SAP HANA - Hızlı Kılavuz
SAP HANA, tek bir pakette HANA Veritabanı, Veri Modelleme, HANA Yönetimi ve Veri Sağlama kombinasyonudur. SAP HANA'da HANA, Yüksek Performanslı Analitik Cihaz anlamına gelir.
Eski SAP yöneticisi Dr. Vishal Sikka'ya göre, HANA, Hasso'nun Yeni Mimarisini temsil ediyor. HANA, 2011'in ortalarında ilgiyi artırdı ve çeşitli Fortune 500 şirketleri, bundan sonra İşletme Deposu ihtiyaçlarını karşılamak için bir seçenek olarak düşünmeye başladı.
SAP HANA'nın Özellikleri
SAP HANA'nın temel özellikleri aşağıda verilmiştir -
SAP HANA, büyük miktarda gerçek zamanlı veriyi işlemek için yazılım ve donanım yeniliğinin bir kombinasyonudur.
Dağıtık sistem ortamında çok çekirdekli mimariye dayanmaktadır.
Veritabanındaki veri depolamanın satır ve sütun türüne göre.
Bellek Hesaplama Motorunda (IMCE) çok büyük miktarda gerçek zamanlı veriyi işlemek ve analiz etmek için yaygın olarak kullanılır.
Sahip olma maliyetini düşürür, uygulama performansını artırır, yeni uygulamaların daha önce mümkün olmayan gerçek zamanlı ortamda çalışmasını sağlar.
C ++ ile yazılmıştır, yalnızca bir İşletim Sistemi Suse Linux Enterprise Server 11 SP1 / 2'yi destekler ve üzerinde çalışır.
SAP HANA İhtiyacı
Günümüzde çoğu başarılı şirket, pazar değişikliklerine ve yeni fırsatlara hızla yanıt vermektedir. Bunun anahtarı, verilerin ve bilgilerin analist ve yöneticiler tarafından etkili ve verimli kullanılmasıdır.
HANA, aşağıda belirtilen sınırlamaların üstesinden gelir -
"Veri Hacmi" ndeki artış nedeniyle, analiz ve iş kullanımı için gerçek zamanlı verilere erişim sağlamak şirketler için bir zorluktur.
BT şirketlerinin büyük veri hacimlerini depolaması ve sürdürmesi için yüksek bakım maliyeti içerir.
Gerçek zamanlı verilerin mevcut olmaması nedeniyle, analiz ve işleme sonuçları gecikir.
SAP HANA Satıcıları
SAP, IBM, Dell, Cisco vb. Gibi önde gelen BT donanım satıcılarıyla ortaklık kurdu ve SAP HANA platformunu satmak için SAP lisanslı hizmetler ve teknolojiyle birleştirdi.
HANA Aletleri üreten ve HANA sisteminin kurulumu ve konfigürasyonu için yerinde destek sağlayan toplam 11 satıcı vardır.
Top few Vendors include -
- IBM
- Dell
- HP
- Cisco
- Fujitsu
- Lenovo (Çin)
- NEC
- Huawei
SAP tarafından sağlanan istatistiklere göre IBM, SAP HANA donanım araçlarının başlıca tedarikçilerinden biridir ve% 50-52 pazar payına sahiptir, ancak HANA müşterileri tarafından yapılan başka bir pazar araştırmasına göre IBM,% 70'e varan bir pazar payına sahiptir.
SAP HANA Kurulumu
HANA Donanım satıcıları, donanım, İşletim Sistemi ve SAP yazılım ürünü için önceden yapılandırılmış cihazlar sağlar.
Satıcı, HANA bileşenlerinin yerinde kurulumu ve konfigürasyonu ile kurulumu tamamlar. Bu yerinde ziyaret, HANA sisteminin Veri Merkezinde konuşlandırılmasını, Kuruluş Ağına Bağlanmayı, SAP sistem kimliği uyarlamasını, Solution Manager'dan güncellemeleri, SAP Router Connectivity, SSL Etkinleştirme ve diğer sistem konfigürasyonunu içerir.
Müşteri / Müşteri, Veri Kaynağı sistemi ve BI istemcilerinin bağlanabilirliği ile başlar. Lokal sistem üzerinde HANA Studio Kurulumu tamamlanır ve Veri modelleme ve yönetimi yapmak için HANA sistemi eklenir.
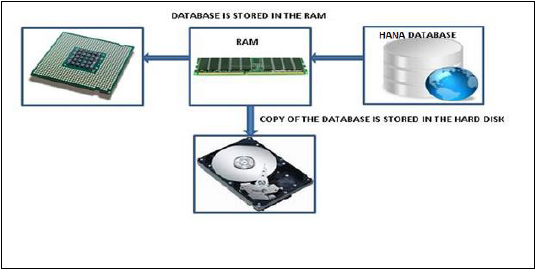
Bir In-Memory veritabanı, kaynak sistemdeki tüm verilerin bir RAM belleğinde saklandığı anlamına gelir. Geleneksel bir Veritabanı sisteminde, tüm veriler sabit diskte saklanır. SAP HANA In-Memory Database, verileri sabit diskten RAM'e yüklemede zaman kaybetmez. Bilgi işleme ve analiz için verilere çok çekirdekli CPU'lara daha hızlı erişim sağlar.
Bellek İçi Veritabanının Özellikleri
SAP HANA bellek içi veritabanının ana özellikleri şunlardır:
SAP HANA, Hibrit Bellek İçi veritabanıdır.
Satır tabanlı, sütun tabanlı ve Nesne Yönelimli temel teknolojiyi birleştirir.
Çok çekirdekli CPU Mimarisi ile paralel işlemeyi kullanır.
Geleneksel Veritabanı, bellek verilerini 5 milisaniyede okur. SAP HANA In-Memory veritabanı verileri 5 nanosaniye içinde okur.
Bu, HANA veritabanındaki bellek okumalarının, geleneksel bir veritabanı sabit disk belleğinin okuduğundan 1 milyon kat daha hızlı olduğu anlamına gelir.
Analistler mevcut verileri anında gerçek zamanlı olarak görmek isterler ve verileri SAP BW sistemine yüklenene kadar beklemek istemezler. SAP HANA In-Memory işleme, çeşitli veri sağlama tekniklerinin kullanılmasıyla gerçek zamanlı verilerin yüklenmesine olanak tanır.
Bellek İçi Veritabanının Avantajları
HANA veritabanı, yüksek ölçekli çevrimiçi işlemlerle veya zamanında tahmin ve planlama ile mücadele eden şirketler için cazip olan en hızlı veri alma hızlarını sağlamak için bellek içi işlemeden yararlanır.
Disk tabanlı depolama hala kurumsal standarttır ve RAM fiyatı istikrarlı bir şekilde düşmektedir, bu nedenle bellek yoğun mimariler sonunda yavaş, mekanik dönen disklerin yerini alacak ve veri depolama maliyetini düşürecektir.
Bellek İçi Sütun tabanlı depolama, 11 kata kadar veri sıkıştırması sağlar, böylece çok büyük verilerin depolama alanını azaltır.
RAM depolama sistemi tarafından sunulan bu hız avantajları, dağıtılmış bir ortamda çok çekirdekli CPU'lar, düğüm başına birden çok CPU ve sunucu başına birden çok düğüm kullanılarak daha da geliştirilmiştir.
SAP HANA studio, Eclipse tabanlı bir araçtır. SAP HANA studio, HANA sistemi için hem merkezi geliştirme ortamı hem de ana yönetim aracıdır. Ek özellikler şunlardır -
Yerel veya uzak HANA sistemine erişmek için kullanılabilen bir istemci aracıdır.
HANA veri tabanında HANA Yönetimi, HANA Bilgi Modellemesi ve Veri Sağlama için bir ortam sağlar.
SAP HANA Studio aşağıdaki platformlarda kullanılabilir -
Microsoft Windows 32 ve 64 bit sürümleri: Windows XP, Windows Vista, Windows 7
SUSE Linux Kurumsal Sunucu SLES11: x86 64 bit
Mac OS, HANA studio istemcisi mevcut değil
HANA Studio kurulumuna bağlı olarak, tüm özellikler mevcut olmayabilir. Studio kurulumu sırasında, yüklemek istediğiniz özellikleri role göre belirtin. HANA stüdyosunun en son sürümü üzerinde çalışmak için, Yazılım Yaşam Döngüsü Yöneticisi istemci güncellemesi için kullanılabilir.
SAP HANA Studio Perspektifleri / Özellikleri
SAP HANA Studio, aşağıdaki HANA özellikleri üzerinde çalışmak için perspektifler sağlar. HANA Studio'da aşağıdaki seçenekten Perspektif'i seçebilirsiniz -
HANA Studio → Window → Open Perspective → Other
Sap Hana Studio Yönetimi
Taşınabilir tasarım zamanı depo nesneleri hariç, çeşitli yönetim görevleri için araç seti. İzleme, katalog tarayıcısı ve SQL Konsolu gibi genel sorun giderme araçları da dahildir.
SAP HANA Studio Veritabanı Geliştirme
İçerik geliştirme için Araç Seti sağlar. Özellikle SAP HANA yerel uygulama geliştirmeyi (XS) içermeyen DataMarts ve ABAP on SAP HANA senaryolarına hitap eder.
SAP HANA Studio Uygulama Geliştirme
SAP HANA sistemi, küçük uygulamaları barındırmak için kullanılabilecek küçük bir Web sunucusu içerir. Java ve HTML ile yazılmış uygulama kodu gibi SAP HANA yerel uygulamalarını geliştirmek için Araç Seti sağlar.
Varsayılan olarak, tüm özellikler yüklenir.
HANA Veritabanı Yönetimi ve izleme özelliklerini gerçekleştirmek için SAP HANA Yönetim Konsolu Perspektifi kullanılabilir.
Yönetici Düzenleyiciye çeşitli şekillerde erişilebilir -
From System View Toolbar - Açık Yönetim varsayılan düğmesini seçin
In System View - HANA Sistemine veya Açık Perspektife Çift Tıklayın
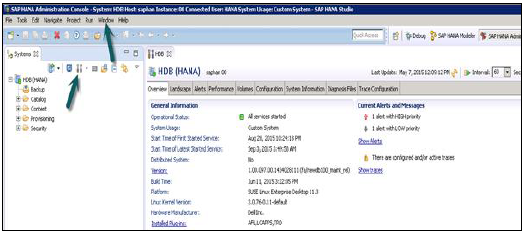
HANA Studio: Yönetici Düzenleyici
Yönetim Görünümünde: HANA studio, HANA sisteminin yapılandırmasını ve sağlığını kontrol etmek için birden çok sekme sağlar. Genel Bakış Sekmesi, Operasyonel Durum, ilk ve son başlatılan hizmetin başlangıç saati, sürüm, yapım tarihi ve saati, Platform, donanım üreticisi vb. Gibi Genel Bilgileri gösterir.
Studio'ya HANA Sistemi Ekleme
HANA stüdyosuna yönetim ve bilgi modelleme amacıyla tekli veya çoklu sistemler eklenebilir. Yeni HANA sistemi eklemek için ana bilgisayar adı, örnek numarası ve veritabanı kullanıcı adı ve şifresi gereklidir.
- Veritabanına bağlanmak için 3615 numaralı bağlantı noktası açık olmalıdır
- Bağlantı Noktası 31015 Örnek No 10
- Bağlantı Noktası 30015 Örnek No 00
- SSh bağlantı noktası da açılmalıdır
Hana Studio'ya Sistem Ekleme
HANA stüdyosuna bir sistem eklemek için verilen adımları izleyin.
Navigator alanına sağ tıklayın ve Sistem Ekle seçeneğine tıklayın. HANA sistem ayrıntılarını, yani Ana Bilgisayar adı ve Örnek numarasını girin ve ileriye tıklayın.
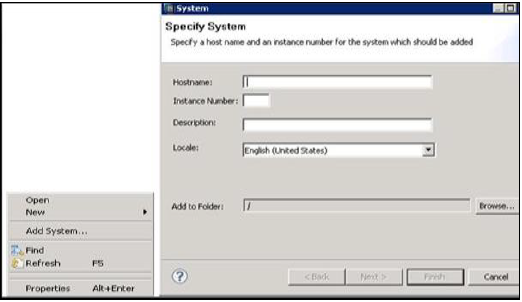
SAP HANA veritabanına bağlanmak için Veritabanı kullanıcı adı ve parolasını girin. İleri'ye ve ardından Bitir'e tıklayın.
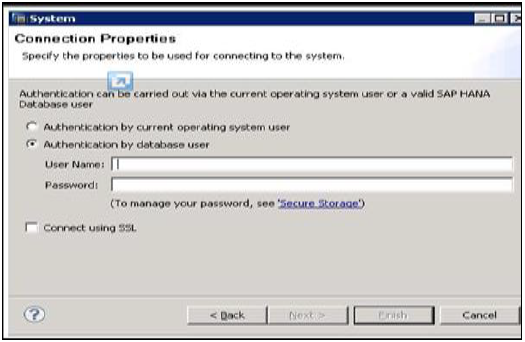
Finish'e tıkladığınızda, HANA sistemi, yönetim ve modelleme amacıyla Sistem Görünümü'ne eklenecektir. Her HANA sisteminin Katalog ve İçerik olmak üzere iki ana alt düğümü vardır.
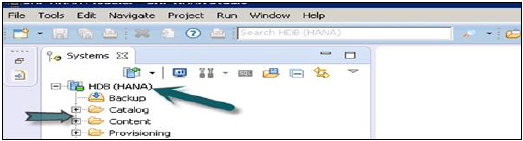
Katalog ve İçerik
Katalog
İçerik sekmesinde kullanılabilen tüm mevcut Şemaları, yani tüm veri yapılarını, tabloları ve verileri, Sütun görünümlerini, Prosedürleri içerir.
İçerik
İçerik sekmesi, HANA Modeler ile oluşturulan veri modellerinin tüm bilgilerini tutan tasarım zamanı havuzunu içerir. Bu modeller Paketler halinde düzenlenmiştir. İçerik düğümü, aynı fiziksel veriler üzerinde farklı görünümler sağlar.
HANA stüdyosundaki Sistem Monitörü bir bakışta tüm HANA sisteminize genel bir bakış sağlar. Sistem Monitörü'nden, Yönetim Düzenleyicisi'nde tek bir sistemin ayrıntılarını inceleyebilirsiniz. Öncelikli olarak Veri Diski, Günlük diski, İzleme Diski, Kaynak kullanımına ilişkin Uyarılar hakkında bilgi verir.
Aşağıdaki Bilgiler Sistem Monitörü'nde mevcuttur -

SAP HANA Bilgi Modelleyici; HANA Veri Modelleyicisi olarak da bilinen HANA Sisteminin kalbidir. Veritabanı tablolarının üst kısmında modelleme görünümleri oluşturmaya ve analiz için anlamlı bir rapor oluşturmak için iş mantığını uygulamaya olanak tanır.
Bilgi Modelleyicisinin Özellikleri
Analiz ve iş mantığı amacıyla HANA veritabanının fiziksel tablolarında depolanan işlem verilerinin birden çok görünümünü sağlar.
Bilgi modelleyici yalnızca sütun tabanlı depolama tabloları için çalışır.
Bilgi Modelleme Görünümleri, raporlama amacıyla Java veya HTML tabanlı uygulamalar veya SAP Lumira veya Analysis Office gibi SAP araçları tarafından kullanılır.
HANA'ya bağlanmak ve raporlar oluşturmak için MS Excel gibi üçüncü taraf araçları kullanmak da mümkündür.
SAP HANA Modeling Views, SAP HANA'nın gerçek gücünden yararlanır.
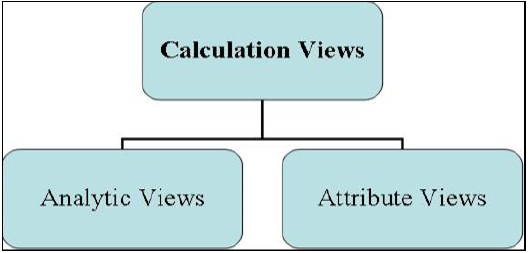
Şu şekilde tanımlanan üç tür Bilgi Görünümü vardır:
- Öznitelik Görünümü
- Analitik Görünüm
- Hesaplama Görünümü
Satır ve Sütun Mağazası
SAP HANA Modeler Görünümleri yalnızca Sütun tabanlı tabloların üstünde oluşturulabilir. Verileri Sütun tablolarında saklamak yeni bir şey değil. Daha önce, Sütunlu tabanlı yapıda veri depolamanın performansı optimize etmek yerine daha fazla bellek boyutu gerektirdiği varsayılıyordu.
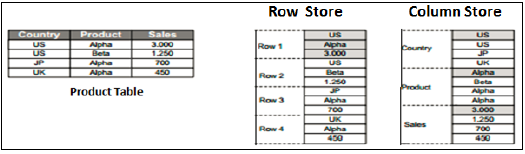
SAP HANA'nın evrimi ile HANA, Bilgi görünümlerinde sütun tabanlı veri depolamayı kullandı ve Satır tabanlı tablolara göre sütunlu tabloların gerçek faydalarını sundu.
Sütun Mağazası
Bir Sütun deposu tablosunda, Veriler dikey olarak depolanır. Dolayısıyla, yukarıdaki örnekte gösterildiği gibi benzer veri türleri bir araya gelir. In-Memory Computing Engine yardımıyla daha hızlı bellek okuma ve yazma işlemleri sağlar.
Geleneksel bir veri tabanında, veriler Satır tabanlı yapıda yani yatay olarak saklanır. SAP HANA, verileri hem satır hem de Sütun tabanlı yapıda depolar. Bu, HANA veritabanında Performans optimizasyonu, esneklik ve veri sıkıştırma sağlar.
Verileri Sütun tabanlı tabloda depolamanın aşağıdaki faydaları vardır:
Veri sıkıştırma
Geleneksel Satır tabanlı depolamaya kıyasla tablolara daha hızlı okuma ve yazma erişimi
Esneklik ve paralel işleme
Toplama ve Hesaplamaları daha yüksek hızda gerçekleştirin
Sütun tabanlı yapıda verilerin nasıl depolanabileceği çeşitli yöntemler ve algoritmalar vardır - Sözlük Sıkıştırılmış, Sıkıştırılmış Çalışma Uzunluğu ve daha fazlası.
Sözlük Sıkıştırılmış'da, hücreler tablolarda sayılar biçiminde depolanır ve sayısal hücreler, karakterlere kıyasla her zaman performansı optimize edilmiştir.
Sıkıştırılmış Çalışma uzunluğunda, çarpanı hücre değeri ile sayısal formatta kaydeder ve çarpan, tabloda tekrarlayan değeri gösterir.

Fonksiyonel Fark - Satır ve Sütun Deposu
SQL deyiminin toplu işlevleri ve hesaplamaları gerçekleştirmesi gerekiyorsa, her zaman Sütun tabanlı depolamanın kullanılması önerilir. Sütun tabanlı tablolar, Sum, Count, Max, Min gibi toplama işlevlerini çalıştırırken her zaman daha iyi performans gösterir.
Çıktının tam satırı döndürmesi gerektiğinde satır tabanlı depolama tercih edilir. Aşağıda verilen örnek anlaşılmasını kolaylaştırır.

Yukarıdaki örnekte, Where cümlesiyle satış sütununda bir Toplama işlevi (Toplam) çalıştırırken, SQL sorgusu çalıştırırken yalnızca Tarih ve Satış sütununu kullanacaktır, bu nedenle sütun tabanlı depolama tablosu ise, performans optimizasyonu, veri kadar hızlı olacaktır. sadece iki sütundan gereklidir.
Basit bir Seçim sorgusu çalıştırırken, tam satır çıktıda yazdırılmalıdır, bu nedenle bu senaryoda tablonun Satır tabanlı olarak depolanması önerilir.
Bilgi Modelleme Görünümleri
Öznitelik Görünümü
Öznitelikler, bir veritabanı tablosundaki ölçülemeyen öğelerdir. Ana verileri temsil ederler ve BW'nin özelliklerine benzerler. Öznitelik Görünümleri, bir veritabanındaki boyutlardır veya modellemede boyutları veya diğer öznitelik görünümlerini birleştirmek için kullanılır.
Önemli özellikler -
- Öznitelik görünümleri, Analitik ve Hesaplama görünümlerinde kullanılır.
- Öznitelik görünümü, ana verileri temsil eder.
- Analitik ve Hesaplama Görünümünde boyut tablolarının boyutlarını filtrelemek için kullanılır.
Analitik Görünüm
Analitik Görünümler, veritabanındaki tablolarda hesaplamalar ve toplama işlevleri gerçekleştirmek için SAP HANA'nın gücünü kullanır. Ölçülere ve boyut tablolarının birincil anahtarlarına sahip olan ve boyut tablolarıyla çevrili en az bir olgu tablosu ana verileri içerir.
Önemli özellikler -
Analitik görünümler, Yıldız şeması sorguları gerçekleştirmek için tasarlanmıştır.
Analitik görünümler en az bir olgu tablosu ve ana verilere sahip birden çok boyut tablosu içerir ve hesaplamalar ve toplamalar gerçekleştirir
SAP BW'deki Bilgi Küpleri ve Bilgi nesnelerine benzerler.
Öznitelik görünümleri ve Olgu tablolarının üstünde analitik görünümler oluşturulabilir ve satılan birim sayısı, toplam fiyat vb. Hesaplamalar gerçekleştirilebilir.
Hesaplama Görünümleri
Hesaplama Görünümleri, Analitik Görünümler ile mümkün olmayan karmaşık hesaplamaları gerçekleştirmek için Analitik ve Öznitelik görünümlerinin üzerinde kullanılır. Hesaplama görünümü, iş mantığı sağlamak için temel sütun tabloları, Öznitelik görünümleri ve Analitik görünümlerin bir kombinasyonudur.
Önemli özellikler -
Hesaplama Görünümleri, HANA Modelleme özelliği kullanılarak grafiksel olarak tanımlanır veya SQL'de kodlanır.
Diğer görünümlerle mümkün olmayan karmaşık hesaplamaları gerçekleştirmek için oluşturulmuştur - SAP HANA modelleyicinin Öznitelik ve Analitik görünümleri.
Bir veya daha fazla Öznitelik görünümü ve Analitik görünüm, Hesaplama Görünümünde Projeler, Birleştirme, Birleştirme, Sıralama gibi yerleşik işlevler yardımıyla kullanılır.
SAP HANA başlangıçta Java ve C ++ ile geliştirilmiş ve yalnızca İşletim Sistemi Suse Linux Enterprise Server 11'i çalıştırmak için tasarlanmıştır. SAP HANA sistemi, HANA sisteminin hesaplama gücünü vurgulamaktan sorumlu birden fazla bileşenden oluşur.
SAP HANA sisteminin en önemli bileşeni, veritabanı için sorgu ifadelerini işlemek için SQL / MDX işlemcisi içeren Index Sunucusudur.
HANA sistemi, küçük web uygulamaları ve çeşitli diğer bileşenlerle iletişim kurmak ve barındırmak için kullanılan Ad Sunucusu, Ön İşlemci Sunucusu, İstatistik Sunucusu ve XS motorunu içerir.

Dizin Sunucusu
Index Server, SAP HANA veritabanı sisteminin kalbidir. Bu verileri işlemek için gerçek verileri ve motorları içerir. SAP HANA sistemi için SQL veya MDX çalıştırıldığında, bir İndeks Sunucusu tüm bu taleplerle ilgilenir ve bunları işler. Tüm HANA işlemleri Dizin Sunucusunda gerçekleşir.
Index Server, HANA veritabanı sistemine gelen tüm SQL / MDX ifadelerini işlemek için Veri motorlarını içerir. Ayrıca, HANA sisteminin dayanıklılığından sorumlu olan ve HANA sisteminin sistem arızası yeniden başlatıldığında en son durumuna geri yüklenmesini sağlayan Kalıcı Katmana sahiptir.
Index Server'da ayrıca işlemleri yöneten ve çalışan ve kapatılan tüm işlemleri takip eden Oturum ve İşlem Yöneticisi bulunur.

