarisi ve türü dikkate alınarak yapılmalıdır.
Aşağıdaki veri yapıları genellikle paralel programlamada kullanılır -
- Bağlantılı liste
- Arrays
- Hypercube Ağı
Bağlantılı liste
Bağlantılı bir liste, işaretçilerle bağlanan sıfır veya daha fazla düğüme sahip bir veri yapısıdır. Düğümler, ardışık bellek konumlarını işgal edebilir veya işgal etmeyebilir. Her düğümün iki veya üç bölümü vardır - birdata part verileri depolayan ve diğer ikisi link fieldsönceki veya sonraki düğümün adresini saklayan. İlk düğümün adresi adı verilen harici bir işaretçide saklanırhead. Olarak bilinen son düğümtail, genellikle herhangi bir adres içermez.
Üç tür bağlantılı liste vardır -
- Tek Bağlantılı Liste
- Çift Bağlantılı Liste
- Dairesel Bağlantılı Liste
Tek Bağlantılı Liste
Tek bağlantılı bir listenin bir düğümü, verileri ve bir sonraki düğümün adresini içerir. Adlı harici bir işaretçihead ilk düğümün adresini depolar.

Çift Bağlantılı Liste
Çift bağlantılı listenin bir düğümü, verileri ve hem önceki hem de sonraki düğümün adresini içerir. Adlı harici bir işaretçihead ilk düğümün adresini ve çağrılan harici işaretçiyi depolar tail son düğümün adresini depolar.

Dairesel Bağlantılı Liste
Döngüsel bağlantılı bir liste, son düğümün ilk düğümün adresini kaydetmesi dışında tek bağlı listeye çok benzer.

Diziler
Bir dizi, benzer veri türlerini depolayabileceğimiz bir veri yapısıdır. Tek boyutlu veya çok boyutlu olabilir. Diziler statik veya dinamik olarak oluşturulabilir.
İçinde statically declared arrays, Dizilerin boyutu ve boyutu derleme sırasında bilinmektedir.
İçinde dynamically declared arrays, Dizinin boyutu ve boyutu çalışma zamanında bilinir.
Paylaşılan bellek programlaması için diziler ortak bir bellek olarak kullanılabilir ve paralel veri programlama için alt dizilere bölümlenerek kullanılabilirler.
Hypercube Ağı
Hypercube mimarisi, her görevin diğer görevlerle iletişim kurması gereken paralel algoritmalar için yararlıdır. Hypercube topolojisi, halka ve ağ gibi diğer topolojileri kolayca yerleştirebilir. Aynı zamanda n-küp olarak da bilinir.nboyutların sayısıdır. Bir hiperküp, özyinelemeli olarak inşa edilebilir.


