Lập trình D - Hướng dẫn nhanh
Ngôn ngữ lập trình D là một ngôn ngữ lập trình hệ thống đa mô hình hướng đối tượng được phát triển bởi Walter Bright của Digital Mars. Sự phát triển của nó bắt đầu vào năm 1999 và được phát hành lần đầu tiên vào năm 2001. Phiên bản chính của D (1.0) được phát hành vào năm 2007. Hiện tại, chúng tôi có phiên bản D2 của D.
D là ngôn ngữ có cú pháp là kiểu C và sử dụng kiểu gõ tĩnh. Có nhiều tính năng của C và C ++ trong D nhưng cũng có một số tính năng từ ngôn ngữ này không được bao gồm trong D. Một số bổ sung đáng chú ý cho D bao gồm,
- Kiểm tra đơn vị
- Mô-đun đích thực
- Thu gom rác thải
- Mảng hạng nhất
- Miễn phí và mở
- Mảng liên kết
- Mảng động
- Các lớp bên trong
- Closures
- Chức năng ẩn danh
- Đánh giá lười biếng
- Closures
Nhiều mô hình
D là một ngôn ngữ lập trình đa mô hình. Nhiều mô hình bao gồm,
- Imperative
- Hướng đối tượng
- Lập trình meta
- Functional
- Concurrent
Thí dụ
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Học D
Điều quan trọng nhất cần làm khi học D là tập trung vào các khái niệm và không bị lạc vào các chi tiết kỹ thuật ngôn ngữ.
Mục đích của việc học một ngôn ngữ lập trình là trở thành một lập trình viên giỏi hơn; nghĩa là, để trở nên hiệu quả hơn trong việc thiết kế và triển khai các hệ thống mới và bảo trì các hệ thống cũ.
Phạm vi của D
Lập trình D có một số tính năng thú vị và trang web chính thức của lập trình D tuyên bố rằng D thông minh, mạnh mẽ và hiệu quả. Lập trình D bổ sung nhiều tính năng trong ngôn ngữ cốt lõi mà ngôn ngữ C đã cung cấp dưới dạng các thư viện chuẩn như mảng có thể thay đổi kích thước và hàm chuỗi. D tạo ra một ngôn ngữ thứ hai tuyệt vời cho các lập trình viên trung cấp đến cao cấp. D tốt hơn trong việc xử lý bộ nhớ và quản lý các con trỏ thường gây ra sự cố trong C ++.
Lập trình D chủ yếu dựa trên các chương trình mới chuyển đổi các chương trình hiện có. Nó cung cấp tính năng kiểm tra và xác minh được xây dựng trong một dự án lý tưởng cho các dự án lớn mới sẽ được viết với hàng triệu dòng mã bởi các nhóm lớn.
Thiết lập môi trường cục bộ cho D
Nếu bạn vẫn sẵn sàng thiết lập môi trường của mình cho ngôn ngữ lập trình D, bạn cần hai phần mềm sau có sẵn trên máy tính của mình, (a) Trình soạn thảo văn bản, (b) Trình biên dịch D.
Trình soạn thảo văn bản cho lập trình D
Điều này sẽ được sử dụng để nhập chương trình của bạn. Ví dụ về một số trình soạn thảo bao gồm Windows Notepad, lệnh Chỉnh sửa hệ điều hành, Tóm tắt, Epsilon, EMACS và vim hoặc vi.
Tên và phiên bản của trình soạn thảo văn bản có thể khác nhau trên các hệ điều hành khác nhau. Ví dụ: Notepad sẽ được sử dụng trên Windows và vim hoặc vi có thể được sử dụng trên windows cũng như Linux hoặc UNIX.
Các tệp bạn tạo bằng trình chỉnh sửa của mình được gọi là tệp nguồn và chứa mã nguồn chương trình. Các tệp nguồn cho các chương trình D được đặt tên với phần mở rộng ".d".
Trước khi bắt đầu lập trình, hãy đảm bảo rằng bạn có sẵn một trình soạn thảo văn bản và bạn có đủ kinh nghiệm để viết một chương trình máy tính, lưu nó vào một tệp, xây dựng nó và cuối cùng là thực thi nó.
Trình biên dịch D
Hầu hết các triển khai D hiện tại đều biên dịch trực tiếp thành mã máy để thực thi hiệu quả.
Chúng tôi có nhiều trình biên dịch D có sẵn và nó bao gồm những phần sau.
DMD - Trình biên dịch Digital Mars D là trình biên dịch D chính thức của Walter Bright.
GDC - Giao diện người dùng cho GCC back-end, được xây dựng bằng mã nguồn trình biên dịch DMD mở.
LDC - Một trình biên dịch dựa trên giao diện người dùng DMD sử dụng LLVM làm mặt sau trình biên dịch của nó.
Các trình biên dịch khác nhau ở trên có thể được tải xuống từ bản tải xuống D
Chúng tôi sẽ sử dụng phiên bản D 2 và chúng tôi khuyên bạn không nên tải xuống D1.
Hãy có một chương trình helloWorld.d như sau. Chúng tôi sẽ sử dụng chương trình này làm chương trình đầu tiên chúng tôi chạy trên nền tảng mà bạn chọn.
import std.stdio;
void main(string[] args) {
writeln("Hello World!");
}Chúng ta có thể xem kết quả sau.
$ hello worldCài đặt D trên Windows
Tải xuống trình cài đặt windows .
Chạy tệp thực thi đã tải xuống để cài đặt D. Việc này có thể được thực hiện bằng cách làm theo hướng dẫn trên màn hình.
Bây giờ chúng ta có thể tạo và chạy tệp quảng cáo say helloWorld.d bằng cách chuyển sang thư mục chứa tệp bằng cd và sau đó thực hiện theo các bước sau:
C:\DProgramming> DMD helloWorld.d
C:\DProgramming> helloWorldChúng ta có thể xem kết quả sau.
hello worldC: \ DProgramming là thư mục, tôi đang sử dụng để lưu các mẫu của mình. Bạn có thể thay đổi nó thành thư mục mà bạn đã lưu các chương trình D.
Cài đặt D trên Ubuntu / Debian
Tải xuống trình cài đặt debian .
Chạy tệp thực thi đã tải xuống để cài đặt D. Việc này có thể được thực hiện bằng cách làm theo hướng dẫn trên màn hình.
Bây giờ chúng ta có thể tạo và chạy tệp quảng cáo say helloWorld.d bằng cách chuyển sang thư mục chứa tệp bằng cd và sau đó thực hiện theo các bước sau:
$ dmd helloWorld.d
$ ./helloWorldChúng ta có thể xem kết quả sau.
$ hello worldCài đặt D trên Mac OS X
Tải xuống trình cài đặt Mac .
Chạy tệp thực thi đã tải xuống để cài đặt D. Việc này có thể được thực hiện bằng cách làm theo hướng dẫn trên màn hình.
Bây giờ chúng ta có thể tạo và chạy tệp quảng cáo say helloWorld.d bằng cách chuyển sang thư mục chứa tệp bằng cd và sau đó thực hiện theo các bước sau:
$ dmd helloWorld.d $ ./helloWorldChúng ta có thể xem kết quả sau.
$ hello worldCài đặt D trên Fedora
Tải xuống trình cài đặt fedora .
Chạy tệp thực thi đã tải xuống để cài đặt D. Việc này có thể được thực hiện bằng cách làm theo hướng dẫn trên màn hình.
Bây giờ chúng ta có thể tạo và chạy tệp quảng cáo say helloWorld.d bằng cách chuyển sang thư mục chứa tệp bằng cd và sau đó thực hiện theo các bước sau:
$ dmd helloWorld.d
$ ./helloWorldChúng ta có thể xem kết quả sau.
$ hello worldCài đặt D trên OpenSUSE
Tải xuống trình cài đặt OpenSUSE .
Chạy tệp thực thi đã tải xuống để cài đặt D. Việc này có thể được thực hiện bằng cách làm theo hướng dẫn trên màn hình.
Bây giờ chúng ta có thể tạo và chạy tệp quảng cáo say helloWorld.d bằng cách chuyển sang thư mục chứa tệp bằng cd và sau đó thực hiện theo các bước sau:
$ dmd helloWorld.d $ ./helloWorldChúng ta có thể xem kết quả sau.
$ hello worldD IDE
Chúng tôi có hỗ trợ IDE cho D dưới dạng plugin trong hầu hết các trường hợp. Điêu nay bao gôm,
Plugin Visual D là một plugin dành cho Visual Studio 2005-13
DDT là một plugin eclipse cung cấp tính năng hoàn thành mã, gỡ lỗi với GDB.
Hoàn thành mã Mono-D , tái cấu trúc với hỗ trợ dmd / ldc / gdc. Nó đã là một phần của GSoC 2012.
Code Blocks là một IDE đa nền tảng hỗ trợ tạo dự án D, làm nổi bật và gỡ lỗi.
D khá đơn giản để học và hãy bắt đầu tạo chương trình D đầu tiên của chúng ta!
Chương trình D đầu tiên
Hãy để chúng tôi viết một chương trình D đơn giản. Tất cả các tệp D sẽ có phần mở rộng .d. Vì vậy, hãy đặt mã nguồn sau vào tệp test.d.
import std.stdio;
/* My first program in D */
void main(string[] args) {
writeln("test!");
}Giả sử môi trường D được thiết lập chính xác, hãy chạy chương trình bằng cách sử dụng -
$ dmd test.d
$ ./testChúng ta có thể xem kết quả sau.
testBây giờ chúng ta hãy xem cấu trúc cơ bản của chương trình D, để bạn có thể dễ dàng hiểu các khối xây dựng cơ bản của ngôn ngữ lập trình D.
Nhập trong D
Thư viện là bộ sưu tập các phần chương trình có thể tái sử dụng có thể được cung cấp cho dự án của chúng tôi với sự trợ giúp của nhập. Ở đây chúng tôi nhập thư viện io tiêu chuẩn cung cấp các hoạt động I / O cơ bản. writeln được sử dụng trong chương trình trên là một hàm trong thư viện chuẩn của D. Nó được sử dụng để in một dòng văn bản. Nội dung thư viện trong D được nhóm thành các mô-đun dựa trên loại nhiệm vụ mà chúng dự định thực hiện. Mô-đun duy nhất mà chương trình này sử dụng là std.stdio, xử lý đầu vào và đầu ra dữ liệu.
Chức năng chính
Chức năng chính là phần khởi động của chương trình và nó xác định thứ tự thực hiện và cách các phần khác của chương trình sẽ được thực thi.
Mã thông báo trong D
Chương trình AD bao gồm các mã thông báo khác nhau và mã thông báo là một từ khóa, một định danh, một hằng số, một chuỗi ký tự hoặc một ký hiệu. Ví dụ: câu lệnh D sau đây bao gồm bốn mã thông báo:
writeln("test!");Các mã thông báo riêng lẻ là -
writeln (
"test!"
)
;Bình luận
Nhận xét giống như văn bản hỗ trợ trong chương trình D của bạn và chúng bị trình biên dịch bỏ qua. Nhận xét nhiều dòng bắt đầu bằng / * và kết thúc bằng các ký tự * / như hình dưới đây -
/* My first program in D */Nhận xét đơn được viết bằng cách sử dụng // ở đầu nhận xét.
// my first program in DĐịnh danh
Mã định danh AD là tên được sử dụng để xác định một biến, hàm hoặc bất kỳ mục nào khác do người dùng xác định. Số nhận dạng bắt đầu bằng chữ cái A đến Z hoặc từ a đến z hoặc dấu gạch dưới _ theo sau là không hoặc nhiều chữ cái, dấu gạch dưới và chữ số (0 đến 9).
D không cho phép các ký tự dấu câu như @, $ và% trong số nhận dạng. D là mộtcase sensitivengôn ngữ lập trình. Do đó Nhân lực và nhân lực là hai định danh khác nhau trong D. Dưới đây là một số ví dụ về các định danh có thể chấp nhận được -
mohd zara abc move_name a_123
myname50 _temp j a23b9 retValTừ khóa
Danh sách sau đây cho thấy một số từ dành riêng trong D. Những từ dành riêng này có thể không được sử dụng làm hằng số hoặc biến hoặc bất kỳ tên định danh nào khác.
| trừu tượng | bí danh | căn chỉnh | asm |
| khẳng định | Tự động | thân hình | bool |
| byte | trường hợp | diễn viên | nắm lấy |
| char | lớp học | hăng sô | tiếp tục |
| dchar | gỡ lỗi | mặc định | ủy nhiệm |
| không dùng nữa | làm | gấp đôi | khác |
| enum | xuất khẩu | bên ngoài | sai |
| sau cùng | cuối cùng | Phao nổi | cho |
| cho mỗi | chức năng | đi đến | nếu |
| nhập khẩu | trong | inout | int |
| giao diện | bất biến | Là | Dài |
| vĩ mô | mixin | mô-đun | Mới |
| vô giá trị | ngoài | ghi đè | gói hàng |
| pragma | riêng tư | được bảo vệ | công cộng |
| thực tế | ref | trở về | phạm vi |
| ngắn | tĩnh | cấu trúc | siêu |
| công tắc điện | đồng bộ | bản mẫu | điều này |
| phi | thật | thử | kiểu chữ |
| loại | ubyte | uint | dài |
| liên hiệp | độc nhất | ushort | phiên bản |
| vô hiệu | wchar | trong khi | với |
Khoảng trắng trong D
Một dòng chỉ chứa khoảng trắng, có thể với chú thích, được gọi là dòng trống và trình biên dịch D hoàn toàn bỏ qua nó.
Khoảng trắng là thuật ngữ được sử dụng trong D để mô tả khoảng trống, tab, ký tự dòng mới và nhận xét. Khoảng trắng phân tách một phần của câu lệnh với phần khác và cho phép trình thông dịch xác định vị trí một phần tử trong câu lệnh, chẳng hạn như int, kết thúc và phần tử tiếp theo bắt đầu. Do đó, trong câu lệnh sau:
local agePhải có ít nhất một ký tự khoảng trắng (thường là khoảng trắng) giữa địa phương và tuổi để trình thông dịch có thể phân biệt chúng. Mặt khác, trong câu lệnh sau
int fruit = apples + oranges //get the total fruitsKhông cần ký tự khoảng trắng nào giữa trái cây và =, hoặc giữa = và táo, mặc dù bạn có thể thêm một số ký tự nếu muốn vì mục đích dễ đọc.
Một biến không là gì ngoài tên được đặt cho một vùng lưu trữ mà chương trình của chúng ta có thể thao tác. Mỗi biến trong D có một kiểu cụ thể, xác định kích thước và cách bố trí bộ nhớ của biến; phạm vi giá trị có thể được lưu trữ trong bộ nhớ đó; và tập hợp các thao tác có thể áp dụng cho biến.
Tên của một biến có thể bao gồm các chữ cái, chữ số và ký tự gạch dưới. Nó phải bắt đầu bằng một chữ cái hoặc một dấu gạch dưới. Chữ hoa và chữ thường khác nhau vì D phân biệt chữ hoa chữ thường. Dựa trên các kiểu cơ bản đã giải thích trong chương trước, sẽ có các kiểu biến cơ bản sau:
| Sr.No. | Loại & Mô tả |
|---|---|
| 1 | char Điển hình là một octet đơn (một byte). Đây là một kiểu số nguyên. |
| 2 | int Kích thước tự nhiên nhất của số nguyên cho máy. |
| 3 | float Một giá trị dấu chấm động chính xác duy nhất. |
| 4 | double Giá trị dấu phẩy động có độ chính xác kép. |
| 5 | void Đại diện cho sự vắng mặt của loại. |
Ngôn ngữ lập trình D cũng cho phép định nghĩa nhiều loại biến khác nhau như Enumeration, Pointer, Array, Structure, Union, v.v., chúng ta sẽ trình bày trong các chương tiếp theo. Đối với chương này, chúng ta hãy chỉ nghiên cứu các loại biến cơ bản.
Định nghĩa biến trong D
Một định nghĩa biến cho trình biên dịch biết vị trí và bao nhiêu không gian cần tạo cho biến. Định nghĩa biến chỉ định một kiểu dữ liệu và chứa danh sách một hoặc nhiều biến của kiểu đó như sau:
type variable_list;Đây, type phải là kiểu dữ liệu D hợp lệ bao gồm char, wchar, int, float, double, bool hoặc bất kỳ đối tượng nào do người dùng xác định, v.v., và variable_listcó thể bao gồm một hoặc nhiều tên định danh được phân tách bằng dấu phẩy. Một số khai báo hợp lệ được hiển thị ở đây -
int i, j, k;
char c, ch;
float f, salary;
double d;Dòng int i, j, k;cả khai báo và định nghĩa các biến i, j và k; hướng dẫn trình biên dịch tạo các biến có tên i, j và k kiểu int.
Các biến có thể được khởi tạo (gán giá trị ban đầu) trong khai báo của chúng. Bộ khởi tạo bao gồm một dấu bằng theo sau là một biểu thức hằng số như sau:
type variable_name = value;Ví dụ
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.Khi một biến được khai báo bằng D, nó luôn được đặt thành 'trình khởi tạo mặc định', có thể được truy cập thủ công dưới dạng T.init Ở đâu T là loại (ví dụ: int.init). Bộ khởi tạo mặc định cho kiểu số nguyên là 0, cho Booleans false và cho số dấu phẩy động NaN.
Khai báo biến trong D
Một khai báo biến cung cấp sự đảm bảo cho trình biên dịch rằng có một biến tồn tại với kiểu và tên đã cho để trình biên dịch tiến hành biên dịch thêm mà không cần chi tiết đầy đủ về biến. Một khai báo biến chỉ có ý nghĩa tại thời điểm biên dịch, trình biên dịch cần khai báo biến thực tế tại thời điểm liên kết của chương trình.
Thí dụ
Hãy thử ví dụ sau, trong đó các biến đã được khai báo khi bắt đầu chương trình, nhưng được định nghĩa và khởi tạo bên trong hàm chính:
import std.stdio;
int a = 10, b = 10;
int c;
float f;
int main () {
writeln("Value of a is : ", a);
/* variable re definition: */
int a, b;
int c;
float f;
/* Initialization */
a = 30;
b = 40;
writeln("Value of a is : ", a);
c = a + b;
writeln("Value of c is : ", c);
f = 70.0/3.0;
writeln("Value of f is : ", f);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Value of a is : 10
Value of a is : 30
Value of c is : 70
Value of f is : 23.3333Giá trị và giá trị trong D
Có hai loại biểu thức trong D -
lvalue - Một biểu thức là một giá trị có thể xuất hiện ở dạng bên trái hoặc bên phải của một phép gán.
rvalue - Một biểu thức là một giá trị có thể xuất hiện ở bên phải nhưng không xuất hiện ở bên trái của một phép gán.
Các biến là giá trị và do đó có thể xuất hiện ở phía bên trái của phép gán. Các chữ số là các giá trị và do đó có thể không được gán và không thể xuất hiện ở phía bên trái. Câu lệnh sau là hợp lệ -
int g = 20;Nhưng sau đây không phải là một câu lệnh hợp lệ và sẽ tạo ra lỗi thời gian biên dịch -
10 = 20;Trong ngôn ngữ lập trình D, kiểu dữ liệu đề cập đến một hệ thống mở rộng được sử dụng để khai báo các biến hoặc hàm thuộc các kiểu khác nhau. Kiểu của một biến xác định bao nhiêu không gian mà nó chiếm trong bộ nhớ và cách diễn giải mẫu bit được lưu trữ.
Các loại trong D có thể được phân loại như sau:
| Sr.No. | Loại & Mô tả |
|---|---|
| 1 | Basic Types Chúng là các kiểu số học và bao gồm ba kiểu: (a) số nguyên, (b) dấu phẩy động và (c) ký tự. |
| 2 | Enumerated types Chúng lại là loại số học. Chúng được sử dụng để định nghĩa các biến chỉ có thể được gán một số giá trị nguyên rời rạc trong suốt chương trình. |
| 3 | The type void Void xác định kiểu chỉ ra rằng không có giá trị nào. |
| 4 | Derived types Chúng bao gồm (a) Kiểu con trỏ, (b) Kiểu mảng, (c) Kiểu cấu trúc, (d) Kiểu liên kết và (e) Kiểu hàm. |
Các kiểu mảng và kiểu cấu trúc được gọi chung là kiểu tổng hợp. Kiểu của một hàm chỉ định kiểu giá trị trả về của hàm. Chúng ta sẽ thấy các loại cơ bản trong phần sau trong khi các loại khác sẽ được đề cập trong các chương sắp tới.
