Teradata - Hızlı Kılavuz
Teradata nedir?
Teradata, popüler İlişkisel Veritabanı Yönetim Sistemlerinden biridir. Esas olarak büyük ölçekli veri depolama uygulamaları oluşturmak için uygundur. Teradata bunu paralellik kavramıyla başarır. Teradata adlı şirket tarafından geliştirilmiştir.
Teradata Tarihi
Aşağıda, önemli kilometre taşlarını listeleyen Teradata tarihinin hızlı bir özeti bulunmaktadır.
1979 - Teradata kuruldu.
1984 - İlk veritabanı bilgisayarı DBC / 1012'nin piyasaya sürülmesi.
1986- Fortune dergisi, Teradata'yı 'Yılın Ürünü' olarak adlandırıyor.
1999 - 130 Terabaytlık Teradata kullanan dünyanın en büyük veritabanı.
2002 - Partition Primary Index ve sıkıştırma ile piyasaya çıkan Teradata V2R5.
2006 - Teradata Master Data Management çözümünün piyasaya sürülmesi.
2008 - Teradata 13.0, Active Data Warehousing ile yayınlandı.
2011 - Teradata Aster'ı satın alır ve Advanced Analytics Space'e girer.
2012 - Teradata 14.0 tanıtıldı.
2014 - Teradata 15.0 tanıtıldı.
Teradata'nın Özellikleri
Aşağıda Teradata'nın bazı özellikleri verilmiştir -
Unlimited Parallelism- Teradata veritabanı sistemi, Massively Parallel Processing (MPP) Mimarisine dayanmaktadır. MPP mimarisi, iş yükünü tüm sisteme eşit olarak böler. Teradata sistemi, görevi süreçleri arasında böler ve görevin hızlı bir şekilde tamamlanmasını sağlamak için paralel olarak çalıştırır.
Shared Nothing Architecture- Teradata'nın mimarisi Paylaşılan Hiçbir Şey Mimarisi olarak adlandırılır. Teradata Düğümleri, Erişim Modülü İşlemcileri (AMP'ler) ve AMP'lerle ilişkili diskler bağımsız olarak çalışır. Başkalarıyla paylaşılmazlar.
Linear Scalability- Teradata sistemleri yüksek oranda ölçeklenebilir. 2048 Düğüme kadar ölçeklenebilirler. Örneğin, AMP sayısını ikiye katlayarak sistemin kapasitesini ikiye katlayabilirsiniz.
Connectivity - Teradata, Mainframe veya Ağa bağlı sistemler gibi Kanala bağlı sistemlere bağlanabilir.
Mature Optimizer- Teradata optimizer, piyasadaki olgunlaşmış optimize edicilerden biridir. Başlangıcından itibaren paralel olacak şekilde tasarlanmıştır. Her sürümde iyileştirildi.
SQL- Teradata, tablolarda depolanan verilerle etkileşim kurmak için endüstri standardı SQL'i destekler. Buna ek olarak kendi uzantısını da sağlar.
Robust Utilities - Teradata, FastLoad, MultiLoad, FastExport ve TPT gibi verileri Teradata sistemine / sisteminden içe / dışa aktarmak için güçlü yardımcı programlar sağlar.
Automatic Distribution - Teradata, herhangi bir manuel müdahale olmaksızın verileri otomatik olarak eşit bir şekilde disklere dağıtır.
Teradata, tamamen işlevsel bir Teradata sanal makinesi olan VMWARE için Teradata express sağlar. 1 terabayta kadar depolama alanı sağlar. Teradata, VMware'in hem 40GB hem de 1TB sürümünü sağlar.
Önkoşullar
VM 64 bit olduğundan, CPU'nuzun 64-bit'i desteklemesi gerekir.
Windows için Kurulum Adımları
Step 1 - Gerekli VM versiyonunu linkten indirin, https://downloads.teradata.com/download/database/teradata-express-for-vmware-player
Step 2 - Dosyayı çıkarın ve hedef klasörü belirtin.
Step 3 - VMWare Workstation oynatıcısını bağlantıdan indirin, https://my.vmware.com/web/vmware/downloads. Hem Windows hem de Linux için mevcuttur. Windows için VMWARE iş istasyonu oynatıcısını indirin.
Step 4 - İndirme işlemi tamamlandıktan sonra yazılımı kurun.
Step 5 - Kurulum tamamlandıktan sonra, VMWARE istemcisini çalıştırın.
Step 6- 'Bir Sanal Makine Aç'ı seçin. Çıkarılan Teradata VMWare klasöründe gezinin ve .vmdk uzantılı dosyayı seçin.
Step 7- Teradata VMWare, VMWare istemcisine eklenir. Eklenen Teradata VMware'i seçin ve 'Sanal Makineyi Oynat'ı tıklayın.

Step 8 - Yazılım güncellemelerinde bir açılır pencere görürseniz, "Daha Sonra Hatırlat" ı seçebilirsiniz.
Step 9 - Kullanıcı adını root olarak girin, sekmeye basın ve şifreyi root olarak girin ve tekrar Enter tuşuna basın.
Step 10- Masaüstünde aşağıdaki ekran göründüğünde, 'kök ana sayfası'na çift tıklayın. Ardından 'Genome's Terminal' üzerine çift tıklayın. Bu, Kabuğu açacaktır.

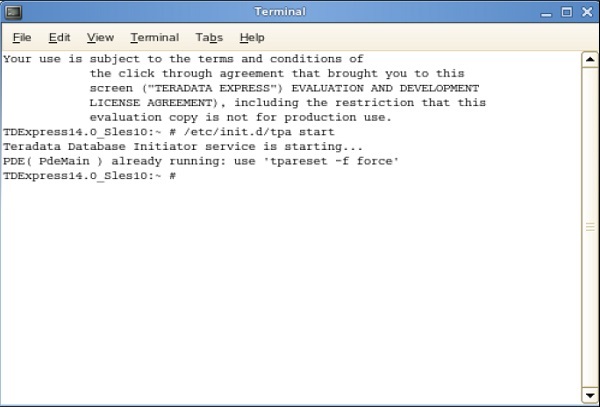
Step 11- Aşağıdaki kabuktan /etc/init.d/tpa start komutunu girin. Bu, Teradata sunucusunu başlatacaktır.
BTEQ başlatılıyor
BTEQ yardımcı programı, SQL sorgularını etkileşimli olarak göndermek için kullanılır. BTEQ yardımcı programını başlatma adımları aşağıdadır.
Step 1 - / sbin / ifconfig komutunu girin ve VMWare'in IP adresini not edin.
Step 2- bteq komutunu çalıştırın. Oturum açma isteminde komutu girin.
Oturum açma <ipaddress> / dbc, dbc; ve girin Parola isteminde, parolayı dbc olarak girin;
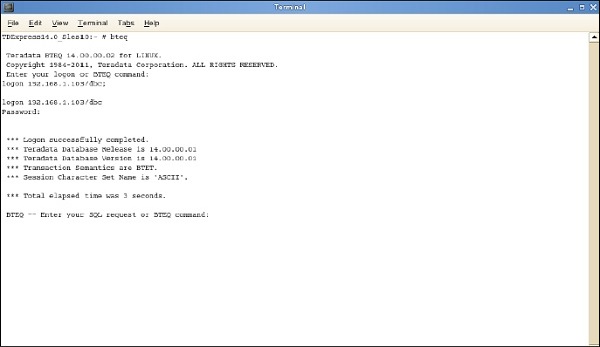
BTEQ kullanarak Teradata sisteminde oturum açabilir ve herhangi bir SQL sorgusu çalıştırabilirsiniz.
Teradata mimarisi, Massively Parallel Processing (MPP) mimarisine dayanmaktadır. Teradata'nın ana bileşenleri Ayrıştırma Motoru, BYNET ve Erişim Modülü İşlemcileridir (AMP'ler). Aşağıdaki diyagram, bir Teradata Düğümünün yüksek seviyeli mimarisini göstermektedir.
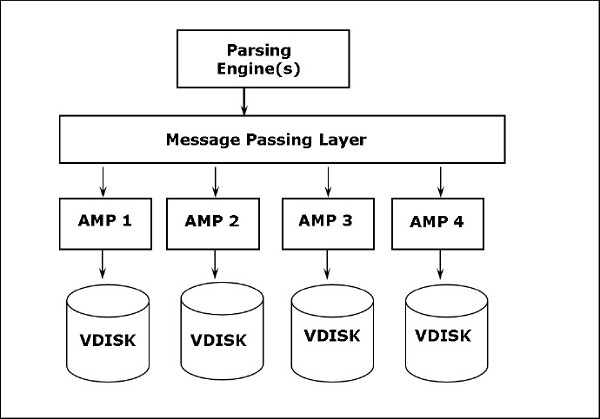
Teradata Bileşenleri
Teradata'nın temel bileşenleri aşağıdaki gibidir -
Node- Teradata Sistemindeki temel birimdir. Bir Teradata sistemindeki her bir sunucuya bir Düğüm denir. Bir düğüm, kendi işletim sistemi, CPU, bellek, kendi Teradata RDBMS yazılımı kopyası ve disk alanından oluşur. Bir kabin, bir veya daha fazla Düğümden oluşur.
Parsing Engine- Ayrıştırma Motoru, istemciden sorgu almaktan ve verimli bir yürütme planı hazırlamaktan sorumludur. Ayrıştırma motorunun sorumlulukları şunlardır:
İstemciden SQL sorgusunu alın
Sözdizimi hataları için SQL sorgu denetimini ayrıştırın
Kullanıcının SQL sorgusunda kullanılan nesnelere karşı gerekli ayrıcalığa sahip olup olmadığını kontrol edin
SQL'de kullanılan nesnelerin gerçekten var olup olmadığını kontrol edin
SQL sorgusunu yürütmek ve BYNET'e geçirmek için yürütme planını hazırlayın
Sonuçları AMP'lerden alır ve müşteriye gönderir
Message Passing Layer- BYNET olarak adlandırılan Mesaj Geçiş Katmanı, Teradata sistemindeki ağ katmanıdır. PE ve AMP arasında ve ayrıca düğümler arasında iletişime izin verir. Yürütme planını Ayrıştırma Motorundan alır ve AMP'ye gönderir. Benzer şekilde AMP'lerden sonuçları alır ve Ayrıştırma Motoruna gönderir.
Access Module Processor (AMP)- Sanal İşlemciler (vprocs) olarak adlandırılan AMP'ler, verileri gerçekten depolayan ve alanlardır. AMP'ler, Ayrıştırma Motorundan veri ve yürütme planını alır, herhangi bir veri türü dönüştürme, toplama, filtreleme, sıralama yapar ve verileri kendileriyle ilişkili disklerde depolar. Tablolardaki kayıtlar, sistemdeki AMP'ler arasında eşit olarak dağıtılır. Her AMP, verilerin depolandığı bir disk setiyle ilişkilendirilir. Yalnızca bu AMP disklerden veri okuyabilir / yazabilir.
Depolama Mimarisi
İstemci kayıt eklemek için sorgu çalıştırdığında, Ayrıştırma motoru kayıtları BYNET'e gönderir. BYNET, kayıtları alır ve satırı hedef AMP'ye gönderir. AMP bu kayıtları disklerinde depolar. Aşağıdaki şema Teradata'nın depolama mimarisini göstermektedir.
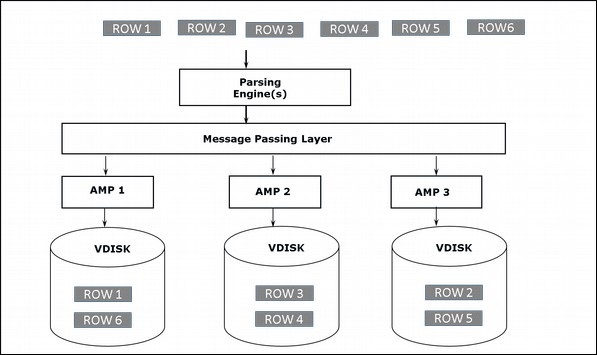
Erişim Mimarisi
İstemci kayıtları almak için sorgular çalıştırdığında, Ayrıştırma motoru BYNET'e bir istek gönderir. BYNET, alma talebini uygun AMP'lere gönderir. Ardından AMP'ler disklerini paralel olarak arar ve gerekli kayıtları belirleyerek BYNET'e gönderir. BYNET daha sonra kayıtları Ayrıştırma Motoruna gönderir ve bu da istemciye gönderilir. Aşağıda Teradata'nın kurtarma mimarisi verilmiştir.
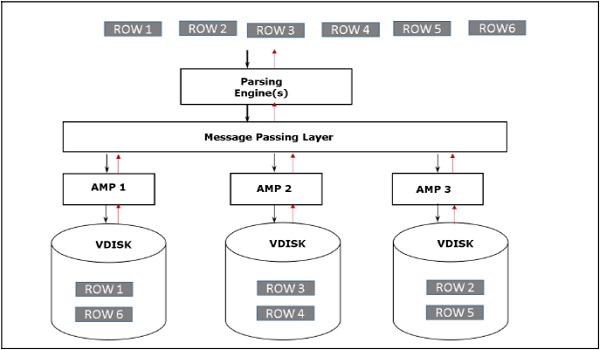
İlişkisel Veritabanı Yönetim Sistemi (RDBMS), veritabanları ile etkileşim kurmaya yardımcı olan bir DBMS yazılımıdır. Tablolarda depolanan verilerle etkileşim kurmak için Yapılandırılmış Sorgu Dili'ni (SQL) kullanırlar.
Veri tabanı
Veritabanı, mantıksal olarak ilişkili verilerin bir koleksiyonudur. Birçok kullanıcı tarafından farklı amaçlarla erişilir. Örneğin, bir satış veritabanı, birçok tabloda depolanan satışlarla ilgili tüm bilgileri içerir.
Tablolar
Tablolar, RDBMS'de verilerin depolandığı temel birimdir. Tablo, satır ve sütunlardan oluşan bir koleksiyondur. Aşağıda bir çalışan tablosu örneği verilmiştir.
| Çalışan Hayır | İsim | Soyadı | Doğum günü |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Peter | Paul | 4/1/1983 |
Sütunlar
Bir sütun benzer veriler içerir. Örneğin, Çalışan tablosundaki Doğum Tarihi sütunu, tüm çalışanlar için doğum_tarihi bilgilerini içerir.
| Doğum günü |
|---|
| 1/5/1980 |
| 11/6/1984 |
| 3/5/1983 |
| 12/1/1984 |
| 4/1/1983 |
Kürek çekmek
Satır, tüm sütunların bir örneğidir. Örneğin, çalışan tablosunda bir satır, tek bir çalışan hakkında bilgi içerir.
| Çalışan Hayır | İsim | Soyadı | Doğum günü |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
Birincil anahtar
Birincil anahtar, bir tablodaki bir satırı benzersiz şekilde tanımlamak için kullanılır. Birincil anahtar sütununda yinelenen değerlere izin verilmez ve NULL değerleri kabul edemezler. Tablodaki zorunlu bir alandır.