Paralel bir algoritma için uygun bir tasarım tekniği seçmek en zor ve önemli görevdir. Paralel programlama problemlerinin çoğunun birden fazla çözümü olabilir. Bu bölümde, paralel algoritmalar için aşağıdaki tasarım tekniklerini tartışacağız -
- Böl ve fethet
- Açgözlü Yöntem
- Dinamik program
- Backtracking
- Şube ve Bağlı
- Doğrusal programlama
Böl ve Yönet Yöntemi
Böl ve yönet yaklaşımında, problem birkaç küçük alt probleme bölünmüştür. Daha sonra alt problemler özyinelemeli olarak çözülür ve orijinal problemin çözümünü elde etmek için birleştirilir.
Böl ve yönet yaklaşımı, her seviyede aşağıdaki adımları içerir -
Divide - Asıl problem alt problemlere bölünmüştür.
Conquer - Alt problemler özyinelemeli olarak çözülür.
Combine - Alt problemlerin çözümleri bir araya getirilerek asıl problemin çözümü elde edilir.
Böl ve yönet yaklaşımı aşağıdaki algoritmalarda uygulanır -
- Ikili arama
- Hızlı sıralama
- Sıralamayı birleştir
- Tamsayı çarpımı
- Matris ters çevirme
- Matris çarpımı
Açgözlü Yöntem
Açgözlü optimizasyon çözüm algoritmasında, her an en iyi çözüm seçilir. Açgözlü bir algoritmanın karmaşık problemlere uygulanması çok kolaydır. Bir sonraki adımda hangi adımın en doğru çözümü sağlayacağına karar verir.
Bu algoritmaya greedyçünkü daha küçük örnek için en uygun çözüm sağlandığında, algoritma toplam programı bir bütün olarak dikkate almaz. Bir çözüm düşünüldüğünde, açgözlü algoritma bir daha asla aynı çözümü düşünmez.
Açgözlü bir algoritma, mümkün olan en küçük bileşen parçalarından bir grup nesne oluşturarak yinelemeli olarak çalışır. Özyineleme, belirli bir sorunun çözümünün, o sorunun daha küçük örneğinin çözümüne bağlı olduğu bir sorunu çözme prosedürüdür.
Dinamik program
Dinamik programlama, problemi daha küçük alt problemlere bölen ve her bir alt problemi çözdükten sonra, dinamik programlama nihai çözümü elde etmek için tüm çözümleri birleştiren bir optimizasyon tekniğidir. Böl ve yönet yönteminin aksine dinamik programlama, alt problemlerin çözümünü birçok kez yeniden kullanır.
Fibonacci Serisi için yinelemeli algoritma, dinamik programlamanın bir örneğidir.
Geri İzleme Algoritması
Geriye dönük izleme, kombinasyonel problemleri çözmek için kullanılan bir optimizasyon tekniğidir. Hem programatik hem de gerçek hayat sorunlarına uygulanır. Sekiz vezir problemi, Sudoku bulmacası ve bir labirentten geçmek geri izleme algoritmasının kullanıldığı popüler örneklerdir.
Geriye dönük izlemede, gerekli tüm koşulları karşılayan olası bir çözümle başlıyoruz. Sonra bir sonraki seviyeye geçiyoruz ve bu seviye tatmin edici bir çözüm üretmezse, bir seviye geri dönüyor ve yeni bir seçenekle başlıyoruz.
Şube ve Sınır
Dal ve sınır algoritması, soruna en uygun çözümü elde etmek için kullanılan bir optimizasyon tekniğidir. Çözümün tüm alanında belirli bir sorun için en iyi çözümü arar. Optimize edilecek fonksiyondaki sınırlar, en son en iyi çözümün değeri ile birleştirilir. Algoritmanın çözüm uzayının parçalarını tam olarak bulmasını sağlar.
Dal ve bağlı aramanın amacı, hedefe giden en düşük maliyetli yolu korumaktır. Bir çözüm bulunduğunda, çözümü geliştirmeye devam edebilir. Dal ve sınır arama, derinlemesine arama ve derinlik ilk aramada uygulanır.
Doğrusal programlama
Doğrusal programlama, hem optimizasyon kriterinin hem de kısıtlamaların doğrusal fonksiyonlar olduğu geniş bir optimizasyon işi sınıfını tanımlar. Maksimum kâr, en kısa yol veya en düşük maliyet gibi en iyi sonucu elde etmek için kullanılan bir tekniktir.
