Apache Spark - Hướng dẫn nhanh
Các ngành đang sử dụng rộng rãi Hadoop để phân tích tập dữ liệu của họ. Lý do là vì khung công tác Hadoop dựa trên một mô hình lập trình đơn giản (MapReduce) và nó cho phép một giải pháp tính toán có thể mở rộng, linh hoạt, chịu lỗi và hiệu quả về chi phí. Ở đây, mối quan tâm chính là duy trì tốc độ xử lý các bộ dữ liệu lớn về thời gian chờ giữa các truy vấn và thời gian chờ để chạy chương trình.
Spark được Apache Software Foundation giới thiệu để tăng tốc quy trình phần mềm tính toán Hadoop.
Trái ngược với một niềm tin thông thường, Spark is not a modified version of Hadoopvà thực sự không phụ thuộc vào Hadoop vì nó có quản lý cụm riêng. Hadoop chỉ là một trong những cách để triển khai Spark.
Spark sử dụng Hadoop theo hai cách - một là storage và thứ hai là processing. Vì Spark có tính toán quản lý cụm riêng nên nó chỉ sử dụng Hadoop cho mục đích lưu trữ.
Apache Spark
Apache Spark là công nghệ điện toán cụm nhanh như chớp, được thiết kế để tính toán nhanh. Nó dựa trên Hadoop MapReduce và nó mở rộng mô hình MapReduce để sử dụng hiệu quả nó cho nhiều loại tính toán hơn, bao gồm các truy vấn tương tác và xử lý luồng. Tính năng chính của Spark làin-memory cluster computing làm tăng tốc độ xử lý của ứng dụng.
Spark được thiết kế để bao gồm một loạt các khối lượng công việc như ứng dụng hàng loạt, thuật toán lặp lại, truy vấn tương tác và phát trực tuyến. Ngoài việc hỗ trợ tất cả khối lượng công việc này trong một hệ thống tương ứng, nó làm giảm gánh nặng quản lý trong việc duy trì các công cụ riêng biệt.
Sự phát triển của Apache Spark
Spark là một trong những dự án phụ của Hadoop được phát triển vào năm 2009 trong AMPLab của UC Berkeley bởi Matei Zaharia. Nó được Open Sourced vào năm 2010 theo giấy phép BSD. Nó đã được quyên góp cho nền tảng phần mềm Apache vào năm 2013 và bây giờ Apache Spark đã trở thành một dự án Apache cấp cao nhất từ tháng 2 năm 2014.
Các tính năng của Apache Spark
Apache Spark có các tính năng sau.
Speed- Spark giúp chạy ứng dụng trong cụm Hadoop, nhanh hơn tới 100 lần trong bộ nhớ và nhanh hơn 10 lần khi chạy trên đĩa. Điều này có thể thực hiện được bằng cách giảm số lượng thao tác đọc / ghi vào đĩa. Nó lưu trữ dữ liệu xử lý trung gian trong bộ nhớ.
Supports multiple languages- Spark cung cấp các API tích hợp trong Java, Scala hoặc Python. Do đó, bạn có thể viết ứng dụng bằng các ngôn ngữ khác nhau. Spark đưa ra 80 toán tử cấp cao để truy vấn tương tác.
Advanced Analytics- Spark không chỉ hỗ trợ 'Bản đồ' và 'thu nhỏ'. Nó cũng hỗ trợ các truy vấn SQL, Dữ liệu truyền trực tuyến, Máy học (ML) và các thuật toán Đồ thị.
Spark được xây dựng trên Hadoop
Sơ đồ sau đây cho thấy ba cách về cách Spark có thể được tạo bằng các thành phần Hadoop.

Có ba cách triển khai Spark như được giải thích bên dưới.
Standalone- Việc triển khai Spark độc lập có nghĩa là Spark chiếm vị trí trên HDFS (Hệ thống tệp phân tán Hadoop) và không gian được phân bổ cho HDFS một cách rõ ràng. Ở đây, Spark và MapReduce sẽ chạy song song với nhau để bao gồm tất cả các công việc tia lửa trên cụm.
Hadoop Yarn- Việc triển khai Hadoop Yarn có nghĩa là đơn giản, spark chạy trên Yarn mà không cần cài đặt trước hoặc truy cập root. Nó giúp tích hợp Spark vào hệ sinh thái Hadoop hoặc ngăn xếp Hadoop. Nó cho phép các thành phần khác chạy trên đầu ngăn xếp.
Spark in MapReduce (SIMR)- Spark trong MapReduce được sử dụng để khởi chạy công việc spark ngoài việc triển khai độc lập. Với SIMR, người dùng có thể khởi động Spark và sử dụng trình bao của nó mà không cần bất kỳ quyền truy cập quản trị nào.
Các thành phần của Spark
Hình minh họa sau đây mô tả các thành phần khác nhau của Spark.

Apache Spark Core
Spark Core là công cụ thực thi chung cơ bản cho nền tảng tia lửa mà tất cả các chức năng khác đều được xây dựng dựa trên. Nó cung cấp tính toán trong bộ nhớ và tham chiếu bộ dữ liệu trong hệ thống lưu trữ bên ngoài.
Spark SQL
Spark SQL là một thành phần trên Spark Core giới thiệu một phần trừu tượng hóa dữ liệu mới được gọi là SchemaRDD, cung cấp hỗ trợ cho dữ liệu có cấu trúc và bán cấu trúc.
Spark Streaming
Spark Streaming tận dụng khả năng lập lịch nhanh chóng của Spark Core để thực hiện phân tích luồng. Nó nhập dữ liệu trong các lô nhỏ và thực hiện các phép biến đổi RDD (Tập dữ liệu phân tán có khả năng phục hồi) trên các lô dữ liệu nhỏ đó.
MLlib (Thư viện học máy)
MLlib là một khung công tác học máy phân tán ở trên Spark vì kiến trúc Spark dựa trên bộ nhớ phân tán. Theo điểm chuẩn, nó được thực hiện bởi các nhà phát triển MLlib dựa trên triển khai Phương diện Ít nhất (ALS) luân phiên. Spark MLlib nhanh gấp 9 lần so với phiên bản dựa trên đĩa Hadoop củaApache Mahout (trước khi Mahout có được giao diện Spark).
