DBMS phân tán - Hướng dẫn nhanh
Để hoạt động tốt của bất kỳ tổ chức nào, cần có một cơ sở dữ liệu được duy trì tốt. Trong quá khứ gần đây, cơ sở dữ liệu thường được tập trung hóa. Tuy nhiên, với sự gia tăng của toàn cầu hóa, các tổ chức có xu hướng được đa dạng hóa trên toàn cầu. Họ có thể chọn phân phối dữ liệu qua các máy chủ cục bộ thay vì cơ sở dữ liệu trung tâm. Do đó, khái niệm vềDistributed Databases.
Chương này giới thiệu tổng quan về cơ sở dữ liệu và Hệ thống quản lý cơ sở dữ liệu (DBMS). Cơ sở dữ liệu là một tập hợp dữ liệu liên quan có thứ tự. DBMS là một gói phần mềm hoạt động dựa trên cơ sở dữ liệu. Nghiên cứu chi tiết về DBMS có sẵn trong hướng dẫn của chúng tôi có tên “Tìm hiểu DBMS”. Trong chương này, chúng tôi sửa đổi các khái niệm chính để việc nghiên cứu DDBMS có thể được thực hiện một cách dễ dàng. Ba chủ đề được đề cập là lược đồ cơ sở dữ liệu, các loại cơ sở dữ liệu và các thao tác trên cơ sở dữ liệu.
Cơ sở dữ liệu và Hệ thống quản lý cơ sở dữ liệu
A databaselà một tập hợp dữ liệu liên quan có thứ tự được xây dựng cho một mục đích cụ thể. Cơ sở dữ liệu có thể được tổ chức như một tập hợp nhiều bảng, trong đó một bảng đại diện cho một phần tử hoặc thực thể trong thế giới thực. Mỗi bảng có một số trường khác nhau đại diện cho các tính năng đặc trưng của thực thể.
Ví dụ, cơ sở dữ liệu công ty có thể bao gồm các bảng cho các dự án, nhân viên, phòng ban, sản phẩm và hồ sơ tài chính. Các trường trong bảng Nhân viên có thể là Name, Company_Id, Date_of_Joining, v.v.
A database management systemlà một tập hợp các chương trình cho phép tạo và duy trì cơ sở dữ liệu. DBMS có sẵn dưới dạng gói phần mềm hỗ trợ định nghĩa, xây dựng, thao tác và chia sẻ dữ liệu trong cơ sở dữ liệu. Định nghĩa cơ sở dữ liệu bao gồm mô tả cấu trúc của cơ sở dữ liệu. Xây dựng cơ sở dữ liệu liên quan đến việc lưu trữ dữ liệu thực tế trong bất kỳ phương tiện lưu trữ nào. Thao tác đề cập đến việc truy xuất thông tin từ cơ sở dữ liệu, cập nhật cơ sở dữ liệu và tạo báo cáo. Chia sẻ dữ liệu tạo điều kiện cho dữ liệu được truy cập bởi những người dùng hoặc chương trình khác nhau.
Ví dụ về các khu vực ứng dụng DBMS
- Máy rút tiền tự động
- Hệ thống đặt trước tàu
- Hệ thống quản lý nhân viên
- Hệ thống thông tin sinh viên
Ví dụ về các gói DBMS
- MySQL
- Oracle
- Máy chủ SQL
- dBASE
- FoxPro
- PostgreSQL, v.v.
Lược đồ cơ sở dữ liệu
Lược đồ cơ sở dữ liệu là một mô tả về cơ sở dữ liệu được chỉ định trong quá trình thiết kế cơ sở dữ liệu và không thường xuyên thay đổi. Nó xác định tổ chức của dữ liệu, mối quan hệ giữa chúng và các ràng buộc liên quan đến chúng.
Cơ sở dữ liệu thường được biểu diễn thông qua three-schema architecture hoặc là ANSISPARC architecture. Mục tiêu của kiến trúc này là tách ứng dụng người dùng khỏi cơ sở dữ liệu vật lý. Ba cấp độ là -
Internal Level having Internal Schema - Nó mô tả cấu trúc vật lý, chi tiết của bộ nhớ trong và các đường dẫn truy cập cho cơ sở dữ liệu.
Conceptual Level having Conceptual Schema- Nó mô tả cấu trúc của toàn bộ cơ sở dữ liệu trong khi ẩn các chi tiết về lưu trữ vật lý của dữ liệu. Điều này minh họa các thực thể, thuộc tính với các kiểu dữ liệu và ràng buộc của chúng, các hoạt động và mối quan hệ của người dùng.
External or View Level having External Schemas or Views - Nó mô tả phần cơ sở dữ liệu liên quan đến một người dùng cụ thể hoặc một nhóm người dùng trong khi ẩn phần còn lại của cơ sở dữ liệu.
Các loại DBMS
Có bốn loại DBMS.
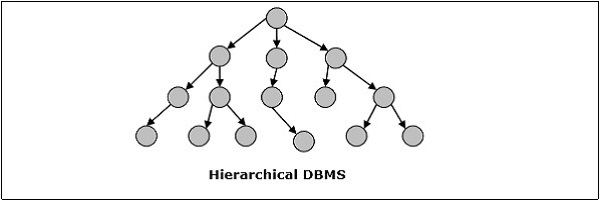
DBMS phân cấp
Trong DBMS phân cấp, các mối quan hệ giữa các dữ liệu trong cơ sở dữ liệu được thiết lập để một phần tử dữ liệu tồn tại như một phần tử cấp dưới của phần tử khác. Các phần tử dữ liệu có mối quan hệ cha-con và được mô hình hóa bằng cách sử dụng cấu trúc dữ liệu “cây”. Đây là rất nhanh chóng và đơn giản.
Mạng DBMS
Mạng DBMS trong đó các mối quan hệ giữa các dữ liệu trong cơ sở dữ liệu thuộc loại nhiều-nhiều dưới dạng mạng. Cấu trúc nói chung là phức tạp do tồn tại nhiều mối quan hệ từ nhiều đến nhiều. Mạng DBMS được mô hình hóa bằng cách sử dụng cấu trúc dữ liệu "đồ thị".

DBMS quan hệ
Trong cơ sở dữ liệu quan hệ, cơ sở dữ liệu được biểu diễn dưới dạng quan hệ. Mỗi quan hệ mô hình một thực thể và được biểu diễn dưới dạng một bảng giá trị. Trong mối quan hệ hoặc bảng, một hàng được gọi là một bộ và biểu thị một bản ghi duy nhất. Một cột được gọi là một trường hoặc một thuộc tính và biểu thị một thuộc tính đặc trưng của thực thể. RDBMS là hệ quản trị cơ sở dữ liệu phổ biến nhất.
Ví dụ - Một quan hệ sinh viên -

DBMS hướng đối tượng
DBMS hướng đối tượng có nguồn gốc từ mô hình của mô hình lập trình hướng đối tượng. Chúng hữu ích trong việc biểu diễn cả dữ liệu nhất quán được lưu trữ trong cơ sở dữ liệu, cũng như dữ liệu tạm thời, như được tìm thấy trong việc thực thi các chương trình. Họ sử dụng các phần tử nhỏ, có thể tái sử dụng được gọi là đối tượng. Mỗi đối tượng chứa một phần dữ liệu và một tập hợp các thao tác hoạt động dựa trên dữ liệu. Đối tượng và các thuộc tính của nó được truy cập thông qua con trỏ thay vì được lưu trữ trong các mô hình bảng quan hệ.
Ví dụ - Cơ sở dữ liệu hướng đối tượng Tài khoản Ngân hàng được đơn giản hóa -

DBMS phân tán
Cơ sở dữ liệu phân tán là một tập hợp các cơ sở dữ liệu được kết nối với nhau được phân phối qua mạng máy tính hoặc internet. Hệ thống quản lý cơ sở dữ liệu phân tán (DDBMS) quản lý cơ sở dữ liệu phân tán và cung cấp các cơ chế để làm cho cơ sở dữ liệu trở nên minh bạch với người dùng. Trong các hệ thống này, dữ liệu được phân phối có chủ đích giữa nhiều nút để tất cả các tài nguyên máy tính của tổ chức có thể được sử dụng một cách tối ưu.
Hoạt động trên DBMS
Bốn hoạt động cơ bản trên cơ sở dữ liệu là Tạo, Truy xuất, Cập nhật và Xóa.
CREATE cấu trúc cơ sở dữ liệu và đưa nó vào dữ liệu - Việc tạo một quan hệ cơ sở dữ liệu bao gồm việc xác định cấu trúc dữ liệu, kiểu dữ liệu và các ràng buộc của dữ liệu sẽ được lưu trữ.
Example - Lệnh SQL để tạo bảng sinh viên -
CREATE TABLE STUDENT (
ROLL INTEGER PRIMARY KEY,
NAME VARCHAR2(25),
YEAR INTEGER,
STREAM VARCHAR2(10)
);Khi định dạng dữ liệu được xác định, dữ liệu thực tế được lưu trữ theo định dạng trong một số phương tiện lưu trữ.
Example Lệnh SQL để chèn một bộ đơn vào bảng sinh viên -
INSERT INTO STUDENT ( ROLL, NAME, YEAR, STREAM)
VALUES ( 1, 'ANKIT JHA', 1, 'COMPUTER SCIENCE');RETRIEVEthông tin từ cơ sở dữ liệu - Lấy thông tin thường bao gồm việc chọn một tập hợp con của bảng hoặc hiển thị dữ liệu từ bảng sau khi một số tính toán đã được thực hiện. Nó được thực hiện bằng cách truy vấn trên bảng.
Example - Để truy xuất tên của tất cả sinh viên của luồng Khoa học Máy tính, truy vấn SQL sau cần được thực hiện:
SELECT NAME FROM STUDENT
WHERE STREAM = 'COMPUTER SCIENCE';UPDATE thông tin được lưu trữ và sửa đổi cấu trúc cơ sở dữ liệu - Cập nhật bảng liên quan đến việc thay đổi các giá trị cũ trong các hàng của bảng hiện có bằng các giá trị mới.
Example - Lệnh SQL để thay đổi luồng từ Điện tử sang Điện tử và Truyền thông -
UPDATE STUDENT
SET STREAM = 'ELECTRONICS AND COMMUNICATIONS'
WHERE STREAM = 'ELECTRONICS';Sửa đổi cơ sở dữ liệu có nghĩa là thay đổi cấu trúc của bảng. Tuy nhiên, việc sửa đổi bảng phải tuân theo một số hạn chế.
Example - Để thêm một trường hoặc cột mới, giả sử địa chỉ vào bảng Sinh viên, chúng tôi sử dụng lệnh SQL sau:
ALTER TABLE STUDENT
ADD ( ADDRESS VARCHAR2(50) );DELETE thông tin được lưu trữ hoặc xóa toàn bộ bảng - Việc xóa thông tin cụ thể bao gồm việc xóa các hàng đã chọn khỏi bảng thỏa mãn các điều kiện nhất định.
Example- Để xóa tất cả học sinh trong 4 ngày hiện năm khi họ đang đi ra ngoài, chúng ta sử dụng lệnh SQL -
DELETE FROM STUDENT
WHERE YEAR = 4;Ngoài ra, toàn bộ bảng có thể bị xóa khỏi cơ sở dữ liệu.
Example - Để xóa hoàn toàn bảng sinh viên, lệnh SQL được sử dụng là:
DROP TABLE STUDENT;Chương này giới thiệu khái niệm DDBMS. Trong cơ sở dữ liệu phân tán, có một số cơ sở dữ liệu có thể được phân phối theo địa lý trên toàn thế giới. DBMS phân tán quản lý cơ sở dữ liệu phân tán theo cách để nó xuất hiện dưới dạng một cơ sở dữ liệu duy nhất cho người dùng. Trong phần sau của chương, chúng ta đi vào nghiên cứu các yếu tố dẫn đến cơ sở dữ liệu phân tán, ưu nhược điểm của nó.
A distributed database là một tập hợp của nhiều cơ sở dữ liệu được kết nối với nhau, được trải rộng về mặt vật lý trên các địa điểm khác nhau giao tiếp qua mạng máy tính.
Đặc trưng
Các cơ sở dữ liệu trong bộ sưu tập có mối quan hệ với nhau một cách logic. Thường thì chúng đại diện cho một cơ sở dữ liệu logic duy nhất.
Dữ liệu được lưu trữ vật lý trên nhiều trang web. Dữ liệu trong mỗi trang web có thể được quản lý bởi một DBMS độc lập với các trang web khác.
Các bộ xử lý trong các trang web được kết nối qua mạng. Chúng không có bất kỳ cấu hình đa xử lý nào.
Cơ sở dữ liệu phân tán không phải là một hệ thống tệp được kết nối lỏng lẻo.
Cơ sở dữ liệu phân tán kết hợp xử lý giao dịch, nhưng nó không đồng nghĩa với một hệ thống xử lý giao dịch.
Hệ thống quản lý cơ sở dữ liệu phân tán
Hệ quản trị cơ sở dữ liệu phân tán (DDBMS) là hệ thống phần mềm tập trung quản lý cơ sở dữ liệu phân tán theo cách như thể tất cả được lưu trữ tại một vị trí duy nhất.
Đặc trưng
Nó được sử dụng để tạo, truy xuất, cập nhật và xóa cơ sở dữ liệu phân tán.
Nó đồng bộ hóa cơ sở dữ liệu theo định kỳ và cung cấp các cơ chế truy cập nhờ đó việc phân phối trở nên minh bạch với người dùng.
Nó đảm bảo rằng dữ liệu được sửa đổi tại bất kỳ trang web nào đều được cập nhật toàn cầu.
Nó được sử dụng trong các lĩnh vực ứng dụng nơi lượng lớn dữ liệu được xử lý và truy cập đồng thời bởi nhiều người dùng.
Nó được thiết kế cho các nền tảng cơ sở dữ liệu không đồng nhất.
Nó duy trì tính bảo mật và tính toàn vẹn dữ liệu của cơ sở dữ liệu.
Các yếu tố khuyến khích DDBMS
Các yếu tố sau khuyến khích chuyển sang DDBMS:
Distributed Nature of Organizational Units- Hầu hết các tổ chức trong thời điểm hiện tại được chia nhỏ thành nhiều đơn vị phân bổ trên toàn cầu. Mỗi đơn vị yêu cầu bộ dữ liệu cục bộ của riêng mình. Do đó, cơ sở dữ liệu tổng thể của tổ chức trở nên phân tán.
Need for Sharing of Data- Nhiều đơn vị tổ chức thường cần giao tiếp với nhau và chia sẻ dữ liệu và tài nguyên của họ. Điều này đòi hỏi cơ sở dữ liệu chung hoặc cơ sở dữ liệu sao chép phải được sử dụng một cách đồng bộ.
Support for Both OLTP and OLAP- Xử lý Giao dịch Trực tuyến (OLTP) và Xử lý Phân tích Trực tuyến (OLAP) hoạt động dựa trên các hệ thống đa dạng có thể có dữ liệu chung. Hệ thống cơ sở dữ liệu phân tán hỗ trợ cả việc xử lý này bằng cách cung cấp dữ liệu đồng bộ.
Database Recovery- Một trong những kỹ thuật phổ biến được sử dụng trong DDBMS là sao chép dữ liệu trên các trang web khác nhau. Nhân rộng dữ liệu tự động giúp khôi phục dữ liệu nếu cơ sở dữ liệu trong bất kỳ trang web nào bị hỏng. Người dùng có thể truy cập dữ liệu từ các trang web khác trong khi trang web bị hỏng đang được xây dựng lại. Do đó, lỗi cơ sở dữ liệu có thể trở nên gần như không dễ thấy đối với người dùng.
Support for Multiple Application Software- Hầu hết các tổ chức sử dụng nhiều phần mềm ứng dụng khác nhau với sự hỗ trợ cơ sở dữ liệu cụ thể của nó. DDBMS cung cấp một chức năng thống nhất để sử dụng cùng một dữ liệu giữa các nền tảng khác nhau.
Ưu điểm của Cơ sở dữ liệu Phân tán
Sau đây là những ưu điểm của cơ sở dữ liệu phân tán so với cơ sở dữ liệu tập trung.