Dizin Sunucusu - Mimari
SQL / MDX İşlemci
Sorguları yürütmekten sorumlu veri motorları ile SQL / MDX işlemlerini işlemekten sorumludur. Tüm sorgu isteklerini segmentlere ayırır ve bunları performans Optimizasyonu için doğru motora yönlendirir.
Ayrıca tüm SQL / MDX isteklerinin yetkilendirilmesini sağlar ve ayrıca bu ifadelerin verimli bir şekilde işlenmesi için hata işleme sağlar. Sorgu yürütme için birkaç motor ve işlemci içerir -
MDX (Multi Dimension Expression), SQL gibi İlişkisel veritabanı için kullanıldığı gibi OLAP sistemleri için sorgu dilidir. MDX Engine, sorguları işlemekten ve OLAP küplerinde depolanan çok boyutlu verileri işlemekten sorumludur.
Planning Engine, SAP HANA veritabanı içinde planlama işlemlerini yürütmekten sorumludur.
Hesaplama Motoru, ifadelerin paralel işlenmesini desteklemek için mantıksal yürütme planı oluşturmak için verileri Hesaplama modellerine dönüştürür.
Depolanan Prosedür işlemcisi, optimize edilmiş işleme için prosedür çağrılarını yürütür; OLAP küplerini HANA için optimize edilmiş küplere dönüştürür.
İşlem ve Oturum Yönetimi
Tüm veritabanı işlemlerini koordine etmek ve tüm devam eden ve kapatılan işlemleri takip etmek sorumludur.
Bir işlem yürütüldüğünde veya başarısız olduğunda, İşlem yöneticisi gerekli önlemleri alması için ilgili veri motorunu bilgilendirir.
Oturum yönetimi bileşeni, önceden tanımlanmış oturum parametrelerini kullanarak SAP HANA sistemi için oturumları ve bağlantıları başlatmak ve yönetmekle sorumludur.
Kalıcılık Katmanı
HANA sistemindeki işlemlerin dayanıklılığından ve atomikliğinden sorumludur. Kalıcılık katmanı, HANA veritabanı için yerleşik olağanüstü durum kurtarma sistemi sağlar.
Veritabanının en son durumuna geri yüklenmesini sağlar ve bir sistem arızası veya yeniden başlatma durumunda tüm işlemlerin tamamlanmasını veya geri alınmasını sağlar.
Ayrıca, verileri ve işlem günlüklerini yönetmekten ve ayrıca veri yedeklemesini, günlük yedeklemesini ve HANA sisteminin yapılandırmasını geri almaktan sorumludur. Yedeklemeler, normalde her 5-10 dakikada bir geri almak üzere ayarlanan bir Kaydetme Noktası koordinatörü aracılığıyla Veri Birimlerinde kaydetme noktaları olarak saklanır.
Önişlemci Sunucusu
SAP HANA sistemindeki Önişlemci Sunucusu, metin veri analizi için kullanılır.
Index Server, metin verilerini analiz etmek ve metin arama yetenekleri kullanıldığında metin verilerinden bilgileri çıkarmak için ön işlemci sunucusunu kullanır.
İsim Sunucusu
NAME sunucusu, HANA sisteminin Sistem Görünümü bilgilerini içerir. Dağıtılmış ortamda, her bir düğümün birden fazla CPU'suna sahip birden çok düğüm vardır, Ad sunucusu HANA sisteminin topolojisini tutar ve çalışan tüm bileşenler hakkında bilgi içerir ve bilgiler tüm bileşenlere yayılır.
SAP HANA sisteminin topolojisi buraya kaydedilir.
Dağıtılmış ortamda hangi verinin hangi sunucuda olduğunu tuttuğu için yeniden indeksleme süresini azaltır.
İstatistik Sunucusu
Bu sunucu, HANA sistemindeki tüm bileşenlerin sağlığını kontrol eder ve analiz eder. İstatistik Sunucusu, sistem kaynakları, kaynakların tahsisi ve tüketimi ile HANA sisteminin genel performansı ile ilgili verilerin toplanmasından sorumludur.
Ayrıca HANA sisteminde performansla ilgili sorunları kontrol etmek ve düzeltmek için analiz amacıyla sistem performansına ilişkin geçmiş verileri sağlar.
XS Motoru
XS motoru, harici Java ve HTML tabanlı uygulamaların XS istemcisi yardımıyla HANA sistemine erişmesine yardımcı olur. SAP HANA sistemi, küçük JAVA / HTML tabanlı uygulamaları barındırmak için kullanılabilecek bir web sunucusu içerdiğinden.
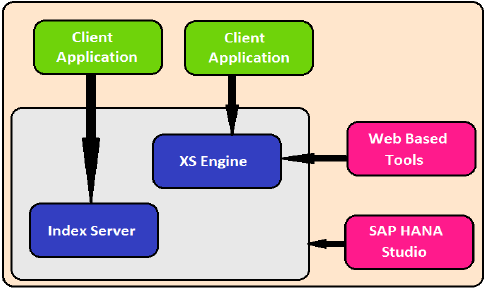
XS Engine, veritabanında depolanan kalıcılık modelini HTTP / HTTPS aracılığıyla sunulan istemciler için tüketim modeline dönüştürür.
SAP Ana Bilgisayar Aracısı
SAP Host aracısı, SAP HANA system Landscape'in parçası olan tüm makinelere kurulmalıdır. SAP Host aracısı, dağıtılmış ortamda HANA sisteminin tüm bileşenlerine otomatik güncellemeleri yüklemek için Software Update Manager SUM tarafından kullanılır.
LM Yapısı
SAP HANA sisteminin LM yapısı, mevcut kurulum ayrıntıları hakkında bilgi içerir. Bu bilgiler, HANA sistem bileşenlerine otomatik güncellemeleri yüklemek için Yazılım Güncelleme Yöneticisi tarafından kullanılır.
SAP Solution Manager (SAP SOLMAN) teşhis Aracısı
Bu teşhis aracı, SAP HANA sistemini izlemek için tüm verileri SAP Solution Manager'a sağlar. Bu aracı, veritabanı güncel durumu ve genel bilgileri içeren HANA veritabanı hakkındaki tüm bilgileri sağlar.
SAP SOLMAN, SAP HANA sistemi ile entegre edildiğinde HANA sisteminin konfigürasyon detaylarını sağlar.
SAP HANA Studio Deposu
SAP HANA stüdyo deposu, HANA geliştiricilerinin HANA stüdyosunun mevcut sürümünü en son sürümlere güncellemelerine yardımcı olur. Studio Repository, bu güncellemeyi yapan kodu tutar.
SAP HANA için Yazılım Güncelleme Yöneticisi
SAP Market Place, SAP sistemleri için güncellemeleri yüklemek için kullanılır. HANA sistemi için Yazılım Güncelleme Yöneticisi, SAP Market'ten HANA sisteminin güncellenmesine yardımcı olur.
HANA sistemi için yazılım indirmeleri, müşteri mesajları, SAP Notları ve lisans anahtarı talep etmek için kullanılır. Ayrıca, HANA stüdyosunu son kullanıcının sistemlerine dağıtmak için kullanılır.
SAP HANA Modeler seçeneği, HANA veritabanındaki şemaların → tablolarının üstünde Bilgi görünümleri oluşturmak için kullanılır. Bu görünümler, JAVA / HTML tabanlı uygulamalar veya SAP Lumira, Office Analysis gibi SAP Uygulamaları veya MS Excel gibi üçüncü taraf yazılımlar tarafından iş mantığını karşılamak ve analiz yapmak ve bilgi çıkarmak için raporlama amacıyla kullanılır.
HANA Modelleme, HANA stüdyosunda Şema altında Katalog sekmesinde bulunan tabloların üst kısmında yapılır ve tüm görünümler Paket altında İçerik tablosu altına kaydedilir.
HANA stüdyosunda İçerik sekmesi altında İçerik ve Yeni'ye sağ tıklayarak yeni Paket oluşturabilirsiniz.
Bir paket içinde oluşturulan tüm Modelleme Görünümleri, HANA stüdyosunda aynı paketin altında gelir ve Görünüm Tipine göre kategorize edilir.
Her Görünümün Boyut ve Olgu tabloları için farklı yapısı vardır. Boyut tabloları ana verilerle tanımlanır ve Olgu tablosunda boyut tabloları için Birincil Anahtar bulunur ve Satılan Birim Sayısı, Ortalama gecikme süresi, Toplam Fiyat vb.
Olgu ve Boyut Tablosu
Olgu Tablosu, Boyut tablosu ve ölçüler için Birincil Anahtarları içerir. İş mantığını karşılamak için HANA Görünümlerinde Boyut tabloları ile birleştirilirler.
Example of Measures - Satılan birim sayısı, Toplam Fiyat, Ortalama Gecikme süresi vb.
Boyut Tablosu ana verileri içerir ve bazı iş mantığı oluşturmak için bir veya daha fazla olgu tablosu ile birleştirilir. Boyut tabloları, olgu tablolarıyla şemalar oluşturmak için kullanılır ve normalleştirilebilir.
Example of Dimension Table - Müşteri, Ürün vb.
Bir şirketin müşterilere ürün sattığını varsayalım. Her satış, şirket içinde gerçekleşen bir gerçektir ve bu gerçekleri kaydetmek için bilgi tablosu kullanılır.
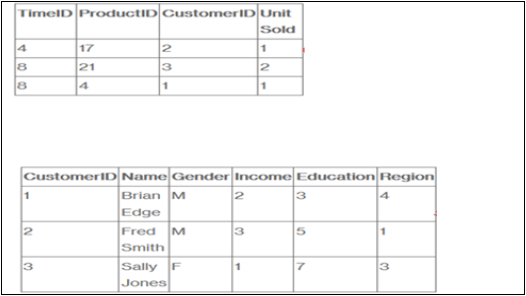
Örneğin, olgu tablosundaki 3. satır, 1. müşterinin (Burak) 4. günde bir ürün satın aldığı gerçeğini kaydeder. Ve tam bir örnekte, ne satın aldığını bilmemiz için bir ürün tablosumuz ve bir zaman çizelgemiz olacaktı. ve tam olarak ne zaman.
Olgu tablosu, şirketimizde meydana gelen olayları (veya en azından analiz etmek istediğimiz olayları - Satılan Birim Sayısı, Marj ve Satış Geliri) listeler. Boyut tabloları, verileri analiz etmek istediğimiz faktörleri (Müşteri, Zaman ve Ürün) listeler.
Şemalar, Veri Ambarı'ndaki tabloların mantıksal açıklamasıdır. Şemalar, bazı iş mantığını karşılamak için birden çok olgu ve Boyut tablolarının birleştirilmesiyle oluşturulur.
Veritabanı, verileri depolamak için ilişkisel modeli kullanır. Ancak Veri Ambarı, iş mantığını karşılamak için boyutları ve olgu tablolarını birleştiren Şemaları kullanır. Veri Ambarında kullanılan üç tür Şema vardır -
- Yıldız Şeması
- Kar Taneleri Şeması
- Galaxy Şeması
Yıldız Şeması
Yıldız Şemasında, Her Boyut tek bir Olgu tablosuna birleştirilir. Her Boyut yalnızca bir boyutla temsil edilir ve daha fazla normalleştirilmez.
Boyut Tablosu, verileri analiz etmek için kullanılan bir dizi öznitelik içerir.
Example - Aşağıda verilen örnekte, tüm Dim tabloları için Birincil anahtarlara sahip olan ve analiz yapmak için satılan birimleri_satış ve doları_ ölçen bir FactSales FactSales var.
Dört Dimension tablomuz var - DimTime, DimItem, DimBranch, DimLocation
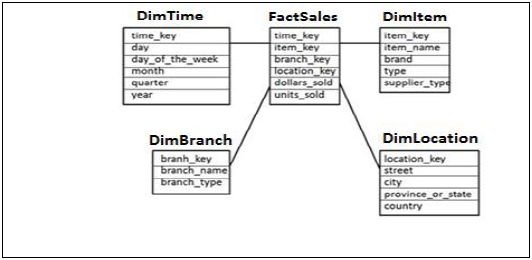
Olgu tablosunun iki tabloyu birleştirmek için kullanılan her Boyut Tablosu için Birincil Anahtarı olduğundan, her bir Boyut tablosu Olgu tablosuna bağlanır.
Olgu Tablosundaki Gerçekler / Ölçüler, Boyut tablolarında öznitelik ile birlikte analiz amacıyla kullanılmaktadır.
Kar Taneleri Şeması
Kar Taneleri şemasında, Boyut tablolarından bazıları daha ileri, normalleştirilir ve Boyut tabloları tek bir Olgu Tablosuna bağlanır. Normalleştirme, veri fazlalığını en aza indirmek için öznitelikleri ve veritabanı tablolarını düzenlemek için kullanılır.
Normalleştirme, bir tabloyu herhangi bir bilgi kaybetmeden daha az yedekli daha küçük tablolara bölmeyi içerir ve daha küçük tablolar Boyut tablosuna birleştirilir.
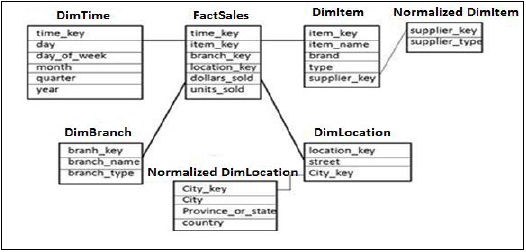
Yukarıdaki örnekte, DimItem ve DimLocation Dimension tabloları herhangi bir bilgi kaybı olmadan normalleştirilmiştir. Buna, boyut tablolarının daha küçük tablolara normalleştirildiği Kar taneleri şeması denir.
Galaxy Şeması
Galaxy Schema'da birden fazla Olgu tablosu ve Boyut tablosu vardır. Her Olgu tablosu, analiz yapmak için birkaç Boyut tablosunun ve ölçümlerin / gerçeklerin birincil anahtarlarını depolar.
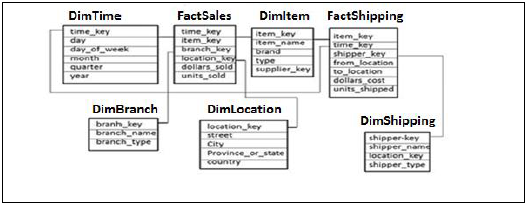
Yukarıdaki örnekte, FactSales, FactShipping ve Fact tablolarına birleştirilmiş birden çok Boyut tablosu olmak üzere iki Fact tablosu vardır. Her bir Olgu tablosu, analiz gerçekleştirmek için birleştirilmiş Dim tabloları ve ölçümler / Gerçekler için Birincil Anahtar içerir.
HANA veri tabanındaki tablolara Şemalar altındaki Katalog sekmesinde bulunan HANA Studio'dan erişilebilir. Aşağıda verilen iki yöntem kullanılarak yeni tablolar oluşturulabilir -
- SQL düzenleyiciyi kullanma
- GUI seçeneğini kullanma
HANA Studio'da SQL Düzenleyici
SQL Konsolu, Sistem Görünümü SQL Düzenleyicisi seçeneği kullanılarak yeni bir tablonun oluşturulması gereken Şema adı seçilerek veya aşağıda gösterildiği gibi Şema adına Sağ tıklanarak açılabilir -

SQL Editör açıldıktan sonra, Şema adı SQL Editör'ün üstünde yazılan addan onaylanabilir. Yeni tablo SQL Create Table deyimi kullanılarak oluşturulabilir -
Create column Table Test1 (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);Bu SQL deyiminde, bir Sütun tablosu “Test1” oluşturduk, tablo veri türlerini ve Birincil Anahtar'ı tanımladık.
Create table SQL sorgusu yazdıktan sonra SQL editörünün sağ tarafında bulunan Execute seçeneğine tıklayın. İfade yürütüldüğünde, aşağıda verilen anlık görüntüde gösterildiği gibi bir onay mesajı alacağız -
'Sütun Tablo Test1 oluştur (ID INTEGER, NAME VARCHAR (10), PRIMARY KEY (ID))'
13 ms 761 μs'de başarıyla yürütüldü (sunucu işlem süresi: 12 ms 979 μs) - Etkilenen Satırlar: 0

Yürütme ifadesi ayrıca ifadenin yürütülmesi için geçen süre hakkında bilgi verir. İfade başarıyla yürütüldüğünde, Sistem Görünümünde Şema adı altında Tablo sekmesine sağ tıklayın ve yenileyin. Yeni Tablo, Şema adı altındaki tablolar listesine yansıtılacaktır.
Ekleme deyimi, verileri SQL düzenleyiciyi kullanarak Tabloya girmek için kullanılır.
Insert into TEST1 Values (1,'ABCD')
Insert into TEST1 Values (2,'EFGH');Yürüt'e tıklayın.
Tablonun veri türünü görmek için Tablo adına sağ tıklayıp Veri Tanımını Aç'ı kullanabilirsiniz. Tablo içeriklerini görmek için Veri Önizleme / Açık İçerik'i açın.
GUI Seçeneğini Kullanarak Tablo Oluşturma
HANA veritabanında tablo oluşturmanın bir başka yolu da HANA Studio'da GUI seçeneğini kullanmaktır.
Şema altındaki Tablo sekmesine sağ tıklayın → Aşağıdaki anlık görüntüde gösterildiği gibi 'Yeni Tablo' seçeneğini seçin.
Yeni Tablo'ya tıkladığınızda → Tablo adını girmek için bir pencere açılacaktır, açılır listeden Şema adını seçin, açılır listeden Tablo türünü Tanımla: Sütun Deposu veya Satır Deposu.
Veri türünü aşağıda gösterildiği gibi tanımlayın. Sütunlar + işaretine tıklanarak eklenebilir, Sütun adının önündeki Birincil anahtar altındaki hücreye tıklanarak Birincil Anahtar seçilebilir, Varsayılan olarak Boş Değil etkin olacaktır.
Sütunlar eklendikten sonra Yürüt'e tıklayın.
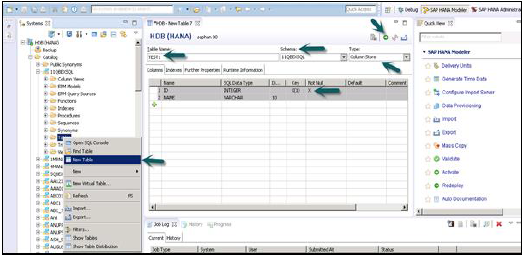
Yürüttüğünüzde (F8), Tablo Sekmesine Sağ Tıklayın → Yenile. Yeni Tablo, seçilen Şema altındaki tablo listesine yansıtılacaktır. Aşağıdaki Ekleme Seçeneği tabloya veri eklemek için kullanılabilir. Tablonun içeriğini görmek için açıklama seçin.

HANA Studio'da GUI kullanarak bir tabloya Veri Ekleme
Tablonun veri türünü görmek için Tablo adına sağ tıklayıp Veri Tanımını Aç'ı kullanabilirsiniz. Tablo içeriklerini görmek için Veri Önizleme / Açık İçerik'i açın.
Görünümler oluşturmak için bir Şemadaki tabloları kullanmak için, HANA Modellemede tüm Görünümleri çalıştıran varsayılan kullanıcıya Şema üzerinde erişim sağlamalıyız. Bu, SQL düzenleyiciye gidip bu sorguyu çalıştırarak yapılabilir -
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
SAP HANA Paketleri, HANA stüdyosunda İçerik sekmesi altında gösterilir. Tüm HANA modellemesi Paketler içine kaydedilir.
İçerik Sekmesine Sağ Tıklayarak Yeni bir Paket oluşturabilirsiniz → Yeni → Paket
Paket adına sağ tıklayarak da bir Paket altında Alt Paket oluşturabilirsiniz. Pakete sağ tıkladığımızda 7 Seçenek elde ederiz: Bir Paket altında HANA Görünümleri Öznitelik Görünümleri, Analitik Görünümler ve Hesaplama Görünümleri oluşturabiliriz.
Ayrıca Karar Tablosu oluşturabilir, Analitik Ayrıcalığı Tanımlayabilir ve bir Paket içinde Prosedürler oluşturabilirsiniz.
Paket'e sağ tıklayıp Yeni'ye tıkladığınızda, bir Paket içinde alt paketler de oluşturabilirsiniz. Paket oluştururken Paket Adı, Açıklama girmelisiniz.
SAP HANA Modellemede Öznitelik Görünümleri, Boyut tablolarının üstünde oluşturulur. Boyut tablolarını veya diğer Öznitelik Görünümlerini birleştirmek için kullanılırlar. Ayrıca, diğer Paketlerin içindeki halihazırda mevcut Öznitelik Görünümlerinden yeni bir Öznitelik Görünümü kopyalayabilirsiniz, ancak bu, Öznitelikleri Görüntülemenize izin vermez.
Öznitelik Görünümünün Özellikleri
HANA'daki Öznitelik Görünümleri, Boyut tablolarını veya diğer Öznitelik Görünümlerini birleştirmek için kullanılır.
Öznitelik Görünümleri, ana verileri geçirmek için analiz için Analitik Görünümlerde ve Hesaplama Görünümlerinde kullanılır.
BM'deki Özellikler'e benzerler ve ana verileri içerirler.
Öznitelik Görünümleri, büyük boyutlu Boyut tablolarında performans optimizasyonu için kullanılır, bir Öznitelik Görünümünde daha sonra Raporlama ve analiz amacıyla kullanılan özniteliklerin sayısını sınırlayabilirsiniz.
Öznitelik Görünümleri, bazı bağlamlar sağlamak için ana verileri modellemek için kullanılır.
Öznitelik Görünümü Nasıl Oluşturulur?
Öznitelik Görünümü oluşturmak istediğiniz Paket adını seçin. Pakete Sağ Tıklayın → Yeniye Git → Öznitelik Görünümü
Öznitelik Görünümü'ne tıkladığınızda Yeni Pencere açılacaktır. Öznitelik Görünümü adını ve açıklamasını girin. Açılır listeden Görünüm Tipi'ni ve alt türü seçin. Alt türde, üç tür Öznitelik görünümü vardır - Standart, Zaman ve Türetilmiş.
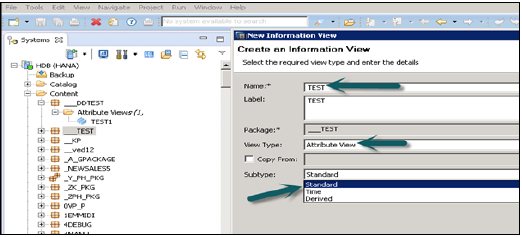
Zaman alt türü Öznitelik Görünümü, Veri Temeli'ne Zaman Boyutu ekleyen özel bir Öznitelik görünümü türüdür. Nitelik adını, Türü ve Alt Türü girip Bitir'e tıkladığınızda, üç çalışma bölmesi açılacaktır -
Veri Temeli ve Anlamsal Katmana sahip senaryo bölmesi.
Ayrıntılar Bölmesi, Data Foundation'a eklenen ve bunlar arasında birleştirilen tüm tabloların özniteliklerini gösterir.
Raporda filtrelemek için Ayrıntı bölmesinden öznitelikler ekleyebileceğimiz çıktı bölmesi.
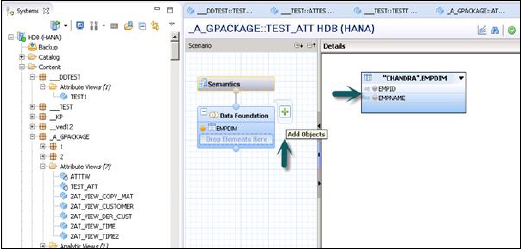
Data Foundation'ın yanındaki '+' işaretine tıklayarak Data Foundation'a Nesneler ekleyebilirsiniz. Senaryo Bölmesinde birden çok Boyut tablosu ve Öznitelik Görünümü ekleyebilir ve bunları bir Birincil Anahtar kullanarak birleştirebilirsiniz.
Data Foundation'da Nesne Ekle'ye tıkladığınızda, Boyut tabloları ve Nitelik görünümlerini Senaryo Bölmesine ekleyebileceğiniz bir arama çubuğu göreceksiniz. Data Foundation'a Tablolar veya Öznitelik Görünümleri eklendikten sonra, aşağıda gösterildiği gibi Ayrıntılar Bölmesinde bir Birincil Anahtar kullanılarak birleştirilebilirler.
Birleştirme tamamlandıktan sonra, ayrıntılar bölmesinde birden çok öznitelik seçin, sağ tıklayın ve Çıktıya Ekle. Tüm sütunlar Çıktı bölmesine eklenecektir. Şimdi Etkinleştir seçeneğine tıklayın ve iş günlüğünde bir onay mesajı alacaksınız.
Artık Öznitelik Görünümü'ne sağ tıklayıp Veri Önizleme'ye gidebilirsiniz.
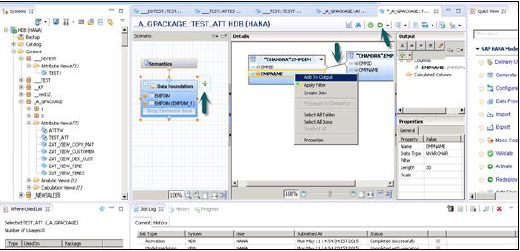
Note- Görünüm etkinleştirilmediğinde üzerinde elmas işareti bulunur. Ancak, bir kez etkinleştirdiğinizde, Görünümün başarıyla etkinleştirildiğini onaylayan o elmas kaybolur.
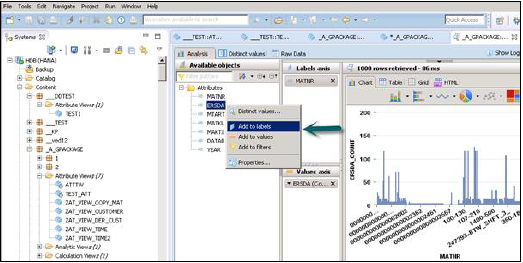
Veri Önizleme'ye tıkladığınızda, Kullanılabilir Nesneler altındaki Çıktı bölmesine eklenen tüm öznitelikleri gösterecektir.
Bu Nesneler, aşağıda gösterildiği gibi nesneleri sağ tıklayıp ekleyerek veya sürükleyerek Etiketler ve Değer eksenine eklenebilir -
Analitik Görünüm, bir Olgu tablosunu birden çok Boyut tablosuyla birleştirdiğimiz Yıldız şeması biçimindedir. Analitik görünümler, tabloları yıldız şeması biçiminde birleştirerek ve Yıldız şeması sorgularını yürüterek karmaşık hesaplamalar ve toplama işlevleri gerçekleştirmek için SAP HANA'nın gerçek gücünü kullanır.
Analitik Görüşün Özellikleri
SAP HANA Analytic View'un özellikleri aşağıda verilmiştir -
Analitik Görünümler, karmaşık hesaplamalar ve Topla, Say, Min, Maks, vb. Gibi Toplama işlevlerini gerçekleştirmek için kullanılır.
Analitik Görünümler, şema başlatma sorgularını çalıştırmak için tasarlanmıştır.
Her Analitik Görünümün birden çok boyut tablosu ile çevrili bir Olgu tablosu vardır. Olgu tablosu, her Dim tablosu ve ölçümleri için birincil anahtarı içerir.
Analitik Görünümler, SAP BW'nin Bilgi Nesneleri ve Bilgi kümelerine benzer.
Analitik Görünüm Nasıl Oluşturulur?
Analitik Görünüm oluşturmak istediğiniz Paket adını seçin. Paket → Yeni → Analitik Görünüme Git'e sağ tıklayın. Bir Analitik Görünüme tıkladığınızda, Yeni Pencere açılacaktır. Görünüm adını ve Açıklamayı girin ve açılır listeden Görünüm Tipi ve Son'u seçin.
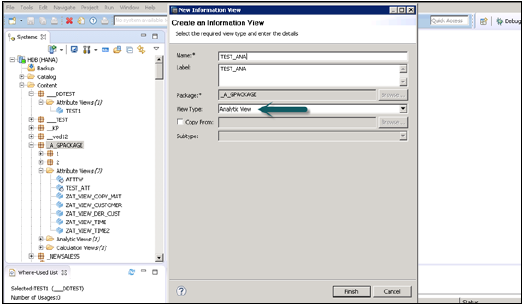
Bitir'e tıkladığınızda, Data Foundation ve Star Join seçeneğiyle bir Analitik Görünüm görebilirsiniz.
Boyut ve Olgu tabloları eklemek için Veri Temeli'ne tıklayın. Öznitelik Görünümleri eklemek için Yıldız Birleştirme'ye tıklayın.
"+" İşaretini kullanarak Dim ve Fact tablolarını Data Foundation'a ekleyin. Aşağıda verilen örnekte, 3 karartma tablosu eklenmiştir: Ayrıntılar Bölmesine DIM_CUSTOMER, DIM_PRODUCT, DIM_REGION ve 1 Fact table FCT_SALES. Fact tablosunda depolanan Birincil Anahtarları kullanarak Dim tablosunu Fact tablosuna katma
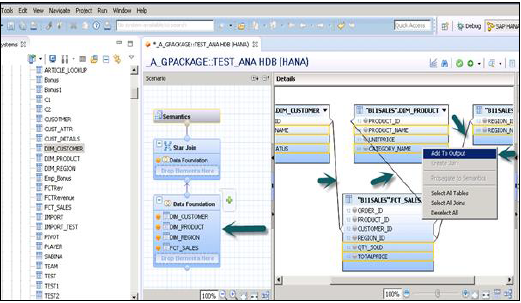
Yukarıda gösterilen anlık görüntüde gösterildiği gibi Çıktı bölmesine eklemek için Dim ve Fact tablosundan Nitelikler'i seçin. Şimdi Olguların veri türünü olgu tablosundan ölçülere değiştirin.
Veri türünü ölçülere dönüştürmek ve Görünümü Etkinleştirmek için Anlamsal katmana tıklayın, gerçekleri seçin ve aşağıda gösterilen ölçü işaretine tıklayın.
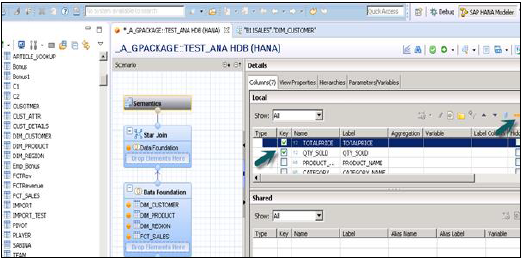
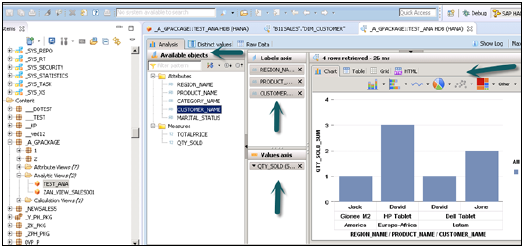
Görünümü etkinleştirip Veri Önizlemesini tıkladığınızda, tüm öznitelikler ve ölçüler Kullanılabilir nesneler listesine eklenecektir. Analiz amacıyla Etiket Eksenine Öznitelikler ve Değer eksenine Ölçü ekleyin.
Farklı türlerde grafik ve grafikler seçme seçeneği vardır.
Hesaplama Görünümleri, diğer Analitik, Öznitelik ve diğer Hesaplama görünümlerini ve temel sütun tablolarını kullanmak için kullanılır. Bunlar, diğer Görünüm türlerinde mümkün olmayan karmaşık hesaplamaları gerçekleştirmek için kullanılır.
Hesaplama Görünümünün Özellikleri
Aşağıda, Hesaplama Görünümlerinin birkaç özelliği verilmiştir -
Hesaplama Görünümleri, Analitik, Nitelik ve diğer Hesaplama Görünümlerini kullanmak için kullanılır.
Diğer Görünümlerle mümkün olmayan karmaşık hesaplamalar yapmak için kullanılırlar.
Hesaplama Görünümleri oluşturmanın iki yolu vardır - SQL Düzenleyici veya Grafik Düzenleyici.
Yerleşik Birleştirme, Birleştirme, Projeksiyon ve Birleştirme düğümleri.
Hesaplama Görünümü nasıl oluşturulur?
Hesaplama Görünümü oluşturmak istediğiniz Paket adını seçin. Paket → Yeniye Git → Hesaplama Görünümüne sağ tıklayın. Hesaplama Görünümü'ne tıkladığınızda Yeni Pencere açılacaktır.
Görünüm adını, Açıklamayı girin ve Görünüm tipini Hesaplama Görünümü, Alt Tip Standardı veya Zaman olarak seçin (bu, zaman boyutu ekleyen özel Görünüm türüdür). İki tür Hesaplama Görünümü kullanabilirsiniz - Grafik ve SQL Komut Dosyası.
Grafik Hesaplama Görünümleri
Aggregation, Projection, Join ve Union gibi varsayılan düğümlere sahiptir. Diğer Nitelik, Analitik ve diğer Hesaplama görünümlerini kullanmak için kullanılır.
SQL Komut Dosyası tabanlı Hesaplama Görünümleri
SQL komutları veya HANA tanımlı fonksiyonlar üzerine kurulu SQL betikleri ile yazılır.
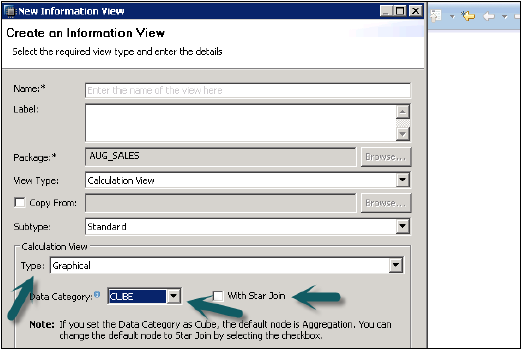
Veri Kategorisi
Bu varsayılan düğümdeki Cube, Aggregation'dır. Küp boyutuyla Yıldız birleştirmeyi seçebilirsiniz.
Boyut, bu varsayılan düğümde Projeksiyondur.
Star Join ile Hesaplama Görünümü
Temel sütun tablolarının, Öznitelik Görünümlerinin veya Analitik görünümlerin veri temeline eklenmesine izin vermez. Yıldız Birleştirme'de kullanmak için tüm Boyut tabloları Boyut Hesaplama görünümlerine dönüştürülmelidir. Tüm Olgu tabloları eklenebilir ve Hesaplama Görünümünde varsayılan düğümleri kullanabilir.
Misal
Aşağıdaki örnek, Hesaplama Görünümünü Star birleştirme ile nasıl kullanabileceğimizi gösterir -
Dört tablonuz, iki Dim tablonuz ve iki Fact tablonuz var. Tüm çalışanların listesini Katılma tarihleri, Çalışan Adı, empId, Maaş ve İkramiye ile bulmalısınız.
Aşağıdaki scripti kopyalayıp SQL editörüne yapıştırın ve çalıştırın.
Dim Tables − Empdim and Empdate
Create column table Empdim (empId nvarchar(3),Empname nvarchar(100));
Insert into Empdim values('AA1','John');
Insert into Empdim values('BB1','Anand');
Insert into Empdim values('CC1','Jason');Create column table Empdate (caldate date, CALMONTH nvarchar(4) ,CALYEAR nvarchar(4));
Insert into Empdate values('20100101','04','2010');
Insert into Empdate values('20110101','05','2011');
Insert into Empdate values('20120101','06','2012');Fact Tables − Empfact1, Empfact2
Create column table Empfact1 (empId nvarchar(3), Empdate date, Sal integer );
Insert into Empfact1 values('AA1','20100101',5000);
Insert into Empfact1 values('BB1','20110101',10000);
Insert into Empfact1 values('CC1','20120101',12000);Create column table Empfact2 (empId nvarchar(3), deptName nvarchar(20), Bonus integer );
Insert into Empfact2 values ('AA1','SAP', 2000);
Insert into Empfact2 values ('BB1','Oracle', 2500);
Insert into Empfact2 values ('CC1','JAVA', 1500);Şimdi Hesaplama Görünümünü Star Join ile uygulamalıyız. Önce her iki Boyut tablosunu Boyut Hesaplama Görünümü olarak değiştirin.
Star Join ile bir Hesaplama Görünümü oluşturun. Grafik bölmesinde, 2 Olgu tablosu için 2 Projeksiyon ekleyin. Her iki olgu tablosunu da Projeksiyonlara ekleyin ve bu Projeksiyonların niteliklerini Çıktı bölmesine ekleyin.