Bu programlamada, bir dizi değişkenimiz var ve bir dizi doğrusal denklemi tatmin etmek ve belirli bir doğrusal amaç fonksiyonunu maksimize etmek veya en aza indirmek için onlara mutlak değerler atamamız gerekiyor.
Bir matris, sabit sayıda satır ve sütun halinde düzenlenmiş sayısal ve sayısal olmayan veriler kümesidir. Matris çarpımı, paralel hesaplamada önemli bir çarpma tasarımıdır. Burada, matris çarpımının mesh ve hypercube gibi çeşitli iletişim ağlarında uygulanmasını tartışacağız. Mesh ve hypercube daha yüksek ağ bağlantısına sahiptir, bu nedenle halka ağ gibi diğer ağlardan daha hızlı algoritmaya izin verirler.
Mesh Ağı
Bir dizi düğümün p-boyutlu bir ızgara oluşturduğu bir topolojiye ağ topolojisi denir. Burada, tüm kenarlar ızgara eksenine paraleldir ve tüm bitişik düğümler kendi aralarında iletişim kurabilir.
Toplam düğüm sayısı = (satırdaki düğüm sayısı) × (sütundaki düğüm sayısı)
Bir örgü ağı aşağıdaki faktörler kullanılarak değerlendirilebilir -
- Diameter
- İkiye bölme genişliği
Diameter - Bir örgü ağda, en uzun distanceiki düğüm arasındaki çaptır. Bir p-boyutlu ağ ağıkP düğümlerin çapı p(k–1).
Bisection width - İkiye bölme genişliği, ağ örgüsünü ikiye bölmek için bir ağdan kaldırılması gereken minimum kenar sayısıdır.
Mesh Ağı Kullanarak Matris Çarpımı
Çevreleyen bağlantıları olan bir 2D örgü ağ SIMD modelini düşündük. Belirli bir süre içinde n 2 işlemci kullanarak iki n × n diziyi çarpmak için bir algoritma tasarlayacağız .
A ve B matrisleri sırasıyla a ij ve b ij öğelerine sahiptir. PE ij işleme öğesi , bir ij ve b ij'yi temsil eder . A ve B matrislerini, her işlemcinin çarpması gereken bir çift elemanı olacak şekilde düzenleyin. A matrisinin elemanları sol yönde hareket edecek ve B matrisinin elemanları yukarı yönde hareket edecektir. A ve B matrisindeki elemanların pozisyonundaki bu değişiklikler, her bir işleme elemanını, PE'yi, çarpılacak yeni bir değer çifti sunar.
Algoritmadaki Adımlar
- İki matrisi kademelendirin.
- Tüm ürünleri hesapla, a ik × b kj
- 2. adım tamamlandığında toplamları hesaplayın.
Algoritma
Procedure MatrixMulti
Begin
for k = 1 to n-1
for all Pij; where i and j ranges from 1 to n
ifi is greater than k then
rotate a in left direction
end if
if j is greater than k then
rotate b in the upward direction
end if
for all Pij ; where i and j lies between 1 and n
compute the product of a and b and store it in c
for k= 1 to n-1 step 1
for all Pi;j where i and j ranges from 1 to n
rotate a in left direction
rotate b in the upward direction
c=c+aXb
EndHypercube Ağı
Bir hiperküp, kenarların kendi aralarında dik olduğu ve aynı uzunlukta olduğu n boyutlu bir yapıdır. N boyutlu bir hiperküp, n-küp veya n-boyutlu küp olarak da bilinir.
2 k düğümlü Hypercube'ün özellikleri
- Çap = k
- İkiye bölme genişliği = 2 k – 1
- Kenar sayısı = k
Hypercube Network kullanarak Matris Çarpma
Hypercube ağlarının genel özellikleri -
İzin Vermek N = 2mtoplam işlemci sayısı. İşlemciler P 0, P 1 … ..P N-1 olsun .
İ ve i b iki tam sayı olsun, 0 <i, i b <N-1 ve ikili gösterimi sadece b, 0 <b <k – 1 konumunda farklı olsun.
İki n × n matrisi, A matrisini ve B matrisini ele alalım.
Step 1- Matris A ve matris B'nin öğeleri, i, j, k konumundaki işlemcinin a ji ve b ik'ye sahip olacağı şekilde n 3 işlemciye atanır .
Step 2 - Pozisyondaki (i, j, k) tüm işlemciler ürünü hesaplar
C (i, j, k) = A (i, j, k) × B (i, j, k)
Step 3 - 0 ≤ i ≤ n-1 için C (0, j, k) = ΣC (i, j, k) toplamı, burada 0 ≤ j, k <n – 1.
Blok Matrisi
Blok Matrisi veya bölümlenmiş matris, her öğenin kendisinin ayrı bir matrisi temsil ettiği bir matristir. Bu ayrı bölümler, birblock veya sub-matrix.
Misal


