KDB + - Hướng dẫn nhanh
Đây là một câu hỏi hoàn chỉnh để kdb+từ hệ thống kx, chủ yếu nhằm vào những người học độc lập. kdb +, được giới thiệu vào năm 2003, là thế hệ mới của cơ sở dữ liệu kdb được thiết kế để thu thập, phân tích, so sánh và lưu trữ dữ liệu.
Hệ thống kdb + chứa hai thành phần sau:
KDB+ - cơ sở dữ liệu (k cơ sở dữ liệu cộng)
Q - ngôn ngữ lập trình để làm việc với kdb +
Cả hai kdb+ và q được viết bằng k programming language (giống như q nhưng ít đọc hơn).
Lý lịch
Kdb + / q có nguồn gốc là một ngôn ngữ học thuật ít người biết đến nhưng qua nhiều năm, nó đã dần dần cải thiện tính thân thiện với người dùng.
APL (1964, Một ngôn ngữ lập trình)
A+ (1988, APL được sửa đổi bởi Arthur Whitney)
K (1993, phiên bản sắc nét của A +, do A. Whitney phát triển)
Kdb (1998, db dựa trên cột trong bộ nhớ)
Kdb+/q (2003, ngôn ngữ q - phiên bản dễ đọc hơn của k)
Tại sao và ở đâu sử dụng KDB +
Tại sao? - Nếu bạn cần một giải pháp duy nhất cho dữ liệu thời gian thực với phân tích, thì bạn nên xem xét kdb +. Kdb + lưu trữ cơ sở dữ liệu dưới dạng các tệp gốc thông thường, vì vậy nó không có bất kỳ nhu cầu đặc biệt nào về phần cứng và kiến trúc lưu trữ. Cần chỉ ra rằng cơ sở dữ liệu chỉ là một tập hợp các tệp, vì vậy công việc quản trị của bạn sẽ không gặp nhiều khó khăn.
Sử dụng KDB + ở đâu?- Thật dễ dàng để đếm xem ngân hàng đầu tư nào KHÔNG sử dụng kdb + vì hầu hết các ngân hàng này hiện đang sử dụng hoặc có kế hoạch chuyển từ cơ sở dữ liệu thông thường sang kdb +. Khi khối lượng dữ liệu đang tăng lên từng ngày, chúng ta cần một hệ thống có thể xử lý khối lượng dữ liệu khổng lồ. KDB + đáp ứng yêu cầu này. KDB + không chỉ lưu trữ một lượng lớn dữ liệu mà còn phân tích nó trong thời gian thực.
Bắt đầu
Với nhiều kiến thức nền tảng này, bây giờ chúng ta hãy bắt đầu và tìm hiểu cách thiết lập môi trường cho KDB +. Chúng ta sẽ bắt đầu với cách tải xuống và cài đặt KDB +.
Tải xuống và cài đặt KDB +
Bạn có thể tải phiên bản 32-bit KDB + miễn phí, với tất cả các chức năng của phiên bản 64-bit từ http://kx.com/software-download.php
Đồng ý với thỏa thuận cấp phép, chọn hệ điều hành (có sẵn cho tất cả các hệ điều hành chính). Đối với hệ điều hành Windows, phiên bản mới nhất là 3.2. Tải xuống phiên bản mới nhất. Sau khi giải nén, bạn sẽ nhận được tên thư mục“windows” và bên trong thư mục windows, bạn sẽ nhận được một thư mục khác “q”. Sao chép toàn bộq vào ổ đĩa c: / của bạn.
Mở thiết bị đầu cuối Run, nhập vị trí nơi bạn lưu trữ qthư mục; nó sẽ giống như “c: /q/w32/q.exe”. Sau khi nhấn Enter, bạn sẽ nhận được một bảng điều khiển mới như sau:
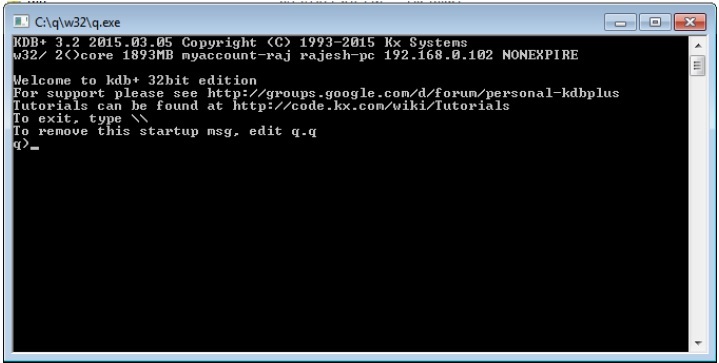
Trên dòng đầu tiên, bạn có thể thấy số phiên bản là 3.2 và ngày phát hành là 2015.03.05
Bố cục thư mục
Phiên bản dùng thử / miễn phí thường được cài đặt trong các thư mục,
For linux/Mac −
~/q / main q directory (under the user’s home)
~/q/l32 / location of linux 32-bit executable
~/q/m32 / Location of mac 32-bit executableFor Windows −
c:/q / Main q directory
c:/q/w32/ / Location of windows 32-bit executableExample Files −
Khi bạn tải xuống kdb +, cấu trúc thư mục trong nền tảng Windows sẽ xuất hiện như sau:
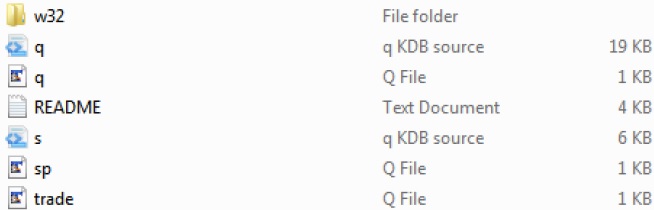
Trong cấu trúc thư mục trên, trade.q và sp.q là các tệp ví dụ mà chúng tôi có thể sử dụng làm điểm tham chiếu.
Kdb + là một cơ sở dữ liệu khối lượng lớn, hiệu suất cao được thiết kế ngay từ đầu để xử lý khối lượng dữ liệu khổng lồ. Nó hoàn toàn là 64-bit và được tích hợp xử lý đa lõi và đa luồng. Kiến trúc tương tự được sử dụng cho dữ liệu lịch sử và thời gian thực. Cơ sở dữ liệu kết hợp ngôn ngữ truy vấn mạnh mẽ của riêng nó,q, để phân tích có thể được chạy trực tiếp trên dữ liệu.
kdb+tick là một kiến trúc cho phép thu thập, xử lý và truy vấn dữ liệu lịch sử và thời gian thực.
Kiến trúc Kdb + / tick
Hình minh họa sau đây cung cấp một phác thảo tổng quát về kiến trúc Kdb + / tick điển hình, tiếp theo là phần giải thích ngắn gọn về các thành phần khác nhau và luồng dữ liệu xuyên suốt.
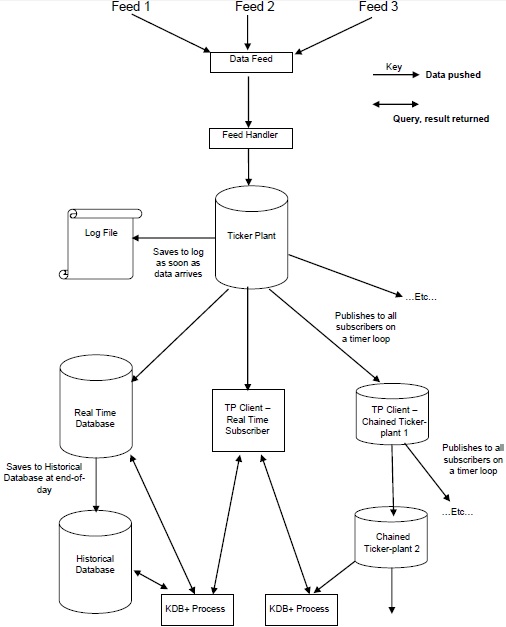
Các Data Feeds là dữ liệu chuỗi thời gian hầu hết được cung cấp bởi các nhà cung cấp nguồn cấp dữ liệu như Reuters, Bloomberg hoặc trực tiếp từ các sàn giao dịch.
Để lấy dữ liệu có liên quan, dữ liệu từ nguồn cấp dữ liệu được phân tích cú pháp feed handler.
Khi dữ liệu được phân tích cú pháp bởi trình xử lý nguồn cấp dữ liệu, nó sẽ chuyển đến ticker-plant.
Để khôi phục dữ liệu sau bất kỳ lỗi nào, đầu tiên nhà máy đánh dấu cập nhật / lưu trữ dữ liệu mới vào tệp nhật ký và sau đó cập nhật các bảng của chính nó.
Sau khi cập nhật các bảng nội bộ và tệp nhật ký, dữ liệu vòng lặp đúng thời gian liên tục được gửi / xuất bản tới cơ sở dữ liệu thời gian thực và tất cả những người đăng ký theo chuỗi đã yêu cầu dữ liệu.
Vào cuối ngày làm việc, tệp nhật ký sẽ bị xóa, tệp mới được tạo và cơ sở dữ liệu thời gian thực được lưu vào cơ sở dữ liệu lịch sử. Khi tất cả dữ liệu được lưu vào cơ sở dữ liệu lịch sử, cơ sở dữ liệu thời gian thực sẽ xóa các bảng của nó.
Các thành phần của Kdb + Tick Architecture
Nguồn cấp dữ liệu
Nguồn cấp dữ liệu có thể là bất kỳ thị trường hoặc dữ liệu chuỗi thời gian nào khác. Hãy coi nguồn cấp dữ liệu là đầu vào thô cho trình xử lý nguồn cấp dữ liệu. Nguồn cấp dữ liệu có thể trực tiếp từ sàn giao dịch (dữ liệu phát trực tuyến), từ các nhà cung cấp tin tức / dữ liệu như Thomson-Reuters, Bloomberg hoặc bất kỳ cơ quan bên ngoài nào khác.
Trình xử lý nguồn cấp dữ liệu
Trình xử lý nguồn cấp dữ liệu chuyển đổi luồng dữ liệu thành định dạng phù hợp để ghi vào kdb +. Nó được kết nối với nguồn cấp dữ liệu và nó truy xuất và chuyển đổi dữ liệu từ định dạng dành riêng cho nguồn cấp dữ liệu thành một thông báo Kdb + được xuất bản tới quy trình ticker-plant. Nói chung, một trình xử lý nguồn cấp dữ liệu được sử dụng để thực hiện các hoạt động sau:
- Thu thập dữ liệu theo một bộ quy tắc.
- Dịch (/ làm giàu) dữ liệu đó từ định dạng này sang định dạng khác.
- Nắm bắt các giá trị gần đây nhất.
Cây mã đề
Ticker Plant là thành phần quan trọng nhất của kiến trúc KDB +. Đây là nhà máy mã mà cơ sở dữ liệu thời gian thực hoặc trực tiếp người đăng ký (khách hàng) được kết nối để truy cập dữ liệu tài chính. Nó hoạt động trongpublish and subscribecơ chế. Khi bạn nhận được đăng ký (giấy phép), một ấn phẩm đánh dấu (thường xuyên) từ nhà xuất bản (nhà máy đánh dấu) sẽ được xác định. Nó thực hiện các hoạt động sau:
Nhận dữ liệu từ trình xử lý nguồn cấp dữ liệu.
Ngay sau khi nhà máy mã nhận được dữ liệu, nó sẽ lưu trữ một bản sao dưới dạng tệp nhật ký và cập nhật nó khi nhà máy mã nhận được bất kỳ bản cập nhật nào để trong trường hợp xảy ra lỗi, chúng tôi sẽ không bị mất dữ liệu.
Khách hàng (người đăng ký theo thời gian thực) có thể đăng ký trực tiếp vào nhà máy mã cổ phiếu.
Vào cuối mỗi ngày làm việc, tức là khi cơ sở dữ liệu thời gian thực nhận được tin nhắn cuối cùng, nó sẽ lưu trữ tất cả dữ liệu của ngày hôm nay vào cơ sở dữ liệu lịch sử và đẩy dữ liệu tương tự đến tất cả những người đăng ký đã đăng ký dữ liệu của ngày hôm nay. Sau đó, nó đặt lại tất cả các bảng của nó. Tệp nhật ký cũng bị xóa sau khi dữ liệu được lưu trữ trong cơ sở dữ liệu lịch sử hoặc người đăng ký được liên kết trực tiếp khác với cơ sở dữ liệu thời gian thực (rtdb).
