AVRO - Hướng dẫn nhanh
Để truyền dữ liệu qua mạng hoặc để lưu trữ liên tục, bạn cần phải tuần tự hóa dữ liệu. Trước khiserialization APIs được cung cấp bởi Java và Hadoop, chúng tôi có một tiện ích đặc biệt, được gọi là Avro, một kỹ thuật tuần tự hóa dựa trên lược đồ.
Hướng dẫn này dạy bạn cách tuần tự hóa và giải mã hóa dữ liệu bằng Avro. Avro cung cấp các thư viện cho nhiều ngôn ngữ lập trình khác nhau. Trong hướng dẫn này, chúng tôi trình bày các ví dụ sử dụng thư viện Java.
Avro là gì?
Apache Avro là một hệ thống tuần tự hóa dữ liệu trung lập với ngôn ngữ. Nó được phát triển bởi Doug Cắt, cha đẻ của Hadoop. Vì các lớp có thể ghi Hadoop thiếu tính di động của ngôn ngữ, nên Avro trở nên khá hữu ích, vì nó xử lý các định dạng dữ liệu có thể được xử lý bằng nhiều ngôn ngữ. Avro là một công cụ ưa thích để tuần tự hóa dữ liệu trong Hadoop.
Avro có một hệ thống dựa trên giản đồ. Một lược đồ độc lập với ngôn ngữ được liên kết với các hoạt động đọc và ghi của nó. Avro tuần tự hóa dữ liệu có một lược đồ tích hợp. Avro tuần tự hóa dữ liệu thành định dạng nhị phân nhỏ gọn, có thể được giải mã bởi bất kỳ ứng dụng nào.
Avro sử dụng định dạng JSON để khai báo cấu trúc dữ liệu. Hiện tại, nó hỗ trợ các ngôn ngữ như Java, C, C ++, C #, Python và Ruby.
Lược đồ Avro
Avro phụ thuộc nhiều vào schema. Nó cho phép mọi dữ liệu được ghi mà không cần biết trước về lược đồ. Nó tuần tự hóa nhanh và kết quả dữ liệu được tuần tự hóa có kích thước nhỏ hơn. Lược đồ được lưu trữ cùng với dữ liệu Avro trong một tệp để xử lý thêm.
Trong RPC, máy khách và máy chủ trao đổi các lược đồ trong quá trình kết nối. Trao đổi này giúp giao tiếp giữa các trường được đặt tên giống nhau, các trường bị thiếu, các trường bổ sung, v.v.
Các lược đồ Avro được định nghĩa bằng JSON giúp đơn giản hóa việc triển khai nó bằng các ngôn ngữ có thư viện JSON.
Giống như Avro, có các cơ chế tuần tự hóa khác trong Hadoop như Sequence Files, Protocol Buffers, và Thrift.
So sánh với Bộ đệm Giao thức và Tiết kiệm
Thrift và Protocol Bufferslà những thư viện có thẩm quyền nhất với Avro. Avro khác với các khung này theo những cách sau:
Avro hỗ trợ cả kiểu động và kiểu tĩnh theo yêu cầu. Bộ đệm Giao thức và Thrift sử dụng Ngôn ngữ Định nghĩa Giao diện (IDL) để chỉ định các lược đồ và kiểu của chúng. Các IDL này được sử dụng để tạo mã cho tuần tự hóa và giải mã hóa.
Avro được xây dựng trong hệ sinh thái Hadoop. Bộ đệm Tiết kiệm và Giao thức không được xây dựng trong hệ sinh thái Hadoop.
Không giống như Thrift và Bộ đệm giao thức, định nghĩa lược đồ của Avro là trong JSON chứ không phải trong bất kỳ IDL độc quyền nào.
| Bất động sản | Avro | Bộ đệm giao thức & tiết kiệm |
|---|---|---|
| Lược đồ động | Đúng | Không |
| Tích hợp vào Hadoop | Đúng | Không |
| Lược đồ trong JSON | Đúng | Không |
| Không cần biên dịch | Đúng | Không |
| Không cần khai báo ID | Đúng | Không |
| Tối tân | Đúng | Không |
Đặc điểm của Avro
Dưới đây là một số tính năng nổi bật của Avro -
Avro là một language-neutral hệ thống tuần tự hóa dữ liệu.
Nó có thể được xử lý bằng nhiều ngôn ngữ (hiện tại là C, C ++, C #, Java, Python và Ruby).
Avro tạo ra định dạng có cấu trúc nhị phân compressible và splittable. Do đó, nó có thể được sử dụng hiệu quả làm đầu vào cho các công việc Hadoop MapReduce.
Avro cung cấp rich data structures. Ví dụ, bạn có thể tạo một bản ghi có chứa một mảng, một kiểu liệt kê và một bản ghi con. Các kiểu dữ liệu này có thể được tạo bằng bất kỳ ngôn ngữ nào, có thể được xử lý trong Hadoop và kết quả có thể được chuyển sang ngôn ngữ thứ ba.
Avro schemas xác định trong JSON, tạo điều kiện triển khai bằng các ngôn ngữ đã có thư viện JSON.
Avro tạo một tệp tự mô tả có tên Tệp Dữ liệu Avro, trong đó tệp này lưu trữ dữ liệu cùng với lược đồ của nó trong phần siêu dữ liệu.
Avro cũng được sử dụng trong các cuộc gọi thủ tục từ xa (RPC). Trong RPC, lược đồ trao đổi máy khách và máy chủ trong kết nối bắt tay.
Hoạt động chung của Avro
Để sử dụng Avro, bạn cần tuân theo quy trình làm việc đã cho -
Step 1- Tạo lược đồ. Ở đây bạn cần thiết kế lược đồ Avro theo dữ liệu của bạn.
Step 2- Đọc các lược đồ vào chương trình của bạn. Nó được thực hiện theo hai cách -
By Generating a Class Corresponding to Schema- Biên dịch lược đồ bằng Avro. Điều này tạo ra một tệp lớp tương ứng với lược đồ
By Using Parsers Library - Bạn có thể đọc trực tiếp lược đồ bằng cách sử dụng thư viện phân tích cú pháp.
Step 3 - Tuần tự hóa dữ liệu bằng cách sử dụng API tuần tự hóa được cung cấp cho Avro, được tìm thấy trong package org.apache.avro.specific.
