Trí tuệ nhân tạo - Hướng dẫn nhanh
Kể từ khi phát minh ra máy tính hoặc máy móc, khả năng thực hiện các nhiệm vụ khác nhau của họ đã tăng lên theo cấp số nhân. Con người đã phát triển sức mạnh của hệ thống máy tính về các lĩnh vực làm việc đa dạng của chúng, tốc độ ngày càng tăng và giảm kích thước theo thời gian.
Một nhánh của Khoa học Máy tính có tên Trí tuệ nhân tạo theo đuổi việc tạo ra các máy tính hoặc máy móc thông minh như con người.
Trí tuệ nhân tạo là gì?
Theo cha đẻ của Trí tuệ nhân tạo, John McCarthy, đó là “Khoa học và kỹ thuật tạo ra các máy thông minh, đặc biệt là các chương trình máy tính thông minh”.
Trí tuệ nhân tạo là một cách making a computer, a computer-controlled robot, or a software think intelligently, theo cách tương tự như con người thông minh nghĩ.
AI được hoàn thiện bằng cách nghiên cứu cách bộ não con người suy nghĩ và cách con người học, quyết định và làm việc trong khi cố gắng giải quyết một vấn đề, sau đó sử dụng kết quả của nghiên cứu này làm cơ sở phát triển phần mềm và hệ thống thông minh.
Triết lý về AI
Trong khi khai thác sức mạnh của hệ thống máy tính, sự tò mò của con người khiến anh ta tự hỏi, "Liệu một cỗ máy có thể suy nghĩ và hành xử như con người không?"
Vì vậy, sự phát triển của AI bắt đầu với ý định tạo ra trí thông minh tương tự trong các máy móc mà chúng ta tìm thấy và đánh giá cao ở con người.
Mục tiêu của AI
To Create Expert Systems - Các hệ thống thể hiện hành vi thông minh, tìm hiểu, chứng minh, giải thích và tư vấn cho người dùng của nó.
To Implement Human Intelligence in Machines - Tạo ra các hệ thống hiểu, suy nghĩ, học hỏi và cư xử như con người.
Điều gì đóng góp cho AI?
Trí tuệ nhân tạo là một ngành khoa học và công nghệ dựa trên các ngành như Khoa học máy tính, Sinh học, Tâm lý học, Ngôn ngữ học, Toán học và Kỹ thuật. Một lực đẩy chính của AI là phát triển các chức năng máy tính liên quan đến trí thông minh của con người, chẳng hạn như lý luận, học tập và giải quyết vấn đề.
Trong số các lĩnh vực sau, một hoặc nhiều lĩnh vực có thể góp phần xây dựng hệ thống thông minh.
Lập trình không cần và có AI
Việc lập trình không có và có AI khác nhau theo những cách sau:
| Lập trình không có AI | Lập trình với AI |
|---|---|
| Một chương trình máy tính không có AI có thể trả lời specific những câu hỏi cần giải quyết. | Một chương trình máy tính với AI có thể trả lời generic những câu hỏi cần giải quyết. |
| Sửa đổi trong chương trình dẫn đến thay đổi cấu trúc của nó. | Các chương trình AI có thể tiếp thu các sửa đổi mới bằng cách ghép các phần thông tin có tính độc lập cao lại với nhau. Do đó, bạn có thể sửa đổi ngay cả một mẩu thông tin nhỏ của chương trình mà không ảnh hưởng đến cấu trúc của nó. |
| Việc sửa đổi không nhanh chóng và dễ dàng. Nó có thể dẫn đến ảnh hưởng đến chương trình một cách bất lợi. | Sửa đổi chương trình nhanh chóng và dễ dàng. |
Kỹ thuật AI là gì?
Trong thế giới thực, kiến thức có một số thuộc tính không được ưa chuộng -
- Khối lượng của nó là rất lớn, bên cạnh không thể tưởng tượng.
- Nó không được tổ chức tốt hoặc được định dạng tốt.
- Nó không ngừng thay đổi.
Kỹ thuật AI là một cách để tổ chức và sử dụng kiến thức một cách hiệu quả theo cách -
- Những người cung cấp nó phải được nhận thức được.
- Nó phải dễ dàng sửa đổi để sửa lỗi.
- Nó sẽ hữu ích trong nhiều trường hợp mặc dù nó không đầy đủ hoặc không chính xác.
Các kỹ thuật AI nâng cao tốc độ thực thi chương trình phức tạp mà nó được trang bị.
Các ứng dụng của AI
AI đã thống trị trong các lĩnh vực khác nhau như -
Gaming - AI đóng vai trò quan trọng trong các trò chơi chiến lược như cờ vua, poker, tic-tac-toe, v.v., nơi máy có thể nghĩ ra một số lượng lớn các vị trí có thể dựa trên kiến thức kinh nghiệm.
Natural Language Processing - Có thể tương tác với máy tính hiểu ngôn ngữ tự nhiên của con người.
Expert Systems- Có một số ứng dụng tích hợp máy móc, phần mềm và thông tin đặc biệt để truyền đạt lý luận và tư vấn. Họ cung cấp giải thích và lời khuyên cho người dùng.
Vision Systems- Các hệ thống này hiểu, diễn giải và lĩnh hội đầu vào trực quan trên máy tính. Ví dụ,
Máy bay do thám chụp ảnh, được sử dụng để tìm ra thông tin không gian hoặc bản đồ của các khu vực.
Các bác sĩ sử dụng hệ thống chuyên gia lâm sàng để chẩn đoán cho bệnh nhân.
Cảnh sát sử dụng phần mềm máy tính có thể nhận dạng khuôn mặt của tội phạm với bức chân dung được lưu trữ do nghệ sĩ pháp y thực hiện.
Speech Recognition- Một số hệ thống thông minh có khả năng nghe và hiểu ngôn ngữ dưới dạng câu và ý nghĩa của chúng trong khi con người nói chuyện với nó. Nó có thể xử lý các trọng âm khác nhau, các từ lóng, tiếng ồn trong nền, thay đổi tiếng ồn của con người do lạnh, v.v.
Handwriting Recognition- Phần mềm nhận dạng chữ viết tay đọc văn bản được viết trên giấy bằng bút hoặc trên màn hình bằng bút cảm ứng. Nó có thể nhận ra hình dạng của các chữ cái và chuyển nó thành văn bản có thể chỉnh sửa.
Intelligent Robots- Robot có thể thực hiện các nhiệm vụ do con người giao. Chúng có các cảm biến để phát hiện dữ liệu vật lý từ thế giới thực như ánh sáng, nhiệt, nhiệt độ, chuyển động, âm thanh, va chạm và áp suất. Chúng có bộ xử lý hiệu quả, nhiều cảm biến và bộ nhớ khổng lồ, để thể hiện trí thông minh. Ngoài ra, họ có khả năng học hỏi từ những sai lầm của mình và họ có thể thích nghi với môi trường mới.
Lịch sử của AI
Đây là lịch sử của AI trong thế kỷ 20 -
| Năm | Milestone / Đổi mới |
|---|---|
| 1923 | Vở kịch của Karel Čapek có tên “Rô bốt đa năng của Rossum” (RUR) khởi chiếu tại London, lần đầu tiên sử dụng từ “rô bốt” trong tiếng Anh. |
| 1943 | Đặt nền móng cho mạng nơ-ron. |
| Năm 1945 | Isaac Asimov, một cựu sinh viên Đại học Columbia, đã đặt ra thuật ngữ Robotics . |
| 1950 | Alan Turing đã giới thiệu Bài kiểm tra Turing để đánh giá trí thông minh và được xuất bản Máy tính và trí thông minh. Claude Shannon đã xuất bản Phân tích chi tiết về Chơi cờ vua như một cuộc tìm kiếm. |
| Năm 1956 | John McCarthy đã đặt ra thuật ngữ Trí tuệ nhân tạo . Trình diễn chương trình AI đầu tiên đang chạy tại Đại học Carnegie Mellon. |
| 1958 | John McCarthy phát minh ra ngôn ngữ lập trình LISP cho AI. |
| Năm 1964 | Luận án của Danny Bobrow tại MIT cho thấy máy tính có thể hiểu ngôn ngữ tự nhiên đủ tốt để giải các bài toán đại số một cách chính xác. |
| 1965 | Joseph Weizenbaum tại MIT đã xây dựng ELIZA , một bài toán tương tác thực hiện cuộc đối thoại bằng tiếng Anh. |
| 1969 | Các nhà khoa học tại Viện Nghiên cứu Stanford đã phát triển Shakey , một robot, được trang bị khả năng vận động, nhận thức và giải quyết vấn đề. |
| Năm 1973 | Nhóm Người máy lắp ráp tại Đại học Edinburgh đã chế tạo Freddy , Người máy nổi tiếng người Scotland, có khả năng sử dụng thị giác để định vị và lắp ráp các mô hình. |
| 1979 | Xe tự hành điều khiển bằng máy tính đầu tiên, Stanford Cart, được chế tạo. |
| 1985 | Harold Cohen đã tạo ra và trình diễn chương trình vẽ, Aaron . |
| 1990 | Những tiến bộ lớn trong tất cả các lĩnh vực của AI -
|
| 1997 | Chương trình Deep Blue Chess đánh bại nhà vô địch cờ vua thế giới lúc bấy giờ, Garry Kasparov. |
| 2000 | Vật nuôi robot tương tác trở nên có sẵn trên thị trường. MIT trưng bày Kismet , một robot có khuôn mặt biểu lộ cảm xúc. Robot Nomad khám phá các vùng xa xôi của Nam Cực và xác định vị trí của các thiên thạch. |
Trong khi nghiên cứu về trí tuệ nhân tạo, bạn cần biết trí thông minh là gì. Chương này bao gồm Ý tưởng về trí thông minh, các loại và các thành phần của trí thông minh.
Thông minh là gì?
Khả năng của một hệ thống để tính toán, suy luận, nhận thức các mối quan hệ và phép loại suy, học hỏi kinh nghiệm, lưu trữ và truy xuất thông tin từ bộ nhớ, giải quyết vấn đề, hiểu các ý tưởng phức tạp, sử dụng ngôn ngữ tự nhiên thành thạo, phân loại, khái quát hóa và thích ứng với các tình huống mới.
Các loại trí thông minh
Theo mô tả của Howard Gardner, một nhà tâm lý học về phát triển người Mỹ, Trí thông minh có nhiều mặt -
| Sự thông minh | Sự miêu tả | Thí dụ |
|---|---|---|
| Trí tuệ ngôn ngữ | Khả năng nói, nhận biết và sử dụng các cơ chế âm vị học (âm thanh lời nói), cú pháp (ngữ pháp) và ngữ nghĩa (ý nghĩa). | Người tường thuật, Người hùng biện |
| Trí tuệ âm nhạc | Khả năng tạo ra, giao tiếp và hiểu ý nghĩa của âm thanh, hiểu cao độ, nhịp điệu. | Nhạc sĩ, Ca sĩ, Nhà soạn nhạc |
| Trí thông minh logic-toán học | Khả năng sử dụng và hiểu các mối quan hệ khi không có hành động hoặc đối tượng. Hiểu các ý tưởng phức tạp và trừu tượng. | Nhà toán học, nhà khoa học |
| Trí tuệ không gian | Khả năng nhận thức thông tin hình ảnh hoặc thông tin không gian, thay đổi nó và tạo lại hình ảnh trực quan mà không cần tham chiếu đến các đối tượng, tạo hình ảnh 3D và di chuyển và xoay chúng. | Người đọc bản đồ, Phi hành gia, Nhà vật lý |
| Trí thông minh thể chất | Khả năng sử dụng toàn bộ hoặc một phần cơ thể để giải quyết các vấn đề hoặc sản phẩm thời trang, kiểm soát các kỹ năng vận động tinh và thô cũng như thao tác các đồ vật. | Người chơi, Vũ công |
| Tình báo intrapersonal | Khả năng phân biệt giữa cảm xúc, ý định và động cơ của chính mình. | Gautam Buddhha |
| Trí thông minh giữa các cá nhân | Khả năng nhận biết và phân biệt cảm xúc, niềm tin và ý định của người khác. | Người giao tiếp đại chúng, Người phỏng vấn |
Bạn có thể nói một cái máy hay một hệ thống là artificially intelligent khi nó được trang bị ít nhất một và nhiều nhất là tất cả các tính năng thông minh trong đó.
Thông minh bao gồm những gì?
Trí thông minh là vô hình. Nó bao gồm -
- Reasoning
- Learning
- Giải quyết vấn đề
- Perception
- Trí tuệ ngôn ngữ

