Sqoop - Hızlı Kılavuz
Geleneksel uygulama yönetim sistemi, yani uygulamaların RDBMS kullanarak ilişkisel veritabanı ile etkileşimi, Büyük Veri üreten kaynaklardan biridir. RDBMS tarafından üretilen bu tür Büyük Veriler, İlişkiselDatabase Servers ilişkisel veritabanı yapısında.
Hadoop ekosisteminin MapReduce, Hive, HBase, Cassandra, Pig vb. Büyük Veri depoları ve analizörleri ortaya çıktığında, içlerinde bulunan Büyük Verileri içe ve dışa aktarmak için ilişkisel veritabanı sunucularıyla etkileşime girecek bir araca ihtiyaç duydular. Burada Sqoop, ilişkisel veritabanı sunucusu ile Hadoop'un HDFS'si arasında uygun etkileşim sağlamak için Hadoop ekosisteminde bir yere sahiptir.
Sqoop - "SQL'den Hadoop'a ve Hadoop'tan SQL'e"
Sqoop, verileri Hadoop ve ilişkisel veritabanı sunucuları arasında aktarmak için tasarlanmış bir araçtır. MySQL, Oracle gibi ilişkisel veritabanlarından Hadoop HDFS'ye veri almak ve Hadoop dosya sisteminden ilişkisel veritabanlarına dışa aktarmak için kullanılır. Apache Software Foundation tarafından sağlanır.
Sqoop Nasıl Çalışır?
Aşağıdaki görüntü Sqoop'un iş akışını açıklamaktadır.
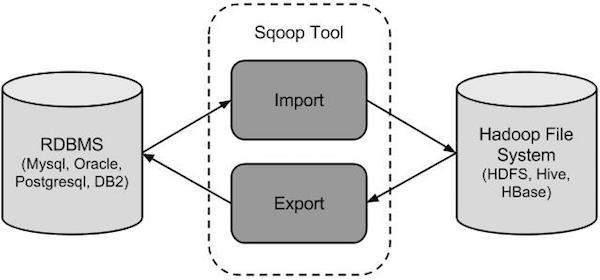
Sqoop İçe Aktarma
İçe aktarma aracı, tek tek tabloları RDBMS'den HDFS'ye aktarır. Tablodaki her satır, HDFS'de kayıt olarak kabul edilir. Tüm kayıtlar, metin dosyalarında metin verileri olarak veya Avro ve Sıra dosyalarında ikili veriler olarak saklanır.
Sqoop İhracat
Dışa aktarma aracı, bir dizi dosyayı HDFS'den bir RDBMS'ye geri aktarır. Sqoop'a girdi olarak verilen dosyalar, tabloda satırlar olarak adlandırılan kayıtları içerir. Bunlar okunur ve bir kayıt kümesine ayrıştırılır ve kullanıcı tanımlı sınırlayıcı ile sınırlandırılır.
Sqoop, Hadoop'un bir alt projesi olduğu için sadece Linux işletim sistemi üzerinde çalışabilir. Sqoop'u sisteminize kurmak için aşağıdaki adımları izleyin.
Adım 1: JAVA Kurulumunu Doğrulama
Sqoop'u kurmadan önce sisteminizde Java'nın kurulu olması gerekir. Aşağıdaki komutu kullanarak Java kurulumunu doğrulayalım -
$ java –versionJava sisteminizde zaten yüklüyse, aşağıdaki yanıtı görürsünüz -
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Sisteminizde Java kurulu değilse, aşağıda verilen adımları izleyin.
Java yükleme
Sisteminize Java yüklemek için aşağıda verilen basit adımları izleyin.
Aşama 1
Aşağıdaki bağlantıyı ziyaret ederek Java'yı (JDK <en son sürüm> - X64.tar.gz) indirin .
Daha sonra jdk-7u71-linux-x64.tar.gz sisteminize indirilecektir.
Adım 2
Genel olarak, indirilen Java dosyasını İndirilenler klasöründe bulabilirsiniz. Doğrulayın ve aşağıdaki komutları kullanarak jdk-7u71-linux-x64.gz dosyasını çıkarın.
$ cd Downloads/
$ ls
jdk-7u71-linux-x64.gz
$ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzAşama 3
Java'yı tüm kullanıcılar için kullanılabilir hale getirmek için, onu "/ usr / local /" konumuna taşımalısınız. Kökü açın ve aşağıdaki komutları yazın.
$ su
password:
# mv jdk1.7.0_71 /usr/local/java
# exitStep IV:4. adım
PATH ve JAVA_HOME değişkenlerini ayarlamak için aşağıdaki komutları ~ / .bashrc dosyasına ekleyin.
