ArangoDB - Hướng dẫn nhanh
ArangoDB được các nhà phát triển ca ngợi là một cơ sở dữ liệu đa mô hình gốc. Điều này không giống như các cơ sở dữ liệu NoSQL khác. Trong cơ sở dữ liệu này, dữ liệu có thể được lưu trữ dưới dạng tài liệu, cặp khóa / giá trị hoặc đồ thị. Và với một ngôn ngữ truy vấn khai báo duy nhất, bất kỳ hoặc tất cả dữ liệu của bạn đều có thể được truy cập. Hơn nữa, các mô hình khác nhau có thể được kết hợp trong một truy vấn duy nhất. Và, nhờ phong cách đa mô hình, người ta có thể tạo ra các ứng dụng tinh gọn, có thể mở rộng theo chiều ngang với bất kỳ hoặc tất cả ba mô hình dữ liệu.
Phân lớp so với Cơ sở dữ liệu đa mô hình gốc
Trong phần này, chúng tôi sẽ làm nổi bật sự khác biệt quan trọng giữa cơ sở dữ liệu đa mẫu gốc và nhiều lớp.
Nhiều nhà cung cấp cơ sở dữ liệu gọi sản phẩm của họ là “đa mô hình”, nhưng việc thêm một lớp biểu đồ vào kho khóa / giá trị hoặc tài liệu không đủ điều kiện là đa mô hình gốc.
Với ArangoDB, cùng một lõi với cùng một ngôn ngữ truy vấn, người ta có thể kết hợp các mô hình và tính năng dữ liệu khác nhau lại với nhau trong một truy vấn duy nhất, như chúng tôi đã trình bày trong phần trước. Trong ArangoDB, không có "chuyển đổi" giữa các mô hình dữ liệu và không có sự chuyển dữ liệu từ A sang B để thực hiện các truy vấn. Nó dẫn đến lợi thế về hiệu suất cho ArangoDB so với các phương pháp tiếp cận “phân lớp”.
Nhu cầu về cơ sở dữ liệu đa phương thức
Việc diễn giải ý tưởng cơ bản của [Fowler] giúp chúng tôi nhận ra lợi ích của việc sử dụng nhiều mô hình dữ liệu thích hợp cho các phần khác nhau của lớp bền vững, lớp là một phần của kiến trúc phần mềm lớn hơn.
Theo điều này, ví dụ, người ta có thể sử dụng cơ sở dữ liệu quan hệ để duy trì dữ liệu dạng bảng, có cấu trúc; một kho lưu trữ tài liệu cho dữ liệu dạng đối tượng, phi cấu trúc; một kho khóa / giá trị cho một bảng băm; và cơ sở dữ liệu đồ thị cho dữ liệu tham chiếu được liên kết cao.
Tuy nhiên, cách thực hiện truyền thống của phương pháp này sẽ dẫn đến việc sử dụng nhiều cơ sở dữ liệu trong cùng một dự án. Nó có thể dẫn đến một số khó khăn trong hoạt động (triển khai phức tạp hơn, nâng cấp thường xuyên hơn) cũng như các vấn đề về tính nhất quán và trùng lặp dữ liệu.
Thách thức tiếp theo sau khi thống nhất dữ liệu cho ba mô hình dữ liệu, là thiết lập và triển khai một ngôn ngữ truy vấn chung có thể cho phép quản trị viên dữ liệu thể hiện nhiều loại truy vấn, chẳng hạn như truy vấn tài liệu, tra cứu khóa / giá trị, truy vấn graphy và các kết hợp tùy ý trong số này.
Bởi graphy queries, chúng tôi có nghĩa là các truy vấn liên quan đến việc xem xét lý thuyết đồ thị. Đặc biệt, những điều này có thể liên quan đến các tính năng kết nối cụ thể đến từ các cạnh. Ví dụ,ShortestPath, GraphTraversalvà Neighbors.
Đồ thị hoàn toàn phù hợp làm mô hình dữ liệu cho các mối quan hệ. Trong nhiều trường hợp trong thế giới thực như mạng xã hội, hệ thống giới thiệu, v.v., mô hình dữ liệu rất tự nhiên là biểu đồ. Nó nắm bắt các quan hệ và có thể giữ thông tin nhãn với mỗi cạnh và với mỗi đỉnh. Hơn nữa, các tài liệu JSON là sự phù hợp tự nhiên để lưu trữ loại dữ liệu đỉnh và cạnh này.
ArangoDB ─ Tính năng
Có nhiều tính năng đáng chú ý khác nhau của ArangoDB. Chúng tôi sẽ nêu ra những đặc điểm nổi bật dưới đây -
- Mô hình đa mô hình
- Thuộc tính ACID
- API HTTP
ArangoDB hỗ trợ tất cả các mô hình cơ sở dữ liệu phổ biến. Sau đây là một số mô hình được hỗ trợ bởi ArangoDB -
- Mô hình tài liệu
- Mô hình khóa / giá trị
- Mô hình đồ thị
Một ngôn ngữ truy vấn duy nhất là đủ để lấy dữ liệu ra khỏi cơ sở dữ liệu
Bốn thuộc tính Atomicity, Consistency, Isolationvà Durability(ACID) mô tả các đảm bảo của các giao dịch cơ sở dữ liệu. ArangoDB hỗ trợ các giao dịch tuân thủ ACID.
ArangoDB cho phép các ứng dụng khách, chẳng hạn như trình duyệt, tương tác với cơ sở dữ liệu bằng API HTTP, API được định hướng tài nguyên và có thể mở rộng bằng JavaScript.
Sau đây là những ưu điểm của việc sử dụng ArangoDB:
Hợp nhất
Là một cơ sở dữ liệu đa mô hình gốc, ArangoDB loại bỏ sự cần thiết phải triển khai nhiều cơ sở dữ liệu và do đó giảm số lượng các thành phần và việc bảo trì chúng. Do đó, nó làm giảm độ phức tạp của công nghệ cho ứng dụng. Ngoài việc hợp nhất các nhu cầu kỹ thuật tổng thể của bạn, việc đơn giản hóa này dẫn đến tổng chi phí sở hữu thấp hơn và tăng tính linh hoạt.
Tỷ lệ hiệu suất được đơn giản hóa
Với các ứng dụng phát triển theo thời gian, ArangoDB có thể giải quyết nhu cầu lưu trữ và hiệu suất ngày càng tăng, bằng cách mở rộng quy mô độc lập với các mô hình dữ liệu khác nhau. Vì ArangoDB có thể mở rộng quy mô theo cả chiều dọc và chiều ngang, vì vậy trong trường hợp hiệu suất của bạn yêu cầu giảm (chậm lại có chủ ý, mong muốn), hệ thống back-end của bạn có thể dễ dàng thu nhỏ để tiết kiệm phần cứng cũng như chi phí vận hành.
Giảm độ phức tạp trong hoạt động
Sắc lệnh của Polyglot Persistence là sử dụng những công cụ tốt nhất cho mọi công việc bạn đảm nhận. Một số tác vụ cần cơ sở dữ liệu tài liệu, trong khi những tác vụ khác có thể cần cơ sở dữ liệu đồ thị. Do kết quả của việc làm việc với cơ sở dữ liệu mô hình đơn, nó có thể dẫn đến nhiều thách thức hoạt động. Việc tích hợp cơ sở dữ liệu mô hình đơn là một công việc khó khăn. Nhưng thách thức lớn nhất là xây dựng một cấu trúc gắn kết lớn với tính nhất quán dữ liệu và khả năng chịu lỗi giữa các hệ thống cơ sở dữ liệu riêng biệt, không liên quan. Nó có thể chứng minh gần như không thể.
Polyglot Persistence có thể được xử lý với cơ sở dữ liệu đa mô hình gốc, vì nó cho phép dễ dàng có dữ liệu đa ô, nhưng đồng thời với tính nhất quán dữ liệu trên hệ thống chịu lỗi. Với ArangoDB, chúng ta có thể sử dụng mô hình dữ liệu chính xác cho công việc phức tạp.
Tính nhất quán dữ liệu mạnh mẽ
Nếu một người sử dụng nhiều cơ sở dữ liệu mô hình đơn, tính nhất quán của dữ liệu có thể trở thành một vấn đề. Các cơ sở dữ liệu này không được thiết kế để giao tiếp với nhau, do đó, một số dạng chức năng giao dịch cần được triển khai để giữ cho dữ liệu của bạn nhất quán giữa các mô hình khác nhau.
Hỗ trợ các giao dịch ACID, ArangoDB quản lý các mô hình dữ liệu khác nhau của bạn bằng một back-end duy nhất, cung cấp tính nhất quán mạnh mẽ trên một phiên bản duy nhất và các hoạt động nguyên tử khi hoạt động ở chế độ cụm.
Khả năng chịu lỗi
Đó là một thách thức để xây dựng các hệ thống chịu lỗi với nhiều thành phần không liên quan. Thử thách này trở nên phức tạp hơn khi làm việc với các cụm. Cần phải có chuyên môn để triển khai và bảo trì các hệ thống như vậy, sử dụng các công nghệ và / hoặc công nghệ khác nhau. Hơn nữa, việc tích hợp nhiều hệ thống con, được thiết kế để chạy độc lập, gây ra chi phí kỹ thuật và vận hành lớn.
Là một ngăn xếp công nghệ hợp nhất, cơ sở dữ liệu đa mô hình trình bày một giải pháp thanh lịch. Được thiết kế để cho phép các kiến trúc mô-đun, hiện đại với các mô hình dữ liệu khác nhau, ArangoDB cũng hoạt động cho việc sử dụng cụm.
Tổng chi phí sở hữu thấp hơn
Mỗi công nghệ cơ sở dữ liệu yêu cầu bảo trì liên tục, các bản vá sửa lỗi và các thay đổi mã khác do nhà cung cấp cung cấp. Việc sử dụng cơ sở dữ liệu đa mô hình làm giảm đáng kể chi phí bảo trì liên quan chỉ đơn giản bằng cách loại bỏ số lượng công nghệ cơ sở dữ liệu trong việc thiết kế một ứng dụng.
Giao dịch
Cung cấp đảm bảo giao dịch trên nhiều máy là một thách thức thực sự và rất ít cơ sở dữ liệu NoSQL đưa ra những đảm bảo này. Là đa mô hình gốc, ArangoDB áp đặt các giao dịch để đảm bảo tính nhất quán của dữ liệu.
Trong chương này, chúng ta sẽ thảo luận về các khái niệm và thuật ngữ cơ bản cho ArangoDB. Điều rất quan trọng là phải có kiến thức về các thuật ngữ cơ bản cơ bản liên quan đến chủ đề kỹ thuật mà chúng ta đang giải quyết.
