DynamoDB - Hướng dẫn nhanh
DynamoDB cho phép người dùng tạo cơ sở dữ liệu có khả năng lưu trữ và truy xuất bất kỳ lượng dữ liệu nào cũng như phục vụ bất kỳ lượng truy cập nào. Nó tự động phân phối dữ liệu và lưu lượng qua các máy chủ để quản lý động các yêu cầu của từng khách hàng và cũng duy trì hiệu suất nhanh chóng.
DynamoDB so với RDBMS
DynamoDB sử dụng mô hình NoSQL, có nghĩa là nó sử dụng một hệ thống không quan hệ. Bảng sau đây nêu rõ sự khác biệt giữa DynamoDB và RDBMS:
| Nhiệm vụ chung | RDBMS | DynamoDB |
|---|---|---|
| Connect to the Source | Nó sử dụng một kết nối liên tục và các lệnh SQL. | Nó sử dụng các yêu cầu HTTP và hoạt động API |
| Create a Table | Cấu trúc cơ bản của nó là các bảng và phải được xác định. | Nó chỉ sử dụng các khóa chính và không có lược đồ khi tạo. Nó sử dụng nhiều nguồn dữ liệu khác nhau. |
| Get Table Info | Tất cả thông tin bảng vẫn có thể truy cập được | Chỉ có khóa chính được tiết lộ. |
| Load Table Data | Nó sử dụng các hàng làm bằng cột. | Trong bảng, nó sử dụng các mục được tạo từ các thuộc tính |
| Read Table Data | Nó sử dụng câu lệnh SELECT và câu lệnh lọc. | Nó sử dụng GetItem, Query và Scan. |
| Manage Indexes | Nó sử dụng các chỉ mục tiêu chuẩn được tạo thông qua các câu lệnh SQL. Các sửa đổi đối với nó xảy ra tự động khi thay đổi bảng. | Nó sử dụng một chỉ số phụ để đạt được chức năng tương tự. Nó yêu cầu các thông số kỹ thuật (khóa phân vùng và khóa sắp xếp). |
| Modify Table Data | Nó sử dụng một câu lệnh UPDATE. | Nó sử dụng một hoạt động UpdateItem. |
| Delete Table Data | Nó sử dụng một câu lệnh DELETE. | Nó sử dụng một hoạt động DeleteItem. |
| Delete a Table | Nó sử dụng câu lệnh DROP TABLE. | Nó sử dụng một hoạt động DeleteTable. |
Ưu điểm
Hai ưu điểm chính của DynamoDB là khả năng mở rộng và tính linh hoạt. Nó không bắt buộc sử dụng một nguồn và cấu trúc dữ liệu cụ thể, cho phép người dùng làm việc với hầu hết mọi thứ, nhưng theo một cách thống nhất.
Thiết kế của nó cũng hỗ trợ nhiều mục đích sử dụng từ các tác vụ và hoạt động nhẹ hơn cho đến các chức năng đòi hỏi của doanh nghiệp. Nó cũng cho phép sử dụng đơn giản nhiều ngôn ngữ: Ruby, Java, Python, C #, Erlang, PHP và Perl.
Hạn chế
DynamoDB có một số hạn chế nhất định, tuy nhiên, những hạn chế này không nhất thiết tạo ra các vấn đề lớn hoặc cản trở sự phát triển vững chắc.
Bạn có thể xem xét chúng từ những điểm sau:
Capacity Unit Sizes- Đơn vị dung lượng đọc là một lần đọc nhất quán duy nhất mỗi giây cho các mục không lớn hơn 4KB. Đơn vị khả năng ghi là một lần ghi mỗi giây cho các mục không lớn hơn 1KB.
Provisioned Throughput Min/Max- Tất cả các bảng và chỉ số phụ chung có tối thiểu một đơn vị khả năng đọc và một đơn vị khả năng ghi. Mức tối đa tùy thuộc vào khu vực. Ở Hoa Kỳ, 40 nghìn lượt đọc và ghi vẫn là giới hạn cho mỗi bảng (80 nghìn cho mỗi tài khoản) và các khu vực khác có giới hạn 10 nghìn cho mỗi bảng với giới hạn tài khoản 20 nghìn.
Provisioned Throughput Increase and Decrease - Bạn có thể tăng mức này thường xuyên nếu cần, nhưng số lần giảm vẫn được giới hạn không quá bốn lần mỗi ngày cho mỗi bảng.
Table Size and Quantity Per Account - Kích thước bảng không có giới hạn, nhưng tài khoản có giới hạn 256 bảng trừ khi bạn yêu cầu giới hạn cao hơn.
Secondary Indexes Per Table - Năm cục bộ và năm toàn cầu được phép.
Projected Secondary Index Attributes Per Table - DynamoDB cho phép 20 thuộc tính.
Partition Key Length and Values - Độ dài tối thiểu của chúng là 1 byte và tối đa là 2048 byte, tuy nhiên, DynamoDB không đặt giới hạn về giá trị.
Sort Key Length and Values - Độ dài tối thiểu của nó là 1 byte và tối đa là 1024 byte, không có giới hạn cho các giá trị trừ khi bảng của nó sử dụng chỉ mục phụ cục bộ.
Table and Secondary Index Names - Tên phải có độ dài tối thiểu 3 ký tự và tối đa là 255. Chúng sử dụng các ký tự sau: AZ, az, 0-9, “_”, “-” và “.”.
Attribute Names - Một ký tự vẫn là tối thiểu và tối đa là 64KB, ngoại trừ các khóa và các thuộc tính nhất định.
Reserved Words - DynamoDB không ngăn việc sử dụng các từ dành riêng làm tên.
Expression Length- Chuỗi biểu thức có giới hạn 4KB. Biểu thức thuộc tính có giới hạn 255 byte. Các biến thay thế của một biểu thức có giới hạn 2MB.
Trước khi sử dụng DynamoDB, bạn phải tự làm quen với các thành phần cơ bản và hệ sinh thái của nó. Trong hệ sinh thái DynamoDB, bạn làm việc với các bảng, thuộc tính và mục. Một bảng chứa các tập hợp các mục và các mục chứa các tập hợp các thuộc tính. Thuộc tính là một phần tử cơ bản của dữ liệu không cần phân hủy thêm, tức là một trường.
Khóa chính
Các Khóa chính đóng vai trò là phương tiện nhận dạng duy nhất cho các mục trong bảng và các chỉ mục phụ cung cấp tính linh hoạt cho truy vấn. Dòng DynamoDB ghi lại các sự kiện bằng cách sửa đổi dữ liệu bảng.
Tạo Bảng không chỉ yêu cầu đặt tên mà còn cả khóa chính; xác định các mục trong bảng. Không có hai mục chia sẻ một khóa. DynamoDB sử dụng hai loại khóa chính:
Partition Key- Khóa chính đơn giản này bao gồm một thuộc tính duy nhất được gọi là “khóa phân vùng”. Bên trong, DynamoDB sử dụng giá trị khóa làm đầu vào cho hàm băm để xác định lưu trữ.
Partition Key and Sort Key - Khóa này, được gọi là “Khóa chính tổng hợp”, bao gồm hai thuộc tính.
Khóa phân vùng và
Phím sắp xếp.
DynamoDB áp dụng thuộc tính đầu tiên cho một hàm băm và lưu trữ các mục có cùng khóa phân vùng với nhau; với thứ tự của chúng được xác định bởi phím sắp xếp. Các mục có thể chia sẻ khóa phân vùng, nhưng không chia sẻ khóa sắp xếp.
Các thuộc tính Khóa chính chỉ cho phép các giá trị vô hướng (đơn); và các kiểu dữ liệu chuỗi, số hoặc nhị phân. Các thuộc tính không phải khóa không có những ràng buộc này.
Chỉ mục phụ
Các chỉ mục này cho phép bạn truy vấn dữ liệu bảng bằng một khóa thay thế. Mặc dù DynamoDB không bắt buộc sử dụng chúng, nhưng chúng tối ưu hóa việc truy vấn.
DynamoDB sử dụng hai loại chỉ mục phụ:
Global Secondary Index - Chỉ mục này sở hữu các khóa phân vùng và sắp xếp, có thể khác với các khóa bảng.
Local Secondary Index - Chỉ mục này sở hữu một khóa phân vùng giống hệt với bảng, tuy nhiên, khóa sắp xếp của nó khác.
API
Các hoạt động API do DynamoDB cung cấp bao gồm các hoạt động của mặt phẳng điều khiển, mặt phẳng dữ liệu (ví dụ: tạo, đọc, cập nhật và xóa) và các luồng. Trong hoạt động của mặt phẳng điều khiển, bạn tạo và quản lý bảng bằng các công cụ sau:
- CreateTable
- DescribeTable
- ListTables
- UpdateTable
- DeleteTable
Trong mặt phẳng dữ liệu, bạn thực hiện các hoạt động CRUD bằng các công cụ sau:
| Tạo nên | Đọc | Cập nhật | Xóa bỏ |
|---|---|---|---|
PutItem BatchWriteItem |
GetItem BatchGetItem Truy vấn Quét |
UpdateItem | Xóa mục BatchWriteItem |
Các hoạt động luồng điều khiển các luồng bảng. Bạn có thể xem lại các công cụ phát trực tiếp sau:
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
Thông lượng được cung cấp
Trong quá trình tạo bảng, bạn chỉ định thông lượng được cấp phép, dự trữ tài nguyên để đọc và ghi. Bạn sử dụng đơn vị công suất để đo lường và thiết lập thông lượng.
Khi các ứng dụng vượt quá thông lượng đã đặt, các yêu cầu sẽ không thành công. Bảng điều khiển DynamoDB GUI cho phép giám sát thông lượng đã đặt và đã sử dụng để cung cấp năng động và tốt hơn.
Đọc nhất quán
DynamoDB sử dụng eventually consistent và strongly consistentđọc để hỗ trợ nhu cầu ứng dụng động. Cuối cùng, các lần đọc nhất quán không phải lúc nào cũng cung cấp dữ liệu hiện tại.
Các lần đọc nhất quán mạnh mẽ luôn cung cấp dữ liệu hiện tại (ngoại trừ lỗi thiết bị hoặc sự cố mạng). Cuối cùng các lần đọc nhất quán đóng vai trò là cài đặt mặc định, yêu cầu cài đặt là true trongConsistentRead để thay đổi nó.
Phân vùng
DynamoDB sử dụng phân vùng để lưu trữ dữ liệu. Các phân bổ lưu trữ này cho các bảng có hỗ trợ SSD và tự động sao chép giữa các vùng. DynamoDB quản lý tất cả các tác vụ phân vùng, không yêu cầu người dùng tham gia.
Khi tạo bảng, bảng đi vào trạng thái CREATING, trạng thái này sẽ phân bổ các phân vùng. Khi nó đạt đến trạng thái ACTIVE, bạn có thể thực hiện các thao tác. Hệ thống thay đổi phân vùng khi dung lượng của nó đạt đến mức tối đa hoặc khi bạn thay đổi thông lượng.
Môi trường DynamoDB chỉ bao gồm việc sử dụng tài khoản Amazon Web Services của bạn để truy cập bảng điều khiển DynamoDB GUI, tuy nhiên, bạn cũng có thể thực hiện cài đặt cục bộ.
Điều hướng đến trang web sau - https://aws.amazon.com/dynamodb/
Nhấp vào nút “Bắt đầu với Amazon DynamoDB” hoặc nút “Tạo tài khoản AWS” nếu bạn chưa có tài khoản Amazon Web Services. Quy trình đơn giản được hướng dẫn sẽ thông báo cho bạn về tất cả các khoản phí và yêu cầu liên quan.
Sau khi thực hiện tất cả các bước cần thiết của quy trình, bạn sẽ có quyền truy cập. Chỉ cần đăng nhập vào bảng điều khiển AWS, sau đó điều hướng đến bảng điều khiển DynamoDB.
Đảm bảo xóa tài liệu không sử dụng hoặc không cần thiết để tránh các khoản phí liên quan.
Cài đặt cục bộ
AWS (Amazon Web Service) cung cấp phiên bản DynamoDB để cài đặt cục bộ. Nó hỗ trợ tạo ứng dụng mà không cần dịch vụ web hoặc kết nối. Nó cũng làm giảm thông lượng cung cấp, lưu trữ dữ liệu và phí chuyển giao bằng cách cho phép một cơ sở dữ liệu cục bộ. Hướng dẫn này giả định cài đặt cục bộ.
Khi sẵn sàng triển khai, bạn có thể thực hiện một vài điều chỉnh nhỏ đối với ứng dụng của mình để chuyển nó sang sử dụng AWS.
Tệp cài đặt là một .jar executable. Nó chạy trong Linux, Unix, Windows và bất kỳ hệ điều hành nào khác có hỗ trợ Java. Tải xuống tệp bằng cách sử dụng một trong các liên kết sau:
Tarball - http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.tar.gz
Zip archive - http://dynamodb-local.s3-website-us-west2.amazonaws.com/dynamodb_local_latest.zip
Note- Các kho lưu trữ khác cung cấp tệp, nhưng không nhất thiết phải là phiên bản mới nhất. Sử dụng các liên kết ở trên cho các tệp cài đặt cập nhật. Ngoài ra, hãy đảm bảo bạn có Java Runtime Engine (JRE) phiên bản 6.x hoặc phiên bản mới hơn. DynamoDB không thể chạy với các phiên bản cũ hơn.
Sau khi tải xuống tệp lưu trữ thích hợp, hãy giải nén thư mục của nó (DynamoDBLocal.jar) và đặt nó vào vị trí mong muốn.
Sau đó, bạn có thể khởi động DynamoDB bằng cách mở dấu nhắc lệnh, điều hướng đến thư mục chứa DynamoDBLocal.jar và nhập lệnh sau:
java -Djava.library.path=./DynamoDBLocal_lib -jar DynamoDBLocal.jar -sharedDbBạn cũng có thể dừng DynamoDB bằng cách đóng dấu nhắc lệnh được sử dụng để khởi động nó.
Môi trường làm việc
Bạn có thể sử dụng trình bao JavaScript, bảng điều khiển GUI và nhiều ngôn ngữ để làm việc với DynamoDB. Các ngôn ngữ có sẵn bao gồm Ruby, Java, Python, C #, Erlang, PHP và Perl.
Trong hướng dẫn này, chúng tôi sử dụng các ví dụ về bảng điều khiển Java và GUI để làm rõ khái niệm và mã. Cài đặt Java IDE, AWS SDK cho Java và thiết lập thông tin xác thực bảo mật AWS cho Java SDK để sử dụng Java.
Chuyển đổi từ Cục bộ sang Mã Dịch vụ Web
Khi sẵn sàng triển khai, bạn sẽ cần phải thay đổi mã của mình. Các điều chỉnh phụ thuộc vào ngôn ngữ mã và các yếu tố khác. Thay đổi chính chỉ bao gồm thay đổiendpointtừ một điểm địa phương đến một vùng AWS. Các thay đổi khác yêu cầu phân tích sâu hơn về ứng dụng của bạn.
Cài đặt cục bộ khác với dịch vụ web theo nhiều cách, bao gồm, nhưng không giới hạn ở những điểm khác biệt chính sau:
Cài đặt cục bộ tạo bảng ngay lập tức, nhưng dịch vụ mất nhiều thời gian hơn.
Cài đặt cục bộ bỏ qua thông lượng.
Việc xóa xảy ra ngay lập tức trong một cài đặt cục bộ.
Việc đọc / ghi diễn ra nhanh chóng trong cài đặt cục bộ do không có mạng.
DynamoDB cung cấp ba tùy chọn để thực hiện các hoạt động: bảng điều khiển GUI dựa trên web, trình bao JavaScript và ngôn ngữ lập trình bạn chọn.
Trong hướng dẫn này, chúng tôi sẽ tập trung vào việc sử dụng bảng điều khiển GUI và ngôn ngữ Java để hiểu rõ và hiểu khái niệm.
Bảng điều khiển GUI
Bạn có thể tìm thấy bảng điều khiển GUI hoặc Bảng điều khiển quản lý AWS cho Amazon DynamoDB tại địa chỉ sau: https://console.aws.amazon.com/dynamodb/home
Nó cho phép bạn thực hiện các tác vụ sau:
- CRUD
- Xem các mục trong bảng
- Thực hiện truy vấn bảng
- Đặt báo thức để theo dõi sức chứa bàn
- Xem số liệu bảng trong thời gian thực
- Xem Báo thức Bảng

Nếu tài khoản DynamoDB của bạn không có bảng, khi có quyền truy cập, nó sẽ hướng dẫn bạn cách tạo bảng. Màn hình chính của nó cung cấp ba phím tắt để thực hiện các thao tác thông thường -
- Tạo bảng
- Thêm và truy vấn bảng
- Theo dõi và quản lý bảng
JavaScript Shell
DynamoDB bao gồm một trình bao JavaScript tương tác. Trình bao chạy bên trong trình duyệt web và các trình duyệt được đề xuất bao gồm Firefox và Chrome.

Note - Sử dụng các trình duyệt khác có thể bị lỗi.
Truy cập shell bằng cách mở trình duyệt web và nhập địa chỉ sau:http://localhost:8000/shell
Sử dụng trình bao bằng cách nhập JavaScript vào ngăn bên trái và nhấp vào nút biểu tượng “Phát” ở góc trên cùng bên phải của ngăn bên trái để chạy mã. Kết quả mã hiển thị trong ngăn bên phải.
DynamoDB và Java
Sử dụng Java với DynamoDB bằng cách sử dụng môi trường phát triển Java của bạn. Các hoạt động xác nhận với cấu trúc và cú pháp Java bình thường.
Các loại dữ liệu được DynamoDB hỗ trợ bao gồm các loại dữ liệu cụ thể cho các thuộc tính, hành động và ngôn ngữ mã hóa bạn chọn.
Các kiểu dữ liệu thuộc tính
DynamoDB hỗ trợ một tập hợp lớn các kiểu dữ liệu cho các thuộc tính bảng. Mỗi loại dữ liệu thuộc một trong ba loại sau:
Scalar - Các kiểu này đại diện cho một giá trị duy nhất và bao gồm số, chuỗi, nhị phân, Boolean và null.
Document - Các kiểu này đại diện cho một cấu trúc phức tạp sở hữu các thuộc tính lồng nhau và bao gồm danh sách và bản đồ.
Set - Các kiểu này đại diện cho nhiều đại lượng vô hướng, và bao gồm các bộ chuỗi, bộ số và bộ nhị phân.
Hãy nhớ DynamoDB là một cơ sở dữ liệu NoSQL không có lớp, không cần định nghĩa thuộc tính hoặc kiểu dữ liệu khi tạo bảng. Nó chỉ yêu cầu kiểu dữ liệu thuộc tính khóa chính trái ngược với RDBMS, yêu cầu kiểu dữ liệu cột khi tạo bảng.
Vô hướng
Numbers - Chúng được giới hạn ở 38 chữ số và là số dương, số âm hoặc số không.
String - Chúng là mã Unicode sử dụng UTF-8, có độ dài tối thiểu> 0 và tối đa là 400KB.
Binary- Chúng lưu trữ bất kỳ dữ liệu nhị phân nào, ví dụ: dữ liệu được mã hóa, hình ảnh và văn bản nén. DynamoDB xem các byte của nó là không dấu.
Boolean - Họ lưu trữ đúng hoặc sai.
Null - Chúng đại diện cho một trạng thái không xác định hoặc không xác định.
Tài liệu
List - Nó lưu trữ các bộ sưu tập giá trị có thứ tự và sử dụng dấu ngoặc vuông ([...]).
Map - Nó lưu trữ các bộ sưu tập cặp giá trị-tên không có thứ tự và sử dụng dấu ngoặc nhọn ({...}).
Bộ
Tập hợp phải chứa các phần tử cùng loại, dù là số, chuỗi hay nhị phân. Các giới hạn duy nhất được đặt trên các bộ bao gồm giới hạn kích thước mục 400KB và mỗi phần tử là duy nhất.
Các loại dữ liệu hành động
API DynamoDB chứa nhiều loại dữ liệu khác nhau được sử dụng bởi các hành động. Bạn có thể xem xét lựa chọn các loại khóa sau:
AttributeDefinition - Nó đại diện cho bảng khóa và lược đồ chỉ mục.
Capacity - Nó thể hiện số lượng thông lượng được tiêu thụ bởi một bảng hoặc chỉ mục.
CreateGlobalSecondaryIndexAction - Nó đại diện cho một chỉ mục phụ toàn cầu mới được thêm vào một bảng.
LocalSecondaryIndex - Nó đại diện cho các thuộc tính chỉ mục thứ cấp cục bộ.
ProvisionedThroughput - Nó đại diện cho thông lượng được cung cấp cho một chỉ mục hoặc bảng.
PutRequest - Nó đại diện cho các yêu cầu PutItem.
TableDescription - Nó đại diện cho các thuộc tính của bảng.
Các kiểu dữ liệu Java được hỗ trợ
DynamoDB cung cấp hỗ trợ cho các kiểu dữ liệu nguyên thủy, Bộ sưu tập và các kiểu tùy ý cho Java.
Việc tạo bảng thường bao gồm tạo bảng, đặt tên, thiết lập các thuộc tính khóa chính của nó và thiết lập các kiểu dữ liệu thuộc tính.
Sử dụng GUI Console, Java hoặc một tùy chọn khác để thực hiện các tác vụ này.
Tạo bảng bằng GUI Console
Tạo bảng bằng cách truy cập bảng điều khiển tại https://console.aws.amazon.com/dynamodb. Sau đó chọn tùy chọn "Tạo bảng".
Ví dụ của chúng tôi tạo một bảng được điền thông tin sản phẩm, với các sản phẩm thuộc tính duy nhất được xác định bằng số ID (thuộc tính số). bên trongCreate Tablemàn hình, nhập tên bảng trong trường tên bảng; nhập khóa chính (ID) trong trường khóa phân vùng; và nhập "Số" cho kiểu dữ liệu.
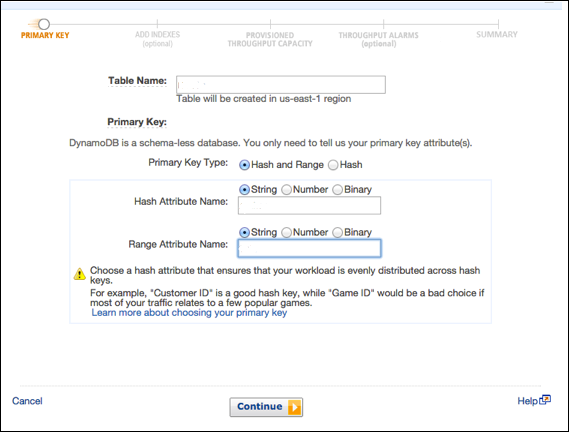
Sau khi nhập đầy đủ thông tin, hãy chọn Create.
Tạo bảng bằng Java
Sử dụng Java để tạo cùng một bảng. Khóa chính của nó bao gồm hai thuộc tính sau:
ID - Sử dụng khóa phân vùng và ScalarAttributeType N, nghĩa là số.
Nomenclature - Sử dụng một khóa sắp xếp và ScalarAttributeType S, nghĩa là chuỗi.
Java sử dụng createTable methodđể tạo một bảng; và trong lệnh gọi, tên bảng, thuộc tính khóa chính và kiểu dữ liệu thuộc tính được chỉ định.
