HCatalog - Hướng dẫn nhanh
HCatalog là gì?
HCatalog là một công cụ quản lý lưu trữ bảng cho Hadoop. Nó hiển thị dữ liệu dạng bảng của Hive di căn cho các ứng dụng Hadoop khác. Nó cho phép người dùng với các công cụ xử lý dữ liệu khác nhau (Pig, MapReduce) dễ dàng ghi dữ liệu lên lưới. Nó đảm bảo rằng người dùng không phải lo lắng về nơi hoặc định dạng dữ liệu của họ được lưu trữ.
HCatalog hoạt động giống như một thành phần chính của Hive và nó cho phép người dùng lưu trữ dữ liệu của họ ở bất kỳ định dạng và cấu trúc nào.
Tại sao HCatalog?
Kích hoạt công cụ phù hợp cho đúng công việc
Hệ sinh thái Hadoop chứa các công cụ khác nhau để xử lý dữ liệu như Hive, Pig và MapReduce. Mặc dù các công cụ này không yêu cầu siêu dữ liệu, nhưng chúng vẫn có thể hưởng lợi từ nó khi nó hiện diện. Chia sẻ kho siêu dữ liệu cũng cho phép người dùng trên các công cụ chia sẻ dữ liệu dễ dàng hơn. Quy trình làm việc trong đó dữ liệu được tải và chuẩn hóa bằng cách sử dụng MapReduce hoặc Pig và sau đó được phân tích qua Hive là rất phổ biến. Nếu tất cả các công cụ này dùng chung một kho lưu trữ, thì người dùng của mỗi công cụ có quyền truy cập ngay vào dữ liệu được tạo bằng công cụ khác. Không cần tải hoặc chuyển các bước.
Ghi lại các trạng thái xử lý để cho phép chia sẻ
HCatalog có thể xuất bản kết quả phân tích của bạn. Vì vậy, lập trình viên khác có thể truy cập nền tảng phân tích của bạn thông qua “REST”. Các lược đồ do bạn xuất bản cũng hữu ích cho các nhà khoa học dữ liệu khác. Các nhà khoa học dữ liệu khác sử dụng khám phá của bạn làm đầu vào cho một khám phá tiếp theo.
Tích hợp Hadoop với mọi thứ
Hadoop như một môi trường xử lý và lưu trữ mở ra rất nhiều cơ hội cho doanh nghiệp; tuy nhiên, để thúc đẩy việc áp dụng, nó phải hoạt động với và tăng cường các công cụ hiện có. Hadoop nên đóng vai trò là đầu vào cho nền tảng phân tích của bạn hoặc tích hợp với các ứng dụng web và kho dữ liệu hoạt động của bạn. Tổ chức nên tận hưởng giá trị của Hadoop mà không cần phải học một bộ công cụ hoàn toàn mới. Các dịch vụ REST mở ra nền tảng cho doanh nghiệp với một ngôn ngữ giống như API và SQL quen thuộc. Hệ thống quản lý dữ liệu doanh nghiệp sử dụng HCatalog để tích hợp sâu hơn với nền tảng Hadoop.
Kiến trúc HCatalog
Hình minh họa sau đây cho thấy kiến trúc tổng thể của HCatalog.
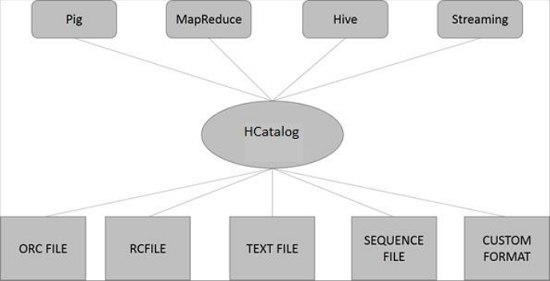
HCatalog hỗ trợ đọc và ghi tệp ở bất kỳ định dạng nào SerDe(serializer-deserializer) có thể được viết. Theo mặc định, HCatalog hỗ trợ các định dạng tệp RCFile, CSV, JSON, SequenceFile và ORC. Để sử dụng định dạng tùy chỉnh, bạn phải cung cấp InputFormat, OutputFormat và SerDe.
HCatalog được xây dựng dựa trên Hive di căn và kết hợp với DDL của Hive. HCatalog cung cấp các giao diện đọc và ghi cho Pig và MapReduce và sử dụng giao diện dòng lệnh của Hive để đưa ra các lệnh định nghĩa dữ liệu và thăm dò siêu dữ liệu.
Tất cả các dự án con Hadoop như Hive, Pig và HBase đều hỗ trợ hệ điều hành Linux. Do đó, bạn cần cài đặt phiên bản Linux trên hệ thống của mình. HCatalog được hợp nhất với Cài đặt Hive vào ngày 26 tháng 3 năm 2013. Từ phiên bản Hive-0.11.0 trở đi, HCatalog đi kèm với cài đặt Hive. Do đó, hãy làm theo các bước dưới đây để cài đặt Hive, từ đó sẽ tự động cài đặt HCatalog trên hệ thống của bạn.
Bước 1: Xác minh cài đặt JAVA
Java phải được cài đặt trên hệ thống của bạn trước khi cài đặt Hive. Bạn có thể sử dụng lệnh sau để kiểm tra xem bạn đã cài đặt Java trên hệ thống của mình chưa -
$ java –versionNếu Java đã được cài đặt trên hệ thống của bạn, bạn sẽ thấy phản hồi sau:
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b13)
Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)Nếu bạn chưa cài đặt Java trên hệ thống của mình, thì bạn cần làm theo các bước dưới đây.
Bước 2: Cài đặt Java
Tải xuống Java (JDK <phiên bản mới nhất> - X64.tar.gz) bằng cách truy cập liên kết sau http://www.oracle.com/
Sau đó jdk-7u71-linux-x64.tar.gz sẽ được tải xuống hệ thống của bạn.
Nói chung, bạn sẽ tìm thấy tệp Java đã tải xuống trong thư mục Tải xuống. Xác minh nó và trích xuấtjdk-7u71-linux-x64.gz sử dụng các lệnh sau.
$ cd Downloads/
$ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz
$ ls
jdk1.7.0_71 jdk-7u71-linux-x64.gzĐể cung cấp Java cho tất cả người dùng, bạn phải chuyển nó đến vị trí “/ usr / local /”. Mở root và nhập các lệnh sau.
$ su
password:
# mv jdk1.7.0_71 /usr/local/
# exitĐể thiết lập PATH và JAVA_HOME biến, thêm các lệnh sau vào ~/.bashrc tập tin.
export JAVA_HOME=/usr/local/jdk1.7.0_71
export PATH=PATH:$JAVA_HOME/binBây giờ hãy xác minh cài đặt bằng lệnh java -version từ thiết bị đầu cuối như đã giải thích ở trên.
Bước 3: Xác minh cài đặt Hadoop
Hadoop phải được cài đặt trên hệ thống của bạn trước khi cài đặt Hive. Hãy để chúng tôi xác minh cài đặt Hadoop bằng lệnh sau:
$ hadoop versionNếu Hadoop đã được cài đặt trên hệ thống của bạn, thì bạn sẽ nhận được phản hồi sau:
Hadoop 2.4.1
Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768
Compiled by hortonmu on 2013-10-07T06:28Z
Compiled with protoc 2.5.0
From source with checksum 79e53ce7994d1628b240f09af91e1af4Nếu Hadoop chưa được cài đặt trên hệ thống của bạn, hãy tiến hành các bước sau:
Bước 4: Tải xuống Hadoop
Tải xuống và giải nén Hadoop 2.4.1 từ Apache Software Foundation bằng các lệnh sau.
$ su
password:
# cd /usr/local
# wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/
hadoop-2.4.1.tar.gz
# tar xzf hadoop-2.4.1.tar.gz
# mv hadoop-2.4.1/* to hadoop/
# exitBước 5: Cài đặt Hadoop ở Chế độ phân tán giả
Các bước sau được sử dụng để cài đặt Hadoop 2.4.1 trong chế độ phân phối giả.
Thiết lập Hadoop
Bạn có thể đặt các biến môi trường Hadoop bằng cách thêm các lệnh sau vào ~/.bashrc tập tin.
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binBây giờ áp dụng tất cả các thay đổi vào hệ thống đang chạy hiện tại.
$ source ~/.bashrcCấu hình Hadoop
Bạn có thể tìm thấy tất cả các tệp cấu hình Hadoop ở vị trí “$ HADOOP_HOME / etc / hadoop”. Bạn cần thực hiện các thay đổi phù hợp trong các tệp cấu hình đó theo cơ sở hạ tầng Hadoop của mình.
