Hệ thống nhúng - Hợp ngữ
Hợp ngữ được phát triển để cung cấp mnemonicshoặc các ký hiệu cho hướng dẫn mã cấp máy. Các chương trình hợp ngữ bao gồm các kỹ năng ghi nhớ, do đó chúng phải được dịch sang mã máy. Một chương trình chịu trách nhiệm cho việc chuyển đổi này được gọi làassembler. Hợp ngữ thường được gọi là ngôn ngữ cấp thấp vì nó hoạt động trực tiếp với cấu trúc bên trong của CPU. Để lập trình bằng hợp ngữ, một lập trình viên phải biết tất cả các thanh ghi của CPU.
Các ngôn ngữ lập trình khác nhau như C, C ++, Java và nhiều ngôn ngữ khác được gọi là ngôn ngữ cấp cao vì chúng không xử lý các chi tiết bên trong của CPU. Ngược lại, một trình hợp dịch được sử dụng để dịch một chương trình hợp ngữ thành mã máy (đôi khi còn được gọi làobject code hoặc là opcode). Tương tự như vậy, trình biên dịch dịch một ngôn ngữ cấp cao thành mã máy. Ví dụ, để viết một chương trình bằng ngôn ngữ C, người ta phải sử dụng một trình biên dịch C để dịch chương trình sang ngôn ngữ máy.
Cấu trúc của hợp ngữ
Một chương trình hợp ngữ là một chuỗi các câu lệnh, là các lệnh hợp ngữ như ADD và MOV, hoặc các câu lệnh được gọi là directives.
An instruction cho CPU biết phải làm gì, trong khi directive (còn được gọi là pseudo-instructions) cung cấp hướng dẫn cho trình hợp dịch. Ví dụ, các lệnh ADD và MOV là các lệnh mà CPU chạy, trong khi ORG và END là các lệnh của trình hợp dịch. Trình hợp dịch đặt opcode vào vị trí bộ nhớ 0 khi chỉ thị ORG được sử dụng, trong khi END chỉ ra phần cuối của mã nguồn. Một chỉ dẫn ngôn ngữ chương trình bao gồm bốn trường sau:
[ label: ] mnemonics [ operands ] [;comment ]Dấu ngoặc vuông ([]) cho biết rằng trường là tùy chọn.
Các label fieldcho phép chương trình tham chiếu đến một dòng mã theo tên. Các trường nhãn không được vượt quá một số ký tự nhất định.
Các mnemonics và operands fieldscùng nhau thực hiện các công việc thực của chương trình và hoàn thành các nhiệm vụ. Các câu lệnh như ADD A, C & MOV C, # 68 trong đó ADD và MOV là thuật ngữ ghi nhớ, tạo ra mã quang; "A, C" và "C, # 68" là các toán hạng. Hai trường này có thể chứa các chỉ thị. Các lệnh không tạo ra mã máy và chỉ được sử dụng bởi trình lắp ráp, trong khi các lệnh được dịch thành mã máy để CPU thực thi.
1.0000 ORG 0H ;start (origin) at location 0
2 0000 7D25 MOV R5,#25H ;load 25H into R5
3.0002 7F34 MOV R7,#34H ;load 34H into R7
4.0004 7400 MOV A,#0 ;load 0 into A
5.0006 2D ADD A,R5 ;add contents of R5 to A
6.0007 2F ADD A,R7 ;add contents of R7 to A
7.0008 2412 ADD A,#12H ;add to A value 12 H
8.000A 80FE HERE: SJMP HERE ;stay in this loop
9.000C END ;end of asm source fileCác comment field bắt đầu bằng dấu chấm phẩy là chỉ báo nhận xét.
Lưu ý Nhãn "TẠI ĐÂY" trong chương trình. Bất kỳ nhãn nào đề cập đến một chỉ dẫn phải được theo sau bởi dấu hai chấm.
Lắp ráp và chạy chương trình 8051
Ở đây chúng ta sẽ thảo luận về dạng cơ bản của một hợp ngữ. Các bước để tạo, lắp ráp và chạy một chương trình hợp ngữ như sau:
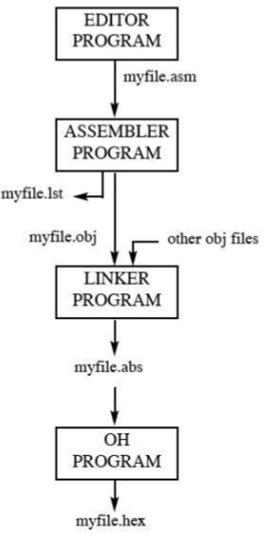
Đầu tiên, chúng ta sử dụng một trình soạn thảo để gõ một chương trình tương tự như chương trình trên. Các trình soạn thảo như chương trình MS-DOS EDIT đi kèm với tất cả các hệ điều hành của Microsoft có thể được sử dụng để tạo hoặc chỉnh sửa chương trình. Trình chỉnh sửa phải có khả năng tạo tệp ASCII. Phần mở rộng "asm" cho tệp nguồn được trình hợp dịch sử dụng trong bước tiếp theo.