Do đó, nhà máy đánh dấu, cơ sở dữ liệu thời gian thực và cơ sở dữ liệu lịch sử hoạt động 24/7.
Vì ticker-plant là một ứng dụng Kdb +, các bảng của nó có thể được truy vấn bằng cách sử dụng qgiống như bất kỳ cơ sở dữ liệu Kdb + nào khác. Tất cả các khách hàng của ticker-plant chỉ nên có quyền truy cập vào cơ sở dữ liệu với tư cách là người đăng ký.
Cơ sở dữ liệu thời gian thực
Cơ sở dữ liệu thời gian thực (rdb) lưu trữ dữ liệu ngày nay. Nó được kết nối trực tiếp với nhà máy mã. Thông thường, nó sẽ được lưu trữ trong bộ nhớ trong giờ thị trường (một ngày) và được ghi vào cơ sở dữ liệu lịch sử (hdb) vào cuối ngày. Vì dữ liệu (dữ liệu rdb) được lưu trữ trong bộ nhớ, quá trình xử lý diễn ra cực kỳ nhanh chóng.
Vì kdb + khuyến nghị nên có kích thước RAM gấp bốn lần kích thước dữ liệu dự kiến mỗi ngày trở lên, truy vấn chạy trên rdb rất nhanh và cung cấp hiệu suất vượt trội. Vì cơ sở dữ liệu thời gian thực chỉ chứa dữ liệu của ngày hôm nay, nên cột ngày (tham số) là không bắt buộc.
Ví dụ: chúng ta có thể có các truy vấn rdb như,
select from trade where sym = `ibm
OR
select from trade where sym = `ibm, price > 100Cơ sở dữ liệu lịch sử
Nếu chúng ta phải tính toán các ước tính của một công ty, chúng ta cần có sẵn dữ liệu lịch sử của nó. Cơ sở dữ liệu lịch sử (hdb) lưu giữ dữ liệu của các giao dịch đã thực hiện trong quá khứ. Bản ghi của mỗi ngày mới sẽ được thêm vào hdb vào cuối ngày. Các bảng lớn trong hdb hoặc được lưu trữ theo từng lớp (mỗi cột được lưu trữ trong tệp riêng của nó) hoặc chúng được lưu trữ phân vùng theo dữ liệu tạm thời. Ngoài ra, một số cơ sở dữ liệu rất lớn có thể được phân vùng thêm bằng cách sử dụngpar.txt (tập tin).
Các chiến lược lưu trữ này (phân vùng, phân vùng, v.v.) hiệu quả khi tìm kiếm hoặc truy cập dữ liệu từ một bảng lớn.
Cơ sở dữ liệu lịch sử cũng có thể được sử dụng cho mục đích báo cáo nội bộ và bên ngoài, tức là để phân tích. Ví dụ: giả sử chúng ta muốn nhận các giao dịch của công ty IBM cho một ngày cụ thể từ tên bảng giao dịch (hoặc bất kỳ) nào, chúng ta cần viết một truy vấn như sau:
thisday: 2014.10.12
select from trade where date = thisday, sym =`ibmNote - Chúng tôi sẽ viết tất cả các truy vấn như vậy khi chúng tôi có một số tổng quan về q ngôn ngữ.
Kdb + đi kèm với ngôn ngữ lập trình tích hợp được gọi là q. Nó kết hợp một tập hợp siêu SQL chuẩn được mở rộng để phân tích chuỗi thời gian và mang lại nhiều lợi thế hơn so với phiên bản chuẩn. Bất kỳ ai quen thuộc với SQL đều có thể họcq trong vài ngày và có thể nhanh chóng viết các truy vấn đặc biệt của riêng mình.
Khởi động Môi trường “q”
Để bắt đầu sử dụng kdb +, bạn cần bắt đầu qphiên họp. Có ba cách để bắt đầu mộtq phiên -
Chỉ cần gõ “c: /q/w32/q.exe” trên thiết bị đầu cuối đang chạy của bạn.
Khởi động đầu cuối lệnh MS-DOS và nhập q.
Sao chép q.exe tập tin vào “C: \ Windows \ System32” và trên cửa sổ chạy, chỉ cần nhập “q”.
Ở đây chúng tôi giả định rằng bạn đang làm việc trên nền tảng Windows.
Loại dữ liệu
Bảng sau cung cấp danh sách các kiểu dữ liệu được hỗ trợ:
| Tên | Thí dụ | Char | Kiểu | Kích thước |
|---|---|---|---|---|
| boolean | 1b | b | 1 | 1 |
| byte | 0xff | x | 4 | 1 |
| ngắn | 23h | h | 5 | 2 |
| int | 23i | Tôi | 6 | 4 |
| Dài | 23j | j | 7 | số 8 |
| thực tế | 2,3e | e | số 8 | 4 |
| Phao nổi | 2,3f | f | 9 | số 8 |
| char | "A" | c | 10 | 1 |
| varchar | `ab | S | 11 | * |
| tháng | 2003,03m | m | 13 | 4 |
| ngày | 2015.03.17T18: 01: 40.134 | z | 15 | số 8 |
| phút | 08:31 | u | 17 | 4 |
| thứ hai | 08:31:53 | v | 18 | 4 |
| thời gian | 18: 03: 18.521 | t | 19 | 4 |
| enum | `u $` b, trong đó u: `a`b | * | 20 | 4 |
Nguyên tử và hình thành danh sách
Nguyên tử là các thực thể đơn lẻ, ví dụ, một số, một ký tự hoặc một ký hiệu. Trong bảng trên (các kiểu dữ liệu khác nhau), tất cả các kiểu dữ liệu được hỗ trợ đều là nguyên tử. Danh sách là một chuỗi các nguyên tử hoặc các loại khác bao gồm danh sách.
Truyền một nguyên tử thuộc bất kỳ loại nào cho hàm loại đơn nguyên (tức là hàm đối số đơn) sẽ trả về giá trị âm, tức là –n, trong khi chuyển một danh sách đơn giản gồm các nguyên tử đó vào hàm type sẽ trả về giá trị dương n.
Ví dụ 1 - Dạng nguyên tử và danh sách
/ Note that the comments begin with a slash “ / ” and cause the parser
/ to ignore everything up to the end of the line.
x: `mohan / `mohan is a symbol, assigned to a variable x
type x / let’s check the type of x
-11h / -ve sign, because it’s single element.
y: (`abc;`bca;`cab) / list of three symbols, y is the variable name.
type y
11h / +ve sign, as it contain list of atoms (symbol).
y1: (`abc`bca`cab) / another way of writing y, please note NO semicolon
y2: (`$”symbols may have interior blanks”) / string to symbol conversion
y[0] / return `abc
y 0 / same as y[0], also returns `abc
y 0 2 / returns `abc`cab, same as does y[0 2]
z: (`abc; 10 20 30; (`a`b); 9.9 8.8 7.7) / List of different types,
z 2 0 / returns (`a`b; `abc),
z[2;0] / return `a. first element of z[2]
x: “Hello World!” / list of character, a string
x 4 0 / returns “oH” i.e. 4th and 0th(first)
elementThường phải thay đổi kiểu dữ liệu của một số dữ liệu từ kiểu này sang kiểu khác. Chức năng truyền tiêu chuẩn là “$”dyadic operator.
Ba cách tiếp cận được sử dụng để truyền từ kiểu này sang kiểu khác (ngoại trừ chuỗi) -
- Chỉ định kiểu dữ liệu mong muốn bằng tên ký hiệu của nó
- Chỉ định kiểu dữ liệu mong muốn theo ký tự của nó
- Chỉ định kiểu dữ liệu mong muốn bằng giá trị ngắn.
Truyền số nguyên sang số nổi
Trong ví dụ sau về ép kiểu số nguyên thành float, cả ba cách ép kiểu khác nhau đều tương đương:
q)a:9 18 27
q)$[`float;a] / Specify desired data type by its symbol name, 1st way
9 18 27f
q)$["f";a] / Specify desired data type by its character, 2nd way
9 18 27f
q)$[9h;a] / Specify desired data type by its short value, 3rd way
9 18 27fKiểm tra xem tất cả ba hoạt động có tương đương nhau không,
q)($[`float;a]~$["f";a]) and ($[`float;a] ~ $[9h;a])
1bTruyền chuỗi thành biểu tượng
Truyền chuỗi sang biểu tượng và ngược lại hoạt động hơi khác một chút. Hãy kiểm tra nó với một ví dụ -
q)b: ("Hello";"World";"HelloWorld") / define a list of strings
q)b
"Hello"
"World"
"HelloWorld"
q)c: `$b / this is how to cast strings to symbols
q)c / Now c is a list of symbols
`Hello`World`HelloWorldCố gắng truyền chuỗi tới các biểu tượng bằng cách sử dụng các từ được khóa `biểu tượng hoặc 11h sẽ không thành công với lỗi loại -
q)b
"Hello"
"World"
"HelloWorld"
q)`symbol$b
'type
q)11h$b
'typeTruyền chuỗi sang không ký hiệu
Truyền chuỗi sang một kiểu dữ liệu khác với ký hiệu được thực hiện như sau:
q)b:900 / b contain single atomic integer
q)c:string b / convert this integer atom to string “900”
q)c
"900"
q)`int $ c / converting string to integer will return the
/ ASCII equivalent of the character “9”, “0” and
/ “0” to produce the list of integer 57, 48 and
/ 48.
57 48 48i
q)6h $ c / Same as above 57 48 48i q)"i" $ c / Same a above
57 48 48i
q)"I" $ c
900iVì vậy, để truyền toàn bộ một chuỗi (danh sách các ký tự) đến một nguyên tử duy nhất của kiểu dữ liệu x yêu cầu chúng tôi chỉ định chữ hoa đại diện cho kiểu dữ liệu x là đối số đầu tiên cho $nhà điều hành. Nếu bạn chỉ định kiểu dữ liệu củax theo bất kỳ cách nào khác, nó dẫn đến việc ép kiểu được áp dụng cho mỗi ký tự của chuỗi.
Các q ngôn ngữ có nhiều cách khác nhau để biểu diễn và thao tác dữ liệu thời gian như thời gian và ngày tháng.
Ngày
Ngày trong kdb + được lưu trữ nội bộ dưới dạng số nguyên ngày kể từ ngày tham chiếu của chúng tôi là 01Jan2000. Ngày sau ngày này được lưu trữ nội bộ dưới dạng số dương và ngày trước đó được tham chiếu dưới dạng số âm.
Theo mặc định, ngày được viết ở định dạng “YYYY.MM.DD”
q)x:2015.01.22 / This is how we write 22nd Jan 2015
q)`int$x / Number of days since 2000.01.01 5500i q)`year$x / Extracting year from the date
2015i
q)x.year / Another way of extracting year
2015i
q)`mm$x / Extracting month from the date 1i q)x.mm / Another way of extracting month 1i q)`dd$x / Extracting day from the date
22i
q)x.dd / Another way of extracting day
22iArithmetic and logical operations có thể được thực hiện trực tiếp vào các ngày.
q)x+1 / Add one day
2015.01.23
q)x-7 / Subtract 7 days
2015.01.15Ngày 1 tháng 1 năm 2000 rơi vào một ngày thứ bảy. Do đó, bất kỳ ngày thứ Bảy nào trong suốt lịch sử hoặc trong tương lai khi chia cho 7, sẽ mang lại phần còn lại là 0, Chủ nhật cho kết quả là 1, Thứ hai cho kết quả là 2.
Day mod 7
Saturday 0
Sunday 1
Monday 2
Tuesday 3
Wednesday 4
Thursday 5
Friday 6Times
Thời gian được lưu trữ nội bộ dưới dạng số nguyên của mili giây kể từ khoảng thời gian nửa đêm. Thời gian được viết ở định dạng HH: MM: SS.MSS
q)tt1: 03:30:00.000 / tt1 store the time 03:30 AM
q)tt1
03:30:00.000
q)`int$tt1 / Number of milliseconds in 3.5 hours 12600000i q)`hh$tt1 / Extract the hour component from time
3i
q)tt1.hh
3i
q)`mm$tt1 / Extract the minute component from time 30i q)tt1.mm 30i q)`ss$tt1 / Extract the second component from time
0i
q)tt1.ss
0iNhư trong trường hợp ngày tháng, số học có thể được thực hiện trực tiếp vào thời gian.