$ cd $HADOOP_HOME/etc/hadoopĐể phát triển các chương trình Hadoop bằng Java, bạn phải đặt lại các biến môi trường Java trong hadoop-env.sh tập tin bằng cách thay thế JAVA_HOME giá trị với vị trí của Java trong hệ thống của bạn.
export JAVA_HOME=/usr/local/jdk1.7.0_71Dưới đây là danh sách các tệp mà bạn phải chỉnh sửa để định cấu hình Hadoop.
core-site.xml
Các core-site.xml tệp chứa thông tin như số cổng được sử dụng cho cá thể Hadoop, bộ nhớ được cấp cho hệ thống tệp, giới hạn bộ nhớ để lưu trữ dữ liệu và kích thước của bộ đệm Đọc / Ghi.
Mở core-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration> và </configuration>.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml
Các hdfs-site.xmltệp chứa thông tin như giá trị của dữ liệu sao chép, đường dẫn nút tên và đường dẫn nút dữ liệu của hệ thống tệp cục bộ của bạn. Nó có nghĩa là nơi bạn muốn lưu trữ cơ sở hạ tầng Hadoop.
Hãy để chúng tôi giả sử dữ liệu sau đây.
dfs.replication (data replication value) = 1
(In the following path /hadoop/ is the user name.
hadoopinfra/hdfs/namenode is the directory created by hdfs file system.)
namenode path = //home/hadoop/hadoopinfra/hdfs/namenode
(hadoopinfra/hdfs/datanode is the directory created by hdfs file system.)
datanode path = //home/hadoop/hadoopinfra/hdfs/datanodeMở tệp này và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode</value>
</property>
</configuration>Note - Trong tệp trên, tất cả các giá trị thuộc tính đều do người dùng xác định và bạn có thể thực hiện thay đổi theo cơ sở hạ tầng Hadoop của mình.
fiber-site.xml
Tệp này được sử dụng để cấu hình sợi thành Hadoop. Mở tệp fiber-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>mapred-site.xml
Tệp này được sử dụng để chỉ định khung MapReduce mà chúng tôi đang sử dụng. Theo mặc định, Hadoop chứa một mẫu sợi-site.xml. Trước hết, bạn cần sao chép tệp từmapred-site,xml.template đến mapred-site.xml sử dụng lệnh sau.
$ cp mapred-site.xml.template mapred-site.xmlMở tệp mapred-site.xml và thêm các thuộc tính sau vào giữa các thẻ <configuration>, </configuration> trong tệp này.
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Bước 6: Xác minh cài đặt Hadoop
Các bước sau được sử dụng để xác minh cài đặt Hadoop.
Thiết lập nút tên
Thiết lập nút tên bằng lệnh “hdfs namenode -format” như sau:
$ cd ~ $ hdfs namenode -formatKết quả mong đợi như sau:
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = localhost/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.4.1
...
...
10/24/14 21:30:56 INFO common.Storage: Storage directory
/home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted.
10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1
images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0
10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11
************************************************************/Xác minh Hadoop DFS
Lệnh sau được sử dụng để khởi động DFS. Thực thi lệnh này sẽ khởi động hệ thống tệp Hadoop của bạn.
$ start-dfs.shSản lượng dự kiến như sau:
10/24/14 21:37:56 Starting namenodes on [localhost]
localhost: starting namenode, logging to
/home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost:
starting datanode, logging to
/home/hadoop/hadoop-2.4.1/logs/hadoop-hadoop-datanode-localhost.out
Starting secondary namenodes [0.0.0.0]Xác minh tập lệnh sợi
Lệnh sau được sử dụng để bắt đầu tập lệnh Yarn. Thực hiện lệnh này sẽ bắt đầu các daemon Yarn của bạn.
$ start-yarn.shSản lượng dự kiến như sau:
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.4.1/logs/
yarn-hadoop-resourcemanager-localhost.out
localhost: starting nodemanager, logging to
/home/hadoop/hadoop-2.4.1/logs/yarn-hadoop-nodemanager-localhost.outTruy cập Hadoop trên trình duyệt
Số cổng mặc định để truy cập Hadoop là 50070. Sử dụng URL sau để tải các dịch vụ Hadoop trên trình duyệt của bạn.
http://localhost:50070/
Xác minh tất cả các ứng dụng cho cụm
Số cổng mặc định để truy cập tất cả các ứng dụng của cụm là 8088. Sử dụng url sau để truy cập dịch vụ này.
http://localhost:8088/
Khi bạn đã hoàn tất cài đặt Hadoop, hãy chuyển sang bước tiếp theo và cài đặt Hive trên hệ thống của bạn.
Bước 7: Tải xuống Hive
Chúng tôi sử dụng hive-0.14.0 trong hướng dẫn này. Bạn có thể tải về bằng cách truy cập liên kết sauhttp://apache.petsads.us/hive/hive-0.14.0/. Hãy để chúng tôi giả sử nó được tải xuống/Downloadsdanh mục. Tại đây, chúng tôi tải xuống kho lưu trữ Hive có tên “apache-hive-0.14.0-bin.tar.gz”Cho hướng dẫn này. Lệnh sau được sử dụng để xác minh tải xuống:
$ cd Downloads $ lsKhi tải xuống thành công, bạn sẽ thấy phản hồi sau:
apache-hive-0.14.0-bin.tar.gzBước 8: Cài đặt Hive
Các bước sau là bắt buộc để cài đặt Hive trên hệ thống của bạn. Hãy giả sử rằng kho lưu trữ Hive được tải xuống/Downloads danh mục.
Giải nén và xác minh kho lưu trữ Hive
Lệnh sau được sử dụng để xác minh tải xuống và giải nén kho lưu trữ Hive:
$ tar zxvf apache-hive-0.14.0-bin.tar.gz $ lsKhi tải xuống thành công, bạn sẽ thấy phản hồi sau:
apache-hive-0.14.0-bin apache-hive-0.14.0-bin.tar.gzSao chép tệp vào thư mục / usr / local / hive
Chúng ta cần sao chép các tệp từ superuser “su -”. Các lệnh sau được sử dụng để sao chép các tệp từ thư mục được trích xuất vào/usr/local/hive" danh mục.
$ su -
passwd:
# cd /home/user/Download
# mv apache-hive-0.14.0-bin /usr/local/hive
# exitThiết lập môi trường cho Hive
Bạn có thể thiết lập môi trường Hive bằng cách nối các dòng sau vào ~/.bashrc tập tin -
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin export CLASSPATH=$CLASSPATH:/usr/local/Hadoop/lib/*:.
export CLASSPATH=$CLASSPATH:/usr/local/hive/lib/*:.Lệnh sau được sử dụng để thực thi tệp ~ / .bashrc.
$ source ~/.bashrcBước 9: Định cấu hình Hive
Để định cấu hình Hive với Hadoop, bạn cần chỉnh sửa hive-env.sh tệp, được đặt trong $HIVE_HOME/confdanh mục. Các lệnh sau chuyển hướng đến Hiveconfig thư mục và sao chép tệp mẫu -
$ cd $HIVE_HOME/conf $ cp hive-env.sh.template hive-env.shChỉnh sửa hive-env.sh tập tin bằng cách nối dòng sau -
export HADOOP_HOME=/usr/local/hadoopVới điều này, quá trình cài đặt Hive đã hoàn tất. Bây giờ bạn yêu cầu một máy chủ cơ sở dữ liệu bên ngoài để cấu hình Metastore. Chúng tôi sử dụng cơ sở dữ liệu Apache Derby.
Bước 10: Tải xuống và cài đặt Apache Derby
Làm theo các bước dưới đây để tải xuống và cài đặt Apache Derby -
Tải xuống Apache Derby
Lệnh sau được sử dụng để tải xuống Apache Derby. Phải mất một thời gian để tải xuống.
$ cd ~ $ wget http://archive.apache.org/dist/db/derby/db-derby-10.4.2.0/db-derby-10.4.2.0-bin.tar.gzLệnh sau được sử dụng để xác minh tải xuống:
$ lsKhi tải xuống thành công, bạn sẽ thấy phản hồi sau:
db-derby-10.4.2.0-bin.tar.gzGiải nén và xác minh kho lưu trữ Derby
Các lệnh sau được sử dụng để giải nén và xác minh kho lưu trữ Derby:
$ tar zxvf db-derby-10.4.2.0-bin.tar.gz
$ lsKhi tải xuống thành công, bạn sẽ thấy phản hồi sau:
db-derby-10.4.2.0-bin db-derby-10.4.2.0-bin.tar.gzSao chép tập tin vào / usr / local / derby Directory
Chúng ta cần sao chép từ superuser “su -”. Các lệnh sau được sử dụng để sao chép các tệp từ thư mục được trích xuất vào/usr/local/derby thư mục -
$ su -
passwd:
# cd /home/user
# mv db-derby-10.4.2.0-bin /usr/local/derby
# exitThiết lập môi trường cho trận Derby
Bạn có thể thiết lập môi trường Derby bằng cách nối các dòng sau vào ~/.bashrc tập tin -
export DERBY_HOME=/usr/local/derby
export PATH=$PATH:$DERBY_HOME/bin
export CLASSPATH=$CLASSPATH:$DERBY_HOME/lib/derby.jar:$DERBY_HOME/lib/derbytools.jarLệnh sau được sử dụng để thực thi ~/.bashrc file -
$ source ~/.bashrcTạo một thư mục cho Metastore
Tạo một thư mục có tên data trong thư mục $ DERBY_HOME để lưu trữ dữ liệu Metastore.