Modular Development- Nếu hệ thống cần được mở rộng đến các địa điểm mới hoặc đơn vị mới, trong các hệ thống cơ sở dữ liệu tập trung, hành động đòi hỏi nỗ lực đáng kể và sự gián đoạn trong hoạt động hiện có. Tuy nhiên, trong cơ sở dữ liệu phân tán, công việc chỉ cần thêm máy tính mới và dữ liệu cục bộ vào trang web mới và cuối cùng là kết nối chúng với hệ thống phân tán, không bị gián đoạn các chức năng hiện tại.
More Reliable- Trong trường hợp cơ sở dữ liệu bị lỗi, hệ thống cơ sở dữ liệu tổng thể tập trung ngừng hoạt động. Tuy nhiên, trong các hệ thống phân tán, khi một thành phần bị lỗi, hoạt động của hệ thống vẫn tiếp tục có thể bị giảm hiệu suất. Do đó DDBMS đáng tin cậy hơn.
Better Response- Nếu dữ liệu được phân phối theo cách hiệu quả, thì các yêu cầu của người dùng có thể được đáp ứng từ chính dữ liệu cục bộ, do đó cung cấp phản hồi nhanh hơn. Mặt khác, trong các hệ thống tập trung, tất cả các truy vấn phải thông qua máy tính trung tâm để xử lý, điều này làm tăng thời gian phản hồi.
Lower Communication Cost- Trong các hệ thống cơ sở dữ liệu phân tán, nếu dữ liệu được đặt tại địa phương nơi nó được sử dụng nhiều nhất, thì chi phí truyền thông để thao tác dữ liệu có thể được giảm thiểu. Điều này không khả thi trong các hệ thống tập trung.
Những bất lợi của Cơ sở dữ liệu Phân tán
Sau đây là một số khó khăn liên quan đến cơ sở dữ liệu phân tán.
Need for complex and expensive software - DDBMS đòi hỏi phần mềm phức tạp và thường đắt tiền để cung cấp tính minh bạch và phối hợp dữ liệu trên nhiều địa điểm.
Processing overhead - Ngay cả các hoạt động đơn giản cũng có thể yêu cầu một số lượng lớn thông tin liên lạc và các tính toán bổ sung để cung cấp tính đồng nhất về dữ liệu trên các trang web.
Data integrity - Nhu cầu cập nhật dữ liệu ở nhiều trang web đặt ra các vấn đề về tính toàn vẹn của dữ liệu.
Overheads for improper data distribution- Khả năng đáp ứng của các truy vấn phụ thuộc phần lớn vào việc phân phối dữ liệu thích hợp. Việc phân phối dữ liệu không đúng cách thường dẫn đến phản hồi rất chậm đối với các yêu cầu của người dùng.
Trong phần này của hướng dẫn, chúng ta sẽ nghiên cứu các khía cạnh khác nhau hỗ trợ trong việc thiết kế môi trường cơ sở dữ liệu phân tán. Chương này bắt đầu với các loại cơ sở dữ liệu phân tán. Cơ sở dữ liệu phân tán có thể được phân loại thành cơ sở dữ liệu đồng nhất và không đồng nhất có sự phân chia sâu hơn. Phần tiếp theo của chương này thảo luận về các kiến trúc phân tán, cụ thể là client - server, peer - to - peer và multi - DBMS. Cuối cùng, các lựa chọn thay thế thiết kế khác nhau như sao chép và phân mảnh được giới thiệu.
Các loại cơ sở dữ liệu phân tán
Cơ sở dữ liệu phân tán có thể được phân loại rộng rãi thành các môi trường cơ sở dữ liệu phân tán đồng nhất và không đồng nhất, mỗi môi trường cơ sở dữ liệu phân tán đều có các phân chia nhỏ hơn, như thể hiện trong minh họa sau.

Cơ sở dữ liệu phân tán đồng nhất
Trong một cơ sở dữ liệu phân tán đồng nhất, tất cả các trang web đều sử dụng hệ điều hành và DBMS giống hệt nhau. Thuộc tính của nó là -
Các trang web sử dụng phần mềm rất giống nhau.
Các trang web sử dụng DBMS hoặc DBMS giống hệt nhau từ cùng một nhà cung cấp.
Mỗi trang web đều biết tất cả các trang khác và hợp tác với các trang khác để xử lý yêu cầu của người dùng.
Cơ sở dữ liệu được truy cập thông qua một giao diện duy nhất như thể nó là một cơ sở dữ liệu duy nhất.
Các loại cơ sở dữ liệu phân tán đồng nhất
Có hai loại cơ sở dữ liệu phân tán đồng nhất -
Autonomous- Mỗi cơ sở dữ liệu là độc lập tự hoạt động. Chúng được tích hợp bởi một ứng dụng kiểm soát và sử dụng tính năng truyền thông báo để chia sẻ cập nhật dữ liệu.
Non-autonomous - Dữ liệu được phân phối trên các nút đồng nhất và DBMS trung tâm hoặc chính điều phối các bản cập nhật dữ liệu trên các trang web.
Cơ sở dữ liệu phân tán không đồng nhất
Trong cơ sở dữ liệu phân tán không đồng nhất, các trang web khác nhau có hệ điều hành, sản phẩm DBMS và mô hình dữ liệu khác nhau. Thuộc tính của nó là -
Các trang web khác nhau sử dụng các lược đồ và phần mềm khác nhau.
Hệ thống có thể bao gồm nhiều loại DBMS khác nhau như quan hệ, mạng, phân cấp hoặc hướng đối tượng.
Xử lý truy vấn rất phức tạp do các lược đồ khác nhau.
Quá trình xử lý giao dịch phức tạp do phần mềm không giống nhau.
Một trang web có thể không biết các trang web khác và do đó có giới hạn hợp tác trong việc xử lý các yêu cầu của người dùng.
Các loại cơ sở dữ liệu phân tán không đồng nhất
Federated - Các hệ cơ sở dữ liệu không đồng nhất có bản chất độc lập và được tích hợp với nhau để chúng hoạt động như một hệ cơ sở dữ liệu duy nhất.
Un-federated - Hệ thống cơ sở dữ liệu sử dụng một mô-đun điều phối trung tâm mà qua đó các cơ sở dữ liệu được truy cập.
Kiến trúc DBMS phân tán
Kiến trúc DDBMS thường được phát triển phụ thuộc vào ba tham số:
Distribution - Nó cho biết sự phân phối vật lý của dữ liệu trên các trang web khác nhau.
Autonomy - Nó chỉ ra sự phân bố quyền kiểm soát hệ thống cơ sở dữ liệu và mức độ mà mỗi DBMS cấu thành có thể hoạt động độc lập.
Heterogeneity - Nó đề cập đến sự đồng nhất hoặc khác biệt của các mô hình dữ liệu, thành phần hệ thống và cơ sở dữ liệu.
Mô hình kiến trúc
Một số mô hình kiến trúc phổ biến là -
- Kiến trúc Máy khách - Máy chủ cho DDBMS
- Kiến trúc ngang hàng cho DDBMS
- Kiến trúc đa DBMS
Kiến trúc Máy khách - Máy chủ cho DDBMS
Đây là một kiến trúc hai cấp trong đó chức năng được chia thành máy chủ và máy khách. Chức năng của máy chủ chủ yếu bao gồm quản lý dữ liệu, xử lý truy vấn, tối ưu hóa và quản lý giao dịch. Các chức năng máy khách chủ yếu bao gồm giao diện người dùng. Tuy nhiên, chúng có một số chức năng như kiểm tra tính nhất quán và quản lý giao dịch.
Hai kiến trúc máy khách - máy chủ khác nhau là -
- Máy chủ đơn Nhiều máy khách
- Nhiều máy chủ Nhiều máy khách (được hiển thị trong sơ đồ sau)

Kiến trúc ngang hàng cho DDBMS
Trong các hệ thống này, mỗi máy ngang hàng hoạt động như một máy khách và máy chủ để truyền tải các dịch vụ cơ sở dữ liệu. Các đồng nghiệp chia sẻ nguồn lực của họ với các đồng nghiệp khác và điều phối các hoạt động của họ.
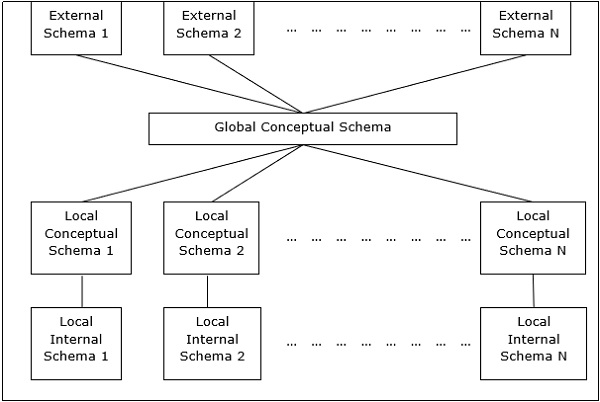
Kiến trúc này thường có bốn cấp độ của lược đồ -
Global Conceptual Schema - Mô tả quan điểm logic toàn cục của dữ liệu.
Local Conceptual Schema - Mô tả tổ chức dữ liệu hợp lý tại mỗi trang web.
Local Internal Schema - Mô tả tổ chức dữ liệu vật lý tại mỗi trang web.
External Schema - Mô tả chế độ xem dữ liệu của người dùng.
Đa kiến trúc DBMS
Đây là một hệ thống cơ sở dữ liệu tích hợp được hình thành bởi một tập hợp của hai hoặc nhiều hệ thống cơ sở dữ liệu tự quản.
Đa DBMS có thể được thể hiện thông qua sáu cấp độ của lược đồ:
Multi-database View Level - Mô tả nhiều chế độ xem của người dùng bao gồm các tập con của cơ sở dữ liệu phân tán tích hợp.
Multi-database Conceptual Level - Mô tả đa cơ sở dữ liệu tích hợp bao gồm các định nghĩa cấu trúc đa cơ sở dữ liệu logic toàn cục.
Multi-database Internal Level - Mô tả việc phân phối dữ liệu trên các trang web khác nhau và đa cơ sở dữ liệu để lập bản đồ dữ liệu cục bộ.
Local database View Level - Mô tả chế độ xem công khai của dữ liệu cục bộ.
Local database Conceptual Level - Mô tả tổ chức dữ liệu cục bộ tại mỗi trang web.
Local database Internal Level - Mô tả tổ chức dữ liệu vật lý tại mỗi trang web.
Có hai lựa chọn thay thế thiết kế cho đa DBMS -
- Mô hình với mức khái niệm đa cơ sở dữ liệu.
- Mô hình không có mức khái niệm đa cơ sở dữ liệu.


Các giải pháp thay thế thiết kế
Các lựa chọn thay thế thiết kế phân phối cho các bảng trong DDBMS như sau:
- Không sao chép và không phân mảnh
- Nhân rộng hoàn toàn
- Sao chép một phần
- Fragmented
- Mixed
Không sao chép & không phân mảnh
Trong phương án thiết kế này, các bảng khác nhau được đặt ở các vị trí khác nhau. Dữ liệu được đặt sao cho gần với địa điểm được sử dụng nhất. Nó phù hợp nhất cho các hệ thống cơ sở dữ liệu nơi tỷ lệ truy vấn cần thiết để nối thông tin trong các bảng được đặt tại các trang web khác nhau là thấp. Nếu một chiến lược phân phối thích hợp được thông qua, thì phương án thiết kế này sẽ giúp giảm chi phí truyền thông trong quá trình xử lý dữ liệu.
Sao chép đầy đủ
Trong phương án thiết kế này, tại mỗi trang web, một bản sao của tất cả các bảng cơ sở dữ liệu được lưu trữ. Vì mỗi trang web có một bản sao riêng của toàn bộ cơ sở dữ liệu, các truy vấn rất nhanh đòi hỏi chi phí truyền thông không đáng kể. Ngược lại, dữ liệu dư thừa lớn đòi hỏi chi phí rất lớn trong các hoạt động cập nhật. Do đó, điều này phù hợp với các hệ thống yêu cầu xử lý một số lượng lớn các truy vấn trong khi số lượng cập nhật cơ sở dữ liệu thấp.
Sao chép một phần
Các bản sao của bảng hoặc các phần của bảng được lưu trữ tại các trang web khác nhau. Việc phân bố các bảng được thực hiện phù hợp với tần suất truy cập. Điều này xét đến thực tế là tần suất truy cập các bảng khác nhau đáng kể giữa các trang web. Số lượng bản sao của bảng (hoặc các phần) phụ thuộc vào tần suất thực thi các truy vấn truy cập và trang web tạo ra các truy vấn.
Bị phân mảnh
Trong thiết kế này, một bảng được chia thành hai hoặc nhiều phần được gọi là phân đoạn hoặc phân vùng và mỗi phân đoạn có thể được lưu trữ tại các vị trí khác nhau. Điều này coi thực tế là hiếm khi xảy ra rằng tất cả dữ liệu được lưu trữ trong một bảng đều được yêu cầu tại một trang web nhất định. Hơn nữa, phân mảnh làm tăng tính song song và cung cấp khả năng phục hồi thảm họa tốt hơn. Ở đây, chỉ có một bản sao của mỗi phân mảnh trong hệ thống, tức là không có dữ liệu thừa.
Ba kỹ thuật phân mảnh là -
- Phân mảnh dọc
- Phân mảnh theo chiều ngang
- Phân mảnh lai
Phân phối hỗn hợp
Đây là sự kết hợp giữa phân mảnh và sao chép từng phần. Ở đây, ban đầu các bảng được phân mảnh theo bất kỳ hình thức nào (ngang hoặc dọc), sau đó các phân mảnh này được sao chép một phần trên các trang web khác nhau theo tần suất truy cập các phân mảnh.
Trong chương trước, chúng tôi đã giới thiệu các phương án thiết kế khác nhau. Trong chương này, chúng ta sẽ nghiên cứu các chiến lược hỗ trợ việc áp dụng các thiết kế. Các chiến lược có thể được chia thành nhân rộng và phân mảnh. Tuy nhiên, trong hầu hết các trường hợp, sự kết hợp của cả hai được sử dụng.
Sao chép dữ liệu
Sao chép dữ liệu là quá trình lưu trữ các bản sao riêng biệt của cơ sở dữ liệu tại hai hoặc nhiều trang web. Đây là một kỹ thuật chịu lỗi phổ biến của cơ sở dữ liệu phân tán.
Ưu điểm của sao chép dữ liệu
Reliability - Trong trường hợp bất kỳ trang nào bị lỗi, hệ thống cơ sở dữ liệu vẫn tiếp tục hoạt động kể từ khi có bản sao ở (các) trang khác.
Reduction in Network Load- Vì có sẵn các bản sao dữ liệu cục bộ nên việc xử lý truy vấn có thể được thực hiện với việc giảm mức sử dụng mạng, đặc biệt là trong các giờ cao điểm. Cập nhật dữ liệu có thể được thực hiện vào những giờ không phải chính.
Quicker Response - Tính sẵn có của các bản sao dữ liệu cục bộ đảm bảo xử lý truy vấn nhanh chóng và do đó thời gian phản hồi nhanh chóng.
Simpler Transactions- Các giao dịch yêu cầu ít hơn số lượng kết hợp của các bảng đặt tại các trang web khác nhau và sự phối hợp tối thiểu trên toàn mạng. Do đó, chúng trở nên đơn giản hơn trong tự nhiên.
Nhược điểm của sao chép dữ liệu
Increased Storage Requirements- Việc duy trì nhiều bản sao dữ liệu có liên quan đến việc tăng chi phí lưu trữ. Không gian lưu trữ cần thiết là bội số của dung lượng lưu trữ cần thiết cho một hệ thống tập trung.
Increased Cost and Complexity of Data Updating- Mỗi khi một mục dữ liệu được cập nhật, bản cập nhật cần được phản ánh trong tất cả các bản sao của dữ liệu tại các trang web khác nhau. Điều này đòi hỏi các kỹ thuật và giao thức đồng bộ phức tạp.
Undesirable Application – Database coupling- Nếu các cơ chế cập nhật phức tạp không được sử dụng, việc loại bỏ sự không nhất quán của dữ liệu đòi hỏi sự phối hợp phức tạp ở cấp ứng dụng. Điều này dẫn đến việc ghép nối cơ sở dữ liệu - ứng dụng không mong muốn.