Các loại số nguyên
Bảng sau đây cung cấp danh sách các kiểu số nguyên tiêu chuẩn với kích thước lưu trữ và phạm vi giá trị của chúng:
| Kiểu | Kích thước lưu trữ | Phạm vi giá trị |
|---|---|---|
| bool | 1 byte | sai hay đúng |
| byte | 1 byte | -128 đến 127 |
| ubyte | 1 byte | 0 đến 255 |
| int | 4 byte | -2.147.483.648 đến 2.147.483.647 |
| uint | 4 byte | 0 đến 4,294,967,295 |
| ngắn | 2 byte | -32,768 đến 32,767 |
| ushort | 2 byte | 0 đến 65,535 |
| Dài | 8 byte | -9223372036854775808 đến 9223372036854775807 |
| dài | 8 byte | 0 đến 18446744073709551615 |
Để có được kích thước chính xác của một loại hoặc một biến, bạn có thể sử dụng sizeofnhà điều hành. Kiểu biểu thức . (Sizeof) mang lại kích thước lưu trữ của đối tượng hoặc kiểu tính bằng byte. Ví dụ sau lấy kích thước của kiểu int trên bất kỳ máy nào:
import std.stdio;
int main() {
writeln("Length in bytes: ", ulong.sizeof);
return 0;
}Khi bạn biên dịch và thực thi chương trình trên, nó tạo ra kết quả sau:
Length in bytes: 8Các loại dấu chấm động
Bảng sau đây đề cập đến các loại dấu phẩy động tiêu chuẩn với kích thước lưu trữ, phạm vi giá trị và mục đích của chúng -
| Kiểu | Kích thước lưu trữ | Phạm vi giá trị | Mục đích |
|---|---|---|---|
| Phao nổi | 4 byte | 1,17549e-38 đến 3,40282e + 38 | 6 chữ số thập phân |
| gấp đôi | 8 byte | 2,22507e-308 đến 1,79769e + 308 | 15 chữ số thập phân |
| thực tế | 10 byte | 3,3621e-4932 đến 1,18973e + 4932 | hoặc là kiểu dấu phẩy động lớn nhất mà phần cứng hỗ trợ, hoặc gấp đôi; cái nào lớn hơn |
| ifloat | 4 byte | 1,17549e-38i đến 3,40282e + 38i | kiểu giá trị ảo của float |
| không có đôi | 8 byte | 2,22507e-308i đến 1,79769e + 308i | loại giá trị tưởng tượng của gấp đôi |
| tôi thật | 10 byte | 3,3621e-4932 đến 1,18973e + 4932 | loại giá trị ảo của thực |
| cfloat | 8 byte | 1,17549e-38 + 1,17549e-38i đến 3,40282e + 38 + 3,40282e + 38i | kiểu số phức được tạo bởi hai dấu nổi |
| đôi | 16 byte | 2,22507e-308 + 2,22507e-308i đến 1,79769e + 308 + 1,79769e + 308i | kiểu số phức tạo bởi hai nhân đôi |
| creal | 20 byte | 3,3621e-4932 + 3,3621e-4932i đến 1,18973e + 4932 + 1,18973e + 4932i | kiểu số phức tạo bởi hai số thực |
Ví dụ sau in không gian lưu trữ được lấy bởi kiểu float và các giá trị phạm vi của nó:
import std.stdio;
int main() {
writeln("Length in bytes: ", float.sizeof);
return 0;
}Khi bạn biên dịch và thực thi chương trình trên, nó tạo ra kết quả sau trên Linux:
Length in bytes: 4Các loại ký tự
Bảng sau liệt kê các kiểu ký tự tiêu chuẩn với kích thước lưu trữ và mục đích của nó.
| Kiểu | Kích thước lưu trữ | Mục đích |
|---|---|---|
| char | 1 byte | Đơn vị mã UTF-8 |
| wchar | 2 byte | Đơn vị mã UTF-16 |
| dchar | 4 byte | Đơn vị mã UTF-32 và điểm mã Unicode |
Ví dụ sau sẽ in không gian lưu trữ được lấy bởi một kiểu char.
import std.stdio;
int main() {
writeln("Length in bytes: ", char.sizeof);
return 0;
}Khi bạn biên dịch và thực thi chương trình trên, nó tạo ra kết quả sau:
Length in bytes: 1Loại trống
Loại void chỉ định rằng không có giá trị nào. Nó được sử dụng trong hai loại tình huống -
| Sr.No. | Loại & Mô tả |
|---|---|
| 1 | Function returns as void Có nhiều hàm khác nhau trong D không trả về giá trị hoặc bạn có thể nói chúng trả về giá trị vô hiệu. Một hàm không có giá trị trả về có kiểu trả về là void. Ví dụ,void exit (int status); |
| 2 | Function arguments as void Có nhiều hàm khác nhau trong D không chấp nhận bất kỳ tham số nào. Một hàm không có tham số có thể chấp nhận là một khoảng trống. Ví dụ,int rand(void); |
Bạn có thể chưa hiểu kiểu void vào lúc này, vì vậy hãy để chúng tôi tiếp tục và chúng tôi sẽ trình bày các khái niệm này trong các chương sắp tới.
Một kiểu liệt kê được sử dụng để xác định các giá trị hằng số được đặt tên. Một kiểu liệt kê được khai báo bằng cách sử dụngenum từ khóa.
Các enum Cú pháp
Dạng đơn giản nhất của định nghĩa enum như sau:
enum enum_name {
enumeration list
}Ở đâu,
Các enum_name chỉ định tên kiểu enumeration.
Các danh sách liệt kê một danh sách bằng dấu phẩy của định danh.
Mỗi ký hiệu trong danh sách liệt kê là viết tắt của một giá trị số nguyên, một giá trị lớn hơn ký hiệu đứng trước nó. Theo mặc định, giá trị của ký hiệu liệt kê đầu tiên là 0. Ví dụ:
enum Days { sun, mon, tue, wed, thu, fri, sat };Thí dụ
Ví dụ sau minh họa việc sử dụng biến enum:
import std.stdio;
enum Days { sun, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
Days day;
day = Days.mon;
writefln("Current Day: %d", day);
writefln("Friday : %d", Days.fri);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Current Day: 1
Friday : 5Trong chương trình trên, chúng ta có thể thấy cách liệt kê có thể được sử dụng. Ban đầu, chúng tôi tạo một biến có tên là Ngày trong số Ngày liệt kê do người dùng của chúng tôi xác định. Sau đó, chúng tôi đặt nó thành mon bằng cách sử dụng toán tử dấu chấm. Chúng ta cần sử dụng phương thức writefln để in giá trị của mon được lưu trữ. Bạn cũng cần chỉ định loại. Nó thuộc kiểu số nguyên, do đó chúng tôi sử dụng% d để in.
Thuộc tính Enums được đặt tên
Ví dụ trên sử dụng tên Days cho kiểu liệt kê và được gọi là tên enums. Các enum được đặt tên này có các thuộc tính sau:
Init - Nó khởi tạo giá trị đầu tiên trong bảng liệt kê.
min - Nó trả về giá trị nhỏ nhất của kiểu liệt kê.
max - Nó trả về giá trị lớn nhất của kiểu liệt kê.
sizeof - Nó trả về kích thước lưu trữ để liệt kê.
Hãy để chúng tôi sửa đổi ví dụ trước để sử dụng các thuộc tính.
import std.stdio;
// Initialized sun with value 1
enum Days { sun = 1, mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Min : %d", Days.min);
writefln("Max : %d", Days.max);
writefln("Size of: %d", Days.sizeof);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Min : 1
Max : 7
Size of: 4Enum ẩn danh
Phép liệt kê không có tên gọi là bảng kê vô danh. Một ví dụ choanonymous enum được đưa ra dưới đây.
import std.stdio;
// Initialized sun with value 1
enum { sun , mon, tue, wed, thu, fri, sat };
int main(string[] args) {
writefln("Sunday : %d", sun);
writefln("Monday : %d", mon);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Sunday : 0
Monday : 1Các enums ẩn danh hoạt động khá giống với các enums đã đặt tên nhưng chúng không có các thuộc tính max, min và sizeof.
Enum với Cú pháp kiểu cơ sở
Cú pháp để liệt kê với kiểu cơ sở được hiển thị bên dưới.
enum :baseType {
enumeration list
}Một số kiểu cơ sở bao gồm long, int và string. Dưới đây là một ví dụ sử dụng long.
import std.stdio;
enum : string {
A = "hello",
B = "world",
}
int main(string[] args) {
writefln("A : %s", A);
writefln("B : %s", B);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
A : hello
B : worldCác tính năng khác
Liệt kê trong D cung cấp các tính năng như khởi tạo nhiều giá trị trong một kiểu liệt kê với nhiều kiểu. Một ví dụ đã được biểu diễn ở dưới.
import std.stdio;
enum {
A = 1.2f, // A is 1.2f of type float
B, // B is 2.2f of type float
int C = 3, // C is 3 of type int
D // D is 4 of type int
}
int main(string[] args) {
writefln("A : %f", A);
writefln("B : %f", B);
writefln("C : %d", C);
writefln("D : %d", D);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
A : 1.200000
B : 2.200000
C : 3
D : 4Các giá trị không đổi được nhập vào chương trình như một phần của mã nguồn được gọi là literals.
Chữ số có thể thuộc bất kỳ kiểu dữ liệu cơ bản nào và có thể được chia thành Chữ số nguyên, Chữ số dấu phẩy động, Ký tự, Chuỗi và Giá trị Boolean.
Một lần nữa, các ký tự được xử lý giống như các biến thông thường ngoại trừ giá trị của chúng không thể được sửa đổi sau khi định nghĩa.
Chữ số nguyên
Một ký tự số nguyên có thể là một trong các loại sau:
Decimal sử dụng lưu lại số bình thường với chữ số đầu tiên không được là 0 vì chữ số đó được dành riêng để chỉ hệ bát phân. Điều này không bao gồm 0 riêng của nó: 0 là số không.
Octal sử dụng 0 làm tiền tố cho số.
Binary sử dụng 0b hoặc 0B làm tiền tố.
Hexadecimal sử dụng 0x hoặc 0X làm tiền tố.
Một chữ số nguyên cũng có thể có một hậu tố là sự kết hợp của U và L, tương ứng là không dấu và dài. Hậu tố có thể là chữ hoa hoặc chữ thường và có thể theo bất kỳ thứ tự nào.
Khi bạn không sử dụng hậu tố, trình biên dịch sẽ tự chọn giữa int, uint, long và ulong dựa trên độ lớn của giá trị.
Dưới đây là một số ví dụ về các ký tự số nguyên -
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffixSau đây là các ví dụ khác về các loại chữ số nguyên khác nhau -
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned long
0b001 // binaryChữ viết dấu chấm động
Các ký tự dấu phẩy động có thể được chỉ định trong hệ thập phân như trong 1.568 hoặc trong hệ thập lục phân như trong 0x91.bc.
Trong hệ thập phân, một số mũ có thể được biểu diễn bằng cách thêm ký tự e hoặc E và một số sau đó. Ví dụ: 2.3e4 có nghĩa là "2,3 nhân 10 thành lũy thừa của 4". Một ký tự “+” có thể được chỉ định trước giá trị của số mũ, nhưng nó không có tác dụng. Ví dụ 2.3e4 và 2.3e + 4 giống nhau.
Ký tự “-” được thêm vào trước giá trị của số mũ thay đổi nghĩa là "chia cho 10 thành lũy thừa của". Ví dụ: 2,3e-2 có nghĩa là "2,3 chia cho 10 thành lũy thừa của 2".
Trong hệ thập lục phân, giá trị bắt đầu bằng 0x hoặc 0X. Số mũ được xác định bởi p hoặc P thay vì e hoặc E. Số mũ không có nghĩa là "10 theo lũy thừa của", mà là "2 theo lũy thừa của". Ví dụ: P4 trong 0xabc.defP4 có nghĩa là "abc.de nhân 2 với lũy thừa của 4".
Dưới đây là một số ví dụ về các ký tự dấu phẩy động -
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fraction
0xabc.defP4 // Legal Hexa decimal with exponent
0xabc.defe4 // Legal Hexa decimal without exponent.Theo mặc định, kiểu của một ký tự dấu phẩy động là kép. F và F có nghĩa là phao, và thông số L có nghĩa là thực.
Boolean Literals
Có hai nghĩa đen Boolean và chúng là một phần của từ khóa D tiêu chuẩn -
Một giá trị của true đại diện cho sự thật.
Một giá trị của false đại diện cho sai.
Bạn không nên coi giá trị của true bằng 1 và giá trị của false bằng 0.
Ký tự chữ
Các ký tự ký tự được đặt trong dấu ngoặc kép.
Một chữ ký tự có thể là một ký tự thuần túy (ví dụ: 'x'), một chuỗi thoát (ví dụ: '\ t'), ký tự ASCII (ví dụ: '\ x21'), ký tự Unicode (ví dụ: '\ u011e') hoặc như ký tự được đặt tên (ví dụ: '\ ©', '\ ♥', '\ €').
Có một số ký tự trong D khi chúng đứng trước dấu gạch chéo ngược, chúng sẽ có ý nghĩa đặc biệt và chúng được sử dụng để biểu thị như dòng mới (\ n) hoặc tab (\ t). Tại đây, bạn có danh sách một số mã trình tự thoát như vậy -
| Trình tự thoát | Ý nghĩa |
|---|---|
| \\ | \ tính cách |
| \ ' | ' tính cách |
| \ " | " tính cách |
| \? | ? tính cách |
| \ a | Cảnh báo hoặc chuông |
| \ b | Backspace |
| \ f | Thức ăn dạng |
| \ n | Dòng mới |
| \ r | Vận chuyển trở lại |
| \ t | Tab ngang |
| \ v | Tab dọc |
Ví dụ sau đây cho thấy một số ký tự trong chuỗi thoát -
import std.stdio;
int main(string[] args) {
writefln("Hello\tWorld%c\n",'\x21');
writefln("Have a good day%c",'\x21');
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Hello World!
Have a good day!Chuỗi chữ
Các ký tự chuỗi được đặt trong dấu ngoặc kép. Một chuỗi chứa các ký tự tương tự như các ký tự: ký tự thuần túy, chuỗi thoát và ký tự phổ quát.
Bạn có thể ngắt một dòng dài thành nhiều dòng bằng cách sử dụng các ký tự chuỗi và phân tách chúng bằng cách sử dụng khoảng trắng.
Dưới đây là một số ví dụ về chuỗi ký tự -
import std.stdio;
int main(string[] args) {
writeln(q"MY_DELIMITER
Hello World
Have a good day
MY_DELIMITER");
writefln("Have a good day%c",'\x21');
auto str = q{int value = 20; ++value;};
writeln(str);
}Trong ví dụ trên, bạn có thể tìm thấy việc sử dụng q "MY_DELIMITER MY_DELIMITER" để biểu thị các ký tự nhiều dòng. Ngoài ra, bạn có thể thấy q {} đại diện cho chính một câu lệnh ngôn ngữ D.
Một toán tử là một ký hiệu yêu cầu trình biên dịch thực hiện các thao tác toán học hoặc logic cụ thể. Ngôn ngữ D có nhiều toán tử cài sẵn và cung cấp các loại toán tử sau:
- Toán tử số học
- Toán tử quan hệ
- Toán tử logic
- Toán tử Bitwise
- Người điều hành nhiệm vụ
- Nhà điều hành khác
Chương này giải thích từng toán tử số học, quan hệ, logic, bitwise, phép gán và các toán tử khác.
Toán tử số học
Bảng sau đây cho thấy tất cả các toán tử số học được ngôn ngữ D hỗ trợ. Giả sử biếnA giữ 10 và biến B giữ 20 sau đó -
Hiển thị các ví dụ
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| + | Nó thêm hai toán hạng. | A + B cho 30 |
| - | Nó trừ toán hạng thứ hai với toán hạng đầu tiên. | A - B cho -10 |
| * | Nó nhân cả hai toán hạng. | A * B cho 200 |
| / | Nó chia tử số cho tử số. | B / A cho 2 |
| % | Nó trả về phần còn lại của một phép chia số nguyên. | B% A cho 0 |
| ++ | Toán tử gia tăng giá trị số nguyên lên một. | A ++ cho 11 |
| - | Toán tử giảm dần giá trị số nguyên một. | A-- cho 9 |
Toán tử quan hệ
Bảng sau đây cho thấy tất cả các toán tử quan hệ được hỗ trợ bởi ngôn ngữ D. Giả sử biếnA giữ 10 và biến B giữ 20, sau đó -
Hiển thị các ví dụ
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| == | Kiểm tra xem giá trị của hai toán hạng có bằng nhau hay không, nếu có thì điều kiện trở thành true. | (A == B) không đúng. |
| ! = | Kiểm tra xem giá trị của hai toán hạng có bằng nhau hay không, nếu các giá trị không bằng nhau thì điều kiện trở thành true. | (A! = B) là đúng. |
| > | Kiểm tra xem giá trị của toán hạng bên trái có lớn hơn giá trị của toán hạng bên phải hay không, nếu có thì điều kiện trở thành true. | (A> B) là không đúng. |
| < | Kiểm tra xem giá trị của toán hạng bên trái có nhỏ hơn giá trị của toán hạng bên phải hay không, nếu có thì điều kiện trở thành true. | (A <B) là đúng. |
| > = | Kiểm tra xem giá trị của toán hạng bên trái có lớn hơn hoặc bằng giá trị của toán hạng bên phải hay không, nếu có thì điều kiện trở thành true. | (A> = B) là không đúng. |
| <= | Kiểm tra xem giá trị của toán hạng bên trái có nhỏ hơn hoặc bằng giá trị của toán hạng bên phải hay không, nếu có thì điều kiện trở thành true. | (A <= B) là đúng. |
Toán tử logic
Bảng sau đây cho thấy tất cả các toán tử logic được hỗ trợ bởi ngôn ngữ D. Giả sử biếnA giữ 1 và biến B giữ 0, sau đó -
Hiển thị các ví dụ
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| && | Nó được gọi là toán tử logic AND. Nếu cả hai toán hạng đều khác 0, thì điều kiện trở thành true. | (A && B) là sai. |
| || | Nó được gọi là Toán tử logic HOẶC. Nếu bất kỳ toán hạng nào trong hai toán hạng khác 0, thì điều kiện trở thành true. | (A || B) là đúng. |
| ! | Nó được gọi là Toán tử logic NOT. Sử dụng để đảo ngược trạng thái logic của toán hạng của nó. Nếu một điều kiện là đúng thì toán tử logic NOT sẽ sai. | ! (A && B) là đúng. |
Toán tử Bitwise
Toán tử bitwise hoạt động trên các bit và thực hiện thao tác từng bit. Bảng sự thật cho &, |, và ^ như sau:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
Giả sử nếu A = 60; và B = 13. Ở định dạng nhị phân, chúng sẽ như sau:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A | B = 0011 1101
A ^ B = 0011 0001
~ A = 1100 0011
Các toán tử Bitwise được hỗ trợ bởi ngôn ngữ D được liệt kê trong bảng sau. Giả sử biến A giữ 60 và biến B giữ 13, thì -
Hiển thị các ví dụ
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| & | Toán tử AND nhị phân sao chép một bit vào kết quả nếu nó tồn tại trong cả hai toán hạng. | (A & B) sẽ cho 12, Nghĩa là 0000 1100. |
| | | Toán tử OR nhị phân sao chép một bit nếu nó tồn tại trong một trong hai toán hạng. | (A | B) cho 61. Nghĩa là 0011 1101. |
| ^ | Toán tử XOR nhị phân sao chép bit nếu nó được đặt trong một toán hạng nhưng không phải cả hai. | (A ^ B) cho 49. Nghĩa là 0011 0001 |
| ~ | Toán tử bổ sung số nhị phân là một ngôi và có tác dụng 'lật' các bit. | (~ A) cho -61. Có nghĩa là 1100 0011 ở dạng bổ sung của 2. |
| << | Toán tử dịch chuyển trái nhị phân. Giá trị toán hạng bên trái được di chuyển sang trái bằng số bit được chỉ định bởi toán hạng bên phải. | A << 2 cho 240. Nghĩa là 1111 0000 |
| >> | Toán tử Shift phải nhị phân. Giá trị của toán hạng bên trái được di chuyển sang phải bằng số bit được chỉ định bởi toán hạng bên phải. | A >> 2 cho 15. Có nghĩa là 0000 1111. |
Người điều hành nhiệm vụ
Các toán tử gán sau được ngôn ngữ D hỗ trợ:
Hiển thị các ví dụ
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| = | Nó là toán tử gán đơn giản. Nó gán giá trị từ toán hạng bên phải cho toán hạng bên trái | C = A + B gán giá trị của A + B vào C |
| + = | Nó là thêm toán tử gán AND. Nó thêm toán hạng bên phải vào toán hạng bên trái và gán kết quả cho toán hạng bên trái | C + = A tương đương với C = C + A |
| - = | Nó là toán tử gán trừ AND. Nó trừ toán hạng bên phải khỏi toán hạng bên trái và gán kết quả cho toán hạng bên trái. | C - = A tương đương với C = C - A |
| * = | Nó là toán tử gán nhân AND. Nó nhân toán hạng bên phải với toán hạng bên trái và gán kết quả cho toán hạng bên trái. | C * = A tương đương với C = C * A |
| / = | Nó là toán tử phân chia AND. Nó chia toán hạng bên trái với toán hạng bên phải và gán kết quả cho toán hạng bên trái. | C / = A tương đương với C = C / A |
| % = | Nó là toán tử gán môđun AND. Cần mô đun bằng cách sử dụng hai toán hạng và gán kết quả cho toán hạng bên trái. | C% = A tương đương với C = C% A |
| << = | Nó là toán tử gán dịch chuyển trái AND. | C << = 2 giống với C = C << 2 |
| >> = | Nó là toán tử gán dịch chuyển phải AND. | C >> = 2 giống với C = C >> 2 |
| & = | Nó là toán tử gán bitwise AND. | C & = 2 giống C = C & 2 |
| ^ = | Nó là toán tử OR và gán độc quyền theo bit. | C ^ = 2 giống với C = C ^ 2 |
| | = | Nó bao gồm theo bitwise OR và toán tử gán | C | = 2 tương tự như C = C | 2 |
Toán tử dao động - Sizeof và Ternary
Có một số toán tử quan trọng khác bao gồm sizeof và ? : được hỗ trợ bởi D Language.