Ngày giờ
Ngày giờ là sự kết hợp của ngày và giờ, được phân tách bằng chữ 'T' như ở định dạng tiêu chuẩn ISO. Giá trị ngày giờ lưu trữ số ngày phân số từ nửa đêm ngày 1 tháng 1 năm 2000.
q)dt:2012.12.20T04:54:59:000 / 04:54.59 AM on 20thDec2012
q)type dt
-15h
q)dt
2012.12.20T04:54:59.000
9
q)`float$dt
4737.205Số ngày phân số cơ bản có thể thu được bằng cách đúc để thả nổi.
Danh sách là nền tảng cơ bản của q language, vì vậy sự hiểu biết kỹ lưỡng về các danh sách là rất quan trọng. Danh sách chỉ đơn giản là một tập hợp có thứ tự các nguyên tử (nguyên tố nguyên tử) và các danh sách khác (nhóm một hoặc nhiều nguyên tử).
Các loại danh sách
A general listđặt các mục của nó trong dấu ngoặc đơn phù hợp và phân tách chúng bằng dấu chấm phẩy. Ví dụ -
(9;8;7) or ("a"; "b"; "c") or (-10.0; 3.1415e; `abcd; "r")Nếu một danh sách bao gồm các nguyên tử cùng loại, nó được gọi là uniform list. Khác, nó được biết đến như mộtgeneral list (loại hỗn hợp).
Đếm
Chúng ta có thể nhận được số lượng các mục trong một danh sách thông qua số lượng của nó.
q)l1:(-10.0;3.1415e;`abcd;"r") / Assigning variable name to general list
q)count l1 / Calculating number of items in the list l1
4Ví dụ về Danh sách đơn giản
q)h:(1h;2h;255h) / Simple Integer List
q)h
1 2 255h
q)f:(123.4567;9876.543;98.7) / Simple Floating Point List
q)f
123.4567 9876.543 98.7
q)b:(0b;1b;0b;1b;1b) / Simple Binary Lists
q)b
01011b
q)symbols:(`Life;`Is;`Beautiful) / Simple Symbols List
q)symbols
`Life`Is`Beautiful
q)chars:("h";"e";"l";"l";"o";" ";"w";"o";"r";"l";"d")
/ Simple char lists and Strings.
q)chars
"hello world"**Note − A simple list of char is called a string.
Một danh sách chứa các nguyên tử hoặc danh sách. To create a single item list, chúng tôi sử dụng -
q)singleton:enlist 42
q)singleton
,42To distinguish between an atom and the equivalent singleton, kiểm tra dấu hiệu của loại của họ.
q)signum type 42
-1i
q)signum type enlist 42
1iMột danh sách được sắp xếp từ trái sang phải theo vị trí của các mục trong đó. Phần bù của một mục từ đầu danh sách được gọi làindex. Như vậy, mục đầu tiên có chỉ số 0, mục thứ hai (nếu có) có chỉ số 1, v.v. Một danh sách đếmn có miền chỉ mục từ 0 đến n–1.
Bảng chỉ mục
Đưa ra một danh sách L, mục ở chỉ mục i được truy cập bởi L[i]. Lấy một mục theo chỉ mục của nó được gọi làitem indexing. Ví dụ,
q)L:(99;98.7e;`b;`abc;"z")
q)L[0]
99
q)L[1]
98.7e
q)L[4]
"zBài tập được lập chỉ mục
Các mục trong danh sách cũng có thể được chỉ định thông qua lập chỉ mục mục. Vì vậy,
q)L1:9 8 7
q)L1[2]:66 / Indexed assignment into a simple list
/ enforces strict type matching.
q)L1
9 8 66Danh sách từ các biến
q)l1:(9;8;40;200)
q)l2:(1 4 3; `abc`xyz)
q)l:(l1;l2) / combining the two list l1 and l2
q)l
9 8 40 200
(1 4 3;`abc`xyz)Tham gia danh sách
Thao tác phổ biến nhất trên hai danh sách là nối chúng lại với nhau để tạo thành một danh sách lớn hơn. Chính xác hơn, toán tử nối (,) nối toán hạng bên phải của nó vào cuối toán hạng bên trái và trả về kết quả. Nó chấp nhận một nguyên tử trong một trong hai đối số.
q)1,2 3 4
1 2 3 4
q)1 2 3, 4.4 5.6 / If the arguments are not of uniform type,
/ the result is a general list.
1
2
3
4.4
5.6Làm tổ
Độ phức tạp của dữ liệu được xây dựng bằng cách sử dụng danh sách dưới dạng các mục của danh sách.
Depth
The number of levels of nesting for a list is called its depth. Atoms have a depth of 0 and simple lists have a depth of 1.
q)l1:(9;8;(99;88))
q)count l1
3Here is a list of depth 3 having two items −
q)l5
9
(90;180;900 1800 2700 3600)
q)count l5
2
q)count l5[1]
3Indexing at Depth
It is possible to index directly into the items of a nested list.
Repeated Item Indexing
Retrieving an item via a single index always retrieves an uppermost item from a nested list.
q)L:(1;(100;200;(300;400;500;600)))
q)L[0]
1
q)L[1]
100
200
300 400 500 600Since the result L[1] is itself a list, we can retrieve its elements using a single index.
q)L[1][2]
300 400 500 600We can repeat single indexing once more to retrieve an item from the innermost nested list.
q)L[1][2][0]
300You can read this as,
Get the item at index 1 from L, and from it retrieve the item at index 2, and from it retrieve the item at index 0.
Notation for Indexing at Depth
There is an alternate notation for repeated indexing into the constituents of a nested list. The last retrieval can also be written as,
q)L[1;2;0]
300Assignment via index also works at depth.
q)L[1;2;1]:900
q)L
1
(100;200;300 900 500 600)Elided Indices
Eliding Indices for a General List
q)L:((1 2 3; 4 5 6 7); (`a`b`c;`d`e`f`g;`0`1`2);("good";"morning"))
q)L
(1 2 3;4 5 6 7)
(`a`b`c;`d`e`f`g;`0`1`2)
("good";"morning")
q)L[;1;]
4 5 6 7
`d`e`f`g
"morning"
q)L[;;2]
3 6
`c`f`2
"or"Interpret L[;1;] as,
Retrieve all items in the second position of each list at the top level.
Interpret L[;;2] as,
Retrieve the items in the third position for each list at the second level.
Dictionaries are an extension of lists which provide the foundation for creating tables. In mathematical terms, dictionary creates the
“domain → Range”
or in general (short) creates
“key → value”
relationship between elements.
A dictionary is an ordered collection of key-value pairs that is roughly equivalent to a hash table. A dictionary is a mapping defined by an explicit I/O association between a domain list and a range list via positional correspondence. The creation of a dictionary uses the "xkey" primitive (!)
ListOfDomain ! ListOfRangeThe most basic dictionary maps a simple list to a simple list.
| Input (I) | Output (O) |
|---|---|
| `Name | `John |
| `Age | 36 |
| `Sex | “M” |
| Weight | 60.3 |
q)d:`Name`Age`Sex`Weight!(`John;36;"M";60.3) / Create a dictionary d
q)d
Name | `John
Age | 36
Sex | "M"
Weight | 60.3
q)count d / To get the number of rows in a dictionary.
4
q)key d / The function key returns the domain
`Name`Age`Sex`Weight
q)value d / The function value returns the range.
`John
36
"M"
60.3
q)cols d / The function cols also returns the domain.
`Name`Age`Sex`WeightLookup
Finding the dictionary output value corresponding to an input value is called looking up the input.
q)d[`Name] / Accessing the value of domain `Name
`John
q)d[`Name`Sex] / extended item-wise to a simple list of keys
`John
"M"Lookup with Verb @
q)d1:`one`two`three!9 18 27
q)d1[`two]
18
q)d1@`two
18Operations on Dictionaries
Amend and Upsert
As with lists, the items of a dictionary can be modified via indexed assignment.
d:`Name`Age`Sex`Weight! (`John;36;"M";60.3)
/ A dictionary d
q)d[`Age]:35 / Assigning new value to key Age
q)d
/ New value assigned to key Age in d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3Dictionaries can be extended via index assignment.
q)d[`Height]:"182 Ft"
q)d
Name | `John
Age | 35
Sex | "M"
Weight | 60.3
Height | "182 Ft"Reverse Lookup with Find (?)
The find (?) operator is used to perform reverse lookup by mapping a range of elements to its domain element.
q)d2:`x`y`z!99 88 77
q)d2?77
`zIn case the elements of a list is not unique, the find returns the first item mapping to it from the domain list.
Removing Entries
To remove an entry from a dictionary, the delete ( _ ) function is used. The left operand of ( _ ) is the dictionary and the right operand is a key value.
q)d2:`x`y`z!99 88 77
q)d2 _`z
x| 99
y| 88Whitespace is required to the left of _ if the first operand is a variable.
q)`x`y _ d2 / Deleting multiple entries
z| 77Column Dictionaries
Column dictionaries are the basics for creation of tables. Consider the following example −
q)scores: `name`id!(`John`Jenny`Jonathan;9 18 27)
/ Dictionary scores
q)scores[`name] / The values for the name column are
`John`Jenny`Jonathan
q)scores.name / Retrieving the values for a column in a
/ column dictionary using dot notation.
`John`Jenny`Jonathan
q)scores[`name][1] / Values in row 1 of the name column
`Jenny
q)scores[`id][2] / Values in row 2 of the id column is
27Flipping a Dictionary
The net effect of flipping a column dictionary is simply reversing the order of the indices. This is logically equivalent to transposing the rows and columns.
Flip on a Column Dictionary
The transpose of a dictionary is obtained by applying the unary flip operator. Take a look at the following example −
q)scores
name | John Jenny Jonathan
id | 9 18 27
q)flip scores
name id
---------------
John 9
Jenny 18
Jonathan 27Flip of a Flipped Column Dictionary
If you transpose a dictionary twice, you obtain the original dictionary,
q)scores ~ flip flip scores
1bTables are at the heart of kdb+. A table is a collection of named columns implemented as a dictionary. q tables are column-oriented.
Creating Tables
Tables are created using the following syntax −
q)trade:([]time:();sym:();price:();size:())
q)trade
time sym price size
-------------------In the above example, we have not specified the type of each column. This will be set by the first insert into the table.
Another way, we can specify column type on initialization −
q)trade:([]time:`time$();sym:`$();price:`float$();size:`int$())Or we can also define non-empty tables −
q)trade:([]sym:(`a`b);price:(1 2))
q)trade
sym price
-------------
a 1
b 2If there are no columns within the square brackets as in the examples above, the table is unkeyed.
To create a keyed table, we insert the column(s) for the key in the square brackets.
q)trade:([sym:`$()]time:`time$();price:`float$();size:`int$())
q)trade
sym | time price size
----- | ---------------One can also define the column types by setting the values to be null lists of various types −
q)trade:([]time:0#0Nt;sym:0#`;price:0#0n;size:0#0N)Getting Table Information
Let’s create a trade table −
trade: ([]sym:`ibm`msft`apple`samsung;mcap:2000 4000 9000 6000;ex:`nasdaq`nasdaq`DAX`Dow)
q)cols trade / column names of a table
`sym`mcap`ex
q)trade.sym / Retrieves the value of column sym
`ibm`msft`apple`samsung
q)show meta trade / Get the meta data of a table trade.
c | t f a
----- | -----
Sym | s
Mcap | j
ex | sPrimary Keys and Keyed Tables
Keyed Table
A keyed table is a dictionary that maps each row in a table of unique keys to a corresponding row in a table of values. Let us take an example −
val:flip `name`id!(`John`Jenny`Jonathan;9 18 27)
/ a flip dictionary create table val
id:flip (enlist `eid)!enlist 99 198 297
/ flip dictionary, having single column eidNow create a simple keyed table containing eid as key,
q)valid: id ! val
q)valid / table name valid, having key as eid
eid | name id
--- | ---------------
99 | John 9
198 | Jenny 18
297 | Jonathan 27ForeignKeys
A foreign key defines a mapping from the rows of the table in which it is defined to the rows of the table with the corresponding primary key.