$ mkdir $DERBY_HOME/dataCài đặt Derby và thiết lập môi trường đã hoàn tất.
Bước 11: Định cấu hình Hive Metastore
Cấu hình Metastore có nghĩa là chỉ định cho Hive nơi lưu trữ cơ sở dữ liệu. Bạn có thể làm điều này bằng cách chỉnh sửahive-site.xml tệp, nằm trong $HIVE_HOME/confdanh mục. Trước hết, hãy sao chép tệp mẫu bằng lệnh sau:
$ cd $HIVE_HOME/conf
$ cp hive-default.xml.template hive-site.xmlBiên tập hive-site.xml và nối các dòng sau giữa thẻ <configuration> và </configuration> -
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby://localhost:1527/metastore_db;create = true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>Tạo một tệp có tên jpox.properties và thêm các dòng sau vào đó -
javax.jdo.PersistenceManagerFactoryClass = org.jpox.PersistenceManagerFactoryImpl
org.jpox.autoCreateSchema = false
org.jpox.validateTables = false
org.jpox.validateColumns = false
org.jpox.validateConstraints = false
org.jpox.storeManagerType = rdbms
org.jpox.autoCreateSchema = true
org.jpox.autoStartMechanismMode = checked
org.jpox.transactionIsolation = read_committed
javax.jdo.option.DetachAllOnCommit = true
javax.jdo.option.NontransactionalRead = true
javax.jdo.option.ConnectionDriverName = org.apache.derby.jdbc.ClientDriver
javax.jdo.option.ConnectionURL = jdbc:derby://hadoop1:1527/metastore_db;create = true
javax.jdo.option.ConnectionUserName = APP
javax.jdo.option.ConnectionPassword = mineBước 12: Xác minh cài đặt Hive
Trước khi chạy Hive, bạn cần tạo /tmpvà một thư mục Hive riêng biệt trong HDFS. Ở đây, chúng tôi sử dụng/user/hive/warehousethư mục. Bạn cần đặt quyền ghi cho các thư mục mới tạo này như hình dưới đây -
chmod g+wBây giờ hãy đặt chúng ở HDFS trước khi xác minh Hive. Sử dụng các lệnh sau:
$ $HADOOP_HOME/bin/hadoop fs -mkdir /tmp $ $HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp $ $HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouseCác lệnh sau được sử dụng để xác minh cài đặt Hive:
$ cd $HIVE_HOME $ bin/hiveKhi cài đặt thành công Hive, bạn sẽ thấy phản hồi sau:
Logging initialized using configuration in
jar:file:/home/hadoop/hive-0.9.0/lib/hive-common-0.9.0.jar!/
hive-log4j.properties Hive history
=/tmp/hadoop/hive_job_log_hadoop_201312121621_1494929084.txt
………………….
hive>Bạn có thể thực hiện lệnh mẫu sau để hiển thị tất cả các bảng -
hive> show tables;
OK Time taken: 2.798 seconds
hive>Bước 13: Xác minh cài đặt HCatalog
Sử dụng lệnh sau để đặt một biến hệ thống HCAT_HOME cho Trang chủ HCatalog.
export HCAT_HOME = $HiVE_HOME/HCatalogSử dụng lệnh sau để xác minh cài đặt HCatalog.
cd $HCAT_HOME/bin
./hcatNếu cài đặt thành công, bạn sẽ thấy kết quả sau:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statementGiao diện dòng lệnh HCatalog (CLI) có thể được gọi từ lệnh $HIVE_HOME/HCatalog/bin/hcat trong đó $ HIVE_HOME là thư mục chính của Hive. hcat là một lệnh được sử dụng để khởi tạo máy chủ HCatalog.
Sử dụng lệnh sau để khởi tạo dòng lệnh HCatalog.
cd $HCAT_HOME/bin
./hcatNếu quá trình cài đặt được thực hiện chính xác, bạn sẽ nhận được kết quả sau:
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
usage: hcat { -e "<query>" | -f "<filepath>" }
[ -g "<group>" ] [ -p "<perms>" ]
[ -D"<name> = <value>" ]
-D <property = value> use hadoop value for given property
-e <exec> hcat command given from command line
-f <file> hcat commands in file
-g <group> group for the db/table specified in CREATE statement
-h,--help Print help information
-p <perms> permissions for the db/table specified in CREATE statementHCatalog CLI hỗ trợ các tùy chọn dòng lệnh này -
| Sr.No | Lựa chọn | Ví dụ & Mô tả |
|---|---|---|
| 1 | -g | hcat -g mygroup ... Bảng được tạo phải có nhóm "mygroup". |
| 2 | -p | hcat -p rwxr-xr-x ... Bảng được tạo phải có các quyền đọc, ghi và thực thi. |
| 3 | -f | hcat -f myscript.HCatalog ... myscript.HCatalog là một tập tin script chứa các lệnh DDL để thực thi. |
| 4 | -e | hcat -e 'create table mytable(a int);' ... Xử lý chuỗi sau như một lệnh DDL và thực thi nó. |
| 5 | -D | hcat -Dkey = value ... Chuyển cặp khóa-giá trị tới HCatalog dưới dạng thuộc tính hệ thống Java. |
| 6 | - | hcat In tin nhắn sử dụng. |
Lưu ý -
Các -g và -p tùy chọn không bắt buộc.
Tại một thời điểm, -e hoặc là -f tùy chọn có thể được cung cấp, không phải cả hai.
Thứ tự của các quyền chọn là phi vật chất; bạn có thể chỉ định các tùy chọn theo bất kỳ thứ tự nào.
| Sr.No | Lệnh & Mô tả DDL |
|---|---|
| 1 | CREATE TABLE Tạo bảng bằng HCatalog. Nếu bạn tạo một bảng với mệnh đề CLUSTERED BY, bạn sẽ không thể ghi vào bảng đó bằng Pig hoặc MapReduce. |
| 2 | ALTER TABLE Được hỗ trợ ngoại trừ các tùy chọn REBUILD và CONCATENATE. Hành vi của nó vẫn giống như trong Hive. |
| 3 | DROP TABLE Được hỗ trợ. Hành vi giống như Hive (Bỏ bảng hoàn chỉnh và cấu trúc). |
| 4 | CREATE/ALTER/DROP VIEW Được hỗ trợ. Hành vi giống như Hive. Note - Pig và MapReduce không thể đọc hoặc ghi vào các khung nhìn. |
| 5 | SHOW TABLES Hiển thị danh sách các bảng. |
| 6 | SHOW PARTITIONS Hiển thị danh sách các phân vùng. |
| 7 | Create/Drop Index Các hoạt động CREATE và DROP FUNCTION được hỗ trợ, nhưng các chức năng đã tạo vẫn phải được đăng ký trong Pig và được đặt trong CLASSPATH cho MapReduce. |
| số 8 | DESCRIBE Được hỗ trợ. Hành vi giống như Hive. Mô tả cấu trúc. |
Một số lệnh từ bảng trên được giải thích trong các chương tiếp theo.
Chương này giải thích cách tạo bảng và cách chèn dữ liệu vào đó. Các quy ước tạo bảng trong HCatalog khá giống với tạo bảng bằng Hive.
Tạo Báo cáo Bảng
Create Table là một câu lệnh được sử dụng để tạo một bảng trong Hive di căn bằng cách sử dụng HCatalog. Cú pháp và ví dụ của nó như sau:
Cú pháp
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[ROW FORMAT row_format]
[STORED AS file_format]Thí dụ
Giả sử bạn cần tạo một bảng có tên employee sử dụng CREATE TABLEtuyên bố. Bảng sau liệt kê các trường và kiểu dữ liệu của chúng trongemployee bàn -
| Sr.No | Tên trường | Loại dữ liệu |
|---|---|---|
| 1 | Eid | int |
| 2 | Tên | Chuỗi |
| 3 | Tiền lương | Phao nổi |
| 4 | Chỉ định | chuỗi |
Dữ liệu sau xác định các trường được hỗ trợ, chẳng hạn như Comment, Các trường được định dạng hàng chẳng hạn như Field terminator, Lines terminatorvà Stored File type.