Hãy để chúng tôi đi qua tất cả các thành phần ngắn gọn -
Reasoning- Đây là tập hợp các quy trình cho phép chúng tôi cung cấp cơ sở để phán đoán, đưa ra quyết định và dự đoán. Có hai loại rộng rãi -
| Lập luận quy nạp | Suy luận suy luận |
|---|---|
| Nó tiến hành các quan sát cụ thể để đưa ra các tuyên bố chung chung. | Nó bắt đầu với một tuyên bố chung và xem xét các khả năng để đi đến một kết luận cụ thể, hợp lý. |
| Ngay cả khi tất cả các tiền đề đều đúng trong một phát biểu, thì suy luận quy nạp vẫn cho phép kết luận là sai. | Nếu điều gì đó đúng với một lớp sự vật nói chung, thì nó cũng đúng cho tất cả các thành viên của lớp đó. |
| Ví dụ - "Nita là một giáo viên. Nita rất chăm học. Do đó, Tất cả các giáo viên đều chăm học." | Ví dụ - "Tất cả phụ nữ trên 60 tuổi đều là bà. Shalini 65 tuổi. Do đó, Shalini là bà". |
Learning- Là hoạt động đạt được kiến thức hoặc kỹ năng bằng cách học tập, thực hành, được dạy hoặc trải nghiệm điều gì đó. Học tập nâng cao nhận thức của các đối tượng nghiên cứu.
Khả năng học tập được sở hữu bởi con người, một số động vật và các hệ thống hỗ trợ AI. Học tập được phân loại là -
Auditory Learning- Đó là học bằng cách nghe và nghe. Ví dụ, học sinh nghe các bài giảng ghi âm.
Episodic Learning- Để học bằng cách ghi nhớ chuỗi sự kiện mà một người đã chứng kiến hoặc trải qua. Đây là tuyến tính và có trật tự.
Motor Learning- Đó là học bằng chuyển động chính xác của các cơ. Ví dụ, chọn đồ vật, Viết, v.v.
Observational Learning- Học hỏi bằng cách quan sát và bắt chước người khác. Ví dụ, trẻ cố gắng học bằng cách bắt chước bố mẹ.
Perceptual Learning- Nó đang học cách nhận biết những kích thích mà người ta đã thấy trước đây. Ví dụ, xác định và phân loại các đối tượng và tình huống.
Relational Learning- Nó liên quan đến việc học cách phân biệt giữa các kích thích khác nhau trên cơ sở các thuộc tính quan hệ, thay vì các thuộc tính tuyệt đối. Ví dụ: Thêm muối 'ít hơn một chút' vào thời điểm nấu khoai tây đã trở nên mặn lần trước, khi nấu chín với thêm một thìa muối.
Spatial Learning - Đó là học thông qua các kích thích thị giác như hình ảnh, màu sắc, bản đồ, v.v ... Ví dụ, Một người có thể tạo ra lộ trình trong đầu trước khi thực sự đi theo con đường.
Stimulus-Response Learning- Nó đang học cách thực hiện một hành vi cụ thể khi có một tác nhân kích thích nào đó. Ví dụ, một con chó dỏng tai lên khi nghe thấy tiếng chuông cửa.
Problem Solving - Đó là quá trình một người nhận thức và cố gắng đạt được một giải pháp mong muốn từ tình huống hiện tại bằng cách đi theo một con đường nào đó, bị chặn bởi những rào cản đã biết hoặc chưa biết.
Giải quyết vấn đề cũng bao gồm decision making, là quá trình lựa chọn phương án thay thế phù hợp nhất trong số nhiều phương án thay thế để đạt được mục tiêu mong muốn có sẵn.
Perception - Là quá trình thu nhận, giải thích, lựa chọn và tổ chức thông tin cảm tính.
Nhận thức giả định sensing. Ở người, nhận thức được hỗ trợ bởi các cơ quan cảm giác. Trong lĩnh vực của AI, cơ chế nhận thức đặt dữ liệu mà các cảm biến thu được lại với nhau theo cách có ý nghĩa.
Linguistic Intelligence- Đó là khả năng sử dụng, hiểu, nói và viết ngôn ngữ nói và viết. Nó quan trọng trong giao tiếp giữa các cá nhân.
Sự khác biệt giữa trí tuệ con người và máy móc
Con người nhận thức theo khuôn mẫu trong khi máy móc nhận thức bằng tập hợp các quy tắc và dữ liệu.
Con người lưu trữ và nhớ lại thông tin theo các mẫu, máy móc làm điều đó bằng các thuật toán tìm kiếm. Ví dụ: số 40404040 rất dễ nhớ, dễ lưu trữ và dễ nhớ vì mẫu của nó rất đơn giản.
Con người có thể tìm ra vật thể hoàn chỉnh ngay cả khi một số phần của nó bị thiếu hoặc bị bóp méo; ngược lại máy móc không thể làm điều đó một cách chính xác.
Lĩnh vực của trí tuệ nhân tạo rất lớn về chiều rộng và chiều rộng. Trong khi tiếp tục, chúng tôi xem xét các lĩnh vực nghiên cứu thịnh vượng và phổ biến rộng rãi trong lĩnh vực AI -

Nhận dạng giọng nói và giọng nói
Cả hai thuật ngữ này đều phổ biến trong lĩnh vực robot, hệ thống chuyên gia và xử lý ngôn ngữ tự nhiên. Mặc dù các thuật ngữ này được sử dụng thay thế cho nhau, nhưng mục tiêu của chúng là khác nhau.
| Nhận dạng giọng nói | Nhận diện giọng nói |
|---|---|
| Nhận dạng giọng nói nhằm mục đích hiểu và lĩnh hội WHAT đã được nói. | Mục tiêu của nhận dạng giọng nói là nhận ra WHO đang nói. |
| Nó được sử dụng trong tính toán rảnh tay, bản đồ hoặc điều hướng menu. | Nó được sử dụng để xác định một người bằng cách phân tích âm điệu, cao độ giọng nói và trọng âm của người đó, v.v. |
| Máy không cần đào tạo về Nhận dạng giọng nói vì nó không phụ thuộc vào loa. | Hệ thống công nhận này cần được đào tạo vì nó được định hướng bởi con người. |
| Hệ thống Nhận dạng giọng nói độc lập với người nói rất khó phát triển. | Hệ thống Nhận dạng giọng nói phụ thuộc vào người nói tương đối dễ phát triển. |
Hoạt động của hệ thống nhận dạng giọng nói và giọng nói
Đầu vào của người dùng được nói tại micrô sẽ chuyển đến thẻ âm thanh của hệ thống. Bộ chuyển đổi biến tín hiệu tương tự thành tín hiệu số tương đương để xử lý giọng nói. Cơ sở dữ liệu được sử dụng để so sánh các mẫu âm thanh để nhận ra các từ. Cuối cùng, một phản hồi ngược lại được đưa ra cho cơ sở dữ liệu.
Văn bản ngôn ngữ nguồn này trở thành đầu vào cho Công cụ dịch, công cụ chuyển đổi nó thành văn bản ngôn ngữ đích. Chúng được hỗ trợ với GUI tương tác, cơ sở dữ liệu từ vựng lớn, v.v.
Ứng dụng thực tế của các khu vực nghiên cứu
Có một loạt các ứng dụng mà AI đang phục vụ những người bình thường trong cuộc sống hàng ngày của họ -
| Sr.No. | Khu vực nghiên cứu | Ứng dụng trong cuộc sống thực |
|---|---|---|
| 1 | Expert Systems Ví dụ - Hệ thống theo dõi chuyến bay, Hệ thống lâm sàng. |

|
| 2 | Natural Language Processing Ví dụ: Tính năng Google Hiện hành, nhận dạng giọng nói, Đầu ra giọng nói tự động. |

|
| 3 | Neural Networks Ví dụ - Hệ thống nhận dạng khuôn mẫu như nhận dạng khuôn mặt, nhận dạng ký tự, nhận dạng chữ viết tay. |

|
| 4 | Robotics Ví dụ - Robot công nghiệp để di chuyển, phun, sơn, kiểm tra độ chính xác, khoan, làm sạch, sơn phủ, chạm khắc, v.v. |

|
| 5 | Fuzzy Logic Systems Ví dụ - Điện tử gia dụng, ô tô, v.v. |

|
Phân loại nhiệm vụ của AI
Lĩnh vực của AI được phân loại thành Formal tasks, Mundane tasks, và Expert tasks.

| Miền nhiệm vụ của trí tuệ nhân tạo | ||
|---|---|---|
| Nhiệm vụ Mundane (Bình thường) | Nhiệm vụ chính thức | Nhiệm vụ chuyên gia |
Nhận thức
|
|
|
Xử lý ngôn ngữ tự nhiên
|
Trò chơi
|
Phân tích khoa học |
| Nhận thức chung | xác minh | Phân tích tài chính |
| Lý luận | Chứng minh định lý | Chẩn đoán y tế |
| Lập kế hoạch | Sáng tạo | |
Người máy
|
||
Con người học mundane (ordinary) taskskể từ khi họ chào đời. Họ học bằng nhận thức, nói, sử dụng ngôn ngữ và đầu máy. Họ học Nhiệm vụ chính thức và Nhiệm vụ chuyên gia sau đó, theo thứ tự đó.
Đối với con người, các nhiệm vụ trần tục là dễ học nhất. Điều này cũng được coi là đúng trước khi cố gắng thực hiện các tác vụ trần tục trong máy móc. Trước đó, tất cả công việc của AI đều tập trung vào lĩnh vực tác vụ trần tục.
Sau đó, hóa ra máy đòi hỏi nhiều kiến thức hơn, biểu diễn kiến thức phức tạp và các thuật toán phức tạp để xử lý các tác vụ thông thường. Đây là lý dowhy AI work is more prospering in the Expert Tasks domain bây giờ, vì miền nhiệm vụ chuyên gia cần kiến thức chuyên môn mà không có kiến thức thông thường, có thể dễ dàng hơn để trình bày và xử lý.
Một hệ thống AI bao gồm một tác nhân và môi trường của nó. Các tác nhân hoạt động trong môi trường của chúng. Môi trường có thể chứa các tác nhân khác.
Tác nhân và Môi trường là gì?
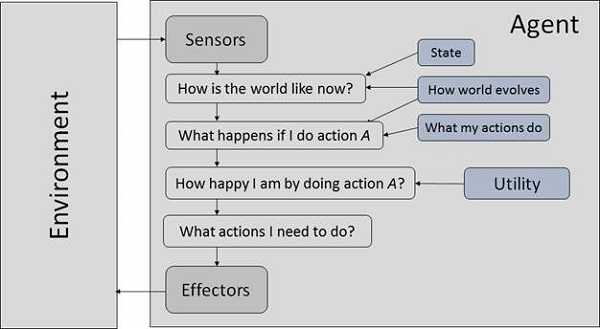
An agent là bất cứ thứ gì có thể nhận thức được môi trường của nó thông qua sensors và hành động dựa trên môi trường đó thông qua effectors.
A human agent có các cơ quan cảm giác như mắt, tai, mũi, lưỡi và da song song với các cảm biến, và các cơ quan khác như tay, chân, miệng để tạo hiệu ứng.
A robotic agent thay thế máy ảnh và công cụ tìm phạm vi hồng ngoại cho các cảm biến, cũng như các động cơ và bộ truyền động khác nhau cho các hiệu ứng.
A software agent có các chuỗi bit được mã hóa làm chương trình và hành động của nó.

Thuật ngữ đại lý
Performance Measure of Agent - Đó là tiêu chí, quyết định mức độ thành công của một đại lý.
Behavior of Agent - Là hành động mà tác nhân thực hiện sau bất kỳ chuỗi khái niệm nhất định nào.
Percept - Đó là đầu vào tri giác của tác nhân tại một trường hợp nhất định.
Percept Sequence - Đó là lịch sử của tất cả những gì mà một đặc vụ đã nhận ra cho đến nay.
Agent Function - Nó là một bản đồ từ trình tự giới luật đến một hành động.
Tính hợp lý
Tính hợp lý không là gì khác ngoài trạng thái hợp lý, hợp lý và có óc phán đoán tốt.
Tính hợp lý liên quan đến các hành động và kết quả mong đợi tùy thuộc vào những gì tác nhân đã nhận thức. Thực hiện các hành động với mục đích thu được thông tin hữu ích là một phần quan trọng của tính hợp lý.
Tác nhân lý tưởng là gì?
Tác nhân hợp lý lý tưởng là tác nhân có khả năng thực hiện các hành động dự kiến để tối đa hóa thước đo hiệu suất của nó, trên cơ sở -
- Trình tự nhận thức của nó
- Cơ sở kiến thức tích hợp của nó
Tính hợp lý của một tác nhân phụ thuộc vào những điều sau:
Các performance measures, yếu tố quyết định mức độ thành công.
Đặc vụ Percept Sequence cho đến bây giờ.
Của đại lý prior knowledge about the environment.
Các actions mà đại lý có thể thực hiện.
Tác nhân hợp lý luôn thực hiện hành động đúng, trong đó hành động đúng có nghĩa là hành động khiến tác nhân thành công nhất trong chuỗi nhận thức đã cho. Vấn đề mà đại lý giải quyết được đặc trưng bởi Đo hiệu suất, Môi trường, Thiết bị truyền động và Cảm biến (PEAS).
Cấu trúc của các tác nhân thông minh
Cấu trúc của Agent có thể được xem như:
- Agent = Architecture + Agent Program
- Architecture = máy móc mà một tác nhân thực thi.
- Chương trình đại lý = triển khai một chức năng đại lý.
Tác nhân phản xạ đơn giản
- Họ chỉ chọn hành động dựa trên nhận thức hiện tại.
- Chúng chỉ hợp lý nếu một quyết định đúng được đưa ra chỉ dựa trên cơ sở của giới luật hiện hành.
- Môi trường của chúng hoàn toàn có thể quan sát được.
Condition-Action Rule - Nó là một quy tắc ánh xạ một trạng thái (điều kiện) đến một hành động.