Một số kỹ thuật sao chép thường được sử dụng là -
- Sao chép ảnh chụp nhanh
- Sao chép gần thời gian thực
- Kéo sao chép
Phân mảnh
Phân mảnh là nhiệm vụ chia một bảng thành một tập hợp các bảng nhỏ hơn. Các tập hợp con của bảng được gọi làfragments. Phân mảnh có thể có ba loại: ngang, dọc và lai (kết hợp giữa chiều ngang và chiều dọc). Phân mảnh ngang có thể được phân loại thành hai kỹ thuật: phân mảnh ngang sơ cấp và phân mảnh ngang có nguồn gốc.
Việc phân mảnh nên được thực hiện theo cách để có thể tái tạo lại bảng gốc từ các mảnh. Điều này là cần thiết để bảng gốc có thể được tạo lại từ các mảnh bất cứ khi nào cần thiết. Yêu cầu này được gọi là "tính tái tạo".
Ưu điểm của phân mảnh
Do dữ liệu được lưu trữ gần nơi sử dụng nên hiệu quả của hệ thống cơ sở dữ liệu được tăng lên.
Các kỹ thuật tối ưu hóa truy vấn cục bộ là đủ cho hầu hết các truy vấn vì dữ liệu có sẵn cục bộ.
Vì dữ liệu không liên quan không có sẵn tại các trang web, nên tính bảo mật và quyền riêng tư của hệ thống cơ sở dữ liệu có thể được duy trì.
Nhược điểm của phân mảnh
Khi dữ liệu từ các đoạn khác nhau được yêu cầu, tốc độ truy cập có thể rất cao.
Trong trường hợp phân mảnh đệ quy, công việc tái tạo sẽ cần những kỹ thuật đắt tiền.
Việc thiếu các bản sao dự phòng của dữ liệu trong các trang web khác nhau có thể làm cho cơ sở dữ liệu không hiệu quả trong trường hợp trang web bị lỗi.
Phân mảnh theo chiều dọc
Trong phân mảnh theo chiều dọc, các trường hoặc cột của bảng được nhóm thành các đoạn. Để duy trì tính tái tạo, mỗi phân đoạn phải chứa (các) trường khóa chính của bảng. Phân mảnh dọc có thể được sử dụng để thực thi quyền riêng tư của dữ liệu.
Ví dụ, chúng ta hãy xem xét rằng cơ sở dữ liệu trường Đại học lưu giữ hồ sơ của tất cả các sinh viên đã đăng ký trong bảng Sinh viên có lược đồ sau.
SINH VIÊN
| Regd_No | Tên | Khóa học | Địa chỉ | Học kỳ | Phí | Điểm |
Bây giờ, chi tiết phí được duy trì trong phần tài khoản. Trong trường hợp này, nhà thiết kế sẽ phân mảnh cơ sở dữ liệu như sau:
CREATE TABLE STD_FEES AS
SELECT Regd_No, Fees
FROM STUDENT;Phân mảnh theo chiều ngang
Phân mảnh ngang nhóm các bộ giá trị của bảng theo các giá trị của một hoặc nhiều trường. Sự phân mảnh theo chiều ngang cũng nên xác nhận quy tắc tái tạo. Mỗi phân mảnh ngang phải có tất cả các cột của bảng cơ sở ban đầu.
Ví dụ, trong lược đồ sinh viên, nếu thông tin chi tiết của tất cả sinh viên của Khóa học Khoa học Máy tính cần được duy trì tại Trường Khoa học Máy tính, thì người thiết kế sẽ phân mảnh cơ sở dữ liệu theo chiều ngang như sau:
CREATE COMP_STD AS
SELECT * FROM STUDENT
WHERE COURSE = "Computer Science";Phân mảnh hỗn hợp
Trong phân mảnh lai, sự kết hợp của các kỹ thuật phân mảnh ngang và dọc được sử dụng. Đây là kỹ thuật phân mảnh linh hoạt nhất vì nó tạo ra các phân mảnh với thông tin ngoại lai tối thiểu. Tuy nhiên, việc tái tạo lại bảng gốc thường là một nhiệm vụ tốn kém.
Phân mảnh kết hợp có thể được thực hiện theo hai cách khác nhau:
Lúc đầu, tạo một tập hợp các đoạn ngang; sau đó tạo các đoạn thẳng đứng từ một hoặc nhiều đoạn ngang.
Lúc đầu, tạo một tập hợp các đoạn thẳng đứng; sau đó tạo các đoạn ngang từ một hoặc nhiều đoạn dọc.
Tính minh bạch của phân phối là tài sản của cơ sở dữ liệu phân tán nhờ đó các chi tiết nội bộ của phân phối được ẩn với người dùng. Người thiết kế DDBMS có thể chọn phân mảnh các bảng, sao chép các phân đoạn và lưu trữ chúng tại các trang web khác nhau. Tuy nhiên, vì người dùng không biết về những chi tiết này, họ thấy cơ sở dữ liệu phân tán dễ sử dụng như bất kỳ cơ sở dữ liệu tập trung nào.
Ba khía cạnh của tính minh bạch trong phân phối là -
- Vị trí minh bạch
- Độ trong suốt của phân mảnh
- Nhân rộng minh bạch
Tính minh bạch của vị trí
Tính minh bạch của vị trí đảm bảo rằng người dùng có thể truy vấn trên bất kỳ (các) bảng hoặc (các) phân đoạn nào của bảng như thể chúng được lưu trữ cục bộ trong trang web của người dùng. Thực tế là bảng hoặc các phân đoạn của nó được lưu trữ tại trang web từ xa trong hệ thống cơ sở dữ liệu phân tán, nên người dùng cuối hoàn toàn không biết. Địa chỉ của (các) trang web từ xa và các cơ chế truy cập hoàn toàn bị ẩn.
Để kết hợp tính minh bạch của vị trí, DDBMS phải có quyền truy cập vào từ điển dữ liệu được cập nhật và chính xác và thư mục DDBMS chứa thông tin chi tiết về vị trí của dữ liệu.
Tính minh bạch của phân mảnh
Tính minh bạch của phân mảnh cho phép người dùng truy vấn trên bất kỳ bảng nào như thể nó không được phân mảnh. Do đó, nó che giấu thực tế rằng bảng mà người dùng đang truy vấn trên thực tế là một phân đoạn hoặc sự kết hợp của một số phân đoạn. Nó cũng che giấu thực tế rằng các mảnh vỡ nằm ở các địa điểm khác nhau.
Điều này hơi giống với người dùng dạng xem SQL, nơi người dùng có thể không biết rằng họ đang sử dụng dạng xem bảng thay vì chính bảng đó.
Tính minh bạch về nhân bản
Tính minh bạch của bản sao đảm bảo rằng bản sao của cơ sở dữ liệu được ẩn khỏi người dùng. Nó cho phép người dùng truy vấn trên một bảng như thể chỉ tồn tại một bản sao duy nhất của bảng.
Tính minh bạch về nhân bản gắn liền với tính minh bạch đồng thời và tính minh bạch về thất bại. Bất cứ khi nào người dùng cập nhật một mục dữ liệu, cập nhật được phản ánh trong tất cả các bản sao của bảng. Tuy nhiên, thao tác này không được người dùng biết. Đây là sự minh bạch đồng thời. Ngoài ra, trong trường hợp trang web bị lỗi, người dùng vẫn có thể tiếp tục các truy vấn của mình bằng cách sử dụng các bản sao mà không biết về lỗi. Đây là sự minh bạch thất bại.
Sự kết hợp của kính trong suốt
Trong bất kỳ hệ thống cơ sở dữ liệu phân tán nào, người thiết kế phải đảm bảo rằng tất cả các tính trong suốt đã nêu được duy trì ở một mức độ đáng kể. Người thiết kế có thể chọn phân mảnh các bảng, sao chép chúng và lưu trữ chúng ở các vị trí khác nhau; tất cả đều bị lãng quên đối với người dùng cuối. Tuy nhiên, hoàn toàn minh bạch phân phối là một nhiệm vụ khó khăn và đòi hỏi những nỗ lực thiết kế đáng kể.
Kiểm soát cơ sở dữ liệu đề cập đến nhiệm vụ thực thi các quy định để cung cấp dữ liệu chính xác cho người dùng và ứng dụng xác thực của cơ sở dữ liệu. Để dữ liệu chính xác có sẵn cho người dùng, tất cả dữ liệu phải tuân theo các ràng buộc toàn vẹn được xác định trong cơ sở dữ liệu. Bên cạnh đó, dữ liệu cần được sàng lọc khỏi những người dùng trái phép để duy trì tính bảo mật và quyền riêng tư của cơ sở dữ liệu. Kiểm soát cơ sở dữ liệu là một trong những nhiệm vụ chính của người quản trị cơ sở dữ liệu (DBA).
Ba khía cạnh của kiểm soát cơ sở dữ liệu là:
- Authentication
- Quyền truy cập
- Ràng buộc hoàn toàn
Xác thực
Trong hệ thống cơ sở dữ liệu phân tán, xác thực là quá trình mà chỉ những người dùng hợp pháp mới có quyền truy cập vào các tài nguyên dữ liệu.
Xác thực có thể được thực thi ở hai cấp độ -
Controlling Access to Client Computer- Ở cấp độ này, quyền truy cập của người dùng bị hạn chế trong khi đăng nhập vào máy tính khách cung cấp giao diện người dùng cho máy chủ cơ sở dữ liệu. Phương pháp phổ biến nhất là kết hợp tên người dùng / mật khẩu. Tuy nhiên, các phương pháp phức tạp hơn như xác thực sinh trắc học có thể được sử dụng cho dữ liệu bảo mật cao.
Controlling Access to the Database Software- Ở cấp độ này, phần mềm / quản trị viên cơ sở dữ liệu chỉ định một số thông tin xác thực cho người dùng. Người dùng có quyền truy cập vào cơ sở dữ liệu bằng các thông tin đăng nhập này. Một trong những phương pháp là tạo tài khoản đăng nhập trong máy chủ cơ sở dữ liệu.
Quyền truy cập
Quyền truy cập của người dùng đề cập đến các đặc quyền mà người dùng được cấp liên quan đến các hoạt động DBMS như quyền tạo bảng, thả bảng, thêm / xóa / cập nhật các bộ giá trị trong bảng hoặc truy vấn trên bảng.
Trong môi trường phân tán, vì có số lượng bảng lớn và số lượng người dùng lớn hơn, nên việc gán quyền truy cập cá nhân cho người dùng là không khả thi. Vì vậy, DDBMS xác định các vai trò nhất định. Vai trò là một cấu trúc với các đặc quyền nhất định trong hệ thống cơ sở dữ liệu. Khi các vai trò khác nhau được xác định, người dùng cá nhân được chỉ định một trong các vai trò này. Thường thì một hệ thống phân cấp các vai trò được xác định theo hệ thống phân cấp quyền hạn và trách nhiệm của tổ chức.
Ví dụ, các câu lệnh SQL sau tạo một vai trò "Kế toán" và sau đó gán vai trò này cho người dùng "ABC".
CREATE ROLE ACCOUNTANT;
GRANT SELECT, INSERT, UPDATE ON EMP_SAL TO ACCOUNTANT;
GRANT INSERT, UPDATE, DELETE ON TENDER TO ACCOUNTANT;
GRANT INSERT, SELECT ON EXPENSE TO ACCOUNTANT;
COMMIT;
GRANT ACCOUNTANT TO ABC;
COMMIT;Kiểm soát toàn vẹn ngữ nghĩa
Kiểm soát toàn vẹn ngữ nghĩa xác định và thực thi các ràng buộc toàn vẹn của hệ thống cơ sở dữ liệu.
Các ràng buộc toàn vẹn như sau:
- Ràng buộc toàn vẹn kiểu dữ liệu
- Ràng buộc toàn vẹn thực thể
- Ràng buộc toàn vẹn tham chiếu
Ràng buộc về tính toàn vẹn của loại dữ liệu
Ràng buộc kiểu dữ liệu hạn chế phạm vi giá trị và kiểu hoạt động có thể được áp dụng cho trường có kiểu dữ liệu được chỉ định.
Ví dụ: chúng ta hãy xem xét rằng một bảng "HOSTEL" có ba trường - số nhà trọ, tên nhà trọ và sức chứa. Số nhà trọ phải bắt đầu bằng chữ cái in hoa "H" và không được NULL và dung lượng không được nhiều hơn 150. Có thể sử dụng lệnh SQL sau để định nghĩa dữ liệu:
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) NOT NULL,
H_NAME VARCHAR2(15),
CAPACITY INTEGER,
CHECK ( H_NO LIKE 'H%'),
CHECK ( CAPACITY <= 150)
);Kiểm soát tính toàn vẹn của thực thể
Kiểm soát tính toàn vẹn của thực thể thực thi các quy tắc để mỗi bộ có thể được nhận dạng duy nhất từ các bộ khác. Đối với điều này, một khóa chính được xác định. Khóa chính là một tập hợp các trường tối thiểu có thể xác định duy nhất một bộ giá trị. Ràng buộc toàn vẹn thực thể tuyên bố rằng không có hai bộ giá trị nào trong bảng có thể có các giá trị giống nhau cho các khóa chính và không trường nào là một phần của khóa chính có thể có giá trị NULL.
Ví dụ: trong bảng nhà trọ ở trên, số nhà trọ có thể được chỉ định làm khóa chính thông qua câu lệnh SQL sau (bỏ qua các bước kiểm tra):
CREATE TABLE HOSTEL (
H_NO VARCHAR2(5) PRIMARY KEY,
H_NAME VARCHAR2(15),
CAPACITY INTEGER
);Ràng buộc về tính toàn vẹn tham chiếu
Ràng buộc toàn vẹn tham chiếu đưa ra các quy tắc của khóa ngoại. Khóa ngoại là một trường trong bảng dữ liệu là khóa chính của bảng có liên quan. Ràng buộc toàn vẹn tham chiếu đưa ra quy tắc rằng giá trị của trường khóa ngoại phải nằm trong số các giá trị của khóa chính của bảng được tham chiếu hoặc hoàn toàn là NULL.
Ví dụ, chúng ta hãy xem xét một bàn sinh viên nơi sinh viên có thể chọn sống trong ký túc xá. Để bao gồm điều này, khóa chính của bảng ký túc xá phải được đưa vào làm khóa ngoại trong bảng sinh viên. Câu lệnh SQL sau kết hợp điều này:
CREATE TABLE STUDENT (
S_ROLL INTEGER PRIMARY KEY,
S_NAME VARCHAR2(25) NOT NULL,
S_COURSE VARCHAR2(10),
S_HOSTEL VARCHAR2(5) REFERENCES HOSTEL
);Khi một truy vấn được đặt, trước tiên nó sẽ được quét, phân tích cú pháp và xác thực. Sau đó, đại diện nội bộ của truy vấn được tạo ra, chẳng hạn như cây truy vấn hoặc biểu đồ truy vấn. Sau đó, các chiến lược thực thi thay thế được đưa ra để lấy kết quả từ các bảng cơ sở dữ liệu. Quá trình lựa chọn chiến lược thực thi thích hợp nhất để xử lý truy vấn được gọi là tối ưu hóa truy vấn.
Các vấn đề về tối ưu hóa truy vấn trong DDBMS
Trong DDBMS, tối ưu hóa truy vấn là một nhiệm vụ quan trọng. Độ phức tạp cao vì số lượng các chiến lược thay thế có thể tăng theo cấp số nhân do các yếu tố sau:
- Sự hiện diện của một số mảnh vỡ.
- Phân phối các phân đoạn hoặc bảng trên các trang web khác nhau.
- Tốc độ liên kết truyền thông.
- Chênh lệch về khả năng xử lý cục bộ.
Do đó, trong một hệ thống phân tán, mục tiêu thường là tìm một chiến lược thực thi tốt để xử lý truy vấn hơn là chiến lược tốt nhất. Thời gian để thực hiện một truy vấn là tổng thời gian sau:
- Đã đến lúc giao tiếp các truy vấn tới cơ sở dữ liệu.
- Thời gian để thực thi các đoạn truy vấn cục bộ.
- Thời gian để tập hợp dữ liệu từ các trang web khác nhau.
- Thời gian hiển thị kết quả ra ứng dụng.