Yabancı anahtar
Tablolar arasında ilişki kurmak için yabancı anahtarlar kullanılır. Alt tablodaki yabancı anahtar, üst tablodaki birincil anahtar olarak tanımlanır. Bir tablonun birden fazla yabancı anahtarı olabilir. Yinelenen değerleri ve ayrıca boş değerleri kabul edebilir. Tabloda yabancı anahtarlar isteğe bağlıdır.
Tablodaki her sütun bir veri türüyle ilişkilendirilir. Veri türleri, sütunda ne tür değerlerin depolanacağını belirtir. Teradata birkaç veri türünü destekler. Aşağıda sık kullanılan veri türlerinden bazıları verilmiştir.
| Veri tipleri | Uzunluk (Bayt) | Değer aralığı |
|---|---|---|
| BYTEINT | 1 | -128 ila +127 |
| SMALLINT | 2 | -32768 ila +32767 |
| TAM | 4 | -2.147.483.648 ile +2147.483.647 |
| BÜYÜK | 8 | -9,233,372,036,854,775,80 8 ile +9,233,372,036,854,775,8 07 |
| ONDALIK | 1-16 | |
| SAYISAL | 1-16 | |
| YÜZER | 8 | IEEE biçimi |
| CHAR | Sabit Format | 1-64.000 |
| VARCHAR | Değişken | 1-64.000 |
| TARİH | 4 | YYYYYAAGG |
| ZAMAN | 6 veya 8 | HHMMSS.nnnnnn or HHMMSS.nnnnnn + HHMM |
| TIMESTAMP | 10 veya 12 | YYAAGGDHHMMSS.nnnnnn or YYAAGGSHMMSS.nnnnnn + HHMM |
İlişkisel modeldeki tablolar veri koleksiyonu olarak tanımlanır. Satırlar ve sütunlar olarak temsil edilirler.
Tablo Türleri
Türler Teradata farklı tablo türlerini destekler.
Permanent Table - Bu varsayılan tablodur ve kullanıcı tarafından eklenen verileri içerir ve verileri kalıcı olarak depolar.
Volatile Table- Uçucu bir tabloya eklenen veriler yalnızca kullanıcı oturumu sırasında saklanır. Tablo ve veriler oturumun sonunda bırakılır. Bu tablolar çoğunlukla veri dönüşümü sırasında ara verileri tutmak için kullanılır.
Global Temporary Table - Global Geçici tablonun tanımı kalıcıdır ancak tablodaki veriler kullanıcı oturumunun sonunda silinir.
Derived Table- Türetilmiş tablo, bir sorgudaki ara sonuçları tutar. Yaşam süreleri, oluşturuldukları, kullanıldığı ve bırakıldıkları sorgu dahilindedir.
Çoklu Küme Karşı Ayarla
Teradata, yinelenen kayıtların nasıl işlendiğine bağlı olarak tabloları SET veya MULTISET tabloları olarak sınıflandırır. SET tablosu olarak tanımlanan bir tablo yinelenen kayıtları saklamaz, oysa MULTISET tablosu yinelenen kayıtları depolayabilir.
| Sr.No | Tablo Komutları ve Açıklama |
|---|---|
| 1 | Tablo Oluştur CREATE TABLE komutu Teradata'da tablolar oluşturmak için kullanılır. |
| 2 | Tabloyu değiştir ALTER TABLE komutu, mevcut bir tablodan sütun eklemek veya çıkarmak için kullanılır. |
| 3 | Bırak Tablo DROP TABLE komutu bir tabloyu düşürmek için kullanılır. |
Bu bölüm, Teradata tablolarında depolanan verileri işlemek için kullanılan SQL komutlarını tanıtır.
Kayıt Ekle
INSERT INTO deyimi, tabloya kayıt eklemek için kullanılır.
Sözdizimi
INSERT INTO için genel sözdizimi aşağıdadır.
INSERT INTO <tablename>
(column1, column2, column3,…)
VALUES
(value1, value2, value3 …);Misal
Aşağıdaki örnek, kayıtları çalışan tablosuna ekler.
INSERT INTO Employee (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
101,
'Mike',
'James',
'1980-01-05',
'2005-03-27',
01
);Yukarıdaki sorgu eklendikten sonra, tablodaki kayıtları görüntülemek için SELECT deyimini kullanabilirsiniz.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Bölüm No | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
Başka Bir Tablodan Ekle
INSERT SELECT deyimi, başka bir tablodan kayıt eklemek için kullanılır.
Sözdizimi
INSERT INTO için genel sözdizimi aşağıdadır.
INSERT INTO <tablename>
(column1, column2, column3,…)
SELECT
column1, column2, column3…
FROM
<source table>;Misal
Aşağıdaki örnek, kayıtları çalışan tablosuna ekler. Aşağıdaki ekleme sorgusunu çalıştırmadan önce, çalışan tablosu ile aynı sütun tanımına sahip Employee_Bkup adlı bir tablo oluşturun.
INSERT INTO Employee_Bkup (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
SELECT
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
FROM
Employee;Yukarıdaki sorgu yürütüldüğünde, çalışan tablosundaki tüm kayıtları staff_bkup tablosuna ekler.
Kurallar
VALUES listesinde belirtilen sütun sayısı, INSERT INTO yan tümcesinde belirtilen sütunlarla eşleşmelidir.
NOT NULL sütunları için değerler zorunludur.
Değer belirtilmezse, null yapılabilir alanlar için NULL eklenir.
VALUES yan tümcesinde belirtilen sütunların veri türleri, INSERT yan tümcesindeki sütunların veri türleri ile uyumlu olmalıdır.
Kayıtları Güncelle
UPDATE deyimi, tablodaki kayıtları güncellemek için kullanılır.
Sözdizimi
UPDATE için genel sözdizimi aşağıdadır.
UPDATE <tablename>
SET <columnnamme> = <new value>
[WHERE condition];Misal
Aşağıdaki örnek, çalışan birimini 101 çalışan için 03 olarak güncellemektedir.
UPDATE Employee
SET DepartmentNo = 03
WHERE EmployeeNo = 101;Aşağıdaki çıktıda, DepartmentNo'nun Çalışan 101 için 1'den 3'e güncellendiğini görebilirsiniz.
SELECT Employeeno, DepartmentNo FROM Employee;
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo
----------- -------------
101 3Kurallar
Tablonun bir veya daha fazla değerini güncelleyebilirsiniz.
WHERE koşulu belirtilmezse, tablonun tüm satırları etkilenir.
Bir tabloyu başka bir tablodaki değerlerle güncelleyebilirsiniz.
Kayıtları Sil
DELETE FROM deyimi tablodaki kayıtları güncellemek için kullanılır.
Sözdizimi
DELETE FROM için genel sözdizimi aşağıdadır.
DELETE FROM <tablename>
[WHERE condition];Misal
Aşağıdaki örnek, çalışan 101'i masa çalışanından siler.
DELETE FROM Employee
WHERE EmployeeNo = 101;Aşağıdaki çıktıda çalışan 101'in tablodan silindiğini görebilirsiniz.
SELECT EmployeeNo FROM Employee;
*** Query completed. No rows found.
*** Total elapsed time was 1 second.Kurallar
Tablonun bir veya daha fazla kaydını güncelleyebilirsiniz.
WHERE koşulu belirtilmezse, tablonun tüm satırları silinir.
Bir tabloyu başka bir tablodaki değerlerle güncelleyebilirsiniz.
SELECT deyimi, bir tablodan kayıtları almak için kullanılır.
Sözdizimi
Aşağıda, SELECT ifadesinin temel sözdizimi verilmiştir.
SELECT
column 1, column 2, .....
FROM
tablename;Misal
Aşağıdaki çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Bölüm No | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25.4.2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21.3.2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Aşağıda bir SELECT ifadesi örneği verilmiştir.
SELECT EmployeeNo,FirstName,LastName
FROM Employee;Bu sorgu yürütüldüğünde, çalışan tablosundan EmployeeNo, FirstName ve LastName sütunlarını alır.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulBir tablodan tüm sütunları getirmek istiyorsanız, tüm sütunları listelemek yerine aşağıdaki komutu kullanabilirsiniz.
SELECT * FROM Employee;Yukarıdaki sorgu, çalışan tablosundaki tüm kayıtları getirecektir.
NEREDE Fıkra
WHERE yan tümcesi, SELECT deyimi tarafından döndürülen kayıtları filtrelemek için kullanılır. Bir koşul, WHERE cümlesiyle ilişkilidir. Yalnızca, WHERE yan tümcesindeki koşulu karşılayan kayıtlar döndürülür.
Sözdizimi
Aşağıda, WHERE yan tümcesine sahip SELECT ifadesinin sözdizimi verilmiştir.
SELECT * FROM tablename
WHERE[condition];Misal
Aşağıdaki sorgu, EmployeeNo'nun 101 olduğu kayıtları getirir.
SELECT * FROM Employee
WHERE EmployeeNo = 101;Bu sorgu yürütüldüğünde aşağıdaki kayıtları döndürür.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
101 Mike JamesTARAFINDAN SİPARİŞ
SELECT ifadesi yürütüldüğünde, döndürülen satırlar belirli bir sırada değildir. ORDER BY yan tümcesi, kayıtları herhangi bir sütunda artan / azalan sırada düzenlemek için kullanılır.
Sözdizimi
Aşağıda, SELECT ifadesinin ORDER BY yan tümcesine sahip sözdizimi verilmiştir.
SELECT * FROM tablename
ORDER BY column 1, column 2..;Misal
Aşağıdaki sorgu, çalışan tablosundan kayıtları alır ve sonuçları Ad'a göre sıralar.
SELECT * FROM Employee
ORDER BY FirstName;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
101 Mike James
103 Peter Paul
102 Robert Williams
105 Robert JamesGRUPLAMA
GROUP BY yan tümcesi, SELECT deyimi ile kullanılır ve benzer kayıtları gruplar halinde düzenler.
Sözdizimi
Aşağıda, SELECT ifadesinin GROUP BY yan tümcesine sahip sözdizimi verilmiştir.
SELECT column 1, column2 …. FROM tablename
GROUP BY column 1, column 2..;Misal
Aşağıdaki örnek, kayıtları DepartmentNo sütununa göre gruplandırır ve her departmanın toplam sayısını tanımlar.
SELECT DepartmentNo,Count(*) FROM
Employee
GROUP BY DepartmentNo;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
DepartmentNo Count(*)
------------ -----------
3 1
1 1
2 3Teradata, aşağıdaki mantıksal ve koşullu operatörleri destekler. Bu operatörler, karşılaştırma yapmak ve birden çok koşulu birleştirmek için kullanılır.
| Sözdizimi | Anlam |
|---|---|
| > | Büyüktür |
| < | Daha az |
| >= | Büyük veya eşit |
| <= | Küçüktür veya eşittir |
| = | Eşittir |
| BETWEEN | Aralık dahilindeki değerler |
| IN | <İfade> içindeki değerler |
| NOT IN | Değerler <ifade> içinde değilse |
| IS NULL | Değer NULL ise |
| IS NOT NULL | Değer NULL DEĞİLSE |
| AND | Birden çok koşulu birleştirin. Yalnızca tüm koşullar karşılanırsa doğru olarak değerlendirilir |
| OR | Birden çok koşulu birleştirin. Yalnızca koşullardan biri karşılanırsa doğru olarak değerlendirilir. |
| NOT | Koşulun anlamını tersine çevirir |
ARASINDA
BETWEEN komutu, bir değerin bir değer aralığı içinde olup olmadığını kontrol etmek için kullanılır.
Misal
Aşağıdaki çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Bölüm No | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25.4.2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21.3.2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Aşağıdaki örnek, 101.102 ile 103 arasında çalışan sayılarına sahip kayıtları getirir.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo BETWEEN 101 AND 103;Yukarıdaki sorgu yürütüldüğünde, 101 ile 103 arasında çalışan numarası olan çalışan kayıtlarını döndürür.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterİÇİNDE
IN komutu, değeri belirli bir değerler listesiyle karşılaştırmak için kullanılır.
Misal
Aşağıdaki örnek, 101, 102 ve 103'te çalışan numaraları olan kayıtları getirir.
SELECT EmployeeNo, FirstName FROM
Employee
WHERE EmployeeNo in (101,102,103);Yukarıdaki sorgu aşağıdaki kayıtları döndürür.
*** Query completed. 3 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName
----------- ------------------------------
101 Mike
102 Robert
103 PeterDEĞİL
NOT IN komutu IN komutunun sonucunu tersine çevirir. Verilen listeyle eşleşmeyen değerlere sahip kayıtları getirir.
Misal
Aşağıdaki örnek, çalışan numaraları 101, 102 ve 103'te olmayan kayıtları getirir.
SELECT * FROM
Employee
WHERE EmployeeNo not in (101,102,103);Yukarıdaki sorgu aşağıdaki kayıtları döndürür.
*** Query completed. 2 rows found. 6 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ -----------------------------
104 Alex Stuart
105 Robert JamesSET operatörleri, birden çok SELECT ifadesinden gelen sonuçları birleştirir. Bu, Joins'e benzer görünebilir, ancak birleşimler birden çok tablodan sütunları birleştirirken SET operatörleri birden çok satırdaki satırları birleştirir.
Kurallar
Her SELECT ifadesindeki sütun sayısı aynı olmalıdır.
Her SELECT'ten gelen veri türleri uyumlu olmalıdır.
ORDER BY yalnızca son SELECT deyimine dahil edilmelidir.
BİRLİK
UNION ifadesi, birden çok SELECT deyiminden gelen sonuçları birleştirmek için kullanılır. Yinelemeleri yok sayar.
Sözdizimi
UNION bildiriminin temel sözdizimi aşağıdadır.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Misal
Aşağıdaki çalışan tablosu ve maaş tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Bölüm No | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25.4.2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21.3.2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Aşağıdaki UNION sorgusu, Employee ve Maaş tablosundaki EmployeeNo değerini birleştirir.
SELECT EmployeeNo
FROM
Employee
UNION
SELECT EmployeeNo
FROM
Salary;Sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
EmployeeNo
-----------
101
102
103
104
105BİRLİĞİ TÜMÜ
UNION ALL ifadesi UNION'a benzer, yinelenen satırlar dahil olmak üzere birden çok tablodan sonuçları birleştirir.
Sözdizimi
UNION ALL ifadesinin temel sözdizimi aşağıdadır.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
UNION ALL
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Misal
Aşağıda UNION ALL bildirisine bir örnek verilmiştir.