Bạn có thể xem lại ví dụ sau:
import java.util.Arrays;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ScalarAttributeType;
public class ProductsCreateTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
String tableName = "Products";
try {
System.out.println("Creating the table, wait...");
Table table = dynamoDB.createTable (tableName,
Arrays.asList (
new KeySchemaElement("ID", KeyType.HASH), // the partition key
// the sort key
new KeySchemaElement("Nomenclature", KeyType.RANGE)
),
Arrays.asList (
new AttributeDefinition("ID", ScalarAttributeType.N),
new AttributeDefinition("Nomenclature", ScalarAttributeType.S)
),
new ProvisionedThroughput(10L, 10L)
);
table.waitForActive();
System.out.println("Table created successfully. Status: " +
table.getDescription().getTableStatus());
} catch (Exception e) {
System.err.println("Cannot create the table: ");
System.err.println(e.getMessage());
}
}
}Trong ví dụ trên, hãy lưu ý điểm cuối: .withEndpoint.
Nó chỉ ra việc sử dụng cài đặt cục bộ bằng cách sử dụng localhost. Ngoài ra, lưu ý yêu cầuProvisionedThroughput parameter, mà cài đặt cục bộ bỏ qua.
Việc tải bảng thường bao gồm việc tạo tệp nguồn, đảm bảo tệp nguồn tuân theo cú pháp tương thích với DynamoDB, gửi tệp nguồn đến đích và sau đó xác nhận một tập hợp thành công.
Sử dụng bảng điều khiển GUI, Java hoặc tùy chọn khác để thực hiện tác vụ.
Tải bảng bằng GUI Console
Tải dữ liệu bằng cách sử dụng kết hợp dòng lệnh và bảng điều khiển. Bạn có thể tải dữ liệu theo nhiều cách, một số cách như sau:
- Bàn điều khiển
- Dòng lệnh
- Mã và cả
- Đường ống dữ liệu (một tính năng được thảo luận ở phần sau của hướng dẫn)
Tuy nhiên, đối với tốc độ, ví dụ này sử dụng cả shell và console. Đầu tiên, tải dữ liệu nguồn vào đích theo cú pháp sau:
aws dynamodb batch-write-item -–request-items file://[filename]Ví dụ -
aws dynamodb batch-write-item -–request-items file://MyProductData.jsonXác minh sự thành công của hoạt động bằng cách truy cập bảng điều khiển tại -
https://console.aws.amazon.com/dynamodb
Chọn Tables từ ngăn dẫn hướng và chọn bảng đích từ danh sách bảng.
Chọn Itemsđể kiểm tra dữ liệu bạn đã sử dụng để điền vào bảng. Lựa chọnCancel để quay lại danh sách bảng.
Tải bảng bằng Java
Sử dụng Java bằng cách tạo một tệp nguồn trước tiên. Tệp nguồn của chúng tôi sử dụng định dạng JSON. Mỗi sản phẩm có hai thuộc tính khóa chính (ID và Danh pháp) và một bản đồ JSON (Stat) -
[
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
{
"ID" : ... ,
"Nomenclature" : ... ,
"Stat" : { ... }
},
...
]Bạn có thể xem lại ví dụ sau:
{
"ID" : 122,
"Nomenclature" : "Particle Blaster 5000",
"Stat" : {
"Manufacturer" : "XYZ Inc.",
"sales" : "1M+",
"quantity" : 500,
"img_src" : "http://www.xyz.com/manuals/particleblaster5000.jpg",
"description" : "A laser cutter used in plastic manufacturing."
}
}Bước tiếp theo là đặt tệp vào thư mục được ứng dụng của bạn sử dụng.
Java chủ yếu sử dụng putItem và path methods để thực hiện tải.
Bạn có thể xem lại ví dụ mã sau để xử lý tệp và tải tệp đó -
import java.io.File;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.fasterxml.jackson.core.JsonFactory;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper
import com.fasterxml.jackson.databind.node.ObjectNode;
public class ProductsLoadData {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
JsonParser parser = new JsonFactory()
.createParser(new File("productinfo.json"));
JsonNode rootNode = new ObjectMapper().readTree(parser);
Iterator<JsonNode> iter = rootNode.iterator();
ObjectNode currentNode;
while (iter.hasNext()) {
currentNode = (ObjectNode) iter.next();
int ID = currentNode.path("ID").asInt();
String Nomenclature = currentNode.path("Nomenclature").asText();
try {
table.putItem(new Item()
.withPrimaryKey("ID", ID, "Nomenclature", Nomenclature)
.withJSON("Stat", currentNode.path("Stat").toString()));
System.out.println("Successful load: " + ID + " " + Nomenclature);
} catch (Exception e) {
System.err.println("Cannot add product: " + ID + " " + Nomenclature);
System.err.println(e.getMessage());
break;
}
}
parser.close();
}
}Truy vấn bảng chủ yếu yêu cầu chọn bảng, chỉ định khóa phân vùng và thực hiện truy vấn; với các tùy chọn sử dụng các chỉ mục phụ và thực hiện lọc sâu hơn thông qua các hoạt động quét.
Sử dụng GUI Console, Java hoặc tùy chọn khác để thực hiện tác vụ.
Bảng truy vấn sử dụng GUI Console
Thực hiện một số truy vấn đơn giản bằng cách sử dụng các bảng đã tạo trước đó. Đầu tiên, mở bảng điều khiển tạihttps://console.aws.amazon.com/dynamodb
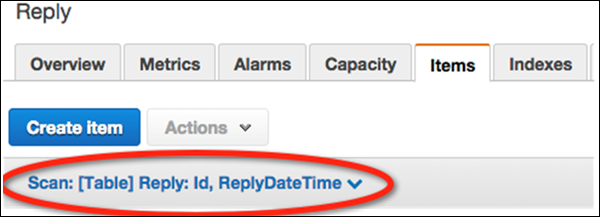
Chọn Tables từ ngăn điều hướng và chọn Replytừ danh sách bảng. Sau đó chọnItems để xem dữ liệu đã tải.
Chọn liên kết lọc dữ liệu (“Quét: [Bảng] Trả lời”) bên dưới Create Item cái nút.
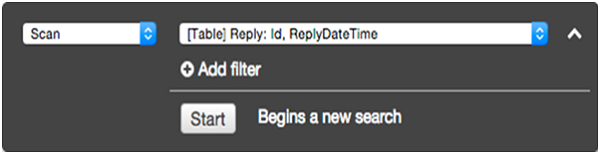
Trong màn hình lọc, chọn Truy vấn cho thao tác. Nhập giá trị khóa phân vùng thích hợp và nhấp vàoStart.
Các Reply bảng sau đó trả về các mục phù hợp.
Bảng truy vấn sử dụng Java
Sử dụng phương thức truy vấn trong Java để thực hiện các thao tác truy xuất dữ liệu. Nó yêu cầu chỉ định giá trị khóa phân vùng, với khóa sắp xếp là tùy chọn.
Mã một truy vấn Java bằng cách tạo một querySpec objectmô tả các thông số. Sau đó, truyền đối tượng vào phương thức truy vấn. Chúng tôi sử dụng khóa phân vùng từ các ví dụ trước.
Bạn có thể xem lại ví dụ sau:
import java.util.HashMap;
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
public class ProductsQuery {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
HashMap<String, String> nameMap = new HashMap<String, String>();
nameMap.put("#ID", "ID");
HashMap<String, Object> valueMap = new HashMap<String, Object>();
valueMap.put(":xxx", 122);
QuerySpec querySpec = new QuerySpec()
.withKeyConditionExpression("#ID = :xxx")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(valueMap);
ItemCollection<QueryOutcome> items = null;
Iterator<Item> iterator = null;
Item item = null;
try {
System.out.println("Product with the ID 122");
items = table.query(querySpec);
iterator = items.iterator();
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.getNumber("ID") + ": "
+ item.getString("Nomenclature"));
}
} catch (Exception e) {
System.err.println("Cannot find products with the ID number 122");
System.err.println(e.getMessage());
}
}
}Lưu ý rằng truy vấn sử dụng khóa phân vùng, tuy nhiên, các chỉ mục phụ cung cấp một tùy chọn khác cho các truy vấn. Tính linh hoạt của chúng cho phép truy vấn các thuộc tính không phải khóa, một chủ đề sẽ được thảo luận sau trong hướng dẫn này.
Phương pháp quét cũng hỗ trợ các hoạt động truy xuất bằng cách thu thập tất cả dữ liệu bảng. Cácoptional .withFilterExpression ngăn các mục nằm ngoài tiêu chí đã chỉ định xuất hiện trong kết quả.
Phần sau của hướng dẫn này, chúng ta sẽ thảo luận về scanningchi tiết. Bây giờ, hãy xem ví dụ sau:
import java.util.Iterator;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.ScanSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class ProductsScan {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
ScanSpec scanSpec = new ScanSpec()
.withProjectionExpression("#ID, Nomenclature , stat.sales")
.withFilterExpression("#ID between :start_id and :end_id")
.withNameMap(new NameMap().with("#ID", "ID"))
.withValueMap(new ValueMap().withNumber(":start_id", 120)
.withNumber(":end_id", 129));
try {
ItemCollection<ScanOutcome> items = table.scan(scanSpec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
Item item = iter.next();
System.out.println(item.toString());
}
} catch (Exception e) {
System.err.println("Cannot perform a table scan:");
System.err.println(e.getMessage());
}
}
}Trong chương này, chúng ta sẽ thảo luận về cách chúng ta có thể xóa một bảng và các cách xóa bảng khác nhau.
Xóa bảng là một thao tác đơn giản yêu cầu ít hơn tên bảng. Sử dụng bảng điều khiển GUI, Java hoặc bất kỳ tùy chọn nào khác để thực hiện tác vụ này.
Xóa bảng bằng GUI Console
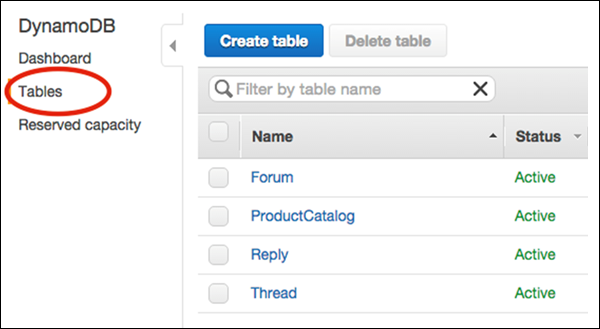
Thực hiện thao tác xóa bằng cách truy cập bảng điều khiển trước tiên tại -
https://console.aws.amazon.com/dynamodb.
Chọn Tables từ ngăn dẫn hướng và chọn bảng muốn xóa khỏi danh sách bảng như được hiển thị trong ảnh chụp màn hình sau.
Cuối cùng, chọn Delete Table. Sau khi chọn Xóa Bảng, một xác nhận sẽ xuất hiện. Bảng của bạn sau đó sẽ bị xóa.
Xóa bảng bằng Java
Sử dụng deletephương pháp để loại bỏ một bảng. Dưới đây là một ví dụ để giải thích khái niệm này tốt hơn.
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ProductsDeleteTable {
public static void main(String[] args) throws Exception {
AmazonDynamoDBClient client = new AmazonDynamoDBClient()
.withEndpoint("http://localhost:8000");
DynamoDB dynamoDB = new DynamoDB(client);
Table table = dynamoDB.getTable("Products");
try {
System.out.println("Performing table delete, wait...");
table.delete();
table.waitForDelete();
System.out.print("Table successfully deleted.");
} catch (Exception e) {
System.err.println("Cannot perform table delete: ");
System.err.println(e.getMessage());
}
}
}DynamoDB cung cấp một loạt các công cụ API mạnh mẽ để thao tác bảng, đọc dữ liệu và sửa đổi dữ liệu.
Amazon khuyên bạn nên sử dụng AWS SDKs(ví dụ: Java SDK) thay vì gọi các API cấp thấp. Các thư viện làm cho việc tương tác trực tiếp với các API cấp thấp trở nên không cần thiết. Các thư viện đơn giản hóa các tác vụ phổ biến như xác thực, tuần tự hóa và kết nối.
Thao tác bảng
DynamoDB cung cấp năm hành động cấp thấp cho Quản lý bảng -
CreateTable- Điều này tạo ra một bảng và bao gồm thông lượng do người dùng đặt. Nó yêu cầu bạn đặt một khóa chính, cho dù phức hợp hay đơn giản. Nó cũng cho phép một hoặc nhiều chỉ mục phụ.
ListTables - Điều này cung cấp danh sách tất cả các bảng trong tài khoản của người dùng AWS hiện tại và được gắn với điểm cuối của họ.
UpdateTable - Điều này làm thay đổi thông lượng và thông lượng chỉ mục thứ cấp toàn cầu.
DescribeTable- Điều này cung cấp siêu dữ liệu bảng; ví dụ: trạng thái, kích thước và chỉ số.
DeleteTable - Thao tác này chỉ đơn giản là xóa bảng và các chỉ số của nó.
Đọc dữ liệu
DynamoDB cung cấp bốn hành động cấp thấp để đọc dữ liệu -
GetItem- Nó chấp nhận một khóa chính và trả về các thuộc tính của mục được liên kết. Nó cho phép thay đổi cài đặt đọc nhất quán cuối cùng mặc định của nó.
BatchGetItem- Nó thực hiện một số yêu cầu GetItem trên nhiều mục thông qua các khóa chính, với tùy chọn một hoặc nhiều bảng. Nó trả về không quá 100 mặt hàng và phải còn dưới 16MB. Nó cho phép những lần đọc cuối cùng nhất quán và nhất quán.
Scan- Nó đọc tất cả các mục trong bảng và tạo ra một tập kết quả nhất quán cuối cùng. Bạn có thể lọc kết quả thông qua các điều kiện. Nó tránh sử dụng một chỉ mục và quét toàn bộ bảng, vì vậy không sử dụng nó cho các truy vấn yêu cầu khả năng dự đoán.
Query- Nó trả về một hoặc nhiều mục bảng hoặc các mục chỉ mục phụ. Nó sử dụng một giá trị được chỉ định cho khóa phân vùng và cho phép sử dụng các toán tử so sánh để thu hẹp phạm vi. Nó bao gồm hỗ trợ cho cả hai loại nhất quán và mỗi phản hồi tuân theo giới hạn 1MB về kích thước.
Sửa đổi dữ liệu
DynamoDB cung cấp bốn hành động cấp thấp để sửa đổi dữ liệu -
PutItem- Điều này sinh ra một vật phẩm mới hoặc thay thế các vật phẩm hiện có. Theo mặc định, khi phát hiện ra các khóa chính giống nhau, nó sẽ thay thế mục đó. Các toán tử có điều kiện cho phép bạn làm việc xung quanh mặc định và chỉ thay thế các mục trong các điều kiện nhất định.
BatchWriteItem- Điều này thực hiện cả nhiều yêu cầu PutItem và DeleteItem, và trên một số bảng. Nếu một yêu cầu không thành công, nó không ảnh hưởng đến toàn bộ hoạt động. Nắp của nó là 25 mục và kích thước 16MB.
UpdateItem - Nó thay đổi các thuộc tính mục hiện có và cho phép sử dụng các toán tử có điều kiện để thực hiện cập nhật chỉ trong các điều kiện nhất định.
DeleteItem - Nó sử dụng khóa chính để xóa một mục, và cũng cho phép sử dụng các toán tử điều kiện để chỉ định các điều kiện xóa.
Việc tạo một mục trong DynamoDB chủ yếu bao gồm đặc điểm kỹ thuật thuộc tính và mục cũng như tùy chọn chỉ định điều kiện. Mỗi mặt hàng tồn tại như một tập hợp các thuộc tính, với mỗi thuộc tính được đặt tên và gán một giá trị của một loại nhất định.
Các loại giá trị bao gồm vô hướng, tài liệu hoặc tập hợp. Các vật phẩm có giới hạn kích thước 400KB, với khả năng có bất kỳ số lượng thuộc tính nào có thể phù hợp trong giới hạn đó. Kích thước tên và giá trị (độ dài nhị phân và UTF-8) xác định kích thước mục. Sử dụng tên thuộc tính ngắn giúp giảm thiểu kích thước mặt hàng.
Note- Bạn phải chỉ định tất cả các thuộc tính khóa chính, với khóa chính chỉ yêu cầu khóa phân vùng; và các khóa tổng hợp yêu cầu cả phân vùng và khóa sắp xếp.
Ngoài ra, hãy nhớ các bảng không có lược đồ được xác định trước. Bạn có thể lưu trữ các bộ dữ liệu khác nhau đáng kể trong một bảng.
Sử dụng bảng điều khiển GUI, Java hoặc công cụ khác để thực hiện tác vụ này.
Làm thế nào để tạo một mục bằng GUI Console?
Điều hướng đến bảng điều khiển. Trong ngăn điều hướng ở bên trái, hãy chọnTables. Chọn tên bảng để sử dụng làm đích, sau đó chọnItems như được hiển thị trong ảnh chụp màn hình sau.
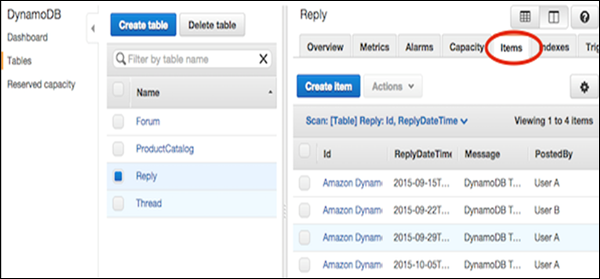
Lựa chọn Create Item. Màn hình Create Item cung cấp một giao diện để nhập các giá trị thuộc tính cần thiết. Bất kỳ chỉ số phụ nào cũng phải được nhập.
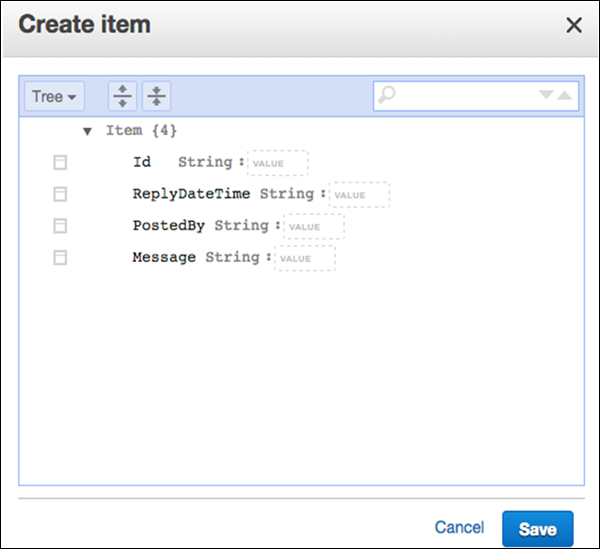
Nếu bạn yêu cầu nhiều thuộc tính hơn, hãy chọn menu tác vụ ở bên trái Message. Sau đó chọnAppendvà kiểu dữ liệu mong muốn.
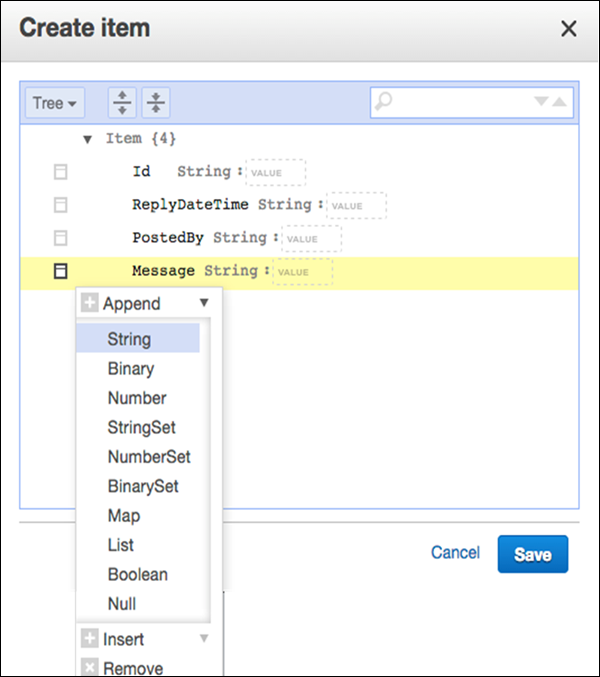
Sau khi nhập tất cả thông tin cần thiết, hãy chọn Save để thêm mục.
Làm thế nào để sử dụng Java trong việc tạo vật phẩm?
Sử dụng Java trong các hoạt động tạo mục bao gồm tạo một cá thể lớp DynamoDB, cá thể lớp Bảng, cá thể lớp Mục và chỉ định khóa chính và các thuộc tính của mục bạn sẽ tạo. Sau đó, thêm mục mới của bạn bằng phương thức putItem.
Thí dụ
DynamoDB dynamoDB = new DynamoDB (new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
// Spawn a related items list
List<Number> RELItems = new ArrayList<Number>();
RELItems.add(123);
RELItems.add(456);
RELItems.add(789);
//Spawn a product picture map
Map<String, String> photos = new HashMap<String, String>();
photos.put("Anterior", "http://xyz.com/products/101_front.jpg");
photos.put("Posterior", "http://xyz.com/products/101_back.jpg");
photos.put("Lateral", "http://xyz.com/products/101_LFTside.jpg");
//Spawn a product review map
Map<String, List<String>> prodReviews = new HashMap<String, List<String>>();
List<String> fiveStarRVW = new ArrayList<String>();
fiveStarRVW.add("Shocking high performance.");
fiveStarRVW.add("Unparalleled in its market.");
prodReviews.put("5 Star", fiveStarRVW);
List<String> oneStarRVW = new ArrayList<String>();
oneStarRVW.add("The worst offering in its market.");
prodReviews.put("1 Star", oneStarRVW);
// Generate the item
Item item = new Item()
.withPrimaryKey("Id", 101)
.withString("Nomenclature", "PolyBlaster 101")
.withString("Description", "101 description")
.withString("Category", "Hybrid Power Polymer Cutter")
.withString("Make", "Brand – XYZ")
.withNumber("Price", 50000)
.withString("ProductCategory", "Laser Cutter")
.withBoolean("Availability", true)
.withNull("Qty")
.withList("ItemsRelated", RELItems)
.withMap("Images", photos)
.withMap("Reviews", prodReviews);
// Add item to the table
PutItemOutcome outcome = table.putItem(item);Bạn cũng có thể xem ví dụ lớn hơn sau đây.
Note- Mẫu sau đây có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Mẫu sau cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class CreateItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
}Việc truy xuất một mục trong DynamoDB yêu cầu sử dụng GetItem và chỉ định tên bảng và khóa chính của mục. Đảm bảo bao gồm một khóa chính đầy đủ thay vì bỏ qua một phần.
Ví dụ: bỏ qua khóa sắp xếp của khóa tổng hợp.
Hành vi GetItem tuân theo ba giá trị mặc định -
- Nó thực hiện như một lần đọc nhất quán cuối cùng.
- Nó cung cấp tất cả các thuộc tính.
- Nó không nêu chi tiết mức tiêu thụ đơn vị công suất của nó.
Các tham số này cho phép bạn ghi đè hành vi GetItem mặc định.