Tác nhân phản xạ dựa trên mô hình
Họ sử dụng một mô hình của thế giới để lựa chọn hành động của họ. Họ duy trì một trạng thái bên trong.
Model - kiến thức về “cách mọi thứ xảy ra trên thế giới”.
Internal State - Nó là một đại diện của các khía cạnh chưa được quan sát của trạng thái hiện tại tùy thuộc vào lịch sử cảm nhận.
Updating the state requires the information about −
- Làm thế nào thế giới phát triển.
- Hành động của đại lý ảnh hưởng đến thế giới như thế nào.

Tác nhân dựa trên mục tiêu
Họ chọn hành động của mình để đạt được mục tiêu. Phương pháp tiếp cận dựa trên mục tiêu linh hoạt hơn phương pháp phản xạ vì kiến thức hỗ trợ một quyết định được mô hình hóa rõ ràng, do đó cho phép sửa đổi.
Goal - Đó là sự mô tả các tình huống mong muốn.

Đại lý dựa trên tiện ích
Họ chọn các hành động dựa trên sở thích (tiện ích) cho mỗi trạng thái.
Mục tiêu không đủ khi -
Có những mục tiêu mâu thuẫn nhau, trong đó chỉ có một số mục tiêu có thể đạt được.
Mục tiêu có một số điều không chắc chắn trong việc đạt được và bạn cần cân nhắc khả năng thành công với tầm quan trọng của mục tiêu.
Bản chất của Môi trường
Một số chương trình hoạt động trong artificial environment được giới hạn trong đầu vào bàn phím, cơ sở dữ liệu, hệ thống tệp máy tính và đầu ra ký tự trên màn hình.
Ngược lại, một số tác nhân phần mềm (robot phần mềm hoặc softbots) tồn tại trong các miền softbots phong phú, không giới hạn. Trình mô phỏng cóvery detailed, complex environment. Tác nhân phần mềm cần chọn từ một loạt các hành động trong thời gian thực. Một softbot được thiết kế để quét các sở thích trực tuyến của khách hàng và hiển thị các mặt hàng thú vị cho khách hàng hoạt động trongreal cũng như một artificial Môi trường.
Nổi tiếng nhất artificial environment là Turing Test environment, trong đó một tác nhân thực và tác nhân nhân tạo khác được thử nghiệm trên mặt bằng bình đẳng. Đây là một môi trường rất thách thức vì rất khó cho một tác nhân phần mềm cũng như con người.
Kiểm tra Turing
Sự thành công của một hành vi thông minh của một hệ thống có thể được đo lường bằng Kiểm tra Turing.
Hai người và một máy được đánh giá tham gia thử nghiệm. Trong số hai người, một người đóng vai trò người thử nghiệm. Mỗi người trong số họ ngồi trong các phòng khác nhau. Người thử nghiệm không biết ai là máy và ai là người. Anh ta thẩm vấn các câu hỏi bằng cách nhập và gửi chúng đến cả hai bộ phận thông minh, nơi anh ta nhận được các câu trả lời đã đánh máy.
Thử nghiệm này nhằm mục đích đánh lừa người thử nghiệm. Nếu người kiểm tra không xác định được phản ứng của máy từ phản ứng của con người, thì máy được cho là thông minh.
Thuộc tính của môi trường
Môi trường có nhiều thuộc tính -
Discrete / Continuous- Nếu có một số hạn chế các trạng thái riêng biệt, xác định rõ ràng, môi trường rời rạc (Ví dụ: cờ vua); nếu không nó là liên tục (Ví dụ: lái xe).
Observable / Partially Observable- Nếu có thể xác định được trạng thái hoàn chỉnh của môi trường tại mỗi thời điểm từ các cảm nhận mà nó có thể quan sát được; nếu không thì nó chỉ có thể quan sát được một phần.
Static / Dynamic- Nếu môi trường không thay đổi trong khi một tác nhân đang hoạt động, thì nó là tĩnh; nếu không thì nó là động.
Single agent / Multiple agents - Môi trường có thể chứa các tác nhân khác có thể cùng loại hoặc khác loại với tác nhân.
Accessible / Inaccessible - Nếu bộ máy cảm quan của tác nhân có thể tiếp cận được trạng thái hoàn chỉnh của môi trường, thì tác nhân đó có thể tiếp cận được môi trường.
Deterministic / Non-deterministic- Nếu trạng thái tiếp theo của môi trường được xác định hoàn toàn bởi trạng thái hiện tại và các hành động của tác nhân thì môi trường là xác định; nếu không nó là không xác định.
Episodic / Non-episodic- Trong môi trường nhiều tập, mỗi tập bao gồm tác nhân nhận thức và sau đó hành động. Chất lượng của hành động phụ thuộc vào chính tập phim. Các tập tiếp theo không phụ thuộc vào các hành động trong các tập trước. Môi trường Episodic đơn giản hơn nhiều vì tác nhân không cần phải suy nghĩ trước.
Tìm kiếm là kỹ thuật giải quyết vấn đề phổ biến trong AI. Có một số trò chơi một người chơi như trò chơi xếp hình, Sudoku, ô chữ, v.v. Các thuật toán tìm kiếm giúp bạn tìm kiếm một vị trí cụ thể trong các trò chơi đó.
Vấn đề tìm đường cho tác nhân đơn lẻ
Các trò chơi như câu đố 3X3 tám ô, 4X4 mười lăm ô và 5X5 hai mươi bốn ô là những thử thách tìm đường cho một tác nhân. Chúng bao gồm một ma trận các ô với một ô trống. Người chơi được yêu cầu sắp xếp các ô bằng cách trượt một ô theo chiều dọc hoặc chiều ngang vào một khoảng trống với mục đích hoàn thành một số mục tiêu.
Các ví dụ khác về các bài toán tìm đường đại lý đơn lẻ là Bài toán người bán hàng đi du lịch, Khối lập phương Rubik và Chứng minh định lý.
Thuật ngữ Tìm kiếm
Problem Space- Đó là môi trường mà cuộc tìm kiếm diễn ra. (Một tập hợp các trạng thái và tập hợp các toán tử để thay đổi các trạng thái đó)
Problem Instance - Đó là Trạng thái ban đầu + Trạng thái mục tiêu.
Problem Space Graph- Nó thể hiện trạng thái vấn đề. Các trạng thái được hiển thị bằng các nút và các toán tử được hiển thị bằng các cạnh.
Depth of a problem - Độ dài của đường đi ngắn nhất hoặc chuỗi toán tử ngắn nhất từ Trạng thái ban đầu đến trạng thái mục tiêu.
Space Complexity - Số lượng nút tối đa được lưu trữ trong bộ nhớ.
Time Complexity - Số lượng nút tối đa được tạo.
Admissibility - Một tính chất của thuật toán để luôn tìm ra một giải pháp tối ưu.
Branching Factor - Số nút con trung bình trong đồ thị không gian bài toán.
Depth - Độ dài của đường đi ngắn nhất từ trạng thái ban đầu đến trạng thái mục tiêu.
Chiến lược tìm kiếm Brute-Force
Chúng đơn giản nhất, vì chúng không cần bất kỳ kiến thức nào về miền cụ thể. Chúng hoạt động tốt với một số trạng thái có thể có.
Yêu cầu -
- Mô tả trạng thái
- Một tập hợp các toán tử hợp lệ
- Trạng thái ban đầu
- Mô tả trạng thái mục tiêu
Breadth-First Search
Nó bắt đầu từ nút gốc, khám phá các nút lân cận trước và chuyển sang các nút lân cận cấp độ tiếp theo. Nó tạo ra từng cây một cho đến khi tìm ra giải pháp. Nó có thể được thực hiện bằng cách sử dụng cấu trúc dữ liệu hàng đợi FIFO. Phương pháp này cung cấp đường dẫn ngắn nhất đến giải pháp.
Nếu branching factor(số nút con trung bình của một nút nhất định) = b và độ sâu = d, khi đó số nút ở mức d = b d .
Tổng số nút được tạo trong trường hợp xấu nhất là b + b 2 + b 3 +… + b d .
Disadvantage- Vì mỗi mức nút được lưu để tạo nút tiếp theo, nên nó tiêu tốn rất nhiều dung lượng bộ nhớ. Yêu cầu không gian để lưu trữ các nút là cấp số nhân.
Độ phức tạp của nó phụ thuộc vào số lượng nút. Nó có thể kiểm tra các nút trùng lặp.

Tìm kiếm sâu-đầu tiên
Nó được thực hiện trong đệ quy với cấu trúc dữ liệu ngăn xếp LIFO. Nó tạo ra cùng một tập hợp các nút như phương thức Breadth-First, chỉ khác thứ tự.
Vì các nút trên đường đơn được lưu trữ trong mỗi lần lặp từ nút gốc đến nút lá, yêu cầu không gian để lưu trữ các nút là tuyến tính. Với hệ số phân nhánh b và độ sâu là m , không gian lưu trữ là bm.
Disadvantage- Thuật toán này có thể không kết thúc và tiếp tục vô hạn trên một con đường. Giải pháp cho vấn đề này là chọn độ sâu cắt. Nếu điểm cắt lý tưởng là d và nếu điểm cắt đã chọn nhỏ hơn d , thì thuật toán này có thể thất bại. Nếu giới hạn được chọn lớn hơn d , thì thời gian thực hiện sẽ tăng lên.
Độ phức tạp của nó phụ thuộc vào số lượng đường dẫn. Nó không thể kiểm tra các nút trùng lặp.