Tệp nguồn "asm" chứa mã chương trình được tạo ở Bước 1. Nó được cung cấp cho bộ hợp dịch 8051. Sau đó, trình hợp dịch chuyển đổi các lệnh hợp ngữ thành các lệnh mã máy và tạo ra một.obj file (tệp đối tượng) và một .lst file(tệp danh sách). Nó còn được gọi làsource file, đó là lý do tại sao một số trình lắp ráp yêu cầu tệp này phải có phần mở rộng "src". Tệp "lst" là tùy chọn. Nó rất hữu ích cho chương trình vì nó liệt kê tất cả các mã quang và địa chỉ cũng như các lỗi mà các nhà lắp ráp đã phát hiện.
Người lắp ráp yêu cầu bước thứ ba được gọi là linking. Chương trình liên kết lấy một hoặc nhiều tệp đối tượng và tạo ra tệp đối tượng tuyệt đối có phần mở rộng là "abs".
Tiếp theo, tệp "abs" được đưa đến một chương trình có tên "OH" (bộ chuyển đổi đối tượng sang hệ hex), chương trình này sẽ tạo ra một tệp có phần mở rộng là "hex" sẵn sàng ghi vào ROM.
Loại dữ liệu
Bộ vi điều khiển 8051 chứa một kiểu dữ liệu duy nhất 8 bit và mỗi thanh ghi cũng có kích thước 8 bit. Lập trình viên phải chia nhỏ dữ liệu lớn hơn 8-bit (00 đến FFH, hoặc 255 trong hệ thập phân) để CPU có thể xử lý.
DB (Xác định Byte)
Chỉ thị DB là chỉ thị dữ liệu được sử dụng rộng rãi nhất trong trình hợp dịch. Nó được sử dụng để xác định dữ liệu 8-bit. Nó cũng có thể được sử dụng để xác định dữ liệu định dạng thập phân, nhị phân, hex hoặc ASCII. Đối với số thập phân, "D" sau số thập phân là tùy chọn, nhưng nó là bắt buộc đối với "B" (nhị phân) và "Hl" (thập lục phân).
Để chỉ ra ASCII, chỉ cần đặt các ký tự trong dấu ngoặc kép ('như thế này'). Trình hợp dịch tự động tạo mã ASCII cho các số / ký tự. Chỉ thị DB là chỉ thị duy nhất có thể được sử dụng để xác định chuỗi ASCII lớn hơn hai ký tự; do đó, nó nên được sử dụng cho tất cả các định nghĩa dữ liệu ASCII. Một số ví dụ về DB được đưa ra dưới đây:
ORG 500H
DATA1: DB 28 ;DECIMAL (1C in hex)
DATA2: DB 00110101B ;BINARY (35 in hex)
DATA3: DB 39H ;HEX
ORG 510H
DATA4: DB "2591" ;ASCII NUMBERS
ORG 520H
DATA6: DA "MY NAME IS Michael" ;ASCII CHARACTERSCó thể sử dụng dấu nháy đơn hoặc dấu ngoặc kép xung quanh chuỗi ASCII. DB cũng được sử dụng để cấp phát bộ nhớ trong các phần có kích thước byte.
Chỉ thị Assembler
Một số chỉ thị của 8051 như sau:
ORG (origin)- Chỉ thị gốc được sử dụng để chỉ ra phần đầu của địa chỉ. Nó lấy các số ở định dạng hexa hoặc thập phân. Nếu H được cung cấp sau số, số được coi là hexa, ngược lại là số thập phân. Trình hợp dịch chuyển đổi số thập phân thành hexa.
EQU (equate)- Nó được sử dụng để định nghĩa một hằng số mà không chiếm vị trí bộ nhớ. EQU liên kết một giá trị không đổi với một nhãn dữ liệu để nhãn xuất hiện trong chương trình, giá trị không đổi của nó sẽ được thay thế cho nhãn. Trong khi thực hiện lệnh "MOV R3, #COUNT", thanh ghi R3 sẽ được nạp giá trị 25 (chú ý dấu #). Ưu điểm của việc sử dụng EQU là lập trình viên có thể thay đổi nó một lần và trình hợp dịch sẽ thay đổi tất cả các lần xuất hiện của nó; người lập trình không phải tìm kiếm toàn bộ chương trình.
END directive- Nó cho biết phần cuối của tệp nguồn (asm). Lệnh END là dòng cuối cùng của chương trình; bất cứ điều gì sau khi lệnh END bị bỏ qua bởi trình hợp dịch.
Nhãn bằng ngôn ngữ hợp ngữ
Tất cả các nhãn trong hợp ngữ phải tuân theo các quy tắc được đưa ra dưới đây:
Mỗi tên nhãn phải là duy nhất. Tên được sử dụng cho các nhãn trong lập trình hợp ngữ bao gồm các chữ cái trong bảng chữ cái cả viết hoa và viết thường, số 0 đến 9 và các ký tự đặc biệt như dấu hỏi (?), Dấu chấm (.), Với tỷ lệ @, dấu gạch dưới (_), và đô la ($).
Ký tự đầu tiên phải là ký tự trong bảng chữ cái; nó không thể là một con số.
Các từ dành riêng không thể được sử dụng làm nhãn trong chương trình. Ví dụ, các từ ADD và MOV là các từ dành riêng, vì chúng là các kỹ năng ghi nhớ hướng dẫn.