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/binŞimdi tüm değişiklikleri mevcut çalışan sisteme uygulayın.
$ source ~/.bashrcAdım 5
Java alternatiflerini yapılandırmak için aşağıdaki komutları kullanın -
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2
# alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2
# alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2
# alternatives --set java usr/local/java/bin/java
# alternatives --set javac usr/local/java/bin/javac
# alternatives --set jar usr/local/java/bin/jarŞimdi komutu kullanarak kurulumu doğrulayın java -version terminalden yukarıda açıklandığı gibi.
Adım 2: Hadoop Kurulumunu Doğrulama
Sqoop'u kurmadan önce sisteminize Hadoop kurulmalıdır. Aşağıdaki komutu kullanarak Hadoop kurulumunu doğrulayalım -
$ hadoop versionHadoop sisteminize zaten yüklüyse, aşağıdaki yanıtı alırsınız -
Hadoop 2.4.1
--
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Sisteminizde Hadoop yüklü değilse, aşağıdaki adımlarla devam edin -
Hadoop'u indirme
Aşağıdaki komutları kullanarak Apache Software Foundation'dan Hadoop 2.4.1'i indirin ve çıkarın.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitHadoop'u Sözde Dağıtılmış Modda Yükleme
Hadoop 2.4.1'i sözde dağıtılmış modda kurmak için aşağıdaki adımları izleyin.
1. Adım: Hadoop'u Kurma
Aşağıdaki komutları ~ / .bashrc dosyasına ekleyerek Hadoop ortam değişkenlerini ayarlayabilirsiniz.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binŞimdi, tüm değişiklikleri mevcut çalışan sisteme uygulayın.
$ source ~/.bashrc2. Adım: Hadoop Yapılandırması
Tüm Hadoop yapılandırma dosyalarını “$ HADOOP_HOME / etc / hadoop” konumunda bulabilirsiniz. Bu konfigürasyon dosyalarında Hadoop altyapınıza göre uygun değişiklikleri yapmanız gerekir.
$ cd $HADOOP_HOME/etc/hadoopJava kullanarak Hadoop programları geliştirmek için, java ortam değişkenlerini sıfırlamanız gerekir. hadoop-env.sh JAVA_HOME değerini java'nın sisteminizdeki konumu ile değiştirerek.
export JAVA_HOME=/usr/local/javaAşağıda, Hadoop'u yapılandırmak için düzenlemeniz gereken dosyaların listesi verilmiştir.
core-site.xml
Core-site.xml dosyası, Hadoop örneği için kullanılan bağlantı noktası numarası, dosya sistemi için ayrılan bellek, verileri depolamak için bellek sınırı ve Okuma / Yazma arabelleklerinin boyutu gibi bilgileri içerir.
Core-site.xml dosyasını açın ve aşağıdaki özellikleri <configuration> ve </configuration> etiketleri arasına ekleyin.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000 </value>
</property>
</configuration>hdfs-site.xml
Hdfs-site.xml dosyası, yerel dosya sistemlerinizin çoğaltma verilerinin değeri, ad kodu yolu ve datanode yolu gibi bilgileri içerir. Hadoop altyapısını depolamak istediğiniz yer anlamına gelir.
Aşağıdaki verileri varsayalım.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeBu dosyayı açın ve bu dosyadaki <configuration>, </configuration> etiketleri arasına aşağıdaki özellikleri ekleyin.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>Note - Yukarıdaki dosyada tüm özellik değerleri kullanıcı tanımlıdır ve Hadoop altyapınıza göre değişiklik yapabilirsiniz.
yarn-site.xml
Bu dosya, ipliği Hadoop'ta yapılandırmak için kullanılır. İplik-site.xml dosyasını açın ve bu dosyadaki <configuration>, </configuration> etiketleri arasına aşağıdaki özellikleri ekleyin.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Bu dosya hangi MapReduce çerçevesini kullandığımızı belirtmek için kullanılır. Varsayılan olarak, Hadoop bir iplik-site.xml şablonu içerir. Öncelikle, aşağıdaki komutu kullanarak dosyayı mapred-site.xml.template'den mapred-site.xml dosyasına kopyalamanız gerekir.
$ cp mapred-site.xml.template mapred-site.xmlMapred-site.xml dosyasını açın ve bu dosyadaki <configuration>, </configuration> etiketleri arasına aşağıdaki özellikleri ekleyin.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hadoop Kurulumunu Doğrulama
Aşağıdaki adımlar Hadoop kurulumunu doğrulamak için kullanılır.
Adım 1: Düğüm Kurulumu Adlandırın
“Hdfs namenode -format” komutunu kullanarak ad kodunu aşağıdaki gibi ayarlayın.
