Kiến trúc KDB +
Kdb + là một cơ sở dữ liệu khối lượng lớn, hiệu suất cao được thiết kế ngay từ đầu để xử lý khối lượng dữ liệu khổng lồ. Nó hoàn toàn là 64-bit và được tích hợp xử lý đa lõi và đa luồng. Kiến trúc tương tự được sử dụng cho dữ liệu lịch sử và thời gian thực. Cơ sở dữ liệu kết hợp ngôn ngữ truy vấn mạnh mẽ của riêng nó,q, để phân tích có thể được chạy trực tiếp trên dữ liệu.
kdb+tick là một kiến trúc cho phép thu thập, xử lý và truy vấn dữ liệu lịch sử và thời gian thực.
Kiến trúc Kdb + / tick
Hình minh họa sau đây cung cấp một phác thảo tổng quát về kiến trúc Kdb + / tick điển hình, tiếp theo là phần giải thích ngắn gọn về các thành phần khác nhau và luồng dữ liệu xuyên suốt.
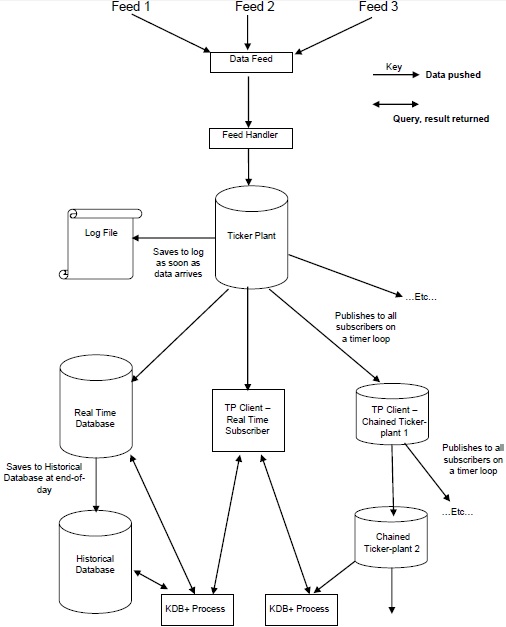
Các Data Feeds là dữ liệu chuỗi thời gian hầu hết được cung cấp bởi các nhà cung cấp nguồn cấp dữ liệu như Reuters, Bloomberg hoặc trực tiếp từ các sàn giao dịch.
Để lấy dữ liệu có liên quan, dữ liệu từ nguồn cấp dữ liệu được phân tích cú pháp feed handler.
Khi dữ liệu được phân tích cú pháp bởi trình xử lý nguồn cấp dữ liệu, nó sẽ chuyển đến ticker-plant.
Để khôi phục dữ liệu sau bất kỳ lỗi nào, đầu tiên nhà máy đánh dấu cập nhật / lưu trữ dữ liệu mới vào tệp nhật ký và sau đó cập nhật các bảng của chính nó.
Sau khi cập nhật các bảng nội bộ và tệp nhật ký, dữ liệu vòng lặp đúng thời gian liên tục được gửi / xuất bản tới cơ sở dữ liệu thời gian thực và tất cả những người đăng ký theo chuỗi đã yêu cầu dữ liệu.
Vào cuối ngày làm việc, tệp nhật ký sẽ bị xóa, tệp mới được tạo và cơ sở dữ liệu thời gian thực được lưu vào cơ sở dữ liệu lịch sử. Khi tất cả dữ liệu được lưu vào cơ sở dữ liệu lịch sử, cơ sở dữ liệu thời gian thực sẽ xóa các bảng của nó.
Các thành phần của Kdb + Tick Architecture
Nguồn cấp dữ liệu
Nguồn cấp dữ liệu có thể là bất kỳ thị trường hoặc dữ liệu chuỗi thời gian nào khác. Hãy coi nguồn cấp dữ liệu là đầu vào thô cho trình xử lý nguồn cấp dữ liệu. Nguồn cấp dữ liệu có thể trực tiếp từ sàn giao dịch (dữ liệu phát trực tuyến), từ các nhà cung cấp tin tức / dữ liệu như Thomson-Reuters, Bloomberg hoặc bất kỳ cơ quan bên ngoài nào khác.
Trình xử lý nguồn cấp dữ liệu
Trình xử lý nguồn cấp dữ liệu chuyển đổi luồng dữ liệu thành định dạng phù hợp để ghi vào kdb +. Nó được kết nối với nguồn cấp dữ liệu và nó truy xuất và chuyển đổi dữ liệu từ định dạng dành riêng cho nguồn cấp dữ liệu thành một thông báo Kdb + được xuất bản tới quy trình ticker-plant. Nói chung, một trình xử lý nguồn cấp dữ liệu được sử dụng để thực hiện các hoạt động sau:
- Thu thập dữ liệu theo một bộ quy tắc.
- Dịch (/ làm giàu) dữ liệu đó từ định dạng này sang định dạng khác.