Lấy một mục
DynamoDB đảm bảo độ tin cậy thông qua việc duy trì nhiều bản sao của các mục trên nhiều máy chủ. Mỗi lần ghi thành công sẽ tạo ra các bản sao này, nhưng cần thời gian đáng kể để thực thi; nghĩa là cuối cùng nhất quán. Điều này có nghĩa là bạn không thể đọc ngay sau khi viết một mục.
Bạn có thể thay đổi cách đọc mặc định cuối cùng nhất quán của GetItem, tuy nhiên, chi phí của nhiều dữ liệu hiện tại hơn vẫn tiêu thụ nhiều đơn vị dung lượng hơn; cụ thể là gấp hai lần. Lưu ý DynamoDB thường đạt được tính nhất quán trên mọi bản sao trong vòng một giây.
Bạn có thể sử dụng bảng điều khiển GUI, Java hoặc một công cụ khác để thực hiện tác vụ này.
Truy xuất mục bằng Java
Sử dụng Java trong các hoạt động truy xuất mục yêu cầu tạo Phiên bản lớp DynamoDB, Phiên bản lớp Bảng và gọi phương thức getItem của cá thể Bảng. Sau đó chỉ định khóa chính của mục.
Bạn có thể xem lại ví dụ sau:
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
Item item = table.getItem("IDnum", 109);Trong một số trường hợp, bạn cần chỉ định các tham số cho thao tác này.
Ví dụ sau sử dụng .withProjectionExpression và GetItemSpec để biết thông số kỹ thuật truy xuất -
GetItemSpec spec = new GetItemSpec()
.withPrimaryKey("IDnum", 122)
.withProjectionExpression("IDnum, EmployeeName, Department")
.withConsistentRead(true);
Item item = table.getItem(spec);
System.out.println(item.toJSONPretty());Bạn cũng có thể xem lại một ví dụ lớn hơn sau đây để hiểu rõ hơn.
Note- Mẫu sau đây có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Mẫu này cũng sử dụng Eclipse IDE, tệp thông tin xác thực AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.io.IOException
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class GetItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void retrieveItem() {
Table table = dynamoDB.getTable(tableName);
try {
Item item = table.getItem("ID", 303, "ID, Nomenclature, Manufacturers", null);
System.out.println("Displaying retrieved items...");
System.out.println(item.toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot retrieve items.");
System.err.println(e.getMessage());
}
}
}Cập nhật một mục trong DynamoDB chủ yếu bao gồm việc chỉ định khóa chính đầy đủ và tên bảng cho mục đó. Nó yêu cầu một giá trị mới cho mỗi thuộc tính bạn sửa đổi. Hoạt động sử dụngUpdateItem, sửa đổi các mục hiện có hoặc tạo chúng khi phát hiện ra một mục bị thiếu.
Trong các bản cập nhật, bạn có thể muốn theo dõi các thay đổi bằng cách hiển thị các giá trị ban đầu và mới, trước và sau các hoạt động. UpdateItem sử dụngReturnValues để đạt được điều này.
Note - Hoạt động không báo cáo mức tiêu thụ đơn vị công suất, nhưng bạn có thể sử dụng ReturnConsumedCapacity tham số.
Sử dụng bảng điều khiển GUI, Java hoặc bất kỳ công cụ nào khác để thực hiện tác vụ này.
Làm thế nào để cập nhật các mục bằng công cụ GUI?
Điều hướng đến bảng điều khiển. Trong ngăn điều hướng ở bên trái, hãy chọnTables. Chọn bảng cần thiết, sau đó chọnItems chuyển hướng.
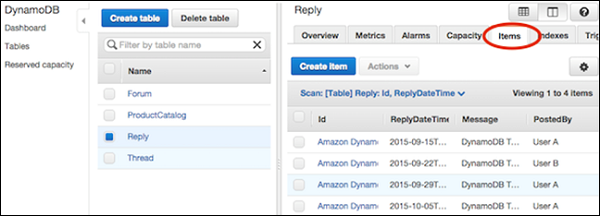
Chọn mục mong muốn để cập nhật và chọn Actions | Edit.
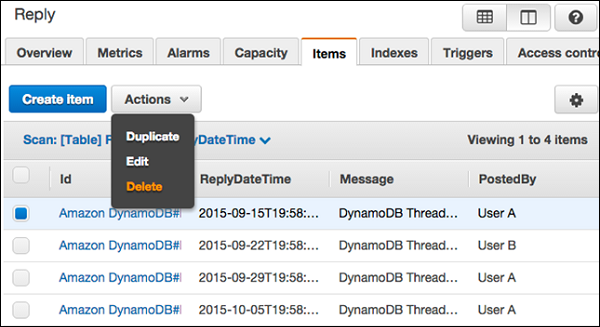
Sửa đổi bất kỳ thuộc tính hoặc giá trị nào cần thiết trong Edit Item cửa sổ.
Cập nhật các mục bằng Java
Sử dụng Java trong các hoạt động cập nhật mục yêu cầu tạo một cá thể lớp Bảng và gọi updateItemphương pháp. Sau đó, bạn chỉ định khóa chính của mặt hàng và cung cấpUpdateExpression chi tiết sửa đổi thuộc tính.
Sau đây là một ví dụ về điều tương tự -
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#M", "Make");
expressionAttributeNames.put("#P", "Price
expressionAttributeNames.put("#N", "ID");
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":val1",
new HashSet<String>(Arrays.asList("Make1","Make2")));
expressionAttributeValues.put(":val2", 1); //Price
UpdateItemOutcome outcome = table.updateItem(
"internalID", // key attribute name
111, // key attribute value
"add #M :val1 set #P = #P - :val2 remove #N", // UpdateExpression
expressionAttributeNames,
expressionAttributeValues);Các updateItem phương thức cũng cho phép xác định các điều kiện, có thể thấy trong ví dụ sau:
Table table = dynamoDB.getTable("ProductList");
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#P", "Price");
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":val1", 44); // change Price to 44
expressionAttributeValues.put(":val2", 15); // only if currently 15
UpdateItemOutcome outcome = table.updateItem (new PrimaryKey("internalID",111),
"set #P = :val1", // Update
"#P = :val2", // Condition
expressionAttributeNames,
expressionAttributeValues);Cập nhật mặt hàng bằng bộ đếm
DynamoDB cho phép bộ đếm nguyên tử, có nghĩa là sử dụng UpdateItem để tăng / giảm các giá trị thuộc tính mà không ảnh hưởng đến các yêu cầu khác; hơn nữa, các quầy luôn cập nhật.
Sau đây là một ví dụ giải thích cách nó có thể được thực hiện.
Note- Mẫu sau đây có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Mẫu này cũng sử dụng Eclipse IDE, tệp thông tin xác thực AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class UpdateItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void updateAddNewAttribute() {
Table table = dynamoDB.getTable(tableName);
try {
Map<String, String> expressionAttributeNames = new HashMap<String, String>();
expressionAttributeNames.put("#na", "NewAttribute");
UpdateItemSpec updateItemSpec = new UpdateItemSpec()
.withPrimaryKey("ID", 303)
.withUpdateExpression("set #na = :val1")
.withNameMap(new NameMap()
.with("#na", "NewAttribute"))
.withValueMap(new ValueMap()
.withString(":val1", "A value"))
.withReturnValues(ReturnValue.ALL_NEW);
UpdateItemOutcome outcome = table.updateItem(updateItemSpec);
// Confirm
System.out.println("Displaying updated item...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot add an attribute in " + tableName);
System.err.println(e.getMessage());
}
}
}Xóa một mục trong DynamoDB chỉ yêu cầu cung cấp tên bảng và khóa mục. Bạn cũng nên sử dụng một biểu thức điều kiện sẽ cần thiết để tránh xóa nhầm các mục.
Như thường lệ, bạn có thể sử dụng bảng điều khiển GUI, Java hoặc bất kỳ công cụ cần thiết nào khác để thực hiện tác vụ này.
Xóa các mục bằng GUI Console
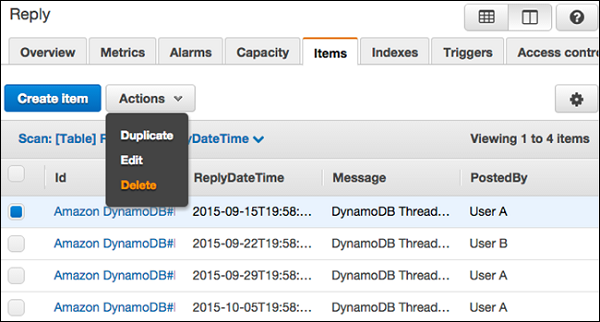
Điều hướng đến bảng điều khiển. Trong ngăn điều hướng ở bên trái, hãy chọnTables. Sau đó, chọn tên bảng vàItems chuyển hướng.
Chọn các mục bạn muốn xóa và chọn Actions | Delete.
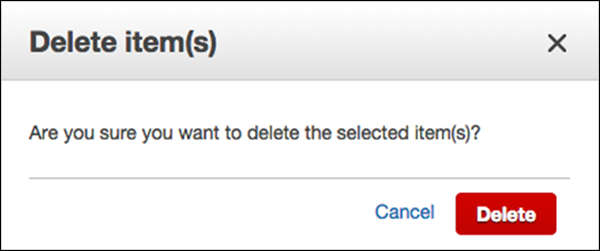
A Delete Item(s)hộp thoại sau đó xuất hiện như được hiển thị trong ảnh chụp dưới đây. Chọn “Xóa” để xác nhận.
Làm thế nào để xóa các mục bằng Java?
Sử dụng Java trong các hoạt động xóa mục chỉ liên quan đến việc tạo một phiên bản máy khách DynamoDB và gọi deleteItem thông qua việc sử dụng khóa của mục.
Bạn có thể xem ví dụ sau, nơi nó đã được giải thích chi tiết.
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ProductList");
DeleteItemOutcome outcome = table.deleteItem("IDnum", 151);Bạn cũng có thể chỉ định các thông số để bảo vệ khỏi việc xóa sai. Đơn giản chỉ cần sử dụngConditionExpression.
Ví dụ -
Map<String,Object> expressionAttributeValues = new HashMap<String,Object>();
expressionAttributeValues.put(":val", false);
DeleteItemOutcome outcome = table.deleteItem("IDnum",151,
"Ship = :val",
null, // doesn't use ExpressionAttributeNames
expressionAttributeValues);Sau đây là một ví dụ lớn hơn để hiểu rõ hơn.
Note- Mẫu sau đây có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Mẫu này cũng sử dụng Eclipse IDE, tệp thông tin xác thực AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DeleteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.UpdateItemOutcome;
import com.amazonaws.services.dynamodbv2.document.spec.DeleteItemSpec;
import com.amazonaws.services.dynamodbv2.document.spec.UpdateItemSpec;
import com.amazonaws.services.dynamodbv2.document.utils.NameMap;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.ReturnValue;
public class DeleteItemOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String tblName = "ProductList";
public static void main(String[] args) throws IOException {
createItems();
retrieveItem();
// Execute updates
updateMultipleAttributes();
updateAddNewAttribute();
updateExistingAttributeConditionally();
// Item deletion
deleteItem();
}
private static void createItems() {
Table table = dynamoDB.getTable(tblName);
try {
Item item = new Item()
.withPrimaryKey("ID", 303)
.withString("Nomenclature", "Polymer Blaster 4000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc.", "LMNOP Inc.")))
.withNumber("Price", 50000)
.withBoolean("InProduction", true)
.withString("Category", "Laser Cutter");
table.putItem(item);
item = new Item()
.withPrimaryKey("ID", 313)
.withString("Nomenclature", "Agitatatron 2000")
.withStringSet( "Manufacturers",
new HashSet<String>(Arrays.asList("XYZ Inc,", "CDE Inc.")))
.withNumber("Price", 40000)
.withBoolean("InProduction", true)
.withString("Category", "Agitator");
table.putItem(item);
} catch (Exception e) {
System.err.println("Cannot create items.");
System.err.println(e.getMessage());
}
}
private static void deleteItem() {
Table table = dynamoDB.getTable(tableName);
try {
DeleteItemSpec deleteItemSpec = new DeleteItemSpec()
.withPrimaryKey("ID", 303)
.withConditionExpression("#ip = :val")
.withNameMap(new NameMap()
.with("#ip", "InProduction"))
.withValueMap(new ValueMap()
.withBoolean(":val", false))
.withReturnValues(ReturnValue.ALL_OLD);
DeleteItemOutcome outcome = table.deleteItem(deleteItemSpec);
// Confirm
System.out.println("Displaying deleted item...");
System.out.println(outcome.getItem().toJSONPretty());
} catch (Exception e) {
System.err.println("Cannot delete item in " + tableName);
System.err.println(e.getMessage());
}
}
}Viết hàng loạt hoạt động trên nhiều mục bằng cách tạo hoặc xóa một số mục. Các hoạt động này sử dụngBatchWriteItem, có giới hạn là không quá 16MB ghi và 25 yêu cầu. Mỗi mặt hàng tuân theo giới hạn kích thước 400KB. Ghi hàng loạt cũng không thể thực hiện cập nhật mặt hàng.
Viết theo lô là gì?
Ghi hàng loạt có thể thao tác các mục trên nhiều bảng. Lệnh gọi hoạt động xảy ra cho từng yêu cầu riêng lẻ, có nghĩa là các hoạt động không tác động lẫn nhau và cho phép các hỗn hợp không đồng nhất; ví dụ, mộtPutItem và ba DeleteItemyêu cầu trong một lô, với việc yêu cầu PutItem không thành công sẽ không ảnh hưởng đến những yêu cầu khác. Yêu cầu không thành công dẫn đến hoạt động trả về thông tin (khóa và dữ liệu) liên quan đến mỗi yêu cầu không thành công.
Note- Nếu DynamoDB trả về bất kỳ mục nào mà không xử lý chúng, hãy thử lại chúng; tuy nhiên, hãy sử dụng phương pháp back-off để tránh một yêu cầu khác bị lỗi do quá tải.
DynamoDB từ chối thao tác ghi hàng loạt khi một hoặc nhiều câu lệnh sau được chứng minh là đúng:
Yêu cầu vượt quá thông lượng được cung cấp.
Yêu cầu cố gắng sử dụng BatchWriteItems để cập nhật một mặt hàng.
Yêu cầu thực hiện một số hoạt động trên một mục duy nhất.
Các bảng yêu cầu không tồn tại.
Các thuộc tính vật phẩm trong yêu cầu không khớp với mục tiêu.
Các yêu cầu vượt quá giới hạn kích thước.
Ghi hàng loạt yêu cầu nhất định RequestItem tham số -
Thao tác xóa cần DeleteRequest Chìa khóa subelements nghĩa là một tên thuộc tính và giá trị.
Các PutRequest các mặt hàng yêu cầu một Item subelement nghĩa là một thuộc tính và bản đồ giá trị thuộc tính.
Response - Hoạt động thành công dẫn đến phản hồi HTTP 200, cho biết các đặc điểm như đơn vị dung lượng tiêu thụ, số liệu xử lý bảng và bất kỳ mục nào chưa được xử lý.
Viết hàng loạt với Java
Thực hiện ghi hàng loạt bằng cách tạo một cá thể lớp DynamoDB, TableWriteItems cá thể lớp mô tả tất cả các hoạt động và gọi batchWriteItem để sử dụng đối tượng TableWriteItems.
Note- Bạn phải tạo một cá thể TableWriteItems cho mọi bảng trong một đợt ghi vào nhiều bảng. Ngoài ra, hãy kiểm tra phản hồi yêu cầu của bạn để biết bất kỳ yêu cầu nào chưa được xử lý.
Bạn có thể xem lại ví dụ sau về ghi hàng loạt:
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
TableWriteItems forumTableWriteItems = new TableWriteItems("Forum")
.withItemsToPut(
new Item()
.withPrimaryKey("Title", "XYZ CRM")
.withNumber("Threads", 0));
TableWriteItems threadTableWriteItems = new TableWriteItems(Thread)
.withItemsToPut(
new Item()
.withPrimaryKey("ForumTitle","XYZ CRM","Topic","Updates")
.withHashAndRangeKeysToDelete("ForumTitle","A partition key value",
"Product Line 1", "A sort key value"));
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem (
forumTableWriteItems, threadTableWriteItems);Chương trình sau đây là một ví dụ lớn hơn để hiểu rõ hơn về cách một loạt ghi bằng Java.
Note- Ví dụ sau có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Ví dụ này cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.BatchWriteItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.TableWriteItems;
import com.amazonaws.services.dynamodbv2.model.WriteRequest;
public class BatchWriteOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
batchWriteMultiItems();
}
private static void batchWriteMultiItems() {
try {
// Place new item in Forum
TableWriteItems forumTableWriteItems = new TableWriteItems(forumTableName)
//Forum
.withItemsToPut(new Item()
.withPrimaryKey("Name", "Amazon RDS")
.withNumber("Threads", 0));
// Place one item, delete another in Thread
// Specify partition key and range key
TableWriteItems threadTableWriteItems = new TableWriteItems(threadTableName)
.withItemsToPut(new Item()
.withPrimaryKey("ForumName","Product
Support","Subject","Support Thread 1")
.withString("Message", "New OS Thread 1 message")
.withHashAndRangeKeysToDelete("ForumName","Subject", "Polymer Blaster",
"Support Thread 100"));
System.out.println("Processing request...");
BatchWriteItemOutcome outcome = dynamoDB.batchWriteItem (
forumTableWriteItems, threadTableWriteItems);
do {
// Confirm no unprocessed items
Map<String, List<WriteRequest>> unprocessedItems
= outcome.getUnprocessedItems();
if (outcome.getUnprocessedItems().size() == 0) {
System.out.println("All items processed.");
} else {
System.out.println("Gathering unprocessed items...");
outcome = dynamoDB.batchWriteItemUnprocessed(unprocessedItems);
}
} while (outcome.getUnprocessedItems().size() > 0);
} catch (Exception e) {
System.err.println("Could not get items: ");
e.printStackTrace(System.err);
}
}
}Các hoạt động Truy xuất hàng loạt trả về các thuộc tính của một hoặc nhiều mục. Các hoạt động này thường bao gồm việc sử dụng khóa chính để xác định (các) mục mong muốn. CácBatchGetItem các hoạt động phải tuân theo các giới hạn của các hoạt động riêng lẻ cũng như các ràng buộc riêng của chúng.
Các yêu cầu sau trong hoạt động truy xuất hàng loạt dẫn đến việc bị từ chối:
- Thực hiện một yêu cầu cho hơn 100 mặt hàng.
- Thực hiện một yêu cầu vượt quá thông lượng.
Các hoạt động truy xuất hàng loạt thực hiện xử lý từng phần các yêu cầu có khả năng vượt quá giới hạn.
For example- yêu cầu truy xuất nhiều mục có kích thước đủ lớn để vượt quá giới hạn dẫn đến một phần của quá trình xử lý yêu cầu và thông báo lỗi ghi nhận phần chưa được xử lý. Khi trả lại các mặt hàng chưa được xử lý, hãy tạo một giải pháp thuật toán dự phòng để quản lý điều này thay vì điều chỉnh các bảng.
Các BatchGetcác hoạt động thực hiện cuối cùng với các lần đọc nhất quán, yêu cầu sửa đổi cho các phép đọc nhất quán mạnh mẽ. Họ cũng thực hiện truy xuất song song.
Note- Thứ tự của các mặt hàng trả lại. DynamoDB không sắp xếp các mục. Nó cũng không chỉ ra sự vắng mặt của các mặt hàng được yêu cầu. Hơn nữa, những yêu cầu đó tiêu tốn đơn vị dung lượng.
Tất cả các hoạt động BatchGet yêu cầu RequestItems các tham số như tính nhất quán đọc, tên thuộc tính và khóa chính.
Response - Hoạt động thành công dẫn đến phản hồi HTTP 200, cho biết các đặc điểm như đơn vị dung lượng tiêu thụ, số liệu xử lý bảng và bất kỳ mục nào chưa được xử lý.
Truy xuất hàng loạt với Java
Sử dụng Java trong các hoạt động BatchGet yêu cầu tạo một phiên bản lớp DynamoDB, TableKeysAndAttributes cá thể lớp mô tả danh sách giá trị khóa chính cho các mục và chuyển đối tượng TableKeysAndAttributes tới BatchGetItem phương pháp.
Sau đây là một ví dụ về hoạt động BatchGet:
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
TableKeysAndAttributes forumTableKeysAndAttributes = new TableKeysAndAttributes
(forumTableName);
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys (
"Title",
"Updates",
"Product Line 1"
);
TableKeysAndAttributes threadTableKeysAndAttributes = new TableKeysAndAttributes (
threadTableName);
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys (
"ForumTitle",
"Topic",
"Product Line 1",
"P1 Thread 1",
"Product Line 1",
"P1 Thread 2",
"Product Line 2",
"P2 Thread 1"
);
BatchGetItemOutcome outcome = dynamoDB.batchGetItem (
forumTableKeysAndAttributes, threadTableKeysAndAttributes);
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Table items " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item);
}
}Bạn có thể xem lại ví dụ lớn hơn sau đây.
Note- Chương trình sau có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Chương trình này cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.io.IOException;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.BatchGetItemOutcome;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.TableKeysAndAttributes;
import com.amazonaws.services.dynamodbv2.model.KeysAndAttributes;
public class BatchGetOpSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
static String forumTableName = "Forum";
static String threadTableName = "Thread";
public static void main(String[] args) throws IOException {
retrieveMultipleItemsBatchGet();
}
private static void retrieveMultipleItemsBatchGet() {
try {
TableKeysAndAttributes forumTableKeysAndAttributes =
new TableKeysAndAttributes(forumTableName);
//Create partition key
forumTableKeysAndAttributes.addHashOnlyPrimaryKeys (
"Name",
"XYZ Melt-O-tron",
"High-Performance Processing"
);
TableKeysAndAttributes threadTableKeysAndAttributes =
new TableKeysAndAttributes(threadTableName);
//Create partition key and sort key
threadTableKeysAndAttributes.addHashAndRangePrimaryKeys (
"ForumName",
"Subject",
"High-Performance Processing",
"HP Processing Thread One",
"High-Performance Processing",
"HP Processing Thread Two",
"Melt-O-Tron",
"MeltO Thread One"
);
System.out.println("Processing...");
BatchGetItemOutcome outcome = dynamoDB.batchGetItem(forumTableKeysAndAttributes,
threadTableKeysAndAttributes);
Map<String, KeysAndAttributes> unprocessed = null;
do {
for (String tableName : outcome.getTableItems().keySet()) {
System.out.println("Table items for " + tableName);
List<Item> items = outcome.getTableItems().get(tableName);
for (Item item : items) {
System.out.println(item.toJSONPretty());
}
}
// Confirm no unprocessed items
unprocessed = outcome.getUnprocessedKeys();
if (unprocessed.isEmpty()) {
System.out.println("All items processed.");
} else {
System.out.println("Gathering unprocessed items...");
outcome = dynamoDB.batchGetItemUnprocessed(unprocessed);
}
} while (!unprocessed.isEmpty());
} catch (Exception e) {
System.err.println("Could not get items.");
System.err.println(e.getMessage());
}
}
}Truy vấn xác định vị trí các mục hoặc chỉ mục phụ thông qua các khóa chính. Thực hiện truy vấn yêu cầu khóa phân vùng và giá trị cụ thể hoặc khóa sắp xếp và giá trị; với tùy chọn để lọc với các so sánh. Hành vi mặc định của truy vấn bao gồm trả về mọi thuộc tính cho các mục được liên kết với khóa chính được cung cấp. Tuy nhiên, bạn có thể chỉ định các thuộc tính mong muốn vớiProjectionExpression tham số.