Các thuật ngữ cho ArangoDB được liệt kê dưới đây:
- Document
- Collection
- Mã định danh bộ sưu tập
- Tên bộ sưu tập
- Database
- Tên cơ sở dữ liệu
- Tổ chức cơ sở dữ liệu
Từ quan điểm của mô hình dữ liệu, ArangoDB có thể được coi là một cơ sở dữ liệu hướng tài liệu, vì khái niệm tài liệu là ý tưởng toán học sau này. Cơ sở dữ liệu hướng tài liệu là một trong những danh mục chính của cơ sở dữ liệu NoSQL.
Cấu trúc phân cấp diễn ra như thế này: Tài liệu được nhóm thành các bộ sưu tập và Bộ sưu tập tồn tại bên trong cơ sở dữ liệu
Rõ ràng là Mã định danh và Tên là hai thuộc tính cho bộ sưu tập và cơ sở dữ liệu.
Thông thường, hai tài liệu (đỉnh) được lưu trữ trong bộ sưu tập tài liệu được liên kết bởi một tài liệu (cạnh) được lưu trữ trong bộ sưu tập cạnh. Đây là mô hình dữ liệu đồ thị của ArangoDB. Nó tuân theo khái niệm toán học về một đồ thị có nhãn, có hướng, ngoại trừ các cạnh không chỉ có nhãn mà còn là các tài liệu đầy đủ.
Sau khi làm quen với các thuật ngữ cốt lõi cho cơ sở dữ liệu này, chúng ta bắt đầu hiểu mô hình dữ liệu đồ thị của ArangoDB. Trong mô hình này, tồn tại hai loại tập hợp: tập hợp tài liệu và tập hợp cạnh. Bộ sưu tập Edge lưu trữ tài liệu và cũng bao gồm hai thuộc tính đặc biệt: đầu tiên là_from và thuộc tính thứ hai là _tothuộc tính. Các thuộc tính này được sử dụng để tạo các cạnh (quan hệ) giữa các tài liệu cần thiết cho cơ sở dữ liệu đồ thị. Tập hợp tài liệu còn được gọi là tập hợp đỉnh trong ngữ cảnh của đồ thị (xem bất kỳ cuốn sách lý thuyết đồ thị nào).
Bây giờ chúng ta hãy xem cơ sở dữ liệu quan trọng như thế nào. Chúng quan trọng vì các bộ sưu tập tồn tại bên trong cơ sở dữ liệu. Trong một phiên bản của ArangoDB, có thể có một hoặc nhiều cơ sở dữ liệu. Các cơ sở dữ liệu khác nhau thường được sử dụng cho các thiết lập nhiều người thuê, vì các bộ dữ liệu khác nhau bên trong chúng (bộ sưu tập, tài liệu, v.v.) được tách biệt với nhau. Cơ sở dữ liệu mặc định_systemlà đặc biệt, bởi vì nó không thể được gỡ bỏ. Người dùng được quản lý trong cơ sở dữ liệu này và thông tin đăng nhập của họ hợp lệ cho tất cả các cơ sở dữ liệu của một phiên bản máy chủ.
Trong chương này, chúng ta sẽ thảo luận về các yêu cầu hệ thống đối với ArangoDB.
Các yêu cầu hệ thống cho ArangoDB như sau:
- Máy chủ VPS có cài đặt Ubuntu
- RAM: 1 GB; CPU: 2,2 GHz
Đối với tất cả các lệnh trong hướng dẫn này, chúng tôi đã sử dụng phiên bản Ubuntu 16.04 (xenial) RAM 1GB với một cpu có sức mạnh xử lý 2,2 GHz. Và tất cả các lệnh arangosh trong hướng dẫn này đã được thử nghiệm cho ArangoDB phiên bản 3.1.27.
Làm thế nào để cài đặt ArangoDB?
Trong phần này, chúng ta sẽ xem cách cài đặt ArangoDB. ArangoDB được tạo sẵn cho nhiều hệ điều hành và bản phân phối. Để biết thêm chi tiết, vui lòng tham khảo tài liệu ArangoDB. Như đã đề cập, đối với hướng dẫn này, chúng tôi sẽ sử dụng Ubuntu 16.04x64.
Bước đầu tiên là tải xuống khóa công khai cho các kho lưu trữ của nó -
# wget https://www.arangodb.com/repositories/arangodb31/
xUbuntu_16.04/Release.keyĐầu ra
--2017-09-03 12:13:24-- https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/Release.key
Resolving https://www.arangodb.com/
(www.arangodb.com)... 104.25.1 64.21, 104.25.165.21,
2400:cb00:2048:1::6819:a415, ...
Connecting to https://www.arangodb.com/
(www.arangodb.com)|104.25. 164.21|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 3924 (3.8K) [application/pgpkeys]
Saving to: ‘Release.key’
Release.key 100%[===================>] 3.83K - .-KB/s in 0.001s
2017-09-03 12:13:25 (2.61 MB/s) - ‘Release.key’ saved [39 24/3924]Điểm quan trọng là bạn nên xem Release.key được lưu ở cuối đầu ra.
Hãy để chúng tôi cài đặt khóa đã lưu bằng dòng mã sau:
# sudo apt-key add Release.keyĐầu ra
OKChạy các lệnh sau để thêm kho lưu trữ apt và cập nhật chỉ mục -
# sudo apt-add-repository 'deb
https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04/ /'
# sudo apt-get updateBước cuối cùng, chúng ta có thể cài đặt ArangoDB -
# sudo apt-get install arangodb3Đầu ra
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following package was automatically installed and is no longer required:
grub-pc-bin
Use 'sudo apt autoremove' to remove it.
The following NEW packages will be installed:
arangodb3
0 upgraded, 1 newly installed, 0 to remove and 17 not upgraded.
Need to get 55.6 MB of archives.
After this operation, 343 MB of additional disk space will be used.nhấn Enter. Bây giờ quá trình cài đặt ArangoDB sẽ bắt đầu -
Get:1 https://www.arangodb.com/repositories/arangodb31/xUbuntu_16.04
arangodb3 3.1.27 [55.6 MB]
Fetched 55.6 MB in 59s (942 kB/s)
Preconfiguring packages ...
Selecting previously unselected package arangodb3.
(Reading database ... 54209 files and directories currently installed.)
Preparing to unpack .../arangodb3_3.1.27_amd64.deb ...
Unpacking arangodb3 (3.1.27) ...
Processing triggers for systemd (229-4ubuntu19) ...
Processing triggers for ureadahead (0.100.0-19) ...
Processing triggers for man-db (2.7.5-1) ...
Setting up arangodb3 (3.1.27) ...
Database files are up-to-date.Khi quá trình cài đặt ArangoDB sắp hoàn tất, màn hình sau sẽ xuất hiện:
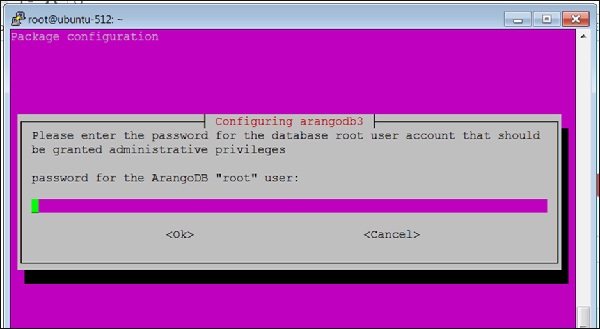
Tại đây, bạn sẽ được yêu cầu cung cấp mật khẩu cho ArangoDB rootngười dùng. Ghi chú lại cẩn thận.
Chọn yes khi hộp thoại sau xuất hiện:
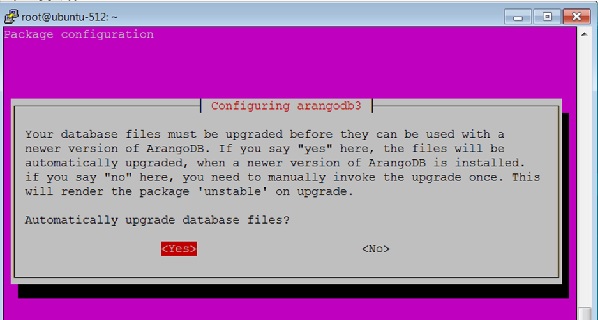
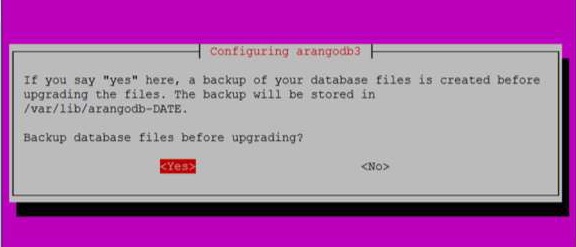
Khi bạn nhấp vào Yesnhư trong hộp thoại trên, hộp thoại sau sẽ xuất hiện. Nhấp chuộtYes đây.
Bạn cũng có thể kiểm tra trạng thái của ArangoDB bằng lệnh sau:
# sudo systemctl status arangodb3Đầu ra
arangodb3.service - LSB: arangodb
Loaded: loaded (/etc/init.d/arangodb3; bad; vendor pre set: enabled)
Active: active (running) since Mon 2017-09-04 05:42:35 UTC;
4min 46s ago
Docs: man:systemd-sysv-generator(8)
Process: 2642 ExecStart=/etc/init.d/arangodb3 start (code = exited,
status = 0/SUC
Tasks: 22
Memory: 158.6M
CPU: 3.117s
CGroup: /system.slice/arangodb3.service
├─2689 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
└─2690 /usr/sbin/arangod --uid arangodb
--gid arangodb --pid-file /va
Sep 04 05:42:33 ubuntu-512 systemd[1]: Starting LSB: arangodb...
Sep 04 05:42:33 ubuntu-512 arangodb3[2642]: * Starting arango database server a
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: {startup} starting up in daemon mode
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: changed working directory for child
Sep 04 05:42:35 ubuntu-512 arangodb3[2642]: ...done.
Sep 04 05:42:35 ubuntu-512 systemd[1]: StartedLSB: arang odb.
Sep 04 05:46:59 ubuntu-512 systemd[1]: Started LSB: arangodb. lines 1-19/19 (END)ArangoDB hiện đã sẵn sàng để sử dụng.