Hiển thị các ví dụ
| Nhà điều hành | Sự miêu tả | Thí dụ |
|---|---|---|
| sizeof () | Trả về kích thước của một biến. | sizeof (a), trong đó a là số nguyên, trả về 4. |
| & | Trả về địa chỉ của một biến. | & a; cung cấp địa chỉ thực của biến. |
| * | Con trỏ đến một biến. | * a; cung cấp con trỏ cho một biến. |
| ? : | Biểu thức điều kiện | Nếu điều kiện là đúng thì giá trị X: Ngược lại giá trị Y. |
Các nhà khai thác ưu tiên trong D
Mức độ ưu tiên của toán tử xác định nhóm các từ trong một biểu thức. Điều này ảnh hưởng đến cách một biểu thức được đánh giá. Một số toán tử nhất định được ưu tiên hơn những toán tử khác.
Ví dụ, toán tử nhân có mức độ ưu tiên cao hơn toán tử cộng.
Chúng ta hãy xem xét một biểu thức
x = 7 + 3 * 2.
Ở đây, x được gán 13 chứ không phải 20. Lý do đơn giản là, toán tử * có mức độ ưu tiên cao hơn +, do đó 3 * 2 được tính trước và sau đó kết quả được cộng thành 7.
Ở đây, các toán tử có mức độ ưu tiên cao nhất xuất hiện ở đầu bảng, những toán tử có mức độ ưu tiên thấp nhất xuất hiện ở cuối bảng. Trong một biểu thức, các toán tử có mức ưu tiên cao hơn được đánh giá đầu tiên.
Hiển thị các ví dụ
| thể loại | Nhà điều hành | Sự liên kết |
|---|---|---|
| Postfix | () [] ->. ++ - - | Trái sang phải |
| Một ngôi | + -! ~ ++ - - (type) * & sizeof | Phải sang trái |
| Phép nhân | * /% | Trái sang phải |
| Phụ gia | + - | Trái sang phải |
| Shift | << >> | Trái sang phải |
| Quan hệ | <<=>> = | Trái sang phải |
| Bình đẳng | ==! = | Trái sang phải |
| Bitwise VÀ | & | Trái sang phải |
| Bitwise XOR | ^ | Trái sang phải |
| Bitwise HOẶC | | | Trái sang phải |
| Logic AND | && | Trái sang phải |
| Logic HOẶC | || | Trái sang phải |
| Có điều kiện | ?: | Phải sang trái |
| Chuyển nhượng | = + = - = * = / =% = >> = << = & = ^ = | = | Phải sang trái |
| Dấu phẩy | , | Trái sang phải |
Có thể có một tình huống, khi bạn cần thực thi một khối mã nhiều lần. Nói chung, các câu lệnh được thực hiện tuần tự: Câu lệnh đầu tiên trong một hàm được thực hiện đầu tiên, tiếp theo là câu lệnh thứ hai, v.v.
Các ngôn ngữ lập trình cung cấp các cấu trúc điều khiển khác nhau cho phép các đường dẫn thực thi phức tạp hơn.
Một câu lệnh lặp thực hiện một câu lệnh hoặc một nhóm câu lệnh nhiều lần. Dạng tổng quát sau của câu lệnh lặp hầu hết được sử dụng trong các ngôn ngữ lập trình:

Ngôn ngữ lập trình D cung cấp các loại vòng lặp sau để xử lý các yêu cầu về lặp. Nhấp vào các liên kết sau để kiểm tra chi tiết của chúng.
| Sr.No. | Loại vòng lặp & Mô tả |
|---|---|
| 1 | trong khi lặp lại Nó lặp lại một câu lệnh hoặc một nhóm câu lệnh trong khi một điều kiện đã cho là đúng. Nó kiểm tra điều kiện trước khi thực thi phần thân của vòng lặp. |
| 2 | vòng lặp for Nó thực hiện một chuỗi các câu lệnh nhiều lần và viết tắt mã quản lý biến vòng lặp. |
| 3 | vòng lặp do ... while Giống như một câu lệnh while, ngoại trừ việc nó kiểm tra điều kiện ở cuối thân vòng lặp. |
| 4 | vòng lồng nhau Bạn có thể sử dụng một hoặc nhiều vòng lặp bên trong bất kỳ vòng lặp while, for hoặc do.. while nào khác. |
Tuyên bố kiểm soát vòng lặp
Các câu lệnh điều khiển vòng lặp thay đổi việc thực thi từ trình tự bình thường của nó. Khi việc thực thi rời khỏi một phạm vi, tất cả các đối tượng tự động được tạo trong phạm vi đó sẽ bị phá hủy.
D hỗ trợ các câu lệnh điều khiển sau:
| Sr.No. | Tuyên bố & Mô tả Kiểm soát |
|---|---|
| 1 | tuyên bố ngắt Kết thúc vòng lặp hoặc câu lệnh switch và chuyển việc thực thi sang câu lệnh ngay sau vòng lặp hoặc lệnh switch. |
| 2 | tiếp tục tuyên bố Làm cho vòng lặp bỏ qua phần còn lại của phần thân và ngay lập tức kiểm tra lại tình trạng của nó trước khi nhắc lại. |
Vòng lặp vô hạn
Một vòng lặp trở thành vòng lặp vô hạn nếu một điều kiện không bao giờ trở thành sai. Cácforvòng lặp thường được sử dụng cho mục đích này. Vì không có biểu thức nào trong ba biểu thức tạo thành vòng lặp for được yêu cầu, bạn có thể tạo một vòng lặp vô tận bằng cách để trống biểu thức điều kiện.
import std.stdio;
int main () {
for( ; ; ) {
writefln("This loop will run forever.");
}
return 0;
}Khi biểu thức điều kiện vắng mặt, nó được giả định là đúng. Bạn có thể có một biểu thức khởi tạo và tăng dần, nhưng các lập trình viên D thường sử dụng cấu trúc for (;;) để biểu thị một vòng lặp vô hạn.
NOTE - Bạn có thể kết thúc một vòng lặp vô hạn bằng cách nhấn các phím Ctrl + C.
Các cấu trúc ra quyết định chứa điều kiện được đánh giá cùng với hai bộ câu lệnh sẽ được thực hiện. Một nhóm câu lệnh được thực thi nếu điều kiện nó đúng và một bộ câu lệnh khác được thực thi nếu điều kiện sai.
Sau đây là dạng chung của cấu trúc ra quyết định điển hình được tìm thấy trong hầu hết các ngôn ngữ lập trình:
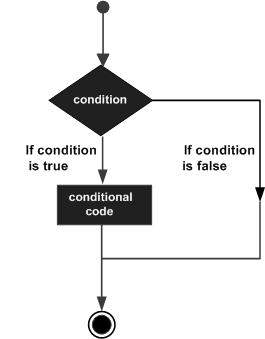
Ngôn ngữ lập trình D giả định bất kỳ non-zero và non-null giá trị như true, và nếu nó là zero hoặc là null, sau đó nó được giả định là false giá trị.
Ngôn ngữ lập trình D cung cấp các loại câu lệnh ra quyết định sau.
| Sr.No. | Statement & Description |
|---|---|
| 1 | if statement An if statement consists of a boolean expression followed by one or more statements. |
| 2 | if...else statement An if statement can be followed by an optional else statement, which executes when the boolean expression is false. |
| 3 | nested if statements You can use one if or else if statement inside another if or else if statement(s). |
| 4 | switch statement A switch statement allows a variable to be tested for equality against a list of values. |
| 5 | nested switch statements You can use one switch statement inside another switch statement(s). |
The ? : Operator in D
We have covered conditional operator ? : in previous chapter which can be used to replace if...else statements. It has the following general form
Exp1 ? Exp2 : Exp3;Where Exp1, Exp2, and Exp3 are expressions. Notice the use and placement of the colon.
The value of a ? expression is determined as follows −
Exp1 is evaluated. If it is true, then Exp2 is evaluated and becomes the value of the entire ? expression.
If Exp1 is false, then Exp3 is evaluated and its value becomes the value of the expression.
This chapter describes the functions used in D programming.
Function Definition in D
A basic function definition consists of a function header and a function body.
Cú pháp
return_type function_name( parameter list ) {
body of the function
}Đây là tất cả các phần của một hàm -
Return Type- Một hàm có thể trả về một giá trị. Cácreturn_typelà kiểu dữ liệu của giá trị mà hàm trả về. Một số hàm thực hiện các hoạt động mong muốn mà không trả về giá trị. Trong trường hợp này, return_type là từ khóavoid.
Function Name- Đây là tên thực của hàm. Tên hàm và danh sách tham số cùng nhau tạo thành chữ ký hàm.
Parameters- Một tham số giống như một trình giữ chỗ. Khi một hàm được gọi, bạn truyền một giá trị cho tham số. Giá trị này được gọi là tham số hoặc đối số thực tế. Danh sách tham số đề cập đến kiểu, thứ tự và số lượng các tham số của một hàm. Các thông số là tùy chọn; nghĩa là, một hàm có thể không chứa tham số.
Function Body - Phần thân hàm chứa tập hợp các câu lệnh xác định chức năng thực hiện.
Gọi một hàm
Bạn có thể gọi một hàm như sau:
function_name(parameter_values)Các loại hàm trong D
Lập trình D hỗ trợ một loạt các chức năng và chúng được liệt kê dưới đây.
- Chức năng thuần túy
- Hàm Nothrow
- Chức năng phản chiếu
- Chức năng tự động
- Chức năng đa dạng
- Chức năng Inout
- Chức năng tài sản
Các chức năng khác nhau được giải thích bên dưới.
Chức năng thuần túy
Các hàm thuần túy là các hàm không thể truy cập lưu trạng thái toàn cục hoặc tĩnh, có thể thay đổi thông qua các đối số của chúng. Điều này có thể cho phép tối ưu hóa dựa trên thực tế là một hàm thuần túy được đảm bảo sẽ thay đổi không có gì không được chuyển cho nó và trong trường hợp trình biên dịch có thể đảm bảo rằng một hàm thuần túy không thể thay đổi các đối số của nó, nó có thể kích hoạt độ thuần khiết đầy đủ của hàm là, đảm bảo rằng hàm sẽ luôn trả về cùng một kết quả cho các đối số giống nhau).
import std.stdio;
int x = 10;
immutable int y = 30;
const int* p;
pure int purefunc(int i,const char* q,immutable int* s) {
//writeln("Simple print"); //cannot call impure function 'writeln'
debug writeln("in foo()"); // ok, impure code allowed in debug statement
// x = i; // error, modifying global state
// i = x; // error, reading mutable global state
// i = *p; // error, reading const global state
i = y; // ok, reading immutable global state
auto myvar = new int; // Can use the new expression:
return i;
}
void main() {
writeln("Value returned from pure function : ",purefunc(x,null,null));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Value returned from pure function : 30Hàm Nothrow
Các hàm Nothrow không ném bất kỳ ngoại lệ nào bắt nguồn từ Exception của lớp. Hàm Nothrow đồng biến với các hàm ném.
Nothrow đảm bảo rằng một hàm không phát ra bất kỳ ngoại lệ nào.
import std.stdio;
int add(int a, int b) nothrow {
//writeln("adding"); This will fail because writeln may throw
int result;
try {
writeln("adding"); // compiles
result = a + b;
} catch (Exception error) { // catches all exceptions
}
return result;
}
void main() {
writeln("Added value is ", add(10,20));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
adding
Added value is 30Chức năng phản chiếu
Các hàm tham chiếu cho phép các hàm trả về bằng tham chiếu. Điều này tương tự với các tham số chức năng ref.
import std.stdio;
ref int greater(ref int first, ref int second) {
return (first > second) ? first : second;
}
void main() {
int a = 1;
int b = 2;
greater(a, b) += 10;
writefln("a: %s, b: %s", a, b);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
a: 1, b: 12Chức năng tự động
Các chức năng tự động có thể trả về giá trị thuộc bất kỳ loại nào. Không có hạn chế về loại được trả lại. Dưới đây là một ví dụ đơn giản cho chức năng loại tự động.
import std.stdio;
auto add(int first, double second) {
double result = first + second;
return result;
}
void main() {
int a = 1;
double b = 2.5;
writeln("add(a,b) = ", add(a, b));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
add(a,b) = 3.5Chức năng đa dạng
Các hàm đa dạng là những hàm trong đó số lượng tham số cho một hàm được xác định trong thời gian chạy. Trong C, có một hạn chế là có ít nhất một tham số. Nhưng trong lập trình D, không có giới hạn như vậy. Một ví dụ đơn giản được hiển thị bên dưới.
import std.stdio;
import core.vararg;
void printargs(int x, ...) {
for (int i = 0; i < _arguments.length; i++) {
write(_arguments[i]);
if (_arguments[i] == typeid(int)) {
int j = va_arg!(int)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(long)) {
long j = va_arg!(long)(_argptr);
writefln("\t%d", j);
} else if (_arguments[i] == typeid(double)) {
double d = va_arg!(double)(_argptr);
writefln("\t%g", d);
}
}
}
void main() {
printargs(1, 2, 3L, 4.5);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
int 2
long 3
double 4.5Chức năng Inout
Inout có thể được sử dụng cho cả kiểu tham số và trả về của hàm. Nó giống như một khuôn mẫu cho biến, hằng và bất biến. Thuộc tính biến đổi được suy ra từ tham số. Có nghĩa là, inout chuyển thuộc tính biến đổi được suy ra thành kiểu trả về. Dưới đây là một ví dụ đơn giản cho thấy khả năng thay đổi được thay đổi như thế nào.
import std.stdio;
inout(char)[] qoutedWord(inout(char)[] phrase) {
return '"' ~ phrase ~ '"';
}
void main() {
char[] a = "test a".dup;
a = qoutedWord(a);
writeln(typeof(qoutedWord(a)).stringof," ", a);
const(char)[] b = "test b";
b = qoutedWord(b);
writeln(typeof(qoutedWord(b)).stringof," ", b);
immutable(char)[] c = "test c";
c = qoutedWord(c);
writeln(typeof(qoutedWord(c)).stringof," ", c);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
char[] "test a"
const(char)[] "test b"
string "test c"Chức năng tài sản
Thuộc tính cho phép sử dụng các hàm thành viên như các biến thành viên. Nó sử dụng từ khóa @property. Các thuộc tính được liên kết với chức năng liên quan trả về giá trị dựa trên yêu cầu. Một ví dụ đơn giản cho tài sản được hiển thị bên dưới.
import std.stdio;
struct Rectangle {
double width;
double height;
double area() const @property {
return width*height;
}
void area(double newArea) @property {
auto multiplier = newArea / area;
width *= multiplier;
writeln("Value set!");
}
}
void main() {
auto rectangle = Rectangle(20,10);
writeln("The area is ", rectangle.area);
rectangle.area(300);
writeln("Modified width is ", rectangle.width);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
The area is 200
Value set!
Modified width is 30Các ký tự là khối xây dựng của chuỗi. Bất kỳ ký hiệu nào của hệ thống chữ viết đều được gọi là ký tự: các chữ cái trong bảng chữ cái, chữ số, dấu câu, ký tự khoảng trắng, v.v. Thật khó hiểu, bản thân các khối xây dựng của ký tự cũng được gọi là ký tự.
Giá trị nguyên của chữ thường a là 97 và giá trị nguyên của chữ số 1 là 49. Các giá trị này chỉ được gán theo quy ước khi bảng ASCII đã được thiết kế.
Bảng sau đây đề cập đến các kiểu ký tự tiêu chuẩn với kích thước và mục đích lưu trữ của chúng.
Các ký tự được biểu thị bằng kiểu char, chỉ có thể chứa 256 giá trị riêng biệt. Nếu bạn đã quen với kiểu ký tự từ các ngôn ngữ khác, bạn có thể đã biết rằng nó không đủ lớn để hỗ trợ các ký hiệu của nhiều hệ thống chữ viết.
| Kiểu | Kích thước lưu trữ | Mục đích |
|---|---|---|
| char | 1 byte | Đơn vị mã UTF-8 |
| wchar | 2 byte | Đơn vị mã UTF-16 |
| dchar | 4 byte | Đơn vị mã UTF-32 và điểm mã Unicode |
Một số hàm ký tự hữu ích được liệt kê bên dưới:
isLower - Xác định nếu một ký tự thường?
isUpper - Xác định nếu một ký tự hoa?
isAlpha - Xác định xem một ký tự chữ và số Unicode (thường là một chữ cái hay một chữ số)?
isWhite - Xác định nếu một ký tự khoảng trắng?
toLower - Nó tạo ra chữ thường của ký tự đã cho.
toUpper - Nó tạo ra chữ hoa của ký tự đã cho.
import std.stdio;
import std.uni;
void main() {
writeln("Is ğ lowercase? ", isLower('ğ'));
writeln("Is Ş lowercase? ", isLower('Ş'));
writeln("Is İ uppercase? ", isUpper('İ'));
writeln("Is ç uppercase? ", isUpper('ç'));
writeln("Is z alphanumeric? ", isAlpha('z'));
writeln("Is new-line whitespace? ", isWhite('\n'));
writeln("Is underline whitespace? ", isWhite('_'));
writeln("The lowercase of Ğ: ", toLower('Ğ'));
writeln("The lowercase of İ: ", toLower('İ'));
writeln("The uppercase of ş: ", toUpper('ş'));
writeln("The uppercase of ı: ", toUpper('ı'));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Is ğ lowercase? true
Is Ş lowercase? false
Is İ uppercase? true
Is ç uppercase? false
Is z alphanumeric? true
Is new-line whitespace? true
Is underline whitespace? false
The lowercase of Ğ: ğ
The lowercase of İ: i
The uppercase of ş: Ş
The uppercase of ı: IĐọc ký tự trong D
Chúng ta có thể đọc các ký tự bằng readf như hình bên dưới.
readf(" %s", &letter);Vì lập trình D hỗ trợ unicode nên để đọc các ký tự unicode, chúng ta cần đọc hai lần và viết hai lần để có kết quả như mong đợi. Điều này không hoạt động trên trình biên dịch trực tuyến. Ví dụ được hiển thị bên dưới.
import std.stdio;
void main() {
char firstCode;
char secondCode;
write("Please enter a letter: ");
readf(" %s", &firstCode);
readf(" %s", &secondCode);
writeln("The letter that has been read: ", firstCode, secondCode);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Please enter a letter: ğ
The letter that has been read: ğD cung cấp hai loại biểu diễn chuỗi sau:
- Mảng ký tự
- Chuỗi ngôn ngữ cốt lõi
Mảng ký tự
Chúng ta có thể biểu diễn mảng ký tự theo một trong hai dạng như hình dưới đây. Biểu mẫu đầu tiên cung cấp kích thước trực tiếp và biểu mẫu thứ hai sử dụng phương pháp lặp để tạo bản sao có thể ghi được của chuỗi "Chào buổi sáng".
char[9] greeting1 = "Hello all";
char[] greeting2 = "Good morning".dup;Thí dụ
Đây là một ví dụ đơn giản sử dụng các dạng mảng ký tự đơn giản ở trên.
import std.stdio;
void main(string[] args) {
char[9] greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả như sau:
Hello all
Good morningChuỗi ngôn ngữ chính
Các chuỗi được tích hợp sẵn trong ngôn ngữ cốt lõi của D. Các chuỗi này có thể tương tác với mảng ký tự được hiển thị ở trên. Ví dụ sau đây cho thấy một biểu diễn chuỗi đơn giản.
string greeting1 = "Hello all";Thí dụ
import std.stdio;
void main(string[] args) {
string greeting1 = "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
string greeting3 = greeting1;
writefln("%s",greeting3);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả như sau:
Hello all
Good morning
Hello allKết nối chuỗi
Việc nối chuỗi trong lập trình D sử dụng ký hiệu dấu ngã (~).
Thí dụ
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
char[] greeting2 = "morning".dup;
char[] greeting3 = greeting1~" "~greeting2;
writefln("%s",greeting3);
string greeting4 = "morning";
string greeting5 = greeting1~" "~greeting4;
writefln("%s",greeting5);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả như sau:
Good morning
Good morningChiều dài của chuỗi
Độ dài của chuỗi tính bằng byte có thể được truy xuất với sự trợ giúp của phép tính độ dài.
