ggplot2 - Hướng dẫn nhanh
ggplot2 là một gói R được thiết kế đặc biệt để trực quan hóa dữ liệu và cung cấp phân tích dữ liệu khám phá tốt nhất. Nó cung cấp các cốt truyện đẹp mắt, không rắc rối, chăm sóc từng chi tiết nhỏ như vẽ huyền thoại và đại diện cho chúng. Các ô có thể được tạo lặp đi lặp lại và chỉnh sửa sau đó. Gói này được thiết kế để hoạt động theo kiểu phân lớp, bắt đầu với một lớp hiển thị dữ liệu thô được thu thập trong quá trình phân tích dữ liệu khám phá với R, sau đó thêm các lớp chú thích và tóm tắt thống kê.
Ngay cả những người dùng R có kinh nghiệm nhất cũng cần trợ giúp để tạo đồ họa trang nhã. Thư viện này là một công cụ hiện tượng để tạo đồ họa trong R nhưng ngay cả sau nhiều năm sử dụng gần như hàng ngày, chúng ta vẫn cần tham khảo Cheat Sheet của chúng tôi.
Gói này hoạt động theo ngữ pháp sâu được gọi là “Ngữ pháp đồ họa” được tạo thành từ một tập hợp các thành phần độc lập có thể được tạo ra theo nhiều cách. “Ngữ pháp đồ họa” là lý do duy nhất khiến ggplot2 trở nên rất mạnh mẽ bởi vì nhà phát triển R không giới hạn đối với bộ đồ họa được chỉ định trước được sử dụng trong các gói khác. Ngữ pháp bao gồm tập hợp các quy tắc và nguyên tắc cốt lõi đơn giản.
Vào năm 2005, Wilkinson đã tạo ra hay nói đúng hơn là khởi nguồn khái niệm ngữ pháp của đồ họa để mô tả các đặc điểm sâu được bao gồm trong tất cả các đồ họa thống kê. Nó tập trung vào lớp chính bao gồm các tính năng thích ứng được nhúng với R.
Mối quan hệ giữa “Grammar of Graphics” và R
Nó cho người dùng hoặc nhà phát triển biết rằng đồ họa thống kê được sử dụng để ánh xạ dữ liệu tới các thuộc tính thẩm mỹ như màu sắc, hình dạng, kích thước của các đối tượng hình học liên quan như điểm, đường và thanh. Biểu đồ cũng có thể chứa các biến đổi thống kê khác nhau của dữ liệu liên quan được vẽ trên hệ tọa độ đã đề cập. Nó cũng bao gồm một tính năng được gọi là "Faceting" thường được sử dụng để tạo cùng một âm mưu cho các tập con khác nhau của tập dữ liệu được đề cập. R bao gồm các bộ dữ liệu tích hợp sẵn khác nhau. Sự kết hợp của các thành phần độc lập này hoàn toàn bao gồm một hình ảnh cụ thể.
Bây giờ chúng ta hãy tập trung vào các loại âm mưu khác nhau có thể được tạo bằng cách tham khảo ngữ pháp -
Dữ liệu
Nếu người dùng muốn trực quan hóa tập hợp các ánh xạ thẩm mỹ đã cho mô tả cách các biến bắt buộc trong dữ liệu được ánh xạ với nhau để tạo các thuộc tính thẩm mỹ được ánh xạ.
Lớp
Nó được tạo thành từ các yếu tố hình học và sự biến đổi thống kê cần thiết. Các lớp bao gồm các đối tượng hình học, địa lý cho dữ liệu ngắn thực sự đại diện cho cốt truyện với sự trợ giúp của các điểm, đường thẳng, đa giác và nhiều hơn nữa. Minh chứng tốt nhất là phân loại và đếm các quan sát để tạo ra biểu đồ cụ thể để tóm tắt mối quan hệ 2D của một mô hình tuyến tính cụ thể.
Quy mô
Các thang đo được sử dụng để ánh xạ các giá trị trong không gian dữ liệu được sử dụng để tạo các giá trị cho dù đó là màu sắc, kích thước và hình dạng. Nó giúp vẽ một chú giải hoặc các trục cần thiết để cung cấp một ánh xạ nghịch đảo, giúp có thể đọc các giá trị dữ liệu ban đầu từ biểu đồ được đề cập.
Hệ tọa độ
Nó mô tả cách các tọa độ dữ liệu được ánh xạ với nhau đến mặt phẳng được đề cập của đồ họa. Nó cũng cung cấp thông tin về các trục và đường lưới cần thiết để đọc biểu đồ. Thông thường nó được sử dụng như một hệ tọa độ Descartes bao gồm các tọa độ cực và các phép chiếu bản đồ.
Khía cạnh
Nó bao gồm đặc tả về cách chia nhỏ dữ liệu thành các tập con bắt buộc và hiển thị các tập con dưới dạng bội số của dữ liệu. Đây còn được gọi là quá trình điều hòa hoặc tạo lưới.
Chủ đề
Nó kiểm soát các điểm hiển thị tốt hơn như kích thước phông chữ và thuộc tính màu nền. Để tạo ra một cốt truyện hấp dẫn, tốt hơn hết là bạn nên xem xét các tài liệu tham khảo.
Bây giờ, điều quan trọng không kém là thảo luận về những hạn chế hoặc tính năng mà ngữ pháp không cung cấp -
Nó thiếu gợi ý về đồ họa nào nên được sử dụng hoặc người dùng quan tâm đến việc đó.
Nó không mô tả tính tương tác vì nó chỉ bao gồm mô tả về đồ họa tĩnh. Để tạo đồ họa động nên áp dụng giải pháp thay thế khác.
Biểu đồ đơn giản được tạo bằng ggplot2 được đề cập bên dưới:

Các gói R đi kèm với các khả năng khác nhau như phân tích thông tin thống kê hoặc nghiên cứu sâu về dữ liệu không gian địa lý hoặc đơn giản là chúng ta có thể tạo các báo cáo cơ bản.
Các gói R có thể được định nghĩa là các hàm R, dữ liệu và mã được biên dịch ở định dạng được xác định rõ. Thư mục hoặc thư mục nơi các gói được lưu trữ được gọi là thư viện.