GraphX
GraphX là một khung xử lý đồ thị phân tán trên Spark. Nó cung cấp một API để thể hiện tính toán đồ thị có thể lập mô hình đồ thị do người dùng xác định bằng cách sử dụng API trừu tượng Pregel. Nó cũng cung cấp thời gian chạy được tối ưu hóa cho sự trừu tượng này.
Tập dữ liệu được phân phối có khả năng phục hồi
Tập dữ liệu phân tán có khả năng phục hồi (RDD) là một cấu trúc dữ liệu cơ bản của Spark. Nó là một tập hợp các đối tượng được phân phối bất biến. Mỗi tập dữ liệu trong RDD được chia thành các phân vùng logic, có thể được tính toán trên các nút khác nhau của cụm. RDD có thể chứa bất kỳ loại đối tượng Python, Java hoặc Scala nào, bao gồm các lớp do người dùng định nghĩa.
Về mặt hình thức, RDD là một tập hợp các bản ghi được phân vùng, chỉ đọc. RDD có thể được tạo thông qua các hoạt động xác định trên dữ liệu trên bộ lưu trữ ổn định hoặc các RDD khác. RDD là một tập hợp các phần tử chịu được lỗi có thể hoạt động song song.
Có hai cách để tạo RDD: parallelizing một bộ sưu tập hiện có trong chương trình trình điều khiển của bạn, hoặc referencing a dataset trong hệ thống lưu trữ bên ngoài, chẳng hạn như hệ thống tệp chia sẻ, HDFS, HBase hoặc bất kỳ nguồn dữ liệu nào cung cấp Định dạng đầu vào Hadoop.
Spark sử dụng khái niệm RDD để đạt được các hoạt động MapReduce nhanh hơn và hiệu quả hơn. Trước tiên, chúng ta hãy thảo luận về cách các hoạt động MapReduce diễn ra và tại sao chúng không hiệu quả như vậy.
Chia sẻ dữ liệu chậm trong MapReduce
MapReduce được sử dụng rộng rãi để xử lý và tạo các tập dữ liệu lớn với một thuật toán phân tán, song song trên một cụm. Nó cho phép người dùng viết các phép tính song song, sử dụng một tập hợp các toán tử cấp cao, mà không phải lo lắng về việc phân phối công việc và khả năng chịu lỗi.
Thật không may, trong hầu hết các khuôn khổ hiện tại, cách duy nhất để sử dụng lại dữ liệu giữa các lần tính toán (Ví dụ - giữa hai công việc MapReduce) là ghi dữ liệu đó vào hệ thống lưu trữ ổn định bên ngoài (Ví dụ - HDFS). Mặc dù khung công tác này cung cấp nhiều nội dung trừu tượng để truy cập tài nguyên tính toán của một cụm, người dùng vẫn muốn nhiều hơn thế.
Cả hai Iterative và Interactivecác ứng dụng yêu cầu chia sẻ dữ liệu nhanh hơn trên các công việc song song. Chia sẻ dữ liệu chậm trong MapReduce doreplication, serializationvà disk IO. Về hệ thống lưu trữ, hầu hết các ứng dụng Hadoop, chúng dành hơn 90% thời gian để thực hiện các thao tác đọc-ghi HDFS.
Hoạt động lặp lại trên MapReduce
Sử dụng lại các kết quả trung gian qua nhiều lần tính toán trong các ứng dụng nhiều giai đoạn. Hình minh họa sau giải thích cách hoạt động của khung hiện tại trong khi thực hiện các hoạt động lặp lại trên MapReduce. Điều này phát sinh chi phí đáng kể do sao chép dữ liệu, I / O đĩa và tuần tự hóa, khiến hệ thống chậm.
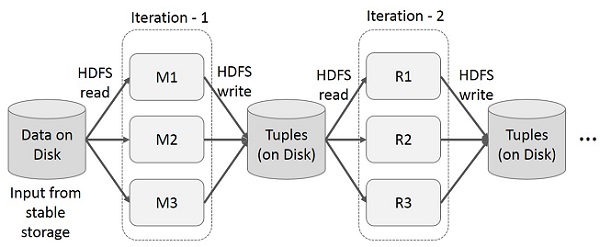
Hoạt động tương tác trên MapReduce
Người dùng chạy các truy vấn đặc biệt trên cùng một tập con dữ liệu. Mỗi truy vấn sẽ thực hiện I / O đĩa trên bộ nhớ ổn định, có thể chi phối thời gian thực thi ứng dụng.
Hình minh họa sau giải thích cách hoạt động của khung hiện tại khi thực hiện các truy vấn tương tác trên MapReduce.
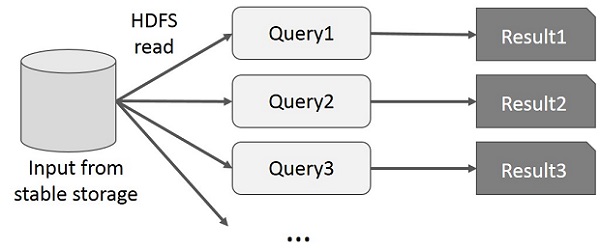
Chia sẻ dữ liệu bằng Spark RDD
Chia sẻ dữ liệu chậm trong MapReduce do replication, serializationvà disk IO. Hầu hết các ứng dụng Hadoop, chúng dành hơn 90% thời gian để thực hiện các thao tác đọc-ghi HDFS.
Nhận thức được vấn đề này, các nhà nghiên cứu đã phát triển một framework chuyên biệt có tên là Apache Spark. Ý tưởng chính của tia lửa làRkhông có lợi Dđược phân bổ Datasets (RDD); nó hỗ trợ tính toán xử lý trong bộ nhớ. Điều này có nghĩa là, nó lưu trữ trạng thái bộ nhớ như một đối tượng trên các công việc và đối tượng có thể chia sẻ giữa các công việc đó. Chia sẻ dữ liệu trong bộ nhớ nhanh hơn mạng và Đĩa từ 10 đến 100 lần.
Bây giờ chúng ta hãy thử tìm hiểu cách các hoạt động lặp lại và tương tác diễn ra trong Spark RDD.
Hoạt động lặp lại trên Spark RDD
Hình minh họa dưới đây cho thấy các hoạt động lặp lại trên Spark RDD. Nó sẽ lưu trữ các kết quả trung gian trong một bộ nhớ phân tán thay vì Ổ lưu trữ ổn định (Đĩa) và làm cho hệ thống nhanh hơn.