Thí dụ
import std.stdio;
void main(string[] args) {
string greeting1 = "Good";
writefln("Length of string greeting1 is %d",greeting1.length);
char[] greeting2 = "morning".dup;
writefln("Length of string greeting2 is %d",greeting2.length);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Length of string greeting1 is 4
Length of string greeting2 is 7So sánh chuỗi
So sánh chuỗi khá dễ dàng trong lập trình D. Bạn có thể sử dụng toán tử ==, <, và> để so sánh chuỗi.
Thí dụ
import std.stdio;
void main() {
string s1 = "Hello";
string s2 = "World";
string s3 = "World";
if (s2 == s3) {
writeln("s2: ",s2," and S3: ",s3, " are the same!");
}
if (s1 < s2) {
writeln("'", s1, "' comes before '", s2, "'.");
} else {
writeln("'", s2, "' comes before '", s1, "'.");
}
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả như sau:
s2: World and S3: World are the same!
'Hello' comes before 'World'.Thay thế chuỗi
Chúng ta có thể thay thế chuỗi bằng chuỗi [].
Thí dụ
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello world ".dup;
char[] s2 = "sample".dup;
s1[6..12] = s2[0..6];
writeln(s1);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả như sau:
hello samplePhương pháp chỉ mục
Các phương thức lập chỉ mục cho vị trí của một chuỗi con trong chuỗi bao gồm indexOf và lastIndexOf được giải thích trong ví dụ sau.
Thí dụ
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo"));
writeln(s1);
writeln("lastIndexOf of O in hello is " ,std.string.lastIndexOf(s1,"O",CaseSensitive.no));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
indexOf.of llo in hello is 2
hello World
lastIndexOf of O in hello is 7Xử lý các trường hợp
Các phương pháp được sử dụng để thay đổi các trường hợp được hiển thị trong ví dụ sau.
Thí dụ
import std.stdio;
import std.string;
void main() {
char[] s1 = "hello World ".dup;
writeln("Capitalized string of s1 is ",capitalize(s1));
writeln("Uppercase string of s1 is ",toUpper(s1));
writeln("Lowercase string of s1 is ",toLower(s1));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Capitalized string of s1 is Hello world
Uppercase string of s1 is HELLO WORLD
Lowercase string of s1 is hello worldHạn chế ký tự
Khôi phục các ký tự trong chuỗi được hiển thị trong ví dụ sau.
Thí dụ
import std.stdio;
import std.string;
void main() {
string s = "H123Hello1";
string result = munch(s, "0123456789H");
writeln("Restrict trailing characters:",result);
result = squeeze(s, "0123456789H");
writeln("Restrict leading characters:",result);
s = " Hello World ";
writeln("Stripping leading and trailing whitespace:",strip(s));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Restrict trailing characters:H123H
Restrict leading characters:ello1
Stripping leading and trailing whitespace:Hello WorldNgôn ngữ lập trình D cung cấp một cấu trúc dữ liệu, có tên arrays, nơi lưu trữ một tập hợp tuần tự có kích thước cố định của các phần tử cùng loại. Một mảng được sử dụng để lưu trữ một tập hợp dữ liệu. Thường sẽ hữu ích hơn nếu coi một mảng là một tập hợp các biến cùng kiểu.
Thay vì khai báo các biến riêng lẻ, chẳng hạn như number0, number1, ... và number99, bạn khai báo một biến mảng chẳng hạn như số và sử dụng số [0], số [1] và ..., số [99] để biểu diễn các biến riêng lẻ. Một phần tử cụ thể trong một mảng được truy cập bởi một chỉ mục.
Tất cả các mảng bao gồm các vị trí bộ nhớ liền nhau. Địa chỉ thấp nhất tương ứng với phần tử đầu tiên và địa chỉ cao nhất cho phần tử cuối cùng.
Khai báo Mảng
Để khai báo một mảng trong ngôn ngữ lập trình D, người lập trình chỉ định kiểu của các phần tử và số phần tử theo yêu cầu của một mảng như sau:
type arrayName [ arraySize ];Đây được gọi là mảng một chiều. Kích thước mảng phải là một hằng số nguyên lớn hơn 0 và kiểu có thể là bất kỳ kiểu dữ liệu ngôn ngữ lập trình D hợp lệ nào. Ví dụ, để khai báo một mảng 10 phần tử được gọi là số dư kiểu double, hãy sử dụng câu lệnh này:
double balance[10];Khởi tạo Mảng
Bạn có thể khởi tạo từng phần tử của mảng ngôn ngữ lập trình D hoặc sử dụng một câu lệnh đơn như sau
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];Số lượng giá trị giữa dấu ngoặc vuông [] ở bên phải không được lớn hơn số phần tử bạn khai báo cho mảng giữa dấu ngoặc vuông []. Ví dụ sau chỉ định một phần tử duy nhất của mảng:
Nếu bạn bỏ qua kích thước của mảng, một mảng vừa đủ lớn để chứa quá trình khởi tạo sẽ được tạo. Do đó, nếu bạn viết
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];thì bạn sẽ tạo chính xác mảng giống như bạn đã làm trong ví dụ trước.
balance[4] = 50.0;Câu lệnh trên gán giá trị phần tử thứ 5 trong mảng là 50.0. Mảng có chỉ số thứ 4 sẽ là thứ 5, tức là phần tử cuối cùng vì tất cả các mảng đều có 0 là chỉ số của phần tử đầu tiên của chúng mà còn được gọi là chỉ số cơ sở. Phần đại diện bằng hình ảnh sau đây cho thấy cùng một mảng mà chúng ta đã thảo luận ở trên -

Truy cập các phần tử mảng
Một phần tử được truy cập bằng cách đánh chỉ mục tên mảng. Điều này được thực hiện bằng cách đặt chỉ mục của phần tử trong dấu ngoặc vuông sau tên của mảng. Ví dụ -
double salary = balance[9];Câu lệnh trên nhận phần tử thứ 10 từ mảng và gán giá trị cho biến lương . Ví dụ sau thực hiện khai báo, gán và truy cập các mảng:
import std.stdio;
void main() {
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Element \t Value");
// output each array element's value
for ( int j = 0; j < 10; j++ ) {
writeln(j," \t ",n[j]);
}
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109Mảng tĩnh so với Mảng động
Nếu độ dài của một mảng được chỉ định trong khi viết chương trình, thì mảng đó là một mảng tĩnh. Khi độ dài có thể thay đổi trong quá trình thực hiện chương trình thì mảng đó là mảng động.
Việc xác định mảng động đơn giản hơn việc xác định mảng có độ dài cố định vì việc bỏ qua độ dài sẽ làm cho mảng động -
int[] dynamicArray;Thuộc tính mảng
Đây là các thuộc tính của mảng -
| Sr.No. | Kê khai tài sản |
|---|---|
| 1 | .init Mảng tĩnh trả về một ký tự mảng với mỗi phần tử của ký tự là thuộc tính .init của kiểu phần tử mảng. |
| 2 | .sizeof Mảng tĩnh trả về độ dài mảng nhân với số byte mỗi phần tử mảng trong khi mảng động trả về kích thước của tham chiếu mảng động, là 8 trong bản dựng 32 bit và 16 trên bản dựng 64 bit. |
| 3 | .length Mảng tĩnh trả về số phần tử trong mảng trong khi mảng động được sử dụng để lấy / đặt số phần tử trong mảng. Chiều dài thuộc loại size_t. |
| 4 | .ptr Trả về một con trỏ đến phần tử đầu tiên của mảng. |
| 5 | .dup Tạo một mảng động có cùng kích thước và sao chép nội dung của mảng vào đó. |
| 6 | .idup Tạo một mảng động có cùng kích thước và sao chép nội dung của mảng vào đó. Bản sao được đánh là bất biến. |
| 7 | .reverse Đảo ngược thứ tự của các phần tử trong mảng. Trả về mảng. |
| số 8 | .sort Sắp xếp theo thứ tự của các phần tử trong mảng. Trả về mảng. |
Thí dụ
Ví dụ sau giải thích các thuộc tính khác nhau của một mảng:
import std.stdio;
void main() {
int n[ 5 ]; // n is an array of 5 integers
// initialize elements of array n to 0
for ( int i = 0; i < 5; i++ ) {
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Initialized value:",n.init);
writeln("Length: ",n.length);
writeln("Size of: ",n.sizeof);
writeln("Pointer:",n.ptr);
writeln("Duplicate Array: ",n.dup);
writeln("iDuplicate Array: ",n.idup);
n = n.reverse.dup;
writeln("Reversed Array: ",n);
writeln("Sorted Array: ",n.sort);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Initialized value:[0, 0, 0, 0, 0]
Length: 5
Size of: 20
Pointer:7FFF5A373920
Duplicate Array: [100, 101, 102, 103, 104]
iDuplicate Array: [100, 101, 102, 103, 104]
Reversed Array: [104, 103, 102, 101, 100]
Sorted Array: [100, 101, 102, 103, 104]Mảng đa chiều trong D
Lập trình D cho phép mảng nhiều chiều. Đây là dạng chung của khai báo mảng nhiều chiều:
type name[size1][size2]...[sizeN];Thí dụ
Khai báo sau tạo ra ba chiều 5. 10. 4 mảng số nguyên -
int threedim[5][10][4];Mảng hai chiều trong D
Dạng đơn giản nhất của mảng nhiều chiều là mảng hai chiều. Về bản chất, mảng hai chiều là một danh sách các mảng một chiều. Để khai báo một mảng số nguyên hai chiều có kích thước [x, y], bạn sẽ viết cú pháp như sau:
type arrayName [ x ][ y ];Ở đâu type có thể là bất kỳ kiểu dữ liệu lập trình D hợp lệ nào và arrayName sẽ là một định danh lập trình D hợp lệ.
Trong đó type có thể là bất kỳ kiểu dữ liệu lập trình D hợp lệ nào và arrayName là mã định danh lập trình D hợp lệ.
Một mảng hai chiều có thể được coi như một bảng, có x số hàng và y số cột. Một mảng hai chiềua chứa ba hàng và bốn cột có thể được hiển thị như sau:
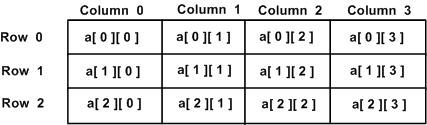
Do đó, mọi phần tử trong mảng a được xác định bởi một phần tử là a[ i ][ j ], Ở đâu a là tên của mảng và i và j là các chỉ số con xác định duy nhất từng phần tử trong a.
Khởi tạo mảng hai chiều
Mảng nhiều thứ nguyên có thể được khởi tạo bằng cách chỉ định các giá trị trong ngoặc cho mỗi hàng. Mảng sau có 3 hàng và mỗi hàng có 4 cột.
int a[3][4] = [
[0, 1, 2, 3] , /* initializers for row indexed by 0 */
[4, 5, 6, 7] , /* initializers for row indexed by 1 */
[8, 9, 10, 11] /* initializers for row indexed by 2 */
];Các dấu ngoặc nhọn lồng nhau, cho biết hàng dự định, là tùy chọn. Khởi tạo sau tương đương với ví dụ trước:
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];Truy cập các phần tử mảng hai chiều
Một phần tử trong mảng 2 chiều được truy cập bằng cách sử dụng các chỉ số con, có nghĩa là chỉ số hàng và chỉ số cột của mảng. Ví dụ
int val = a[2][3];Câu lệnh trên nhận phần tử thứ 4 từ hàng thứ 3 của mảng. Bạn có thể xác minh nó trong biểu đồ trên.
import std.stdio;
void main () {
// an array with 5 rows and 2 columns.
int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]];
// output each array element's value
for ( int i = 0; i < 5; i++ ) for ( int j = 0; j < 2; j++ ) {
writeln( "a[" , i , "][" , j , "]: ",a[i][j]);
}
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8Các phép toán mảng phổ biến trong D
Dưới đây là các hoạt động khác nhau được thực hiện trên các mảng:
Mảng Slicing
Chúng ta thường sử dụng một phần của mảng và việc cắt mảng thường khá hữu ích. Dưới đây là một ví dụ đơn giản về cắt mảng.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double[] b;
b = a[1..3];
writeln(b);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
[2, 3.4]Sao chép mảng
Chúng tôi cũng sử dụng mảng sao chép. Một ví dụ đơn giản để sao chép mảng được hiển thị bên dưới.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double b[5];
writeln("Array a:",a);
writeln("Array b:",b);
b[] = a; // the 5 elements of a[5] are copied into b[5]
writeln("Array b:",b);
b[] = a[]; // the 5 elements of a[3] are copied into b[5]
writeln("Array b:",b);
b[1..2] = a[0..1]; // same as b[1] = a[0]
writeln("Array b:",b);
b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2]
writeln("Array b:",b);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Array a:[1000, 2, 3.4, 17, 50]
Array b:[nan, nan, nan, nan, nan]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 1000, 3.4, 17, 50]
Array b:[2, 3.4, 3.4, 17, 50]Thiết lập mảng
Dưới đây là một ví dụ đơn giản để thiết lập giá trị trong một mảng.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5];
a[] = 5;
writeln("Array a:",a);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Array a:[5, 5, 5, 5, 5]Kết nối mảng
Dưới đây là một ví dụ đơn giản cho việc nối hai mảng.
import std.stdio;
void main () {
// an array with 5 elements.
double a[5] = 5;
double b[5] = 10;
double [] c;
c = a~b;
writeln("Array c: ",c);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]Mảng liên kết có chỉ mục không nhất thiết phải là số nguyên và có thể được nhập thưa thớt. Chỉ mục cho một mảng kết hợp được gọi làKeyvà loại của nó được gọi là KeyType.
Mảng liên kết được khai báo bằng cách đặt KeyType trong [] của khai báo mảng. Dưới đây là một ví dụ đơn giản cho mảng kết hợp.
import std.stdio;
void main () {
int[string] e; // associative array b of ints that are
e["test"] = 3;
writeln(e["test"]);
string[string] f;
f["test"] = "Tuts";
writeln(f["test"]);
writeln(f);
f.remove("test");
writeln(f);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
3
Tuts
["test":"Tuts"]
[]Khởi tạo mảng liên kết
Một khởi tạo đơn giản của mảng kết hợp được hiển thị bên dưới.
import std.stdio;
void main () {
int[string] days =
[ "Monday" : 0,
"Tuesday" : 1,
"Wednesday" : 2,
"Thursday" : 3,
"Friday" : 4,
"Saturday" : 5,
"Sunday" : 6 ];
writeln(days["Tuesday"]);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
1Thuộc tính của mảng liên kết
Đây là các thuộc tính của một mảng kết hợp:
| Sr.No. | Kê khai tài sản |
|---|---|
| 1 | .sizeof Trả về kích thước của tham chiếu đến mảng kết hợp; nó là 4 trong các bản dựng 32-bit và 8 trên các bản dựng 64-bit. |
| 2 | .length Trả về số lượng giá trị trong mảng kết hợp. Không giống như đối với mảng động, nó ở chế độ chỉ đọc. |
| 3 | .dup Tạo một mảng kết hợp mới có cùng kích thước và sao chép nội dung của mảng kết hợp vào đó. |
| 4 | .keys Trả về mảng động, các phần tử là khóa trong mảng kết hợp. |
| 5 | .values Trả về mảng động, các phần tử là giá trị trong mảng kết hợp. |
| 6 | .rehash Tổ chức lại mảng kết hợp tại chỗ để tra cứu hiệu quả hơn. rehash có hiệu quả khi, ví dụ, chương trình đã tải xong một bảng biểu tượng và bây giờ cần tra cứu nhanh trong đó. Trả về một tham chiếu đến mảng được sắp xếp lại. |
| 7 | .byKey() Trả về một đại biểu thích hợp để sử dụng như một Tổng hợp cho một ForeachStatement sẽ lặp lại qua các khóa của mảng kết hợp. |
| số 8 | .byValue() Trả về một đại biểu phù hợp để sử dụng làm Tổng hợp cho một ForeachStatement sẽ lặp qua các giá trị của mảng kết hợp. |
| 9 | .get(Key key, lazy Value defVal) Tìm kiếm chìa khóa; nếu nó tồn tại trả về giá trị tương ứng, khác đánh giá và trả về defVal. |
| 10 | .remove(Key key) Loại bỏ một đối tượng cho khóa. |
Thí dụ
Dưới đây là một ví dụ để sử dụng các thuộc tính trên.
import std.stdio;
void main () {
int[string] array1;
array1["test"] = 3;
array1["test2"] = 20;
writeln("sizeof: ",array1.sizeof);
writeln("length: ",array1.length);
writeln("dup: ",array1.dup);
array1.rehash;
writeln("rehashed: ",array1);
writeln("keys: ",array1.keys);
writeln("values: ",array1.values);
foreach (key; array1.byKey) {
writeln("by key: ",key);
}
foreach (value; array1.byValue) {
writeln("by value ",value);
}
writeln("get value for key test: ",array1.get("test",10));
writeln("get value for key test3: ",array1.get("test3",10));
array1.remove("test");
writeln(array1);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
sizeof: 8
length: 2
dup: ["test":3, "test2":20]
rehashed: ["test":3, "test2":20]
keys: ["test", "test2"]
values: [3, 20]
by key: test
by key: test2
by value 3
by value 20
get value for key test: 3
get value for key test3: 10
["test2":20]Con trỏ lập trình D rất dễ học và thú vị. Một số tác vụ lập trình D được thực hiện dễ dàng hơn với con trỏ và các tác vụ lập trình D khác, chẳng hạn như cấp phát bộ nhớ động, không thể thực hiện được nếu không có chúng. Một con trỏ đơn giản được hiển thị bên dưới.
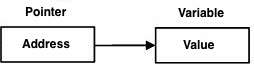
Thay vì trỏ trực tiếp đến biến, con trỏ trỏ đến địa chỉ của biến. Như bạn đã biết, mọi biến đều là một vị trí bộ nhớ và mọi vị trí bộ nhớ đều có địa chỉ của nó được xác định có thể được truy cập bằng cách sử dụng toán tử dấu và (&) biểu thị một địa chỉ trong bộ nhớ. Hãy xem xét phần sau in ra địa chỉ của các biến được xác định:
import std.stdio;
void main () {
int var1;
writeln("Address of var1 variable: ",&var1);
char var2[10];
writeln("Address of var2 variable: ",&var2);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Address of var1 variable: 7FFF52691928
Address of var2 variable: 7FFF52691930Con trỏ là gì?
A pointerlà một biến có giá trị là địa chỉ của một biến khác. Giống như bất kỳ biến hoặc hằng số nào, bạn phải khai báo một con trỏ trước khi bạn có thể làm việc với nó. Dạng chung của khai báo biến con trỏ là:
type *var-name;Đây, typelà kiểu cơ sở của con trỏ; nó phải là một kiểu lập trình hợp lệ vàvar-namelà tên của biến con trỏ. Dấu hoa thị bạn đã sử dụng để khai báo một con trỏ giống với dấu hoa thị mà bạn sử dụng cho phép nhân. Tuy nhiên; trong câu lệnh này, dấu hoa thị đang được sử dụng để chỉ định một biến làm con trỏ. Sau đây là khai báo con trỏ hợp lệ:
int *ip; // pointer to an integer
double *dp; // pointer to a double
float *fp; // pointer to a float
char *ch // pointer to characterKiểu dữ liệu thực tế của giá trị của tất cả các con trỏ, cho dù là số nguyên, số thực, ký tự hay cách khác, đều giống nhau, một số thập lục phân dài đại diện cho địa chỉ bộ nhớ. Sự khác biệt duy nhất giữa các con trỏ của các kiểu dữ liệu khác nhau là kiểu dữ liệu của biến hoặc hằng số mà con trỏ trỏ tới.
Sử dụng con trỏ trong lập trình D
Có một vài thao tác quan trọng khi chúng ta sử dụng con trỏ thường xuyên.
chúng tôi xác định một biến con trỏ
gán địa chỉ của một biến cho một con trỏ
cuối cùng là truy cập giá trị tại địa chỉ có sẵn trong biến con trỏ.
Điều này được thực hiện bằng cách sử dụng toán tử một ngôi *trả về giá trị của biến nằm tại địa chỉ được chỉ định bởi toán hạng của nó. Ví dụ sau sử dụng các thao tác này:
import std.stdio;
void main () {
int var = 20; // actual variable declaration.
int *ip; // pointer variable
ip = &var; // store address of var in pointer variable
writeln("Value of var variable: ",var);
writeln("Address stored in ip variable: ",ip);
writeln("Value of *ip variable: ",*ip);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Value of var variable: 20
Address stored in ip variable: 7FFF5FB7E930
Value of *ip variable: 20Con trỏ rỗng
Việc gán con trỏ NULL cho một biến con trỏ luôn là một phương pháp hay trong trường hợp bạn không có địa chỉ chính xác để gán. Điều này được thực hiện tại thời điểm khai báo biến. Một con trỏ được gán null được gọi lànull con trỏ.