Tìm kiếm hai chiều
Nó tìm kiếm về phía trước từ trạng thái ban đầu và ngược lại từ trạng thái mục tiêu cho đến khi cả hai gặp nhau để xác định một trạng thái chung.
Đường dẫn từ trạng thái ban đầu được nối với đường dẫn nghịch đảo từ trạng thái mục tiêu. Mỗi tìm kiếm chỉ được thực hiện tối đa một nửa tổng số đường dẫn.
Tìm kiếm chi phí thống nhất
Việc sắp xếp được thực hiện làm tăng chi phí của đường dẫn đến một nút. Nó luôn luôn mở rộng nút có chi phí thấp nhất. Nó giống với tìm kiếm Breadth First nếu mỗi chuyển đổi có cùng chi phí.
Nó khám phá các con đường theo thứ tự tăng dần của chi phí.
Disadvantage- Có thể có nhiều đường đi dài với chi phí ≤ C *. Tìm kiếm Chi phí thống nhất phải khám phá tất cả.
Độ sâu lặp đi lặp lại-Tìm kiếm đầu tiên
Nó thực hiện tìm kiếm theo chiều sâu đến cấp độ 1, bắt đầu lại, thực hiện tìm kiếm theo chiều sâu hoàn chỉnh đến cấp độ 2 và tiếp tục theo cách đó cho đến khi tìm ra giải pháp.
Nó không bao giờ tạo một nút cho đến khi tất cả các nút thấp hơn được tạo. Nó chỉ lưu một chồng nút. Thuật toán kết thúc khi nó tìm thấy lời giải ở độ sâu d . Số nút được tạo ra ở độ sâu d là b d và ở độ sâu d-1 là b d-1.
So sánh các thuật toán phức tạp khác nhau
Hãy để chúng tôi xem hiệu suất của các thuật toán dựa trên các tiêu chí khác nhau -
| Tiêu chuẩn | Bề rộng đầu tiên | Độ sâu đầu tiên | Hai chiều | Chi phí thống nhất | Đào sâu tương tác |
|---|---|---|---|---|---|
| Thời gian | b d | b m | b d / 2 | b d | b d |
| Không gian | b d | b m | b d / 2 | b d | b d |
| Sự tối ưu | Đúng | Không | Đúng | Đúng | Đúng |
| Sự hoàn chỉnh | Đúng | Không | Đúng | Đúng | Đúng |
Các chiến lược tìm kiếm được thông báo (Heuristic)
Để giải quyết các vấn đề lớn với số lượng lớn các trạng thái có thể xảy ra, kiến thức cụ thể về vấn đề cần được bổ sung để tăng hiệu quả của thuật toán tìm kiếm.
Các chức năng đánh giá Heuristic
Họ tính toán chi phí của con đường tối ưu giữa hai trạng thái. Một hàm heuristic cho trò chơi xếp hình trượt được tính bằng cách đếm số lần di chuyển mà mỗi ô thực hiện từ trạng thái mục tiêu của nó và cộng số lần di chuyển này cho tất cả các ô.
Tìm kiếm Heuristic thuần túy
Nó mở rộng các nút theo thứ tự các giá trị heuristic của chúng. Nó tạo ra hai danh sách, một danh sách đóng cho các nút đã được mở rộng và một danh sách mở cho các nút đã tạo nhưng chưa mở rộng.
Trong mỗi lần lặp, một nút có giá trị heuristic tối thiểu được mở rộng, tất cả các nút con của nó được tạo và đặt trong danh sách đóng. Sau đó, hàm heuristic được áp dụng cho các nút con và chúng được đặt trong danh sách mở theo giá trị heuristic của chúng. Những con đường ngắn hơn được lưu và những con đường dài hơn sẽ bị loại bỏ.
A * Tìm kiếm
Đây là hình thức tìm kiếm Tốt nhất được biết đến nhiều nhất. Nó tránh mở rộng các con đường vốn đã đắt đỏ, nhưng mở rộng hầu hết các con đường hứa hẹn trước.
f (n) = g (n) + h (n), trong đó
- g (n) chi phí (cho đến nay) để đến được nút
- h (n) chi phí ước tính để đi từ nút đến mục tiêu
- f (n) tổng chi phí ước tính của đường dẫn từ n đến mục tiêu. Nó được thực hiện bằng cách sử dụng hàng đợi ưu tiên bằng cách tăng f (n).
Greedy Best First Search
Nó mở rộng nút được ước tính là gần nhất với mục tiêu. Nó mở rộng các nút dựa trên f (n) = h (n). Nó được thực hiện bằng cách sử dụng hàng đợi ưu tiên.
Disadvantage- Nó có thể bị kẹt trong các vòng lặp. Nó không phải là tối ưu.
Thuật toán tìm kiếm cục bộ
Họ bắt đầu từ một giải pháp tương lai và sau đó chuyển sang một giải pháp lân cận. Họ có thể trả về một giải pháp hợp lệ ngay cả khi nó bị gián đoạn bất kỳ lúc nào trước khi chúng kết thúc.
Tìm kiếm leo đồi
Nó là một thuật toán lặp lại bắt đầu với một giải pháp tùy ý cho một vấn đề và cố gắng tìm ra giải pháp tốt hơn bằng cách thay đổi từng bước một thành phần của giải pháp. Nếu sự thay đổi tạo ra một giải pháp tốt hơn, một sự thay đổi gia tăng được coi là một giải pháp mới. Quá trình này được lặp lại cho đến khi không có cải tiến nào nữa.
chức năng Hill-Climbing (sự cố), trả về trạng thái là mức tối đa cục bộ.
inputs: problem, a problem
local variables: current, a node
neighbor, a node
current <-Make_Node(Initial-State[problem])
loop
do neighbor <- a highest_valued successor of current
if Value[neighbor] ≤ Value[current] then
return State[current]
current <- neighbor
endDisadvantage - Thuật toán này không hoàn chỉnh, cũng không tối ưu.
Tìm kiếm chùm cục bộ
Trong thuật toán này, nó chứa k số trạng thái tại bất kỳ thời điểm nào. Khi bắt đầu, các trạng thái này được tạo ngẫu nhiên. Kế thừa của k trạng thái này được tính với sự trợ giúp của hàm mục tiêu. Nếu bất kỳ giá trị kế thừa nào là giá trị lớn nhất của hàm mục tiêu, thì thuật toán dừng lại.
Nếu không, (k trạng thái ban đầu và k số trạng thái kế tiếp của các trạng thái = 2k) trạng thái được đặt trong một nhóm. Pool sau đó được sắp xếp theo số. K trạng thái cao nhất được chọn làm trạng thái ban đầu mới. Quá trình này tiếp tục cho đến khi đạt đến giá trị lớn nhất.
hàm BeamSearch ( vấn đề, k ), trả về một trạng thái giải pháp.
start with k randomly generated states
loop
generate all successors of all k states
if any of the states = solution, then return the state
else select the k best successors
endỦ mô phỏng
Ủ là quá trình làm nóng và làm lạnh một kim loại để thay đổi cấu trúc bên trong nhằm thay đổi các đặc tính vật lý của nó. Khi kim loại nguội đi, cấu trúc mới của nó được giữ lại và kim loại vẫn giữ được các đặc tính mới thu được. Trong quá trình ủ mô phỏng, nhiệt độ được giữ ở mức thay đổi.
Ban đầu chúng tôi đặt nhiệt độ cao và sau đó để nhiệt độ 'nguội' từ từ khi thuật toán tiến hành. Khi nhiệt độ cao, thuật toán được phép chấp nhận các giải pháp kém hơn với tần số cao.
Khởi đầu
- Khởi tạo k = 0; L = số nguyên của biến;
- Từ i → j, tìm kiếm hiệu suất Δ.
- If Δ <= 0 then accept else if exp (-Δ / T (k))> random (0,1) then accept;
- Lặp lại các bước 1 và 2 cho các bước L (k).
- k = k + 1;
Lặp lại các bước từ 1 đến 4 cho đến khi các tiêu chí được đáp ứng.
Kết thúc
Vấn đề nhân viên bán hàng đi du lịch
Trong thuật toán này, mục tiêu là tìm một chuyến tham quan chi phí thấp bắt đầu từ một thành phố, thăm tất cả các thành phố trên đường bay chính xác một lần và kết thúc tại cùng một thành phố xuất phát.
Start
Find out all (n -1)! Possible solutions, where n is the total number of cities.
Determine the minimum cost by finding out the cost of each of these (n -1)! solutions.
Finally, keep the one with the minimum cost.
end
Hệ thống logic mờ (FLS) tạo ra đầu ra có thể chấp nhận được nhưng xác định để đáp ứng với đầu vào không đầy đủ, không rõ ràng, bị bóp méo hoặc không chính xác (mờ).
Logic mờ là gì?
Logic mờ (FL) là một phương pháp lập luận giống với suy luận của con người. Cách tiếp cận của FL bắt chước cách ra quyết định của con người liên quan đến tất cả các khả năng trung gian giữa các giá trị kỹ thuật số CÓ và KHÔNG.
Khối logic thông thường mà máy tính có thể hiểu được nhận đầu vào chính xác và tạo ra đầu ra xác định là TRUE hoặc FALSE, tương đương với YES hoặc NO của con người.
Người phát minh ra logic mờ, Lotfi Zadeh, đã nhận xét rằng không giống như máy tính, việc ra quyết định của con người bao gồm một loạt các khả năng giữa CÓ và KHÔNG, chẳng hạn như -
| CHẮC CHẮN CÓ |
| CÓ THỂ CÓ |
| KHÔNG THỂ NÓI |
| CÓ THỂ KHÔNG |
| CHẮC CHẮN LÀ KHÔNG |
Logic mờ hoạt động trên các mức khả năng của đầu vào để đạt được đầu ra xác định.
Thực hiện
Nó có thể được thực hiện trong các hệ thống với nhiều kích cỡ và khả năng khác nhau, từ các bộ điều khiển vi mô nhỏ đến các hệ thống điều khiển máy trạm lớn, được nối mạng.
Nó có thể được thực hiện trong phần cứng, phần mềm hoặc kết hợp cả hai.
Tại sao Logic mờ?
Logic mờ rất hữu ích cho các mục đích thương mại và thực tế.
- Nó có thể kiểm soát máy móc và các sản phẩm tiêu dùng.
- Nó có thể không đưa ra lý luận chính xác, nhưng có thể chấp nhận được.
- Logic mờ giúp đối phó với sự không chắc chắn trong kỹ thuật.
Kiến trúc hệ thống logic mờ
Nó có bốn phần chính như hình:
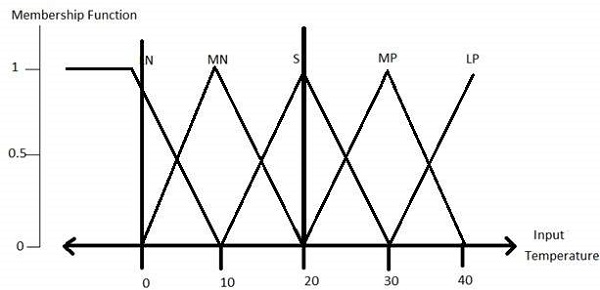
Fuzzification Module- Nó biến đổi các đầu vào của hệ thống, là các số rõ nét, thành các tập mờ. Nó chia tín hiệu đầu vào thành năm bước như -
| LP | x là dương lớn |
| MP | x là Trung bình Tích cực |
| S | x là nhỏ |
| MN | x là Âm trung bình |
| LN | x là âm lớn |
Knowledge Base - Nó lưu trữ các quy tắc IF-THEN do các chuyên gia cung cấp.
Inference Engine - Nó mô phỏng quá trình suy luận của con người bằng cách đưa ra suy luận mờ trên các đầu vào và quy tắc IF-THEN.
Defuzzification Module - Nó biến đổi tập mờ thu được bởi công cụ suy luận thành một giá trị rõ nét.

Các membership functions work on tập mờ của các biến.
Chức năng thành viên
Các hàm thành viên cho phép bạn định lượng thuật ngữ ngôn ngữ và biểu diễn một tập mờ bằng đồ thị. Amembership functionđối với một tập mờ A trên vũ trụ của diễn ngôn X được định nghĩa là μ A : X → [0,1].
Ở đây, mỗi phần tử của X được ánh xạ tới một giá trị từ 0 đến 1. Nó được gọi làmembership value hoặc là degree of membership. Nó định lượng mức độ thành viên của phần tử trong X vào tập mờ A .
- trục x đại diện cho vũ trụ của diễn ngôn.
- trục y đại diện cho các bậc thành viên trong khoảng [0, 1].
Có thể có nhiều hàm thành viên áp dụng để làm mờ một giá trị số. Các hàm thành viên đơn giản được sử dụng vì việc sử dụng các hàm phức tạp không làm tăng thêm độ chính xác trong đầu ra.
Tất cả các chức năng thành viên cho LP, MP, S, MN, và LN được hiển thị như dưới đây -

Các hình dạng hàm liên thuộc tam giác là phổ biến nhất trong số các hình dạng hàm liên thuộc khác như hình thang, singleton và Gaussian.
Ở đây, đầu vào cho bộ tạo sóng 5 mức thay đổi từ -10 volt đến +10 volt. Do đó đầu ra tương ứng cũng thay đổi.
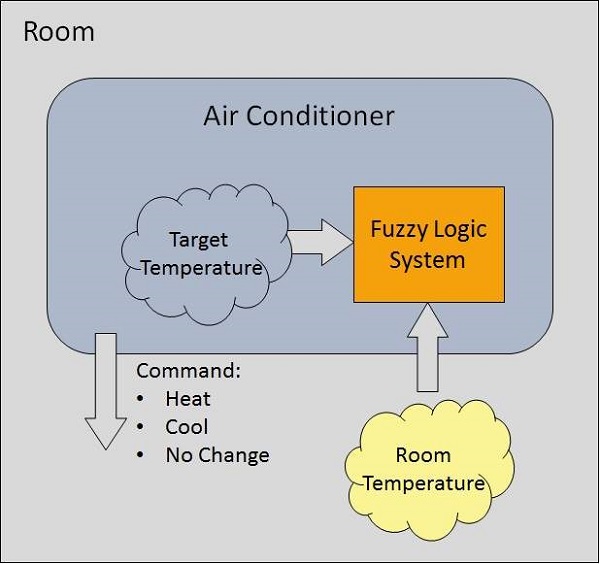
Ví dụ về một hệ thống lôgic mờ
Chúng ta hãy xem xét một hệ thống điều hòa không khí với hệ thống logic mờ 5 cấp. Hệ thống này điều chỉnh nhiệt độ của máy điều hòa không khí bằng cách so sánh nhiệt độ phòng và giá trị nhiệt độ mục tiêu.
Thuật toán
- Xác định các biến và thuật ngữ ngôn ngữ (bắt đầu)
- Xây dựng các hàm thành viên cho chúng. (khởi đầu)
- Xây dựng cơ sở kiến thức về các quy tắc (bắt đầu)
- Chuyển đổi dữ liệu rõ nét thành các tập dữ liệu mờ bằng cách sử dụng các hàm thành viên. (mờ)
- Đánh giá các quy tắc trong cơ sở quy tắc. (Động cơ suy diễn)
- Kết hợp các kết quả từ mỗi quy tắc. (Động cơ suy diễn)
- Chuyển đổi dữ liệu đầu ra thành các giá trị không mờ. (giải mờ)
Phát triển
Step 1 − Define linguistic variables and terms
Biến ngôn ngữ là các biến đầu vào và đầu ra dưới dạng các từ hoặc câu đơn giản. Đối với nhiệt độ phòng, lạnh, ấm, nóng, v.v., là các thuật ngữ ngôn ngữ.
Nhiệt độ (t) = {rất lạnh, lạnh, ấm, rất ấm, nóng}
Mọi thành viên của tập hợp này là một thuật ngữ ngôn ngữ và nó có thể bao hàm một số phần của các giá trị nhiệt độ tổng thể.
Step 2 − Construct membership functions for them
Các hàm liên thuộc của biến nhiệt độ như được hiển thị:
Step3 − Construct knowledge base rules
Tạo ma trận các giá trị nhiệt độ phòng so với các giá trị nhiệt độ mục tiêu mà hệ thống điều hòa không khí dự kiến cung cấp.
| PhòngTemp. /Mục tiêu | Rất lạnh | Lạnh | Ấm áp | Nóng bức | Rất nóng |
|---|---|---|---|---|---|
| Rất lạnh | Không thay đổi | Nhiệt | Nhiệt | Nhiệt | Nhiệt |
| Lạnh | Mát mẻ | Không thay đổi | Nhiệt | Nhiệt | Nhiệt |
| Ấm áp | Mát mẻ | Mát mẻ | Không thay đổi | Nhiệt | Nhiệt |
| Nóng bức | Mát mẻ | Mát mẻ | Mát mẻ | Không thay đổi | Nhiệt |
| Rất nóng | Mát mẻ | Mát mẻ | Mát mẻ | Mát mẻ | Không thay đổi |
Xây dựng bộ quy tắc thành cơ sở tri thức dưới dạng cấu trúc IF-THEN-ELSE.
| Sơ không. | Tình trạng | Hoạt động |
|---|---|---|
| 1 | NẾU nhiệt độ = (Lạnh HOẶC Rất lạnh) VÀ mục tiêu = Ấm áp THEN | Nhiệt |
| 2 | NẾU nhiệt độ = (Nóng HOẶC Rất_Hot) VÀ mục tiêu = Ấm THEN | Mát mẻ |
| 3 | NẾU (nhiệt độ = Ấm) VÀ (mục tiêu = Ấm) THÌ | Không thay đổi |
Step 4 − Obtain fuzzy value
Các phép toán tập mờ thực hiện đánh giá các luật. Các phép toán được sử dụng cho OR và AND tương ứng là Max và Min. Kết hợp tất cả các kết quả đánh giá để tạo thành kết quả cuối cùng. Kết quả này là một giá trị mờ.
Step 5 − Perform defuzzification
Sau đó, khử mờ được thực hiện theo hàm liên thuộc cho biến đầu ra.