COMMENT ‘Employee details’
FIELDS TERMINATED BY ‘\t’
LINES TERMINATED BY ‘\n’
STORED IN TEXT FILETruy vấn sau tạo một bảng có tên employee sử dụng dữ liệu trên.
./hcat –e "CREATE TABLE IF NOT EXISTS employee ( eid int, name String,
salary String, destination String) \
COMMENT 'Employee details' \
ROW FORMAT DELIMITED \
FIELDS TERMINATED BY ‘\t’ \
LINES TERMINATED BY ‘\n’ \
STORED AS TEXTFILE;"Nếu bạn thêm tùy chọn IF NOT EXISTS, HCatalog bỏ qua câu lệnh trong trường hợp bảng đã tồn tại.
Khi tạo bảng thành công, bạn sẽ thấy phản hồi sau:
OK
Time taken: 5.905 secondsTải báo cáo dữ liệu
Nói chung, sau khi tạo bảng trong SQL, chúng ta có thể chèn dữ liệu bằng câu lệnh Insert. Nhưng trong HCatalog, chúng tôi chèn dữ liệu bằng câu lệnh LOAD DATA.
Trong khi chèn dữ liệu vào HCatalog, tốt hơn nên sử dụng LOAD DATA để lưu trữ các bản ghi hàng loạt. Có hai cách để tải dữ liệu: một là từlocal file system và thứ hai là từ Hadoop file system.
Cú pháp
Cú pháp cho TẢI DỮ LIỆU như sau:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]- LOCAL là định danh để chỉ định đường dẫn cục bộ. Nó là tùy chọn.
- OVERWRITE là tùy chọn để ghi đè dữ liệu trong bảng.
- PARTITION là tùy chọn.
Thí dụ
Chúng tôi sẽ chèn dữ liệu sau vào bảng. Nó là một tệp văn bản có tênsample.txt trong /home/user danh mục.
1201 Gopal 45000 Technical manager
1202 Manisha 45000 Proof reader
1203 Masthanvali 40000 Technical writer
1204 Kiran 40000 Hr Admin
1205 Kranthi 30000 Op AdminTruy vấn sau tải văn bản đã cho vào bảng.
./hcat –e "LOAD DATA LOCAL INPATH '/home/user/sample.txt'
OVERWRITE INTO TABLE employee;"Khi tải xuống thành công, bạn sẽ thấy phản hồi sau:
OK
Time taken: 15.905 secondsChương này giải thích cách thay đổi các thuộc tính của bảng như thay đổi tên bảng, thay đổi tên cột, thêm cột và xóa hoặc thay thế cột.
Tuyên bố bảng thay đổi
Bạn có thể sử dụng câu lệnh ALTER TABLE để thay đổi bảng trong Hive.
Cú pháp
Câu lệnh nhận bất kỳ cú pháp nào sau đây dựa trên những thuộc tính mà chúng ta muốn sửa đổi trong bảng.
ALTER TABLE name RENAME TO new_name
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
ALTER TABLE name DROP [COLUMN] column_name
ALTER TABLE name CHANGE column_name new_name new_type
ALTER TABLE name REPLACE COLUMNS (col_spec[, col_spec ...])Một số tình huống được giải thích dưới đây.
Đổi tên thành… Tuyên bố
Truy vấn sau đổi tên một bảng từ employee đến emp.
./hcat –e "ALTER TABLE employee RENAME TO emp;"Thay đổi Tuyên bố
Bảng sau chứa các trường employee bảng và nó hiển thị các trường cần thay đổi (in đậm).
| Tên trường | Chuyển đổi từ Loại dữ liệu | Thay đổi tên trường | Chuyển đổi sang kiểu dữ liệu |
|---|---|---|---|
| eid | int | eid | int |
| Tên | Chuỗi | ename | Chuỗi |
| tiền lương | Phao nổi | tiền lương | Gấp đôi |
| sự chỉ định | Chuỗi | sự chỉ định | Chuỗi |
Các truy vấn sau đổi tên tên cột và kiểu dữ liệu cột bằng cách sử dụng dữ liệu trên:
./hcat –e "ALTER TABLE employee CHANGE name ename String;"
./hcat –e "ALTER TABLE employee CHANGE salary salary Double;"Thêm tuyên bố cột
Truy vấn sau đây thêm một cột có tên dept đến employee bàn.
./hcat –e "ALTER TABLE employee ADD COLUMNS (dept STRING COMMENT 'Department name');"Thay thế Tuyên bố
Truy vấn sau sẽ xóa tất cả các cột khỏi employee bảng và thay thế nó bằng emp và name cột -
./hcat – e "ALTER TABLE employee REPLACE COLUMNS ( eid INT empid Int, ename STRING name String);"Tuyên bố bảng thả
Chương này mô tả cách bỏ một bảng trong HCatalog. Khi bạn thả một bảng khỏi kho lưu trữ, nó sẽ xóa dữ liệu bảng / cột và siêu dữ liệu của chúng. Nó có thể là một bảng bình thường (được lưu trữ trong siêu thị) hoặc một bảng bên ngoài (được lưu trữ trong hệ thống tệp cục bộ); HCatalog xử lý cả hai theo cùng một cách, không phân biệt loại của chúng.
Cú pháp như sau:
DROP TABLE [IF EXISTS] table_name;Truy vấn sau đây đưa ra một bảng có tên employee -
./hcat –e "DROP TABLE IF EXISTS employee;"Khi thực hiện thành công truy vấn, bạn sẽ thấy phản hồi sau:
OK
Time taken: 5.3 secondsChương này mô tả cách tạo và quản lý viewtrong HCatalog. Chế độ xem cơ sở dữ liệu được tạo bằng cách sử dụngCREATE VIEWtuyên bố. Các dạng xem có thể được tạo từ một bảng, nhiều bảng hoặc một dạng xem khác.
Để tạo chế độ xem, người dùng phải có các đặc quyền hệ thống thích hợp theo cách triển khai cụ thể.
Tạo Tuyên bố Chế độ xem
CREATE VIEWtạo một khung nhìn với tên đã cho. Một lỗi sẽ xảy ra nếu một bảng hoặc dạng xem có cùng tên đã tồn tại. Bạn có thể dùngIF NOT EXISTS để bỏ qua lỗi.
Nếu không có tên cột nào được cung cấp, tên của các cột của chế độ xem sẽ được lấy tự động từ defining SELECT expression.
Note - Nếu SELECT chứa các biểu thức vô hướng không phân biệt như x + y, tên cột chế độ xem kết quả sẽ được tạo ở dạng _C0, _C1, v.v.
Khi đổi tên cột, các chú thích cột cũng có thể được cung cấp. Nhận xét không được kế thừa tự động từ các cột bên dưới.
Câu lệnh TẠO CHẾ ĐỘ XEM sẽ không thành công nếu chế độ xem defining SELECT expression không có hiệu lực.
Cú pháp
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ...;Thí dụ
Sau đây là dữ liệu bảng nhân viên. Bây giờ chúng ta hãy xem cách tạo một dạng xem có tênEmp_Deg_View chứa các trường id, tên, Chức vụ và mức lương của một nhân viên có mức lương lớn hơn 35.000.
+------+-------------+--------+-------------------+-------+
| ID | Name | Salary | Designation | Dept |
+------+-------------+--------+-------------------+-------+
| 1201 | Gopal | 45000 | Technical manager | TP |
| 1202 | Manisha | 45000 | Proofreader | PR |
| 1203 | Masthanvali | 30000 | Technical writer | TP |
| 1204 | Kiran | 40000 | Hr Admin | HR |
| 1205 | Kranthi | 30000 | Op Admin | Admin |
+------+-------------+--------+-------------------+-------+Sau đây là lệnh tạo khung nhìn dựa trên dữ liệu đã cho ở trên.
./hcat –e "CREATE VIEW Emp_Deg_View (salary COMMENT ' salary more than 35,000')
AS SELECT id, name, salary, designation FROM employee WHERE salary ≥ 35000;"Đầu ra
OK
Time taken: 5.3 secondsTuyên bố Drop View
DROP VIEW xóa siêu dữ liệu cho chế độ xem được chỉ định. Khi bỏ một chế độ xem được tham chiếu bởi các chế độ xem khác, không có cảnh báo nào được đưa ra (các chế độ xem phụ thuộc bị treo lơ lửng là không hợp lệ và người dùng phải bỏ hoặc tạo lại).
Cú pháp
DROP VIEW [IF EXISTS] view_name;Thí dụ
Lệnh sau được sử dụng để thả một dạng xem có tên Emp_Deg_View.
DROP VIEW Emp_Deg_View;Bạn thường muốn liệt kê tất cả các bảng trong cơ sở dữ liệu hoặc liệt kê tất cả các cột trong một bảng. Rõ ràng, mọi cơ sở dữ liệu đều có cú pháp riêng để liệt kê các bảng và cột.