Varsayılan düğümden bir birleştirme ekleyin ve her iki olgu tablosunu da birleştirin. Çıktı bölmesine Fact Join parametrelerini ekleyin.
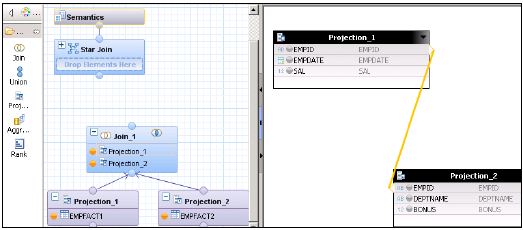
Star Join'de, her iki Boyut Hesaplama görünümünü ekleyin ve aşağıda gösterildiği gibi Star Join'e Fact Join'i ekleyin. Çıktı bölmesinde parametreleri seçin ve Görünümü etkinleştirin.
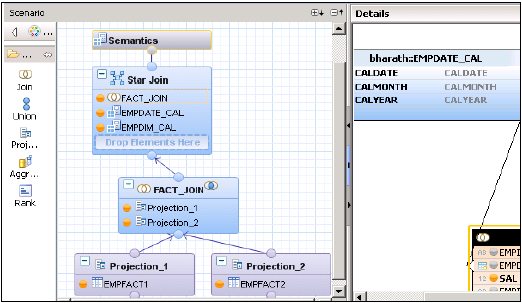
SAP HANA Hesaplama Görünümü - Star Join
Görünüm başarıyla etkinleştirildikten sonra, görünüm adına sağ tıklayın ve Veri Önizleme'ye tıklayın. Değerlere ve etiket eksenine nitelikler ve ölçüler ekleyin ve analizi yapın.
Star Join kullanmanın avantajları
Tasarım sürecini basitleştirir. Analitik görünümler ve Öznitelik Görünümleri oluşturmanıza gerek yoktur ve doğrudan Olgu tabloları Projeksiyon olarak kullanılabilir.
3NF, Star Join ile mümkündür.
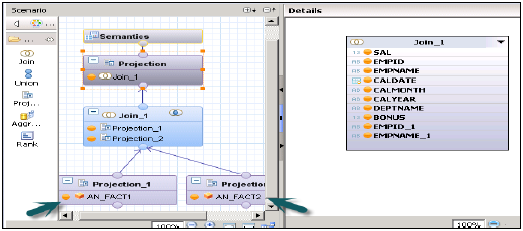
Yıldız Birleştirme olmadan Hesaplama Görünümü
2 Dim tablo üzerinde 2 Nitelik Görünümü oluşturun - Çıktı ekleyin ve her iki görünümü de etkinleştirin.
Olgu Tablolarında 2 Analitik Görünüm Oluşturun → Analitik görünümde Veri Temelinde hem Nitelik görünümlerini hem de Gerçek1 / Gerçek2'yi ekleyin.
Şimdi bir Hesaplama Görünümü Oluşturun → Boyut (Projeksiyon). Hem Analitik Görünümlerin Projeksiyonlarını Oluşturun ve Onlara Katılın Çıktı bölmesine bu Birleştir'in niteliklerini ekleyin. Şimdi Projeksiyona Katılın ve çıktıyı tekrar ekleyin.
Görünümü başarıyla etkinleştirin ve analiz için Veri önizlemeye gidin.
Analitik Ayrıcalıklar, HANA Bilgi görünümlerine erişimi sınırlamak için kullanılır. Analitik Ayrıcalıklarda bir Görünümün farklı bileşenlerinde farklı kullanıcılara farklı hak türleri atayabilirsiniz.
Bazen, aynı görünümdeki verilere, söz konusu veriler için herhangi bir ilgili gereksinimi olmayan diğer kullanıcılar tarafından erişilebilir olmaması gerekir.
Misal
Bir şirketin çalışanları hakkında ayrıntılar içeren bir Analitik görünüm EmpDetails'e sahip olduğunuzu varsayalım - Çalışan adı, İş Kimliği, Departman, Maaş, Katılma Tarihi, Çalışan oturumu açma vb. Şimdi Rapor geliştiricinizin Maaş ayrıntılarını veya Çalışan'ı görmesini istemiyorsanız tüm çalışanların oturum açma detaylarını Analitik ayrıcalıklar seçeneğini kullanarak gizleyebilirsiniz.
Analitik Ayrıcalıklar yalnızca Bilgi Görünümündeki özniteliklere uygulanır. Analitik ayrıcalıklara erişimi kısıtlamak için önlemler ekleyemeyiz.
Analitik Ayrıcalıklar, SAP HANA Bilgi görünümlerinde okuma erişimini kontrol etmek için kullanılır.
Dolayısıyla, verileri maaş, ikramiye gibi sayısal değerlerle değil, Empname, EmpId, Emp oturum açma veya Emp Dept ile sınırlayabiliriz.
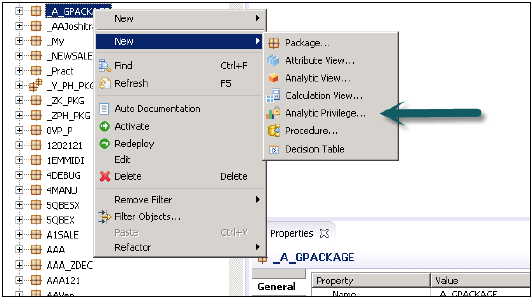
Analitik Ayrıcalıklar Yaratmak
Paket adına sağ tıklayın ve yeni Analitik Ayrıcalığa gidin veya HANA Modeler hızlı başlatmayı kullanarak açabilirsiniz.
Analitik Ayrıcalığın adını ve Açıklamasını girin → Bitir. Yeni pencere açılacaktır.
Bitir'e tıklamadan önce İleri düğmesine tıklayabilir ve bu pencerede Modelleme görünümünü ekleyebilirsiniz. Mevcut bir Analitik Ayrıcalık paketini kopyalama seçeneği de vardır.
Ekle düğmesine tıkladığınızda, size İçerik sekmesi altındaki tüm görünümleri gösterecektir.
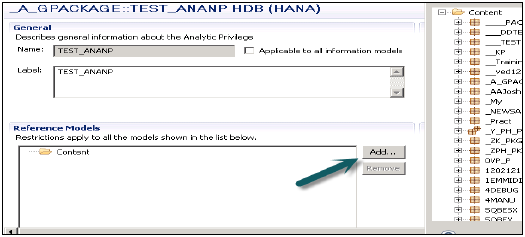
Analitik Ayrıcalık paketine eklemek istediğiniz Görünüm'ü seçin ve Tamam'a tıklayın. Seçilen Görünüm referans modellerin altına eklenecektir.
Şimdi Analitik Ayrıcalık altındaki seçili görünümden öznitelik eklemek için İlişkili Öznitelikler Kısıtlamaları pencereli ekle düğmesine tıklayın.
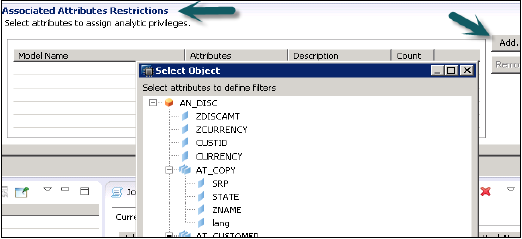
Seçili nesne seçeneğinden Analitik ayrıcalıklarına eklemek istediğiniz nesneleri ekleyin ve Tamam'a tıklayın.
Kısıtlama Ata seçeneğinde, Modelleme Görünümünde belirli bir kullanıcıdan gizlemek istediğiniz değerleri eklemenize olanak tanır. Modelleme Görünümünün Veri Önizlemesine yansıtılmayacak Nesne değeri ekleyebilirsiniz.
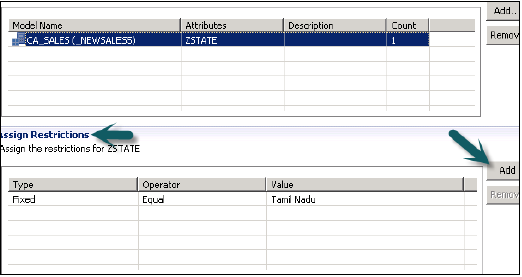
Şimdi üstteki Yeşil yuvarlak simgeye tıklayarak Analitik Ayrıcalığı etkinleştirmeliyiz. Durum mesajı - başarıyla tamamlandı, aktivasyonu iş günlüğü altında başarıyla onaylar ve bu görünümü şimdi bir role ekleyerek kullanabiliriz.
Şimdi bu rolü bir kullanıcıya eklemek için, güvenlik sekmesine gidin → Kullanıcı → Bu Analitik ayrıcalıklarını uygulamak istediğiniz Kullanıcıyı seçin.
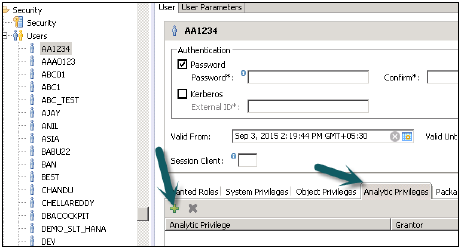
Ad ile uygulamak istediğiniz Analitik Ayrıcalıklarını arayın ve Tamam'a tıklayın. Bu görünüm, Analitik Ayrıcalıklar altındaki kullanıcı rolüne eklenecektir.
Belirli bir kullanıcıdan Analitik Ayrıcalıkları silmek için sekme altındaki görünümü seçin ve Kırmızı silme seçeneğini kullanın. Dağıt'ı kullanın (bunu kullanıcı profiline uygulamak için üstteki ok işareti veya F8).
SAP HANA Information Composer, son kullanıcıların veri kümesini analiz etmeleri için bir self servis modelleme ortamıdır. Çalışma kitabı biçimindeki (.xls, .csv) verileri HANA veritabanına aktarmanıza ve analiz için Modelleme görünümleri oluşturmanıza olanak tanır.
Information Composer, HANA Modeler'den çok farklıdır ve her ikisi de ayrı bir kullanıcı grubunu hedeflemek için tasarlanmıştır. Veri modelleme konusunda güçlü deneyime sahip teknik olarak sağlam insanlar HANA Modeler'ı kullanır. Herhangi bir teknik bilgiye sahip olmayan bir iş kullanıcısı, Information Composer'ı kullanır. Kullanımı kolay arayüzü ile basit işlevler sağlar.
Bilgi Düzenleyicinin Özellikleri
Data extraction - Information Composer, verilerin çıkarılmasına, verilerin temizlenmesine, verilerin önizlenmesine ve HANA veritabanında fiziksel tablo oluşturma sürecinin otomatikleştirilmesine yardımcı olur.
Manipulating data - İki nesneyi (Fiziksel tablolar, Analitik Görünüm, öznitelik görünümü ve hesaplama görünümleri) birleştirmemize ve SAP Business Objects Analysis, SAP Business Objects Explorer ve MS Excel gibi diğer araçlar gibi SAP BO Tools tarafından kullanılabilecek bilgi görünümü oluşturmamıza yardımcı olur.
Her yerden erişilebilen, URL biçiminde merkezi bir BT hizmeti sağlar.
Information Composer kullanılarak veriler nasıl yüklenir?
Büyük miktarda veri (5 milyon hücreye kadar) yüklememize olanak tanır. Information Composer'a erişim bağlantısı -
http://<server>:<port>/IC
SAP HANA Information Composer'da oturum açın. Bu aracı kullanarak veri yükleme veya işleme gerçekleştirebilirsiniz.
Verileri yüklemek için bu iki şekilde yapılabilir -
- .Xls, .csv dosyasını doğrudan HANA veritabanına yükleme
- Diğer bir yol, verileri panoya kopyalamak ve oradan HANA veritabanına kopyalamaktır.
- Verilerin başlık ile birlikte yüklenmesine izin verir.
Information Composer'ın sol tarafında üç seçeneğiniz var -
Veri kaynağı → Verileri sınıflandır → Yayınla'yı seçin
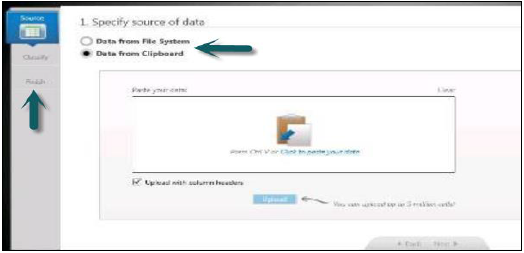
Veriler HANA veritabanına yayınlandıktan sonra tabloyu yeniden adlandıramazsınız. Bu durumda, tabloyu HANA veritabanındaki Schema'dan silmeniz gerekir.
IC_MODELS, IC_SPREADSHEETS gibi tabloların bulunduğu "SAP_IC" şeması. IC kullanılarak oluşturulan tabloların detayları bu tabloların altında bulunabilir.

Pano Kullanımı
IC'ye veri yüklemenin başka bir yolu da panoyu kullanmaktır. Verileri panoya kopyalayın ve Information Composer yardımıyla yükleyin. Information Composer ayrıca verilerin önizlemesini görmenize ve hatta geçici depolamadaki verilerin özetini sağlamanıza olanak tanır. Verilerdeki tutarsızlıkları gidermek için kullanılan dahili veri temizleme özelliğine sahiptir.
Veriler temizlendikten sonra, verilere atıfta bulunulup bulunulmadığını sınıflandırmanız gerekir. IC, yüklenen verilerin veri türünü kontrol etmek için dahili bir özelliğe sahiptir.
Son adım, verileri HANA veritabanındaki fiziksel tablolara yayınlamaktır. Tablonun teknik adını ve açıklamasını sağlayın, bu IC_Tables Schema içine yüklenecektir.
Information Composer ile yayınlanan verileri kullanmak için Kullanıcı Rolleri
IC'den yayınlanan verileri kullanmak için iki kullanıcı grubu tanımlanabilir.
IC_MODELER, fiziksel tablolar oluşturmak, veri yüklemek ve bilgi görünümleri oluşturmak içindir.
IC_PUBLIC, kullanıcıların diğer kullanıcılar tarafından oluşturulan bilgi görünümlerini görüntülemesine izin verir. Bu rol, kullanıcının IC kullanarak herhangi bir bilgi görünümü yüklemesine veya oluşturmasına izin vermez.
Bilgi Oluşturucu için Sistem Gereksinimi
Server Requirements −
En az 2GB kullanılabilir RAM gereklidir.
Sunucuya Java 6 (64-bit) yüklenmelidir.
Bilgi Oluşturucu Sunucusu fiziksel olarak HANA sunucusunun yanında yer almalıdır.
Client Requirements −
- Silverlight 4 yüklü Internet Explorer.
HANA Export and Import seçeneği, tabloların, Bilgi modellerinin, Peyzajların farklı veya mevcut bir sisteme taşınmasına izin verir. Eforu azaltmak için yeni sisteme aktarabileceğiniz veya mevcut bir hedef sisteme aktarabileceğiniz için tüm tabloları ve bilgi modellerini yeniden oluşturmanız gerekmez.
Bu seçeneğe üst kısımdaki Dosya menüsünden veya HANA stüdyosundaki herhangi bir tabloya veya Bilgi modeline sağ tıklayarak erişilebilir.
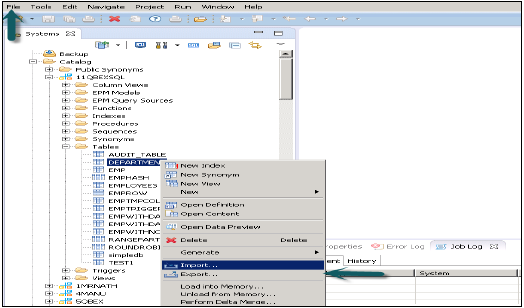
HANA Studio'da bir tabloyu / Bilgi modelini dışa aktarma
Dosya menüsüne gidin → Dışa aktar → Seçenekleri aşağıda gösterildiği gibi göreceksiniz -

SAP HANA İçeriği Altında İhracat Seçenekleri
Teslimat Birimi
Teslimat birimi, birden çok pakete eşlenebilen ve tek bir varlık olarak dışa aktarılabilen tek bir birimdir, böylece Dağıtım Birimine atanan tüm paketler tek birim olarak ele alınabilir.
Kullanıcılar bu seçeneği, bir teslimat birimini oluşturan tüm paketleri ve içindeki ilgili nesneleri bir HANA Sunucusuna veya yerel İstemci konumuna dışa aktarmak için kullanabilir.
Kullanıcı kullanmadan önce Teslimat Birimi oluşturmalıdır.
Bu, HANA Modeler → Dağıtım Birimi → Sistem Seç ve Sonraki → Oluştur → Ad, Sürüm vb. Ayrıntıları doldurun → Tamam → Teslimat birimine Paket Ekle → Sonlandır aracılığıyla yapılabilir
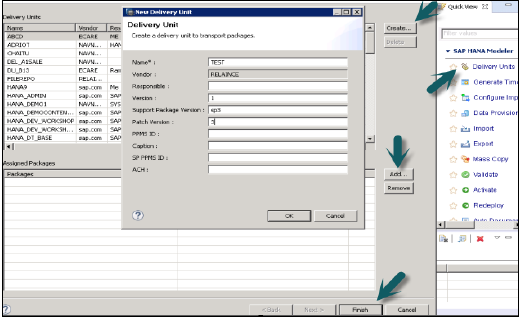
Teslimat Birimi oluşturulduktan ve paketler ona atandıktan sonra, kullanıcı Dışa Aktar seçeneğini kullanarak paketlerin listesini görebilir -
Dosya → Dışa Aktar → Dağıtım Birimi'ne gidin → Dağıtım Birimini seçin.
Teslimat birimine atanan tüm paketlerin listesini görebilirsiniz. Dışa aktarma konumunu seçme seçeneği sunar -
- Sunucuya Aktar
- Müşteriye Aktar
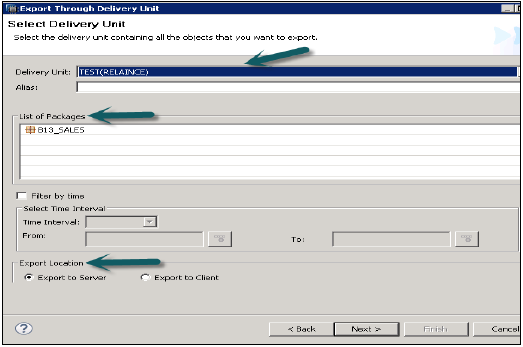
Teslimat Birimini gösterildiği gibi HANA Sunucusu konumuna veya bir İstemci konumuna aktarabilirsiniz.
Kullanıcı, "Zamana göre filtrele" yoluyla dışa aktarımı kısıtlayabilir; bu, belirtilen zaman aralığında güncellenen Bilgi görünümlerinin yalnızca dışa aktarılacağı anlamına gelir.
Teslimat Birimini ve Dışa Aktarma Konumunu seçin ve ardından İleri → Son'u tıklayın. Bu, seçilen Teslimat Birimini belirtilen konuma aktaracaktır.
Geliştirici modu
Bu seçenek, tek tek nesneleri yerel sistemdeki bir konuma aktarmak için kullanılabilir. Kullanıcı, tek bir Bilgi görünümünü veya Görünümler ve Paketler grubunu seçebilir ve dışa aktarma ve Sonlandırma için yerel İstemci konumunu seçebilir.
Bu, aşağıdaki anlık görüntüde gösterilmektedir.
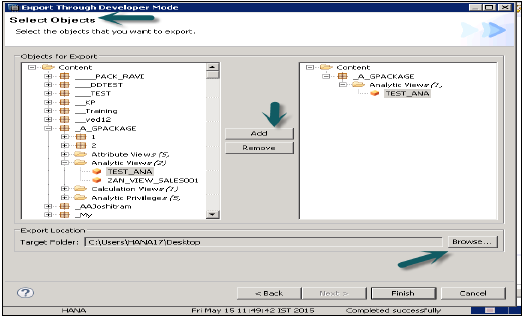
Destek Modu
Bu, nesnelerin yanı sıra verileri SAP desteği amacıyla dışa aktarmak için kullanılabilir. Bu istendiğinde kullanılabilir.
Example- Kullanıcı, bir hata atan ve çözemeyen bir Bilgi Görünümü oluşturur. Bu durumda, görünümü verilerle birlikte dışa aktarmak ve hata ayıklama amacıyla SAP ile paylaşmak için bu seçeneği kullanabilir.

Export Options under SAP HANA Studio -
Landscape - Manzarayı bir sistemden diğerine aktarmak için.
Tables - Bu seçenek, içeriğiyle birlikte tabloları dışa aktarmak için kullanılabilir.
SAP HANA İçeriği Altında İçe Aktarma Seçeneği
Dosyaya Git → İçe Aktar, İçe Aktar altında aşağıda gösterilen tüm seçenekleri göreceksiniz.
Yerel Dosyadan Veriler
Bu, .xls veya .csv dosyası gibi düz bir dosyadan verileri içe aktarmak için kullanılır.
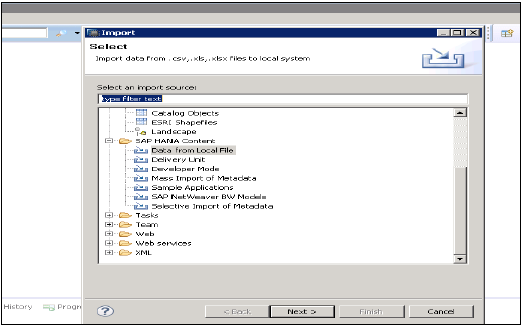
Nex'e tıklayın → Hedef Sistem Seçin → İçe Aktarma Özelliklerini Tanımlayın
Yerel sisteme göz atarak Kaynak dosyayı seçin. Ayrıca başlık satırını korumak istiyorsanız bir seçenek de sunar. Ayrıca, mevcut Şema altında yeni bir tablo oluşturma veya bir dosyadan mevcut bir tabloya veri aktarmak istiyorsanız bir seçenek sunar.
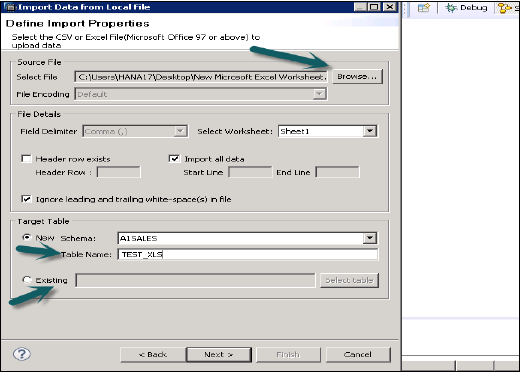
İleri'ye tıkladığınızda, Birincil Anahtar tanımlama, sütunların veri türünü değiştirme, tablonun saklama türünü tanımlama ve ayrıca tablonun önerilen yapısını değiştirmenize olanak tanır.
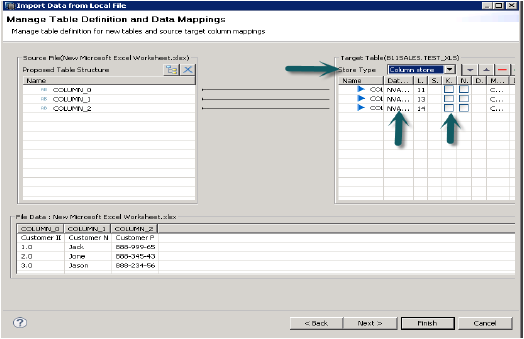
Bitir'e tıkladığınızda, bu tablo söz konusu Şemadaki tablolar listesi altında doldurulacaktır. Veri önizlemesini yapabilir ve tablonun veri tanımını kontrol edebilirsiniz ve bu .xls dosyasıyla aynı olacaktır.

Teslimat Birimi
Dosya → İçe Aktar → Teslimat birimine giderek Teslimat birimini seçin. Bir sunucu veya yerel istemciden seçim yapabilirsiniz.
Var olan nesnelerin herhangi bir etkin olmayan sürümünün üzerine yazmanıza izin veren "Etkin olmayan sürümlerin üzerine yaz" ı seçebilirsiniz. Kullanıcı "Nesneleri etkinleştir" i seçerse, içe aktarmanın ardından, içe aktarılan tüm nesneler varsayılan olarak etkinleştirilecektir. Kullanıcının içe aktarılan görünümler için etkinleştirmeyi manuel olarak tetiklemesi gerekmez.

Bitir'e tıklayın ve başarıyla tamamlandıktan sonra hedef sisteme yerleştirilecektir.
Geliştirici modu
Görünümlerin dışa aktarıldığı Yerel İstemci konumuna göz atın ve içe aktarılacak görünümleri seçin, kullanıcı tek tek Görünümleri veya Görünümler ve Paketler grubunu seçebilir ve Bitir'e tıklayın.
Meta Verilerin Toplu İçe Aktarımı
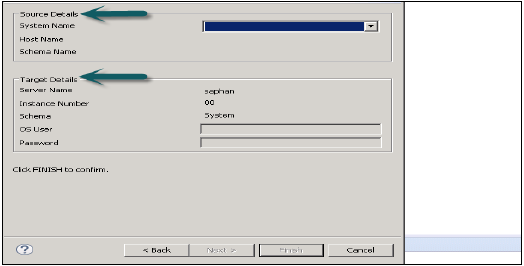
Dosya → İçe Aktar → Meta Verilerin Toplu İçe Aktarımı → İleri'ye gidin ve kaynak ve hedef sistemi seçin.
Sistemi Toplu İçe Aktarma için yapılandırın ve Bitir öğesine tıklayın.
Meta Verilerin Seçmeli İçe Aktarımı
SAP Uygulamalarından Meta verilerini içe aktarmak için tabloları ve hedef şemayı seçmenize olanak tanır.
Dosya → İçe Aktar → Meta Verileri Seçmeli İçe Aktarma → İleri'ye gidin
"SAP Uygulamaları" türü Kaynak Bağlantısını seçin. Veri Deposunun zaten SAP Uygulamaları türünde yaratılmış olması gerektiğini unutmayın → İleri'ye tıklayın
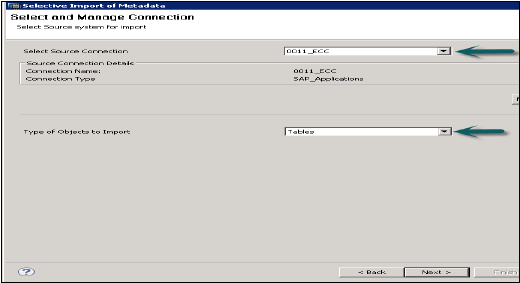
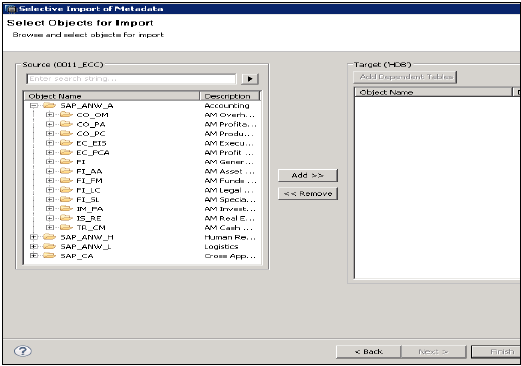
Gerekirse verileri içe aktarmak ve doğrulamak istediğiniz tabloları seçin. Bundan sonra Bitir'i tıklayın.
SAP HANA'da Bilgi Modelleme özelliğinin kullanılmasıyla farklı Bilgi görünümleri Öznitelik Görünümleri, Analitik Görünümler, Hesaplama görünümleri oluşturabileceğimizi biliyoruz. Bu Görünümler, SAP Business Object, SAP Lumira, Design Studio, Office Analysis gibi farklı raporlama araçları ve hatta MS Excel gibi üçüncü taraf araçları tarafından kullanılabilir.
Bu raporlama araçları, İşletme Yöneticilerinin, Analistlerin, Satış Yöneticilerinin ve üst yönetim çalışanlarının, iş senaryoları oluşturmak ve şirketin iş stratejisine karar vermek için tarihi bilgileri analiz etmelerini sağlar.
Bu, HANA Modelleme görünümlerini farklı raporlama araçlarıyla kullanma ve son kullanıcılar için anlaşılması kolay raporlar ve gösterge tabloları oluşturma ihtiyacını doğurur.