SELECT EmployeeNo
FROM
Employee
UNION ALL
SELECT EmployeeNo
FROM
Salary;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Yinelenenleri de döndürdüğünü görebilirsiniz.
EmployeeNo
-----------
101
104
102
105
103
101
104
102
103INTERSECT
INTERSECT komutu, birden çok SELECT deyiminden gelen sonuçları birleştirmek için de kullanılır. İkinci SELECT deyiminde karşılık gelen eşleşmeye sahip olan ilk SELECT deyiminden satırları döndürür. Başka bir deyişle, her iki SELECT deyiminde bulunan satırları döndürür.
Sözdizimi
INTERSECT ifadesinin temel sözdizimi aşağıdadır.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
INTERSECT
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Misal
Aşağıda INTERSECT ifadesine bir örnek verilmiştir. Her iki tabloda da bulunan EmployeeNo değerlerini döndürür.
SELECT EmployeeNo
FROM
Employee
INTERSECT
SELECT EmployeeNo
FROM
Salary;Yukarıdaki sorgu yürütüldüğünde aşağıdaki kayıtları döndürür. EmployeeNo 105, MAAŞ tablosunda bulunmadığı için hariç tutulmuştur.
EmployeeNo
-----------
101
104
102
103EKSİ / HARİÇ
MINUS / EXCEPT komutları, birden çok tablodan satırları birleştirir ve ilk SELECT'te olan ancak ikinci SELECT'te olmayan satırları döndürür. İkisi de aynı sonuçları verir.
Sözdizimi
MINUS ifadesinin temel sözdizimi aşağıdadır.
SELECT col1, col2, col3…
FROM
<table 1>
[WHERE condition]
MINUS
SELECT col1, col2, col3…
FROM
<table 2>
[WHERE condition];Misal
Aşağıda bir MINUS ifadesi örneği verilmiştir.
SELECT EmployeeNo
FROM
Employee
MINUS
SELECT EmployeeNo
FROM
Salary;Bu sorgu yürütüldüğünde aşağıdaki kaydı döndürür.
EmployeeNo
-----------
105Teradata, dizeleri değiştirmek için çeşitli işlevler sağlar. Bu işlevler ANSI standardıyla uyumludur.
| Sr.No | Dize İşlevi ve Açıklaması |
|---|---|
| 1 | || Dizeleri birlikte birleştirir |
| 2 | SUBSTR Bir dizenin bir kısmını çıkarır (Teradata uzantısı) |
| 3 | SUBSTRING Bir dizenin bir bölümünü çıkarır (ANSI standardı) |
| 4 | INDEX Bir dizedeki bir karakterin konumunu bulur (Teradata uzantısı) |
| 5 | POSITION Bir dizedeki bir karakterin konumunu bulur (ANSI standardı) |
| 6 | TRIM Bir dizeden boşlukları kırpar |
| 7 | UPPER Bir dizeyi büyük harfe dönüştürür |
| 8 | LOWER Bir dizeyi küçük harfe dönüştürür |
Misal
Aşağıdaki tablo sonuçlarla birlikte bazı dizi işlevlerini listeler.
| String Fonksiyonu | Sonuç |
|---|---|
| ALT DİZGİ SEÇİN (4 İÇİN 1'DEN 'depo') | eşya |
| SUBSTR ('depo', 1,4) SEÇİN | eşya |
| 'Veri' SEÇİN || '' || 'depo' | Veri deposu |
| ÜST SEÇİN ('veri') | VERİ |
| DÜŞÜK SEÇİN ('VERİ') | veri |
Bu bölüm, Teradata'da bulunan tarih / saat işlevlerini tartışır.
Tarih Saklama
Tarihler, aşağıdaki formül kullanılarak dahili olarak tamsayı olarak saklanır.
((YEAR - 1900) * 10000) + (MONTH * 100) + DAYTarihlerin nasıl saklandığını kontrol etmek için aşağıdaki sorguyu kullanabilirsiniz.
SELECT CAST(CURRENT_DATE AS INTEGER);Tarihler tamsayı olarak saklandığı için üzerlerinde bazı aritmetik işlemler gerçekleştirebilirsiniz. Teradata, bu işlemleri gerçekleştirmek için işlevler sağlar.
AYIKLA
EXTRACT işlevi, DATE değerinden gün, ay ve yıl bölümlerini çıkarır. Bu fonksiyon aynı zamanda TIME / TIMESTAMP değerinden saat, dakika ve saniyeyi çıkarmak için kullanılır.
Misal
Aşağıdaki örnekler, Tarih ve Zaman Damgası değerlerinden Yıl, Ay, Tarih, Saat, Dakika ve saniye değerlerinin nasıl çıkarılacağını gösterir.
SELECT EXTRACT(YEAR FROM CURRENT_DATE);
EXTRACT(YEAR FROM Date)
-----------------------
2016
SELECT EXTRACT(MONTH FROM CURRENT_DATE);
EXTRACT(MONTH FROM Date)
------------------------
1
SELECT EXTRACT(DAY FROM CURRENT_DATE);
EXTRACT(DAY FROM Date)
------------------------
1
SELECT EXTRACT(HOUR FROM CURRENT_TIMESTAMP);
EXTRACT(HOUR FROM Current TimeStamp(6))
---------------------------------------
4
SELECT EXTRACT(MINUTE FROM CURRENT_TIMESTAMP);
EXTRACT(MINUTE FROM Current TimeStamp(6))
-----------------------------------------
54
SELECT EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
EXTRACT(SECOND FROM Current TimeStamp(6))
-----------------------------------------
27.140000ARALIK
Teradata, DATE ve TIME değerleri üzerinde aritmetik işlemler gerçekleştirmek için INTERVAL işlevi sağlar. İki tür INTERVAL işlevi vardır.
Yıl-Ay Aralığı
- YEAR
- YILDAN AYA
- MONTH
Gün-Saat Aralığı
- DAY
- GÜN-SAAT
- DAKİKA GÜN
- İKİNCİYE GÜN
- HOUR
- SAAT - DAKİKA
- İKİNCİYE SAAT
- MINUTE
- İKİNCİYE DAKİKA
- SECOND
Misal
Aşağıdaki örnek, geçerli tarihe 3 yıl ekler.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03' YEAR;
Date (Date+ 3)
-------- ---------
16/01/01 19/01/01Aşağıdaki örnek, geçerli tarihe 3 yıl ve 01 ay ekler.
SELECT CURRENT_DATE, CURRENT_DATE + INTERVAL '03-01' YEAR TO MONTH;
Date (Date+ 3-01)
-------- ------------
16/01/01 19/02/01Aşağıdaki örnek, geçerli zaman damgasına 01 gün, 05 saat ve 10 dakika ekler.
SELECT CURRENT_TIMESTAMP,CURRENT_TIMESTAMP + INTERVAL '01 05:10' DAY TO MINUTE;
Current TimeStamp(6) (Current TimeStamp(6)+ 1 05:10)
-------------------------------- --------------------------------
2016-01-01 04:57:26.360000+00:00 2016-01-02 10:07:26.360000+00:00Teradata, SQL'in uzantıları olan yerleşik işlevler sağlar. Yaygın yerleşik işlevler aşağıdadır.
| Fonksiyon | Sonuç |
|---|---|
| TARİH SEÇ; | Tarih -------- 16/01/01 |
| CURRENT_DATE SEÇİN; | Tarih -------- 16/01/01 |
| ZAMAN SEÇ; | Zaman -------- 04:50:29 |
| CURRENT_TIME SEÇİN; | Zaman -------- 04:50:29 |
| CURRENT_TIMESTAMP SEÇİN; | Geçerli Zaman Damgası (6) -------------------------------- 2016-01-01 04: 51: 06.990000 + 00: 00 |
| VERİTABANI SEÇİN; | Veritabanı ------------------------------ TDUSER |
Teradata, ortak toplama işlevlerini destekler. SELECT ifadesiyle birlikte kullanılabilirler.
COUNT - Satırları sayar
SUM - Belirtilen sütun (lar) ın değerlerini özetler
MAX - Belirtilen sütunun büyük değerini verir
MIN - Belirtilen sütunun minimum değerini verir
AVG - Belirtilen sütunun ortalama değerini verir
Misal
Aşağıdaki Maaş Tablosunu düşünün.
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 104 | 75.000 | 5.000 | 70.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 105 | 70.000 | 4.000 | 66.000 |
| 103 | 90.000 | 7.000 | 83.000 |
MİKTAR
Aşağıdaki örnek, Maaş tablosundaki kayıtların sayısını sayar.
SELECT count(*) from Salary;
Count(*)
-----------
5MAX
Aşağıdaki örnek, maksimum çalışan net maaş değerini döndürür.
SELECT max(NetPay) from Salary;
Maximum(NetPay)
---------------------
83000MIN
Aşağıdaki örnek, Maaş tablosundan minimum çalışan net maaş değerini döndürür.
SELECT min(NetPay) from Salary;
Minimum(NetPay)
---------------------
36000AVG
Aşağıdaki örnek, tablodan çalışanların ortalama net maaş değerini döndürür.
SELECT avg(NetPay) from Salary;
Average(NetPay)
---------------------
65800SUM
Aşağıdaki örnek, Maaş tablosunun tüm kayıtlarından çalışanların net maaşının toplamını hesaplar.
SELECT sum(NetPay) from Salary;
Sum(NetPay)
-----------------
329000Bu bölüm, Teradata'nın CASE ve COALESCE işlevlerini açıklamaktadır.
CASE İfadesi
CASE ifadesi, her satırı bir koşula veya WHEN yan tümcesine göre değerlendirir ve ilk eşleşmenin sonucunu döndürür. Eşleşme yoksa, ELSE kısmının sonucu döndürülür.
Sözdizimi
Aşağıda CASE ifadesinin sözdizimi verilmiştir.
CASE <expression>
WHEN <expression> THEN result-1
WHEN <expression> THEN result-2
ELSE
Result-n
ENDMisal
Aşağıdaki Çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Bölüm No | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25.4.2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21.3.2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Aşağıdaki örnek, DepartmentNo sütununu değerlendirir ve bölüm numarası 1 ise 1 değerini döndürür; bölüm numarası 3 ise 2 döndürür; aksi takdirde değeri geçersiz departman olarak döndürür.
SELECT
EmployeeNo,
CASE DepartmentNo
WHEN 1 THEN 'Admin'
WHEN 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo Department
----------- ------------
101 Admin
104 IT
102 IT
105 Invalid Dept
103 ITYukarıdaki CASE ifadesi, yukarıdaki ile aynı sonucu verecek şekilde aşağıdaki biçimde de yazılabilir.
SELECT
EmployeeNo,
CASE
WHEN DepartmentNo = 1 THEN 'Admin'
WHEN DepartmentNo = 2 THEN 'IT'
ELSE 'Invalid Dept'
END AS Department
FROM Employee;KÖMÜR
COALESCE, ifadenin ilk boş olmayan değerini döndüren bir ifadedir. İfadenin tüm bağımsız değişkenleri NULL olarak değerlendirilirse NULL döndürür. Sözdizimi aşağıdadır.
Sözdizimi
COALESCE(expression 1, expression 2, ....)Misal
SELECT
EmployeeNo,
COALESCE(dept_no, 'Department not found')
FROM
employee;NULLIF
NULLIF deyimi, bağımsız değişkenler eşitse NULL döndürür.
Sözdizimi
NULLIF ifadesinin sözdizimi aşağıdadır.
NULLIF(expression 1, expression 2)Misal
Aşağıdaki örnek, DepartmentNo 3'e eşitse NULL döndürür. Aksi takdirde, DepartmentNo değerini döndürür.
SELECT
EmployeeNo,
NULLIF(DepartmentNo,3) AS department
FROM Employee;Yukarıdaki sorgu aşağıdaki kayıtları döndürür. 105 numaralı çalışanın departman numarasına sahip olduğunu görebilirsiniz. NULL olarak.
*** Query completed. 5 rows found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo department
----------- ------------------
101 1
104 2
102 2
105 ?
103 2Birincil dizin, verilerin Teradata'da nerede bulunduğunu belirtmek için kullanılır. Hangi AMP'nin veri satırını alacağını belirtmek için kullanılır. Teradata'daki her tablonun tanımlanmış bir birincil dizine sahip olması gerekir. Birincil dizin tanımlanmamışsa, Teradata otomatik olarak birincil dizini atar. Birincil dizin, verilere erişmenin en hızlı yolunu sağlar. Bir birincil maksimum 64 sütuna sahip olabilir.
Bir tablo oluşturulurken birincil dizin tanımlanır. 2 tür Birincil Dizin vardır.
- Benzersiz Birincil İndeks (UPI)
- Benzersiz Olmayan Birincil Endeks (NUPI)
Benzersiz Birincil İndeks (UPI)
Tablo UPI'ye sahip olarak tanımlanmışsa, UPI olarak kabul edilen sütunun herhangi bir yinelenen değeri olmamalıdır. Yinelenen değerler girilirse reddedilecektir.
Benzersiz Birincil Dizin Oluşturun
Aşağıdaki örnek, EmployeeNo sütununu Benzersiz Birincil Dizin olarak içeren Maaş tablosunu oluşturur.
CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Benzersiz Olmayan Birincil Endeks (NUPI)
Tablonun NUPI'ye sahip olduğu tanımlanmışsa, UPI olarak kabul edilen sütun yinelenen değerleri kabul edebilir.
Benzersiz Olmayan Birincil Dizin Oluşturun
Aşağıdaki örnek, Benzersiz Olmayan Birincil Dizin olarak EmployeeNo sütunuyla çalışan hesapları tablosunu oluşturur. EmployeeNo, bir çalışanın tabloda birden çok hesabı olabileceğinden, Benzersiz Olmayan Birincil Dizin olarak tanımlanır; biri maaş hesabı için diğeri geri ödeme hesabı için.
CREATE SET TABLE Employee _Accounts (
EmployeeNo INTEGER,
employee_bank_account_type BYTEINT.
employee_bank_account_number INTEGER,
employee_bank_name VARCHAR(30),
employee_bank_city VARCHAR(30)
)
PRIMARY INDEX(EmployeeNo);Birleştirme, birden fazla tablodaki kayıtları birleştirmek için kullanılır. Tablolar, bu tablolardaki ortak sütunlara / değerlere göre birleştirilir.
Farklı Birleştirme türleri mevcuttur.
- İç birleşim
- Sol dış katılma
- Sağ Dış Birleştirme
- Tam Dış Birleştirme
- Kendinden Katılma
- Çapraz Birleşim
- Kartezyen Üretim Birleşimi
İÇ BİRLEŞİM
Inner Join, birden çok tablodaki kayıtları birleştirir ve her iki tabloda da bulunan değerleri döndürür.
Sözdizimi
INNER JOIN deyiminin sözdizimi aşağıdadır.
SELECT col1, col2, col3….