Các lĩnh vực ứng dụng của Logic mờ
Các lĩnh vực ứng dụng chính của logic mờ như đã cho:
Automotive Systems
- Hộp số tự động
- Tay lái bốn bánh
- Kiểm soát môi trường phương tiện
Consumer Electronic Goods
- Hệ thống Hi-Fi
- Photocopiers
- Máy ảnh tĩnh và máy quay video
- Television
Domestic Goods
- Nhiều lò vi sóng
- Refrigerators
- Toasters
- Máy hút bụi
- Máy giặt
Environment Control
- Máy lạnh / Máy sấy / Máy sưởi
- Humidifiers
Ưu điểm của FLSs
Các khái niệm toán học trong suy luận mờ rất đơn giản.
Bạn có thể sửa đổi một FLS chỉ bằng cách thêm hoặc xóa các quy tắc do tính linh hoạt của logic mờ.
Hệ thống logic mờ có thể lấy thông tin đầu vào không chính xác, bị bóp méo, nhiễu.
FLS rất dễ xây dựng và dễ hiểu.
Logic mờ là một giải pháp cho các vấn đề phức tạp trong tất cả các lĩnh vực của cuộc sống, bao gồm cả y học, vì nó giống với suy luận và ra quyết định của con người.
Nhược điểm của FLSs
- Không có cách tiếp cận hệ thống để thiết kế hệ thống mờ.
- Chúng chỉ dễ hiểu khi đơn giản.
- Chúng phù hợp với các bài toán không cần độ chính xác cao.
Xử lý ngôn ngữ tự nhiên (NLP) đề cập đến phương pháp AI giao tiếp với một hệ thống thông minh bằng cách sử dụng ngôn ngữ tự nhiên như tiếng Anh.
Xử lý ngôn ngữ tự nhiên là bắt buộc khi bạn muốn một hệ thống thông minh như rô-bốt thực hiện theo chỉ dẫn của bạn, khi bạn muốn nghe quyết định từ hệ thống chuyên gia lâm sàng dựa trên đối thoại, v.v.
Lĩnh vực NLP liên quan đến việc chế tạo máy tính để thực hiện các tác vụ hữu ích với ngôn ngữ tự nhiên mà con người sử dụng. Đầu vào và đầu ra của một hệ thống NLP có thể là:
- Speech
- Văn bản viết tay
Các thành phần của NLP
Có hai thành phần của NLP như đã cho:
Hiểu ngôn ngữ tự nhiên (NLU)
Hiểu biết bao gồm các nhiệm vụ sau:
- Ánh xạ đầu vào đã cho bằng ngôn ngữ tự nhiên thành các biểu diễn hữu ích.
- Phân tích các khía cạnh khác nhau của ngôn ngữ.
Thế hệ ngôn ngữ tự nhiên (NLG)
Đó là quá trình tạo ra các cụm từ và câu có nghĩa dưới dạng ngôn ngữ tự nhiên từ một số biểu diễn bên trong.
Nó liên quan đến -
Text planning - Nó bao gồm việc truy xuất nội dung có liên quan từ cơ sở tri thức.
Sentence planning - Nó bao gồm việc lựa chọn các từ cần thiết, tạo thành các cụm từ có nghĩa, thiết lập giọng điệu của câu.
Text Realization - Nó là ánh xạ kế hoạch câu thành cấu trúc câu.
NLU khó hơn NLG.
Những khó khăn trong trường ĐHNL
NL có hình thức và cấu trúc vô cùng phong phú.
Nó rất mơ hồ. Có thể có nhiều mức độ mơ hồ khác nhau -
Lexical ambiguity - Nó ở cấp độ rất sơ khai như cấp độ từ.
Ví dụ, coi từ “board” là danh từ hay động từ?
Syntax Level ambiguity - Một câu có thể được phân tích cú pháp theo nhiều cách khác nhau.
Ví dụ: "Anh ta nâng con bọ có mũ màu đỏ." - Anh ta dùng nắp để nhấc con bọ lên hay anh ta nhấc một con bọ cánh cứng có nắp màu đỏ?
Referential ambiguity- Đề cập đến điều gì đó bằng cách sử dụng đại từ. Ví dụ, Rima đã đến Gauri. Cô ấy nói, "Tôi mệt mỏi." - Chính xác là ai đang mệt?
Một đầu vào có thể có nghĩa khác nhau.
Nhiều đầu vào có thể có nghĩa giống nhau.
Thuật ngữ NLP
Phonology - Đó là nghiên cứu về tổ chức âm thanh một cách hệ thống.
Morphology - Đó là nghiên cứu về cấu tạo của từ từ các đơn vị có nghĩa nguyên thủy.
Morpheme - Nó là đơn vị nghĩa nguyên thủy trong ngôn ngữ.
Syntax- Nó đề cập đến việc sắp xếp các từ để tạo thành một câu. Nó cũng liên quan đến việc xác định vai trò cấu trúc của các từ trong câu và trong các cụm từ.
Semantics - Nó quan tâm đến nghĩa của từ và cách kết hợp các từ thành các cụm từ và câu có nghĩa.
Pragmatics - Nó đề cập đến việc sử dụng và hiểu các câu trong các tình huống khác nhau và cách giải thích câu bị ảnh hưởng.
Discourse - Nó đề cập đến việc câu ngay trước đó có thể ảnh hưởng như thế nào đến việc giải thích câu tiếp theo.
World Knowledge - Nó bao gồm những kiến thức chung về thế giới.
Các bước trong NLP
Có năm bước chung -
Lexical Analysis- Nó liên quan đến việc xác định và phân tích cấu trúc của từ. Từ vựng của một ngôn ngữ có nghĩa là tập hợp các từ và cụm từ trong một ngôn ngữ. Phân tích từ vựng là phân chia toàn bộ đoạn văn bản thành các đoạn văn, câu và từ.
Syntactic Analysis (Parsing)- Nó liên quan đến việc phân tích các từ trong câu để tìm ngữ pháp và sắp xếp các từ theo cách thể hiện mối quan hệ giữa các từ. Câu như "The school go to boy" bị từ chối bởi bộ phân tích cú pháp tiếng Anh.

Semantic Analysis- Nó rút ra ý nghĩa chính xác hoặc nghĩa từ điển từ văn bản. Văn bản được kiểm tra xem có ý nghĩa hay không. Nó được thực hiện bằng cách ánh xạ các cấu trúc cú pháp và các đối tượng trong miền tác vụ. Bộ phân tích ngữ nghĩa bỏ qua câu chẳng hạn như "kem nóng".
Discourse Integration- Ý nghĩa của bất kỳ câu nào phụ thuộc vào nghĩa của câu ngay trước nó. Ngoài ra nó còn mang ý nghĩa câu thành công ngay lập tức.
Pragmatic Analysis- Trong lúc này, những gì đã nói sẽ được diễn giải lại dựa trên ý nghĩa thực sự của nó. Nó liên quan đến việc tạo ra những khía cạnh của ngôn ngữ đòi hỏi kiến thức thế giới thực.
Các khía cạnh triển khai của phân tích cú pháp
Có một số thuật toán mà các nhà nghiên cứu đã phát triển để phân tích cú pháp, nhưng chúng tôi chỉ xem xét các phương pháp đơn giản sau:
- Ngữ pháp không theo ngữ cảnh
- Trình phân tích cú pháp từ trên xuống
Hãy để chúng tôi xem chúng chi tiết -
Ngữ pháp không theo ngữ cảnh
Đó là ngữ pháp bao gồm các quy tắc với một ký hiệu duy nhất ở phía bên trái của các quy tắc viết lại. Hãy để chúng tôi tạo ngữ pháp để phân tích cú pháp một câu -
"Con chim mổ hạt"
Articles (DET)- a | an | các
Nouns- con chim | chim | hạt | hạt
Noun Phrase (NP)- Điều + Danh từ | Bài viết + Tính từ + Danh từ
= ĐẶT N | DET ADJ N
Verbs- mổ xẻ | mổ xẻ | mổ
Verb Phrase (VP)- NP V | V NP
Adjectives (ADJ)- đẹp | nhỏ | ríu rít
Cây phân tích cú pháp chia nhỏ câu thành các phần có cấu trúc để máy tính có thể dễ dàng hiểu và xử lý nó. Để thuật toán phân tích cú pháp xây dựng cây phân tích cú pháp này, cần phải xây dựng một tập hợp các quy tắc viết lại, mô tả cấu trúc cây nào là hợp pháp.
Các quy tắc này nói rằng một biểu tượng nhất định có thể được mở rộng trong cây bằng một chuỗi các biểu tượng khác. Theo quy tắc logic bậc nhất, nếu có hai chuỗi Cụm danh từ (NP) và Cụm động từ (VP), thì chuỗi kết hợp bởi NP theo sau là VP là một câu. Quy tắc viết lại câu như sau:
S → NP VP
NP → DET N | DET ADJ N
VP → V NP
Lexocon −
HẾT → a | các
ADJ → đẹp | chim đậu
N → chim | chim | hạt | hạt
V → mổ | mổ xẻ | mổ
Cây phân tích cú pháp có thể được tạo như minh họa -

Bây giờ hãy xem xét các quy tắc viết lại ở trên. Vì V có thể được thay thế bằng cả hai, "peck" hoặc "pecks", những câu như "Con chim mổ những hạt" có thể bị sai. tức là lỗi thỏa thuận chủ ngữ-động từ được chấp thuận là đúng.
Merit - Kiểu ngữ pháp đơn giản nhất, do đó được sử dụng rộng rãi.
Demerits −
Chúng không có độ chính xác cao. Ví dụ, "Các hạt mổ con chim", là một cú pháp chính xác theo trình phân tích cú pháp, nhưng ngay cả khi nó không có nghĩa, trình phân tích cú pháp sẽ coi nó là một câu đúng.
Để mang lại độ chính xác cao, bạn cần chuẩn bị nhiều bộ ngữ pháp. Nó có thể yêu cầu một bộ quy tắc hoàn toàn khác để phân tích cú pháp các biến thể số ít và số nhiều, câu bị động, v.v., có thể dẫn đến việc tạo ra một bộ quy tắc khổng lồ không thể quản lý được.
Trình phân tích cú pháp từ trên xuống
Ở đây, trình phân tích cú pháp bắt đầu bằng ký hiệu S và cố gắng viết lại nó thành một chuỗi ký hiệu đầu cuối khớp với các lớp của các từ trong câu đầu vào cho đến khi nó bao gồm hoàn toàn các ký hiệu đầu cuối.
Sau đó chúng được kiểm tra với câu đầu vào để xem nó có khớp hay không. Nếu không, quá trình sẽ được bắt đầu lại với một bộ quy tắc khác. Điều này được lặp lại cho đến khi tìm thấy một quy tắc cụ thể mô tả cấu trúc của câu.
Merit - Nó là đơn giản để thực hiện.
Demerits −
- Nó không hiệu quả, vì quá trình tìm kiếm phải được lặp lại nếu xảy ra lỗi.
- Tốc độ làm việc chậm.
Hệ thống chuyên gia (ES) là một trong những lĩnh vực nghiên cứu nổi bật của AI. Nó được giới thiệu bởi các nhà nghiên cứu tại Đại học Stanford, Khoa Khoa học Máy tính.
Hệ thống chuyên gia là gì?
Hệ thống chuyên gia là các ứng dụng máy tính được phát triển để giải quyết các vấn đề phức tạp trong một lĩnh vực cụ thể, ở mức độ thông thường và chuyên môn của con người.
Đặc điểm của hệ thống chuyên gia
- Hiệu suất cao
- Understandable
- Reliable
- Phản hồi cao
Khả năng của Hệ thống Chuyên gia
Hệ thống chuyên gia có khả năng -
- Advising
- Hướng dẫn và hỗ trợ con người ra quyết định
- Demonstrating
- Tìm ra giải pháp
- Diagnosing
- Explaining
- Thông dịch đầu vào
- Dự đoán kết quả
- Biện minh cho kết luận
- Đề xuất các phương án thay thế cho một vấn đề
Họ không có khả năng -
- Thay người ra quyết định
- Có năng lực con người
- Sản xuất đầu ra chính xác cho cơ sở kiến thức không đầy đủ
- Tinh chỉnh kiến thức của riêng họ
Các thành phần của Hệ thống Chuyên gia
Các thành phần của ES bao gồm:
- Kiến thức cơ bản
- Động cơ suy diễn
- Giao diện người dùng
Hãy để chúng tôi xem từng cái một trong thời gian ngắn -