SAP'nin uygulandığı şirketlerin çoğunda HANA ile ilgili raporlama, İlişkisel ve OLAP bağlantıları yardımıyla hem SQL hem de MDX sorgularını tüketen BI platformları araçlarıyla yapılmaktadır. Web Intelligence, Crystal Reports, Dashboard, Explorer, Office Analysis ve çok daha fazlası gibi çok çeşitli BI araçları vardır.
Raporlama Araçları
Web Intelligence ve Crystal Reports, raporlama için kullanılan en yaygın BI araçlarıdır. WebI, veri kaynağına bağlanmak için Evren adlı bir anlamsal katman kullanır ve bu Evrenler, araç içinde raporlama için kullanılır. Bu Evrenler, Evren tasarım aracı UDT veya Bilgi Tasarımı aracı IDT yardımıyla tasarlanmıştır. IDT, çok kaynaklı etkin veri kaynağını destekler. Ancak, UDT yalnızca Tek kaynağı destekler.
Etkileşimli gösterge tabloları tasarlamak için kullanılan ana araçlar - Design Studio ve Dashboard Designer. Design Studio, BI tüketici Hizmeti BICS bağlantısı aracılığıyla HANA görünümlerini tüketen gösterge panosu tasarlamak için gelecekteki bir araçtır. Pano tasarımı (xcelsius), İlişkisel veya OLAP bağlantısıyla HANA veritabanındaki şemaları kullanmak için IDT kullanır.
SAP Lumira, HANA veritabanından doğrudan bağlantı veya veri yükleme gibi dahili bir özelliğe sahiptir. HANA görünümleri, görselleştirme ve hikayeler oluşturmak için doğrudan Lumira'da kullanılabilir.
Office Analysis, HANA Bilgi görünümlerine bağlanmak için bir OLAP bağlantısı kullanır. Bu OLAP bağlantısı CMC veya IDT'de oluşturulabilir.
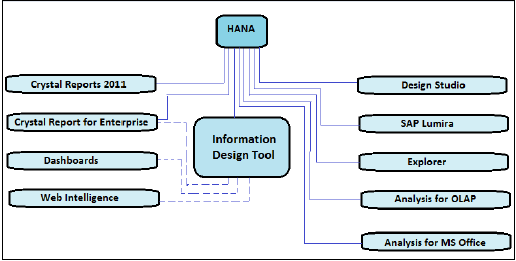
Yukarıda verilen resimde, bir OLAP bağlantısı kullanılarak SAP HANA ile doğrudan bağlanabilen ve entegre edilebilen düz çizgilerle tüm BI araçlarını göstermektedir. Ayrıca, HANA'ya bağlanmak için IDT kullanılarak ilişkisel bir bağlantıya ihtiyaç duyan araçlar noktalı çizgilerle gösterilmektedir.
İlişkisel ve OLAP Bağlantısı
Buradaki fikir temelde verilere bir tablodan veya geleneksel bir veritabanından erişmeniz gerekiyorsa, bağlantınız ilişkisel bir bağlantı olmalıdır, ancak kaynağınız bir uygulama ise ve veriler küpte saklanıyorsa (Bilgi küpleri, Bilgi modelleri gibi çok boyutlu) o zaman OLAP bağlantısı kullanın.
- İlişkisel bir bağlantı yalnızca IDT / UDT'de oluşturulabilir.
- Bir OLAP hem IDT hem de CMC'de oluşturulabilir.
Unutulmaması gereken bir diğer husus, ilişkisel bir bağlantının her zaman rapordan tetiklenecek bir SQL ifadesi oluştururken, OLAP bağlantısı normalde bir MDX ifadesi oluşturmasıdır
Bilgi Tasarım Aracı
Bilgi tasarım aracında (IDT), JDBC veya ODBC sürücülerini kullanarak bir SAP HANA görünümüne veya tablosuna ilişkisel bir bağlantı oluşturabilir ve yukarıdaki resimde gösterildiği gibi Gösterge Tabloları ve Web Intelligence gibi istemci araçlarına erişim sağlamak için bu bağlantıyı kullanarak bir Evren oluşturabilirsiniz.
JDBC veya ODBC sürücülerini kullanarak SAP HANA ile doğrudan bağlantı oluşturabilirsiniz.
Enterprise için Crystal Reports
Crystal Reports for Enterprise'da, bilgi tasarım aracı kullanılarak oluşturulan mevcut bir ilişkisel bağlantıyı kullanarak SAP HANA verilerine erişebilirsiniz.
Bilgi tasarım aracı veya CMC kullanılarak oluşturulan bir OLAP bağlantısını kullanarak da SAP HANA'ya bağlanabilirsiniz.
Tasarım Stüdyosu
Design Studio, Bilgi tasarım aracında oluşturulan mevcut bir OLAP bağlantısını veya Office Analysis gibi CMC'yi kullanarak SAP HANA verilerine erişebilir.
Gösterge tabloları
Gösterge tabloları SAP HANA'ya yalnızca ilişkisel bir Evren aracılığıyla bağlanabilir. SAP HANA'nın üzerinde Gösterge Tabloları kullanan müşteriler, yeni gösterge tablolarını Design Studio ile oluşturmayı kesinlikle düşünmelidir.
Web Intelligence
Web Intelligence, SAP HANA'ya yalnızca İlişkisel Evren aracılığıyla bağlanabilir.
SAP Lumira
Lumira, SAP HANA Analitik ve Hesaplama görünümlerine doğrudan bağlanabilir. İlişkisel bir Evren kullanarak SAP BI Platform aracılığıyla SAP HANA'ya da bağlanabilir.
Office Analysis, OLAP sürümü
OLAP için Office Analysis sürümünde, Merkezi Yönetim Konsolu veya Bilgi tasarım aracında tanımlanan bir OLAP bağlantısını kullanarak SAP HANA'ya bağlanabilirsiniz.
Explorer
JDBC sürücülerini kullanarak SAP HANA görünümüne dayalı bir bilgi alanı oluşturabilirsiniz.
CMC'de OLAP Bağlantısı Oluşturma
Analiz için OLAP, İşletmeler için Crystal Report, Design Studio gibi HANA görünümlerinin yanı sıra kullanmak istediğimiz tüm BI araçları için bir OLAP Bağlantısı oluşturabiliriz. IDT aracılığıyla ilişkisel bağlantı, Web Intelligence ve Dashboard'ları HANA veritabanına bağlamak için kullanılır.
Bu bağlantılar IDT ve CMC kullanılarak oluşturulabilir ve her iki bağlantı da BO Deposuna kaydedilir.
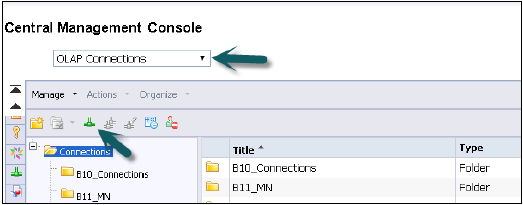
Kullanıcı adı ve şifre ile CMC'ye giriş yapın.
Bağlantıların açılır listesinden bir OLAP bağlantısı seçin. Ayrıca CMC'de önceden oluşturulmuş bağlantıları da gösterecektir. Yeni bir bağlantı oluşturmak için yeşil simgeye gidin ve buna tıklayın.
OLAP bağlantısının adını ve açıklamasını girin. Farklı BI Platform araçlarında HANA görünümlerine bağlanmak için birden fazla kişi bu bağlantıyı kullanabilir.
Provider - SAP HANA
Server - HANA Sunucu adını girin
Instance - Örnek numarası
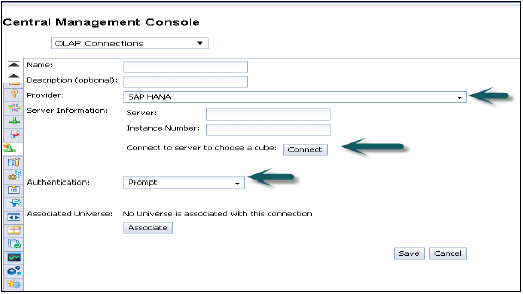
Ayrıca, tek bir Küp'e (Tek Analitik veya Hesaplama görünümüne bağlanmayı da seçebilirsiniz) veya tam HANA sistemine bağlanma seçeneği sunar.
Bağlan'a tıklayın ve kullanıcı adı ve şifre girerek modelleme görünümünü seçin.
Kimlik Doğrulama Türleri - CMC'de OLAP bağlantısı oluştururken üç tür Kimlik Doğrulama mümkündür.
Predefined - Bu bağlantıyı kullanırken tekrar kullanıcı adı ve şifre sormayacaktır.
Prompt - Her seferinde kullanıcı adı ve şifre soracak
SSO - Kullanıcıya özel
Enter user - HANA sistemi için kullanıcı adı ve şifresi ile kaydetme ve yeni bağlantı mevcut bağlantılar listesine eklenecektir.
Şimdi, OLAP için Office Analysis gibi raporlama için tüm BI platformu araçlarını açmak için BI Launchpad'i açın ve bir bağlantı seçmenizi isteyecektir. Varsayılan olarak, bu bağlantıyı oluştururken belirlediyseniz size Bilgi Görünümünü gösterecektir, aksi takdirde İleri'ye tıklayın ve klasörlere gidin → Görünümleri Seçin (Analitik veya Hesaplama Görünümleri).
SAP Lumira connectivity with HANA system
Başlangıç Programı'ndan SAP Lumira'yı açın, dosya menüsüne tıklayın → Yeni → Yeni veri kümesi ekle → SAP HANA'ya bağlan → İleri

SAP HANA'ya bağlanma ile SAP HANA'dan indirme arasındaki fark, verileri Hana sisteminden BO deposuna indirmesi ve HANA sistemindeki değişikliklerle verilerin yenilenmesinin gerçekleşmemesidir. HANA sunucu adını ve Örnek numarasını girin. Kullanıcı adını ve parolayı girin → Bağlan'a tıklayın.
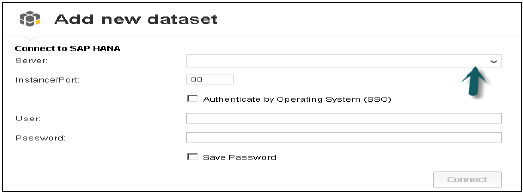
Tüm görünümleri gösterecektir. Görünüm adı ile arama yapabilirsiniz → Görünüm Seç → İleri. Tüm ölçüleri ve boyutları gösterecektir. İsterseniz bu nitelikler arasından seçim yapabilirsiniz → oluşturma seçeneğine tıklayın.
SAP Lumira'da dört sekme vardır -
Prepare - Verileri görebilir ve herhangi bir özel hesaplama yapabilirsiniz.
Visualize- Grafikler ve Grafikler ekleyebilirsiniz. Öznitelik eklemek için X ekseni ve Y ekseni + işaretine tıklayın.
Compose- Bu seçenek Görselleştirme dizisi (hikaye) oluşturmak için kullanılabilir → pano sayısı eklemek için Panele tıklayın → oluştur → sol tarafta tüm görselleştirmeleri gösterecektir. İlk Görselleştirmeyi sürükleyin, ardından sayfayı ekleyin, ardından ikinci görselleştirmeyi ekleyin.
Share- SAP HANA üzerine kurulu ise, sadece SAP Lumira sunucusunda yayınlayabiliriz. Aksi takdirde, hikayeyi SAP Lumira'dan SAP Community Network SCN veya BI Platform'a da yayınlayabilirsiniz.
Dosyayı daha sonra kullanmak için kaydedin → Dosya Kaydet'e gidin → Yerel → Kaydet'i seçin
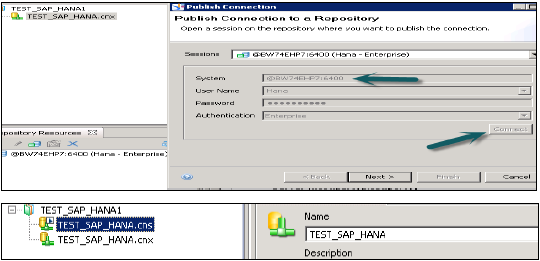
Creating a Relational Connection in IDT to use with HANA views in WebI and Dashboard -
BI Platform İstemci araçlarına giderek Bilgi Tasarım Aracını açın →. Yeni → Proje Proje Adı Girin → Bitir üzerine tıklayın.
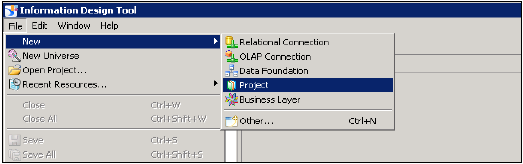
Proje adına sağ tıklayın → Yeni'ye Git → İlişkisel Bağlantıyı Seçin → Bağlantı / kaynak adını girin → Sonraki → HANA sistemine bağlanmak için listeden SAP'yi seçin → SAP HANA → JDBC / ODBC sürücülerini seçin → İleri'ye tıklayın → HANA sistem ayrıntılarını girin → İleri'ye ve Bitir'e tıklayın.

Bu bağlantıyı Test Bağlantısı seçeneğine tıklayarak da test edebilirsiniz.
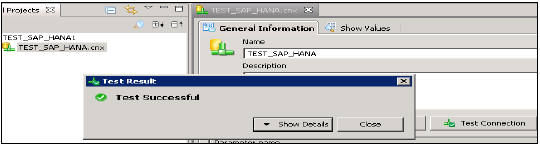
Test Bağlantısı → Başarılı. Sonraki adım, bu bağlantıyı Depo'da yayınlayarak kullanıma hazır hale getirmektir.
Bağlantı adına sağ tıklayın → Depoya bağlantı yayınla seçeneğine tıklayın → BO Depo adı ve şifresini girin → Bağlan → İleri → Bitir → Evet seçeneğine tıklayın.
.Cns uzantısı ile yeni bir ilişkisel bağlantı oluşturacaktır.
.cns - bağlantı türü, Veri temeli oluşturmak için kullanılması gereken güvenli Depo bağlantısını temsil eder.
.cnx - yerel güvenli olmayan bağlantıyı temsil eder. Bu bağlantıyı bir Evren oluştururken ve yayınlarken kullanırsanız, bunu depoda yayınlamanıza izin vermeyecektir.
.Cns bağlantı türünü seçin → Sağ tıklayın → Yeni Veri temeli üzerine tıklayın → Veri temelinin Adını Girin → Sonraki → Tek kaynak / çoklu kaynak → İleri'ye tıklayın → Bitir.

Orta bölmede Şema adı ile HANA veritabanındaki tüm tabloları gösterecektir.
Bir Evren oluşturmak için tüm tabloları HANA veritabanından ana bölmeye aktarın. Şema oluşturmak için Dim tablolarındaki birincil anahtarlarla Dim ve Fact tablolarını birleştirin.
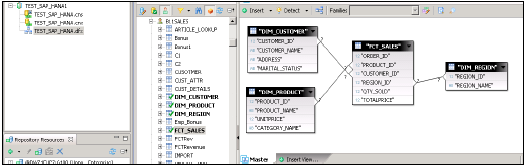
Birleşimler'e çift tıklayın ve Kardinalliği tespit edin → Algıla → Tamam → En üstte Tümünü Kaydet. Şimdi, BI Uygulama araçları tarafından tüketilecek veri temelinde yeni bir İş katmanı oluşturmamız gerekiyor.
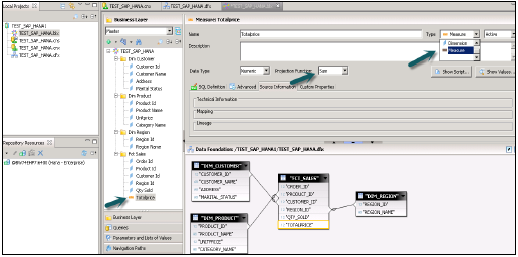
.Dfx'e sağ tıklayın ve yeni İş Katmanı'nı seçin → Ad Girin → Bitir →. Ana bölme altında tüm nesneleri otomatik olarak gösterecektir →. Boyutu Ölçüler olarak Değiştirin (Gerektiği gibi Tür-Ölçü değişikliği Projeksiyonu) → Tümünü Kaydet.
.Bfx dosyasına sağ tıklayın → Yayınla → Depoya tıklayın → İleri → Bitir → Evren Başarıyla Yayınlandı seçeneğine tıklayın.
Şimdi BI Launchpad'den WebI Report'u veya BI Platform istemci araçlarından Webi zengin istemciyi açın → Yeni → Evren → TEST_SAP_HANA → Tamam'ı seçin.
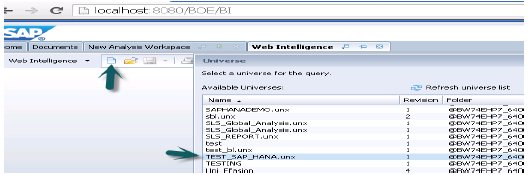
Tüm Nesneler Sorgu Paneline eklenecektir. Sol bölmeden nitelikleri ve hesaplamaları seçebilir ve bunları Sonuç Nesnelerine ekleyebilirsiniz. Run query SQL sorgusunu çalıştıracak ve çıktı aşağıda gösterildiği gibi WebI'de Rapor şeklinde üretilecektir.
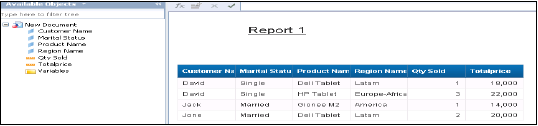
Microsoft Excel, birçok kuruluş tarafından en yaygın BI raporlama ve analiz aracı olarak kabul edilir. İşletme Yöneticileri ve Analistler, analiz için Pivot tabloları ve grafikler çizmek için HANA veritabanına bağlayabilir.
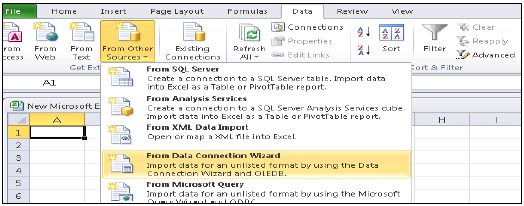
MS Excel'i HANA'ya Bağlama
Excel'i açın ve Veri sekmesine gidin → diğer kaynaklardan → Veri bağlantı sihirbazı → Diğer / Gelişmiş'e tıklayın ve İleri'ye tıklayın → Veri bağlantısı özellikleri açılacaktır.
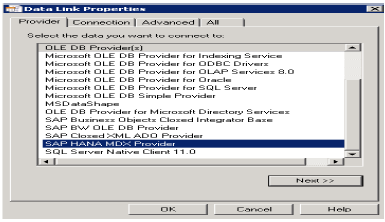
Herhangi bir MDX veri kaynağına bağlanmak için bu listeden SAP HANA MDX Sağlayıcısını seçin → HANA sistem ayrıntılarını girin (sunucu adı, örnek, kullanıcı adı ve şifre) → Test Bağlantısı → Bağlantı başarılı → Tamam'a tıklayın.
HANA sisteminde bulunan açılır listede size tüm paketlerin listesini verecektir. Bir Bilgi görünümü seçebilirsiniz → İleri'ye tıklayın → Pivot tablo / diğerlerini seçin → Tamam.
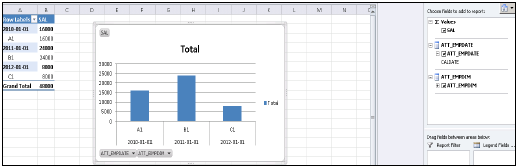
Bilgi görünümündeki tüm öznitelikler MS Excel'e eklenecektir. Gösterildiği gibi raporlamak için farklı öznitelikler ve hesaplamalar seçebilir ve en üstteki tasarım seçeneğinden pasta grafikler ve çubuk grafikler gibi farklı grafikler seçebilirsiniz.
Güvenlik, şirketin kritik verilerini yetkisiz erişim ve kullanımdan korumak ve Şirket politikasına göre Uyum ve standartların karşılanmasını sağlamak anlamına gelir. SAP HANA, müşterinin farklı güvenlik politikaları ve prosedürleri uygulamasını ve şirketin uyumluluk gereksinimlerini karşılamasını sağlar.
SAP HANA, tek bir HANA sisteminde birden çok veritabanını destekler ve bu, çok kiracılı veritabanı kapsayıcıları olarak bilinir. HANA sistemi ayrıca birden fazla çok kiracılı veritabanı kabı içerebilir. Bir çoklu konteyner sistemi her zaman tam olarak bir sistem veritabanına ve herhangi bir sayıda çok kiracılı veritabanı konteynerine sahiptir. Bu ortama kurulan bir SAP HANA sistemi, tek bir sistem kimliği (SID) ile tanımlanır. HANA sistemindeki veritabanı kapsayıcıları bir SID ve veritabanı adı ile tanımlanır. HANA studio olarak bilinen SAP HANA istemcisi, belirli veritabanlarına bağlanır.
SAP HANA, Kimlik Doğrulama, Yetkilendirme, Şifreleme ve Denetim gibi güvenlikle ilgili tüm özellikleri ve diğer çok kullanıcılı veritabanlarında desteklenmeyen bazı ek özellikleri sağlar.
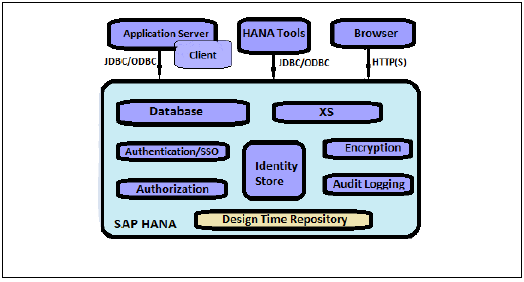
Aşağıda, SAP HANA tarafından sağlanan güvenlikle ilgili özelliklerin bir listesi verilmiştir -
- Kullanıcı ve Rol Yönetimi
- Kimlik Doğrulama ve SSO
- Authorization
- Ağda veri iletişiminin şifrelenmesi
- Kalıcılık Katmanında verilerin şifrelenmesi
Çok kiracılı HANA veritabanındaki Ek Özellikler -
Database Isolation - İşletim sistemi mekanizması aracılığıyla çapraz kiracı saldırılarının önlenmesini içerir
Configuration Change blacklist - Belirli sistem özelliklerinin kiracı veritabanı yöneticileri tarafından değiştirilmesini önlemeyi içerir
Restricted Features - Dosya sistemine, ağa veya diğer kaynaklara doğrudan erişim sağlayan belirli veritabanı özelliklerinin devre dışı bırakılmasını içerir.
SAP HANA Kullanıcı ve Rol Yönetimi
SAP HANA kullanıcı ve rol yönetimi yapılandırması, HANA sisteminizin mimarisine bağlıdır.
SAP HANA, BI platform araçlarıyla entegre edilirse ve raporlama veritabanı görevi görürse, son kullanıcı ve rol uygulama sunucusunda yönetilir.
Son kullanıcı SAP HANA veritabanına doğrudan bağlanırsa, hem son kullanıcılar hem de yöneticiler için HANA sisteminin veritabanı katmanındaki kullanıcı ve rol gereklidir.
HANA veritabanı ile çalışmak isteyen her kullanıcı, gerekli yetkilere sahip bir veritabanı kullanıcısına sahip olmalıdır. HANA sistemine erişen kullanıcı, erişim gereksinimine bağlı olarak teknik kullanıcı veya son kullanıcı olabilir. Sistemde başarılı bir şekilde oturum açıldıktan sonra, kullanıcının gerekli işlemi gerçekleştirme yetkisi doğrulanır. Bu işlemin yürütülmesi, kullanıcıya verilen ayrıcalıklara bağlıdır. Bu ayrıcalıklar, HANA Security içindeki roller kullanılarak verilebilir. HANA Studio, HANA veritabanı sistemi için kullanıcı ve rolleri yönetmek için güçlü araçlardan biridir.
Kullanıcı Türleri
Kullanıcı türleri, güvenlik politikalarına ve kullanıcı profiline atanan farklı ayrıcalıklara göre değişir. Kullanıcı türü, bir teknik veritabanı kullanıcısı olabilir veya son kullanıcının raporlama amacıyla veya veri manipülasyonu için HANA sistemine erişime ihtiyacı olabilir.
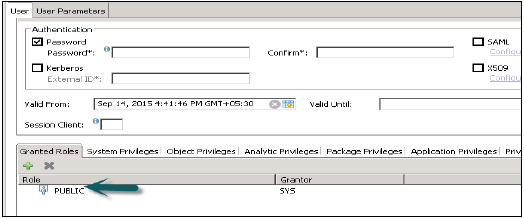
Standart Kullanıcılar
Standart kullanıcılar, kendi Şemalarında nesne oluşturabilen ve sistem Bilgi modellerinde okuma erişimine sahip olan kullanıcılardır. Okuma erişimi, her standart kullanıcıya atanan PUBLIC rolü tarafından sağlanır.
Kısıtlanmış Kullanıcılar
Kısıtlı kullanıcılar, bazı uygulamalarla HANA sistemine erişen ve HANA sisteminde SQL ayrıcalıklarına sahip olmayan kullanıcılardır. Bu kullanıcılar oluşturulduğunda, başlangıçta herhangi bir erişimleri yoktur.
Kısıtlanmış kullanıcıları Standart kullanıcılarla karşılaştırırsak -
Kısıtlanmış kullanıcılar, HANA veritabanında veya kendi Şemalarında nesne oluşturamaz.
Standart kullanıcılar gibi profile eklenmiş genel Genel rolü olmadığından veritabanındaki herhangi bir veriyi görüntüleme erişimine sahip değillerdir.
HANA veritabanına yalnızca HTTP / HTTPS kullanarak bağlanabilirler.
Teknik veri tabanı kullanıcıları sadece veri tabanında yeni nesneler oluşturmak, diğer kullanıcılara ayrıcalıklar atamak, paketler üzerinde, uygulamalar vb. Gibi yönetimsel amaçlarla kullanılmaktadır.
SAP HANA Kullanıcı Yönetimi Faaliyetleri
HANA sisteminin iş ihtiyaçlarına ve konfigürasyonuna bağlı olarak, HANA studio gibi kullanıcı yönetim aracı kullanılarak gerçekleştirilebilecek farklı kullanıcı etkinlikleri vardır.
En yaygın faaliyetler şunları içerir:
- Kullanıcı Oluşturun
- Kullanıcılara rol verin
- Rol Tanımlayın ve Oluşturun
- Kullanıcıları Silme
- Kullanıcı şifrelerinin sıfırlanması
- Çok sayıda başarısız oturum açma girişiminden sonra kullanıcıları yeniden etkinleştirme
- Gerektiğinde kullanıcıların devre dışı bırakılması
HANA Studio'da Kullanıcılar nasıl oluşturulur?
Yalnızca ROLE ADMIN sistem ayrıcalığına sahip veritabanı kullanıcılarının HANA stüdyosunda kullanıcılar ve roller oluşturmasına izin verilir. HANA studio'da kullanıcılar ve roller oluşturmak için HANA Yönetici Konsolu'na gidin. Sistem görünümünde güvenlik sekmesini göreceksiniz -
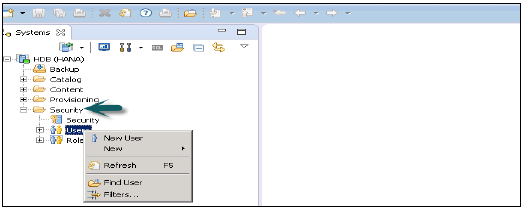
Güvenlik sekmesini genişlettiğinizde Kullanıcı ve Roller seçeneği sunar. Yeni bir kullanıcı oluşturmak için Kullanıcı'ya sağ tıklayın ve Yeni Kullanıcı'ya gidin. Kullanıcı ve Kullanıcı parametrelerini tanımladığınız yerde yeni pencere açılacaktır.
Kullanıcı adını (yetki) girin ve Kimlik Doğrulama alanına şifreyi girin. Yeni bir kullanıcı için şifre kaydedilirken şifre uygulanır. Ayrıca kısıtlı bir kullanıcı oluşturmayı da seçebilirsiniz.
Belirtilen rol adı, mevcut bir kullanıcının veya rolün adıyla aynı olmamalıdır. Parola kuralları, minimum parola uzunluğunu ve hangi karakter türlerinin (alt, üst, rakam, özel karakterler) parolanın parçası olması gerektiğinin bir tanımını içerir.
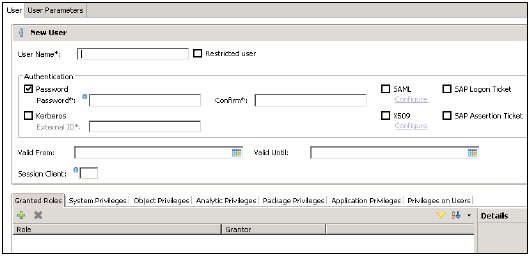
SAML, X509 sertifikaları, SAP Logon bileti vb. Gibi farklı Yetkilendirme yöntemleri yapılandırılabilir. Veritabanındaki kullanıcılar çeşitli mekanizmalarla doğrulanabilir -
Parola kullanan dahili kimlik doğrulama mekanizması.
Kerberos, SAML, SAP Logon Ticket, SAP Assertion Ticket veya X.509 gibi harici mekanizmalar.
Bir kullanıcının kimliği aynı anda birden fazla mekanizma ile doğrulanabilir. Ancak, Kerberos için yalnızca bir parola ve bir asıl ad aynı anda geçerli olabilir. Kullanıcının veritabanı örneğine bağlanmasına ve onunla çalışmasına izin vermek için bir kimlik doğrulama mekanizması belirtilmelidir.
Ayrıca kullanıcının geçerliliğini belirleme seçeneği sunar, tarihleri seçerek geçerlilik aralığından bahsedebilirsiniz. Geçerlilik belirtimi, isteğe bağlı bir kullanıcı parametresidir.
Varsayılan olarak SAP HANA veri tabanı ile teslim edilen bazı kullanıcılar şunlardır: SYS, SYSTEM, _SYS_REPO, _SYS_STATISTICS.
Bu yapıldıktan sonra, sonraki adım kullanıcı profili için ayrıcalıkları tanımlamaktır. Bir kullanıcı profiline eklenebilecek farklı ayrıcalık türleri vardır.
Bir Kullanıcıya Verilen Roller
Bu, kullanıcı profiline dahili SAP.HANA rolleri eklemek veya Roller sekmesi altında oluşturulan özel roller eklemek için kullanılır. Özel roller, erişim gereksinimine göre roller tanımlamanıza olanak tanır ve bu rolleri doğrudan kullanıcı profiline ekleyebilirsiniz. Bu, farklı erişim türleri için her seferinde bir kullanıcı profiline nesne ekleme ve hatırlama ihtiyacını ortadan kaldırır.
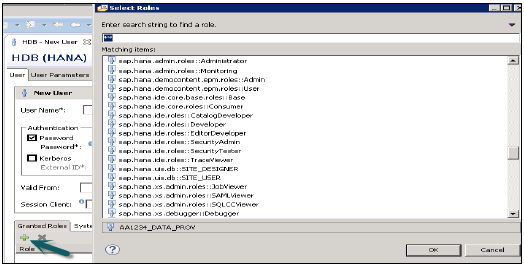
PUBLIC- Bu Genel roldür ve varsayılan olarak tüm veritabanı kullanıcılarına atanır. Bu rol, sistem görünümlerine salt okunur erişimi ve bazı prosedürler için yürütme ayrıcalıklarını içerir. Bu roller geri alınamaz.