$ cd ~
$ hdfs namenode -formatBeklenen sonuç aşağıdaki gibidir.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to
retain 1 images with txid >= 0
10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/2. Adım: Hadoop dfs'yi doğrulama
Aşağıdaki komut dfs'yi başlatmak için kullanılır. Bu komutu çalıştırmak Hadoop dosya sisteminizi başlatacaktır.
$ start-dfs.shBeklenen çıktı aşağıdaki gibidir -
10/24/14 21:37:56
Starting namenodes on [localhost]
localhost: starting namenode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-namenode-localhost.out
localhost: starting datanode, logging to /home/hadoop/hadoop-
2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Adım 3: İplik Komut Dosyasını Doğrulama
İplik betiğini başlatmak için aşağıdaki komut kullanılır. Bu komutun yürütülmesi iplik daemonlarınızı başlatacaktır.
$ start-yarn.shBeklenen çıktı aşağıdaki gibidir -
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out
localhost: starting node manager, logging to /home/hadoop/hadoop-
2.4.1/logs/yarn-hadoop-nodemanager-localhost.out4. Adım: Tarayıcıda Hadoop'a Erişim
Hadoop'a erişmek için varsayılan bağlantı noktası numarası 50070'tir. Tarayıcınızda Hadoop hizmetlerini almak için aşağıdaki URL'yi kullanın.
http://localhost:50070/Aşağıdaki görüntü bir Hadoop tarayıcısını göstermektedir.

5. Adım: Küme için Tüm Uygulamaları Doğrulayın
Kümenin tüm uygulamalarına erişmek için varsayılan bağlantı noktası numarası 8088'dir. Bu hizmeti ziyaret etmek için aşağıdaki url'yi kullanın.
http://localhost:8088/Aşağıdaki görüntü Hadoop küme tarayıcısını göstermektedir.

3. Adım: Sqoop'u İndirme
Sqoop'un en son sürümünü aşağıdaki bağlantıdan indirebiliriz Bu eğitim için 1.4.5 sürümünü kullanıyoruz, yani,sqoop-1.4.5.bin__hadoop-2.0.4-alpha.tar.gz.
Adım 4: Sqoop'u Kurma
Aşağıdaki komutlar Sqoop tar topunu çıkartmak ve onu "/ usr / lib / sqoop" dizinine taşımak için kullanılır.
$tar -xvf sqoop-1.4.4.bin__hadoop-2.0.4-alpha.tar.gz
$ su
password:
# mv sqoop-1.4.4.bin__hadoop-2.0.4-alpha /usr/lib/sqoop
#exitAdım 5: bashrc'yi yapılandırma
Aşağıdaki satırları ~ / satırına ekleyerek Sqoop ortamını kurmanız gerekir..bashrc dosya -
#Sqoop
export SQOOP_HOME=/usr/lib/sqoop export PATH=$PATH:$SQOOP_HOME/binAşağıdaki komut ~ / yürütmek için kullanılır.bashrc dosya.
$ source ~/.bashrcAdım 6: Sqoop'u Yapılandırma
Sqoop'u Hadoop ile yapılandırmak için, sqoop-env.sh yerleştirilen dosya $SQOOP_HOME/confdizin. Her şeyden önce, Sqoop yapılandırma dizinine yönlendirin ve aşağıdaki komutu kullanarak şablon dosyasını kopyalayın -
$ cd $SQOOP_HOME/conf
$ mv sqoop-env-template.sh sqoop-env.shAçık sqoop-env.sh ve aşağıdaki satırları düzenleyin -
export HADOOP_COMMON_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=/usr/local/hadoop7. Adım: mysql-connector-java'yı indirin ve yapılandırın
İndirebiliriz mysql-connector-java-5.1.30.tar.gzaşağıdaki bağlantıdan dosya .
Aşağıdaki komutlar mysql-connector-java tarball'ı ayıklamak ve taşımak için kullanılır mysql-connector-java-5.1.30-bin.jar / usr / lib / sqoop / lib dizinine.
$ tar -zxf mysql-connector-java-5.1.30.tar.gz
$ su
password:
# cd mysql-connector-java-5.1.30
# mv mysql-connector-java-5.1.30-bin.jar /usr/lib/sqoop/lib8. Adım: Sqoop'u doğrulama
Aşağıdaki komut Sqoop sürümünü doğrulamak için kullanılır.
$ cd $SQOOP_HOME/bin
$ sqoop-versionBeklenen çıktı -
14/12/17 14:52:32 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
Sqoop 1.4.5 git commit id 5b34accaca7de251fc91161733f906af2eddbe83
Compiled by abe on Fri Aug 1 11:19:26 PDT 2014Sqoop kurulumu tamamlandı.