Show Tablescâu lệnh hiển thị tên của tất cả các bảng. Theo mặc định, nó liệt kê các bảng từ cơ sở dữ liệu hiện tại hoặc vớiIN trong một cơ sở dữ liệu cụ thể.
Chương này mô tả cách liệt kê tất cả các bảng từ cơ sở dữ liệu hiện tại trong HCatalog.
Hiển thị Tuyên bố Bảng
Cú pháp của SHOW TABLES như sau:
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];Truy vấn sau đây hiển thị danh sách các bảng -
./hcat –e "Show tables;"Khi thực hiện thành công truy vấn, bạn sẽ thấy phản hồi sau:
OK
emp
employee
Time taken: 5.3 secondsPhân vùng là một điều kiện cho dữ liệu dạng bảng được sử dụng để tạo một bảng hoặc dạng xem riêng biệt. SHOW PARTITIONS liệt kê tất cả các phân vùng hiện có cho một bảng cơ sở nhất định. Các phần được liệt kê theo thứ tự bảng chữ cái. Sau Hive 0.6, cũng có thể chỉ định các phần của đặc tả phân vùng để lọc danh sách kết quả.
Bạn có thể sử dụng lệnh SHOW PARTITIONS để xem các phân vùng tồn tại trong một bảng cụ thể. Chương này mô tả cách liệt kê các phân vùng của một bảng cụ thể trong HCatalog.
Hiển thị Tuyên bố Phân vùng
Cú pháp như sau:
SHOW PARTITIONS table_name;Truy vấn sau đây đưa ra một bảng có tên employee -
./hcat –e "Show partitions employee;"Khi thực hiện thành công truy vấn, bạn sẽ thấy phản hồi sau:
OK
Designation = IT
Time taken: 5.3 secondsPhân vùng động
HCatalog tổ chức các bảng thành các phân vùng. Đây là cách chia bảng thành các phần liên quan dựa trên giá trị của các cột được phân vùng như ngày tháng, thành phố và phòng ban. Sử dụng phân vùng, có thể dễ dàng truy vấn một phần dữ liệu.
Ví dụ, một bảng có tên Tab1chứa dữ liệu của nhân viên như id, tên, dept và yoj (tức là năm gia nhập). Giả sử bạn cần truy xuất thông tin chi tiết của tất cả nhân viên đã tham gia vào năm 2012. Một truy vấn tìm kiếm toàn bộ bảng cho thông tin cần thiết. Tuy nhiên, nếu bạn phân vùng dữ liệu nhân viên với năm và lưu trữ trong một tệp riêng, nó sẽ làm giảm thời gian xử lý truy vấn. Ví dụ sau đây cho thấy cách phân vùng tệp và dữ liệu của nó:
Tệp sau đây chứa employeedata bàn.
/ tab1 / Employeedata / file1
id, name, dept, yoj
1, gopal, TP, 2012
2, kiran, HR, 2012
3, kaleel, SC, 2013
4, Prasanth, SC, 2013Dữ liệu trên được phân chia thành hai tệp sử dụng năm.
/ tab1 / Employeedata / 2012 / file2
1, gopal, TP, 2012
2, kiran, HR, 2012/ tab1 / Employeedata / 2013 / file3
3, kaleel, SC, 2013
4, Prasanth, SC, 2013Thêm phân vùng
Chúng ta có thể thêm phân vùng vào bảng bằng cách thay đổi bảng. Giả sử chúng ta có một bảng được gọi làemployee với các trường như Id, Tên, Lương, Chức vụ, Bộ phận và yoj.
Cú pháp
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec
[LOCATION 'location1'] partition_spec [LOCATION 'location2'] ...;
partition_spec:
: (p_column = p_col_value, p_column = p_col_value, ...)Truy vấn sau được sử dụng để thêm phân vùng vào employee bàn.
./hcat –e "ALTER TABLE employee ADD PARTITION (year = '2013') location '/2012/part2012';"Đổi tên phân vùng
Bạn có thể sử dụng lệnh RENAME-TO để đổi tên phân vùng. Cú pháp của nó như sau:
./hact –e "ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;"Truy vấn sau được sử dụng để đổi tên một phân vùng:
./hcat –e "ALTER TABLE employee PARTITION (year=’1203’) RENAME TO PARTITION (Yoj='1203');"Bỏ phân vùng
Cú pháp của lệnh được sử dụng để thả một phân vùng như sau:
./hcat –e "ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec,.
PARTITION partition_spec,...;"Truy vấn sau được sử dụng để thả phân vùng:
./hcat –e "ALTER TABLE employee DROP [IF EXISTS] PARTITION (year=’1203’);"Tạo chỉ mục
Chỉ mục không là gì ngoài một con trỏ trên một cột cụ thể của bảng. Tạo chỉ mục có nghĩa là tạo một con trỏ trên một cột cụ thể của bảng. Cú pháp của nó như sau:
CREATE INDEX index_name
ON TABLE base_table_name (col_name, ...)
AS 'index.handler.class.name'
[WITH DEFERRED REBUILD]
[IDXPROPERTIES (property_name = property_value, ...)]
[IN TABLE index_table_name]
[PARTITIONED BY (col_name, ...)][
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
]
[LOCATION hdfs_path]
[TBLPROPERTIES (...)]Thí dụ
Chúng ta hãy lấy một ví dụ để hiểu khái niệm về chỉ mục. Sử dụng giống nhauemployee bảng mà chúng ta đã sử dụng trước đó với các trường Id, Tên, Lương, Chức vụ và Phòng ban Tạo một chỉ mục có tên index_salary trên salary cột của employee bàn.
Truy vấn sau tạo chỉ mục:
./hcat –e "CREATE INDEX inedx_salary ON TABLE employee(salary)
AS 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler';"Nó là một con trỏ đến salarycột. Nếu cột được sửa đổi, các thay đổi được lưu trữ bằng giá trị chỉ mục.
Giảm chỉ số
Cú pháp sau được sử dụng để giảm một chỉ mục:
DROP INDEX <index_name> ON <table_name>Truy vấn sau làm giảm chỉ mục index_salary -
./hcat –e "DROP INDEX index_salary ON employee;"HCatalog chứa API truyền dữ liệu cho đầu vào và đầu ra song song mà không cần sử dụng MapReduce. API này sử dụng trừu tượng lưu trữ cơ bản của các bảng và hàng để đọc dữ liệu từ cụm Hadoop và ghi dữ liệu vào đó.
API truyền dữ liệu chủ yếu chứa ba lớp; đó là -
HCatReader - Đọc dữ liệu từ một cụm Hadoop.
HCatWriter - Ghi dữ liệu vào một cụm Hadoop.
DataTransferFactory - Tạo phiên bản người đọc và người viết.
API này phù hợp để thiết lập nút chủ-tớ. Hãy để chúng tôi thảo luận thêm vềHCatReader và HCatWriter.
HCatReader
HCatReader là một lớp trừu tượng bên trong HCatalog và trừu tượng hóa sự phức tạp của hệ thống cơ bản từ nơi các bản ghi sẽ được truy xuất.
| S. Không. | Tên & Mô tả phương pháp |
|---|---|
| 1 | Public abstract ReaderContext prepareRead() throws HCatException Điều này sẽ được gọi tại nút chính để lấy ReaderContext mà sau đó sẽ được tuần tự hóa và gửi các nút phụ. |
| 2 | Public abstract Iterator <HCatRecorder> read() throws HCaException Điều này sẽ được gọi tại các nút nô lệ để đọc HCatRecords. |
| 3 | Public Configuration getConf() Nó sẽ trả về đối tượng lớp cấu hình. |
Lớp HCatReader được sử dụng để đọc dữ liệu từ HDFS. Đọc là một quá trình gồm hai bước, trong đó bước đầu tiên xảy ra trên nút chính của hệ thống bên ngoài. Bước thứ hai được thực hiện song song trên nhiều nút phụ.
Đọc được thực hiện trên một ReadEntity. Trước khi bắt đầu đọc, bạn cần xác định ReadEntity để đọc. Điều này có thể được thực hiện thông quaReadEntity.Builder. Bạn có thể chỉ định tên cơ sở dữ liệu, tên bảng, phân vùng và chuỗi bộ lọc. Ví dụ -
ReadEntity.Builder builder = new ReadEntity.Builder();
ReadEntity entity = builder.withDatabase("mydb").withTable("mytbl").build(); 10.Đoạn mã trên xác định đối tượng ReadEntity (“thực thể”), bao gồm một bảng có tên mytbl trong một cơ sở dữ liệu có tên mydb, có thể được sử dụng để đọc tất cả các hàng của bảng này. Lưu ý rằng bảng này phải tồn tại trong HCatalog trước khi bắt đầu thao tác này.
