Apache Flume - Hướng dẫn nhanh
Flume là gì?
Apache Flume là một công cụ / dịch vụ / cơ chế nhập dữ liệu để thu thập tổng hợp và vận chuyển một lượng lớn dữ liệu trực tuyến như tệp nhật ký, sự kiện (v.v.) từ nhiều nguồn khác nhau đến một kho dữ liệu tập trung.
Flume là một công cụ có độ tin cậy cao, phân tán và có thể định cấu hình. Nó được thiết kế chủ yếu để sao chép dữ liệu trực tuyến (dữ liệu nhật ký) từ các máy chủ web khác nhau sang HDFS.
Các ứng dụng của Flume
Giả sử một ứng dụng web thương mại điện tử muốn phân tích hành vi của khách hàng từ một khu vực cụ thể. Để làm như vậy, họ cần chuyển dữ liệu nhật ký có sẵn vào Hadoop để phân tích. Tại đây, Apache Flume đến giải cứu chúng ta.
Flume được sử dụng để di chuyển dữ liệu nhật ký được tạo bởi các máy chủ ứng dụng sang HDFS với tốc độ cao hơn.
Ưu điểm của Flume
Dưới đây là những lợi thế của việc sử dụng Flume -
Sử dụng Apache Flume, chúng tôi có thể lưu trữ dữ liệu vào bất kỳ cửa hàng tập trung nào (HBase, HDFS).
Khi tốc độ dữ liệu đến vượt quá tốc độ dữ liệu có thể được ghi tới đích, Flume đóng vai trò trung gian giữa nhà sản xuất dữ liệu và các cửa hàng tập trung và cung cấp luồng dữ liệu ổn định giữa chúng.
Flume cung cấp tính năng của contextual routing.
Các giao dịch trong Flume dựa trên kênh trong đó hai giao dịch (một người gửi và một người nhận) được duy trì cho mỗi tin nhắn. Nó đảm bảo cung cấp thông điệp đáng tin cậy.
Flume đáng tin cậy, có khả năng chịu lỗi, có thể mở rộng, có thể quản lý và có thể tùy chỉnh.
Đặc điểm của Flume
Một số tính năng đáng chú ý của Flume như sau:
Flume nhập dữ liệu nhật ký từ nhiều máy chủ web vào một cửa hàng tập trung (HDFS, HBase) một cách hiệu quả.
Sử dụng Flume, chúng ta có thể lấy dữ liệu từ nhiều máy chủ ngay lập tức vào Hadoop.
Cùng với các tệp nhật ký, Flume cũng được sử dụng để nhập khối lượng lớn dữ liệu sự kiện do các trang mạng xã hội như Facebook và Twitter, và các trang web thương mại điện tử như Amazon và Flipkart tạo ra.
Flume hỗ trợ một tập hợp lớn các loại nguồn và đích.
Flume hỗ trợ luồng đa bước nhảy, luồng quạt vào quạt ra, định tuyến theo ngữ cảnh, v.v.
Flume có thể được thu nhỏ theo chiều ngang.
Big Data,như chúng ta biết, là một tập hợp các bộ dữ liệu lớn không thể được xử lý bằng các kỹ thuật tính toán truyền thống. Dữ liệu lớn (Big Data) khi được phân tích sẽ cho kết quả có giá trị.Hadoop là một khung công tác mã nguồn mở cho phép lưu trữ và xử lý Dữ liệu lớn trong môi trường phân tán trên các cụm máy tính sử dụng các mô hình lập trình đơn giản.
Truyền / Ghi dữ liệu
Nói chung, hầu hết dữ liệu sẽ được phân tích sẽ được tạo ra bởi nhiều nguồn dữ liệu khác nhau như máy chủ ứng dụng, trang mạng xã hội, máy chủ đám mây và máy chủ doanh nghiệp. Dữ liệu này sẽ ở dạnglog files và events.
Log file - Nói chung, tệp nhật ký là một fileliệt kê các sự kiện / hành động xảy ra trong hệ điều hành. Ví dụ: máy chủ web liệt kê mọi yêu cầu được thực hiện đối với máy chủ trong tệp nhật ký.
Khi thu thập dữ liệu nhật ký như vậy, chúng tôi có thể nhận được thông tin về -
- hiệu suất ứng dụng và xác định các lỗi phần mềm và phần cứng khác nhau.
- hành vi của người dùng và có được thông tin chi tiết tốt hơn về doanh nghiệp.
Phương pháp truyền thống để truyền dữ liệu vào hệ thống HDFS là sử dụng putchỉ huy. Hãy để chúng tôi xem cách sử dụngput chỉ huy.
HDFS đặt lệnh
Thách thức chính trong việc xử lý dữ liệu nhật ký là di chuyển các nhật ký này được tạo bởi nhiều máy chủ sang môi trường Hadoop.
Hadoop File System Shellcung cấp các lệnh để chèn dữ liệu vào Hadoop và đọc từ nó. Bạn có thể chèn dữ liệu vào Hadoop bằng cách sử dụngput lệnh như hình dưới đây.
$ Hadoop fs –put /path of the required file /path in HDFS where to save the fileSự cố với lệnh put
Chúng ta có thể sử dụng putlệnh của Hadoop để chuyển dữ liệu từ các nguồn này sang HDFS. Tuy nhiên, nó có những nhược điểm sau:
Sử dụng put lệnh, chúng ta có thể chuyển only one file at a timetrong khi bộ tạo dữ liệu tạo ra dữ liệu với tốc độ cao hơn nhiều. Do các phân tích được thực hiện trên dữ liệu cũ kém chính xác hơn nên chúng ta cần có giải pháp truyền dữ liệu theo thời gian thực.
Nếu chúng ta sử dụng put, dữ liệu cần được đóng gói và sẵn sàng để tải lên. Vì các máy chủ web tạo ra dữ liệu liên tục nên đây là một nhiệm vụ rất khó khăn.
Cái chúng ta cần ở đây là một giải pháp có thể khắc phục được những nhược điểm của put ra lệnh và chuyển "dữ liệu trực tuyến" từ bộ tạo dữ liệu đến các cửa hàng tập trung (đặc biệt là HDFS) với độ trễ ít hơn.
Sự cố với HDFS
Trong HDFS, tệp tồn tại dưới dạng một mục nhập thư mục và độ dài của tệp sẽ được coi là 0 cho đến khi nó bị đóng. Ví dụ, nếu một nguồn đang ghi dữ liệu vào HDFS và mạng bị gián đoạn giữa chừng (mà không đóng tệp), thì dữ liệu được ghi trong tệp sẽ bị mất.
Do đó, chúng tôi cần một hệ thống đáng tin cậy, có thể cấu hình và bảo trì để chuyển dữ liệu nhật ký sang HDFS.
Note- Trong hệ thống tệp POSIX, bất cứ khi nào chúng ta đang truy cập một tệp (giả sử thực hiện thao tác ghi), các chương trình khác vẫn có thể đọc tệp này (ít nhất là phần đã lưu của tệp). Điều này là do tệp tồn tại trên đĩa trước khi nó bị đóng.
Các giải pháp có sẵn
Để gửi dữ liệu phát trực tuyến (tệp nhật ký, sự kiện, v.v.,) từ nhiều nguồn khác nhau tới HDFS, chúng tôi có sẵn các công cụ sau:
Người ghi chép của Facebook
Scribe là một công cụ vô cùng phổ biến được sử dụng để tổng hợp và truyền trực tuyến dữ liệu nhật ký. Nó được thiết kế để mở rộng quy mô đến một số lượng rất lớn các nút và mạnh mẽ đối với các lỗi mạng và nút.