Để gọi thiết bị đầu cuối arangosh, hãy nhập lệnh sau vào thiết bị đầu cuối:
# arangoshĐầu ra
Please specify a password:Cung cấp root mật khẩu được tạo tại thời điểm cài đặt -
_
__ _ _ __ __ _ _ __ __ _ ___ | |
/ | '__/ _ | ’ \ / ` |/ _ / | ’
| (| | | | (| | | | | (| | () _ \ | | |
_,|| _,|| ||_, |_/|/| ||
|__/arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27 [server],
database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system> exit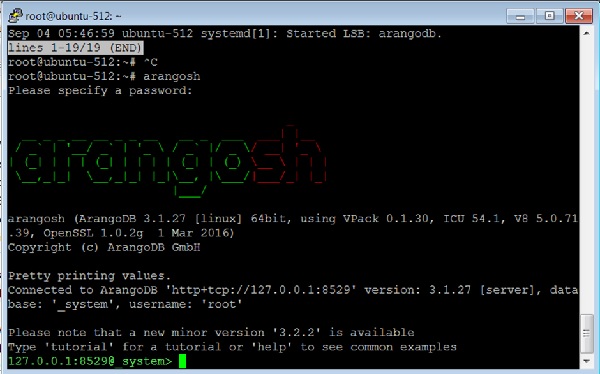
Để đăng xuất khỏi ArangoDB, hãy nhập lệnh sau:
127.0.0.1:8529@_system> exitĐầu ra
Uf wiederluege! Na shledanou! Auf Wiedersehen! Bye Bye! Adiau! ¡Hasta luego!
Εις το επανιδείν!
להתראות ! Arrivederci! Tot ziens! Adjö! Au revoir! さようなら До свидания! Até
Breve! !خداحافظTrong chương này, chúng ta sẽ thảo luận về cách Arangosh hoạt động như Dòng lệnh cho ArangoDB. Chúng ta sẽ bắt đầu bằng cách học cách thêm người dùng Cơ sở dữ liệu.
Note - Ghi nhớ bàn phím số có thể không hoạt động trên Arangosh.
Giả sử rằng người dùng là "harry" và mật khẩu là "hpwdb".
127.0.0.1:8529@_system> require("org/arangodb/users").save("harry", "hpwdb");Đầu ra
{
"user" : "harry",
"active" : true,
"extra" : {},
"changePassword" : false,
"code" : 201
}Trong chương này, chúng ta sẽ tìm hiểu cách bật / tắt Xác thực và cách liên kết ArangoDB với Giao diện Mạng Công cộng.
# arangosh --server.endpoint tcp://127.0.0.1:8529 --server.database "_system"Nó sẽ nhắc bạn về mật khẩu đã lưu trước đó -
Please specify a password:Sử dụng mật khẩu bạn đã tạo cho root, tại cấu hình.
Bạn cũng có thể sử dụng curl để kiểm tra xem bạn có thực sự nhận được phản hồi của máy chủ HTTP 401 (Không được phép) cho các yêu cầu yêu cầu xác thực hay không -
# curl --dump - http://127.0.0.1:8529/_api/versionĐầu ra
HTTP/1.1 401 Unauthorized
X-Content-Type-Options: nosniff
Www-Authenticate: Bearer token_type = "JWT", realm = "ArangoDB"
Server: ArangoDB
Connection: Keep-Alive
Content-Type: text/plain; charset = utf-8
Content-Length: 0Để tránh nhập mật khẩu mỗi lần trong quá trình học, chúng tôi sẽ tắt xác thực. Để làm điều đó, hãy mở tệp cấu hình -
# vim /etc/arangodb3/arangod.confBạn nên thay đổi bảng màu nếu mã không hiển thị đúng.
:colorscheme desertĐặt xác thực thành false như được hiển thị trong ảnh chụp màn hình bên dưới.
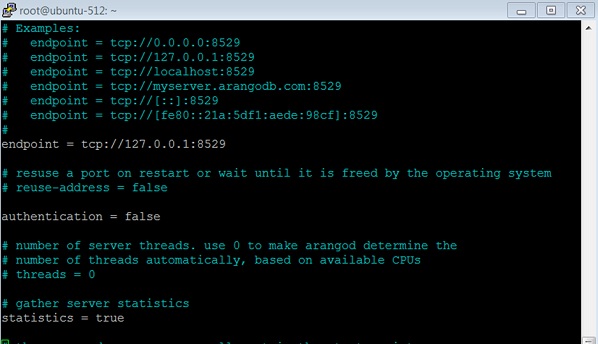
Khởi động lại dịch vụ -
# service arangodb3 restartKhi xác thực sai, bạn sẽ có thể đăng nhập (bằng root hoặc người dùng được tạo như Harry trong trường hợp này) mà không cần nhập bất kỳ mật khẩu nào vào please specify a password.
Hãy để chúng tôi kiểm tra api phiên bản khi tắt xác thực -
# curl --dump - http://127.0.0.1:8529/_api/versionĐầu ra
HTTP/1.1 200 OK
X-Content-Type-Options: nosniff
Server: ArangoDB
Connection: Keep-Alive
Content-Type: application/json; charset=utf-8
Content-Length: 60
{"server":"arango","version":"3.1.27","license":"community"}Trong chương này, chúng ta sẽ xem xét hai tình huống ví dụ. Những ví dụ này dễ hiểu hơn và sẽ giúp chúng ta hiểu cách hoạt động của chức năng ArangoDB.
Để chứng minh các API, ArangoDB được tải sẵn một tập hợp các biểu đồ dễ hiểu. Có hai phương pháp để tạo các bản sao của các biểu đồ này trong ArangoDB của bạn -
- Thêm tab Ví dụ trong cửa sổ tạo đồ thị trong giao diện web,
- hoặc tải mô-đun @arangodb/graph-examples/example-graph ở Arangosh.
Để bắt đầu, chúng ta hãy tải một biểu đồ với sự trợ giúp của giao diện web. Để làm điều đó, hãy khởi chạy giao diện web và nhấp vàographs chuyển hướng.
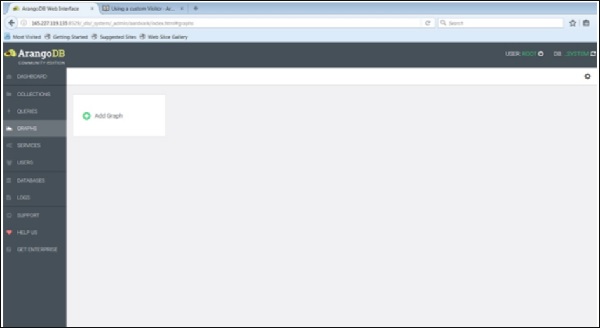
Các Create Graphhộp thoại xuất hiện. Wizard chứa hai tab -Examples và Graph. CácGraphtab được mở theo mặc định; giả sử chúng ta muốn tạo một đồ thị mới, nó sẽ hỏi tên và các định nghĩa khác cho đồ thị.
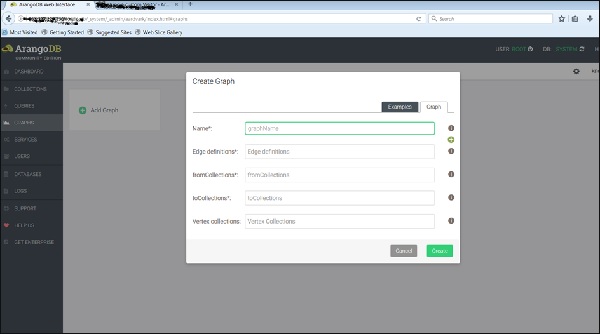
Bây giờ, chúng tôi sẽ tải lên biểu đồ đã được tạo. Đối với điều này, chúng tôi sẽ chọnExamples chuyển hướng.
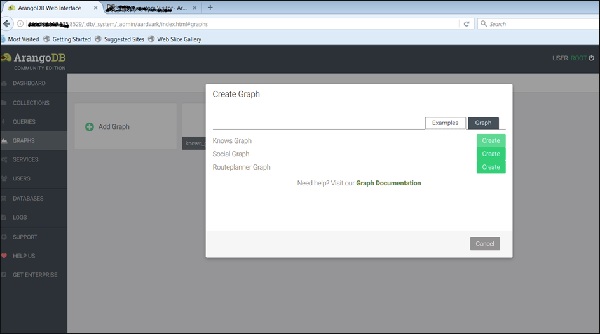
Chúng ta có thể xem ba biểu đồ ví dụ. ChọnKnows_Graph và nhấp vào nút màu xanh lá cây Tạo.
Khi bạn đã tạo chúng, bạn có thể kiểm tra chúng trong giao diện web - được sử dụng để tạo các bức ảnh bên dưới.
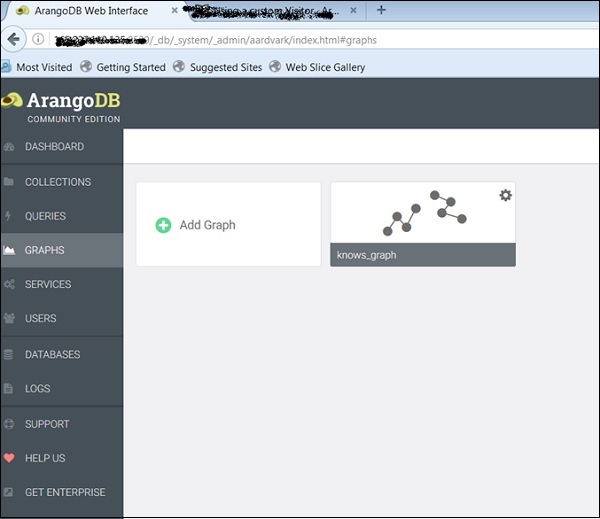
The Knows_Graph
Bây giờ chúng ta hãy xem làm thế nào Knows_Graphlàm. Chọn Knows_Graph và nó sẽ tìm nạp dữ liệu biểu đồ.
Knows_Graph bao gồm một tập hợp đỉnh persons được kết nối thông qua một bộ sưu tập cạnh knows. Nó sẽ chứa năm người Alice, Bob, Charlie, Dave và Eve dưới dạng các đỉnh. Chúng tôi sẽ có những quan hệ chỉ đạo sau
Alice knows Bob
Bob knows Charlie
Bob knows Dave
Eve knows Alice
Eve knows Bob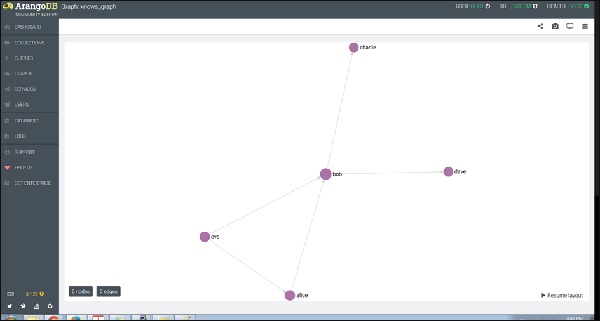
Nếu bạn nhấp vào một nút (đỉnh), nói 'bob', nó sẽ hiển thị tên thuộc tính ID (people / bob).