Như có thể thấy trong hình trên, libPaths () là hàm hiển thị cho bạn thư viện được đặt và thư viện hàm hiển thị các gói được lưu trong thư viện.
R bao gồm số chức năng thao tác các gói. Chúng tôi sẽ tập trung vào ba chức năng chính được sử dụng chủ yếu, chúng là -
- Cài đặt gói
- Đang tải một gói hàng
- Tìm hiểu về Gói
Cú pháp với hàm để cài đặt một gói trong R là:
Install.packages(“<package-name>”)Trình diễn đơn giản về cài đặt một gói có thể nhìn thấy bên dưới. Hãy xem xét chúng ta cần cài đặt gói “ggplot2” là thư viện trực quan hóa dữ liệu, cú pháp sau được sử dụng:
Install.packages(“ggplot2”)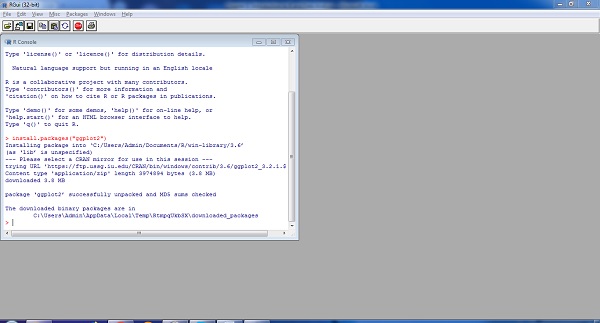
Để nạp gói cụ thể, chúng ta cần thực hiện theo cú pháp được đề cập bên dưới -
Library(<package-name>)Điều tương tự cũng áp dụng cho ggplot2 như được đề cập bên dưới -
library(“ggplot2”)Đầu ra được mô tả trong ảnh chụp nhanh bên dưới -

Để hiểu nhu cầu của gói yêu cầu và chức năng cơ bản, R cung cấp chức năng trợ giúp cung cấp chi tiết đầy đủ về gói được cài đặt.
Cú pháp hoàn chỉnh được đề cập bên dưới -
help(ggplot2)
Trong chương này, chúng ta sẽ tập trung vào việc tạo ra một cốt truyện đơn giản với sự trợ giúp của ggplot2. Chúng tôi sẽ sử dụng các bước sau để tạo âm mưu mặc định trong R.
Bao gồm thư viện và tập dữ liệu trong không gian làm việc
Bao gồm thư viện trong R. Đang tải gói cần thiết. Bây giờ chúng ta sẽ tập trung vào gói ggplot2.
# Load ggplot2
library(ggplot2)Chúng tôi sẽ triển khai tập dữ liệu cụ thể là “Iris”. Tập dữ liệu chứa 3 lớp, mỗi lớp 50 trường hợp, trong đó mỗi lớp đề cập đến một loại cây iris. Một lớp có thể phân tách tuyến tính với hai lớp kia; những cái sau KHÔNG phân tách tuyến tính với nhau.
# Read in dataset
data(iris)Dưới đây là danh sách các thuộc tính được bao gồm trong tập dữ liệu:

Sử dụng các thuộc tính cho ô mẫu
Vẽ biểu đồ tập dữ liệu mống mắt với ggplot2 theo cách đơn giản hơn bao gồm cú pháp sau:
# Plot
IrisPlot <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species))
+ geom_point()
print(IrisPlot)Tham số đầu tiên lấy tập dữ liệu làm đầu vào, tham số thứ hai đề cập đến chú giải và các thuộc tính cần được vẽ trong cơ sở dữ liệu. Trong ví dụ này, chúng tôi đang sử dụng các loài trong truyền thuyết. Geom_point () ngụ ý cốt truyện phân tán sẽ được thảo luận chi tiết trong chương sau.
Đầu ra được tạo ra được đề cập dưới đây:
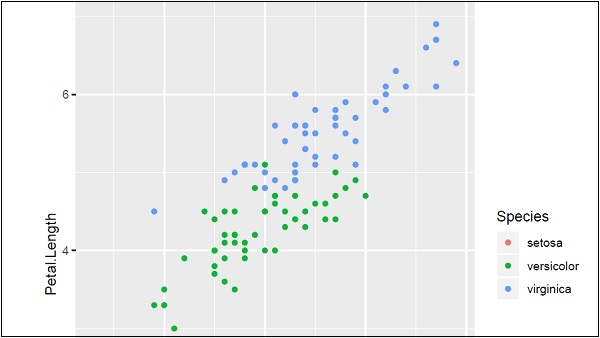
Ở đây chúng ta có thể sửa đổi tiêu đề, nhãn x và nhãn y có nghĩa là nhãn trục x và trục y ở định dạng có hệ thống như được đưa ra bên dưới:
print(IrisPlot + labs(y="Petal length (cm)", x = "Sepal length (cm)")
+ ggtitle("Petal and sepal length of iris"))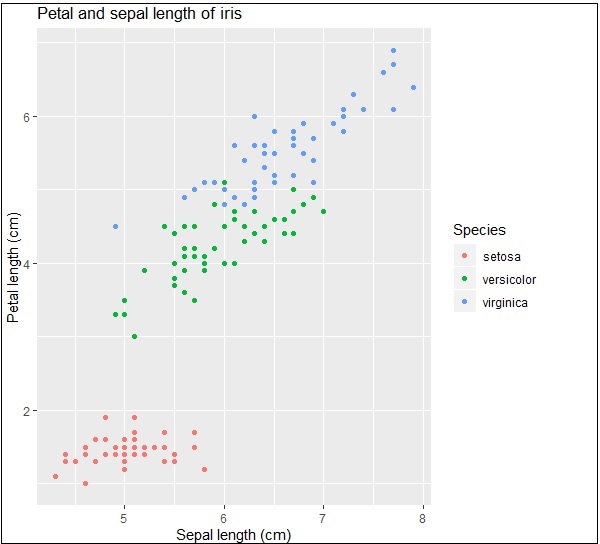
Khi chúng ta nói về các trục trong đồ thị, đó là tất cả về trục x và y được biểu diễn theo cách thức hai chiều. Trong chương này, chúng ta sẽ tập trung vào hai tập dữ liệu “Plantgrowth” và “Iris” thường được các nhà khoa học dữ liệu sử dụng.
Triển khai các trục trong tập dữ liệu Iris
Chúng tôi sẽ sử dụng các bước sau để làm việc trên trục x và y bằng cách sử dụng gói ggplot2 của R.
Điều quan trọng là phải tải thư viện để có được các chức năng của gói.
# Load ggplot
library(ggplot2)
# Read in dataset
data(iris)Tạo các điểm cốt truyện
Giống như đã thảo luận trong chương trước, chúng ta sẽ tạo ra một cốt truyện với các điểm trong đó. Nói cách khác, nó được định nghĩa là cốt truyện phân tán.
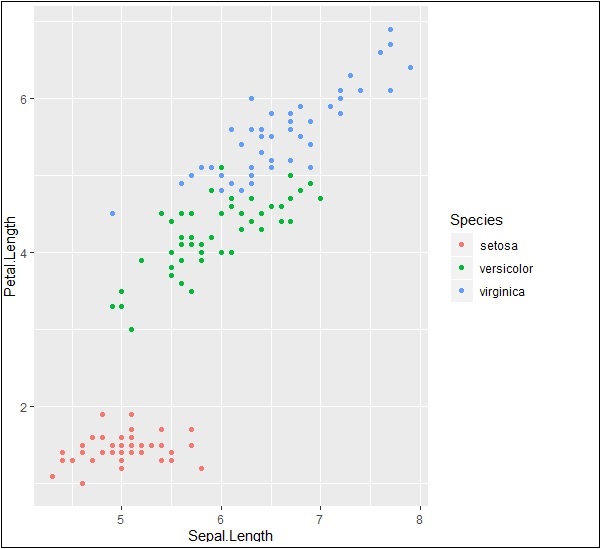
# Plot
p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point()
p
Bây giờ chúng ta hãy hiểu chức năng của aes đề cập đến cấu trúc ánh xạ của “ggplot2”. Ánh xạ thẩm mỹ mô tả cấu trúc biến cần thiết để vẽ biểu đồ và dữ liệu cần được quản lý ở định dạng lớp riêng lẻ.
Đầu ra được đưa ra dưới đây -
Đánh dấu và đánh dấu đánh dấu
Vẽ đồ thị các điểm đánh dấu với tọa độ được đề cập của trục x và y như được đề cập bên dưới. Nó bao gồm thêm văn bản, lặp lại văn bản, đánh dấu khu vực cụ thể và thêm phân đoạn như sau:
# add text
p + annotate("text", x = 6, y = 5, label = "text")
# add repeat
p + annotate("text", x = 4:6, y = 5:7, label = "text")
# highlight an area
p + annotate("rect", xmin = 5, xmax = 7, ymin = 4, ymax = 6, alpha = .5)
# segment
p + annotate("segment", x = 5, xend = 7, y = 4, yend = 5, colour = "black")Đầu ra được tạo để thêm văn bản được đưa ra dưới đây:

Việc lặp lại văn bản cụ thể với các tọa độ đã đề cập sẽ tạo ra kết quả sau. Văn bản được tạo với tọa độ x từ 4 đến 6 và tọa độ y từ 5 đến 7 -
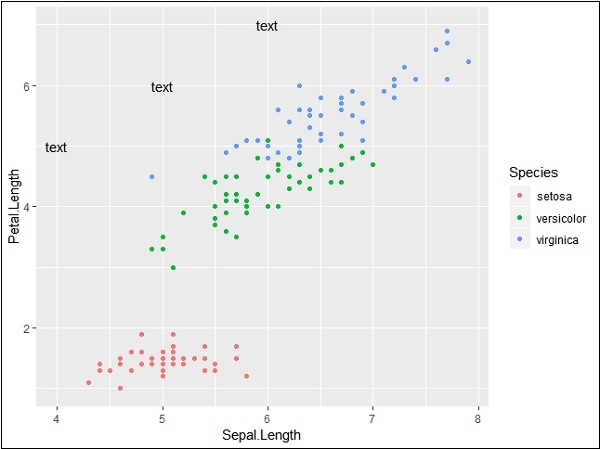
Phân đoạn và làm nổi bật đầu ra khu vực cụ thể được đưa ra dưới đây:

Bộ dữ liệu PlantGrowth
Bây giờ chúng ta hãy tập trung làm việc với tập dữ liệu khác có tên là “Plantgrowth” và bước cần thiết được đưa ra bên dưới.
Gọi cho thư viện và kiểm tra các thuộc tính của "Plantgrowth". Bộ dữ liệu này bao gồm các kết quả từ một thí nghiệm để so sánh sản lượng (được đo bằng trọng lượng khô của cây) thu được trong một đối chứng và hai điều kiện xử lý khác nhau.
> PlantGrowth
weight group
1 4.17 ctrl
2 5.58 ctrl
3 5.18 ctrl
4 6.11 ctrl
5 4.50 ctrl
6 4.61 ctrl
7 5.17 ctrl
8 4.53 ctrl
9 5.33 ctrl
10 5.14 ctrl
11 4.81 trt1
12 4.17 trt1
13 4.41 trt1
14 3.59 trt1
15 5.87 trt1
16 3.83 trt1
17 6.03 trt1Thêm thuộc tính với trục
Hãy thử vẽ một biểu đồ đơn giản với trục x và y bắt buộc của biểu đồ như được đề cập bên dưới -
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) +
+ geom_point()
> bpKết quả đầu ra được đưa ra dưới đây:

Cuối cùng, chúng ta có thể vuốt trục x và y theo yêu cầu của mình với chức năng cơ bản như được đề cập bên dưới:
> bp <- ggplot(PlantGrowth, aes(x=group, y=weight)) +
+ geom_point()
> bp
Về cơ bản, chúng ta có thể sử dụng nhiều thuộc tính với ánh xạ thẩm mỹ để làm việc với các trục bằng ggplot2.
Axes và huyền thoại được gọi chung là hướng dẫn. Chúng cho phép chúng tôi đọc các quan sát từ cốt truyện và lập bản đồ trở lại các giá trị ban đầu. Các phím chú giải và nhãn đánh dấu đều được xác định bởi các dấu ngắt tỷ lệ. Huyền thoại và rìu được sản xuất tự động dựa trên các tỷ lệ và địa lý tương ứng cần thiết cho cốt truyện.
Các bước sau sẽ được thực hiện để hiểu hoạt động của các huyền thoại trong ggplot2 -
Bao gồm gói và tập dữ liệu trong không gian làm việc
Hãy để chúng tôi tạo cùng một âm mưu để tập trung vào chú giải của biểu đồ được tạo bằng ggplot2 -
> # Load ggplot
> library(ggplot2)
>
> # Read in dataset
> data(iris)
>
> # Plot
> p <- ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) + geom_point()
> p
Nếu bạn quan sát cốt truyện, các huyền thoại được tạo ra ở hầu hết các góc bên trái như được đề cập bên dưới -

Ở đây, chú thích bao gồm nhiều loại loài khác nhau của tập dữ liệu đã cho.
Thay đổi thuộc tính cho huyền thoại
Chúng tôi có thể xóa chú giải với sự trợ giúp của thuộc tính “legend.position” và chúng tôi nhận được kết quả phù hợp -
> # Remove Legend
> p + theme(legend.position="none")
Chúng tôi cũng có thể ẩn tiêu đề chú giải với thuộc tính “element_blank ()” như được cung cấp bên dưới -
> # Hide the legend title
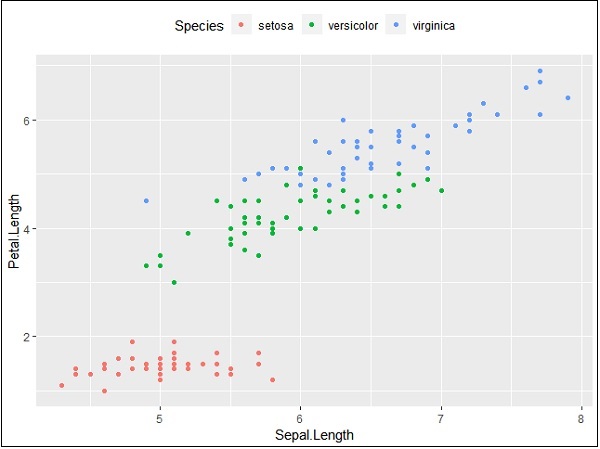
> p + theme(legend.title=element_blank())Chúng ta cũng có thể sử dụng vị trí chú giải khi cần thiết. Thuộc tính này được sử dụng để tạo biểu đồ chính xác.
> #Change the legend position
> p + theme(legend.position="top")
>
> p + theme(legend.position="bottom")Top representation
Bottom representation