Bu bölümde, verilerin MySQL veritabanından Hadoop HDFS'ye nasıl aktarılacağı açıklanmaktadır. 'İçe Aktarma aracı', tek tek tabloları RDBMS'den HDFS'ye aktarır. Tablodaki her satır, HDFS'de kayıt olarak kabul edilir. Tüm kayıtlar, metin dosyalarında metin verileri olarak veya Avro ve Sıra dosyalarında ikili veriler olarak saklanır.
Sözdizimi
Verileri HDFS'ye aktarmak için aşağıdaki sözdizimi kullanılır.
$ sqoop import (generic-args) (import-args)
$ sqoop-import (generic-args) (import-args)Misal
Şöyle adlı üç tablodan bir örnek alalım emp, emp_add, ve emp_contactMySQL veritabanı sunucusunda userdb adlı bir veritabanında bulunanlar.
Üç tablo ve verileri aşağıdaki gibidir.
emp:
| İD | isim | derece | maaş | borç |
|---|---|---|---|---|
| 1201 | gopal | yönetici | 50.000 | TP |
| 1202 | Manisha | Prova okuyucu | 50.000 | TP |
| 1203 | Khalil | php dev | 30.000 | AC |
| 1204 | prasant | php dev | 30.000 | AC |
| 1204 | Kranthi | yönetici | 20.000 | TP |
emp_add:
| İD | hno | sokak | Kent |
|---|---|---|---|
| 1201 | 288A | Vgiri | Jublee |
| 1202 | 108I | aoc | sn-kötü |
| 1203 | 144Z | pgutta | hid |
| 1204 | 78B | eski şehir | sn-kötü |
| 1205 | 720X | yüksek teknoloji | sn-kötü |
emp_contact:
| İD | phno | e-posta |
|---|---|---|
| 1201 | 2356742 | [email protected] |
| 1202 | 1661663 | [email protected] |
| 1203 | 8887776 | [email protected] |
| 1204 | 9988774 | [email protected] |
| 1205 | 1231231 | [email protected] |
Tablo İçe Aktarma
Sqoop aracı 'içe aktarma', tablo verilerini tablodan Hadoop dosya sistemine metin dosyası veya ikili dosya olarak içe aktarmak için kullanılır.
Aşağıdaki komut, emp MySQL veritabanı sunucusundan HDFS'ye tablo.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp --m 1Başarıyla yürütülürse, aşağıdaki çıktıyı alırsınız.
14/12/22 15:24:54 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
14/12/22 15:24:56 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
14/12/22 15:24:56 INFO tool.CodeGenTool: Beginning code generation
14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM `emp` AS t LIMIT 1
14/12/22 15:24:58 INFO manager.SqlManager: Executing SQL statement:
SELECT t.* FROM `emp` AS t LIMIT 1
14/12/22 15:24:58 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
14/12/22 15:25:11 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-hadoop/compile/cebe706d23ebb1fd99c1f063ad51ebd7/emp.jar
-----------------------------------------------------
-----------------------------------------------------
14/12/22 15:25:40 INFO mapreduce.Job: The url to track the job:
http://localhost:8088/proxy/application_1419242001831_0001/
14/12/22 15:26:45 INFO mapreduce.Job: Job job_1419242001831_0001 running in uber mode :
false
14/12/22 15:26:45 INFO mapreduce.Job: map 0% reduce 0%
14/12/22 15:28:08 INFO mapreduce.Job: map 100% reduce 0%
14/12/22 15:28:16 INFO mapreduce.Job: Job job_1419242001831_0001 completed successfully
-----------------------------------------------------
-----------------------------------------------------
14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Transferred 145 bytes in 177.5849 seconds
(0.8165 bytes/sec)
14/12/22 15:28:17 INFO mapreduce.ImportJobBase: Retrieved 5 records.İçe aktarılan verileri HDFS'de doğrulamak için aşağıdaki komutu kullanın.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*Size gösterir emp tablo verileri ve alanlar virgül (,) ile ayrılmıştır.
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TPHedef Dizine Aktarma
Sqoop içe aktarma aracını kullanarak tablo verilerini HDFS'ye aktarırken hedef dizini belirleyebiliriz.
Hedef dizini Sqoop içe aktarma komutuna seçenek olarak belirtmek için sözdizimi aşağıdadır.
--target-dir <new or exist directory in HDFS>İçe aktarmak için aşağıdaki komut kullanılır emp_add tablo verilerini '/ queryresult' dizinine yerleştirin.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp_add \
--m 1 \
--target-dir /queryresultAşağıdaki komut, / queryresult dizin formundaki içeri aktarılan verileri doğrulamak için kullanılır. emp_add tablo.