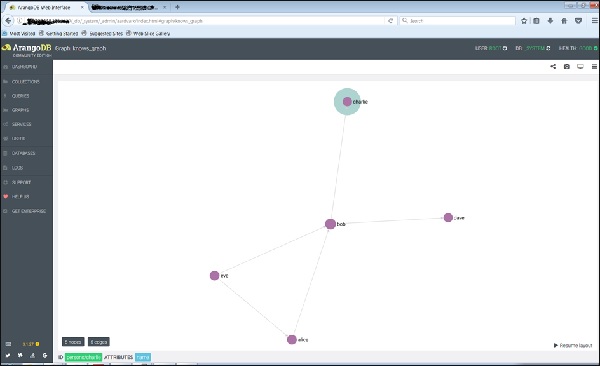
Và khi nhấp vào bất kỳ cạnh nào, nó sẽ hiển thị thuộc tính ID (know / 4590).
Đây là cách chúng tôi tạo ra nó, kiểm tra các đỉnh và các cạnh của nó.
Hãy để chúng tôi thêm một đồ thị khác, lần này là sử dụng Arangosh. Để làm được điều đó, chúng ta cần đưa một điểm cuối khác vào tệp cấu hình ArangoDB.
Cách thêm nhiều điểm cuối
Mở tệp cấu hình -
# vim /etc/arangodb3/arangod.confThêm một điểm cuối khác như được hiển thị trong ảnh chụp màn hình thiết bị đầu cuối bên dưới.
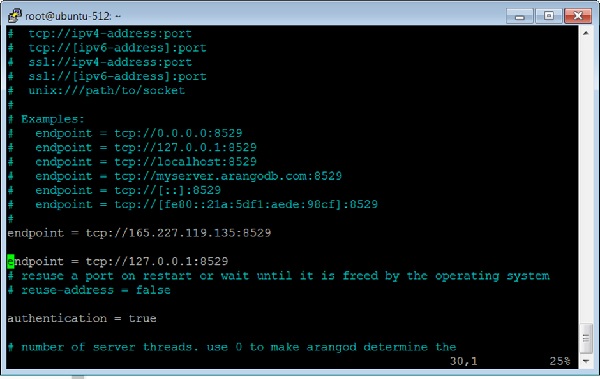
Khởi động lại ArangoDB -
# service arangodb3 restartKhởi chạy Arangosh -
# arangosh
Please specify a password:
_
__ _ _ __ __ _ _ __ __ _ ___ ___| |__
/ _` | '__/ _` | '_ \ / _` |/ _ \/ __| '_ \
| (_| | | | (_| | | | | (_| | (_) \__ \ | | |
\__,_|_| \__,_|_| |_|\__, |\___/|___/_| |_|
|___/
arangosh (ArangoDB 3.1.27 [linux] 64bit, using VPack 0.1.30, ICU 54.1, V8
5.0.71.39, OpenSSL 1.0.2g 1 Mar 2016)
Copyright (c) ArangoDB GmbH
Pretty printing values.
Connected to ArangoDB 'http+tcp://127.0.0.1:8529' version: 3.1.27
[server], database: '_system', username: 'root'
Please note that a new minor version '3.2.2' is available
Type 'tutorial' for a tutorial or 'help' to see common examples
127.0.0.1:8529@_system>Social_Graph
Bây giờ chúng ta hãy hiểu Social_Graph là gì và nó hoạt động như thế nào. Biểu đồ cho thấy một nhóm người và mối quan hệ của họ -
Ví dụ này có những người nữ và nam là các đỉnh trong hai tập hợp đỉnh - nữ và nam. Các cạnh là kết nối của chúng trong tập hợp cạnh quan hệ. Chúng tôi đã mô tả cách tạo biểu đồ này bằng Arangosh. Người đọc có thể làm việc xung quanh nó và khám phá các thuộc tính của nó, như chúng tôi đã làm với Knows_Graph.
Trong chương này, chúng ta sẽ tập trung vào các chủ đề sau:
- Tương tác cơ sở dữ liệu
- Mô hình dữ liệu
- Phục hồi dữ liệu
ArangoDB hỗ trợ mô hình dữ liệu dựa trên tài liệu cũng như mô hình dữ liệu dựa trên đồ thị. Đầu tiên chúng ta hãy mô tả mô hình dữ liệu dựa trên tài liệu.
Các tài liệu của ArangoDB gần giống với định dạng JSON. Không hoặc nhiều thuộc tính được chứa trong một tài liệu và một giá trị được đính kèm với mỗi thuộc tính. Giá trị thuộc kiểu nguyên tử, chẳng hạn như số, Boolean hoặc null, chuỗi ký tự hoặc của kiểu dữ liệu phức hợp, chẳng hạn như tài liệu / đối tượng được nhúng hoặc một mảng. Mảng hoặc đối tượng con có thể bao gồm các kiểu dữ liệu này, điều này ngụ ý rằng một tài liệu duy nhất có thể đại diện cho cấu trúc dữ liệu không tầm thường.
Hơn nữa trong hệ thống phân cấp, các tài liệu được sắp xếp thành các bộ sưu tập, có thể không chứa tài liệu nào (về lý thuyết) hoặc nhiều hơn một tài liệu. Người ta có thể so sánh tài liệu với hàng và bộ sưu tập với bảng (Ở đây bảng và hàng đề cập đến những tài liệu của hệ quản trị cơ sở dữ liệu quan hệ - RDBMS).
Tuy nhiên, trong RDBMS, xác định cột là điều kiện tiên quyết để lưu trữ các bản ghi vào một bảng, gọi các lược đồ định nghĩa này. Tuy nhiên, là một tính năng mới, ArangoDB không có lược đồ - không có lý do tiên nghiệm nào để chỉ định tài liệu sẽ có những thuộc tính nào.
Và không giống như RDBMS, mỗi tài liệu có thể được cấu trúc theo một cách hoàn toàn khác với một tài liệu khác. Các tài liệu này có thể được lưu cùng nhau trong một bộ sưu tập duy nhất. Trên thực tế, các đặc điểm chung có thể tồn tại giữa các tài liệu trong bộ sưu tập, tuy nhiên hệ thống cơ sở dữ liệu, tức là bản thân ArangoDB, không ràng buộc bạn với một cấu trúc dữ liệu cụ thể.
Bây giờ chúng ta sẽ cố gắng hiểu ArangoDB của [graph data model], yêu cầu hai loại tập hợp - thứ nhất là tập hợp tài liệu (được gọi là tập hợp đỉnh trong ngôn ngữ lý thuyết nhóm), loại thứ hai là tập hợp cạnh. Có một sự khác biệt tinh tế giữa hai loại này. Bộ sưu tập Edge cũng lưu trữ tài liệu, nhưng chúng có đặc điểm là bao gồm hai thuộc tính duy nhất,_from và _tođể tạo quan hệ giữa các tài liệu. Trong thực tế, một tài liệu (cạnh đọc) liên kết hai tài liệu (đọc đỉnh), cả hai đều được lưu trữ trong bộ sưu tập tương ứng của chúng. Kiến trúc này bắt nguồn từ khái niệm lý thuyết đồ thị của một đồ thị có nhãn, có hướng, loại trừ các cạnh không chỉ có nhãn mà còn có thể là một JSON hoàn chỉnh như tài liệu.
Để tính toán dữ liệu mới, xóa tài liệu hoặc để thao tác chúng, các truy vấn được sử dụng để chọn hoặc lọc tài liệu theo tiêu chí đã cho. Hoặc đơn giản như một "truy vấn mẫu" hoặc phức tạp như "kết hợp", các truy vấn được mã hóa bằng AQL - Ngôn ngữ truy vấn ArangoDB.
Trong chương này, chúng ta sẽ thảo luận về các Phương thức Cơ sở dữ liệu khác nhau trong ArangoDB.
Để bắt đầu, chúng ta hãy lấy các thuộc tính của Cơ sở dữ liệu -
- Name
- ID
- Path
Đầu tiên, chúng tôi gọi Arangosh. Khi Arangosh được gọi, chúng tôi sẽ liệt kê các cơ sở dữ liệu mà chúng tôi đã tạo cho đến nay -
Chúng tôi sẽ sử dụng dòng mã sau để gọi Arangosh:
127.0.0.1:8529@_system> db._databases()Đầu ra
[
"_system",
"song_collection"
]Chúng tôi thấy hai cơ sở dữ liệu, một _system được tạo theo mặc định và thứ hai song_collection mà chúng tôi đã tạo.
Bây giờ chúng ta hãy chuyển sang cơ sở dữ liệu song_collection với dòng mã sau:
127.0.0.1:8529@_system> db._useDatabase("song_collection")Đầu ra
true
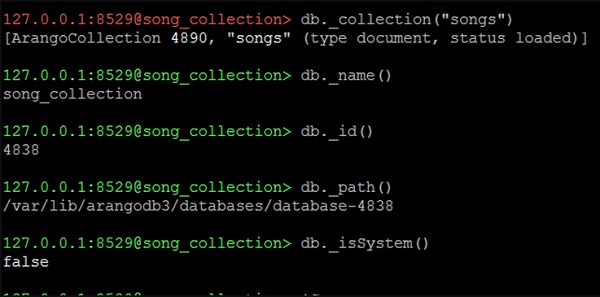
127.0.0.1:8529@song_collection>Chúng ta sẽ khám phá các thuộc tính của cơ sở dữ liệu song_collection.
Để tìm tên
Chúng tôi sẽ sử dụng dòng mã sau để tìm tên.
127.0.0.1:8529@song_collection> db._name()Đầu ra
song_collectionĐể tìm id -
Chúng tôi sẽ sử dụng dòng mã sau để tìm id.
song_collectionĐầu ra
4838Để tìm đường đi -
Chúng tôi sẽ sử dụng dòng mã sau để tìm đường dẫn.
127.0.0.1:8529@song_collection> db._path()Đầu ra
/var/lib/arangodb3/databases/database-4838Bây giờ chúng ta hãy kiểm tra xem chúng ta có đang ở trong cơ sở dữ liệu hệ thống hay không bằng cách sử dụng dòng mã sau:
127.0.0.1:8529@song_collection&t; db._isSystem()Đầu ra
falseNó có nghĩa là chúng tôi không có trong cơ sở dữ liệu hệ thống (vì chúng tôi đã tạo và chuyển sang song_collection). Ảnh chụp màn hình sau đây sẽ giúp bạn hiểu điều này.
Để tải một bộ sưu tập cụ thể, hãy nói các bài hát -
Chúng tôi sẽ sử dụng dòng mã sau để lấy một bộ sưu tập cụ thể.
127.0.0.1:8529@song_collection> db._collection("songs")Đầu ra
[ArangoCollection 4890, "songs" (type document, status loaded)]Dòng mã trả về một tập hợp duy nhất.