Foreign keys provide referential integrity. In other words, an attempt to insert a foreign key value that is not in the primary key will fail.
Consider the following examples. In the first example, we will define a foreign key explicitly on initialization. In the second example, we will use foreign key chasing which does not assume any prior relationship between the two tables.
Example 1 − Define foreign key on initialization
q)sector:([sym:`SAMSUNG`HSBC`JPMC`APPLE]ex:`N`CME`DAQ`N;MC:1000 2000 3000 4000)
q)tab:([]sym:`sector$`HSBC`APPLE`APPLE`APPLE`HSBC`JPMC;price:6?9f)
q)show meta tab
c | t f a
------ | ----------
sym | s sector
price | f
q)show select from tab where sym.ex=`N
sym price
----------------
APPLE 4.65382
APPLE 4.643817
APPLE 3.659978Example 2 − no pre-defined relationship between tables
sector: ([symb:`IBM`MSFT`HSBC]ex:`N`CME`N;MC:1000 2000 3000)
tab:([]sym:`IBM`MSFT`MSFT`HSBC`HSBC;price:5?9f)To use foreign key chasing, we must create a table to key into sector.
q)show update mc:(sector([]symb:sym))[`MC] from tab
sym price mc
--------------------------
IBM 7.065297 1000
MSFT 4.812387 2000
MSFT 6.400545 2000
HSBC 3.704373 3000
HSBC 4.438651 3000General notation for a predefined foreign key −
select a.b from c where a is the foreign key (sym), b is a
field in the primary key table (ind), c is the
foreign key table (trade)
Manipulating Tables
Let’s create one trade table and check the result of different table expression −
q)trade:([]sym:5?`ibm`msft`hsbc`samsung;price:5?(303.00*3+1);size:5?(900*5);time:5?(.z.T-365))
q)trade
sym price size time
-----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842Let us now take a look at the statements that are used to manipulate tables using q language.
Select
The syntax to use a Select statement is as follows −
select [columns] [by columns] from table [where clause]Let us now take an example to demonstrate how to use Select statement −
q)/ select expression example
q)select sym,price,size by time from trade where size > 2000
time | sym price size
------------- | -----------------------
01:44:56.936 | msft 641.7307 2917
02:32:17.036 | msft 743.8592 3162
07:24:26.842 | ibm 838.6471 4006Insert
The syntax to use an Insert statement is as follows −
`tablename insert (values)
Insert[`tablename; values]Let us now take an example to demonstrate how to use Insert statement −
q)/ Insert expression example
q)`trade insert (`hsbc`apple;302.0 730.40;3020 3012;09:30:17.00409:15:00.000)
5 6
q)trade
sym price size time
------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
q)/Insert another value
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000]
']
q)insert[`trade;(`samsung;302.0; 3333;10:30:00.000)]
,7
q)trade
sym price size time
----------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000Delete
The syntax to use a Delete statement is as follows −
delete columns from table
delete from table where clauseLet us now take an example to demonstrate how to use Delete statement −
q)/Delete expression example
q)delete price from trade
sym size time
-------------------------------
msft 3162 02:32:17.036
msft 2917 01:44:56.936
hsbc 1492 00:25:23.210
samsung 1983 00:29:38.945
ibm 4006 07:24:26.842
hsbc 3020 09:30:17.004
apple 3012 09:15:00.000
samsung 3333 10:30:00.000
q)delete from trade where price > 3000
sym price size time
-------------------------------------------
msft 743.8592 3162 02:32:17.036
msft 641.7307 2917 01:44:56.936
hsbc 838.2311 1492 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 4006 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 3012 09:15:00.000
samsung 302 3333 10:30:00.000
q)delete from trade where price > 500
sym price size time
-----------------------------------------
samsung 278.3498 1983 00:29:38.945
hsbc 302 3020 09:30:17.004
samsung 302 3333 10:30:00.000Update
The syntax to use an Update statement is as follows −
update column: newValue from table where ….Use the following syntax to update the format/datatype of a column using the cast function −
update column:newValue from `table where …Let us now take an example to demonstrate how to use Update statement −
q)/Update expression example
q)update size:9000 from trade where price > 600
sym price size time
------------------------------------------
msft 743.8592 9000 02:32:17.036
msft 641.7307 9000 01:44:56.936
hsbc 838.2311 9000 00:25:23.210
samsung 278.3498 1983 00:29:38.945
ibm 838.6471 9000 07:24:26.842
hsbc 302 3020 09:30:17.004
apple 730.4 9000 09:15:00.000
samsung 302 3333 10:30:00.000
q)/Update the datatype of a column using the cast function
q)meta trade
c | t f a
----- | --------
sym | s
price| f
size | j
time | t
q)update size:`float$size from trade sym price size time ------------------------------------------ msft 743.8592 3162 02:32:17.036 msft 641.7307 2917 01:44:56.936 hsbc 838.2311 1492 00:25:23.210 samsung 278.3498 1983 00:29:38.945 ibm 838.6471 4006 07:24:26.842 hsbc 302 3020 09:30:17.004 apple 730.4 3012 09:15:00.000 samsung 302 3333 10:30:00.000 q)/ Above statement will not update the size column datatype permanently q)meta trade c | t f a ------ | -------- sym | s price | f size | j time | t q)/to make changes in the trade table permanently, we have do q)update size:`float$size from `trade
`trade
q)meta trade
c | t f a
------ | --------
sym | s
price | f
size | f
time | tKdb+ has nouns, verbs, and adverbs. All data objects and functions are nouns. Verbs enhance the readability by reducing the number of square brackets and parentheses in expressions. Adverbs modify dyadic (2 arguments) functions and verbs to produce new, related verbs. The functions produced by adverbs are called derived functions or derived verbs.
Each
The adverb each, denoted by ( ` ), modifies dyadic functions and verbs to apply to the items of lists instead of the lists themselves. Take a look at the following example −
q)1, (2 3 5) / Join
1 2 3 5
q)1, '( 2 3 4) / Join each
1 2
1 3
1 4There is a form of Each for monadic functions that uses the keyword “each”. For example,
q)reverse ( 1 2 3; "abc") /Reverse
a b c
1 2 3
q)each [reverse] (1 2 3; "abc") /Reverse-Each
3 2 1
c b a
q)'[reverse] ( 1 2 3; "abc")
3 2 1
c b aEach-Left and Each-Right
There are two variants of Each for dyadic functions called Each-Left (\:) and Each-Right (/:). The following example explains how to use them.
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each
9 10
18 20
27 30
36 40
q)x: 9 18 27 36
q)y:10 20 30 40
q)x,y / join
9 18 27 36 10 20 30 40
q)x,'y / each, will return a list of pairs
9 10
18 20
27 30
36 40
q)x, \:y / each left, returns a list of each element
/ from x with all of y
9 10 20 30 40
18 10 20 30 40
27 10 20 30 40
36 10 20 30 40
q)x,/:y / each right, returns a list of all the x with
/ each element of y
9 18 27 36 10
9 18 27 36 20
9 18 27 36 30
9 18 27 36 40
q)1 _x / drop the first element
18 27 36
q)-2_y / drop the last two element
10 20
q) / Combine each left and each right to be a
/ cross-product (cartesian product)
q)x,/:\:y
9 10 9 20 9 30 9 40
18 10 18 20 18 30 18 40
27 10 27 20 27 30 27 40
36 10 36 20 36 30 36 40In q language, we have different kinds of joins based on the input tables supplied and the kind of joined tables we desire. A join combines data from two tables. Besides foreign key chasing, there are four other ways to join tables −
- Simple join
- Asof join
- Left join
- Union join
Here, in this chapter, we will discuss each of these joins in detail.
Simple Join
Simple join is the most basic type of join, performed with a comma ‘,’. In this case, the two tables have to be type conformant, i.e., both the tables have the same number of columns in the same order, and same key.
table1,:table2 / table1 is assigned the value of table2We can use comma-each join for tables with same length to join sideways. One of the tables can be keyed here,
Table1, `Table2Asof Join (aj)
It is the most powerful join which is used to get the value of a field in one table asof the time in another table. Generally it is used to get the prevailing bid and ask at the time of each trade.
General format
aj[joinColumns;tbl1;tbl2]For example,
aj[`sym`time;trade;quote]Example
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show aj[`a`b;tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Left Join(lj)
It’s a special case of aj where the second argument is a keyed table and the first argument contains the columns of the right argument’s key.
General format
table1 lj Keyed-tableExample
q)/Left join- syntax table1 lj table2 or lj[table1;table2]
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([a:(2 3 4);b:(3 4 5)]; c:( 4 5 6))
q)show lj[tab1;tab2]
a b d c
-------------
1 2 6
2 3 7 4
3 4 8 5
4 5 9 6Union Join (uj)
It allows to create a union of two tables with distinct schemas. It is basically an extension to the simple join ( , )
q)tab1:([]a:(1 2 3 4);b:(2 3 4 5);d:(6 7 8 9))
q)tab2:([]a:(2 3 4);b:(3 4 5); c:( 4 5 6))
q)show uj[tab1;tab2]
a b d c
------------
1 2 6
2 3 7
3 4 8
4 5 9
2 3 4
3 4 5
4 5 6If you are using uj on keyed tables, then the primary keys must match.
Types of Functions
Functions can be classified in a number of ways. Here we have classified them based on the number and type of argument they take and the result type. Functions can be,
Atomic − Where the arguments are atomic and produce atomic results
Aggregate − atom from list
Uniform (list from list) − Extended the concept of atom as they apply to lists. The count of the argument list equals the count of the result list.
Other − if the function is not from the above category.
Binary operations in mathematics are called dyadic functions in q; for example, “+”. Similarly unary operations are called monadic functions; for example, “abs” or “floor”.
Frequently Used Functions
There are quite a few functions used frequently in q programming. Here, in this section, we will see the usage of some popular functions −
abs
q) abs -9.9 / Absolute value, Negates -ve number & leaves non -ve number
9.9all
q) all 4 5 0 -4 / Logical AND (numeric min), returns the minimum value
0bMax (&), Min (|), and Not (!)
q) /And, Or, and Logical Negation
q) 1b & 1b / And (Max)
1b
q) 1b|0b / Or (Min)
1b
q) not 1b /Logical Negate (Not)
0basc
q)asc 1 3 5 7 -2 0 4 / Order list ascending, sorted list
/ in ascending order i
s returned
`s#-2 0 1 3 4 5 7
q)/attr - gives the attributes of data, which describe how it's sorted.
`s denotes fully sorted, `u denotes unique and `p and `g are used to
refer to lists with repetition, with `p standing for parted and `g for groupedavg
q)avg 3 4 5 6 7 / Return average of a list of numeric values
5f
q)/Create on trade table
q)trade:([]time:3?(.z.Z-200);sym:3?(`ibm`msft`apple);price:3?99.0;size:3?100)by
q)/ by - Groups rows in a table at given sym
q)select sum price by sym from trade / find total price for each sym
sym | price
------ | --------
apple | 140.2165
ibm | 16.11385cols
q)cols trade / Lists columns of a table
`time`sym`price`sizeđếm
q)count (til 9) / Count list, count the elements in a list and
/ return a single int value 9Hải cảng
q)\p 9999 / assign port number
q)/csv - This command allows queries in a browser to be exported to
excel by prefixing the query, such as http://localhost:9999/.csv?select from trade where sym =`ibmcắt
q)/ cut - Allows a table or list to be cut at a certain point
q)(1 3 5) cut "abcdefghijkl"
/ the argument is split at 1st, 3rd and 5th letter.
"bc"
"de"
"fghijkl"
q)5 cut "abcdefghijkl" / cut the right arg. Into 5 letters part
/ until its end.
"abcde"
"fghij"
"kl"Xóa bỏ
q)/delete - Delete rows/columns from a table
q)delete price from trade
time sym size
---------------------------------------
2009.06.18T06:04:42.919 apple 36
2009.11.14T12:42:34.653 ibm 12
2009.12.27T17:02:11.518 apple 97Khác biệt
q)/distinct - Returns the distinct element of a list
q)distinct 1 2 3 2 3 4 5 2 1 3 / generate unique set of number
1 2 3 4 5nhập ngũ
q)/enlist - Creates one-item list.
q)enlist 37
,37
q)type 37 / -ve type value
-7h
q)type enlist 37 / +ve type value
7hĐiền (^)
q)/fill - used with nulls. There are three functions for processing null values.