Một truy vấn sử dụng KeyConditionExpressionđể chọn các mục, yêu cầu cung cấp tên và giá trị khóa phân vùng ở dạng điều kiện bình đẳng. Bạn cũng có tùy chọn cung cấp một điều kiện bổ sung cho bất kỳ khóa sắp xếp nào hiện có.
Một vài ví dụ về các điều kiện chính sắp xếp là:
| Sr.No | Tình trạng & Mô tả |
|---|---|
| 1 | x = y Nó đánh giá là true nếu thuộc tính x bằng y. |
| 2 | x < y Nó đánh giá là true nếu x nhỏ hơn y. |
| 3 | x <= y Nó đánh giá là true nếu x nhỏ hơn hoặc bằng y. |
| 4 | x > y Nó đánh giá là true nếu x lớn hơn y. |
| 5 | x >= y Nó đánh giá là true nếu x lớn hơn hoặc bằng y. |
| 6 | x BETWEEN y AND z Nó đánh giá là true nếu x là cả> = y và <= z. |
DynamoDB cũng hỗ trợ các chức năng sau: begins_with (x, substr)
Nó đánh giá là true nếu thuộc tính x bắt đầu bằng chuỗi được chỉ định.
Các điều kiện sau đây phải phù hợp với các yêu cầu nhất định:
Tên thuộc tính phải bắt đầu bằng một ký tự trong bộ az hoặc AZ.
Ký tự thứ hai của tên thuộc tính phải thuộc bộ az, AZ hoặc 0-9.
Tên thuộc tính không được sử dụng các từ dành riêng.
Tên thuộc tính không tuân thủ các ràng buộc ở trên có thể xác định trình giữ chỗ.
Truy vấn xử lý bằng cách thực hiện truy xuất theo thứ tự khóa sắp xếp và sử dụng bất kỳ biểu thức điều kiện và bộ lọc nào hiện có. Các truy vấn luôn trả về một tập hợp kết quả và nếu không có kết quả nào phù hợp, nó sẽ trả về một tập hợp trống.
Kết quả luôn trả về theo thứ tự khóa sắp xếp và thứ tự dựa trên kiểu dữ liệu với mặc định có thể sửa đổi là thứ tự tăng dần.
Truy vấn với Java
Các truy vấn trong Java cho phép bạn truy vấn các bảng và chỉ mục phụ. Chúng yêu cầu đặc tả các khóa phân vùng và điều kiện bình đẳng, với tùy chọn để chỉ định các khóa và điều kiện sắp xếp.
Các bước bắt buộc chung cho một truy vấn trong Java bao gồm tạo một cá thể lớp DynamoDB, cá thể lớp Bảng cho bảng đích và gọi phương thức truy vấn của cá thể Bảng để nhận đối tượng truy vấn.
Phản hồi cho truy vấn chứa một ItemCollection đối tượng cung cấp tất cả các mặt hàng trả lại.
Ví dụ sau minh họa truy vấn chi tiết:
DynamoDB dynamoDB = new DynamoDB (
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1"));
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
Item item = null;
while (iterator.hasNext()) {
item = iterator.next();
System.out.println(item.toJSONPretty());
}Phương thức truy vấn hỗ trợ nhiều tham số tùy chọn. Ví dụ sau minh họa cách sử dụng các tham số này:
Table table = dynamoDB.getTable("Response");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("ID = :nn and ResponseTM > :nn_responseTM")
.withFilterExpression("Author = :nn_author")
.withValueMap(new ValueMap()
.withString(":nn", "Product Line 1#P1 Thread 1")
.withString(":nn_responseTM", twoWeeksAgoStr)
.withString(":nn_author", "Member 123"))
.withConsistentRead(true);
ItemCollection<QueryOutcome> items = table.query(spec);
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}Bạn cũng có thể xem lại ví dụ lớn hơn sau đây.
Note- Chương trình sau có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Ví dụ này cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
package com.amazonaws.codesamples.document;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.Page;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
public class QueryOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "Reply";
public static void main(String[] args) throws Exception {
String forumName = "PolyBlaster";
String threadSubject = "PolyBlaster Thread 1";
getThreadReplies(forumName, threadSubject);
}
private static void getThreadReplies(String forumName, String threadSubject) {
Table table = dynamoDB.getTable(tableName);
String replyId = forumName + "#" + threadSubject;
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Id = :v_id")
.withValueMap(new ValueMap()
.withString(":v_id", replyId));
ItemCollection<QueryOutcome> items = table.query(spec);
System.out.println("\ngetThreadReplies results:");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}Thao tác quét đọc tất cả các mục trong bảng hoặc chỉ số phụ. Chức năng mặc định của nó dẫn đến việc trả về tất cả các thuộc tính dữ liệu của tất cả các mục trong một chỉ mục hoặc bảng. Sử dụngProjectionExpression trong các thuộc tính lọc.
Mỗi lần quét trả về một tập hợp kết quả, ngay cả khi không tìm thấy kết quả nào phù hợp, dẫn đến một tập hợp trống. Các bản quét truy xuất không quá 1MB, với tùy chọn lọc dữ liệu.
Note - Các tham số và bộ lọc của quét cũng áp dụng cho truy vấn.
Các loại hoạt động quét
Filtering- Các hoạt động quét cung cấp khả năng lọc tốt thông qua các biểu thức bộ lọc, giúp sửa đổi dữ liệu sau khi quét hoặc truy vấn; trước khi trả kết quả. Các biểu thức sử dụng các toán tử so sánh. Cú pháp của chúng giống với biểu thức điều kiện ngoại trừ các thuộc tính khóa, mà các biểu thức lọc không cho phép. Bạn không thể sử dụng phân vùng hoặc khóa sắp xếp trong biểu thức bộ lọc.
Note - Giới hạn 1MB được áp dụng trước bất kỳ ứng dụng lọc nào.
Throughput Specifications- Quá trình quét tiêu thụ thông lượng, tuy nhiên, tiêu thụ tập trung vào kích thước mặt hàng hơn là dữ liệu trả về. Mức tiêu thụ vẫn giữ nguyên cho dù bạn yêu cầu mọi thuộc tính hay chỉ một số thuộc tính và việc sử dụng hay không sử dụng biểu thức bộ lọc cũng không ảnh hưởng đến mức tiêu thụ.
Pagination- DynamoDB phân trang kết quả gây chia kết quả thành các trang cụ thể. Giới hạn 1MB áp dụng cho các kết quả trả về và khi bạn vượt quá giới hạn này, cần phải quét một lần nữa để thu thập phần còn lại của dữ liệu. CácLastEvaluatedKeygiá trị cho phép bạn thực hiện quét tiếp theo này. Chỉ cần áp dụng giá trị choExclusiveStartkey. Khi màLastEvaluatedKeygiá trị trở thành null, hoạt động đã hoàn thành tất cả các trang dữ liệu. Tuy nhiên, giá trị không rỗng không tự động có nghĩa là còn nhiều dữ liệu hơn. Chỉ một giá trị null cho biết trạng thái.
The Limit Parameter- Tham số giới hạn quản lý kích thước kết quả. DynamoDB sử dụng nó để thiết lập số lượng mục cần xử lý trước khi trả về dữ liệu và không hoạt động bên ngoài phạm vi. Nếu bạn đặt giá trị là x, DynamoDB sẽ trả về x đầu tiên các mục phù hợp.
Giá trị LastEvalishedKey cũng được áp dụng trong các trường hợp tham số giới hạn mang lại kết quả từng phần. Sử dụng nó để hoàn thành quá trình quét.
Result Count - Phản hồi cho các truy vấn và quét cũng bao gồm thông tin liên quan đến ScannedCountvà Đếm, định lượng các mục được quét / truy vấn và định lượng các mục được trả lại. Nếu bạn không lọc, giá trị của chúng giống hệt nhau. Khi bạn vượt quá 1MB, số lượng chỉ đại diện cho phần được xử lý.
Consistency- Kết quả truy vấn và kết quả quét cuối cùng là các lần đọc nhất quán, tuy nhiên, bạn cũng có thể đặt các lần đọc nhất quán mạnh mẽ. Sử dụngConsistentRead để thay đổi cài đặt này.
Note - Cài đặt đọc nhất quán ảnh hưởng đến mức tiêu thụ bằng cách sử dụng gấp đôi đơn vị công suất khi được đặt thành nhất quán mạnh.
Performance- Các truy vấn cung cấp hiệu suất tốt hơn so với quét do quét thu thập dữ liệu toàn bộ bảng hoặc chỉ mục phụ, dẫn đến phản hồi chậm và tiêu tốn nhiều thông lượng. Quét hoạt động tốt nhất cho các bảng nhỏ và tìm kiếm với ít bộ lọc hơn, tuy nhiên, bạn có thể thiết kế quét tinh gọn bằng cách tuân theo một số phương pháp hay nhất như tránh hoạt động đọc đột ngột, tăng tốc và khai thác quét song song.
Một truy vấn tìm một dải khóa nhất định thỏa mãn một điều kiện nhất định, với hiệu suất được quyết định bởi lượng dữ liệu mà nó truy xuất thay vì khối lượng của các khóa. Các thông số của hoạt động và số lượng trận đấu ảnh hưởng cụ thể đến hiệu suất.
Quét song song
Các hoạt động quét thực hiện xử lý tuần tự theo mặc định. Sau đó, chúng trả về dữ liệu ở các phần 1MB, điều này sẽ nhắc ứng dụng tìm nạp phần tiếp theo. Điều này dẫn đến việc quét lâu cho các bảng và chỉ số lớn.
Đặc điểm này cũng có nghĩa là các bản quét có thể không phải lúc nào cũng khai thác đầy đủ thông lượng khả dụng. DynamoDB phân phối dữ liệu bảng trên nhiều phân vùng; và thông lượng quét vẫn bị giới hạn ở một phân vùng duy nhất do hoạt động của phân vùng đơn.
Một giải pháp cho vấn đề này đến từ việc phân chia các bảng hoặc chỉ số thành các phân đoạn một cách hợp lý. Sau đó, "công nhân" quét các đoạn song song (đồng thời). Nó sử dụng các tham số của Phân đoạn vàTotalSegments để chỉ định các phân đoạn được quét bởi một số công nhân nhất định và chỉ định tổng số lượng phân đoạn được xử lý.
Số công nhân
Bạn phải thử nghiệm với các giá trị worker (Tham số phân đoạn) để đạt được hiệu suất ứng dụng tốt nhất.
Note- Quét song song với nhiều nhóm công nhân tác động đến thông lượng bằng cách có thể tiêu thụ tất cả thông lượng. Quản lý vấn đề này bằng tham số Giới hạn, bạn có thể sử dụng tham số này để ngăn một nhân viên tiêu thụ tất cả thông lượng.
Sau đây là một ví dụ quét sâu.
Note- Chương trình sau có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Ví dụ này cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.ScanOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
public class ScanOpSample {
static DynamoDB dynamoDB = new DynamoDB(
new AmazonDynamoDBClient(new ProfileCredentialsProvider()));
static String tableName = "ProductList";
public static void main(String[] args) throws Exception {
findProductsUnderOneHun(); //finds products under 100 dollars
}
private static void findProductsUnderOneHun() {
Table table = dynamoDB.getTable(tableName);
Map<String, Object> expressionAttributeValues = new HashMap<String, Object>();
expressionAttributeValues.put(":pr", 100);
ItemCollection<ScanOutcome> items = table.scan (
"Price < :pr", //FilterExpression
"ID, Nomenclature, ProductCategory, Price", //ProjectionExpression
null, //No ExpressionAttributeNames
expressionAttributeValues);
System.out.println("Scanned " + tableName + " to find items under $100.");
Iterator<Item> iterator = items.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}DynamoDB sử dụng chỉ mục cho các thuộc tính khóa chính để cải thiện quyền truy cập. Chúng tăng tốc độ truy cập ứng dụng và truy xuất dữ liệu, đồng thời hỗ trợ hiệu suất tốt hơn bằng cách giảm độ trễ ứng dụng.
Chỉ mục phụ
Chỉ mục phụ chứa một tập hợp con thuộc tính và một khóa thay thế. Bạn sử dụng nó thông qua truy vấn hoặc thao tác quét, thao tác này nhắm mục tiêu chỉ mục.
Nội dung của nó bao gồm các thuộc tính bạn chiếu hoặc sao chép. Trong quá trình tạo, bạn xác định một khóa thay thế cho chỉ mục và bất kỳ thuộc tính nào bạn muốn chiếu vào chỉ mục. Sau đó, DynamoDB thực hiện sao chép các thuộc tính vào chỉ mục, bao gồm các thuộc tính khóa chính được lấy từ bảng. Sau khi thực hiện các tác vụ này, bạn chỉ cần sử dụng truy vấn / quét như thể thực hiện trên bảng.
DynamoDB tự động duy trì tất cả các chỉ số phụ. Trên các hoạt động mục, chẳng hạn như thêm hoặc xóa, nó cập nhật bất kỳ chỉ mục nào trên bảng mục tiêu.
DynamoDB cung cấp hai loại chỉ mục phụ -
Global Secondary Index- Chỉ mục này bao gồm khóa phân vùng và khóa sắp xếp, có thể khác với bảng nguồn. Nó sử dụng nhãn "toàn cầu" do khả năng truy vấn / quét trên chỉ mục để mở rộng tất cả dữ liệu bảng và trên tất cả các phân vùng.
Local Secondary Index- Chỉ mục này chia sẻ một khóa phân vùng với bảng, nhưng sử dụng một khóa sắp xếp khác. Tính chất “cục bộ” của nó là kết quả của tất cả các phân vùng của nó trong phạm vi phân vùng bảng có giá trị khóa phân vùng giống hệt nhau.
Loại chỉ mục tốt nhất để sử dụng tùy thuộc vào nhu cầu ứng dụng. Hãy xem xét sự khác biệt giữa hai loại được trình bày trong bảng sau:
| Chất lượng | Chỉ số thứ cấp toàn cầu | Chỉ mục phụ cục bộ |
|---|---|---|
| Lược đồ chính | Nó sử dụng một khóa chính đơn giản hoặc tổng hợp. | Nó luôn sử dụng một khóa chính tổng hợp. |
| Những điểm chính | Khóa phân vùng chỉ mục và khóa sắp xếp có thể bao gồm các thuộc tính chuỗi, số hoặc bảng nhị phân. | Khóa phân vùng của chỉ mục là một thuộc tính được chia sẻ với khóa phân vùng bảng. Khóa sắp xếp có thể là thuộc tính chuỗi, số hoặc bảng nhị phân. |
| Giới hạn kích thước cho mỗi giá trị khóa phân vùng | Chúng không có giới hạn về kích thước. | Nó áp đặt giới hạn tối đa 10GB trên tổng kích thước của các mục được lập chỉ mục được liên kết với giá trị khóa phân vùng. |
| Hoạt động lập chỉ mục trực tuyến | Bạn có thể sinh ra chúng khi tạo bảng, thêm chúng vào bảng hiện có hoặc xóa những bảng hiện có. | Bạn phải tạo chúng khi tạo bảng, nhưng không thể xóa chúng hoặc thêm chúng vào bảng hiện có. |
| Truy vấn | Nó cho phép các truy vấn bao phủ toàn bộ bảng và mọi phân vùng. | Chúng giải quyết các phân vùng đơn lẻ thông qua giá trị khóa phân vùng được cung cấp trong truy vấn. |
| Tính nhất quán | Các truy vấn của các chỉ số này chỉ cung cấp tùy chọn nhất quán cuối cùng. | Các truy vấn trong số này cung cấp các tùy chọn cuối cùng nhất quán hoặc nhất quán mạnh mẽ. |
| Chi phí thông lượng | Nó bao gồm các cài đặt thông lượng để đọc và ghi. Truy vấn / quét tiêu thụ dung lượng từ chỉ mục, không phải bảng, điều này cũng áp dụng cho các bản cập nhật ghi bảng. | Truy vấn / quét tiêu tốn dung lượng đọc bảng. Bảng ghi cập nhật các chỉ mục cục bộ và sử dụng các đơn vị dung lượng bảng. |
| Phép chiếu | Các truy vấn / quét chỉ có thể yêu cầu các thuộc tính được chiếu vào chỉ mục, không truy xuất các thuộc tính bảng. | Các truy vấn / quét có thể yêu cầu các thuộc tính không được chiếu; hơn nữa, tự động tìm nạp chúng xảy ra. |
Khi tạo nhiều bảng với các chỉ mục phụ, hãy thực hiện tuần tự; nghĩa là tạo một bảng và đợi nó đạt đến trạng thái ACTIVE trước khi tạo một bảng khác và chờ đợi một lần nữa. DynamoDB không cho phép tạo đồng thời.
Mỗi chỉ mục phụ yêu cầu các thông số kỹ thuật nhất định -
Type - Chỉ định cục bộ hoặc toàn cầu.
Name - Nó sử dụng các quy tắc đặt tên giống hệt với các bảng.
Key Schema - Chỉ cho phép loại chuỗi, số hoặc nhị phân cấp cao nhất, với loại chỉ mục xác định các yêu cầu khác.
Attributes for Projection - DynamoDB tự động chiếu chúng và cho phép bất kỳ kiểu dữ liệu nào.
Throughput - Chỉ định khả năng đọc / ghi cho các chỉ mục phụ toàn cầu.
Giới hạn cho các chỉ mục vẫn là 5 toàn cầu và 5 cục bộ trên mỗi bảng.
Bạn có thể truy cập thông tin chi tiết về các chỉ mục với DescribeTable. Nó trả về tên, kích thước và số lượng mặt hàng.
Note - Các giá trị này cập nhật 6 giờ một lần.
Trong các truy vấn hoặc quét được sử dụng để truy cập dữ liệu chỉ mục, hãy cung cấp tên bảng và chỉ mục, các thuộc tính mong muốn cho kết quả và bất kỳ câu lệnh điều kiện nào. DynamoDB cung cấp tùy chọn trả về kết quả theo thứ tự tăng dần hoặc giảm dần.
Note - Việc xóa một bảng cũng xóa tất cả các chỉ mục.
Các ứng dụng yêu cầu nhiều loại truy vấn với các thuộc tính khác nhau có thể sử dụng một hoặc nhiều chỉ mục phụ toàn cầu để thực hiện các truy vấn chi tiết này.
For example - Hệ thống theo dõi người dùng, trạng thái đăng nhập và thời gian họ đăng nhập. Sự phát triển của ví dụ trước làm chậm các truy vấn trên dữ liệu của nó.
Các chỉ mục phụ toàn cầu tăng tốc các truy vấn bằng cách tổ chức lựa chọn các thuộc tính từ một bảng. Chúng sử dụng khóa chính để sắp xếp dữ liệu và không yêu cầu thuộc tính bảng khóa hoặc lược đồ khóa giống hệt bảng.
Tất cả các chỉ mục phụ toàn cầu phải bao gồm một khóa phân vùng, với tùy chọn khóa sắp xếp. Lược đồ khóa chỉ mục có thể khác với bảng và các thuộc tính khóa chỉ mục có thể sử dụng bất kỳ thuộc tính chuỗi, số hoặc bảng nhị phân cấp cao nhất nào.
Trong một phép chiếu, bạn có thể sử dụng các thuộc tính bảng khác, tuy nhiên, các truy vấn không truy xuất từ bảng mẹ.
Phép chiếu thuộc tính
Phép chiếu bao gồm một tập thuộc tính được sao chép từ bảng sang chỉ mục phụ. Phép chiếu luôn xảy ra với khóa phân vùng bảng và khóa sắp xếp. Trong các truy vấn, phép chiếu cho phép DynamoDB truy cập vào bất kỳ thuộc tính nào của phép chiếu; về cơ bản chúng tồn tại như một bảng riêng của chúng.
Trong tạo chỉ mục phụ, bạn phải chỉ định các thuộc tính cho phép chiếu. DynamoDB cung cấp ba cách để thực hiện tác vụ này:
KEYS_ONLY- Tất cả các mục chỉ mục bao gồm phân vùng bảng và sắp xếp các giá trị khóa, và giá trị khóa chỉ mục. Điều này tạo ra chỉ số nhỏ nhất.
INCLUDE - Nó bao gồm các thuộc tính KEYS_ONLY và các thuộc tính không phải khóa được chỉ định.
ALL - Nó bao gồm tất cả các thuộc tính bảng nguồn, tạo chỉ mục lớn nhất có thể.
Lưu ý sự cân bằng trong việc chiếu các thuộc tính vào một chỉ số thứ cấp toàn cầu, liên quan đến thông lượng và chi phí lưu trữ.
Hãy xem xét các điểm sau:
Nếu bạn chỉ cần truy cập vào một vài thuộc tính, với độ trễ thấp, hãy chỉ chiếu những thuộc tính bạn cần. Điều này làm giảm chi phí lưu trữ và ghi.
Nếu một ứng dụng thường xuyên truy cập các thuộc tính không phải khóa nhất định, hãy chiếu chúng vì chi phí lưu trữ thấp hơn so với mức tiêu thụ quét.
Bạn có thể chiếu các tập hợp lớn các thuộc tính được truy cập thường xuyên, tuy nhiên, điều này có chi phí lưu trữ cao.
Sử dụng KEYS_ONLY cho các truy vấn bảng không thường xuyên và ghi / cập nhật thường xuyên. Điều này kiểm soát kích thước, nhưng vẫn cung cấp hiệu suất tốt trên các truy vấn.
Truy vấn và quét chỉ mục thứ cấp toàn cầu
Bạn có thể sử dụng các truy vấn để truy cập một hoặc nhiều mục trong một chỉ mục. Bạn phải chỉ định chỉ mục và tên bảng, các thuộc tính và điều kiện mong muốn; với tùy chọn trả về kết quả theo thứ tự tăng dần hoặc giảm dần.
Bạn cũng có thể sử dụng quét để lấy tất cả dữ liệu chỉ mục. Nó yêu cầu tên bảng và chỉ mục. Bạn sử dụng biểu thức bộ lọc để truy xuất dữ liệu cụ thể.
Đồng bộ hóa dữ liệu bảng và chỉ mục
DynamoDB tự động thực hiện đồng bộ hóa các chỉ mục với bảng mẹ của chúng. Mỗi thao tác sửa đổi trên các mục sẽ gây ra cập nhật không đồng bộ, tuy nhiên, các ứng dụng không ghi trực tiếp vào chỉ mục.
Bạn cần hiểu tác động của việc bảo trì DynamoDB đối với các chỉ số. Khi tạo chỉ mục, bạn chỉ định các thuộc tính và kiểu dữ liệu chính, có nghĩa là khi ghi, các kiểu dữ liệu đó phải khớp với kiểu dữ liệu lược đồ chính.
Tuy nhiên, khi tạo hoặc xóa mục, các chỉ mục cập nhật theo cách nhất quán cuối cùng, các cập nhật đối với dữ liệu sẽ truyền trong một phần của giây (trừ khi xảy ra lỗi hệ thống thuộc một số loại). Bạn phải giải trình cho sự chậm trễ này trong các ứng dụng.