$ $HADOOP_HOME/bin/hadoop fs -cat /queryresult/part-m-*Size emp_add tablo verilerini virgülle (,) ayrılmış alanlarla gösterecektir.
1201, 288A, vgiri, jublee
1202, 108I, aoc, sec-bad
1203, 144Z, pgutta, hyd
1204, 78B, oldcity, sec-bad
1205, 720C, hitech, sec-badTablo Verilerinin Alt Kümesini İçe Aktar
Sqoop içe aktarma aracındaki 'where' cümlesini kullanarak bir tablonun alt kümesini içe aktarabiliriz. İlgili veritabanı sunucusunda karşılık gelen SQL sorgusunu yürütür ve sonucu HDFS'de bir hedef dizinde depolar.
Where cümlesi için sözdizimi aşağıdaki gibidir.
--where <condition>Aşağıdaki komut bir alt kümesini içe aktarmak için kullanılır emp_addtablo verileri. Alt küme sorgusu, Secunderabad şehrinde yaşayan çalışan kimliği ve adresini almak içindir.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp_add \
--m 1 \
--where “city =’sec-bad’” \
--target-dir /wherequeryAşağıdaki komut, / wherequery dizinindeki içe aktarılan verileri doğrulamak için kullanılır. emp_add tablo.
$ $HADOOP_HOME/bin/hadoop fs -cat /wherequery/part-m-*Size gösterecek emp_add virgülle (,) ayrılmış alanlara sahip tablo verileri.
1202, 108I, aoc, sec-bad
1204, 78B, oldcity, sec-bad
1205, 720C, hitech, sec-badArtımlı İçe Aktarma
Artımlı içe aktarma, bir tabloya yalnızca yeni eklenen satırları içe aktaran bir tekniktir. Artımlı içe aktarmayı gerçekleştirmek için 'artımlı', 'kontrol sütunu' ve 'son değer' seçeneklerinin eklenmesi gerekir.
Sqoop import komutundaki artımlı seçenek için aşağıdaki sözdizimi kullanılır.
--incremental <mode>
--check-column <column name>
--last value <last check column value>Yeni eklenen verileri varsayalım. emp tablo aşağıdaki gibidir -
1206, satish p, grp des, 20000, GRAşağıdaki komut, artımlı içe aktarmayı gerçekleştirmek için kullanılır. emp tablo.
$ sqoop import \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table emp \
--m 1 \
--incremental append \
--check-column id \
-last value 1205Aşağıdaki komut, içeri aktarılan verileri doğrulamak için kullanılır. emp HDFS emp / dizinine tablo.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*Size gösterir emp virgülle (,) ayrılmış alanlara sahip tablo verileri.
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TP
1206, satish p, grp des, 20000, GRAşağıdaki komut, listeden değiştirilen veya yeni eklenen satırları görmek için kullanılır. emp tablo.
$ $HADOOP_HOME/bin/hadoop fs -cat /emp/part-m-*1Size yeni eklenen satırları gösterir. emp virgülle (,) ayrılmış alanlara sahip tablo.
1206, satish p, grp des, 20000, GRBu bölümde, tüm tabloların RDBMS veritabanı sunucusundan HDFS'ye nasıl alınacağı açıklanmaktadır. Her tablo verisi ayrı bir dizinde saklanır ve dizin adı tablo adıyla aynıdır.
Sözdizimi
Tüm tabloları içe aktarmak için aşağıdaki sözdizimi kullanılır.
$ sqoop import-all-tables (generic-args) (import-args)
$ sqoop-import-all-tables (generic-args) (import-args)Misal
Tüm tabloları, userdbveri tabanı. Veritabanının sakladığı tabloların listesiuserdb aşağıdaki gibidir.
+--------------------+
| Tables |
+--------------------+
| emp |
| emp_add |
| emp_contact |
+--------------------+Aşağıdaki komut, tüm tabloları bilgisayardan içe aktarmak için kullanılır. userdb veri tabanı.
$ sqoop import-all-tables \
--connect jdbc:mysql://localhost/userdb \
--username rootNote - Tüm tabloları içe aktar kullanıyorsanız, bu veritabanındaki her tablonun bir birincil anahtar alanına sahip olması zorunludur.
Aşağıdaki komut, tüm tablo verilerini HDFS'deki userdb veritabanına doğrulamak için kullanılır.
$ $HADOOP_HOME/bin/hadoop fs -lsSize userdb veritabanındaki tablo isimlerinin listesini dizinler olarak gösterecektir.