Xử lý truy vấn
Xử lý truy vấn là một tập hợp tất cả các hoạt động bắt đầu từ vị trí đặt truy vấn đến hiển thị kết quả của truy vấn. Các bước được hiển thị trong sơ đồ sau:

Đại số quan hệ
Đại số quan hệ xác định tập hợp các hoạt động cơ bản của mô hình cơ sở dữ liệu quan hệ. Một chuỗi các phép toán đại số quan hệ tạo thành một biểu thức đại số quan hệ. Kết quả của biểu thức này đại diện cho kết quả của một truy vấn cơ sở dữ liệu.
Các hoạt động cơ bản là -
- Projection
- Selection
- Union
- Intersection
- Minus
- Join
Phép chiếu
Phép chiếu hiển thị một tập hợp con các trường của bảng. Điều này tạo ra một phân vùng dọc của bảng.
Syntax in Relational Algebra
$$ \ pi _ {<{AttributeList}>} {(<{Tên bảng}>)} $$
Ví dụ, chúng ta hãy xem xét cơ sở dữ liệu Sinh viên sau:
|
|
||||
| Roll_No | Name | Course | Semester | Gender |
| 2 | Amit Prasad | BCA | 1 | Nam giới |
| 4 | Varsha Tiwari | BCA | 1 | Giống cái |
| 5 | Asif Ali | MCA | 2 | Nam giới |
| 6 | Joe Wallace | MCA | 1 | Nam giới |
| số 8 | Shivani Iyengar | BCA | 1 | Giống cái |
Nếu chúng ta muốn hiển thị tên và khóa học của tất cả sinh viên, chúng ta sẽ sử dụng biểu thức đại số quan hệ sau:
$$\pi_{Name,Course}{(STUDENT)}$$
Lựa chọn
Phép toán lựa chọn hiển thị một tập hợp con các bộ giá trị của một bảng thỏa mãn các điều kiện nhất định. Điều này tạo ra một phân vùng ngang của bảng.
Syntax in Relational Algebra
$$ \ sigma _ {<{Điều kiện}>} {(<{Tên bảng}>)} $$
Ví dụ, trong bảng Sinh viên, nếu chúng ta muốn hiển thị chi tiết của tất cả sinh viên đã chọn tham gia khóa học MCA, chúng ta sẽ sử dụng biểu thức đại số quan hệ sau:
$$\sigma_{Course} = {\small "BCA"}^{(STUDENT)}$$
Kết hợp các hoạt động chiếu và lựa chọn
Đối với hầu hết các truy vấn, chúng ta cần kết hợp các thao tác chiếu và lựa chọn. Có hai cách để viết các biểu thức này:
- Sử dụng trình tự các phép chiếu và lựa chọn.
- Sử dụng thao tác đổi tên để tạo kết quả trung gian.
Ví dụ: để hiển thị tên của tất cả các sinh viên nữ của khóa học BCA -
- Biểu thức đại số quan hệ sử dụng trình tự các phép chiếu và phép chọn
$$\pi_{Name}(\sigma_{Gender = \small "Female" AND \: Course = \small "BCA"}{(STUDENT)})$$
- Biểu thức đại số quan hệ sử dụng thao tác đổi tên để tạo kết quả trung gian
$$FemaleBCAStudent \leftarrow \sigma_{Gender = \small "Female" AND \: Course = \small "BCA"} {(STUDENT)}$$
$$Result \leftarrow \pi_{Name}{(FemaleBCAStudent)}$$
liên hiệp
Nếu P là kết quả của một phép toán và Q là kết quả của một phép toán khác, thì sự kết hợp của P và Q ($p \cup Q$) là tập hợp tất cả các bộ giá trị trong P hoặc trong Q hoặc trong cả hai mà không có bản sao.
Ví dụ: để hiển thị tất cả học sinh đang ở Học kỳ 1 hoặc đang tham gia khóa học BCA -
$$Sem1Student \leftarrow \sigma_{Semester = 1}{(STUDENT)}$$
$$BCAStudent \leftarrow \sigma_{Course = \small "BCA"}{(STUDENT)}$$
$$Result \leftarrow Sem1Student \cup BCAStudent$$
Ngã tư
Nếu P là kết quả của một phép toán và Q là kết quả của một phép toán khác thì giao điểm của P và Q ( $p \cap Q$ ) là tập hợp tất cả các bộ giá trị cả P và Q.
Ví dụ, cho hai lược đồ sau:
EMPLOYEE
| EmpID | Tên | Tp. | Phòng ban | Tiền lương |
PROJECT
| PId | Tp. | Phòng ban | Trạng thái |
Để hiển thị tên của tất cả các thành phố nơi có dự án và cả nhân viên cư trú -
$$CityEmp \leftarrow \pi_{City}{(EMPLOYEE)}$$
$$CityProject \leftarrow \pi_{City}{(PROJECT)}$$
$$Result \leftarrow CityEmp \cap CityProject$$
Dấu trừ
Nếu P là kết quả của một phép toán và Q là kết quả của một phép toán khác thì P - Q là tập hợp tất cả các bộ giá trị nằm trong P và không thuộc Q.
Ví dụ: để liệt kê tất cả các phòng ban không có dự án đang thực hiện (dự án có trạng thái = đang tiếp tục) -
$$AllDept \leftarrow \pi_{Department}{(EMPLOYEE)}$$
$$ProjectDept \leftarrow \pi_{Department} (\sigma_{Status = \small "ongoing"}{(PROJECT)})$$
$$Result \leftarrow AllDept - ProjectDept$$
Tham gia
Phép toán tham gia kết hợp các bộ giá trị liên quan của hai bảng khác nhau (kết quả của các truy vấn) thành một bảng duy nhất.
Ví dụ: hãy xem xét hai lược đồ, Khách hàng và Chi nhánh trong cơ sở dữ liệu Ngân hàng như sau:
CUSTOMER
| CustID | AccNo | TypeOfAc | BranchID | DateOfOpening |
BRANCH
| BranchID | Tên chi nhánh | IFSCcode | Địa chỉ |
Để liệt kê chi tiết nhân viên cùng với chi tiết chi nhánh -
$$Result \leftarrow CUSTOMER \bowtie_{Customer.BranchID=Branch.BranchID}{BRANCH}$$
Dịch các truy vấn SQL thành Đại số quan hệ
Các truy vấn SQL được dịch thành các biểu thức đại số quan hệ tương đương trước khi tối ưu hóa. Lúc đầu, một truy vấn được phân tách thành các khối truy vấn nhỏ hơn. Các khối này được dịch sang các biểu thức đại số quan hệ tương đương. Tối ưu hóa bao gồm tối ưu hóa từng khối và sau đó tối ưu hóa toàn bộ truy vấn.
Ví dụ
Chúng ta hãy xem xét các lược đồ sau:
NHÂN VIÊN
| EmpID | Tên | Tp. | Phòng ban | Tiền lương |
DỰ ÁN
| PId | Tp. | Phòng ban | Trạng thái |
LÀM
| EmpID | PID | Giờ |
ví dụ 1
Để hiển thị chi tiết của tất cả nhân viên kiếm được mức lương ÍT hơn mức lương trung bình, chúng tôi viết truy vấn SQL:
SELECT * FROM EMPLOYEE
WHERE SALARY < ( SELECT AVERAGE(SALARY) FROM EMPLOYEE ) ;Truy vấn này chứa một truy vấn con lồng nhau. Vì vậy, điều này có thể được chia thành hai khối.
Khối bên trong là -
SELECT AVERAGE(SALARY)FROM EMPLOYEE ;Nếu kết quả của truy vấn này là AvgSal, thì khối bên ngoài là -
SELECT * FROM EMPLOYEE WHERE SALARY < AvgSal;Biểu thức đại số quan hệ cho khối bên trong -
$$AvgSal \leftarrow \Im_{AVERAGE(Salary)}{EMPLOYEE}$$
Biểu thức đại số quan hệ cho khối bên ngoài -
$$ \ sigma_ {Lương <{AvgSal}>} {EMPLOYEE} $$
Ví dụ 2
Để hiển thị ID dự án và trạng thái của tất cả các dự án của nhân viên 'Arun Kumar', chúng tôi viết truy vấn SQL:
SELECT PID, STATUS FROM PROJECT
WHERE PID = ( SELECT FROM WORKS WHERE EMPID = ( SELECT EMPID FROM EMPLOYEE
WHERE NAME = 'ARUN KUMAR'));Truy vấn này chứa hai truy vấn con lồng nhau. Do đó, có thể được chia thành ba khối, như sau:
SELECT EMPID FROM EMPLOYEE WHERE NAME = 'ARUN KUMAR';
SELECT PID FROM WORKS WHERE EMPID = ArunEmpID;
SELECT PID, STATUS FROM PROJECT WHERE PID = ArunPID;(Ở đây ArunEmpID và ArunPID là kết quả của các truy vấn bên trong)
Biểu thức đại số quan hệ cho ba khối là:
$$ArunEmpID \leftarrow \pi_{EmpID}(\sigma_{Name = \small "Arun Kumar"} {(EMPLOYEE)})$$
$$ArunPID \leftarrow \pi_{PID}(\sigma_{EmpID = \small "ArunEmpID"} {(WORKS)})$$
$$Result \leftarrow \pi_{PID, Status}(\sigma_{PID = \small "ArunPID"} {(PROJECT)})$$
Tính toán các toán tử đại số quan hệ
Việc tính toán các toán tử đại số quan hệ có thể được thực hiện theo nhiều cách khác nhau và mỗi cách thay thế được gọi là access path.
Phương án tính toán phụ thuộc vào ba yếu tố chính:
- Loại nhà điều hành
- Bộ nhớ khả dụng
- Cấu trúc đĩa
Thời gian để thực hiện một phép toán đại số quan hệ là tổng của:
- Đã đến lúc xử lý các bộ giá trị.
- Đã đến lúc tìm nạp các bộ giá trị của bảng từ đĩa vào bộ nhớ.
Vì thời gian để xử lý một tuple nhỏ hơn rất nhiều so với thời gian tìm nạp tuple từ bộ lưu trữ, đặc biệt là trong hệ thống phân tán, truy cập đĩa thường được coi là thước đo để tính toán chi phí của biểu thức quan hệ.
Tính toán lựa chọn
Việc tính toán hoạt động lựa chọn phụ thuộc vào độ phức tạp của điều kiện lựa chọn và tính khả dụng của các chỉ mục trên các thuộc tính của bảng.
Sau đây là các lựa chọn thay thế tính toán tùy thuộc vào các chỉ số -
No Index- Nếu bảng không được sắp xếp và không có chỉ mục, thì quá trình lựa chọn bao gồm việc quét tất cả các khối đĩa của bảng. Mỗi khối được đưa vào bộ nhớ và mỗi bộ trong khối được kiểm tra để xem liệu nó có thỏa mãn điều kiện lựa chọn hay không. Nếu điều kiện được thỏa mãn, nó được hiển thị dưới dạng đầu ra. Đây là cách tiếp cận tốn kém nhất vì mỗi bộ được đưa vào bộ nhớ và mỗi bộ được xử lý.
B+ Tree Index- Hầu hết các hệ thống cơ sở dữ liệu được xây dựng dựa trên chỉ mục B + Tree. Nếu điều kiện lựa chọn dựa trên trường, là khóa của chỉ mục B + Tree này, thì chỉ mục này được sử dụng để truy xuất kết quả. Tuy nhiên, việc xử lý các câu lệnh lựa chọn với các điều kiện phức tạp có thể liên quan đến số lượng truy cập khối đĩa lớn hơn và trong một số trường hợp, quá trình quét hoàn thành bảng.
Hash Index- Nếu các chỉ mục băm được sử dụng và trường khóa của nó được sử dụng trong điều kiện lựa chọn, thì việc truy xuất các bộ giá trị bằng chỉ mục băm trở thành một quá trình đơn giản. Chỉ mục băm sử dụng hàm băm để tìm địa chỉ của một thùng chứa giá trị khóa tương ứng với giá trị băm. Để tìm giá trị khóa trong chỉ mục, hàm băm được thực thi và địa chỉ thùng được tìm thấy. Các giá trị chính trong nhóm được tìm kiếm. Nếu tìm thấy kết quả khớp, bộ giá trị thực sẽ được tải từ khối đĩa vào bộ nhớ.
Tính toán tham gia
Khi chúng ta muốn nối hai bảng, giả sử P và Q, mỗi bộ trong P phải được so sánh với mỗi bộ trong Q để kiểm tra xem điều kiện nối có thỏa mãn không. Nếu điều kiện được thỏa mãn, các bộ giá trị tương ứng được nối với nhau, loại bỏ các trường trùng lặp và được nối vào quan hệ kết quả. Do đó, đây là hoạt động tốn kém nhất.
Các phương pháp phổ biến cho phép nối máy tính là:
Phương pháp tiếp cận vòng lặp lồng nhau
Đây là cách tiếp cận tham gia thông thường. Nó có thể được minh họa thông qua mã giả sau (Bảng P và Q, với các bộ giá trị tuple_p và tuple_q và thuộc tính nối a) -
For each tuple_p in P
For each tuple_q in Q
If tuple_p.a = tuple_q.a Then
Concatenate tuple_p and tuple_q and append to Result
End If
Next tuple_q
Next tuple-pPhương pháp tiếp cận sắp xếp-hợp nhất
Trong cách tiếp cận này, hai bảng được sắp xếp riêng dựa trên thuộc tính nối và sau đó các bảng đã sắp xếp được hợp nhất. Các kỹ thuật sắp xếp bên ngoài được áp dụng vì số lượng bản ghi rất nhiều và không thể chứa trong bộ nhớ. Khi các bảng riêng lẻ được sắp xếp, mỗi bảng trong số các bảng được sắp xếp sẽ được đưa vào bộ nhớ, được hợp nhất dựa trên thuộc tính nối và các bộ giá trị đã nối sẽ được viết ra.
Phương pháp kết hợp băm
Cách tiếp cận này bao gồm hai giai đoạn: giai đoạn phân vùng và giai đoạn thăm dò. Trong giai đoạn phân vùng, các bảng P và Q được chia thành hai tập hợp các phân vùng riêng biệt. Một hàm băm chung được quyết định dựa trên. Hàm băm này được sử dụng để gán các bộ giá trị cho các phân vùng. Trong giai đoạn thăm dò, các bộ giá trị trong một phân vùng của P được so sánh với các bộ giá trị của phân vùng tương ứng của Q. Nếu chúng khớp nhau, thì chúng được viết ra.
Khi các đường dẫn truy cập thay thế để tính toán biểu thức đại số quan hệ được bắt nguồn, đường dẫn truy cập tối ưu được xác định. Trong chương này, chúng ta sẽ xem xét tối ưu hóa truy vấn trong hệ thống tập trung trong khi trong chương tiếp theo, chúng ta sẽ nghiên cứu tối ưu hóa truy vấn trong hệ thống phân tán.
Trong một hệ thống tập trung, xử lý truy vấn được thực hiện với mục đích sau:
Giảm thiểu thời gian phản hồi của truy vấn (thời gian cần thiết để tạo ra kết quả cho truy vấn của người dùng).
Tối đa hóa thông lượng hệ thống (số lượng yêu cầu được xử lý trong một khoảng thời gian nhất định).
Giảm dung lượng bộ nhớ và dung lượng lưu trữ cần thiết để xử lý.
Tăng tính song song.
Phân tích cú pháp và dịch truy vấn
Ban đầu, truy vấn SQL được quét. Sau đó, nó được phân tích cú pháp để tìm kiếm lỗi cú pháp và tính đúng đắn của các kiểu dữ liệu. Nếu truy vấn vượt qua bước này, truy vấn được phân tách thành các khối truy vấn nhỏ hơn. Mỗi khối sau đó được dịch sang biểu thức đại số quan hệ tương đương.
Các bước để tối ưu hóa truy vấn
Tối ưu hóa truy vấn bao gồm ba bước, đó là tạo cây truy vấn, tạo kế hoạch và tạo mã kế hoạch truy vấn.
Step 1 − Query Tree Generation
Cây truy vấn là một cấu trúc dữ liệu dạng cây biểu diễn một biểu thức đại số quan hệ. Các bảng của truy vấn được biểu diễn dưới dạng các nút lá. Các phép toán đại số quan hệ được biểu diễn dưới dạng các nút bên trong. Gốc đại diện cho toàn bộ truy vấn.
Trong quá trình thực thi, một nút bên trong được thực thi bất cứ khi nào các bảng toán hạng của nó có sẵn. Sau đó, nút được thay thế bằng bảng kết quả. Quá trình này tiếp tục cho tất cả các nút bên trong cho đến khi nút gốc được thực thi và được thay thế bởi bảng kết quả.