Throughput Considerations in Global Secondary Indexes- Nhiều chỉ số thứ cấp toàn cầu tác động đến thông lượng. Việc tạo chỉ mục yêu cầu các thông số kỹ thuật của đơn vị dung lượng, tồn tại tách biệt với bảng, dẫn đến các hoạt động sử dụng đơn vị dung lượng chỉ mục hơn là đơn vị bảng.
Điều này có thể dẫn đến điều chỉnh nếu truy vấn hoặc ghi vượt quá thông lượng được cấp phép. Xem cài đặt thông lượng bằng cách sử dụngDescribeTable.
Read Capacity- Các chỉ mục thứ cấp toàn cầu cung cấp tính nhất quán cuối cùng. Trong các truy vấn, DynamoDB thực hiện các tính toán cung cấp giống hệt như được sử dụng cho các bảng, với sự khác biệt duy nhất là sử dụng kích thước mục nhập chỉ mục thay vì kích thước mục. Giới hạn của một truy vấn trả về vẫn là 1MB, bao gồm kích thước tên thuộc tính và các giá trị trên mọi mặt hàng được trả về.
Ghi dung lượng
Khi hoạt động ghi xảy ra, chỉ mục bị ảnh hưởng sẽ sử dụng các đơn vị ghi. Chi phí thông lượng ghi là tổng đơn vị khả năng ghi được tiêu thụ trong quá trình ghi bảng và đơn vị tiêu thụ trong cập nhật chỉ mục. Một thao tác ghi thành công yêu cầu đủ dung lượng, nếu không sẽ dẫn đến việc điều chỉnh.
Chi phí ghi cũng phụ thuộc vào các yếu tố nhất định, một số yếu tố như sau:
Các mục mới xác định thuộc tính được lập chỉ mục hoặc cập nhật mặt hàng xác định các thuộc tính được lập chỉ mục chưa xác định sử dụng một thao tác ghi để thêm mặt hàng vào chỉ mục.
Các bản cập nhật thay đổi giá trị thuộc tính khóa được lập chỉ mục sử dụng hai lần ghi để xóa một mục và ghi một mục mới.
Việc kích hoạt ghi bảng khi xóa thuộc tính được lập chỉ mục sử dụng một lần ghi duy nhất để xóa phép chiếu mục cũ trong chỉ mục.
Các mục vắng mặt trong chỉ mục trước và sau khi thao tác cập nhật không được ghi.
Các bản cập nhật chỉ thay đổi giá trị thuộc tính dự kiến trong lược đồ khóa chỉ mục và không thay đổi giá trị thuộc tính khóa được lập chỉ mục, sử dụng một lần ghi để cập nhật giá trị của các thuộc tính dự kiến vào chỉ mục.
Tất cả các yếu tố này giả định kích thước mặt hàng nhỏ hơn hoặc bằng 1KB.
Lưu trữ chỉ mục thứ cấp toàn cầu
Trên một mục ghi, DynamoDB tự động sao chép tập hợp các thuộc tính phù hợp vào bất kỳ chỉ số nào mà các thuộc tính đó phải tồn tại. Điều này ảnh hưởng đến tài khoản của bạn bằng cách tính phí nó cho việc lưu trữ mục trong bảng và lưu trữ thuộc tính. Không gian được sử dụng là kết quả từ tổng các đại lượng này -
- Kích thước byte của khóa chính của bảng
- Kích thước byte của thuộc tính khóa chỉ mục
- Kích thước byte của các thuộc tính dự kiến
- Chi phí 100 byte cho mỗi mục chỉ mục
Bạn có thể ước tính nhu cầu lưu trữ thông qua ước tính kích thước mục trung bình và nhân với số lượng mục trong bảng có thuộc tính khóa chỉ mục phụ toàn cầu.
DynamoDB không ghi dữ liệu mục cho một mục bảng có thuộc tính không xác định được định nghĩa là phân vùng chỉ mục hoặc khóa sắp xếp.
Chỉ số thứ cấp toàn cầu Crud
Tạo một bảng với các chỉ mục phụ chung bằng cách sử dụng CreateTable hoạt động được ghép nối với GlobalSecondaryIndexestham số. Bạn phải chỉ định một thuộc tính dùng làm khóa phân vùng chỉ mục hoặc sử dụng một thuộc tính khác cho khóa sắp xếp chỉ mục. Tất cả các thuộc tính khóa chỉ mục phải là chuỗi, số hoặc vô hướng nhị phân. Bạn cũng phải cung cấp cài đặt thông lượng, bao gồmReadCapacityUnits và WriteCapacityUnits.
Sử dụng UpdateTable để thêm các chỉ mục phụ toàn cầu vào các bảng hiện có bằng cách sử dụng lại tham số GlobalSecondaryIndexes.
Trong thao tác này, bạn phải cung cấp các đầu vào sau:
- Tên chỉ mục
- Lược đồ chính
- Thuộc tính dự kiến
- Cài đặt thông lượng
Bằng cách thêm chỉ mục phụ toàn cầu, có thể mất một khoảng thời gian đáng kể với các bảng lớn do khối lượng mục, khối lượng thuộc tính dự kiến, khả năng ghi và hoạt động ghi. Sử dụngCloudWatch số liệu để giám sát quá trình.
Sử dụng DescribeTableđể tìm nạp thông tin trạng thái cho chỉ mục phụ toàn cầu. Nó trả về một trong bốnIndexStatus cho GlobalSecondaryIndexes -
CREATING - Nó chỉ ra giai đoạn xây dựng của chỉ mục và tính khả dụng của nó.
ACTIVE - Nó cho biết mức độ sẵn sàng của chỉ số để sử dụng.
UPDATING - Nó cho biết trạng thái cập nhật của cài đặt thông lượng.
DELETING - Nó cho biết trạng thái xóa của chỉ mục và vĩnh viễn không có sẵn để sử dụng.
Cập nhật cài đặt thông lượng được cung cấp chỉ mục thứ cấp toàn cầu trong giai đoạn tải / lấp đầy (ghi các thuộc tính DynamoDB vào chỉ mục và theo dõi các mục được thêm / xóa / cập nhật). Sử dụngUpdateTable để thực hiện thao tác này.
Bạn nên nhớ rằng bạn không thể thêm / xóa các chỉ số khác trong giai đoạn lấp đầy.
Sử dụng UpdateTable để xóa các chỉ mục phụ toàn cầu. Nó chỉ cho phép xóa một chỉ mục cho mỗi thao tác, tuy nhiên, bạn có thể chạy nhiều thao tác đồng thời, tối đa năm. Quá trình xóa không ảnh hưởng đến hoạt động đọc / ghi của bảng mẹ, nhưng bạn không thể thêm / xóa các chỉ số khác cho đến khi thao tác hoàn tất.
Sử dụng Java để làm việc với các chỉ mục thứ cấp toàn cầu
Tạo một bảng với một chỉ mục thông qua CreateTable. Chỉ cần tạo một phiên bản lớp DynamoDB,CreateTableRequest cá thể lớp cho thông tin yêu cầu và chuyển đối tượng yêu cầu đến phương thức CreateTable.
Chương trình sau đây là một ví dụ ngắn gọn:
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
// Attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("City")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Date")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Wind")
.withAttributeType("N"));
// Key schema of the table
ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("City")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.RANGE)); //Sort key
// Wind index
GlobalSecondaryIndex windIndex = new GlobalSecondaryIndex()
.withIndexName("WindIndex")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 10)
.withWriteCapacityUnits((long) 1))
.withProjection(new Projection().withProjectionType(ProjectionType.ALL));
ArrayList<KeySchemaElement> indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Date")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Wind")
.withKeyType(KeyType.RANGE)); //Sort key
windIndex.setKeySchema(indexKeySchema);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName("ClimateInfo")
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 5)
.withWriteCapacityUnits((long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(windIndex);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());Truy xuất thông tin chỉ mục với DescribeTable. Đầu tiên, tạo một cá thể lớp DynamoDB. Sau đó, tạo một cá thể lớp Bảng để nhắm mục tiêu một chỉ mục. Cuối cùng, chuyển bảng cho phương thức mô tả.
Đây là một ví dụ ngắn -
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ClimateInfo");
TableDescription tableDesc = table.describe();
Iterator<GlobalSecondaryIndexDescription> gsiIter =
tableDesc.getGlobalSecondaryIndexes().iterator();
while (gsiIter.hasNext()) {
GlobalSecondaryIndexDescription gsiDesc = gsiIter.next();
System.out.println("Index data " + gsiDesc.getIndexName() + ":");
Iterator<KeySchemaElement> kse7Iter = gsiDesc.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType());
}
Projection projection = gsiDesc.getProjection();
System.out.println("\tProjection type: " + projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tNon-key projected attributes: "
+ projection.getNonKeyAttributes());
}
}Sử dụng Truy vấn để thực hiện truy vấn chỉ mục như với truy vấn bảng. Chỉ cần tạo một cá thể lớp DynamoDB, một cá thể lớp Bảng cho chỉ mục đích, một cá thể lớp Chỉ mục cho chỉ mục cụ thể và chuyển chỉ mục và đối tượng truy vấn cho phương thức truy vấn.
Hãy xem đoạn mã sau để hiểu rõ hơn -
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
Table table = dynamoDB.getTable("ClimateInfo");
Index index = table.getIndex("WindIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("#d = :v_date and Wind = :v_wind")
.withNameMap(new NameMap()
.with("#d", "Date"))
.withValueMap(new ValueMap()
.withString(":v_date","2016-05-15")
.withNumber(":v_wind",0));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> iter = items.iterator();
while (iter.hasNext()) {
System.out.println(iter.next().toJSONPretty());
}Chương trình sau đây là một ví dụ lớn hơn để hiểu rõ hơn -
Note- Chương trình sau có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Ví dụ này cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Index;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.GlobalSecondaryIndex;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.Projection;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
public class GlobalSecondaryIndexSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient (
new ProfileCredentialsProvider()));
public static String tableName = "Bugs";
public static void main(String[] args) throws Exception {
createTable();
queryIndex("CreationDateIndex");
queryIndex("NameIndex");
queryIndex("DueDateIndex");
}
public static void createTable() {
// Attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("BugID")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Name")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CreationDate")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("DueDate")
.withAttributeType("S"));
// Table Key schema
ArrayList<KeySchemaElement> tableKeySchema = new ArrayList<KeySchemaElement>();
tableKeySchema.add (new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add (new KeySchemaElement()
.withAttributeName("Name")
.withKeyType(KeyType.RANGE)); //Sort key
// Indexes' initial provisioned throughput
ProvisionedThroughput ptIndex = new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L);
// CreationDateIndex
GlobalSecondaryIndex creationDateIndex = new GlobalSecondaryIndex()
.withIndexName("CreationDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("CreationDate")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("INCLUDE")
.withNonKeyAttributes("Description", "Status"));
// NameIndex
GlobalSecondaryIndex nameIndex = new GlobalSecondaryIndex()
.withIndexName("NameIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("Name")
.withKeyType(KeyType.HASH), //Partition key
new KeySchemaElement()
.withAttributeName("BugID")
.withKeyType(KeyType.RANGE)) //Sort key
.withProjection(new Projection()
.withProjectionType("KEYS_ONLY"));
// DueDateIndex
GlobalSecondaryIndex dueDateIndex = new GlobalSecondaryIndex()
.withIndexName("DueDateIndex")
.withProvisionedThroughput(ptIndex)
.withKeySchema(new KeySchemaElement()
.withAttributeName("DueDate")
.withKeyType(KeyType.HASH)) //Partition key
.withProjection(new Projection()
.withProjectionType("ALL"));
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput( new ProvisionedThroughput()
.withReadCapacityUnits( (long) 1)
.withWriteCapacityUnits( (long) 1))
.withAttributeDefinitions(attributeDefinitions)
.withKeySchema(tableKeySchema)
.withGlobalSecondaryIndexes(creationDateIndex, nameIndex, dueDateIndex);
System.out.println("Creating " + tableName + "...");
dynamoDB.createTable(createTableRequest);
// Pause for active table state
System.out.println("Waiting for ACTIVE state of " + tableName);
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void queryIndex(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println
("\n*****************************************************\n");
System.out.print("Querying index " + indexName + "...");
Index index = table.getIndex(indexName);
ItemCollection<QueryOutcome> items = null;
QuerySpec querySpec = new QuerySpec();
if (indexName == "CreationDateIndex") {
System.out.println("Issues filed on 2016-05-22");
querySpec.withKeyConditionExpression("CreationDate = :v_date and begins_with
(BugID, :v_bug)")
.withValueMap(new ValueMap()
.withString(":v_date","2016-05-22")
.withString(":v_bug","A-"));
items = index.query(querySpec);
} else if (indexName == "NameIndex") {
System.out.println("Compile error");
querySpec.withKeyConditionExpression("Name = :v_name and begins_with
(BugID, :v_bug)")
.withValueMap(new ValueMap()
.withString(":v_name","Compile error")
.withString(":v_bug","A-"));
items = index.query(querySpec);
} else if (indexName == "DueDateIndex") {
System.out.println("Items due on 2016-10-15");
querySpec.withKeyConditionExpression("DueDate = :v_date")
.withValueMap(new ValueMap()
.withString(":v_date","2016-10-15"));
items = index.query(querySpec);
} else {
System.out.println("\nInvalid index name");
return;
}
Iterator<Item> iterator = items.iterator();
System.out.println("Query: getting result...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}Một số ứng dụng chỉ thực hiện truy vấn với khóa chính, nhưng một số trường hợp được hưởng lợi từ khóa sắp xếp thay thế. Cho phép ứng dụng của bạn lựa chọn bằng cách tạo một hoặc nhiều chỉ mục phụ cục bộ.
Các yêu cầu truy cập dữ liệu phức tạp, chẳng hạn như kết hợp hàng triệu mục, khiến nó cần thực hiện các truy vấn / quét hiệu quả hơn. Các chỉ mục phụ cục bộ cung cấp khóa sắp xếp thay thế cho giá trị khóa phân vùng. Họ cũng giữ bản sao của tất cả hoặc một số thuộc tính bảng. Họ sắp xếp dữ liệu theo khóa phân vùng bảng, nhưng sử dụng khóa sắp xếp khác.
Sử dụng chỉ mục phụ cục bộ loại bỏ nhu cầu quét toàn bộ bảng và cho phép truy vấn đơn giản và nhanh chóng bằng cách sử dụng khóa sắp xếp.
Tất cả các chỉ mục phụ cục bộ phải đáp ứng các điều kiện nhất định -
- Khóa phân vùng giống hệt nhau và khóa phân vùng bảng nguồn.
- Một khóa sắp xếp của chỉ một thuộc tính vô hướng.
- Phép chiếu của bảng nguồn sắp xếp khóa hoạt động như một thuộc tính không phải khóa.
Tất cả các chỉ mục phụ cục bộ tự động giữ các khóa phân vùng và sắp xếp từ các bảng cha. Trong các truy vấn, điều này có nghĩa là thu thập hiệu quả các thuộc tính được chiếu và cũng có thể truy xuất các thuộc tính không được chiếu.
Giới hạn lưu trữ cho một chỉ mục phụ cục bộ vẫn là 10GB cho mỗi giá trị khóa phân vùng, bao gồm tất cả các mục bảng và các mục chỉ mục chia sẻ giá trị khóa phân vùng.
Dự báo một thuộc tính
Một số hoạt động yêu cầu đọc / tìm nạp vượt quá do phức tạp. Các hoạt động này có thể tiêu tốn thông lượng đáng kể. Phép chiếu cho phép bạn tránh tìm nạp tốn kém và thực hiện các truy vấn phong phú bằng cách cô lập các thuộc tính này. Hãy nhớ các phép chiếu bao gồm các thuộc tính được sao chép vào một chỉ mục phụ.
Khi tạo chỉ mục phụ, bạn chỉ định các thuộc tính được chiếu. Nhớ lại ba tùy chọn được cung cấp bởi DynamoDB:KEYS_ONLY, INCLUDE, and ALL.
Khi chọn một số thuộc tính nhất định trong dự báo, hãy xem xét sự cân bằng chi phí liên quan -
Nếu bạn chỉ chiếu một tập hợp nhỏ các thuộc tính cần thiết, bạn sẽ giảm đáng kể chi phí lưu trữ.
Nếu bạn chiếu các thuộc tính không phải khóa được truy cập thường xuyên, bạn sẽ bù đắp chi phí quét bằng chi phí lưu trữ.
Nếu bạn chiếu hầu hết hoặc tất cả các thuộc tính không phải khóa, điều này tối đa hóa tính linh hoạt và giảm thông lượng (không truy xuất); tuy nhiên, chi phí lưu trữ tăng lên.
Nếu bạn chiếu KEYS_ONLY để ghi / cập nhật thường xuyên và các truy vấn không thường xuyên, nó sẽ giảm thiểu kích thước, nhưng vẫn duy trì việc chuẩn bị truy vấn.
Tạo chỉ mục phụ cục bộ
Sử dụng LocalSecondaryIndextham số CreateTable để tạo một hoặc nhiều chỉ mục phụ cục bộ. Bạn phải chỉ định một thuộc tính không phải khóa cho khóa sắp xếp. Khi tạo bảng, bạn tạo các chỉ mục phụ cục bộ. Khi xóa, bạn xóa các chỉ mục này.
Các bảng có chỉ mục phụ cục bộ phải tuân theo giới hạn kích thước 10GB cho mỗi giá trị khóa phân vùng, nhưng có thể lưu trữ bất kỳ lượng mục nào.
Truy vấn và quét chỉ mục phụ cục bộ
Thao tác truy vấn trên các chỉ mục phụ cục bộ trả về tất cả các mục có giá trị khóa phân vùng phù hợp khi nhiều mục trong chỉ mục chia sẻ giá trị khóa sắp xếp. Các mục phù hợp không trở lại theo một thứ tự nhất định. Các truy vấn cho các chỉ mục phụ cục bộ sử dụng tính nhất quán cuối cùng hoặc mạnh mẽ, với các lần đọc nhất quán cao cung cấp các giá trị mới nhất.
Thao tác quét trả về tất cả dữ liệu chỉ mục phụ cục bộ. Quá trình quét yêu cầu bạn cung cấp bảng và tên chỉ mục, đồng thời cho phép sử dụng biểu thức bộ lọc để loại bỏ dữ liệu.
Viết mục
Khi tạo chỉ mục phụ cục bộ, bạn chỉ định thuộc tính khóa sắp xếp và kiểu dữ liệu của nó. Khi bạn viết một mục, kiểu của nó phải khớp với kiểu dữ liệu của lược đồ khóa nếu mục đó xác định một thuộc tính của khóa chỉ mục.
DynamoDB không áp đặt các yêu cầu về mối quan hệ một-một đối với các mục bảng và các mục chỉ mục phụ cục bộ. Các bảng có nhiều chỉ mục phụ cục bộ có chi phí ghi cao hơn các bảng có ít chỉ mục hơn.
Cân nhắc thông lượng trong chỉ mục phụ cục bộ
Mức tiêu thụ dung lượng đọc của một truy vấn phụ thuộc vào bản chất của việc truy cập dữ liệu. Các truy vấn sử dụng tính nhất quán cuối cùng hoặc mạnh mẽ, với các lần đọc nhất quán cao sử dụng một đơn vị so với một nửa đơn vị trong các lần đọc cuối cùng nhất quán.
Giới hạn kết quả bao gồm kích thước tối đa 1MB. Kích thước kết quả đến từ tổng kích thước mục chỉ mục phù hợp được làm tròn đến 4KB gần nhất và kích thước mục phù hợp cũng được làm tròn lên 4KB gần nhất.
Mức tiêu thụ dung lượng ghi vẫn nằm trong các đơn vị được cung cấp. Tính tổng chi phí dự phòng bằng cách tìm tổng số đơn vị tiêu thụ khi ghi bảng và đơn vị tiêu thụ khi cập nhật chỉ số.
Bạn cũng có thể xem xét các yếu tố chính ảnh hưởng đến chi phí, một số trong số đó có thể là:
Khi bạn viết một mục xác định một thuộc tính được lập chỉ mục hoặc cập nhật một mục để xác định một thuộc tính được lập chỉ mục không xác định, một thao tác ghi sẽ xảy ra.
Khi cập nhật bảng thay đổi giá trị thuộc tính khóa được lập chỉ mục, hai lần ghi xảy ra để xóa và sau đó - thêm một mục.
Khi một lần ghi gây ra việc xóa một thuộc tính được lập chỉ mục, một lần ghi xảy ra để xóa phép chiếu mục cũ.
Khi một mục không tồn tại trong chỉ mục trước hoặc sau khi cập nhật, không có lần ghi nào xảy ra.
Lưu trữ chỉ mục phụ cục bộ
Khi ghi một mục trong bảng, DynamoDB sẽ tự động sao chép thuộc tính bên phải được đặt thành các chỉ mục phụ cục bộ được yêu cầu. Điều này tính phí tài khoản của bạn. Không gian được sử dụng là kết quả từ tổng kích thước byte khóa chính của bảng, kích thước byte thuộc tính khóa chỉ mục, bất kỳ kích thước byte thuộc tính dự kiến nào hiện tại và 100 byte chi phí cho mỗi mục chỉ mục.
Việc lưu trữ ước tính có được bằng cách ước tính kích thước mục chỉ mục trung bình và nhân với số lượng mục trong bảng.
Sử dụng Java để làm việc với các chỉ mục phụ cục bộ
Tạo một chỉ mục phụ cục bộ bằng cách tạo một phiên bản lớp DynamoDB trước tiên. Sau đó, tạo một cá thể lớp CreateTableRequest với thông tin yêu cầu cần thiết. Cuối cùng, sử dụng phương thức createTable.
Thí dụ
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
CreateTableRequest createTableRequest = new
CreateTableRequest().withTableName(tableName);
//Provisioned Throughput
createTableRequest.setProvisionedThroughput (
new ProvisionedThroughput()
.withReadCapacityUnits((long)5)
.withWriteCapacityUnits(( long)5));
//Attributes
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Make")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Model")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("Line")
.withAttributeType("S"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
//Key Schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Make")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("Model")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Make")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("Line")
.withKeyType(KeyType.RANGE)); //Sort key
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("Type");
nonKeyAttributes.add("Year");
projection.setNonKeyAttributes(nonKeyAttributes);
LocalSecondaryIndex localSecondaryIndex = new LocalSecondaryIndex()
.withIndexName("ModelIndex")
.withKeySchema(indexKeySchema)
.withProjection(p rojection);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
localSecondaryIndexes.add(localSecondaryIndex);
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
Table table = dynamoDB.createTable(createTableRequest);
System.out.println(table.getDescription());Lấy thông tin về một chỉ mục phụ cục bộ với phương thức mô tả. Chỉ cần tạo một cá thể lớp DynamoDB, tạo một cá thể lớp Bảng và chuyển bảng vào phương thức mô tả.
