Gensim - Phát triển tính năng Nhúng từ
Chương này sẽ giúp chúng ta hiểu việc phát triển tính năng nhúng từ trong Gensim.
Nhúng từ, cách tiếp cận để biểu diễn từ & tài liệu, là một biểu diễn vectơ dày đặc cho văn bản trong đó các từ có cùng nghĩa có cách biểu diễn tương tự. Sau đây là một số đặc điểm của nhúng từ -
Nó là một lớp kỹ thuật biểu diễn các từ riêng lẻ dưới dạng vectơ có giá trị thực trong một không gian vectơ được xác định trước.
Kỹ thuật này thường được gộp chung vào lĩnh vực DL (học sâu) vì mỗi từ được ánh xạ tới một vectơ và các giá trị vectơ được học theo cách mà NN (Neural Networks) thực hiện.
Cách tiếp cận chính của kỹ thuật nhúng từ là một biểu diễn phân tán dày đặc cho mỗi từ.
Các phương pháp / thuật toán nhúng Word khác nhau
Như đã thảo luận ở trên, các phương pháp / thuật toán nhúng từ học cách biểu diễn vectơ có giá trị thực từ một kho văn bản. Quá trình học tập này có thể sử dụng với mô hình NN trong nhiệm vụ như phân loại tài liệu hoặc là một quá trình không được giám sát như thống kê tài liệu. Ở đây chúng ta sẽ thảo luận về hai phương pháp / thuật toán có thể được sử dụng để học cách nhúng từ từ văn bản -
Word2Vec của Google
Word2Vec, được phát triển bởi Tomas Mikolov, et. al. tại Google vào năm 2013, là một phương pháp thống kê để học cách nhúng từ từ kho ngữ liệu văn bản một cách hiệu quả. Nó thực sự được phát triển như một phản ứng để làm cho quá trình đào tạo nhúng từ dựa trên NN hiệu quả hơn. Nó đã trở thành tiêu chuẩn thực tế cho việc nhúng từ.
Nhúng từ bằng Word2Vec liên quan đến việc phân tích các vectơ đã học cũng như khám phá toán học vectơ về cách biểu diễn các từ. Sau đây là hai phương pháp học tập khác nhau có thể được sử dụng như một phần của phương pháp Word2Vec:
- Mô hình CBoW (Túi từ liên tục)
- Mô hình Skip-Gram liên tục
GloVe của Standford
GloVe (Vectơ toàn cầu cho Biểu diễn Word), là một phần mở rộng của phương thức Word2Vec. Nó được phát triển bởi Pennington et al. tại Stanford. Thuật toán GloVe là sự kết hợp của cả hai -
- Thống kê toàn cầu của các kỹ thuật phân tích nhân tử ma trận như LSA (Phân tích ngữ nghĩa tiềm ẩn)
- Học dựa trên ngữ cảnh cục bộ trong Word2Vec.
Nếu chúng ta nói về hoạt động của nó thì thay vì sử dụng cửa sổ để xác định ngữ cảnh cục bộ, GloVe xây dựng một ma trận đồng xuất hiện từ rõ ràng bằng cách sử dụng thống kê trên toàn bộ ngữ liệu văn bản.
Phát triển Nhúng Word2Vec
Ở đây, chúng tôi sẽ phát triển tính năng nhúng Word2Vec bằng cách sử dụng Gensim. Để làm việc với mô hình Word2Vec, Gensim cung cấp cho chúng tôiWord2Vec lớp có thể được nhập từ models.word2vec. Để triển khai, word2vec yêu cầu rất nhiều văn bản, ví dụ như toàn bộ kho tài liệu đánh giá của Amazon. Nhưng ở đây, chúng tôi sẽ áp dụng nguyên tắc này trên văn bản có bộ nhớ nhỏ.
Ví dụ triển khai
Đầu tiên, chúng ta cần nhập lớp Word2Vec từ gensim.models như sau:
from gensim.models import Word2VecTiếp theo, chúng ta cần xác định dữ liệu đào tạo. Thay vì sử dụng tệp văn bản lớn, chúng tôi sử dụng một số câu để thực hiện điều này.
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]Khi dữ liệu đào tạo được cung cấp, chúng tôi cần đào tạo mô hình. nó có thể được thực hiện như sau:
model = Word2Vec(sentences, min_count=1)Chúng ta có thể tóm tắt mô hình như sau -;
print(model)Chúng ta có thể tóm tắt các từ vựng như sau:
words = list(model.wv.vocab)
print(words)Tiếp theo, hãy truy cập vector cho một từ. Chúng tôi đang làm điều đó cho từ 'hướng dẫn'.