Note - Nếu bộ nhớ phân tán (RAM) đủ để lưu các kết quả trung gian (State of the JOB), thì nó sẽ lưu các kết quả đó trên đĩa.

Hoạt động tương tác trên Spark RDD
Hình minh họa này cho thấy các hoạt động tương tác trên Spark RDD. Nếu các truy vấn khác nhau được chạy lặp lại trên cùng một tập dữ liệu, thì dữ liệu cụ thể này có thể được lưu trong bộ nhớ để có thời gian thực thi tốt hơn.

Theo mặc định, mỗi RDD đã chuyển đổi có thể được tính toán lại mỗi khi bạn chạy một hành động trên đó. Tuy nhiên, bạn cũng có thểpersistmột RDD trong bộ nhớ, trong trường hợp đó Spark sẽ giữ các phần tử xung quanh trên cụm để truy cập nhanh hơn nhiều, vào lần tiếp theo bạn truy vấn nó. Ngoài ra còn có hỗ trợ cho các RDD lâu dài trên đĩa hoặc được sao chép qua nhiều nút.
Spark là dự án con của Hadoop. Do đó, tốt hơn là cài đặt Spark vào một hệ thống dựa trên Linux. Các bước sau đây hướng dẫn cách cài đặt Apache Spark.
Bước 1: Xác minh cài đặt Java
Cài đặt Java là một trong những điều bắt buộc trong quá trình cài đặt Spark. Hãy thử lệnh sau để xác minh phiên bản JAVA.
$java -versionNếu Java đã được cài đặt trên hệ thống của bạn, bạn sẽ thấy phản hồi sau:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Trong trường hợp bạn chưa cài đặt Java trên hệ thống của mình, hãy Cài đặt Java trước khi chuyển sang bước tiếp theo.
Bước 2: Xác minh cài đặt Scala
Bạn nên dùng ngôn ngữ Scala để triển khai Spark. Vì vậy, hãy để chúng tôi xác minh cài đặt Scala bằng lệnh sau.
$scala -versionNếu Scala đã được cài đặt trên hệ thống của bạn, bạn sẽ thấy phản hồi sau:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLTrong trường hợp bạn chưa cài đặt Scala trên hệ thống của mình, hãy chuyển sang bước tiếp theo để cài đặt Scala.
Bước 3: Tải xuống Scala
Tải xuống phiên bản mới nhất của Scala bằng cách truy cập liên kết sau Tải xuống Scala . Đối với hướng dẫn này, chúng tôi đang sử dụng phiên bản scala-2.11.6. Sau khi tải xuống, bạn sẽ tìm thấy tệp tar Scala trong thư mục tải xuống.
Bước 4: Cài đặt Scala
Làm theo các bước dưới đây để cài đặt Scala.
Giải nén tệp tar Scala
Gõ lệnh sau để giải nén tệp tar Scala.
$ tar xvf scala-2.11.6.tgzDi chuyển tệp phần mềm Scala
Sử dụng các lệnh sau để di chuyển các tệp phần mềm Scala, vào thư mục tương ứng (/usr/local/scala).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv scala-2.11.6 /usr/local/scala
# exitĐặt PATH cho Scala
Sử dụng lệnh sau để thiết lập PATH cho Scala.
$ export PATH = $PATH:/usr/local/scala/binXác minh cài đặt Scala
Sau khi cài đặt, tốt hơn là xác minh nó. Sử dụng lệnh sau để xác minh cài đặt Scala.
$scala -versionNếu Scala đã được cài đặt trên hệ thống của bạn, bạn sẽ thấy phản hồi sau:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFLBước 5: Tải xuống Apache Spark
Tải xuống phiên bản mới nhất của Spark bằng cách truy cập liên kết sau Tải xuống Spark . Đối với hướng dẫn này, chúng tôi đang sử dụngspark-1.3.1-bin-hadoop2.6phiên bản. Sau khi tải xuống, bạn sẽ tìm thấy tệp Spark tar trong thư mục tải xuống.
Bước 6: Cài đặt Spark
Làm theo các bước dưới đây để cài đặt Spark.
Giải nén nhựa đường Spark
Lệnh sau để giải nén tệp spark tar.
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgzDi chuyển tệp phần mềm Spark
Các lệnh sau để di chuyển các tệp phần mềm Spark vào thư mục tương ứng (/usr/local/spark).
$ su –
Password:
# cd /home/Hadoop/Downloads/
# mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark
# exitThiết lập môi trường cho Spark
Thêm dòng sau vào ~/.bashrctập tin. Nó có nghĩa là thêm vị trí, nơi đặt tệp phần mềm tia lửa vào biến PATH.
export PATH=$PATH:/usr/local/spark/binSử dụng lệnh sau để tìm nguồn cung cấp tệp ~ / .bashrc.
$ source ~/.bashrcBước 7: Xác minh cài đặt Spark
Viết lệnh sau để mở Spark shell.
$spark-shellNếu spark được cài đặt thành công thì bạn sẽ tìm thấy kết quả sau.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Spark Core là cơ sở của toàn bộ dự án. Nó cung cấp chức năng điều phối tác vụ, lập lịch và I / O cơ bản. Spark sử dụng cấu trúc dữ liệu cơ bản chuyên biệt được gọi là RDD (Tập dữ liệu phân tán có khả năng phục hồi) là một tập hợp dữ liệu hợp lý được phân vùng trên các máy. RDD có thể được tạo theo hai cách; một là bằng cách tham chiếu các tập dữ liệu trong hệ thống lưu trữ bên ngoài và thứ hai là bằng cách áp dụng các phép biến đổi (ví dụ: bản đồ, bộ lọc, bộ giảm, nối) trên các RDD hiện có.
Phần trừu tượng RDD được hiển thị thông qua một API tích hợp ngôn ngữ. Điều này đơn giản hóa độ phức tạp của lập trình vì cách ứng dụng thao tác với RDD tương tự như thao tác với các bộ sưu tập dữ liệu cục bộ.