Thay đổi kiểu phông chữ của huyền thoại
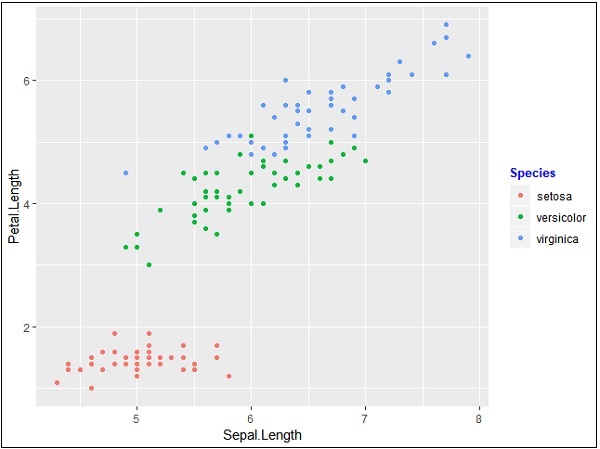
Chúng tôi có thể thay đổi kiểu phông chữ và kiểu phông chữ của tiêu đề và các thuộc tính khác của chú giải như được đề cập bên dưới -
> #Change the legend title and text font styles
> # legend title
> p + theme(legend.title = element_text(colour = "blue", size = 10, + face = "bold"))
> # legend labels
> p + theme(legend.text = element_text(colour = "red", size = 8, + face = "bold"))Kết quả đầu ra được đưa ra dưới đây:

Các chương sắp tới sẽ tập trung vào nhiều loại ô khác nhau với các đặc tính nền khác nhau như màu sắc, chủ đề và tầm quan trọng của từng ô theo quan điểm khoa học dữ liệu.
Biểu đồ phân tán tương tự như biểu đồ đường thường được sử dụng để vẽ biểu đồ. Biểu đồ phân tán cho biết mức độ liên quan của một biến với biến khác. Mối quan hệ giữa các biến được gọi là mối tương quan thường được sử dụng trong các phương pháp thống kê. Chúng tôi sẽ sử dụng cùng một tập dữ liệu được gọi là “Iris”, bao gồm rất nhiều biến thể giữa mỗi biến. Đây là tập dữ liệu nổi tiếng cung cấp các phép đo tính bằng cm của các biến chiều dài và chiều rộng của đài hoa với chiều dài và chiều rộng của cánh hoa cho 50 bông hoa từ 3 loài trong số 3 loài hoa diên vĩ. Các loài này được gọi là Iris setosa, versicolor và virginica.
Tạo lô phân tán cơ bản
Các bước sau được thực hiện để tạo các biểu đồ phân tán với gói “ggplot2” -
Để tạo một biểu đồ phân tán cơ bản, lệnh sau được thực hiện:
> # Basic Scatter Plot
> ggplot(iris, aes(Sepal.Length, Petal.Length)) +
+ geom_point()
Thêm thuộc tính
Chúng ta có thể thay đổi hình dạng của các điểm với một thuộc tính gọi là shape trong hàm geom_point ().
> # Change the shape of points
> ggplot(iris, aes(Sepal.Length, Petal.Length)) +
+ geom_point(shape=1)
Chúng ta có thể thêm màu cho các điểm được thêm vào trong các ô phân tán bắt buộc.
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1)
Trong ví dụ này, chúng tôi đã tạo ra màu sắc theo loài được đề cập trong truyền thuyết. Ba loài được phân biệt duy nhất trong lô đề cập.
Bây giờ chúng ta sẽ tập trung vào việc thiết lập mối quan hệ giữa các biến.
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1) +
+ geom_smooth(method=lm)geom_smooth hàm hỗ trợ mô hình chồng chéo và tạo ra mô hình của các biến cần thiết.
Phương thức thuộc tính “lm” đề cập đến dòng hồi quy cần được phát triển.
> # Add a regression line
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1) +
+ geom_smooth(method=lm)
Chúng tôi cũng có thể thêm một dòng hồi quy không có vùng tin cậy được tô bóng bằng cú pháp được đề cập bên dưới:
># Add a regression line but no shaded confidence region
> ggplot(iris, aes(Sepal.Length, Petal.Length, colour=Species)) +
+ geom_point(shape=1) +
+ geom_smooth(method=lm, se=FALSE)
Vùng bóng mờ đại diện cho những thứ khác ngoài vùng tin cậy.
Lô đất
Các âm mưu Jitter bao gồm các hiệu ứng đặc biệt mà các ô phân tán có thể được mô tả. Jitter không là gì ngoài một giá trị ngẫu nhiên được gán cho các dấu chấm để phân tách chúng như được đề cập bên dưới -
> ggplot(mpg, aes(cyl, hwy)) +
+ geom_point() +
+ geom_jitter(aes(colour = class))
Biểu đồ thanh thể hiện dữ liệu phân loại ở dạng hình chữ nhật. Các thanh có thể được vẽ theo chiều dọc và chiều ngang. Chiều cao hoặc chiều dài tỷ lệ với các giá trị được biểu thị trong biểu đồ. Trục x và y của biểu đồ thanh chỉ định danh mục được bao gồm trong tập dữ liệu cụ thể.
Biểu đồ là một biểu đồ cột biểu thị dữ liệu thô với bức tranh rõ ràng về sự phân bố của tập dữ liệu được đề cập.
Trong chương này, chúng ta sẽ tập trung vào việc tạo các biểu đồ thanh và biểu đồ với sự trợ giúp của ggplot2.
Hiểu tập dữ liệu MPG
Hãy cho chúng tôi hiểu tập dữ liệu sẽ được sử dụng. Tập dữ liệu Mpg chứa một tập hợp con dữ liệu tiết kiệm nhiên liệu mà EPA cung cấp trong liên kết bên dưới:
http://fueleconomy.gov
Nó bao gồm các mô hình được phát hành mới hàng năm từ năm 1999 đến năm 2008. Điều này được sử dụng như một đại diện cho sự phổ biến của chiếc xe.
Lệnh sau được thực hiện để hiểu danh sách các thuộc tính cần thiết cho tập dữ liệu.
> library(ggplot2)Gói đính kèm là ggplot2.
Đối tượng sau được che _by_ .GlobalEnv -
mpgThông báo cảnh báo
- gói arules được xây dựng theo phiên bản R 3.5.1
- gói tuneR được xây dựng theo phiên bản R 3.5.3
- gói ggplot2 được xây dựng theo phiên bản R 3.5.3

Tạo lô đếm thanh
Cốt truyện Bar Count có thể được tạo với cốt truyện được đề cập dưới đây:
> # A bar count plot
> p <- ggplot(mpg, aes(x=factor(cyl)))+
+ geom_bar(stat="count")
> p
geom_bar () là hàm được sử dụng để tạo các biểu đồ thanh. Nó nhận thuộc tính của giá trị thống kê được gọi là số đếm.
Biểu đồ
Biểu đồ đếm biểu đồ có thể được tạo với biểu đồ được đề cập dưới đây:
> # A historgram count plot
> ggplot(data=mpg, aes(x=hwy)) +
+ geom_histogram( col="red",
+ fill="green",
+ alpha = .2,
+ binwidth = 5)geom_histogram () bao gồm tất cả các thuộc tính cần thiết để tạo biểu đồ. Ở đây, nó lấy thuộc tính của hwy với số lượng tương ứng. Màu sắc được lấy theo yêu cầu.