Apache Kafka
Kafka đã được phát triển bởi Apache Software Foundation. Nó là một nhà môi giới tin nhắn mã nguồn mở. Sử dụng Kafka, chúng tôi có thể xử lý các nguồn cấp dữ liệu với thông lượng cao và độ trễ thấp.
Apache Flume
Apache Flume là một công cụ / dịch vụ / cơ chế nhập dữ liệu để thu thập tổng hợp và vận chuyển một lượng lớn dữ liệu truyền trực tuyến như dữ liệu nhật ký, sự kiện (v.v.) từ các trang web khác nhau đến một kho dữ liệu tập trung.
Đây là một công cụ có độ tin cậy cao, phân tán và có thể cấu hình được thiết kế chủ yếu để truyền dữ liệu trực tuyến từ nhiều nguồn khác nhau sang HDFS.
Trong hướng dẫn này, chúng ta sẽ thảo luận chi tiết về cách sử dụng Flume với một số ví dụ.
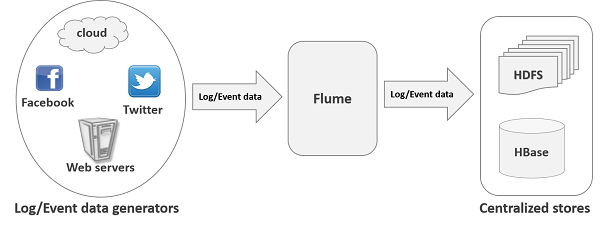
Hình minh họa sau đây mô tả kiến trúc cơ bản của Flume. Như trong hình minh họa,data generators (chẳng hạn như Facebook, Twitter) tạo dữ liệu được thu thập bởi Flume riêng lẻ agentschạy trên chúng. Sau đó, mộtdata collector (cũng là một tác nhân) thu thập dữ liệu từ các tác nhân được tổng hợp và đẩy vào một kho lưu trữ tập trung như HDFS hoặc HBase.

Sự kiện Flume
An event là đơn vị cơ bản của dữ liệu được vận chuyển bên trong Flume. Nó chứa một trọng tải mảng byte sẽ được vận chuyển từ nguồn đến đích kèm theo các tiêu đề tùy chọn. Một sự kiện Flume điển hình sẽ có cấu trúc sau:

Tác nhân Flume
An agentlà một quy trình daemon độc lập (JVM) trong Flume. Nó nhận dữ liệu (sự kiện) từ khách hàng hoặc các tác nhân khác và chuyển tiếp nó đến đích tiếp theo (bồn rửa hoặc tác nhân). Flume có thể có nhiều hơn một tác nhân. Sơ đồ sau thể hiện mộtFlume Agent

Như trong sơ đồ, Flume Agent chứa ba thành phần chính, source, channelvà sink.
Nguồn
A source là thành phần của Tác nhân nhận dữ liệu từ bộ tạo dữ liệu và chuyển nó đến một hoặc nhiều kênh dưới dạng các sự kiện Flume.
Apache Flume hỗ trợ một số loại nguồn và mỗi nguồn nhận các sự kiện từ một trình tạo dữ liệu cụ thể.
Example - Nguồn Avro, Nguồn tiết kiệm, Nguồn twitter 1%, v.v.
Kênh
A channellà một kho lưu trữ tạm thời nhận các sự kiện từ nguồn và đệm chúng cho đến khi chúng được tiêu thụ bởi các phần mềm chìm. Nó hoạt động như một cầu nối giữa nguồn và phần chìm.
Các kênh này hoàn toàn có thể giao dịch và chúng có thể hoạt động với bất kỳ số lượng nguồn và ổ chìm nào.
Example - Kênh JDBC, Kênh hệ thống tệp, Kênh bộ nhớ, v.v.
Bồn rửa
A sinklưu trữ dữ liệu vào các cửa hàng tập trung như HBase và HDFS. Nó sử dụng dữ liệu (sự kiện) từ các kênh và phân phối nó đến đích. Điểm đến của bồn rửa chén có thể là một đại lý khác hoặc các cửa hàng trung tâm.
Example - HDFS chìm
Note- Một tác nhân tạo khói có thể có nhiều nguồn, bồn rửa và kênh. Chúng tôi đã liệt kê tất cả các nguồn, bộ chìm, kênh được hỗ trợ trong chương cấu hình Flume của hướng dẫn này.
Các thành phần bổ sung của tác nhân khói
Những gì chúng ta đã thảo luận ở trên là các thành phần ban đầu của tác nhân. Ngoài ra, chúng tôi có một số thành phần khác đóng vai trò quan trọng trong việc chuyển các sự kiện từ trình tạo dữ liệu đến các cửa hàng tập trung.
Đánh chặn
Các thiết bị đánh chặn được sử dụng để thay đổi / kiểm tra các sự kiện đèn được chuyển giữa nguồn và kênh.
Bộ chọn kênh
Chúng được sử dụng để xác định kênh nào sẽ được chọn để truyền dữ liệu trong trường hợp có nhiều kênh. Có hai loại bộ chọn kênh -
Default channel selectors - Đây còn được gọi là bộ chọn kênh sao chép, chúng sao chép tất cả các sự kiện trong mỗi kênh.
Multiplexing channel selectors - Những điều này quyết định kênh gửi một sự kiện dựa trên địa chỉ trong tiêu đề của sự kiện đó.
Bộ xử lý bồn rửa
Chúng được sử dụng để gọi một bồn rửa cụ thể từ nhóm bồn rửa đã chọn. Chúng được sử dụng để tạo đường dẫn chuyển đổi dự phòng cho các phần chìm của bạn hoặc các sự kiện cân bằng tải trên nhiều phần chìm từ một kênh.
Flume là một khuôn khổ được sử dụng để di chuyển dữ liệu nhật ký vào HDFS. Nói chung các sự kiện và dữ liệu nhật ký được tạo bởi các máy chủ nhật ký và các máy chủ này có tác nhân Flume chạy trên chúng. Các tác nhân này nhận dữ liệu từ bộ tạo dữ liệu.
Dữ liệu trong các tác nhân này sẽ được thu thập bởi một nút trung gian được gọi là Collector. Cũng giống như các đại lý, có thể có nhiều người thu gom trong Flume.
Cuối cùng, dữ liệu từ tất cả các bộ thu thập này sẽ được tổng hợp và chuyển đến một cửa hàng tập trung như HBase hoặc HDFS. Sơ đồ sau giải thích luồng dữ liệu trong Flume.
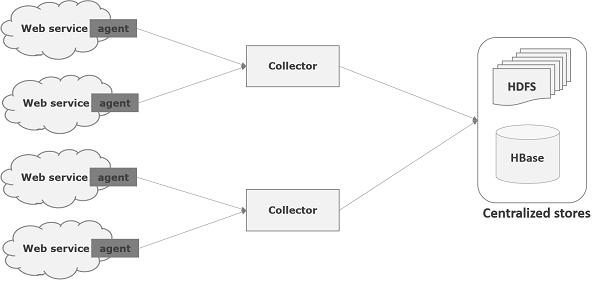
Luồng đa bước
Trong Flume, có thể có nhiều đại lý và trước khi đến đích cuối cùng, một sự kiện có thể đi qua nhiều đại lý. Điều này được gọi làmulti-hop flow.