Thí dụ
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
Table table = dynamoDB.getTable(tableName);
TableDescription tableDescription = table.describe();
List<LocalSecondaryIndexDescription> localSecondaryIndexes =
tableDescription.getLocalSecondaryIndexes();
Iterator<LocalSecondaryIndexDescription> lsiIter =
localSecondaryIndexes.iterator();
while (lsiIter.hasNext()) {
LocalSecondaryIndexDescription lsiDescription = lsiIter.next();
System.out.println("Index info " + lsiDescription.getIndexName() + ":");
Iterator<KeySchemaElement> kseIter = lsiDescription.getKeySchema().iterator();
while (kseIter.hasNext()) {
KeySchemaElement kse = kseIter.next();
System.out.printf("\t%s: %s\n", kse.getAttributeName(), kse.getKeyType());
}
Projection projection = lsiDescription.getProjection();
System.out.println("\tProjection type: " + projection.getProjectionType());
if (projection.getProjectionType().toString().equals("INCLUDE")) {
System.out.println("\t\tNon-key projected attributes: " +
projection.getNonKeyAttributes());
}
}Thực hiện truy vấn bằng cách sử dụng các bước tương tự như truy vấn bảng. Chỉ tạo một cá thể lớp DynamoDB, một cá thể lớp Bảng, một cá thể lớp Chỉ mục, một đối tượng truy vấn và sử dụng phương thức truy vấn.
Thí dụ
DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
String tableName = "Tools";
Table table = dynamoDB.getTable(tableName);
Index index = table.getIndex("LineIndex");
QuerySpec spec = new QuerySpec()
.withKeyConditionExpression("Make = :v_make and Line = :v_line")
.withValueMap(new ValueMap()
.withString(":v_make", "Depault")
.withString(":v_line", "SuperSawz"));
ItemCollection<QueryOutcome> items = index.query(spec);
Iterator<Item> itemsIter = items.iterator();
while (itemsIter.hasNext()) {
Item item = itemsIter.next();
System.out.println(item.toJSONPretty());
}Bạn cũng có thể xem lại ví dụ sau.
Note- Ví dụ sau có thể giả sử một nguồn dữ liệu đã tạo trước đó. Trước khi cố gắng thực thi, hãy thu thập các thư viện hỗ trợ và tạo các nguồn dữ liệu cần thiết (các bảng có các đặc điểm bắt buộc hoặc các nguồn tham chiếu khác).
Ví dụ sau cũng sử dụng Eclipse IDE, tệp thông tin đăng nhập AWS và Bộ công cụ AWS trong Dự án Java AWS của Eclipse.
Thí dụ
import java.util.ArrayList;
import java.util.Iterator;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.document.DynamoDB;
import com.amazonaws.services.dynamodbv2.document.Index;
import com.amazonaws.services.dynamodbv2.document.Item;
import com.amazonaws.services.dynamodbv2.document.ItemCollection;
import com.amazonaws.services.dynamodbv2.document.PutItemOutcome;
import com.amazonaws.services.dynamodbv2.document.QueryOutcome;
import com.amazonaws.services.dynamodbv2.document.Table;
import com.amazonaws.services.dynamodbv2.document.spec.QuerySpec;
import com.amazonaws.services.dynamodbv2.document.utils.ValueMap;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.LocalSecondaryIndex;
import com.amazonaws.services.dynamodbv2.model.Projection;
import com.amazonaws.services.dynamodbv2.model.ProjectionType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.ReturnConsumedCapacity;
import com.amazonaws.services.dynamodbv2.model.Select;
public class LocalSecondaryIndexSample {
static DynamoDB dynamoDB = new DynamoDB(new AmazonDynamoDBClient(
new ProfileCredentialsProvider()));
public static String tableName = "ProductOrders";
public static void main(String[] args) throws Exception {
createTable();
query(null);
query("IsOpenIndex");
query("OrderCreationDateIndex");
}
public static void createTable() {
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits((long) 1)
.withWriteCapacityUnits((long) 1));
// Table partition and sort keys attributes
ArrayList<AttributeDefinition> attributeDefinitions = new
ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("CustomerID")
.withAttributeType("S"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderID")
.withAttributeType("N"));
// Index primary key attributes
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OrderDate")
.withAttributeType("N"));
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("OpenStatus")
.withAttributeType("N"));
createTableRequest.setAttributeDefinitions(attributeDefinitions);
// Table key schema
ArrayList<KeySchemaElement> tableKeySchema = new
ArrayList<KeySchemaElement>();
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
tableKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderID")
.withKeyType(KeyType.RANGE)); //Sort key
createTableRequest.setKeySchema(tableKeySchema);
ArrayList<LocalSecondaryIndex> localSecondaryIndexes = new
ArrayList<LocalSecondaryIndex>();
// OrderDateIndex
LocalSecondaryIndex orderDateIndex = new LocalSecondaryIndex()
.withIndexName("OrderDateIndex");
// OrderDateIndex key schema
ArrayList<KeySchemaElement> indexKeySchema = new
ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OrderDate")
.withKeyType(KeyType.RANGE)); //Sort key
orderDateIndex.setKeySchema(indexKeySchema);
// OrderCreationDateIndex projection w/attributes list
Projection projection = new Projection()
.withProjectionType(ProjectionType.INCLUDE);
ArrayList<String> nonKeyAttributes = new ArrayList<String>();
nonKeyAttributes.add("ProdCat");
nonKeyAttributes.add("ProdNomenclature");
projection.setNonKeyAttributes(nonKeyAttributes);
orderCreationDateIndex.setProjection(projection);
localSecondaryIndexes.add(orderDateIndex);
// IsOpenIndex
LocalSecondaryIndex isOpenIndex = new LocalSecondaryIndex()
.withIndexName("IsOpenIndex");
// OpenStatusIndex key schema
indexKeySchema = new ArrayList<KeySchemaElement>();
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("CustomerID")
.withKeyType(KeyType.HASH)); //Partition key
indexKeySchema.add(new KeySchemaElement()
.withAttributeName("OpenStatus")
.withKeyType(KeyType.RANGE)); //Sort key
// OpenStatusIndex projection
projection = new Projection() .withProjectionType(ProjectionType.ALL);
OpenStatusIndex.setKeySchema(indexKeySchema);
OpenStatusIndex.setProjection(projection);
localSecondaryIndexes.add(OpenStatusIndex);
// Put definitions in CreateTable request
createTableRequest.setLocalSecondaryIndexes(localSecondaryIndexes);
System.out.println("Spawning table " + tableName + "...");
System.out.println(dynamoDB.createTable(createTableRequest));
// Pause for ACTIVE status
System.out.println("Waiting for ACTIVE table:" + tableName);
try {
Table table = dynamoDB.getTable(tableName);
table.waitForActive();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void query(String indexName) {
Table table = dynamoDB.getTable(tableName);
System.out.println("\n*************************************************\n");
System.out.println("Executing query on" + tableName);
QuerySpec querySpec = new QuerySpec()
.withConsistentRead(true)
.withScanIndexForward(true)
.withReturnConsumedCapacity(ReturnConsumedCapacity.TOTAL);
if (indexName == "OpenStatusIndex") {
System.out.println("\nEmploying index: '" + indexName
+ "' open orders for this customer.");
System.out.println(
"Returns only user-specified attribute list\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerID = :v_custmid and
OpenStatus = :v_openstat")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]")
.withNumber(":v_openstat", 1));
querySpec.withProjectionExpression(
"OrderDate, ProdCat, ProdNomenclature, OrderStatus");
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else if (indexName == "OrderDateIndex") {
System.out.println("\nUsing index: '" + indexName
+ "': this customer's orders placed after 05/22/2016.");
System.out.println("Projected attributes are returned\n");
Index index = table.getIndex(indexName);
querySpec.withKeyConditionExpression("CustomerID = :v_custmid and OrderDate
>= :v_ordrdate")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]")
.withNumber(":v_ordrdate", 20160522));
querySpec.withSelect(Select.ALL_PROJECTED_ATTRIBUTES);
ItemCollection<QueryOutcome> items = index.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
} else {
System.out.println("\nNo index: All Jane's orders by OrderID:\n");
querySpec.withKeyConditionExpression("CustomerID = :v_custmid")
.withValueMap(new ValueMap()
.withString(":v_custmid", "[email protected]"));
ItemCollection<QueryOutcome> items = table.query(querySpec);
Iterator<Item> iterator = items.iterator();
System.out.println("Printing query results...");
while (iterator.hasNext()) {
System.out.println(iterator.next().toJSONPretty());
}
}
}
}DynamoDB không cung cấp chức năng tổng hợp. Bạn phải sử dụng sáng tạo các truy vấn, quét, chỉ số và các công cụ khác nhau để thực hiện các tác vụ này. Trong tất cả những điều này, chi phí thông lượng của các truy vấn / quét trong các hoạt động này có thể rất lớn.
Bạn cũng có tùy chọn sử dụng thư viện và các công cụ khác cho ngôn ngữ mã hóa DynamoDB ưa thích của mình. Đảm bảo khả năng tương thích của chúng với DynamoDB trước khi sử dụng.
Tính toán tối đa hoặc tối thiểu
Sử dụng thứ tự lưu trữ tăng dần / giảm dần của kết quả, tham số Giới hạn và bất kỳ tham số nào đặt thứ tự để tìm giá trị cao nhất và thấp nhất.
Ví dụ -
Map<String, AttributeValue> eaval = new HashMap<>();
eaval.put(":v1", new AttributeValue().withS("hashval"));
queryExpression = new DynamoDBQueryExpression<Table>()
.withIndexName("yourindexname")
.withKeyConditionExpression("HK = :v1")
.withExpressionAttributeValues(values)
.withScanIndexForward(false); //descending order
queryExpression.setLimit(1);
QueryResultPage<Lookup> res =
dynamoDBMapper.queryPage(Table.class, queryExpression);Tính số
Sử dụng DescribeTableTuy nhiên, để có được số lượng các mục trong bảng, hãy lưu ý rằng nó cung cấp dữ liệu cũ. Ngoài ra, hãy sử dụng JavagetScannedCount method.
Tận dụng LastEvaluatedKey để đảm bảo nó mang lại tất cả các kết quả.
Ví dụ -
ScanRequest scanRequest = new ScanRequest().withTableName(yourtblName);
ScanResult yourresult = client.scan(scanRequest);
System.out.println("#items:" + yourresult.getScannedCount());Tính toán trung bình và tổng
Sử dụng các chỉ mục và truy vấn / quét để truy xuất và lọc các giá trị trước khi xử lý. Sau đó, chỉ cần thao tác trên các giá trị đó thông qua một đối tượng.
DynamoDB sử dụng thông tin xác thực bạn cung cấp để xác thực các yêu cầu. Các thông tin xác thực này là bắt buộc và phải bao gồm quyền truy cập tài nguyên AWS. Các quyền này hầu như trải dài mọi khía cạnh của DynamoDB cho đến các tính năng nhỏ của một hoạt động hoặc chức năng.
Các loại quyền
Trong phần này, chúng ta sẽ thảo luận về các quyền khác nhau và quyền truy cập tài nguyên trong DynamoDB.
Xác thực người dùng
Khi đăng ký, bạn đã cung cấp mật khẩu và email, được coi là thông tin đăng nhập gốc. DynamoDB liên kết dữ liệu này với tài khoản AWS của bạn và sử dụng nó để cấp quyền truy cập đầy đủ vào tất cả các tài nguyên.
AWS khuyến nghị bạn chỉ sử dụng thông tin đăng nhập gốc của mình để tạo tài khoản quản trị. Điều này cho phép bạn tạo tài khoản IAM / người dùng với ít đặc quyền hơn. Người dùng IAM là các tài khoản khác được sinh ra với dịch vụ IAM. Quyền truy cập / đặc quyền của họ bao gồm quyền truy cập vào các trang an toàn và một số quyền tùy chỉnh nhất định như sửa đổi bảng.
Các khóa truy cập cung cấp một tùy chọn khác cho các tài khoản và quyền truy cập bổ sung. Sử dụng chúng để cấp quyền truy cập và cũng để tránh cấp quyền truy cập thủ công trong một số tình huống nhất định. Người dùng liên kết cung cấp một tùy chọn khác bằng cách cho phép truy cập thông qua nhà cung cấp danh tính.
Hành chính
Tài nguyên AWS vẫn thuộc quyền sở hữu của một tài khoản. Chính sách quyền chi phối các quyền được cấp để sinh sản hoặc truy cập tài nguyên. Quản trị viên liên kết chính sách quyền với danh tính IAM, nghĩa là vai trò, nhóm, người dùng và dịch vụ. Họ cũng đính kèm quyền đối với tài nguyên.
Quyền chỉ định người dùng, tài nguyên và hành động. Lưu ý rằng quản trị viên chỉ là những tài khoản có đặc quyền của quản trị viên.
Hoạt động và Tài nguyên
Các bảng vẫn là tài nguyên chính trong DynamoDB. Nguồn phụ đóng vai trò là tài nguyên bổ sung, ví dụ: luồng và chỉ số. Các tài nguyên này sử dụng các tên riêng, một số được đề cập trong bảng sau:
| Kiểu | ARN (Tên tài nguyên Amazon) |
|---|---|
| Suối | arn: aws: dynamicodb: region: account-id: table / table-name / stream / stream-label |
| Mục lục | arn: aws: dynamicodb: region: account-id: table / table-name / index / index-name |
| Bàn | arn: aws: dynamicodb: region: account-id: table / table-name |
Quyền sở hữu
Chủ sở hữu tài nguyên được định nghĩa là tài khoản AWS sinh ra tài nguyên hoặc tài khoản thực thể chính chịu trách nhiệm yêu cầu xác thực trong việc tạo tài nguyên. Xem xét cách chức năng này trong môi trường DynamoDB -
Khi sử dụng thông tin đăng nhập gốc để tạo bảng, tài khoản của bạn vẫn là chủ sở hữu tài nguyên.
Khi tạo người dùng IAM và cấp quyền cho người dùng tạo bảng, tài khoản của bạn vẫn là chủ sở hữu tài nguyên.
Khi tạo người dùng IAM và cấp quyền cho người dùng và bất kỳ ai có khả năng đảm nhận vai trò, quyền tạo bảng, tài khoản của bạn vẫn là chủ sở hữu tài nguyên.
Quản lý quyền truy cập tài nguyên
Việc quản lý quyền truy cập chủ yếu yêu cầu chú ý đến chính sách cấp phép mô tả người dùng và quyền truy cập tài nguyên. Bạn liên kết các chính sách với danh tính hoặc tài nguyên IAM. Tuy nhiên, DynamoDB chỉ hỗ trợ các chính sách IAM / danh tính.
Chính sách dựa trên danh tính (IAM) cho phép bạn cấp đặc quyền theo những cách sau:
- Đính kèm quyền cho người dùng hoặc nhóm.
- Đính kèm quyền với vai trò để có quyền trên nhiều tài khoản.
AWS khác cho phép các chính sách dựa trên tài nguyên. Các chính sách này cho phép truy cập vào những thứ như nhóm S3.
Các yếu tố chính sách
Các chính sách xác định các hành động, tác động, nguồn lực và nguyên tắc; và cấp quyền để thực hiện các hoạt động này.
Note - Các hoạt động API có thể yêu cầu quyền cho nhiều hành động.
Hãy xem xét kỹ hơn các yếu tố chính sách sau:
Resource - ARN xác định điều này.
Action - Từ khóa xác định các hoạt động tài nguyên này và cho phép hay từ chối.
Effect - Nó chỉ định hiệu ứng cho một yêu cầu của người dùng cho một hành động, nghĩa là cho phép hoặc từ chối với từ chối làm mặc định.
Principal - Điều này xác định người dùng gắn liền với chính sách.
Điều kiện
Khi cấp quyền, bạn có thể chỉ định các điều kiện khi các chính sách bắt đầu hoạt động, chẳng hạn như vào một ngày cụ thể. Thể hiện điều kiện bằng các khóa điều kiện, bao gồm các khóa trên toàn hệ thống AWS và khóa DynamoDB. Các phím này sẽ được thảo luận chi tiết trong phần sau của hướng dẫn.
Quyền điều khiển
Người dùng yêu cầu một số quyền cơ bản nhất định để sử dụng bảng điều khiển. Họ cũng yêu cầu quyền cho bảng điều khiển trong các dịch vụ tiêu chuẩn khác -
- CloudWatch
- Đường ống dữ liệu
- Quản lý Danh tính và Truy cập
- Dịch vụ thông báo
- Lambda
Nếu chính sách IAM quá giới hạn, người dùng không thể sử dụng bảng điều khiển một cách hiệu quả. Ngoài ra, bạn không cần phải lo lắng về quyền của người dùng đối với những người chỉ gọi CLI hoặc API.
Chính sách Iam Sử dụng Phổ biến
AWS bao gồm các hoạt động phổ biến trong quyền với các chính sách IAM được quản lý độc lập. Họ cung cấp các quyền chính cho phép bạn tránh các cuộc điều tra sâu về những gì bạn phải cấp.
Một số trong số chúng như sau:
AmazonDynamoDBReadOnlyAccess - Nó cung cấp quyền truy cập chỉ đọc thông qua bảng điều khiển.
AmazonDynamoDBFullAccess - Nó cho phép truy cập đầy đủ thông qua bảng điều khiển.
AmazonDynamoDBFullAccesswithDataPipeline - Nó cho phép toàn quyền truy cập thông qua bảng điều khiển và cho phép xuất / nhập với Data Pipeline.
Tất nhiên bạn cũng có thể đưa ra các chính sách tùy chỉnh.
Cấp đặc quyền: Sử dụng The Shell
Bạn có thể cấp quyền với trình bao Javascript. Chương trình sau đây cho thấy một chính sách cấp phép điển hình:
{
"Version": "2016-05-22",
"Statement": [
{
"Sid": "DescribeQueryScanToolsTable",
"Effect": "Deny",
"Action": [
"dynamodb:DescribeTable",
"dynamodb:Query",
"dynamodb:Scan"
],
"Resource": "arn:aws:dynamodb:us-west-2:account-id:table/Tools"
}
]
}Bạn có thể xem lại ba ví dụ như sau:
Block the user from executing any table action.
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "AllAPIActionsOnTools",
"Effect": "Deny",
"Action": "dynamodb:*",
"Resource": "arn:aws:dynamodb:us-west-2:155556789012:table/Tools"
}
]
}Block access to a table and its indices.
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "AccessAllIndexesOnTools",
"Effect": "Deny",
"Action": [
"dynamodb:*"
],
"Resource": [
"arn:aws:dynamodb:us-west-2:155556789012:table/Tools",
"arn:aws:dynamodb:us-west-2:155556789012:table/Tools/index/*"
]
}
]
}Block a user from making a reserved capacity offering purchase.
{
"Version": "2016-05-23",
"Statement": [
{
"Sid": "BlockReservedCapacityPurchases",
"Effect": "Deny",
"Action": "dynamodb:PurchaseReservedCapacityOfferings",
"Resource": "arn:aws:dynamodb:us-west-2:155556789012:*"
}
]
}Cấp các đặc quyền: Sử dụng GUI Console
Bạn cũng có thể sử dụng bảng điều khiển GUI để tạo các chính sách IAM. Để bắt đầu, hãy chọnTablestừ ngăn điều hướng. Trong danh sách bảng, hãy chọn bảng mục tiêu và làm theo các bước sau.
Step 1 - Chọn Access control chuyển hướng.
Step 2- Chọn nhà cung cấp danh tính, hành động và thuộc tính chính sách. Lựa chọnCreate policy sau khi nhập tất cả các cài đặt.
Step 3 - Chọn Attach policy instructionsvà hoàn thành từng bước bắt buộc để liên kết chính sách với vai trò IAM thích hợp.
API DynamoDB cung cấp một tập hợp lớn các hành động, yêu cầu quyền. Khi đặt quyền, bạn phải thiết lập các hành động được phép, tài nguyên được phép và điều kiện của từng quyền.
Bạn có thể chỉ định các hành động trong trường Hành động của chính sách. Chỉ định giá trị tài nguyên trong trường Tài nguyên của chính sách. Nhưng hãy đảm bảo rằng bạn sử dụng đúng cú pháp có chứa tiền tố Dynamodb: với thao tác API.
Ví dụ - dynamodb:CreateTable
Bạn cũng có thể sử dụng các phím điều kiện để lọc các quyền.
Quyền và Hành động API
Hãy xem kỹ các hành động API và các quyền liên quan được cung cấp trong bảng sau:
| Hoạt động API | Quyền cần thiết |
|---|---|
| BatchGetItem | dynamicodb: BatchGetItem |
| BatchWriteItem | dynamicodb: BatchWriteItem |
| Tạo bảng | dynamicodb: CreateTable |
| Xóa mục | dynamicodb: DeleteItem |
| DeleteTable | dynamicodb: DeleteTable |
| DescribeLimits | dynamicodb: DescribeLimits |
| DescribeReservedCapacity | dynamicodb: DescribeReservedCapacity |
| DescribeReservedCapacityOfferings | dynamicodb: DescribeReservedCapacityOfferings |
| DescribeStream | dynamicodb: DescribeStream |
| DescribeTable | dynamicodb: DescribeTable |
| GetItem | dynamicodb: GetItem |
| GetRecords | dynamicodb: GetRecords |
| GetShardIterator | dynamicodb: GetShardIterator |
| ListStreams | dynamicodb: ListStreams |
| ListTables | dynamicodb: ListTables |
| PurchaseReservedCapacityOfferings | dynamicodb: PurchaseReservedCapacityOfferings |
| PutItem | dynamicodb: PutItem |
| Truy vấn | dynamicodb: Truy vấn |
| Quét | Dyodb: Quét |
| UpdateItem | dynamicodb: UpdateItem |
| UpdateTable | dynamicodb: UpdateTable |
Tài nguyên
Trong bảng sau, bạn có thể xem lại các tài nguyên được liên kết với từng hành động API được phép -
| Hoạt động API | Nguồn |
|---|---|
| BatchGetItem | arn: aws: dynamicodb: region: account-id: table / table-name |
| BatchWriteItem | arn: aws: dynamicodb: region: account-id: table / table-name |
| Tạo bảng | arn: aws: dynamicodb: region: account-id: table / table-name |
| Xóa mục | arn: aws: dynamicodb: region: account-id: table / table-name |
| DeleteTable | arn: aws: dynamicodb: region: account-id: table / table-name |
| DescribeLimits | arn: aws: dynamicodb: region: account-id: * |
| DescribeReservedCapacity | arn: aws: dynamicodb: region: account-id: * |
| DescribeReservedCapacityOfferings | arn: aws: dynamicodb: region: account-id: * |
| DescribeStream | arn: aws: dynamicodb: region: account-id: table / table-name / stream / stream-label |
| DescribeTable | arn: aws: dynamicodb: region: account-id: table / table-name |
| GetItem | arn: aws: dynamicodb: region: account-id: table / table-name |
| GetRecords | arn: aws: dynamicodb: region: account-id: table / table-name / stream / stream-label |
| GetShardIterator | arn: aws: dynamicodb: region: account-id: table / table-name / stream / stream-label |
| ListStreams | arn: aws: dynamicodb: region: account-id: table / table-name / stream / * |
| ListTables | * |
| PurchaseReservedCapacityOfferings | arn: aws: dynamicodb: region: account-id: * |
| PutItem | arn: aws: dynamicodb: region: account-id: table / table-name |
| Truy vấn | arn: aws: dynamicodb: region: account-id: table / table-name hoặc là arn: aws: dynamicodb: region: account-id: table / table-name / index / index-name |
| Quét | arn: aws: dynamicodb: region: account-id: table / table-name hoặc là arn: aws: dynamicodb: region: account-id: table / table-name / index / index-name |
| UpdateItem | arn: aws: dynamicodb: region: account-id: table / table-name |
| UpdateTable | arn: aws: dynamicodb: region: account-id: table / table-name |
Khi cấp quyền, DynamoDB cho phép chỉ định các điều kiện cho chúng thông qua chính sách IAM chi tiết với các khóa điều kiện. Điều này hỗ trợ các cài đặt như quyền truy cập vào các mục và thuộc tính cụ thể.