Vỏ tia lửa
Spark cung cấp một trình bao tương tác - một công cụ mạnh mẽ để phân tích dữ liệu một cách tương tác. Nó có sẵn bằng ngôn ngữ Scala hoặc Python. Tính trừu tượng chính của Spark là một tập hợp phân tán của các mục được gọi là Tập dữ liệu phân tán có khả năng phục hồi (RDD). Các RDD có thể được tạo từ các Định dạng Đầu vào Hadoop (chẳng hạn như các tệp HDFS) hoặc bằng cách chuyển đổi các RDD khác.
Mở Spark Shell
Lệnh sau được sử dụng để mở Spark shell.
$ spark-shellTạo RDD đơn giản
Hãy để chúng tôi tạo một RDD đơn giản từ tệp văn bản. Sử dụng lệnh sau để tạo một RDD đơn giản.
scala> val inputfile = sc.textFile(“input.txt”)Đầu ra cho lệnh trên là
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12API Spark RDD giới thiệu một số Transformations và ít Actions để thao tác RDD.
Biến đổi RDD
Các phép biến đổi RDD trả về con trỏ tới RDD mới và cho phép bạn tạo các phụ thuộc giữa các RDD. Mỗi RDD trong chuỗi phụ thuộc (Chuỗi phụ thuộc) có một hàm để tính toán dữ liệu của nó và có một con trỏ (phụ thuộc) tới RDD mẹ của nó.
Spark là lười biếng, vì vậy sẽ không có gì được thực thi trừ khi bạn gọi một số chuyển đổi hoặc hành động sẽ kích hoạt tạo và thực thi công việc. Hãy xem đoạn mã sau của ví dụ đếm từ.
Do đó, biến đổi RDD không phải là một tập dữ liệu mà là một bước trong chương trình (có thể là bước duy nhất) cho Spark biết cách lấy dữ liệu và phải làm gì với nó.
| S. không | Sự biến đổi và ý nghĩa |
|---|---|
| 1 | map(func) Trả về tập dữ liệu được phân phối mới, được hình thành bằng cách chuyển từng phần tử của nguồn thông qua một hàm func. |
| 2 | filter(func) Trả về tập dữ liệu mới được tạo bằng cách chọn các phần tử của nguồn mà trên đó func trả về true. |
| 3 | flatMap(func) Tương tự như bản đồ, nhưng mỗi mục đầu vào có thể được ánh xạ tới 0 hoặc nhiều mục đầu ra (vì vậy func nên trả về một Seq thay vì một mục duy nhất). |
| 4 | mapPartitions(func) Tương tự như bản đồ, nhưng chạy riêng biệt trên từng phân vùng (khối) của RDD, vì vậy func phải thuộc loại Trình lặp <T> ⇒ Trình lặp <U> khi chạy trên RDD kiểu T. |
| 5 | mapPartitionsWithIndex(func) Tương tự như Phân vùng bản đồ, nhưng cũng cung cấp func với một giá trị số nguyên đại diện cho chỉ mục của phân vùng, vì vậy func phải có kiểu (Int, Iterator <T>) ⇒ Iterator <U> khi chạy trên RDD kiểu T. |
| 6 | sample(withReplacement, fraction, seed) Mẫu a fraction của dữ liệu, có hoặc không thay thế, bằng cách sử dụng hạt giống tạo số ngẫu nhiên nhất định. |
| 7 | union(otherDataset) Trả về một tập dữ liệu mới có chứa sự kết hợp của các phần tử trong tập dữ liệu nguồn và đối số. |
| số 8 | intersection(otherDataset) Trả về một RDD mới có chứa giao điểm của các phần tử trong tập dữ liệu nguồn và đối số. |
| 9 | distinct([numTasks]) Trả về một tập dữ liệu mới có chứa các phần tử riêng biệt của tập dữ liệu nguồn. |
| 10 | groupByKey([numTasks]) Khi được gọi trên một tập dữ liệu gồm các cặp (K, V), trả về một tập dữ liệu gồm các cặp (K, Iterable <V>). Note - Nếu bạn đang nhóm để thực hiện tổng hợp (chẳng hạn như tổng hoặc trung bình) trên mỗi khóa, thì việc sử dụng ReduceByKey hoặc tổng hợpByKey sẽ mang lại hiệu suất tốt hơn nhiều. |
| 11 | reduceByKey(func, [numTasks]) Khi được gọi trên tập dữ liệu của các cặp (K, V), trả về tập dữ liệu của các cặp (K, V) trong đó các giá trị cho mỗi khóa được tổng hợp bằng cách sử dụng hàm rút gọn đã cho , hàm này phải thuộc loại (V, V) ⇒ V Giống như trong groupByKey, số lượng tác vụ giảm có thể định cấu hình thông qua đối số thứ hai tùy chọn. |
| 12 | aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) Khi được gọi trên tập dữ liệu của các cặp (K, V), trả về tập dữ liệu của các cặp (K, U) trong đó các giá trị cho mỗi khóa được tổng hợp bằng cách sử dụng các hàm kết hợp đã cho và giá trị "0" trung tính. Cho phép loại giá trị tổng hợp khác với loại giá trị đầu vào, đồng thời tránh phân bổ không cần thiết. Giống như trong groupByKey, số lượng tác vụ giảm có thể định cấu hình thông qua đối số thứ hai tùy chọn. |
| 13 | sortByKey([ascending], [numTasks]) Khi được gọi trên tập dữ liệu của các cặp (K, V) trong đó K triển khai Có thứ tự, trả về tập dữ liệu của các cặp (K, V) được sắp xếp theo các khóa theo thứ tự tăng dần hoặc giảm dần, như được chỉ định trong đối số tăng dần Boolean. |
| 14 | join(otherDataset, [numTasks]) Khi được gọi trên các tập dữ liệu kiểu (K, V) và (K, W), trả về một tập dữ liệu gồm các cặp (K, (V, W)) với tất cả các cặp phần tử cho mỗi khóa. Tham gia bên ngoài được hỗ trợ thông qua leftOuterJoin, rightOuterJoin và fullOuterJoin. |
| 15 | cogroup(otherDataset, [numTasks]) Khi được gọi trên các tập dữ liệu kiểu (K, V) và (K, W), trả về một tập dữ liệu gồm các bộ dữ liệu (K, (Iterable <V>, Iterable <W>)). Thao tác này còn được gọi là nhóm Với. |