Luồng quạt ra
Luồng dữ liệu từ một nguồn đến nhiều kênh được gọi là fan-out flow. Nó có hai loại -
Replicating - Luồng dữ liệu nơi dữ liệu sẽ được sao chép trong tất cả các kênh được cấu hình.
Multiplexing - Luồng dữ liệu nơi dữ liệu sẽ được gửi đến một kênh đã chọn được đề cập trong tiêu đề của sự kiện.
Luồng quạt vào
Luồng dữ liệu trong đó dữ liệu sẽ được chuyển từ nhiều nguồn sang một kênh được gọi là fan-in flow.
Xử lý lỗi
Trong Flume, đối với mỗi sự kiện, hai giao dịch diễn ra: một giao dịch ở người gửi và một giao dịch ở người nhận. Người gửi gửi các sự kiện đến người nhận. Ngay sau khi nhận được dữ liệu, người nhận thực hiện giao dịch của chính mình và gửi tín hiệu “đã nhận” đến người gửi. Sau khi nhận được tín hiệu, người gửi sẽ thực hiện giao dịch của mình. (Người gửi sẽ không thực hiện giao dịch của mình cho đến khi nhận được tín hiệu từ người nhận.)
Chúng ta đã thảo luận về kiến trúc của Flume trong chương trước. Trong chương này, chúng ta hãy xem cách tải xuống và thiết lập Apache Flume.
Trước khi tiếp tục, bạn cần có một môi trường Java trong hệ thống của mình. Vì vậy, trước hết, hãy đảm bảo rằng bạn đã cài đặt Java trong hệ thống của mình. Đối với một số ví dụ trong hướng dẫn này, chúng tôi đã sử dụng Hadoop HDFS (dưới dạng chìm). Do đó, chúng tôi khuyên bạn nên cài đặt Hadoop cùng với Java. Để thu thập thêm thông tin, hãy theo liên kết -http://www.tutorialspoint.com/hadoop/hadoop_enviornment_setup.htm
Cài đặt Flume
Trước hết, hãy tải xuống phiên bản mới nhất của phần mềm Apache Flume từ trang web https://flume.apache.org/.
Bước 1
Mở trang web. Bấm vàodownloadliên kết ở phía bên trái của trang chủ. Nó sẽ đưa bạn đến trang tải xuống Apache Flume.
Bước 2
Trong trang Tải xuống, bạn có thể thấy các liên kết cho tệp nhị phân và tệp nguồn của Apache Flume. Nhấp vào liên kết apache-flume-1.6.0-bin.tar.gz
Bạn sẽ được chuyển hướng đến danh sách các bản sao mà bạn có thể bắt đầu tải xuống bằng cách nhấp vào bất kỳ bản sao nào trong số các bản sao này. Theo cách tương tự, bạn có thể tải xuống mã nguồn của Apache Flume bằng cách nhấp vào apache-flume-1.6.0-src.tar.gz .
Bước 3
Tạo một thư mục với tên Flume trong cùng một thư mục chứa các thư mục cài đặt của Hadoop, HBase, và phần mềm khác đã được cài đặt (nếu bạn đã cài đặt bất kỳ phần mềm nào) như hình dưới đây.
$ mkdir FlumeBước 4
Giải nén các tệp tar đã tải xuống như hình dưới đây.
$ cd Downloads/
$ tar zxvf apache-flume-1.6.0-bin.tar.gz
$ tar zxvf apache-flume-1.6.0-src.tar.gzBước 5
Di chuyển nội dung của apache-flume-1.6.0-bin.tar nộp vào Flumethư mục đã tạo trước đó như hình dưới đây. (Giả sử chúng ta đã tạo thư mục Flume trong người dùng cục bộ có tên Hadoop.)
$ mv apache-flume-1.6.0-bin.tar/* /home/Hadoop/Flume/Cấu hình Flume
Để cấu hình Flume, chúng ta phải sửa đổi ba tệp, cụ thể là, flume-env.sh, flumeconf.properties, và bash.rc.
Đặt Path / Classpath
bên trong .bashrc tập tin, thiết lập thư mục chính, đường dẫn và classpath cho Flume như hình dưới đây.
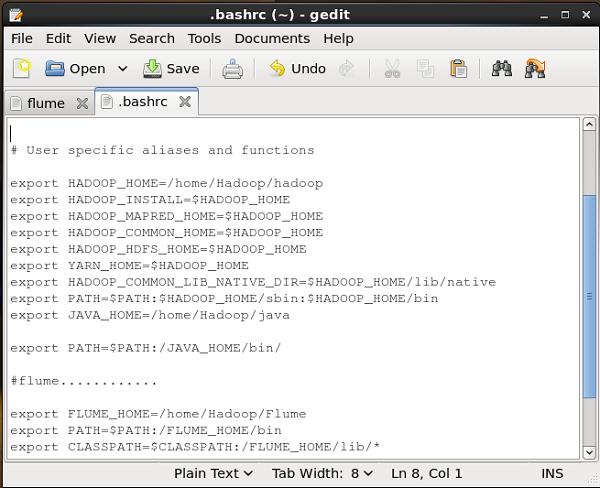
Thư mục conf
Nếu bạn mở conf thư mục của Apache Flume, bạn sẽ có bốn tệp sau:
- flume-conf.properties.template,
- flume-env.sh.template,
- flume-env.ps1.template và
- log4j.properties.

Bây giờ đổi tên
flume-conf.properties.template nộp hồ sơ như flume-conf.properties và
flume-env.sh.template như flume-env.sh
flume-env.sh
Mở flume-env.sh tập tin và đặt JAVA_Home vào thư mục nơi Java đã được cài đặt trong hệ thống của bạn.
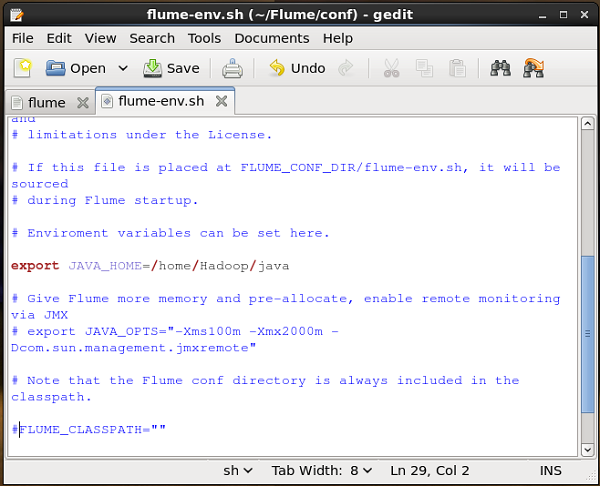
Xác minh cài đặt
Xác minh việc cài đặt Apache Flume bằng cách duyệt qua bin và gõ lệnh sau.
$ ./flume-ngNếu bạn đã cài đặt thành công Flume, bạn sẽ nhận được lời nhắc trợ giúp của Flume như hình bên dưới.