Kiến thức cơ bản
Nó chứa kiến thức chất lượng cao và dành riêng cho từng miền.
Cần phải có kiến thức để thể hiện trí thông minh. Sự thành công của bất kỳ ES nào chủ yếu phụ thuộc vào việc thu thập kiến thức chính xác và chính xác cao.
Kiến thức là gì?
Dữ liệu là tập hợp các dữ kiện. Thông tin được tổ chức dưới dạng dữ liệu và dữ kiện về miền nhiệm vụ.Data, information, và past experience kết hợp với nhau được gọi là kiến thức.
Các thành phần của Cơ sở Kiến thức
Cơ sở kiến thức của một ES là một kho lưu trữ cả kiến thức thực tế và kiến thức kinh nghiệm.
Factual Knowledge - Đây là thông tin được chấp nhận rộng rãi bởi các Kỹ sư tri thức và các học giả trong lĩnh vực nhiệm vụ.
Heuristic Knowledge - Đó là về thực hành, phán đoán chính xác, khả năng đánh giá và đoán của một người.
Biểu diễn tri thức
Nó là phương pháp được sử dụng để tổ chức và hình thức hóa kiến thức trong cơ sở tri thức. Nó ở dạng quy tắc IF-THEN-ELSE.
Thu nhận kiến thức
Sự thành công của bất kỳ hệ thống chuyên gia nào chủ yếu phụ thuộc vào chất lượng, tính đầy đủ và chính xác của thông tin được lưu trữ trong cơ sở tri thức.
Cơ sở kiến thức được hình thành bởi các bài đọc từ các chuyên gia, học giả khác nhau và Knowledge Engineers. Kỹ sư tri thức là người có tố chất đồng cảm, học hỏi nhanh và kỹ năng phân tích tình huống.
Anh ta thu thập thông tin từ chuyên gia chủ đề bằng cách ghi lại, phỏng vấn và quan sát anh ta tại nơi làm việc, v.v. Sau đó, anh ta phân loại và sắp xếp thông tin theo cách có ý nghĩa, dưới dạng quy tắc IF-THEN-ELSE, để được sử dụng bởi máy can thiệp. Kỹ sư kiến thức cũng giám sát sự phát triển của ES.
Động cơ suy diễn
Việc sử dụng các quy trình và quy tắc hiệu quả của Inference Engine là điều cần thiết để đưa ra một giải pháp chính xác, hoàn hảo.
Trong trường hợp ES dựa trên kiến thức, Công cụ suy luận thu nhận và vận dụng kiến thức từ cơ sở kiến thức để đi đến một giải pháp cụ thể.
Trong trường hợp ES dựa trên quy tắc, nó -
Áp dụng các quy tắc nhiều lần cho các dữ kiện, có được từ ứng dụng quy tắc trước đó.
Bổ sung kiến thức mới vào nền tảng kiến thức nếu được yêu cầu.
Giải quyết xung đột quy tắc khi nhiều quy tắc được áp dụng cho một trường hợp cụ thể.
Để đề xuất giải pháp, Công cụ suy luận sử dụng các chiến lược sau:
- Chuyển tiếp chuỗi
- Chuỗi ngược
Chuyển tiếp chuỗi
Đó là một chiến lược của một hệ thống chuyên gia để trả lời câu hỏi, “What can happen next?”
Ở đây, Công cụ suy luận tuân theo chuỗi các điều kiện và dẫn xuất và cuối cùng suy ra kết quả. Nó xem xét tất cả các sự kiện và quy tắc, và sắp xếp chúng trước khi đưa ra giải pháp.
Chiến lược này được tuân theo để làm việc về kết luận, kết quả hoặc hiệu quả. Ví dụ, dự đoán về tình trạng thị trường cổ phiếu như là một tác động của những thay đổi trong lãi suất.

Chuỗi ngược
Với chiến lược này, một hệ thống chuyên gia sẽ tìm ra câu trả lời cho câu hỏi, “Why this happened?”
Trên cơ sở những gì đã xảy ra, Công cụ suy luận cố gắng tìm ra điều kiện nào có thể đã xảy ra trong quá khứ cho kết quả này. Chiến lược này được tuân theo để tìm ra nguyên nhân hoặc lý do. Ví dụ, chẩn đoán ung thư máu ở người.
Giao diện người dùng
Giao diện người dùng cung cấp sự tương tác giữa người dùng ES và chính ES. Nó nói chung là Xử lý ngôn ngữ tự nhiên để được sử dụng bởi người dùng thành thạo trong miền tác vụ. Người dùng ES không nhất thiết phải là chuyên gia về Trí tuệ nhân tạo.
Nó giải thích cách ES đã đạt được một khuyến nghị cụ thể. Lời giải thích có thể xuất hiện dưới các hình thức sau:
- Ngôn ngữ tự nhiên hiển thị trên màn hình.
- Lời tường thuật bằng ngôn ngữ tự nhiên.
- Danh sách các số quy tắc hiển thị trên màn hình.
Giao diện người dùng giúp dễ dàng theo dõi độ tin cậy của các khoản khấu trừ.
Yêu cầu của giao diện người dùng ES hiệu quả
Nó sẽ giúp người dùng hoàn thành mục tiêu của họ theo cách ngắn nhất có thể.
Nó phải được thiết kế để hoạt động cho các phương pháp làm việc hiện tại hoặc mong muốn của người dùng.
Công nghệ của nó phải thích ứng với yêu cầu của người dùng; không phải ngược lại.
Nó sẽ sử dụng hiệu quả đầu vào của người dùng.
Giới hạn của hệ thống chuyên gia
Không có công nghệ nào có thể đưa ra giải pháp dễ dàng và đầy đủ. Hệ thống lớn có chi phí cao, yêu cầu thời gian phát triển đáng kể và tài nguyên máy tính. ES có những hạn chế bao gồm:
- Hạn chế của công nghệ
- Tiếp thu kiến thức khó
- ES rất khó duy trì
- Chi phí phát triển cao
Các ứng dụng của Hệ thống Chuyên gia
Bảng sau đây cho thấy những nơi có thể áp dụng ES.
| Ứng dụng | Sự miêu tả |
|---|---|
| Miền thiết kế | Thiết kế ống kính máy ảnh, thiết kế ô tô. |
| Lĩnh vực y tế | Hệ thống chẩn đoán để suy ra nguyên nhân gây bệnh từ dữ liệu quan sát, dẫn truyền các hoạt động y tế trên người. |
| Hệ thống giám sát | So sánh dữ liệu liên tục với hệ thống quan sát hoặc với hành vi theo quy định như giám sát rò rỉ trong đường ống xăng dầu dài. |
| Hệ thống kiểm soát quy trình | Kiểm soát quá trình vật lý dựa trên giám sát. |
| Miền tri thức | Tìm ra lỗi trên xe, máy tính. |
| Tài chính / Thương mại | Phát hiện gian lận có thể xảy ra, giao dịch đáng ngờ, giao dịch trên thị trường chứng khoán, lên lịch hàng không, lên lịch hàng hóa. |
Công nghệ Hệ thống Chuyên gia
Có một số cấp độ của công nghệ ES. Công nghệ hệ thống chuyên gia bao gồm:
Expert System Development Environment- Môi trường phát triển ES bao gồm phần cứng và công cụ. Họ là -
Máy trạm, máy tính mini, máy tính lớn.
Ngôn ngữ lập trình biểu tượng cấp cao như LISt Programming (LISP) và PROngữ pháp vi LOGique (PROLOG).
Cơ sở dữ liệu lớn.
Tools - Họ giảm nỗ lực và chi phí liên quan đến việc phát triển một hệ thống chuyên gia ở mức độ lớn.
Trình chỉnh sửa và công cụ gỡ lỗi mạnh mẽ với nhiều cửa sổ.
Họ cung cấp tạo mẫu nhanh chóng
Có sẵn các định nghĩa về mô hình, biểu diễn tri thức và thiết kế suy luận.
Shells- Một trình bao không là gì ngoài một hệ thống chuyên gia không có cơ sở kiến thức. Một trình bao cung cấp cho các nhà phát triển khả năng thu thập kiến thức, công cụ suy luận, giao diện người dùng và cơ sở giải thích. Ví dụ, một số shell được đưa ra dưới đây:
Java Expert System Shell (JESS) cung cấp Java API được phát triển đầy đủ để tạo một hệ thống chuyên gia.
Vidwan , một trình bao được phát triển tại Trung tâm Công nghệ Phần mềm Quốc gia, Mumbai vào năm 1993. Nó cho phép mã hóa tri thức dưới dạng các quy tắc IF-THEN.
Phát triển hệ thống chuyên gia: Các bước chung
Quá trình phát triển ES là lặp đi lặp lại. Các bước phát triển ES bao gồm:
Xác định miền sự cố
- Vấn đề phải phù hợp với một hệ thống chuyên gia để giải quyết nó.
- Tìm các chuyên gia trong miền nhiệm vụ cho dự án ES.
- Thiết lập hiệu quả chi phí của hệ thống.
Thiết kế hệ thống
Xác định Công nghệ ES
Biết và thiết lập mức độ tích hợp với các hệ thống và cơ sở dữ liệu khác.
Nhận ra cách các khái niệm có thể đại diện cho kiến thức miền tốt nhất.
Phát triển mẫu thử nghiệm
Từ Cơ sở Kiến thức: Kỹ sư kiến thức làm việc để -
- Tiếp thu kiến thức miền từ chuyên gia.
- Biểu diễn nó dưới dạng các quy tắc If-THEN-ELSE.
Kiểm tra và tinh chỉnh nguyên mẫu
Kỹ sư kiến thức sử dụng các trường hợp mẫu để kiểm tra nguyên mẫu xem có bất kỳ khiếm khuyết nào trong hiệu suất.
Người dùng cuối kiểm tra các nguyên mẫu của ES.
Phát triển và hoàn thiện ES
Kiểm tra và đảm bảo sự tương tác của ES với tất cả các yếu tố trong môi trường của nó, bao gồm người dùng cuối, cơ sở dữ liệu và các hệ thống thông tin khác.
Ghi chép tốt dự án ES.
Huấn luyện người dùng sử dụng ES.
Duy trì hệ thống
Luôn cập nhật nền tảng kiến thức bằng cách xem xét và cập nhật thường xuyên.
Phục vụ cho các giao diện mới với các hệ thống thông tin khác, khi các hệ thống đó phát triển.
Lợi ích của Hệ thống Chuyên gia
Availability - Chúng dễ dàng có sẵn do sản xuất hàng loạt phần mềm.
Less Production Cost- Giá thành sản xuất hợp lý. Điều này làm cho chúng có giá cả phải chăng.
Speed- Họ cung cấp tốc độ tuyệt vời. Chúng làm giảm khối lượng công việc của một cá nhân.
Less Error Rate - Tỷ lệ lỗi thấp so với lỗi của con người.
Reducing Risk - Chúng có thể làm việc trong môi trường nguy hiểm cho con người.
Steady response - Chúng hoạt động ổn định mà không bị kích động, căng thẳng hoặc mệt mỏi.
Robotics là một lĩnh vực trí tuệ nhân tạo liên quan đến việc nghiên cứu tạo ra các robot thông minh và hiệu quả.
Robot là gì?
Robot là tác nhân nhân tạo hoạt động trong môi trường thế giới thực.
Mục tiêu
Robot nhằm mục đích điều khiển các đối tượng bằng cách nhận thức, chọn, di chuyển, sửa đổi các thuộc tính vật lý của đối tượng, phá hủy nó hoặc để tạo ra một hiệu ứng do đó giải phóng con người khỏi việc thực hiện các chức năng lặp đi lặp lại mà không cảm thấy nhàm chán, mất tập trung hoặc kiệt sức.
Robotics là gì?
Robotics là một nhánh của AI, bao gồm Kỹ thuật Điện, Kỹ thuật Cơ khí và Khoa học Máy tính để thiết kế, xây dựng và ứng dụng rô bốt.
Các khía cạnh của người máy
Người máy có mechanical construction, hình thức hoặc hình dạng được thiết kế để hoàn thành một nhiệm vụ cụ thể.
Họ có electrical components cung cấp năng lượng và điều khiển máy móc.
Chúng chứa một số cấp độ computer program xác định cái gì, khi nào và như thế nào một rô bốt làm điều gì đó.
Sự khác biệt trong Hệ thống Robot và Chương trình AI khác
Đây là sự khác biệt giữa hai -
| Chương trình AI | Rô bốt |
|---|---|
| Họ thường hoạt động trong thế giới được máy tính kích thích. | Họ hoạt động trong thế giới thực |
| Đầu vào cho một chương trình AI là các ký hiệu và quy tắc. | Đầu vào cho rô bốt là tín hiệu tương tự ở dạng sóng giọng nói hoặc hình ảnh |
| Họ cần máy tính đa năng để hoạt động. | Họ cần phần cứng đặc biệt với cảm biến và hiệu ứng. |
Chuyển động robot
Locomotion là cơ chế giúp robot có thể di chuyển trong môi trường của nó. Có nhiều loại đầu máy khác nhau -
- Legged
- Wheeled
- Sự kết hợp của vận động bằng chân và bánh xe
- Trượt / trượt theo dõi
Vận động bằng chân
Loại vận động này tiêu thụ nhiều điện năng hơn trong khi thể hiện bước đi, nhảy, chạy nước kiệu, nhảy lò cò, leo lên hoặc xuống, v.v.
Nó đòi hỏi nhiều động cơ hơn để thực hiện một chuyển động. Nó phù hợp với địa hình gồ ghề cũng như trơn nhẵn, nơi bề mặt không đều hoặc quá nhẵn khiến nó tiêu thụ nhiều điện năng hơn cho xe cào cào có bánh. Nó hơi khó thực hiện vì vấn đề ổn định.
Nó có nhiều loại một, hai, bốn và sáu chân. Nếu rô bốt có nhiều chân thì sự phối hợp chân là cần thiết để vận động.
Tổng số có thể gaits (một chuỗi tuần tự các sự kiện nâng và thả cho mỗi chân trong tổng số chân) mà rô bốt có thể di chuyển phụ thuộc vào số chân của nó.
Nếu một robot có k chân, thì số sự kiện có thể xảy ra N = (2k-1) !.
Trong trường hợp robot hai chân (k = 2), số sự kiện có thể xảy ra là N = (2k-1)! = (2 * 2-1)! = 3! = 6.
Do đó, có thể có sáu sự kiện khác nhau -
- Nâng chân trái
- Thả chân trái
- Nâng chân phải
- Thả chân phải
- Nâng cả hai chân vào nhau
- Thả cả hai chân vào nhau
Trong trường hợp k = 6 chân, có 39916800 sự kiện có thể xảy ra. Do đó, độ phức tạp của robot tỷ lệ thuận với số lượng chân.

