Spark SQL - Giriş
Spark, Spark SQL adlı yapılandırılmış veri işleme için bir programlama modülü sunar. DataFrame adlı bir programlama soyutlaması sağlar ve dağıtılmış SQL sorgu motoru olarak işlev görebilir.
Spark SQL'in Özellikleri
Aşağıdakiler Spark SQL'in özellikleridir -
Integrated- SQL sorgularını Spark programlarıyla sorunsuz bir şekilde karıştırın. Spark SQL, Python, Scala ve Java'daki entegre API'ler ile yapılandırılmış verileri Spark'ta dağıtılmış bir veri kümesi (RDD) olarak sorgulamanıza olanak tanır. Bu sıkı entegrasyon, karmaşık analitik algoritmalarla birlikte SQL sorgularının çalıştırılmasını kolaylaştırır.
Unified Data Access- Çeşitli kaynaklardan veri yükleyin ve sorgulayın. Schema-RDD'ler, Apache Hive tabloları, parke dosyaları ve JSON dosyaları dahil olmak üzere yapılandırılmış verilerle verimli bir şekilde çalışmak için tek bir arabirim sağlar.
Hive Compatibility- Mevcut ambarlarda değiştirilmemiş Hive sorguları çalıştırın. Spark SQL, Hive ön ucunu ve MetaStore'u yeniden kullanarak size mevcut Hive verileri, sorguları ve UDF'lerle tam uyumluluk sağlar. Basitçe Hive ile birlikte kurun.
Standard Connectivity- JDBC veya ODBC üzerinden bağlanın. Spark SQL, endüstri standardı JDBC ve ODBC bağlantısına sahip bir sunucu modu içerir.
Scalability- Hem etkileşimli hem de uzun sorgular için aynı motoru kullanın. Spark SQL, orta sorgu hata toleransını desteklemek için RDD modelinden yararlanarak büyük işler için ölçeklendirilmesine de olanak tanır. Geçmiş veriler için farklı bir motor kullanma konusunda endişelenmeyin.
Spark SQL Mimarisi
Aşağıdaki çizim, Spark SQL'in mimarisini açıklamaktadır -
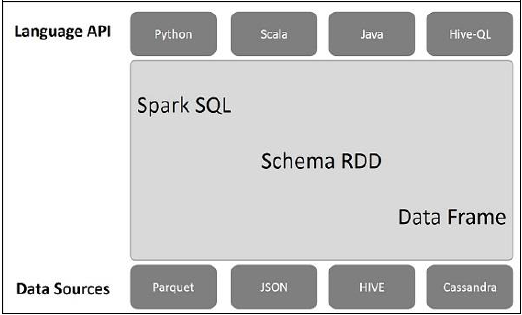
Bu mimari Dil API, Şema RDD ve Veri Kaynakları olmak üzere üç katman içerir.
Language API- Spark farklı diller ve Spark SQL ile uyumludur. Ayrıca bu diller tarafından desteklenmektedir - API (python, scala, java, HiveQL).
Schema RDD- Spark Core, RDD adı verilen özel veri yapısı ile tasarlanmıştır. Spark SQL genellikle şemalar, tablolar ve kayıtlar üzerinde çalışır. Bu nedenle Schema RDD'yi geçici tablo olarak kullanabiliriz. Bu Schema RDD'yi Data Frame olarak adlandırabiliriz.
Data Sources- Genellikle spark-core için Veri kaynağı bir metin dosyası, Avro dosyası, vs.'dir. Ancak, Spark SQL için Veri Kaynakları farklıdır. Bunlar Parquet dosyası, JSON belgesi, HIVE tabloları ve Cassandra veritabanıdır.
Sonraki bölümlerde bunlar hakkında daha fazla tartışacağız.