print(model['tutorial'])Tiếp theo, chúng ta cần lưu mô hình -
model.save('model.bin')Tiếp theo, chúng ta cần tải mô hình -
new_model = Word2Vec.load('model.bin')Cuối cùng, in mô hình đã lưu như sau:
print(new_model)Hoàn thành ví dụ triển khai
from gensim.models import Word2Vec
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
print(model)
words = list(model.wv.vocab)
print(words)
print(model['tutorial'])
model.save('model.bin')
new_model = Word2Vec.load('model.bin')
print(new_model)Đầu ra
Word2Vec(vocab=20, size=100, alpha=0.025)
[
'this', 'is', 'gensim', 'tutorial', 'for', 'free', 'the', 'tutorialspoint',
'website', 'you', 'can', 'read', 'technical', 'tutorials', 'we', 'are',
'implementing', 'word2vec', 'learn', 'full'
]
[
-2.5256255e-03 -4.5352755e-03 3.9024993e-03 -4.9509313e-03
-1.4255195e-03 -4.0217536e-03 4.9407515e-03 -3.5925603e-03
-1.1933431e-03 -4.6682903e-03 1.5440651e-03 -1.4101702e-03
3.5070938e-03 1.0914479e-03 2.3334436e-03 2.4452661e-03
-2.5336299e-04 -3.9676363e-03 -8.5054158e-04 1.6443320e-03
-4.9968651e-03 1.0974540e-03 -1.1123562e-03 1.5393364e-03
9.8941079e-04 -1.2656028e-03 -4.4471184e-03 1.8309267e-03
4.9302122e-03 -1.0032534e-03 4.6892050e-03 2.9563988e-03
1.8730218e-03 1.5343715e-03 -1.2685956e-03 8.3664013e-04
4.1721235e-03 1.9445885e-03 2.4097660e-03 3.7517555e-03
4.9687522e-03 -1.3598346e-03 7.1032363e-04 -3.6595813e-03
6.0000515e-04 3.0872561e-03 -3.2115565e-03 3.2270295e-03
-2.6354722e-03 -3.4988276e-04 1.8574356e-04 -3.5757164e-03
7.5391348e-04 -3.5205986e-03 -1.9795434e-03 -2.8321696e-03
4.7155009e-03 -4.3349937e-04 -1.5320212e-03 2.7013756e-03
-3.7055744e-03 -4.1658725e-03 4.8034848e-03 4.8594419e-03
3.7129463e-03 4.2385766e-03 2.4612297e-03 5.4920948e-04
-3.8912550e-03 -4.8226118e-03 -2.2763973e-04 4.5571579e-03
-3.4609400e-03 2.7903817e-03 -3.2709218e-03 -1.1036445e-03
2.1492650e-03 -3.0384419e-04 1.7709908e-03 1.8429896e-03
-3.4038599e-03 -2.4872608e-03 2.7693063e-03 -1.6352943e-03
1.9182395e-03 3.7772327e-03 2.2769428e-03 -4.4629495e-03
3.3151123e-03 4.6509290e-03 -4.8521687e-03 6.7615538e-04
3.1034781e-03 2.6369948e-05 4.1454583e-03 -3.6932561e-03
-1.8769916e-03 -2.1958587e-04 6.3395966e-04 -2.4969708e-03
]
Word2Vec(vocab=20, size=100, alpha=0.025)Hình dung Nhúng từ
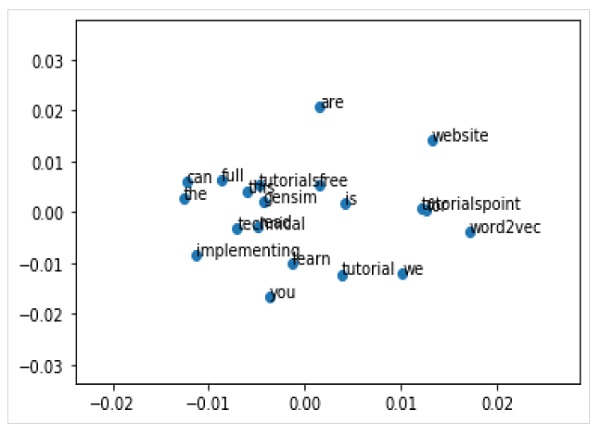
Chúng ta cũng có thể khám phá cách nhúng từ bằng hình ảnh. Nó có thể được thực hiện bằng cách sử dụng phương pháp chiếu cổ điển (như PCA) để giảm các vectơ từ chiều cao thành các ô 2-D. Sau khi giảm, chúng ta có thể vẽ chúng trên đồ thị.
Vẽ các vectơ Word bằng PCA
Đầu tiên, chúng ta cần truy xuất tất cả các vectơ từ một mô hình được đào tạo như sau:
Z = model[model.wv.vocab]Tiếp theo, chúng ta cần tạo một mô hình 2-D PCA của các vectơ từ bằng cách sử dụng lớp PCA như sau:
pca = PCA(n_components=2)
result = pca.fit_transform(Z)Bây giờ, chúng ta có thể vẽ biểu đồ kết quả bằng cách sử dụng matplotlib như sau:
Pyplot.scatter(result[:,0],result[:,1])Chúng ta cũng có thể chú thích các điểm trên biểu đồ bằng chính các từ. Vẽ đồ thị kết quả bằng cách sử dụng matplotlib như sau:
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))Hoàn thành ví dụ triển khai
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from matplotlib import pyplot
sentences = [
['this', 'is', 'gensim', 'tutorial', 'for', 'free'],
['this', 'is', 'the', 'tutorials' 'point', 'website'],
['you', 'can', 'read', 'technical','tutorials', 'for','free'],
['we', 'are', 'implementing','word2vec'],
['learn', 'full', 'gensim', 'tutorial']
]
model = Word2Vec(sentences, min_count=1)
X = model[model.wv.vocab]
pca = PCA(n_components=2)
result = pca.fit_transform(X)
pyplot.scatter(result[:, 0], result[:, 1])
words = list(model.wv.vocab)
for i, word in enumerate(words):
pyplot.annotate(word, xy=(result[i, 0], result[i, 1]))
pyplot.show()Đầu ra