Hadoop - Giải pháp dữ liệu lớn
Cách tiếp cận truyền thống
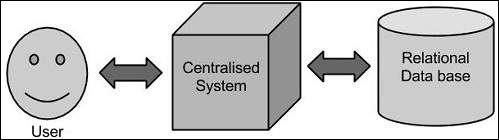
Theo cách tiếp cận này, doanh nghiệp sẽ có một máy tính để lưu trữ và xử lý dữ liệu lớn. Đối với mục đích lưu trữ, các lập trình viên sẽ nhận được sự trợ giúp của sự lựa chọn của các nhà cung cấp cơ sở dữ liệu như Oracle, IBM, v.v. Trong cách tiếp cận này, người dùng tương tác với ứng dụng, từ đó xử lý phần lưu trữ và phân tích dữ liệu.
Giới hạn
Cách tiếp cận này hoạt động tốt với những ứng dụng xử lý dữ liệu ít khổng lồ hơn có thể được cung cấp bởi máy chủ cơ sở dữ liệu tiêu chuẩn hoặc lên đến giới hạn của bộ xử lý đang xử lý dữ liệu. Nhưng khi phải xử lý một lượng lớn dữ liệu có thể mở rộng, thì việc xử lý dữ liệu đó thông qua một nút cổ chai cơ sở dữ liệu là một nhiệm vụ bận rộn.
Giải pháp của Google
Google đã giải quyết vấn đề này bằng cách sử dụng một thuật toán có tên là MapReduce. Thuật toán này chia nhiệm vụ thành các phần nhỏ và giao chúng cho nhiều máy tính, đồng thời thu thập kết quả từ chúng mà khi được tích hợp, tạo thành tập dữ liệu kết quả.

Hadoop
Sử dụng giải pháp do Google cung cấp, Doug Cutting và nhóm của anh ấy đã phát triển một Dự án nguồn mở có tên là HADOOP.
Hadoop chạy các ứng dụng sử dụng thuật toán MapReduce, nơi dữ liệu được xử lý song song với những dữ liệu khác. Nói tóm lại, Hadoop được sử dụng để phát triển các ứng dụng có thể thực hiện phân tích thống kê hoàn chỉnh trên một lượng lớn dữ liệu.