Ví dụ, chúng ta hãy xem xét các lược đồ sau:
NHÂN VIÊN
| EmpID | EName | Tiền lương | DeptNo | Ngày tham gia |
PHÒNG BAN
| DNo | DName | Vị trí |
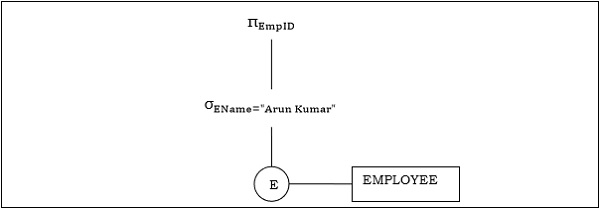
ví dụ 1
Chúng ta hãy xem xét truy vấn như sau.
$$\pi_{EmpID} (\sigma_{EName = \small "ArunKumar"} {(EMPLOYEE)})$$
Cây truy vấn tương ứng sẽ là:
Ví dụ 2
Hãy để chúng tôi xem xét một truy vấn khác liên quan đến một phép nối.
$\pi_{EName, Salary} (\sigma_{DName = \small "Marketing"} {(DEPARTMENT)}) \bowtie_{DNo=DeptNo}{(EMPLOYEE)}$
Sau đây là cây truy vấn cho truy vấn trên.

Step 2 − Query Plan Generation
Sau khi cây truy vấn được tạo, một kế hoạch truy vấn được thực hiện. Kế hoạch truy vấn là một cây truy vấn mở rộng bao gồm các đường dẫn truy cập cho tất cả các thao tác trong cây truy vấn. Các đường dẫn truy cập chỉ định cách thực hiện các phép toán quan hệ trong cây. Ví dụ, một thao tác lựa chọn có thể có một đường dẫn truy cập cung cấp thông tin chi tiết về việc sử dụng chỉ mục cây B + để lựa chọn.
Bên cạnh đó, một kế hoạch truy vấn cũng chỉ ra cách các bảng trung gian nên được chuyển từ toán tử này sang toán tử tiếp theo, cách bảng tạm thời nên được sử dụng và cách hoạt động nên được kết hợp / kết hợp.
Step 3− Code Generation
Tạo mã là bước cuối cùng trong tối ưu hóa truy vấn. Đây là dạng thực thi của truy vấn, dạng của nó phụ thuộc vào loại hệ điều hành cơ bản. Khi mã truy vấn được tạo, Trình quản lý thực thi sẽ chạy nó và tạo ra kết quả.
Các cách tiếp cận để tối ưu hóa truy vấn
Trong số các cách tiếp cận để tối ưu hóa truy vấn, các thuật toán dựa trên tìm kiếm toàn diện và dựa trên kinh nghiệm thường được sử dụng nhiều nhất.
Tối ưu hóa Tìm kiếm Hoàn toàn
Trong các kỹ thuật này, đối với một truy vấn, ban đầu tất cả các kế hoạch truy vấn có thể được tạo và sau đó kế hoạch tốt nhất được chọn. Mặc dù các kỹ thuật này cung cấp giải pháp tốt nhất, nhưng nó có độ phức tạp về không gian và thời gian theo cấp số nhân do không gian giải pháp lớn. Ví dụ, kỹ thuật lập trình động.
Tối ưu hóa Dựa trên Heuristic
Tối ưu hóa dựa trên heuristic sử dụng các phương pháp tối ưu hóa dựa trên quy tắc để tối ưu hóa truy vấn. Các thuật toán này có độ phức tạp về thời gian và không gian đa thức, thấp hơn độ phức tạp theo cấp số nhân của các thuật toán dựa trên tìm kiếm toàn diện. Tuy nhiên, các thuật toán này không nhất thiết phải tạo ra kế hoạch truy vấn tốt nhất.
Một số quy tắc heuristic phổ biến là:
Thực hiện các hoạt động chọn và dự án trước khi tham gia các hoạt động. Điều này được thực hiện bằng cách di chuyển các hoạt động chọn và dự án xuống cây truy vấn. Điều này làm giảm số lượng bộ giá trị có sẵn để tham gia.
Thực hiện các hoạt động chọn / dự án hạn chế nhất lúc đầu trước các hoạt động khác.
Tránh thao tác chéo sản phẩm vì chúng tạo ra các bảng trung gian có kích thước rất lớn.
Chương này thảo luận về tối ưu hóa truy vấn trong hệ thống cơ sở dữ liệu phân tán.
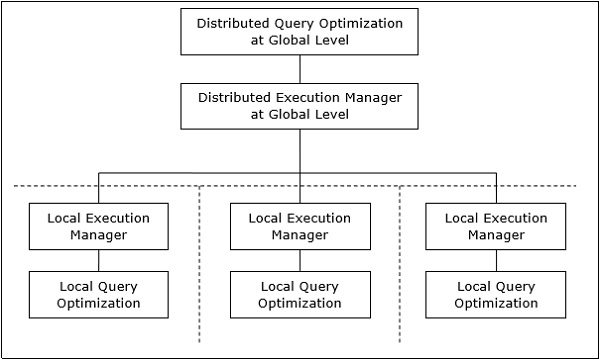
Kiến trúc xử lý truy vấn phân tán
Trong hệ thống cơ sở dữ liệu phân tán, việc xử lý một truy vấn bao gồm việc tối ưu hóa ở cả cấp độ cục bộ và toàn cục. Truy vấn đi vào hệ thống cơ sở dữ liệu tại máy khách hoặc trang web điều khiển. Tại đây, người dùng được xác thực, truy vấn được kiểm tra, dịch và tối ưu hóa ở cấp độ toàn cầu.
Kiến trúc có thể được biểu diễn dưới dạng:
Ánh xạ các truy vấn toàn cầu thành các truy vấn cục bộ
Quá trình ánh xạ các truy vấn toàn cục đến các truy vấn cục bộ có thể được thực hiện như sau:
Các bảng được yêu cầu trong một truy vấn toàn cầu có các phân đoạn được phân phối trên nhiều trang web. Cơ sở dữ liệu cục bộ chỉ có thông tin về dữ liệu cục bộ. Trang web kiểm soát sử dụng từ điển dữ liệu toàn cầu để thu thập thông tin về phân phối và xây dựng lại chế độ xem toàn cầu từ các phân đoạn.
Nếu không có bản sao, trình tối ưu hóa toàn cục sẽ chạy các truy vấn cục bộ tại các trang web lưu trữ các phân đoạn. Nếu có bản sao, trình tối ưu hóa toàn cầu sẽ chọn trang web dựa trên chi phí truyền thông, khối lượng công việc và tốc độ máy chủ.
Trình tối ưu hóa toàn cầu tạo một kế hoạch thực thi phân tán sao cho lượng dữ liệu truyền ít nhất xảy ra trên các trang web. Kế hoạch nêu rõ vị trí của các phân đoạn, thứ tự các bước truy vấn cần được thực hiện và các quy trình liên quan đến việc chuyển các kết quả trung gian.
Các truy vấn cục bộ được tối ưu hóa bởi các máy chủ cơ sở dữ liệu cục bộ. Cuối cùng, các kết quả truy vấn cục bộ được hợp nhất với nhau thông qua phép toán liên hợp trong trường hợp các đoạn ngang và phép toán nối cho các đoạn dọc.
Ví dụ: chúng ta hãy xem xét lược đồ Dự án sau đây được phân mảnh theo chiều ngang theo Thành phố, các thành phố là New Delhi, Kolkata và Hyderabad.
DỰ ÁN
| PId | Tp. | Phòng ban | Trạng thái |
Giả sử có một truy vấn để lấy thông tin chi tiết của tất cả các dự án có trạng thái là "Đang thực hiện".
Truy vấn toàn cục sẽ & inus;
$$\sigma_{status} = {\small "ongoing"}^{(PROJECT)}$$
Truy vấn trong máy chủ của New Delhi sẽ là -
$$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})}$$
Truy vấn trong máy chủ của Kolkata sẽ là -
$$\sigma_{status} = {\small "ongoing"}^{({Kol}_-{PROJECT})}$$
Truy vấn trong máy chủ của Hyderabad sẽ là -
$$\sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$$
Để có được kết quả tổng thể, chúng ta cần kết hợp các kết quả của ba truy vấn như sau:
$\sigma_{status} = {\small "ongoing"}^{({NewD}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({kol}_-{PROJECT})} \cup \sigma_{status} = {\small "ongoing"}^{({Hyd}_-{PROJECT})}$
Tối ưu hóa Truy vấn Phân tán
Tối ưu hóa truy vấn phân tán yêu cầu đánh giá một số lượng lớn các cây truy vấn, mỗi cây trong số đó tạo ra kết quả cần thiết của một truy vấn. Điều này chủ yếu là do sự hiện diện của một lượng lớn dữ liệu được sao chép và phân mảnh. Do đó, mục tiêu là tìm ra giải pháp tối ưu thay vì giải pháp tốt nhất.
Các vấn đề chính để tối ưu hóa truy vấn phân tán là -
- Sử dụng tối ưu tài nguyên trong hệ thống phân tán.
- Giao dịch truy vấn.
- Giảm không gian giải pháp của truy vấn.
Sử dụng tối ưu tài nguyên trong hệ thống phân tán
Hệ thống phân tán có một số máy chủ cơ sở dữ liệu trong các trang web khác nhau để thực hiện các hoạt động liên quan đến truy vấn. Sau đây là các cách tiếp cận để sử dụng tài nguyên tối ưu -
Operation Shipping- Trong vận chuyển hoạt động, hoạt động được thực hiện tại trang web lưu trữ dữ liệu chứ không phải tại trang web khách hàng. Kết quả sau đó được chuyển đến trang khách hàng. Điều này thích hợp cho các hoạt động mà các toán hạng có sẵn tại cùng một trang web. Ví dụ: Các thao tác Chọn và Dự án.
Data Shipping- Trong vận chuyển dữ liệu, các đoạn dữ liệu được chuyển đến máy chủ cơ sở dữ liệu, nơi các hoạt động được thực hiện. Điều này được sử dụng trong các hoạt động mà toán hạng được phân phối tại các vị trí khác nhau. Điều này cũng thích hợp trong các hệ thống có chi phí truyền thông thấp và bộ xử lý cục bộ chậm hơn nhiều so với máy chủ khách.
Hybrid Shipping- Đây là sự kết hợp giữa dữ liệu và vận chuyển hoạt động. Tại đây, các đoạn dữ liệu được chuyển đến bộ xử lý tốc độ cao, nơi hoạt động chạy. Kết quả sau đó được gửi đến trang web của khách hàng.

Giao dịch truy vấn
Trong thuật toán giao dịch truy vấn cho hệ thống cơ sở dữ liệu phân tán, trang web kiểm soát / khách hàng cho truy vấn phân tán được gọi là người mua và các trang web thực hiện truy vấn cục bộ được gọi là người bán. Người mua đưa ra một số phương án thay thế để chọn người bán và để xây dựng lại kết quả toàn cầu. Mục tiêu của người mua là đạt được chi phí tối ưu.
Thuật toán bắt đầu với việc người mua chỉ định các truy vấn phụ cho các trang web của người bán. Kế hoạch tối ưu được tạo từ các kế hoạch truy vấn được tối ưu hóa cục bộ do người bán đề xuất kết hợp với chi phí truyền thông để tạo lại kết quả cuối cùng. Khi kế hoạch tối ưu chung được xây dựng, truy vấn sẽ được thực hiện.
Giảm không gian giải pháp của truy vấn
Giải pháp tối ưu thường liên quan đến việc giảm không gian giải pháp để giảm chi phí truy vấn và truyền dữ liệu. Điều này có thể đạt được thông qua một tập hợp các quy tắc heuristic, cũng giống như heuristics trong các hệ thống tập trung.
Sau đây là một số quy tắc -
Thực hiện các thao tác lựa chọn và chiếu càng sớm càng tốt. Điều này làm giảm luồng dữ liệu qua mạng truyền thông.
Đơn giản hóa các thao tác trên các phân đoạn ngang bằng cách loại bỏ các điều kiện lựa chọn không liên quan đến một trang web cụ thể.
Trong trường hợp các hoạt động kết hợp và liên kết bao gồm các phân đoạn nằm trong nhiều trang web, hãy chuyển dữ liệu bị phân mảnh đến trang web có hầu hết dữ liệu và thực hiện hoạt động ở đó.
Sử dụng thao tác bán nối để đủ điều kiện các bộ giá trị sẽ được tham gia. Điều này làm giảm số lượng truyền dữ liệu do đó làm giảm chi phí truyền thông.
Hợp nhất các lá chung và cây con trong một cây truy vấn phân tán.
Chương này thảo luận về các khía cạnh khác nhau của quá trình xử lý giao dịch. Chúng tôi cũng sẽ nghiên cứu các nhiệm vụ cấp thấp được bao gồm trong một giao dịch, các trạng thái giao dịch và thuộc tính của một giao dịch. Trong phần cuối cùng, chúng ta sẽ xem xét lịch trình và khả năng tuần tự của lịch trình.
Giao dịch
Một giao dịch là một chương trình bao gồm một tập hợp các hoạt động cơ sở dữ liệu, được thực thi như một đơn vị logic xử lý dữ liệu. Các hoạt động được thực hiện trong một giao dịch bao gồm một hoặc nhiều hoạt động cơ sở dữ liệu như chèn, xóa, cập nhật hoặc truy xuất dữ liệu. Nó là một quá trình nguyên tử được thực hiện hoàn toàn hoặc hoàn toàn không được thực hiện. Một giao dịch chỉ liên quan đến truy xuất dữ liệu mà không có bất kỳ cập nhật dữ liệu nào được gọi là giao dịch chỉ đọc.
Mỗi hoạt động cấp cao có thể được chia thành một số nhiệm vụ hoặc hoạt động cấp thấp. Ví dụ: thao tác cập nhật dữ liệu có thể được chia thành ba tác vụ:
read_item() - đọc mục dữ liệu từ bộ nhớ lưu trữ đến bộ nhớ chính.
modify_item() - thay đổi giá trị của mục trong bộ nhớ chính.
write_item() - ghi giá trị đã sửa đổi từ bộ nhớ chính vào bộ nhớ.
Quyền truy cập cơ sở dữ liệu bị hạn chế đối với các hoạt động read_item () và write_item (). Tương tự như vậy, đối với tất cả các giao dịch, đọc và ghi tạo thành các hoạt động cơ sở dữ liệu cơ bản.
Hoạt động giao dịch
Các hoạt động cấp thấp được thực hiện trong một giao dịch là:
begin_transaction - Một điểm đánh dấu chỉ định bắt đầu thực hiện giao dịch.
read_item or write_item - Các hoạt động cơ sở dữ liệu có thể được xen kẽ với các hoạt động bộ nhớ chính như một phần của giao dịch.
end_transaction - Một điểm đánh dấu chỉ định kết thúc giao dịch.
commit - Một tín hiệu để xác định rằng giao dịch đã được hoàn tất thành công toàn bộ và sẽ không được hoàn tác.
rollback- Một tín hiệu để chỉ định rằng giao dịch đã không thành công và do đó tất cả các thay đổi tạm thời trong cơ sở dữ liệu sẽ được hoàn tác. Không thể hoàn nguyên giao dịch đã cam kết.
Bang giao dịch
Một giao dịch có thể trải qua một tập hợp con gồm năm trạng thái, hoạt động, cam kết một phần, cam kết, thất bại và bị hủy bỏ.
Active- Trạng thái ban đầu mà giao dịch đi vào là trạng thái đang hoạt động. Giao dịch vẫn ở trạng thái này trong khi nó đang thực hiện đọc, ghi hoặc các thao tác khác.
Partially Committed - Giao dịch chuyển sang trạng thái này sau khi câu lệnh cuối cùng của giao dịch đã được thực hiện.
Committed - Giao dịch chuyển sang trạng thái này sau khi hoàn thành giao dịch thành công và hệ thống kiểm tra đã phát tín hiệu cam kết.
Failed - Giao dịch chuyển từ trạng thái đã cam kết một phần hoặc trạng thái hoạt động sang trạng thái không thành công khi phát hiện ra rằng việc thực hiện bình thường không thể tiếp tục được nữa hoặc kiểm tra hệ thống không thành công.