| 16 | cartesian(otherDataset) Khi được gọi trên các tập dữ liệu kiểu T và U, trả về một tập dữ liệu gồm (T, U) các cặp (tất cả các cặp phần tử). |
| 17 | pipe(command, [envVars]) Đưa từng phân vùng của RDD thông qua một lệnh shell, ví dụ như tập lệnh Perl hoặc bash. Các phần tử RDD được ghi vào stdin của quá trình và các dòng xuất ra stdout của nó được trả về dưới dạng RDD của các chuỗi. |
| 18 | coalesce(numPartitions) Giảm số lượng phân vùng trong RDD xuống numPartitions. Hữu ích để chạy các hoạt động hiệu quả hơn sau khi lọc bớt một tập dữ liệu lớn. |
| 19 | repartition(numPartitions) Sắp xếp lại dữ liệu trong RDD một cách ngẫu nhiên để tạo nhiều hoặc ít phân vùng hơn và cân bằng giữa chúng. Điều này luôn luôn xáo trộn tất cả dữ liệu trên mạng. |
| 20 | repartitionAndSortWithinPartitions(partitioner) Phân vùng lại RDD theo trình phân vùng đã cho và trong mỗi phân vùng kết quả, sắp xếp các bản ghi theo các khóa của chúng. Điều này hiệu quả hơn việc gọi phân vùng lại và sau đó sắp xếp trong mỗi phân vùng vì nó có thể đẩy việc phân loại xuống bộ máy xáo trộn. |
Hành động
| S. không | Hành động & Ý nghĩa |
|---|---|
| 1 | reduce(func) Tổng hợp các phần tử của tập dữ liệu bằng một hàm func(nhận hai đối số và trả về một). Hàm phải có tính chất giao hoán và liên kết để nó có thể được tính toán song song một cách chính xác. |
| 2 | collect() Trả về tất cả các phần tử của tập dữ liệu dưới dạng một mảng tại chương trình điều khiển. Điều này thường hữu ích sau khi bộ lọc hoặc hoạt động khác trả về một tập hợp con đủ nhỏ của dữ liệu. |
| 3 | count() Trả về số phần tử trong tập dữ liệu. |
| 4 | first() Trả về phần tử đầu tiên của tập dữ liệu (tương tự như lấy (1)). |
| 5 | take(n) Trả về một mảng có giá trị đầu tiên n các phần tử của tập dữ liệu. |
| 6 | takeSample (withReplacement,num, [seed]) Trả về một mảng với một mẫu ngẫu nhiên là num các phần tử của tập dữ liệu, có hoặc không có thay thế, tùy chọn chỉ định trước hạt tạo số ngẫu nhiên. |
| 7 | takeOrdered(n, [ordering]) Trả lại cái đầu tiên n các phần tử của RDD sử dụng thứ tự tự nhiên của chúng hoặc bộ so sánh tùy chỉnh. |
| số 8 | saveAsTextFile(path) Ghi các phần tử của tập dữ liệu dưới dạng tệp văn bản (hoặc tập hợp tệp văn bản) trong một thư mục nhất định trong hệ thống tệp cục bộ, HDFS hoặc bất kỳ hệ thống tệp nào khác được Hadoop hỗ trợ. Spark gọi toString trên mỗi phần tử để chuyển nó thành một dòng văn bản trong tệp. |
| 9 | saveAsSequenceFile(path) (Java and Scala) Ghi các phần tử của tập dữ liệu dưới dạng Hadoop SequenceFile trong một đường dẫn nhất định trong hệ thống tệp cục bộ, HDFS hoặc bất kỳ hệ thống tệp nào khác được Hadoop hỗ trợ. Điều này có sẵn trên RDD của các cặp khóa-giá trị triển khai giao diện Ghi của Hadoop. Trong Scala, nó cũng có sẵn trên các loại có thể chuyển đổi hoàn toàn thành W ghi được (Spark bao gồm các chuyển đổi cho các loại cơ bản như Int, Double, String, v.v.). |
| 10 | saveAsObjectFile(path) (Java and Scala) Viết các phần tử của tập dữ liệu ở một định dạng đơn giản bằng cách sử dụng tuần tự hóa Java, sau đó có thể được tải bằng SparkContext.objectFile (). |
| 11 | countByKey() Chỉ có sẵn trên RDD của loại (K, V). Trả về một bản đồ băm của các cặp (K, Int) với số lượng của mỗi khóa. |
| 12 | foreach(func) Chạy một chức năng functrên mỗi phần tử của tập dữ liệu. Điều này thường được thực hiện đối với các tác dụng phụ như cập nhật Bộ tích lũy hoặc tương tác với hệ thống lưu trữ bên ngoài. Note- việc sửa đổi các biến khác với Accumulators bên ngoài foreach () có thể dẫn đến hành vi không xác định. Xem phần Tìm hiểu về việc đóng cửa để biết thêm chi tiết |
Lập trình với RDD
Chúng ta hãy xem cách triển khai của một số hành động và biến đổi RDD trong lập trình RDD với sự trợ giúp của một ví dụ.
Thí dụ
Hãy xem xét một ví dụ đếm từ - Nó đếm từng từ xuất hiện trong một tài liệu. Hãy coi văn bản sau như một đầu vào và được lưu dưới dạnginput.txt tệp trong thư mục chính.
input.txt - tập tin đầu vào.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Làm theo quy trình dưới đây để thực hiện ví dụ đã cho.
Mở Spark-Shell
Lệnh sau được sử dụng để mở spark shell. Nói chung, spark được xây dựng bằng Scala. Do đó, một chương trình Spark chạy trên môi trường Scala.
$ spark-shellNếu Spark shell mở thành công thì bạn sẽ tìm thấy kết quả sau. Nhìn vào dòng cuối cùng của đầu ra “Có sẵn ngữ cảnh tia lửa dưới dạng sc” có nghĩa là vùng chứa Spark được tạo tự động đối tượng ngữ cảnh tia lửa với tênsc. Trước khi bắt đầu bước đầu tiên của chương trình, đối tượng SparkContext phải được tạo.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>Tạo RDD
Đầu tiên, chúng ta phải đọc tệp đầu vào bằng API Spark-Scala và tạo một RDD.