- Nắm bắt các giá trị gần đây nhất.
Cây mã đề
Ticker Plant là thành phần quan trọng nhất của kiến trúc KDB +. Đây là nhà máy mã mà cơ sở dữ liệu thời gian thực hoặc trực tiếp người đăng ký (khách hàng) được kết nối để truy cập dữ liệu tài chính. Nó hoạt động trongpublish and subscribecơ chế. Khi bạn nhận được đăng ký (giấy phép), một ấn phẩm đánh dấu (thường xuyên) từ nhà xuất bản (nhà máy đánh dấu) sẽ được xác định. Nó thực hiện các hoạt động sau:
Nhận dữ liệu từ trình xử lý nguồn cấp dữ liệu.
Ngay sau khi nhà máy mã nhận được dữ liệu, nó sẽ lưu trữ một bản sao dưới dạng tệp nhật ký và cập nhật nó khi nhà máy mã nhận được bất kỳ bản cập nhật nào để trong trường hợp xảy ra lỗi, chúng tôi sẽ không bị mất dữ liệu.
Khách hàng (người đăng ký theo thời gian thực) có thể đăng ký trực tiếp vào nhà máy mã cổ phiếu.
Vào cuối mỗi ngày làm việc, tức là khi cơ sở dữ liệu thời gian thực nhận được tin nhắn cuối cùng, nó sẽ lưu trữ tất cả dữ liệu của ngày hôm nay vào cơ sở dữ liệu lịch sử và đẩy dữ liệu tương tự đến tất cả những người đăng ký đã đăng ký dữ liệu của ngày hôm nay. Sau đó, nó đặt lại tất cả các bảng của nó. Tệp nhật ký cũng bị xóa sau khi dữ liệu được lưu trữ trong cơ sở dữ liệu lịch sử hoặc người đăng ký được liên kết trực tiếp khác với cơ sở dữ liệu thời gian thực (rtdb).
Do đó, nhà máy đánh dấu, cơ sở dữ liệu thời gian thực và cơ sở dữ liệu lịch sử hoạt động 24/7.
Vì ticker-plant là một ứng dụng Kdb +, các bảng của nó có thể được truy vấn bằng cách sử dụng qgiống như bất kỳ cơ sở dữ liệu Kdb + nào khác. Tất cả các khách hàng của ticker-plant chỉ nên có quyền truy cập vào cơ sở dữ liệu với tư cách là người đăng ký.
Cơ sở dữ liệu thời gian thực
Cơ sở dữ liệu thời gian thực (rdb) lưu trữ dữ liệu ngày nay. Nó được kết nối trực tiếp với nhà máy mã. Thông thường, nó sẽ được lưu trữ trong bộ nhớ trong giờ thị trường (một ngày) và được ghi vào cơ sở dữ liệu lịch sử (hdb) vào cuối ngày. Vì dữ liệu (dữ liệu rdb) được lưu trữ trong bộ nhớ, quá trình xử lý diễn ra cực kỳ nhanh chóng.
Vì kdb + khuyến nghị nên có kích thước RAM gấp bốn lần kích thước dữ liệu dự kiến mỗi ngày trở lên, truy vấn chạy trên rdb rất nhanh và cung cấp hiệu suất vượt trội. Vì cơ sở dữ liệu thời gian thực chỉ chứa dữ liệu của ngày hôm nay, nên cột ngày (tham số) là không bắt buộc.
Ví dụ: chúng ta có thể có các truy vấn rdb như,
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100Cơ sở dữ liệu lịch sử
Nếu chúng ta phải tính toán các ước tính của một công ty, chúng ta cần có sẵn dữ liệu lịch sử của nó. Cơ sở dữ liệu lịch sử (hdb) lưu giữ dữ liệu của các giao dịch đã thực hiện trong quá khứ. Bản ghi của mỗi ngày mới sẽ được thêm vào hdb vào cuối ngày. Các bảng lớn trong hdb hoặc được lưu trữ theo từng lớp (mỗi cột được lưu trữ trong tệp riêng của nó) hoặc chúng được lưu trữ phân vùng theo dữ liệu tạm thời. Ngoài ra, một số cơ sở dữ liệu rất lớn có thể được phân vùng thêm bằng cách sử dụngpar.txt (tập tin).
Các chiến lược lưu trữ này (phân vùng, phân vùng, v.v.) hiệu quả khi tìm kiếm hoặc truy cập dữ liệu từ một bảng lớn.
Cơ sở dữ liệu lịch sử cũng có thể được sử dụng cho mục đích báo cáo nội bộ và bên ngoài, tức là để phân tích. Ví dụ: giả sử chúng ta muốn nhận các giao dịch của công ty IBM cho một ngày cụ thể từ tên bảng giao dịch (hoặc bất kỳ) nào, chúng ta cần viết một truy vấn như sau:
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - Chúng tôi sẽ viết tất cả các truy vấn như vậy khi chúng tôi có một số tổng quan về q ngôn ngữ.