Apache Flink - Kiến trúc
Apache Flink hoạt động trên kiến trúc Kappa. Kiến trúc Kappa có một bộ xử lý duy nhất - luồng, coi tất cả đầu vào là luồng và công cụ phát trực tuyến xử lý dữ liệu trong thời gian thực. Dữ liệu hàng loạt trong kiến trúc kappa là một trường hợp đặc biệt của truyền trực tuyến.
Sơ đồ sau đây cho thấy Apache Flink Architecture.
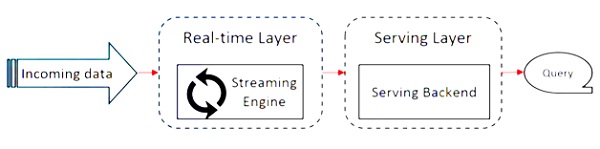
Ý tưởng chính trong kiến trúc Kappa là xử lý cả dữ liệu hàng loạt và dữ liệu thời gian thực thông qua một công cụ xử lý luồng duy nhất.
Hầu hết các khung dữ liệu lớn hoạt động trên kiến trúc Lambda, có các bộ xử lý riêng biệt cho dữ liệu hàng loạt và truyền trực tuyến. Trong kiến trúc Lambda, bạn có các cơ sở mã riêng biệt cho chế độ xem hàng loạt và luồng. Để truy vấn và nhận được kết quả, các cơ sở mã cần được hợp nhất. Không duy trì các cơ sở mã / chế độ xem riêng biệt và hợp nhất chúng là một điều khó khăn, nhưng kiến trúc Kappa giải quyết vấn đề này vì nó chỉ có một chế độ xem - thời gian thực, do đó không cần hợp nhất các cơ sở mã.
Điều đó không có nghĩa là kiến trúc Kappa thay thế kiến trúc Lambda, nó hoàn toàn phụ thuộc vào trường hợp sử dụng và ứng dụng mà quyết định kiến trúc nào sẽ phù hợp hơn.
Sơ đồ sau đây cho thấy kiến trúc thực thi công việc Apache Flink.

Chương trình
Nó là một đoạn mã mà bạn chạy trên Flink Cluster.
Khách hàng
Nó chịu trách nhiệm lấy mã (chương trình) và xây dựng biểu đồ luồng dữ liệu công việc, sau đó chuyển nó đến JobManager. Nó cũng truy xuất kết quả Công việc.
JobManager
Sau khi nhận được Đồ thị luồng dữ liệu công việc từ Khách hàng, nó có trách nhiệm tạo đồ thị thực thi. Nó giao công việc cho TaskManagers trong cụm và giám sát việc thực hiện công việc.
Quản lý công việc
Nó chịu trách nhiệm thực hiện tất cả các nhiệm vụ đã được giao bởi JobManager. Tất cả các TaskManagers chạy các tác vụ trong các vị trí riêng biệt của chúng theo chế độ song song được chỉ định. Có trách nhiệm gửi trạng thái của các nhiệm vụ cho JobManager.
Các tính năng của Apache Flink
Các tính năng của Apache Flink như sau:
Nó có một bộ xử lý phát trực tuyến, có thể chạy cả chương trình hàng loạt và dòng.
Nó có thể xử lý dữ liệu với tốc độ cực nhanh.
API có sẵn trong Java, Scala và Python.
Cung cấp các API cho tất cả các hoạt động phổ biến, rất dễ dàng cho các lập trình viên sử dụng.
Xử lý dữ liệu với độ trễ thấp (nano giây) và thông lượng cao.
Khả năng chịu lỗi của nó. Nếu một nút, ứng dụng hoặc phần cứng bị lỗi, nó không ảnh hưởng đến cụm.
Có thể dễ dàng tích hợp với Apache Hadoop, Apache MapReduce, Apache Spark, HBase và các công cụ dữ liệu lớn khác.
Quản lý trong bộ nhớ có thể được tùy chỉnh để tính toán tốt hơn.
Nó có khả năng mở rộng cao và có thể mở rộng quy mô lên đến hàng nghìn nút trong một cụm.
Windowing rất linh hoạt trong Apache Flink.
Cung cấp các thư viện Xử lý đồ thị, Học máy, Xử lý sự kiện phức tạp.