Step 4 - Hủy số hóa dữ liệu bằng cách sử dụng API giải mã được cung cấp cho Avro, được tìm thấy trong package org.apache.avro.specific.
Dữ liệu được tuần tự hóa cho hai mục tiêu -
Để lưu trữ liên tục
Để vận chuyển dữ liệu qua mạng
Serialization là gì?
Tuần tự hóa là quá trình dịch cấu trúc dữ liệu hoặc trạng thái đối tượng sang dạng nhị phân hoặc dạng văn bản để vận chuyển dữ liệu qua mạng hoặc lưu trữ trên một số bộ lưu trữ liên tục. Sau khi dữ liệu được truyền qua mạng hoặc được truy xuất từ bộ lưu trữ liên tục, dữ liệu đó cần được giải mã hóa lại. Serialization được gọi làmarshalling và deserialization được gọi là unmarshalling.
Serialization trong Java
Java cung cấp một cơ chế, được gọi là object serialization trong đó một đối tượng có thể được biểu diễn dưới dạng một chuỗi các byte bao gồm dữ liệu của đối tượng cũng như thông tin về kiểu của đối tượng và các kiểu dữ liệu được lưu trữ trong đối tượng.
Sau khi một đối tượng tuần tự hóa được ghi vào một tệp, nó có thể được đọc từ tệp và được giải mã hóa. Đó là, thông tin kiểu và byte đại diện cho đối tượng và dữ liệu của nó có thể được sử dụng để tạo lại đối tượng trong bộ nhớ.
ObjectInputStream và ObjectOutputStream các lớp được sử dụng để tuần tự hóa và giải mã hóa một đối tượng tương ứng trong Java.
Serialization trong Hadoop
Nói chung trong các hệ thống phân tán như Hadoop, khái niệm tuần tự hóa được sử dụng cho Interprocess Communication và Persistent Storage.
Giao tiếp giữa các quy trình
Để thiết lập giao tiếp liên quá trình giữa các nút được kết nối trong mạng, kỹ thuật RPC đã được sử dụng.
RPC đã sử dụng tuần tự hóa nội bộ để chuyển đổi thông điệp sang định dạng nhị phân trước khi gửi đến nút từ xa qua mạng. Ở đầu kia, hệ thống từ xa sẽ giải dòng nhị phân thành tin nhắn gốc.
Định dạng tuần tự hóa RPC được yêu cầu như sau:
Compact - Sử dụng tối ưu băng thông mạng, nguồn tài nguyên khan hiếm nhất trong trung tâm dữ liệu.
Fast - Vì giao tiếp giữa các nút là rất quan trọng trong hệ thống phân tán, quá trình tuần tự hóa và giải mã hóa phải nhanh chóng, tạo ra ít chi phí hơn.
Extensible - Các giao thức thay đổi theo thời gian để đáp ứng các yêu cầu mới, vì vậy cần phải phát triển giao thức một cách có kiểm soát cho các máy khách và máy chủ.
Interoperable - Định dạng thông báo nên hỗ trợ các nút được viết bằng các ngôn ngữ khác nhau.
Lưu trữ liên tục
Lưu trữ liên tục là một phương tiện lưu trữ kỹ thuật số không bị mất dữ liệu khi mất nguồn điện. Tệp, thư mục, cơ sở dữ liệu là những ví dụ về lưu trữ liên tục.
Giao diện ghi
Đây là giao diện trong Hadoop cung cấp các phương pháp tuần tự hóa và giải mã hóa. Bảng sau đây mô tả các phương pháp:
| Không. | Phương pháp và Mô tả |
|---|---|
| 1 | void readFields(DataInput in) Phương thức này được sử dụng để giải mã hóa các trường của đối tượng đã cho. |
| 2 | void write(DataOutput out) Phương thức này được sử dụng để tuần tự hóa các trường của đối tượng đã cho. |
Giao diện có thể so sánh được
Nó là sự kết hợp của Writable và Comparablecác giao diện. Giao diện này kế thừaWritable giao diện của Hadoop cũng như Comparablegiao diện của Java. Do đó, nó cung cấp các phương pháp tuần tự hóa, giải mã hóa và so sánh dữ liệu.
| Không. | Phương pháp và Mô tả |
|---|---|
| 1 | int compareTo(class obj) Phương thức này so sánh đối tượng hiện tại với đối tượng đã cho. |
Ngoài các lớp này, Hadoop còn hỗ trợ một số lớp trình bao bọc thực hiện giao diện có thể so sánh được. Mỗi lớp bao bọc một kiểu nguyên thủy Java. Phân cấp lớp của tuần tự hóa Hadoop được đưa ra dưới đây:
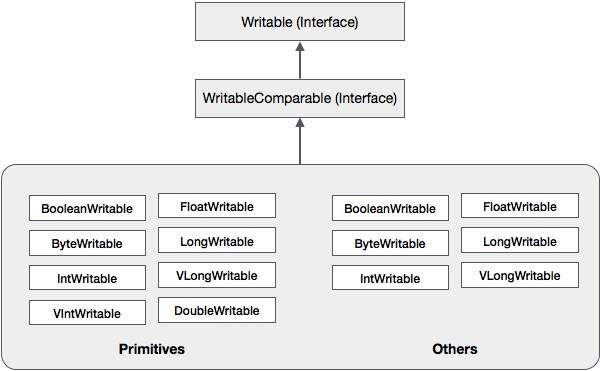
Các lớp này hữu ích để tuần tự hóa nhiều loại dữ liệu khác nhau trong Hadoop. Ví dụ, chúng ta hãy xem xétIntWritablelớp học. Hãy để chúng tôi xem cách lớp này được sử dụng để tuần tự hóa và giải mã hóa dữ liệu trong Hadoop.
Lớp ghi âm
Lớp này thực hiện Writable, Comparable, và WritableComparablecác giao diện. Nó bao bọc một kiểu dữ liệu số nguyên trong đó. Lớp này cung cấp các phương thức dùng để tuần tự hóa và giải mã hóa kiểu số nguyên của dữ liệu.