Modelleme
SAP HANA stüdyosunda bilgi modelleyiciyi kullanmak için gereken tüm ayrıcalıkları içerir.
Sistem Ayrıcalıkları
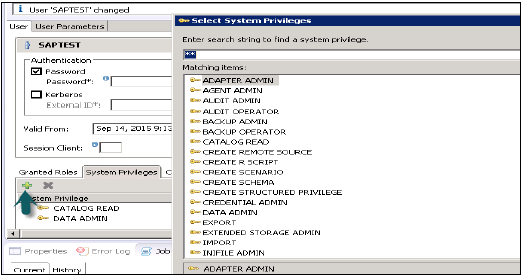
Bir kullanıcı profiline eklenebilecek farklı türde Sistem ayrıcalıkları vardır. Bir kullanıcı profiline sistem ayrıcalıkları eklemek için + işaretine tıklayın.
Sistem ayrıcalıkları Yedekleme / Geri Yükleme, Kullanıcı Yönetimi, Örneği başlatma ve durdurma vb. İçin kullanılır.
İçerik Yöneticisi
MODELLEME rolündeki ile benzer ayrıcalıkları içerir, ancak buna ek olarak, bu rolün diğer kullanıcılara bu ayrıcalıkları vermesine izin verilir. Ayrıca, içe aktarılan nesnelerle çalışmak için depo ayrıcalıklarını içerir.
Veri Yöneticisi
Bu, nesnelerden kullanıcı profiline Veri eklemek için gerekli olan bir ayrıcalık türüdür.
Aşağıda verilen, yaygın olarak desteklenen Sistem Ayrıcalıklarıdır -
Hata Ayıklayıcı Ekle
Farklı bir kullanıcı tarafından çağrılan bir prosedür çağrısının hata ayıklamasına yetki verir. Ek olarak, ilgili yordam için DEBUG ayrıcalığı gereklidir.
Denetim Yöneticisi
Aşağıdaki denetimle ilgili komutların yürütülmesini kontrol eder - DENETİM POLİTİKASI OLUŞTURMA, DROP DENETİM POLİTİKASI ve DEĞİŞTİRME DENETİM POLİTİKASI ve denetim yapılandırmasındaki değişiklikler. Ayrıca AUDIT_LOG sistem görünümüne erişim sağlar.
Denetim Operatörü
Aşağıdaki komutun yürütülmesine izin verir - ALTER SYSTEM CLEAR AUDIT LOG. Ayrıca AUDIT_LOG sistem görünümüne erişim sağlar.
Yedekleme Yöneticisi
Yedekleme ve kurtarma prosedürlerini tanımlamak ve başlatmak için BACKUP ve RECOVERY komutlarını yetkilendirir.
Yedekleme Operatörü
Bir yedekleme işlemini başlatmak için BACKUP komutuna yetki verir.
Kataloğu Oku
Kullanıcılara, tüm sistem görünümlerine filtrelenmemiş salt okunur erişim yetkisi verir. Normalde, bu görünümlerin içeriği, erişen kullanıcının ayrıcalıklarına göre filtrelenir.
Şema Oluştur
CREATE SCHEMA komutunu kullanarak veritabanı şemalarının oluşturulmasına yetki verir. Varsayılan olarak, her kullanıcı bir şemaya sahiptir ve bu ayrıcalıkla kullanıcının ek şemalar oluşturmasına izin verilir.
YAPILANDIRILMIŞ AYRICALIK OLUŞTURUN
Yapılandırılmış Ayrıcalıkların (Analitik Ayrıcalıklar) oluşturulmasına yetki verir. Yalnızca bir Analitik Ayrıcalığın sahibi bu ayrıcalığı diğer kullanıcılara veya rollere daha fazla verebilir veya iptal edebilir.
Kimlik Bilgisi Yöneticisi
Kimlik bilgisi komutlarını yetkilendirir - CREATE / ALTER / DROP CREDENTIAL.
Veri Yöneticisi
Sistem görünümlerindeki tüm verilerin okunmasına izin verir. Ayrıca SAP HANA veritabanındaki herhangi bir Veri Tanımlama Dili (DDL) komutunun yürütülmesini sağlar
Bu ayrıcalığa sahip bir kullanıcı, erişim ayrıcalıklarına sahip olmadıkları veri depolanan tabloları seçemez veya değiştiremez, ancak tabloları bırakabilir veya tablo tanımlarını değiştirebilir.
Veritabanı Yöneticisi
CREATE, DROP, ALTER, RENAME, BACKUP, RECOVERY gibi çoklu veritabanındaki veritabanları ile ilgili tüm komutları yetkilendirir.
İhracat
EXPORT TABLE komutu ile veri tabanındaki ihracat işlemine izin verir.
Bu ayrıcalığın yanı sıra, kullanıcının dışa aktarılması için kaynak tablolarda SELECT ayrıcalığına ihtiyaç duyduğunu unutmayın.
İthalat
İTHALAT komutlarını kullanarak veri tabanındaki içe aktarma etkinliğini yetkilendirir.
Bu ayrıcalığın yanı sıra, kullanıcının içe aktarılacak hedef tablolarda INSERT ayrıcalığına ihtiyaç duyduğunu unutmayın.
Inifile Admin
Sistem ayarlarının değiştirilmesine izin verir.
Lisans Yöneticisi
SET SYSTEM LICENSE komutuna yeni bir lisans yükleme yetkisi verir.
Günlük Yöneticisi
Günlük temizleme mekanizmasını etkinleştirmek veya devre dışı bırakmak için ALTER SYSTEM LOGGING [ON | OFF] komutlarını yetkilendirir.
Yöneticiyi İzle
OLAYLAR için ALTER SYSTEM komutlarını yetkilendirir.
Doktor Yöneticisi
Sorgu iyileştiricisinin davranışını etkileyen SQL PLAN CACHE ve ALTER SYSTEM UPDATE STATISTICS komutlarıyla ilgili ALTER SYSTEM komutlarını yetkilendirir.
Kaynak Yöneticisi
Bu ayrıcalık, sistem kaynaklarıyla ilgili komutlara yetki verir. Örneğin, ALTER SYSTEM RECLAIM DATAVOLUME ve ALTER SYSTEM RESET MONITORING VIEW. Ayrıca, Yönetim Konsolunda bulunan birçok komuta da yetki verir.
Rol Yöneticisi
Bu ayrıcalık, CREATE ROLE ve DROP ROLE komutlarını kullanarak rollerin oluşturulmasına ve silinmesine izin verir. Ayrıca GRANT ve REVOKE komutlarını kullanarak rollerin verilmesi ve iptaline izin verir.
Etkinleştirilmiş roller, yani yaratıcısı önceden tanımlanmış kullanıcı _SYS_REPO olan roller anlamına gelir, başka rollere veya kullanıcılara atanamaz veya doğrudan bırakılamaz. ROLE ADMIN ayrıcalığına sahip kullanıcılar bile bunu yapamaz. Lütfen etkinleştirilen nesnelerle ilgili belgeleri kontrol edin.
Savepoint Yöneticisi
ALTER SYSTEM SAVEPOINT komutunu kullanarak bir kayıt noktası işleminin yürütülmesine izin verir.
SAP HANA veritabanının bileşenleri yeni sistem ayrıcalıkları oluşturabilir. Bu ayrıcalıklar, sistem ayrıcalığının ilk tanımlayıcısı olarak bileşen adını ve ikinci tanımlayıcı olarak bileşen ayrıcalık adını kullanır.
Nesne / SQL Ayrıcalıkları
Nesne ayrıcalıkları, SQL ayrıcalıkları olarak da bilinir. Bu ayrıcalıklar, Tablolar, Görünümler veya Şemalar Seçme, Ekleme, Güncelleme ve Silme gibi nesnelere erişim sağlamak için kullanılır.
Aşağıda, olası Nesne Ayrıcalıklarının türleri verilmiştir -
Yalnızca çalışma zamanında var olan veritabanı nesnelerinde nesne ayrıcalığı
Hesaplama görünümleri gibi bilgi havuzunda oluşturulan etkin nesnelerde nesne ayrıcalığı
Depoda oluşturulan aktif nesneleri içeren şema üzerinde nesne ayrıcalığı,
Nesne / SQL Ayrıcalıkları, veritabanı nesnelerindeki tüm DDL ve DML ayrıcalıklarının koleksiyonudur.
Aşağıda verilen, yaygın olarak desteklenen Nesne Ayrıcalıklarıdır -
HANA veritabanında birden fazla veritabanı nesnesi vardır, bu nedenle tüm ayrıcalıklar tüm veritabanı nesneleri için geçerli değildir.
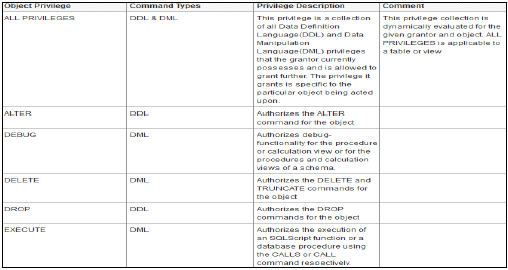
Nesne Ayrıcalıkları ve bunların veritabanı nesnelerine uygulanabilirliği -
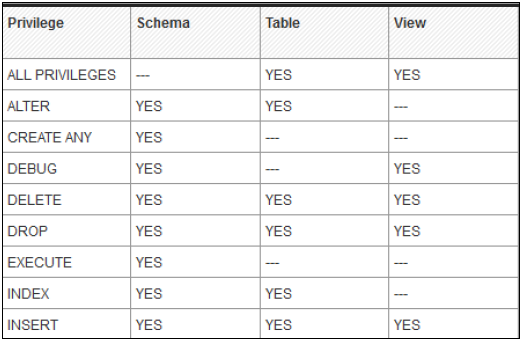
Analitik Ayrıcalıklar
Bazen, aynı görünümdeki verilere, söz konusu veriler için herhangi bir ilgili gereksinimi olmayan diğer kullanıcılar tarafından erişilebilir olmaması gerekir.
HANA Bilgi Görünümlerine erişimi nesne düzeyinde sınırlamak için analitik ayrıcalıklar kullanılır. Analitik Ayrıcalıklarda satır ve sütun düzeyinde güvenlik uygulayabiliriz.
Analitik Ayrıcalıklar aşağıdakiler için kullanılır:
- Belirli bir değer aralığı için satır ve sütun düzeyinde güvenlik tahsisi.
- Görünümleri modellemek için satır ve sütun düzeyinde güvenlik tahsisi.
Paket Ayrıcalıkları
SAP HANA havuzunda, belirli bir kullanıcı veya bir rol için paket yetkilerini ayarlayabilirsiniz. Paket ayrıcalıkları, veri modellerine - Analitik veya Hesaplama görünümlerine veya Depo nesnelerine erişim sağlamak için kullanılır. Bir havuz paketine atanan tüm ayrıcalıklar, tüm alt paketlere de atanır. Ayrıca, atanan kullanıcı yetkilerinin diğer kullanıcılara aktarılıp aktarılamayacağını da belirtebilirsiniz.
Kullanıcı profiline paket ayrıcalıkları ekleme adımları -
Bir veya daha fazla paket eklemek için HANA stüdyosunda Kullanıcı oluşturma → + öğesini seçin altında Paket ayrıcalığı sekmesine tıklayın. Birden çok paket seçmek için Ctrl tuşunu kullanın.
Depo Paketi Seç iletişim kutusunda, erişim yetkisi vermek istediğiniz depo paketini bulmak için paket adının tamamını veya bir kısmını kullanın.
Erişim yetkisi vermek istediğiniz bir veya daha fazla depo paketini seçin, seçilen paketler Paket Ayrıcalıkları sekmesinde görünür.
Aşağıda, kullanıcıya nesneleri değiştirme yetkisi vermek için depo paketlerinde kullanılan izin ayrıcalıkları verilmiştir -
REPO.READ - Seçilen pakete ve tasarım zamanı nesnelerine (hem yerel hem de içe aktarılmış) okuma erişimi
REPO.EDIT_NATIVE_OBJECTS - Paketlerdeki nesneleri değiştirme yetkisi.
Grantable to Others - Bunun için 'Evet'i seçerseniz, bu, atanan kullanıcı yetkisinin diğer kullanıcılara geçmesine izin verir.
Uygulama Ayrıcalıkları
Bir kullanıcı profilindeki uygulama ayrıcalıkları, HANA XS uygulamasına erişim yetkisini tanımlamak için kullanılır. Bu, bireysel bir kullanıcıya veya kullanıcı grubuna atanabilir. Veritabanı yöneticileri için gelişmiş işlevler ve normal kullanıcılara salt okunur erişim sağlamak gibi aynı uygulamaya farklı erişim düzeyleri sağlamak için uygulama ayrıcalıkları da kullanılabilir.
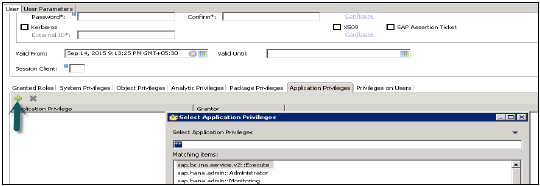
Bir kullanıcı profilinde Uygulamaya özel ayrıcalıkları tanımlamak veya kullanıcı grubu eklemek için aşağıdaki ayrıcalıklar kullanılmalıdır -
- Uygulama ayrıcalıkları dosyası (.xsprivileges)
- Uygulama erişim dosyası (.xsaccess)
- Rol tanım dosyası (<RoleName> .hdbrole)
HANA veri tabanına erişimi olan tüm SAP HANA kullanıcıları, farklı Kimlik Doğrulama yöntemiyle doğrulanır. SAP HANA sistemi, çeşitli kimlik doğrulama yöntemlerini destekler ve tüm bu oturum açma yöntemleri, profil oluşturma sırasında yapılandırılır.
SAP HANA tarafından desteklenen kimlik doğrulama yöntemlerinin listesi aşağıdadır -
- Kullanıcı adı Şifre
- Kerberos
- SAML 2.0
- SAP Logon biletleri
- X.509
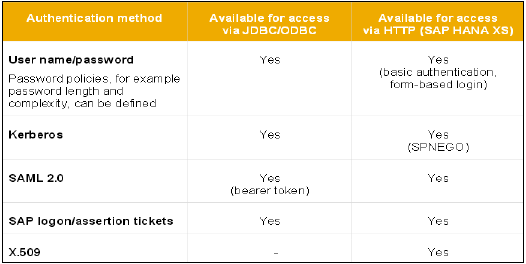
Kullanıcı adı Şifre
Bu yöntem, bir HANA kullanıcısının veritabanında oturum açmak için kullanıcı adı ve şifre girmesini gerektirir. Bu kullanıcı profili, HANA Studio → Güvenlik Sekmesinde Kullanıcı yönetimi altında oluşturulur.
Parola, parola politikasına göre olmalıdır, yani Parola uzunluğu, karmaşıklığı, küçük ve büyük harfler vb.
Parola politikasını kuruluşunuzun güvenlik standartlarına göre değiştirebilirsiniz. Lütfen parola politikasının devre dışı bırakılamayacağını unutmayın.
Kerberos
Harici bir kimlik doğrulama yöntemi kullanarak HANA veritabanı sistemine bağlanan tüm kullanıcıların ayrıca bir veritabanı kullanıcısı olmalıdır. Harici girişi dahili veritabanı kullanıcısıyla eşleştirmek gerekir.
Bu yöntem, kullanıcıların HANA sistemini doğrudan ağ üzerinden JDBC / ODBC sürücülerini kullanarak veya SAP Business Objects'teki ön uç uygulamaları kullanarak doğrulamasını sağlar.
Ayrıca HANA XS motorunu kullanarak HANA Genişletilmiş Hizmette HTTP erişimine izin verir. Kerberos kimlik doğrulaması için SPENGO mekanizmasını kullanır.
SAML
SAML, Güvenlik Onaylama Biçimlendirme Dili anlamına gelir ve HANA sistemine doğrudan ODBC / JDBC istemcilerinden erişen kullanıcıların kimliğini doğrulamak için kullanılabilir. HANA XS motoru aracılığıyla HTTP aracılığıyla gelen HANA sistemindeki kullanıcıların kimliklerini doğrulamak için de kullanılabilir.
SAML yalnızca kimlik doğrulama amacıyla kullanılır, yetkilendirme için kullanılmaz.
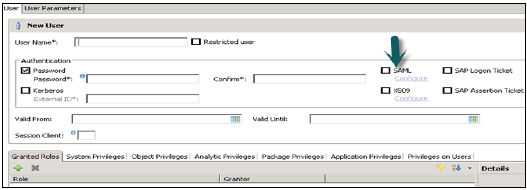
SAP Oturum Açma ve Onaylama Biletleri
SAP Logon / assertion biletleri, HANA sistemindeki kullanıcıların kimliğini doğrulamak için kullanılabilir. Bu biletler, kullanıcılara SAP Portal vb. Gibi biletleri düzenleyecek şekilde yapılandırılan SAP sisteminde oturum açtıklarında verilir. SAP oturum açma biletlerinde belirtilen kullanıcı, haritalama kullanıcıları için destek sağlamadığından HANA sisteminde oluşturulmalıdır.
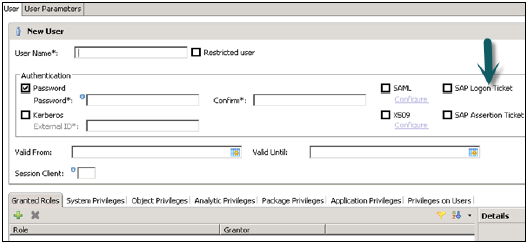
X.509 İstemci Sertifikaları
X.509 sertifikaları, HANA XS motorundan HTTP erişim talebi ile HANA sistemine giriş yapmak için de kullanılabilir. Kullanıcılar, HANA XS sisteminde depolanan güvenilir Sertifika Yetkilisinden imzalanmış sertifikalarla doğrulanır.
Güvenilir sertifikadaki kullanıcı, kullanıcı eşleştirme desteği olmadığından HANA sisteminde bulunmalıdır.
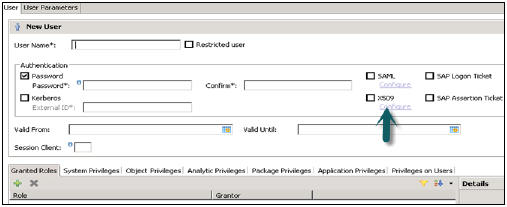
HANA sisteminde Tek Oturum Açma
Tek oturum açma, kullanıcıların istemcideki ilk kimlik doğrulamasından HANA sistemine oturum açmasına olanak tanıyan HANA sisteminde yapılandırılabilir. İstemci uygulamalarında farklı kimlik doğrulama yöntemleri ve SSO kullanan kullanıcı oturumları, kullanıcının HANA sistemine doğrudan erişmesine olanak tanır.
SSO, aşağıdaki yapılandırma yöntemlerinde yapılandırılabilir -
- SAML
- Kerberos
- HANA XS motorundan HTTP erişimi için X.509 istemci sertifikaları
- SAP Logon / Assertion biletleri
Bir kullanıcı HANA veritabanına bağlanmaya ve bazı veritabanı işlemlerini gerçekleştirmeye çalıştığında yetkilendirme kontrol edilir. Bir kullanıcı, veritabanı nesneleri üzerinde bazı işlemleri gerçekleştirmek için JDBC / ODBC veya Via HTTP aracılığıyla istemci araçlarını kullanarak HANA veritabanına bağlandığında, ilgili eylem kullanıcıya verilen erişim tarafından belirlenir.
Bir kullanıcıya verilen ayrıcalıklar, kullanıcıya verilen kullanıcı profiline veya rolüne atanan Nesne ayrıcalıklarına göre belirlenir. Yetkilendirme, her iki erişimin birleşimidir. Bir kullanıcı HANA veri tabanında bir işlem yapmaya çalıştığında, sistem bir yetkilendirme kontrolü gerçekleştirir. Gerekli tüm ayrıcalıklar bulunduğunda, sistem bu kontrolü durdurur ve istenen erişimi verir.
SAP HANA'da Kullanıcı rolü ve Yönetim altında belirtildiği gibi kullanılan farklı ayrıcalık türleri vardır -
Sistem Ayrıcalıkları
Kullanıcılar için sistem ve veritabanı yetkilendirmesi ve kontrol sistemi faaliyetleri için geçerlidir. Şema oluşturma, veri yedeklemeleri, kullanıcılar ve roller oluşturma gibi yönetim görevleri için kullanılırlar. Depo işlemlerini gerçekleştirmek için sistem ayrıcalıkları da kullanılır.
Nesne Ayrıcalıkları
Veritabanı işlemlerine uygulanabilir ve tablolar, Şemalar vb. Gibi veritabanı nesnelerine uygulanırlar. Tablolar ve görünümler gibi veritabanı nesnelerini yönetmek için kullanılırlar. Veritabanı nesnelerine göre Seç, Yürüt, Değiştir, Bırak, Sil gibi farklı eylemler tanımlanabilir.
Ayrıca, SAP HANA'ya SMART veri erişimi aracılığıyla bağlanan uzak veri nesnelerini kontrol etmek için de kullanılırlar.
Analitik Ayrıcalıklar
HANA deposunda oluşturulan tüm paketlerin içindeki veriler için geçerlidir. Öznitelik Görünümü, Analitik Görünüm ve Hesaplama Görünümü gibi paketlerin içinde oluşturulan modelleme görünümlerini kontrol etmek için kullanılırlar. HANA paketlerindeki modelleme görünümlerinde tanımlanan özniteliklere satır ve sütun düzeyinde güvenlik uygularlar.
Paket Ayrıcalıkları
HANA veritabanı havuzunda oluşturulan paketlere erişime ve bunları kullanma becerisine izin vermek için geçerlidirler. Paket, Öznitelik, Analitik ve Hesaplama görünümleri gibi farklı Modelleme görünümlerini ve ayrıca HANA veri havuzu veritabanında tanımlanan Analitik Ayrıcalıkları içerir.
Uygulama Ayrıcalıkları
HANA veritabanına HTTP isteği aracılığıyla erişen HANA XS uygulaması için geçerlidir. HANA XS motoru ile oluşturulan uygulamalara erişimi kontrol etmek için kullanılırlar.
Uygulama Ayrıcalıkları, HANA studio kullanılarak kullanıcılara / rollere doğrudan uygulanabilir ancak tasarım zamanında depoda oluşturulan rollere uygulanması tercih edilir.
SAP HANA Veritabanında Depo Yetkilendirmesi
_SYS_REPO, kullanıcının HANA deposundaki tüm nesnelerin sahibidir. HANA sisteminde depo nesnelerinin modellendiği nesneler için bu kullanıcı harici olarak yetkilendirilmelidir. _SYS_REPO tüm nesnelerin sahibidir, bu nedenle yalnızca bu nesnelere erişim sağlamak için kullanılabilir, başka hiçbir kullanıcı _SYS_REPO kullanıcısı olarak oturum açamaz.
GRANT SELECT ON SCHEMA "<SCHEMA_NAME>" TO _SYS_REPO WITH GRANT OPTION
HANA veritabanını kullanmak için SAP HANA Lisans yönetimi ve anahtarları gerekir. HANA Studio kullanarak HANA Lisans anahtarlarını yükleyebilir veya silebilirsiniz.
Lisans anahtarı türleri
SAP HANA sistemi iki tür Lisans anahtarını destekler -
Temporary License Key- Geçici Lisans anahtarları, HANA veritabanını kurduğunuzda otomatik olarak yüklenir. Bu anahtarlar yalnızca 90 gün için geçerlidir ve kurulumdan sonraki bu 90 günlük sürenin dolmasından önce SAP pazarından kalıcı lisans anahtarları talep etmelisiniz.
Permanent License Key- Kalıcı Lisans anahtarları yalnızca önceden tanımlanan sona erme tarihine kadar geçerlidir. Lisans anahtarları, HANA kurulumunu hedeflemek için lisanslanan bellek miktarını belirtir. SAP Marketplace'ten Anahtarlar ve İstekler sekmesinden kurulabilirler. Kalıcı bir Lisans anahtarının süresi dolduğunda, yalnızca 28 gün geçerli olan geçici bir lisans anahtarı verilir. Bu süre zarfında, kalıcı bir Lisans anahtarı tekrar yüklemeniz gerekir.
HANA sistemi için iki tür kalıcı Lisans anahtarı vardır -
Unenforced - Zorunlu olmayan lisans anahtarı yüklenirse ve HANA sisteminin kullanımı bellek lisans miktarını aşarsa, bu durumda SAP HANA'nın çalışması etkilenmez.
Enforced- Zorunlu lisans anahtarı takılırsa ve HANA sisteminin tüketimi bellek lisans miktarını aşarsa, HANA sistemi kilitlenir. Bu durum ortaya çıkarsa, HANA sistemi yeniden başlatılmalı veya yeni bir lisans anahtarı istenip kurulmalıdır.
Sistemin yapısına bağlı olarak HANA sisteminde kullanılabilecek farklı Lisans senaryoları vardır (Bağımsız, HANA Cloud, HANA üzerinde BW, vb.) Ve bu modellerin tümü HANA sistem kurulumunun belleğine dayalı değildir.
HANA'nın Lisans Özellikleri Nasıl Kontrol Edilir
HANA sistemine sağ tıklayın → Özellikler → Lisans
Lisans türü, Başlangıç Tarihi ve Son Kullanma Tarihi, Bellek Tahsisi ve SAP Market Place aracılığıyla yeni bir lisans talep etmek için gereken bilgileri (Donanım Anahtarı, Sistem Kimliği) anlatır.
Lisans anahtarını yükle → Gözat → Yol Gir, yeni bir Lisans anahtarı yüklemek için kullanılır ve silme seçeneği herhangi bir eski sona erme anahtarını silmek için kullanılır.
Lisans altındaki Tüm Lisanslar sekmesi, Ürün adı, açıklaması, Donanım anahtarı, İlk kurulum zamanı vb. Hakkında bilgi verir.
SAP HANA denetim politikası, denetlenecek eylemleri ve ayrıca denetimle ilgili olması için eylemin hangi koşullar altında gerçekleştirilmesi gerektiğini söyler. Denetim Politikası, HANA sisteminde hangi faaliyetlerin gerçekleştirildiğini ve bu faaliyetleri kimin ne zaman gerçekleştirdiğini tanımlar.
SAP HANA veritabanı denetim özelliği, HANA sisteminde gerçekleştirilen izleme eylemine izin verir. SAP HANA denetim politikası, kullanmak için HANA sisteminde etkinleştirilmelidir. Bir eylem gerçekleştirildiğinde, politika, denetim izine yazmak için bir denetim olayını tetikler. Denetim takibinde de denetim girdilerini silebilirsiniz.
Birden fazla veritabanınızın olduğu dağıtılmış bir ortamda, Denetim ilkesi her bir sistemde etkinleştirilebilir. Sistem veritabanı için denetim politikası nameserver.ini dosyasında, kiracı veritabanı için ise global.ini dosyasında tanımlanır.
Bir Denetim Politikasının Etkinleştirilmesi
HANA sisteminde Denetim politikasını tanımlamak için, sistem ayrıcalığına sahip olmalısınız - Denetim Yöneticisi.
HANA sisteminde Güvenlik seçeneğine gidin → Denetim
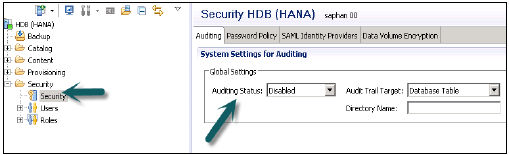
Global Ayarlar altında → Denetim durumunu etkin olarak ayarlayın.
Denetim izi hedeflerini de seçebilirsiniz. Aşağıdaki denetim izi hedefleri mümkündür -
Syslog (varsayılan) - Linux İşletim Sisteminin günlük kaydı sistemi.
Database Table - Dahili veritabanı tablosu, Audit admin veya Audit operatörü sistem ayrıcalığına sahip kullanıcı, bu tabloda sadece seçme işlemini çalıştırabilir.
CSV text - Bu tür denetim izi, yalnızca üretim dışı bir ortamda test amacıyla kullanılır.
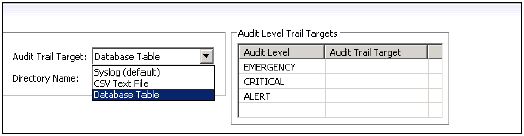
Ayrıca Denetim Politikaları alanında yeni bir Denetim politikası oluşturabilirsiniz → Yeni Politika Oluştur'u seçin. Politika adını ve denetlenecek eylemleri girin.
Dağıt düğmesini kullanarak yeni politikayı kaydedin. Yeni bir ilke otomatik olarak etkinleştirilir, bir eylem koşulu karşılandığında, Denetim izi tablosunda bir denetim girişi oluşturulur. Devre dışı bırakmak için durumu değiştirerek bir politikayı devre dışı bırakabilir veya politikayı da silebilirsiniz.
SAP HANA Replication, verilerin kaynak sistemlerden SAP HANA veritabanına taşınmasına izin verir. Verileri mevcut SAP sisteminden HANA'ya taşımanın basit yolu, çeşitli veri çoğaltma tekniklerini kullanmaktır.
Sistem replikasyonu, komut satırı üzerinden veya HANA studio kullanılarak konsolda kurulabilir. Birincil ECC veya işlem sistemleri bu işlem sırasında çevrimiçi kalabilir. HANA sisteminde üç tür veri çoğaltma yöntemimiz var -
- SAP LT Çoğaltma yöntemi
- ETL aracı SAP Business Object Data Service (BODS) yöntemi
- Direct Extractor bağlantı yöntemi (DXC)
SAP LT Çoğaltma Yöntemi
SAP Landscape Transformation Replication, HANA sisteminde tetik tabanlı bir veri replikasyon yöntemidir. SAP ve SAP dışı kaynaklardan gerçek zamanlı verileri veya program tabanlı replikasyonu kopyalamak için mükemmel bir çözümdür. Tüm tetikleme talepleriyle ilgilenen SAP LT Replication sunucusuna sahiptir. Çoğaltma sunucusu bağımsız bir sunucu olarak kurulabilir veya SAP NW 7.02 veya üzeri ile herhangi bir SAP sisteminde çalıştırılabilir.
HANA DB ile ECC işlem sistemi arasında, HANA sistem ortamında tetik tabanlı veri replikasyonunu mümkün kılan Güvenilir RFC bağlantısı vardır.