Con trỏ null là một hằng số có giá trị bằng 0 được xác định trong một số thư viện chuẩn, bao gồm cả iostream. Hãy xem xét chương trình sau:
import std.stdio;
void main () {
int *ptr = null;
writeln("The value of ptr is " , ptr) ;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
The value of ptr is nullTrên hầu hết các hệ điều hành, các chương trình không được phép truy cập bộ nhớ ở địa chỉ 0 vì bộ nhớ đó được hệ điều hành dành riêng. Tuy nhiên; địa chỉ bộ nhớ 0 có ý nghĩa đặc biệt; nó báo hiệu rằng con trỏ không nhằm mục đích trỏ đến vị trí bộ nhớ có thể truy cập được.
Theo quy ước, nếu một con trỏ chứa giá trị null (không), nó được coi là không trỏ tới. Để kiểm tra con trỏ null, bạn có thể sử dụng câu lệnh if như sau:
if(ptr) // succeeds if p is not null
if(!ptr) // succeeds if p is nullDo đó, nếu tất cả các con trỏ không sử dụng đều được cung cấp giá trị null và bạn tránh sử dụng con trỏ null, bạn có thể tránh việc vô tình sử dụng sai con trỏ chưa được khởi tạo. Nhiều khi, các biến chưa được khởi tạo giữ một số giá trị rác và việc gỡ lỗi chương trình trở nên khó khăn.
Số học con trỏ
Có bốn toán tử số học có thể được sử dụng trên con trỏ: ++, -, + và -
Để hiểu số học con trỏ, chúng ta hãy xem xét một con trỏ số nguyên có tên ptr, trỏ đến địa chỉ 1000. Giả sử là số nguyên 32 bit, chúng ta hãy thực hiện phép toán số học sau trên con trỏ:
ptr++sau đó ptrsẽ trỏ đến vị trí 1004 vì mỗi lần ptr được tăng lên, nó trỏ đến số nguyên tiếp theo. Thao tác này sẽ di chuyển con trỏ đến vị trí bộ nhớ tiếp theo mà không ảnh hưởng đến giá trị thực tại vị trí bộ nhớ.
Nếu ptr trỏ đến một ký tự có địa chỉ là 1000, thì thao tác trên trỏ đến vị trí 1001 vì ký tự tiếp theo sẽ có sẵn tại 1001.
Tăng một con trỏ
Chúng tôi thích sử dụng một con trỏ trong chương trình của chúng tôi thay vì một mảng vì con trỏ biến có thể được tăng lên, không giống như tên mảng không thể tăng vì nó là một con trỏ hằng. Chương trình sau tăng con trỏ biến để truy cập vào từng phần tử kế tiếp của mảng:
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Address of var[0] = 18FDBC
Value of var[0] = 10
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 200Con trỏ so với Mảng
Con trỏ và mảng có liên quan chặt chẽ với nhau. Tuy nhiên, con trỏ và mảng không hoàn toàn có thể hoán đổi cho nhau. Ví dụ, hãy xem xét chương trình sau:
import std.stdio;
const int MAX = 3;
void main () {
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
var.ptr[2] = 290;
ptr[0] = 220;
for (int i = 0; i < MAX; i++, ptr++) {
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}Trong chương trình trên, bạn có thể thấy var.ptr [2] để đặt phần tử thứ hai và ptr [0] được sử dụng để đặt phần tử thứ không. Toán tử tăng dần có thể được sử dụng với ptr nhưng không được sử dụng với var.
Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Address of var[0] = 18FDBC
Value of var[0] = 220
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 290Con trỏ tới con trỏ
Một con trỏ tới một con trỏ là một dạng của nhiều hướng hoặc một chuỗi con trỏ. Thông thường, một con trỏ chứa địa chỉ của một biến. Khi chúng ta định nghĩa một con trỏ tới một con trỏ, con trỏ đầu tiên chứa địa chỉ của con trỏ thứ hai, con trỏ này sẽ trỏ đến vị trí chứa giá trị thực như hình dưới đây.

Một biến là một con trỏ đến một con trỏ phải được khai báo như vậy. Điều này được thực hiện bằng cách đặt một dấu hoa thị bổ sung trước tên của nó. Ví dụ, sau đây là cú pháp để khai báo một con trỏ tới một con trỏ kiểu int -
int **var;Khi một giá trị đích được trỏ gián tiếp bởi một con trỏ tới một con trỏ, thì việc truy cập giá trị đó yêu cầu phải áp dụng toán tử dấu hoa thị hai lần, như được minh họa bên dưới trong ví dụ:
import std.stdio;
const int MAX = 3;
void main () {
int var = 3000;
writeln("Value of var :" , var);
int *ptr = &var;
writeln("Value available at *ptr :" ,*ptr);
int **pptr = &ptr;
writeln("Value available at **pptr :",**pptr);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Value of var :3000
Value available at *ptr :3000
Value available at **pptr :3000Chuyển con trỏ đến các hàm
D cho phép bạn chuyển một con trỏ đến một hàm. Để làm như vậy, nó chỉ cần khai báo tham số hàm như một kiểu con trỏ.
Ví dụ đơn giản sau đây chuyển một con trỏ đến một hàm.
import std.stdio;
void main () {
// an int array with 5 elements.
int balance[5] = [1000, 2, 3, 17, 50];
double avg;
avg = getAverage( &balance[0], 5 ) ;
writeln("Average is :" , avg);
}
double getAverage(int *arr, int size) {
int i;
double avg, sum = 0;
for (i = 0; i < size; ++i) {
sum += arr[i];
}
avg = sum/size;
return avg;
}Khi đoạn mã trên được biên dịch cùng nhau và được thực thi, nó sẽ tạo ra kết quả sau:
Average is :214.4Con trỏ trả về từ các hàm
Hãy xem xét hàm sau, hàm này trả về 10 số bằng cách sử dụng con trỏ, có nghĩa là địa chỉ của phần tử mảng đầu tiên.
import std.stdio;
void main () {
int *p = getNumber();
for ( int i = 0; i < 10; i++ ) {
writeln("*(p + " , i , ") : ",*(p + i));
}
}
int * getNumber( ) {
static int r [10];
for (int i = 0; i < 10; ++i) {
r[i] = i;
}
return &r[0];
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
*(p + 0) : 0
*(p + 1) : 1
*(p + 2) : 2
*(p + 3) : 3
*(p + 4) : 4
*(p + 5) : 5
*(p + 6) : 6
*(p + 7) : 7
*(p + 8) : 8
*(p + 9) : 9Con trỏ đến một mảng
Tên mảng là một con trỏ hằng đến phần tử đầu tiên của mảng. Do đó, trong khai báo -
double balance[50];balancelà một con trỏ tới & balance [0], là địa chỉ của phần tử đầu tiên của số dư mảng. Do đó, đoạn chương trình sau sẽ gánp địa chỉ của phần tử đầu tiên của balance -
double *p;
double balance[10];
p = balance;Việc sử dụng tên mảng làm con trỏ hằng và ngược lại là hợp pháp. Do đó, * (balance + 4) là một cách hợp pháp để truy cập dữ liệu tại số dư [4].
Khi bạn lưu trữ địa chỉ của phần tử đầu tiên trong p, bạn có thể truy cập các phần tử mảng bằng cách sử dụng * p, * (p + 1), * (p + 2), v.v. Ví dụ sau đây cho thấy tất cả các khái niệm được thảo luận ở trên -
import std.stdio;
void main () {
// an array with 5 elements.
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double *p;
p = &balance[0];
// output each array element's value
writeln("Array values using pointer " );
for ( int i = 0; i < 5; i++ ) {
writeln( "*(p + ", i, ") : ", *(p + i));
}
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Array values using pointer
*(p + 0) : 1000
*(p + 1) : 2
*(p + 2) : 3.4
*(p + 3) : 17
*(p + 4) : 50Các bộ giá trị được sử dụng để kết hợp nhiều giá trị thành một đối tượng duy nhất. Tuples chứa một chuỗi các phần tử. Các phần tử có thể là kiểu, biểu thức hoặc bí danh. Số lượng và các phần tử của một bộ tuple được cố định tại thời điểm biên dịch và chúng không thể thay đổi tại thời điểm chạy.
Tuples có đặc điểm của cả cấu trúc và mảng. Các phần tử tuple có thể thuộc nhiều loại khác nhau như cấu trúc. Các phần tử có thể được truy cập thông qua lập chỉ mục như mảng. Chúng được triển khai như một tính năng thư viện bởi mẫu Tuple từ mô-đun std.typecons. Tuple sử dụng TypeTuple từ mô-đun std.typetuple cho một số hoạt động của nó.
Tuple Sử dụng tuple ()
Tuple có thể được xây dựng bởi hàm tuple (). Các thành viên của một tuple được truy cập bởi các giá trị chỉ mục. Một ví dụ đã được biểu diễn ở dưới.
Thí dụ
import std.stdio;
import std.typecons;
void main() {
auto myTuple = tuple(1, "Tuts");
writeln(myTuple);
writeln(myTuple[0]);
writeln(myTuple[1]);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Tuple!(int, string)(1, "Tuts")
1
TutsTuple bằng cách sử dụng Mẫu Tuple
Tuple cũng có thể được tạo trực tiếp bằng mẫu Tuple thay vì hàm tuple (). Loại và tên của mỗi thành viên được chỉ định là hai tham số mẫu liên tiếp. Có thể truy cập các thành viên theo thuộc tính khi được tạo bằng các mẫu.
import std.stdio;
import std.typecons;
void main() {
auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts");
writeln(myTuple);
writeln("by index 0 : ", myTuple[0]);
writeln("by .id : ", myTuple.id);
writeln("by index 1 : ", myTuple[1]);
writeln("by .value ", myTuple.value);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau
Tuple!(int, "id", string, "value")(1, "Tuts")
by index 0 : 1
by .id : 1
by index 1 : Tuts
by .value TutsMở rộng các tham số thuộc tính và chức năng
Các thành viên của Tuple có thể được mở rộng bằng thuộc tính .expand hoặc bằng cách cắt. Giá trị được mở rộng / cắt lát này có thể được chuyển dưới dạng danh sách đối số hàm. Một ví dụ đã được biểu diễn ở dưới.
Thí dụ
import std.stdio;
import std.typecons;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(int a, float b, char c) {
writeln("method 2 ",a,"\t",b,"\t",c);
}
void main() {
auto myTuple = tuple(5, "my string", 3.3, 'r');
writeln("method1 call 1");
method1(myTuple[]);
writeln("method1 call 2");
method1(myTuple.expand);
writeln("method2 call 1");
method2(myTuple[0], myTuple[$-2..$]);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
method1 call 1
method 1 5 my string 3.3 r
method1 call 2
method 1 5 my string 3.3 r
method2 call 1
method 2 5 3.3 rTypeTuple
TypeTuple được định nghĩa trong mô-đun std.typetuple. Danh sách giá trị và loại được phân tách bằng dấu phẩy. Dưới đây là một ví dụ đơn giản sử dụng TypeTuple. TypeTuple được sử dụng để tạo danh sách đối số, danh sách mẫu và danh sách mảng chữ.
import std.stdio;
import std.typecons;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(int a, string b, float c, char d) {
writeln("method 1 ",a,"\t",b,"\t",c,"\t",d);
}
void method2(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
auto arguments = TypeTuple!(5, "my string", 3.3,'r');
method1(arguments);
method2(5, 6L);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
method 1 5 my string 3.3 r
5 6Các structure là một kiểu dữ liệu do người dùng xác định khác có sẵn trong lập trình D, cho phép bạn kết hợp các mục dữ liệu thuộc các loại khác nhau.
Các cấu trúc được sử dụng để biểu diễn một bản ghi. Giả sử bạn muốn theo dõi sách của mình trong thư viện. Bạn có thể muốn theo dõi các thuộc tính sau về mỗi cuốn sách -
- Title
- Author
- Subject
- Mã sách
Xác định cấu trúc
Để xác định cấu trúc, bạn phải sử dụng structtuyên bố. Câu lệnh struct xác định một kiểu dữ liệu mới, với nhiều hơn một thành viên cho chương trình của bạn. Định dạng của câu lệnh struct là:
struct [structure tag] {
member definition;
member definition;
...
member definition;
} [one or more structure variables];Các structure taglà tùy chọn và mỗi định nghĩa thành viên là một định nghĩa biến bình thường, chẳng hạn như int i; hoặc float f; hoặc bất kỳ định nghĩa biến hợp lệ nào khác. Ở cuối định nghĩa của cấu trúc trước dấu chấm phẩy, bạn có thể chỉ định một hoặc nhiều biến cấu trúc là tùy chọn. Đây là cách bạn khai báo cấu trúc Sách -
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};Truy cập thành viên cấu trúc
Để truy cập bất kỳ thành viên nào của một cấu trúc, bạn sử dụng member access operator (.). Toán tử truy cập thành viên được mã hóa là dấu chấm giữa tên biến cấu trúc và thành viên cấu trúc mà chúng ta muốn truy cập. Bạn sẽ sử dụngstructtừ khóa để xác định các biến của kiểu cấu trúc. Ví dụ sau giải thích cách sử dụng cấu trúc:
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
writeln( "Book 1 title : ", Book1.title);
writeln( "Book 1 author : ", Book1.author);
writeln( "Book 1 subject : ", Book1.subject);
writeln( "Book 1 book_id : ", Book1.book_id);
/* print Book2 info */
writeln( "Book 2 title : ", Book2.title);
writeln( "Book 2 author : ", Book2.author);
writeln( "Book 2 subject : ", Book2.subject);
writeln( "Book 2 book_id : ", Book2.book_id);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Book 1 title : D Programming
Book 1 author : Raj
Book 1 subject : D Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : D Programming
Book 2 author : Raj
Book 2 subject : D Programming Tutorial
Book 2 book_id : 6495700Cấu trúc dưới dạng đối số hàm
Bạn có thể truyền một cấu trúc như một đối số của hàm theo cách tương tự như khi bạn truyền bất kỳ biến hoặc con trỏ nào khác. Bạn sẽ truy cập các biến cấu trúc theo cách tương tự như bạn đã truy cập trong ví dụ trên -
import std.stdio;
struct Books {
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( ) {
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "D Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "D Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495700Khởi tạo cấu trúc
Các cấu trúc có thể được khởi tạo ở hai dạng, một dạng sử dụng hàm tạo và dạng khác sử dụng định dạng {}. Một ví dụ đã được biểu diễn ở dưới.
Thí dụ
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id = -1;
char [] author = "Raj".dup;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 );
printBook( Book1 );
Books Book2 = Books("D Programming".dup,
"D Programming Tutorial".dup, 6495407,"Raj".dup );
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id : 1001};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1001Thành viên tĩnh
Các biến static chỉ được khởi tạo một lần. Ví dụ: để có id duy nhất cho sách, chúng ta có thể đặt book_id ở dạng tĩnh và tăng id sách. Một ví dụ đã được biểu diễn ở dưới.
Thí dụ
import std.stdio;
struct Books {
char [] title;
char [] subject = "Empty".dup;
int book_id;
char [] author = "Raj".dup;
static int id = 1000;
};
void main( ) {
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id );
printBook( Book1 );
Books Book2 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id);
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id};
printBook( Book3 );
}
void printBook( Books book ) {
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1001
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1002
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1003A unionlà kiểu dữ liệu đặc biệt có sẵn trong D cho phép bạn lưu trữ các kiểu dữ liệu khác nhau trong cùng một vị trí bộ nhớ. Bạn có thể xác định một liên hợp với nhiều thành viên, nhưng chỉ một thành viên có thể chứa một giá trị tại bất kỳ thời điểm nào. Unions cung cấp một cách hiệu quả để sử dụng cùng một vị trí bộ nhớ cho nhiều mục đích.
Xác định một Liên minh trong D
Để định nghĩa một union, bạn phải sử dụng câu lệnh union theo cách tương tự như khi xác định cấu trúc. Câu lệnh union xác định một kiểu dữ liệu mới, với nhiều hơn một thành viên cho chương trình của bạn. Định dạng của câu lệnh liên minh như sau:
union [union tag] {
member definition;
member definition;
...
member definition;
} [one or more union variables];Các union taglà tùy chọn và mỗi định nghĩa thành viên là một định nghĩa biến bình thường, chẳng hạn như int i; hoặc float f; hoặc bất kỳ định nghĩa biến hợp lệ nào khác. Ở cuối định nghĩa của union, trước dấu chấm phẩy cuối cùng, bạn có thể chỉ định một hoặc nhiều biến union nhưng nó là tùy chọn. Đây là cách bạn xác định một kiểu liên hợp có tên là Dữ liệu có ba thành viêni, fvà str -
union Data {
int i;
float f;
char str[20];
} data;Một biến của Datakiểu có thể lưu trữ một số nguyên, một số dấu phẩy động hoặc một chuỗi ký tự. Điều này có nghĩa là một biến duy nhất (cùng một vị trí bộ nhớ) có thể được sử dụng để lưu trữ nhiều loại dữ liệu. Bạn có thể sử dụng bất kỳ kiểu dữ liệu tích hợp sẵn hoặc do người dùng xác định bên trong liên hợp dựa trên yêu cầu của bạn.
Bộ nhớ được chiếm bởi một liên minh sẽ đủ lớn để chứa thành viên lớn nhất của liên minh. Ví dụ, trong ví dụ trên, Kiểu dữ liệu sẽ chiếm 20 byte không gian bộ nhớ vì đây là không gian tối đa có thể bị chiếm bởi chuỗi ký tự. Ví dụ sau đây hiển thị tổng dung lượng bộ nhớ bị chiếm bởi liên hợp trên:
import std.stdio;
union Data {
int i;
float f;
char str[20];
};
int main( ) {
Data data;
writeln( "Memory size occupied by data : ", data.sizeof);
return 0;
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Memory size occupied by data : 20Tiếp cận các thành viên của Liên minh
Để tiếp cận bất kỳ thành viên nào của một công đoàn, chúng tôi sử dụng member access operator (.). Toán tử truy cập thành viên được mã hóa là dấu chấm giữa tên biến liên hợp và thành viên liên hợp mà chúng ta muốn truy cập. Bạn sẽ sử dụng từ khóa union để xác định các biến của kiểu union.
Thí dụ
Ví dụ sau giải thích cách sử dụng union -
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
data.i = 10;
data.f = 220.5;
data.str = "D Programming".dup;
writeln( "size of : ", data.sizeof);
writeln( "data.i : ", data.i);
writeln( "data.f : ", data.f);
writeln( "data.str : ", data.str);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
size of : 16
data.i : 1917853764
data.f : 4.12236e+30
data.str : D ProgrammingTại đây, bạn có thể thấy các giá trị của i và f các thành viên của union đã bị hỏng vì giá trị cuối cùng được gán cho biến đã chiếm vị trí bộ nhớ và đây là lý do mà giá trị của str thành viên đang được in rất tốt.
Bây giờ chúng ta hãy xem xét cùng một ví dụ một lần nữa, nơi chúng ta sẽ sử dụng một biến tại một thời điểm, mục đích chính của việc kết hợp -
Ví dụ sửa đổi
import std.stdio;
union Data {
int i;
float f;
char str[13];
};
void main( ) {
Data data;
writeln( "size of : ", data.sizeof);
data.i = 10;
writeln( "data.i : ", data.i);
data.f = 220.5;
writeln( "data.f : ", data.f);
data.str = "D Programming".dup;
writeln( "data.str : ", data.str);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
size of : 16
data.i : 10
data.f : 220.5
data.str : D ProgrammingỞ đây, tất cả các thành viên đang được in rất tốt vì một thành viên đang được sử dụng tại một thời điểm.
Phạm vi là một sự trừu tượng của quyền truy cập phần tử. Sự trừu tượng này cho phép sử dụng số lượng lớn các thuật toán trên số lượng lớn các loại vùng chứa. Phạm vi nhấn mạnh cách các phần tử vùng chứa được truy cập, trái ngược với cách các vùng chứa được triển khai. Dải là một khái niệm rất đơn giản dựa trên việc một kiểu có xác định các bộ hàm thành viên nhất định hay không.
Phạm vi là một phần không thể thiếu trong các lát cắt của D. D tình cờ là triển khai của phạm vi mạnh nhất RandomAccessRange và có nhiều tính năng phạm vi trong Phobos. Nhiều thuật toán Phobos trả về các đối tượng phạm vi tạm thời. Ví dụ: filter () chọn các phần tử lớn hơn 10 trong đoạn mã sau thực sự trả về một đối tượng phạm vi, không phải một mảng.
Dải số
Dải số được sử dụng khá phổ biến và những dải số này thuộc kiểu int. Dưới đây là một số ví dụ cho các dải số:
// Example 1
foreach (value; 3..7)
// Example 2
int[] slice = array[5..10];Dãy Phobos
Phạm vi liên quan đến cấu trúc và giao diện lớp là phạm vi phobos. Phobos là thư viện tiêu chuẩn và thời gian chạy chính thức đi kèm với trình biên dịch ngôn ngữ D.