The dyadic function named fill replaces null values in the right argument with the atomic left argument.
q)100 ^ 3 4 0N 0N -5
3 4 100 100 -5
q)`Hello^`jack`herry``john`
`jack`herry`Hello`john`HelloĐiền
q)/fills - fills in nulls with the previous not null value.
q)fills 1 0N 2 0N 0N 2 3 0N -5 0N
1 1 2 2 2 2 3 3 -5 -5Đầu tiên
q)/first - returns the first atom of a list
q)first 1 3 34 5 3
1Lật
q)/flip - Monadic primitive that applies to lists and associations. It interchange the top two levels of its argument.
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
q)flip trade
time | 2009.06.18T06:04:42.919 2009.11.14T12:42:34.653
2009.12.27T17:02:11.518
sym | apple ibm apple
price | 72.05742 16.11385 68.15909
size | 36 12 97iasc
q)/iasc - Index ascending, return the indices of the ascended sorted list relative to the input list.
q)iasc 5 4 0 3 4 9
2 3 1 4 0 5Idesc
q)/idesc - Index desceding, return the descended sorted list relative to the input list
q)idesc 0 1 3 4
3 2 1 0trong
q)/in - In a list, dyadic function used to query list (on the right-handside) about their contents.
q)(2 4) in 1 2 3
10bchèn
q)/insert - Insert statement, upload new data into a table.
q)insert[`trade;((.z.Z);`samsung;48.35;99)],3
q)trade
time sym price size
------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99Chìa khóa
q)/key - three different functions i.e. generate +ve integer number, gives content of a directory or key of a table/dictionary.
q)key 9
0 1 2 3 4 5 6 7 8
q)key `:c:
`$RECYCLE.BIN`Config.Msi`Documents and Settings`Drivers`Geojit`hiberfil.sys`I..thấp hơn
q)/lower - Convert to lower case and floor
q)lower ("JoHn";`HERRY`SYM)
"john"
`herry`symMax và Min (tức là | và &)
q)/Max and Min / a|b and a&b
q)9|7
9
q)9&5
5vô giá trị
q)/null - return 1b if the atom is a null else 0b from the argument list
q)null 1 3 3 0N
0001bĐào
q)/peach - Parallel each, allows process across slaves
q)foo peach list1 / function foo applied across the slaves named in list1
'list1
q)foo:{x+27}
q)list1:(0 1 2 3 4)
q)foo peach list1 / function foo applied across the slaves named in list1
27 28 29 30 31Trước đó
q)/prev - returns the previous element i.e. pushes list forwards
q)prev 0 1 3 4 5 7
0N 0 1 3 4 5Ngẫu nhiên (?)
q)/random - syntax - n?list, gives random sequences of ints and floats
q)9?5
0 0 4 0 3 2 2 0 1
q)3?9.9
0.2426823 1.674133 3.901671Nâng lên
q)/raze - Flattn a list of lists, removes a layer of indexing from a list of lists. for instance:
q)raze (( 12 3 4; 30 0);("hello";7 8); 1 3 4)
12 3 4
30 0
"hello"
7 8
1
3
4đọc0
q)/read0 - Read in a text file
q)read0 `:c:/q/README.txt / gives the contents of *.txt fileread1
q)/read1 - Read in a q data file
q)read1 `:c:/q/t1
0xff016200630b000500000073796d0074696d6500707269636…đảo ngược
q)/reverse - Reverse a list
q)reverse 2 30 29 1 3 4
4 3 1 29 30 2
q)reverse "HelloWorld"
"dlroWolleH"bộ
q)/set - set value of a variable
q)`x set 9
`x
q)x
9
q)`:c:/q/test12 set trade
`:c:/q/test12
q)get `:c:/q/test12
time sym price size
---------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99ssr
q)/ssr - String search and replace, syntax - ssr["string";searchstring;replaced-with]
q)ssr["HelloWorld";"o";"O"]
"HellOWOrld"chuỗi
q)/string - converts to string, converts all types to a string format.
q)string (1 2 3; `abc;"XYZ";0b)
(,"1";,"2";,"3")
"abc"
(,"X";,"Y";,"Z")
,"0"SV
q)/sv - Scalar from vector, performs different tasks dependent on its arguments.
It evaluates the base representation of numbers, which allows us to calculate the number of seconds in a month or convert a length from feet and inches to centimeters.
q)24 60 60 sv 11 30 49
41449 / number of seconds elapsed in a day at 11:30:49hệ thống
q)/system - allows a system command to be sent,
q)system "dir *.py"
" Volume in drive C is New Volume"
" Volume Serial Number is 8CD2-05B2"
""
" Directory of C:\\Users\\myaccount-raj"
""
"09/14/2014 06:32 PM 22 hello1.py"
" 1 File(s) 22 bytes"những cái bàn
q)/tables - list all tables
q)tables `
`s#`tab1`tab2`tradeĐến
q)/til - Enumerate
q)til 5
0 1 2 3 4cắt tỉa
q)/trim - Eliminate string spaces
q)trim " John "
"John"vs
q)/vs - Vector from scaler , produces a vector quantity from a scaler quantity
q)"|" vs "20150204|msft|20.45"
"20150204"
"msft"
"20.45"xasc
q)/xasc - Order table ascending, allows a table (right-hand argument) to be sorted such that (left-hand argument) is in ascending order
q)`price xasc trade
time sym price size
----------------------------------------------------------
2009.11.14T12:42:34.653 ibm 16.11385 12
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.12.27T17:02:11.518 apple 68.15909 97
2009.06.18T06:04:42.919 apple 72.05742 36xcol
q)/xcol - Renames columns of a table
q)`timeNew`symNew xcol trade
timeNew symNew price size
-------------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.11.14T12:42:34.653 ibm 16.11385 12
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99xcols
q)/xcols - Reorders the columns of a table,
q)`size`price xcols trade
size price time sym
-----------------------------------------------------------
36 72.05742 2009.06.18T06:04:42.919 apple
12 16.11385 2009.11.14T12:42:34.653 ibm
97 68.15909 2009.12.27T17:02:11.518 apple
99 48.35 2015.04.06T10:03:36.738 samsung
99 48.35 2015.04.06T10:03:47.540 samsung
99 48.35 2015.04.06T10:04:44.844 samsungxdesc
q)/xdesc - Order table descending, allows tables to be sorted such that the left-hand argument is in descending order.
q)`price xdesc trade
time sym price size
-----------------------------------------------------------
2009.06.18T06:04:42.919 apple 72.05742 36
2009.12.27T17:02:11.518 apple 68.15909 97
2015.04.06T10:03:36.738 samsung 48.35 99
2015.04.06T10:03:47.540 samsung 48.35 99
2015.04.06T10:04:44.844 samsung 48.35 99
2009.11.14T12:42:34.653 ibm 16.11385 12xgroup
q)/xgroup - Creates nested table
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40)
'length
q)`x xgroup ([]x:9 18 9 18 27 9 9;y:10 20 10 20 30 40 10)
x | y
---- | -----------
9 | 10 10 40 10
18 | 20 20
27 | ,30xkey
q)/xkey - Set key on table
q)`sym xkey trade
sym | time price size
--------- | -----------------------------------------------
apple | 2009.06.18T06:04:42.919 72.05742 36
ibm | 2009.11.14T12:42:34.653 16.11385 12
apple | 2009.12.27T17:02:11.518 68.15909 97
samsung | 2015.04.06T10:03:36.738 48.35 99
samsung | 2015.04.06T10:03:47.540 48.35 99
samsung | 2015.04.06T10:04:44.844 48.35 99Lệnh hệ thống
Lệnh hệ thống kiểm soát qMôi trường. Chúng có dạng sau:
\cmd [p] where p may be optionalMột số lệnh hệ thống phổ biến đã được thảo luận dưới đây:
\ a [không gian tên] - Liệt kê các bảng trong không gian tên đã cho
q)/Tables in default namespace
q)\a
,`trade
q)\a .o / table in .o namespace.
,`TI\ b - Xem phần phụ thuộc
q)/ views/dependencies
q)a:: x+y / global assingment
q)b:: x+1
q)\b
`s#`a`b\ B - Chế độ xem / phụ thuộc đang chờ xử lý
q)/ Pending views/dependencies
q)a::x+1 / a depends on x
q)\B / the dependency is pending
' / the dependency is pending
q)\B
`s#`a`b
q)\b
`s#`a`b
q)b
29
q)a
29
q)\B
`symbol$()\ cd - Thay đổi thư mục
q)/change directory, \cd [name]
q)\cd
"C:\\Users\\myaccount-raj"
q)\cd ../new-account
q)\cd
"C:\\Users\\new-account"\ d - đặt không gian tên hiện tại
q)/ sets current namespace \d [namespace]
q)\d /default namespace
'
q)\d .o /change to .o
q.o)\d
`.o
q.o)\d . / return to default
q)key ` /lists namespaces other than .z
`q`Q`h`j`o
q)\d .john /change to non-existent namespace
q.john)\d
`.john
q.john)\d .
q)\d
`.\ l - tải tệp hoặc thư mục từ db
q)/ Load file or directory, \l
q)\l test2.q / loading test2.q which is stored in current path.
ric | date ex openP closeP MCap
----------- | -------------------------------------------------
JPMORGAN | 2008.05.23 SENSEX 18.30185 17.16319 17876
HSBC | 2002.05.21 NIFTY 2.696749 16.58846 26559
JPMORGAN | 2006.09.07 NIFTY 14.15219 20.05624 14557
HSBC | 2010.10.11 SENSEX 7.394497 25.45859 29366
JPMORGAN | 2007.10.02 SENSEX 1.558085 25.61478 20390
ric | date ex openP closeP MCap
---------- | ------------------------------------------------
INFOSYS | 2003.10.30 DOW 21.2342 7.565652 2375
RELIANCE | 2004.08.12 DOW 12.34132 17.68381 4201
SBIN | 2008.02.14 DOW 1.830857 9.006485 15465
INFOSYS | 2009.06.11 HENSENG 19.47664 12.05208 11143
SBIN | 2010.07.05 DOW 18.55637 10.54082 15873\ p - số cổng
q)/ assign port number, \p
q)\p
5001i
q)\p 8888
q)\p
8888i\\ - Thoát khỏi bảng điều khiển q
\\ - exit
Exit form q.Các qngôn ngữ lập trình có một tập hợp các hàm tích hợp phong phú và mạnh mẽ. Một hàm tích hợp có thể thuộc các loại sau:
String function - Lấy một chuỗi làm đầu vào và trả về một chuỗi.
Aggregate function - Lấy một danh sách làm đầu vào và trả về một nguyên tử.
Uniform function - Lấy một danh sách và trả về một danh sách có cùng số lượng.
Mathematical function - Lấy đối số số và trả về đối số số.
Miscellaneous function - Tất cả các chức năng khác ngoài các chức năng nêu trên.