Biểu đồ thanh xếp chồng
Các đồ thị chung của biểu đồ thanh và biểu đồ có thể được tạo như dưới đây:
> p <- ggplot(mpg, aes(class))
> p + geom_bar()
> p + geom_bar()
Biểu đồ này bao gồm tất cả các danh mục được xác định trong biểu đồ thanh với lớp tương ứng. Biểu đồ này được gọi là đồ thị xếp chồng.
Biểu đồ hình tròn được coi như một biểu đồ thống kê hình tròn, được chia thành các phần để minh họa tỷ lệ số. Trong biểu đồ hình tròn đã đề cập, độ dài cung của mỗi lát cắt tỷ lệ với số lượng mà nó đại diện. Độ dài cung biểu diễn góc của biểu đồ hình tròn. Tổng số độ của biểu đồ hình tròn là 360 độ. Biểu đồ hình bán nguyệt hoặc nửa hình tròn bao gồm 180 độ.
Tạo biểu đồ hình tròn
Tải gói trong không gian làm việc được đề cập như hình dưới đây -
> # Load modules
> library(ggplot2)
>
> # Source: Frequency table
> df <- as.data.frame(table(mpg$class))
> colnames(df) <- c("class", "freq")
Biểu đồ mẫu có thể được tạo bằng lệnh sau:
> pie <- ggplot(df, aes(x = "", y=freq, fill = factor(class))) +
+ geom_bar(width = 1, stat = "identity") +
+ theme(axis.line = element_blank(),
+ plot.title = element_text(hjust=0.5)) +
+ labs(fill="class",
+ x=NULL,
+ y=NULL,
+ title="Pie Chart of class",
+ caption="Source: mpg")
> pieNếu bạn quan sát đầu ra, sơ đồ không được tạo theo cách tròn như được đề cập bên dưới -
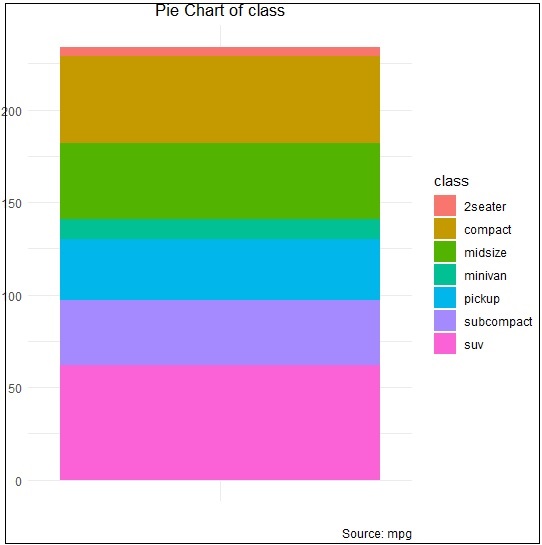
Tạo phối hợp
Hãy để chúng tôi thực hiện lệnh sau để tạo biểu đồ hình tròn được yêu cầu như sau:
> pie + coord_polar(theta = "y", start=0)
Trong chương này, chúng ta sẽ thảo luận về các Lô biên.
Hiểu các lô biên
Đồ thị biên được sử dụng để đánh giá mối quan hệ giữa hai biến và kiểm tra sự phân bố của chúng. Khi chúng ta nói về việc tạo các biểu đồ biên, chúng không là gì khác ngoài các biểu đồ phân tán có biểu đồ, biểu đồ hộp hoặc biểu đồ chấm ở biên của các trục x và y tương ứng.
Các bước sau sẽ được sử dụng để tạo biểu đồ biên với R bằng gói “ggExtra”. Gói này được thiết kế để nâng cao các tính năng của gói “ggplot2” và bao gồm các chức năng khác nhau để tạo các lô biên thành công.
Bước 1
Cài đặt gói “ggExtra” bằng lệnh sau để thực thi thành công (nếu gói chưa được cài đặt trong hệ thống của bạn).
> install.packages("ggExtra")Bước 2
Bao gồm các thư viện bắt buộc trong không gian làm việc để tạo các ô biên.
> library(ggplot2)
> library(ggExtra)Bước 3
Đọc tập dữ liệu bắt buộc “mpg” mà chúng tôi đã sử dụng trong các chương trước.
> data(mpg)
> head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~
>Bước 4
Bây giờ chúng ta hãy tạo một biểu đồ đơn giản bằng cách sử dụng “ggplot2” sẽ giúp chúng ta hiểu khái niệm về các biểu đồ cận biên.
> #Plot
> g <- ggplot(mpg, aes(cty, hwy)) +
+ geom_count() +
+ geom_smooth(method="lm", se=F)
> g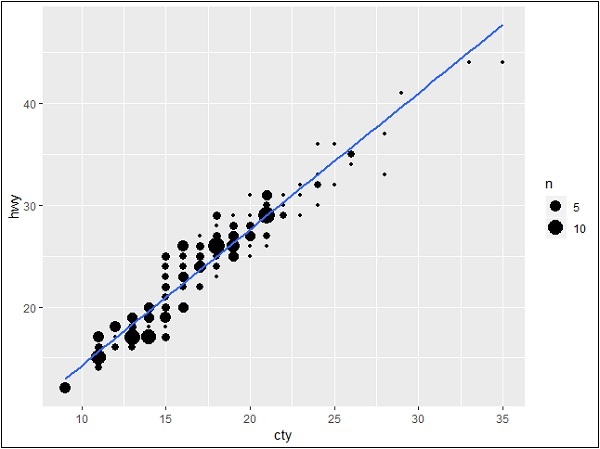
Mối quan hệ giữa các biến
Bây giờ chúng ta hãy tạo các đồ thị biên bằng cách sử dụng hàm ggMarginal để tạo ra mối quan hệ giữa hai thuộc tính “hwy” và “cty”.
> ggMarginal(g, type = "histogram", fill="transparent")
> ggMarginal(g, type = "boxplot", fill="transparent")Đầu ra cho các đồ thị biên biểu đồ được đề cập dưới đây:

Đầu ra cho các ô biên dạng hộp được đề cập dưới đây:

Biểu đồ bong bóng không có gì khác ngoài biểu đồ bong bóng về cơ bản là một biểu đồ phân tán với một biến số thứ ba được sử dụng cho kích thước vòng tròn. Trong chương này, chúng ta sẽ tập trung vào việc tạo ra các biểu đồ đếm thanh và các biểu đồ đếm biểu đồ được coi là bản sao của các biểu đồ bong bóng.
Các bước sau được sử dụng để tạo biểu đồ bong bóng và đếm biểu đồ với gói được đề cập:
Hiểu tập dữ liệu
Tải gói tương ứng và tập dữ liệu cần thiết để tạo biểu đồ bong bóng và biểu đồ đếm.
> # Load ggplot
> library(ggplot2)
>
> # Read in dataset
> data(mpg)
> head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~Biểu đồ đếm thanh có thể được tạo bằng lệnh sau:
> # A bar count plot
> p <- ggplot(mpg, aes(x=factor(cyl)))+
+ geom_bar(stat="count")
> p
Phân tích với biểu đồ
Biểu đồ đếm có thể được tạo bằng lệnh sau:
> # A historgram count plot
> ggplot(data=mpg, aes(x=hwy)) +
+ geom_histogram( col="red",
+ fill="green",
+ alpha = .2,
+ binwidth = 5)
Biểu đồ bong bóng
Bây giờ chúng ta hãy tạo biểu đồ bong bóng cơ bản nhất với các thuộc tính cần thiết để tăng thứ nguyên của các điểm được đề cập trong biểu đồ phân tán.
ggplot(mpg, aes(x=cty, y=hwy, size = pop)) +geom_point(alpha=0.7)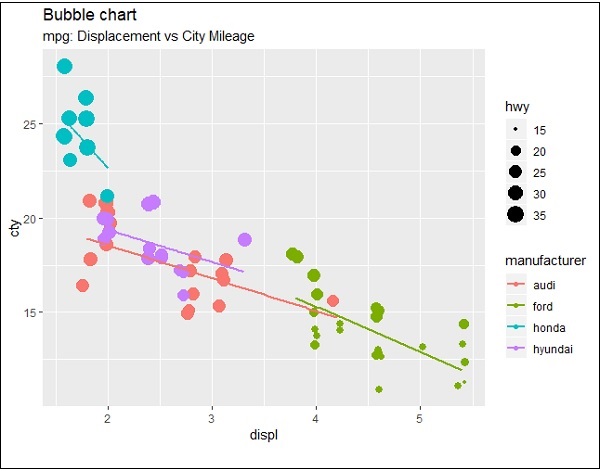
Cốt truyện mô tả bản chất của các nhà sản xuất được đưa vào định dạng chú giải. Các giá trị được đại diện bao gồm các thứ nguyên khác nhau của thuộc tính “hwy”.
Trong các chương trước, chúng ta đã xem xét các loại biểu đồ khác nhau có thể được tạo bằng gói “ggplot2”. Bây giờ chúng ta sẽ tập trung vào các biến thể tương tự như biểu đồ thanh phân kỳ, biểu đồ hình kẹo mút và nhiều thứ khác. Để bắt đầu, chúng ta sẽ bắt đầu với việc tạo biểu đồ thanh phân kỳ và các bước tiếp theo được đề cập bên dưới:
Hiểu tập dữ liệu
Tải gói yêu cầu và tạo một cột mới có tên 'tên xe' trong tập dữ liệu mpg.
#Load ggplot
> library(ggplot2)
> # create new column for car names
> mtcars$`car name` <- rownames(mtcars)
> # compute normalized mpg
> mtcars$mpg_z <- round((mtcars$mpg - mean(mtcars$mpg))/sd(mtcars$mpg), 2)
> # above / below avg flag
> mtcars$mpg_type <- ifelse(mtcars$mpg_z < 0, "below", "above")
> # sort
> mtcars <- mtcars[order(mtcars$mpg_z), ]Việc tính toán trên liên quan đến việc tạo một cột mới cho tên xe, tính toán tập dữ liệu chuẩn hóa với sự trợ giúp của hàm vòng. Chúng tôi cũng có thể sử dụng cờ trung bình trên và dưới để nhận các giá trị của chức năng "loại". Sau đó, chúng tôi sắp xếp các giá trị để tạo tập dữ liệu cần thiết.
Kết quả nhận được như sau:

Chuyển đổi các giá trị thành hệ số để giữ lại thứ tự đã sắp xếp trong một ô cụ thể như được đề cập bên dưới -
> # convert to factor to retain sorted order in plot.
> mtcars$`car name` <- factor(mtcars$`car name`, levels = mtcars$`car name`)Đầu ra thu được được đề cập dưới đây:

Biểu đồ thanh phân kỳ
Bây giờ, hãy tạo một biểu đồ thanh phân kỳ với các thuộc tính đã đề cập được lấy làm tọa độ bắt buộc.
> # Diverging Barcharts
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_bar(stat='identity', aes(fill=mpg_type), width=.5) +
+ scale_fill_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ labs(subtitle="Normalised mileage from 'mtcars'",
+ title= "Diverging Bars") +
+ coord_flip()Note - Biểu đồ thanh phân kỳ đánh dấu cho một số thành viên thứ nguyên chỉ theo hướng lên hoặc xuống đối với các giá trị đã đề cập.
Đầu ra của biểu đồ thanh phân kỳ được đề cập bên dưới, nơi chúng tôi sử dụng hàm geom_bar để tạo biểu đồ thanh -

Biểu đồ kẹo mút phân kỳ
Tạo biểu đồ hình lollipop phân kỳ với các thuộc tính và tọa độ giống nhau mà chỉ thay đổi chức năng được sử dụng, tức là geom_segment () giúp tạo biểu đồ hình lollipop.
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_point(stat='identity', fill="black", size=6) +
+ geom_segment(aes(y = 0,
+ x = `car name`,
+ yend = mpg_z,
+ xend = `car name`),
+ color = "black") +
+ geom_text(color="white", size=2) +
+ labs(title="Diverging Lollipop Chart",
+ subtitle="Normalized mileage from 'mtcars': Lollipop") +
+ ylim(-2.5, 2.5) +
+ coord_flip()
Lô dấu chấm phân kỳ
Tạo một biểu đồ chấm phân kỳ theo cách tương tự trong đó các chấm đại diện cho các điểm trong các ô phân tán ở kích thước lớn hơn.
> ggplot(mtcars, aes(x=`car name`, y=mpg_z, label=mpg_z)) +
+ geom_point(stat='identity', aes(col=mpg_type), size=6) +
+ scale_color_manual(name="Mileage",
+ labels = c("Above Average", "Below Average"),
+ values = c("above"="#00ba38", "below"="#f8766d")) +
+ geom_text(color="white", size=2) +
+ labs(title="Diverging Dot Plot",
+ subtitle="Normalized mileage from 'mtcars': Dotplot") +
+ ylim(-2.5, 2.5) +
+ coord_flip()
Ở đây, các chú giải đại diện cho các giá trị "Trên Trung bình" và "Dưới Trung bình" với các màu riêng biệt là xanh lục và đỏ. Dấu chấm truyền tải thông tin tĩnh. Các nguyên tắc giống như nguyên tắc trong biểu đồ thanh Phân kỳ, ngoại trừ điểm duy nhất được sử dụng.
Trong chương này, chúng tôi sẽ tập trung vào việc sử dụng chủ đề tùy chỉnh được sử dụng để thay đổi giao diện của không gian làm việc. Chúng tôi sẽ sử dụng gói “ggthemes” để hiểu khái niệm quản lý chủ đề trong không gian làm việc của R.
Hãy để chúng tôi thực hiện các bước sau để sử dụng chủ đề được yêu cầu trong tập dữ liệu được đề cập.
GGTHEMES
Cài đặt gói “ggthemes” với gói bắt buộc trong R workspace.
> install.packages("ggthemes")
> Library(ggthemes)
Triển khai chủ đề mới để tạo ra huyền thoại về các nhà sản xuất với năm sản xuất và thay thế.
> library(ggthemes)
> ggplot(mpg, aes(year, displ, color=factor(manufacturer)))+
+ geom_point()+ggtitle("This plot looks a lot different from the default")+
+ theme_economist()+scale_colour_economist()
Có thể nhận thấy rằng kích thước mặc định của văn bản đánh dấu, chú thích và các yếu tố khác là hơi nhỏ với quản lý chủ đề trước đó. Việc thay đổi kích thước của tất cả các thành phần văn bản cùng một lúc là vô cùng dễ dàng. Điều này có thể được thực hiện khi tạo một chủ đề tùy chỉnh mà chúng ta có thể quan sát trong bước dưới đây rằng kích thước của tất cả các phần tử là tương đối (rel ()) với base_size.
> theme_set(theme_gray(base_size = 30))
> ggplot(mpg, aes(x=year, y=class))+geom_point(color="red")
Biểu đồ nhiều bảng có nghĩa là tạo ra nhiều biểu đồ cùng nhau trong một ô duy nhất. Chúng ta sẽ sử dụng hàm par () để đưa nhiều đồ thị vào một biểu đồ duy nhất bằng cách chuyển các tham số đồ họa mfrow và mfcol.
Ở đây, chúng tôi sẽ sử dụng tập dữ liệu “AirQuality” để triển khai các ô nhiều bảng điều khiển. Trước tiên, hãy để chúng tôi hiểu tập dữ liệu để có cái nhìn về việc tạo các ô nhiều bảng. Bộ dữ liệu này bao gồm Chứa các phản hồi của một thiết bị đa cảm biến khí được triển khai trên thực địa ở một thành phố của Ý. Các phản ứng trung bình hàng giờ được ghi lại cùng với các tham chiếu về nồng độ khí từ một máy phân tích được chứng nhận.
Thông tin chi tiết về hàm par ()
Hiểu hàm par () để tạo thứ nguyên cho các ô nhiều bảng được yêu cầu.
> par(mfrow=c(1,2))
> # set the plotting area into a 1*2 arrayĐiều này tạo ra một ô trống với kích thước 1 * 2.