Chuyển động bánh xe
Nó yêu cầu ít động cơ hơn để thực hiện một chuyển động. Nó hơi dễ thực hiện vì có ít vấn đề về độ ổn định hơn trong trường hợp số lượng bánh xe nhiều hơn. Nó tiết kiệm năng lượng so với đầu máy bằng chân.
Standard wheel - Quay quanh trục bánh xe và xung quanh tiếp điểm
Castor wheel - Quay quanh trục bánh xe và khớp lái bù.
Swedish 45o and Swedish 90o wheels - Bánh xe đa năng, quay xung quanh điểm tiếp xúc, quanh trục bánh xe và xung quanh các con lăn.
Ball or spherical wheel - Bánh xe đa hướng, kỹ thuật khó thực hiện.

Chuyển động trượt / trượt
Trong loại hình này, các phương tiện sử dụng đường ray như trong xe tăng. Robot được điều khiển bằng cách di chuyển các đường ray với tốc độ khác nhau theo cùng hướng hoặc ngược chiều. Nó mang lại sự ổn định vì diện tích tiếp xúc của đường đua và mặt đất lớn.

Các thành phần của Robot
Robot được xây dựng với những điều sau đây:
Power Supply - Robot được chạy bằng pin, năng lượng mặt trời, nguồn thủy lực hoặc khí nén.
Actuators - Chúng chuyển hóa năng lượng thành chuyển động.
Electric motors (AC/DC) - Chúng được yêu cầu cho chuyển động quay.
Pneumatic Air Muscles - Chúng co lại gần 40% khi không khí bị hút vào.
Muscle Wires - Chúng co lại 5% khi có dòng điện chạy qua chúng.
Piezo Motors and Ultrasonic Motors - Tốt nhất cho robot công nghiệp.
Sensors- Họ cung cấp kiến thức về thông tin thời gian thực trên môi trường nhiệm vụ. Robot được trang bị cảm biến thị giác để tính toán độ sâu trong môi trường. Cảm biến xúc giác mô phỏng các đặc tính cơ học của các cơ quan tiếp nhận cảm ứng của đầu ngón tay người.
Tầm nhìn máy tính
Đây là một công nghệ AI mà robot có thể nhìn thấy. Thị giác máy tính đóng vai trò quan trọng trong các lĩnh vực an toàn, bảo mật, sức khỏe, truy cập và giải trí.
Thị giác máy tính tự động trích xuất, phân tích và hiểu thông tin hữu ích từ một hình ảnh hoặc một mảng hình ảnh. Quá trình này liên quan đến việc phát triển các thuật toán để hoàn thành việc hiểu trực quan tự động.
Phần cứng của Hệ thống Thị giác Máy tính
Điều này liên quan đến -
- Nguồn cấp
- Thiết bị thu nhận hình ảnh như máy ảnh
- Một bộ xử lý
- Một phần mềm
- Một thiết bị hiển thị để giám sát hệ thống
- Các phụ kiện như chân đế máy ảnh, dây cáp và đầu nối
Nhiệm vụ của Thị giác Máy tính
OCR - Trong lĩnh vực máy tính, Trình đọc ký tự quang học, một phần mềm chuyển đổi tài liệu đã quét thành văn bản có thể chỉnh sửa, đi kèm với máy quét.
Face Detection- Nhiều máy ảnh hiện đại đi kèm với tính năng này, cho phép đọc khuôn mặt và chụp ảnh với biểu cảm hoàn hảo đó. Nó được sử dụng để cho phép người dùng truy cập vào phần mềm phù hợp.
Object Recognition - Được lắp đặt trong siêu thị, camera, các dòng xe cao cấp như BMW, GM, Volvo.
Estimating Position - Nó là ước tính vị trí của một đối tượng đối với máy ảnh như vị trí của khối u trong cơ thể người.
Miền ứng dụng của Thị giác máy tính
- Agriculture
- Xe tự hành
- Biometrics
- Nhận dạng ký tự
- Pháp y, an ninh và giám sát
- Kiểm tra chất lượng công nghiệp
- Nhận dạng khuôn mặt
- Phân tích cử chỉ
- Geoscience
- Hình ảnh y tế
- Giám sát ô nhiễm
- Kiểm soát quy trình
- Viễn thám
- Robotics
- Transport
Các ứng dụng của Robotics
Người máy đã trở thành công cụ trong các lĩnh vực khác nhau như -
Industries - Robot được sử dụng để xử lý vật liệu, cắt, hàn, sơn màu, khoan, đánh bóng, v.v.
Military- Robot tự hành có thể tiếp cận các khu vực nguy hiểm và khó tiếp cận trong chiến tranh. Một robot có tên Daksh , do Tổ chức Nghiên cứu và Phát triển Quốc phòng (DRDO) phát triển, có chức năng tiêu diệt các vật thể đe dọa tính mạng một cách an toàn.
Medicine - Các robot có khả năng thực hiện hàng trăm cuộc kiểm tra lâm sàng đồng thời, phục hồi chức năng cho người tàn tật vĩnh viễn và thực hiện các phẫu thuật phức tạp như u não.
Exploration - Hãy kể tên một số robot leo núi đá dùng để thám hiểm không gian, máy bay không người lái dưới nước dùng để khám phá đại dương.
Entertainment - Các kỹ sư của Disney đã tạo ra hàng trăm robot để làm phim.
Tuy nhiên, một lĩnh vực nghiên cứu khác trong AI, mạng lưới thần kinh, được lấy cảm hứng từ mạng lưới thần kinh tự nhiên của hệ thần kinh con người.
Mạng thần kinh nhân tạo (ANN) là gì?
Người phát minh ra máy tính thần kinh đầu tiên, Tiến sĩ Robert Hecht-Nielsen, định nghĩa một mạng lưới thần kinh là -
"... một hệ thống máy tính được tạo thành từ một số phần tử xử lý đơn giản, có tính kết nối cao, xử lý thông tin bằng phản ứng trạng thái động của chúng với các đầu vào bên ngoài."
Cấu trúc cơ bản của ANN
Ý tưởng của ANN dựa trên niềm tin rằng hoạt động của bộ não con người bằng cách tạo ra các kết nối phù hợp, có thể được bắt chước bằng cách sử dụng silicon và dây điện như cuộc sống neurons và dendrites.
Bộ não con người bao gồm 86 tỷ tế bào thần kinh được gọi là neurons. Chúng được kết nối với hàng nghìn ô khác bằng Axons.Các kích thích từ môi trường bên ngoài hoặc đầu vào từ các cơ quan cảm giác được các đuôi gai chấp nhận. Các đầu vào này tạo ra các xung điện, truyền nhanh qua mạng nơ-ron. Sau đó, một tế bào thần kinh có thể gửi thông điệp đến tế bào thần kinh khác để xử lý sự cố hoặc không gửi đi.

ANN bao gồm nhiều nodes, bắt chước sinh học neuronscủa bộ não con người. Các tế bào thần kinh được kết nối với nhau bằng các liên kết và chúng tương tác với nhau. Các nút có thể lấy dữ liệu đầu vào và thực hiện các thao tác đơn giản trên dữ liệu. Kết quả của các hoạt động này được chuyển cho các tế bào thần kinh khác. Đầu ra tại mỗi nút được gọi làactivation hoặc là node value.
Mỗi liên kết được liên kết với weight.ANN có khả năng học hỏi, diễn ra bằng cách thay đổi các giá trị trọng lượng. Hình minh họa sau đây cho thấy một ANN đơn giản -