Người xây dựng
| Không. | Tóm lược |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
Phương pháp
| Không. | Tóm lược |
|---|---|
| 1 | int get() Sử dụng phương pháp này, bạn có thể nhận được giá trị số nguyên có trong đối tượng hiện tại. |
| 2 | void readFields(DataInput in) Phương pháp này được sử dụng để giải mã dữ liệu trong DataInput vật. |
| 3 | void set(int value) Phương pháp này được sử dụng để đặt giá trị của dòng điện IntWritable vật. |
| 4 | void write(DataOutput out) Phương thức này được sử dụng để tuần tự hóa dữ liệu trong đối tượng hiện tại thành DataOutput vật. |
Sắp xếp thứ tự dữ liệu trong Hadoop
Quy trình tuần tự hóa kiểu dữ liệu số nguyên được thảo luận dưới đây.
Khởi tạo IntWritable lớp bằng cách gói một giá trị số nguyên trong đó.
Khởi tạo ByteArrayOutputStream lớp học.
Khởi tạo DataOutputStream lớp và chuyển đối tượng của ByteArrayOutputStream lớp với nó.
Tuần tự hóa giá trị số nguyên trong đối tượng IntW ghi bằng cách sử dụng write()phương pháp. Phương thức này cần một đối tượng của lớp DataOutputStream.
Dữ liệu được tuần tự hóa sẽ được lưu trữ trong đối tượng mảng byte được truyền dưới dạng tham số cho DataOutputStreamtại thời điểm khởi tạo. Chuyển đổi dữ liệu trong đối tượng thành mảng byte.
Thí dụ
Ví dụ sau cho thấy cách tuần tự hóa dữ liệu kiểu số nguyên trong Hadoop:
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Giải mã dữ liệu trong Hadoop
Quy trình giải mã dữ liệu kiểu số nguyên được thảo luận dưới đây:
Khởi tạo IntWritable lớp bằng cách gói một giá trị số nguyên trong đó.
Khởi tạo ByteArrayOutputStream lớp học.
Khởi tạo DataOutputStream lớp và chuyển đối tượng của ByteArrayOutputStream lớp với nó.
Hủy số liệu hóa dữ liệu trong đối tượng của DataInputStream sử dụng readFields() phương thức của lớp IntWille.
Dữ liệu được giải mã sẽ được lưu trữ trong đối tượng của lớp IntWille. Bạn có thể lấy dữ liệu này bằng cách sử dụngget() phương thức của lớp này.
Thí dụ
Ví dụ sau cho thấy cách giải mã dữ liệu kiểu số nguyên trong Hadoop:
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Lợi thế của Hadoop so với Java Serialization
Tuần tự hóa dựa trên ghi của Hadoop có khả năng giảm chi phí tạo đối tượng bằng cách sử dụng lại các đối tượng có thể ghi, điều này không thể thực hiện được với khuôn khổ tuần tự hóa gốc của Java.
Nhược điểm của Hadoop Serialization
Để tuần tự hóa dữ liệu Hadoop, có hai cách:
Bạn có thể dùng Writable các lớp, được cung cấp bởi thư viện gốc của Hadoop.
Bạn cũng có thể dùng Sequence Files lưu trữ dữ liệu ở định dạng nhị phân.
Hạn chế chính của hai cơ chế này là Writables và SequenceFiles chỉ có một API Java và chúng không thể được viết hoặc đọc bằng bất kỳ ngôn ngữ nào khác.
Do đó, bất kỳ tệp nào được tạo trong Hadoop với hai cơ chế trên đều không thể đọc được bằng bất kỳ ngôn ngữ thứ ba nào khác, điều này làm cho Hadoop như một hộp giới hạn. Để giải quyết nhược điểm này, Doug Cắt đã tạoAvro, mà là một language independent data structure.
Nền tảng phần mềm Apache cung cấp cho Avro nhiều bản phát hành khác nhau. Bạn có thể tải xuống bản phát hành bắt buộc từ Apache mirror. Hãy để chúng tôi xem, cách thiết lập môi trường để làm việc với Avro -
Tải xuống Avro
Để tải xuống Apache Avro, hãy thực hiện theo các bước sau:
Mở trang web Apache.org . Bạn sẽ thấy trang chủ của Apache Avro như hình bên dưới:
Nhấp vào dự án → phát hành. Bạn sẽ nhận được một danh sách các bản phát hành.
Chọn bản phát hành mới nhất dẫn bạn đến liên kết tải xuống.
mirror.nexcess là một trong những liên kết nơi bạn có thể tìm thấy danh sách tất cả các thư viện của các ngôn ngữ khác nhau mà Avro hỗ trợ như hình dưới đây -

Bạn có thể chọn và tải xuống thư viện cho bất kỳ ngôn ngữ nào được cung cấp. Trong hướng dẫn này, chúng tôi sử dụng Java. Do đó, hãy tải xuống các tệp jaravro-1.7.7.jar và avro-tools-1.7.7.jar.
Avro với Eclipse
Để sử dụng Avro trong môi trường Eclipse, bạn cần làm theo các bước dưới đây:
Step 1. Nhật thực mở.
Step 2. Tạo một dự án.
Step 3.Nhấp chuột phải vào tên dự án. Bạn sẽ nhận được một menu lối tắt.
Step 4. Bấm vào Build Path. Nó dẫn bạn đến một menu lối tắt khác.
Step 5. Bấm vào Configure Build Path... Bạn có thể thấy cửa sổ Thuộc tính của dự án của bạn như hình dưới đây:

Step 6. Trong tab thư viện, nhấp vào ADD EXternal JARs... cái nút.
Step 7. Chọn tệp jar avro-1.77.jar bạn đã tải xuống.
Step 8. Bấm vào OK.
Avro với Maven
Bạn cũng có thể đưa thư viện Avro vào dự án của mình bằng Maven. Dưới đây là tệp pom.xml cho Avro.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>Test</groupId>
<artifactId>Test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-tools</artifactId>
<version>1.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>2.0-beta9</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.0-beta9</version>
</dependency>
</dependencies>
</project>Đặt Classpath
Để làm việc với Avro trong môi trường Linux, hãy tải xuống các tệp jar sau:
- avro-1.77.jar
- avro-tools-1.77.jar
- log4j-api-2.0-beta9.jar
- og4j-core-2.0.beta9.jar.
Sao chép các tệp này vào một thư mục và đặt classpath vào thư mục, trong./bashrc tập tin như hình dưới đây.