Aborted - Đây là trạng thái sau khi giao dịch đã được khôi phục sau khi thất bại và cơ sở dữ liệu đã được khôi phục về trạng thái trước khi giao dịch bắt đầu.
Biểu đồ chuyển đổi trạng thái sau đây mô tả các trạng thái trong giao dịch và các hoạt động giao dịch cấp thấp gây ra sự thay đổi trong các trạng thái.
Thuộc tính mong muốn của giao dịch
Bất kỳ giao dịch nào cũng phải duy trì thuộc tính ACID, viz. Tính nguyên tử, tính nhất quán, tính cô lập và độ bền.
Atomicity- Thuộc tính này nói rằng một giao dịch là một đơn vị xử lý nguyên tử, có nghĩa là nó được thực hiện toàn bộ hoặc không được thực hiện gì cả. Không có bản cập nhật nào nên tồn tại.
Consistency- Một giao dịch nên đưa cơ sở dữ liệu từ trạng thái nhất quán này sang trạng thái nhất quán khác. Nó sẽ không ảnh hưởng xấu đến bất kỳ mục dữ liệu nào trong cơ sở dữ liệu.
Isolation- Một giao dịch phải được thực hiện như thể nó là giao dịch duy nhất trong hệ thống. Không được có bất kỳ sự can thiệp nào từ các giao dịch đồng thời khác đang chạy đồng thời.
Durability - Nếu một giao dịch đã cam kết dẫn đến một sự thay đổi, thì sự thay đổi đó phải tồn tại lâu dài trong cơ sở dữ liệu và không bị mất trong trường hợp có bất kỳ sự cố nào.
Lịch trình và xung đột
Trong một hệ thống có một số giao dịch đồng thời, schedulelà tổng thứ tự thực hiện các phép toán. Cho một lịch trình S bao gồm n giao dịch, giả sử T1, T2, T3 ……… ..Tn; đối với bất kỳ giao dịch Ti nào, các hoạt động trong Ti phải thực hiện như đã trình bày trong lịch trình S.
Các loại lịch trình
Có hai loại lịch trình -
Serial Schedules- Trong một lịch trình nối tiếp, tại bất kỳ thời điểm nào, chỉ có một giao dịch đang hoạt động, tức là không có sự chồng chéo của các giao dịch. Điều này được mô tả trong biểu đồ sau:

Parallel Schedules- Trong lịch biểu song song, nhiều hơn một giao dịch đang hoạt động đồng thời, tức là các giao dịch chứa các hoạt động trùng lặp tại thời điểm. Điều này được mô tả trong biểu đồ sau:

Xung đột trong lịch biểu
Trong một lịch trình bao gồm nhiều giao dịch, conflictxảy ra khi hai giao dịch đang hoạt động thực hiện các hoạt động không tương thích. Hai hoạt động được cho là xung đột, khi tất cả ba điều kiện sau đây tồn tại đồng thời -
Hai hoạt động này là một phần của các giao dịch khác nhau.
Cả hai hoạt động đều truy cập vào cùng một mục dữ liệu.
Ít nhất một trong các hoạt động là hoạt động write_item (), tức là nó cố gắng sửa đổi mục dữ liệu.
Khả năng nối tiếp
A serializable schedulecủa các giao dịch 'n' là một lịch trình song song tương đương với một lịch trình nối tiếp bao gồm các giao dịch 'n' giống nhau. Lịch trình có thể tuần tự hóa chứa tính chính xác của lịch trình nối tiếp đồng thời xác định việc sử dụng CPU tốt hơn của lịch trình song song.
Tương đương của các lịch trình
Sự tương đương của hai lịch trình có thể thuộc các loại sau:
Result equivalence - Hai lịch trình tạo ra kết quả giống hệt nhau được cho là kết quả tương đương.
View equivalence - Hai lịch trình thực hiện hành động tương tự theo cách tương tự được cho là chế độ xem tương đương.
Conflict equivalence - Hai lịch biểu được cho là tương đương xung đột nếu cả hai đều chứa cùng một tập hợp các giao dịch và có cùng thứ tự các cặp thao tác xung đột.
Các kỹ thuật kiểm soát đồng thời đảm bảo rằng nhiều giao dịch được thực hiện đồng thời trong khi vẫn duy trì các thuộc tính ACID của các giao dịch và khả năng tuần tự hóa trong lịch trình.
Trong chương này, chúng ta sẽ nghiên cứu các cách tiếp cận khác nhau để điều khiển đồng thời.
Khóa giao thức kiểm soát đồng thời dựa trên khóa
Các giao thức kiểm soát đồng thời dựa trên khóa sử dụng khái niệm khóa các mục dữ liệu. Alocklà một biến được liên kết với một mục dữ liệu xác định xem có thể thực hiện các thao tác đọc / ghi trên mục dữ liệu đó hay không. Nói chung, ma trận khả năng tương thích khóa được sử dụng cho biết liệu một mục dữ liệu có thể bị khóa bởi hai giao dịch cùng một lúc hay không.
Hệ thống điều khiển đồng thời dựa trên khóa có thể sử dụng giao thức khóa một pha hoặc hai pha.
Giao thức khóa một pha
Trong phương pháp này, mỗi giao dịch sẽ khóa một mục trước khi sử dụng và mở khóa ngay sau khi sử dụng xong. Phương pháp khóa này cung cấp sự đồng thời tối đa nhưng không phải lúc nào cũng thực thi khả năng tuần tự hóa.
Giao thức khóa hai pha
Trong phương pháp này, tất cả các thao tác khóa trước thao tác mở khóa hoặc mở khóa đầu tiên. Giao dịch bao gồm hai giai đoạn. Trong giai đoạn đầu, một giao dịch chỉ có được tất cả các khóa mà nó cần và không phát hành bất kỳ khóa nào. Điều này được gọi là mở rộng hoặcgrowing phase. Trong giai đoạn thứ hai, giao dịch giải phóng khóa và không thể yêu cầu bất kỳ khóa mới nào. Đây được gọi làshrinking phase.
Mọi giao dịch tuân theo giao thức khóa hai pha được đảm bảo có thể tuần tự hóa. Tuy nhiên, cách tiếp cận này cung cấp tính song song thấp giữa hai giao dịch xung đột.
Thuật toán kiểm soát đồng thời dấu thời gian
Các thuật toán kiểm soát đồng thời dựa trên dấu thời gian sử dụng dấu thời gian của giao dịch để điều phối quyền truy cập đồng thời vào một mục dữ liệu nhằm đảm bảo khả năng tuần tự hóa. Dấu thời gian là một định danh duy nhất được DBMS cấp cho một giao dịch đại diện cho thời gian bắt đầu của giao dịch.
Các thuật toán này đảm bảo rằng các giao dịch cam kết theo thứ tự được quy định bởi dấu thời gian của chúng. Giao dịch cũ hơn nên cam kết trước giao dịch trẻ hơn, vì giao dịch cũ hơn vào hệ thống trước giao dịch trẻ hơn.
Các kỹ thuật kiểm soát đồng thời dựa trên dấu thời gian tạo ra các lịch trình có thể tuần tự hóa sao cho lịch trình nối tiếp tương đương được sắp xếp theo thứ tự tuổi của các giao dịch tham gia.
Một số thuật toán điều khiển đồng thời dựa trên dấu thời gian là:
- Thuật toán sắp xếp dấu thời gian cơ bản.
- Thuật toán sắp xếp dấu thời gian bảo thủ.
- Thuật toán đa vũ trụ dựa trên thứ tự dấu thời gian.
Thứ tự dựa trên dấu thời gian tuân theo ba quy tắc để thực thi khả năng tuần tự hóa -
Access Rule- Khi hai giao dịch cố gắng truy cập đồng thời vào cùng một mục dữ liệu, đối với các hoạt động xung đột, giao dịch cũ hơn sẽ được ưu tiên. Điều này khiến giao dịch trẻ hơn phải đợi giao dịch cũ hơn để cam kết trước.
Late Transaction Rule- Nếu một giao dịch trẻ hơn đã ghi một mục dữ liệu, thì một giao dịch cũ hơn không được phép đọc hoặc ghi mục dữ liệu đó. Quy tắc này ngăn giao dịch cũ hơn cam kết sau khi giao dịch trẻ hơn đã được cam kết.
Younger Transaction Rule - Một giao dịch trẻ hơn có thể đọc hoặc ghi một mục dữ liệu đã được ghi bởi một giao dịch cũ hơn.
Thuật toán điều khiển đồng thời lạc quan
Trong các hệ thống có tỷ lệ xung đột thấp, nhiệm vụ xác thực mọi giao dịch về khả năng tuần tự hóa có thể làm giảm hiệu suất. Trong những trường hợp này, kiểm tra khả năng tuần tự hóa được hoãn lại ngay trước khi cam kết. Vì tỷ lệ xung đột thấp nên xác suất hủy bỏ các giao dịch không thể tuần tự hóa cũng thấp. Cách tiếp cận này được gọi là kỹ thuật điều khiển đồng thời lạc quan.
Theo cách tiếp cận này, vòng đời của giao dịch được chia thành ba giai đoạn sau:
Execution Phase - Một giao dịch tìm nạp các mục dữ liệu vào bộ nhớ và thực hiện các hoạt động trên chúng.
Validation Phase - Một giao dịch thực hiện kiểm tra để đảm bảo rằng việc cam kết các thay đổi của nó đối với cơ sở dữ liệu sẽ vượt qua kiểm tra khả năng tuần tự hóa.
Commit Phase - Một giao dịch ghi lại mục dữ liệu đã sửa đổi trong bộ nhớ vào đĩa.
Thuật toán này sử dụng ba quy tắc để thực thi khả năng tuần tự hóa trong giai đoạn xác thực -
Rule 1- Cho hai giao dịch T i và T j , nếu T i đang đọc mục dữ liệu mà T j đang ghi, thì pha thực hiện của T i không được trùng lặp với pha cam kết của T j . T j chỉ có thể cam kết sau khi T i đã thực hiện xong.
Rule 2- Cho hai giao dịch T i và T j , nếu T i đang ghi mục dữ liệu mà T j đang đọc, thì giai đoạn cam kết của T i ’s không được trùng lặp với giai đoạn thực hiện của T j ’. T j chỉ có thể bắt đầu thực hiện sau khi T i đã cam kết.
Rule 3- Cho hai giao dịch T i và T j , nếu T i đang ghi mục dữ liệu mà T j cũng đang viết thì pha cam kết của T i ’s không được trùng lặp với pha cam kết của T j . T j chỉ có thể bắt đầu cam kết sau khi T tôi đã cam kết.
Kiểm soát đồng thời trong các hệ thống phân tán
Trong phần này, chúng ta sẽ xem các kỹ thuật trên được thực hiện như thế nào trong hệ thống cơ sở dữ liệu phân tán.
Thuật toán khóa hai pha phân tán
Nguyên tắc cơ bản của khóa hai pha phân tán cũng giống như giao thức khóa hai pha cơ bản. Tuy nhiên, trong một hệ thống phân tán có các trang web được chỉ định làm trình quản lý khóa. Trình quản lý khóa kiểm soát các yêu cầu mua khóa từ các trình giám sát giao dịch. Để thực thi sự phối hợp giữa những người quản lý khóa trong các trang web khác nhau, ít nhất một trang web được cấp quyền xem tất cả các giao dịch và phát hiện xung đột khóa.
Tùy thuộc vào số lượng trang web có thể phát hiện xung đột khóa, các phương pháp khóa hai pha phân tán có thể có ba loại:
Centralized two-phase locking- Trong cách tiếp cận này, một trang web được chỉ định làm trình quản lý khóa trung tâm. Tất cả các trang web trong môi trường đều biết vị trí của trình quản lý khóa trung tâm và nhận được khóa từ đó trong khi giao dịch.
Primary copy two-phase locking- Theo cách tiếp cận này, một số địa điểm được chỉ định làm trung tâm điều khiển khóa. Mỗi trang web này có trách nhiệm quản lý một bộ khóa xác định. Tất cả các trang web đều biết trung tâm điều khiển khóa nào chịu trách nhiệm quản lý khóa của bảng dữ liệu / mục phân mảnh nào.
Distributed two-phase locking- Trong cách tiếp cận này, có một số trình quản lý khóa, trong đó mỗi trình quản lý khóa kiểm soát các khóa của các mục dữ liệu được lưu trữ tại trang web cục bộ của nó. Vị trí của trình quản lý khóa dựa trên việc phân phối và nhân rộng dữ liệu.
Kiểm soát đồng thời dấu thời gian phân tán
Trong một hệ thống tập trung, dấu thời gian của bất kỳ giao dịch nào được xác định bằng cách đọc đồng hồ vật lý. Tuy nhiên, trong hệ thống phân tán, số đọc đồng hồ logic / vật lý cục bộ của bất kỳ trang web nào không thể được sử dụng làm dấu thời gian toàn cầu, vì chúng không phải là duy nhất trên toàn cầu. Vì vậy, dấu thời gian bao gồm sự kết hợp của ID trang web và số đọc đồng hồ của trang web đó.
Để triển khai các thuật toán sắp xếp dấu thời gian, mỗi trang web có một bộ lập lịch để duy trì một hàng đợi riêng cho mỗi người quản lý giao dịch. Trong quá trình giao dịch, người quản lý giao dịch sẽ gửi một yêu cầu khóa đến bộ lập lịch của trang web. Bộ lập lịch đưa yêu cầu vào hàng đợi tương ứng theo thứ tự dấu thời gian tăng dần. Yêu cầu được xử lý từ phía trước hàng đợi theo thứ tự dấu thời gian của chúng, tức là yêu cầu cũ nhất trước.
Đồ thị xung đột
Một phương pháp khác là tạo đồ thị xung đột. Đối với các lớp giao dịch này được xác định. Một lớp giao dịch chứa hai tập dữ liệu được gọi là tập đọc và tập ghi. Một giao dịch thuộc về một lớp cụ thể nếu tập đọc của giao dịch là tập con của tập đọc 'lớp và tập ghi của giao dịch là tập con của tập ghi' của lớp. Trong giai đoạn đọc, mỗi giao dịch đưa ra yêu cầu đọc cho các mục dữ liệu trong tập đọc của nó. Trong giai đoạn ghi, mỗi giao dịch đưa ra các yêu cầu ghi của nó.
Biểu đồ xung đột được tạo cho các lớp mà các giao dịch đang hoạt động thuộc về. Điều này chứa một tập hợp các cạnh dọc, ngang và chéo. Một cạnh thẳng đứng kết nối hai nút trong một lớp và biểu thị các xung đột trong lớp. Một cạnh ngang kết nối hai nút trên hai lớp và biểu thị xung đột ghi-ghi giữa các lớp khác nhau. Một cạnh chéo kết nối hai nút trên hai lớp và biểu thị sự xung đột ghi-đọc hoặc đọc-ghi giữa hai lớp.
Các đồ thị xung đột được phân tích để xác định liệu hai giao dịch trong cùng một lớp hoặc trên hai lớp khác nhau có thể chạy song song hay không.
Thuật toán điều khiển đồng thời lạc quan phân tán
Thuật toán điều khiển đồng thời lạc quan phân tán mở rộng thuật toán điều khiển đồng thời lạc quan. Đối với phần mở rộng này, hai quy tắc được áp dụng:
Rule 1- Theo quy tắc này, một giao dịch phải được xác thực cục bộ tại tất cả các trang web khi nó thực thi. Nếu một giao dịch được phát hiện là không hợp lệ tại bất kỳ trang web nào, nó sẽ bị hủy bỏ. Xác thực cục bộ đảm bảo rằng giao dịch duy trì khả năng tuần tự hóa tại các trang web nơi nó đã được thực hiện. Sau khi một giao dịch vượt qua kiểm tra xác thực cục bộ, nó sẽ được xác thực trên toàn cầu.
Rule 2- Theo quy tắc này, sau khi một giao dịch vượt qua kiểm tra xác thực cục bộ, nó sẽ được xác thực toàn cầu. Xác thực toàn cầu đảm bảo rằng nếu hai giao dịch xung đột chạy cùng nhau tại nhiều hơn một trang web, chúng phải cam kết theo cùng một thứ tự tương đối tại tất cả các trang mà chúng chạy cùng nhau. Điều này có thể yêu cầu một giao dịch phải đợi giao dịch xung đột khác, sau khi xác thực trước khi cam kết. Yêu cầu này làm cho thuật toán kém lạc quan hơn vì một giao dịch có thể không thể thực hiện ngay sau khi nó được xác thực tại một trang web.