FROM
Table-1
INNER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Misal
Aşağıdaki çalışan tablosu ve maaş tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Bölüm No | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25.4.2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21.3.2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Aşağıdaki sorgu, EmployeeNo ortak sütunundaki Çalışan tablosu ve Maaş tablosunu birleştirir. Her tabloya bir takma ad A & B atanır ve sütunlara doğru takma adla başvurulur.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
INNER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo);Yukarıdaki sorgu yürütüldüğünde aşağıdaki kayıtları döndürür. Çalışan 105, Maaş tablosunda eşleşen kayıtlara sahip olmadığı için sonuca dahil edilmemiştir.
*** Query completed. 4 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000DIŞ BİRLEŞTİRME
LEFT OUTER JOIN ve RIGHT OUTER JOIN de birden çok tablodan sonuçları birleştirir.
LEFT OUTER JOIN soldaki tablodaki tüm kayıtları döndürür ve yalnızca sağ tablodaki eşleşen kayıtları döndürür.
RIGHT OUTER JOIN sağ tablodaki tüm kayıtları döndürür ve yalnızca soldaki tablodaki eşleşen satırları döndürür.
FULL OUTER JOINSOL DIŞ ve SAĞ DIŞ BİRLEŞTİRMELERDEN elde edilen sonuçları birleştirir. Birleştirilen tablolardan hem eşleşen hem de eşleşmeyen satırları döndürür.
Sözdizimi
OUTER JOIN deyiminin sözdizimi aşağıdadır. LEFT OUTER JOIN, RIGHT OUTER JOIN veya FULL OUTER JOIN seçeneklerinden birini kullanmanız gerekir.
SELECT col1, col2, col3….
FROM
Table-1
LEFT OUTER JOIN/RIGHT OUTER JOIN/FULL OUTER JOIN
Table-2
ON (col1 = col2)
<WHERE condition>;Misal
LEFT OUTER JOIN sorgusunun aşağıdaki örneğini düşünün. Çalışan tablosundaki tüm kayıtları ve Maaş tablosundaki eşleşen kayıtları döndürür.
SELECT A.EmployeeNo, A.DepartmentNo, B.NetPay
FROM
Employee A
LEFT OUTER JOIN
Salary B
ON (A.EmployeeNo = B. EmployeeNo)
ORDER BY A.EmployeeNo;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Çalışan 105 için NetPay değeri, Maaş tablosunda eşleşen kayıtlara sahip olmadığından NULL'dur.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo NetPay
----------- ------------ -----------
101 1 36000
102 2 74000
103 2 83000
104 2 70000
105 3 ?CROSS JOIN
Çapraz Birleştirme, sol tablodan her satıra sağ tablodan her satıra katılır.
Sözdizimi
CROSS JOIN deyiminin sözdizimi aşağıdadır.
SELECT A.EmployeeNo, A.DepartmentNo, B.EmployeeNo,B.NetPay
FROM
Employee A
CROSS JOIN
Salary B
WHERE A.EmployeeNo = 101
ORDER BY B.EmployeeNo;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Çalışan tablosundan 101 No'lu Çalışan, Maaş Tablosundaki her kayıt ile birleştirilir.
*** Query completed. 4 rows found. 4 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo DepartmentNo EmployeeNo NetPay
----------- ------------ ----------- -----------
101 1 101 36000
101 1 104 70000
101 1 102 74000
101 1 103 83000Bir alt sorgu, başka bir tablodaki değerleri temel alarak bir tablodaki kayıtları döndürür. Başka bir sorgu içindeki bir SELECT sorgusudur. İlk olarak iç sorgu olarak adlandırılan SELECT sorgusu çalıştırılır ve sonuç dış sorgu tarafından kullanılır. Göze çarpan özelliklerinden bazıları -
Bir sorgu birden çok alt sorguya sahip olabilir ve alt sorgular başka bir alt sorgu içerebilir.
Alt sorgular, yinelenen kayıtlar döndürmez.
Alt sorgu yalnızca bir değer döndürürse, bunu dış sorgu ile kullanmak için = işlecini kullanabilirsiniz. Birden fazla değer döndürürse, IN veya NOT IN kullanabilirsiniz.
Sözdizimi
Aşağıda, alt sorguların genel sözdizimi verilmiştir.
SELECT col1, col2, col3,…
FROM
Outer Table
WHERE col1 OPERATOR ( Inner SELECT Query);Misal
Aşağıdaki Maaş tablosunu düşünün.
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Aşağıdaki sorgu, en yüksek maaşı alan çalışan numarasını tanımlar. İçteki SELECT, maksimum NetPay değerini döndürmek için toplama işlevini gerçekleştirir ve dış SELECT sorgusu bu değeri çalışan kaydını bu değerle döndürmek için kullanır.
SELECT EmployeeNo, NetPay
FROM Salary
WHERE NetPay =
(SELECT MAX(NetPay)
FROM Salary);Bu sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- -----------
103 83000Teradata, geçici verileri tutmak için aşağıdaki tablo türlerini destekler.
- Türetilmiş Tablo
- Uçucu Tablo
- Global Geçici Tablo
Türetilmiş Tablo
Türetilmiş tablolar oluşturulur, kullanılır ve bir sorgu içinde bırakılır. Bunlar, ara sonuçları bir sorgu içinde depolamak için kullanılır.
Misal
Aşağıdaki örnek, maaşı 75000'den fazla olan çalışanların kayıtlarıyla türetilmiş bir EmpSal tablosu oluşturur.
SELECT
Emp.EmployeeNo,
Emp.FirstName,
Empsal.NetPay
FROM
Employee Emp,
(select EmployeeNo , NetPay
from Salary
where NetPay >= 75000) Empsal
where Emp.EmployeeNo = Empsal.EmployeeNo;Yukarıdaki sorgu yürütüldüğünde, maaşı 75000'den fazla olan çalışanları döndürür.
*** Query completed. One row found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName NetPay
----------- ------------------------------ -----------
103 Peter 83000Uçucu Tablo
Bir kullanıcı oturumu içinde geçici tablolar oluşturulur, kullanılır ve bırakılır. Tanımları veri sözlüğünde saklanmaz. Sık kullanılan sorgunun ara verilerini tutarlar. Sözdizimi aşağıdadır.
Sözdizimi
CREATE [SET|MULTISET] VOALTILE TABLE tablename
<table definitions>
<column definitions>
<index definitions>
ON COMMIT [DELETE|PRESERVE] ROWSMisal
CREATE VOLATILE TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no)
ON COMMIT PRESERVE ROWS;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
*** Table has been created.
*** Total elapsed time was 1 second.Global Geçici Tablo
Global Geçici tablonun tanımı veri sözlüğünde saklanır ve birçok kullanıcı / oturum tarafından kullanılabilir. Ancak genel geçici tabloya yüklenen veriler yalnızca oturum sırasında tutulur. Oturum başına 2000 adede kadar genel geçici tablo gerçekleştirebilirsiniz. Sözdizimi aşağıdadır.
Sözdizimi
CREATE [SET|MULTISET] GLOBAL TEMPORARY TABLE tablename
<table definitions>
<column definitions>
<index definitions>Misal
CREATE SET GLOBAL TEMPORARY TABLE dept_stat (
dept_no INTEGER,
avg_salary INTEGER,
max_salary INTEGER,
min_salary INTEGER
)
PRIMARY INDEX(dept_no);Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
*** Table has been created.
*** Total elapsed time was 1 second.Teradata'da kullanılabilen üç tür alan vardır.
Kalıcı Alan
Kalıcı alan, kullanıcının / veritabanının veri satırlarını tutabileceği maksimum alan miktarıdır. Kalıcı tablolar, günlükler, geri dönüş tabloları ve ikincil dizin alt tabloları kalıcı alan kullanır.
Kalıcı alan, veritabanı / kullanıcı için önceden tahsis edilmemiştir. Veritabanının / kullanıcının kullanabileceği maksimum alan miktarı olarak tanımlanırlar. Kalıcı alan miktarı, AMP sayısına bölünür. AMP sınırı başına her aşıldığında, bir hata mesajı oluşturulur.
Biriktirme Alanı
Biriktirme alanı, SQL sorgusunun ara sonuçlarını tutmak için sistem tarafından kullanılan kullanılmayan kalıcı alandır. Biriktirme alanı olmayan kullanıcılar herhangi bir sorgu yürütemez.
Kalıcı alana benzer şekilde, biriktirme alanı, kullanıcının kullanabileceği maksimum alan miktarını tanımlar. Biriktirme alanı, AMP sayısına bölünür. AMP sınırı başına her aşıldığında, kullanıcı bir biriktirme alanı hatası alır.
Sıcaklık Alanı
Geçici alan, Global Geçici tablolar tarafından kullanılan kullanılmayan kalıcı alandır. Geçici alan ayrıca AMP sayısına bölünür.
Bir tablo yalnızca bir birincil dizin içerebilir. Daha sık olarak, tablonun diğer sütunları içerdiği ve bunları kullanarak verilere sıklıkla erişilen senaryolarla karşılaşırsınız. Teradata, bu sorgular için tam tablo taraması gerçekleştirecektir. İkincil dizinler bu sorunu çözer.
İkincil dizinler, verilere erişmek için alternatif bir yoldur. Birincil dizin ile ikincil dizin arasında bazı farklılıklar vardır.
İkincil dizin, veri dağıtımına dahil değildir.
İkincil indeks değerleri alt tablolarda saklanır. Bu tablolar tüm AMP'lerde oluşturulmuştur.
İkincil dizinler isteğe bağlıdır.
Tablo oluşturma sırasında veya bir tablo oluşturulduktan sonra oluşturulabilirler.
Alt tablo oluşturdukları için ek alan kaplarlar ve ayrıca her yeni satır için alt tabloların güncellenmesi gerektiğinden bakım gerektirirler.
İki tür ikincil dizin vardır -
- Benzersiz İkincil Endeks (USI)
- Benzersiz Olmayan İkincil Endeks (NUSI)
Benzersiz İkincil Endeks (USI)
Benzersiz İkincil Dizin, USI olarak tanımlanan sütunlar için yalnızca benzersiz değerlere izin verir. Sıraya USI ile erişim iki amperlik bir işlemdir.
Benzersiz İkincil Dizin Oluşturun
Aşağıdaki örnek, çalışan tablosunun EmployeeNo sütununda USI oluşturur.
CREATE UNIQUE INDEX(EmployeeNo) on employee;Benzersiz Olmayan İkincil Endeks (NUSI)
Benzersiz Olmayan İkincil Dizin, NUSI olarak tanımlanan sütunlar için yinelenen değerlere izin verir. Sıraya NUSI ile erişmek, tamamen amfi işlemidir.
Benzersiz Olmayan İkincil Dizin Oluşturun
Aşağıdaki örnek, çalışan tablosunun FirstName sütununda NUSI oluşturur.
CREATE INDEX(FirstName) on Employee;Teradata optimizer, her SQL sorgusu için bir yürütme stratejisi ile gelir. Bu yürütme stratejisi, SQL sorgusu içinde kullanılan tablolarda toplanan istatistiklere dayanmaktadır. Tablo üzerindeki istatistikler COLLECT STATISTICS komutu kullanılarak toplanır. Optimize edici, optimum yürütme stratejisi bulmak için ortam bilgilerine ve veri demografisine ihtiyaç duyar.
Çevre Bilgileri
- Düğüm, AMP ve CPU Sayısı
- Bellek miktarı
Veri Demografisi
- Satır sayısı
- Satır boyutu
- Tablodaki değer aralığı
- Değer başına satır sayısı
- Null Sayısı
Tabloda istatistik toplamak için üç yaklaşım vardır.
- Rastgele AMP Örneklemesi
- Tam istatistik koleksiyonu
- ÖRNEK seçeneğini kullanma
İstatistik Toplama
COLLECT STATISTICS komutu, bir tablo üzerinde istatistik toplamak için kullanılır.
Sözdizimi
Aşağıda, bir tabloda istatistik toplamak için temel sözdizimi verilmiştir.
COLLECT [SUMMARY] STATISTICS
INDEX (indexname) COLUMN (columnname)
ON <tablename>;Misal
Aşağıdaki örnek, Employee tablosunun EmployeeNo sütununda istatistikleri toplar.
COLLECT STATISTICS COLUMN(EmployeeNo) ON Employee;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
*** Update completed. 2 rows changed.
*** Total elapsed time was 1 second.İstatistikleri Görüntüleme
HELP STATISTICS komutunu kullanarak toplanan istatistikleri görüntüleyebilirsiniz.
Sözdizimi
Toplanan istatistikleri görüntülemek için sözdizimi aşağıdadır.
HELP STATISTICS <tablename>;Misal
Çalışan tablosunda toplanan istatistikleri görüntülemek için bir örnek aşağıdadır.
HELP STATISTICS employee;Yukarıdaki sorgu yürütüldüğünde aşağıdaki sonucu verir.
Date Time Unique Values Column Names
-------- -------- -------------------- -----------------------
16/01/01 08:07:04 5 *
16/01/01 07:24:16 3 DepartmentNo
16/01/01 08:07:04 5 EmployeeNoTablolar tarafından kullanılan depolamayı azaltmak için sıkıştırma kullanılır. Teradata'da sıkıştırma, NULL dahil 255'e kadar farklı değeri sıkıştırabilir. Depolama azaldığından, Teradata bir blokta daha fazla kayıt depolayabilir. Bu, herhangi bir G / Ç işlemi blok başına daha fazla satır işleyebileceğinden, iyileştirilmiş sorgu yanıt süresi ile sonuçlanır. Sıkıştırma, CREATE TABLE kullanılarak tablo oluştururken veya ALTER TABLE komutu kullanılarak tablo oluşturulduktan sonra eklenebilir.
Sınırlamalar
- Sütun başına yalnızca 255 değer sıkıştırılabilir.
- Birincil Dizin sütunu sıkıştırılamaz.
- Uçucu tablolar sıkıştırılamaz.
Çok Değerli Sıkıştırma (MVC)
Aşağıdaki tablo, DepatmentNo alanını 1, 2 ve 3 değerleri için sıkıştırır. Bir sütuna sıkıştırma uygulandığında, bu sütunun değerleri satırla birlikte depolanmaz. Bunun yerine, değerler her AMP'deki Tablo başlığında saklanır ve değeri belirtmek için satıra yalnızca varlık bitleri eklenir.
CREATE SET TABLE employee (
EmployeeNo integer,
FirstName CHAR(30),
LastName CHAR(30),
BirthDate DATE FORMAT 'YYYY-MM-DD-',
JoinedDate DATE FORMAT 'YYYY-MM-DD-',
employee_gender CHAR(1),
DepartmentNo CHAR(02) COMPRESS(1,2,3)
)
UNIQUE PRIMARY INDEX(EmployeeNo);Çok Değerli sıkıştırma, sonlu değerlere sahip büyük bir tabloda bir sütununuz olduğunda kullanılabilir.