Lệnh sau được sử dụng để đọc tệp từ vị trí nhất định. Tại đây, RDD mới được tạo với tên của inputfile. Chuỗi được đưa ra làm đối số trong phương thức textFile (“”) là đường dẫn tuyệt đối cho tên tệp đầu vào. Tuy nhiên, nếu chỉ có tên tệp thì có nghĩa là tệp đầu vào đang ở vị trí hiện tại.
scala> val inputfile = sc.textFile("input.txt")Thực hiện chuyển đổi số lượng từ
Mục đích của chúng tôi là đếm các từ trong một tệp. Tạo một bản đồ phẳng để tách từng dòng thành các từ (flatMap(line ⇒ line.split(“ ”)).
Tiếp theo, đọc từng từ dưới dạng khóa có giá trị ‘1’ (<key, value> = <word, 1>) sử dụng hàm bản đồ (map(word ⇒ (word, 1)).
Cuối cùng, giảm các khóa đó bằng cách thêm giá trị của các khóa tương tự (reduceByKey(_+_)).
Lệnh sau được sử dụng để thực hiện logic đếm từ. Sau khi thực hiện điều này, bạn sẽ không tìm thấy bất kỳ đầu ra nào vì đây không phải là một hành động, đây là một sự chuyển đổi; trỏ một RDD mới hoặc cho biết phải làm gì với dữ liệu đã cho)
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);RDD hiện tại
Trong khi làm việc với RDD, nếu bạn muốn biết về RDD hiện tại, hãy sử dụng lệnh sau. Nó sẽ hiển thị cho bạn mô tả về RDD hiện tại và các phụ thuộc của nó để gỡ lỗi.
scala> counts.toDebugStringLưu trữ các biến đổi
Bạn có thể đánh dấu một RDD sẽ được duy trì bằng cách sử dụng các phương thức Kiên trì () hoặc cache () trên đó. Lần đầu tiên nó được tính toán trong một hành động, nó sẽ được lưu trong bộ nhớ trên các nút. Sử dụng lệnh sau để lưu các phép biến đổi trung gian trong bộ nhớ.
scala> counts.cache()Áp dụng hành động
Áp dụng một hành động, chẳng hạn như lưu trữ tất cả các biến đổi, kết quả vào một tệp văn bản. Đối số String cho phương thức saveAsTextFile (“”) là đường dẫn tuyệt đối của thư mục đầu ra. Hãy thử lệnh sau để lưu kết quả đầu ra trong tệp văn bản. Trong ví dụ sau, thư mục 'đầu ra' ở vị trí hiện tại.
scala> counts.saveAsTextFile("output")Kiểm tra đầu ra
Mở một thiết bị đầu cuối khác để đi đến thư mục chính (nơi tia lửa được thực thi trong thiết bị đầu cuối khác). Sử dụng các lệnh sau để kiểm tra thư mục đầu ra.
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1
part-00000
part-00001
_SUCCESSLệnh sau được sử dụng để xem kết quả từ Part-00000 các tập tin.
[hadoop@localhost output]$ cat part-00000Đầu ra
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Lệnh sau được sử dụng để xem kết quả từ Part-00001 các tập tin.
[hadoop@localhost output]$ cat part-00001Đầu ra
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)UN Persist the Storage
Trước khi UN-dai dẳng, nếu bạn muốn xem dung lượng lưu trữ được sử dụng cho ứng dụng này, hãy sử dụng URL sau trong trình duyệt của bạn.
http://localhost:4040Bạn sẽ thấy màn hình sau, hiển thị không gian lưu trữ được sử dụng cho ứng dụng đang chạy trên Spark shell.

Nếu bạn muốn duy trì không gian lưu trữ của RDD cụ thể, hãy sử dụng lệnh sau.
Scala> counts.unpersist()Bạn sẽ thấy kết quả như sau:
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list
15/06/27 00:57:33 INFO BlockManager: Removing RDD 9
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810)
15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0
15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106)
res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14Để xác minh không gian lưu trữ trong trình duyệt, hãy sử dụng URL sau.
http://localhost:4040/Bạn sẽ thấy màn hình sau. Nó hiển thị không gian lưu trữ được sử dụng cho ứng dụng đang chạy trên Spark shell.
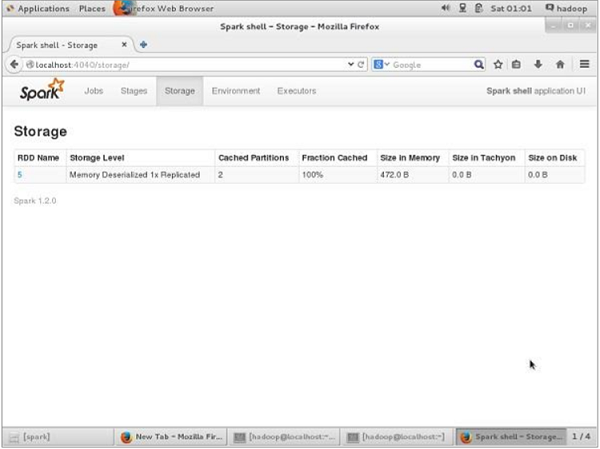
Ứng dụng Spark, sử dụng spark-submit, là một lệnh shell được sử dụng để triển khai ứng dụng Spark trên một cụm. Nó sử dụng tất cả các trình quản lý cụm tương ứng thông qua một giao diện thống nhất. Do đó, bạn không phải định cấu hình ứng dụng của mình cho từng ứng dụng.
Thí dụ
Chúng ta hãy lấy ví dụ tương tự về số từ, chúng ta đã sử dụng trước đây, bằng cách sử dụng các lệnh shell. Ở đây, chúng tôi coi ví dụ tương tự như một ứng dụng tia lửa.
Đầu vào mẫu
Văn bản sau là dữ liệu đầu vào và tệp có tên là in.txt.
people are not as beautiful as they look,
as they walk or as they talk.
they are only as beautiful as they love,
as they care as they share.Xem chương trình sau -
SparkWordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object SparkWordCount {
def main(args: Array[String]) {
val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map())
/* local = master URL; Word Count = application name; */
/* /usr/local/spark = Spark Home; Nil = jars; Map = environment */
/* Map = variables to work nodes */
/*creating an inputRDD to read text file (in.txt) through Spark context*/
val input = sc.textFile("in.txt")
/* Transform the inputRDD into countRDD */
val count = input.flatMap(line ⇒ line.split(" "))
.map(word ⇒ (word, 1))
.reduceByKey(_ + _)
/* saveAsTextFile method is an action that effects on the RDD */
count.saveAsTextFile("outfile")
System.out.println("OK");
}
}Lưu chương trình trên vào một tệp có tên SparkWordCount.scala và đặt nó trong một thư mục do người dùng xác định có tên spark-application.
