Hadoop - Tổng quan về HDFS
Hệ thống tệp Hadoop được phát triển bằng cách sử dụng thiết kế hệ thống tệp phân tán. Nó được chạy trên phần cứng hàng hóa. Không giống như các hệ thống phân tán khác, HDFS có khả năng chống lỗi cao và được thiết kế bằng cách sử dụng phần cứng giá rẻ.
HDFS chứa một lượng lớn dữ liệu và cung cấp khả năng truy cập dễ dàng hơn. Để lưu trữ dữ liệu khổng lồ như vậy, các tệp được lưu trữ trên nhiều máy. Những tệp này được lưu trữ theo kiểu dự phòng để giải cứu hệ thống khỏi những mất mát dữ liệu có thể xảy ra trong trường hợp bị lỗi. HDFS cũng cung cấp các ứng dụng để xử lý song song.
Các tính năng của HDFS
- Nó phù hợp cho việc lưu trữ và xử lý phân tán.
- Hadoop cung cấp giao diện lệnh để tương tác với HDFS.
- Các máy chủ tích hợp của nút tên và nút dữ liệu giúp người dùng dễ dàng kiểm tra trạng thái của cụm.
- Truyền trực tuyến quyền truy cập vào dữ liệu hệ thống tệp.
- HDFS cung cấp quyền và xác thực tệp.
Kiến trúc HDFS
Dưới đây là kiến trúc của Hệ thống tệp Hadoop.
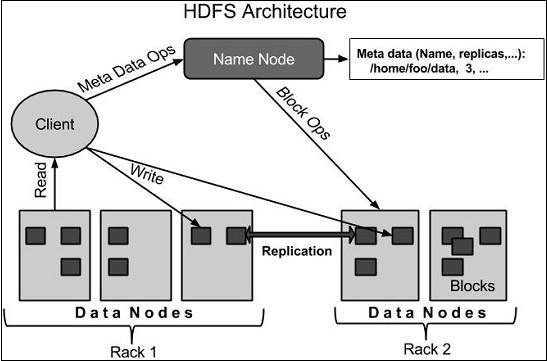
HDFS tuân theo kiến trúc master-slave và nó có các yếu tố sau.
Nút tên
Nút tên là phần cứng hàng hóa có chứa hệ điều hành GNU / Linux và phần mềm nút tên. Nó là một phần mềm có thể chạy trên phần cứng hàng hóa. Hệ thống có nút tên hoạt động như máy chủ chính và nó thực hiện các nhiệm vụ sau:
Quản lý không gian tên hệ thống tệp.
Kiểm soát quyền truy cập của khách hàng vào tệp.
Nó cũng thực hiện các hoạt động của hệ thống tệp như đổi tên, đóng và mở tệp và thư mục.
Datanode
Datanode là một phần cứng hàng hóa có hệ điều hành GNU / Linux và phần mềm datanode. Đối với mỗi nút (Phần cứng hàng hóa / Hệ thống) trong một cụm, sẽ có một nút dữ liệu. Các nút này quản lý việc lưu trữ dữ liệu của hệ thống của họ.
Các nút dữ liệu thực hiện các thao tác đọc-ghi trên hệ thống tệp, theo yêu cầu của khách hàng.
Chúng cũng thực hiện các hoạt động như tạo khối, xóa và sao chép theo hướng dẫn của nút tên.
Khối
Nói chung, dữ liệu người dùng được lưu trữ trong các tệp HDFS. Tệp trong hệ thống tệp sẽ được chia thành một hoặc nhiều phân đoạn và / hoặc được lưu trữ trong các nút dữ liệu riêng lẻ. Các phân đoạn tệp này được gọi là khối. Nói cách khác, lượng dữ liệu tối thiểu mà HDFS có thể đọc hoặc ghi được gọi là Block. Kích thước khối mặc định là 64MB, nhưng nó có thể được tăng lên tùy theo nhu cầu thay đổi trong cấu hình HDFS.
Mục tiêu của HDFS
Fault detection and recovery- Vì HDFS bao gồm một số lượng lớn phần cứng hàng hóa, nên việc hỏng hóc các thành phần là thường xuyên. Do đó HDFS cần có cơ chế phát hiện và phục hồi lỗi nhanh chóng và tự động.
Huge datasets - HDFS nên có hàng trăm nút trên mỗi cụm để quản lý các ứng dụng có bộ dữ liệu lớn.
Hardware at data- Một nhiệm vụ được yêu cầu có thể được thực hiện một cách hiệu quả, khi việc tính toán diễn ra gần dữ liệu. Đặc biệt là khi các bộ dữ liệu lớn có liên quan, nó làm giảm lưu lượng mạng và tăng thông lượng.