Có nhiều loại phạm vi bao gồm:
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
InputRange
Phạm vi đơn giản nhất là phạm vi đầu vào. Các phạm vi khác mang lại nhiều yêu cầu hơn so với phạm vi mà chúng dựa trên. Có ba chức năng mà InputRange yêu cầu:
empty- Nó chỉ định xem phạm vi có trống không; nó phải trả về true khi phạm vi được coi là trống; sai khác.
front - Nó cung cấp quyền truy cập vào phần tử ở đầu phạm vi.
popFront() - Nó rút ngắn phạm vi ngay từ đầu bằng cách loại bỏ phần tử đầu tiên.
Thí dụ
import std.stdio;
import std.string;
struct Student {
string name;
int number;
string toString() const {
return format("%s(%s)", name, number);
}
}
struct School {
Student[] students;
}
struct StudentRange {
Student[] students;
this(School school) {
this.students = school.students;
}
@property bool empty() const {
return students.length == 0;
}
@property ref Student front() {
return students[0];
}
void popFront() {
students = students[1 .. $];
}
}
void main() {
auto school = School([ Student("Raj", 1), Student("John", 2), Student("Ram", 3)]);
auto range = StudentRange(school);
writeln(range);
writeln(school.students.length);
writeln(range.front);
range.popFront;
writeln(range.empty);
writeln(range);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
[Raj(1), John(2), Ram(3)]
3
Raj(1)
false
[John(2), Ram(3)]ForwardRange
ForwardRange cũng yêu cầu phần chức năng thành viên lưu từ ba chức năng khác của InputRange và trả về một bản sao của phạm vi khi chức năng lưu được gọi.
import std.array;
import std.stdio;
import std.string;
import std.range;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%s: %s", title, range.take(5));
}
void main() {
auto range = FibonacciSeries();
report("Original range", range);
range.popFrontN(2);
report("After removing two elements", range);
auto theCopy = range.save;
report("The copy", theCopy);
range.popFrontN(3);
report("After removing three more elements", range);
report("The copy", theCopy);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Original range: [0, 1, 1, 2, 3]
After removing two elements: [1, 2, 3, 5, 8]
The copy: [1, 2, 3, 5, 8]
After removing three more elements: [5, 8, 13, 21, 34]
The copy: [1, 2, 3, 5, 8]Hai chiềuRange
BidirectionalRange cung cấp thêm hai chức năng thành viên so với các chức năng thành viên của ForwardRange. Hàm back tương tự như front, cung cấp quyền truy cập vào phần tử cuối cùng của phạm vi. Hàm popBack tương tự như hàm popFront và nó loại bỏ phần tử cuối cùng khỏi phạm vi.
Thí dụ
import std.array;
import std.stdio;
import std.string;
struct Reversed {
int[] range;
this(int[] range) {
this.range = range;
}
@property bool empty() const {
return range.empty;
}
@property int front() const {
return range.back; // reverse
}
@property int back() const {
return range.front; // reverse
}
void popFront() {
range.popBack();
}
void popBack() {
range.popFront();
}
}
void main() {
writeln(Reversed([ 1, 2, 3]));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
[3, 2, 1]Vô hạn ngẫu nhiênAccessRange
opIndex () cũng được yêu cầu khi so sánh với ForwardRange. Ngoài ra, giá trị của một hàm trống được biết tại thời điểm biên dịch là false. Một ví dụ đơn giản được giải thích với phạm vi hình vuông được hiển thị bên dưới.
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
void main() {
auto squares = new SquaresRange();
writeln(squares[5]);
writeln(squares[10]);
squares.popFrontN(5);
writeln(squares[0]);
writeln(squares.take(50).filter!are_lastTwoDigitsSame);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
25
100
25
[100, 144, 400, 900, 1444, 1600, 2500]Finite RandomAccessRange
opIndex () và độ dài cũng được yêu cầu khi so sánh với phạm vi hai chiều. Điều này được giải thích với sự trợ giúp của ví dụ chi tiết sử dụng chuỗi Fibonacci và ví dụ Phạm vi hình vuông được sử dụng trước đó. Ví dụ này hoạt động tốt trên trình biên dịch D bình thường nhưng không hoạt động trên trình biên dịch trực tuyến.
Thí dụ
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
struct FibonacciSeries {
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const {
return first;
}
void popFront() {
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const {
return this;
}
}
void report(T)(const dchar[] title, const ref T range) {
writefln("%40s: %s", title, range.take(5));
}
class SquaresRange {
int first;
this(int first = 0) {
this.first = first;
}
enum empty = false;
@property int front() const {
return opIndex(0);
}
void popFront() {
++first;
}
@property SquaresRange save() const {
return new SquaresRange(first);
}
int opIndex(size_t index) const {
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value) {
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
struct Together {
const(int)[][] slices;
this(const(int)[][] slices ...) {
this.slices = slices.dup;
clearFront();
clearBack();
}
private void clearFront() {
while (!slices.empty && slices.front.empty) {
slices.popFront();
}
}
private void clearBack() {
while (!slices.empty && slices.back.empty) {
slices.popBack();
}
}
@property bool empty() const {
return slices.empty;
}
@property int front() const {
return slices.front.front;
}
void popFront() {
slices.front.popFront();
clearFront();
}
@property Together save() const {
return Together(slices.dup);
}
@property int back() const {
return slices.back.back;
}
void popBack() {
slices.back.popBack();
clearBack();
}
@property size_t length() const {
return reduce!((a, b) => a + b.length)(size_t.init, slices);
}
int opIndex(size_t index) const {
/* Save the index for the error message */
immutable originalIndex = index;
foreach (slice; slices) {
if (slice.length > index) {
return slice[index];
} else {
index -= slice.length;
}
}
throw new Exception(
format("Invalid index: %s (length: %s)", originalIndex, this.length));
}
}
void main() {
auto range = Together(FibonacciSeries().take(10).array, [ 777, 888 ],
(new SquaresRange()).take(5).array);
writeln(range.save);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]Phạm vi đầu ra
OutputRange đại diện cho đầu ra phần tử được phát trực tiếp, tương tự như việc gửi các ký tự đến stdout. OutputRange yêu cầu hỗ trợ cho hoạt động đặt (phạm vi, phần tử). put () là một hàm được định nghĩa trong mô-đun std.range. Nó xác định khả năng của phạm vi và phần tử tại thời điểm biên dịch và sử dụng phương pháp thích hợp nhất để sử dụng để xuất các phần tử. Một ví dụ đơn giản được hiển thị bên dưới.
import std.algorithm;
import std.stdio;
struct MultiFile {
string delimiter;
File[] files;
this(string delimiter, string[] fileNames ...) {
this.delimiter = delimiter;
/* stdout is always included */
this.files ~= stdout;
/* A File object for each file name */
foreach (fileName; fileNames) {
this.files ~= File(fileName, "w");
}
}
void put(T)(T element) {
foreach (file; files) {
file.write(element, delimiter);
}
}
}
void main() {
auto output = MultiFile("\n", "output_0", "output_1");
copy([ 1, 2, 3], output);
copy([ "red", "blue", "green" ], output);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
[1, 2, 3]
["red", "blue", "green"]Bí danh, như tên đề cập cung cấp một tên thay thế cho các tên hiện có. Cú pháp cho bí danh được hiển thị bên dưới.
alias new_name = existing_name;Sau đây là cú pháp cũ hơn, đề phòng trường hợp bạn tham khảo một số ví dụ định dạng cũ hơn. Nó không khuyến khích việc sử dụng cái này.
alias existing_name new_name;Cũng có một cú pháp khác được sử dụng với biểu thức và nó được đưa ra bên dưới, trong đó chúng ta có thể sử dụng trực tiếp tên bí danh thay cho biểu thức.
alias expression alias_name ;Như bạn có thể biết, một typedef bổ sung khả năng tạo các kiểu mới. Bí danh có thể thực hiện công việc của một typedef và thậm chí hơn thế nữa. Dưới đây là một ví dụ đơn giản để sử dụng bí danh sử dụng tiêu đề std.conv cung cấp khả năng chuyển đổi kiểu.
import std.stdio;
import std.conv:to;
alias to!(string) toString;
void main() {
int a = 10;
string s = "Test"~toString(a);
writeln(s);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Test10Trong ví dụ trên thay vì sử dụng to! String (a), chúng tôi đã gán nó cho tên bí danh toString để thuận tiện hơn và dễ hiểu hơn.
Bí danh cho Tuple
Hãy để chúng tôi xem xét một ví dụ khác, nơi chúng tôi có thể đặt tên bí danh cho Tuple.
import std.stdio;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(TL tl) {
writeln(tl[0],"\t", tl[1] );
}
void main() {
method1(5, 6L);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
5 6Trong ví dụ trên, kiểu tuple được gán cho biến bí danh và nó đơn giản hóa định nghĩa phương thức và quyền truy cập của các biến. Loại truy cập này thậm chí còn hữu ích hơn khi chúng tôi cố gắng sử dụng lại các bộ giá trị kiểu như vậy.
Bí danh cho các loại dữ liệu
Nhiều khi, chúng tôi có thể xác định các kiểu dữ liệu chung cần được sử dụng trên toàn ứng dụng. Khi nhiều người lập trình mã hóa một ứng dụng, có thể xảy ra trường hợp một người sử dụng int, một người khác sử dụng double, v.v. Để tránh xung đột như vậy, chúng tôi thường sử dụng các kiểu cho các kiểu dữ liệu. Một ví dụ đơn giản được hiển thị bên dưới.
Thí dụ
import std.stdio;
alias int myAppNumber;
alias string myAppString;
void main() {
myAppNumber i = 10;
myAppString s = "TestString";
writeln(i,s);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
10TestStringBí danh cho các biến lớp
Thường có một yêu cầu mà chúng ta cần truy cập vào các biến thành viên của lớp cha trong lớp con, điều này có thể thực hiện được với bí danh, có thể dưới một tên khác.
Trong trường hợp bạn chưa quen với khái niệm lớp và kế thừa, hãy xem hướng dẫn về lớp và kế thừa trước khi bắt đầu với phần này.
Thí dụ
Một ví dụ đơn giản được hiển thị bên dưới.
import std.stdio;
class Shape {
int area;
}
class Square : Shape {
string name() const @property {
return "Square";
}
alias Shape.area squareArea;
}
void main() {
auto square = new Square;
square.squareArea = 42;
writeln(square.name);
writeln(square.squareArea);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Square
42Bí danh này
Bí danh này cung cấp khả năng chuyển đổi kiểu tự động của các kiểu do người dùng xác định. Cú pháp được hiển thị bên dưới nơi các từ khóa bí danh và bí danh này được viết ở hai bên của biến thành viên hoặc hàm thành viên.
alias member_variable_or_member_function this;Thí dụ
Một ví dụ được hiển thị dưới đây để cho thấy sức mạnh của bí danh này.
import std.stdio;
struct Rectangle {
long length;
long breadth;
double value() const @property {
return cast(double) length * breadth;
}
alias value this;
}
double volume(double rectangle, double height) {
return rectangle * height;
}
void main() {
auto rectangle = Rectangle(2, 3);
writeln(volume(rectangle, 5));
}Trong ví dụ trên, bạn có thể thấy rằng hình chữ nhật struct được chuyển đổi thành giá trị kép với sự trợ giúp của phương thức này là bí danh.
Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
30Mixin là cấu trúc cho phép trộn mã đã tạo vào mã nguồn. Mixin có thể thuộc các loại sau:
- Chuỗi mixin
- Mixin mẫu
- Khoảng trắng tên trộn
Chuỗi mixin
D có khả năng chèn mã dưới dạng chuỗi miễn là chuỗi đó được biết tại thời điểm biên dịch. Cú pháp của chuỗi mixin được hiển thị bên dưới:
mixin (compile_time_generated_string)Thí dụ
Dưới đây là một ví dụ đơn giản về mixin chuỗi.
import std.stdio;
void main() {
mixin(`writeln("Hello World!");`);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Hello World!Đây là một ví dụ khác mà chúng ta có thể chuyển chuỗi trong thời gian biên dịch để các mixin có thể sử dụng các hàm để sử dụng lại mã. Nó được hiển thị bên dưới.
import std.stdio;
string print(string s) {
return `writeln("` ~ s ~ `");`;
}
void main() {
mixin (print("str1"));
mixin (print("str2"));
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
str1
str2Mixin mẫu
D mẫu xác định các mẫu mã chung, để trình biên dịch tạo các phiên bản thực tế từ mẫu đó. Các mẫu có thể tạo ra các hàm, cấu trúc, hợp nhất, lớp, giao diện và bất kỳ mã D hợp pháp nào khác. Cú pháp của mixin mẫu như được hiển thị bên dưới.
mixin a_template!(template_parameters)Một ví dụ đơn giản cho chuỗi mixin được hiển thị bên dưới, nơi chúng tôi tạo một mẫu với Bộ phận lớp và một mixin khởi tạo một mẫu và do đó làm cho các hàm setName và printNames có sẵn cho trường cấu trúc.
Thí dụ
import std.stdio;
template Department(T, size_t count) {
T[count] names;
void setName(size_t index, T name) {
names[index] = name;
}
void printNames() {
writeln("The names");
foreach (i, name; names) {
writeln(i," : ", name);
}
}
}
struct College {
mixin Department!(string, 2);
}
void main() {
auto college = College();
college.setName(0, "name1");
college.setName(1, "name2");
college.printNames();
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
The names
0 : name1
1 : name2Mixin Name Spaces
Khoảng trống tên mixin được sử dụng để tránh sự mơ hồ trong các mixin mẫu. Ví dụ: có thể có hai biến, một biến được xác định rõ ràng trong main và biến còn lại được trộn vào. Khi tên hỗn hợp giống với tên trong phạm vi xung quanh, thì tên trong phạm vi xung quanh sẽ được đã sử dụng. Ví dụ này được hiển thị bên dưới.
Thí dụ
import std.stdio;
template Person() {
string name;
void print() {
writeln(name);
}
}
void main() {
string name;
mixin Person a;
name = "name 1";
writeln(name);
a.name = "name 2";
print();
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
name 1
name 2Mô-đun là cơ sở xây dựng của D. Chúng dựa trên một khái niệm đơn giản. Mỗi tệp nguồn là một mô-đun. Theo đó, các tệp đơn mà chúng tôi viết các chương trình là các mô-đun riêng lẻ. Theo mặc định, tên của mô-đun giống với tên tệp của nó mà không có phần mở rộng .d.
Khi được chỉ định rõ ràng, tên của mô-đun được xác định bởi từ khóa mô-đun, từ khóa này phải xuất hiện dưới dạng dòng không chú thích đầu tiên trong tệp nguồn. Ví dụ: giả sử rằng tên của tệp nguồn là "worker.d". Sau đó, tên của mô-đun được chỉ định bởi từ khóa mô-đun theo sau là nhân viên . Nó như hình dưới đây.
module employee;
class Employee {
// Class definition goes here.
}Dòng mô-đun là tùy chọn. Khi không được chỉ định, nó giống như tên tệp không có phần mở rộng .d.
Tên tệp và mô-đun
D hỗ trợ Unicode trong mã nguồn và tên mô-đun. Tuy nhiên, sự hỗ trợ Unicode của các hệ thống tệp khác nhau. Ví dụ: mặc dù hầu hết các hệ thống tệp Linux hỗ trợ Unicode, tên tệp trong hệ thống tệp Windows có thể không phân biệt giữa chữ thường và chữ hoa. Ngoài ra, hầu hết các hệ thống tệp đều giới hạn các ký tự có thể được sử dụng trong tên tệp và thư mục. Vì lý do di động, tôi khuyên bạn chỉ nên sử dụng các chữ cái ASCII viết thường trong tên tệp. Ví dụ: "worker.d" sẽ là tên tệp phù hợp cho một lớp có tên là nhân viên.
Theo đó, tên của mô-đun cũng sẽ bao gồm các chữ cái ASCII -
module employee; // Module name consisting of ASCII letters
class eëmployëë { }Gói D
Một tổ hợp các mô-đun liên quan được gọi là một gói. Gói D cũng là một khái niệm đơn giản: Các tệp nguồn nằm trong cùng một thư mục được coi là thuộc cùng một gói. Tên của thư mục trở thành tên của gói, cũng phải được chỉ định như phần đầu tiên của tên mô-đun.
Ví dụ: nếu "worker.d" và "office.d" nằm trong thư mục "company", thì việc chỉ định tên thư mục cùng với tên mô-đun làm cho chúng trở thành một phần của cùng một gói -
module company.employee;
class Employee { }Tương tự, đối với mô-đun văn phòng -
module company.office;
class Office { }Vì tên gói tương ứng với tên thư mục, tên gói của mô-đun sâu hơn một cấp thư mục phải phản ánh hệ thống phân cấp đó. Ví dụ: nếu thư mục "công ty" bao gồm thư mục "chi nhánh", tên của mô-đun bên trong thư mục đó cũng sẽ bao gồm cả chi nhánh.
module company.branch.employee;Sử dụng mô-đun trong chương trình
Từ khóa import, mà chúng tôi đã sử dụng trong hầu hết mọi chương trình cho đến nay, là để giới thiệu một mô-đun cho mô-đun hiện tại -
import std.stdio;Tên mô-đun cũng có thể chứa tên gói. Ví dụ, std. phần trên chỉ ra rằng stdio là một mô-đun là một phần của gói std.
Vị trí của các mô-đun
Trình biên dịch tìm các tệp mô-đun bằng cách chuyển đổi gói và tên mô-đun trực tiếp thành tên thư mục và tệp.
Ví dụ: hai mô-đun nhân viên và văn phòng sẽ được đặt lần lượt là "company / worker.d" và "animal / office.d" (hoặc "company \ worker.d" và "company \ office.d", tùy thuộc vào hệ thống tệp) cho company.employee và company.office.
Tên mô-đun dài và ngắn
Các tên được sử dụng trong chương trình có thể được viết bằng tên mô-đun và gói như hình dưới đây.
import company.employee;
auto employee0 = Employee();
auto employee1 = company.employee.Employee();Những cái tên dài bình thường không cần thiết nhưng đôi khi có những xung đột về tên. Ví dụ, khi đề cập đến một tên xuất hiện trong nhiều mô-đun, trình biên dịch không thể quyết định tên đó có nghĩa là gì. Chương trình sau đây viết ra các tên dài để phân biệt giữa hai cấu trúc nhân viên riêng biệt được xác định trong hai mô-đun riêng biệt: công ty và trường đại học. .
Mô-đun nhân viên đầu tiên trong công ty thư mục như sau.
module company.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("Company Employee: ",str);
}
}Mô-đun nhân viên thứ hai trong trường cao đẳng thư mục như sau.
module college.employee;
import std.stdio;
class Employee {
public:
string str;
void print() {
writeln("College Employee: ",str);
}
}Mô-đun chính trong hello.d nên được lưu trong thư mục chứa thư mục trường đại học và công ty. Nó như sau.
import company.employee;
import college.employee;
import std.stdio;
void main() {
auto myemployee1 = new company.employee.Employee();
myemployee1.str = "emp1";
myemployee1.print();
auto myemployee2 = new college.employee.Employee();
myemployee2.str = "emp2";
myemployee2.print();
}Từ khóa nhập không đủ để làm cho các mô-đun trở thành một phần của chương trình. Nó chỉ đơn giản là cung cấp các tính năng của một mô-đun bên trong mô-đun hiện tại. Đó là chỉ cần thiết để biên dịch mã.
Đối với chương trình ở trên được xây dựng, "công ty / nhân viên.d" và "cao đẳng / nhân viên.d" cũng phải được chỉ định trên dòng biên dịch.
Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
$ dmd hello.d company/employee.d college/employee.d -ofhello.amx
$ ./hello.amx
Company Employee: emp1
College Employee: emp2Mẫu là nền tảng của lập trình chung, liên quan đến việc viết mã theo cách độc lập với bất kỳ kiểu cụ thể nào.
Mẫu là một kế hoạch chi tiết hoặc công thức để tạo một lớp hoặc một hàm chung.
Mẫu là tính năng cho phép mô tả mã dưới dạng mẫu, để trình biên dịch tự động tạo mã chương trình. Các phần của mã nguồn có thể được để cho trình biên dịch điền vào cho đến khi phần đó thực sự được sử dụng trong chương trình. Trình biên dịch điền vào những phần còn thiếu.