Şekil (a) 'da X, A, B, C, D'nin kendilerinin matris olduğu bir blok matristir. Şekil (f) toplam matrisi göstermektedir.
Blok Matris Çarpımı
İki blok matris kare matris olduğunda, o zaman basit matris çarpımını gerçekleştirdiğimiz şekilde çarpılırlar. Örneğin,

Sıralama, bir gruptaki öğeleri belirli bir sırayla düzenleme işlemidir, yani artan sıra, azalan sıra, alfabetik sıra, vb. Burada aşağıdakileri tartışacağız -
- Numaralandırma Sıralaması
- Tek-Çift Aktarım Sıralaması
- Paralel Birleştirme Sıralaması
- Hiper Hızlı Sıralama
Bir öğe listesinin sıralanması çok yaygın bir işlemdir. Sıralı bir sıralama algoritması, büyük hacimli verileri sıralamak zorunda olduğumuzda yeterince verimli olmayabilir. Bu nedenle, sıralamada paralel algoritmalar kullanılır.
Numaralandırma Sıralaması
Numaralandırma sıralaması, sıralı bir listedeki her bir öğenin son konumunu bularak bir listedeki tüm öğeleri düzenleme yöntemidir. Her bir öğeyi diğer tüm öğelerle karşılaştırarak ve daha küçük değere sahip öğe sayısını bularak yapılır.
Bu nedenle, herhangi iki öğe için a i ve a j aşağıdaki durumlardan herhangi biri doğru olmalıdır -
- a i <a j
- a i > a j
- bir i = bir j
Algoritma
procedure ENUM_SORTING (n)
begin
for each process P1,j do
C[j] := 0;
for each process Pi, j do
if (A[i] < A[j]) or A[i] = A[j] and i < j) then
C[j] := 1;
else
C[j] := 0;
for each process P1, j do
A[C[j]] := A[j];
end ENUM_SORTINGTek-Çift Aktarım Sıralaması
Tek-Çift Transpozisyon Sıralama, Kabarcık Sıralama tekniğine dayanır. İki bitişik sayıyı karşılaştırır ve ilk sayı ikinci sayıdan büyükse artan bir sıra listesi almak için bunları değiştirir. Tersi durum bir azalan sıra dizisi için geçerlidir. Tek-Çift aktarım sıralaması iki aşamada çalışır -odd phase ve even phase. Her iki aşamada da işlemler, sağdaki bitişik sayıları ile sayı alışverişinde bulunur.
Algoritma
procedure ODD-EVEN_PAR (n)
begin
id := process's label
for i := 1 to n do
begin
if i is odd and id is odd then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
if i is even and id is even then
compare-exchange_min(id + 1);
else
compare-exchange_max(id - 1);
end for
end ODD-EVEN_PARParalel Birleştirme Sıralaması
Birleştirme sıralaması ilk olarak sıralanmamış listeyi mümkün olan en küçük alt listelere böler, onu bitişik listeyle karşılaştırır ve sıralı bir sırada birleştirir. Böl ve fethet algoritmasını takip ederek paralelliği çok güzel bir şekilde uygular.