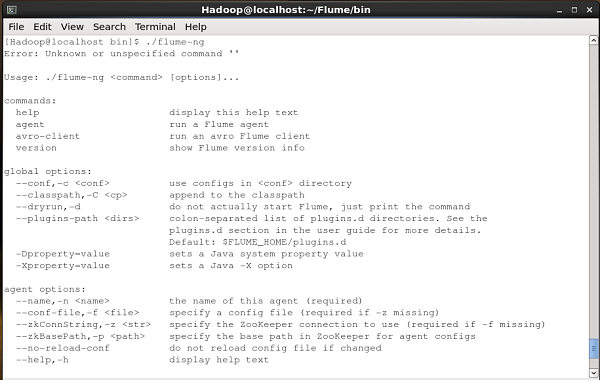
Sau khi cài đặt Flume, chúng ta cần định cấu hình nó bằng cách sử dụng tệp cấu hình là tệp thuộc tính Java có key-value pairs. Chúng ta cần chuyển các giá trị cho các khóa trong tệp.
Trong tệp cấu hình Flume, chúng ta cần -
- Kể tên các thành phần của tác nhân hiện tại.
- Mô tả / Cấu hình nguồn.
- Mô tả / Cấu hình bồn rửa.
- Mô tả / Định cấu hình kênh.
- Ràng nguồn và mạch chìm vào kênh.
Thông thường chúng ta có thể có nhiều tác nhân trong Flume. Chúng ta có thể phân biệt từng tác nhân bằng cách sử dụng một tên duy nhất. Và sử dụng tên này, chúng ta phải cấu hình từng tác nhân.
Đặt tên cho các thành phần
Trước hết, bạn cần đặt tên / liệt kê các thành phần như nguồn, chìm và kênh của tác nhân, như hình dưới đây.
agent_name.sources = source_name
agent_name.sinks = sink_name
agent_name.channels = channel_nameFlume hỗ trợ nhiều nguồn, bồn rửa và kênh khác nhau. Chúng được liệt kê trong bảng dưới đây.
| Nguồn | Kênh truyền hình | Chìm |
|---|---|---|
|
|
|
Bạn có thể sử dụng bất kỳ trong số chúng. Ví dụ: nếu bạn đang chuyển dữ liệu Twitter bằng nguồn Twitter thông qua kênh bộ nhớ đến ổ cắm HDFS và id tên tác nhânTwitterAgent, sau đó
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFSSau khi liệt kê các thành phần của tác nhân, bạn phải mô tả (các) nguồn, (các) phần chìm và (các) kênh bằng cách cung cấp giá trị cho các thuộc tính của chúng.
Mô tả Nguồn
Mỗi nguồn sẽ có một danh sách các thuộc tính riêng biệt. Thuộc tính có tên “type” chung cho mọi nguồn và nó được sử dụng để chỉ định loại nguồn mà chúng tôi đang sử dụng.
Cùng với thuộc tính “type”, cần cung cấp các giá trị của tất cả các required thuộc tính của một nguồn cụ thể để định cấu hình nó, như được hiển thị bên dưới.
agent_name.sources. source_name.type = value
agent_name.sources. source_name.property2 = value
agent_name.sources. source_name.property3 = valueVí dụ, nếu chúng ta xem xét twitter source, sau đây là các thuộc tính mà chúng tôi phải cung cấp các giá trị để định cấu hình nó.
TwitterAgent.sources.Twitter.type = Twitter (type name)
TwitterAgent.sources.Twitter.consumerKey =
TwitterAgent.sources.Twitter.consumerSecret =
TwitterAgent.sources.Twitter.accessToken =
TwitterAgent.sources.Twitter.accessTokenSecret =Mô tả bồn rửa
Cũng giống như nguồn, mỗi bồn rửa sẽ có một danh sách các thuộc tính riêng biệt. Thuộc tính có tên “type” phổ biến đối với mọi bồn rửa và nó được sử dụng để chỉ định loại bồn rửa mà chúng tôi đang sử dụng. Cùng với thuộc tính “type”, cần cung cấp giá trị cho tất cả cácrequired thuộc tính của một bồn rửa cụ thể để định cấu hình nó, như hình dưới đây.
agent_name.sinks. sink_name.type = value
agent_name.sinks. sink_name.property2 = value
agent_name.sinks. sink_name.property3 = valueVí dụ, nếu chúng ta xem xét HDFS sink, sau đây là các thuộc tính mà chúng tôi phải cung cấp các giá trị để định cấu hình nó.
TwitterAgent.sinks.HDFS.type = hdfs (type name)
TwitterAgent.sinks.HDFS.hdfs.path = HDFS directory’s Path to store the dataMô tả kênh
Flume cung cấp nhiều kênh khác nhau để truyền dữ liệu giữa các nguồn và bồn rửa. Do đó, cùng với các nguồn và các kênh, cần phải mô tả kênh được sử dụng trong tác nhân.
Để mô tả từng kênh, bạn cần đặt các thuộc tính bắt buộc, như hình dưới đây.
agent_name.channels.channel_name.type = value
agent_name.channels.channel_name. property2 = value
agent_name.channels.channel_name. property3 = valueVí dụ, nếu chúng ta xem xét memory channel, sau đây là các thuộc tính mà chúng tôi phải cung cấp các giá trị để định cấu hình nó.
TwitterAgent.channels.MemChannel.type = memory (type name)Ràng buộc Nguồn và Chìm với Kênh
Vì các kênh kết nối nguồn và nguồn chìm, nên cần phải liên kết cả hai nguồn với kênh, như hình dưới đây.
agent_name.sources.source_name.channels = channel_name
agent_name.sinks.sink_name.channels = channel_nameVí dụ sau đây cho thấy cách liên kết các nguồn và phần chìm với một kênh. Ở đây, chúng tôi xem xéttwitter source, memory channel, và HDFS sink.
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channels = MemChannelBắt đầu một tác nhân Flume
Sau khi cấu hình, chúng ta phải khởi động tác nhân Flume. Nó được thực hiện như sau:
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentở đâu -
agent - Lệnh khởi động tác nhân Flume
--conf ,-c<conf> - Sử dụng tệp cấu hình trong thư mục conf
-f<file> - Chỉ định một đường dẫn tệp cấu hình, nếu thiếu
--name, -n <name> - Tên của đại lý twitter
-D property =value - Đặt giá trị thuộc tính hệ thống Java.
Sử dụng Flume, chúng tôi có thể tìm nạp dữ liệu từ các dịch vụ khác nhau và vận chuyển nó đến các cửa hàng tập trung (HDFS và HBase). Chương này giải thích cách tìm nạp dữ liệu từ dịch vụ Twitter và lưu trữ nó trong HDFS bằng Apache Flume.
Như đã thảo luận trong Kiến trúc Flume, một máy chủ web tạo ra dữ liệu nhật ký và dữ liệu này được thu thập bởi một tác nhân trong Flume. Kênh đệm dữ liệu này vào một bồn rửa, cuối cùng đẩy dữ liệu này đến các cửa hàng tập trung.
Trong ví dụ được cung cấp trong chương này, chúng tôi sẽ tạo một ứng dụng và lấy các tweet từ nó bằng cách sử dụng nguồn twitter thử nghiệm do Apache Flume cung cấp. Chúng tôi sẽ sử dụng kênh bộ nhớ để đệm các tweet này và HDFS chìm để đẩy các tweet này vào HDFS.

Để tìm nạp dữ liệu Twitter, chúng tôi sẽ phải làm theo các bước dưới đây:
- Tạo một ứng dụng twitter
- Cài đặt / Khởi động HDFS
- Định cấu hình Flume
Tạo ứng dụng Twitter
Để nhận được các tweet từ Twitter, bạn cần tạo một ứng dụng Twitter. Làm theo các bước dưới đây để tạo một ứng dụng Twitter.