EXPLAIN komutu, ayrıştırma motorunun yürütme planını İngilizce olarak döndürür. Başka bir EXPLAIN komutu dışında herhangi bir SQL ifadesiyle kullanılabilir. Bir sorgudan önce EXPLAIN komutu geldiğinde, Ayrıştırma Motorunun yürütme planı AMP'ler yerine kullanıcıya döndürülür.
EXPLAIN örnekleri
Aşağıdaki tanıma sahip Çalışan tablosunu düşünün.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30),
LastName VARCHAR(30),
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );EXPLAIN planının bazı örnekleri aşağıda verilmiştir.
Tam Tablo Tarama (FTS)
SELECT deyiminde hiçbir koşul belirtilmediğinde, optimize edici tablonun her satırına erişilen Tam Tablo Taramasını kullanmayı seçebilir.
Misal
Aşağıda, optimize edicinin FTS'yi seçebileceği örnek bir sorgu verilmiştir.
EXPLAIN SELECT * FROM employee;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Görüldüğü gibi, optimize edici tüm AMP'lere ve AMP içindeki tüm satırlara erişmeyi seçer.
1) First, we lock a distinct TDUSER."pseudo table" for read on a
RowHash to prevent global deadlock for TDUSER.employee.
2) Next, we lock TDUSER.employee for read.
3) We do an all-AMPs RETRIEVE step from TDUSER.employee by way of an
all-rows scan with no residual conditions into Spool 1
(group_amps), which is built locally on the AMPs. The size of
Spool 1 is estimated with low confidence to be 2 rows (116 bytes).
The estimated time for this step is 0.03 seconds.
4) Finally, we send out an END TRANSACTION step to all AMPs involved
in processing the request.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.03 seconds.Benzersiz Birincil Dizin
Satırlara Benzersiz Birincil Dizin kullanılarak erişildiğinde, bu bir AMP işlemidir.
EXPLAIN SELECT * FROM employee WHERE EmployeeNo = 101;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Görüldüğü gibi, bu tek bir AMP alımıdır ve optimize edici, satıra erişmek için benzersiz birincil dizini kullanıyor.
1) First, we do a single-AMP RETRIEVE step from TDUSER.employee by
way of the unique primary index "TDUSER.employee.EmployeeNo = 101"
with no residual conditions. The estimated time for this step is
0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Benzersiz İkincil Endeks
Sıralara Unique Secondary Index kullanılarak erişildiğinde, bu iki amperlik bir işlemdir.
Misal
Aşağıdaki tanıma sahip Maaş tablosunu düşünün.
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Aşağıdaki SELECT ifadesini düşünün.
EXPLAIN SELECT * FROM Salary WHERE EmployeeNo = 101;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Görülebileceği gibi, optimize edici, benzersiz ikincil indeks kullanarak iki amper işleminde satırı alır.
1) First, we do a two-AMP RETRIEVE step from TDUSER.Salary
by way of unique index # 4 "TDUSER.Salary.EmployeeNo =
101" with no residual conditions. The estimated time for this
step is 0.01 seconds.
→ The row is sent directly back to the user as the result of
statement 1. The total estimated time is 0.01 seconds.Ek koşullar
EXPLAIN planında yaygın olarak görülen terimlerin listesi aşağıdadır.
... (Last Use) …
Bir biriktirme dosyası artık gerekli değildir ve bu adım tamamlandığında serbest bırakılacaktır.
... with no residual conditions …
Satırlara tüm uygulanabilir koşullar uygulanmıştır.
... END TRANSACTION …
İşlem kilitleri serbest bırakılır ve değişiklikler yapılır.
... eliminating duplicate rows ...
Yinelenen satırlar ayar tablolarında değil, yalnızca biriktirme dosyalarında bulunur. DISTINCT işlemi yapmak.
... by way of a traversal of index #n extracting row ids only …
İkincil bir dizinde bulunan Satır Kimliklerini içeren bir biriktirme dosyası oluşturulur (dizin #n)
... we do a SMS (set manipulation step) …
Bir UNION, MINUS veya INTERSECT operatörü kullanarak satırları birleştirmek.
... which is redistributed by hash code to all AMPs.
Bir birleştirme hazırlığında verileri yeniden dağıtma.
... which is duplicated on all AMPs.
Bir birleştirmeye hazırlık olarak daha küçük tablodan (SPOOL açısından) verilerin çoğaltılması.
... (one_AMP) or (group_AMPs)
Tüm AMP'ler yerine bir AMP veya AMP alt kümesinin kullanılacağını belirtir.
Bir satır, birincil dizin değerine göre belirli bir AMP'ye atanır. Teradata, satırı hangi AMP'nin alacağını belirlemek için karma algoritma kullanır.
Aşağıda, karma algoritma hakkında yüksek seviyeli bir diyagram bulunmaktadır.

Verileri eklemek için adımlar aşağıdadır.
İstemci bir sorgu gönderir.
Ayrıştırıcı sorguyu alır ve kaydın PI değerini karma algoritmaya iletir.
Karma algoritması, birincil dizin değerini hash eder ve Satır Karma adı verilen 32 bitlik bir sayı döndürür.
Satır özetinin yüksek dereceli bitleri (ilk 16 bit), karma harita girişini tanımlamak için kullanılır. Karma harita bir AMP # içerir. Karma harita, belirli AMP # içeren bir grup dizisidir.
BYNET, verileri tanımlanan AMP'ye gönderir.
AMP, diski içindeki satırı bulmak için 32 bit Satır hashini kullanır.
Aynı satır özetine sahip herhangi bir kayıt varsa, 32 bitlik bir sayı olan benzersizlik kimliğini artırır. Yeni satır karması için, benzersizlik kimliği 1 olarak atanır ve aynı satır özetine sahip bir kayıt eklendiğinde artırılır.
Satır hash ve Benzersizlik Kimliği kombinasyonu, Satır Kimliği olarak adlandırılır.
Satır kimliği, diskteki her kaydın ön ekini oluşturur.
AMP'deki her tablo satırı mantıksal olarak Satır Kimliklerine göre sıralanır.
Tablolar Nasıl Saklanır
Tablolar, Satır Kimliğine (Satır karması + benzersizlik kimliği) göre sıralanır ve ardından AMP'lerde saklanır. Satır kimliği, her veri satırıyla birlikte saklanır.
| Satır Hash | Benzersizlik kimliği | Çalışan Hayır | İsim | Soyadı |
|---|---|---|---|---|
| 2A01 2611 | 0000 0001 | 101 | Mike | James |
| 2A01 2612 | 0000 0001 | 104 | Alex | Stuart |
| 2A01 2613 | 0000 0001 | 102 | Robert | Williams |
| 2A01 2614 | 0000 0001 | 105 | Robert | James |
| 2A01 2615 | 0000 0001 | 103 | Peter | Paul |
JOIN INDEX, somutlaştırılmış bir görünümdür. Tanımı kalıcı olarak saklanır ve birleştirme indeksinde belirtilen temel tablolar her güncellendiğinde veriler güncellenir. JOIN INDEX, bir veya daha fazla tablo içerebilir ve ayrıca önceden toplanmış veriler içerebilir. Birleştirme dizinleri esas olarak performansı artırmak için kullanılır.
Farklı tipte birleştirme indeksleri mevcuttur.
- Tek Tablo Birleştirme Dizini (STJI)
- Çoklu Masa Birleştirme Endeksi (MTJI)
- Toplu Katılım Dizini (AJI)
Tek Tablo Birleştirme Dizini
Tek Tablo Birleştirme indeksi, büyük bir tabloyu temel tablodakinden farklı birincil indeks sütunlarına göre bölümlemeye izin verir.
Sözdizimi
Bir JOIN INDEX'in sözdizimi aşağıdadır.
CREATE JOIN INDEX <index name>
AS
<SELECT Query>
<Index Definition>;Misal
Aşağıdaki Çalışan ve Maaş tablolarını düşünün.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );
CREATE SET TABLE SALARY,FALLBACK (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
PRIMARY INDEX ( EmployeeNo )
UNIQUE INDEX (EmployeeNo);Aşağıda, Employee tablosunda Employee_JI adlı bir Join dizini oluşturan bir örnek verilmiştir.
CREATE JOIN INDEX Employee_JI
AS
SELECT EmployeeNo,FirstName,LastName,
BirthDate,JoinedDate,DepartmentNo
FROM Employee
PRIMARY INDEX(FirstName);Kullanıcı EmployeeNo'da WHERE yan tümcesi içeren bir sorgu gönderirse, sistem benzersiz birincil dizini kullanarak Çalışan tablosunu sorgulayacaktır. Kullanıcı, çalışan_adı kullanarak çalışan tablosunu sorgularsa, sistem çalışan_adı kullanarak Employee_JI katılma dizinine erişebilir. Birleştirme dizininin satırları, çalışan_adı sütununda karma hale getirilmiştir. Birleştirme dizini tanımlanmamışsa ve çalışan_adı ikincil dizin olarak tanımlanmamışsa, sistem, zaman alan satırlara erişmek için tam tablo taraması gerçekleştirecektir.
Aşağıdaki EXPLAIN planını çalıştırabilir ve optimize edici planını doğrulayabilirsiniz. Aşağıdaki örnekte, tablo Employee_Name sütununu kullanarak sorguladığında, optimize edicinin temel Çalışan tablosu yerine Katılma Dizini kullandığını görebilirsiniz.
EXPLAIN SELECT * FROM EMPLOYEE WHERE FirstName='Mike';
*** Help information returned. 8 rows.
*** Total elapsed time was 1 second.
Explanation
------------------------------------------------------------------------
1) First, we do a single-AMP RETRIEVE step from EMPLOYEE_JI by
way of the primary index "EMPLOYEE_JI.FirstName = 'Mike'"
with no residual conditions into Spool 1 (one-amp), which is built
locally on that AMP. The size of Spool 1 is estimated with low
confidence to be 2 rows (232 bytes). The estimated time for this
step is 0.02 seconds.
→ The contents of Spool 1 are sent back to the user as the result of
statement 1. The total estimated time is 0.02 seconds.Çoklu Masa Birleştirme Dizini
Birden fazla tablonun birleştirilmesiyle çoklu tablo birleştirme indeksi oluşturulur. Çoklu tablo birleştirme indeksi, performansı artırmak için sık birleştirilmiş tabloların sonuç kümesini depolamak için kullanılabilir.
Misal
Aşağıdaki örnek, Employee ve Salary tablolarına katılarak Employee_Salary_JI adlı bir JOIN INDEX oluşturur.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.EmployeeNo,a.FirstName,a.LastName,
a.BirthDate,a.JoinedDate,a.DepartmentNo,b.Gross,b.Deduction,b.NetPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
PRIMARY INDEX(FirstName);Çalışan veya Maaş temel tabloları güncellendiğinde, Katılma indeksi Employee_Salary_JI da otomatik olarak güncellenir. Çalışan ve Maaş tablolarını birleştiren bir sorgu çalıştırıyorsanız, optimize edici, tabloları birleştirmek yerine Employee_Salary_JI'deki verilere doğrudan erişmeyi seçebilir. Sorgudaki EXPLAIN planı, optimize edicinin temel tabloyu veya Birleştirme dizini seçip seçmeyeceğini doğrulamak için kullanılabilir.
Toplu Katılma Dizini
Bir tablo belirli sütunlarda tutarlı bir şekilde toplanmışsa, performansı artırmak için toplu birleştirme indeksi tabloda tanımlanabilir. Toplam birleştirme dizininin bir sınırlaması, yalnızca SUM ve COUNT işlevlerini desteklemesidir.
Misal
Aşağıdaki örnekte Çalışan ve Maaş, Departman başına toplam maaşı belirlemek için birleştirilmiştir.
CREATE JOIN INDEX Employee_Salary_JI
AS
SELECT a.DepartmentNo,SUM(b.NetPay) AS TotalPay
FROM Employee a
INNER JOIN Salary b
ON(a.EmployeeNo = b.EmployeeNo)
GROUP BY a.DepartmentNo
Primary Index(DepartmentNo);Görünümler, sorgu tarafından oluşturulan veritabanı nesneleridir. Görünümler, tek bir tablo veya birleştirme yoluyla birden çok tablo kullanılarak oluşturulabilir. Tanımları veri sözlüğünde kalıcı olarak saklanır, ancak verilerin kopyasını saklamazlar. Görünüm için veriler dinamik olarak oluşturulur.
Bir görünüm, tablonun satırlarının bir alt kümesini veya tablonun sütunlarının bir alt kümesini içerebilir.
Görünüm Oluşturun
Görünümler, CREATE VIEW deyimi kullanılarak oluşturulur.
Sözdizimi
Görünüm oluşturmak için sözdizimi aşağıdadır.
CREATE/REPLACE VIEW <viewname>
AS
<select query>;Misal
Aşağıdaki Çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | Doğum günü |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Peter | Paul | 4/1/1983 |
Aşağıdaki örnek, Çalışan tablosunda bir görünüm oluşturur.
CREATE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
LastName,
FROM
Employee;Görünümleri Kullanma
Görünümlerden veri almak için normal SELECT deyimini kullanabilirsiniz.
Misal
Aşağıdaki örnek, kayıtları Employee_View'dan alır;
SELECT EmployeeNo, FirstName, LastName FROM Employee_View;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
104 Alex Stuart
102 Robert Williams
105 Robert James
103 Peter PaulGörünümleri Değiştirme
Mevcut bir görünüm REPLACE VIEW deyimi kullanılarak değiştirilebilir.
Bir görünümü değiştirmek için sözdizimi aşağıdadır.
REPLACE VIEW <viewname>
AS
<select query>;Misal
Aşağıdaki örnek, ek sütunlar eklemek için Employee_View görünümünü değiştirir.
REPLACE VIEW Employee_View
AS
SELECT
EmployeeNo,
FirstName,
BirthDate,
JoinedDate
DepartmentNo
FROM
Employee;Görünümü Bırak
DROP VIEW deyimi kullanılarak mevcut bir görünüm bırakılabilir.
Sözdizimi
DROP VIEW sözdizimi aşağıdadır.
DROP VIEW <viewname>;Misal
Aşağıda Employee_View görünümünü düşürmek için bir örnek verilmiştir.
DROP VIEW Employee_View;Görünümlerin Avantajları
Görünümler, bir tablonun satırlarını veya sütunlarını kısıtlayarak ek güvenlik düzeyi sağlar.
Kullanıcılara temel tablolar yerine yalnızca görünümlere erişim verilebilir.
Görünümler kullanarak bunları önceden birleştirerek birden çok tablonun kullanımını basitleştirir.
