AVRO - Serialization
Dữ liệu được tuần tự hóa cho hai mục tiêu -
Để lưu trữ liên tục
Để vận chuyển dữ liệu qua mạng
Serialization là gì?
Tuần tự hóa là quá trình dịch cấu trúc dữ liệu hoặc trạng thái đối tượng sang dạng nhị phân hoặc dạng văn bản để vận chuyển dữ liệu qua mạng hoặc để lưu trữ trên một số bộ lưu trữ lâu dài. Khi dữ liệu được truyền qua mạng hoặc được truy xuất từ bộ lưu trữ liên tục, dữ liệu đó cần được giải mã hóa lại. Serialization được gọi làmarshalling và deserialization được gọi là unmarshalling.
Serialization trong Java
Java cung cấp một cơ chế, được gọi là object serialization trong đó một đối tượng có thể được biểu diễn dưới dạng một chuỗi các byte bao gồm dữ liệu của đối tượng cũng như thông tin về kiểu của đối tượng và các kiểu dữ liệu được lưu trữ trong đối tượng.
Sau khi một đối tượng tuần tự hóa được ghi vào một tệp, nó có thể được đọc từ tệp và được giải mã hóa. Có nghĩa là, thông tin kiểu và byte đại diện cho đối tượng và dữ liệu của nó có thể được sử dụng để tạo lại đối tượng trong bộ nhớ.
ObjectInputStream và ObjectOutputStream các lớp được sử dụng để tuần tự hóa và giải mã hóa một đối tượng tương ứng trong Java.
Serialization trong Hadoop
Nói chung trong các hệ thống phân tán như Hadoop, khái niệm tuần tự hóa được sử dụng cho Interprocess Communication và Persistent Storage.
Giao tiếp giữa các quy trình
Để thiết lập giao tiếp liên quy trình giữa các nút được kết nối trong mạng, kỹ thuật RPC đã được sử dụng.
RPC đã sử dụng tuần tự hóa nội bộ để chuyển đổi thông điệp thành định dạng nhị phân trước khi gửi nó đến nút từ xa qua mạng. Ở đầu kia, hệ thống từ xa sẽ giải mã luồng nhị phân thành thông điệp gốc.
Định dạng tuần tự hóa RPC được yêu cầu như sau:
Compact - Sử dụng tối ưu băng thông mạng, nguồn tài nguyên khan hiếm nhất trong trung tâm dữ liệu.
Fast - Vì thông tin liên lạc giữa các nút là rất quan trọng trong các hệ thống phân tán, quá trình tuần tự hóa và giải mã hóa phải nhanh chóng, tạo ra ít chi phí hơn.
Extensible - Các giao thức thay đổi theo thời gian để đáp ứng các yêu cầu mới, vì vậy cần phải phát triển giao thức một cách có kiểm soát cho các máy khách và máy chủ.
Interoperable - Định dạng thông báo nên hỗ trợ các nút được viết bằng các ngôn ngữ khác nhau.
Lưu trữ liên tục
Lưu trữ liên tục là một phương tiện lưu trữ kỹ thuật số không bị mất dữ liệu khi mất nguồn điện. Tệp, thư mục, cơ sở dữ liệu là những ví dụ về lưu trữ liên tục.
Giao diện ghi
Đây là giao diện trong Hadoop cung cấp các phương pháp tuần tự hóa và giải mã hóa. Bảng sau đây mô tả các phương pháp:
| Không. | Phương pháp và Mô tả |
|---|---|
| 1 | void readFields(DataInput in) Phương thức này được sử dụng để giải mã hóa các trường của đối tượng đã cho. |
| 2 | void write(DataOutput out) Phương thức này được sử dụng để tuần tự hóa các trường của đối tượng đã cho. |
Giao diện có thể so sánh được
Nó là sự kết hợp của Writable và Comparablecác giao diện. Giao diện này kế thừaWritable giao diện của Hadoop cũng như Comparablegiao diện của Java. Do đó, nó cung cấp các phương pháp tuần tự hóa, giải mã hóa và so sánh dữ liệu.
| Không. | Phương pháp và Mô tả |
|---|---|
| 1 | int compareTo(class obj) Phương thức này so sánh đối tượng hiện tại với đối tượng đã cho. |
Ngoài các lớp này, Hadoop còn hỗ trợ một số lớp trình bao bọc thực hiện giao diện có thể so sánh được. Mỗi lớp bao bọc một kiểu nguyên thủy Java. Phân cấp lớp của tuần tự hóa Hadoop được đưa ra dưới đây:
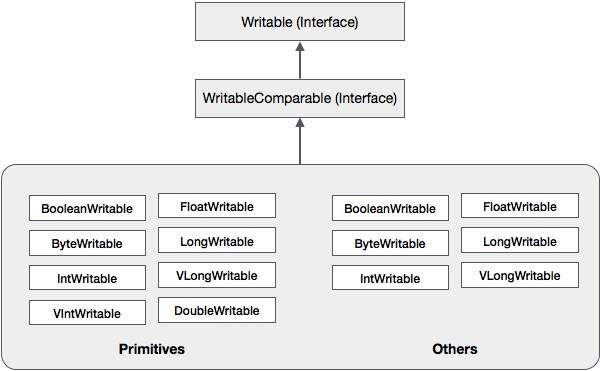
Các lớp này hữu ích để tuần tự hóa nhiều loại dữ liệu khác nhau trong Hadoop. Ví dụ, chúng ta hãy xem xétIntWritablelớp học. Hãy để chúng tôi xem cách lớp này được sử dụng để tuần tự hóa và giải mã hóa dữ liệu trong Hadoop.