Çıktı
drwxr-xr-x - hadoop supergroup 0 2014-12-22 22:50 _sqoop
drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:46 emp
drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:50 emp_add
drwxr-xr-x - hadoop supergroup 0 2014-12-23 01:52 emp_contactBu bölümde verilerin HDFS'den RDBMS veritabanına nasıl geri aktarılacağı açıklanmaktadır. Hedef tablo, hedef veritabanında bulunmalıdır. Sqoop'a girdi olarak verilen dosyalar, tablodaki satırlar olarak adlandırılan kayıtları içerir. Bunlar okunur ve bir kayıt kümesine ayrıştırılır ve kullanıcı tanımlı sınırlayıcı ile sınırlandırılır.
Varsayılan işlem, INSERT deyimini kullanarak girdi dosyalarındaki tüm kayıtları veritabanı tablosuna eklemektir. Güncelleme modunda, Sqoop var olan kaydı veritabanında değiştiren UPDATE deyimini oluşturur.
Sözdizimi
Dışa aktarma komutunun sözdizimi aşağıdadır.
$ sqoop export (generic-args) (export-args)
$ sqoop-export (generic-args) (export-args)Misal
HDFS'deki dosyadaki çalışan verilerinin bir örneğini ele alalım. Çalışan verileri şurada mevcuttur:emp_datadosya HDFS'de 'emp /' dizininde. emp_data Şöyleki.
1201, gopal, manager, 50000, TP
1202, manisha, preader, 50000, TP
1203, kalil, php dev, 30000, AC
1204, prasanth, php dev, 30000, AC
1205, kranthi, admin, 20000, TP
1206, satish p, grp des, 20000, GRDışa aktarılacak tablonun manuel olarak oluşturulması ve dışa aktarılması gereken veritabanında bulunması zorunludur.
Aşağıdaki sorgu mysql komut satırında 'çalışan' tablosunu oluşturmak için kullanılır.
$ mysql
mysql> USE db;
mysql> CREATE TABLE employee (
id INT NOT NULL PRIMARY KEY,
name VARCHAR(20),
deg VARCHAR(20),
salary INT,
dept VARCHAR(10));Aşağıdaki komut, tablo verilerini dışa aktarmak için kullanılır ( emp_data HDFS dosyası) Mysql veritabanı sunucusunun db veritabanındaki çalışan tablosuna.
$ sqoop export \
--connect jdbc:mysql://localhost/db \
--username root \
--table employee \
--export-dir /emp/emp_dataAşağıdaki komut mysql komut satırındaki tabloyu doğrulamak için kullanılır.
mysql>select * from employee;Verilen veriler başarıyla saklanırsa, verilen çalışan verilerinin aşağıdaki tablosunu bulabilirsiniz.
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | kalil | php dev | 30000 | AC |
| 1204 | prasanth | php dev | 30000 | AC |
| 1205 | kranthi | admin | 20000 | TP |
| 1206 | satish p | grp des | 20000 | GR |
+------+--------------+-------------+-------------------+--------+Bu bölümde Sqoop işlerinin nasıl oluşturulacağı ve korunacağı açıklanmaktadır. Sqoop işi, içe ve dışa aktarma komutlarını oluşturur ve kaydeder. Kaydedilen işi tanımlamak ve geri çağırmak için parametreleri belirtir. Bu yeniden arama veya yeniden çalıştırma, güncellenmiş satırları RDBMS tablosundan HDFS'ye aktarabilen artımlı içe aktarmada kullanılır.
Sözdizimi
Aşağıda bir Sqoop işi oluşturmak için sözdizimi verilmiştir.
$ sqoop job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]İş Oluştur (--create)
Burada adıyla bir iş yaratıyoruz myjob, tablo verilerini RDBMS tablosundan HDFS'ye aktarabilir. Aşağıdaki komut, bilgisayardan verileri içe aktaran bir iş oluşturmak için kullanılır.employee tablo db veritabanı HDFS dosyasına.
$ sqoop job --create myjob \
-- import \
--connect jdbc:mysql://localhost/db \
--username root \
--table employee --m 1İşi Doğrula (- liste)
‘--list’argüman kaydedilen işleri doğrulamak için kullanılır. Aşağıdaki komut, kaydedilen Sqoop işlerinin listesini doğrulamak için kullanılır.
$ sqoop job --listKaydedilen işlerin listesini gösterir.
Available jobs:
myjobİşi İncele (--göster)
‘--show’argüman, belirli işleri ve ayrıntılarını incelemek veya doğrulamak için kullanılır. Aşağıdaki komut ve örnek çıktı, çağrılan bir işi doğrulamak için kullanılır.myjob.