Algoritma
procedureparallelmergesort(id, n, data, newdata)
begin
data = sequentialmergesort(data)
for dim = 1 to n
data = parallelmerge(id, dim, data)
endfor
newdata = data
endHiper Hızlı Sıralama
Hiper hızlı sıralama, hiperküp üzerinde hızlı sıralamanın bir uygulamasıdır. Adımları aşağıdaki gibidir -
- Sıralanmamış listeyi her düğüm arasında bölün.
- Her düğümü yerel olarak sıralayın.
- 0 düğümünden medyan değeri yayınlayın.
- Her listeyi yerel olarak bölün, ardından yarıları en yüksek boyutta değiştirin.
- Boyut 0'a ulaşana kadar 3. ve 4. adımları paralel olarak tekrarlayın.
Algoritma
procedure HYPERQUICKSORT (B, n)
begin
id := process’s label;
for i := 1 to d do
begin
x := pivot;
partition B into B1 and B2 such that B1 ≤ x < B2;
if ith bit is 0 then
begin
send B2 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B1 U C;
endif
else
send B1 to the process along the ith communication link;
C := subsequence received along the ith communication link;
B := B2 U C;
end else
end for
sort B using sequential quicksort;
end HYPERQUICKSORTArama, bilgisayar bilimindeki temel işlemlerden biridir. Bir elemanın verilen listede olup olmadığını bulmamız gereken tüm uygulamalarda kullanılır. Bu bölümde aşağıdaki arama algoritmalarını tartışacağız -
- Böl ve fethet
- Derinlik öncelikli arama
- Kapsamlı Arama
- En İyi İlk Arama
Böl ve fethet
Böl ve yönet yaklaşımında, problem birkaç küçük alt probleme bölünmüştür. Daha sonra alt problemler özyinelemeli olarak çözülür ve orijinal problemin çözümünü elde etmek için birleştirilir.
Böl ve yönet yaklaşımı, her seviyede aşağıdaki adımları içerir -
Divide - Asıl problem alt problemlere bölünmüştür.
Conquer - Alt problemler özyinelemeli olarak çözülür.
Combine - Alt problemlerin çözümleri birleştirilerek asıl problemin çözümü elde edilir.
İkili arama, böl ve yönet algoritmasına bir örnektir.
Sözde kod
Binarysearch(a, b, low, high)
if low < high then
return NOT FOUND
else
mid ← (low+high) / 2
if b = key(mid) then
return key(mid)
else if b < key(mid) then
return BinarySearch(a, b, low, mid−1)
else
return BinarySearch(a, b, mid+1, high)Derinlik öncelikli arama
Derinlik-İlk Arama (veya DFS), bir ağaç veya yönlendirilmemiş bir grafik veri yapısını aramak için kullanılan bir algoritmadır. Burada konsept, başlangıç noktası olarak bilinen başlangıç düğümünden başlamaktır.rootve aynı dalda olabildiğince uzağa gidin. Ardıl düğümü olmayan bir düğüm alırsak, geri döner ve henüz ziyaret edilmemiş olan tepe noktasından devam ederiz.
Derinlik-İlk Arama Adımları
Daha önce ziyaret edilmemiş bir düğüm (kök) düşünün ve ziyaret edildi olarak işaretleyin.
İlk bitişik halef düğümü ziyaret edin ve ziyaret edildiğini işaretleyin.
Dikkate alınan düğümün tüm ardıl düğümleri zaten ziyaret edilmişse veya başka bir ardıl düğüme sahip değilse, ana düğümüne dönün.
Sözde kod
İzin Vermek v Grafikte aramanın başladığı tepe noktası olun G.
DFS(G,v)
Stack S := {};
for each vertex u, set visited[u] := false;
push S, v;
while (S is not empty) do
u := pop S;
if (not visited[u]) then
visited[u] := true;
for each unvisited neighbour w of u
push S, w;
end if
end while
END DFS()Kapsamlı Arama
Genişlik İlk Arama (veya BFS), bir ağaç veya yönlendirilmemiş bir grafik veri yapısını aramak için kullanılan bir algoritmadır. Burada bir düğümle başlıyoruz ve ardından aynı seviyedeki tüm bitişik düğümleri ziyaret ediyoruz ve ardından bir sonraki seviyedeki bitişik halef düğüme geçiyoruz. Bu aynı zamandalevel-by-level search.
Kapsamlı Arama Adımları
- Kök düğümle başlayın, ziyaret edildi olarak işaretleyin.
- Kök düğümün aynı düzeyde düğümü olmadığından, bir sonraki düzeye geçin.
- Tüm bitişik düğümleri ziyaret edin ve ziyaret edildi olarak işaretleyin.
- Bir sonraki seviyeye gidin ve ziyaret edilmeyen tüm bitişik düğümleri ziyaret edin.
- Tüm düğümler ziyaret edilene kadar bu işleme devam edin.
Sözde kod
İzin Vermek v Grafikte aramanın başladığı tepe noktası olun G.
BFS(G,v)
Queue Q := {};
for each vertex u, set visited[u] := false;
insert Q, v;
while (Q is not empty) do
u := delete Q;
if (not visited[u]) then
visited[u] := true;
for each unvisited neighbor w of u
insert Q, w;
end if
end while
END BFS()En İyi İlk Arama
En İyi İlk Arama, bir hedefe mümkün olan en kısa yoldan ulaşmak için bir grafiği tarayan bir algoritmadır. BFS ve DFS'nin aksine, En İyi İlk Arama, hangi düğümün bir sonraki geçişe en uygun olduğunu belirlemek için bir değerlendirme işlevini izler.
En İyi İlk Aramanın Adımları
- Kök düğümle başlayın, ziyaret edildi olarak işaretleyin.
- Sonraki uygun düğümü bulun ve ziyaret edildi olarak işaretleyin.
- Bir sonraki seviyeye gidin ve uygun düğümü bulun ve ziyaret edildi olarak işaretleyin.
- Hedefe ulaşılana kadar bu işleme devam edin.
Sözde kod
BFS( m )
Insert( m.StartNode )
Until PriorityQueue is empty
c ← PriorityQueue.DeleteMin
If c is the goal
Exit
Else
Foreach neighbor n of c
If n "Unvisited"
Mark n "Visited"
Insert( n )
Mark c "Examined"
End procedureGrafik, nesne çiftleri arasındaki bağlantıyı temsil etmek için kullanılan soyut bir gösterimdir. Bir grafik şunlardan oluşur:
Vertices- Bir grafikteki birbirine bağlı nesnelere köşeler denir. Tepe noktaları olarak da bilinirnodes.
Edges - Kenarlar, köşeleri birbirine bağlayan bağlantılardır.
İki tür grafik vardır -
Directed graph - Yönlendirilmiş bir grafikte, kenarların yönü vardır, yani kenarlar bir tepe noktasından diğerine gider.
Undirected graph - Yönsüz bir grafikte kenarların yönü yoktur.
Grafik Renklendirme
Grafik renklendirme, iki bitişik köşenin aynı renge sahip olmaması için grafiğin köşelerine renk atama yöntemidir. Bazı grafik renklendirme sorunları -
Vertex coloring - Bir grafiğin köşelerini, bitişik iki köşenin aynı rengi paylaşmaması için renklendirmenin bir yolu.
Edge Coloring - İki bitişik kenarın aynı renge sahip olmaması için her kenara bir renk atama yöntemidir.
Face coloring - Bir düzlemsel grafiğin her yüzüne veya bölgesine bir renk atar, böylece ortak bir sınırı paylaşan iki yüz aynı renge sahip olmaz.
Kromatik Sayı
Kromatik sayı, bir grafiği renklendirmek için gereken minimum renk sayısıdır. Örneğin, aşağıdaki grafiğin kromatik sayısı 3'tür.