Bước 1
Để tạo một ứng dụng Twitter, hãy nhấp vào liên kết sau https://apps.twitter.com/. Đăng nhập vào tài khoản Twitter của bạn. Bạn sẽ có cửa sổ Quản lý ứng dụng Twitter nơi bạn có thể tạo, xóa và quản lý Ứng dụng Twitter.
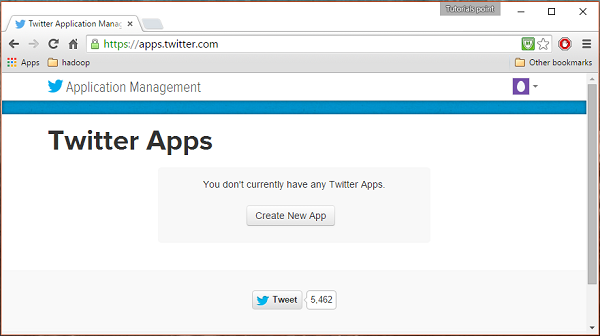
Bước 2
Bấm vào Create New Appcái nút. Bạn sẽ được chuyển hướng đến một cửa sổ nơi bạn sẽ nhận được một mẫu đơn đăng ký trong đó bạn phải điền thông tin chi tiết của mình để tạo Ứng dụng. Trong khi điền địa chỉ trang web, hãy cung cấp mẫu URL hoàn chỉnh, ví dụ:http://example.com.
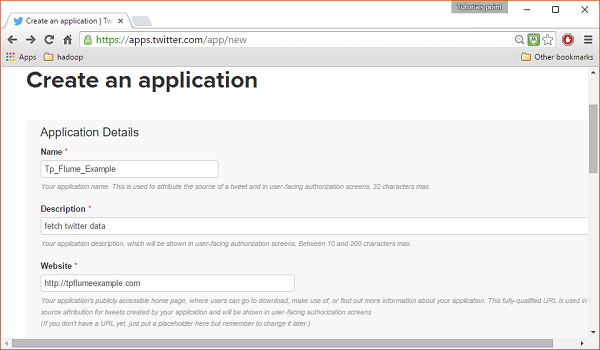
Bước 3
Điền vào các chi tiết, chấp nhận Developer Agreement khi hoàn thành, hãy nhấp vào Create your Twitter application buttonở cuối trang. Nếu mọi thứ suôn sẻ, một Ứng dụng sẽ được tạo với các chi tiết cụ thể như hình dưới đây.
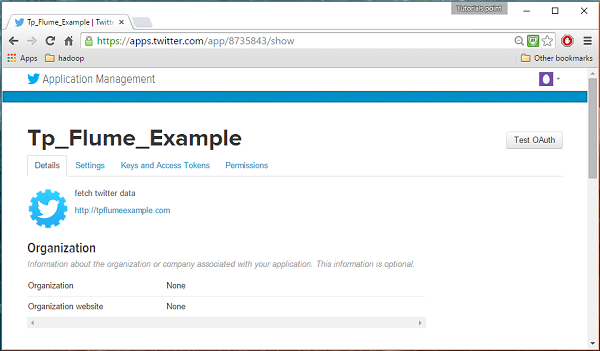
Bước 4
Dưới keys and Access Tokens ở cuối trang, bạn có thể thấy một nút có tên Create my access token. Nhấp vào nó để tạo mã thông báo truy cập.
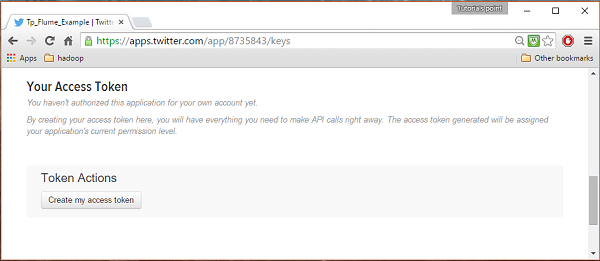
Bước 5
Cuối cùng, nhấp vào Test OAuthnút ở phía trên bên phải của trang. Điều này sẽ dẫn đến một trang hiển thịConsumer key, Consumer secret, Access token, và Access token secret. Sao chép các chi tiết này. Chúng hữu ích để cấu hình tác nhân trong Flume.

Khởi động HDFS
Vì chúng tôi đang lưu trữ dữ liệu trong HDFS, chúng tôi cần cài đặt / xác minh Hadoop. Khởi động Hadoop và tạo một thư mục trong đó để lưu trữ dữ liệu Flume. Làm theo các bước dưới đây trước khi định cấu hình Flume.
Bước 1: Cài đặt / Xác minh Hadoop
Cài đặt Hadoop . Nếu Hadoop đã được cài đặt trong hệ thống của bạn, hãy xác minh cài đặt bằng lệnh phiên bản Hadoop, như được hiển thị bên dưới.
$ hadoop versionNếu hệ thống của bạn chứa Hadoop và nếu bạn đã đặt biến đường dẫn, thì bạn sẽ nhận được kết quả sau:
Hadoop 2.6.0
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r
e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1
Compiled by jenkins on 2014-11-13T21:10Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /home/Hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jarBước 2: Khởi động Hadoop
Duyệt qua sbin thư mục của Hadoop và bắt đầu sợi và Hadoop dfs (hệ thống tệp phân tán) như hình dưới đây.
cd /$Hadoop_Home/sbin/
$ start-dfs.sh
localhost: starting namenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-namenode-localhost.localdomain.out
localhost: starting datanode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-datanode-localhost.localdomain.out
Starting secondary namenodes [0.0.0.0]
starting secondarynamenode, logging to
/home/Hadoop/hadoop/logs/hadoop-Hadoop-secondarynamenode-localhost.localdomain.out
$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-resourcemanager-localhost.localdomain.out
localhost: starting nodemanager, logging to
/home/Hadoop/hadoop/logs/yarn-Hadoop-nodemanager-localhost.localdomain.outBước 3: Tạo thư mục trong HDFS
Trong Hadoop DFS, bạn có thể tạo các thư mục bằng lệnh mkdir. Duyệt qua nó và tạo một thư mục với têntwitter_data trong đường dẫn bắt buộc như hình dưới đây.
$cd /$Hadoop_Home/bin/
$ hdfs dfs -mkdir hdfs://localhost:9000/user/Hadoop/twitter_dataCấu hình Flume
Chúng tôi phải định cấu hình nguồn, kênh và bồn rửa bằng cách sử dụng tệp cấu hình trong confthư mục. Ví dụ được đưa ra trong chương này sử dụng nguồn thử nghiệm do Apache Flume cung cấp có tênTwitter 1% Firehose Kênh bộ nhớ và HDFS chìm.
Nguồn Twitter 1% Firehose
Nguồn này mang tính thử nghiệm cao. Nó kết nối với Twitter Firehose mẫu 1% bằng cách sử dụng API phát trực tuyến và liên tục tải xuống các tweet, chuyển đổi chúng sang định dạng Avro và gửi các sự kiện Avro đến một bồn chứa Flume hạ lưu.
Chúng tôi sẽ lấy nguồn này theo mặc định cùng với việc cài đặt Flume. Cácjar các tệp tương ứng với nguồn này có thể được đặt trong lib thư mục như hình dưới đây.