Lớp ghi âm
Lớp này thực hiện Writable, Comparable, và WritableComparablecác giao diện. Nó bao bọc một kiểu dữ liệu số nguyên trong đó. Lớp này cung cấp các phương thức dùng để tuần tự hóa và giải mã hóa kiểu số nguyên của dữ liệu.
Người xây dựng
| Không. | Tóm lược |
|---|---|
| 1 | IntWritable() |
| 2 | IntWritable( int value) |
Phương pháp
| Không. | Tóm lược |
|---|---|
| 1 | int get() Sử dụng phương pháp này, bạn có thể nhận được giá trị số nguyên có trong đối tượng hiện tại. |
| 2 | void readFields(DataInput in) Phương pháp này được sử dụng để giải mã dữ liệu trong DataInput vật. |
| 3 | void set(int value) Phương pháp này được sử dụng để đặt giá trị của dòng điện IntWritable vật. |
| 4 | void write(DataOutput out) Phương thức này được sử dụng để tuần tự hóa dữ liệu trong đối tượng hiện tại thành DataOutput vật. |
Sắp xếp thứ tự dữ liệu trong Hadoop
Quy trình tuần tự hóa kiểu dữ liệu số nguyên được thảo luận dưới đây.
Khởi tạo IntWritable lớp bằng cách gói một giá trị số nguyên trong đó.
Khởi tạo ByteArrayOutputStream lớp học.
Khởi tạo DataOutputStream lớp và chuyển đối tượng của ByteArrayOutputStream lớp với nó.
Sắp xếp thứ tự giá trị số nguyên trong đối tượng có thể ghi được bằng cách sử dụng write()phương pháp. Phương thức này cần một đối tượng của lớp DataOutputStream.
Dữ liệu được tuần tự hóa sẽ được lưu trữ trong đối tượng mảng byte được truyền dưới dạng tham số cho DataOutputStreamtại thời điểm khởi tạo. Chuyển đổi dữ liệu trong đối tượng thành mảng byte.
Thí dụ
Ví dụ sau cho thấy cách tuần tự hóa dữ liệu kiểu số nguyên trong Hadoop:
import java.io.ByteArrayOutputStream;
import java.io.DataOutputStream;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
public class Serialization {
public byte[] serialize() throws IOException{
//Instantiating the IntWritable object
IntWritable intwritable = new IntWritable(12);
//Instantiating ByteArrayOutputStream object
ByteArrayOutputStream byteoutputStream = new ByteArrayOutputStream();
//Instantiating DataOutputStream object
DataOutputStream dataOutputStream = new
DataOutputStream(byteoutputStream);
//Serializing the data
intwritable.write(dataOutputStream);
//storing the serialized object in bytearray
byte[] byteArray = byteoutputStream.toByteArray();
//Closing the OutputStream
dataOutputStream.close();
return(byteArray);
}
public static void main(String args[]) throws IOException{
Serialization serialization= new Serialization();
serialization.serialize();
System.out.println();
}
}Giải mã dữ liệu trong Hadoop
Quy trình giải mã dữ liệu kiểu số nguyên được thảo luận dưới đây:
Khởi tạo IntWritable lớp bằng cách gói một giá trị số nguyên trong đó.
Khởi tạo ByteArrayOutputStream lớp học.
Khởi tạo DataOutputStream lớp và chuyển đối tượng của ByteArrayOutputStream lớp với nó.
Hủy số liệu hóa dữ liệu trong đối tượng của DataInputStream sử dụng readFields() phương thức của lớp IntWille.
Dữ liệu được giải mã sẽ được lưu trữ trong đối tượng của lớp IntWille. Bạn có thể lấy dữ liệu này bằng cách sử dụngget() phương thức của lớp này.
Thí dụ
Ví dụ sau cho thấy cách giải mã dữ liệu kiểu số nguyên trong Hadoop:
import java.io.ByteArrayInputStream;
import java.io.DataInputStream;
import org.apache.hadoop.io.IntWritable;
public class Deserialization {
public void deserialize(byte[]byteArray) throws Exception{
//Instantiating the IntWritable class
IntWritable intwritable =new IntWritable();
//Instantiating ByteArrayInputStream object
ByteArrayInputStream InputStream = new ByteArrayInputStream(byteArray);
//Instantiating DataInputStream object
DataInputStream datainputstream=new DataInputStream(InputStream);
//deserializing the data in DataInputStream
intwritable.readFields(datainputstream);
//printing the serialized data
System.out.println((intwritable).get());
}
public static void main(String args[]) throws Exception {
Deserialization dese = new Deserialization();
dese.deserialize(new Serialization().serialize());
}
}Lợi thế của Hadoop so với Java Serialization
Tuần tự hóa dựa trên ghi của Hadoop có khả năng giảm thiểu chi phí tạo đối tượng bằng cách sử dụng lại các đối tượng có thể ghi, điều này không thể thực hiện được với khung tuần tự hóa gốc của Java.
Nhược điểm của Hadoop Serialization
Để tuần tự hóa dữ liệu Hadoop, có hai cách:
Bạn có thể dùng Writable các lớp, được cung cấp bởi thư viện gốc của Hadoop.
Bạn cũng có thể dùng Sequence Files lưu trữ dữ liệu ở định dạng nhị phân.
Hạn chế chính của hai cơ chế này là Writables và SequenceFiles chỉ có một API Java và chúng không thể được viết hoặc đọc bằng bất kỳ ngôn ngữ nào khác.
Do đó, bất kỳ tệp nào được tạo trong Hadoop với hai cơ chế trên đều không thể đọc được bằng bất kỳ ngôn ngữ thứ ba nào khác, điều này làm cho Hadoop như một hộp giới hạn. Để giải quyết nhược điểm này, Doug Cắt đã tạoAvro, mà là một language independent data structure.