Chương này giới thiệu tổng quan về các cơ chế xử lý deadlock trong hệ cơ sở dữ liệu. Chúng tôi sẽ nghiên cứu các cơ chế xử lý bế tắc trong cả hệ thống cơ sở dữ liệu tập trung và phân tán.
Deadlocks là gì?
Deadlock là trạng thái của một hệ thống cơ sở dữ liệu có từ hai giao dịch trở lên, khi mỗi giao dịch đang chờ một mục dữ liệu đang bị khóa bởi một số giao dịch khác. Bế tắc có thể được biểu thị bằng một chu kỳ trong biểu đồ chờ đợi. Đây là một đồ thị có hướng, trong đó các đỉnh biểu thị các giao dịch và các cạnh biểu thị chờ các mục dữ liệu.
Ví dụ, trong biểu đồ chờ đợi sau, giao dịch T1 đang chờ mục dữ liệu X bị khóa bởi T3. T3 đang chờ Y bị T2 khóa và T2 đang chờ Z bị T1 khóa. Do đó, một chu kỳ chờ được hình thành và không có giao dịch nào có thể tiến hành thực hiện.

Xử lý bế tắc trong các hệ thống tập trung
Có ba cách tiếp cận cổ điển để xử lý bế tắc, đó là -
- Phòng ngừa bế tắc.
- Tránh bế tắc.
- Phát hiện và loại bỏ bế tắc.
Tất cả ba cách tiếp cận có thể được kết hợp trong cả hệ thống cơ sở dữ liệu tập trung và phân tán.
Ngăn chặn bế tắc
Phương pháp ngăn chặn bế tắc không cho phép bất kỳ giao dịch nào có được các khóa sẽ dẫn đến bế tắc. Quy ước là khi có nhiều giao dịch yêu cầu khóa cùng một mục dữ liệu, thì chỉ một trong số chúng được cấp khóa.
Một trong những phương pháp ngăn chặn bế tắc phổ biến nhất là mua trước tất cả các ổ khóa. Trong phương pháp này, một giao dịch có được tất cả các khóa trước khi bắt đầu thực hiện và giữ lại các khóa trong toàn bộ thời gian giao dịch. Nếu một giao dịch khác cần bất kỳ khóa nào đã có được, nó phải đợi cho đến khi tất cả các khóa mà nó cần có sẵn. Sử dụng phương pháp này, hệ thống sẽ không bị bế tắc vì không có giao dịch đang chờ nào bị khóa.
Tránh bế tắc
Phương pháp tránh bế tắc xử lý các bế tắc trước khi chúng xảy ra. Nó phân tích các giao dịch và các khóa để xác định xem liệu việc chờ đợi có dẫn đến bế tắc hay không.
Phương pháp có thể được phát biểu ngắn gọn như sau. Các giao dịch bắt đầu thực hiện và yêu cầu các mục dữ liệu mà chúng cần khóa. Người quản lý khóa kiểm tra xem khóa có sẵn không. Nếu nó có sẵn, trình quản lý khóa sẽ phân bổ mục dữ liệu và giao dịch mua lại khóa. Tuy nhiên, nếu mục bị khóa bởi một số giao dịch khác ở chế độ không tương thích, trình quản lý khóa sẽ chạy một thuật toán để kiểm tra xem việc giữ giao dịch ở trạng thái chờ có gây ra bế tắc hay không. Theo đó, thuật toán quyết định liệu giao dịch có thể chờ hay một trong các giao dịch nên bị hủy bỏ.
Có hai thuật toán cho mục đích này, cụ thể là wait-die và wound-wait. Giả sử rằng có hai giao dịch, T1 và T2, trong đó T1 cố gắng khóa một mục dữ liệu đã bị khóa bởi T2. Các thuật toán như sau:
Wait-Die- Nếu T1 lớn hơn T2 thì T1 được phép chờ. Ngược lại, nếu T1 nhỏ hơn T2, T1 bị hủy bỏ và sau đó được khởi động lại.
Wound-Wait- Nếu T1 cũ hơn T2, T2 bị hủy bỏ và sau đó được khởi động lại. Ngược lại, nếu T1 nhỏ hơn T2 thì T1 được phép chờ.
Phát hiện và loại bỏ bế tắc
Phương pháp phát hiện và loại bỏ deadlock chạy một thuật toán phát hiện deadlock định kỳ và loại bỏ deadlock trong trường hợp có. Nó không kiểm tra bế tắc khi giao dịch đặt yêu cầu khóa. Khi một giao dịch yêu cầu khóa, người quản lý khóa sẽ kiểm tra xem nó có khả dụng hay không. Nếu nó có sẵn, giao dịch được phép khóa mục dữ liệu; nếu không thì giao dịch được phép chờ.
Since there are no precautions while granting lock requests, some of the transactions may be deadlocked. To detect deadlocks, the lock manager periodically checks if the wait-forgraph has cycles. If the system is deadlocked, the lock manager chooses a victim transaction from each cycle. The victim is aborted and rolled back; and then restarted later. Some of the methods used for victim selection are −
- Choose the youngest transaction.
- Choose the transaction with fewest data items.
- Choose the transaction that has performed least number of updates.
- Choose the transaction having least restart overhead.
- Choose the transaction which is common to two or more cycles.
This approach is primarily suited for systems having transactions low and where fast response to lock requests is needed.
Deadlock Handling in Distributed Systems
Transaction processing in a distributed database system is also distributed, i.e. the same transaction may be processing at more than one site. The two main deadlock handling concerns in a distributed database system that are not present in a centralized system are transaction location and transaction control. Once these concerns are addressed, deadlocks are handled through any of deadlock prevention, deadlock avoidance or deadlock detection and removal.
Transaction Location
Transactions in a distributed database system are processed in multiple sites and use data items in multiple sites. The amount of data processing is not uniformly distributed among these sites. The time period of processing also varies. Thus the same transaction may be active at some sites and inactive at others. When two conflicting transactions are located in a site, it may happen that one of them is in inactive state. This condition does not arise in a centralized system. This concern is called transaction location issue.
This concern may be addressed by Daisy Chain model. In this model, a transaction carries certain details when it moves from one site to another. Some of the details are the list of tables required, the list of sites required, the list of visited tables and sites, the list of tables and sites that are yet to be visited and the list of acquired locks with types. After a transaction terminates by either commit or abort, the information should be sent to all the concerned sites.
Transaction Control
Transaction control is concerned with designating and controlling the sites required for processing a transaction in a distributed database system. There are many options regarding the choice of where to process the transaction and how to designate the center of control, like −
- One server may be selected as the center of control.
- The center of control may travel from one server to another.
- The responsibility of controlling may be shared by a number of servers.
Distributed Deadlock Prevention
Just like in centralized deadlock prevention, in distributed deadlock prevention approach, a transaction should acquire all the locks before starting to execute. This prevents deadlocks.
The site where the transaction enters is designated as the controlling site. The controlling site sends messages to the sites where the data items are located to lock the items. Then it waits for confirmation. When all the sites have confirmed that they have locked the data items, transaction starts. If any site or communication link fails, the transaction has to wait until they have been repaired.
Though the implementation is simple, this approach has some drawbacks −
Pre-acquisition of locks requires a long time for communication delays. This increases the time required for transaction.
In case of site or link failure, a transaction has to wait for a long time so that the sites recover. Meanwhile, in the running sites, the items are locked. This may prevent other transactions from executing.
If the controlling site fails, it cannot communicate with the other sites. These sites continue to keep the locked data items in their locked state, thus resulting in blocking.
Distributed Deadlock Avoidance
As in centralized system, distributed deadlock avoidance handles deadlock prior to occurrence. Additionally, in distributed systems, transaction location and transaction control issues needs to be addressed. Due to the distributed nature of the transaction, the following conflicts may occur −
- Conflict between two transactions in the same site.
- Conflict between two transactions in different sites.
In case of conflict, one of the transactions may be aborted or allowed to wait as per distributed wait-die or distributed wound-wait algorithms.
Let us assume that there are two transactions, T1 and T2. T1 arrives at Site P and tries to lock a data item which is already locked by T2 at that site. Hence, there is a conflict at Site P. The algorithms are as follows −
Distributed Wound-Die
If T1 is older than T2, T1 is allowed to wait. T1 can resume execution after Site P receives a message that T2 has either committed or aborted successfully at all sites.
If T1 is younger than T2, T1 is aborted. The concurrency control at Site P sends a message to all sites where T1 has visited to abort T1. The controlling site notifies the user when T1 has been successfully aborted in all the sites.
Distributed Wait-Wait
If T1 is older than T2, T2 needs to be aborted. If T2 is active at Site P, Site P aborts and rolls back T2 and then broadcasts this message to other relevant sites. If T2 has left Site P but is active at Site Q, Site P broadcasts that T2 has been aborted; Site L then aborts and rolls back T2 and sends this message to all sites.
If T1 is younger than T1, T1 is allowed to wait. T1 can resume execution after Site P receives a message that T2 has completed processing.
Distributed Deadlock Detection
Just like centralized deadlock detection approach, deadlocks are allowed to occur and are removed if detected. The system does not perform any checks when a transaction places a lock request. For implementation, global wait-for-graphs are created. Existence of a cycle in the global wait-for-graph indicates deadlocks. However, it is difficult to spot deadlocks since transaction waits for resources across the network.
Alternatively, deadlock detection algorithms can use timers. Each transaction is associated with a timer which is set to a time period in which a transaction is expected to finish. If a transaction does not finish within this time period, the timer goes off, indicating a possible deadlock.
Another tool used for deadlock handling is a deadlock detector. In a centralized system, there is one deadlock detector. In a distributed system, there can be more than one deadlock detectors. A deadlock detector can find deadlocks for the sites under its control. There are three alternatives for deadlock detection in a distributed system, namely.
Centralized Deadlock Detector − One site is designated as the central deadlock detector.
Hierarchical Deadlock Detector − A number of deadlock detectors are arranged in hierarchy.
Distributed Deadlock Detector − All the sites participate in detecting deadlocks and removing them.
This chapter looks into replication control, which is required to maintain consistent data in all sites. We will study the replication control techniques and the algorithms required for replication control.
As discussed earlier, replication is a technique used in distributed databases to store multiple copies of a data table at different sites. The problem with having multiple copies in multiple sites is the overhead of maintaining data consistency, particularly during update operations.
In order to maintain mutually consistent data in all sites, replication control techniques need to be adopted. There are two approaches for replication control, namely −
- Synchronous Replication Control
- Asynchronous Replication Control
Synchronous Replication Control
In synchronous replication approach, the database is synchronized so that all the replications always have the same value. A transaction requesting a data item will have access to the same value in all the sites. To ensure this uniformity, a transaction that updates a data item is expanded so that it makes the update in all the copies of the data item. Generally, two-phase commit protocol is used for the purpose.
For example, let us consider a data table PROJECT(PId, PName, PLocation). We need to run a transaction T1 that updates PLocation to ‘Mumbai’, if PLocation is ‘Bombay’. If no replications are there, the operations in transaction T1 will be −
Begin T1:
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1;If the data table has two replicas in Site A and Site B, T1 needs to spawn two children T1A and T1B corresponding to the two sites. The expanded transaction T1 will be −
Begin T1:
Begin T1A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T1A;
Begin T2A :
Update PROJECT Set PLocation = 'Mumbai'
Where PLocation = 'Bombay';
End T2A;
End T1;Asynchronous Replication Control
In asynchronous replication approach, the replicas do not always maintain the same value. One or more replicas may store an outdated value, and a transaction can see the different values. The process of bringing all the replicas to the current value is called synchronization.
A popular method of synchronization is store and forward method. In this method, one site is designated as the primary site and the other sites are secondary sites. The primary site always contains updated values. All the transactions first enter the primary site. These transactions are then queued for application in the secondary sites. The secondary sites are updated using rollout method only when a transaction is scheduled to execute on it.
Replication Control Algorithms
Some of the replication control algorithms are −
- Master-slave replication control algorithm.
- Distributed voting algorithm.
- Majority consensus algorithm.
- Circulating token algorithm.
Master-Slave Replication Control Algorithm
There is one master site and ‘N’ slave sites. A master algorithm runs at the master site to detect conflicts. A copy of slave algorithm runs at each slave site. The overall algorithm executes in the following two phases −
Transaction acceptance/rejection phase − When a transaction enters the transaction monitor of a slave site, the slave site sends a request to the master site. The master site checks for conflicts. If there aren’t any conflicts, the master sends an “ACK+” message to the slave site which then starts the transaction application phase. Otherwise, the master sends an “ACK-” message to the slave which then rejects the transaction.
Transaction application phase − Upon entering this phase, the slave site where transaction has entered broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it sends a “DONE” message to the master site. The master understands that the transaction has been completed and removes it from the pending queue.
Distributed Voting Algorithm
This comprises of ‘N’ peer sites, all of whom must “OK” a transaction before it starts executing. Following are the two phases of this algorithm −
Distributed transaction acceptance phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site resolves conflicts using priority based voting rules. If all the peer sites are “OK” with the transaction, the requesting site starts application phase. If any of the peer sites does not “OK” a transaction, the requesting site rejects the transaction.
Distributed transaction application phase − Upon entering this phase, the site where the transaction has entered, broadcasts a request to all slaves for executing the transaction. On receiving the requests, the peer slaves execute the transaction and send an “ACK” message to the requesting slave on completion. After the requesting slave has received “ACK” messages from all its peers, it lets the transaction manager know that the transaction has been completed.
Majority Consensus Algorithm
This is a variation from the distributed voting algorithm, where a transaction is allowed to execute when a majority of the peers “OK” a transaction. This is divided into three phases −
Voting phase − When a transaction enters the transaction manager of a site, it sends a transaction request to all other sites. On receiving a request, a peer site tests for conflicts using voting rules and keeps the conflicting transactions, if any, in pending queue. Then, it sends either an “OK” or a “NOT OK” message.
Transaction acceptance/rejection phase − If the requesting site receives a majority “OK” on the transaction, it accepts the transaction and broadcasts “ACCEPT” to all the sites. Otherwise, it broadcasts “REJECT” to all the sites and rejects the transaction.
Transaction application phase − When a peer site receives a “REJECT” message, it removes this transaction from its pending list and reconsiders all deferred transactions. When a peer site receives an “ACCEPT” message, it applies the transaction and rejects all the deferred transactions in the pending queue which are in conflict with this transaction. It sends an “ACK” to the requesting slave on completion.
Circulating Token Algorithm
In this approach the transactions in the system are serialized using a circulating token and executed accordingly against every replica of the database. Thus, all the transactions are accepted, i.e. none is rejected. This has two phases −
Transaction serialization phase − In this phase, all transactions are scheduled to run in a serialization order. Each transaction in each site is assigned a unique ticket from a sequential series, indicating the order of transaction. Once a transaction has been assigned a ticket, it is broadcasted to all the sites.
Transaction application phase − When a site receives a transaction along with its ticket, it places the transaction for execution according to its ticket. After the transaction has finished execution, this site broadcasts an appropriate message. A transaction ends when it has completed execution in all the sites.
A database management system is susceptible to a number of failures. In this chapter we will study the failure types and commit protocols. In a distributed database system, failures can be broadly categorized into soft failures, hard failures and network failures.
Soft Failure
Soft failure is the type of failure that causes the loss in volatile memory of the computer and not in the persistent storage. Here, the information stored in the non-persistent storage like main memory, buffers, caches or registers, is lost. They are also known as system crash. The various types of soft failures are as follows −
- Operating system failure.
- Main memory crash.
- Transaction failure or abortion.
- System generated error like integer overflow or divide-by-zero error.
- Failure of supporting software.
- Power failure.
Hard Failure
A hard failure is the type of failure that causes loss of data in the persistent or non-volatile storage like disk. Disk failure may cause corruption of data in some disk blocks or failure of the total disk. The causes of a hard failure are −
- Power failure.
- Faults in media.
- Read-write malfunction.
- Corruption of information on the disk.
- Read/write head crash of disk.
Recovery from disk failures can be short, if there is a new, formatted, and ready-to-use disk on reserve. Otherwise, duration includes the time it takes to get a purchase order, buy the disk, and prepare it.