#class path for Avro
export CLASSPATH=$CLASSPATH://home/Hadoop/Avro_Work/jars/*
Avro, là một tiện ích tuần tự hóa dựa trên lược đồ, chấp nhận các lược đồ làm đầu vào. Mặc dù có sẵn nhiều lược đồ khác nhau, nhưng Avro vẫn tuân theo các tiêu chuẩn xác định lược đồ của riêng mình. Các lược đồ này mô tả các chi tiết sau:
- loại tệp (ghi theo mặc định)
- vị trí của bản ghi
- tên của bản ghi
- các trường trong bản ghi với kiểu dữ liệu tương ứng của chúng
Sử dụng các lược đồ này, bạn có thể lưu trữ các giá trị được tuần tự hóa ở định dạng nhị phân sử dụng ít dung lượng hơn. Các giá trị này được lưu trữ mà không có bất kỳ siêu dữ liệu nào.
Tạo lược đồ Avro
Lược đồ Avro được tạo ở định dạng tài liệu JavaScript Object Notation (JSON), là một định dạng trao đổi dữ liệu dựa trên văn bản nhẹ. Nó được tạo theo một trong những cách sau:
- Một chuỗi JSON
- Một đối tượng JSON
- Một mảng JSON
Example - Ví dụ sau đây cho thấy một lược đồ, định nghĩa một tài liệu, dưới không gian tên Tutorialspoint, với tên Employee, có tên trường và tuổi.
{
"type" : "record",
"namespace" : "Tutorialspoint",
"name" : "Employee",
"fields" : [
{ "name" : "Name" , "type" : "string" },
{ "name" : "Age" , "type" : "int" }
]
}Trong ví dụ này, bạn có thể thấy rằng có bốn trường cho mỗi bản ghi -
type - Trường này nằm dưới tài liệu cũng như các trường dưới tên trường.
Trong trường hợp tài liệu, nó hiển thị loại tài liệu, nói chung là một bản ghi vì có nhiều trường.
Khi nó là trường, kiểu mô tả kiểu dữ liệu.
namespace - Trường này mô tả tên của không gian tên mà đối tượng cư trú.
name - Trường này nằm dưới tài liệu cũng như các trường dưới tên trường.
Trong trường hợp tài liệu, nó mô tả tên lược đồ. Tên lược đồ này cùng với không gian tên, xác định duy nhất lược đồ trong cửa hàng (Namespace.schema name). Trong ví dụ trên, tên đầy đủ của lược đồ sẽ là Tutorialspoint.Empleteee.
Trong trường hợp các trường, nó mô tả tên của trường.
Các kiểu dữ liệu ban đầu của Avro
Lược đồ Avro có các kiểu dữ liệu nguyên thủy cũng như các kiểu dữ liệu phức tạp. Bảng sau đây mô tảprimitive data types của Avro -
| Loại dữ liệu | Sự miêu tả |
|---|---|
| vô giá trị | Null là một kiểu không có giá trị. |
| int | Số nguyên có dấu 32 bit. |
| Dài | Số nguyên có dấu 64 bit. |
| Phao nổi | số dấu phẩy động IEEE 754 chính xác đơn (32-bit). |
| gấp đôi | số dấu phẩy động IEEE 754 chính xác kép (64-bit). |
| byte | chuỗi các byte không dấu 8 bit. |
| chuỗi | Chuỗi ký tự Unicode. |
Các kiểu dữ liệu phức tạp của Avro
Cùng với các kiểu dữ liệu nguyên thủy, Avro cung cấp sáu kiểu dữ liệu phức tạp là Bản ghi, Vùng, Mảng, Bản đồ, Liên hợp và Cố định.
Ghi lại
Kiểu dữ liệu bản ghi trong Avro là một tập hợp nhiều thuộc tính. Nó hỗ trợ các thuộc tính sau:
name - Giá trị của trường này giữ tên của bản ghi.
namespace - Giá trị của trường này chứa tên của không gian tên nơi lưu trữ đối tượng.
type - Giá trị của thuộc tính này chứa kiểu tài liệu (bản ghi) hoặc kiểu dữ liệu của trường trong lược đồ.
fields - Trường này chứa một mảng JSON, có danh sách tất cả các trường trong lược đồ, mỗi trường có tên và thuộc tính kiểu.
Example
Dưới đây là ví dụ về một bản ghi.
{
" type " : "record",
" namespace " : "Tutorialspoint",
" name " : "Employee",
" fields " : [
{ "name" : " Name" , "type" : "string" },
{ "name" : "age" , "type" : "int" }
]
}Enum
Liệt kê là một danh sách các mục trong một tập hợp, liệt kê Avro hỗ trợ các thuộc tính sau:
name - Giá trị của trường này chứa tên của kiểu liệt kê.
namespace - Giá trị của trường này chứa chuỗi đủ điều kiện tên của Bảng kê.
symbols - Giá trị của trường này chứa các ký hiệu của enum dưới dạng một mảng tên.
Example
Dưới đây là ví dụ về kiểu liệt kê.
{
"type" : "enum",
"name" : "Numbers",
"namespace": "data",
"symbols" : [ "ONE", "TWO", "THREE", "FOUR" ]
}Mảng
Kiểu dữ liệu này xác định một trường mảng có một mục thuộc tính duy nhất. Thuộc tính items này chỉ định loại item trong mảng.
Example
{ " type " : " array ", " items " : " int " }Bản đồ
Kiểu dữ liệu bản đồ là một mảng các cặp khóa-giá trị, nó tổ chức dữ liệu thành các cặp khóa-giá trị. Khóa cho một bản đồ Avro phải là một chuỗi. Các giá trị của bản đồ giữ kiểu dữ liệu của nội dung bản đồ.
Example
{"type" : "map", "values" : "int"}Đoàn thể
Một kiểu dữ liệu liên hợp được sử dụng bất cứ khi nào trường có một hoặc nhiều kiểu dữ liệu. Chúng được biểu diễn dưới dạng mảng JSON. Ví dụ: nếu một trường có thể là int hoặc null, thì liên hợp được biểu diễn là ["int", "null"].