SLT Çoğaltmanın Avantajları
SLT Replikasyon yöntemi, birden çok kaynak sisteminden tek bir HANA sistemine ve ayrıca tek kaynak sistemden birden çok HANA sistemine veri replikasyonuna izin verir.
SAP LT, tetikleyici tabanlı yaklaşım kullanır. Kaynak sistemde ölçülebilir bir performans etkisi yoktur.
Ayrıca HANA veritabanına yüklenmeden önce veri dönüştürme ve filtreleme yeteneği sağlar.
SAP ve SAP dışı kaynak sistemlerden yalnızca ilgili verileri HANA'ya kopyalayarak gerçek zamanlı veri replikasyonuna izin verir.
HANA Sistemi ve HANA stüdyosu ile tam entegredir.
ECC sisteminde Güvenilir bir RFC Bağlantısı Oluşturma
Kaynak SAP sisteminiz AA1'de, hedef sistem BB1'e yönelik güvenilir bir RFC kurmak istiyorsunuz. Tamamlandığında, AA1'de oturum açtığınızda ve kullanıcınız BB1'de yeterli yetkiye sahip olduğunda, kullanıcı ve parolayı yeniden girmek zorunda kalmadan RFC bağlantısını kullanabilir ve BB1'de oturum açabilirsiniz.
İki SAP sistemi arasındaki RFC güvenilen / güvenen ilişkisini kullanarak, güvenilir bir sistemden güvenen bir sisteme RFC, güvenen sistemde oturum açmak için parola gerekmez.
SAP oturum açmayı kullanarak SAP ECC sistemini açın. Sm59 işlem numarasını girin → bu yeni bir Güvenilir RFC bağlantısı oluşturmak için işlem numarasıdır → Yeni bir bağlantı sihirbazı açmak için 3. simgeye tıklayın → Oluştur'a tıklayın ve yeni pencere açılacaktır.
RFC Hedefi ECCHANA (RFC hedefinin adını girin) Bağlantı Türü - 3 (ABAP sistemi için)
Teknik Ayarlara Git
Hedef ana bilgisayar - ECC sistem adı, IP ve Sistem numarasını girin.
Oturum Açma ve Güvenlik sekmesine, Dil Gir, İstemci, ECC sistem kullanıcı adı ve parolasına gidin.
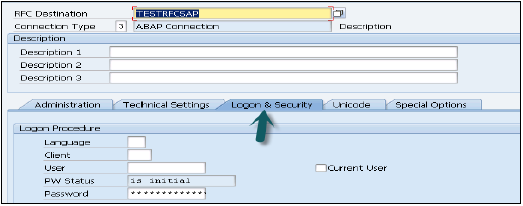
En üstteki Kaydet seçeneğine tıklayın.

Bağlantıyı Test Et'e tıklayın ve bağlantıyı başarıyla test edecektir.
RFC bağlantısını yapılandırmak için
İşlemi çalıştır - ltr (RFC bağlantısını yapılandırmak için) → Yeni tarayıcı açılacaktır → ECC sistem kullanıcı adını ve şifresini girin ve oturum açın.

Yeni → Yeni Pencere açılacaktır → Konfigürasyon adını girin → İleri'ye tıklayın → RFC Hedefini Gir (daha önce oluşturulmuş bağlantı adı), Arama seçeneğini kullanın, adı seçin ve ileriye tıklayın.
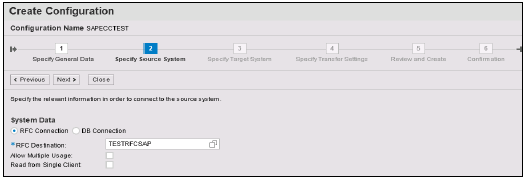
Hedef sistemi Belirt bölümünde, HANA sistem yöneticisi kullanıcı adı ve şifresini, ana bilgisayar adını, Örnek numarasını girin ve ileriyi tıklayın. 007 gibi Veri aktarım işi sayısını girin (000 olamaz) → Sonraki → Yapılandırma Oluştur.
Şimdi bu bağlantıyı kullanmak için HANA Studio'ya gidin -
HANA Studio'ya gidin → Veri Sağlama'ya tıklayın → HANA sistemini seçin
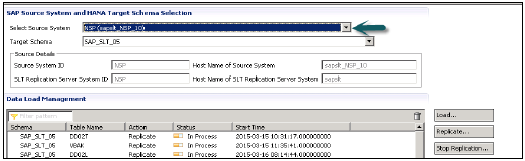
ECC sisteminden tabloları yüklemek istediğiniz kaynak sistemi (güvenilir RFC bağlantısının adı) ve hedef şema adını seçin. HANA veritabanına taşımak istediğiniz tabloları seçin → EKLE → Bitir.

Seçilen tablolar HANA veri tabanı altında seçilen şemaya taşınacaktır.
SAP HANA ETL tabanlı replikasyon, verileri SAP veya SAP dışı kaynak sistemden hedef HANA veritabanına geçirmek için SAP Data Services kullanır. BODS sistemi, verileri kaynak sistemden hedef sisteme çıkarmak, dönüştürmek ve yüklemek için kullanılan bir ETL aracıdır.
İş verilerinin Uygulama katmanında okunmasını sağlar. Veri Hizmetlerinde veri akışlarını tanımlamanız, bir çoğaltma işi planlamanız ve Veri Hizmetleri tasarımcısındaki veri deposunda kaynak ve hedef sistemi tanımlamanız gerekir.
SAP HANA Data Services ETL tabanlı Replication nasıl kullanılır?
Veri Hizmetleri Tasarımcısı'nda oturum açın (Depo seçin) → Veri deposu oluştur
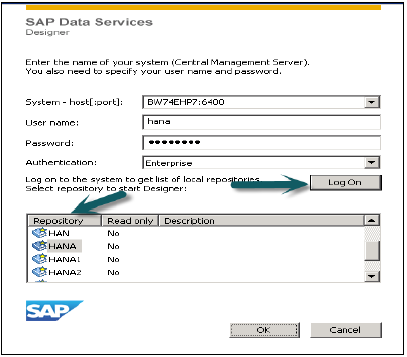
SAP ECC sistemi için SAP Uygulamaları olarak veritabanını seçin, ECC sunucu adı, ECC sistemi için kullanıcı adı ve şifre girin, Gelişmiş sekmesi örnek numarası, müşteri numarası vb. Ayrıntıları seçin ve uygulayın.
Bu veri deposu yerel nesne kitaplığı altına gelir, eğer bunu genişletirseniz içinde tablo yoktur.
Tablo → Ada göre içe aktar'a sağ tıklayın → ECC sisteminden içe aktarmak için ECC tablosunu girin (MARA, ECC sisteminde varsayılan tablodur) → İçe aktar → Şimdi Tabloyu genişletin → MARA → Verileri Görüntüle'ye Sağ Tıklayın. Veri görüntüleniyorsa, Veri deposu bağlantısı iyidir.
Şimdi hedef sistemi HANA veritabanı olarak seçmek için yeni bir veri deposu oluşturun. Veri deposu oluştur → Veri deposu adı SAP_HANA_TEST → Veri deposu türü (veritabanı) → Veritabanı türü SAP HANA → Veritabanı sürümü HANA 1.x.
HANA sistemi için HANA sunucu adını, kullanıcı adını ve şifresini girin ve Tamam.
Bu veri deposu Yerel Nesne Kitaplığına eklenecektir. Verileri kaynak tablodan HANA veritabanındaki belirli bir tabloya taşımak istiyorsanız tablo ekleyebilirsiniz. Hedef tablonun kaynak tablo ile benzer veri türünde olması gerektiğini unutmayın.
Bir Çoğaltma İşi Oluşturma
Yeni bir Proje Oluşturun → Proje Adı Girin → Proje adına Sağ tıklayın → Yeni Toplu İş → İş adını girin.
Sağ taraftaki sekmeden, iş akışını seçin → İş akışı adını girin → Toplu iş altına eklemek için çift tıklayın → Veri akışını girin → Veri akışı adını girin → Üstteki Proje alanında Tümünü kaydet seçeneğini toplu iş altına eklemek için çift tıklayın.

Tabloyu First Data Store ECC'den (MARA) çalışma alanına sürükleyin. HANA DB'de benzer veri türlerine sahip yeni tablo oluşturmak için onu seçin ve sağ tıklayın → Yeni ekle → Şablon tablosu → Tablo adı girin, Veri deposu ECC_HANA_TEST2 → Sahip adı (şema adı) → Tamam
Tabloyu öne sürükleyin ve her iki tabloyu bağlayın → tümünü kaydedin. Şimdi toplu işe git → Sağ Tıkla → Yürüt → Evet → Tamam
Çoğaltma işini yürüttüğünüzde, işin başarıyla tamamlandığına dair bir onay alacaksınız.
HANA studio → Şemayı Genişlet → Tablolar → Verileri doğrula seçeneğine gidin. Bu, bir toplu işin manuel olarak yürütülmesidir.
Toplu İşin Planlanması
Ayrıca Veri Hizmetleri Yönetimi konsoluna giderek bir toplu iş planlayabilirsiniz. Veri Hizmetleri Yönetim Konsolunda oturum açın.
Sol taraftan depoyu seçin → İşlerin listesini göreceğiniz 'Toplu İş Yapılandırması' sekmesine gidin → Planlamak istediğiniz işe karşı → zamanlama ekle'ye tıklayın → 'Zamanlama adı'nı girin ve aşağıdaki gibi parametreleri ayarlayın ( uygun olduğu şekilde saat, tarih, tekrarlayan vb.) ve 'Uygula'yı tıklayın.
Bu aynı zamanda HANA sisteminde Sybase Replication olarak da bilinir. Bu replikasyon yönteminin ana bileşenleri, SAP kaynak uygulama sisteminin bir parçası olan Sybase Replication Agent, Replication Agent ve SAP HANA sisteminde uygulanacak Sybase Replication Server'dır.
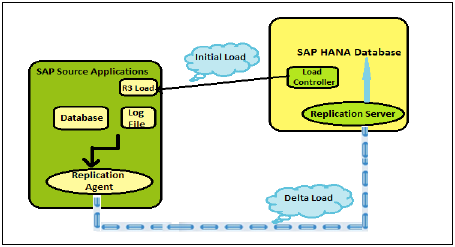
Sybase Replication yönteminde İlk Yükleme, SAP HANA'da Yük Denetleyicisi tarafından başlatılır ve yönetici tarafından tetiklenir. İlk yükü HANA veri tabanına aktarması için R3 Yükünü bilgilendirir. Kaynak sistemdeki R3 yükü, kaynak sistemdeki seçili tablolar için verileri dışa aktarır ve bu verileri HANA sistemindeki R3 yük bileşenlerine aktarır. Hedef sistemdeki R3 yükü, verileri SAP HANA veritabanına aktarır.
SAP Host aracısı, kaynak sistemin bir parçası olan kaynak sistem ile hedef sistem arasındaki kimlik doğrulamasını yönetir. Sybase Replication aracı, ilk yükleme sırasında herhangi bir veri değişikliğini tespit eder ve her değişikliğin tamamlanmasını sağlar. Kaynak sistemdeki bir tablonun girişlerinde değişiklik, güncelleme ve silme olduğunda, bir tablo günlüğü oluşturulur. Bu tablo günlüğü, verileri kaynak sistemden HANA veritabanına taşır.
İlk Yüklemeden Sonra Delta Replikasyonu
Delta çoğaltma, ilk yükleme ve çoğaltma tamamlandıktan sonra kaynak sistemdeki veri değişikliklerini gerçek zamanlı olarak yakalar. Kaynak sistemdeki diğer tüm değişiklikler, yukarıda belirtilen yöntem kullanılarak kaynak sistemden HANA veri tabanına yakalanır ve kopyalanır.
Bu yöntem, SAP HANA replikasyonu için ilk teklifin bir parçasıydı, ancak lisans sorunları ve karmaşıklığı nedeniyle artık konumlandırılmıyor / desteklenmiyor ve ayrıca SLT aynı özellikleri sağlıyor.
Note - Bu yöntem yalnızca veri kaynağı olarak SAP ERP sistemini ve veritabanı olarak DB2'yi destekler.
Direct Extractor Connection veri çoğaltma, SAP HANA'ya basit bir HTTP (S) bağlantısı aracılığıyla SAP Business Suite sistemlerinde yerleşik olan mevcut çıkarma, dönüştürme ve yükleme mekanizmasını yeniden kullanır. Toplu işlem odaklı bir veri çoğaltma tekniğidir. Veri çıkarma için sınırlı yeteneklere sahip çıkarma, dönüştürme ve yükleme yöntemi olarak kabul edilir.
DXC, toplu olarak yürütülen bir işlemdir ve DXC'yi belirli aralıklarla kullanarak veri çıkarma çoğu durumda yeterlidir. Toplu iş örneğin yürütüldüğünde bir aralık ayarlayabilirsiniz: her 20 dakikada bir ve çoğu durumda bu toplu işleri kullanarak belirli zaman aralıklarında veri çıkarmak yeterlidir.
DXC Veri Çoğaltmanın Avantajları
Bu yöntem, SAP HANA sistem ortamında hiçbir ek sunucu veya uygulama gerektirmez.
DXC yöntemi, Kaynak Sistemdeki tüm iş çıkarıcı mantıklarını uyguladıktan sonra veriler HANA'ya gönderildiği için SAP HANA'daki veri modellemenin karmaşıklığını azaltır.
SAP HANA uygulama projesi için zaman çizelgelerini hızlandırır
SAP Business Suite'ten SAP HANA'ya semantik olarak zengin veriler sağlar
SAP HANA'ya basit bir HTTP (S) bağlantısı üzerinden SAP Business Suite sistemlerinde yerleşik olan mevcut tescilli çıkarma, dönüştürme ve yükleme mekanizmasını yeniden kullanır.
DXC Veri Çoğaltmanın Sınırlamaları
Veri Kaynağı çıkarma, dönüştürme ve yükleme için önceden tanımlanmış bir mekanizmaya sahip olmalıdır ve yoksa bir tane tanımlamamız gerekir.
En azından SP'nin altında olan Net Weaver 7.0 veya üzeri tabanlı bir Business Suite Sistemi gerektirir: Sürüm 700 SAPKW70021 (Kasım 2008'den itibaren SP yığını 19).
DXC Veri Çoğaltmayı Yapılandırma
Enabling XS Engine service in Configuration tab in HANA Studio- Sistemin HANA stüdyosunda Yönetici sekmesine gidin. Configuration → xsengine.ini'ye gidin ve örnek değerini 1 olarak ayarlayın.
Enabling ICM Web Dispatcher service in HANA Studio - Yapılandırma → webdispatcher.ini'ye gidin ve örnek değerini 1 olarak ayarlayın.
HANA sisteminde ICM Web Dispatcher hizmetini etkinleştirir. Web dağıtıcısı, HANA sisteminde veri okumak ve yüklemek için ICM yöntemini kullanır.
Setup SAP HANA Direct Extractor Connection- DXC teslimat birimini SAP HANA'ya indirin. Birimi / usr / sap / HDB / SYS / global / hdb / content konumuna içe aktarabilirsiniz.
SAP HANA Content Node'da Import Dialog'u kullanarak birimi içe aktarın → XS Uygulama sunucusunu DXC'yi kullanmak için yapılandırın → application_container değerini libxsdxc olarak değiştirin
Creating a HTTP connection in SAP BW - Şimdi, SM59 işlem kodunu kullanarak SAP BW'de http bağlantısı oluşturmamız gerekiyor.
Input Parameters - RFC Bağlantısının Adı, HANA Ana Bilgisayar Adı ve <Örnek Numarası> girin
Oturum Açma Güvenliği Sekmesinde, temel Kimlik Doğrulama yöntemini kullanarak HANA stüdyosunda oluşturulan DXC kullanıcısını girin -
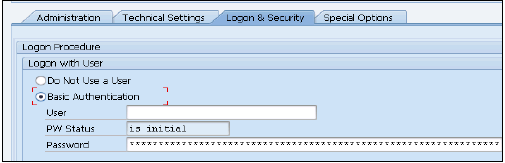
Setting up BW Parameters for HANA - SE 38 işlemini kullanarak BW'de Aşağıdaki Parametreleri Ayarlamanız Gerekiyor. Parametre Listesi -
PSA_TO_HDB_DESTINATION - Gelen verileri nereye taşımamız gerektiğini belirtmemiz gerekiyor (SM 59 kullanılarak oluşturulan Bağlantı Adı)
PSA_TO_HDB_SCHEMA - Çoğaltılan verilerin hangi Şemaya atanması gerektiği
PSA_TO_HDB- Tüm veri kaynağını HANA'ya Çoğaltmak İçin GLOBAL. SİSTEM - DXC'yi Kullanacak belirli istemciler. DATASOURCE - Yalnızca Belirtilen Veri Kaynağı,
PSA_TO_HDB_DATASOURCETABLE - DXC için kullanılan veri kaynaklarının listesini içeren Tablo adını vermeniz gerekir.
Veri Kaynağı Çoğaltma
RSA5 kullanarak ECC'de veri kaynağını kurun.
Meta veriyi belirtilen uygulama bileşenini kullanarak çoğaltın (veri kaynağı sürümü 7.0'a ihtiyaç var, eğer 3.5 sürüm veri kaynağımız varsa bunu taşımamız gerekir. Veri Kaynağını SAP BW'de etkinleştirin. Veri kaynağı SAP BW'de etkinleştirildiğinde aşağıdaki Tabloyu oluşturur tanımlı şemada -
/ BIC / A <veri kaynağı> 00 - IMDSO Aktif Tablosu
/ BIC / A <veri kaynağı> 40 –IMDSO Etkinleştirme Sırası
/ BIC / A <veri kaynağı> 70 - Kayıt Modu İşleme Tablosu
/ BIC / A <veri kaynağı> 80 - İstek ve Paket Kimliği bilgileri Tablosu
/ BIC / A <veri kaynağı> A0 - Zaman Damgası Tablosu İste
RSODSO_IMOLOG - IMDSO ile ilgili tablo. DXC ile ilgili tüm veri kaynakları hakkındaki bilgileri depolar.
Şimdi veriler, etkinleştirildikten sonra başarıyla Table / BIC / A0FI_AA_2000'e yüklenir.
SAP HANA Studio'yu açın → Katalog sekmesi altında Şema Oluştur. <Buradan başlayın>
Verileri hazırlayın ve csv formatında kaydedin. Şimdi aşağıdaki sözdizimine sahip "ctl" uzantılı dosya oluşturun -
---------------------------------------
import data into table Schema."Table name"
from 'file.csv'
records delimited by '\n'
fields delimited by ','
Optionally enclosed by '"'
error log 'table.err'
-----------------------------------------Bu "ctl" dosyasını FTP'ye aktarın ve verileri içe aktarmak için bu dosyayı çalıştırın -
table.ctl'den içe aktar
HANA Studio → Katalog → Şema → Tablolar → İçeriği Görüntüle seçeneğine giderek tablodaki verileri kontrol edin
MDX Sağlayıcı, MS Excel'i SAP HANA veritabanı sistemine bağlamak için kullanılır. HANA sistemini Excel'e bağlamak için sürücü sağlar ve ayrıca veri modelleme için kullanılır. Hem 32 bit hem de 64 bit Windows için HANA ile bağlantı için Microsoft Office Excel 2010/2013'ü kullanabilirsiniz.
SAP HANA, her iki sorgu dilini de destekler - SQL ve MDX. Her iki dil de kullanılabilir: SQL için JDBC ve ODBC ve MDX işleme için ODBO kullanılır. Excel Pivot tabloları, SAP HANA sisteminden verileri okumak için sorgu dili olarak MDX kullanır. MDX, Microsoft'un ODBO (OLAP için OLE DB) spesifikasyonunun bir parçası olarak tanımlanır ve veri seçimleri, hesaplamalar ve düzen için kullanılır. MDX, çok boyutlu veri modelini destekler ve raporlama ve Analiz gereksinimini destekler.
MDX sağlayıcısı, HANA stüdyosunda tanımlanan Bilgi görünümlerinin SAP ve SAP dışı raporlama araçları tarafından kullanılmasını sağlar. Mevcut fiziksel tablolar ve şemalar, Bilgi modelleri için veri temelini sunar.
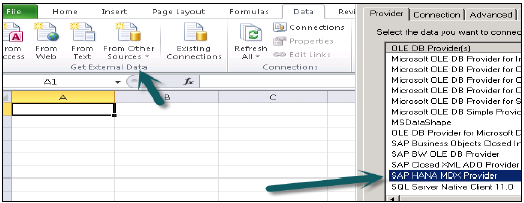
Bağlanmak istediğiniz veri kaynağı listesinden SAP HANA MDX sağlayıcısını seçtikten sonra, ana bilgisayar adı, örnek numarası, kullanıcı adı ve şifre gibi HANA sistem ayrıntılarını iletin.
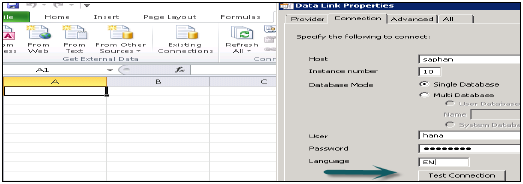
Bağlantı başarılı olduktan sonra, Pivot tablolar oluşturmak için Paket adı → HANA Modelleme görünümlerini seçebilirsiniz.
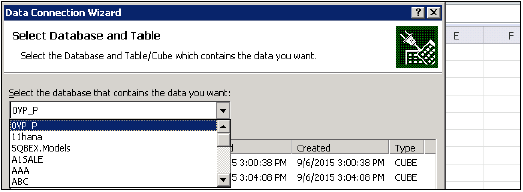
MDX, HANA veritabanına sıkı bir şekilde entegre edilmiştir. HANA veritabanının Bağlantı ve Oturum yönetimi, HANA tarafından yürütülen ifadeleri işler. Bu ifadeler yürütüldüğünde, MDX arabirimi tarafından ayrıştırılır ve her MDX ifadesi için bir hesaplama modeli oluşturulur. Bu hesaplama modeli, MDX için standart sonuçlar üreten bir yürütme planı oluşturur. Bu sonuçlar doğrudan OLAP istemcileri tarafından tüketilir.
HANA veri tabanına MDX bağlantısı yapmak için HANA istemci araçları gereklidir. Bu müşteri aracını SAP pazarından indirebilirsiniz. HANA istemcisinin kurulumu tamamlandıktan sonra, MS Excel'deki veri kaynağı listesinde SAP HANA MDX sağlayıcısı seçeneğini göreceksiniz.
SAP HANA uyarı izleme, HANA sisteminde çalışan sistem kaynaklarının ve hizmetlerin durumunu izlemek için kullanılır. Uyarı izleme, CPU kullanımı, disk dolu, FS eşiğine ulaşma vb. Gibi kritik uyarıları işlemek için kullanılır. HANA sisteminin izleme bileşeni, HANA veritabanının tüm bileşenlerinin sağlığı, kullanımı ve performansı hakkında sürekli bilgi toplar. Herhangi bir bileşen ayarlanan eşik değerini ihlal ettiğinde bir uyarı verir.
HANA sisteminde ortaya çıkan uyarının önceliği, sorunun önemini belirtir ve bileşen üzerinde gerçekleştirilen kontrole bağlıdır. Örnek - CPU kullanımı% 80 ise, düşük öncelikli bir uyarı ortaya çıkar. Bununla birlikte,% 96'ya ulaşırsa, sistem yüksek öncelikli bir alarm verir.
Sistem Monitörü, HANA sistemini izlemenin ve tüm SAP HANA sistem bileşenlerinizin kullanılabilirliğini doğrulamanın en yaygın yoludur. Sistem monitörü, bir HANA sisteminin tüm temel bileşenlerini ve hizmetlerini kontrol etmek için kullanılır.

Ayrıca, Yönetim Düzenleyicisi'nde tek bir sistemin ayrıntılarına inebilirsiniz. Veri Diski, Günlük diski, İzleme Diski, kaynak kullanımına ilişkin uyarıları öncelikli olarak anlatır.

Yönetici editöründeki Uyarı sekmesi, mevcut ve HANA sistemindeki tüm uyarıları kontrol etmek için kullanılır.
Ayrıca, bir uyarının ne zaman verildiğini, uyarının açıklamasını, uyarının önceliğini vb. Anlatır.
SAP HANA izleme panosu, sistem sağlığı ve yapılandırmasının temel yönlerini anlatır -
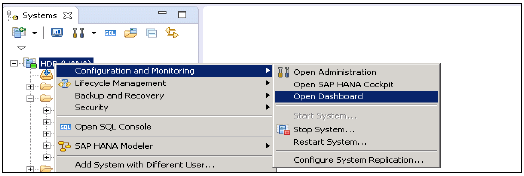
- Yüksek ve Orta öncelikli uyarılar.
- Bellek ve CPU kullanımı
- Veri yedeklemeleri
SAP HANA veritabanı kalıcılık katmanı, standart veri yedekleme ve sistem geri yükleme işlevi sağlamak için tüm işlemlerin günlüklerini yönetmekten sorumludur.
Veritabanının yeniden başlatıldıktan sonra veya bir sistem çökmesinden sonra en son kaydedilen duruma geri yüklenmesini ve işlemlerin tamamen veya tamamen geri alınmasını sağlar. SAP HANA Persistent Layer, Index sunucusunun bir parçasıdır ve HANA sistemi için veri ve işlem günlüğü hacimlerine sahiptir ve bellek içi veriler düzenli olarak bu birimlere kaydedilir. HANA sisteminde kendi kalıcılığı olan servisler bulunmaktadır. Ayrıca son kaydetme noktasından itibaren tüm veritabanı işlemleri için kaydetme noktaları ve günlükler sağlar.
SAP HANA veritabanı neden bir Kalıcı Katmana ihtiyaç duyar?
Ana bellek geçicidir, bu nedenle yeniden başlatma veya elektrik kesintisi sırasında veriler kaybolur.
Verilerin kalıcı bir ortamda saklanması gerekir.
Yedekleme ve Geri Yükleme mevcuttur.
Yeniden başlatmanın ardından veritabanının en son kaydedilen duruma geri yüklenmesini ve bu işlemin tamamen yürütülmesini veya tamamen geri alınmasını sağlar.
Veri ve İşlem Günlüğü Hacimleri
Veritabanındaki verilerde yapılan bu değişikliklerin düzenli olarak diske kopyalanmasını sağlamak için veritabanı her zaman en son durumuna geri yüklenebilir. Veri değişikliklerini ve belirli işlem olaylarını içeren günlük dosyaları da düzenli olarak diske kaydedilir. Bir sistemin verileri ve günlükleri Günlük hacimlerinde saklanır.
Veri birimleri, SQL verilerini depolar ve günlük bilgilerini ve ayrıca SAP HANA bilgi modelleme verilerini geri alır. Bu bilgiler, Bloklar adı verilen veri sayfalarında saklanır. Bu bloklar, kaydetme noktası olarak bilinen düzenli zaman aralığında veri hacimlerine yazılır.
Günlük hacimleri, veri değişiklikleri hakkındaki bilgileri depolar. İki günlük noktası arasında yapılan değişiklikler Günlük hacimlerine yazılır ve günlük girişleri olarak adlandırılır. İşlem gerçekleştirildiğinde ara belleğe kaydedilirler.
Kayıt noktaları
SAP HANA veritabanında, değiştirilen veriler otomatik olarak bellekten diske kaydedilir. Bu düzenli aralıklara kayıt noktaları adı verilir ve varsayılan olarak bunlar her beş dakikada bir gerçekleşecek şekilde ayarlanır. SAP HANA veritabanındaki Kalıcılık Katmanı bu kayıt noktasını düzenli aralıklarla gerçekleştirir. Bu işlem sırasında değiştirilen veriler diske yazılır ve yineleme günlükleri de diske kaydedilir.
Bir Savepoint'e ait veriler, diskteki verilerin tutarlı durumunu söyler ve bir sonraki kayıt noktası işlemi tamamlanana kadar orada kalır. Kalıcı verilerde yapılan tüm değişiklikler için yineleme günlüğü girişleri günlük hacimlerine yazılır. Veritabanının yeniden başlatılması durumunda, en son tamamlanan kayıt noktasındaki veriler, veri birimlerinden okunabilir ve günlük hacimlerine yazılan günlük girişlerini yeniden yapabilir.
Kayıt noktası sıklığı, global.ini dosyasıyla yapılandırılabilir. Kayıt noktaları, veritabanı kapatma veya sistemi yeniden başlatma gibi diğer işlemlerle başlatılabilir. Ayrıca aşağıdaki komutu uygulayarak da savepoint çalıştırabilirsiniz -
ALTER Sistem SAVEPOINT
Verileri kaydetmek ve günlükleri günlük birimlerine yeniden yapmak için bunları yakalamak için yeterli disk alanı olduğundan emin olmalısınız, aksi takdirde sistem bir disk dolu olayı yayınlayacak ve veritabanı çalışmayı durduracaktır.
HANA sistem kurulumu sırasında, veri ve günlük hacimleri için depolama konumu olarak aşağıdaki varsayılan dizinler oluşturulur -
- /usr/sap/<SID>/SYS/global/hdb/data
- /usr/sap/<SID>/SYS/global/hdb/log
Bu dizinler global.ini dosyasında tanımlanır ve daha sonra değiştirilebilir.
Kaydetme noktalarının HANA sisteminde yürütülen işlemlerin performansını etkilemediğini unutmayın. Kayıt noktası işlemi sırasında işlemler normal şekilde çalışmaya devam eder. HANA sistemi doğru donanım üzerinde çalışırken, kayıt noktalarının sistemin performansı üzerindeki etkisi ihmal edilebilir düzeydedir.
SAP HANA yedekleme ve kurtarma, herhangi bir veritabanı arızası durumunda HANA sistem yedeklemeleri ve sistemin kurtarılması için kullanılır.
Genel Bakış Sekmesi
Şu anda çalışan veri yedeklemesinin ve son başarılı veri yedeklemesinin durumunu söyler.
Şimdi yedekle seçeneği, veri yedekleme sihirbazını çalıştırmak için kullanılabilir.
Yapılandırma Sekmesi
Yedekleme aralığı ayarları, dosya tabanlı veri yedekleme ayarları ve günlük tabanlı veri yedekleme ayarı hakkında bilgi verir.