Hàm chuỗi
Thích - khớp mẫu
q)/like is a dyadic, performs pattern matching, return 1b on success else 0b
q)"John" like "J??n"
1b
q)"John My Name" like "J*"
1bltrim - loại bỏ các khoảng trống ở đầu
q)/ ltrim - monadic ltrim takes string argument, removes leading blanks
q)ltrim " Rick "
"Rick "rtrim - loại bỏ các khoảng trống ở cuối
q)/rtrim - takes string argument, returns the result of removing trailing blanks
q)rtrim " Rick "
" Rick"ss - tìm kiếm chuỗi
q)/ss - string search, perform pattern matching, same as "like" but return the indices of the matches of the pattern in source.
q)"Life is beautiful" ss "i"
1 5 13trim - loại bỏ các khoảng trống ở đầu và cuối
q)/trim - takes string argument, returns the result of removing leading & trailing blanks
q)trim " John "
"John"Các hàm toán học
acos - nghịch đảo của cos
q)/acos - inverse of cos, for input between -1 and 1, return float between 0 and pi
q)acos 1
0f
q)acos -1
3.141593
q)acos 0
1.570796cor - cho sự tương quan
q)/cor - the dyadic takes two numeric lists of same count, returns a correlation between the items of the two arguments
q)27 18 18 9 0 cor 27 36 45 54 63
-0.9707253chéo - sản phẩm Descartes
q)/cross - takes atoms or lists as arguments and returns their Cartesian product
q)9 18 cross `x`y`z
9 `x
9 `y
9 `z
18 `x
18 `y
18 `zvar - phương sai
q)/var - monadic, takes a scaler or numeric list and returns a float equal to the mathematical variance of the items
q)var 45
0f
q)var 9 18 27 36
101.25wavg
q)/wavg - dyadic, takes two numeric lists of the same count and returns the average of the second argument weighted by the first argument.
q)1 2 3 4 wavg 200 300 400 500
400fChức năng tổng hợp
tất cả - & hoạt động
q)/all - monadic, takes a scaler or list of numeric type and returns the result of & applied across the items.
q)all 0b
0b
q)all 9 18 27 36
1b
q)all 10 20 30
1bBất kỳ - | hoạt động
q)/any - monadic, takes scaler or list of numeric type and the return the result of | applied across the items
q)any 20 30 40 50
1b
q)any 20012.02.12 2013.03.11
'20012.02.12prd - tích số học
q)/prd - monadic, takes scaler, list, dictionary or table of numeric type and returns the arithmetic product.
q)prd `x`y`z! 10 20 30
6000
q)prd ((1 2; 3 4);(10 20; 30 40))
10 40
90 160Sum - tổng số học
q)/sum - monadic, takes a scaler, list,dictionary or table of numeric type and returns the arithmetic sum.
q)sum 2 3 4 5 6
20
q)sum (1 2; 4 5)
5 7Chức năng thống nhất
Deltas - sự khác biệt so với mặt hàng trước của nó.
q)/deltas -takes a scalar, list, dictionary or table and returns the difference of each item from its predecessor.
q)deltas 2 3 5 7 9
2 1 2 2 2
q)deltas `x`y`z!9 18 27
x | 9
y | 9
z | 9điền vào - điền giá trị null
q)/fills - takes scalar, list, dictionary or table of numeric type and returns a c copy of the source in which non-null items are propagated forward to fill nulls
q)fills 1 0N 2 0N 4
1 1 2 2 4
q)fills `a`b`c`d! 10 0N 30 0N
a | 10
b | 10
c | 30
d | 30tối đa - tối đa tích lũy
q)/maxs - takes scalar, list, dictionary or table and returns the cumulative maximum of the source items.
q)maxs 1 2 4 3 9 13 2
1 2 4 4 9 13 13
q)maxs `a`b`c`d!9 18 0 36
a | 9
b | 18
c | 18
d | 36Các chức năng khác
Đếm - số phần tử trả về
q)/count - returns the number of entities in its argument.
q)count 10 30 30
3
q)count (til 9)
9
q)count ([]a:9 18 27;b:1.1 2.2 3.3)
3Riêng biệt - trả về các thực thể riêng biệt
q)/distinct - monadic, returns the distinct entities in its argument
q)distinct 1 2 3 4 2 3 4 5 6 9
1 2 3 4 5 6 9Ngoại trừ - phần tử không có trong đối số thứ hai.
q)/except - takes a simple list (target) as its first argument and returns a list containing the items of target that are not in its second argument
q)1 2 3 4 3 1 except 1
2 3 4 3điền - điền null với đối số đầu tiên
q)/fill (^) - takes an atom as its first argument and a list(target) as its second argument and return a list obtained by substituting the first argument for every occurrence of null in target
q)42^ 9 18 0N 27 0N 36
9 18 42 27 42 36
q)";"^"Life is Beautiful"
"Life;is;Beautiful"Truy vấn trong qngắn hơn và đơn giản hơn và mở rộng khả năng của sql. Biểu thức truy vấn chính là 'biểu thức chọn', ở dạng đơn giản nhất, nó trích xuất các bảng con nhưng nó cũng có thể tạo các cột mới.
Dạng tổng quát của một Select expression như sau -
Select columns by columns from table where conditions**Note − by & where các cụm từ là tùy chọn, chỉ có 'biểu thức từ' là bắt buộc.
Nói chung, cú pháp sẽ là:
select [a] [by b] from t [where c]
update [a] [by b] from t [where c]Cú pháp của q các biểu thức trông khá giống với SQL, nhưng qbiểu thức rất đơn giản và mạnh mẽ. Một biểu thức sql tương đương cho ở trênq biểu thức sẽ như sau:
select [b] [a] from t [where c] [group by b order by b]
update t set [a] [where c]Tất cả các mệnh đề thực thi trên các cột và do đó qcó thể tận dụng lợi thế của đơn đặt hàng. Vì các truy vấn Sql không dựa trên thứ tự, chúng không thể tận dụng lợi thế đó.
qcác truy vấn quan hệ thường có kích thước nhỏ hơn nhiều so với sql tương ứng của chúng. Các truy vấn có thứ tự và chức năng thực hiện những việc khó trong sql.
Trong cơ sở dữ liệu lịch sử, thứ tự của wheremệnh đề rất quan trọng vì nó ảnh hưởng đến hiệu suất của truy vấn. Cácpartition biến (ngày / tháng / ngày) luôn đứng trước, sau đó là cột đã sắp xếp và lập chỉ mục (thường là cột sym).
Ví dụ,
select from table where date in d, sym in snhanh hơn nhiều so với,
select from table where sym in s, date in dTruy vấn cơ bản
Hãy viết một tập lệnh truy vấn trong notepad (như bên dưới), lưu (dưới dạng * .q), rồi tải nó.
sym:asc`AIG`CITI`CSCO`IBM`MSFT;
ex:"NASDAQ"
dst:`$":c:/q/test/data/"; /database destination @[dst;`sym;:;sym]; n:1000000; trade:([]sym:n?`sym;time:10:30:00.0+til n;price:n?3.3e;size:n?9;ex:n?ex); quote:([]sym:n?`sym;time:10:30:00.0+til n;bid:n?3.3e;ask:n?3.3e;bsize:n?9;asize:n?9;ex:n?ex); {@[;`sym;`p#]`sym xasc x}each`trade`quote; d:2014.08.07 2014.08.08 2014.08.09 2014.08.10 2014.08.11; /Date vector can also be changed by the user dt:{[d;t].[dst;(`$string d;t;`);:;value t]};
d dt/:\:`trade`quote;
Note: Once you run this query, two folders .i.e. "test" and "data" will be created under "c:/q/", and date partition data can be seen inside data folder.Truy vấn có ràng buộc
* Denotes HDB query
Select all IBM trades
select from trade where sym in `IBM*Select all IBM trades on a certain day
thisday: 2014.08.11
select from trade where date=thisday,sym=`IBMSelect all IBM trades with a price > 100
select from trade where sym=`IBM, price > 100.0Select all IBM trades with a price less than or equal to 100
select from trade where sym=`IBM,not price > 100.0*Select all IBM trades between 10.30 and 10.40, in the morning, on a certain date
thisday: 2014.08.11
select from trade where
date = thisday, sym = `IBM, time > 10:30:00.000,time < 10:40:00.000Select all IBM trades in ascending order of price
`price xasc select from trade where sym =`IBM*Select all IBM trades in descending order of price in a certain time frame
`price xdesc select from trade where date within 2014.08.07 2014.08.11, sym =`IBMComposite sort − sort ascending order by sym and then sort the result in descending order of price
`sym xasc `price xdesc select from trade where date = 2014.08.07,size = 5Select all IBM or MSFT trades
select from trade where sym in `IBM`MSFT*Calculate count of all symbols in ascending order within a certain time frame
`numsym xasc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11*Calculate count of all symbols in descending order within a certain time frame
`numsym xdesc select numsym: count i by sym from trade where date within 2014.08.07 2014.08.11* What is the maximum price of IBM stock within a certain time frame, and when does this first happen?
select time,ask from quote where date within 2014.08.07 2014.08.11,
sym =`IBM, ask = exec first ask from select max ask from quote where
sym =`IBMSelect the last price for each sym in hourly buckets
select last price by hour:time.hh, sym from tradeTruy vấn với Tổng hợp
* Calculate vwap (Volume Weighted Average Price) of all symbols
select vwap:size wavg price by sym from trade* Count the number of records (in millions) for a certain month
(select trade:1e-6*count i by date.dd from trade where date.month=2014.08m) + select quote:1e-6*count i by date.dd from quote where date.month=2014.08m* HLOC – Daily High, Low, Open and Close for CSCO in a certain month
select high:max price,low:min price,open:first price,close:last price by date.dd from trade where date.month=2014.08m,sym =`CSCO* Daily Vwap for CSCO in a certain month
select vwap:size wavg price by date.dd from trade where date.month = 2014.08m ,sym = `CSCO* Calculate the hourly mean, variance and standard deviation of the price for AIG
select mean:avg price, variance:var price, stdDev:dev price by date, hour:time.hh from trade where sym = `AIGSelect the price range in hourly buckets
select range:max[price] – min price by date,sym,hour:time.hh from trade* Daily Spread (average bid-ask) for CSCO in a certain month
select spread:avg bid-ask by date.dd from quote where date.month = 2014.08m, sym = `CSCO* Daily Traded Values for all syms in a certain month
select dtv:sum size by date,sym from trade where date.month = 2014.08mExtract a 5 minute vwap for CSCO
select size wavg price by 5 xbar time.minute from trade where sym = `CSCO* Extract 10 minute bars for CSCO
select high:max price,low:min price,close:last price by date, 10 xbar time.minute from trade where sym = `CSCO* Find the times when the price exceeds 100 basis points (100e-4) over the last price for CSCO for a certain day
select time from trade where date = 2014.08.11,sym = `CSCO,price > 1.01*last price* Full Day Price and Volume for MSFT in 1 Minute Intervals for the last date in the database
select last price,last size by time.minute from trade where date = last date, sym = `MSFTKDB + cho phép một quá trình giao tiếp với một quá trình khác thông qua giao tiếp giữa các quá trình. Các quy trình Kdb + có thể kết nối với bất kỳ kdb + nào khác trên cùng một máy tính, cùng một mạng hoặc thậm chí từ xa. Chúng ta chỉ cần xác định cổng và sau đó các máy khách có thể nói chuyện với cổng đó. Bất kìq quy trình có thể giao tiếp với bất kỳ q xử lý miễn là nó có thể truy cập được trên mạng và đang lắng nghe các kết nối.
một quy trình máy chủ lắng nghe các kết nối và xử lý mọi yêu cầu
một quy trình khách khởi tạo kết nối và gửi các lệnh để được thực thi
Máy khách và máy chủ có thể trên cùng một máy hoặc trên các máy khác nhau. Một tiến trình có thể vừa là máy khách vừa là máy chủ.
Một giao tiếp có thể là,
Synchronous (đợi trả về kết quả)
Asynchronous (không chờ đợi và không có kết quả trả về)
Khởi tạo máy chủ
A q máy chủ được khởi tạo bằng cách chỉ định cổng để lắng nghe,
q –p 5001 / command line
\p 5001 / session commandXử lý giao tiếp
Ô điều khiển giao tiếp là một ký hiệu bắt đầu bằng “:” và có dạng -
`:[server]:port-numberThí dụ
`::5001 / server and client on same machine
`:jack:5001 / server on machine jack
`:192.168.0.156 / server on specific IP address
`:www.myfx.com:5001 / server at www.myfx.comĐể bắt đầu kết nối, chúng ta sử dụng hàm “hopen” để trả về một chốt kết nối số nguyên. Xử lý này được sử dụng cho tất cả các yêu cầu khách hàng tiếp theo. Ví dụ -
q)h:hopen `::5001
q)h"til 5"
0 1 2 3 4
q)hclose hTin nhắn đồng bộ và không đồng bộ
Khi chúng ta có một xử lý, chúng ta có thể gửi một tin nhắn đồng bộ hoặc không đồng bộ.
Synchronous Message- Sau khi một tin nhắn được gửi đi, nó sẽ chờ và trả về kết quả. Định dạng của nó như sau:
handle “message”Asynchronous Message- Sau khi gửi tin nhắn, bắt đầu xử lý câu lệnh tiếp theo ngay lập tức mà không cần đợi và trả kết quả. Định dạng của nó như sau:
neg[handle] “message”Các tin nhắn yêu cầu phản hồi, ví dụ như lệnh gọi hàm hoặc câu lệnh chọn, thông thường sẽ sử dụng dạng đồng bộ; trong khi các thông báo không cần trả về đầu ra, ví dụ như chèn các bản cập nhật vào bảng, sẽ không đồng bộ.