Example
Dưới đây là một tài liệu ví dụ sử dụng công đoàn -
{
"type" : "record",
"namespace" : "tutorialspoint",
"name" : "empdetails ",
"fields" :
[
{ "name" : "experience", "type": ["int", "null"] }, { "name" : "age", "type": "int" }
]
}đã sửa
Kiểu dữ liệu này được sử dụng để khai báo một trường có kích thước cố định có thể được sử dụng để lưu trữ dữ liệu nhị phân. Nó có tên trường và dữ liệu là thuộc tính. Tên chứa tên của trường và kích thước chứa kích thước của trường.
Example
{ "type" : "fixed" , "name" : "bdata", "size" : 1048576}Trong chương trước, chúng ta đã mô tả kiểu đầu vào của Avro, tức là, lược đồ Avro. Trong chương này, chúng tôi sẽ giải thích các lớp và phương thức được sử dụng trong tuần tự hóa và giải hóa các lược đồ Avro.
Lớp SpecificDatumWriter
Lớp này thuộc về gói org.apache.avro.specific. Nó thực hiệnDatumWriter giao diện chuyển đổi các đối tượng Java thành định dạng tuần tự hóa trong bộ nhớ.
Constructor
| Không. | Sự miêu tả |
|---|---|
| 1 | SpecificDatumWriter(Schema schema) |
phương pháp
| Không. | Sự miêu tả |
|---|---|
| 1 | SpecificData getSpecificData() Trả về triển khai Dữ liệu cụ thể được người viết này sử dụng. |
Lớp đọc cụ thể
Lớp này thuộc về gói org.apache.avro.specific. Nó thực hiệnDatumReader giao diện đọc dữ liệu của một lược đồ và xác định biểu diễn dữ liệu trong bộ nhớ. SpecificDatumReader là lớp hỗ trợ các lớp java được tạo.
Constructor
| Không. | Sự miêu tả |
|---|---|
| 1 | SpecificDatumReader(Schema schema) Xây dựng trong đó lược đồ của người viết và người đọc giống nhau. |
Phương pháp
| Không. | Sự miêu tả |
|---|---|
| 1 | SpecificData getSpecificData() Trả về dữ liệu cụ thể được chứa. |
| 2 | void setSchema(Schema actual) Phương pháp này được sử dụng để thiết lập lược đồ của người viết. |
DataFileWriter
Instantiates DataFileWrite cho emplớp học. Lớp này ghi một chuỗi các bản ghi dữ liệu được tuần tự hóa theo một lược đồ, cùng với lược đồ trong một tệp.
Constructor
| Không. | Sự miêu tả |
|---|---|
| 1 | DataFileWriter(DatumWriter<D> dout) |
Phương pháp
| S. không | Sự miêu tả |
|---|---|
| 1 | void append(D datum) Thêm một dữ liệu vào một tệp. |
| 2 | DataFileWriter<D> appendTo(File file) Phương pháp này được sử dụng để mở một trình viết thêm vào một tệp hiện có. |
Data FileReader
Lớp này cung cấp quyền truy cập ngẫu nhiên vào các tệp được viết bằng DataFileWriter. Nó kế thừa lớpDataFileStream.
Constructor
| Không. | Sự miêu tả |
|---|---|
| 1 | DataFileReader(File file, DatumReader<D> reader)) |
Phương pháp
| Không. | Sự miêu tả |
|---|---|
| 1 | next() Đọc dữ liệu tiếp theo trong tệp. |
| 2 | Boolean hasNext() Trả về true nếu còn nhiều mục trong tệp này. |
Lớp Schema.parser
Lớp này là trình phân tích cú pháp cho các lược đồ định dạng JSON. Nó chứa các phương thức để phân tích cú pháp lược đồ. Nó thuộc vềorg.apache.avro gói hàng.
Constructor
| Không. | Sự miêu tả |
|---|---|
| 1 | Schema.Parser() |
Phương pháp
| Không. | Sự miêu tả |
|---|---|
| 1 | parse (File file) Phân tích cú pháp lược đồ được cung cấp trong file. |
| 2 | parse (InputStream in) Phân tích cú pháp lược đồ được cung cấp trong InputStream. |
| 3 | parse (String s) Phân tích cú pháp lược đồ được cung cấp trong String. |
Giao diện GenricRecord
Giao diện này cung cấp các phương thức để truy cập các trường theo tên cũng như chỉ mục.
Phương pháp
| Không. | Sự miêu tả |
|---|---|
| 1 | Object get(String key) Trả về giá trị của một trường đã cho. |
| 2 | void put(String key, Object v) Đặt giá trị của một trường có tên của nó. |
Class GenericData.Record
Constructor
| Không. | Sự miêu tả |
|---|---|
| 1 | GenericData.Record(Schema schema) |
Phương pháp
| Không. | Sự miêu tả |
|---|---|
| 1 | Object get(String key) Trả về giá trị của một trường tên đã cho. |
| 2 | Schema getSchema() Trả về lược đồ của trường hợp này. |
| 3 | void put(int i, Object v) Đặt giá trị của một trường cho vị trí của nó trong lược đồ. |
| 4 | void put(String key, Object value) Đặt giá trị của một trường có tên của nó. |
Người ta có thể đọc một lược đồ Avro vào chương trình bằng cách tạo một lớp tương ứng với một lược đồ hoặc bằng cách sử dụng thư viện phân tích cú pháp. Chương này mô tả cách đọc lược đồby generating a class và Serializing dữ liệu sử dụng Avr.

Serialization bằng cách tạo một lớp
Để tuần tự hóa dữ liệu bằng Avro, hãy làm theo các bước như dưới đây -
Viết giản đồ Avro.
Biên dịch lược đồ bằng tiện ích Avro. Bạn nhận được mã Java tương ứng với lược đồ đó.
Điền vào lược đồ với dữ liệu.
Tuần tự hóa nó bằng cách sử dụng thư viện Avro.
Xác định một lược đồ
Giả sử bạn muốn một lược đồ với các chi tiết sau:
| Field | Tên | Tôi | tuổi tác | tiền lương | Địa chỉ |
| type | Chuỗi | int | int | int | chuỗi |
Tạo một lược đồ Avro như hình dưới đây.
Lưu nó thành emp.avsc.
{
"namespace": "tutorialspoint.com",
"type": "record",
"name": "emp",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "salary", "type": "int"},
{"name": "age", "type": "int"},
{"name": "address", "type": "string"}
]
}Biên dịch lược đồ
Sau khi tạo một lược đồ Avro, bạn cần biên dịch lược đồ đã tạo bằng các công cụ Avro. avro-tools-1.7.7.jar là hũ đựng các dụng cụ.