Yedekleme Aralığı Ayarları
Arka plan ayarları, veriler için üçüncü taraf aracı kullanma ve yedekleme aracısının yapılandırmasıyla günlük yedekleme seçeneği sunar.
Backint aracısı için bir parametre dosyası belirterek üçüncü taraf bir yedekleme aracıyla bağlantıyı yapılandırın.
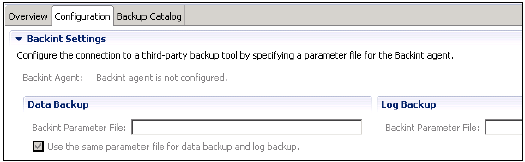
Dosya ve Günlüğe Dayalı Veri Yedekleme Ayarları
Dosya tabanlı veri yedekleme ayarı, HANA sistemine veri yedeklemesini nereye kaydetmek istediğinizi söyler. Yedek klasörünüzü değiştirebilirsiniz.
Veri yedekleme dosyalarının boyutunu da sınırlayabilirsiniz. Sistem verisi yedeklemesi bu dosya boyutunu aşarsa, birden çok dosyaya bölünür.
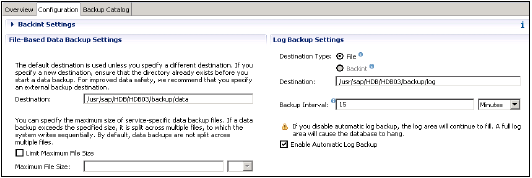
Günlük yedekleme ayarları, günlük yedeklemeyi harici sunucuya kaydetmek istediğiniz hedef klasöre söyler. Günlük yedekleme için bir hedef türü seçebilirsiniz
Dosya - yedeklemeleri depolamak için sistemde yeterli alan olmasını sağlar
Backint - dosya sisteminde bulunan ancak disk alanı gerektirmeyen özel adlandırılmış kanaldır.
Açılır listeden yedekleme aralığını seçebilirsiniz. Yeni bir günlük yedeklemesi yazılmadan önce geçebilecek en uzun süreyi söyler. Yedekleme Aralığı: Saniye, dakika veya saat cinsinden olabilir.
Otomatik günlük yedekleme seçeneğini etkinleştirin: Günlük alanını boş tutmanıza yardımcı olur. Bu günlük alanını devre dışı bırakırsanız, dolmaya devam eder ve bu, veritabanının askıda kalmasına neden olabilir.
Yedekleme Sihirbazını Aç - sistemin yedeklemesini çalıştırmak için.
Yedekleme sihirbazı, yedekleme ayarlarını belirlemek için kullanılır. Yedekleme tipini, hedef Tipi, Yedekleme Hedefi klasörünü, Yedekleme önekini, yedeklemenin boyutunu vb. Söyler.
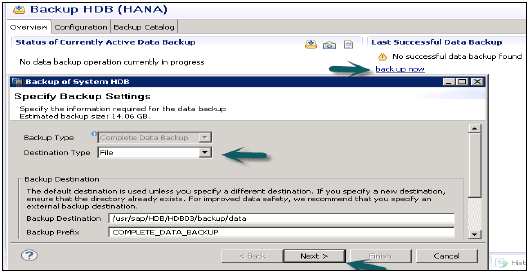
İleri'ye tıkladığınızda → Yedekleme ayarlarını gözden geçirin → Bitir
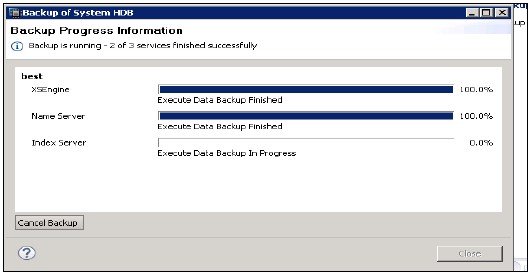
Sistem yedeklemelerini çalıştırır ve her sunucu için yedeklemeyi tamamlama zamanını söyler.
HANA Sisteminin Kurtarılması
SAP HANA veritabanını kurtarmak için veritabanının kapatılması gerekir. Bu nedenle, kurtarma sırasında, son kullanıcılar veya SAP uygulamaları veritabanına erişemez.
SAP HANA veritabanının kurtarılması aşağıdaki durumlarda gereklidir:
Veri alanındaki bir disk kullanılamaz veya günlük alanındaki disk kullanılamaz.
Mantıksal bir hatanın bir sonucu olarak, veritabanının belirli bir zamanda durumuna sıfırlanması gerekir.
Veritabanının bir kopyasını oluşturmak istiyorsunuz.
HANA sistemi nasıl kurtarılır?
HANA sistemini seçin → Sağ tıklayın → Geri ve Kurtarma → Sistemi Kurtar
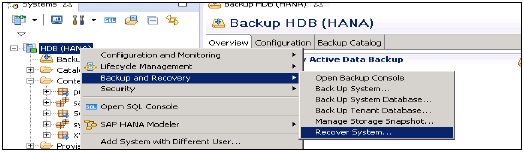
HANA sisteminde kurtarma türleri
Most Recent State- Veritabanını geçerli saate mümkün olduğunca yakın bir zamana kurtarmak için kullanılır. Bu kurtarma için, veri yedekleme ve günlük yedeklemesi, yukarıdaki tür kurtarmayı gerçekleştirmek için son veri yedekleme ve günlük alanı gerektiğinden beri mevcut olmalıdır.
Point in Time- Veritabanını belirli bir zamanda kurtarmak için kullanılır. Bu kurtarma için, veri yedekleme ve günlük yedeklemesi, son veri yedeklemesinden itibaren mevcut olmalıdır ve yukarıdaki tür kurtarmayı gerçekleştirmek için günlük alanı gereklidir.
Specific Data Backup- Veritabanını belirli bir veri yedeklemesine kurtarmak için kullanılır. Yukarıdaki kurtarma seçeneği türü için özel veri yedeklemesi gereklidir.
Specific Log Position - Bu kurtarma türü, önceki bir kurtarmanın başarısız olduğu istisnai durumlarda kullanılabilen gelişmiş bir seçenektir.
Note - Kurtarma sihirbazını çalıştırmak için HANA sisteminde yönetici ayrıcalıklarına sahip olmanız gerekir.
SAP HANA, sistem hataları ve yazılım hataları için iş sürekliliği ve felaket kurtarma mekanizması sağlar. HANA sistemindeki yüksek kullanılabilirlik, veri merkezlerindeki elektrik kesintileri, yangın, sel vb. Doğal afetler veya herhangi bir donanım arızası gibi felaket durumunda iş sürekliliğinin sağlanmasına yardımcı olan bir dizi uygulamayı tanımlar.
SAP HANA yüksek kullanılabilirlik, hata toleransı ve sistemin minimum iş kaybı ile bir kesinti sonrasında sistem işlemlerini sürdürme yeteneği sağlar.
Aşağıdaki çizim, HANA sisteminde yüksek kullanılabilirliğin aşamalarını göstermektedir -
Arıza için ilk aşama hazırlanıyor. Bir hata otomatik olarak veya bir idari işlemle tespit edilebilir. Veriler yedeklenir ve bekleme sistemleri işlemleri devralır. Bir kurtarma işlemi, arızalı sistemin onarımını ve önceki yapılandırmaya geri yüklenecek orijinal sistemi içerir.
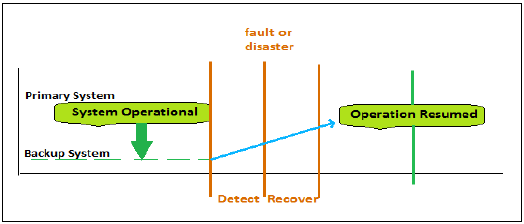
HANA sisteminde yüksek kullanılabilirlik elde etmek için anahtar, diğer bileşenlerin arızalanması durumunda çalışması ve kullanılması gerekmeyen ekstra bileşenlerin dahil edilmesidir. Donanım yedekliliği, ağ yedekliliği ve veri merkezi yedekliliği içerir. SAP HANA, aşağıdaki gibi çeşitli düzeylerde donanım ve yazılım yedekliliği sağlar -
HANA Sistem Donanım Yedekliliği
SAP HANA cihaz satıcıları, yedek güç kaynakları ve fanlar, hata düzeltici bellekler, tamamen yedekli ağ anahtarları ve yönlendiriciler ve kesintisiz güç kaynağı (UPS) gibi çok sayıda yedekli donanım, yazılım ve ağ bileşeni katmanı sunar. Disk depolama sistemi, elektrik kesintisi durumunda bile yazmayı garanti eder ve disk arızalarından otomatik kurtarma için artıklık sağlamak için şeritleme ve yansıtma özelliklerini kullanır.
SAP HANA Yazılım Yedekliliği
SAP HANA, SAP için SUSE Linux Enterprise 11'i temel alır ve güvenlik ön yapılandırmalarını içerir.
SAP HANA sistem yazılımı, algılanan durma durumunda (öldürülen veya kilitlenen) yapılandırılmış hizmetleri (dizin sunucusu, ad sunucusu vb.) Otomatik olarak yeniden başlatan bir bekçi uygulaması işlevi içerir.
SAP HANA Kalıcılık Yedekliliği
SAP HANA, minimum gecikmeyle ve veri kaybı olmadan sistemin yeniden başlatılmasını ve arızalardan kurtarılmasını desteklemek için işlem günlüklerinin, kayıt noktalarının ve anlık görüntülerin kalıcılığını sağlar.
HANA Sistem Bekleme ve Yük Devretme
SAP HANA sistemi, birincil sistemin arızalanması durumunda yük devretme için kullanılan ayrı yedek ana bilgisayarları içerir. Bu, bir kesintiden kaynaklanan kurtarma süresini azaltarak HANA sisteminin kullanılabilirliğini iyileştirir.
SAP HANA sistemi, günlük girişlerinde uygulama verilerini veya veritabanı kataloğunu değiştiren tüm işlemleri günlüğe kaydeder ve bunları günlük alanında depolar. Bu günlük girişlerini günlük alanında geri almak veya SQL ifadelerini tekrarlamak için kullanır. Günlük dosyaları HANA sisteminde mevcuttur ve Yönetici editörü altındaki Teşhis dosyaları sayfasındaki HANA stüdyosu aracılığıyla erişilebilir.
Günlük yedekleme işlemi sırasında, yalnızca günlük bölümlerinin gerçek verileri günlük alanından hizmete özel günlük yedekleme dosyalarına veya üçüncü taraf bir yedekleme aracına yazılır.
Bir sistem arızasından sonra, veritabanını istenen duruma geri yüklemek için günlük yedeklerinden günlük girişlerini yeniden yapmanız gerekebilir.
Kalıcılığı olan bir veritabanı hizmeti durursa, yeniden başlatılmasını sağlamak önemlidir, aksi takdirde kurtarma yalnızca hizmetin durdurulmasından önceki bir noktaya kadar mümkün olacaktır.
Günlük yedekleme Zaman Aşımını Yapılandırma
Günlük yedekleme zaman aşımı, bu aralıkta bir kaydetme gerçekleşmişse günlük segmentlerinin yedekleneceği aralığı belirler. SAP HANA studio'daki Yedekleme Konsolu'nu kullanarak günlük yedekleme zaman aşımını yapılandırabilirsiniz -
Log_backup_timeout_s aralığını global.ini yapılandırma dosyasında da yapılandırabilirsiniz.
SAP HANA sisteminin kurulumundan sonra otomatik günlük yedekleme işlevi için "Dosya" ve yedekleme modu "NORMAL" için günlük yedeklemesi varsayılan ayarlardır. Otomatik günlük yedekleme yalnızca en az bir tam veri yedeklemesi gerçekleştirilmişse çalışır.
İlk tam veri yedeklemesi gerçekleştirildiğinde, otomatik günlük yedekleme işlevi etkindir. SAP HANA studio, otomatik günlük yedekleme işlevini etkinleştirmek / devre dışı bırakmak için kullanılabilir. Otomatik günlük yedeklemenin etkin tutulması önerilir, aksi takdirde günlük alanı dolmaya devam eder. Tam günlük alanı, HANA sisteminde bir veritabanının donmasına neden olabilir.
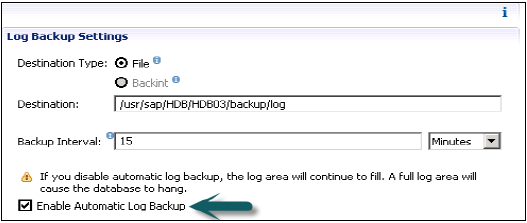
Ayrıca global.ini yapılandırma dosyasının kalıcılık bölümünde enable_auto_log_backup parametresini de değiştirebilirsiniz.
SQL, Yapılandırılmış Sorgu Dili anlamına gelir.
Bir veritabanı ile iletişim kurmak için standartlaştırılmış bir dildir. SQL, verileri almak, veritabanındaki verileri depolamak veya işlemek için kullanılır.
SQL deyimleri aşağıdaki işlevleri gerçekleştirir -
- Veri tanımı ve manipülasyonu
- Sistem Yönetimi
- Oturum yönetimi
- İşlem yönetimi
- Şema tanımı ve manipülasyonu
Geliştiricilerin veri tabanına veri göndermesine olanak tanıyan SQL uzantılarının adı SQL scripts.
Veri Manipülasyon Dili (DML)
DML ifadeleri, şema nesneleri içindeki verileri yönetmek için kullanılır. Bazı örnekler -
SELECT - veri tabanından veri alın
INSERT - bir tabloya veri eklemek
UPDATE - bir tablo içindeki mevcut verileri günceller
Veri Tanımlama Dili (DDL)
DDL ifadeleri, veritabanı yapısını veya şemasını tanımlamak için kullanılır. Bazı örnekler -
CREATE - veritabanında nesneler oluşturmak için
ALTER - veritabanının yapısını değiştirir
DROP - veritabanından nesneleri silin
Veri Kontrol Dili (DCL)
Bazı DCL ifadeleri örnekleri -
GRANT - kullanıcıya veritabanına erişim ayrıcalıkları verir
REVOKE - GRANT komutuyla verilen erişim ayrıcalıklarını geri çekin
Neden SQL'e İhtiyacımız Var?
SAP HANA Modeler'da Bilgi Görünümleri oluşturduğumuzda, bunu bazı OLTP uygulamalarının üzerinde oluşturuyoruz. Bunların hepsi arka uçta SQL üzerinde çalışıyor. Veritabanı yalnızca bu dili anlar.
Raporumuzun iş gereksinimlerini karşılayıp karşılamayacağını test etmek için, Çıktı gereksinime göre ise veritabanında SQL deyimini çalıştırmamız gerekir.
HANA Hesaplama görünümleri iki şekilde oluşturulabilir - Grafiksel veya SQL komut dosyası kullanılarak. Daha karmaşık Hesaplama görünümleri oluşturduğumuzda, doğrudan SQL betikleri kullanmak zorunda kalabiliriz.
HANA Studio'da SQL konsolu nasıl açılır?
HANA sistemini seçin ve sistem görünümünde SQL konsolu seçeneğine tıklayın. SQL konsolunu Katalog sekmesine veya herhangi bir Şema adına sağ tıklayarak da açabilirsiniz.
SAP HANA hem İlişkisel hem de OLAP veritabanı olarak hareket edebilir. HANA üzerinde BW kullandığımızda, BW ve HANA'da ilişkisel veritabanı görevi gören ve her zaman bir SQL İfadesi üreten küpler oluştururuz. Bununla birlikte, OLAP bağlantısını kullanarak HANA görünümlerine doğrudan eriştiğimizde, OLAP veritabanı olarak hareket edecek ve MDX oluşturulacaktır.
SAP HANA'da tablo oluşturma seçeneğini kullanarak satır veya Sütun deposu tabloları oluşturabilirsiniz. Bir veri tanımı oluşturma tablosu deyimi çalıştırılarak veya HANA stüdyosunda grafik seçeneği kullanılarak bir tablo oluşturulabilir.
Bir tablo oluşturduğunuzda, içindeki nitelikleri de tanımlamanız gerekir.
SQL statement to create a table in HANA Studio SQL Console -
Create column Table TEST (
ID INTEGER,
NAME VARCHAR(10),
PRIMARY KEY (ID)
);Creating a table in HANA studio using GUI option -
Bir tablo oluşturduğunuzda, sütun adlarını ve SQL veri türlerini tanımlamanız gerekir. Boyut alanı, değerin uzunluğunu ve onu birincil anahtar olarak tanımlamak için Anahtar seçeneğini belirtir.
SAP HANA, bir tabloda aşağıdaki veri türlerini destekler -
SAP HANA, 7 SQL veri türü kategorisini destekler ve bir sütunda saklamanız gereken veri türüne bağlıdır.
- Numeric
- Karakter dizesi
- Boolean
- Tarih Saat
- Binary
- Büyük Nesneler
- Multi-Valued
Aşağıdaki tablo, her kategorideki veri türlerinin listesini vermektedir -