Đặt đường dẫn classpath
Đặt classpath biến thành lib thư mục Flume trong Flume-env.sh tập tin như hình dưới đây.
export CLASSPATH=$CLASSPATH:/FLUME_HOME/lib/*Nguồn này cần các chi tiết như Consumer key, Consumer secret, Access token, và Access token secretcủa một ứng dụng Twitter. Trong khi định cấu hình nguồn này, bạn phải cung cấp giá trị cho các thuộc tính sau:
Channels
Source type : org.apache.flume.source.twitter.TwitterSource
consumerKey - Khóa người dùng OAuth
consumerSecret - Bí mật của người tiêu dùng OAuth
accessToken - Mã thông báo truy cập OAuth
accessTokenSecret - Bí mật mã thông báo OAuth
maxBatchSize- Số lượng tin nhắn twitter tối đa phải có trong một đợt twitter. Giá trị mặc định là 1000 (tùy chọn).
maxBatchDurationMillis- Số mili giây tối đa để chờ trước khi đóng một lô. Giá trị mặc định là 1000 (tùy chọn).
Kênh
Chúng tôi đang sử dụng kênh bộ nhớ. Để cấu hình kênh bộ nhớ, bạn phải cung cấp giá trị cho loại kênh.
type- Nó chứa loại kênh. Trong ví dụ của chúng tôi, loại làMemChannel.
Capacity- Đây là số lượng sự kiện tối đa được lưu trữ trong kênh. Giá trị mặc định của nó là 100 (tùy chọn).
TransactionCapacity- Là số lượng sự kiện tối đa mà kênh chấp nhận hoặc gửi. Giá trị mặc định của nó là 100 (tùy chọn).
HDFS Sink
Phần chìm này ghi dữ liệu vào HDFS. Để cấu hình bồn rửa này, bạn phải cung cấp các chi tiết sau.
Channel
type - hdfs
hdfs.path - đường dẫn của thư mục trong HDFS nơi dữ liệu sẽ được lưu trữ.
Và chúng tôi có thể cung cấp một số giá trị tùy chọn dựa trên kịch bản. Dưới đây là các thuộc tính tùy chọn của ổ HDFS mà chúng tôi đang định cấu hình trong ứng dụng của mình.
fileType - Đây là định dạng tệp bắt buộc của tệp HDFS của chúng tôi. SequenceFile, DataStream và CompressedStreamlà ba loại có sẵn với luồng này. Trong ví dụ của chúng tôi, chúng tôi đang sử dụngDataStream.
writeFormat - Có thể là văn bản hoặc có thể ghi.
batchSize- Đó là số sự kiện được ghi vào một tệp trước khi nó được chuyển vào HDFS. Giá trị mặc định của nó là 100.
rollsize- Đó là kích thước tệp để kích hoạt cuộn. Giá trị mặc định là 100.
rollCount- Là số sự kiện được ghi vào tệp trước khi cuộn. Giá trị mặc định của nó là 10.
Ví dụ - Tệp cấu hình
Dưới đây là một ví dụ về tệp cấu hình. Sao chép nội dung này và lưu dưới dạngtwitter.conf trong thư mục conf của Flume.
# Naming the components on the current agent.
TwitterAgent.sources = Twitter
TwitterAgent.channels = MemChannel
TwitterAgent.sinks = HDFS
# Describing/Configuring the source
TwitterAgent.sources.Twitter.type = org.apache.flume.source.twitter.TwitterSource
TwitterAgent.sources.Twitter.consumerKey = Your OAuth consumer key
TwitterAgent.sources.Twitter.consumerSecret = Your OAuth consumer secret
TwitterAgent.sources.Twitter.accessToken = Your OAuth consumer key access token
TwitterAgent.sources.Twitter.accessTokenSecret = Your OAuth consumer key access token secret
TwitterAgent.sources.Twitter.keywords = tutorials point,java, bigdata, mapreduce, mahout, hbase, nosql
# Describing/Configuring the sink
TwitterAgent.sinks.HDFS.type = hdfs
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/twitter_data/
TwitterAgent.sinks.HDFS.hdfs.fileType = DataStream
TwitterAgent.sinks.HDFS.hdfs.writeFormat = Text
TwitterAgent.sinks.HDFS.hdfs.batchSize = 1000
TwitterAgent.sinks.HDFS.hdfs.rollSize = 0
TwitterAgent.sinks.HDFS.hdfs.rollCount = 10000
# Describing/Configuring the channel
TwitterAgent.channels.MemChannel.type = memory
TwitterAgent.channels.MemChannel.capacity = 10000
TwitterAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
TwitterAgent.sources.Twitter.channels = MemChannel
TwitterAgent.sinks.HDFS.channel = MemChannelChấp hành
Duyệt qua thư mục chính của Flume và thực thi ứng dụng như hình dưới đây.
$ cd $FLUME_HOME
$ bin/flume-ng agent --conf ./conf/ -f conf/twitter.conf
Dflume.root.logger=DEBUG,console -n TwitterAgentNếu mọi thứ diễn ra tốt đẹp, việc phát trực tuyến các tweet vào HDFS sẽ bắt đầu. Dưới đây là ảnh chụp nhanh của cửa sổ nhắc lệnh trong khi tìm nạp các tweet.
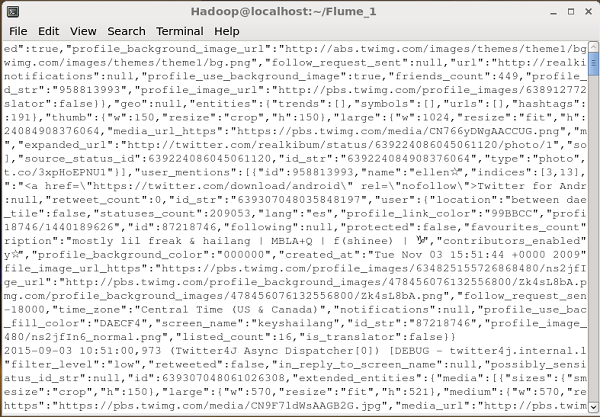
Xác minh HDFS
Bạn có thể truy cập giao diện người dùng Web quản trị Hadoop bằng URL được cung cấp bên dưới.
http://localhost:50070/Nhấp vào menu thả xuống có tên Utilitiesở phía bên phải của trang. Bạn có thể thấy hai tùy chọn như được hiển thị trong ảnh chụp nhanh bên dưới.
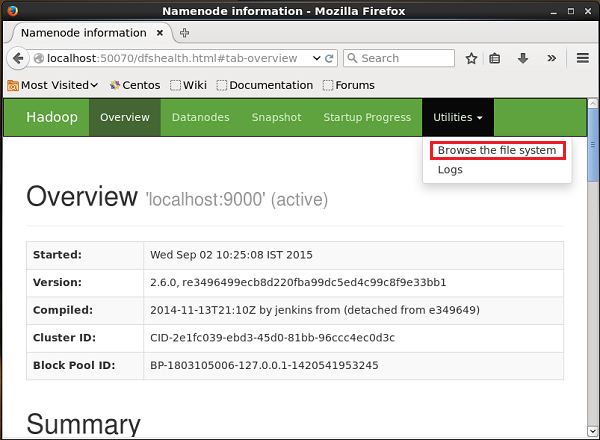
Bấm vào Browse the file systemvà nhập đường dẫn của thư mục HDFS nơi bạn đã lưu trữ các tweet. Trong ví dụ của chúng tôi, đường dẫn sẽ là/user/Hadoop/twitter_data/. Sau đó, bạn có thể xem danh sách các tệp nhật ký twitter được lưu trữ trong HDFS như bên dưới.