Khi một q quy trình kết nối với một quy trình khác qxử lý thông qua giao tiếp giữa các quá trình, nó được xử lý bởi các trình xử lý tin nhắn. Các trình xử lý thư này có một hành vi mặc định. Ví dụ, trong trường hợp xử lý thông báo đồng bộ, trình xử lý trả về giá trị của truy vấn. Trình xử lý đồng bộ trong trường hợp này là.z.pg, mà chúng tôi có thể ghi đè theo yêu cầu.
Quy trình Kdb + có một số trình xử lý thông báo được xác định trước. Các trình xử lý thông báo rất quan trọng để định cấu hình cơ sở dữ liệu. Một số cách sử dụng bao gồm:
Logging - Ghi nhật ký các tin nhắn đến (hữu ích trong trường hợp xảy ra bất kỳ lỗi nghiêm trọng nào),
Security- Cho phép / không cho phép truy cập vào cơ sở dữ liệu, các lệnh gọi hàm nhất định, v.v., dựa trên tên người dùng / địa chỉ ip. Nó chỉ giúp cung cấp quyền truy cập cho những người đăng ký được ủy quyền.
Handle connections/disconnections từ các quy trình khác.
Trình xử lý tin nhắn được xác định trước
Một số trình xử lý thư xác định trước được thảo luận bên dưới.
.z.pg
Nó là một trình xử lý thông báo đồng bộ (process get). Hàm này được gọi tự động bất cứ khi nào nhận được thông báo đồng bộ trên một cá thể kdb +.
Tham số là lệnh gọi chuỗi / hàm được thực hiện, tức là thông báo được truyền. Theo mặc định, nó được định nghĩa như sau:
.z.pg: {value x} / simply execute the message
received but we can overwrite it to
give any customized result.
.z.pg : {handle::.z.w;value x} / this will store the remote handle
.z.pg : {show .z.w;value x} / this will show the remote handle.z.ps
Nó là một trình xử lý thông báo không đồng bộ (bộ quy trình). Nó là trình xử lý tương đương cho các thông báo không đồng bộ. Tham số là lệnh gọi chuỗi / hàm được thực thi. Theo mặc định, nó được định nghĩa là,
.z.pg : {value x} / Can be overriden for a customized action.Sau đây là trình xử lý thông báo tùy chỉnh cho các thông báo không đồng bộ, nơi chúng tôi đã sử dụng thực thi được bảo vệ,
.z.pg: {@[value; x; errhandler x]}Đây errhandler là một chức năng được sử dụng trong trường hợp có bất kỳ lỗi không mong muốn nào.
.z.po []
Nó là một trình xử lý mở kết nối (process-open). Nó được thực thi khi một quá trình từ xa mở kết nối. Để xem xử lý khi một kết nối với một quy trình được mở, chúng ta có thể xác định .z.po là,
.z.po : {Show “Connection opened by” , string h: .z.h}.z.pc []
Nó là một trình xử lý kết nối chặt chẽ (đóng quá trình). Nó được gọi khi một kết nối bị đóng. Chúng ta có thể tạo trình xử lý đóng của riêng mình. Trình xử lý này có thể đặt lại trình xử lý kết nối chung về 0 và đưa ra lệnh đặt bộ hẹn giờ kích hoạt (thực thi) sau mỗi 3 giây (3000 mili giây).
.z.pc : { h::0; value “\\t 3000”}Bộ xử lý bộ hẹn giờ (.z.ts) cố gắng mở lại kết nối. Khi thành công, nó sẽ tắt bộ hẹn giờ.
.z.ts : { h:: hopen `::5001; if [h>0; value “\\t 0”] }.z.pi []
PI là viết tắt của đầu vào quy trình. Nó được gọi cho bất kỳ loại đầu vào nào. Nó có thể được sử dụng để xử lý đầu vào bảng điều khiển hoặc đầu vào máy khách từ xa. Sử dụng .z.pi [], người ta có thể xác thực đầu vào bảng điều khiển hoặc thay thế màn hình mặc định. Ngoài ra, nó có thể được sử dụng cho bất kỳ loại hoạt động ghi nhật ký nào.
q).z.pi
'.z.pi
q).z.pi:{">", .Q.s value x}
q)5+4
>9
q)30+42
>72
q)30*2
>60
q)\x .z.pi
>q)
q)5+4
9.z.pw
Nó là một trình xử lý kết nối xác thực (xác thực người dùng). Nó thêm một cuộc gọi lại bổ sung khi một kết nối đang được mở cho một phiên kdb +. Nó được gọi sau khi –u / -U kiểm tra và trước .z.po (cổng mở).
.z.pw : {[user_id;passwd] 1b}Đầu vào là userid (biểu tượng) và password (bản văn).
Danh sách, từ điển hoặc cột của bảng có thể có các thuộc tính được áp dụng cho chúng. Các thuộc tính áp đặt các thuộc tính nhất định trên danh sách. Một số thuộc tính có thể biến mất khi sửa đổi.
Các loại thuộc tính
Đã sắp xếp (`s #)
`s # có nghĩa là danh sách được sắp xếp theo thứ tự tăng dần. Nếu một danh sách được sắp xếp rõ ràng theo asc (hoặc xasc), danh sách sẽ tự động có bộ thuộc tính được sắp xếp.
q)L1: asc 40 30 20 50 9 4
q)L1
`s#4 9 20 30 40 50Một danh sách được biết là đã được sắp xếp cũng có thể có thuộc tính được đặt rõ ràng. Q sẽ kiểm tra xem danh sách có được sắp xếp hay không và nếu không, s-fail lỗi sẽ được ném ra.
q)L2:30 40 24 30 2
q)`s#L2
's-failThuộc tính đã sắp xếp sẽ bị mất khi có một phần phụ không được sắp xếp.
Đã chia tay (`p #)
`p # có nghĩa là danh sách được chia nhỏ và các mục giống nhau được lưu trữ liền kề.
Phạm vi là một int hoặc là temporal type có giá trị int cơ bản, chẳng hạn như năm, tháng, ngày, v.v. Bạn cũng có thể phân vùng qua một ký hiệu miễn là nó được liệt kê.
Việc áp dụng thuộc tính parted sẽ tạo ra một từ điển chỉ mục ánh xạ từng giá trị đầu ra duy nhất đến vị trí xuất hiện đầu tiên của nó. Khi một danh sách được tách ra, việc tra cứu sẽ nhanh hơn nhiều, vì tìm kiếm tuyến tính được thay thế bằng tra cứu bảng băm.
q)L:`p# 99 88 77 1 2 3
q)L
`p#99 88 77 1 2 3
q)L,:3
q)L
99 88 77 1 2 3 3Note −
Thuộc tính parted không được giữ nguyên trong một thao tác trên danh sách, ngay cả khi thao tác đó giữ nguyên phân vùng.
Thuộc tính parted nên được xem xét khi số lượng thực thể lên đến một tỷ và hầu hết các phân vùng có kích thước đáng kể, tức là có sự lặp lại đáng kể.
Đã nhóm (`g #)
`g # có nghĩa là danh sách được nhóm lại. Một từ điển nội bộ được xây dựng và duy trì để ánh xạ từng mục duy nhất với từng chỉ mục của nó, đòi hỏi không gian lưu trữ đáng kể. Để biết danh sách độ dàiL chứa đựng u các mặt hàng độc đáo có kích thước s, cái này sẽ (L × 4) + (u × s) byte.
Nhóm có thể được áp dụng cho một danh sách khi không có giả định nào khác về cấu trúc của nó.
Thuộc tính có thể được áp dụng cho bất kỳ danh sách đã nhập nào. Nó được duy trì khi bổ sung, nhưng bị mất khi xóa.
q)L: `g# 1 2 3 4 5 4 2 3 1 4 5 6
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6
q)L,:9
q)L
`g#1 2 3 4 5 4 2 3 1 4 5 6 9
q)L _:2
q)L
1 2 4 5 4 2 3 1 4 5 6 9Duy nhất (`#u)
Việc áp dụng thuộc tính duy nhất (`u #) cho một danh sách chỉ ra rằng các mục của danh sách là khác biệt. Biết rằng các phần tử của danh sách là duy nhất giúp tăng tốc đáng kểdistinct và cho phép q để thực hiện một số so sánh sớm.
Khi một danh sách được gắn cờ là duy nhất, một bản đồ băm nội bộ sẽ được tạo cho từng mục trong danh sách. Các thao tác trong danh sách phải bảo toàn tính duy nhất nếu không thuộc tính sẽ bị mất.
q)LU:`u#`MSFT`SAMSUNG`APPLE
q)LU
`u#`MSFT`SAMSUNG`APPLE
q)LU,:`IBM /Uniqueness preserved
q)LU
`u#`MSFT`SAMSUNG`APPLE`IBM
q)LU,:`SAMSUNG / Attribute lost
q)LU
`MSFT`SAMSUNG`APPLE`IBM`SAMSUNGNote −
`u # được bảo toàn trên các nối để bảo toàn tính duy nhất. Nó bị mất khi xóa và nối không duy nhất.
Tìm kiếm trên danh sách `u # được thực hiện thông qua một hàm băm.
Xóa các thuộc tính
Có thể loại bỏ các thuộc tính bằng cách áp dụng `#.
Áp dụng các thuộc tính
Ba định dạng để áp dụng các thuộc tính là:
L: `s# 14 2 3 3 9/ Chỉ định trong khi tạo danh sách
@[ `.; `L ; `s#]/ Áp dụng chức năng, tức là cho danh sách biến L
/ trong không gian tên mặc định (tức là `.) áp dụng
/ thuộc tính `s # đã được sắp xếp
Update `s#time from `tab
/ Cập nhật bảng (tab) để áp dụng
/ thuộc tính.
Hãy áp dụng ba định dạng khác nhau ở trên với các ví dụ.
q)/ set the attribute during creation
q)L:`s# 3 4 9 10 23 84 90
q)/apply the attribute to existing list data
q)L1: 9 18 27 36 42 54
q)@[`.;`L1;`s#]
`.
q)L1 / check
`s#9 18 27 36 42 54
q)@[`.;`L1;`#] / clear attribute
`.
q)L1
9 18 27 36 42 54
q)/update a table to apply the attribute
q)t: ([] sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t:([]time:09:00 09:30 10:00t;sym:`ibm`msft`samsung; mcap:9000 18000 27000)
q)t
time sym mcap
---------------------------------
09:00:00.000 ibm 9000
09:30:00.000 msft 18000
10:00:00.000 samsung 27000
q)update `s#time from `t
`t
q)meta t / check it was applied
c | t f a
------ | -----
time | t s
sym | s
mcap | j
Above we can see that the attribute column in meta table results shows the time column is sorted (`s#).Các truy vấn chức năng (Động) cho phép chỉ định tên cột làm biểu tượng cho các cột chọn / thực thi / xóa q-sql điển hình. Nó rất tiện dụng khi chúng ta muốn chỉ định động tên cột.
Các dạng chức năng là -
?[t;c;b;a] / for select
![t;c;b;a] / for updateỞ đâu
t là một cái bàn;
a là từ điển về uẩn;
bcụm từ; và
c là một danh sách các ràng buộc.
Lưu ý -
Tất cả q các thực thể trong a, bvà c phải được tham chiếu bằng tên, nghĩa là các ký hiệu chứa tên thực thể.
Các dạng cú pháp của lựa chọn và cập nhật được phân tích cú pháp thành các dạng chức năng tương đương của chúng bằng q thông dịch viên, vì vậy không có sự khác biệt về hiệu suất giữa hai hình thức.