$ sqoop job --show myjobKullanılan araçları ve seçeneklerini gösterir. myjob.
Job: myjob
Tool: import Options:
----------------------------
direct.import = true
codegen.input.delimiters.record = 0
hdfs.append.dir = false
db.table = employee
...
incremental.last.value = 1206
...İşi Yürüt (--exec)
‘--exec’seçeneği kaydedilmiş bir işi yürütmek için kullanılır. Aşağıdaki komut, adı verilen kaydedilmiş bir işi yürütmek için kullanılır.myjob.
$ sqoop job --exec myjobSize aşağıdaki çıktıyı gösterir.
10/08/19 13:08:45 INFO tool.CodeGenTool: Beginning code generation
...Bu bölüm, 'codegen' aracının önemini açıklamaktadır. Nesne yönelimli uygulamanın bakış açısından, her veritabanı tablosunun nesneleri başlatmak için 'alıcı' ve 'ayarlayıcı' yöntemlerini içeren bir DAO sınıfı vardır. Bu araç (-codegen) DAO sınıfını otomatik olarak oluşturur.
Tablo Şeması yapısına göre Java'da DAO sınıfı oluşturur. Java tanımı, içe aktarma işleminin bir parçası olarak somutlaştırılır. Bu aracın ana kullanımı, Java'nın Java kodunu kaybedip kaybetmediğini kontrol etmektir. Öyleyse, alanlar arasında varsayılan sınırlayıcı ile yeni bir Java sürümü oluşturacaktır.
Sözdizimi
Sqoop codegen komutunun sözdizimi aşağıdadır.
$ sqoop codegen (generic-args) (codegen-args)
$ sqoop-codegen (generic-args) (codegen-args)Misal
Şunun için Java kodu üreten bir örnek alalım. emp tablo userdb veri tabanı.
Aşağıdaki komut, verilen örneği yürütmek için kullanılır.
$ sqoop codegen \
--connect jdbc:mysql://localhost/userdb \
--username root \
--table empKomut başarıyla yürütülürse, terminalde aşağıdaki çıktıyı üretecektir.
14/12/23 02:34:40 INFO sqoop.Sqoop: Running Sqoop version: 1.4.5
14/12/23 02:34:41 INFO tool.CodeGenTool: Beginning code generation
……………….
14/12/23 02:34:42 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is /usr/local/hadoop
Note: /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.java uses or
overrides a deprecated API.
Note: Recompile with -Xlint:deprecation for details.
14/12/23 02:34:47 INFO orm.CompilationManager: Writing jar file:
/tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/emp.jarDoğrulama
Çıktıya bir göz atalım. Kalın yazılan yol, Java kodunun bulunduğu konumdur.emptablo oluşturur ve depolar. Aşağıdaki komutları kullanarak o konumdaki dosyaları doğrulayalım.
$ cd /tmp/sqoop-hadoop/compile/9a300a1f94899df4a9b10f9935ed9f91/
$ ls
emp.class
emp.jar
emp.javaDerinlemesine doğrulamak istiyorsanız, karşılaştırın emp tablo userdb veritabanı ve emp.java aşağıdaki dizinde
/ tmp / sqoop-hadoop / compile / 9a300a1f94899df4a9b10f9935ed9f91 /.
Bu bölümde Sqoop 'eval' aracının nasıl kullanılacağı açıklanmaktadır. Kullanıcıların ilgili veritabanı sunucularına karşı kullanıcı tanımlı sorguları yürütmesine ve sonucu konsolda önizlemesine olanak tanır. Böylece, kullanıcı sonuçtaki tablo verilerinin içe aktarılmasını bekleyebilir. Eval kullanarak, DDL veya DML ifadesi olabilecek her tür SQL sorgusunu değerlendirebiliriz.
Sözdizimi
Sqoop eval komutu için aşağıdaki sözdizimi kullanılır.
$ sqoop eval (generic-args) (eval-args)
$ sqoop-eval (generic-args) (eval-args)Sorgu Değerlendirmesini Seçin
Eval aracını kullanarak her tür SQL sorgusunu değerlendirebiliriz. Sınırlı satırları seçmeye bir örnek verelim.employee masası dbveri tabanı. Aşağıdaki komut, verilen örneği SQL sorgusu kullanarak değerlendirmek için kullanılır.
$ sqoop eval \
--connect jdbc:mysql://localhost/db \
--username root \
--query “SELECT * FROM employee LIMIT 3”Komut başarıyla yürütülürse, terminalde aşağıdaki çıktıyı üretecektir.