Bây giờ tạo biểu đồ thanh và biểu đồ hình tròn của tập dữ liệu được đề cập bằng cách sử dụng lệnh sau. Hiện tượng tương tự có thể đạt được với tham số đồ họa mfcol.
Tạo nhiều ô bảng điều khiển
Sự khác biệt duy nhất giữa cả hai là, mfrow điền vào hàng khu vực phụ là khôn ngoan trong khi mfcol điền vào cột khôn ngoan.
> Temperature <- airquality$Temp
> Ozone <- airquality$Ozone
> par(mfrow=c(2,2))
> hist(Temperature)
> boxplot(Temperature, horizontal=TRUE)
> hist(Ozone)
> boxplot(Ozone, horizontal=TRUE)
Ô hộp và ô trống được tạo trong một cửa sổ về cơ bản tạo ra một ô nhiều bảng.
Cùng một âm mưu với sự thay đổi kích thước trong hàm par sẽ như sau:
par(mfcol = c(2, 2))
Trong chương này, chúng tôi sẽ tập trung vào việc tạo nhiều ô có thể được sử dụng thêm để tạo các ô 3 chiều. Danh sách các mảnh đất sẽ được bao gồm:
- Lô mật độ
- Ô hộp
- Châm điểm
- Lô đàn vĩ cầm
Chúng tôi sẽ sử dụng tập dữ liệu “mpg” như được sử dụng trong các chương trước. Bộ dữ liệu này cung cấp dữ liệu tiết kiệm nhiên liệu từ năm 1999 và 2008 cho 38 mẫu ô tô phổ biến. Tập dữ liệu được vận chuyển cùng với gói ggplot2. Điều quan trọng là làm theo các bước được đề cập dưới đây để tạo ra các loại lô khác nhau.
> # Load Modules
> library(ggplot2)
>
> # Dataset
> head(mpg)
# A tibble: 6 x 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa~
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa~
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa~
4 audi a4 2 2008 4 auto(av) f 21 30 p compa~
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa~
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa~Lô mật độ
Biểu đồ mật độ là một biểu diễn đồ họa về sự phân bố của bất kỳ biến số nào trong tập dữ liệu được đề cập. Nó sử dụng ước tính mật độ nhân để hiển thị hàm mật độ xác suất của biến.
Gói “ggplot2” bao gồm một hàm có tên là geom_density () để tạo một biểu đồ mật độ.
Chúng ta sẽ thực hiện lệnh sau để tạo biểu đồ mật độ:
> p −- ggplot(mpg, aes(cty)) +
+ geom_density(aes(fill=factor(cyl)), alpha=0.8)
> pChúng ta có thể quan sát các mật độ khác nhau từ âm mưu được tạo bên dưới -
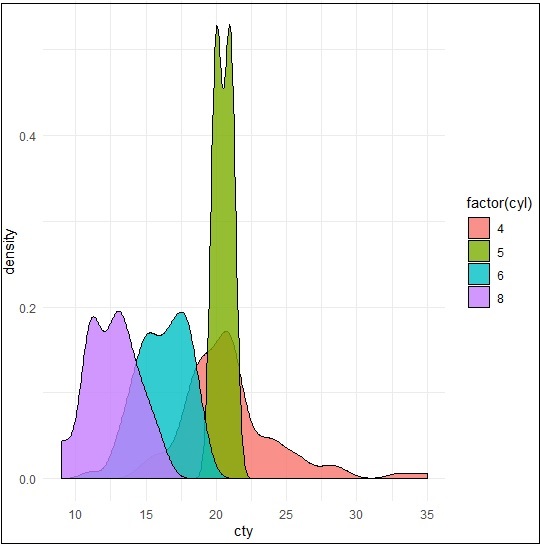
Chúng ta có thể tạo cốt truyện bằng cách đổi tên các trục x và y để duy trì sự rõ ràng hơn với việc bao gồm tiêu đề và truyền thuyết với các kết hợp màu sắc khác nhau.
> p + labs(title="Density plot",
+ subtitle="City Mileage Grouped by Number of cylinders",
+ caption="Source: mpg",
+ x="City Mileage",
+ fill="# Cylinders")
Ô hộp
Biểu đồ hộp còn được gọi là biểu đồ hộp và biểu đồ râu ria đại diện cho bản tóm tắt năm số của dữ liệu. Tóm tắt năm số bao gồm các giá trị như tối thiểu, phần tư thứ nhất, trung vị, phần tư thứ ba và tối đa. Đường thẳng đứng đi qua phần giữa của ô hình hộp được coi là "đường trung bình".
Chúng ta có thể tạo biểu đồ hộp bằng lệnh sau:
> p <- ggplot(mpg, aes(class, cty)) +
+ geom_boxplot(varwidth=T, fill="blue")
> p + labs(title="A Box plot Example",
+ subtitle="Mileage by Class",
+ caption="MPG Dataset",
+ x="Class",
+ y="Mileage")
>pỞ đây, chúng tôi đang tạo biểu đồ hộp đối với các thuộc tính của lớp và cty.