Sau khi xác định ReadEntity, bạn có được một phiên bản của HCatReader bằng cách sử dụng cấu hình ReadEntity và cụm -
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);Bước tiếp theo là lấy ReaderContext từ trình đọc như sau:
ReaderContext cntxt = reader.prepareRead();HCatWriter
Sự trừu tượng này là nội bộ của HCatalog. Điều này là để tạo điều kiện cho việc ghi vào HCatalog từ các hệ thống bên ngoài. Đừng cố gắng thực hiện điều này một cách trực tiếp. Thay vào đó, hãy sử dụng DataTransferFactory.
| Sr.No. | Tên & Mô tả phương pháp |
|---|---|
| 1 | Public abstract WriterContext prepareRead() throws HCatException Hệ thống bên ngoài sẽ gọi phương thức này chính xác một lần từ một nút chính. Nó trả về mộtWriterContext. Điều này sẽ được tuần tự hóa và gửi đến các nút phụ để xây dựngHCatWriter ở đó. |
| 2 | Public abstract void write(Iterator<HCatRecord> recordItr) throws HCaException Phương thức này nên được sử dụng tại các nút nô lệ để thực hiện ghi. RecordItr là một đối tượng vòng lặp có chứa tập hợp các bản ghi được ghi vào HCatalog. |
| 3 | Public abstract void abort(WriterContext cntxt) throws HCatException Phương thức này nên được gọi tại nút chính. Mục đích chính của phương pháp này là dọn dẹp trong trường hợp hỏng hóc. |
| 4 | public abstract void commit(WriterContext cntxt) throws HCatException Phương thức này nên được gọi tại nút chính. Mục đích của phương pháp này là thực hiện cam kết siêu dữ liệu. |
Tương tự như đọc, ghi cũng là một quá trình gồm hai bước, trong đó bước đầu tiên xảy ra trên nút chính. Sau đó, bước thứ hai xảy ra song song trên các nút phụ.
Viết được thực hiện trên một WriteEntity có thể được xây dựng theo cách tương tự như đọc -
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withDatabase("mydb").withTable("mytbl").build();Đoạn mã trên tạo một đối tượng WriteEntity entitycó thể được sử dụng để ghi vào một bảng có tênmytbl trong cơ sở dữ liệu mydb.
Sau khi tạo WriteEntity, bước tiếp theo là lấy WriterContext -
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();Tất cả các bước trên đều xảy ra trên nút chính. Sau đó, nút chính sẽ tuần tự hóa đối tượng WriterContext và cung cấp nó cho tất cả các nô lệ.
Trên các nút nô lệ, bạn cần lấy một HCatWriter bằng WriterContext như sau:
HCatWriter writer = DataTransferFactory.getHCatWriter(context);Sau đó, writerlấy một trình lặp làm đối số cho writephương thức -
writer.write(hCatRecordItr);Các writer sau đó gọi getNext() trên trình lặp này trong một vòng lặp và ghi ra tất cả các bản ghi được đính kèm với trình lặp.
Các TestReaderWriter.javatệp được sử dụng để kiểm tra các lớp HCatreader và HCatWriter. Chương trình sau đây trình bày cách sử dụng HCatReader và HCatWriter API để đọc dữ liệu từ một tệp nguồn và sau đó ghi nó vào một tệp đích.
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.metastore.api.MetaException;
import org.apache.hadoop.hive.ql.CommandNeedRetryException;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hive.HCatalog.common.HCatException;
import org.apache.hive.HCatalog.data.transfer.DataTransferFactory;
import org.apache.hive.HCatalog.data.transfer.HCatReader;
import org.apache.hive.HCatalog.data.transfer.HCatWriter;
import org.apache.hive.HCatalog.data.transfer.ReadEntity;
import org.apache.hive.HCatalog.data.transfer.ReaderContext;
import org.apache.hive.HCatalog.data.transfer.WriteEntity;
import org.apache.hive.HCatalog.data.transfer.WriterContext;
import org.apache.hive.HCatalog.mapreduce.HCatBaseTest;
import org.junit.Assert;
import org.junit.Test;
public class TestReaderWriter extends HCatBaseTest {
@Test
public void test() throws MetaException, CommandNeedRetryException,
IOException, ClassNotFoundException {
driver.run("drop table mytbl");
driver.run("create table mytbl (a string, b int)");
Iterator<Entry<String, String>> itr = hiveConf.iterator();
Map<String, String> map = new HashMap<String, String>();
while (itr.hasNext()) {
Entry<String, String> kv = itr.next();
map.put(kv.getKey(), kv.getValue());
}
WriterContext cntxt = runsInMaster(map);
File writeCntxtFile = File.createTempFile("hcat-write", "temp");
writeCntxtFile.deleteOnExit();
// Serialize context.
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(writeCntxtFile));
oos.writeObject(cntxt);
oos.flush();
oos.close();
// Now, deserialize it.
ObjectInputStream ois = new ObjectInputStream(new FileInputStream(writeCntxtFile));
cntxt = (WriterContext) ois.readObject();
ois.close();
runsInSlave(cntxt);
commit(map, true, cntxt);
ReaderContext readCntxt = runsInMaster(map, false);
File readCntxtFile = File.createTempFile("hcat-read", "temp");
readCntxtFile.deleteOnExit();
oos = new ObjectOutputStream(new FileOutputStream(readCntxtFile));
oos.writeObject(readCntxt);
oos.flush();
oos.close();
ois = new ObjectInputStream(new FileInputStream(readCntxtFile));
readCntxt = (ReaderContext) ois.readObject();
ois.close();
for (int i = 0; i < readCntxt.numSplits(); i++) {
runsInSlave(readCntxt, i);
}
}
private WriterContext runsInMaster(Map<String, String> config) throws HCatException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
WriterContext info = writer.prepareWrite();
return info;
}
private ReaderContext runsInMaster(Map<String, String> config,
boolean bogus) throws HCatException {
ReadEntity entity = new ReadEntity.Builder().withTable("mytbl").build();
HCatReader reader = DataTransferFactory.getHCatReader(entity, config);
ReaderContext cntxt = reader.prepareRead();
return cntxt;
}
private void runsInSlave(ReaderContext cntxt, int slaveNum) throws HCatException {
HCatReader reader = DataTransferFactory.getHCatReader(cntxt, slaveNum);
Iterator<HCatRecord> itr = reader.read();
int i = 1;
while (itr.hasNext()) {
HCatRecord read = itr.next();
HCatRecord written = getRecord(i++);
// Argh, HCatRecord doesnt implement equals()
Assert.assertTrue("Read: " + read.get(0) + "Written: " + written.get(0),
written.get(0).equals(read.get(0)));
Assert.assertTrue("Read: " + read.get(1) + "Written: " + written.get(1),
written.get(1).equals(read.get(1)));
Assert.assertEquals(2, read.size());
}
//Assert.assertFalse(itr.hasNext());
}
private void runsInSlave(WriterContext context) throws HCatException {
HCatWriter writer = DataTransferFactory.getHCatWriter(context);
writer.write(new HCatRecordItr());
}
private void commit(Map<String, String> config, boolean status,
WriterContext context) throws IOException {
WriteEntity.Builder builder = new WriteEntity.Builder();
WriteEntity entity = builder.withTable("mytbl").build();
HCatWriter writer = DataTransferFactory.getHCatWriter(entity, config);
if (status) {
writer.commit(context);
} else {
writer.abort(context);
}
}
private static HCatRecord getRecord(int i) {
List<Object> list = new ArrayList<Object>(2);
list.add("Row #: " + i);
list.add(i);
return new DefaultHCatRecord(list);
}
private static class HCatRecordItr implements Iterator<HCatRecord> {
int i = 0;
@Override
public boolean hasNext() {
return i++ < 100 ? true : false;
}
@Override
public HCatRecord next() {
return getRecord(i);
}
@Override
public void remove() {
throw new RuntimeException();
}
}
}Chương trình trên đọc dữ liệu từ HDFS dưới dạng bản ghi và ghi dữ liệu bản ghi vào mytable
Các HCatInputFormat và HCatOutputFormatgiao diện được sử dụng để đọc dữ liệu từ HDFS và sau khi xử lý, ghi dữ liệu kết quả vào HDFS bằng công việc MapReduce. Hãy để chúng tôi xây dựng các giao diện định dạng Đầu vào và Đầu ra.