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | khalil | php dev | 30000 | AC |
+------+--------------+-------------+-------------------+--------+Sorgu Değerlendirmesi Ekle
Sqoop eval aracı, SQL ifadelerinin hem modellenmesi hem de tanımlanması için uygulanabilir. Yani, insert ifadeleri için de eval kullanabiliriz. Aşağıdaki komut, yeni bir satır eklemek için kullanılır.employee masası db veri tabanı.
$ sqoop eval \
--connect jdbc:mysql://localhost/db \
--username root \
-e “INSERT INTO employee VALUES(1207,‘Raju’,‘UI dev’,15000,‘TP’)”Komut başarıyla yürütülürse, konsolda güncellenmiş satırların durumunu gösterecektir.
Ya da MySQL konsolunda çalışan tablosunu doğrulayabilirsiniz. Aşağıdaki komut, satırlarını doğrulamak için kullanılır.employee masası db veritabanı select 'sorgusunu kullanarak.
mysql>
mysql> use db;
mysql> SELECT * FROM employee;
+------+--------------+-------------+-------------------+--------+
| Id | Name | Designation | Salary | Dept |
+------+--------------+-------------+-------------------+--------+
| 1201 | gopal | manager | 50000 | TP |
| 1202 | manisha | preader | 50000 | TP |
| 1203 | khalil | php dev | 30000 | AC |
| 1204 | prasanth | php dev | 30000 | AC |
| 1205 | kranthi | admin | 20000 | TP |
| 1206 | satish p | grp des | 20000 | GR |
| 1207 | Raju | UI dev | 15000 | TP |
+------+--------------+-------------+-------------------+--------+Bu bölümde Sqoop kullanılarak veritabanlarının nasıl listeleneceği açıklanmaktadır. Sqoop liste-veritabanları aracı, veritabanı sunucusunda 'VERİTABANLARINI GÖSTER' sorgusunu ayrıştırır ve yürütür. Daha sonra sunucudaki mevcut veritabanlarını listeler.
Sözdizimi
Aşağıdaki sözdizimi Sqoop list-databases komutu için kullanılır.
$ sqoop list-databases (generic-args) (list-databases-args)
$ sqoop-list-databases (generic-args) (list-databases-args)Örnek Sorgu
Aşağıdaki komut, MySQL veritabanı sunucusundaki tüm veritabanlarını listelemek için kullanılır.
$ sqoop list-databases \
--connect jdbc:mysql://localhost/ \
--username rootKomut başarılı bir şekilde yürütülürse, MySQL veritabanı sunucunuzdaki veritabanlarının listesini aşağıdaki gibi görüntüler.
...
13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
mysql
test
userdb
dbBu bölüm, Sqoop kullanılarak MySQL veritabanı sunucusunda belirli bir veritabanının tablolarının nasıl listeleneceğini açıklar. Sqoop liste tabloları aracı, belirli bir veritabanında 'TABLOLARI GÖSTER' sorgusunu ayrıştırır ve yürütür. Daha sonra mevcut tabloları bir veri tabanında listeler.
Sözdizimi
Sqoop liste tabloları komutu için aşağıdaki sözdizimi kullanılır.
$ sqoop list-tables (generic-args) (list-tables-args)
$ sqoop-list-tables (generic-args) (list-tables-args)Örnek Sorgu
Aşağıdaki komut, içindeki tüm tabloları listelemek için kullanılır. userdb MySQL veritabanı sunucusunun veritabanı.
$ sqoop list-tables \
--connect jdbc:mysql://localhost/userdb \
--username rootKomut başarılı bir şekilde yürütülürse, o zaman tabloların listesini userdb veritabanı aşağıdaki gibidir.
...
13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
emp
emp_add
emp_contactBu bölüm, Sqoop kullanılarak MySQL veritabanı sunucusunda belirli bir veritabanının tablolarının nasıl listeleneceğini açıklar. Sqoop liste tabloları aracı, belirli bir veritabanında 'TABLOLARI GÖSTER' sorgusunu ayrıştırır ve yürütür. Daha sonra mevcut tabloları bir veri tabanında listeler.
Sözdizimi
Sqoop liste tabloları komutu için aşağıdaki sözdizimi kullanılır.
$ sqoop list-tables (generic-args) (list-tables-args)
$ sqoop-list-tables (generic-args) (list-tables-args)Örnek Sorgu
Aşağıdaki komut, içindeki tüm tabloları listelemek için kullanılır. userdb MySQL veritabanı sunucusunun veritabanı.
$ sqoop list-tables \
--connect jdbc:mysql://localhost/userdb \
--username rootKomut başarılı bir şekilde yürütülürse, o zaman tabloların listesini userdb veritabanı aşağıdaki gibidir.
...
13/05/31 16:45:58 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
emp
emp_add
emp_contact