Chúng ta hãy chuyển sang những điều cơ bản của hoạt động cơ sở dữ liệu với các chương tiếp theo của chúng ta.
Trong chương này, chúng ta sẽ tìm hiểu các hoạt động khác nhau với Arangosh.
Sau đây là các thao tác có thể thực hiện với Arangosh:
- Tạo bộ sưu tập tài liệu
- Tạo tài liệu
- Đọc tài liệu
- Cập nhật tài liệu
Hãy để chúng tôi bắt đầu bằng cách tạo một cơ sở dữ liệu mới. Chúng tôi sẽ sử dụng dòng mã sau để tạo cơ sở dữ liệu mới:
127.0.0.1:8529@_system> db._createDatabase("song_collection")
trueDòng mã sau sẽ giúp bạn chuyển sang cơ sở dữ liệu mới:
127.0.0.1:8529@_system> db._useDatabase("song_collection")
trueLời nhắc sẽ chuyển thành "@@ song_collection"
127.0.0.1:8529@song_collection>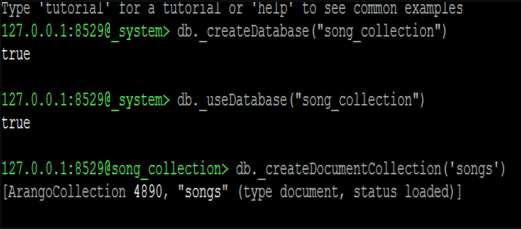
Từ đây chúng ta sẽ nghiên cứu về Hoạt động CRUD. Hãy để chúng tôi tạo một bộ sưu tập vào cơ sở dữ liệu mới -
127.0.0.1:8529@song_collection> db._createDocumentCollection('songs')Đầu ra
[ArangoCollection 4890, "songs" (type document, status loaded)]
127.0.0.1:8529@song_collection>Hãy để chúng tôi thêm một vài tài liệu (đối tượng JSON) vào bộ sưu tập 'bài hát' của chúng tôi.
Chúng tôi thêm tài liệu đầu tiên theo cách sau:
127.0.0.1:8529@song_collection> db.songs.save({title: "A Man's Best Friend",
lyricist: "Johnny Mercer", composer: "Johnny Mercer", Year: 1950, _key:
"A_Man"})Đầu ra
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVClbW---"
}Hãy để chúng tôi thêm các tài liệu khác vào cơ sở dữ liệu. Điều này sẽ giúp chúng ta tìm hiểu quá trình truy vấn dữ liệu. Bạn có thể sao chép các mã này và dán mã tương tự vào Arangosh để mô phỏng quá trình -
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Accentchuate The Politics",
lyricist: "Johnny Mercer",
composer: "Harold Arlen", Year: 1944,
_key: "Accentchuate_The"
}
)
{
"_id" : "songs/Accentchuate_The",
"_key" : "Accentchuate_The",
"_rev" : "_VjVDnzO---"
}
127.0.0.1:8529@song_collection> db.songs.save(
{
title: "Affable Balding Me",
lyricist: "Johnny Mercer",
composer: "Robert Emmett Dolan",
Year: 1950,
_key: "Affable_Balding"
}
)
{
"_id" : "songs/Affable_Balding",
"_key" : "Affable_Balding",
"_rev" : "_VjVEFMm---"
}Cách đọc tài liệu
Các _keyhoặc tay cầm tài liệu có thể được sử dụng để truy xuất tài liệu. Sử dụng tay cầm tài liệu nếu không cần phải duyệt qua chính bộ sưu tập. Nếu bạn có một bộ sưu tập, chức năng tài liệu rất dễ sử dụng -
127.0.0.1:8529@song_collection> db.songs.document("A_Man");
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVClbW---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950
}Cách cập nhật tài liệu
Hai tùy chọn có sẵn để cập nhật dữ liệu đã lưu - replace và update.
Chức năng cập nhật vá một tài liệu, hợp nhất nó với các thuộc tính đã cho. Mặt khác, chức năng thay thế sẽ thay thế tài liệu trước đó bằng tài liệu mới. Việc thay thế sẽ vẫn diễn ra ngay cả khi các thuộc tính hoàn toàn khác được cung cấp. Đầu tiên chúng ta sẽ quan sát một bản cập nhật không phá hủy, cập nhật thuộc tính Production` trong một bài hát -
127.0.0.1:8529@song_collection> db.songs.update("songs/A_Man",{production:
"Top Banana"});Đầu ra
{
"_id" : "songs/A_Man",
"_key" : "A_Man",
"_rev" : "_VjVOcqe---",
"_oldRev" : "_VjVClbW---"
}Bây giờ chúng ta hãy đọc các thuộc tính của bài hát được cập nhật -
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Đầu ra
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVOcqe---",
"title" : "A Man's Best Friend",
"lyricist" : "Johnny Mercer",
"composer" : "Johnny Mercer",
"Year" : 1950,
"production" : "Top Banana"
}Một tài liệu lớn có thể được cập nhật dễ dàng với update chức năng, đặc biệt khi các thuộc tính rất ít.
Ngược lại, replace chức năng sẽ hủy bỏ dữ liệu của bạn khi sử dụng nó với cùng một tài liệu.
127.0.0.1:8529@song_collection> db.songs.replace("songs/A_Man",{production:
"Top Banana"});Bây giờ chúng ta hãy kiểm tra bài hát mà chúng ta vừa cập nhật với dòng mã sau:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Đầu ra
{
"_key" : "A_Man",
"_id" : "songs/A_Man",
"_rev" : "_VjVRhOq---",
"production" : "Top Banana"
}Bây giờ, bạn có thể quan sát rằng tài liệu không còn dữ liệu ban đầu.
Cách xóa tài liệu
Chức năng loại bỏ được sử dụng kết hợp với xử lý tài liệu để xóa tài liệu khỏi bộ sưu tập -
127.0.0.1:8529@song_collection> db.songs.remove('A_Man');Bây giờ chúng ta hãy kiểm tra các thuộc tính của bài hát mà chúng ta vừa xóa bằng cách sử dụng dòng mã sau:
127.0.0.1:8529@song_collection> db.songs.document('A_Man');Chúng tôi sẽ nhận được một lỗi ngoại lệ như sau dưới dạng đầu ra:
JavaScript exception in file
'/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js' at 97,7:
ArangoError 1202: document not found
! throw error;
! ^
stacktrace: ArangoError: document not found
at Object.exports.checkRequestResult
(/usr/share/arangodb3/js/client/modules/@arangodb/arangosh.js:95:21)
at ArangoCollection.document
(/usr/share/arangodb3/js/client/modules/@arangodb/arango-collection.js:667:12)
at <shell command>:1:10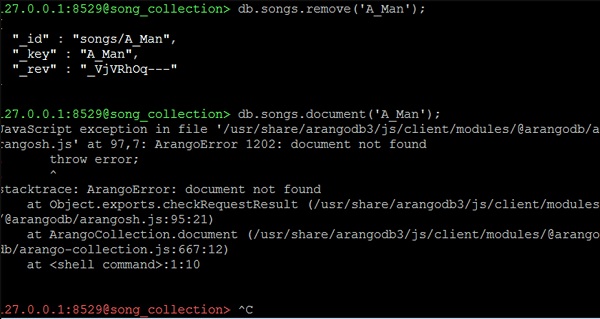
Trong chương trước, chúng ta đã học cách thực hiện các thao tác khác nhau trên tài liệu với Arangosh, dòng lệnh. Bây giờ chúng ta sẽ tìm hiểu cách thực hiện các thao tác tương tự bằng giao diện web. Để bắt đầu, hãy nhập địa chỉ sau - http: // your_server_ip: 8529 / _db / song_collection / _admin / aardvark / index.html # đăng nhập vào thanh địa chỉ của trình duyệt của bạn. Bạn sẽ được dẫn đến trang đăng nhập sau.
Bây giờ, hãy nhập tên người dùng và mật khẩu.
Nếu thành công, màn hình sau sẽ xuất hiện. Chúng tôi cần đưa ra lựa chọn để cơ sở dữ liệu hoạt động,_systemcơ sở dữ liệu là cơ sở dữ liệu mặc định. Hãy để chúng tôi chọnsong_collection cơ sở dữ liệu và nhấp vào tab màu xanh lá cây -
Tạo Bộ sưu tập
Trong phần này, chúng ta sẽ học cách tạo một bộ sưu tập. Nhấn vào tab Bộ sưu tập trong thanh điều hướng ở trên cùng.
Bộ sưu tập bài hát được thêm vào dòng lệnh của chúng tôi được hiển thị. Nhấp vào đó sẽ hiển thị các mục nhập. Bây giờ chúng tôi sẽ thêm mộtartists’bộ sưu tập bằng giao diện web. Bộ sưu tậpsongsmà chúng tôi đã tạo với Arangosh đã có ở đó. Trong trường Tên, hãy viếtartists bên trong New Collectionhộp thoại xuất hiện. Các tùy chọn nâng cao có thể được bỏ qua một cách an toàn và loại bộ sưu tập mặc định, tức là Tài liệu, vẫn ổn.

Nhấp vào nút Lưu cuối cùng sẽ tạo bộ sưu tập và bây giờ hai bộ sưu tập sẽ hiển thị trên trang này.
Làm đầy bộ sưu tập mới tạo bằng tài liệu
Bạn sẽ thấy một bộ sưu tập trống khi nhấp vào artists bộ sưu tập -
Để thêm tài liệu, bạn cần nhấp vào dấu + đặt ở góc trên bên phải. Khi bạn được nhắc về một_key, đi vào Affable_Balding là chìa khóa.
Bây giờ, một biểu mẫu sẽ xuất hiện để thêm và chỉnh sửa các thuộc tính của tài liệu. Có hai cách để thêm thuộc tính:Graphical và Tree. Cách đồ họa trực quan nhưng chậm, do đó, chúng tôi sẽ chuyển sangCode xem, sử dụng menu thả xuống Cây để chọn nó -
Để làm cho quá trình dễ dàng hơn, chúng tôi đã tạo một dữ liệu mẫu ở định dạng JSON, bạn có thể sao chép và sau đó dán vào vùng soạn thảo truy vấn -
{"artist": "Johnny Mercer", "title": "Affable Balding Me", "composer": "Robert Emmett Dolan", "Year": 1950}
(Lưu ý: Chỉ nên sử dụng một cặp dấu ngoặc nhọn; xem ảnh chụp màn hình bên dưới)
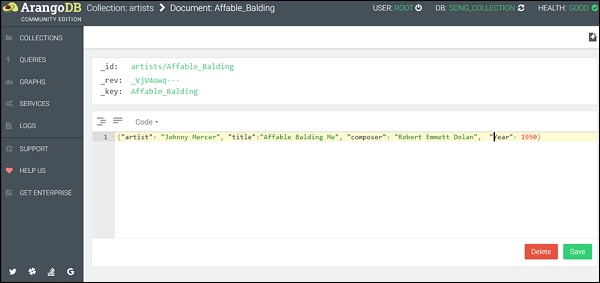
Bạn có thể thấy rằng chúng tôi đã trích dẫn các khóa và cả các giá trị trong chế độ xem mã. Bây giờ, hãy nhấp vàoSave. Sau khi hoàn thành thành công, một đèn flash màu xanh lục sẽ xuất hiện trên trang trong giây lát.