Note - DynamoDB không hỗ trợ bất kỳ thẻ nào.
Kiểm soát chi tiết
Một số điều kiện cho phép cụ thể hóa các mục và thuộc tính như cấp quyền truy cập chỉ đọc cho các mục cụ thể dựa trên tài khoản người dùng. Thực hiện mức độ kiểm soát này với các chính sách IAM có điều kiện, chính sách này quản lý thông tin xác thực bảo mật. Sau đó, chỉ cần áp dụng chính sách cho người dùng, nhóm và vai trò mong muốn. Web Identity Federation, một chủ đề được thảo luận sau, cũng cung cấp một cách để kiểm soát quyền truy cập của người dùng thông qua các thông tin đăng nhập Amazon, Facebook và Google.
Yếu tố điều kiện của chính sách IAM thực hiện kiểm soát truy cập. Bạn chỉ cần thêm nó vào một chính sách. Một ví dụ về việc sử dụng nó bao gồm từ chối hoặc cho phép truy cập vào các mục và thuộc tính của bảng. Phần tử điều kiện cũng có thể sử dụng các khóa điều kiện để giới hạn quyền.
Bạn có thể xem lại hai ví dụ sau về các phím điều kiện:
dynamodb:LeadingKeys - Nó ngăn người dùng truy cập mục mà không có ID khớp với giá trị khóa phân vùng.
dynamodb:Attributes - Nó ngăn người dùng truy cập hoặc thao tác trên các thuộc tính bên ngoài những thuộc tính được liệt kê.
Khi đánh giá, các chính sách IAM dẫn đến giá trị đúng hoặc sai. Nếu bất kỳ phần nào đánh giá là false, thì toàn bộ chính sách sẽ đánh giá là false, dẫn đến việc từ chối quyền truy cập. Đảm bảo chỉ định tất cả thông tin cần thiết trong các khóa điều kiện để đảm bảo người dùng có quyền truy cập thích hợp.
Các phím điều kiện được xác định trước
AWS cung cấp một bộ sưu tập các khóa điều kiện được xác định trước, áp dụng cho tất cả các dịch vụ. Chúng hỗ trợ nhiều mục đích sử dụng và chi tiết tốt trong việc kiểm tra người dùng và quyền truy cập.
Note - Có phân biệt chữ hoa chữ thường trong các phím điều kiện.
Bạn có thể xem lại lựa chọn các khóa dành riêng cho dịch vụ sau:
dynamodb:LeadingKey- Nó đại diện cho thuộc tính khóa đầu tiên của bảng; khóa phân vùng. Sử dụng công cụ sửa đổi ForAllValues trong các điều kiện.
dynamodb:Select- Nó đại diện cho một truy vấn / yêu cầu quét Chọn tham số. Nó phải có giá trị ALL_ATTRIBUTES, ALL_PROJECTED_ATTRIBUTES, SPECIFIC_ATTRIBUTES hoặc COUNT.
dynamodb:Attributes- Nó đại diện cho một danh sách tên thuộc tính trong một yêu cầu hoặc các thuộc tính được trả về từ một yêu cầu. Các giá trị và chức năng của nó giống với các tham số hành động API, ví dụ: BatchGetItem sử dụng AttributesToGet.
dynamodb:ReturnValues - Nó đại diện cho tham số ReturnValues của yêu cầu và có thể sử dụng các giá trị sau: ALL_OLD, UPDATED_OLD, ALL_NEW, UPDATED_NEW và NONE.
dynamodb:ReturnConsumedCapacity - Nó đại diện cho tham số ReturnConsumedCapacity của một yêu cầu và có thể sử dụng các giá trị sau: TOTAL và NONE.
Liên kết nhận dạng web cho phép bạn đơn giản hóa xác thực và ủy quyền cho các nhóm người dùng lớn. Bạn có thể bỏ qua việc tạo tài khoản cá nhân và yêu cầu người dùng đăng nhập vào nhà cung cấp danh tính để nhận thông tin xác thực hoặc mã thông báo tạm thời. Nó sử dụng AWS Security Token Service (STS) để quản lý thông tin đăng nhập. Các ứng dụng sử dụng các mã thông báo này để tương tác với các dịch vụ.
Liên đoàn Nhận dạng Web cũng hỗ trợ các nhà cung cấp nhận dạng khác như - Amazon, Google và Facebook.
Function- Trong quá trình sử dụng, Web Identity Federation trước tiên sẽ gọi nhà cung cấp danh tính để xác thực người dùng và ứng dụng và nhà cung cấp này sẽ trả về một mã thông báo. Điều này dẫn đến ứng dụng gọi AWS STS và chuyển mã thông báo để nhập. STS ủy quyền cho ứng dụng và cấp cho nó thông tin xác thực truy cập tạm thời, cho phép ứng dụng sử dụng vai trò IAM và truy cập tài nguyên dựa trên chính sách.
Triển khai Liên kết Nhận dạng Web
Bạn phải thực hiện ba bước sau trước khi sử dụng:
Sử dụng nhà cung cấp danh tính bên thứ ba được hỗ trợ để đăng ký làm nhà phát triển.
Đăng ký ứng dụng của bạn với nhà cung cấp để lấy ID ứng dụng.
Tạo một hoặc nhiều vai trò IAM, bao gồm cả phần đính kèm chính sách. Bạn phải sử dụng một vai trò cho mỗi nhà cung cấp cho mỗi ứng dụng.
Giả sử một trong các vai trò IAM của bạn để sử dụng Liên kết Nhận dạng Web. Sau đó, ứng dụng của bạn phải thực hiện quy trình ba bước -
- Authentication
- Chuyển đổi thông tin xác thực
- Quyền truy cập tài nguyên
Ở bước đầu tiên, ứng dụng của bạn sử dụng giao diện riêng để gọi nhà cung cấp và sau đó quản lý quy trình mã thông báo.
Sau đó, bước hai quản lý mã thông báo và yêu cầu ứng dụng của bạn gửi AssumeRoleWithWebIdentityyêu cầu AWS STS. Yêu cầu chứa mã thông báo đầu tiên, ID ứng dụng của nhà cung cấp và ARN của vai trò IAM. STS cung cấp thông tin xác thực được đặt sẽ hết hạn sau một khoảng thời gian nhất định.
Ở bước cuối cùng, ứng dụng của bạn nhận được phản hồi từ STS chứa thông tin truy cập cho các tài nguyên DynamoDB. Nó bao gồm thông tin xác thực truy cập, thời gian hết hạn, vai trò và ID vai trò.
Data Pipeline cho phép xuất và nhập dữ liệu vào / từ bảng, tệp hoặc nhóm S3. Tất nhiên, điều này tỏ ra hữu ích trong việc sao lưu, thử nghiệm và cho các nhu cầu hoặc tình huống tương tự.
Trong quá trình xuất, bạn sử dụng bảng điều khiển Đường ống dữ liệu, bảng điều khiển này tạo một đường ống mới và khởi chạy một cụm Amazon EMR (Elastic MapReduce) để thực hiện xuất. EMR đọc dữ liệu từ DynamoDB và ghi vào mục tiêu. Chúng ta sẽ thảo luận chi tiết về EMR ở phần sau trong hướng dẫn này.
Trong thao tác nhập, bạn sử dụng bảng điều khiển Đường ống dữ liệu, bảng điều khiển này tạo một đường dẫn và khởi chạy EMR để thực hiện nhập. Nó đọc dữ liệu từ nguồn và ghi vào đích.
Note - Hoạt động xuất / nhập chịu một khoản chi phí cho các dịch vụ được sử dụng, cụ thể là EMR và S3.
Sử dụng đường ống dữ liệu
Bạn phải chỉ định các quyền hành động và tài nguyên khi sử dụng Data Pipeline. Bạn có thể sử dụng vai trò hoặc chính sách IAM để xác định chúng. Những người dùng đang thực hiện nhập / xuất nên lưu ý rằng họ sẽ yêu cầu ID khóa truy cập hoạt động và khóa bí mật.
IAM Roles cho Data Pipeline
Bạn cần hai vai trò IAM để sử dụng Đường ống dữ liệu -
DataPipelineDefaultRole - Điều này có tất cả các hành động mà bạn cho phép đường ống thực hiện cho bạn.
DataPipelineDefaultResourceRole - Điều này có các tài nguyên mà bạn cho phép đường ống cung cấp cho bạn.
Nếu bạn chưa quen với Data Pipeline, bạn phải xuất hiện từng vai trò. Tất cả những người dùng trước đây đều có các vai trò này do các vai trò hiện có.
Sử dụng bảng điều khiển IAM để tạo vai trò IAM cho Đường ống dữ liệu và thực hiện bốn bước sau:
Step 1 - Đăng nhập vào bảng điều khiển IAM có tại https://console.aws.amazon.com/iam/
Step 2 - Chọn Roles từ bảng điều khiển.
Step 3 - Chọn Create New Role. Sau đó nhập DataPipelineDefaultRole vàoRole Name trường và chọn Next Step. bên trongAWS Service Roles danh sách trong Role Type bảng điều khiển, điều hướng đến Data Pipeline, và lựa chọn Select. Lựa chọnCreate Role bên trong Review bảng điều khiển.
Step 4 - Chọn Create New Role.
Sử dụng chức năng nhập / xuất của Data Pipeline để thực hiện sao lưu. Cách bạn thực hiện sao lưu phụ thuộc vào việc bạn sử dụng bảng điều khiển GUI hay sử dụng trực tiếp Đường ống dữ liệu (API). Tạo đường ống riêng biệt cho từng bảng khi sử dụng bảng điều khiển hoặc nhập / xuất nhiều bảng trong một đường dẫn duy nhất nếu sử dụng tùy chọn trực tiếp.
Xuất và Nhập dữ liệu
Bạn phải tạo nhóm Amazon S3 trước khi thực hiện xuất. Bạn có thể xuất từ một hoặc nhiều bảng.
Thực hiện quy trình bốn bước sau để thực hiện xuất -
Step 1 - Đăng nhập vào Bảng điều khiển quản lý AWS và mở bảng điều khiển Đường ống dữ liệu tại https://console.aws.amazon.com/datapipeline/
Step 2 - Nếu bạn không sử dụng đường ống dẫn nào trong vùng AWS, hãy chọn Get started now. Nếu bạn có một hoặc nhiều, hãy chọnCreate new pipeline.
Step 3- Trên trang tạo, nhập tên cho đường dẫn của bạn. ChọnBuild using a templatecho tham số Nguồn. Lựa chọnExport DynamoDB table to S3khỏi danh sách. Nhập bảng nguồn trongSource DynamoDB table name cánh đồng.
Nhập nhóm S3 đích vào Output S3 Folderhộp văn bản sử dụng định dạng sau: s3: // nameOfBucket / region / nameOfFolder. Nhập điểm đến S3 cho tệp nhật ký đăng nhậpS3 location for logs hộp văn bản.
Step 4 - Chọn Activate sau khi nhập tất cả các cài đặt.
Quá trình tạo có thể mất vài phút để hoàn tất quá trình tạo. Sử dụng bảng điều khiển để theo dõi trạng thái của nó. Xác nhận xử lý thành công với bảng điều khiển S3 bằng cách xem tệp đã xuất.
Nhập dữ liệu
Việc nhập thành công chỉ có thể xảy ra nếu các điều kiện sau là đúng: bạn đã tạo một bảng đích, đích và nguồn sử dụng tên giống nhau, đích và nguồn sử dụng lược đồ khóa giống hệt nhau.
Tuy nhiên, bạn có thể sử dụng bảng đích đã được phổ biến, nhập thay thế các mục dữ liệu dùng chung một khóa với các mục nguồn và cũng thêm các mục thừa vào bảng. Điểm đến cũng có thể sử dụng một khu vực khác.
Mặc dù bạn có thể xuất nhiều nguồn, bạn chỉ có thể nhập một nguồn cho mỗi thao tác. Bạn có thể thực hiện nhập bằng cách tuân thủ các bước sau:
Step 1 - Đăng nhập vào Bảng điều khiển quản lý AWS, sau đó mở bảng điều khiển Đường ống dữ liệu.
Step 2 - Nếu bạn đang có ý định thực hiện nhập vùng chéo, thì bạn nên chọn vùng đích.
Step 3 - Chọn Create new pipeline.
Step 4 - Nhập tên đường ống vào Namecánh đồng. ChọnBuild using a template đối với thông số Nguồn và trong danh sách mẫu, hãy chọn Import DynamoDB backup data from S3.
Nhập vị trí của tệp nguồn trong Input S3 Folderhộp văn bản. Nhập tên bảng đích vàoTarget DynamoDB table namecánh đồng. Sau đó, nhập vị trí cho tệp nhật ký trongS3 location for logs hộp văn bản.
Step 5 - Chọn Activate sau khi nhập tất cả các cài đặt.
Quá trình nhập bắt đầu ngay sau khi tạo đường ống. Có thể mất vài phút để đường dẫn hoàn tất quá trình tạo.
Lỗi
Khi lỗi xảy ra, bảng điều khiển Đường ống Dữ liệu hiển thị LỖI dưới dạng trạng thái đường ống. Việc nhấp vào đường dẫn có lỗi sẽ đưa bạn đến trang chi tiết của nó, trang này hiển thị từng bước của quy trình và điểm xảy ra lỗi. Các tệp nhật ký bên trong cũng cung cấp một số thông tin chi tiết.
Bạn có thể xem lại các nguyên nhân phổ biến của lỗi như sau:
Bảng đích cho một lần nhập không tồn tại hoặc không sử dụng lược đồ khóa giống hệt với nguồn.
Nhóm S3 không tồn tại hoặc bạn không có quyền đọc / ghi cho nó.
Đường ống đã hết thời gian chờ.
Bạn không có quyền xuất / nhập cần thiết.
Tài khoản AWS của bạn đã đạt đến giới hạn tài nguyên.
Amazon cung cấp CloudWatch để tổng hợp và phân tích hiệu suất thông qua bảng điều khiển CloudWatch, dòng lệnh hoặc API CloudWatch. Bạn cũng có thể sử dụng nó để đặt báo thức và thực hiện các tác vụ. Nó thực hiện các hành động cụ thể trên các sự kiện nhất định.
Bảng điều khiển Cloudwatch
Sử dụng CloudWatch bằng cách truy cập Bảng điều khiển quản lý, sau đó mở bảng điều khiển CloudWatch tại https://console.aws.amazon.com/cloudwatch/.
Sau đó, bạn có thể thực hiện các bước sau:
Lựa chọn Metrics từ ngăn điều hướng.
Dưới chỉ số DynamoDB trong CloudWatch Metrics by Category ngăn, chọn Table Metrics.
Sử dụng ngăn trên để cuộn xuống bên dưới và kiểm tra toàn bộ danh sách các chỉ số của bảng. CácViewing danh sách cung cấp các tùy chọn số liệu.
Trong giao diện kết quả, bạn có thể chọn / bỏ chọn từng chỉ số bằng cách chọn hộp kiểm bên cạnh tên tài nguyên và chỉ số. Sau đó, bạn sẽ có thể xem đồ thị cho từng mục.
Tích hợp API
Bạn có thể truy cập CloudWatch bằng các truy vấn. Sử dụng các giá trị chỉ số để thực hiện các hành động trên CloudWatch. Lưu ý DynamoDB không gửi số liệu có giá trị bằng 0. Nó chỉ đơn giản là bỏ qua các số liệu trong khoảng thời gian mà các số liệu đó vẫn ở giá trị đó.
Sau đây là một số chỉ số được sử dụng phổ biến nhất -
ConditionalCheckFailedRequests- Nó theo dõi số lần thất bại trong các lần ghi có điều kiện như ghi PutItem có điều kiện. Việc ghi không thành công làm tăng số liệu này lên từng điểm một khi đánh giá thành sai. Nó cũng tạo ra lỗi HTTP 400.
ConsumedReadCapacityUnits- Nó định lượng các đơn vị công suất được sử dụng trong một khoảng thời gian nhất định. Bạn có thể sử dụng điều này để kiểm tra mức tiêu thụ bảng và chỉ mục riêng lẻ.
ConsumedWriteCapacityUnits- Nó định lượng các đơn vị công suất được sử dụng trong một khoảng thời gian nhất định. Bạn có thể sử dụng điều này để kiểm tra mức tiêu thụ bảng và chỉ mục riêng lẻ.
ReadThrottleEvents- Nó định lượng các yêu cầu vượt quá đơn vị dung lượng được cung cấp trong các lần đọc bảng / chỉ mục. Nó tăng lên trên mỗi van tiết lưu bao gồm các hoạt động hàng loạt với nhiều van tiết lưu.
ReturnedBytes - Nó định lượng các byte trả về trong các hoạt động truy xuất trong một khoảng thời gian nhất định.
ReturnedItemCount- Nó định lượng các mục được trả về trong các hoạt động Truy vấn và Quét trong một khoảng thời gian nhất định. Nó chỉ giải quyết các mục được trả lại, không phải những mục được đánh giá, thường là những số liệu hoàn toàn khác nhau.
Note - Có nhiều số liệu khác tồn tại và hầu hết các số liệu này cho phép bạn tính trung bình, tổng, tối đa, tối thiểu và số.
DynamoDB bao gồm tích hợp CloudTrail. Nó nắm bắt các yêu cầu API cấp thấp từ hoặc cho DynamoDB trong tài khoản và gửi các tệp nhật ký đến một nhóm S3 cụ thể. Nó nhắm mục tiêu các cuộc gọi từ bảng điều khiển hoặc API. Bạn có thể sử dụng dữ liệu này để xác định các yêu cầu được thực hiện và nguồn, người dùng, dấu thời gian, v.v. của chúng.
Khi được bật, nó theo dõi các hành động trong tệp nhật ký, bao gồm các bản ghi dịch vụ khác. Nó hỗ trợ tám hành động và hai luồng -
Tám hành động như sau:
- CreateTable
- DeleteTable
- DescribeTable
- ListTables
- UpdateTable
- DescribeReservedCapacity
- DescribeReservedCapacityOfferings
- PurchaseReservedCapacityOfferings
Trong khi, hai luồng là -
- DescribeStream
- ListStreams
Tất cả các nhật ký đều chứa thông tin về các tài khoản thực hiện yêu cầu. Bạn có thể xác định thông tin chi tiết như liệu người dùng root hay IAM đã đưa ra yêu cầu hay bằng thông tin xác thực tạm thời hay được liên kết.
Các tệp nhật ký vẫn được lưu trữ trong bao lâu mà bạn chỉ định, với các cài đặt để lưu trữ và xóa. Mặc định tạo nhật ký được mã hóa. Bạn có thể đặt cảnh báo cho nhật ký mới. Bạn cũng có thể sắp xếp nhiều nhật ký, giữa các vùng và tài khoản vào một nhóm duy nhất.
Thông dịch tệp nhật ký
Mỗi tệp chứa một hoặc nhiều mục nhập. Mỗi mục nhập bao gồm nhiều sự kiện định dạng JSON. Mục nhập thể hiện một yêu cầu và bao gồm thông tin liên quan; không đảm bảo thứ tự.
Bạn có thể xem lại tệp nhật ký mẫu sau:
{"Records": [
{
"eventVersion": "5.05",
"userIdentity": {
"type": "AssumedRole",
"principalId": "AKTTIOSZODNN8SAMPLE:jane",
"arn": "arn:aws:sts::155522255533:assumed-role/users/jane",
"accountId": "155522255533",
"accessKeyId": "AKTTIOSZODNN8SAMPLE",
"sessionContext": {
"attributes": {
"mfaAuthenticated": "false",
"creationDate": "2016-05-11T19:01:01Z"
},
"sessionIssuer": {
"type": "Role",
"principalId": "AKTTI44ZZ6DHBSAMPLE",
"arn": "arn:aws:iam::499955777666:role/admin-role",
"accountId": "499955777666",
"userName": "jill"
}
}
},
"eventTime": "2016-05-11T14:33:20Z",
"eventSource": "dynamodb.amazonaws.com",
"eventName": "DeleteTable",
"awsRegion": "us-west-2",
"sourceIPAddress": "192.0.2.0",
"userAgent": "console.aws.amazon.com",
"requestParameters": {"tableName": "Tools"},
"responseElements": {"tableDescription": {
"tableName": "Tools",
"itemCount": 0,
"provisionedThroughput": {
"writeCapacityUnits": 25,
"numberOfDecreasesToday": 0,
"readCapacityUnits": 25
},
"tableStatus": "DELETING",
"tableSizeBytes": 0
}},
"requestID": "4D89G7D98GF7G8A7DF78FG89AS7GFSO5AEMVJF66Q9ASUAAJG",
"eventID": "a954451c-c2fc-4561-8aea-7a30ba1fdf52",
"eventType": "AwsApiCall",
"apiVersion": "2013-04-22",
"recipientAccountId": "155522255533"
}
]}Amazon's Elastic MapReduce (EMR) cho phép bạn xử lý dữ liệu lớn một cách nhanh chóng và hiệu quả. EMR chạy Apache Hadoop trên các phiên bản EC2, nhưng đơn giản hóa quy trình. Bạn sử dụng Apache Hive để truy vấn bản đồ giảm luồng công việc thông qua HiveQL , một ngôn ngữ truy vấn tương tự như SQL. Apache Hive đóng vai trò như một cách để tối ưu hóa các truy vấn và ứng dụng của bạn.
Bạn có thể sử dụng tab EMR của bảng điều khiển quản lý, EMR CLI, API hoặc SDK để khởi chạy quy trình công việc. Bạn cũng có tùy chọn chạy Hive tương tác hoặc sử dụng tập lệnh.
Các hoạt động đọc / ghi EMR ảnh hưởng đến việc tiêu thụ thông lượng, tuy nhiên, trong các yêu cầu lớn, nó thực hiện thử lại với sự bảo vệ của một thuật toán dự phòng. Ngoài ra, chạy EMR đồng thời với các hoạt động và tác vụ khác có thể dẫn đến việc điều chỉnh.
Tích hợp DynamoDB / EMR không hỗ trợ các thuộc tính bộ nhị phân và nhị phân.
Điều kiện tiên quyết về tích hợp DynamoDB / EMR
Xem lại danh sách kiểm tra các mục cần thiết này trước khi sử dụng EMR -
- Tài khoản AWS
- Một bảng được điền trong cùng một tài khoản được sử dụng trong các hoạt động EMR
- Một phiên bản Hive tùy chỉnh với kết nối DynamoDB
- Hỗ trợ kết nối DynamoDB
- Một thùng S3 (tùy chọn)
- Máy khách SSH (tùy chọn)
- Một cặp khóa EC2 (tùy chọn)
Thiết lập Hive
Trước khi sử dụng EMR, hãy tạo một cặp khóa để chạy Hive ở chế độ tương tác. Cặp khóa cho phép kết nối với các cá thể EC2 và các nút chính của luồng công việc.