HCatInputFormat
Các HCatInputFormatđược sử dụng với các công việc MapReduce để đọc dữ liệu từ các bảng do HCatalog quản lý. HCatInputFormat hiển thị một API MapReduce Hadoop 0.20 để đọc dữ liệu như thể nó đã được xuất bản lên một bảng.
| Sr.No. | Tên & Mô tả phương pháp |
|---|---|
| 1 | public static HCatInputFormat setInput(Job job, String dbName, String tableName)throws IOException Đặt đầu vào để sử dụng cho công việc. Nó truy vấn siêu thị với đặc điểm kỹ thuật đầu vào đã cho và tuần tự hóa các phân vùng phù hợp thành cấu hình công việc cho các tác vụ MapReduce. |
| 2 | public static HCatInputFormat setInput(Configuration conf, String dbName, String tableName) throws IOException Đặt đầu vào để sử dụng cho công việc. Nó truy vấn siêu thị với đặc điểm kỹ thuật đầu vào đã cho và tuần tự hóa các phân vùng phù hợp thành cấu hình công việc cho các tác vụ MapReduce. |
| 3 | public HCatInputFormat setFilter(String filter)throws IOException Đặt bộ lọc trên bảng đầu vào. |
| 4 | public HCatInputFormat setProperties(Properties properties) throws IOException Đặt thuộc tính cho định dạng đầu vào. |
API HCatInputFormat bao gồm các phương thức sau:
- setInput
- setOutputSchema
- getTableSchema
Để sử dụng HCatInputFormat để đọc dữ liệu, trước tiên hãy khởi tạo một InputJobInfo với thông tin cần thiết từ bảng được đọc và sau đó gọi setInput với InputJobInfo.
Bạn có thể dùng setOutputSchema phương pháp bao gồm một projection schema, để chỉ định các trường đầu ra. Nếu một lược đồ không được chỉ định, tất cả các cột trong bảng sẽ được trả về. Bạn có thể sử dụng phương thức getTableSchema để xác định lược đồ bảng cho một bảng đầu vào được chỉ định.
HCatOutputFormat
HCatOutputFormat được sử dụng với các công việc MapReduce để ghi dữ liệu vào các bảng do HCatalog quản lý. HCatOutputFormat đưa ra một API MapReduce Hadoop 0.20 để ghi dữ liệu vào bảng. Khi một công việc MapReduce sử dụng HCatOutputFormat để ghi đầu ra, OutputFormat mặc định được cấu hình cho bảng sẽ được sử dụng và phân vùng mới được xuất bản lên bảng sau khi công việc hoàn thành.
| Sr.No. | Tên & Mô tả phương pháp |
|---|---|
| 1 | public static void setOutput (Configuration conf, Credentials credentials, OutputJobInfo outputJobInfo) throws IOException Đặt thông tin về đầu ra để ghi cho công việc. Nó truy vấn máy chủ siêu dữ liệu để tìm StorageHandler để sử dụng cho bảng. Nó gây ra lỗi nếu phân vùng đã được xuất bản. |
| 2 | public static void setSchema (Configuration conf, HCatSchema schema) throws IOException Đặt lược đồ cho dữ liệu đang được ghi vào phân vùng. Lược đồ bảng được sử dụng theo mặc định cho phân vùng nếu nó không được gọi. |
| 3 | public RecordWriter <WritableComparable<?>, HCatRecord > getRecordWriter (TaskAttemptContext context)throws IOException, InterruptedException Nhận người viết hồ sơ cho công việc. Nó sử dụng OutputFormat mặc định của StorageHandler để lấy trình ghi bản ghi. |
| 4 | public OutputCommitter getOutputCommitter (TaskAttemptContext context) throws IOException, InterruptedException Nhận trình cam kết đầu ra cho định dạng đầu ra này. Nó đảm bảo rằng đầu ra được cam kết chính xác. |
Các HCatOutputFormat API bao gồm các phương thức sau:
- setOutput
- setSchema
- getTableSchema
Cuộc gọi đầu tiên trên HCatOutputFormat phải là setOutput; bất kỳ lệnh gọi nào khác sẽ ném ra một ngoại lệ nói rằng định dạng đầu ra không được khởi tạo.
Lược đồ cho dữ liệu đang được ghi ra được chỉ định bởi setSchemaphương pháp. Bạn phải gọi phương thức này, cung cấp lược đồ dữ liệu bạn đang viết. Nếu dữ liệu của bạn có cùng một giản đồ với giản đồ bảng, bạn có thể sử dụngHCatOutputFormat.getTableSchema() để lấy giản đồ bảng và sau đó chuyển nó cùng với setSchema().
Thí dụ
Chương trình MapReduce sau đây đọc dữ liệu từ một bảng mà nó giả định có một số nguyên trong cột thứ hai ("cột 1") và đếm có bao nhiêu trường hợp của mỗi giá trị riêng biệt mà nó tìm thấy. Nghĩa là, nó tương đương với "select col1, count(*) from $table group by col1;".
Ví dụ: nếu các giá trị trong cột thứ hai là {1, 1, 1, 3, 3, 5}, thì chương trình sẽ tạo ra kết quả sau của các giá trị và số đếm:
1, 3
3, 2
5, 1Bây giờ chúng ta hãy xem mã chương trình -
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import org.apache.HCatalog.common.HCatConstants;
import org.apache.HCatalog.data.DefaultHCatRecord;
import org.apache.HCatalog.data.HCatRecord;
import org.apache.HCatalog.data.schema.HCatSchema;
import org.apache.HCatalog.mapreduce.HCatInputFormat;
import org.apache.HCatalog.mapreduce.HCatOutputFormat;
import org.apache.HCatalog.mapreduce.InputJobInfo;
import org.apache.HCatalog.mapreduce.OutputJobInfo;
public class GroupByAge extends Configured implements Tool {
public static class Map extends Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable> {
int age;
@Override
protected void map(
WritableComparable key, HCatRecord value,
org.apache.hadoop.mapreduce.Mapper<WritableComparable,
HCatRecord, IntWritable, IntWritable>.Context context
)throws IOException, InterruptedException {
age = (Integer) value.get(1);
context.write(new IntWritable(age), new IntWritable(1));
}
}
public static class Reduce extends Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord> {
@Override
protected void reduce(
IntWritable key, java.lang.Iterable<IntWritable> values,
org.apache.hadoop.mapreduce.Reducer<IntWritable, IntWritable,
WritableComparable, HCatRecord>.Context context
)throws IOException ,InterruptedException {
int sum = 0;
Iterator<IntWritable> iter = values.iterator();
while (iter.hasNext()) {
sum++;
iter.next();
}
HCatRecord record = new DefaultHCatRecord(2);
record.set(0, key.get());
record.set(1, sum);
context.write(null, record);
}
}
public int run(String[] args) throws Exception {
Configuration conf = getConf();
args = new GenericOptionsParser(conf, args).getRemainingArgs();
String serverUri = args[0];
String inputTableName = args[1];
String outputTableName = args[2];
String dbName = null;
String principalID = System
.getProperty(HCatConstants.HCAT_METASTORE_PRINCIPAL);
if (principalID != null)
conf.set(HCatConstants.HCAT_METASTORE_PRINCIPAL, principalID);
Job job = new Job(conf, "GroupByAge");
HCatInputFormat.setInput(job, InputJobInfo.create(dbName, inputTableName, null));
// initialize HCatOutputFormat
job.setInputFormatClass(HCatInputFormat.class);
job.setJarByClass(GroupByAge.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(WritableComparable.class);
job.setOutputValueClass(DefaultHCatRecord.class);
HCatOutputFormat.setOutput(job, OutputJobInfo.create(dbName, outputTableName, null));
HCatSchema s = HCatOutputFormat.getTableSchema(job);
System.err.println("INFO: output schema explicitly set for writing:" + s);
HCatOutputFormat.setSchema(job, s);
job.setOutputFormatClass(HCatOutputFormat.class);
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new GroupByAge(), args);
System.exit(exitCode);
}
}Trước khi biên dịch chương trình trên, bạn phải tải xuống một số jars và thêm chúng vào classpathcho ứng dụng này. Bạn cần tải xuống tất cả các lọ Hive và lọ HCatalog (HCatalog-core-0.5.0.jar, hive-di căn-0.10.0.jar, libthrift-0.7.0.jar, hive-executive-0.10.0.jar, libfb303-0.7.0.jar, jdo2-api-2.3-ec.jar, slf4j-api-1.6.1.jar).
Sử dụng các lệnh sau để sao chép những jar tập tin từ local đến HDFS và thêm chúng vào classpath.
bin/hadoop fs -copyFromLocal $HCAT_HOME/share/HCatalog/HCatalog-core-0.5.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-metastore-0.10.0.jar /tmp
bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libthrift-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/hive-exec-0.10.0.jar /tmp
bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/libfb303-0.7.0.jar /tmp bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/jdo2-api-2.3-ec.jar /tmp
bin/hadoop fs -copyFromLocal $HIVE_HOME/lib/slf4j-api-1.6.1.jar /tmp
export LIB_JARS=hdfs:///tmp/HCatalog-core-0.5.0.jar,
hdfs:///tmp/hive-metastore-0.10.0.jar,
hdfs:///tmp/libthrift-0.7.0.jar,
hdfs:///tmp/hive-exec-0.10.0.jar,
hdfs:///tmp/libfb303-0.7.0.jar,
hdfs:///tmp/jdo2-api-2.3-ec.jar,
hdfs:///tmp/slf4j-api-1.6.1.jarSử dụng lệnh sau để biên dịch và thực thi chương trình đã cho.