Network Failure
Network failures are prevalent in distributed or network databases. These comprises of the errors induced in the database system due to the distributed nature of the data and transferring data over the network. The causes of network failure are as follows −
- Communication link failure.
- Network congestion.
- Information corruption during transfer.
- Site failures.
- Network partitioning.
Commit Protocols
Any database system should guarantee that the desirable properties of a transaction are maintained even after failures. If a failure occurs during the execution of a transaction, it may happen that all the changes brought about by the transaction are not committed. This makes the database inconsistent. Commit protocols prevent this scenario using either transaction undo (rollback) or transaction redo (roll forward).
Commit Point
The point of time at which the decision is made whether to commit or abort a transaction, is known as commit point. Following are the properties of a commit point.
It is a point of time when the database is consistent.
At this point, the modifications brought about by the database can be seen by the other transactions. All transactions can have a consistent view of the database.
At this point, all the operations of transaction have been successfully executed and their effects have been recorded in transaction log.
At this point, a transaction can be safely undone, if required.
At this point, a transaction releases all the locks held by it.
Transaction Undo
The process of undoing all the changes made to a database by a transaction is called transaction undo or transaction rollback. This is mostly applied in case of soft failure.
Transaction Redo
The process of reapplying the changes made to a database by a transaction is called transaction redo or transaction roll forward. This is mostly applied for recovery from a hard failure.
Transaction Log
A transaction log is a sequential file that keeps track of transaction operations on database items. As the log is sequential in nature, it is processed sequentially either from the beginning or from the end.
Purposes of a transaction log −
- To support commit protocols to commit or support transactions.
- To aid database recovery after failure.
A transaction log is usually kept on the disk, so that it is not affected by soft failures. Additionally, the log is periodically backed up to an archival storage like magnetic tape to protect it from disk failures as well.
Lists in Transaction Logs
The transaction log maintains five types of lists depending upon the status of the transaction. This list aids the recovery manager to ascertain the status of a transaction. The status and the corresponding lists are as follows −
A transaction that has a transaction start record and a transaction commit record, is a committed transaction – maintained in commit list.
A transaction that has a transaction start record and a transaction failed record but not a transaction abort record, is a failed transaction – maintained in failed list.
A transaction that has a transaction start record and a transaction abort record is an aborted transaction – maintained in abort list.
A transaction that has a transaction start record and a transaction before-commit record is a before-commit transaction, i.e. a transaction where all the operations have been executed but not committed – maintained in before-commit list.
A transaction that has a transaction start record but no records of before-commit, commit, abort or failed, is an active transaction – maintained in active list.
Immediate Update and Deferred Update
Immediate Update and Deferred Update are two methods for maintaining transaction logs.
In immediate update mode, when a transaction executes, the updates made by the transaction are written directly onto the disk. The old values and the updates values are written onto the log before writing to the database in disk. On commit, the changes made to the disk are made permanent. On rollback, changes made by the transaction in the database are discarded and the old values are restored into the database from the old values stored in the log.
In deferred update mode, when a transaction executes, the updates made to the database by the transaction are recorded in the log file. On commit, the changes in the log are written onto the disk. On rollback, the changes in the log are discarded and no changes are applied to the database.
In order to recuperate from database failure, database management systems resort to a number of recovery management techniques. In this chapter, we will study the different approaches for database recovery.
The typical strategies for database recovery are −
In case of soft failures that result in inconsistency of database, recovery strategy includes transaction undo or rollback. However, sometimes, transaction redo may also be adopted to recover to a consistent state of the transaction.
In case of hard failures resulting in extensive damage to database, recovery strategies encompass restoring a past copy of the database from archival backup. A more current state of the database is obtained through redoing operations of committed transactions from transaction log.
Recovery from Power Failure
Power failure causes loss of information in the non-persistent memory. When power is restored, the operating system and the database management system restart. Recovery manager initiates recovery from the transaction logs.
In case of immediate update mode, the recovery manager takes the following actions −
Transactions which are in active list and failed list are undone and written on the abort list.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
In case of deferred update mode, the recovery manager takes the following actions −
Transactions which are in the active list and failed list are written onto the abort list. No undo operations are required since the changes have not been written to the disk yet.
Transactions which are in before-commit list are redone.
No action is taken for transactions in commit or abort lists.
Recovery from Disk Failure
A disk failure or hard crash causes a total database loss. To recover from this hard crash, a new disk is prepared, then the operating system is restored, and finally the database is recovered using the database backup and transaction log. The recovery method is same for both immediate and deferred update modes.
The recovery manager takes the following actions −
The transactions in the commit list and before-commit list are redone and written onto the commit list in the transaction log.
The transactions in the active list and failed list are undone and written onto the abort list in the transaction log.
Checkpointing
Checkpoint is a point of time at which a record is written onto the database from the buffers. As a consequence, in case of a system crash, the recovery manager does not have to redo the transactions that have been committed before checkpoint. Periodical checkpointing shortens the recovery process.
The two types of checkpointing techniques are −
- Consistent checkpointing
- Fuzzy checkpointing
Consistent Checkpointing
Consistent checkpointing creates a consistent image of the database at checkpoint. During recovery, only those transactions which are on the right side of the last checkpoint are undone or redone. The transactions to the left side of the last consistent checkpoint are already committed and needn’t be processed again. The actions taken for checkpointing are −
- The active transactions are suspended temporarily.
- All changes in main-memory buffers are written onto the disk.
- A “checkpoint” record is written in the transaction log.
- The transaction log is written to the disk.
- The suspended transactions are resumed.
If in step 4, the transaction log is archived as well, then this checkpointing aids in recovery from disk failures and power failures, otherwise it aids recovery from only power failures.
Fuzzy Checkpointing
In fuzzy checkpointing, at the time of checkpoint, all the active transactions are written in the log. In case of power failure, the recovery manager processes only those transactions that were active during checkpoint and later. The transactions that have been committed before checkpoint are written to the disk and hence need not be redone.
Example of Checkpointing
Let us consider that in system the time of checkpointing is tcheck and the time of system crash is tfail. Let there be four transactions Ta, Tb, Tc and Td such that −
Ta commits before checkpoint.
Tb starts before checkpoint and commits before system crash.
Tc starts after checkpoint and commits before system crash.
Td starts after checkpoint and was active at the time of system crash.
The situation is depicted in the following diagram −
The actions that are taken by the recovery manager are −
- Nothing is done with Ta.
- Transaction redo is performed for Tb and Tc.
- Transaction undo is performed for Td.
Transaction Recovery Using UNDO / REDO
Transaction recovery is done to eliminate the adverse effects of faulty transactions rather than to recover from a failure. Faulty transactions include all transactions that have changed the database into undesired state and the transactions that have used values written by the faulty transactions.
Transaction recovery in these cases is a two-step process −
UNDO all faulty transactions and transactions that may be affected by the faulty transactions.
REDO all transactions that are not faulty but have been undone due to the faulty transactions.
Steps for the UNDO operation are −
If the faulty transaction has done INSERT, the recovery manager deletes the data item(s) inserted.
If the faulty transaction has done DELETE, the recovery manager inserts the deleted data item(s) from the log.
If the faulty transaction has done UPDATE, the recovery manager eliminates the value by writing the before-update value from the log.
Steps for the REDO operation are −
If the transaction has done INSERT, the recovery manager generates an insert from the log.
If the transaction has done DELETE, the recovery manager generates a delete from the log.
If the transaction has done UPDATE, the recovery manager generates an update from the log.
In a local database system, for committing a transaction, the transaction manager has to only convey the decision to commit to the recovery manager. However, in a distributed system, the transaction manager should convey the decision to commit to all the servers in the various sites where the transaction is being executed and uniformly enforce the decision. When processing is complete at each site, it reaches the partially committed transaction state and waits for all other transactions to reach their partially committed states. When it receives the message that all the sites are ready to commit, it starts to commit. In a distributed system, either all sites commit or none of them does.
The different distributed commit protocols are −
- One-phase commit
- Two-phase commit
- Three-phase commit
Distributed One-phase Commit
Distributed one-phase commit is the simplest commit protocol. Let us consider that there is a controlling site and a number of slave sites where the transaction is being executed. The steps in distributed commit are −
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site.
The slaves wait for “Commit” or “Abort” message from the controlling site. This waiting time is called window of vulnerability.
When the controlling site receives “DONE” message from each slave, it makes a decision to commit or abort. This is called the commit point. Then, it sends this message to all the slaves.
On receiving this message, a slave either commits or aborts and then sends an acknowledgement message to the controlling site.
Distributed Two-phase Commit
Distributed two-phase commit reduces the vulnerability of one-phase commit protocols. The steps performed in the two phases are as follows −
Phase 1: Prepare Phase
After each slave has locally completed its transaction, it sends a “DONE” message to the controlling site. When the controlling site has received “DONE” message from all slaves, it sends a “Prepare” message to the slaves.
The slaves vote on whether they still want to commit or not. If a slave wants to commit, it sends a “Ready” message.
A slave that does not want to commit sends a “Not Ready” message. This may happen when the slave has conflicting concurrent transactions or there is a timeout.
Phase 2: Commit/Abort Phase
After the controlling site has received “Ready” message from all the slaves −
The controlling site sends a “Global Commit” message to the slaves.
The slaves apply the transaction and send a “Commit ACK” message to the controlling site.
When the controlling site receives “Commit ACK” message from all the slaves, it considers the transaction as committed.
After the controlling site has received the first “Not Ready” message from any slave −
The controlling site sends a “Global Abort” message to the slaves.
The slaves abort the transaction and send a “Abort ACK” message to the controlling site.
When the controlling site receives “Abort ACK” message from all the slaves, it considers the transaction as aborted.
Distributed Three-phase Commit
The steps in distributed three-phase commit are as follows −
Phase 1: Prepare Phase
The steps are same as in distributed two-phase commit.
Phase 2: Prepare to Commit Phase
- The controlling site issues an “Enter Prepared State” broadcast message.
- The slave sites vote “OK” in response.
Phase 3: Commit / Abort Phase
The steps are same as two-phase commit except that “Commit ACK”/”Abort ACK” message is not required.
In this chapter, we will look into the threats that a database system faces and the measures of control. We will also study cryptography as a security tool.
Database Security and Threats
Data security is an imperative aspect of any database system. It is of particular importance in distributed systems because of large number of users, fragmented and replicated data, multiple sites and distributed control.
Threats in a Database
Availability loss − Availability loss refers to non-availability of database objects by legitimate users.
Integrity loss − Integrity loss occurs when unacceptable operations are performed upon the database either accidentally or maliciously. This may happen while creating, inserting, updating or deleting data. It results in corrupted data leading to incorrect decisions.
Confidentiality loss − Confidentiality loss occurs due to unauthorized or unintentional disclosure of confidential information. It may result in illegal actions, security threats and loss in public confidence.
Measures of Control
The measures of control can be broadly divided into the following categories −
Access Control − Access control includes security mechanisms in a database management system to protect against unauthorized access. A user can gain access to the database after clearing the login process through only valid user accounts. Each user account is password protected.
Flow Control − Distributed systems encompass a lot of data flow from one site to another and also within a site. Flow control prevents data from being transferred in such a way that it can be accessed by unauthorized agents. A flow policy lists out the channels through which information can flow. It also defines security classes for data as well as transactions.
Data Encryption − Data encryption refers to coding data when sensitive data is to be communicated over public channels. Even if an unauthorized agent gains access of the data, he cannot understand it since it is in an incomprehensible format.
What is Cryptography?
Cryptography is the science of encoding information before sending via unreliable communication paths so that only an authorized receiver can decode and use it.
The coded message is called cipher text and the original message is called plain text. The process of converting plain text to cipher text by the sender is called encoding or encryption. The process of converting cipher text to plain text by the receiver is called decoding or decryption.
The entire procedure of communicating using cryptography can be illustrated through the following diagram −

Conventional Encryption Methods
In conventional cryptography, the encryption and decryption is done using the same secret key. Here, the sender encrypts the message with an encryption algorithm using a copy of the secret key. The encrypted message is then send over public communication channels. On receiving the encrypted message, the receiver decrypts it with a corresponding decryption algorithm using the same secret key.
Security in conventional cryptography depends on two factors −
A sound algorithm which is known to all.
A randomly generated, preferably long secret key known only by the sender and the receiver.
The most famous conventional cryptography algorithm is Data Encryption Standard or DES.
The advantage of this method is its easy applicability. However, the greatest problem of conventional cryptography is sharing the secret key between the communicating parties. The ways to send the key are cumbersome and highly susceptible to eavesdropping.
Public Key Cryptography
In contrast to conventional cryptography, public key cryptography uses two different keys, referred to as public key and the private key. Each user generates the pair of public key and private key. The user then puts the public key in an accessible place. When a sender wants to sends a message, he encrypts it using the public key of the receiver. On receiving the encrypted message, the receiver decrypts it using his private key. Since the private key is not known to anyone but the receiver, no other person who receives the message can decrypt it.
The most popular public key cryptography algorithms are RSA algorithm and Diffie– Hellman algorithm. This method is very secure to send private messages. However, the problem is, it involves a lot of computations and so proves to be inefficient for long messages.
The solution is to use a combination of conventional and public key cryptography. The secret key is encrypted using public key cryptography before sharing between the communicating parties. Then, the message is send using conventional cryptography with the aid of the shared secret key.
Digital Signatures
A Digital Signature (DS) is an authentication technique based on public key cryptography used in e-commerce applications. It associates a unique mark to an individual within the body of his message. This helps others to authenticate valid senders of messages.
Typically, a user’s digital signature varies from message to message in order to provide security against counterfeiting. The method is as follows −
The sender takes a message, calculates the message digest of the message and signs it digest with a private key.
The sender then appends the signed digest along with the plaintext message.
The message is sent over communication channel.
The receiver removes the appended signed digest and verifies the digest using the corresponding public key.
The receiver then takes the plaintext message and runs it through the same message digest algorithm.
If the results of step 4 and step 5 match, then the receiver knows that the message has integrity and authentic.
A distributed system needs additional security measures than centralized system, since there are many users, diversified data, multiple sites and distributed control. In this chapter, we will look into the various facets of distributed database security.
In distributed communication systems, there are two types of intruders −
Passive eavesdroppers − They monitor the messages and get hold of private information.
Active attackers − They not only monitor the messages but also corrupt data by inserting new data or modifying existing data.
Security measures encompass security in communications, security in data and data auditing.
Communications Security
In a distributed database, a lot of data communication takes place owing to the diversified location of data, users and transactions. So, it demands secure communication between users and databases and between the different database environments.
Security in communication encompasses the following −
Data should not be corrupt during transfer.
The communication channel should be protected against both passive eavesdroppers and active attackers.
In order to achieve the above stated requirements, well-defined security algorithms and protocols should be adopted.
Two popular, consistent technologies for achieving end-to-end secure communications are −
- Secure Socket Layer Protocol or Transport Layer Security Protocol.
- Virtual Private Networks (VPN).
Data Security
In distributed systems, it is imperative to adopt measure to secure data apart from communications. The data security measures are −
Authentication and authorization − These are the access control measures adopted to ensure that only authentic users can use the database. To provide authentication digital certificates are used. Besides, login is restricted through username/password combination.
Data encryption − The two approaches for data encryption in distributed systems are −
Internal to distributed database approach: The user applications encrypt the data and then store the encrypted data in the database. For using the stored data, the applications fetch the encrypted data from the database and then decrypt it.
External to distributed database: The distributed database system has its own encryption capabilities. The user applications store data and retrieve them without realizing that the data is stored in an encrypted form in the database.
Validated input − In this security measure, the user application checks for each input before it can be used for updating the database. An un-validated input can cause a wide range of exploits like buffer overrun, command injection, cross-site scripting and corruption in data.
Data Auditing
A database security system needs to detect and monitor security violations, in order to ascertain the security measures it should adopt. It is often very difficult to detect breach of security at the time of occurrences. One method to identify security violations is to examine audit logs. Audit logs contain information such as −
- Date, time and site of failed access attempts.
- Details of successful access attempts.
- Vital modifications in the database system.
- Access of huge amounts of data, particularly from databases in multiple sites.
All the above information gives an insight of the activities in the database. A periodical analysis of the log helps to identify any unnatural activity along with its site and time of occurrence. This log is ideally stored in a separate server so that it is inaccessible to attackers.