Lựa chọn chức năng
Khối mã sau đây cho thấy cách sử dụng functional select -
q)t:([]n:`ibm`msft`samsung`apple;p:40 38 45 54)
q)t
n p
-------------------
ibm 40
msft 38
samsung 45
apple 54
q)select m:max p,s:sum p by name:n from t where p>36, n in `ibm`msft`apple
name | m s
------ | ---------
apple | 54 54
ibm | 40 40
msft | 38 38ví dụ 1
Hãy bắt đầu với trường hợp đơn giản nhất, phiên bản chức năng của “select from t” sẽ giống như -
q)?[t;();0b;()] / select from t
n p
-----------------
ibm 40
msft 38
samsung 45
apple 54Ví dụ 2
Trong ví dụ sau, chúng tôi sử dụng hàm tranh thủ để tạo các thẻ đơn để đảm bảo rằng các thực thể thích hợp là danh sách.
q)wherecon: enlist (>;`p;40)
q)?[`t;wherecon;0b;()] / select from t where p > 40
n p
----------------
samsung 45
apple 54Ví dụ 3
q)groupby: enlist[`p] ! enlist `p
q)selcols: enlist [`n]!enlist `n
q)?[ `t;(); groupby;selcols] / select n by p from t
p | n
----- | -------
38 | msft
40 | ibm
45 | samsung
54 | appleThực thi chức năng
Dạng hàm thực thi là dạng đơn giản hóa của select.
q)?[t;();();`n] / exec n from t (functional form of exec)
`ibm`msft`samsung`apple
q)?[t;();`n;`p] / exec p by n from t (functional exec)
apple | 54
ibm | 40
msft | 38
samsung | 45Cập nhật chức năng
Hình thức cập nhật chức năng hoàn toàn tương tự như select. Trong ví dụ sau, việc sử dụng tranh thủ là để tạo các thẻ đơn, để đảm bảo rằng các thực thể đầu vào là danh sách.
q)c:enlist (>;`p;0)
q)b: (enlist `n)!enlist `n
q)a: (enlist `p) ! enlist (max;`p)
q)![t;c;b;a]
n p
-------------
ibm 40
msft 38
samsung 45
apple 54Chức năng xóa
Xóa chức năng là một hình thức cập nhật chức năng được đơn giản hóa. Cú pháp của nó như sau:
![t;c;0b;a] / t is a table, c is a list of where constraints, a is a
/ list of column namesBây giờ chúng ta hãy lấy một ví dụ để cho thấy chức năng xóa hoạt động như thế nào -
q)![t; enlist (=;`p; 40); 0b;`symbol$()]
/ delete from t where p = 40
n p
---------------
msft 38
samsung 45
apple 54Trong chương này, chúng ta sẽ học cách hoạt động trên từ điển và sau đó là bảng. Hãy bắt đầu với từ điển -
q)d:`u`v`x`y`z! 9 18 27 36 45 / Creating a dictionary d
q)/ key of this dictionary (d) is given by
q)key d
`u`v`x`y`z
q)/and the value by
q)value d
9 18 27 36 45
q)/a specific value
q)d`x
27
q)d[`x]
27
q)/values can be manipulated by using the arithmetic operator +-*% as,
q)45 + d[`x`y]
72 81Nếu một người cần sửa đổi các giá trị từ điển, thì công thức sửa đổi có thể là:
q)@[`d;`z;*;9]
`d
q)d
u | 9
v | 18
x | 27
y | 36
q)/Example, table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
z | 405
q)/Example table tab
q)tab:([]sym:`;time:0#0nt;price:0n;size:0N)
q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT
q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)] 0 1 2 3 4 5 6 7 8 9 q)`time xasc `tab `tab q)/ to get particular column from table tab q)tab[`size] 12 10 1 90 73 90 43 90 84 63 q)tab[`size]+9 21 19 10 99 82 99 52 99 93 72 q)/Example table tab q)tab:([]sym:`;time:0#0nt;price:0n;size:0N) q)n:10;sym:`IBM`SAMSUNG`APPLE`MSFT q)insert[`tab;(n?sym;("t"$.z.Z);n?100.0;n?100)]
0 1 2 3 4 5 6 7 8 9
q)`time xasc `tab
`tab
q)/ to get particular column from table tab
q)tab[`size]
12 10 1 90 73 90 43 90 84 63
q)tab[`size]+9
21 19 10 99 82 99 52 99 93 72
q)/We can also use the @ amend too
q)@[tab;`price;-;2]
sym time price size
--------------------------------------------
APPLE 11:16:39.779 6.388858 12
MSFT 11:16:39.779 17.59907 10
IBM 11:16:39.779 35.5638 1
SAMSUNG 11:16:39.779 59.37452 90
APPLE 11:16:39.779 50.94808 73
SAMSUNG 11:16:39.779 67.16099 90
APPLE 11:16:39.779 20.96615 43
SAMSUNG 11:16:39.779 67.19531 90
IBM 11:16:39.779 45.07883 84
IBM 11:16:39.779 61.46716 63
q)/if the table is keyed
q)tab1:`sym xkey tab[0 1 2 3 4]
q)tab1
sym | time price size
--------- | ----------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73
q)/To work on specific column, try this
q){tab1[x]`size} each sym
1 90 12 10
q)(0!tab1)`size
12 10 1 90 73
q)/once we got unkeyed table, manipulation is easy
q)2+ (0!tab1)`size
14 12 3 92 75Dữ liệu trên đĩa cứng của bạn (còn được gọi là cơ sở dữ liệu lịch sử) có thể được lưu ở ba định dạng khác nhau - Tệp phẳng, Bảng xếp chồng và Bảng phân vùng. Sau đây chúng ta sẽ học cách sử dụng ba định dạng này để lưu dữ liệu.
Tệp phẳng
Các tệp phẳng được tải đầy đủ vào bộ nhớ, đó là lý do tại sao kích thước của chúng (diện tích bộ nhớ) phải nhỏ. Các bảng được lưu trên đĩa hoàn toàn trong một tệp (vì vậy kích thước rất quan trọng).
Các chức năng được sử dụng để thao tác các bảng này là set/get -
`:path_to_file/filename set tablenameHãy lấy một ví dụ để chứng minh cách nó hoạt động -
q)tables `.
`s#`t`tab`tab1
q)`:c:/q/w32/tab1_test set tab1
`:c:/q/w32/tab1_testTrong môi trường Windows, các tệp phẳng được lưu tại vị trí - C:\q\w32
Lấy tệp phẳng từ đĩa của bạn (db lịch sử) và sử dụng get lệnh như sau:
q)tab2: get `:c:/q/w32/tab1_test
q)tab2
sym | time price size
--------- | -------------------------------
APPLE | 11:16:39.779 8.388858 12
MSFT | 11:16:39.779 19.59907 10
IBM | 11:16:39.779 37.5638 1
SAMSUNG | 11:16:39.779 61.37452 90
APPLE | 11:16:39.779 52.94808 73Một bảng mới được tạo tab2 với nội dung của nó được lưu trữ trong tab1_test tập tin.
Bảng xếp chồng
Nếu có quá nhiều cột trong một bảng, thì chúng tôi lưu trữ các bảng như vậy ở định dạng xếp chồng, tức là chúng tôi lưu chúng trên đĩa trong một thư mục. Bên trong thư mục, mỗi cột được lưu trong một tệp riêng biệt dưới tên giống như tên cột. Mỗi cột được lưu dưới dạng danh sách loại tương ứng trong tệp nhị phân kdb +.
Lưu một bảng ở định dạng có lớp phủ rất hữu ích khi chúng ta phải truy cập thường xuyên vào một vài cột trong số nhiều cột của nó. Thư mục bảng được xếp chồng chứa.d tệp nhị phân chứa thứ tự của các cột.
Giống như một tệp phẳng, một bảng có thể được lưu dưới dạng hiển thị bằng cách sử dụng setchỉ huy. Để lưu bảng dưới dạng hiển thị, đường dẫn tệp phải kết thúc bằng dấu gạch chéo ngược -
`:path_to_filename/filename/ set tablenameĐể đọc một bảng có lớp phủ, chúng ta có thể sử dụng get chức năng -
tablename: get `:path_to_file/filenameNote - Để một bảng được lưu dưới dạng splayed, nó phải được bỏ khóa và liệt kê.
Trong môi trường Windows, cấu trúc tệp của bạn sẽ xuất hiện như sau:
Bảng phân vùng
Các bảng được phân vùng cung cấp một phương tiện hiệu quả để quản lý các bảng khổng lồ chứa khối lượng dữ liệu đáng kể. Bảng được phân vùng là các bảng được xếp chồng lên nhau trên nhiều phân vùng (thư mục) hơn.
Bên trong mỗi phân vùng, một bảng sẽ có thư mục riêng, với cấu trúc của một bảng được xếp chồng lên nhau. Các bảng có thể được chia theo ngày / tháng / năm để cung cấp quyền truy cập tối ưu vào nội dung của nó.
Để lấy nội dung của một bảng được phân vùng, hãy sử dụng khối mã sau:
q)get `:c:/q/data/2000.01.13 // “get” command used, sample folder
quote| +`sym`time`bid`ask`bsize`asize`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0
0 0 0….
trade| +`sym`time`price`size`ex!(`p#`sym!0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 ….Hãy thử lấy nội dung của một bảng giao dịch -
q)get `:c:/q/data/2000.01.13/trade
sym time price size ex
--------------------------------------------------
0 09:30:00.496 0.4092016 7 T
0 09:30:00.501 1.428629 4 N
0 09:30:00.707 0.5647834 6 T
0 09:30:00.781 1.590509 5 T
0 09:30:00.848 2.242627 3 A
0 09:30:00.860 2.277041 8 T
0 09:30:00.931 0.8044885 8 A
0 09:30:01.197 1.344031 2 A
0 09:30:01.337 1.875 3 A
0 09:30:01.399 2.187723 7 ANote - Chế độ phân vùng phù hợp với các bảng có hàng triệu bản ghi mỗi ngày (tức là dữ liệu chuỗi thời gian)
Sym tệp
Tệp sym là một tệp nhị phân kdb + chứa danh sách các ký hiệu từ tất cả các bảng được phân vùng và phân vùng. Nó có thể được đọc với,
get `:symtệp par.txt (tùy chọn)
Đây là một tệp cấu hình, được sử dụng khi các phân vùng được trải rộng trên một số thư mục / ổ đĩa và chứa các đường dẫn đến các phân vùng đĩa.
.Q.en
.Q.enlà một hàm dyadic giúp hiển thị bảng bằng cách liệt kê một cột ký hiệu. Nó đặc biệt hữu ích khi chúng ta đang xử lý db lịch sử (bảng phân vùng, hiển thị, v.v.). -
.Q.en[`:directory;table]Ở đâu directory là thư mục chính của cơ sở dữ liệu lịch sử, nơi sym file nằm và table là bảng được liệt kê.
Việc liệt kê các bảng theo cách thủ công không cần thiết để lưu chúng dưới dạng bảng xếp chồng, vì điều này sẽ được thực hiện bởi -
.Q.en[`:directory_where_symbol_file_stored]table_name.Q.dpft
Các .Q.dpftchức năng giúp tạo bảng được phân vùng và phân đoạn. Nó là dạng nâng cao của.Q.en, vì nó không chỉ hiển thị bảng mà còn tạo bảng phân vùng.
Có bốn đối số được sử dụng trong .Q.dpft -
xử lý tệp tượng trưng của cơ sở dữ liệu nơi chúng tôi muốn tạo phân vùng,
q giá trị dữ liệu mà chúng ta sẽ phân vùng bảng,
tên của trường mà thuộc tính parted (`p #) sẽ được áp dụng (thường là` sym), và
tên bảng.
Hãy lấy một ví dụ để xem nó hoạt động như thế nào -
q)tab:([]sym:5?`msft`hsbc`samsung`ibm;time:5?(09:30:30);price:5?30.25)
q).Q.dpft[`:c:/q/;2014.08.24;`sym;`tab]
`tab
q)delete tab from `
'type
q)delete tab from `/
'type
q)delete tab from .
'type
q)delete tab from `.
`.
q)tab
'tabChúng tôi đã xóa bảng tabtừ bộ nhớ. Bây giờ chúng ta hãy tải nó từ db
q)\l c:/q/2014.08.24/
q)\a
,`tab
q)tab
sym time price
-------------------------------
hsbc 07:38:13 15.64201
hsbc 07:21:05 5.387037
msft 06:16:58 11.88076
msft 08:09:26 12.30159
samsung 04:57:56 15.60838.Q.chk
.Q.chk là một hàm đơn nguyên có tham số duy nhất là xử lý tệp tượng trưng của thư mục gốc. Nó tạo các bảng trống trong một phân vùng, bất cứ khi nào cần thiết, bằng cách kiểm tra từng thư mục con của phân vùng trong thư mục gốc.
.Q.chk `:directoryỞ đâu directory là thư mục chính của cơ sở dữ liệu lịch sử.