$HADOOP_HOME/bin/hadoop jar GroupByAge tmp/hiveBây giờ, hãy kiểm tra thư mục đầu ra của bạn (hdfs: user / tmp / hive) cho đầu ra (part_0000, part_0001).
Các HCatLoader và HCatStorerAPI được sử dụng với tập lệnh Pig để đọc và ghi dữ liệu trong các bảng do HCatalog quản lý. Không cần thiết lập HCatalog dành riêng cho các giao diện này.
Tốt hơn là bạn nên có một số kiến thức về tập lệnh Apache Pig để hiểu chương này tốt hơn. Để tham khảo thêm, vui lòng xem qua hướng dẫn Apache Pig của chúng tôi .
HCatloader
HCatLoader được sử dụng với các tập lệnh Pig để đọc dữ liệu từ các bảng do HCatalog quản lý. Sử dụng cú pháp sau để tải dữ liệu vào HDFS bằng HCatloader.
A = LOAD 'tablename' USING org.apache.HCatalog.pig.HCatLoader();Bạn phải chỉ định tên bảng trong dấu nháy đơn: LOAD 'tablename'. Nếu bạn đang sử dụng cơ sở dữ liệu không phải mặc định, thì bạn phải chỉ định đầu vào của mình là 'dbname.tablename'.
Hive di căn cho phép bạn tạo bảng mà không cần chỉ định cơ sở dữ liệu. Nếu bạn đã tạo bảng theo cách này, thì tên cơ sở dữ liệu là'default' và không bắt buộc khi chỉ định bảng cho HCatLoader.
Bảng sau đây chứa các phương thức quan trọng và mô tả của lớp HCatloader.
| Sr.No. | Tên & Mô tả phương pháp |
|---|---|
| 1 | public InputFormat<?,?> getInputFormat()throws IOException Đọc định dạng đầu vào của dữ liệu tải bằng lớp HCatloader. |
| 2 | public String relativeToAbsolutePath(String location, Path curDir) throws IOException Nó trả về định dạng Chuỗi của Absolute path. |
| 3 | public void setLocation(String location, Job job) throws IOException Nó thiết lập vị trí nơi công việc có thể được thực hiện. |
| 4 | public Tuple getNext() throws IOException Trả về tuple hiện tại (key và value) từ vòng lặp. |
HCatStorer
HCatStorer được sử dụng với các tập lệnh Pig để ghi dữ liệu vào các bảng do HCatalog quản lý. Sử dụng cú pháp sau cho hoạt động Lưu trữ.
A = LOAD ...
B = FOREACH A ...
...
...
my_processed_data = ...
STORE my_processed_data INTO 'tablename' USING org.apache.HCatalog.pig.HCatStorer();Bạn phải chỉ định tên bảng trong dấu nháy đơn: LOAD 'tablename'. Cả cơ sở dữ liệu và bảng phải được tạo trước khi chạy tập lệnh Pig của bạn. Nếu bạn đang sử dụng cơ sở dữ liệu không phải mặc định, thì bạn phải chỉ định đầu vào của mình là'dbname.tablename'.
Hive di căn cho phép bạn tạo bảng mà không cần chỉ định cơ sở dữ liệu. Nếu bạn đã tạo bảng theo cách này, thì tên cơ sở dữ liệu là'default' và bạn không cần chỉ định tên cơ sở dữ liệu trong store tuyên bố.
Cho USING, bạn có thể có một đối số chuỗi đại diện cho các cặp khóa / giá trị cho các phân vùng. Đây là đối số bắt buộc khi bạn đang ghi vào bảng được phân vùng và cột phân vùng không có trong cột đầu ra. Các giá trị cho khóa phân vùng KHÔNG được trích dẫn.
Bảng sau đây chứa các phương thức quan trọng và mô tả của lớp HCatStorer.
| Sr.No. | Tên & Mô tả phương pháp |
|---|---|
| 1 | public OutputFormat getOutputFormat() throws IOException Đọc định dạng đầu ra của dữ liệu được lưu trữ bằng cách sử dụng lớp HCatStorer. |
| 2 | public void setStoreLocation (String location, Job job) throws IOException Đặt vị trí để thực hiện điều này store ứng dụng. |
| 3 | public void storeSchema (ResourceSchema schema, String arg1, Job job) throws IOException Lưu trữ lược đồ. |
| 4 | public void prepareToWrite (RecordWriter writer) throws IOException Nó giúp ghi dữ liệu vào một tệp cụ thể bằng RecordWriter. |
| 5 | public void putNext (Tuple tuple) throws IOException Ghi dữ liệu tuple vào tệp. |
Running Pig với HCatalog
Heo không tự động nhặt lọ HCatalog. Để mang các lọ cần thiết vào, bạn có thể sử dụng cờ trong lệnh Pig hoặc đặt các biến môi trườngPIG_CLASSPATH và PIG_OPTS như mô tả dưới đây.
Để mang theo các lọ thích hợp để làm việc với HCatalog, chỉ cần bao gồm cờ sau:
pig –useHCatalog <Sample pig scripts file>Đặt CLASSPATH để thực thi
Sử dụng cài đặt CLASSPATH sau để đồng bộ hóa HCatalog với Apache Pig.
export HADOOP_HOME = <path_to_hadoop_install>
export HIVE_HOME = <path_to_hive_install>
export HCAT_HOME = <path_to_hcat_install>
export PIG_CLASSPATH = $HCAT_HOME/share/HCatalog/HCatalog-core*.jar:\ $HCAT_HOME/share/HCatalog/HCatalog-pig-adapter*.jar:\
$HIVE_HOME/lib/hive-metastore-*.jar:$HIVE_HOME/lib/libthrift-*.jar:\
$HIVE_HOME/lib/hive-exec-*.jar:$HIVE_HOME/lib/libfb303-*.jar:\
$HIVE_HOME/lib/jdo2-api-*-ec.jar:$HIVE_HOME/conf:$HADOOP_HOME/conf:\ $HIVE_HOME/lib/slf4j-api-*.jarThí dụ
Giả sử chúng tôi có một tệp student_details.txt trong HDFS với nội dung sau.
student_details.txt
001, Rajiv, Reddy, 21, 9848022337, Hyderabad
002, siddarth, Battacharya, 22, 9848022338, Kolkata
003, Rajesh, Khanna, 22, 9848022339, Delhi
004, Preethi, Agarwal, 21, 9848022330, Pune
005, Trupthi, Mohanthy, 23, 9848022336, Bhuwaneshwar
006, Archana, Mishra, 23, 9848022335, Chennai
007, Komal, Nayak, 24, 9848022334, trivendram
008, Bharathi, Nambiayar, 24, 9848022333, ChennaiChúng tôi cũng có một kịch bản mẫu với tên sample_script.pig, trong cùng một thư mục HDFS. Tệp này chứa các câu lệnh thực hiện các phép toán và phép biến đổi trênstudent quan hệ, như được hiển thị bên dưới.
student = LOAD 'hdfs://localhost:9000/pig_data/student_details.txt' USING
PigStorage(',') as (id:int, firstname:chararray, lastname:chararray,
phone:chararray, city:chararray);
student_order = ORDER student BY age DESC;
STORE student_order INTO 'student_order_table' USING org.apache.HCatalog.pig.HCatStorer();
student_limit = LIMIT student_order 4;
Dump student_limit;Câu lệnh đầu tiên của tập lệnh sẽ tải dữ liệu trong tệp có tên student_details.txt như một mối quan hệ có tên student.
Câu lệnh thứ hai của tập lệnh sẽ sắp xếp các bộ giá trị của mối quan hệ theo thứ tự giảm dần, dựa trên độ tuổi và lưu trữ nó dưới dạng student_order.
Câu lệnh thứ ba lưu trữ dữ liệu đã xử lý student_order kết quả trong một bảng riêng biệt có tên student_order_table.
Câu lệnh thứ tư của script sẽ lưu trữ bốn bộ giá trị đầu tiên của student_order như student_limit.
Cuối cùng câu lệnh thứ năm sẽ kết xuất nội dung của mối quan hệ student_limit.
Bây giờ hãy để chúng tôi thực hiện sample_script.pig như hình bên dưới.
$./pig -useHCatalog hdfs://localhost:9000/pig_data/sample_script.pigBây giờ, hãy kiểm tra thư mục đầu ra của bạn (hdfs: user / tmp / hive) cho đầu ra (part_0000, part_0001).