Trong chương trước, chúng ta đã biết cách tìm nạp dữ liệu từ nguồn twitter sang HDFS. Chương này giải thích cách tìm nạp dữ liệu từSequence generator.
Điều kiện tiên quyết
Để chạy ví dụ được cung cấp trong chương này, bạn cần cài đặt HDFS cùng với Flume. Do đó, hãy xác minh cài đặt Hadoop và khởi động HDFS trước khi tiếp tục. (Tham khảo chương trước để biết cách khởi động HDFS).
Cấu hình Flume
Chúng tôi phải định cấu hình nguồn, kênh và bồn rửa bằng cách sử dụng tệp cấu hình trong confthư mục. Ví dụ được đưa ra trong chương này sử dụngsequence generator source, một memory channel, và một HDFS sink.
Nguồn trình tạo trình tự
Nó là nguồn tạo ra các sự kiện liên tục. Nó duy trì một bộ đếm bắt đầu từ 0 và tăng lên 1. Nó được sử dụng cho mục đích thử nghiệm. Trong khi định cấu hình nguồn này, bạn phải cung cấp giá trị cho các thuộc tính sau:
Channels
Source type - seq
Kênh
Chúng tôi đang sử dụng memorykênh. Để cấu hình kênh bộ nhớ, bạn phải cung cấp giá trị cho loại kênh. Dưới đây là danh sách các thuộc tính mà bạn cần cung cấp trong khi định cấu hình kênh bộ nhớ -
type- Nó chứa loại kênh. Trong ví dụ của chúng tôi, loại là MemChannel.
Capacity- Đây là số lượng sự kiện tối đa được lưu trữ trong kênh. Giá trị mặc định của nó là 100. (tùy chọn)
TransactionCapacity- Là số lượng sự kiện tối đa mà kênh chấp nhận hoặc gửi. Mặc định của nó là 100. (tùy chọn).
HDFS Sink
Phần chìm này ghi dữ liệu vào HDFS. Để cấu hình bồn rửa này, bạn phải cung cấp các chi tiết sau.
Channel
type - hdfs
hdfs.path - đường dẫn của thư mục trong HDFS nơi dữ liệu sẽ được lưu trữ.
Và chúng tôi có thể cung cấp một số giá trị tùy chọn dựa trên kịch bản. Dưới đây là các thuộc tính tùy chọn của ổ HDFS mà chúng tôi đang định cấu hình trong ứng dụng của mình.
fileType - Đây là định dạng tệp bắt buộc của tệp HDFS của chúng tôi. SequenceFile, DataStream và CompressedStreamlà ba loại có sẵn với luồng này. Trong ví dụ của chúng tôi, chúng tôi đang sử dụngDataStream.
writeFormat - Có thể là văn bản hoặc có thể ghi.
batchSize- Đó là số sự kiện được ghi vào một tệp trước khi nó được chuyển vào HDFS. Giá trị mặc định của nó là 100.
rollsize- Đó là kích thước tệp để kích hoạt cuộn. Giá trị mặc định là 100.
rollCount- Là số sự kiện được ghi vào tệp trước khi cuộn. Giá trị mặc định của nó là 10.
Ví dụ - Tệp cấu hình
Dưới đây là một ví dụ về tệp cấu hình. Sao chép nội dung này và lưu dưới dạngseq_gen .conf trong thư mục conf của Flume.
# Naming the components on the current agent
SeqGenAgent.sources = SeqSource
SeqGenAgent.channels = MemChannel
SeqGenAgent.sinks = HDFS
# Describing/Configuring the source
SeqGenAgent.sources.SeqSource.type = seq
# Describing/Configuring the sink
SeqGenAgent.sinks.HDFS.type = hdfs
SeqGenAgent.sinks.HDFS.hdfs.path = hdfs://localhost:9000/user/Hadoop/seqgen_data/
SeqGenAgent.sinks.HDFS.hdfs.filePrefix = log
SeqGenAgent.sinks.HDFS.hdfs.rollInterval = 0
SeqGenAgent.sinks.HDFS.hdfs.rollCount = 10000
SeqGenAgent.sinks.HDFS.hdfs.fileType = DataStream
# Describing/Configuring the channel
SeqGenAgent.channels.MemChannel.type = memory
SeqGenAgent.channels.MemChannel.capacity = 1000
SeqGenAgent.channels.MemChannel.transactionCapacity = 100
# Binding the source and sink to the channel
SeqGenAgent.sources.SeqSource.channels = MemChannel
SeqGenAgent.sinks.HDFS.channel = MemChannelChấp hành
Duyệt qua thư mục chính của Flume và thực thi ứng dụng như hình dưới đây.
$ cd $FLUME_HOME
$./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/seq_gen.conf
--name SeqGenAgentNếu mọi thứ suôn sẻ, nguồn bắt đầu tạo số thứ tự sẽ được đẩy vào HDFS dưới dạng tệp nhật ký.
Dưới đây là ảnh chụp nhanh của cửa sổ nhắc lệnh tìm nạp dữ liệu được tạo bởi trình tạo chuỗi vào HDFS.

Xác minh HDFS
Bạn có thể truy cập giao diện người dùng Web quản trị Hadoop bằng URL sau:
http://localhost:50070/Nhấp vào menu thả xuống có tên Utilitiesở phía bên phải của trang. Bạn có thể thấy hai tùy chọn như được hiển thị trong sơ đồ dưới đây.
Bấm vào Browse the file system và nhập đường dẫn của thư mục HDFS nơi bạn đã lưu trữ dữ liệu được tạo bởi trình tạo chuỗi.
Trong ví dụ của chúng tôi, đường dẫn sẽ là /user/Hadoop/ seqgen_data /. Sau đó, bạn có thể xem danh sách các tệp nhật ký được tạo bởi trình tạo trình tự, được lưu trữ trong HDFS như được cung cấp bên dưới.
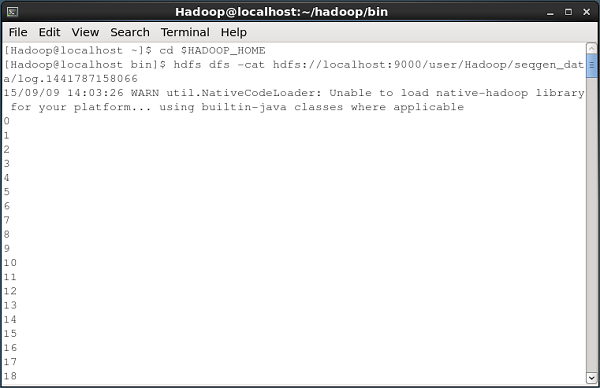
Xác minh nội dung của tệp
Tất cả các tệp nhật ký này chứa các số ở định dạng tuần tự. Bạn có thể xác minh nội dung của tệp này trong hệ thống tệp bằng cách sử dụngcat lệnh như hình dưới đây.
Chương này lấy một ví dụ để giải thích cách bạn có thể tạo các sự kiện và sau đó đăng nhập chúng vào bảng điều khiển. Đối với điều này, chúng tôi đang sử dụngNetCat nguồn và logger bồn rửa.
Điều kiện tiên quyết
Để chạy ví dụ được cung cấp trong chương này, bạn cần cài đặt Flume.
Cấu hình Flume
Chúng tôi phải định cấu hình nguồn, kênh và bồn rửa bằng cách sử dụng tệp cấu hình trong confthư mục. Ví dụ được đưa ra trong chương này sử dụngNetCat Source, Memory channel, và một logger sink.