Makro, Makro adını çağırarak saklanan ve çalıştırılan bir SQL deyimleri kümesidir. Makroların tanımı Veri Sözlüğü'nde saklanır. Kullanıcılar, Makroyu yürütmek için yalnızca EXEC ayrıcalığına ihtiyaç duyar. Kullanıcılar, Makro içinde kullanılan veritabanı nesneleri üzerinde ayrı ayrıcalıklara ihtiyaç duymazlar. Makro ifadeleri tek bir işlem olarak yürütülür. Makrodaki SQL ifadelerinden biri başarısız olursa, tüm ifadeler geri alınır. Makrolar parametreleri kabul edebilir. Makrolar DDL ifadeleri içerebilir, ancak bu Makrodaki son ifade olmalıdır.
Makrolar Oluşturun
Makrolar, CREATE MACRO deyimi kullanılarak oluşturulur.
Sözdizimi
Aşağıda CREATE MACRO komutunun genel sözdizimi verilmiştir.
CREATE MACRO <macroname> [(parameter1, parameter2,...)] (
<sql statements>
);Misal
Aşağıdaki Çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | Doğum günü |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Peter | Paul | 4/1/1983 |
Aşağıdaki örnek, Get_Emp adlı bir Makro oluşturur. Çalışan tablosundan kayıtları almak için bir seçme ifadesi içerir.
CREATE MACRO Get_Emp AS (
SELECT
EmployeeNo,
FirstName,
LastName
FROM
employee
ORDER BY EmployeeNo;
);Makroları Yürütme
Makrolar, EXEC komutu kullanılarak yürütülür.
Sözdizimi
Aşağıdaki EXECUTE MACRO komutunun sözdizimidir.
EXEC <macroname>;Misal
Aşağıdaki örnek, Get_Emp Makro adlarını çalıştırır; Aşağıdaki komut yürütüldüğünde, tüm kayıtları çalışan tablosundan alır.
EXEC Get_Emp;
*** Query completed. 5 rows found. 3 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo FirstName LastName
----------- ------------------------------ ---------------------------
101 Mike James
102 Robert Williams
103 Peter Paul
104 Alex Stuart
105 Robert JamesParametreli Makrolar
Teradata Makroları parametreleri kabul edebilir. Bir Makro içinde bu parametrelere; (noktalı virgül).
Aşağıda, parametreleri kabul eden bir Makro örneği verilmiştir.
CREATE MACRO Get_Emp_Salary(EmployeeNo INTEGER) AS (
SELECT
EmployeeNo,
NetPay
FROM
Salary
WHERE EmployeeNo = :EmployeeNo;
);Parametreli Makroları Yürütme
Makrolar, EXEC komutu kullanılarak yürütülür. Makroları yürütmek için EXEC ayrıcalığına ihtiyacınız var.
Sözdizimi
EXECUTE MACRO ifadesinin sözdizimi aşağıdadır.
EXEC <macroname>(value);Misal
Aşağıdaki örnek, Get_Emp Makro adlarını çalıştırır; Çalışan numarasını parametre olarak kabul eder ve o çalışan için çalışan tablosundan kayıtları çıkarır.
EXEC Get_Emp_Salary(101);
*** Query completed. One row found. 2 columns returned.
*** Total elapsed time was 1 second.
EmployeeNo NetPay
----------- ------------
101 36000Bir saklı yordam, bir dizi SQL deyimi ve yordamsal deyim içerir. Yalnızca usule ilişkin ifadeler içerebilirler. Depolanan prosedürün tanımı veritabanında saklanır ve parametreler veri sözlüğü tablolarında depolanır.
Avantajlar
Saklanan prosedürler, istemci ve sunucu arasındaki ağ yükünü azaltır.
Verilere doğrudan erişmek yerine depolanan prosedürler aracılığıyla erişildiği için daha iyi güvenlik sağlar.
İş mantığı test edilip sunucuda saklandığı için daha iyi bakım sağlar.
Prosedür Oluşturma
Depolanan Prosedürler, CREATE PROCEDURE deyimi kullanılarak oluşturulur.
Sözdizimi
Aşağıda, CREATE PROCEDURE ifadesinin genel sözdizimi verilmiştir.
CREATE PROCEDURE <procedurename> ( [parameter 1 data type, parameter 2 data type..] )
BEGIN
<SQL or SPL statements>;
END;Misal
Aşağıdaki Maaş Tablosunu düşünün.
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Aşağıdaki örnek, değerleri kabul etmek ve Maaş Tablosuna eklemek için InsertSalary adında bir saklı yordam oluşturur.
CREATE PROCEDURE InsertSalary (
IN in_EmployeeNo INTEGER, IN in_Gross INTEGER,
IN in_Deduction INTEGER, IN in_NetPay INTEGER
)
BEGIN
INSERT INTO Salary (
EmployeeNo,
Gross,
Deduction,
NetPay
)
VALUES (
:in_EmployeeNo,
:in_Gross,
:in_Deduction,
:in_NetPay
);
END;Yürütme Prosedürleri
Depolanan Prosedürler, CALL deyimi kullanılarak yürütülür.
Sözdizimi
Aşağıda, CALL ifadesinin genel sözdizimi verilmiştir.
CALL <procedure name> [(parameter values)];Misal
Aşağıdaki örnek, saklı yordamı InsertSalary çağırır ve kayıtları Maaş Tablosuna ekler.
CALL InsertSalary(105,20000,2000,18000);Yukarıdaki sorgu yürütüldüğünde, aşağıdaki çıktıyı üretir ve eklenen satırı Maaş tablosunda görebilirsiniz.
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
| 105 | 20.000 | 2.000 | 18.000 |
Bu bölüm, Teradata'da bulunan çeşitli JOIN stratejilerini tartışmaktadır.
Birleştirme Yöntemleri
Teradata, birleştirme işlemlerini gerçekleştirmek için farklı birleştirme yöntemleri kullanır. Yaygın olarak kullanılan Birleştirme yöntemlerinden bazıları şunlardır:
- Birleştir Katıl
- İç içe Birleştirme
- Ürün Birleştirme
Birleştir Katıl
Birleştirme Birleştirme yöntemi, birleştirme eşitlik koşuluna dayandığında gerçekleşir. Birleştirme Birleştirme, birleştirme satırlarının aynı AMP'de olmasını gerektirir. Satırlar, satır karmalarına göre birleştirilir. Birleştirme Birleştirme, satırları aynı AMP'ye getirmek için farklı birleştirme stratejileri kullanır.
Strateji 1
Birleştirme sütunları, karşılık gelen tabloların birincil diziniyse, birleşen satırlar zaten aynı AMP üzerindedir. Bu durumda dağıtıma gerek yoktur.
Aşağıdaki Çalışan ve Maaş Tablolarını düşünün.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE Salary (
EmployeeNo INTEGER,
Gross INTEGER,
Deduction INTEGER,
NetPay INTEGER
)
UNIQUE PRIMARY INDEX(EmployeeNo);Bu iki tablo EmployeeNo sütununda birleştirildiğinde, EmployeeNo birleştirilen her iki tablonun birincil indeksi olduğundan yeniden dağıtım gerçekleşmez.
Strateji 2
Aşağıdaki Çalışan ve Departman tablolarını inceleyin.
CREATE SET TABLE EMPLOYEE,FALLBACK (
EmployeeNo INTEGER,
FirstName VARCHAR(30) ,
LastName VARCHAR(30) ,
DOB DATE FORMAT 'YYYY-MM-DD',
JoinedDate DATE FORMAT 'YYYY-MM-DD',
DepartmentNo BYTEINT
)
UNIQUE PRIMARY INDEX ( EmployeeNo );CREATE SET TABLE DEPARTMENT,FALLBACK (
DepartmentNo BYTEINT,
DepartmentName CHAR(15)
)
UNIQUE PRIMARY INDEX ( DepartmentNo );Bu iki tablo DeparmentNo sütununda birleştirilirse, DepartmentNo bir tablodaki birincil dizin ve başka bir tablodaki birincil olmayan dizin olduğundan satırların yeniden dağıtılması gerekir. Bu senaryoda, birleştirme satırları aynı AMP üzerinde olmayabilir. Böyle bir durumda Teradata, çalışan tablosunu DepartmentNo sütununda yeniden dağıtabilir.
Strateji 3
Yukarıdaki Çalışan ve Departman tabloları için Teradata, Departman tablosunun boyutu küçükse Departman tablosunu tüm AMP'lerde çoğaltabilir.
İç içe Birleştirme
İç İçe Birleştirme tüm AMP'leri kullanmaz. İç İçe Birleştirme işleminin gerçekleşmesi için koşullardan birinin, bir tablonun benzersiz birincil dizininde eşitlik olması ve ardından bu sütunun diğer tablodaki herhangi bir dizine katılması gerekir.
Bu senaryoda, sistem bir tablonun Benzersiz Birincil dizinini kullanarak bir satırı alır ve diğer tablodan eşleşen kayıtları almak için bu satır karmasını kullanır. İç içe birleştirme, tüm Birleştirme yöntemleri arasında en verimli olanıdır.
Ürün Birleştirme
Product Join, bir tablodaki her uygun satırı, diğer tablodaki her niteleyici satırla karşılaştırır. Ürün birleştirme, aşağıdaki faktörlerden bazıları nedeniyle gerçekleşebilir -
- Koşulun eksik olduğu yer.
- Birleştirme koşulu eşitlik koşuluna bağlı değildir.
- Tablo takma adları doğru değil.
- Çoklu katılma koşulları.
Partitioned Primary Index (ÜFE), belirli sorguların performansını iyileştirmede yararlı olan bir indeksleme mekanizmasıdır. Satırlar bir tabloya eklendiğinde, bir AMP'de depolanır ve satır karma sırasına göre düzenlenir. Bir tablo PPI ile tanımlandığında, satırlar bölüm numaralarına göre sıralanır. Her bölüm içinde, satır hashlerine göre düzenlenirler. Satırlar, tanımlanan bölüm ifadesine göre bir bölüme atanır.
Avantajlar
Belirli sorgular için tam tablo taramasından kaçının.
Ek fiziksel yapı ve ek G / Ç bakımı gerektiren ikincil dizini kullanmaktan kaçının.
Büyük bir tablonun bir alt kümesine hızla erişin.
Eski verileri hızlıca bırakın ve yeni veriler ekleyin.
Misal
SiparişNo'da Birincil Endeks içeren aşağıdaki Siparişler tablosunu göz önünde bulundurun.
| MağazaNo | Sipariş No | Sipariş tarihi | Sipariş toplamı |
|---|---|---|---|
| 101 | 7501 | 2015-10-01 | 900 |
| 101 | 7502 | 2015-10-02 | 1.200 |
| 102 | 7503 | 2015-10-02 | 3.000 |
| 102 | 7504 | 2015-10-03 | 2.454 |
| 101 | 7505 | 2015-10-03 | 1201 |
| 103 | 7506 | 2015-10-04 | 2.454 |
| 101 | 7507 | 2015-10-05 | 1201 |
| 101 | 7508 | 2015-10-05 | 1201 |
Aşağıdaki tablolarda gösterildiği gibi kayıtların AMP'ler arasında dağıtıldığını varsayın. Kaydedilenler, satır karmalarına göre sıralanan AMP'lerde saklanır.
| RowHash | Sipariş No | Sipariş tarihi |
|---|---|---|
| 1 | 7505 | 2015-10-03 |
| 2 | 7504 | 2015-10-03 |
| 3 | 7501 | 2015-10-01 |
| 4 | 7508 | 2015-10-05 |
| RowHash | Sipariş No | Sipariş tarihi |
|---|---|---|
| 1 | 7507 | 2015-10-05 |
| 2 | 7502 | 2015-10-02 |
| 3 | 7506 | 2015-10-04 |
| 4 | 7503 | 2015-10-02 |
Belirli bir tarihe ait siparişleri çıkarmak için bir sorgu çalıştırırsanız, optimize edici Tam Tablo Taramasını kullanmayı seçebilir, ardından AMP içindeki tüm kayıtlara erişilebilir. Bunu önlemek için sipariş tarihini Bölümlenmiş Birincil Dizin olarak tanımlayabilirsiniz. Siparişler tablosuna satırlar eklendiğinde, sipariş tarihine göre bölümlenirler. Her bölüm içinde satır hash'lerine göre sıralanacaklar.
Aşağıdaki veriler, Sipariş Tarihine göre bölümlenmişlerse kayıtların AMP'lerde nasıl depolanacağını gösterir. Kayıtlara Sipariş Tarihine göre erişmek için bir sorgu çalıştırılırsa, yalnızca söz konusu sipariş için kayıtları içeren bölüme erişilecektir.
| Bölüm | RowHash | Sipariş No | Sipariş tarihi |
|---|---|---|---|
| 0 | 3 | 7501 | 2015-10-01 |
| 1 | 1 | 7505 | 2015-10-03 |
| 1 | 2 | 7504 | 2015-10-03 |
| 2 | 4 | 7508 | 2015-10-05 |
| Bölüm | RowHash | Sipariş No | Sipariş tarihi |
|---|---|---|---|
| 0 | 2 | 7502 | 2015-10-02 |
| 0 | 4 | 7503 | 2015-10-02 |
| 1 | 3 | 7506 | 2015-10-04 |
| 2 | 1 | 7507 | 2015-10-05 |
Aşağıda, birincil Dizin bölümü içeren bir tablo oluşturmak için bir örnek verilmiştir. PARTITION BY yan tümcesi, bölümü tanımlamak için kullanılır.
CREATE SET TABLE Orders (
StoreNo SMALLINT,
OrderNo INTEGER,
OrderDate DATE FORMAT 'YYYY-MM-DD',
OrderTotal INTEGER
)
PRIMARY INDEX(OrderNo)
PARTITION BY RANGE_N (
OrderDate BETWEEN DATE '2010-01-01' AND '2016-12-31' EACH INTERVAL '1' DAY
);Yukarıdaki örnekte, tablo SiparişTarihi sütununa göre bölümlenmiştir. Her gün için ayrı bir bölüm olacaktır.
OLAP işlevleri, toplama işlevlerinin yalnızca bir değer döndürmesi dışında, OLAP işlevinin toplamalara ek olarak tek tek satırları sağlaması dışında toplama işlevlerine benzer.
Sözdizimi
OLAP işlevinin genel sözdizimi aşağıdadır.
<aggregate function> OVER
([PARTITION BY] [ORDER BY columnname][ROWS BETWEEN
UNBOUDED PRECEDING AND UNBOUNDED FOLLOWING)Toplama işlevleri SUM, COUNT, MAX, MIN, AVG olabilir.
Misal
Aşağıdaki Maaş tablosunu düşünün.
| Çalışan Hayır | Brüt | Kesinti | Net ödeme |
|---|---|---|---|
| 101 | 40.000 | 4.000 | 36.000 |
| 102 | 80.000 | 6.000 | 74.000 |
| 103 | 90.000 | 7.000 | 83.000 |
| 104 | 75.000 | 5.000 | 70.000 |
Aşağıda, Maaş tablosunda NetPay'in kümülatif toplamını veya cari toplamını bulmak için bir örnek verilmiştir. Kayıtlar ÇalışanNo'ya göre sıralanır ve kümülatif toplam NetPay sütununda hesaplanır.