Mẫu hàm
Việc xác định một hàm làm khuôn mẫu là để lại một hoặc nhiều kiểu mà nó sử dụng là không xác định, sẽ được trình biên dịch suy ra sau này. Các kiểu không được chỉ định được xác định trong danh sách tham số mẫu, nằm giữa tên của hàm và danh sách tham số hàm. Vì lý do đó, các mẫu hàm có hai danh sách tham số:
- danh sách tham số mẫu
- danh sách tham số chức năng
import std.stdio;
void print(T)(T value) {
writefln("%s", value);
}
void main() {
print(42);
print(1.2);
print("test");
}Nếu chúng ta biên dịch và chạy đoạn mã trên, điều này sẽ tạo ra kết quả sau:
42
1.2
testMẫu hàm với nhiều tham số loại
Có thể có nhiều loại tham số. Chúng được hiển thị trong ví dụ sau.
import std.stdio;
void print(T1, T2)(T1 value1, T2 value2) {
writefln(" %s %s", value1, value2);
}
void main() {
print(42, "Test");
print(1.2, 33);
}Nếu chúng ta biên dịch và chạy đoạn mã trên, điều này sẽ tạo ra kết quả sau:
42 Test
1.2 33Mẫu lớp
Cũng giống như chúng ta có thể xác định các mẫu hàm, chúng ta cũng có thể xác định các mẫu lớp. Ví dụ sau định nghĩa lớp Stack và thực hiện các phương thức chung để đẩy và bật các phần tử từ ngăn xếp.
import std.stdio;
import std.string;
class Stack(T) {
private:
T[] elements;
public:
void push(T element) {
elements ~= element;
}
void pop() {
--elements.length;
}
T top() const @property {
return elements[$ - 1];
}
size_t length() const @property {
return elements.length;
}
}
void main() {
auto stack = new Stack!string;
stack.push("Test1");
stack.push("Test2");
writeln(stack.top);
writeln(stack.length);
stack.pop;
writeln(stack.top);
writeln(stack.length);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Test2
2
Test1
1Chúng tôi thường sử dụng các biến có thể thay đổi nhưng có thể có nhiều trường hợp không cần thiết phải có thể thay đổi. Các biến bất biến có thể được sử dụng trong những trường hợp như vậy. Một vài ví dụ được đưa ra dưới đây để sử dụng biến bất biến.
Trong trường hợp các hằng số toán học chẳng hạn như pi không bao giờ thay đổi.
Trong trường hợp mảng mà chúng ta muốn giữ lại các giá trị và nó không phải là yêu cầu đột biến.
Tính bất biến giúp chúng ta có thể hiểu được liệu các biến là bất biến hay có thể thay đổi đảm bảo rằng một số hoạt động nhất định không thay đổi một số biến nhất định. Nó cũng làm giảm nguy cơ mắc một số loại lỗi chương trình. Khái niệm bất biến của D được biểu diễn bằng các từ khóa const và bất biến. Mặc dù bản thân hai từ này gần nghĩa với nhau, nhưng trách nhiệm của chúng trong các chương trình là khác nhau và chúng đôi khi không tương thích.
Khái niệm bất biến của D được biểu diễn bằng các từ khóa const và bất biến. Mặc dù bản thân hai từ này gần nghĩa với nhau, nhưng trách nhiệm của chúng trong các chương trình là khác nhau và chúng đôi khi không tương thích.
Các loại biến bất biến trong D
Có ba loại biến xác định không bao giờ có thể thay đổi được.
- hằng số enum
- biến bất biến
- biến const
enum Hằng số trong D
Hằng số enum làm cho nó có thể liên kết các giá trị hằng số với các tên có nghĩa. Một ví dụ đơn giản được hiển thị bên dưới.
Thí dụ
import std.stdio;
enum Day{
Sunday = 1,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
void main() {
Day day;
day = Day.Sunday;
if (day == Day.Sunday) {
writeln("The day is Sunday");
}
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
The day is SundayCác biến bất biến trong D
Các biến bất biến có thể được xác định trong quá trình thực thi chương trình. Nó chỉ hướng dẫn trình biên dịch mà sau khi khởi tạo, nó sẽ trở thành bất biến. Một ví dụ đơn giản được hiển thị bên dưới.
Thí dụ
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
immutable number = uniform(min, max + 1);
// cannot modify immutable expression number
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
immutable(int)4
immutable(int)100Bạn có thể thấy trong ví dụ trên cách có thể chuyển kiểu dữ liệu sang một biến khác và sử dụng stringof trong khi in.
Biến Const trong D
Biến Const không thể được sửa đổi tương tự như bất biến. Các biến bất biến có thể được truyền cho các hàm như là các tham số bất biến của chúng và do đó, nên sử dụng bất biến thay vì const. Ví dụ tương tự được sử dụng trước đó được sửa đổi cho const như được hiển thị bên dưới.
Thí dụ
import std.stdio;
import std.random;
void main() {
int min = 1;
int max = 10;
const number = uniform(min, max + 1);
// cannot modify const expression number|
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}Nếu chúng ta biên dịch và chạy đoạn mã trên, điều này sẽ tạo ra kết quả sau:
const(int)7
const(int)100Các tham số bất biến trong D
const xóa thông tin về việc liệu biến ban đầu có thể thay đổi hay không thay đổi được và do đó, việc sử dụng không thay đổi làm cho nó chuyển các hàm khác với kiểu ban đầu được giữ lại. Một ví dụ đơn giản được hiển thị bên dưới.
Thí dụ
import std.stdio;
void print(immutable int[] array) {
foreach (i, element; array) {
writefln("%s: %s", i, element);
}
}
void main() {
immutable int[] array = [ 1, 2 ];
print(array);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
0: 1
1: 2Tệp được đại diện bởi cấu trúc Tệp của mô-đun std.stdio. Tệp đại diện cho một chuỗi các byte, không quan trọng đó là tệp văn bản hay tệp nhị phân.
Ngôn ngữ lập trình D cung cấp quyền truy cập vào các chức năng cấp cao cũng như các lệnh gọi cấp thấp (cấp hệ điều hành) để xử lý tệp trên thiết bị lưu trữ của bạn.
Mở tệp trong D
Các luồng đầu vào và đầu ra tiêu chuẩn stdin và stdout đã được mở khi chương trình bắt đầu chạy. Chúng đã sẵn sàng để được sử dụng. Mặt khác, trước tiên phải mở tệp bằng cách chỉ định tên tệp và các quyền truy cập cần thiết.
File file = File(filepath, "mode");Đây, filename là chuỗi ký tự, bạn sử dụng để đặt tên tệp và truy cập mode có thể có một trong các giá trị sau:
| Sr.No. | Chế độ & Mô tả |
|---|---|
| 1 | r Mở tệp văn bản hiện có cho mục đích đọc. |
| 2 | w Mở tệp văn bản để ghi, nếu tệp không tồn tại thì tệp mới sẽ được tạo. Tại đây chương trình của bạn sẽ bắt đầu ghi nội dung từ đầu tệp. |
| 3 | a Mở tệp văn bản để ghi ở chế độ thêm, nếu tệp đó không tồn tại thì tệp mới sẽ được tạo. Tại đây, chương trình của bạn sẽ bắt đầu thêm nội dung vào nội dung tệp hiện có. |
| 4 | r+ Mở tệp văn bản để đọc và ghi cả hai. |
| 5 | w+ Mở tệp văn bản để đọc và ghi cả hai. Đầu tiên nó cắt ngắn tệp thành độ dài bằng 0 nếu nó tồn tại, nếu không, hãy tạo tệp nếu nó không tồn tại. |
| 6 | a+ Mở tệp văn bản để đọc và ghi cả hai. Nó tạo ra tệp nếu nó không tồn tại. Việc đọc sẽ bắt đầu lại từ đầu nhưng phần viết chỉ có thể được thêm vào. |
Đóng tệp trong D
Để đóng tệp, hãy sử dụng hàm file.close () nơi tệp chứa tham chiếu tệp. Nguyên mẫu của chức năng này là -
file.close();Bất kỳ tệp nào đã được mở bởi một chương trình phải được đóng khi chương trình kết thúc việc sử dụng tệp đó. Trong hầu hết các trường hợp, các tệp không cần phải được đóng một cách rõ ràng; chúng được đóng tự động khi các đối tượng Tệp bị kết thúc.
Viết tệp trong D
file.writeln được sử dụng để ghi vào một tệp đang mở.
file.writeln("hello");import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ tạo ra một tệp mới test.txt trong thư mục mà nó đã được khởi động theo (trong thư mục làm việc của chương trình).
Đọc tệp trong D
Phương pháp sau đây đọc một dòng từ tệp:
string s = file.readln();Dưới đây là một ví dụ đầy đủ về đọc và ghi.
import std.stdio;
import std.file;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
file = File("test.txt", "r");
string s = file.readln();
writeln(s);
file.close();
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
helloĐây là một ví dụ khác để đọc tệp cho đến cuối tệp.
import std.stdio;
import std.string;
void main() {
File file = File("test.txt", "w");
file.writeln("hello");
file.writeln("world");
file.close();
file = File("test.txt", "r");
while (!file.eof()) {
string line = chomp(file.readln());
writeln("line -", line);
}
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
line -hello
line -world
line -Bạn có thể thấy trong ví dụ trên một dòng thứ ba trống vì writeln sẽ đưa nó đến dòng tiếp theo khi nó được thực thi.
Concurrency đang làm cho một chương trình chạy trên nhiều luồng cùng một lúc. Một ví dụ về chương trình đồng thời là một máy chủ web đáp ứng nhiều máy khách cùng một lúc. Đồng thời dễ dàng với việc truyền thông điệp nhưng rất khó viết nếu chúng dựa trên việc chia sẻ dữ liệu.
Dữ liệu được chuyển giữa các luồng được gọi là thông báo. Thông báo có thể bao gồm bất kỳ loại nào và bất kỳ số lượng biến nào. Mỗi chuỗi đều có một id, được sử dụng để chỉ định người nhận thư. Bất kỳ luồng nào bắt đầu một luồng khác được gọi là chủ sở hữu của luồng mới.
Bắt đầu chuỗi trong D
Hàm spawn () nhận một con trỏ làm tham số và bắt đầu một luồng mới từ hàm đó. Bất kỳ hoạt động nào được thực hiện bởi hàm đó, bao gồm các hàm khác mà nó có thể gọi, sẽ được thực thi trên luồng mới. Chủ sở hữu và công nhân đều bắt đầu thực hiện riêng lẻ như thể chúng là các chương trình độc lập.
Thí dụ
import std.stdio;
import std.stdio;
import std.concurrency;
import core.thread;
void worker(int a) {
foreach (i; 0 .. 4) {
Thread.sleep(1);
writeln("Worker Thread ",a + i);
}
}
void main() {
foreach (i; 1 .. 4) {
Thread.sleep(2);
writeln("Main Thread ",i);
spawn(≈worker, i * 5);
}
writeln("main is done.");
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
Main Thread 1
Worker Thread 5
Main Thread 2
Worker Thread 6
Worker Thread 10
Main Thread 3
main is done.
Worker Thread 7
Worker Thread 11
Worker Thread 15
Worker Thread 8
Worker Thread 12
Worker Thread 16
Worker Thread 13
Worker Thread 17
Worker Thread 18Số nhận dạng chuỗi trong D
Biến thisTid có sẵn trên toàn cầu ở cấp mô-đun luôn là id của luồng hiện tại. Ngoài ra, bạn có thể nhận threadId khi spawn được gọi. Một ví dụ đã được biểu diễn ở dưới.
Thí dụ
import std.stdio;
import std.concurrency;
void printTid(string tag) {
writefln("%s: %s, address: %s", tag, thisTid, &thisTid);
}
void worker() {
printTid("Worker");
}
void main() {
Tid myWorker = spawn(&worker);
printTid("Owner ");
writeln(myWorker);
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C
Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C
Tid(std.concurrency.MessageBox)Tin nhắn chuyển trong D
Hàm send () gửi tin nhắn và hàm nhậnOnly () đợi một loại tin nhắn cụ thể. Có các hàm khác được đặt tên là prioritySend (), accept (), và acceptTimeout (), sẽ được giải thích ở phần sau.
Chủ sở hữu trong chương trình sau sẽ gửi cho worker của nó một thông báo kiểu int và chờ một thông báo từ worker kiểu double. Các chuỗi tiếp tục gửi tin nhắn qua lại cho đến khi chủ sở hữu gửi một số nguyên âm. Một ví dụ đã được biểu diễn ở dưới.
Thí dụ
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
int value = 0;
while (value >= 0) {
value = receiveOnly!int();
auto result = to!double(value) * 5; tid.send(result);
}
}
void main() {
Tid worker = spawn(&workerFunc,thisTid);
foreach (value; 5 .. 10) {
worker.send(value);
auto result = receiveOnly!double();
writefln("sent: %s, received: %s", value, result);
}
worker.send(-1);
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
sent: 5, received: 25
sent: 6, received: 30
sent: 7, received: 35
sent: 8, received: 40
sent: 9, received: 45Tin nhắn chuyển với Chờ trong D
Dưới đây là một ví dụ đơn giản với thông báo đi kèm với chờ đợi.
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid) {
Thread.sleep(dur!("msecs")( 500 ),);
tid.send("hello");
}
void main() {
spawn(&workerFunc,thisTid);
writeln("Waiting for a message");
bool received = false;
while (!received) {
received = receiveTimeout(dur!("msecs")( 100 ), (string message) {
writeln("received: ", message);
});
if (!received) {
writeln("... no message yet");
}
}
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
Waiting for a message
... no message yet
... no message yet
... no message yet
... no message yet
received: helloMột ngoại lệ là một vấn đề phát sinh trong quá trình thực hiện một chương trình. Ngoại lệ AD là phản ứng đối với một trường hợp ngoại lệ phát sinh trong khi chương trình đang chạy, chẳng hạn như nỗ lực chia cho không.
Ngoại lệ cung cấp một cách để chuyển quyền kiểm soát từ một phần của chương trình sang phần khác. Xử lý ngoại lệ D được xây dựng dựa trên ba từ khóatry, catchvà throw.
throw- Một chương trình ném ra một ngoại lệ khi một vấn đề xuất hiện. Điều này được thực hiện bằng cách sử dụngthrow từ khóa.
catch- Một chương trình bắt một ngoại lệ với một trình xử lý ngoại lệ tại vị trí trong chương trình mà bạn muốn xử lý vấn đề. Cáccatch từ khóa chỉ ra việc bắt một ngoại lệ.
try - A trykhối xác định một khối mã mà các ngoại lệ cụ thể được kích hoạt. Theo sau nó là một hoặc nhiều khối bắt.
Giả sử một khối sẽ tạo ra một ngoại lệ, một phương thức bắt một ngoại lệ bằng cách sử dụng kết hợp try và catchtừ khóa. Một khối try / catch được đặt xung quanh mã có thể tạo ra một ngoại lệ. Mã trong khối try / catch được gọi là mã được bảo vệ và cú pháp để sử dụng try / catch trông giống như sau:
try {
// protected code
}
catch( ExceptionName e1 ) {
// catch block
}
catch( ExceptionName e2 ) {
// catch block
}
catch( ExceptionName eN ) {
// catch block
}Bạn có thể liệt kê nhiều catch các câu lệnh để nắm bắt các loại ngoại lệ khác nhau trong trường hợp try khối tăng nhiều hơn một ngoại lệ trong các tình huống khác nhau.
Ném Ngoại lệ trong D
Các ngoại lệ có thể được ném vào bất kỳ đâu trong một khối mã bằng cách sử dụng throwcác câu lệnh. Toán hạng của các câu lệnh ném xác định một kiểu cho ngoại lệ và có thể là bất kỳ biểu thức nào và kiểu kết quả của biểu thức xác định kiểu ngoại lệ được ném ra.
Ví dụ sau ném một ngoại lệ khi điều kiện chia cho 0 xảy ra:
Thí dụ
double division(int a, int b) {
if( b == 0 ) {
throw new Exception("Division by zero condition!");
}
return (a/b);
}Bắt ngoại lệ trong D
Các catch khối theo sau trykhối bắt bất kỳ ngoại lệ nào. Bạn có thể chỉ định loại ngoại lệ bạn muốn bắt và điều này được xác định bởi khai báo ngoại lệ xuất hiện trong dấu ngoặc đơn theo sau từ khóa catch.
try {
// protected code
}
catch( ExceptionName e ) {
// code to handle ExceptionName exception
}Đoạn mã trên bắt một ngoại lệ ExceptionNamekiểu. Nếu bạn muốn chỉ định rằng khối catch phải xử lý bất kỳ loại ngoại lệ nào được đưa vào khối try, bạn phải đặt dấu chấm lửng, ..., giữa các dấu ngoặc đơn bao quanh khai báo ngoại lệ như sau:
try {
// protected code
}
catch(...) {
// code to handle any exception
}Ví dụ sau ném một phép chia cho không ngoại lệ. Nó bị kẹt trong khối bắt.
import std.stdio;
import std.string;
string division(int a, int b) {
string result = "";
try {
if( b == 0 ) {
throw new Exception("Cannot divide by zero!");
} else {
result = format("%s",a/b);
}
} catch (Exception e) {
result = e.msg;
}
return result;
}
void main () {
int x = 50;
int y = 0;
writeln(division(x, y));
y = 10;
writeln(division(x, y));
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
Cannot divide by zero!
5Lập trình hợp đồng trong lập trình D tập trung vào việc cung cấp một phương tiện xử lý lỗi đơn giản và dễ hiểu. Lập trình hợp đồng trong D được thực hiện bởi ba loại khối mã:
- khối cơ thể
- trong khối
- ra khối
Khối cơ thể trong D
Khối nội dung chứa mã thực thi chức năng thực tế. Các khối vào và ra là tùy chọn trong khi khối nội là bắt buộc. Một cú pháp đơn giản được hiển thị bên dưới.
return_type function_name(function_params)
in {
// in block
}
out (result) {
// in block
}
body {
// actual function block
}Trong khối cho các điều kiện trước trong D
Trong khối dành cho các điều kiện trước đơn giản để xác minh xem các tham số đầu vào có được chấp nhận hay không và trong phạm vi có thể được mã xử lý. Lợi ích của một trong khối là tất cả các điều kiện đầu vào có thể được giữ cùng nhau và tách biệt khỏi nội dung thực tế của hàm. Điều kiện tiên quyết đơn giản để xác thực mật khẩu cho độ dài tối thiểu của nó được hiển thị bên dưới.
import std.stdio;
import std.string;
bool isValid(string password)
in {
assert(password.length>=5);
}
body {
// other conditions
return true;
}
void main() {
writeln(isValid("password"));
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
trueCác khối cho các điều kiện đăng trong D
Khối out xử lý các giá trị trả về từ hàm. Nó xác nhận giá trị trả về nằm trong phạm vi mong đợi. Dưới đây là một ví dụ đơn giản chứa cả in và out để chuyển đổi tháng, năm thành dạng tuổi thập phân kết hợp.
import std.stdio;
import std.string;
double getAge(double months,double years)
in {
assert(months >= 0);
assert(months <= 12);
}
out (result) {
assert(result>=years);
}
body {
return years + months/12;
}
void main () {
writeln(getAge(10,12));
}Khi đoạn mã trên được biên dịch và thực thi, nó sẽ đọc tệp được tạo trong phần trước và tạo ra kết quả sau:
12.8333Biên dịch có điều kiện là quá trình chọn mã nào để biên dịch và mã nào không biên dịch tương tự như #if / #else / #endif trong C và C ++. Bất kỳ câu lệnh nào không được biên dịch trong vẫn phải đúng về mặt cú pháp.
Biên dịch có điều kiện liên quan đến việc kiểm tra điều kiện có giá trị tại thời điểm biên dịch. Các câu lệnh điều kiện thời gian chạy như if, for, while không phải là các tính năng biên dịch có điều kiện. Các tính năng sau của D dùng để biên dịch có điều kiện:
- debug
- version
- tĩnh nếu
Tuyên bố gỡ lỗi trong D
Các debug rất hữu ích trong quá trình phát triển chương trình. Các biểu thức và câu lệnh được đánh dấu là gỡ lỗi chỉ được biên dịch vào chương trình khi bật chuyển đổi trình biên dịch -debug.
debug a_conditionally_compiled_expression;
debug {
// ... conditionally compiled code ...
} else {
// ... code that is compiled otherwise ...
}Mệnh đề else là tùy chọn. Cả biểu thức đơn và khối mã ở trên chỉ được biên dịch khi bật chuyển đổi trình biên dịch -debug.
Thay vì bị xóa hoàn toàn, các dòng có thể được đánh dấu là gỡ lỗi.
debug writefln("%s debug only statement", value);Những dòng như vậy chỉ được đưa vào chương trình khi bật công tắc trình biên dịch -debug.
dmd test.d -oftest -w -debugCâu lệnh Debug (tag) trong D
Các câu lệnh gỡ lỗi có thể được đặt tên (thẻ) để đưa vào chương trình một cách chọn lọc.
debug(mytag) writefln("%s not found", value);Những dòng như vậy chỉ được đưa vào chương trình khi bật công tắc trình biên dịch -debug.
dmd test.d -oftest -w -debug = mytagCác khối gỡ lỗi cũng có thể có thẻ.
debug(mytag) {
//
}Có thể bật nhiều thẻ gỡ lỗi cùng một lúc.
dmd test.d -oftest -w -debug = mytag1 -debug = mytag2Câu lệnh gỡ lỗi (cấp độ) trong D
Đôi khi, việc kết hợp các câu lệnh gỡ lỗi theo cấp số sẽ hữu ích hơn. Tăng cấp độ có thể cung cấp thông tin chi tiết hơn.
import std.stdio;
void myFunction() {
debug(1) writeln("debug1");
debug(2) writeln("debug2");
}
void main() {
myFunction();
}Các biểu thức gỡ lỗi và các khối thấp hơn hoặc bằng mức được chỉ định sẽ được biên dịch.