Cách đọc tài liệu
Để đọc tài liệu, hãy quay lại trang Bộ sưu tập.
Khi một người nhấp vào artist bộ sưu tập, một mục mới xuất hiện.
Cách cập nhật tài liệu
Thật đơn giản để chỉnh sửa các mục nhập trong một tài liệu; bạn chỉ cần nhấp vào hàng bạn muốn chỉnh sửa trong tổng quan tài liệu. Tại đây, một lần nữa trình soạn thảo truy vấn tương tự sẽ được trình bày như khi tạo tài liệu mới.
Xóa tài liệu
Bạn có thể xóa tài liệu bằng cách nhấn biểu tượng '-'. Mọi hàng tài liệu đều có dấu này ở cuối. Nó sẽ nhắc bạn xác nhận để tránh xóa mất an toàn.
Hơn nữa, đối với một tập hợp cụ thể, các hoạt động khác như lọc tài liệu, quản lý chỉ mục và nhập dữ liệu cũng tồn tại trên Collections Overview trang.
Trong chương tiếp theo của chúng ta, chúng ta sẽ thảo luận về một tính năng quan trọng của Giao diện Web, tức là Trình soạn thảo truy vấn AQL.
Trong chương này, chúng ta sẽ thảo luận về cách truy vấn dữ liệu với AQL. Chúng ta đã thảo luận trong các chương trước rằng ArangoDB đã phát triển ngôn ngữ truy vấn của riêng mình và nó có tên là AQL.
Bây giờ chúng ta hãy bắt đầu tương tác với AQL. Như hình bên dưới, trong giao diện web, nhấnAQL Editorđược đặt ở đầu thanh điều hướng. Một trình soạn thảo truy vấn trống sẽ xuất hiện.
Khi cần, bạn có thể chuyển sang trình chỉnh sửa từ chế độ xem kết quả và ngược lại, bằng cách nhấp vào tab Truy vấn hoặc tab Kết quả ở góc trên cùng bên phải như trong hình dưới đây -
Trong số những thứ khác, trình soạn thảo có chức năng tô sáng cú pháp, hoàn tác / làm lại và lưu truy vấn. Để tham khảo chi tiết, người ta có thể xem tài liệu chính thức. Chúng tôi sẽ nêu bật một số tính năng cơ bản và thường được sử dụng của trình soạn thảo truy vấn AQL.
Các nguyên tắc cơ bản về AQL
Trong AQL, một truy vấn thể hiện kết quả cuối cùng cần đạt được, nhưng không phải là quá trình đạt được kết quả cuối cùng. Tính năng này thường được biết đến như một thuộc tính khai báo của ngôn ngữ. Hơn nữa, AQL có thể truy vấn cũng như sửa đổi dữ liệu và do đó có thể tạo các truy vấn phức tạp bằng cách kết hợp cả hai quy trình.
Xin lưu ý rằng AQL hoàn toàn tuân thủ ACID. Việc đọc hoặc sửa đổi các truy vấn sẽ kết thúc toàn bộ hoặc hoàn toàn không. Ngay cả việc đọc dữ liệu của tài liệu cũng sẽ kết thúc với một đơn vị dữ liệu nhất quán.
Chúng tôi thêm hai mới songsvào bộ sưu tập bài hát mà chúng tôi đã tạo. Thay vì nhập, bạn có thể sao chép truy vấn sau và dán vào trình soạn thảo AQL -
FOR song IN [
{
title: "Air-Minded Executive", lyricist: "Johnny Mercer",
composer: "Bernie Hanighen", Year: 1940, _key: "Air-Minded"
},
{
title: "All Mucked Up", lyricist: "Johnny Mercer", composer:
"Andre Previn", Year: 1974, _key: "All_Mucked"
}
]
INSERT song IN songsNhấn nút Execute ở phía dưới bên trái.
Nó sẽ viết hai tài liệu mới trong songs bộ sưu tập.
Truy vấn này mô tả cách hoạt động của vòng lặp FOR trong AQL; nó lặp lại danh sách các tài liệu được mã hóa JSON, thực hiện các hoạt động được mã hóa trên từng tài liệu trong bộ sưu tập. Các hoạt động khác nhau có thể là tạo cấu trúc mới, lọc, chọn tài liệu, sửa đổi hoặc chèn tài liệu vào cơ sở dữ liệu (tham khảo ví dụ tức thời). Về bản chất, AQL có thể thực hiện các hoạt động CRUD một cách hiệu quả.
Để tìm tất cả các bài hát trong cơ sở dữ liệu của chúng tôi, hãy một lần nữa chúng tôi chạy truy vấn sau, tương đương với SELECT * FROM songs của cơ sở dữ liệu kiểu SQL (vì trình soạn thảo ghi nhớ truy vấn cuối cùng, hãy nhấn *New* nút để làm sạch trình chỉnh sửa) -
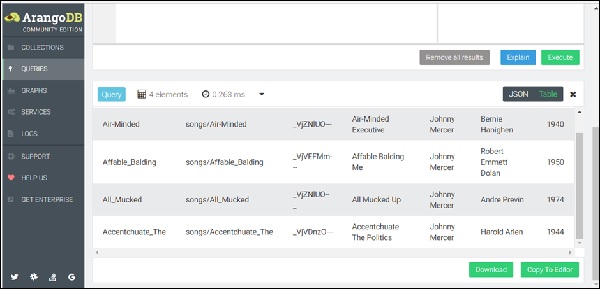
FOR song IN songs
RETURN songTập kết quả sẽ hiển thị danh sách các bài hát được lưu trong songs bộ sưu tập như thể hiện trong ảnh chụp màn hình bên dưới.
Các hoạt động như FILTER, SORT và LIMIT có thể được thêm vào For loop để thu hẹp và sắp xếp kết quả.
FOR song IN songs
FILTER song.Year > 1940
RETURN songTruy vấn trên sẽ đưa ra các bài hát được tạo sau năm 1940 trong tab Kết quả (xem hình bên dưới).
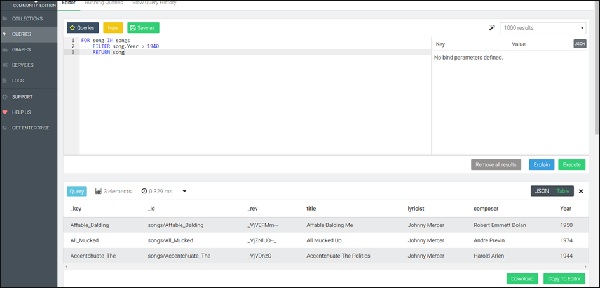
Khóa tài liệu được sử dụng trong ví dụ này, nhưng bất kỳ thuộc tính nào khác cũng có thể được sử dụng làm thuộc tính tương đương để lọc. Vì khóa tài liệu được đảm bảo là duy nhất, không nhiều hơn một tài liệu duy nhất sẽ khớp với bộ lọc này. Đối với các thuộc tính khác, điều này có thể không đúng. Để trả về một tập hợp con người dùng đang hoạt động (được xác định bởi một thuộc tính được gọi là trạng thái), được sắp xếp theo tên theo thứ tự tăng dần, chúng tôi sử dụng cú pháp sau:
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
RETURN song
LIMIT 2Chúng tôi đã cố tình đưa vào ví dụ này. Ở đây, chúng tôi quan sát thấy một thông báo lỗi cú pháp truy vấn được AQL đánh dấu màu đỏ. Cú pháp này làm nổi bật các lỗi và hữu ích trong việc gỡ lỗi các truy vấn của bạn như được hiển thị trong ảnh chụp màn hình bên dưới.
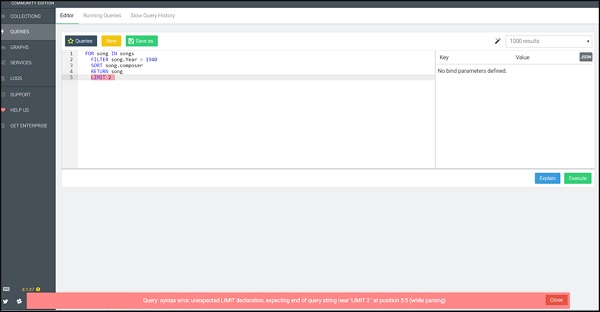
Bây giờ hãy để chúng tôi chạy truy vấn chính xác (lưu ý sửa chữa) -
FOR song IN songs
FILTER song.Year > 1940
SORT song.composer
LIMIT 2
RETURN song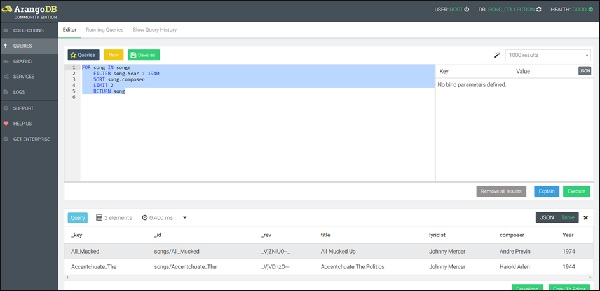
Truy vấn phức tạp trong AQL
AQL được trang bị nhiều chức năng cho tất cả các kiểu dữ liệu được hỗ trợ. Phép gán biến trong một truy vấn cho phép xây dựng các cấu trúc lồng nhau rất phức tạp. Bằng cách này, các hoạt động sử dụng nhiều dữ liệu di chuyển đến gần dữ liệu ở phần phụ trợ hơn là đối với máy khách (chẳng hạn như trình duyệt). Để hiểu điều này, trước tiên chúng ta hãy thêm thời lượng (độ dài) tùy ý cho các bài hát.
Chúng ta hãy bắt đầu với chức năng đầu tiên, tức là, chức năng Cập nhật -
UPDATE { _key: "All_Mucked" }
WITH { length: 180 }
IN songs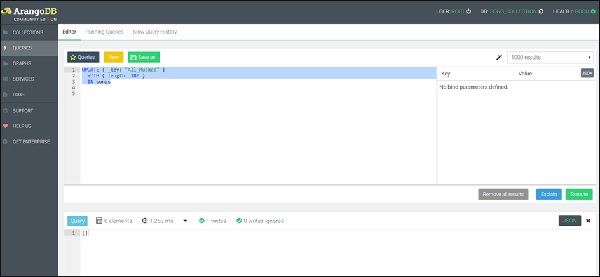
Chúng ta có thể thấy một tài liệu đã được viết như trong ảnh chụp màn hình ở trên.