Grafik renklendirme kavramı, zaman çizelgeleri, mobil radyo frekansı ataması, Suduku, kayıt tahsisi ve haritaların renklendirilmesinde uygulanır.
Grafik renklendirme adımları
N boyutlu dizideki her işlemcinin başlangıç değerini 1 olarak ayarlayın.
Şimdi bir tepe noktasına belirli bir renk atamak için, o rengin zaten bitişik köşelere atanıp atanmadığını belirleyin.
Bir işlemci bitişik köşelerde aynı rengi algılarsa, dizideki değerini 0 olarak ayarlar.
N 2 karşılaştırma yaptıktan sonra dizinin herhangi bir elemanı 1 ise geçerli bir renklendirme olur.
Grafik renklendirme için sözde kod
begin
create the processors P(i0,i1,...in-1) where 0_iv < m, 0 _ v < n
status[i0,..in-1] = 1
for j varies from 0 to n-1 do
begin
for k varies from 0 to n-1 do
begin
if aj,k=1 and ij=ikthen
status[i0,..in-1] =0
end
end
ok = ΣStatus
if ok > 0, then display valid coloring exists
else
display invalid coloring
endMinimal Kapsayan Ağaç
Tüm kenarlarının toplam ağırlığı (veya uzunluğu), G grafiğinin tüm diğer olası yayılma ağacından daha az olan yayılan bir ağaç, minimal spanning tree veya minimum cost spanningağaç. Aşağıdaki şekil ağırlıklı bir bağlantılı grafiği göstermektedir.