Note - Trong khi chuyển inputRDD thành countRDD, chúng tôi đang sử dụng flatMap () để mã hóa các dòng (từ tệp văn bản) thành các từ, phương thức map () để đếm tần suất từ và phương thức ReduceByKey () để đếm từng từ lặp lại.
Sử dụng các bước sau để gửi đơn đăng ký này. Thực hiện tất cả các bước trongspark-application thư mục thông qua thiết bị đầu cuối.
Bước 1: Tải xuống Spark Ja
Spark core jar là bắt buộc để biên dịch, do đó, hãy tải xuống spark-core_2.10-1.3.0.jar từ liên kết sau Spark core jar và di chuyển tệp jar từ thư mục tải xuống sangspark-application danh mục.
Bước 2: Biên dịch chương trình
Biên dịch chương trình trên bằng lệnh dưới đây. Lệnh này sẽ được thực thi từ thư mục ứng dụng tia lửa. Đây,/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar là một jar hỗ trợ Hadoop được lấy từ thư viện Spark.
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scalaBước 3: Tạo JAR
Tạo một tệp jar của ứng dụng tia lửa bằng lệnh sau. Đây,wordcount là tên tệp cho tệp jar.
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jarBước 4: Gửi ứng dụng spark
Gửi ứng dụng tia lửa bằng lệnh sau:
spark-submit --class SparkWordCount --master local wordcount.jarNếu nó được thực thi thành công, thì bạn sẽ tìm thấy kết quả được đưa ra bên dưới. CácOKcho phép đầu ra sau là để nhận dạng người dùng và đó là dòng cuối cùng của chương trình. Nếu bạn đọc kỹ kết quả sau, bạn sẽ thấy những điều khác nhau, chẳng hạn như -
- đã bắt đầu thành công dịch vụ 'sparkDriver' trên cổng 42954
- MemoryStore bắt đầu với dung lượng 267,3 MB
- Bắt đầu SparkUI tại http://192.168.1.217:4040
- Đã thêm tệp JAR: /home/hadoop/piapplication/count.jar
- Kết quả Giai đoạn 1 (saveAsTextFile tại SparkPi.scala: 11) hoàn thành trong 0,566 giây
- Đã dừng giao diện người dùng web Spark tại http://192.168.1.217:4040
- MemoryStore đã bị xóa
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started
15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954.
15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:42954]
15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB
15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server
15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707.
15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040
15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029
15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader
15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54
15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver
(MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable
15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11)
15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s
15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s
OK
15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook
15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040
15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler
15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion.
15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared
15/07/08 13:56:14 INFO BlockManager: BlockManager stopped
15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped
15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext
15/07/08 13:56:14 INFO Utils: Shutdown hook called
15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af
15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!Bước 5: Kiểm tra đầu ra
Sau khi thực hiện thành công chương trình, bạn sẽ tìm thấy thư mục có tên outfile trong thư mục ứng dụng spark.
Các lệnh sau được sử dụng để mở và kiểm tra danh sách các tệp trong thư mục outfile.
$ cd outfile $ ls
Part-00000 part-00001 _SUCCESSCác lệnh để kiểm tra đầu ra trong part-00000 tập tin là -
$ cat part-00000
(people,1)
(are,2)
(not,1)
(as,8)
(beautiful,2)
(they, 7)
(look,1)Các lệnh để kiểm tra kết quả đầu ra trong tệp part-00001 là:
$ cat part-00001
(walk, 1)
(or, 1)
(talk, 1)
(only, 1)
(love, 1)
(care, 1)
(share, 1)Xem qua phần sau để biết thêm về lệnh 'spark-submit'.
Cú pháp gửi Spark
spark-submit [options] <app jar | python file> [app arguments]Tùy chọn
| S. không | Lựa chọn | Sự miêu tả |
|---|---|---|
| 1 | --bậc thầy | spark: // host: port, mesos: // host: port, fiber hoặc local. |
| 2 | - chế độ triển khai | Khởi chạy chương trình trình điều khiển cục bộ ("máy khách") hoặc trên một trong các máy công nhân bên trong cụm ("cụm") (Mặc định: máy khách). |
| 3 | --lớp học | Lớp chính của ứng dụng của bạn (dành cho ứng dụng Java / Scala). |
| 4 | --Tên | Tên ứng dụng của bạn. |
| 5 | --jars | Danh sách các lọ cục bộ được phân tách bằng dấu phẩy để đưa vào các đường dẫn trình điều khiển và trình thực thi. |
| 6 | - gói hàng | Danh sách tọa độ maven của các chum được phân tách bằng dấu phẩy để đưa vào đường dẫn classpath của trình điều khiển và trình thực thi. |
| 7 | - kho lưu trữ | Danh sách các kho lưu trữ từ xa bổ sung được phân tách bằng dấu phẩy để tìm kiếm tọa độ maven được cung cấp với --packages. |
| số 8 | --py-files | Danh sách các tệp .zip, .egg hoặc .py được phân tách bằng dấu phẩy để đặt trên PYTHON PATH cho ứng dụng Python. |
| 9 | --các tập tin | Danh sách tệp được phân tách bằng dấu phẩy sẽ được đặt trong thư mục làm việc của mỗi trình thực thi. |
| 10 | --conf (prop = val) | Thuộc tính cấu hình Spark tùy ý. |
| 11 | --properties-file | Đường dẫn đến tệp để tải các thuộc tính bổ sung. Nếu không được chỉ định, điều này sẽ tìm kiếm mặc định conf / spark. |
| 12 | --driver-memory | Bộ nhớ cho trình điều khiển (ví dụ: 1000M, 2G) (Mặc định: 512M). |
| 13 | --driver-java-options | Các tùy chọn Java bổ sung để chuyển cho trình điều khiển. |
| 14 | --driver-library-path | Các mục nhập đường dẫn thư viện bổ sung để chuyển cho trình điều khiển. |
| 15 | --driver-class-path | Các mục nhập đường dẫn lớp bổ sung để chuyển cho người lái xe. Lưu ý rằng các bình được thêm vào với --jars sẽ tự động được đưa vào classpath. |
| 16 | --executor-memory | Bộ nhớ cho mỗi trình thực thi (ví dụ: 1000M, 2G) (Mặc định: 1G). |
| 17 | - người dùng proxy | Người dùng mạo danh khi nộp hồ sơ. |
| 18 | - trợ giúp, -h | Hiển thị thông báo trợ giúp này và thoát. |
| 19 | --verbose, -v | In đầu ra gỡ lỗi bổ sung. |
| 20 | --phiên bản | In phiên bản của Spark hiện tại. |
| 21 | --driver-core NUM | Lõi cho trình điều khiển (Mặc định: 1). |
| 22 | --supervise | Nếu được đưa ra, hãy khởi động lại trình điều khiển khi bị lỗi. |
| 23 | --giết chết | Nếu được đưa ra, giết người lái xe được chỉ định. |
| 24 | --trạng thái | Nếu được đưa ra, hãy yêu cầu trạng thái của trình điều khiển được chỉ định. |
| 25 | --total-executive-core | Tổng số lõi cho tất cả người thực thi. |
| 26 | --executor-core | Số lõi trên mỗi trình thực thi. (Mặc định: 1 ở chế độ YARN hoặc tất cả các lõi có sẵn trên worker ở chế độ độc lập). |
Spark chứa hai loại biến chia sẻ khác nhau - một là broadcast variables và thứ hai là accumulators.