Cú pháp để biên dịch một lược đồ Avro
java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>Mở thiết bị đầu cuối trong thư mục chính.
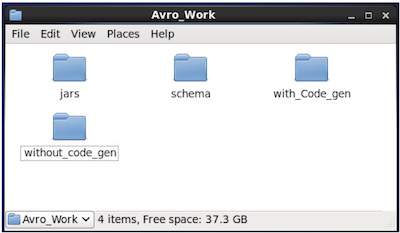
Tạo một thư mục mới để làm việc với Avro như hình dưới đây -
$ mkdir Avro_WorkTrong thư mục mới tạo, hãy tạo ba thư mục con -
Được đặt tên đầu tiên schema, để đặt lược đồ.
Thứ hai được đặt tên with_code_gen, để đặt mã đã tạo.
Thứ ba được đặt tên jars, để đặt các tệp jar.
$ mkdir schema $ mkdir with_code_gen
$ mkdir jarsẢnh chụp màn hình sau đây cho thấy cách Avro_work thư mục sẽ trông giống như sau khi tạo tất cả các thư mục.
Hiện nay /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar là đường dẫn cho thư mục mà bạn đã tải xuống tệp avro-tools-1.7.7.jar.
/home/Hadoop/Avro_work/schema/ là đường dẫn cho thư mục nơi lưu trữ tệp giản đồ emp.avsc của bạn.
/home/Hadoop/Avro_work/with_code_gen là thư mục mà bạn muốn lưu trữ các tệp lớp đã tạo.
Bây giờ, hãy biên dịch lược đồ như được hiển thị bên dưới:
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_genSau khi biên dịch, một gói theo không gian tên của lược đồ được tạo trong thư mục đích. Trong gói này, mã nguồn Java với tên lược đồ được tạo. Mã nguồn được tạo này là mã Java của lược đồ đã cho có thể được sử dụng trực tiếp trong các ứng dụng.
Ví dụ, trong trường hợp này, một gói / thư mục, có tên tutorialspoint được tạo có chứa một thư mục khác có tên com (vì không gian tên là tutorialspoint.com) và bên trong nó, bạn có thể quan sát tệp được tạo emp.java. Ảnh chụp nhanh sau đây cho thấyemp.java -

Lớp này hữu ích để tạo dữ liệu theo lược đồ.
Lớp được tạo chứa -
- Hàm tạo mặc định và hàm tạo tham số chấp nhận tất cả các biến của lược đồ.
- Phương thức setter và getter cho tất cả các biến trong lược đồ.
- Phương thức get () trả về lược đồ.
- Các phương thức xây dựng.
Tạo và tuần tự hóa dữ liệu
Trước hết, sao chép tệp java đã tạo được sử dụng trong dự án này vào thư mục hiện tại hoặc nhập tệp từ vị trí của tệp.
Bây giờ chúng ta có thể viết một tệp Java mới và khởi tạo lớp trong tệp được tạo (emp) để thêm dữ liệu nhân viên vào lược đồ.
Chúng ta hãy xem quy trình tạo dữ liệu theo lược đồ bằng apache Avro.
Bước 1
Khởi tạo emp lớp học.
emp e1=new emp( );Bước 2
Sử dụng các phương thức setter, chèn dữ liệu của nhân viên đầu tiên. Ví dụ, chúng tôi đã tạo các chi tiết của nhân viên tên là Omar.
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);Tương tự, hãy điền tất cả thông tin chi tiết của nhân viên bằng các phương pháp setter.
Bước 3
Tạo một đối tượng của DatumWriter giao diện sử dụng SpecificDatumWriterlớp học. Điều này chuyển đổi các đối tượng Java thành định dạng tuần tự trong bộ nhớ. Ví dụ sau khởi tạoSpecificDatumWriter đối tượng lớp cho emp lớp học.
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);Bước 4
Khởi tạo DataFileWriter cho emplớp học. Lớp này ghi một bản ghi dữ liệu được tuần tự hóa theo trình tự tuân theo một lược đồ, cùng với chính lược đồ đó, trong một tệp. Lớp này yêu cầuDatumWriter đối tượng, như một tham số cho hàm tạo.
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);Bước 5
Mở một tệp mới để lưu trữ dữ liệu khớp với lược đồ đã cho bằng cách sử dụng create()phương pháp. Phương thức này yêu cầu lược đồ và đường dẫn của tệp nơi lưu trữ dữ liệu, dưới dạng các tham số.
Trong ví dụ sau, lược đồ được chuyển bằng cách sử dụng getSchema() và tệp dữ liệu được lưu trữ trong đường dẫn - /home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));Bước 6
Thêm tất cả các bản ghi đã tạo vào tệp bằng cách sử dụng append() như hình dưới đây -
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);Ví dụ - Tuần tự hóa bằng cách tạo một lớp
Chương trình hoàn chỉnh sau đây cho thấy cách tuần tự hóa dữ liệu thành một tệp bằng Apache Avro -
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.io.DatumWriter;
import org.apache.avro.specific.SpecificDatumWriter;
public class Serialize {
public static void main(String args[]) throws IOException{
//Instantiating generated emp class
emp e1=new emp();
//Creating values according the schema
e1.setName("omar");
e1.setAge(21);
e1.setSalary(30000);
e1.setAddress("Hyderabad");
e1.setId(001);
emp e2=new emp();
e2.setName("ram");
e2.setAge(30);
e2.setSalary(40000);
e2.setAddress("Hyderabad");
e2.setId(002);
emp e3=new emp();
e3.setName("robbin");
e3.setAge(25);
e3.setSalary(35000);
e3.setAddress("Hyderabad");
e3.setId(003);
//Instantiate DatumWriter class
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);
DataFileWriter<emp> empFileWriter = new DataFileWriter<emp>(empDatumWriter);
empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro"));
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);
empFileWriter.close();
System.out.println("data successfully serialized");
}
}Duyệt qua thư mục nơi mã đã tạo được đặt. Trong trường hợp này, tạihome/Hadoop/Avro_work/with_code_gen.