Yukarıdaki grafiğin bazı olası yayılma ağaçları aşağıda gösterilmektedir -



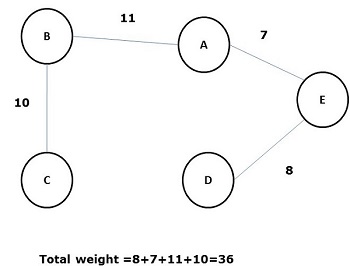



Yukarıdaki yayılan ağaçlar arasında, şekil (d) minimum kapsayan ağaçtır. Minimum maliyet kapsamındaki ağaç kavramı, seyahat eden satıcı probleminde, elektronik devrelerin tasarlanmasında, verimli ağların tasarlanmasında ve verimli yönlendirme algoritmalarının tasarlanmasında uygulanır.
Minimum maliyet aralığını uygulamak için aşağıdaki iki yöntem kullanılır -
- Prim Algoritması
- Kruskal Algoritması
Prim Algoritması
Prim'in algoritması açgözlü bir algoritmadır ve ağırlıklı yönlendirilmemiş bir grafik için minimum yayılma ağacını bulmamıza yardımcı olur. Önce bir tepe noktası seçer ve o tepe noktasında en düşük ağırlık olayına sahip bir kenar bulur.
Prim Algoritmasının Adımları
Herhangi bir tepe noktası seçin, diyelim ki Grafik G'nin v 1'i .
E, bir kenar seçin demek 1 G gibi, e 1 = V 1 h 2 ve v, 1 ≠ h 2 ve e 1 v kenarları olay arasından en az bir ağırlığa sahiptir 1 grafiktir G.
Şimdi, 2. adımı izleyerek, v 2'deki minimum ağırlıklı kenar olayını seçin .
Buna n – 1 kenar seçilinceye kadar devam edin. Burayan köşe sayısıdır.

Minimum kapsayan ağaç -

Kruskal Algoritması
Kruskal'ın algoritması açgözlü bir algoritmadır ve bağlı ağırlıklı bir grafik için minimum yayılma ağacını bulmamıza yardımcı olur ve her adımda maliyet artışlarını artırır. Ormandaki herhangi iki ağacı birbirine bağlayan, mümkün olan en az ağırlıktaki bir kenarı bulan, minimum kapsayan ağaç algoritmasıdır.
Kruskal Algoritmasının Adımları
Minimum ağırlıkta bir kenar seçin; mesela e 1 Grafik G ve e 1 bir ilmek değildir.
E 1'e bağlı bir sonraki minimum ağırlıklı kenarı seçin .
Buna n – 1 kenar seçilinceye kadar devam edin. Burayan köşe sayısıdır.

Yukarıdaki grafiğin minimum yayılma ağacı -
En Kısa Yol Algoritması
En Kısa Yol algoritması, kaynak düğümden (S) hedef düğüme (D) en düşük maliyetli yolu bulma yöntemidir. Burada, Genişlik İlk Arama Algoritması olarak da bilinen Moore algoritmasını tartışacağız.
Moore algoritması
Kaynak tepe noktasını S etiketleyin ve etiketleyin i ve ayarla i=0.
Etiketli tepe noktasına bitişik tüm etiketlenmemiş köşeleri bulun i. Köşeye hiçbir köşe bağlı değilse, S, sonra köşe, D, S'ye bağlı değildir. S'ye bağlı köşeler varsa bunları etiketleyini+1.
D etiketlenmişse, 4. adıma gidin, aksi takdirde i = i + 1'i artırmak için 2. adıma gidin.
En kısa yolun uzunluğu bulunduktan sonra durun.