Bây giờ chúng tôi cũng cập nhật các tài liệu (bài hát) khác.
UPDATE { _key: "Affable_Balding" }
WITH { length: 200 }
IN songsBây giờ chúng tôi có thể kiểm tra xem tất cả các bài hát của chúng tôi có thuộc tính mới không length -
FOR song IN songs
RETURN songĐầu ra
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_VkC5lbS---",
"title": "Air-Minded Executive",
"lyricist": "Johnny Mercer",
"composer": "Bernie Hanighen",
"Year": 1940,
"length": 210
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_VkC4eM2---",
"title": "Affable Balding Me",
"lyricist": "Johnny Mercer",
"composer": "Robert Emmett Dolan",
"Year": 1950,
"length": 200
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vjah9Pu---",
"title": "All Mucked Up",
"lyricist": "Johnny Mercer",
"composer": "Andre Previn",
"Year": 1974,
"length": 180
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_VkC3WzW---",
"title": "Accentchuate The Politics",
"lyricist": "Johnny Mercer",
"composer": "Harold Arlen",
"Year": 1944,
"length": 190
}
]Để minh họa việc sử dụng các từ khóa khác của AQL như LET, FILTER, SORT, v.v., bây giờ chúng tôi định dạng thời lượng của bài hát trong mm:ss định dạng.
Truy vấn
FOR song IN songs
FILTER song.length > 150
LET seconds = song.length % 60
LET minutes = FLOOR(song.length / 60)
SORT song.composer
RETURN
{
Title: song.title,
Composer: song.composer,
Duration: CONCAT_SEPARATOR(':',minutes, seconds)
}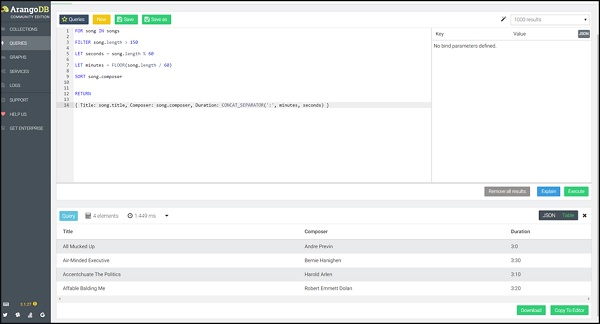
Lần này chúng tôi sẽ trả lại tên bài hát cùng với thời lượng. CácReturn hàm cho phép bạn tạo một đối tượng JSON mới để trả về cho mỗi tài liệu đầu vào.
Bây giờ chúng ta sẽ nói về tính năng 'Tham gia' của cơ sở dữ liệu AQL.
Hãy để chúng tôi bắt đầu bằng cách tạo một bộ sưu tập composer_dob. Hơn nữa, chúng tôi sẽ tạo bốn tài liệu với ngày sinh giả định của các nhà soạn nhạc bằng cách chạy truy vấn sau trong hộp câu hỏi:
FOR dob IN [
{composer: "Bernie Hanighen", Year: 1909}
,
{composer: "Robert Emmett Dolan", Year: 1922}
,
{composer: "Andre Previn", Year: 1943}
,
{composer: "Harold Arlen", Year: 1910}
]
INSERT dob in composer_dob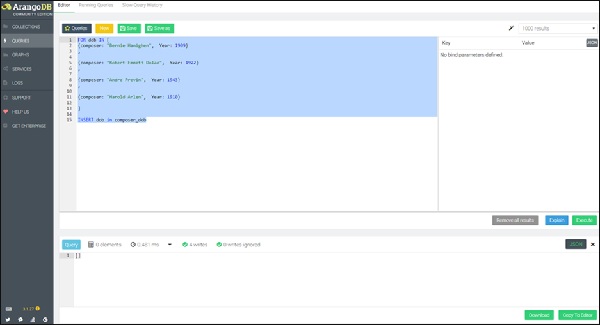
Để làm nổi bật sự tương đồng với SQL, chúng tôi trình bày một truy vấn vòng lặp FOR lồng nhau trong AQL, dẫn đến hoạt động REPLACE, lặp lại đầu tiên trong vòng lặp bên trong, trên tất cả dob của nhà soạn nhạc và sau đó trên tất cả các bài hát liên quan, tạo một tài liệu mới chứa thuộc tính song_with_composer_key thay cho song thuộc tính.
Đây là truy vấn -
FOR s IN songs
FOR c IN composer_dob
FILTER s.composer == c.composer
LET song_with_composer_key = MERGE(
UNSET(s, 'composer'),
{composer_key:c._key}
)
REPLACE s with song_with_composer_key IN songs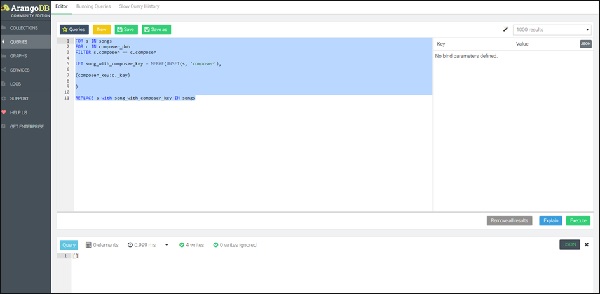
Bây giờ chúng ta hãy chạy truy vấn FOR song IN songs RETURN song một lần nữa để xem bộ sưu tập bài hát đã thay đổi như thế nào.
Đầu ra
[
{
"_key": "Air-Minded",
"_id": "songs/Air-Minded",
"_rev": "_Vk8kFoK---",
"Year": 1940,
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive"
},
{
"_key": "Affable_Balding",
"_id": "songs/Affable_Balding",
"_rev": "_Vk8kFoK--_",
"Year": 1950,
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me"
},
{
"_key": "All_Mucked",
"_id": "songs/All_Mucked",
"_rev": "_Vk8kFoK--A",
"Year": 1974,
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up"
},
{
"_key": "Accentchuate_The",
"_id": "songs/Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"Year": 1944,
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics"
}
]Truy vấn trên hoàn tất quá trình di chuyển dữ liệu, thêm vào composer_key cho mỗi bài hát.
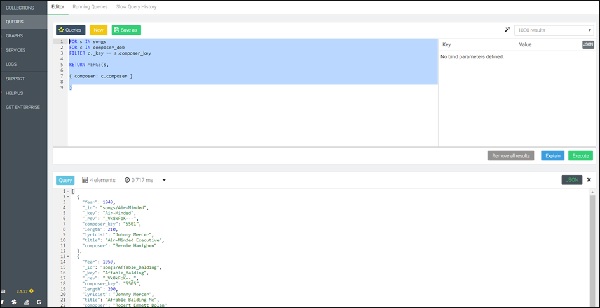
Bây giờ, truy vấn tiếp theo lại là truy vấn vòng lặp FOR lồng nhau, nhưng lần này dẫn đến thao tác Tham gia, thêm tên của nhà soạn nhạc được liên kết (chọn với sự trợ giúp của `composer_key`) vào mỗi bài hát -
FOR s IN songs
FOR c IN composer_dob
FILTER c._key == s.composer_key
RETURN MERGE(s,
{ composer: c.composer }
)Đầu ra
[
{
"Year": 1940,
"_id": "songs/Air-Minded",
"_key": "Air-Minded",
"_rev": "_Vk8kFoK---",
"composer_key": "5501",
"length": 210,
"lyricist": "Johnny Mercer",
"title": "Air-Minded Executive",
"composer": "Bernie Hanighen"
},
{
"Year": 1950,
"_id": "songs/Affable_Balding",
"_key": "Affable_Balding",
"_rev": "_Vk8kFoK--_",
"composer_key": "5505",
"length": 200,
"lyricist": "Johnny Mercer",
"title": "Affable Balding Me",
"composer": "Robert Emmett Dolan"
},
{
"Year": 1974,
"_id": "songs/All_Mucked",
"_key": "All_Mucked",
"_rev": "_Vk8kFoK--A",
"composer_key": "5507",
"length": 180,
"lyricist": "Johnny Mercer",
"title": "All Mucked Up",
"composer": "Andre Previn"
},
{
"Year": 1944,
"_id": "songs/Accentchuate_The",
"_key": "Accentchuate_The",
"_rev": "_Vk8kFoK--B",
"composer_key": "5509",
"length": 190,
"lyricist": "Johnny Mercer",
"title": "Accentchuate The Politics",
"composer": "Harold Arlen"
}
]
Trong chương này, chúng ta sẽ xem xét một số Truy vấn Ví dụ AQL về Actors and MoviesCơ sở dữ liệu. Các truy vấn này dựa trên đồ thị.
Vấn đề
Đưa ra một bộ sưu tập các diễn viên và một bộ sưu tập phim, và một bộ sưu tập các cạnh actIn (với thuộc tính năm) để kết nối đỉnh như được chỉ ra bên dưới -
[Actor] <- act in -> [Movie]
Làm thế nào để chúng tôi nhận được -
- Tất cả các diễn viên đã tham gia diễn xuất trong "movie1" HOẶC "movie2"?
- Tất cả các diễn viên đã tham gia cả "movie1" VÀ "movie2"?
- Tất cả các bộ phim chung giữa "Actor1" và "Actor2"?
- Tất cả các diễn viên đã đóng từ 3 phim trở lên?
- Tất cả các phim có chính xác 6 diễn viên tham gia?
- Số lượng diễn viên của phim?
- Số lượng phim của diễn viên?
- Số lượng các bộ phim đã tham gia diễn xuất từ năm 2005 đến năm 2010 của diễn viên?
Giải pháp
Trong quá trình giải quyết và thu được câu trả lời cho các câu hỏi trên, chúng tôi sẽ sử dụng Arangosh để tạo tập dữ liệu và chạy các truy vấn trên đó. Tất cả các truy vấn AQL đều là chuỗi và có thể đơn giản được sao chép sang trình điều khiển yêu thích của bạn thay vì Arangosh.
Chúng ta hãy bắt đầu bằng cách tạo Tập dữ liệu thử nghiệm trong Arangosh. Trước tiên, hãy tải xuống tệp này -
# wget -O dataset.js
https://drive.google.com/file/d/0B4WLtBDZu_QWMWZYZ3pYMEdqajA/view?usp=sharingĐầu ra
...