Nguồn NetCat
Trong khi cấu hình nguồn NetCat, chúng ta phải chỉ định một cổng trong khi cấu hình nguồn. Bây giờ nguồn (nguồn NetCat) lắng nghe cổng đã cho và nhận từng dòng chúng ta đã nhập vào cổng đó dưới dạng một sự kiện riêng lẻ và chuyển nó đến bộ phận chìm thông qua kênh được chỉ định.
Trong khi định cấu hình nguồn này, bạn phải cung cấp giá trị cho các thuộc tính sau:
channels
Source type - netcat
bind - Tên máy chủ hoặc địa chỉ IP để liên kết.
port - Số cổng mà chúng ta muốn nguồn lắng nghe.
Kênh
Chúng tôi đang sử dụng memorykênh. Để cấu hình kênh bộ nhớ, bạn phải cung cấp giá trị cho loại kênh. Dưới đây là danh sách các thuộc tính mà bạn cần cung cấp trong khi định cấu hình kênh bộ nhớ -
type- Nó chứa loại kênh. Trong ví dụ của chúng tôi, loại làMemChannel.
Capacity- Đây là số lượng sự kiện tối đa được lưu trữ trong kênh. Giá trị mặc định của nó là 100. (tùy chọn)
TransactionCapacity- Là số lượng sự kiện tối đa mà kênh chấp nhận hoặc gửi. Giá trị mặc định của nó là 100. (tùy chọn).
Logger Sink
Bồn rửa này ghi lại tất cả các sự kiện được chuyển đến nó. Nói chung, nó được sử dụng cho mục đích thử nghiệm hoặc gỡ lỗi. Để cấu hình bồn rửa này, bạn phải cung cấp các chi tiết sau.
Channel
type - người khai thác gỗ
Tệp cấu hình mẫu
Dưới đây là một ví dụ về tệp cấu hình. Sao chép nội dung này và lưu dưới dạngnetcat.conf trong thư mục conf của Flume.
# Naming the components on the current agent
NetcatAgent.sources = Netcat
NetcatAgent.channels = MemChannel
NetcatAgent.sinks = LoggerSink
# Describing/Configuring the source
NetcatAgent.sources.Netcat.type = netcat
NetcatAgent.sources.Netcat.bind = localhost
NetcatAgent.sources.Netcat.port = 56565
# Describing/Configuring the sink
NetcatAgent.sinks.LoggerSink.type = logger
# Describing/Configuring the channel
NetcatAgent.channels.MemChannel.type = memory
NetcatAgent.channels.MemChannel.capacity = 1000
NetcatAgent.channels.MemChannel.transactionCapacity = 100
# Bind the source and sink to the channel
NetcatAgent.sources.Netcat.channels = MemChannel
NetcatAgent.sinks. LoggerSink.channel = MemChannelChấp hành
Duyệt qua thư mục chính của Flume và thực thi ứng dụng như hình dưới đây.
$ cd $FLUME_HOME
$ ./bin/flume-ng agent --conf $FLUME_CONF --conf-file $FLUME_CONF/netcat.conf
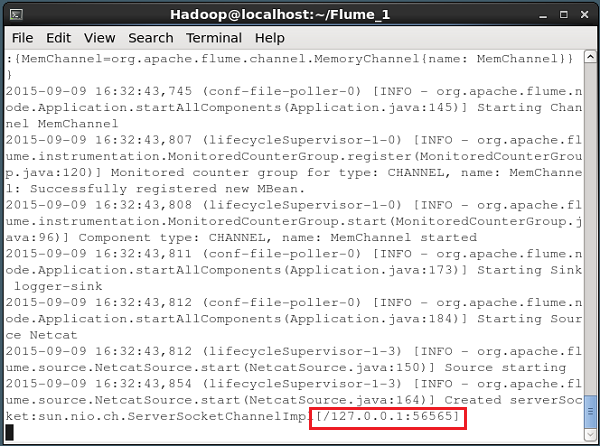
--name NetcatAgent -Dflume.root.logger=INFO,consoleNếu mọi thứ diễn ra tốt đẹp, nguồn bắt đầu lắng nghe cổng đã cho. Trong trường hợp này, nó là56565. Dưới đây là ảnh chụp nhanh cửa sổ nhắc lệnh của nguồn NetCat đã khởi động và nghe cổng 56565.
Truyền dữ liệu đến nguồn
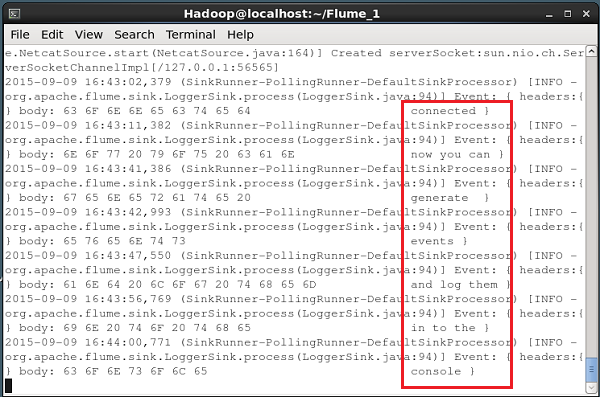
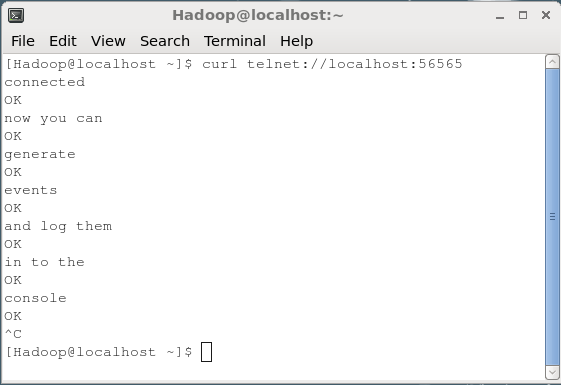
Để chuyển dữ liệu đến nguồn NetCat, bạn phải mở cổng được cung cấp trong tệp cấu hình. Mở một thiết bị đầu cuối riêng biệt và kết nối với nguồn (56565) bằng cách sử dụngcurlchỉ huy. Khi kết nối thành công, bạn sẽ nhận được thông báo “connected”Như hình bên dưới.
$ curl telnet://localhost:56565
connectedBây giờ bạn có thể nhập từng dòng dữ liệu của mình (sau mỗi dòng, bạn phải nhấn Enter). Nguồn NetCat nhận mỗi dòng dưới dạng một sự kiện riêng lẻ và bạn sẽ nhận được thông báo “OK”.
Bất cứ khi nào bạn hoàn tất việc chuyển dữ liệu, bạn có thể thoát khỏi bảng điều khiển bằng cách nhấn (Ctrl+C). Dưới đây là ảnh chụp nhanh của bảng điều khiển mà chúng tôi đã kết nối với nguồn bằng cách sử dụngcurl chỉ huy.
Mỗi dòng được nhập vào bảng điều khiển trên sẽ được nguồn nhận như một sự kiện riêng lẻ. Vì chúng tôi đã sử dụngLogger chìm, các sự kiện này sẽ được đăng nhập vào bảng điều khiển (bảng điều khiển nguồn) thông qua kênh được chỉ định (kênh bộ nhớ trong trường hợp này).
Ảnh chụp nhanh sau đây cho thấy bảng điều khiển NetCat nơi các sự kiện được ghi lại.