Broadcast variables - được sử dụng để phân phối hiệu quả, giá trị lớn.
Accumulators - được sử dụng để tổng hợp thông tin của bộ sưu tập cụ thể.
Các biến truyền phát
Các biến quảng bá cho phép lập trình viên giữ một biến chỉ đọc được lưu vào bộ nhớ đệm trên mỗi máy thay vì gửi một bản sao của nó cùng với các tác vụ. Ví dụ, chúng có thể được sử dụng để cung cấp cho mọi nút, một bản sao của tập dữ liệu đầu vào lớn, một cách hiệu quả. Spark cũng cố gắng phân phối các biến quảng bá bằng cách sử dụng các thuật toán quảng bá hiệu quả để giảm chi phí truyền thông.
Các hành động Spark được thực hiện thông qua một tập hợp các giai đoạn, được phân tách bằng các hoạt động “xáo trộn” phân tán. Spark tự động truyền phát dữ liệu chung cần thiết cho các tác vụ trong từng giai đoạn.
Dữ liệu được truyền theo cách này được lưu trong bộ nhớ cache ở dạng tuần tự hóa và được giải mã hóa trước khi chạy mỗi tác vụ. Điều này có nghĩa là việc tạo biến quảng bá một cách rõ ràng, chỉ hữu ích khi các tác vụ qua nhiều giai đoạn cần cùng một dữ liệu hoặc khi bộ nhớ đệm dữ liệu ở dạng deserialized là quan trọng.
Các biến quảng bá được tạo từ một biến v bằng cách gọi SparkContext.broadcast(v). Biến quảng bá là một trình bao bọc xung quanhvvà giá trị của nó có thể được truy cập bằng cách gọi valuephương pháp. Đoạn mã dưới đây cho thấy điều này -
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))Output -
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)Sau khi biến quảng bá được tạo, nó sẽ được sử dụng thay vì giá trị v trong bất kỳ chức năng nào chạy trên cụm, để vkhông được chuyển đến các nút nhiều hơn một lần. Ngoài ra, đối tượngv không được sửa đổi sau khi phát sóng của nó, để đảm bảo rằng tất cả các nút đều nhận được cùng một giá trị của biến quảng bá.
Bộ tích lũy
Bộ tích lũy là các biến chỉ được “thêm vào” thông qua một hoạt động kết hợp và do đó, có thể được hỗ trợ song song một cách hiệu quả. Chúng có thể được sử dụng để triển khai bộ đếm (như trong MapReduce) hoặc tính tổng. Spark nguyên bản hỗ trợ tích lũy kiểu số và lập trình viên có thể thêm hỗ trợ cho các kiểu mới. Nếu bộ tích lũy được tạo bằng tên, chúng sẽ được hiển thị trongSpark’s UI. Điều này có thể hữu ích để hiểu tiến trình của các giai đoạn đang chạy (LƯU Ý - điều này chưa được hỗ trợ trong Python).
Bộ tích lũy được tạo từ giá trị ban đầu v bằng cách gọi SparkContext.accumulator(v). Các tác vụ đang chạy trên cụm sau đó có thể thêm vào nó bằng cách sử dụngaddhoặc toán tử + = (trong Scala và Python). Tuy nhiên, họ không thể đọc được giá trị của nó. Chỉ chương trình trình điều khiển mới có thể đọc giá trị của bộ tích lũy, sử dụngvalue phương pháp.
Đoạn mã dưới đây cho thấy một bộ tích lũy đang được sử dụng để cộng các phần tử của một mảng -
scala> val accum = sc.accumulator(0)
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)Nếu bạn muốn xem đầu ra của đoạn mã trên, hãy sử dụng lệnh sau:
scala> accum.valueĐầu ra
res2: Int = 10Hoạt động RDD dạng số
Spark cho phép bạn thực hiện các thao tác khác nhau trên dữ liệu số, sử dụng một trong các phương thức API được xác định trước. Các hoạt động số của Spark được thực hiện với một thuật toán phát trực tuyến cho phép xây dựng mô hình, từng phần tử một.
Các hoạt động này được tính toán và trả về dưới dạng StatusCounter phản đối bằng cách gọi status() phương pháp.
| S. không | Phương pháp & Ý nghĩa |
|---|---|
| 1 | count() Số phần tử trong RDD. |
| 2 | Mean() Trung bình của các phần tử trong RDD. |
| 3 | Sum() Tổng giá trị của các phần tử trong RDD. |
| 4 | Max() Giá trị lớn nhất trong số tất cả các phần tử trong RDD. |
| 5 | Min() Giá trị nhỏ nhất trong số tất cả các phần tử trong RDD. |
| 6 | Variance() Phương sai của các phần tử. |
| 7 | Stdev() Độ lệch chuẩn. |
Nếu bạn chỉ muốn sử dụng một trong các phương thức này, bạn có thể gọi phương thức tương ứng trực tiếp trên RDD.