$ dmd test.d -oftest -w -debug = 1 $ ./test
debug1Phiên bản (thẻ) và Phiên bản (cấp độ) Tuyên bố trong D
Phiên bản tương tự như gỡ lỗi và được sử dụng theo cách tương tự. Mệnh đề else là tùy chọn. Mặc dù phiên bản hoạt động về cơ bản giống như gỡ lỗi, nhưng việc có các từ khóa riêng biệt sẽ giúp phân biệt các cách sử dụng không liên quan của chúng. Cũng như gỡ lỗi, nhiều phiên bản có thể được bật.
import std.stdio;
void myFunction() {
version(1) writeln("version1");
version(2) writeln("version2");
}
void main() {
myFunction();
}Các biểu thức gỡ lỗi và các khối thấp hơn hoặc bằng mức được chỉ định sẽ được biên dịch.
$ dmd test.d -oftest -w -version = 1 $ ./test
version1Tĩnh nếu
Static if là thời gian biên dịch tương đương với câu lệnh if. Cũng giống như câu lệnh if, static if nhận một biểu thức logic và đánh giá nó. Không giống như câu lệnh if, static if không phải là về luồng thực thi; thay vào đó, nó xác định xem một đoạn mã có nên được đưa vào chương trình hay không.
Biểu thức if không liên quan đến toán tử is mà chúng ta đã thấy trước đó, cả về mặt cú pháp và ngữ nghĩa. Nó được đánh giá tại thời điểm biên dịch. Nó tạo ra một giá trị int, 0 hoặc 1; tùy thuộc vào biểu thức được chỉ định trong ngoặc đơn. Mặc dù biểu thức mà nó nhận không phải là một biểu thức logic, bản thân biểu thức is được sử dụng như một biểu thức logic thời gian biên dịch. Nó đặc biệt hữu ích trong điều kiện tĩnh if và ràng buộc mẫu.
import std.stdio;
enum Days {
sun,
mon,
tue,
wed,
thu,
fri,
sat
};
void myFunction(T)(T mytemplate) {
static if (is (T == class)) {
writeln("This is a class type");
} else static if (is (T == enum)) {
writeln("This is an enum type");
}
}
void main() {
Days day;
myFunction(day);
}Khi chúng tôi biên dịch và chạy, chúng tôi sẽ nhận được một số đầu ra như sau.
This is an enum typeCác lớp là đặc điểm trung tâm của lập trình D hỗ trợ lập trình hướng đối tượng và thường được gọi là các kiểu do người dùng định nghĩa.
Một lớp được sử dụng để chỉ định dạng của một đối tượng và nó kết hợp biểu diễn dữ liệu và các phương thức để thao tác dữ liệu đó thành một gói gọn gàng. Dữ liệu và các hàm trong một lớp được gọi là thành viên của lớp.
Định nghĩa Lớp D
Khi bạn xác định một lớp, bạn xác định một bản thiết kế cho một kiểu dữ liệu. Điều này không thực sự xác định bất kỳ dữ liệu nào, nhưng nó xác định tên lớp có nghĩa là gì, tức là, một đối tượng của lớp sẽ bao gồm những gì và những thao tác nào có thể được thực hiện trên một đối tượng đó.
Định nghĩa lớp bắt đầu bằng từ khóa classtiếp theo là tên lớp; và phần thân của lớp, được bao bởi một cặp dấu ngoặc nhọn. Định nghĩa lớp phải được theo sau bởi dấu chấm phẩy hoặc danh sách các khai báo. Ví dụ: chúng tôi đã xác định kiểu dữ liệu Hộp bằng từ khóaclass như sau -
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}Từ khóa publicxác định các thuộc tính truy cập của các thành viên của lớp theo sau nó. Một thành viên công cộng có thể được truy cập từ bên ngoài lớp ở bất kỳ đâu trong phạm vi của đối tượng lớp. Bạn cũng có thể chỉ định các thành viên của một lớp làprivate hoặc là protected mà chúng ta sẽ thảo luận trong một phần phụ.
Định nghĩa đối tượng D
Một lớp cung cấp bản thiết kế cho các đối tượng, vì vậy về cơ bản một đối tượng được tạo ra từ một lớp. Bạn khai báo các đối tượng của một lớp với cùng kiểu khai báo mà bạn khai báo các biến thuộc kiểu cơ bản. Các câu lệnh sau khai báo hai đối tượng của lớp Box:
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type BoxCả hai đối tượng Box1 và Box2 đều có bản sao dữ liệu của riêng chúng.
Truy cập các thành viên dữ liệu
Các thành viên dữ liệu công khai của các đối tượng của một lớp có thể được truy cập bằng toán tử truy cập thành viên trực tiếp (.). Chúng ta hãy thử ví dụ sau để làm rõ mọi thứ -
import std.stdio;
class Box {
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main() {
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Volume of Box1 : 210
Volume of Box2 : 1560Điều quan trọng cần lưu ý là không thể truy cập trực tiếp các thành viên riêng tư và được bảo vệ bằng cách sử dụng toán tử truy cập thành viên trực tiếp (.). Trong thời gian ngắn, bạn sẽ biết cách truy cập các thành viên riêng tư và được bảo vệ.
Lớp và Đối tượng trong D
Cho đến nay, bạn đã có ý tưởng rất cơ bản về Lớp D và Đối tượng. Có những khái niệm thú vị khác liên quan đến Lớp và Đối tượng D mà chúng ta sẽ thảo luận trong các phần phụ khác nhau được liệt kê bên dưới -
| Sr.No. | Khái niệm & Mô tả |
|---|---|
| 1 | Các chức năng thành viên trong lớp Hàm thành viên của một lớp là một hàm có định nghĩa hoặc nguyên mẫu của nó trong định nghĩa lớp giống như bất kỳ biến nào khác. |
| 2 | Công cụ sửa đổi quyền truy cập lớp Một thành viên trong lớp có thể được định nghĩa là công khai, riêng tư hoặc được bảo vệ. Theo mặc định, các thành viên sẽ được coi là riêng tư. |
| 3 | Bộ tạo & hàm hủy Hàm tạo lớp là một hàm đặc biệt trong lớp được gọi khi một đối tượng mới của lớp được tạo. Hàm hủy cũng là một hàm đặc biệt được gọi khi đối tượng đã tạo bị xóa. |
| 4 | Con trỏ này trong D Mỗi đối tượng đều có một con trỏ đặc biệt this mà trỏ đến chính đối tượng. |
| 5 | Con trỏ đến các lớp D Một con trỏ tới một lớp được thực hiện giống hệt như cách con trỏ tới một cấu trúc. Trong thực tế, một lớp thực sự chỉ là một cấu trúc với các chức năng trong đó. |
| 6 | Các thành viên tĩnh của một lớp Cả thành viên dữ liệu và thành viên hàm của một lớp đều có thể được khai báo là tĩnh. |
Một trong những khái niệm quan trọng nhất trong lập trình hướng đối tượng là tính kế thừa. Tính kế thừa cho phép định nghĩa một lớp theo nghĩa của một lớp khác, giúp tạo và duy trì một ứng dụng dễ dàng hơn. Điều này cũng tạo cơ hội để sử dụng lại chức năng mã và thời gian thực hiện nhanh chóng.
Khi tạo một lớp, thay vì viết các thành viên dữ liệu hoàn toàn mới và các hàm thành viên, lập trình viên có thể chỉ định rằng lớp mới sẽ kế thừa các thành viên của một lớp hiện có. Lớp hiện có này được gọi làbase lớp và lớp mới được gọi là derived lớp học.
Ý tưởng kế thừa thực hiện là một mối quan hệ. Ví dụ, động vật IS-A động vật có vú, chó IS-A động vật có vú, do đó chó IS-A động vật cũng như vậy.
Các lớp cơ sở và các lớp có nguồn gốc trong D
Một lớp có thể được dẫn xuất từ nhiều lớp, có nghĩa là nó có thể kế thừa dữ liệu và chức năng từ nhiều lớp cơ sở. Để định nghĩa một lớp dẫn xuất, chúng tôi sử dụng danh sách dẫn xuất lớp để chỉ định (các) lớp cơ sở. Một danh sách dẫn xuất lớp đặt tên cho một hoặc nhiều lớp cơ sở và có dạng:
class derived-class: base-classXem xét một lớp cơ sở Shape và lớp dẫn xuất của nó Rectangle như sau -
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Total area: 35Kiểm soát truy cập và kế thừa
Một lớp dẫn xuất có thể truy cập tất cả các thành viên không riêng tư của lớp cơ sở của nó. Do đó, các thành viên lớp cơ sở không thể truy cập vào các hàm thành viên của các lớp dẫn xuất nên được khai báo là private trong lớp cơ sở.
Một lớp dẫn xuất kế thừa tất cả các phương thức của lớp cơ sở với các ngoại lệ sau:
- Các hàm tạo, hàm hủy và sao chép các hàm tạo của lớp cơ sở.
- Các toán tử bị quá tải của lớp cơ sở.
Kế thừa đa cấp
Sự kế thừa có thể có nhiều cấp độ và nó được thể hiện trong ví dụ sau.
import std.stdio;
// Base class
class Shape {
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape {
public:
int getArea() {
return (width * height);
}
}
class Square: Rectangle {
this(int side) {
this.setWidth(side);
this.setHeight(side);
}
}
void main() {
Square square = new Square(13);
// Print the area of the object.
writeln("Total area: ", square.getArea());
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Total area: 169D cho phép bạn chỉ định nhiều hơn một định nghĩa cho một function tên hoặc một operator trong cùng một phạm vi, được gọi là function overloading và operator overloading tương ứng.
Khai báo quá tải là một khai báo đã được khai báo trùng tên với một khai báo trước đó trong cùng một phạm vi, ngoại trừ việc cả hai khai báo có các đối số khác nhau và rõ ràng là khác định nghĩa (thực thi).
Khi bạn gọi một quá tải function hoặc là operator, trình biên dịch xác định định nghĩa thích hợp nhất để sử dụng bằng cách so sánh các kiểu đối số bạn đã sử dụng để gọi hàm hoặc toán tử với các kiểu tham số được chỉ định trong định nghĩa. Quá trình chọn hàm hoặc toán tử được nạp chồng thích hợp nhất được gọi làoverload resolution..
Quá tải chức năng
Bạn có thể có nhiều định nghĩa cho cùng một tên hàm trong cùng một phạm vi. Định nghĩa của hàm phải khác nhau theo kiểu và / hoặc số lượng đối số trong danh sách đối số. Bạn không thể nạp chồng các khai báo hàm chỉ khác nhau theo kiểu trả về.
Thí dụ
Ví dụ sau sử dụng cùng một chức năng print() để in các kiểu dữ liệu khác nhau -
import std.stdio;
import std.string;
class printData {
public:
void print(int i) {
writeln("Printing int: ",i);
}
void print(double f) {
writeln("Printing float: ",f );
}
void print(string s) {
writeln("Printing string: ",s);
}
};
void main() {
printData pd = new printData();
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello D");
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Printing int: 5
Printing float: 500.263
Printing string: Hello DNgười vận hành quá tải
Bạn có thể xác định lại hoặc nạp chồng hầu hết các toán tử tích hợp sẵn có trong D. Do đó, một lập trình viên cũng có thể sử dụng các toán tử với các kiểu do người dùng xác định.
Các toán tử có thể được nạp chồng bằng cách sử dụng chuỗi op theo sau là Thêm, Phụ, v.v. dựa trên toán tử đang được nạp chồng. Chúng ta có thể nạp chồng toán tử + để thêm hai hộp như hình dưới đây.
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}Ví dụ sau đây cho thấy khái niệm nạp chồng toán tử bằng cách sử dụng một hàm thành viên. Ở đây, một đối tượng được truyền dưới dạng một đối số có thuộc tính được truy cập bằng đối tượng này. Đối tượng gọi toán tử này có thể được truy cập bằngthis toán tử như được giải thích bên dưới -
import std.stdio;
class Box {
public:
double getVolume() {
return length * breadth * height;
}
void setLength( double len ) {
length = len;
}
void setBreadth( double bre ) {
breadth = bre;
}
void setHeight( double hei ) {
height = hei;
}
Box opAdd(Box b) {
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
void main( ) {
Box box1 = new Box(); // Declare box1 of type Box
Box box2 = new Box(); // Declare box2 of type Box
Box box3 = new Box(); // Declare box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.setLength(6.0);
box1.setBreadth(7.0);
box1.setHeight(5.0);
// box 2 specification
box2.setLength(12.0);
box2.setBreadth(13.0);
box2.setHeight(10.0);
// volume of box 1
volume = box1.getVolume();
writeln("Volume of Box1 : ", volume);
// volume of box 2
volume = box2.getVolume();
writeln("Volume of Box2 : ", volume);
// Add two object as follows:
box3 = box1 + box2;
// volume of box 3
volume = box3.getVolume();
writeln("Volume of Box3 : ", volume);
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400Các kiểu quá tải của nhà điều hành
Về cơ bản, có ba kiểu nạp chồng toán tử như được liệt kê dưới đây.
| Sr.No. | Quá tải các loại |
|---|---|
| 1 | Quá tải các nhà khai thác đơn lẻ |
| 2 | Quá tải toán tử nhị phân |
| 3 | Quá tải toán tử so sánh |
Tất cả các chương trình D đều bao gồm hai yếu tố cơ bản sau:
Program statements (code) - Đây là một phần của chương trình thực hiện các hành động và chúng được gọi là các hàm.
Program data - Là thông tin của chương trình bị ảnh hưởng bởi các chức năng của chương trình.
Đóng gói là một khái niệm Lập trình hướng đối tượng liên kết dữ liệu và các chức năng thao tác dữ liệu với nhau, đồng thời giữ an toàn trước sự can thiệp và lạm dụng từ bên ngoài. Tính năng đóng gói dữ liệu đã dẫn đến khái niệm OOP quan trọng vềdata hiding.
Data encapsulation là cơ chế nhóm dữ liệu và các chức năng sử dụng chúng và data abstraction là một cơ chế chỉ để lộ các giao diện và ẩn các chi tiết triển khai với người dùng.
D hỗ trợ các thuộc tính đóng gói và ẩn dữ liệu thông qua việc tạo ra các kiểu do người dùng xác định, được gọi là classes. Chúng tôi đã nghiên cứu rằng một lớp có thể chứaprivate, được bảo vệ và publiccác thành viên. Theo mặc định, tất cả các mục được định nghĩa trong một lớp là riêng tư. Ví dụ -
class Box {
public:
double getVolume() {
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};Các biến chiều dài, chiều rộng và chiều cao là private. Điều này có nghĩa là chúng chỉ có thể được truy cập bởi các thành viên khác của lớp Box chứ không phải bất kỳ phần nào khác trong chương trình của bạn. Đây là một cách để đạt được sự đóng gói.
Để tạo ra các phần của một lớp public (tức là, có thể truy cập vào các phần khác của chương trình của bạn), bạn phải khai báo chúng sau publictừ khóa. Tất cả các biến hoặc hàm được xác định sau mã chỉ định công khai đều có thể truy cập được bởi tất cả các hàm khác trong chương trình của bạn.
Việc biến một lớp này thành bạn của lớp khác sẽ làm lộ ra các chi tiết triển khai và giảm bớt tính đóng gói. Lý tưởng nhất là giữ càng nhiều chi tiết của mỗi lớp ẩn với tất cả các lớp khác càng tốt.
Đóng gói dữ liệu trong D
Bất kỳ chương trình D nào mà bạn triển khai một lớp với các thành viên công cộng và riêng tư là một ví dụ về đóng gói dữ liệu và trừu tượng hóa dữ liệu. Hãy xem xét ví dụ sau:
Thí dụ
import std.stdio;
class Adder {
public:
// constructor
this(int i = 0) {
total = i;
}
// interface to outside world
void addNum(int number) {
total += number;
}
// interface to outside world
int getTotal() {
return total;
};
private:
// hidden data from outside world
int total;
}
void main( ) {
Adder a = new Adder();
a.addNum(10);
a.addNum(20);
a.addNum(30);
writeln("Total ",a.getTotal());
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Total 60Lớp trên cộng các số lại với nhau và trả về tổng. Các thành viên công cộngaddNum và getTotallà các giao diện với thế giới bên ngoài và người dùng cần biết chúng để sử dụng lớp. Tổng thành viên riêng là một cái gì đó ẩn với thế giới bên ngoài, nhưng cần thiết để lớp hoạt động bình thường.
Chiến lược thiết kế lớp trong D
Hầu hết chúng ta đã học được qua kinh nghiệm cay đắng để đặt các thành viên trong lớp ở chế độ riêng tư theo mặc định trừ khi chúng ta thực sự cần để lộ chúng. Điều đó thật tốtencapsulation.
Sự khôn ngoan này được áp dụng thường xuyên nhất cho các thành viên dữ liệu, nhưng nó áp dụng như nhau cho tất cả các thành viên, bao gồm cả các hàm ảo.
Giao diện là một cách buộc các lớp kế thừa từ nó phải triển khai các hàm hoặc biến nhất định. Các chức năng không được thực hiện trong một giao diện vì chúng luôn được thực hiện trong các lớp kế thừa từ giao diện.
Giao diện được tạo bằng cách sử dụng từ khóa giao diện thay vì từ khóa lớp mặc dù hai giao diện này giống nhau về nhiều mặt. Khi bạn muốn kế thừa từ một giao diện và lớp đã kế thừa từ một lớp khác thì bạn cần phân tách tên của lớp và tên của giao diện bằng dấu phẩy.
Chúng ta hãy xem một ví dụ đơn giản giải thích việc sử dụng một giao diện.
Thí dụ
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Total area: 35Giao diện với các chức năng cuối cùng và tĩnh trong D
Một giao diện có thể có phương thức cuối cùng và phương thức tĩnh mà các định nghĩa sẽ được đưa vào chính giao diện. Lớp dẫn xuất không thể ghi đè các hàm này. Một ví dụ đơn giản được hiển thị bên dưới.
Thí dụ
import std.stdio;
// Base class
interface Shape {
public:
void setWidth(int w);
void setHeight(int h);
static void myfunction1() {
writeln("This is a static method");
}
final void myfunction2() {
writeln("This is a final method");
}
}
// Derived class
class Rectangle: Shape {
int width;
int height;
public:
void setWidth(int w) {
width = w;
}
void setHeight(int h) {
height = h;
}
int getArea() {
return (width * height);
}
}
void main() {
Rectangle rect = new Rectangle();
rect.setWidth(5);
rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", rect.getArea());
rect.myfunction1();
rect.myfunction2();
}Khi đoạn mã trên được biên dịch và thực thi, nó tạo ra kết quả sau:
Total area: 35
This is a static method
This is a final methodTính trừu tượng đề cập đến khả năng làm cho một lớp trừu tượng trong OOP. Một lớp trừu tượng là một lớp không thể được khởi tạo. Tất cả các chức năng khác của lớp vẫn tồn tại và các trường, phương thức và hàm tạo của nó đều được truy cập theo cùng một cách. Bạn chỉ không thể tạo một thể hiện của lớp trừu tượng.
Nếu một lớp là trừu tượng và không thể được khởi tạo, thì lớp đó không có nhiều công dụng trừ khi nó là lớp con. Đây thường là cách các lớp trừu tượng xuất hiện trong giai đoạn thiết kế. Lớp cha chứa chức năng chung của một tập hợp các lớp con, nhưng bản thân lớp cha quá trừu tượng để có thể sử dụng riêng.
Sử dụng lớp trừu tượng trong D
Sử dụng abstracttừ khóa để khai báo một lớp trừu tượng. Từ khóa xuất hiện trong khai báo lớp ở đâu đó trước từ khóa lớp. Sau đây là một ví dụ về cách lớp trừu tượng có thể được kế thừa và sử dụng.
Thí dụ
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
}
class Employee : Person {
int empID;
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
writeln(emp.name);
writeln(emp.getAge);
}Khi chúng ta biên dịch và chạy chương trình trên, chúng ta sẽ nhận được kết quả sau.
Emp1
37Các hàm trừu tượng
Tương tự như các hàm, các lớp cũng có thể trừu tượng. Việc triển khai hàm như vậy không được cung cấp trong lớp của nó nhưng phải được cung cấp trong lớp kế thừa lớp có hàm trừu tượng. Ví dụ trên được cập nhật với hàm trừu tượng.
Thí dụ
import std.stdio;
import std.string;
import std.datetime;
abstract class Person {
int birthYear, birthDay, birthMonth;
string name;
int getAge() {
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
abstract void print();
}
class Employee : Person {
int empID;
override void print() {
writeln("The employee details are as follows:");
writeln("Emp ID: ", this.empID);
writeln("Emp Name: ", this.name);
writeln("Age: ",this.getAge);
}
}
void main() {
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
emp.print();
}Khi chúng ta biên dịch và chạy chương trình trên, chúng ta sẽ nhận được kết quả sau.
The employee details are as follows:
Emp ID: 101
Emp Name: Emp1
Age: 37