In Terminal −
$ cd home/Hadoop/Avro_work/with_code_gen/In GUI −
Bây giờ sao chép và lưu chương trình trên trong tệp có tên Serialize.java
Biên dịch và thực thi nó như hình dưới đây -
$ javac Serialize.java
$ java SerializeĐầu ra
data successfully serializedNếu bạn xác minh đường dẫn được cung cấp trong chương trình, bạn có thể tìm thấy tệp được tuần tự hóa được tạo như hình dưới đây.
Như đã mô tả trước đó, người ta có thể đọc một lược đồ Avro vào một chương trình bằng cách tạo một lớp tương ứng với lược đồ hoặc bằng cách sử dụng thư viện phân tích cú pháp. Chương này mô tả cách đọc lược đồby generating a class và Deserialize dữ liệu sử dụng Avro.
Hủy đăng ký bằng cách tạo một lớp
Dữ liệu tuần tự hóa được lưu trữ trong tệp emp.avro. Bạn có thể deserialize và đọc nó bằng Avro.

Làm theo quy trình dưới đây để giải mã dữ liệu tuần tự hóa từ tệp.
Bước 1
Tạo một đối tượng của DatumReader giao diện sử dụng SpecificDatumReader lớp học.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);Bước 2
Khởi tạo DataFileReader cho emplớp học. Lớp này đọc dữ liệu tuần tự từ một tệp. Nó yêu cầuDataumeader đối tượng và đường dẫn của tệp nơi dữ liệu được tuần tự hóa đang tồn tại, như một tham số cho hàm tạo.
DataFileReader<emp> dataFileReader = new DataFileReader(new File("/path/to/emp.avro"), empDatumReader);Bước 3
In dữ liệu được giải hóa bằng cách sử dụng các phương pháp của DataFileReader.
Các hasNext() phương thức sẽ trả về boolean nếu có bất kỳ phần tử nào trong Reader.
Các next() phương pháp của DataFileReader trả về dữ liệu trong Trình đọc.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}Ví dụ - Hủy đăng ký bằng cách tạo lớp
Chương trình hoàn chỉnh sau đây chỉ ra cách giải mã dữ liệu trong tệp bằng Avro.
import java.io.File;
import java.io.IOException;
import org.apache.avro.file.DataFileReader;
import org.apache.avro.io.DatumReader;
import org.apache.avro.specific.SpecificDatumReader;
public class Deserialize {
public static void main(String args[]) throws IOException{
//DeSerializing the objects
DatumReader<emp> empDatumReader = new SpecificDatumReader<emp>(emp.class);
//Instantiating DataFileReader
DataFileReader<emp> dataFileReader = new DataFileReader<emp>(new
File("/home/Hadoop/Avro_Work/with_code_genfile/emp.avro"), empDatumReader);
emp em=null;
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}
}
}Duyệt vào thư mục nơi mã đã tạo được đặt. Trong trường hợp này, tạihome/Hadoop/Avro_work/with_code_gen.
$ cd home/Hadoop/Avro_work/with_code_gen/Bây giờ, sao chép và lưu chương trình trên trong tệp có tên DeSerialize.java. Biên dịch và thực thi nó như hình dưới đây -
$ javac Deserialize.java $ java DeserializeĐầu ra
{"name": "omar", "id": 1, "salary": 30000, "age": 21, "address": "Hyderabad"}
{"name": "ram", "id": 2, "salary": 40000, "age": 30, "address": "Hyderabad"}
{"name": "robbin", "id": 3, "salary": 35000, "age": 25, "address": "Hyderabad"}Người ta có thể đọc một lược đồ Avro vào một chương trình bằng cách tạo một lớp tương ứng với một lược đồ hoặc bằng cách sử dụng thư viện phân tích cú pháp. Trong Avro, dữ liệu luôn được lưu trữ với lược đồ tương ứng của nó. Do đó, chúng ta luôn có thể đọc một lược đồ mà không cần tạo mã.
Chương này mô tả cách đọc lược đồ by using parsers library và để serialize dữ liệu sử dụng Avro.

Serialization sử dụng thư viện phân tích cú pháp
Để tuần tự hóa dữ liệu, chúng ta cần đọc lược đồ, tạo dữ liệu theo lược đồ và tuần tự hóa lược đồ bằng cách sử dụng API Avro. Quy trình sau đây tuần tự hóa dữ liệu mà không tạo ra bất kỳ mã nào -
Bước 1
Trước hết, hãy đọc lược đồ từ tệp. Để làm như vậy, hãy sử dụngSchema.Parserlớp học. Lớp này cung cấp các phương thức để phân tích cú pháp lược đồ theo các định dạng khác nhau.
Khởi tạo Schema.Parser lớp bằng cách chuyển đường dẫn tệp nơi lược đồ được lưu trữ.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));Bước 2
Tạo đối tượng của GenericRecord giao diện, bằng cách khởi tạo GenericData.Recordlớp như hình bên dưới. Truyền đối tượng lược đồ đã tạo ở trên vào phương thức khởi tạo của nó.
GenericRecord e1 = new GenericData.Record(schema);Bước 3
Chèn các giá trị vào giản đồ bằng cách sử dụng put() phương pháp của GenericData lớp học.
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chennai");Bước 4
Tạo một đối tượng của DatumWriter giao diện sử dụng SpecificDatumWriterlớp học. Nó chuyển đổi các đối tượng Java thành định dạng tuần tự hóa trong bộ nhớ. Ví dụ sau khởi tạoSpecificDatumWriter đối tượng lớp cho emp lớp học -
DatumWriter<emp> empDatumWriter = new SpecificDatumWriter<emp>(emp.class);Bước 5
Khởi tạo DataFileWriter cho emplớp học. Lớp này ghi các bản ghi dữ liệu được tuần tự hóa theo một lược đồ, cùng với bản thân lược đồ, trong một tệp. Lớp này yêu cầuDatumWriter đối tượng, như một tham số cho hàm tạo.
DataFileWriter<emp> dataFileWriter = new DataFileWriter<emp>(empDatumWriter);Bước 6
Mở một tệp mới để lưu trữ dữ liệu khớp với lược đồ đã cho bằng cách sử dụng create()phương pháp. Phương thức này yêu cầu lược đồ và đường dẫn của tệp nơi lưu trữ dữ liệu, dưới dạng các tham số.