Các loại mạng thần kinh nhân tạo
Có hai cấu trúc liên kết Mạng thần kinh Nhân tạo - FeedForward và Feedback.
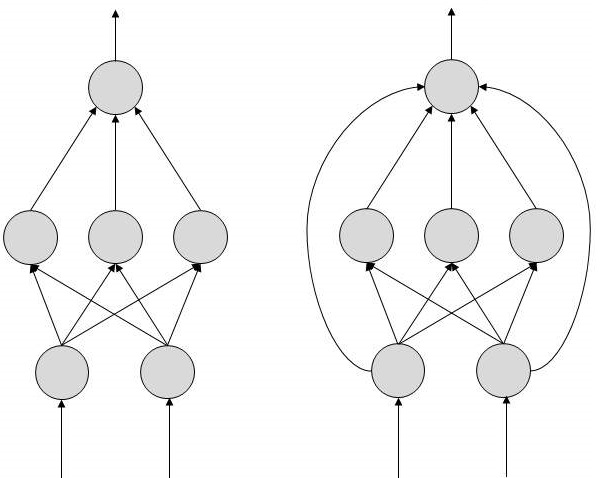
FeedForward ANN
Trong ANN này, luồng thông tin là một chiều. Một đơn vị gửi thông tin cho đơn vị khác mà từ đó nó không nhận được bất kỳ thông tin nào. Không có vòng lặp phản hồi. Chúng được sử dụng trong tạo / nhận dạng / phân loại mẫu. Họ có đầu vào và đầu ra cố định.
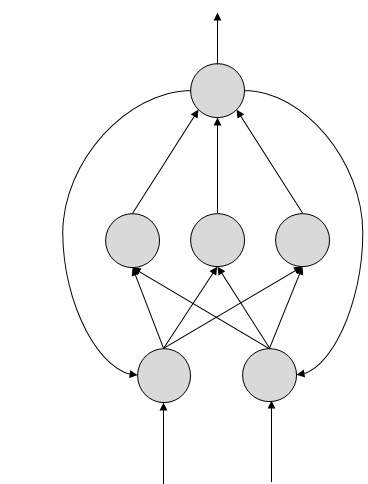
FeedBack ANN
Ở đây, các vòng phản hồi được cho phép. Chúng được sử dụng trong các bộ nhớ có thể giải quyết nội dung
Hoạt động của ANN
Trong sơ đồ cấu trúc liên kết được hiển thị, mỗi mũi tên biểu thị kết nối giữa hai nơ-ron và chỉ ra đường dẫn dòng thông tin. Mỗi kết nối có một trọng số, một số nguyên điều khiển tín hiệu giữa hai nơ-ron.
Nếu mạng tạo ra đầu ra “tốt hoặc mong muốn” thì không cần điều chỉnh trọng số. Tuy nhiên, nếu mạng tạo ra đầu ra “kém hoặc không mong muốn” hoặc lỗi, thì hệ thống sẽ thay đổi trọng số để cải thiện kết quả tiếp theo.
Học máy trong ANN
ANN có khả năng học hỏi và họ cần được đào tạo. Có một số chiến lược học tập -
Supervised Learning- Nó liên quan đến một giáo viên có học thức hơn chính ANN. Ví dụ: giáo viên cung cấp một số dữ liệu ví dụ mà giáo viên đã biết câu trả lời.
Ví dụ, nhận dạng mẫu. ANN đưa ra các phỏng đoán trong khi nhận dạng. Sau đó, giáo viên cung cấp ANN với các câu trả lời. Sau đó, mạng lưới sẽ so sánh kết quả phỏng đoán với câu trả lời “đúng” của giáo viên và thực hiện điều chỉnh theo lỗi.
Unsupervised Learning- Nó được yêu cầu khi không có tập dữ liệu ví dụ với các câu trả lời đã biết. Ví dụ: tìm kiếm một mẫu ẩn. Trong trường hợp này, phân cụm tức là chia tập hợp các phần tử thành các nhóm theo một số mẫu chưa biết được thực hiện dựa trên các tập dữ liệu hiện có.
Reinforcement Learning- Chiến lược này được xây dựng dựa trên sự quan sát. ANN đưa ra quyết định bằng cách quan sát môi trường của nó. Nếu kết quả quan sát là tiêu cực, mạng sẽ điều chỉnh trọng số của nó để có thể đưa ra quyết định cần thiết khác vào lần sau.
Thuật toán lan truyền ngược
Nó là thuật toán đào tạo hoặc học tập. Nó học bằng ví dụ. Nếu bạn gửi cho thuật toán ví dụ về những gì bạn muốn mạng thực hiện, nó sẽ thay đổi trọng số của mạng để nó có thể tạo ra đầu ra mong muốn cho một đầu vào cụ thể khi kết thúc khóa đào tạo.
Mạng lan truyền ngược là lý tưởng cho các tác vụ ánh xạ và nhận dạng mẫu đơn giản.
Bayesian Networks (BN)
Đây là những cấu trúc đồ họa được sử dụng để biểu diễn mối quan hệ xác suất giữa một tập hợp các biến ngẫu nhiên. Mạng Bayes còn được gọi làBelief Networks hoặc là Bayes Nets. BN lý do về miền không chắc chắn.
Trong các mạng này, mỗi nút đại diện cho một biến ngẫu nhiên với các mệnh đề cụ thể. Ví dụ, trong lĩnh vực chẩn đoán y tế, nút Ung thư đại diện cho đề xuất rằng một bệnh nhân bị ung thư.
Các cạnh kết nối các nút đại diện cho sự phụ thuộc xác suất giữa các biến ngẫu nhiên đó. Nếu trong số hai nút, một nút đang ảnh hưởng đến nút kia thì chúng phải được kết nối trực tiếp theo các hướng của hiệu ứng. Độ mạnh của mối quan hệ giữa các biến được định lượng bằng xác suất liên quan đến mỗi nút.
Có một hạn chế duy nhất đối với các cung trong BN là bạn không thể quay lại một nút chỉ đơn giản bằng cách đi theo các cung có hướng. Do đó, BN được gọi là Đồ thị vòng có hướng (DAG).
BN có khả năng xử lý đồng thời các biến đa giá trị. Các biến BN bao gồm hai thứ nguyên -
- Phạm vi giới từ
- Xác suất được gán cho mỗi giới từ.
Xét tập hữu hạn X = {X 1 , X 2 ,…, X n } gồm các biến ngẫu nhiên rời rạc, trong đó mỗi biến X i có thể nhận các giá trị từ một tập hữu hạn, ký hiệu là Val (X i ). Nếu có một liên kết có hướng từ biến X i đến biến X j , thì biến X i sẽ là cha của biến X j thể hiện sự phụ thuộc trực tiếp giữa các biến.
Cấu trúc của BN là lý tưởng để kết hợp kiến thức trước đây và dữ liệu quan sát. BN có thể được sử dụng để tìm hiểu các mối quan hệ nhân quả và hiểu các lĩnh vực vấn đề khác nhau và để dự đoán các sự kiện trong tương lai, ngay cả trong trường hợp thiếu dữ liệu.
Xây dựng mạng Bayes
Một kỹ sư kiến thức có thể xây dựng một mạng Bayes. Có một số bước mà kỹ sư kiến thức cần thực hiện trong khi xây dựng nó.
Example problem- Bệnh ung thư phổi. Một bệnh nhân đã bị khó thở. Anh đi khám, bác sĩ nghi ngờ mình bị ung thư phổi. Bác sĩ biết rằng ngoài ung thư phổi, bệnh nhân có thể mắc nhiều bệnh khác như bệnh lao và viêm phế quản.
Gather Relevant Information of Problem
- Bệnh nhân có phải là người hút thuốc lá không? Nếu có thì khả năng cao bị ung thư và viêm phế quản.
- Bệnh nhân có tiếp xúc với không khí ô nhiễm không? Nếu có, loại ô nhiễm không khí nào?
- Chụp X-quang dương tính với tia X sẽ chỉ ra bệnh lao hoặc ung thư phổi.
Identify Interesting Variables
Kỹ sư kiến thức cố gắng trả lời các câu hỏi -
- Những nút nào để đại diện?
- Những giá trị nào họ có thể nhận? Họ có thể ở trạng thái nào?
Bây giờ chúng ta hãy xem xét các nút, chỉ với các giá trị rời rạc. Biến phải nhận chính xác một trong các giá trị này tại một thời điểm.
Common types of discrete nodes are -
Boolean nodes - Chúng biểu diễn các mệnh đề, nhận các giá trị nhị phân TRUE (T) và FALSE (F).
Ordered values- Một nút Ô nhiễm có thể đại diện và lấy các giá trị từ {thấp, trung bình, cao} mô tả mức độ tiếp xúc với ô nhiễm của bệnh nhân.
Integral values- Một nút được gọi là Tuổi có thể đại diện cho tuổi của bệnh nhân với các giá trị có thể từ 1 đến 120. Ngay cả ở giai đoạn đầu này, các lựa chọn mô hình hóa đang được thực hiện.
Các nút và giá trị có thể có cho ví dụ ung thư phổi -
| Tên nút | Kiểu | Giá trị | Tạo nút |
|---|---|---|---|
| Thận trọng | Nhị phân | {THẤP, CAO, TRUNG BÌNH} |

|
| Người hút thuốc | Boolean | {TRUE, FASLE} | |
| Ung thư phổi | Boolean | {TRUE, FASLE} | |
| Tia X | Nhị phân | {Tích cực, Tiêu cực} |
Create Arcs between Nodes
Cấu trúc liên kết của mạng nên nắm bắt các mối quan hệ định tính giữa các biến.
Ví dụ, nguyên nhân nào khiến một bệnh nhân bị ung thư phổi? - Ô nhiễm và hút thuốc lá. Sau đó, thêm các vòng cung từ nút Ô nhiễm và nút Người hút thuốc đến nút Ung thư phổi.
Tương tự nếu bệnh nhân bị ung thư phổi, kết quả chụp X-quang sẽ dương tính. Sau đó, thêm vòng cung từ nút Ung thư phổi đến nút X-Ray.

Specify Topology
Thông thường, BN được bố trí sao cho các vòng cung hướng từ trên xuống dưới. Tập hợp các nút cha của một nút X được cung cấp bởi Cha mẹ (X).
Các Lung-Ung thư nút có hai cha mẹ (lý do hoặc nguyên nhân): Ô nhiễm và Smoker , trong khi nút Smoker là mộtancestorcủa nút X-Ray . Tương tự, X-Ray là con (hậu quả hoặc ảnh hưởng) của ung thư phổi nút vàsuccessorcủa các nút Hút thuốc và Ô nhiễm.
Conditional Probabilities
Bây giờ định lượng các mối quan hệ giữa các nút được kết nối: điều này được thực hiện bằng cách chỉ định phân phối xác suất có điều kiện cho mỗi nút. Vì chỉ các biến rời rạc được xem xét ở đây, điều này có dạngConditional Probability Table (CPT).
Đầu tiên, đối với mỗi nút, chúng ta cần xem xét tất cả các tổ hợp giá trị có thể có của các nút cha đó. Mỗi kết hợp như vậy được gọi làinstantiationcủa tập hợp mẹ. Đối với mỗi sự khởi tạo riêng biệt của các giá trị nút cha, chúng ta cần xác định xác suất mà nút con sẽ nhận.
Ví dụ, cha mẹ của nút Ung thư phổi là Ô nhiễm và Hút thuốc. Chúng lấy các giá trị có thể có = {(H, T), (H, F), (L, T), (L, F)}. CPT chỉ định xác suất ung thư cho từng trường hợp này lần lượt là <0,05, 0,02, 0,03, 0,001>.
Mỗi nút sẽ có xác suất có điều kiện được liên kết như sau:

Các ứng dụng của mạng thần kinh
Họ có thể thực hiện các nhiệm vụ dễ dàng đối với con người nhưng khó đối với máy móc -
Aerospace - Lái máy bay tự động, phát hiện lỗi máy bay.
Automotive - Hệ thống hướng dẫn ô tô.
Military - Định hướng và chỉ đạo vũ khí, theo dõi mục tiêu, phân biệt đối tượng, nhận dạng khuôn mặt, nhận dạng tín hiệu / hình ảnh.
Electronics - Dự đoán trình tự mã, bố trí chip IC, phân tích lỗi chip, thị giác máy, tổng hợp giọng nói.
Financial - Thẩm định bất động sản, cố vấn khoản vay, sàng lọc thế chấp, xếp hạng trái phiếu doanh nghiệp, chương trình giao dịch danh mục đầu tư, phân tích tài chính doanh nghiệp, dự đoán giá trị tiền tệ, trình đọc tài liệu, đánh giá hồ sơ tín dụng.
Industrial - Kiểm soát quá trình sản xuất, thiết kế và phân tích sản phẩm, hệ thống kiểm tra chất lượng, phân tích chất lượng hàn, dự đoán chất lượng giấy, phân tích thiết kế sản phẩm hóa chất, mô hình hóa động lực của hệ thống quy trình hóa học, phân tích bảo trì máy, đấu thầu dự án, lập kế hoạch và quản lý.
Medical - Phân tích tế bào ung thư, phân tích điện não đồ và điện tâm đồ, thiết kế bộ phận giả, bộ tối ưu hóa thời gian cấy ghép.
Speech - Nhận dạng giọng nói, phân loại giọng nói, chuyển văn bản thành giọng nói.
Telecommunications - Nén hình ảnh và dữ liệu, dịch vụ thông tin tự động, dịch ngôn ngữ nói theo thời gian thực.
Transportation - Hệ thống chẩn đoán phanh xe tải, lập lịch trình xe, hệ thống định tuyến.
Software - Nhận dạng mẫu trong nhận dạng khuôn mặt, nhận dạng ký tự quang học, v.v.
Time Series Prediction - ANN được sử dụng để đưa ra dự đoán về trữ lượng và thiên tai.
Signal Processing - Mạng nơron có thể được đào tạo để xử lý tín hiệu âm thanh và lọc tín hiệu đó một cách thích hợp trong máy trợ thính.
Control - ANN thường được sử dụng để đưa ra quyết định lái của phương tiện vật lý.
Anomaly Detection - Vì ANN là chuyên gia trong việc nhận dạng các mẫu, họ cũng có thể được đào tạo để tạo ra kết quả đầu ra khi có điều gì đó bất thường xảy ra làm sai mẫu.
AI đang phát triển với một tốc độ đáng kinh ngạc, đôi khi nó có vẻ kỳ diệu. Có một ý kiến trong số các nhà nghiên cứu và nhà phát triển rằng AI có thể phát triển vô cùng mạnh mẽ đến mức con người khó có thể kiểm soát được.
Con người đã phát triển các hệ thống AI bằng cách đưa vào chúng mọi trí thông minh có thể có, mà chính con người hiện đang bị đe dọa.
Đe dọa quyền riêng tư
Một chương trình AI nhận dạng giọng nói và hiểu ngôn ngữ tự nhiên về mặt lý thuyết có khả năng hiểu từng cuộc trò chuyện trên e-mail và điện thoại.
Đe doạ đến nhân phẩm
Hệ thống AI đã bắt đầu thay thế con người trong một số ngành công nghiệp. Nó không nên thay thế những người trong những ngành mà họ đang giữ những chức vụ cao quý liên quan đến đạo đức như y tá, bác sĩ phẫu thuật, thẩm phán, cảnh sát, v.v.
Đe doạ an toàn
Các hệ thống AI tự cải thiện có thể trở nên hùng mạnh hơn con người đến mức rất khó để ngăn chặn việc đạt được mục tiêu của họ, điều này có thể dẫn đến những hậu quả không lường trước được.
Dưới đây là danh sách các thuật ngữ được sử dụng thường xuyên trong lĩnh vực AI -
| Sr.No | Thuật ngữ & Ý nghĩa |
|---|---|
| 1 | Agent Tác nhân là hệ thống hoặc chương trình phần mềm có khả năng tự quản, có mục đích và lý luận hướng tới một hoặc nhiều mục tiêu. Chúng còn được gọi là trợ lý, môi giới, bot, droid, đại lý thông minh và đại lý phần mềm. |
| 2 | Autonomous Robot Robot không bị kiểm soát hoặc ảnh hưởng từ bên ngoài và có thể tự điều khiển độc lập. |
| 3 | Backward Chaining Chiến lược làm việc lùi cho Lý do / Nguyên nhân của vấn đề. |
| 4 | Blackboard Nó là bộ nhớ bên trong máy tính, được sử dụng để liên lạc giữa các hệ thống chuyên gia hợp tác. |
| 5 | Environment Nó là một phần của thế giới thực hoặc thế giới máy tính mà đặc vụ sinh sống. |
| 6 | Forward Chaining Chiến lược làm việc để đưa ra kết luận / giải pháp của một vấn đề. |
| 7 | Heuristics Đó là kiến thức dựa trên Thử-và-sai, đánh giá và thử nghiệm. |
| số 8 | Knowledge Engineering Tiếp thu kiến thức từ các chuyên gia về con người và các nguồn lực khác. |
| 9 | Percepts Đây là định dạng mà tác nhân thu được thông tin về môi trường. |
| 10 | Pruning Ghi đè những cân nhắc không cần thiết và không liên quan trong hệ thống AI. |
| 11 | Rule Nó là một định dạng đại diện cho cơ sở tri thức trong Hệ thống Chuyên gia. Nó ở dạng IF-THEN-ELSE. |
| 12 | Shell Shell là một phần mềm giúp thiết kế công cụ suy luận, cơ sở kiến thức và giao diện người dùng của một hệ thống chuyên gia. |
| 13 | Task Đó là mục tiêu mà đại lý đang cố gắng hoàn thành. |
| 14 | Turing Test Một bài kiểm tra do Allan Turing phát triển để kiểm tra trí thông minh của một cỗ máy so với trí thông minh của con người. |