Châm điểm
Ô chấm tương tự như ô phân tán chỉ khác về kích thước. Trong phần này, chúng tôi sẽ thêm biểu đồ chấm vào ô hộp hiện có để có hình ảnh rõ nét hơn.
Biểu đồ hộp có thể được tạo bằng lệnh sau:
> p <- ggplot(mpg, aes(manufacturer, cty)) +
+ geom_boxplot() +
+ theme(axis.text.x = element_text(angle=65, vjust=0.6))
> p
Biểu đồ chấm được tạo như được đề cập bên dưới -
> p + geom_dotplot(binaxis='y',
+ stackdir='center',
+ dotsize = .5
+ )
Lô đàn vĩ cầm
Cốt truyện vĩ cầm cũng được tạo ra theo cách tương tự, chỉ thay đổi cấu trúc của vĩ cầm thay vì hộp. Đầu ra được đề cập rõ ràng bên dưới -
> p <- ggplot(mpg, aes(class, cty))
>
> p + geom_violin()
Có nhiều cách để thay đổi toàn bộ diện mạo của cốt truyện của bạn bằng một chức năng như được đề cập bên dưới. Nhưng nếu bạn chỉ muốn thay đổi màu nền của bảng điều khiển, bạn có thể sử dụng cách sau:
Nền bảng triển khai
Chúng ta có thể thay đổi màu nền bằng lệnh sau giúp thay đổi bảng điều khiển (panel.background) -
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+
+ theme(panel.background = element_rect(fill = 'grey75'))Sự thay đổi màu sắc được mô tả rõ ràng trong hình dưới đây -

Triển khai Panel.grid.major
Chúng ta có thể thay đổi các đường lưới bằng cách sử dụng thuộc tính “panel.grid.major” như được đề cập trong lệnh bên dưới:
> ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+
+ theme(panel.background = element_rect(fill = 'grey75'),
+ panel.grid.major = element_line(colour = "orange", size=2),
+ panel.grid.minor = element_line(colour = "blue"))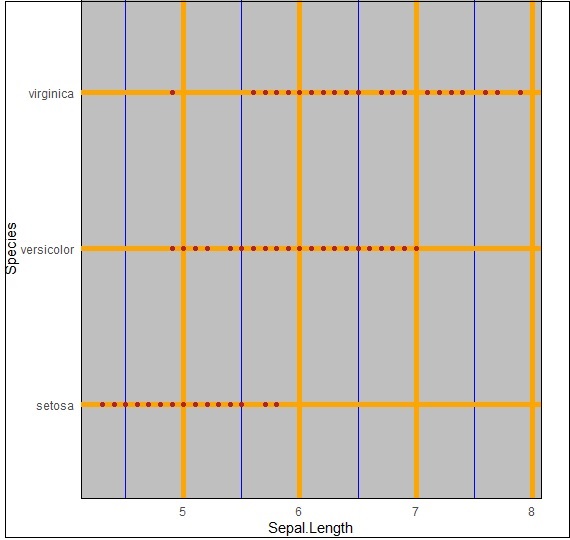
Chúng tôi thậm chí có thể thay đổi nền cốt truyện, đặc biệt là loại trừ bảng điều khiển bằng cách sử dụng thuộc tính “plot.background” như được đề cập bên dưới -
ggplot(iris, aes(Sepal.Length, Species))+geom_point(color="firebrick")+
+ theme(plot.background = element_rect(fill = 'pink'))
Chuỗi thời gian là một biểu đồ đồ họa đại diện cho chuỗi các điểm dữ liệu theo một thứ tự thời gian cụ thể. Chuỗi thời gian là một chuỗi được thực hiện với một chuỗi tại các điểm thời gian cách nhau liên tiếp bằng nhau. Chuỗi thời gian có thể được coi là dữ liệu thời gian rời rạc. Tập dữ liệu mà chúng ta sẽ sử dụng trong chương này là tập dữ liệu “kinh tế học” bao gồm tất cả các chi tiết của chuỗi thời gian kinh tế Hoa Kỳ.
Khung dữ liệu bao gồm các thuộc tính sau được đề cập bên dưới:
| Ngày | Tháng thu thập dữ liệu |
| Psavert | Tỷ lệ tiết kiệm cá nhân |
| Pce | Chi tiêu tiêu dùng cá nhân |
| Thất nghiệp | Số người thất nghiệp hàng nghìn người |
| Chưa được giải quyết | Thời gian thất nghiệp trung bình |
| Pop | Tổng dân số hàng nghìn |
Tải các gói cần thiết và đặt chủ đề mặc định để tạo chuỗi thời gian.
> library(ggplot2)
> theme_set(theme_minimal())
> # Demo dataset
> head(economics)
# A tibble: 6 x 6
date pce pop psavert uempmed unemploy
<date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1967-07-01 507. 198712 12.6 4.5 2944
2 1967-08-01 510. 198911 12.6 4.7 2945
3 1967-09-01 516. 199113 11.9 4.6 2958
4 1967-10-01 512. 199311 12.9 4.9 3143
5 1967-11-01 517. 199498 12.8 4.7 3066
6 1967-12-01 525. 199657 11.8 4.8 3018Tạo một biểu đồ đường cơ bản tạo cấu trúc chuỗi thời gian.
> # Basic line plot
> ggplot(data = economics, aes(x = date, y = pop))+
+ geom_line(color = "#00AFBB", size = 2)
Chúng ta có thể vẽ biểu đồ tập con dữ liệu bằng lệnh sau:
> # Plot a subset of the data
> ss <- subset(economics, date > as.Date("2006-1-1"))
> ggplot(data = ss, aes(x = date, y = pop)) +
+ geom_line(color = "#FC4E07", size = 2)
Tạo chuỗi thời gian
Ở đây chúng tôi sẽ vẽ biểu đồ các biến psavert và uempmed theo ngày. Ở đây chúng ta phải định hình lại dữ liệu bằng cách sử dụng gói gọn gàng hơn. Điều này có thể đạt được bằng cách thu gọn các giá trị psavert và uempmed trong cùng một cột (cột mới). Hàm R: collect () [hiddenr]. Bước tiếp theo liên quan đến việc tạo một biến nhóm với các mức = psavert và uempmed.
> library(tidyr)
> library(dplyr)
Attaching package: ‘dplyr’
The following object is masked from ‘package:ggplot2’: vars
The following objects are masked from ‘package:stats’: filter, lag
The following objects are masked from ‘package:base’: intersect, setdiff, setequal, union
> df <- economics %>%
+ select(date, psavert, uempmed) %>%
+ gather(key = "variable", value = "value", -date)
> head(df, 3)
# A tibble: 3 x 3
date variable value
<date> <chr> <dbl>
1 1967-07-01 psavert 12.6
2 1967-08-01 psavert 12.6
3 1967-09-01 psavert 11.9Tạo nhiều biểu đồ dòng bằng cách sử dụng lệnh sau để xem mối quan hệ giữa “psavert” và “unmpmed” -
> ggplot(df, aes(x = date, y = value)) +
+ geom_line(aes(color = variable), size = 1) +
+ scale_color_manual(values = c("#00AFBB", "#E7B800")) +
+ theme_minimal()