Bạn có thể thực hiện việc này bằng cách làm theo các bước tiếp theo:
Đăng nhập vào bảng điều khiển quản lý và mở bảng điều khiển EC2 tại https://console.aws.amazon.com/ec2/
Chọn một vùng ở phía trên bên phải của bảng điều khiển. Đảm bảo vùng khớp với vùng DynamoDB.
Trong ngăn Điều hướng, hãy chọn Key Pairs.
Lựa chọn Create Key Pair.
bên trong Key Pair Name trường, nhập tên và chọn Create.
Tải xuống tệp khóa cá nhân kết quả sử dụng định dạng sau: filename.pem.
Note - Bạn không thể kết nối với các phiên bản EC2 mà không có cặp khóa.
Hive Cluster
Tạo một cụm hỗ trợ tổ ong để chạy Hive. Nó xây dựng môi trường cần thiết của các ứng dụng và cơ sở hạ tầng cho kết nối Hive-to-DynamoDB.
Bạn có thể thực hiện tác vụ này bằng cách sử dụng các bước sau:
Truy cập bảng điều khiển EMR.
Lựa chọn Create Cluster.
Trong màn hình tạo, đặt cấu hình cụm với tên mô tả cho cụm, chọn Yes để bảo vệ chấm dứt và kiểm tra Enabled để ghi nhật ký, một điểm đến S3 cho log folder S3 locationvà Enabled để gỡ lỗi.
Trong màn hình Cấu hình phần mềm, đảm bảo các trường giữ Amazon cho bản phân phối Hadoop, phiên bản mới nhất cho phiên bản AMI, phiên bản Hive mặc định cho Ứng dụng sẽ được Cài đặt-Hive và phiên bản Pig mặc định cho Ứng dụng được cài đặt-Pig.
Trong màn hình Cấu hình phần cứng, đảm bảo các trường giữ Launch into EC2-Classic cho Mạng, No Preference đối với Vùng khả dụng EC2, mặc định cho Loại phiên bản Master-Amazon EC2, không kiểm tra đối với Phiên bản Spot yêu cầu, mặc định cho Loại phiên bản Core-Amazon EC2, 2 cho Số lượng, không kiểm tra Yêu cầu Phiên bản Spot, mặc định cho Loại Phiên bản Task-Amazon EC2, 0 cho Đếm và không kiểm tra Yêu cầu Phiên bản Spot.
Đảm bảo đặt giới hạn cung cấp đủ dung lượng để ngăn chặn lỗi cụm.
Trong màn hình Bảo mật và Truy cập, hãy đảm bảo các trường giữ cặp khóa của bạn trong cặp khóa EC2, No other IAM users trong quyền truy cập của người dùng IAM và Proceed without roles trong vai trò IAM.
Xem lại màn hình Bootstrap Actions, nhưng không sửa đổi nó.
Xem lại cài đặt và chọn Create Cluster khi hoàn thành.
A Summary ngăn xuất hiện ở đầu cụm.
Kích hoạt phiên SSH
Bạn cần một phiên SSH đang hoạt động để kết nối với nút chính và thực hiện các hoạt động CLI. Định vị nút chính bằng cách chọn cụm trong bảng điều khiển EMR. Nó liệt kê nút chính làMaster Public DNS Name.
Cài đặt PuTTY nếu bạn chưa có. Sau đó khởi chạy PuTTYgen và chọnLoad. Chọn tệp PEM của bạn và mở nó. PuTTYgen sẽ thông báo cho bạn nhập thành công. Lựa chọnSave private key để lưu ở định dạng khóa cá nhân PuTTY (PPK) và chọn Yesđể lưu mà không có cụm từ vượt qua. Sau đó nhập tên cho phím PuTTY, nhấnSavevà đóng PuTTYgen.
Sử dụng PuTTY để tạo kết nối với nút chính bằng cách khởi động PuTTY trước. ChọnSessiontừ danh sách Danh mục. Nhập hadoop @ DNS trong trường Tên máy chủ. Mở rộngConnection > SSH trong danh sách Danh mục và chọn Auth. Trong màn hình tùy chọn điều khiển, hãy chọnBrowsecho tệp khóa riêng để xác thực. Sau đó chọn tệp khóa riêng của bạn và mở nó. Lựa chọnYes cho cửa sổ bật lên cảnh báo bảo mật.
Khi được kết nối với nút chính, dấu nhắc lệnh Hadoop xuất hiện, có nghĩa là bạn có thể bắt đầu một phiên Hive tương tác.
Bàn Hive
Hive đóng vai trò như một công cụ kho dữ liệu cho phép truy vấn trên các cụm EMR sử dụng HiveQL . Các thiết lập trước cung cấp cho bạn lời nhắc làm việc. Chạy các lệnh Hive một cách tương tác bằng cách chỉ cần nhập “hive”, sau đó nhập bất kỳ lệnh nào bạn muốn. Xem hướng dẫn về Hive của chúng tôi để biết thêm thông tin về Hive .
Các luồng DynamoDB cho phép bạn theo dõi và phản hồi các thay đổi của mục trong bảng. Sử dụng chức năng này để tạo một ứng dụng đáp ứng các thay đổi bằng cách cập nhật thông tin giữa các nguồn. Đồng bộ dữ liệu cho hàng nghìn người dùng của một hệ thống lớn, nhiều người dùng. Sử dụng nó để gửi thông báo cho người dùng về các bản cập nhật. Các ứng dụng của nó chứng tỏ sự đa dạng và đáng kể. Các luồng DynamoDB đóng vai trò là công cụ chính được sử dụng để đạt được chức năng này.
Các luồng nắm bắt các trình tự theo thứ tự thời gian chứa các sửa đổi mục trong bảng. Họ giữ dữ liệu này trong tối đa 24 giờ. Các ứng dụng sử dụng chúng để xem các mục gốc và các mục đã sửa đổi, gần như trong thời gian thực.
Các luồng được bật trên bảng ghi lại tất cả các sửa đổi. Trên bất kỳ hoạt động CRUD nào, DynamoDB tạo một bản ghi luồng với các thuộc tính khóa chính của các mục được sửa đổi. Bạn có thể định cấu hình các luồng để biết thêm thông tin như hình ảnh trước và sau.
Luồng mang hai đảm bảo -
Mỗi bản ghi xuất hiện một lần trong luồng và
Mỗi sửa đổi mục dẫn đến các bản ghi luồng có cùng thứ tự với các sửa đổi.
Tất cả các luồng xử lý trong thời gian thực để cho phép bạn sử dụng chúng cho các chức năng liên quan trong các ứng dụng.
Quản lý luồng
Khi tạo bảng, bạn có thể bật luồng. Các bảng hiện có cho phép tắt luồng hoặc thay đổi cài đặt. Luồng cung cấp tính năng hoạt động không đồng bộ, có nghĩa là không ảnh hưởng đến hiệu suất bảng.
Sử dụng bảng điều khiển Quản lý AWS để quản lý luồng đơn giản. Đầu tiên, điều hướng đến bảng điều khiển và chọnTables. Trong tab Tổng quan, chọnManage Stream. Bên trong cửa sổ, chọn thông tin được thêm vào luồng sửa đổi dữ liệu bảng. Sau khi nhập tất cả các cài đặt, hãy chọnEnable.
Nếu bạn muốn tắt mọi luồng hiện có, hãy chọn Manage Stream, và sau đó Disable.
Bạn cũng có thể sử dụng APIs CreateTable và UpdateTable để bật hoặc thay đổi luồng. Sử dụng tham số StreamSpecification để định cấu hình luồng. StreamEnabled chỉ định trạng thái, nghĩa là đúng đối với đã bật và sai đối với đã tắt.
StreamViewType chỉ định thông tin được thêm vào luồng: KEYS_ONLY, NEW_IMAGE, OLD_IMAGE và NEW_AND_OLD_IMAGES.
Đọc trực tuyến
Đọc và xử lý các luồng bằng cách kết nối với một điểm cuối và thực hiện các yêu cầu API. Mỗi luồng bao gồm các bản ghi luồng và mọi bản ghi tồn tại dưới dạng một sửa đổi duy nhất sở hữu luồng. Bản ghi luồng bao gồm một số thứ tự tiết lộ thứ tự xuất bản. Bản ghi thuộc về nhóm còn được gọi là mảnh. Các mảnh có chức năng như các thùng chứa cho một số bản ghi và cũng chứa thông tin cần thiết để truy cập và duyệt qua các bản ghi. Sau 24 giờ, hồ sơ tự động xóa.
Các mảnh này được tạo và xóa khi cần thiết và không tồn tại lâu. Chúng cũng tự động phân chia thành nhiều phân đoạn mới, thường là để phản ứng với việc ghi tăng đột biến hoạt động. Khi tắt luồng, các phân đoạn đang mở sẽ đóng lại. Mối quan hệ phân cấp giữa các phân đoạn có nghĩa là các ứng dụng phải ưu tiên các phân đoạn mẹ để có thứ tự xử lý chính xác. Bạn có thể sử dụng Kinesis Adapter để tự động thực hiện việc này.
Note − The operations resulting in no change do not write stream records.
Accessing and processing records requires performing the following tasks −
- Determine the ARN of the target stream.
- Determine the shard(s) of the stream holding the target records.
- Access the shard(s) to retrieve the desired records.
Note − There should be a maximum of 2 processes reading a shard at once. If it exceeds 2 processes, then it can throttle the source.
The stream API actions available include
- ListStreams
- DescribeStream
- GetShardIterator
- GetRecords
You can review the following example of the stream reading −
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.amazonaws.auth.profile.ProfileCredentialsProvider;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClient;
import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClient;
import com.amazonaws.services.dynamodbv2.model.AttributeAction;
import com.amazonaws.services.dynamodbv2.model.AttributeDefinition;
import com.amazonaws.services.dynamodbv2.model.AttributeValue;
import com.amazonaws.services.dynamodbv2.model.AttributeValueUpdate;
import com.amazonaws.services.dynamodbv2.model.CreateTableRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeStreamRequest;
import com.amazonaws.services.dynamodbv2.model.DescribeStreamResult;
import com.amazonaws.services.dynamodbv2.model.DescribeTableResult;
import com.amazonaws.services.dynamodbv2.model.GetRecordsRequest;
import com.amazonaws.services.dynamodbv2.model.GetRecordsResult;
import com.amazonaws.services.dynamodbv2.model.GetShardIteratorRequest;
import com.amazonaws.services.dynamodbv2.model.GetShardIteratorResult;
import com.amazonaws.services.dynamodbv2.model.KeySchemaElement;
import com.amazonaws.services.dynamodbv2.model.KeyType;
import com.amazonaws.services.dynamodbv2.model.ProvisionedThroughput;
import com.amazonaws.services.dynamodbv2.model.Record;
import com.amazonaws.services.dynamodbv2.model.Shard;
import com.amazonaws.services.dynamodbv2.model.ShardIteratorType;
import com.amazonaws.services.dynamodbv2.model.StreamSpecification;
import com.amazonaws.services.dynamodbv2.model.StreamViewType;
import com.amazonaws.services.dynamodbv2.util.Tables;
public class StreamsExample {
private static AmazonDynamoDBClient dynamoDBClient =
new AmazonDynamoDBClient(new ProfileCredentialsProvider());
private static AmazonDynamoDBStreamsClient streamsClient =
new AmazonDynamoDBStreamsClient(new ProfileCredentialsProvider());
public static void main(String args[]) {
dynamoDBClient.setEndpoint("InsertDbEndpointHere");
streamsClient.setEndpoint("InsertStreamEndpointHere");
// table creation
String tableName = "MyTestingTable";
ArrayList<AttributeDefinition> attributeDefinitions =
new ArrayList<AttributeDefinition>();
attributeDefinitions.add(new AttributeDefinition()
.withAttributeName("ID")
.withAttributeType("N"));
ArrayList<KeySchemaElement> keySchema = new
ArrayList<KeySchemaElement>();
keySchema.add(new KeySchemaElement()
.withAttributeName("ID")
.withKeyType(KeyType.HASH)); //Partition key
StreamSpecification streamSpecification = new StreamSpecification();
streamSpecification.setStreamEnabled(true);
streamSpecification.setStreamViewType(StreamViewType.NEW_AND_OLD_IMAGES);
CreateTableRequest createTableRequest = new CreateTableRequest()
.withTableName(tableName)
.withKeySchema(keySchema)
.withAttributeDefinitions(attributeDefinitions)
.withProvisionedThroughput(new ProvisionedThroughput()
.withReadCapacityUnits(1L)
.withWriteCapacityUnits(1L))
.withStreamSpecification(streamSpecification);
System.out.println("Executing CreateTable for " + tableName);
dynamoDBClient.createTable(createTableRequest);
System.out.println("Creating " + tableName);
try {
Tables.awaitTableToBecomeActive(dynamoDBClient, tableName);
} catch (InterruptedException e) {
e.printStackTrace();
}
// Get the table's stream settings
DescribeTableResult describeTableResult =
dynamoDBClient.describeTable(tableName);
String myStreamArn = describeTableResult.getTable().getLatestStreamArn();
StreamSpecification myStreamSpec =
describeTableResult.getTable().getStreamSpecification();
System.out.println("Current stream ARN for " + tableName + ": "+ myStreamArn);
System.out.println("Stream enabled: "+ myStreamSpec.getStreamEnabled());
System.out.println("Update view type: "+ myStreamSpec.getStreamViewType());
// Add an item
int numChanges = 0;
System.out.println("Making some changes to table data");
Map<String, AttributeValue> item = new HashMap<String, AttributeValue>();
item.put("ID", new AttributeValue().withN("222"));
item.put("Alert", new AttributeValue().withS("item!"));
dynamoDBClient.putItem(tableName, item);
numChanges++;
// Update the item
Map<String, AttributeValue> key = new HashMap<String, AttributeValue>();
key.put("ID", new AttributeValue().withN("222"));
Map<String, AttributeValueUpdate> attributeUpdates =
new HashMap<String, AttributeValueUpdate>();
attributeUpdates.put("Alert", new AttributeValueUpdate()
.withAction(AttributeAction.PUT)
.withValue(new AttributeValue().withS("modified item")));
dynamoDBClient.updateItem(tableName, key, attributeUpdates);
numChanges++;
// Delete the item
dynamoDBClient.deleteItem(tableName, key);
numChanges++;
// Get stream shards
DescribeStreamResult describeStreamResult =
streamsClient.describeStream(new DescribeStreamRequest()
.withStreamArn(myStreamArn));
String streamArn =
describeStreamResult.getStreamDescription().getStreamArn();
List<Shard> shards =
describeStreamResult.getStreamDescription().getShards();
// Process shards
for (Shard shard : shards) {
String shardId = shard.getShardId();
System.out.println("Processing " + shardId + " in "+ streamArn);
// Get shard iterator
GetShardIteratorRequest getShardIteratorRequest = new
GetShardIteratorRequest()
.withStreamArn(myStreamArn)
.withShardId(shardId)
.withShardIteratorType(ShardIteratorType.TRIM_HORIZON);
GetShardIteratorResult getShardIteratorResult =
streamsClient.getShardIterator(getShardIteratorRequest);
String nextItr = getShardIteratorResult.getShardIterator();
while (nextItr != null && numChanges > 0) {
// Read data records with iterator
GetRecordsResult getRecordsResult =
streamsClient.getRecords(new GetRecordsRequest().
withShardIterator(nextItr));
List<Record> records = getRecordsResult.getRecords();
System.out.println("Pulling records...");
for (Record record : records) {
System.out.println(record);
numChanges--;
}
nextItr = getRecordsResult.getNextShardIterator();
}
}
}
}Khi xử lý yêu cầu không thành công, DynamoDB sẽ thông báo lỗi. Mỗi lỗi bao gồm các thành phần sau: mã trạng thái HTTP, tên ngoại lệ và thông báo. Việc quản lý lỗi nằm trên SDK của bạn, SDK này sẽ truyền lỗi hoặc mã của riêng bạn.
Mã và tin nhắn
Các trường hợp ngoại lệ rơi vào các mã trạng thái tiêu đề HTTP khác nhau. 4xx và 5xx giữ các lỗi liên quan đến các vấn đề yêu cầu và AWS.
Lựa chọn các ngoại lệ trong danh mục HTTP 4xx như sau:
AccessDeniedException - Khách hàng không thể ký yêu cầu một cách chính xác.
ConditionalCheckFailedException - Một điều kiện được đánh giá là sai.
IncompleteSignatureException - Yêu cầu bao gồm một chữ ký không đầy đủ.
Các ngoại lệ trong danh mục HTTP 5xx như sau:
- Lỗi máy chủ nội bộ
- dịch vụ Không sẵn có
Thử lại và thuật toán dự phòng
Lỗi đến từ nhiều nguồn khác nhau như máy chủ, thiết bị chuyển mạch, bộ cân bằng tải và các phần khác của cấu trúc và hệ thống. Các giải pháp phổ biến bao gồm các lần thử lại đơn giản, hỗ trợ độ tin cậy. Tất cả các SDK đều tự động bao gồm logic này và bạn có thể đặt các thông số thử lại cho phù hợp với nhu cầu ứng dụng của mình.
For example - Java cung cấp giá trị maxErrorRetry để dừng thử lại.
Amazon khuyên bạn nên sử dụng giải pháp dự phòng ngoài việc thử lại để kiểm soát luồng. Điều này bao gồm khoảng thời gian chờ tăng dần giữa các lần thử lại và cuối cùng dừng lại sau một khoảng thời gian khá ngắn. Lưu ý rằng SDK thực hiện thử lại tự động, nhưng không phải lùi theo cấp số nhân.
Chương trình sau là một ví dụ về quá trình thử lại:
public enum Results {
SUCCESS,
NOT_READY,
THROTTLED,
SERVER_ERROR
}
public static void DoAndWaitExample() {
try {
// asynchronous operation.
long token = asyncOperation();
int retries = 0;
boolean retry = false;
do {
long waitTime = Math.min(getWaitTime(retries), MAX_WAIT_INTERVAL);
System.out.print(waitTime + "\n");
// Pause for result
Thread.sleep(waitTime);
// Get result
Results result = getAsyncOperationResult(token);
if (Results.SUCCESS == result) {
retry = false;
} else if (Results.NOT_READY == result) {
retry = true;
} else if (Results.THROTTLED == result) {
retry = true;
} else if (Results.SERVER_ERROR == result) {
retry = true;
} else {
// stop on other error
retry = false;
}
} while (retry && (retries++ < MAX_RETRIES));
}
catch (Exception ex) {
}
}
public static long getWaitTime(int retryCount) {
long waitTime = ((long) Math.pow(3, retryCount) * 100L);
return waitTime;
}Một số phương pháp tối ưu hóa mã, ngăn ngừa lỗi và giảm thiểu chi phí thông lượng khi làm việc với các nguồn và phần tử khác nhau.
Sau đây là một số phương pháp hay nhất quan trọng nhất và thường được sử dụng trong DynamoDB.
Những cái bàn
Việc phân bố các bảng có nghĩa là các cách tiếp cận tốt nhất trải đều hoạt động đọc / ghi trên tất cả các mục trong bảng.
Nhằm mục đích truy cập dữ liệu thống nhất trên các mục trong bảng. Việc sử dụng thông lượng tối ưu phụ thuộc vào lựa chọn khóa chính và các mẫu khối lượng công việc mục. Chia đều khối lượng công việc trên các giá trị chính của phân vùng. Tránh những thứ như một lượng nhỏ giá trị khóa phân vùng được sử dụng nhiều. Chọn các lựa chọn tốt hơn như số lượng lớn các giá trị khóa phân vùng riêng biệt.
Hiểu được hành vi của phân vùng. Ước tính các phân vùng được DynamoDB phân bổ tự động.
DynamoDB cung cấp việc sử dụng thông lượng liên tục, dự trữ thông lượng chưa sử dụng cho các "bùng nổ" công suất. Tránh sử dụng nhiều tùy chọn này vì các đợt bùng nổ tiêu thụ một lượng lớn thông lượng một cách nhanh chóng; hơn nữa, nó không chứng minh một nguồn đáng tin cậy.
Khi tải lên, hãy phân phối dữ liệu để đạt được hiệu suất tốt hơn. Thực hiện điều này bằng cách tải lên đồng thời tất cả các máy chủ được phân bổ.
Bộ nhớ cache các mục được sử dụng thường xuyên để giảm tải hoạt động đọc vào bộ nhớ cache thay vì cơ sở dữ liệu.
Mặt hàng
Tiết kiệm, hiệu suất, kích thước và chi phí truy cập vẫn là mối quan tâm lớn nhất với các mặt hàng. Chọn một-nhiều bảng. Loại bỏ các thuộc tính và phân chia bảng để phù hợp với các mẫu truy cập. Bạn có thể cải thiện hiệu quả đáng kể thông qua cách tiếp cận đơn giản này.
Nén các giá trị lớn trước khi lưu trữ. Sử dụng các công cụ nén tiêu chuẩn. Sử dụng bộ nhớ thay thế cho các giá trị thuộc tính lớn như S3. Bạn có thể lưu trữ đối tượng trong S3 và một số nhận dạng trong mục.
Phân phối các thuộc tính lớn trên một số vật phẩm thông qua các mảnh vật phẩm ảo. Điều này cung cấp một giải pháp cho những hạn chế của kích thước mặt hàng.
Truy vấn và quét
Các truy vấn và quét chủ yếu gặp phải những thách thức về tiêu thụ thông lượng. Tránh bùng phát, thường là kết quả của những thứ như chuyển sang một bài đọc nhất quán cao. Sử dụng tính năng quét song song theo cách tốn ít tài nguyên (tức là chức năng nền không có điều chỉnh). Hơn nữa, chỉ sử dụng chúng với các bảng lớn và các trường hợp bạn không sử dụng đầy đủ thông lượng hoặc hoạt động quét mang lại hiệu suất kém.
Chỉ số phụ cục bộ
Các chỉ mục trình bày các vấn đề trong các lĩnh vực thông lượng và chi phí lưu trữ cũng như hiệu quả của các truy vấn. Tránh lập chỉ mục trừ khi bạn truy vấn các thuộc tính thường xuyên. Trong các phép chiếu, hãy chọn một cách khôn ngoan vì chúng làm phình chỉ mục. Chỉ chọn những người được sử dụng nhiều.
Sử dụng các chỉ mục thưa thớt, nghĩa là các chỉ mục trong đó các khóa sắp xếp không xuất hiện trong tất cả các mục của bảng. Chúng có lợi cho các truy vấn về các thuộc tính không có trong hầu hết các mục trong bảng.
Chú ý đến việc mở rộng bộ sưu tập vật phẩm (tất cả các mục trong bảng và chỉ số của chúng). Các thao tác thêm / cập nhật khiến cả bảng và chỉ mục đều tăng lên và 10GB vẫn là giới hạn cho các bộ sưu tập.
Chỉ số phụ toàn cầu
Các chỉ mục trình bày các vấn đề trong các lĩnh vực thông lượng và chi phí lưu trữ cũng như hiệu quả của các truy vấn. Chọn trải rộng các thuộc tính chính, như trải rộng đọc / ghi trong bảng cung cấp sự đồng nhất về khối lượng công việc. Chọn thuộc tính trải đều dữ liệu. Ngoài ra, hãy sử dụng các chỉ mục thưa thớt.
Khai thác các chỉ số phụ toàn cầu để tìm kiếm nhanh trong các truy vấn yêu cầu một lượng dữ liệu khiêm tốn.