SELECT
EmployeeNo, NetPay,
SUM(Netpay) OVER(ORDER BY EmployeeNo ROWS
UNBOUNDED PRECEDING) as TotalSalary
FROM Salary;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
EmployeeNo NetPay TotalSalary
----------- ----------- -----------
101 36000 36000
102 74000 110000
103 83000 193000
104 70000 263000
105 18000 281000RANK
RANK işlevi, kayıtları sağlanan sütuna göre sıralar. RANK işlevi, sıralamaya göre döndürülen kayıtların sayısını da filtreleyebilir.
Sözdizimi
RANK işlevini kullanmak için genel sözdizimi aşağıdadır.
RANK() OVER
([PARTITION BY columnnlist] [ORDER BY columnlist][DESC|ASC])Misal
Aşağıdaki Çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | JoinedDate | Departman Kimliği | Doğum günü |
|---|---|---|---|---|---|
| 101 | Mike | James | 27.3.2005 | 1 | 1/5/1980 |
| 102 | Robert | Williams | 25.4.2007 | 2 | 3/5/1983 |
| 103 | Peter | Paul | 21.3.2007 | 2 | 4/1/1983 |
| 104 | Alex | Stuart | 2/1/2008 | 2 | 11/6/1984 |
| 105 | Robert | James | 1/4/2008 | 3 | 12/1/1984 |
Sorguyu takiben, çalışan tablosu kayıtlarını Katılma Tarihine göre sıralar ve Katılma Tarihindeki sıralamayı belirler.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(ORDER BY JoinedDate) as Seniority
FROM Employee;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir.
EmployeeNo JoinedDate Seniority
----------- ---------- -----------
101 2005-03-27 1
103 2007-03-21 2
102 2007-04-25 3
105 2008-01-04 4
104 2008-02-01 5PARTITION BY yan tümcesi, verileri PARTITION BY yan tümcesinde tanımlanan sütunlara göre gruplandırır ve her grup içinde OLAP işlevini gerçekleştirir. Aşağıda PARTITION BY yan tümcesini kullanan sorguya bir örnek verilmiştir.
SELECT EmployeeNo, JoinedDate,RANK()
OVER(PARTITION BY DeparmentNo ORDER BY JoinedDate) as Seniority
FROM Employee;Yukarıdaki sorgu yürütüldüğünde aşağıdaki çıktıyı üretir. Her Departman için Derecenin sıfırlandığını görebilirsiniz.
EmployeeNo DepartmentNo JoinedDate Seniority
----------- ------------ ---------- -----------
101 1 2005-03-27 1
103 2 2007-03-21 1
102 2 2007-04-25 2
104 2 2008-02-01 3
105 3 2008-01-04 1Bu bölümde, Teradata'da veri koruma için kullanılabilen özellikler anlatılmaktadır.
Geçici Dergisi
Teradata, verileri işlem hatalarından korumak için Transient Journal kullanır. Herhangi bir işlem çalıştırıldığında, Transient günlük, işlem başarılı olana veya başarıyla geri alınana kadar etkilenen satırların önceki görüntülerinin bir kopyasını tutar. Ardından önceki görüntüler atılır. Her AMP'de geçici günlük tutulur. Otomatik bir işlemdir ve devre dışı bırakılamaz.
Geri çekil
Fallback, bir tablonun satırlarının ikinci kopyasını Fallback AMP olarak adlandırılan başka bir AMP'de depolayarak tablo verilerini korur. Bir AMP başarısız olursa, yedek satırlara erişilir. Bununla, bir AMP başarısız olsa bile, yedek AMP aracılığıyla veriler yine de kullanılabilir. Geri dönüş seçeneği tablo oluştururken veya tablo oluşturduktan sonra kullanılabilir. Geri dönüş, verileri AMP hatasından korumak için tablonun satırlarının ikinci kopyasının her zaman başka bir AMP'de depolanmasını sağlar. Ancak, yedek, iki kat daha fazla depolama alanı ve Ekleme / Silme / Güncelleme için G / Ç'yi kaplar.
Aşağıdaki diyagram, satırların yedek kopyasının başka bir AMP'de nasıl saklandığını gösterir.
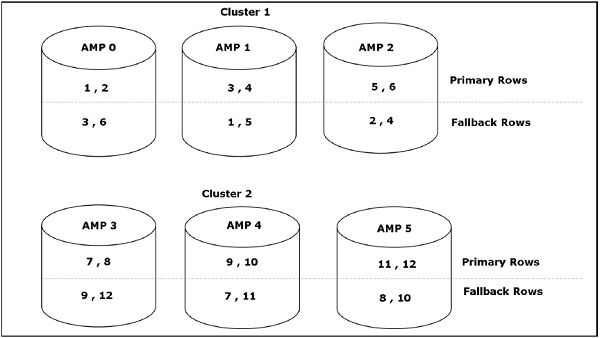
Aşağı AMP Kurtarma Günlüğü
Down AMP kurtarma günlüğü, AMP başarısız olduğunda ve tablo geri dönüş korumalı olduğunda etkinleştirilir. Bu günlük, başarısız AMP verilerindeki tüm değişikliklerin kaydını tutar. Günlük, kümedeki kalan AMP'lerde etkinleştirilir. Otomatik bir işlemdir ve devre dışı bırakılamaz. Başarısız AMP yayınlandığında, Down AMP kurtarma günlüğündeki veriler AMP ile senkronize edilir. Bu yapıldıktan sonra dergi atılır.
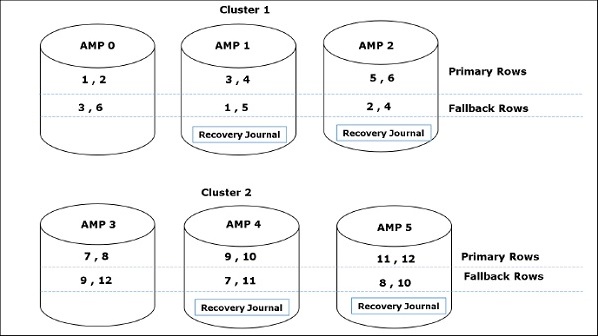
Cliques
Clique, verileri Düğüm hatalarından korumak için Teradata tarafından kullanılan bir mekanizmadır. Klik, ortak bir Disk Dizisi kümesini paylaşan bir dizi Teradata düğümünden başka bir şey değildir. Bir düğüm başarısız olduğunda, başarısız olan düğümden gelen vprocs, klikteki diğer düğümlere geçecek ve disk dizilerine erişmeye devam edecektir.
Çalışırken Bekleme Düğümü
Çalışırken Bekleme Düğümü, üretim ortamına katılmayan bir düğümdür. Bir düğüm başarısız olursa, başarısız olan düğümlerden gelen vprocs, çalışırken bekleme düğümüne geçecektir. Başarısız olan düğüm kurtarıldığında, etkin bekleme düğümü haline gelir. Düğüm arızaları durumunda performansı korumak için Hot Standby düğümleri kullanılır.
RAID
Yedekli Bağımsız Diskler Dizisi (RAID), verileri Disk Hatalarından korumak için kullanılan bir mekanizmadır. Disk Dizisi, mantıksal birim olarak gruplandırılmış bir dizi diskten oluşur. Bu birim kullanıcıya tek bir birim gibi görünebilir, ancak birkaç diske yayılmış olabilir.
RAID 1, Teradata'da yaygın olarak kullanılır. RAID 1'de her disk bir ayna disk ile ilişkilendirilir. Birincil diskteki verilerde yapılan herhangi bir değişiklik, ayna kopyasına da yansıtılır. Birincil disk arızalanırsa, ayna diskteki verilere erişilebilir.

Bu bölüm, Teradata'daki çeşitli kullanıcı yönetimi stratejilerini tartıştı.
Kullanıcılar
CREATE USER komutu kullanılarak bir kullanıcı oluşturulur. Teradata'da bir kullanıcı aynı zamanda bir veritabanına benzer. Her ikisine de alan atanabilir ve kullanıcıya bir parola atanması dışında veritabanı nesneleri içerebilir.
Sözdizimi
CREATE USER için sözdizimi aşağıdadır.
CREATE USER username
AS
[PERMANENT|PERM] = n BYTES
PASSWORD = password
TEMPORARY = n BYTES
SPOOL = n BYTES;Bir kullanıcı oluştururken, kullanıcı adı, Kalıcı alan ve Parola değerleri zorunludur. Diğer alanlar isteğe bağlıdır.
Misal
Aşağıda, TD01 kullanıcısını oluşturmak için bir örnek verilmiştir.
CREATE USER TD01
AS
PERMANENT = 1000000 BYTES
PASSWORD = ABC$124
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES;Hesaplar
Yeni bir kullanıcı oluştururken, kullanıcı bir hesaba atanabilir. CREATE USER'deki HESAP seçeneği hesabı atamak için kullanılır. Bir kullanıcı birden fazla hesaba atanabilir.
Sözdizimi
Hesap seçeneğiyle KULLANICI CREATE için sözdizimi aşağıdadır.
CREATE USER username
PERM = n BYTES
PASSWORD = password
ACCOUNT = accountidMisal
Aşağıdaki örnek, TD02 kullanıcısını oluşturur ve hesabı BT ve Yönetici olarak atar.
CREATE USER TD02
AS
PERMANENT = 1000000 BYTES
PASSWORD = abc$123
TEMPORARY = 1000000 BYTES
SPOOL = 1000000 BYTES
ACCOUNT = (‘IT’,’Admin’);Kullanıcı, Teradata sisteminde oturum açarken veya SET SESSION komutunu kullanarak sisteme giriş yaptıktan sonra hesap kimliğini belirleyebilir.
.LOGON username, passowrd,accountid
OR
SET SESSION ACCOUNT = accountidAyrıcalıklar Verin
GRANT komutu, veritabanı nesnelerinde kullanıcıya veya veritabanına bir veya daha fazla ayrıcalık atamak için kullanılır.
Sözdizimi
Aşağıda GRANT komutunun sözdizimi verilmiştir.
GRANT privileges ON objectname TO username;Ayrıcalıklar INSERT, SELECT, UPDATE, REFERENCES olabilir.
Misal
Aşağıda bir GRANT ifadesi örneği verilmiştir.
GRANT SELECT,INSERT,UPDATE ON Employee TO TD01;Ayrıcalıkları İptal Edin
REVOKE komutu, kullanıcılardan veya veritabanlarından ayrıcalıkları kaldırır. REVOKE komutu yalnızca açık ayrıcalıkları kaldırabilir.
Sözdizimi
REVOKE komutunun temel sözdizimi aşağıdadır.
REVOKE [ALL|privileges] ON objectname FROM username;Misal
Aşağıda bir REVOKE komutu örneği verilmiştir.
REVOKE INSERT,SELECT ON Employee FROM TD01;Bu bölümde, Teradata'da performans ayarlama prosedürü anlatılmaktadır.
Açıklamak
Performans ayarlamadaki ilk adım, sorgunuzda EXPLAIN kullanmaktır. EXPLAIN planı, optimize edicinin sorgunuzu nasıl yürüteceğinin ayrıntılarını verir. Açıklama planında, güven seviyesi, kullanılan birleştirme stratejisi, biriktirme dosyası boyutu, yeniden dağıtım vb. Gibi anahtar kelimeleri kontrol edin.
İstatistikleri Toplayın
Optimizer, etkili yürütme stratejisi oluşturmak için Veri demografisini kullanır. COLLECT STATISTICS komutu, tablonun demografik veri verilerini toplamak için kullanılır. Sütunlarda toplanan istatistiklerin güncel olduğundan emin olun.
WHERE yan tümcesinde kullanılan sütunlar ve birleştirme koşulunda kullanılan sütunlar hakkında istatistikler toplayın.
Benzersiz Birincil Dizin sütunlarıyla ilgili istatistikleri toplayın.
Benzersiz Olmayan İkincil Dizin sütunlarıyla ilgili istatistikleri toplayın. Optimizer, NUSI veya Tam Tablo Tarama kullanıp kullanamayacağına karar verecektir.
Temel tablodaki istatistikler toplansa da Katılım Dizini ile ilgili istatistikleri toplayın.
Bölümleme sütunlarıyla ilgili istatistikleri toplayın.
Veri tipleri
Uygun veri türlerinin kullanıldığından emin olun. Bu, gereğinden fazla depolama kullanımını önleyecektir.
Dönüştürmek
Açık veri dönüşümlerinden kaçınmak için birleştirme koşulunda kullanılan sütunların veri türlerinin uyumlu olduğundan emin olun.
Çeşit
Gerekmedikçe gereksiz ORDER BY cümlelerini kaldırın.
Biriktirme Alanı Sorunu
Biriktirme alanı hatası, sorgu o kullanıcı için her AMP biriktirme alanı sınırını aşarsa oluşturulur. Açıklama planını doğrulayın ve daha fazla biriktirme alanı tüketen adımı belirleyin. Bu ara sorgular bölünebilir ve geçici tablolar oluşturmak için ayrı ayrı yerleştirilebilir.
Birincil Dizin
Birincil Dizinin tablo için doğru şekilde tanımlandığından emin olun. Birincil dizin sütunu, verileri eşit olarak dağıtmalı ve verilere erişmek için sık sık kullanılmalıdır.
SET Tablosu
Bir SET tablosu tanımlarsanız, optimize edici, eklenen her kayıt için kaydın yinelenip yinelenmediğini kontrol eder. Yinelenen kontrol koşulunu kaldırmak için tablo için Benzersiz İkincil Dizin tanımlayabilirsiniz.
Büyük Masada GÜNCELLEME
Büyük tablonun güncellenmesi zaman alıcı olacaktır. Tabloyu güncellemek yerine kayıtları silebilir ve değiştirilmiş satırlara sahip kayıtları ekleyebilirsiniz.
Geçici Tabloları Kaldırmak
Artık gerekmiyorsa geçici tabloları (aşama tabloları) ve uçucuları bırakın. Bu kalıcı alan ve biriktirme alanı boşaltacaktır.
MULTISET Tablosu
Giriş kayıtlarının yinelenen kayıtları olmayacağından eminseniz, SET tablosu tarafından kullanılan yinelenen satır denetimini önlemek için hedef tabloyu MULTISET tablosu olarak tanımlayabilirsiniz.
FastLoad yardımcı programı, verileri boş tablolara yüklemek için kullanılır. Geçici günlükleri kullanmadığı için veriler hızlı bir şekilde yüklenebilir. Hedef tablo bir MULTISET tablosu olsa bile yinelenen satırları yüklemez.