HTTP request sent, awaiting response... 200 OK
Length: unspecified [text/html]
Saving to: ‘dataset.js’
dataset.js [ <=> ] 115.14K --.-KB/s in 0.01s
2017-09-17 14:19:12 (11.1 MB/s) - ‘dataset.js’ saved [117907]Bạn có thể thấy trong đầu ra ở trên rằng chúng tôi đã tải xuống một tệp JavaScript dataset.js.Tệp này chứa các lệnh Arangosh để tạo tập dữ liệu trong cơ sở dữ liệu. Thay vì sao chép và dán từng lệnh một, chúng tôi sẽ sử dụng--javascript.executetrên Arangosh để thực hiện nhiều lệnh không tương tác. Hãy coi đó là lệnh cứu mạng!
Bây giờ thực hiện lệnh sau trên shell:
$ arangosh --javascript.execute dataset.js
Cung cấp mật khẩu khi được nhắc như bạn có thể thấy trong ảnh chụp màn hình ở trên. Bây giờ chúng ta đã lưu dữ liệu, vì vậy chúng ta sẽ xây dựng các truy vấn AQL để trả lời các câu hỏi cụ thể được nêu ra ở đầu chương này.
Câu hỏi đầu tiên
Hãy để chúng tôi trả lời câu hỏi đầu tiên: All actors who acted in "movie1" OR "movie2". Giả sử, chúng ta muốn tìm tên của tất cả các diễn viên đã đóng trong "TheMatrix" HOẶC "TheDevilsAdvocate" -
Chúng ta sẽ bắt đầu với từng bộ phim một để biết tên của các diễn viên -
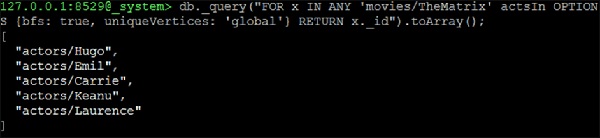
127.0.0.1:8529@_system> db._query("FOR x IN ANY 'movies/TheMatrix' actsIn
OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN x._id").toArray();Đầu ra
Chúng tôi sẽ nhận được kết quả sau:
[
"actors/Hugo",
"actors/Emil",
"actors/Carrie",
"actors/Keanu",
"actors/Laurence"
]
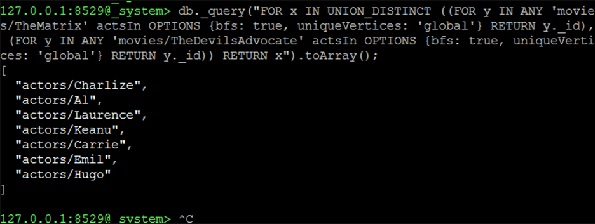
Bây giờ chúng tôi tiếp tục tạo UNION_DISTINCT gồm hai truy vấn NEIGHBORS, đây sẽ là giải pháp -
127.0.0.1:8529@_system> db._query("FOR x IN UNION_DISTINCT ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Đầu ra
[
"actors/Charlize",
"actors/Al",
"actors/Laurence",
"actors/Keanu",
"actors/Carrie",
"actors/Emil",
"actors/Hugo"
]
Câu hỏi thứ hai
Bây giờ chúng ta hãy xem xét câu hỏi thứ hai: All actors who acted in both "movie1" AND "movie2". Điều này gần giống với câu hỏi trên. Nhưng lần này chúng tôi không quan tâm đến CÔNG ĐOÀN mà quan tâm đến sự TRUYỀN CẢM HỨNG -
127.0.0.1:8529@_system> db._query("FOR x IN INTERSECTION ((FOR y IN ANY
'movies/TheMatrix' actsIn OPTIONS {bfs: true, uniqueVertices: 'global'} RETURN
y._id), (FOR y IN ANY 'movies/TheDevilsAdvocate' actsIn OPTIONS {bfs: true,
uniqueVertices: 'global'} RETURN y._id)) RETURN x").toArray();Đầu ra
Chúng tôi sẽ nhận được kết quả sau:
[
"actors/Keanu"
]
Câu hỏi thứ ba
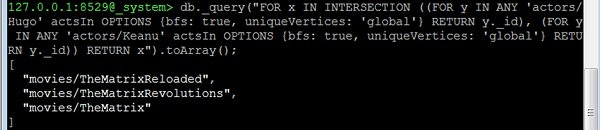
Bây giờ chúng ta hãy xem xét câu hỏi thứ ba: All common movies between "actor1" and "actor2". Điều này thực sự giống với câu hỏi về các diễn viên thường gặp trong movie1 và movie2. Chúng ta chỉ cần thay đổi các đỉnh bắt đầu. Ví dụ: chúng ta hãy tìm tất cả các phim mà Hugo Weaving ("Hugo") và Keanu Reeves cùng đóng -
127.0.0.1:8529@_system> db._query(
"FOR x IN INTERSECTION (
(
FOR y IN ANY 'actors/Hugo' actsIn OPTIONS
{bfs: true, uniqueVertices: 'global'}
RETURN y._id
),
(
FOR y IN ANY 'actors/Keanu' actsIn OPTIONS
{bfs: true, uniqueVertices:'global'} RETURN y._id
)
)
RETURN x").toArray();Đầu ra
Chúng tôi sẽ nhận được kết quả sau:
[
"movies/TheMatrixReloaded",
"movies/TheMatrixRevolutions",
"movies/TheMatrix"
]
Câu hỏi thứ tư
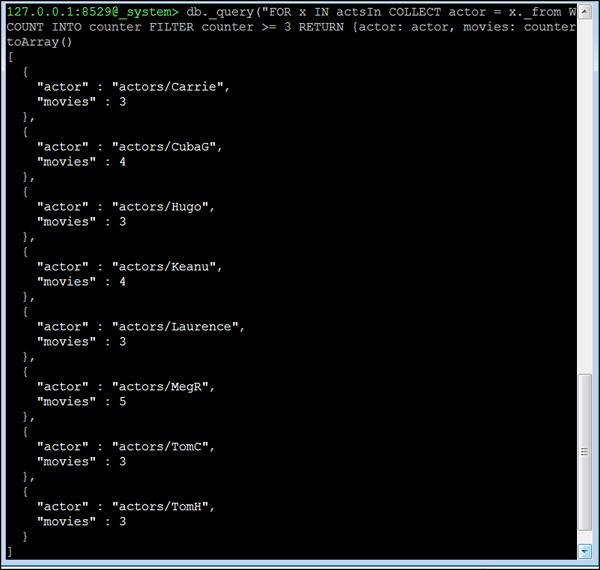
Bây giờ chúng ta hãy xem xét câu hỏi thứ tư. All actors who acted in 3 or more movies. Câu hỏi này là khác nhau; chúng ta không thể sử dụng chức năng hàng xóm ở đây. Thay vào đó, chúng ta sẽ sử dụng chỉ mục cạnh và câu lệnh COLLECT của AQL để phân nhóm. Ý tưởng cơ bản là nhóm tất cả các cạnh theostartVertex(trong tập dữ liệu này luôn là tác nhân). Sau đó, chúng tôi xóa tất cả các diễn viên có ít hơn 3 phim khỏi kết quả vì ở đây chúng tôi đã bao gồm số phim mà một diễn viên đã tham gia -
127.0.0.1:8529@_system> db._query("FOR x IN actsIn COLLECT actor = x._from WITH
COUNT INTO counter FILTER counter >= 3 RETURN {actor: actor, movies:
counter}"). toArray()Đầu ra
[
{
"actor" : "actors/Carrie",
"movies" : 3
},
{
"actor" : "actors/CubaG",
"movies" : 4
},
{
"actor" : "actors/Hugo",
"movies" : 3
},
{
"actor" : "actors/Keanu",
"movies" : 4
},
{
"actor" : "actors/Laurence",
"movies" : 3
},
{
"actor" : "actors/MegR",
"movies" : 5
},
{
"actor" : "actors/TomC",
"movies" : 3
},
{
"actor" : "actors/TomH",
"movies" : 3
}
]
Đối với các câu hỏi còn lại, chúng tôi sẽ thảo luận về việc hình thành truy vấn và chỉ cung cấp các truy vấn. Người đọc nên tự chạy truy vấn trên thiết bị đầu cuối Arangosh.
Câu hỏi thứ năm
Bây giờ chúng ta hãy xem xét câu hỏi thứ năm: All movies where exactly 6 actors acted in. Ý tưởng tương tự như trong truy vấn trước đó, nhưng với bộ lọc bình đẳng. Tuy nhiên, bây giờ chúng tôi cần bộ phim thay vì diễn viên, vì vậy chúng tôi trả lại_to attribute -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter FILTER
counter == 6 RETURN movie").toArray()Số lượng diễn viên của phim?
Chúng tôi nhớ trong tập dữ liệu của mình _to ở rìa tương ứng với bộ phim, vì vậy chúng tôi tính tần suất _toxuất hiện. Đây là số lượng diễn viên. Truy vấn gần giống với những truy vấn trước đó nhưngwithout the FILTER after COLLECT -
db._query("FOR x IN actsIn COLLECT movie = x._to WITH COUNT INTO counter RETURN
{movie: movie, actors: counter}").toArray()Câu hỏi thứ sáu
Bây giờ chúng ta hãy xem xét câu hỏi thứ sáu: The number of movies by an actor.
Cách chúng tôi tìm ra giải pháp cho các truy vấn ở trên cũng sẽ giúp bạn tìm ra giải pháp cho truy vấn này.
db._query("FOR x IN actsIn COLLECT actor = x._from WITH COUNT INTO counter
RETURN {actor: actor, movies: counter}").toArray()Trong chương này, chúng tôi sẽ mô tả các khả năng khác nhau để triển khai ArangoDB.
Triển khai: Phiên bản đơn
Chúng ta đã học cách triển khai phiên bản Linux (Ubuntu) đơn lẻ trong một trong những chương trước của chúng tôi. Bây giờ chúng ta hãy xem cách triển khai bằng Docker.
Triển khai: Docker
Để triển khai bằng docker, chúng tôi sẽ cài đặt Docker trên máy của mình. Để biết thêm thông tin về Docker, vui lòng tham khảo hướng dẫn của chúng tôi về Docker .
Khi Docker được cài đặt, bạn có thể sử dụng lệnh sau:
docker run -e ARANGO_RANDOM_ROOT_PASSWORD = 1 -d --name agdb-foo -d
arangodb/arangodbNó sẽ tạo và khởi chạy phiên bản Docker của ArangoDB với tên nhận dạng agdbfoo như một quy trình nền Docker.
Ngoài ra, thiết bị đầu cuối sẽ in mã nhận dạng quy trình.
Theo mặc định, cổng 8529 được dành riêng cho ArangoDB để lắng nghe các yêu cầu. Ngoài ra, cổng này tự động có sẵn cho tất cả các vùng chứa ứng dụng Docker mà bạn có thể đã liên kết.