Trong ví dụ dưới đây, lược đồ được chuyển bằng cách sử dụng getSchema() phương pháp và tệp dữ liệu được lưu trữ trong đường dẫn
/home/Hadoop/Avro/serialized_file/emp.avro.
empFileWriter.create(e1.getSchema(), new
File("/home/Hadoop/Avro/serialized_file/emp.avro"));Bước 7
Thêm tất cả các bản ghi đã tạo vào tệp bằng cách sử dụng append( ) như hình dưới đây.
empFileWriter.append(e1);
empFileWriter.append(e2);
empFileWriter.append(e3);Ví dụ - Serialization sử dụng Parsers
Chương trình hoàn chỉnh sau đây cho thấy cách tuần tự hóa dữ liệu bằng trình phân tích cú pháp:
import java.io.File;
import java.io.IOException;
import org.apache.avro.Schema;
import org.apache.avro.file.DataFileWriter;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericDatumWriter;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.io.DatumWriter;
public class Seriali {
public static void main(String args[]) throws IOException{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
//Instantiating the GenericRecord class.
GenericRecord e1 = new GenericData.Record(schema);
//Insert data according to schema
e1.put("name", "ramu");
e1.put("id", 001);
e1.put("salary",30000);
e1.put("age", 25);
e1.put("address", "chenni");
GenericRecord e2 = new GenericData.Record(schema);
e2.put("name", "rahman");
e2.put("id", 002);
e2.put("salary", 35000);
e2.put("age", 30);
e2.put("address", "Delhi");
DatumWriter<GenericRecord> datumWriter = new GenericDatumWriter<GenericRecord>(schema);
DataFileWriter<GenericRecord> dataFileWriter = new DataFileWriter<GenericRecord>(datumWriter);
dataFileWriter.create(schema, new File("/home/Hadoop/Avro_work/without_code_gen/mydata.txt"));
dataFileWriter.append(e1);
dataFileWriter.append(e2);
dataFileWriter.close();
System.out.println(“data successfully serialized”);
}
}Duyệt vào thư mục nơi mã đã tạo được đặt. Trong trường hợp này, tạihome/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/
Bây giờ sao chép và lưu chương trình trên trong tệp có tên Serialize.java. Biên dịch và thực thi nó như hình dưới đây -
$ javac Serialize.java
$ java SerializeĐầu ra
data successfully serializedNếu bạn xác minh đường dẫn được cung cấp trong chương trình, bạn có thể tìm thấy tệp được tuần tự hóa được tạo như hình dưới đây.
Như đã đề cập trước đó, người ta có thể đọc một lược đồ Avro vào một chương trình bằng cách tạo một lớp tương ứng với một lược đồ hoặc bằng cách sử dụng thư viện phân tích cú pháp. Trong Avro, dữ liệu luôn được lưu trữ với lược đồ tương ứng của nó. Do đó, chúng ta luôn có thể đọc một mục được tuần tự hóa mà không cần tạo mã.
Chương này mô tả cách đọc lược đồ using parsers library và Deserializing dữ liệu sử dụng Avro.
Hủy đăng ký bằng Thư viện phân tích cú pháp
Dữ liệu tuần tự hóa được lưu trữ trong tệp mydata.txt. Bạn có thể deserialize và đọc nó bằng Avro.
Làm theo quy trình dưới đây để giải mã dữ liệu tuần tự hóa từ tệp.
Bước 1
Trước hết, hãy đọc lược đồ từ tệp. Để làm như vậy, hãy sử dụngSchema.Parserlớp học. Lớp này cung cấp các phương thức để phân tích cú pháp lược đồ theo các định dạng khác nhau.
Khởi tạo Schema.Parser lớp bằng cách chuyển đường dẫn tệp nơi lược đồ được lưu trữ.
Schema schema = new Schema.Parser().parse(new File("/path/to/emp.avsc"));Bước 2
Tạo một đối tượng của DatumReader giao diện sử dụng SpecificDatumReader lớp học.
DatumReader<emp>empDatumReader = new SpecificDatumReader<emp>(emp.class);Bước 3
Khởi tạo DataFileReaderlớp học. Lớp này đọc dữ liệu tuần tự từ một tệp. Nó yêu cầuDatumReader đối tượng và đường dẫn của tệp nơi dữ liệu được tuần tự hóa tồn tại, như một tham số cho hàm tạo.
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/path/to/mydata.txt"), datumReader);Bước 4
In dữ liệu được giải hóa bằng cách sử dụng các phương pháp của DataFileReader.
Các hasNext() phương thức trả về một boolean nếu có bất kỳ phần tử nào trong Reader.
Các next() phương pháp của DataFileReader trả về dữ liệu trong Trình đọc.
while(dataFileReader.hasNext()){
em=dataFileReader.next(em);
System.out.println(em);
}Ví dụ - Hủy đăng ký sử dụng Thư viện phân tích cú pháp
Chương trình hoàn chỉnh sau đây cho thấy cách giải mã dữ liệu tuần tự hóa bằng thư viện Parsers:
public class Deserialize {
public static void main(String args[]) throws Exception{
//Instantiating the Schema.Parser class.
Schema schema = new Schema.Parser().parse(new File("/home/Hadoop/Avro/schema/emp.avsc"));
DatumReader<GenericRecord> datumReader = new GenericDatumReader<GenericRecord>(schema);
DataFileReader<GenericRecord> dataFileReader = new DataFileReader<GenericRecord>(new File("/home/Hadoop/Avro_Work/without_code_gen/mydata.txt"), datumReader);
GenericRecord emp = null;
while (dataFileReader.hasNext()) {
emp = dataFileReader.next(emp);
System.out.println(emp);
}
System.out.println("hello");
}
}Duyệt vào thư mục nơi mã đã tạo được đặt. Trong trường hợp này, nó ởhome/Hadoop/Avro_work/without_code_gen.
$ cd home/Hadoop/Avro_work/without_code_gen/Bây giờ sao chép và lưu chương trình trên trong tệp có tên DeSerialize.java. Biên dịch và thực thi nó như hình dưới đây -
$ javac Deserialize.java $ java DeserializeĐầu ra
{"name": "ramu", "id": 1, "salary": 30000, "age": 25, "address": "chennai"}
{"name": "rahman", "id": 2, "salary": 35000, "age": 30, "address": "Delhi"}