Sınırlama
Hedef tabloda ikincil dizin, birleştirme dizini ve yabancı anahtar referansı olmamalıdır.
FastLoad Nasıl Çalışır?
FastLoad iki aşamada yürütülür.
Faz 1
Ayrıştırma motorları giriş dosyasındaki kayıtları okur ve her AMP'ye bir blok gönderir.
Her AMP, kayıt bloklarını depolar.
Daha sonra AMP'ler her bir kayda hashing uygular ve bunları doğru AMP'ye yeniden dağıtır.
1. Aşamanın sonunda, her AMP'nin kendi satırları vardır, ancak bunlar satır hash dizisinde değildir.
Faz 2
FastLoad, END LOADING deyimini aldığında 2. aşama başlar.
Her AMP, satır karmasında kayıtları sıralar ve diske yazar.
Hedef tablodaki kilitler kaldırılır ve hata tabloları kaldırılır.
Misal
Aşağıdaki kayıtlarla bir metin dosyası oluşturun ve dosyayı Employee.txt olarak adlandırın.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Aşağıda, yukarıdaki dosyayı Employee_Stg tablosuna yüklemek için örnek bir FastLoad komut dosyası verilmiştir.
LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
BEGIN LOADING tduser.Employee_Stg
ERRORFILES Employee_ET, Employee_UV
CHECKPOINT 10;
SET RECORD VARTEXT ",";
DEFINE in_EmployeeNo (VARCHAR(10)),
in_FirstName (VARCHAR(30)),
in_LastName (VARCHAR(30)),
in_BirthDate (VARCHAR(10)),
in_JoinedDate (VARCHAR(10)),
in_DepartmentNo (VARCHAR(02)),
FILE = employee.txt;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_LastName,
:in_BirthDate (FORMAT 'YYYY-MM-DD'),
:in_JoinedDate (FORMAT 'YYYY-MM-DD'),
:in_DepartmentNo
);
END LOADING;
LOGOFF;FastLoad Komut Dosyasını Yürütme
EmployeeLoad.fl giriş dosyası oluşturulduğunda ve FastLoad komut dosyası EmployeeLoad.fl olarak adlandırıldığında, UNIX ve Windows'ta aşağıdaki komutu kullanarak FastLoad komut dosyasını çalıştırabilirsiniz.
FastLoad < EmployeeLoad.fl;Yukarıdaki komut yürütüldüğünde, FastLoad betiği çalışacak ve günlüğü oluşturacaktır. Günlükte, FastLoad tarafından işlenen kayıtların sayısını ve durum kodunu görebilirsiniz.
**** 03:19:14 END LOADING COMPLETE
Total Records Read = 5
Total Error Table 1 = 0 ---- Table has been dropped
Total Error Table 2 = 0 ---- Table has been dropped
Total Inserts Applied = 5
Total Duplicate Rows = 0
Start: Fri Jan 8 03:19:13 2016
End : Fri Jan 8 03:19:14 2016
**** 03:19:14 Application Phase statistics:
Elapsed time: 00:00:01 (in hh:mm:ss)
0008 LOGOFF;
**** 03:19:15 Logging off all sessionsHızlı Yükleme Koşulları
FastLoad komut dosyasında kullanılan genel terimlerin listesi aşağıdadır.
LOGON - Teradata'da oturum açar ve bir veya daha fazla oturum başlatır.
DATABASE - Varsayılan veritabanını ayarlar.
BEGIN LOADING - Yüklenecek tabloyu belirtir.
ERRORFILES - Oluşturulması / güncellenmesi gereken 2 hata tablosunu belirtir.
CHECKPOINT - Kontrol noktasının ne zaman alınacağını tanımlar.
SET RECORD - Girdi dosyası formatının formatlı mı, ikili mi, metin mi yoksa formatsız mı olduğunu belirtir.
DEFINE - Giriş dosyası düzenini tanımlar.
FILE - Girdi dosyası adını ve yolunu belirtir.
INSERT - Giriş dosyasındaki kayıtları hedef tabloya ekler.
END LOADING- FastLoad'un 2. aşamasını başlatır. Kayıtları hedef tabloya dağıtır.
LOGOFF - Tüm oturumları sonlandırır ve FastLoad'u sonlandırır.
MultiLoad bir seferde birden fazla tablo yükleyebilir ve ayrıca INSERT, DELETE, UPDATE ve UPSERT gibi farklı görev türlerini gerçekleştirebilir. Bir seferde en fazla 5 tablo yükleyebilir ve bir kodda en fazla 20 DML işlemi gerçekleştirebilir. MultiLoad için hedef tablo gerekli değildir.
MultiLoad iki modu destekler -
- IMPORT
- DELETE
MultiLoad, hedef tabloya ek olarak bir çalışma tablosu, bir günlük tablosu ve iki hata tablosu gerektirir.
Log Table - Yeniden başlatma için kullanılacak olan yükleme sırasında alınan kontrol noktalarını korumak için kullanılır.
Error Tables- Bu tablolar, bir hata oluştuğunda yükleme sırasında eklenir. İlk hata tablosu dönüştürme hatalarını saklarken, ikinci hata tablosu yinelenen kayıtları saklar.
Log Table - Yeniden başlatma amacıyla MultiLoad'un her aşamasından sonuçları korur.
Work table- MultiLoad komut dosyası, hedef tablo başına bir çalışma tablosu oluşturur. Çalışma tablosu, DML görevlerini ve giriş verilerini tutmak için kullanılır.
Sınırlama
MultiLoad'un bazı sınırlamaları vardır.
- Benzersiz İkincil Dizin, hedef tabloda desteklenmiyor.
- Bilgi tutarlılığı desteklenmiyor.
- Tetikleyiciler desteklenmez.
MultiLoad Nasıl Çalışır?
MultiLoad içe aktarmanın beş aşaması vardır -
Phase 1 - Ön Aşama - Temel kurulum etkinliklerini gerçekleştirir.
Phase 2 - DML İşlem Aşaması - DML ifadelerinin sözdizimini doğrular ve bunları Teradata sistemine getirir.
Phase 3 - Edinme Aşaması - Giriş verilerini çalışma tablolarına getirir ve tabloyu kilitler.
Phase 4 - Uygulama Aşaması - Tüm DML işlemlerini uygular.
Phase 5 - Temizleme Aşaması - Masa kilidini kaldırır.
Bir MultiLoad betiğinde yer alan adımlar şunlardır:
Step 1 - Günlük tablosunu ayarlayın.
Step 2 - Teradata'da oturum açın.
Step 3 - Hedef, Çalışma ve Hata tablolarını belirtin.
Step 4 - INPUT dosya düzenini tanımlayın.
Step 5 - DML sorgularını tanımlayın.
Step 6 - İTHALAT dosyasını adlandırın.
Step 7 - Kullanılacak DÜZENİ belirtin.
Step 8 - Yükü başlatın.
Step 9 - Yüklemeyi bitirin ve seansları sonlandırın.
Misal
Aşağıdaki kayıtlarla bir metin dosyası oluşturun ve dosyayı Employee.txt olarak adlandırın.
101,Mike,James,1980-01-05,2010-03-01,1
102,Robert,Williams,1983-03-05,2010-09-01,1
103,Peter,Paul,1983-04-01,2009-02-12,2
104,Alex,Stuart,1984-11-06,2014-01-01,2
105,Robert,James,1984-12-01,2015-03-09,3Aşağıdaki örnek, çalışan tablosundaki kayıtları okuyan ve Employee_Stg tablosuna yükleyen bir MultiLoad betiğidir.
.LOGTABLE tduser.Employee_log;
.LOGON 192.168.1.102/dbc,dbc;
.BEGIN MLOAD TABLES Employee_Stg;
.LAYOUT Employee;
.FIELD in_EmployeeNo * VARCHAR(10);
.FIELD in_FirstName * VARCHAR(30);
.FIELD in_LastName * VARCHAR(30);
.FIELD in_BirthDate * VARCHAR(10);
.FIELD in_JoinedDate * VARCHAR(10);
.FIELD in_DepartmentNo * VARCHAR(02);
.DML LABEL EmpLabel;
INSERT INTO Employee_Stg (
EmployeeNo,
FirstName,
LastName,
BirthDate,
JoinedDate,
DepartmentNo
)
VALUES (
:in_EmployeeNo,
:in_FirstName,
:in_Lastname,
:in_BirthDate,
:in_JoinedDate,
:in_DepartmentNo
);
.IMPORT INFILE employee.txt
FORMAT VARTEXT ','
LAYOUT Employee
APPLY EmpLabel;
.END MLOAD;
LOGOFF;MultiLoad Komut Dosyasını Yürütme
EmployeeLoad.ml giriş dosyası oluşturulup multiload komut dosyası EmployeeLoad.ml olarak adlandırıldıktan sonra, UNIX ve Windows'ta aşağıdaki komutu kullanarak Multiload komut dosyasını çalıştırabilirsiniz.
Multiload < EmployeeLoad.ml;FastExport yardımcı programı, verileri Teradata tablolarından düz dosyalara aktarmak için kullanılır. Ayrıca verileri rapor formatında da oluşturabilir. Birleştirme kullanılarak veriler bir veya daha fazla tablodan çıkarılabilir. FastExport, verileri 64K bloklar halinde dışa aktardığından, büyük hacimli verilerin çıkarılması için kullanışlıdır.
Misal
Aşağıdaki Çalışan tablosunu düşünün.
| Çalışan Hayır | İsim | Soyadı | Doğum günü |
|---|---|---|---|
| 101 | Mike | James | 1/5/1980 |
| 104 | Alex | Stuart | 11/6/1984 |
| 102 | Robert | Williams | 3/5/1983 |
| 105 | Robert | James | 12/1/1984 |
| 103 | Peter | Paul | 4/1/1983 |
Aşağıda bir FastExport komut dosyası örneği verilmiştir. Çalışan tablosundaki verileri dışa aktarır ve bir çalışanata.txt dosyasına yazar.
.LOGTABLE tduser.employee_log;
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
.BEGIN EXPORT SESSIONS 2;
.EXPORT OUTFILE employeedata.txt
MODE RECORD FORMAT TEXT;
SELECT CAST(EmployeeNo AS CHAR(10)),
CAST(FirstName AS CHAR(15)),
CAST(LastName AS CHAR(15)),
CAST(BirthDate AS CHAR(10))
FROM
Employee;
.END EXPORT;
.LOGOFF;FastExport Komut Dosyasını Yürütme
Komut dosyası yazıldıktan ve çalışanı.fx olarak adlandırıldıktan sonra, komut dosyasını çalıştırmak için aşağıdaki komutu kullanabilirsiniz.
fexp < employee.fxYukarıdaki komutu yürüttükten sonra, aşağıdaki çıktıyı empendedata.txt dosyasında alacaksınız.
103 Peter Paul 1983-04-01
101 Mike James 1980-01-05
102 Robert Williams 1983-03-05
105 Robert James 1984-12-01
104 Alex Stuart 1984-11-06FastExport Koşulları
FastExport komut dosyasında yaygın olarak kullanılan terimlerin listesi aşağıdadır.
LOGTABLE - Yeniden başlatma amacıyla günlük tablosunu belirtir.
LOGON - Teradata'da oturum açar ve bir veya daha fazla oturum başlatır.
DATABASE - Varsayılan veritabanını ayarlar.
BEGIN EXPORT - Dışa aktarmanın başlangıcını gösterir.
EXPORT - Hedef dosyayı ve dışa aktarma formatını belirtir.
SELECT - Verilerin dışa aktarılacağı seçme sorgusunu belirtir.
END EXPORT - FastExport'un sonunu belirtir.
LOGOFF - Tüm oturumları sonlandırır ve FastExport'u sonlandırır.
BTEQ yardımcı programı, Teradata'da hem toplu hem de etkileşimli modda kullanılabilen güçlü bir yardımcı programdır. Herhangi bir DDL ifadesini, DML ifadesini çalıştırmak, Makrolar ve saklı prosedürler oluşturmak için kullanılabilir. BTEQ, verileri düz dosyadan Teradata tablolarına aktarmak için kullanılabilir ve ayrıca tablolardan dosyalara veya raporlara veri çıkarmak için de kullanılabilir.
BTEQ Şartları
BTEQ komut dosyalarında yaygın olarak kullanılan terimlerin listesi aşağıdadır.
LOGON - Teradata sistemine giriş yapmak için kullanılır.
ACTIVITYCOUNT - Önceki sorgudan etkilenen satır sayısını döndürür.
ERRORCODE - Önceki sorgunun durum kodunu döndürür.
DATABASE - Varsayılan veritabanını ayarlar.
LABEL - Bir dizi SQL komutuna bir etiket atar.
RUN FILE - Bir dosyada bulunan sorguyu yürütür.
GOTO - Kontrolü bir etikete aktarır.
LOGOFF - Veritabanından çıkış yapar ve tüm oturumları sonlandırır.
IMPORT - Girdi dosyası yolunu belirtir.
EXPORT - Çıktı dosyası yolunu belirtir ve dışa aktarmayı başlatır.
Misal
Aşağıda örnek bir BTEQ komut dosyası verilmiştir.
.LOGON 192.168.1.102/dbc,dbc;
DATABASE tduser;
CREATE TABLE employee_bkup (
EmployeeNo INTEGER,
FirstName CHAR(30),
LastName CHAR(30),
DepartmentNo SMALLINT,
NetPay INTEGER
)
Unique Primary Index(EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
SELECT * FROM
Employee
Sample 1;
.IF ACTIVITYCOUNT <> 0 THEN .GOTO InsertEmployee;
DROP TABLE employee_bkup;
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LABEL InsertEmployee
INSERT INTO employee_bkup
SELECT a.EmployeeNo,
a.FirstName,
a.LastName,
a.DepartmentNo,
b.NetPay
FROM
Employee a INNER JOIN Salary b
ON (a.EmployeeNo = b.EmployeeNo);
.IF ERRORCODE <> 0 THEN .EXIT ERRORCODE;
.LOGOFF;Yukarıdaki komut dosyası aşağıdaki görevleri gerçekleştirir.
Teradata Sisteminde oturum açar.
Varsayılan Veritabanını ayarlar.
Employee_bkup adlı bir tablo oluşturur.
Tabloda herhangi bir kayıt olup olmadığını kontrol etmek için Çalışan tablosundan bir kayıt seçer.
Tablo boşsa, employee_bkup tablosunu bırakır.
Denetimi, staff_bkup tablosuna kayıt ekleyen bir Label InsertEmployee'ye aktarır
Her SQL ifadesinin ardından, ifadenin başarılı olduğundan emin olmak için ERRORCODE öğesini kontrol eder.
ACTIVITYCOUNT, önceki SQL sorgusu tarafından seçilen / etkilenen kayıtların sayısını döndürür.