Tarih Saat
Bu veri türleri, tarih ve saati HANA veritabanındaki bir tabloda depolamak için kullanılır.
DATE- veri türü, bir sütundaki tarih değerini temsil eden yıl, ay ve gün bilgilerinden oluşur. Bir Tarih veri türü için varsayılan format YYYY-AA-GG şeklindedir.
TIME- veri türü, HANA veritabanındaki bir tablodaki saat, dakika ve saniye değerlerinden oluşur. Zaman veri türü için varsayılan format HH: MI: SS şeklindedir.
SECOND DATE- veri türü HANA veritabanındaki bir tablodaki yıl, ay, gün, saat, dakika, saniye değerlerinden oluşur. SECONDDATE veri türü için varsayılan format YYYY-AA-GG SS: DD: SS şeklindedir.
TIMESTAMP- veri türü, HANA veritabanındaki bir tablodaki tarih ve saat bilgilerinden oluşur. TIMESTAMP veri türü için varsayılan format YYYY-AA-GG SS: DD: SS: FFn şeklindedir, burada FFn saniyenin kesirini temsil eder.
Sayısal
TinyINT- 8 bitlik işaretsiz tamsayı depolar. Min değer: 0 ve maksimum değer: 255
SMALLINT- 16 bitlik işaretli tamsayı depolar. Min değer: -32,768 ve maksimum değer: 32,767
Integer- 32 bit işaretli tamsayıyı depolar. Minimum değer: -2.147.483.648 ve maksimum değer: 2.147.483.648
BIGINT- 64 bit işaretli tamsayıyı depolar. Minimum değer: -9,223,372,036,854,775,808 ve maksimum değer: 9,223,372,036,854,775,808
SMALL - Ondalık ve Ondalık: Minimum değer: -10 ^ 38 +1 ve maksimum değer: 10 ^ 38 -1
REAL - Min Değer: -3.40E + 38 ve maksimum değer: 3.40E + 38
DOUBLE- 64 bit kayan nokta numarasını kaydeder. Min değer: -1.7976931348623157E308 ve maksimum değer: 1.7976931348623157E308
Boole
Boolean veri türleri, DOĞRU, YANLIŞ olan Boole değerini depolar
Karakter
Varchar - maksimum 8000 karakter.
Nvarchar - maksimum 4000 karakter uzunluk
ALPHANUM- alfanümerik karakterleri depolar. Bir tamsayı için değer 1 ile 127 arasındadır.
SHORTTEXT - metin arama özelliklerini ve dizi arama özelliklerini destekleyen değişken uzunluklu karakter dizesini depolar.
İkili
İkili türler, bayt ikili veri depolamak için kullanılır.
VARBINARY- ikili verileri bayt cinsinden depolar. Maksimum tam sayı uzunluğu 1 ile 5000 arasındadır.
Büyük Nesneler
LARGEOBJECTS, metin belgeleri ve resimler gibi büyük miktarda veriyi depolamak için kullanılır.
NCLOB - büyük UNICODE karakter nesnesini depolar.
BLOB - Büyük miktarda İkili veri depolar.
CLOB - büyük miktarda ASCII karakter verisi depolar.
TEXT- metin arama özelliklerini etkinleştirir. Bu veri türü yalnızca sütun tabloları için tanımlanabilir ve satır saklama tabloları için tanımlanamaz.
BINTEXT - metin arama özelliklerini destekler ancak ikili veri eklemek mümkündür.
Birden çok değerli
Birden çok değerli veri türleri, aynı veri türüne sahip değerler koleksiyonunu depolamak için kullanılır.
Dizi
Diziler, aynı veri türüne sahip değer koleksiyonlarını depolar. Boş değerler de içerebilirler.
İşleç, karşılaştırmalar ve aritmetik işlemler gibi işlemleri gerçekleştirmek için öncelikle WHERE yan tümcesine sahip SQL ifadelerinde kullanılan özel bir karakterdir. Bir SQL sorgusundaki koşulları geçirmek için kullanılırlar.
Aşağıda verilen operatör tipleri HANA'daki SQL ifadelerinde kullanılabilir -
- Aritmetik operatörler
- Karşılaştırma / İlişkisel Operatörler
- Mantıksal operatörler
- Operatörleri Ayarla
Aritmetik operatörler
Aritmetik operatörler, toplama, çıkarma, çarpma, bölme ve yüzde gibi basit hesaplama işlevlerini gerçekleştirmek için kullanılır.
| Şebeke | Açıklama |
|---|---|
| + | Ekleme - Operatörün her iki tarafına da değerler ekler |
| - | Çıkarma - Sağ el işleneni sol el işlenenden çıkarır |
| * | Çarpma - Operatörün her iki tarafındaki değerleri çarpar |
| / | Bölme - Sol el işleneni sağ el işlenene böler |
| % | Modulus - Sol el operandı sağ el operandına böler ve kalanı döndürür |
Karşılaştırma Operatörleri
Karşılaştırma operatörleri, SQL ifadesindeki değerleri karşılaştırmak için kullanılır.
| Şebeke | Açıklama |
|---|---|
| = | İki işlenenin değerlerinin eşit olup olmadığını kontrol eder, evet ise koşul doğru olur. |
| ! = | İki işlenenin değerlerinin eşit olup olmadığını kontrol eder, değerler eşit değilse koşul doğru olur. |
| <> | İki işlenenin değerlerinin eşit olup olmadığını kontrol eder, değerler eşit değilse koşul doğru olur. |
| > | Soldaki işlenenin değerinin sağ işlenenin değerinden büyük olup olmadığını kontrol eder, evet ise koşul doğru olur. |
| < | Soldaki işlenenin değerinin sağ işlenenin değerinden küçük olup olmadığını kontrol eder, evet ise koşul doğru olur. |
| > = | Sol işlenenin değerinin sağ işlenenin değerinden büyük veya ona eşit olup olmadığını kontrol eder, evet ise koşul doğru olur. |
| <= | Soldaki işlenenin değerinin sağ işlenenin değerinden küçük veya ona eşit olup olmadığını kontrol eder, evet ise koşul doğru olur. |
| ! < | Soldaki işlenenin değerinin sağ işlenenin değerinden küçük olup olmadığını kontrol eder, evet ise koşul doğru olur. |
| !> | Sol işlenenin değerinin sağ işlenenin değerinden büyük olup olmadığını kontrol eder, evet ise koşul doğru olur. |
Mantıksal operatörler
Mantıksal operatörler, SQL deyiminde birden çok koşulu geçirmek için veya koşulların sonuçlarını işlemek için kullanılır.
| Şebeke | Açıklama |
|---|---|
| HERŞEY | TÜM İşleci, bir değeri başka bir değer kümesindeki tüm değerlerle karşılaştırmak için kullanılır. |
| VE | AND operatörü, bir SQL ifadesinin WHERE yan tümcesinde birden çok koşulun varlığına izin verir. |
| HİÇ | ANY operatörü, bir değeri duruma göre listedeki herhangi bir uygulanabilir değerle karşılaştırmak için kullanılır. |
| ARASINDA | BETWEEN operatörü, minimum değer ve maksimum değer verildiğinde, bir değerler kümesi dahilindeki değerleri aramak için kullanılır. |
| VAR | EXISTS operatörü, belirli bir tablodaki belirli kriterleri karşılayan bir satırın varlığını aramak için kullanılır. |
| İÇİNDE | IN operatörü, bir değeri belirtilen değişmez değerler listesiyle karşılaştırmak için kullanılır. |
| SEVMEK | LIKE operatörü, joker karakter operatörleri kullanarak bir değeri benzer değerlerle karşılaştırmak için kullanılır. |
| DEĞİL | NOT operatörü, birlikte kullanıldığı mantıksal operatörün anlamını tersine çevirir. Örneğin - MEVCUT DEĞİL, ARASI DEĞİL, İÇİNDE DEĞİL vb.This is a negate operator. |
| VEYA | OR operatörü, bir SQL ifadesinin WHERE cümlesindeki birden çok koşulu karşılaştırmak için kullanılır. |
| BOŞ | NULL operatörü, bir değeri NULL değerle karşılaştırmak için kullanılır. |
| BENZERSİZ | UNIQUE operatörü, belirli bir tablonun her satırında benzersizlik için arama yapar (yineleme yok). |
Operatörleri Ayarla
Set operatörleri, iki sorgunun sonuçlarını tek bir sonuçta birleştirmek için kullanılır. Veri türü her iki tablo için aynı olmalıdır.
UNION- İki veya daha fazla Select ifadesinin sonuçlarını birleştirir. Ancak yinelenen satırları ortadan kaldıracaktır.
UNION ALL - Bu operatör Birleşmeye benzer, ancak aynı zamanda yinelenen satırları da gösterir.
INTERSECT- Kesişim işlemi, iki SELECT deyimini birleştirmek için kullanılır ve her iki SELECT deyiminde ortak olan kayıtları döndürür. Kesişim durumunda, sütun sayısı ve veri türü her iki tabloda da aynı olmalıdır.
MINUS - Eksi işlemi, iki SELECT ifadesinin sonucunu birleştirir ve yalnızca ilk sonuç kümesine ait olan sonuçları döndürür ve ikinci ifadedeki satırları ilk çıktısından çıkarır.
SAP HANA veritabanı tarafından sağlanan çeşitli SQL işlevleri vardır -
- Sayısal İşlevler
- String Fonksiyonları
- Tam Metin İşlevleri
- Tarih ve Saat İşlevleri
- Toplama İşlevleri
- Veri Türü Dönüştürme İşlevleri
- Pencere Fonksiyonları
- Seri Veri Fonksiyonları
- Çeşitli Fonksiyonlar
Sayısal İşlevler
Bunlar SQL'deki dahili sayısal işlevlerdir ve komut dosyası oluşturmada kullanılır. Sayısal değerleri veya sayısal karakterli dizeleri alır ve sayısal değerler döndürür.
ABS - Sayısal bir değişkenin mutlak değerini döndürür.
Example − SELECT ABS (-1) "abs" FROM TEST;
abs
1ACOS, ASIN, ATAN, ATAN2 (Bu işlevler, argümanın trigonometrik değerini döndürür)
BINTOHEX - İkili bir değeri onaltılık bir değere dönüştürür.
BITAND - Geçilen bağımsız değişkenin bitleri üzerinde bir VE işlemi gerçekleştirir.
BITCOUNT - Bir bağımsız değişkendeki set bitlerinin sayısını gerçekleştirir.
BITNOT - Argüman bitleri üzerinde bit düzeyinde NOT işlemi gerçekleştirir.
BITOR - Aktarılan bağımsız değişken bitleri üzerinde OR işlemi gerçekleştirir.
BITSET - <start_bit> konumundan <target_num> içinde bitleri 1 olarak ayarlamak için kullanılır.
BITUNSET - <start_bit> konumundan <target_num> içindeki bitleri 0 olarak ayarlamak için kullanılır.
BITXOR - Aktarılan bağımsız değişkenin bitleri üzerinde XOR işlemi gerçekleştirir.
CEIL - Aktarılan değerden büyük veya ona eşit olan ilk tamsayıyı döndürür.
COS, COSH, COT ((Bu işlevler, argümanın trigonometrik değerini döndürür)
EXP - Geçirilen değerin gücüne yükseltilmiş doğal logaritma e tabanının sonucunu döndürür.
FLOOR - Sayısal bağımsız değişkenden büyük olmayan en büyük tamsayıyı döndürür.
HEXTOBIN - Onaltılık bir değeri ikili bir değere dönüştürür.
LN - Argümanın doğal logaritmasını döndürür.
LOG- Geçilen pozitif bir değerin algoritma değerini döndürür. Hem taban hem de günlük değeri pozitif olmalıdır.
Çeşitli diğer sayısal işlevler de kullanılabilir - MOD, GÜÇ, RAND, YUVARLAK, İŞARET, SIN, SINH, SQRT, TAN, TANH, UMINUS
String Fonksiyonları
HANA'da SQL komut dosyası ile çeşitli SQL dizge işlevleri kullanılabilir. En yaygın dize işlevleri şunlardır -
ASCII - Aktarılan dizgenin ASCII tamsayı değerini döndürür.
CHAR - Aktarılan ASCII değeriyle ilişkili karakteri döndürür.
CONCAT - Birleştirme operatörüdür ve birleştirilmiş geçirilen dizeleri döndürür.
LCASE - Bir dizenin tüm karakterlerini Küçük harfe dönüştürür.
LEFT - Belirtilen değere göre iletilen dizenin ilk karakterlerini döndürür.
LENGTH - Aktarılan dizedeki karakter sayısını döndürür.
LOCATE - İletilen dizge içindeki alt dizenin konumunu döndürür.
LOWER - Dize içindeki tüm karakterleri küçük harfe dönüştürür.
NCHAR - Geçilen tamsayı değerine sahip Unicode karakterini döndürür.
REPLACE - Arama dizesinin tüm oluşumlarını geçen orijinal dizede arar ve bunları değiştirme dizesi ile değiştirir.
RIGHT - Belirtilen dizenin en sağdaki geçirilen değer karakterlerini döndürür.
UPPER - Aktarılan dizedeki tüm karakterleri büyük harfe dönüştürür.
UCASE- UPPER işleviyle aynıdır. Aktarılan dizedeki tüm karakterleri büyük harfe dönüştürür.
Kullanılabilecek diğer dizi işlevleri şunlardır: LPAD, LTRIM, RTRIM, STRTOBIN, SUBSTR_AFTER, SUBSTR_BEFORE, SUBSTRING, TRIM, UNICODE, RPAD, BINTOSTR
Tarih Saat işlevleri
SQL betiklerinde HANA'da kullanılabilen çeşitli Tarih Saat fonksiyonları vardır. En yaygın Tarih Saat işlevleri şunlardır:
CURRENT_DATE - Geçerli yerel sistem tarihini döndürür.
CURRENT_TIME - Geçerli yerel sistem saatini döndürür.
CURRENT_TIMESTAMP - Geçerli yerel sistem zaman damgası ayrıntılarını döndürür (YYYY-AA-GG SS: DD: SS: FF).
CURRENT_UTCDATE - Geçerli UTC (Greenwich Ortalama tarihi) tarihini döndürür.
CURRENT_UTCTIME - Geçerli UTC (Greenwich Ortalama Saati) saatini döndürür.
CURRENT_UTCTIMESTAMP
DAYOFMONTH - Argümanda geçen tarihte günün tamsayı değerini döndürür.
HOUR - Argümanda geçen zamanda saatin tamsayı değerini döndürür.
YEAR - Geçen tarihin yıl değerini döndürür.
Diğer Tarih Saat işlevleri şunlardır: DAYOFYEAR, DAYNAME, DAYS_BETWEEN, EXTRACT, NANO100_BETWEEN, NEXT_DAY, NOW, QUARTER, SECOND, SECONDS_BETWEEN, UTCTOLOCAL, WEEK, WEEKDAY, WORKDAYS_BETTHDAYSDAY, WEEKDAY, WORKDAYS_BETTHDAYSDAYSDAY, ADNDAYS_BETTHDAYSDAYSDAY ADD_SECONDS, ADD_WORKDAYS
Veri Türü Dönüştürme İşlevleri
Bu işlevler, bir veri türünü diğerine dönüştürmek veya dönüştürmenin mümkün olup olmadığını kontrol etmek için kullanılır.
SQL betiklerinde HANA'da kullanılan en yaygın veri türü dönüştürme işlevleri -
CAST - Sağlanan veri türüne dönüştürülmüş bir ifadenin değerini döndürür.
TO_ALPHANUM - Geçilen bir değeri ALFANUM veri türüne dönüştürür
TO_REAL - Bir değeri GERÇEK veri türüne dönüştürür.
TO_TIME - Geçen zaman dizesini TIME veri türüne dönüştürür.
TO_CLOB - Bir değeri CLOB veri türüne dönüştürür.
Diğer benzer Veri Türü dönüştürme işlevleri şunlardır: TO_BIGINT, TO_BINARY, TO_BLOB, TO_DATE, TO_DATS, TO_DECIMAL, TO_DOUBLE, TO_FIXEDCHAR, TO_INT, TO_INTEGER, TO_NCLOB, TO_NVARCHAR, TO_TIMMESTAMP, TO_NCLOB, TO_NVARCHAR, TO_TIMMESTAMP, TOIM_TINAR_INT, TO_VARCHAR
HANA SQL betiklerinde kullanılabilen çeşitli Windows ve diğer çeşitli işlevler de vardır.
Current_Schema - Mevcut şema adını içeren bir dize döndürür.
Session_User - Mevcut oturumun kullanıcı adını döndürür
Değerleri döndürmek için bir cümleyi değerlendirmek için bir İfade kullanılır. HANA'da kullanılabilecek farklı SQL ifadeleri vardır -
- Durum İfadeleri
- İşlev İfadeleri
- Toplu İfadeler
- İfadelerde Alt Sorgular
Durum İfadesi
Bu, bir SQL ifadesindeki birden çok koşulu geçirmek için kullanılır. SQL deyimlerinde prosedürler kullanmadan IF-ELSE-THEN mantığının kullanımına izin verir.
Misal
SELECT COUNT( CASE WHEN sal < 2000 THEN 1 ELSE NULL END ) count1,
COUNT( CASE WHEN sal BETWEEN 2001 AND 4000 THEN 1 ELSE NULL END ) count2,
COUNT( CASE WHEN sal > 4000 THEN 1 ELSE NULL END ) count3 FROM emp;Bu ifade, geçirilen koşula göre tamsayı değeriyle count1, count2, count3 döndürür.
İşlev İfadeleri
İşlev ifadeleri, İfadelerde kullanılacak SQL dahili işlevlerini içerir.
Toplu İfadeler
Toplama işlevleri, Toplama, Yüzde, Min, Maks, Sayma, Mod, Medyan vb. Gibi karmaşık hesaplamaları gerçekleştirmek için kullanılır. Toplama İfadesi, birden çok değerden tek bir değeri hesaplamak için Toplama işlevlerini kullanır.
Aggregate Functions- Toplam, Sayım, Minimum, Maksimum. Bunlar ölçü değerlerine (gerçekler) uygulanır ve her zaman bir boyutla ilişkilendirilir.
Ortak toplama işlevleri şunları içerir -
- Ortalama ()
- Miktar ()
- Maksimum ()
- Medyan ()
- Minimum ()
- Mod ()
- Toplam ()
İfadelerde Alt Sorgular
İfade olarak alt sorgu bir Select ifadesidir. Bir ifadede kullanıldığında, sıfır veya tek bir değer döndürür.
Bir alt sorgu, alınacak verileri daha da kısıtlamak için bir koşul olarak ana sorguda kullanılacak verileri döndürmek için kullanılır.
Alt sorgular SELECT, INSERT, UPDATE ve DELETE ifadeleriyle birlikte =, <,>,> =, <=, IN, BETWEEN vb. Gibi işleçlerle kullanılabilir.
Alt sorguların uyması gereken birkaç kural vardır -
Alt sorgular parantez içine alınmalıdır.
Alt sorgunun seçili sütunlarını karşılaştırması için ana sorguda birden çok sütun olmadığı sürece, bir alt sorgunun SELECT yan tümcesinde yalnızca bir sütun olabilir.
ORDER BY, bir alt sorguda kullanılamaz, ancak ana sorgu ORDER BY kullanabilir. GROUP BY, bir alt sorguda ORDER BY ile aynı işlevi gerçekleştirmek için kullanılabilir.
Birden fazla satır döndüren alt sorgular yalnızca, IN operatörü gibi birden çok değer operatörüyle kullanılabilir.
SEÇİM listesi, BLOB, ARRAY, CLOB veya NCLOB olarak değerlendirilen değerlere herhangi bir referans içeremez.
Bir alt sorgu, bir küme işlevinin içine hemen eklenemez.
BETWEEN operatörü bir alt sorgu ile kullanılamaz; ancak, BETWEEN operatörü alt sorgu içinde kullanılabilir.
SELECT İfadesine sahip alt sorgular
Alt sorgular en çok SELECT deyimiyle kullanılır. Temel sözdizimi aşağıdaki gibidir -
Misal
SELECT * FROM CUSTOMERS
WHERE ID IN (SELECT ID
FROM CUSTOMERS
WHERE SALARY > 4500) ;+----+----------+-----+---------+----------+
| ID | NAME | AGE | ADDRESS | SALARY |
+----+----------+-----+---------+----------+
| 4 | Chaitali | 25 | Mumbai | 6500.00 |
| 5 | Hardik | 27 | Bhopal | 8500.00 |
| 7 | Muffy | 24 | Indore | 10000.00 |
+----+----------+-----+---------+----------+Bir prosedür, SQL ifadesini tek bir blok halinde gruplamanıza izin verir. Depolanan Prosedürler, uygulamalar arasında belirli bir sonuca ulaşmak için kullanılır. SQL deyimleri kümesi ve bazı belirli görevleri gerçekleştirmek için kullanılan mantık, SQL Depolanan Prosedürlerde saklanır. Bu saklı yordamlar, bu görevi gerçekleştirmek için uygulamalar tarafından yürütülür.
Depolanan Prosedürler, çıktı parametreleri (tamsayı veya karakter) veya bir imleç değişkeni biçiminde veri döndürebilir. Ayrıca, diğer Depolanan Prosedürler tarafından kullanılan Seçim ifadeleri kümesiyle de sonuçlanabilir.
Depolanan Prosedürler ayrıca, bir dizi SQL ifadesi içerdiğinden ve bir dizi ifadenin sonuçları yürütülecek bir sonraki ifade kümesini belirlediğinden performans optimizasyonu için kullanılır. Saklanan prosedürler, kullanıcıların bir veritabanındaki tabloların karmaşıklığını ve ayrıntılarını görmesini engeller. Depolanan prosedürler belirli iş mantığını içerdiğinden, kullanıcıların prosedür adını yürütmesi veya çağırması gerekir.
Tek tek ifadeleri yeniden yayınlamaya gerek yoktur, ancak veritabanı prosedürüne başvurabilir.
Prosedür Oluşturmak için Örnek Açıklama
Create procedure prc_name (in inp integer, out opt "EFASION"."ARTICLE_LOOKUP")
as
begin
opt = select * from "EFASION"."ARTICLE_LOOKUP" where article_id = :inp ;
end;Bir dizi, talep üzerine sırayla üretilen 1, 2, 3 tamsayıları kümesidir. Diziler sıklıkla veritabanlarında kullanılır çünkü birçok uygulama bir tablodaki her satırın benzersiz bir değer içermesini gerektirir ve diziler bunları oluşturmak için kolay bir yol sağlar.
AUTO_INCREMENT sütunu kullanılıyor
MySQL'de dizileri kullanmanın en basit yolu, bir sütunu AUTO_INCREMENT olarak tanımlamak ve geri kalan şeyleri ilgilenmesi için MySQL'e bırakmaktır.
Misal
Aşağıdaki örneği deneyin. Bu, tablo oluşturacak ve bundan sonra bu tabloya, MySQL tarafından otomatik olarak artırıldığı için kayıt kimliği vermenin gerekli olmadığı birkaç satır ekleyecektir.
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);
Query OK, 0 rows affected (0.02 sec)
mysql> INSERT INTO INSECT (id,name,date,origin) VALUES
-> (NULL,'housefly','2001-09-10','kitchen'),
-> (NULL,'millipede','2001-09-10','driveway'),
-> (NULL,'grasshopper','2001-09-10','front yard');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM INSECT ORDER BY id;+----+-------------+------------+------------+
| id | name | date | origin |
+----+-------------+------------+------------+
| 1 | housefly | 2001-09-10 | kitchen |
| 2 | millipede | 2001-09-10 | driveway |
| 3 | grasshopper | 2001-09-10 | front yard |
+----+-------------+------------+------------+
3 rows in set (0.00 sec)AUTO_INCREMENT Değerlerini Alın
LAST_INSERT_ID () bir SQL işlevidir, bu nedenle onu SQL ifadelerinin nasıl yayınlanacağını anlayan herhangi bir istemcinin içinden kullanabilirsiniz. Aksi takdirde, PERL ve PHP betikleri, son kaydın otomatik olarak artan değerini almak için özel işlevler sağlar.
PERL Örneği
Bir sorgu tarafından oluşturulan AUTO_INCREMENT değerini elde etmek için mysql_insertid özniteliğini kullanın. Bu özniteliğe, sorguyu nasıl yayınladığınıza bağlı olarak bir veritabanı tanıtıcısı veya bir ifade tutamacıyla erişilir. Aşağıdaki örnek, buna veritabanı tanıtıcısı aracılığıyla başvurur -
$dbh->do ("INSERT INTO INSECT (name,date,origin) VALUES('moth','2001-09-14','windowsill')"); my $seq = $dbh->{mysql_insertid};PHP Örneği
AUTO_INCREMENT değeri üreten bir sorgu gönderdikten sonra, mysql_insert_id () 'i çağırarak değeri alın -
mysql_query ("INSERT INTO INSECT (name,date,origin)
VALUES('moth','2001-09-14','windowsill')", $conn_id);
$seq = mysql_insert_id ($conn_id);Mevcut Bir Sırayı Yeniden Numaralandırma
Bir tablodan çok sayıda kayıt sildiğiniz ve tüm kayıtları yeniden sıralamak istediğiniz bir durum olabilir. Bu, basit bir numara kullanılarak yapılabilir, ancak masanız diğer masayla birleştiriliyorsa bunu yapmak için çok dikkatli olmalısınız.
Bir AUTO_INCREMENT sütununun yeniden dizilmesinin kaçınılmaz olduğunu belirlerseniz, bunu yapmanın yolu sütunu tablodan bırakıp tekrar eklemektir. Aşağıdaki örnek, bu tekniği kullanarak böcek tablosundaki id değerlerinin nasıl yeniden numaralandırılacağını gösterir -
mysql> ALTER TABLE INSECT DROP id;
mysql> ALTER TABLE insect
-> ADD id INT UNSIGNED NOT NULL AUTO_INCREMENT FIRST,
-> ADD PRIMARY KEY (id);Sıraya Belirli Bir Değerden Başlama
MySQL varsayılan olarak 1'den başlayacaktır, ancak tablo oluşturma sırasında başka herhangi bir sayıyı da belirtebilirsiniz. Aşağıda MySQL'in diziyi 100'den başlayacağı örnek verilmiştir.
mysql> CREATE TABLE INSECT
-> (
-> id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100,
-> PRIMARY KEY (id),
-> name VARCHAR(30) NOT NULL, # type of insect
-> date DATE NOT NULL, # date collected
-> origin VARCHAR(30) NOT NULL # where collected
);Alternatif olarak, tabloyu oluşturabilir ve ardından ALTER TABLE ile ilk sıra değerini ayarlayabilirsiniz.
Tetikleyiciler, bazı olaylar meydana geldiğinde otomatik olarak yürütülen veya tetiklenen kayıtlı programlardır. Tetikleyiciler, aslında, aşağıdaki olaylardan herhangi birine yanıt olarak yürütülecek şekilde yazılmıştır:
Bir veritabanı işleme (DML) ifadesi (DELETE, INSERT veya UPDATE).
Bir veritabanı tanımı (DDL) ifadesi (CREATE, ALTER veya DROP).
Bir veritabanı işlemi (SUNUCU HATASI, OTURUM AÇMA, LOGOFF, BAŞLATMA veya KAPATMA).
Tetikleyiciler, olayın ilişkilendirildiği tablo, görünüm, şema veya veritabanı üzerinde tanımlanabilir.
Tetikleyicilerin Faydaları
Tetikleyiciler aşağıdaki amaçlar için yazılabilir -
- Bazı türetilmiş sütun değerlerini otomatik olarak oluşturma
- Bilgi tutarlılığını zorunlu kılma
- Olay günlüğü ve tablo erişimi hakkında bilgi saklama
- Auditing
- Tabloların eşzamanlı çoğaltılması
- Güvenlik yetkilerinin dayatılması
- Geçersiz işlemlerin önlenmesi
SQL Eş anlamlıları, bir veritabanındaki tablo veya Şema nesnesi için bir takma addır. İstemci uygulamalarını bir nesnenin adı veya konumunda yapılan değişikliklerden korumak için kullanılırlar.
Eş anlamlılar, uygulamaların, tablonun sahibi olan ve hangi veritabanının tablo veya nesneyi barındırdığından bağımsız olarak çalışmasına izin verir.
Eşanlamlı ifade oluştur ifadesi, tablo, görünüm, paket, prosedür, nesneler vb. İçin Eşanlamlı oluşturmak için kullanılır.
Misal
Bir Sunucu1'de bulunan efashion Müşteri tablosu var. Buna Sunucu2'den erişmek için, bir istemci uygulamasının adı Sunucu1.efashion.Customer olarak kullanması gerekir. Şimdi, Müşteri tablosunun konumunu değiştiriyoruz, istemci uygulamasının değişikliği yansıtacak şekilde değiştirilmesi gerekecek.
Bunları ele almak için, Sunucu1'deki tablo için Sunucu2'de Müşteri tablosu Cust_Table'ın eşanlamlıını oluşturabiliriz. Şimdi istemci uygulamasının bu tabloya başvurmak için Cust_Table tek parça adını kullanması gerekiyor. Şimdi, bu tablonun konumu değişirse, eşanlamlıyı tablonun yeni konumuna işaret edecek şekilde değiştirmeniz gerekecektir.
ALTER SYNONYM ifadesi olmadığından, Cust_Table eşanlamlıını bırakmanız ve ardından aynı isimle eşanlamlıyı yeniden oluşturmanız ve eşanlamlıyı Müşteri tablosunun yeni konumuna yönlendirmeniz gerekir.
Herkese Açık Eşanlamlılar
Genel Eş anlamlılar, bir veritabanındaki PUBLIC şemasına aittir. Genel eş anlamlılar veritabanındaki tüm kullanıcılar tarafından referans alınabilir. Uygulama sahibi tarafından tablolar ve prosedürler ve paketler gibi diğer nesneler için oluşturulurlar, böylece uygulama kullanıcıları nesneleri görebilir.
Sözdizimi
CREATE PUBLIC SYNONYM Cust_table for efashion.Customer;Bir KAMU Eşanlamlısı oluşturmak için, PUBLIC anahtar kelimesini gösterildiği gibi kullanmanız gerekir.
Özel Eşanlamlılar
Özel Eşanlamlılar bir veritabanı şemasında bir tablonun, prosedürün, görünümün veya başka herhangi bir veritabanı nesnesinin gerçek adını gizlemek için kullanılır.
Özel eşanlamlılara yalnızca tablo veya nesnenin sahibi olan şema tarafından başvurulabilir.
Sözdizimi
CREATE SYNONYM Cust_table FOR efashion.Customer;Bir Eşanlamlı Bırak
Eşanlamlılar DROP Eşanlamlı komutu kullanılarak bırakılabilir. Genel bir Eşanlamlıyı kaldırıyorsanız, anahtar kelimeyi kullanmanız gerekirpublic drop ifadesinde.
Sözdizimi
DROP PUBLIC Synonym Cust_table;
DROP Synonym Cust_table;SQL açıklama planları, SQL ifadelerinin ayrıntılı açıklamasını oluşturmak için kullanılır. SAP HANA veritabanının SQL ifadelerini yürütmek için izlediği yürütme planını değerlendirmek için kullanılırlar.
Açıklama planının sonuçları, değerlendirme için EXPLAIN_PLAN_TABLE'a kaydedilir. Açıklama Planı kullanmak için, geçirilen SQL sorgusu bir veri işleme dili (DML) olmalıdır.
Yaygın DML İfadeleri
SELECT - bir veritabanından veri almak
INSERT - bir tabloya veri eklemek
UPDATE - bir tablo içindeki mevcut verileri günceller
SQL Açıklama Planları DDL ve DCL SQL ifadeleriyle kullanılamaz.
Veritabanındaki PLAN TABLOSUNU AÇIKLAYIN
EXPLAIN PLAN_TABLE veritabanında birden çok sütundan oluşur. Birkaç yaygın sütun adı - OPERATOR_NAME, OPERATOR_ID, PARENT_OPERATOR_ID, LEVEL ve POSITION, vb.
SÜTUN ARAMA değeri sütun motoru operatörlerinin başlangıç konumunu belirtir.
SATIR ARAMA değeri, sıralı motor operatörlerinin başlangıç konumunu belirtir.
SQL sorgusu için AÇIKLAMA PLAN İFADESİ oluşturmak için
EXPLAIN PLAN SET STATEMENT_NAME = ‘statement_name’ FOR <SQL DML statement>DEĞERLERİ AÇIK PLAN TABLOSUNDA görmek için
SELECT Operator_Name, Operator_ID
FROM explain_plan_table
WHERE statement_name = 'statement_name';EXPLAIN PLAN TABLE'deki bir ifadeyi silmek için
DELETE FROM explain_plan_table WHERE statement_name = 'TPC-H Q10';SQL Veri Profili Oluşturma görevi, birden çok veri kaynağından gelen verileri anlamak ve analiz etmek için kullanılır. Veri ambarına yüklenmeden önce yanlış, eksik verileri kaldırmak ve veri kalitesi sorunlarını önlemek için kullanılır.
SQL Veri Profili Oluşturma görevlerinin avantajları şunlardır:
Kaynak verinin daha etkili bir şekilde analiz edilmesine yardımcı olur.
Kaynak verilerin daha iyi anlaşılmasına yardımcı olur.
Hatalı, eksik verileri kaldırır ve Veri ambarına yüklenmeden önce veri kalitesini iyileştirir.
Ekstraksiyon, Dönüştürme ve Yükleme görevi ile kullanılır.
Veri Profili Oluşturma görevi, bir veri kaynağını anlamaya ve düzeltilmesi gereken verilerdeki sorunları belirlemeye yardımcı olan profilleri kontrol eder.
SQL Server'da depolanan verilerin profilini çıkarmak ve veri kalitesiyle ilgili olası sorunları belirlemek için Entegrasyon Hizmetleri paketindeki Veri Profili Oluşturma görevini kullanabilirsiniz.
Note - Veri Profili Oluşturma Görevi yalnızca SQL Server veri kaynaklarıyla çalışır ve diğer dosya tabanlı veya üçüncü taraf veri kaynaklarını desteklemez.
Erişim Gereksinimi
Veri Profil Oluşturma görevi içeren bir paketi çalıştırmak için, kullanıcı hesabının tempdb veritabanında CREATE TABLE izinlerine sahip okuma / yazma izinlerine sahip olması gerekir.
Veri Profilcisi Görüntüleyicisi
Veri Profili Görüntüleyicisi, profil oluşturucu çıktısını incelemek için kullanılır. Veri Profili Görüntüleyicisi ayrıca profil çıktısında tanımlanan veri kalitesi sorunlarını anlamanıza yardımcı olacak ayrıntılı inceleme özelliğini de destekler. Bu ayrıntılı inceleme özelliği, canlı sorguları orijinal veri kaynağına gönderir.
Veri Profili Oluşturma Görevi Kurulumu ve İncelenmesi
Veri Profili Oluşturma Görevini Ayarlama
Profilleri hesaplamak için Veri Profili Oluşturma görevini içeren bir paketin yürütülmesini içerir. Görev, çıktıyı XML biçiminde bir dosyaya veya paket değişkenine kaydeder.
Profilleri İnceleme
Veri profillerini görüntülemek için çıktıyı bir dosyaya gönderin ve ardından Veri Profili Görüntüleyicisini kullanın. Bu görüntüleyici, profil çıktısını hem özet hem de ayrıntı biçiminde, isteğe bağlı ayrıntılı inceleme özelliğiyle görüntüleyen bağımsız bir yardımcı programdır.
Veri Profili Oluşturma - Yapılandırma Seçenekleri
Veri Profili Oluşturma görevi şu uygun yapılandırma seçeneklerine sahiptir -
Joker karakter sütunları
Bir profil isteğini yapılandırırken görev, sütun adı yerine '*' joker karakterini kabul eder. Bu, yapılandırmayı basitleştirir ve bilinmeyen verilerin özelliklerini keşfetmeyi kolaylaştırır. Görev çalıştığında, görev, uygun veri türüne sahip her sütunu profiller.
Hızlı Profil
Görevi hızlı bir şekilde yapılandırmak için Hızlı Profil'i seçebilirsiniz. Hızlı Profil, tüm varsayılan profilleri ve ayarları kullanarak bir tablo veya görünümün profilini çıkarır.
Veri Profili Oluşturma Görevi, sekiz farklı veri profilini hesaplayabilir. Bu profillerden beşi tek tek sütunları kontrol edebilir ve kalan üçü birden çok sütunu veya sütunlar arasındaki ilişkileri analiz edebilir.
Veri Profili Oluşturma - Görev Çıktıları
Veri Profili Oluşturma görevi, seçilen profilleri DataProfile.xsd şeması gibi yapılandırılmış XML biçiminde çıkarır.
Şemanın yerel bir kopyasını kaydedebilir ve şemanın yerel kopyasını Microsoft Visual Studio'da veya başka bir şema düzenleyicide, bir XML düzenleyicide veya Not Defteri gibi bir metin düzenleyicide görüntüleyebilirsiniz.
Geliştiricinin karmaşık mantığı veritabanına geçirmesine izin veren HANA veritabanı için SQL ifadeleri kümesi SQL Komut Dosyası olarak adlandırılır. SQL Script, SQL uzantılarının koleksiyonları olarak bilinir. Bu uzantılar Veri Uzantıları, İşlev Uzantıları ve Prosedür Uzantısı'dır.
SQL Script, depolanmış İşlevleri ve Prosedürleri destekler ve bu, Uygulama mantığının karmaşık bölümlerinin veritabanına aktarılmasına olanak tanır.
SQL Script kullanmanın ana yararı, karmaşık hesaplamaların SAP HANA veritabanı içinde yürütülmesine izin vermektir. Tek sorgu yerine SQL Komut Dosyalarının kullanılması, İşlevlerin birden çok değer döndürmesini sağlar. Karmaşık SQL işlevleri daha da küçük işlevlere ayrıştırılabilir. SQL Komut Dosyası, tek SQL deyiminde bulunmayan kontrol mantığı sağlar.
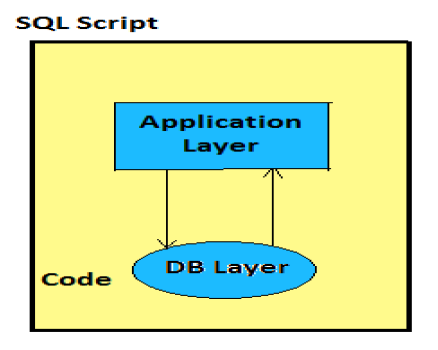
SQL Komut Dosyaları, DB katmanında komut dosyaları çalıştırarak HANA'da performans optimizasyonu elde etmek için kullanılır -
Veritabanı katmanında SQL betikleri çalıştırarak, büyük miktarda veriyi veritabanından uygulamaya aktarma ihtiyacını ortadan kaldırır.
Hesaplamalar, sütun işlemleri, sorguların paralel olarak işlenmesi gibi HANA veri tabanından faydalanmak için veri tabanı katmanında yürütülür
Bilgi Modelleyici ile Entegrasyon
Bilgi Modelleyicide SQL betikleri kullanılırken aşağıda verilen Prosedürler için geçerlidir -
- Giriş parametreleri skaler veya tablo tipinde olabilir.
- Çıkış parametreleri tablo tiplerinde olmalıdır.
- İmza için gerekli olan tablo türleri otomatik olarak oluşturulur.
Hesaplama Görünümlü SQL Komut Dosyaları
SQL betiği, betik tabanlı Hesaplama görünümleri oluşturmak için kullanılır. Mevcut ham tablolara veya sütun deposuna karşı SQL ifadeleri yazın. Çıktı yapısını tanımlayın, görünümün etkinleştirilmesi yapıya göre tablo tipi oluşturur.
SQL Script ile Hesaplama Görünümü nasıl oluşturulur?
Launch SAP HANA studio. İçerik düğümünü genişletin → Yeni Hesaplama görünümünü oluşturmak istediğiniz bir paket seçin. Sağ Tıklama → Yeni Hesaplama Görünümü Gezinme yolunun sonu → Ad ve açıklama girin.
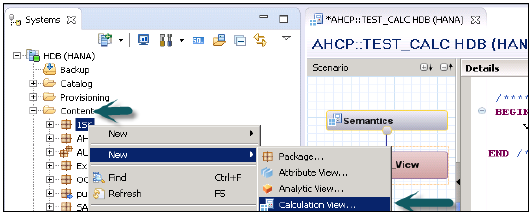
Select calculation view type → Tür açılır listesinden SQL Komut Dosyası → Hesaplama görünümünün çıktı parametreleri için adlandırma kuralına nasıl ihtiyaç duyduğunuza bağlı olarak Parametre Büyük / Küçük Harfe Duyarlıyı Doğru veya Yanlış Olarak Ayarla'yı seçin → Bitir'i seçin.
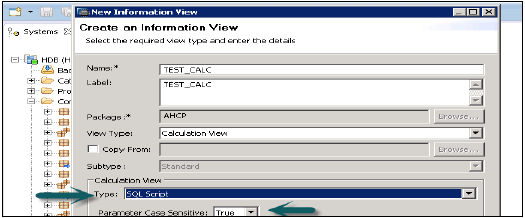
Select default schema - Semantik düğümünü seçin → Görünüm Özellikleri sekmesini seçin → Varsayılan Şema açılır listesinde varsayılan şemayı seçin.
Choose SQL Script node in the Semantics node→ Çıktı yapısını tanımlayın. Çıktı bölmesinde Hedef Oluştur'u seçin. Gerekli çıktı parametrelerini ekleyin ve uzunluğunu ve türünü belirtin.

Kod tabanlı hesaplama görünümlerinin çıktı yapısına mevcut bilgi görünümlerinin veya katalog tablolarının veya tablo işlevlerinin parçası olan birden çok sütun eklemek için -
Çıktı bölmesinde, Gezinme yolunun başlangıcını seçin Yeni Sonraki gezinme adımı Gezinme yolunun Sonundan Sütun Ekle → Çıktıya eklemek istediğiniz sütunları içeren nesnenin adı → Açılır listeden bir veya daha fazla nesne seçin → İleri'yi seçin.
Kaynak bölmesinde, çıktıya eklemek istediğiniz sütunları seçin → Çıkışa seçici sütunlar eklemek için, ardından bu sütunları seçin ve Ekle'yi seçin. Bir nesnenin tüm sütunlarını çıktıya eklemek için, nesneyi seçin ve Ekle → Son'u seçin.
Activate the script-based calculation view- SAP HANA Modeler perspektifinde - Kaydet ve Etkinleştir - mevcut görünümü etkinleştirmek ve etkilenen nesnenin etkin bir sürümü mevcutsa etkilenen nesneleri yeniden dağıtmak için. Aksi takdirde, yalnızca mevcut görünüm etkinleştirilir.
Save and activate all - mevcut görünümü gerekli ve etkilenen nesnelerle birlikte etkinleştirmek için.
In the SAP HANA Development perspective- Proje Gezgini görünümünde gerekli nesneyi seçin. Bağlam menüsünde, navigasyon yolunun başlangıcını seçin Takım Sonraki gezinme adımı Gezinme yolunun sonunu etkinleştirin.
HANA Information Modeler'da SQL Scripting, GUI seçeneğini kullanarak oluşturulması mümkün olmayan karmaşık Hesaplama Görünümleri oluşturmak için kullanılır.